1. Introduction
Monitoring and enhancing indoor environmental standards, such as air quality, thermal comfort, or acoustics, are of great importance for improving human health, comfort, and productivity [
1]. Due to the complexity of indoor structures typical of human-centered environments, airborne pollutants are not distributed homogeneously, resulting in significant spatio-temporal variations. In this work, we focus on mobile sensing approaches, an interesting and promising alternative to the traditional use of a static network of sensors [
2,
3] because of their versatility and coverage capabilities.
Mobile robotic olfaction, the discipline that combines artificial olfaction with mobile robotics, often involves applications where a robot has to detect the contour of a gas distribution and measure its intensity [
4]. In these situations, the robot’s role is to explore an environment to obtain a map of the gas distribution. These maps could then be an asset, for example, to tailor an automated fire evacuation response depending on how smoke is spreading through a building [
5], to determine the origin of a volatile substance during robotic Gas Source Localization (GSL) [
6,
7], or as an intermediate tool to investigate urban air pollution [
8].
Acquiring the necessary data to generate such gas distribution maps is not a trivial task. The phenomena of diffusion and advection often lead gases to spread in a highly stochastic fashion [
9], making it very hard or even impossible to accurately predict how gas particles move with dispersion models alone. Moreover, limitations in current gas sensing technologies have to be taken into account. To date, no gas sensor allows capturing a complete gas distribution with a single
snapshot [
10], and visiting every possible location to take a gas sample with an electronic nose (e-nose), for instance, is either very time-consuming or, quite often, intractable if there are places that the robot cannot physically reach. Hence, the prevailing approach for olfaction-enabled mobile robots is to perform a partial exploration of the environment and then extrapolate the gas concentration to non-visited locations. This is accomplished with Gas Distribution Modeling (GDM) [
11,
12,
13], the process that estimates the shape of a gas distribution from a set of sparse measurements that are composed of gas observations (e.g., from the robot’s e-nose [
14,
15]) and, in some cases, wind data from an anemometer [
16,
17]. For a detailed review of gas sensing technologies and e-noses commonly used in mobile robotics, please refer to [
18,
19].
Multiple GDM approaches have been proposed for mobile robotics. Some techniques extrapolate the robot measurements to nearby locations with
Gaussian kernels [
20], others rely on Source Term Estimation (STE) [
21] to predict the parameters that govern the shape and origin of a gas plume [
22], and others constrain the gas dispersion to the presence of obstacles [
23]. Regardless of the mathematical formulation, all GDM techniques for mobile robotics aim to fulfil one requirement: their computation must happen in real time, or as close as possible to it, to provide the robot with a continuously updated gas map that accounts for the latest gas measurements. This is paramount for applications such as industrial safety [
24], where fast decision making is necessary and where more accurate Computational Fluid Dynamics (CFD) simulations would be too slow to perform.
One such real-time GDM algorithm is Gas-Wind Gaussian Markov Random Field (GW-GMRF) distribution modeling [
25]. This algorithm treats the environment as a lattice and models the interaction between adjacent cells as a probability distribution to estimate the most likely gas concentration at remote locations (see
Section 3 for more details). The main advantage of GW-GMRF over similar techniques is that it also accounts for the obstacles in the environment and for the local wind measurements captured by the robot to reduce the total number of samples it has to gather. Moreover, because GW-GMRF combines all gas and wind samples under a probabilistic approach, it can assign an uncertainty level to each location of the output map. This provides valuable feedback to determine how trustworthy the estimates are, which, in turn, allows GW-GMRF to deal with challenging situations, such as physically separated areas (e.g., walls), eddies near obstacles, or environments that are only partially explored, without impairing its overall reliability.
Similar to most GDM techniques, GW-GMRF has one important limitation: it is an open-loop method that provides no feedback on where the robot should explore next; it only takes a set of input samples and computes the gas distribution map that explains them the best. However, the limited time and power available to explore the environment with a robot imply that it is critical to plan sampling locations that yield the most informative sensor readings. The main difficulty herein lies in the lack of a priori knowledge about how the gas is distributed, which prevents the robot from computing the optimal exploration path in advance. A conventional sensing strategy that samples along a predefined path does not take into account the distribution and valuable resources might be wasted at locations of little interest [
26]. Certainly, a better strategy would be one where the robot can dynamically adapt to the latest gas distribution estimates and plan the remainder of its exploration accordingly. In the case of GW-GMRF, this can be achieved by resorting to an uncertainty map, whose function is precisely to highlight where the estimate is deficient and more data are needed. However, just visiting the locations with the highest uncertainty in sequence might still lead to erratic and sub-optimal behavior. For example, the robot could end up in an unintended loop where it repeatedly transverses the same areas to reach locations with high uncertainty at opposite ends of the environment.
For situations where a mobile robot needs to acquire information about the environment yet is unable to plan an optimal strategy without this very information [
27], a Partially Observable Markov Decision Process (POMDP) can be a possible solution. The POMDP framework was originally conceived for robotic control, dealing with the uncertainty in the robot measurements and the outcome of its actions [
28]. In particular, it is useful for non-deterministic scenarios where a robot has to maximize a goal (e.g., get close to a target or collect objects) whilst saving on resources (e.g., energy and execution time). In these cases, the robot is provided with a complete representation of the environment, which is subsequently leveraged to predict the likely outcomes of an action. After implementing some slight modifications, the POMDP framework can also be applied for information gathering tasks [
22,
29]. For example, when it is applied to GDM, the robot might know the shape of the environment, but not how the gas is distributed within it.
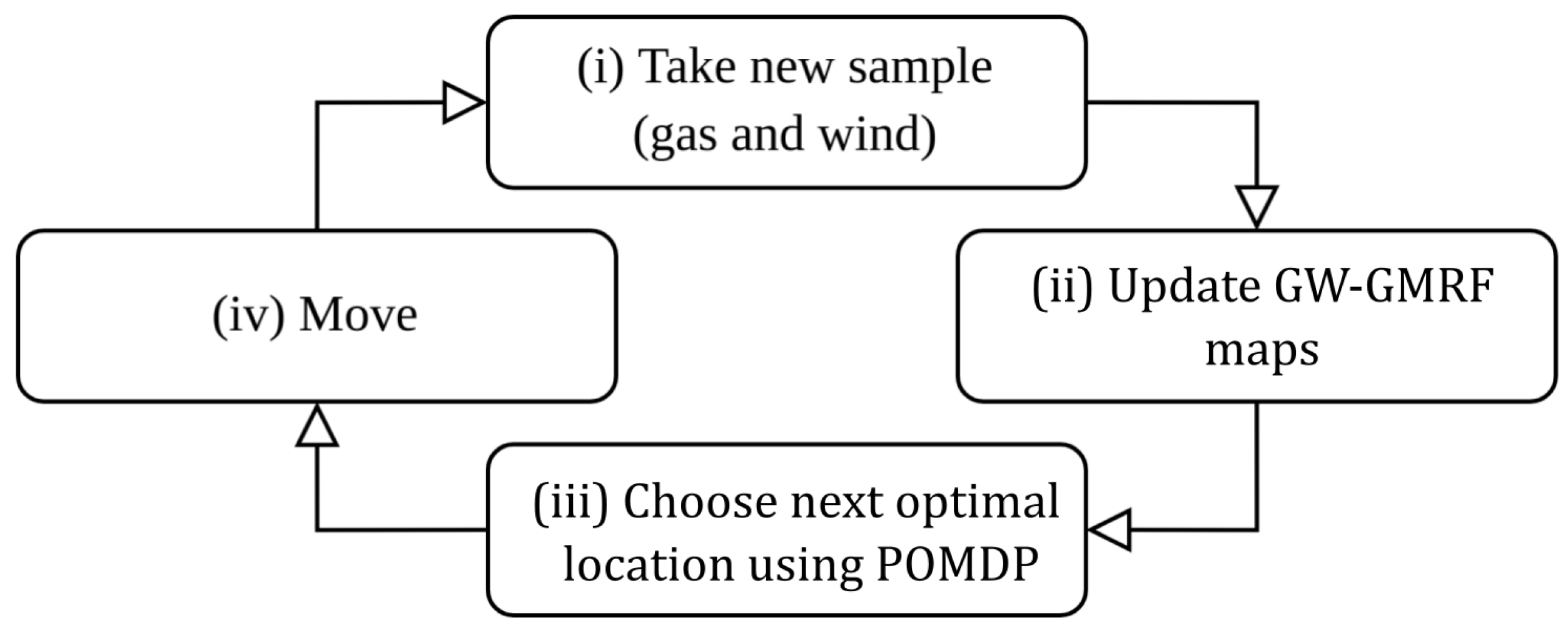
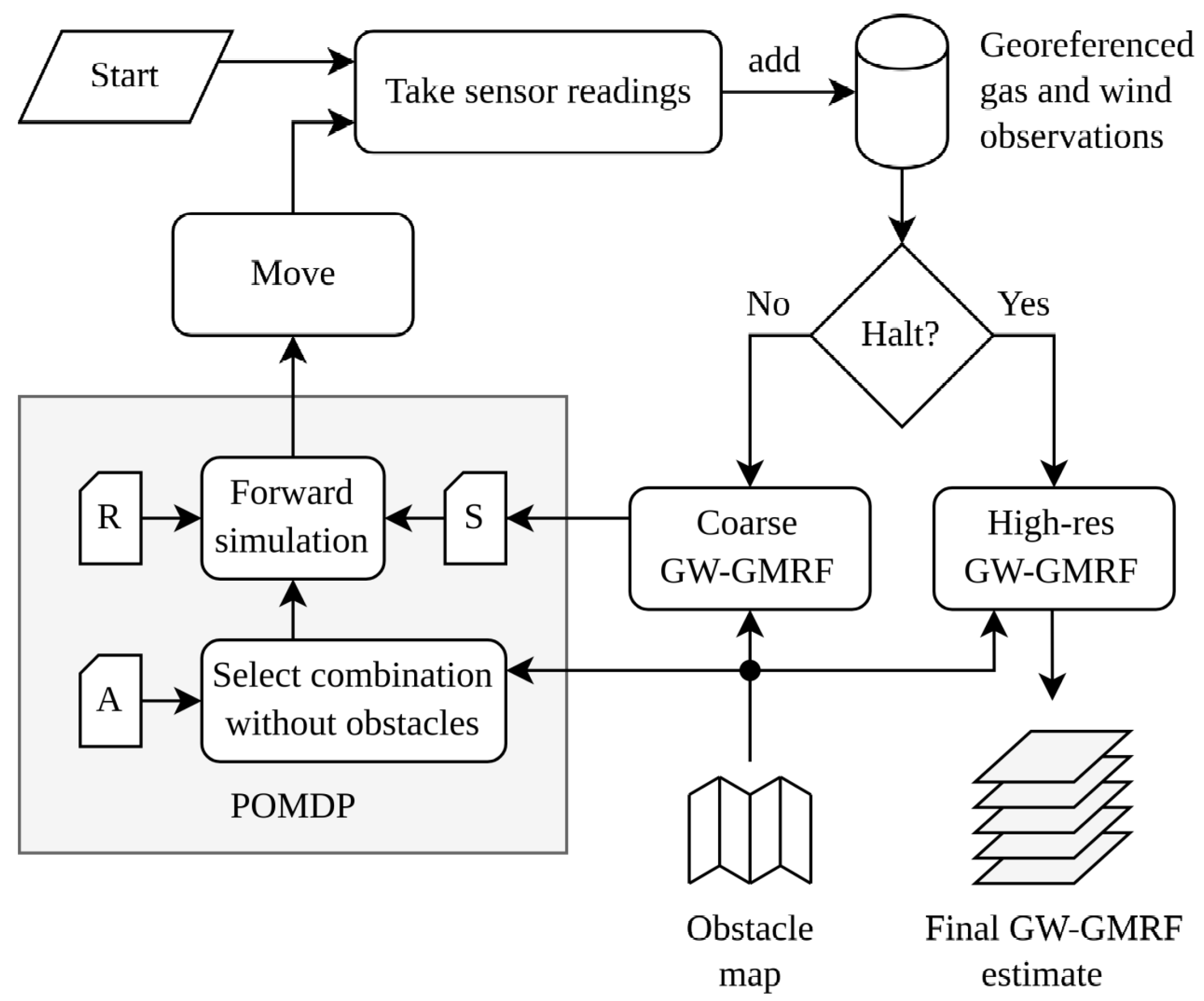
This paper combines GW-GMRF with a POMDP method to create a closed control loop for autonomous GDM. Although GW-GMRF is compatible with multi-agent systems and sensor networks alike, we will focus on the case of a single mobile robot equipped with an e-nose and a 2D anemometer. Our system’s control loop, as shown in
Figure 1, comprises four steps: the robot (i) takes a new set of gas and wind measurements, (ii) updates the corresponding GW-GMRF maps, (iii) exploits the estimated current map to predict the most likely outcome of its future movement options, and (iv) executes the one that yields, a priori, the highest information gain. The role of the POMDP in this loop is to ensure that the robot movements attain the greatest reduction in the uncertainty of GW-GMRFs estimates while moving along the shortest possible path, or, equivalently, to maximize the information added to the gas distribution map after each step. Therefore, we refer to this method as Information-driven Gas Distribution Mapping (IGDM).
2. Related Work
Autonomous mapping, understood as an Informative Path Planning (IPP) problem, is an active research topic that centers on optimizing a robot’s exploration path to gather information about a physical phenomenon with the objective of reconstructing its spatial distribution. In this section, we review some of the most relevant publications centered on reconstructing how chemical volatiles distribute in the environment, including alternative GDM methods as well as some precursors to IGDM (our method).
Our work draws inspiration from the work on
infotaxis [
30], a strategy that searches for gases by maximizing the expected information gain.
Infotaxis relies on an underlying gas dispersion model to compute a prior probability distribution over the environment from past gas measurements. For each incremental step of the exploration, this prior distribution enables the robot to determine the travel direction that should, hypothetically, yield the most informative and valuable samples. The behavior and capabilities of
infotaxis are, consequently, not static, but determined by the employed gas dispersion model and its fitness for the task at hand. The first version of this strategy [
30] and its multi-robot variant [
31], for instance, were exclusively aimed at GSL, finding the release point of a target gas. These employed a simple yet effective model of how frequently a robot is expected to encounter gas patches given its distance to the source. This model worked well to track sparse gas plumes, but not to map their spatial distribution.
Another infotactic approach, based on STE [
22,
32], models the gas distribution as a pseudo-Gaussian plume whose origin coincides with the source and whose concentration can be computed for every point in space (also in 3D). However, it aims to track relatively straight gas plumes under stable wind conditions, and thus may fail to provide reliable gas maps in the presence of obstacles. Our work, on the other hand, takes full advantage of GW-GMRFs ability to deal with complex indoor environments, albeit oriented purely towards infotactic GDM rather than GSL.
An important aspect of IPP approaches is how to determine the informative content and overall importance of each potential sampling site. In applications that involve gases [
26,
33], this is usually accomplished by computing the Kullback–Leibler Divergence (KLD) between the prior distribution and the later one that would be obtained after taking measurements at each candidate goal position. However, just choosing the sampling sites that yield the most information alone would not lead to a sensible exploration of the environment. The robot must also take into account the time and effort it takes to reach them, and if there are multiple sites of interest, in what order they should be visited. One possible tool to determine such a (pseudo) optimal path could be a POMDP formulation (more details in
Section 4). A POMDP simulates the outcome of every possible movement and then picks the one with the best score according to a given reward function, so that it may also account for other relevant parameters (travel time, distance, and energy cost) aside from the KLD gain [
34,
35].
Regarding computational efficiency, POMDPs and similar IPP methods are usually constrained by the fact that the robot may only choose from a finite set of actions, which have to be checked individually. Efficient alternatives have been proposed for Gaussian Markov random field (GMRF)-based IPP [
36,
37] exploiting their closed-form solution. However, GW-GMRF introduces a dependency between a gas map (a scalar field) and a wind map (a vector field) that must be solved numerically, and avoids such implementations.
3. GW-GMRF Gas Distribution Mapper
To keep this manuscript self-contained, we will start by reviewing the main characteristics of the GW-GMRF algorithm [
25]. GW-GMRF is a 2D gdm method that combines gas and wind measurements to account for advection, i.e., the effect by which gas molecules are carried in the general direction of the wind [
38]. To do so, GW-GMRF leverages the robot’s knowledge about obstacles in the environment (usually its navigation map) to simultaneously model how the gas distribution and wind currents spread out and interact with each other. This allows GW-GMRF to compute far-reaching yet robust estimates for both magnitudes even when the robot has gathered only a few observations or is operating in complex indoor environments.
As its name implies, GW-GMRF is formulated as a Gaussian Markov random field, a grid map whose cells encode the gas and wind values as Gaussian variables. Although modeling the gas concentration with a Gaussian distribution may lead to the consideration of negative concentration values with non-zero probability, a fact that has no physical meaning, it leads nonetheless to an efficient solution that works well in practice, as shown experimentally. To attain an efficient solution, GW-GMRF only models the relationships between neighboring cells [
25], computing the grid map that best satisfies all rules at a given time step, interpreted as a least-squares problem [
39]. For example, if there are no obstacles between two adjacent cells, they must have similar gas and wind values (i.e., no abrupt changes allowed). Additionally, if wind enters a cell from any side, then it must leave through any of the others (i.e., the total air mass is conserved) and may not flow if there is no exit for it. Moreover, the gas concentration between neighbors may not significantly change in the direction of the wind (i.e., advection causes gas plumes). The robot’s measurements are also taken into account by constraining that the value of any measured cell must be very close to the corresponding sensor reading, but may not be necessarily the same, accounting for sensor noise, contradictory inputs, and the diminishing relevance of old samples (i.e., the measured value of a cell may change when sampled repeatedly).
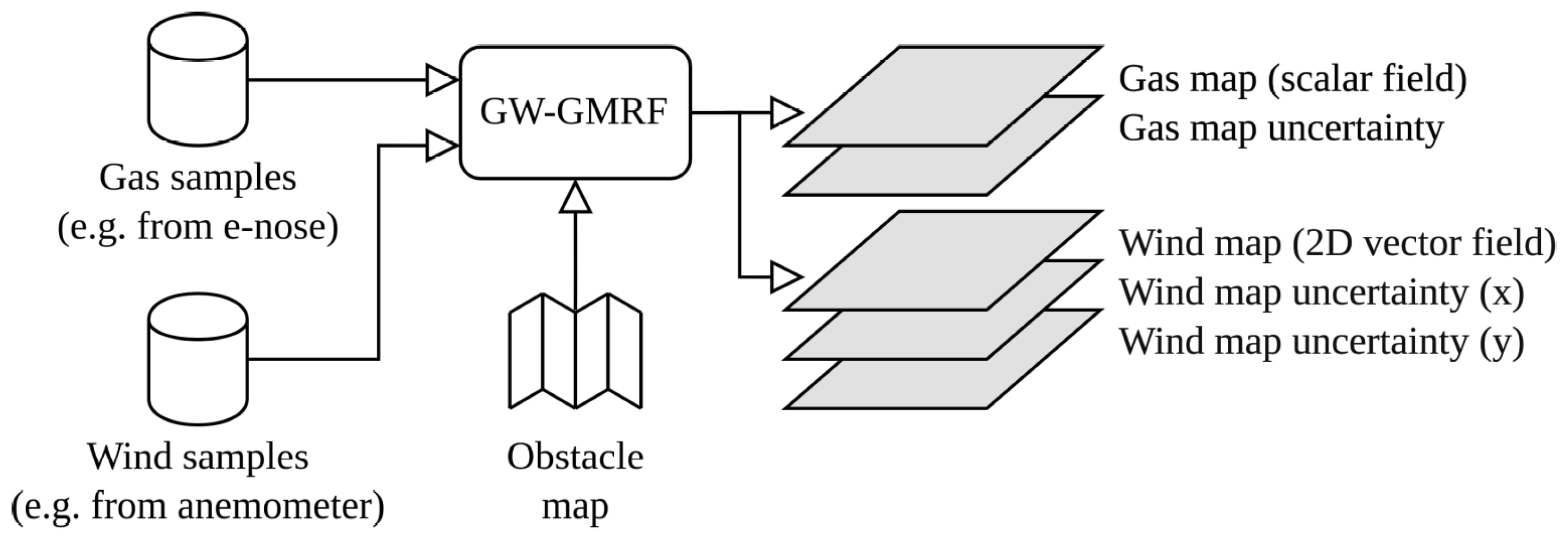
As shown in
Figure 2, the input of GW-GMRF is a set of gas and wind samples gathered at known positions. Since the grid map represents the gas and wind estimations in each cell as Gaussians, the output can be separated into five maps for convenience. These maps represent the estimated mean value and uncertainty (standard deviation) of the gas concentration and the wind components in the X and Y directions. Notice that the mean value of the wind flow is provided as a vector field. These estimates and uncertainties are, however, not computed simultaneously. GW-GMRF first produces the gas and wind estimates, with a computational complexity of
for a map with
n cells, and then, separately from each other, the gas uncertainty map (
) and the wind uncertainty maps in both the X and Y directions (
).
Another consideration in this regard is that the output of the GW-GMRF algorithm has a fixed, albeit user-configurable, resolution. Usually, smaller cells are desirable to obtain more accurate estimates. However, a trade-off between resolution and computational complexity is necessary, usually taking into account the dimensions of the robotic platform and the environment [
23,
25].
GW-GMRF has a total of 11 control parameters, including the aforementioned cell size, how fast the robot’s observations age and lose relevance, and the relative weights of all the cell connectivity rules. These parameters can be adjusted depending on the target application and its requirements, for example, to limit the influence of older samples or to fine tune the accuracy of the sensor input. In this work, we chose the parametric values proposed by Gongora et al. [
25] for generic indoor scenarios, except for the cell size, the value of which is dynamically altered in
Section 5 to attain a more efficient implementation.
4. POMDP Formulation
The function of a generic POMDP, composed of and applicable to control problems in general, is to determine a (pseudo) optimal sequential control policy for an agent in a non-deterministic system. It maintains a belief distribution s over all possible states S that the agent can be in. At every iteration, out of the set of possible actions , it chooses the one that maximizes its reward function . The reward function is a user-defined metric describing how well the agent is fulfilling its goal and how many resources (e.g., energy and time) its action would likely require. Additionally, the POMDP must account for the state transition probability of the actions over the probability distribution of possible states , since arriving at state that is different from the intended one might offset the reward in favor of other options. Lastly, the set of all possible observations , distributed according to , where denotes the probability distribution, participates after the action has been completed and the POMDP updates its state belief before the next iteration.
A POMDP can be an efficient strategy for situations where the state space
S and the number of possible observations
are both finite and modest in number [
29]. However, neither condition applies in our case. Consider, for instance, all the possible gas distributions that this map could eventually represent. The number of variables it will need is enormous, even if the value of each cell is discrete, and so will be the set of all observations the robot could eventually gather, which encompasses all possible combinations of e-nose and anemometer readings for all locations in the environment. However, by limiting its scope, both temporal and spatial, it can be reformulated as an information gathering task [
29]; a limited variation of the POMDP that is specifically meant to gather information in unknown environments.
4.1. Formulation as an Information Gathering Task
Instead of solving for an analytical solution, information gathering POMDPs rely on forward simulation to approximate the outcome of the actions on a case-by-case basis. In this way, the POMDP no longer has to consider all possible scenarios, but can only focus on those that are actually relevant at any given time. In our case, the accuracy of the GW-GMRF gas map improves depending on where the robot takes the next measurements by sequentially choosing the option with the highest projected reward given its latest belief about the gas distribution.
The drawback of this approach, however, is that the robot may no longer move in just any direction. Since it has to simulate the outcome of all available movements for every new state belief, after updating its GW-GMRF map with the previous measurement, the problem now becomes NP complete [
40]. Usually, this can be alleviated through Monte Carlo-based approximations [
22,
41]. However, due to the already elevated computational cost of GW-GMRF, a reasonable alternative is to limit the robot’s movements to a few discrete options that are computationally affordable to check.
The POMDP for IGDM is formulated with only three elements: its belief distribution, the set of actions the robot may take, and the reward function that governs the exploration. Once all three are defined, we can solve our problem through forward simulation, as explained in
Section 4.2.
4.1.1. IGDMs State Space Belief, s
We make use of GW-GMRFs latest estimated gas map as the belief distribution s over the environment. The actual gas distribution cannot be directly observed; thus, this represents the IGDM algorithm’s best estimate of the ground truth and therefore serves to predict the values the robot would measure when evaluating its movement options for the next step.
4.1.2. IGDMs Movement Actions, A
Instead of considering the full range of motion, IGDM limits the robot’s movements to the underlying GW-GMRF grid map one axis at a time. Accounting for positive and negative movements with a fixed distance , this results in a total of possible movements (N, W, S, and E). This allows IGDM to fully explore the environment and, as long as is selected in proportion to the environment geometry, to circumvent all obstacles. It must be noted that is the maximum step distance. If IGDM detects that a step would lead to a collision on the robot’s obstacle map, it might shorten the distance accordingly.
4.1.3. IGDMs Reward Function, R
The reward function determines how IGDM chooses the next movement by assigning a numeric profit score to each possible goal position. Ideally, it should favor movements that lead to sample locations with useful information, whilst providing little incentive for those that were recently visited. Since GW-GMRFs gas uncertainty map can only improve with new samples, a suitable reward function would be one that assigns better scores for greater reductions in uncertainty.
We measure this change as the KLD between GW-GMRFs current gas estimate and the one it should produce after acquiring new data. Naturally, there is no way to anticipate the exact gas and wind values that will be observed, but, for relatively short steps, these can be predicted from GW-GMRF maps. It must be noted that GW-GMRF maps are intrinsically multivariate Gaussian distributions and therefore handle the uncertainty on the estimated gas concentration or wind vector, respectively (see [
25] for more details). Once the new estimate is then forward simulated, we can compare its gas map to the current one with the following reward function:
which measures the information gain between the current gas estimate
computed for the real samples and the expected estimate
after movement
a predicted during forward simulation, both expressed as multivariate
Gaussian distributions, since they stem from GW-GMRF estimates.
To capitalize on the physical correlation between wind flow and gas dispersion (e.g., if a cell contains gas, we can extrapolate gas presence in the downwind direction), the reward function
R should prioritize actions that drive the robot to measure new areas with expected gas presence. Thus, to balance the robot’s tendency to map the gas it has already detected against its other tendency to explore new areas, we scale the reward function by the following component:
where the integral denotes the accumulated gas that is expected (according to the latest state belief) along the segment of path
that the robot would explore if it were to execute action
a, treated as the input of a
sigmoid function (in our implementation a hyperbolic tangent tanh) that is 0 if no gas is measured and saturates at a value of 1, meant to prevent locations with extreme gas concentrations from eclipsing those with more moderate values. The parameter
controls the saturation rate and can be adjusted depending on the importance of the gas concentration; small values lead to little saturation whereas higher ones cause
to behave in a binary fashion, where the reward will be 0 if there is no gas and 1 if the presence of gas is detected.
Lastly, the reward function should also minimize the amount of energy and time spent during exploration, which, depending on the particular configuration of the robot, usually means minimizing the length of the path. For a generic robot, the simplest option is to penalize each action according to:
where
and
denote, respectively, how much distance the robot would advance and rotate for any given action and
and
control their respective unit costs.
Combining all terms together in an equivalent way, similar to [
42], we obtain the following reward function, where the information gain
is scaled up depending on the detected gas component
and its relative weight
, and scaled down by the movement energy
:
Please note that the final reward function does not demand computing the wind uncertainty at any stage. Our goal only entails minimizing GW-GMRFs gas uncertainty when mapping out the environment. This does not, however, prevent the robot from computing said uncertainty if it were to need it for other purposes, but it allows us to skip GW-GMRFs computationally most expensive part when computing the reward for all action sequences in this specific implementation.
4.2. Finite Horizon Forward Simulation
In forward simulation, the robot has to evaluate the reward function for all possible actions before it can pick the best one. This involves predicting the observations each future action will presumably yield, followed by simulating how they would impact the current belief state and finally choosing the most promising one. When forward simulation is applied for information gathering tasks where the robot has no prior knowledge about the environment, the real outcome of any given action can differ from its expectation. It makes therefore little sense to plan multiple actions ahead of time while their true effects cannot be predicted, and as a result, action planning in these cases is usually restricted to a
greedy exploration that only considers the immediate best action [
29].
In the case of this work, however, since GW-GMRF is assumed to have a relatively complete map of the environment (usually the robot’s navigation map), some prior knowledge about the environment exists. This means that, even though we do not know how the gas is distributed, we can still identify movements that lead to areas with high uncertainty or where advection should lead to strong extrapolation. After all, the disposition of walls and obstacles constrains how the gas and air currents distribute, which, in turn, limits the cumulative error between sequential predictions. Therefore, by constraining GW-GMRFs estimate as well as the available actions to the obstacle map, we may leverage a multi-step action plan during forward simulation.
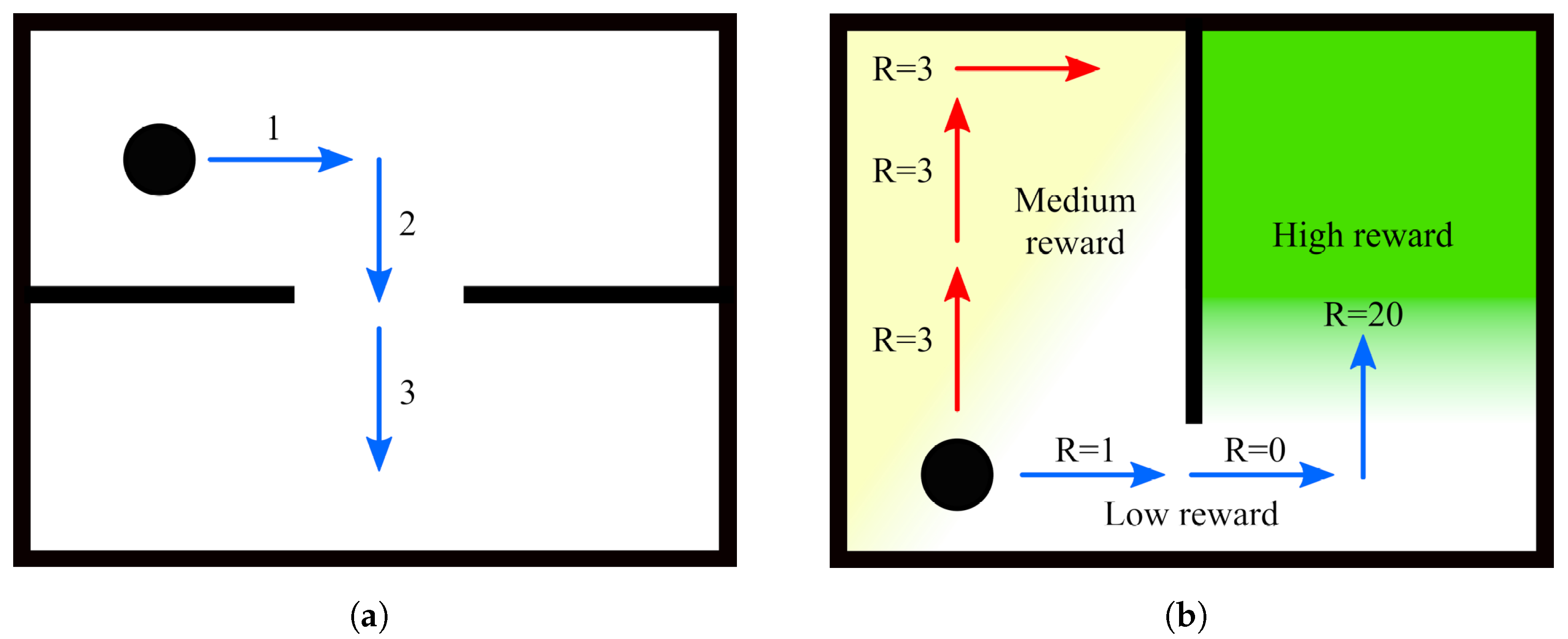
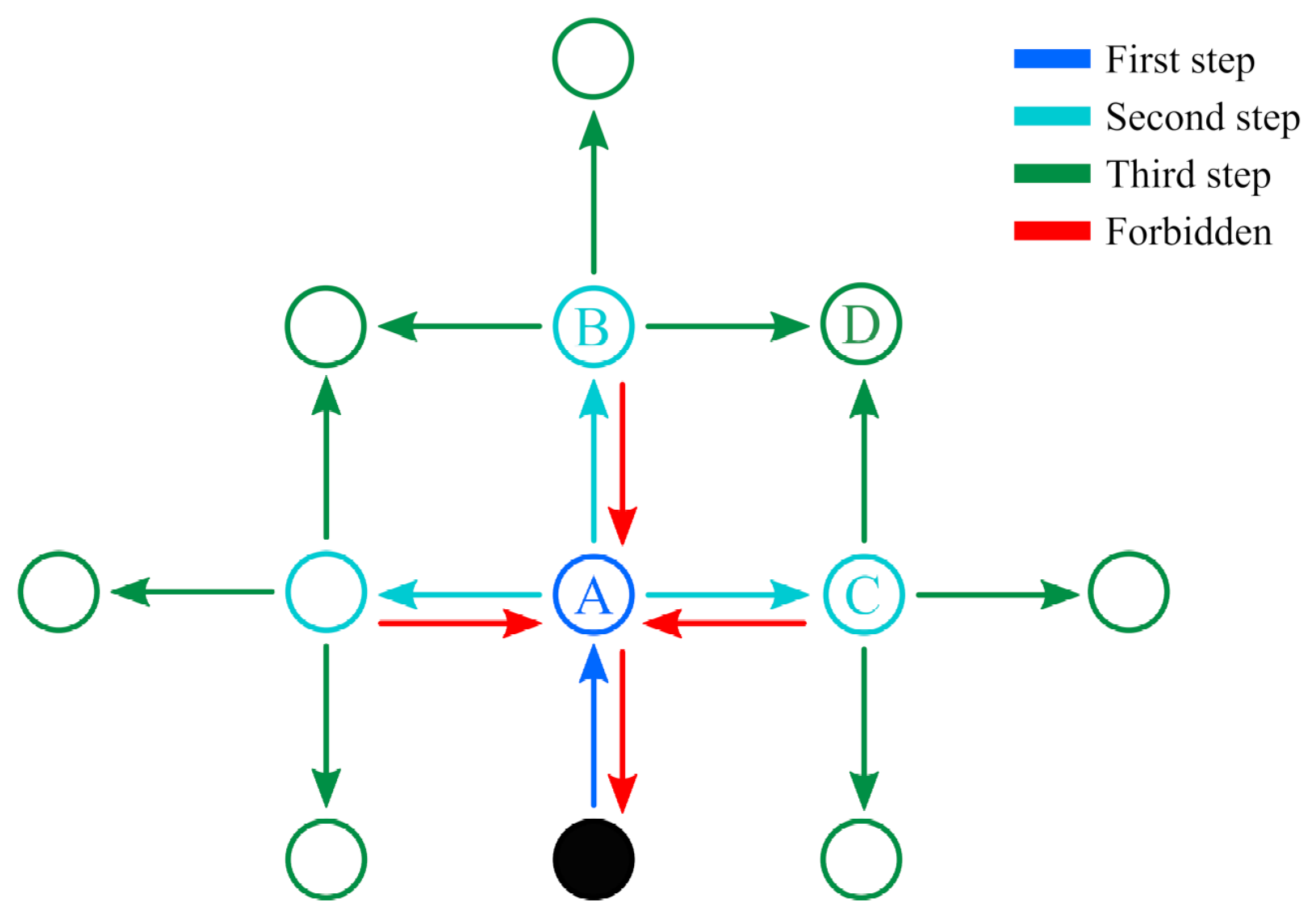
The advantage of planning several steps into the future is that it allows the robot to cope with more challenging situations, such as planning a path around corners (
Figure 3a) or reaching locations that are separated by already explored areas (
Figure 3b). Note that although several actions are planned, only the first in the sequence is executed, after which the robot reevaluates its state belief and updates the action plan accordingly. Thus, under this
finite horizon action planning, the goal of IGDM becomes to determine the sequence of movements
M composed of a combination of actions from
A that maximizes the total expected reward for
H consecutive steps:
where
is the state belief after the previous action (
is the current GW-GMRF estimate) and
is a discount function that diminishes the reward of later movements to account for their less certain outcome, which in our case is an exponential with constant base
so that it evaluates to 1 for
.
One important remark about the search of all possible sequences for
M is that all combinations must be evaluated independently and do not benefit from techniques such as Monte Carlo Tree Search (MCTS) [
43] or variants of the Rapidly Exploring Random Tree (RRT) [
44]. The reason for this limitation lies in the fact that the reward of a given action
is not correlated with the reward of its preceding action
, yet it depends on the state
said former action would have led to. This means that sequences that start with an action that yields a low initial reward, and would thus be discarded by the aforementioned techniques, may actually branch out to the path that has the highest final reward, such as in the example of
Figure 3b. Nonetheless, there are still some performance gains that can be easily obtained to accelerate the search and which we discuss in the next section, as well as other heuristics that could be exploited in future works.
6. Experiments and Discussion
This section describes the experiments carried out using a wheeled mobile robot running the IGDM algorithm. We first present a set of simulations where the ground truth is available and the algorithm’s performance can be measured precisely. Then, we report on physical experiments carried out in a wind tunnel, where we focused on the exploration’s consistency for a realistic gas plume as well as a gas distribution distorted by obstacles. Lastly, we discuss the performance of the algorithm to provide a better insight into its capabilities and justify some of the implementation decisions from the previous section. Please note that, unless otherwise specified, all parameters were set as described in the previous section.
6.1. Simulation Experiments
The simulation experiments are intended to validate the IGDM algorithm under controlled and repeatable conditions. Next, we specify the setup and tools employed for the generation of these experiments.
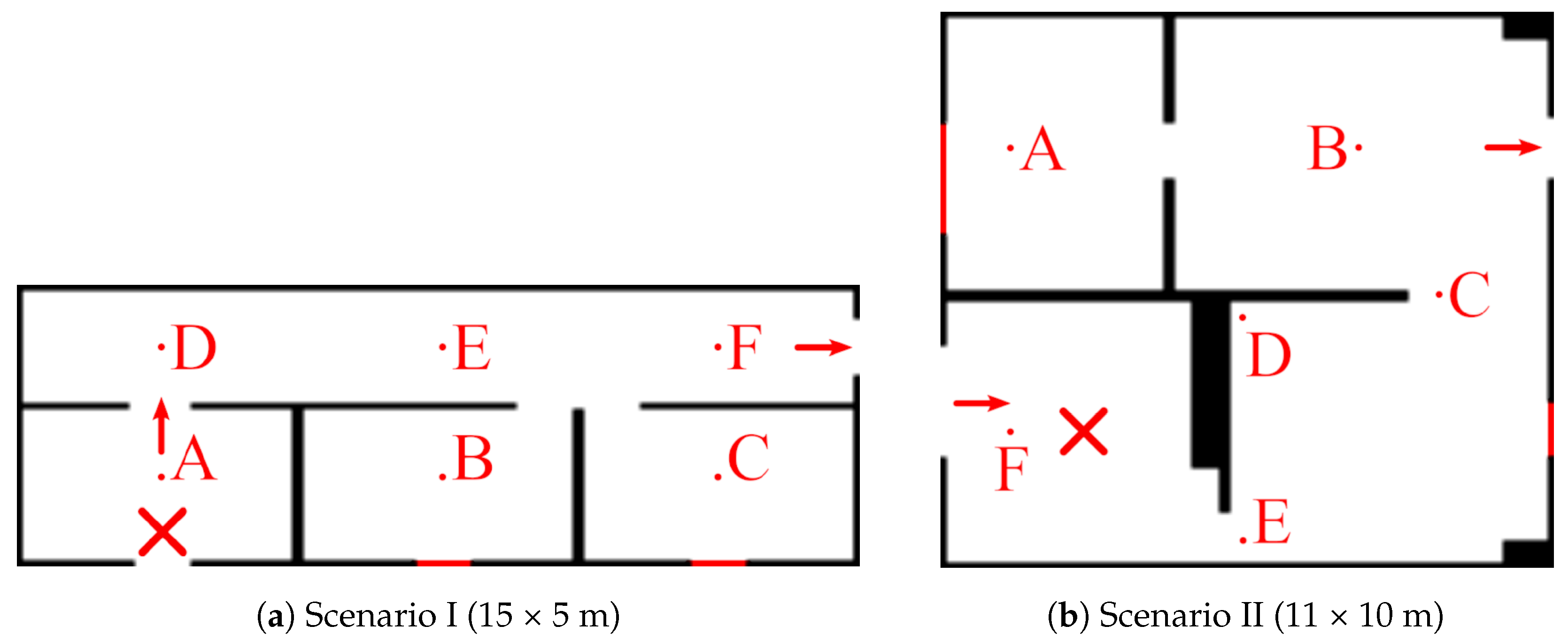
Scenarios: We considered two test scenarios, shown in
Figure 6, that were selected to represent situations a robot might encounter in a real indoor environment. On the one hand, Scenario I depicts a long corridor with adjacent rooms where we simulated a 2D quasi-ideal gas plume (i.e., continuous and with straight sections). On the other hand, Scenario II presents a more challenging scenario depicting an office-like environment, simulated in 3D, that leads to a very diffuse gas distribution with many discontinuities. A snapshot of the simulated plumes and both gas concentration and wind vector maps can be seen in
Figure 7 (top) and
Figure 8 (top), respectively.
Wind Flow Simulation: The wind flow in each scenario was simulated with OpenFOAM [
47], a realistic CFD toolbox. The wind conditions were determined by closing all inlets and outlets except two: one that acts as a wind inlet at 1 m/s (typical of indoor scenarios [
48]) and another that serves as an isobaric outlet. It is important to note that during the mapping process, the robot knows the location of the inlets/outlets in the environment, but does not know if they are open or closed, which needs to be learned from the measurements during execution.
Gas Dispersion Simulation: For the gas dispersal, we relied on the open-access gas dispersion simulator GADEN [
49]. The gas distribution was simulated for a single, fixed gas source, consisting of an ethanol gas release at an approximate rate of 100 ppm/sec. All simulations were conducted in continuous time, which means both wind and gas fields contain dynamic eddies and gas patches, respectively. We allowed a 30 second time window before starting experiments to ensure that the transient response had settled, and guarantee impartial conditions with respect to the robot’s starting position. The gas concentration of both scenarios was also normalized for convenience and easier comparison between their distributions.
Simulated Robot and Sensors: To attain similar conditions to the real experimental setting presented in
Section 6.2, we simulated a differential drive wheeled robot, equipped with a chemical sensor and a 2D anemometer, sampling at 2 Hz. The robot was programmed to move at
m/s with a turn rate of
rad/s.
Performance Comparison: Since the performance of GW-GMRF has been validated separately in a previous work [
25], we will focus on analyzing how well the path chosen by POMDP fares when compared against different randomized navigation techniques. These are a Brownian exploration where the robot chooses between the same four movements as IGDM (N, W, S, E), a Brownian exploration without back tracking (i.e., movements that lead to the immediate last position are not considered), and a strategy where the robot advances until it collides with an obstacle and then turns randomly in a new direction. An illustration of these strategies is shown in
Figure 9. For the sake of fairness, all strategies will be evaluated with identical conditions to ensure comparable results between our method, IGDM, and the estimates that GW-GMRF would yield when sampling along either of the random paths.
Repetitions: To account for the effect of randomness and to obtain a more meaningful representation of the possible outcomes, we ran all experiments 12 times for each starting robot position (A to F), leading to 72 repetitions for each scenario.
6.1.1. Scenario I: Results
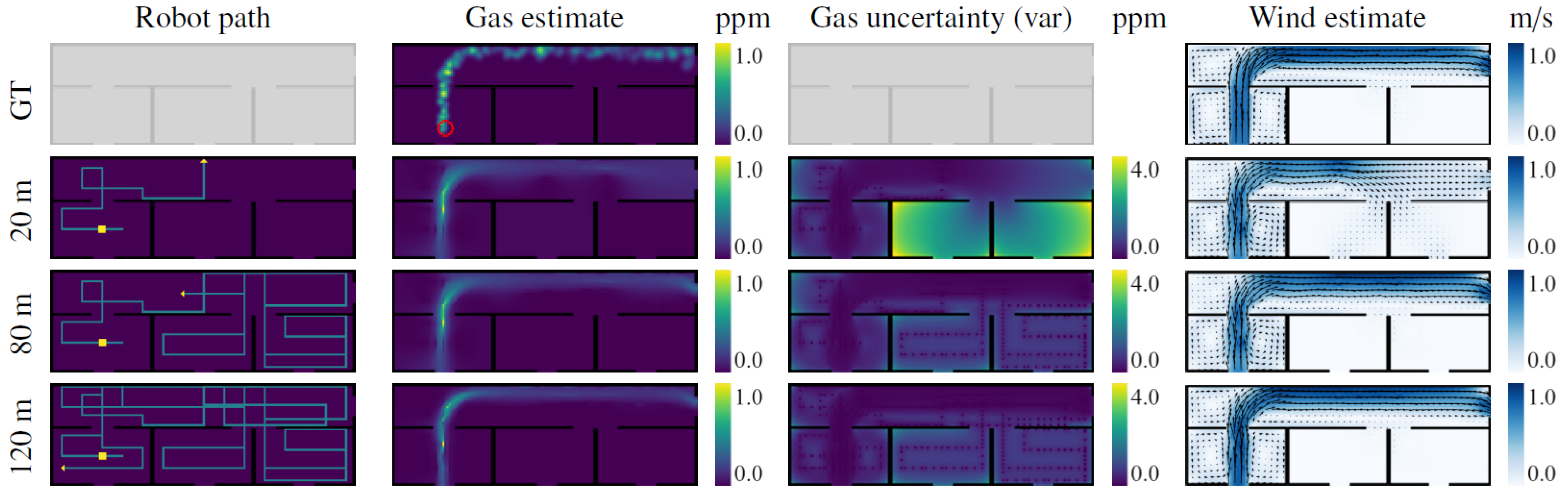
Figure 7 shows multiple snapshots of the gas concentration and wind vector estimates after different exploration lengths for one run of the simulated experiment. It can be seen how during the first 20 m of exploration, the robot moves mostly perpendicular to the wind and wanders out of the room. This provides enough information to estimate the general shape of the gas plume, but it is still not enough to determine whether there is more than one exit for the wind, and whether there is gas in the other rooms as well. The robot then inspects each room until the uncertainties therein drop to the point where the IGDM reward function favors re-inspection of areas expected to contain gas. At this point, after 80 m of exploration, the environment is mostly explored and the gas and wind estimates are very close to the ground truth. If the robot is allowed to continue its exploration, it will also visit some of the locations that were only extrapolated and not sampled, including the center of the main corridor and the lower part of the first room, as shown for the 120 m path.
For comparison with the other movement strategies, we computed the RMSE between the estimated gas maps and the ground truth. As depicted in
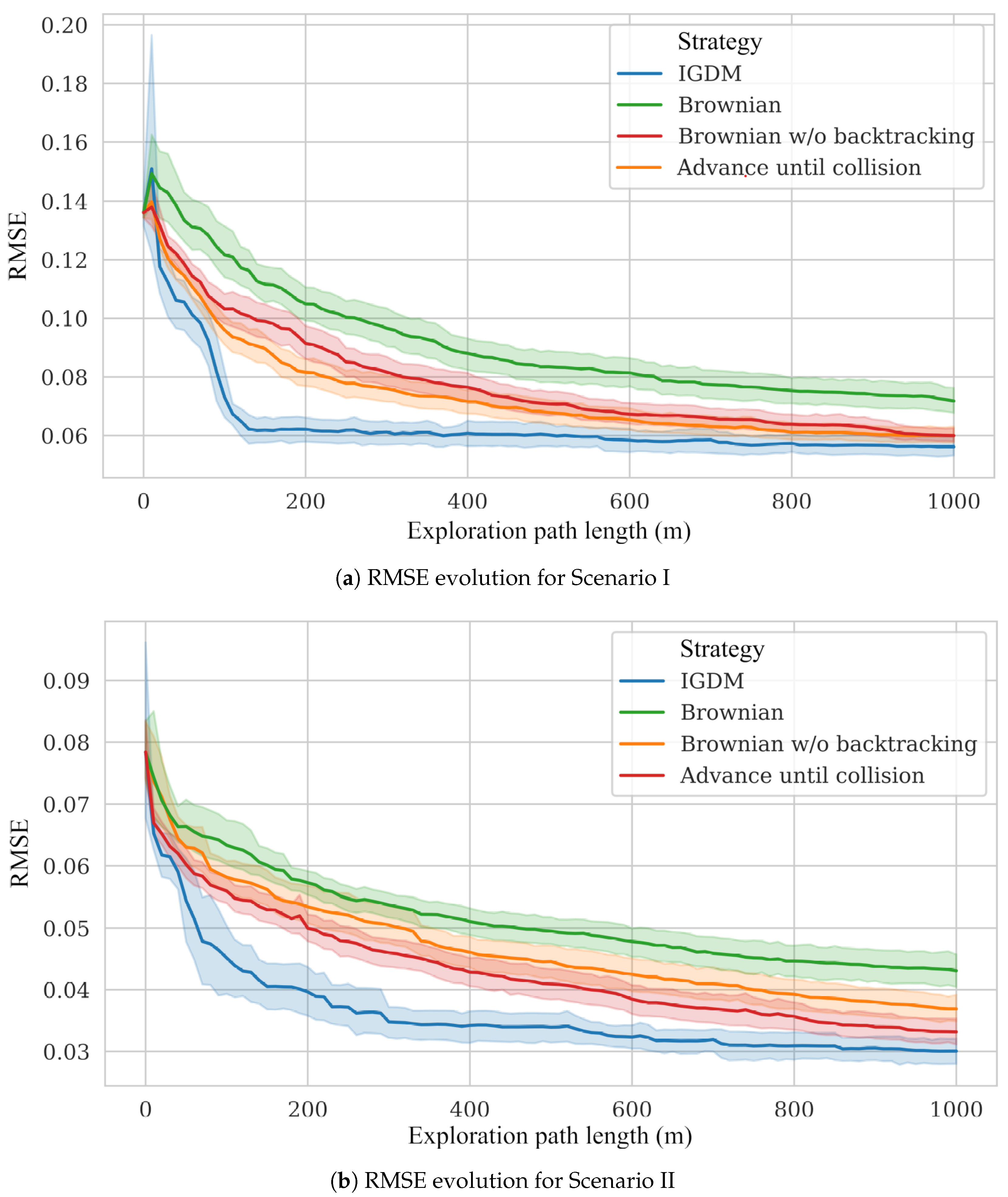
Figure 10a, IGDM outperforms all of the randomized navigation strategies, as it prioritizes the areas that provide the highest reduction in uncertainty. The difference is so pronounced that, after about 150 m of exploration, IGDM achieves the same RMSE that other methods achieve after over 600 m.
6.1.2. Scenario II: Results
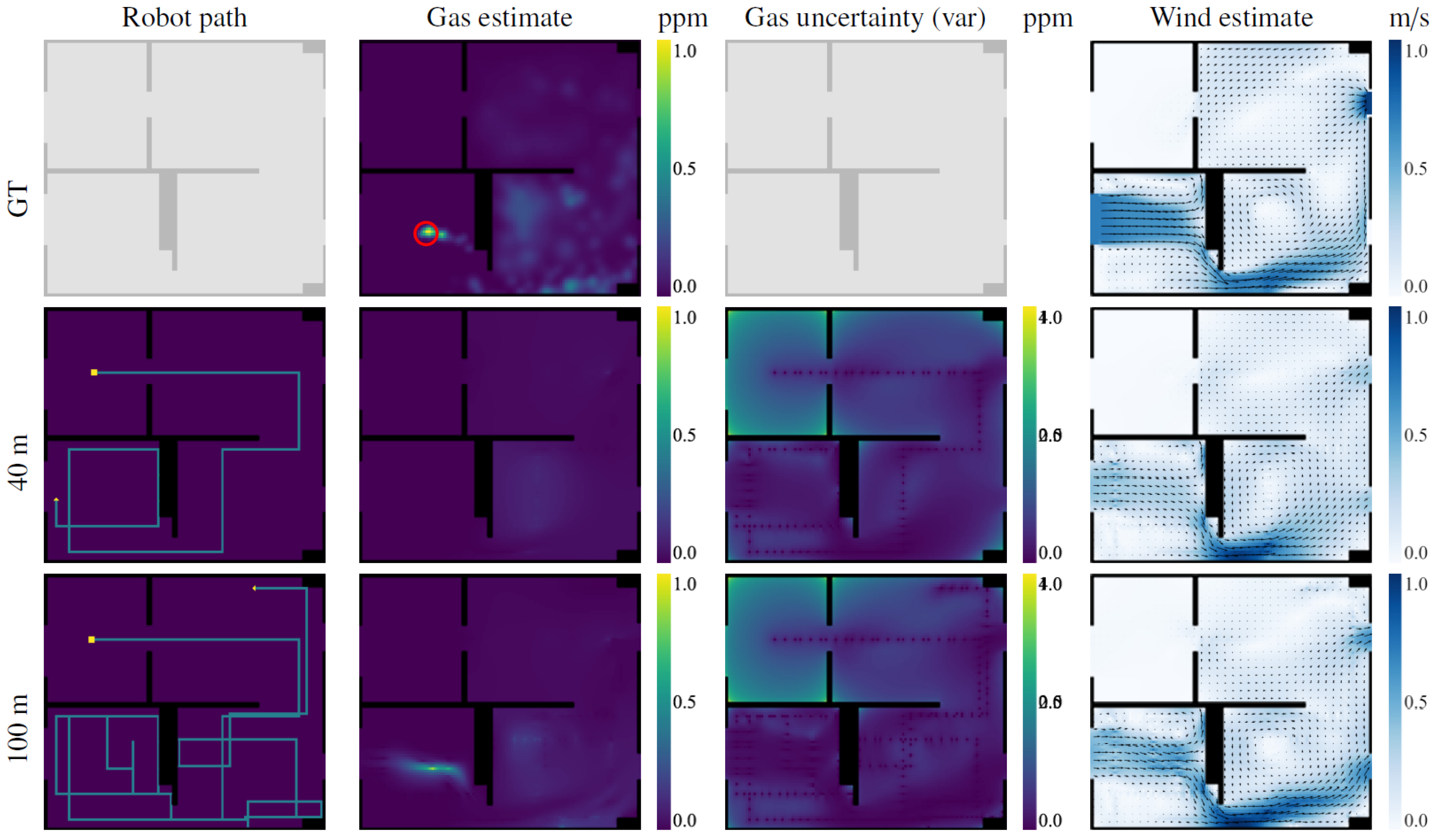
The robot’s behavior in scenario II, depicted in
Figure 8, is very similar to the one in Scenario I despite the differences in the gas distribution. At the beginning of the exploration, while the robot senses no gas, it tries to minimize the overall uncertainty of the map with the shortest possible path. This behavior is best appreciated during the first 40 m, where the robot travels between rooms in a very straight fashion. However, once the robot detects gas in the lower-left room, its path starts to spiral around the gas source. This simulation was conducted in 3D; thus, most of the gas lies either above or below the plane at which the robot is sampling and consequently is harder to detect. Eventually, after crossing the room several times, the robot detects a gas patch and updates its estimation, and after 100 m of exploration, it will also have mapped the distribution in the lower-right room.
When compared to the other navigation strategies, IGDM shows again a faster reduction in the RMSE (as shown in
Figure 10b). In this scenario, given the intermittency of the gas plume, the decay in the RMSE is not as steep as in scenario I.
6.2. Physical Experiments
Physical experiments were conducted in a wind tunnel with a volume of , generating a constant wind speed of 1 m/s. The wind tunnel was constructed so that the airflow is first conveyed through a flow straightener consisting of tubes of 10 cm diameter and assembled into a honeycomb structure. This leads to a Reynolds number that lies between 4000 and 6000 for the considered wind speed at 15 °C. Afterwards, the wind flow is further laminated through a very fine-structured filter, becoming quasi-laminar right before it enters the main chamber where the experiments were carried out. Here, we placed an electric pump that vaporized ethanol in the air and created a gas plume in the downwind direction. Ethanol was employed for these experiments because it is safe to handle without special equipment, the quantities dispersed are not toxic for humans, and it can be easily removed between experiments by venting the wind tunnel for a few minutes. Moreover, ethanol is heavier than air and stays close to the floor, which makes it easier for wheeled ground robots to detect it.
We repeated the physical experiments under two different conditions to allow for a qualitative comparison with the simulation results described above. The first test was conducted in the 10 m long central section of the tunnel (see
Figure 11a) so that the resulting ethanol distribution would approximately be a straight and continuous plume. Then, for the second test, we added an obstacle course that would disrupt the plume and represent a generic indoor environment (see
Figure 11b). Although the stacked boxes we used were only 30 cm high, as depicted in
Figure 12, we did not measure significant concentrations of ethanol above them with our testing equipment. Running the experiment in a wind tunnel compensated for the lack of an explicit ground truth such as the one we had during simulation. We were able to control, to some extent, the gas distribution based on the disposition of obstacles as well as reproduce almost identical test conditions since the wind speed and gas release point were always the same. We always placed the gas source outside the robot’s test area (see
Figure 11) to prevent the robot from getting tangled up in the outlet pipe of the pump.
As shown in
Figure 12, the robot used for the experiments was the Khepera IV, a small, 14 cm wide differential drive robot equipped with a MiCS-5521 CO/VOC gas sensor by SGX Sensortech as well as a custom-made wind sensor board [
50]. Robot localization was achieved using overhead cameras placed on the ceiling of the wind tunnel, as well as the SwisTrack 4.2 software [
51] (
https://github.com/d28b/swistrack, accessed on 23 April 2023) running on a separate desktop computer to detect the active markers on the robot. Since the robot’s resources were limited for the purpose of this algorithm, all gas and wind measurements were also relayed to the same desktop computer. After receiving the sensor data, the algorithm first processes the gas sensor readings to mitigate the slow recovery of the employed gas sensor [
52] when the robot moves between areas of different concentration, then updates the GW-GMRF estimate and finally computes the next movement command to be sent to the robot. This process is repeated every time the robot complements its movement and sends its new sensor readings.
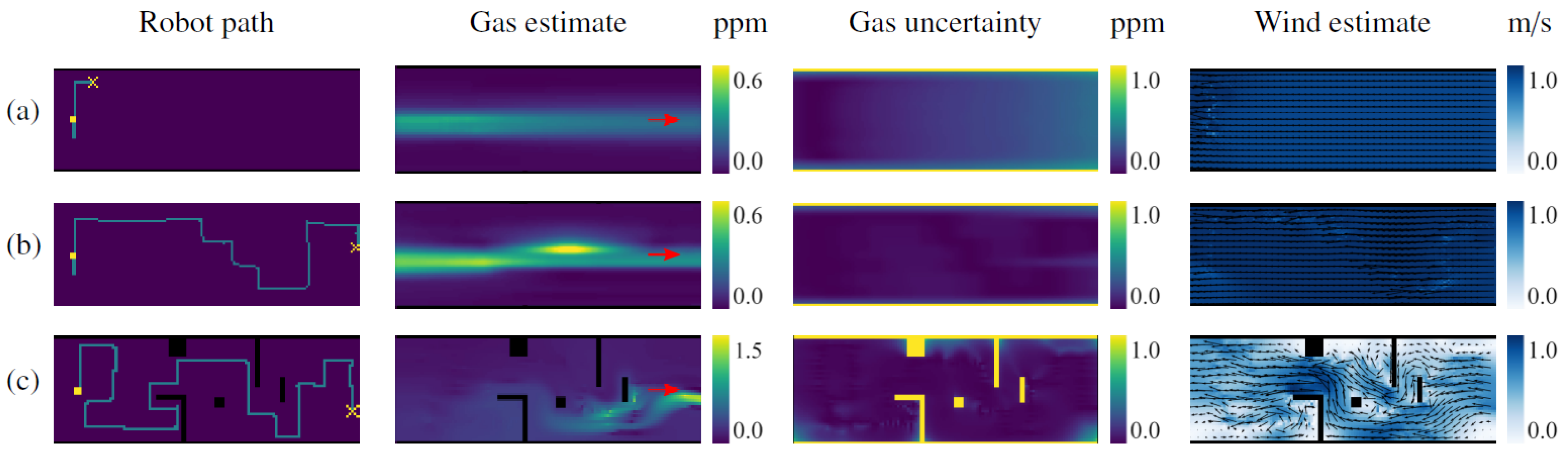
Although there was no ground truth for the gas and wind maps in the physical experiments, the IGDM algorithm’s behavior appeared appropriate for the selected test conditions. In fact, in the test without obstacles, the robot started by moving perpendicular to the wind, as this provides the highest amount of information. In doing so, the robot was able to estimate the general shape of the gas plume and the complete wind map after only 5 m of exploration, as shown in
Figure 13a. The remainder of the path (
Figure 13b) consists of upwind crossing from one side of the room to the other. We observed a similar behavior when obstacles were placed in the wind tunnel, as shown in
Figure 13c. However, this time, the robot performed a more thorough exploration, focusing more on areas that were shielded from the wind (e.g., the inverted “L” shape), since those areas are harder to extrapolate without wind information. After 40 m, the robot passed in front of the gas source and the estimated gas map was completed.
The results obtained in the real experiments highlight that the behavior of the robot is consistent to the one observed in simulations. Therefore, we can conclude that the IGDM algorithm successfully achieves its purpose in real-world scenarios as well.
7. Conclusions and Outlook
In this paper, we presented IGDM, an information-driven algorithm to map complex gas distributions with an autonomous mobile robot. IGDM relies on GW-GMRF to estimate a gas map of the robot’s surroundings from a sparse set of gas and wind measurements, and on an information-gathering POMDP to determine how the robot should move to obtain more relevant samples to complete the map. IGDM leverages the strength of GW-GMRF, namely the ability to deal with wind currents and obstacles, and closes its control loop so that the robot’s exploration yields reliable gas estimates even in complex indoor environments, as demonstrated experimentally.
One relevant aspect of IGDM is that it shares the same approach as
infotaxis [
30], an information-driven search strategy, to locate the source of a gas distribution. Instead of following a predictable pattern or moving to locations with a higher gas concentration, both strategies (IGDM and
infotaxis) focus on minimizing the uncertainty of the gas distribution, even if this means sampling at locations with no gas at all to confirm its absence [
53]. Despite their differences, one being aimed at Gas Distribution Modeling (GDM) and the other at Gas Source Localization (GSL), it is reasonable to consider that they could be eventually brought together for mutual benefit. For instance, the robot could estimate the likely position of the gas source given an estimated gas map and then refine said estimate through CFD techniques once the source is confirmed. However, this warrants more research before it can be put into practice.
In this regard, one of our future goals is to develop a new GSL strategy similar to IGDM that also produces a probability map of gas source locations [
7]. This could be especially relevant for safety-related applications such as gas leak detection, where the algorithm could provide a gas map to take immediate palliative actions (e.g., evacuation of human personnel) as well as information about the origin of the leak to plan for corrective actions (e.g., dispatching a robot that is equipped with a sealant gun). Still, before we can achieve this, we first have to further reduce the computational requirements of IGDMs current formulation. One option is changing the underlying grid map of GW-GMRF to one with a variable resolution. In this way, adjacent areas that share similar gas values could be bundled together and computed as a single unit. However, doing so implies that the complete lattice may change between iterations, which brings a whole new set of challenges. Another option might be to reduce the number of action combinations that are evaluated during each forward simulation. As discussed previously, the most immediate solution would be to replace the decision stage in the POMDP with a Monte Carlo Tree Search (MCTS) or a variation of Rapidly Exploring Random Trees (RRT), which would also help to mitigate the exponential cost of increasing the finite horizon beyond the values we have used in this work.
Lastly, we are also planning to extend the IGDM algorithm to multi-robot systems. Although our current implementation might work if run on several robots that explore the same environment, they would not be aware of each other’s intentions. Possibly, the best option is to include an additional term to the reward function that accounts for the relative position of the robots, as this would fit well under the current formulation. However, this is still a hypothetical approach, and more research is needed on this front.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}