1. Introduction
With the progress of society and the rise in people’s income, the consumption of meat maintains an upward trend, which has resulted in a sharp surge in the demand for livestock, including live pigs, and prompted heightened expectations for the animals’ welfare and productivity [
1,
2,
3]. A current topic of interest is finding an accurate and efficient solution to the problem of individual pig identification. Traditional methods such as painting, branding, ear tagging, and radio frequency identification (RFID) require significant human and material resources, resulting in a high workload and low efficiency. This is not conducive to intelligent [
4,
5,
6], healthy, and precise pig farming [
7,
8]. Therefore, there is an urgent need for a simple and efficient method for individual pig identification.
Individual pig identification methods can be invasive or noninvasive. In recent years, farming has gradually adopted non-invasive methods, using neural networks as machine learning progresses. For instance, Wang Z et al. [
9] proposed a two-stage pig face recognition method based on triple-edge loss. This approach ensures non-contact pig face recognition and significantly improves the average accuracy of pig face recognition to 94.04%. Similarly, an enhanced CNN model was developed by Hansen M F et al. [
10] to facilitate the recognition of pig faces for non-invasive biometric identification purposes, achieving a certain level of improvement. Marsot M et al. [
11] improved the algorithm for pig face recognition by detecting and refining the algorithms for pig face and pig eye, ultimately achieving an accuracy of 83%. In another study, Wang Z et al. [
12] have introduced an enhanced ResNAM network as the principal framework for pig face image feature extraction, resulting in an improvement of 3% in recognition accuracy. Lastly, Posta, E et al. [
13] have developed an algorithm specifically for instance segmentation of live pigs, achieving an accuracy of 91%.Additionally, Ahn H et al. [
14] presents a novel method for detecting individual pigs, solving the problem of difficulty in detecting pigs due to high exposure, with an accuracy of up to 94.33%. Ocepek M et al. [
15] proposed establishing an automated detection system for live pigs to improve recognition accuracy by optimizing the YOLOv4 algorithm, achieving up to 90% accuracy. Li, Y et al. [
16] proposed an adaptive pig individual detection algorithm that introduces new parameters into the Gaussian mixture model and uses different learning rates to improve identification of live pigs in motion. Zhuang, Y et al. [
17] suggested creating a pig feeding-and-drinking behavior software that identifies and judges pig behavior using convolutional neural networks, providing technical support for intelligent pig breeding. Yu S et al. [
18] put forward a pig individual recognition method for edge devices that uses deep learning algorithms to detect pig individuals and pruning technology to improve computing efficiency. Seo J et al. [
19] proposed a lightweight pig automatic detection network that reduces computational load through filtering and clustering modules, achieving 8.7 times higher performance than the original detector. Sa J et al. [
20] suggested using image denoising and simple processing technologies to detect pig individuals, with an accuracy of 0.79 and an execution time of 8.71 ms. Cowton J et al. [
21] developed a pig multi-object detection and tracking system using regional convolutional neural networks and real-time multi-object tracking. T. Psota et al. [
22] proposed a tracking method based on probabilistic detection, assigning unique identifiers to instances using a classification network and assigning ear tags through algorithms, and creating a set of continuous trajectories for real-time tracking. Wang M et al. [
23] optimized FairMOT with a deep learning algorithm, realizing the recognition and tracking of reappearing pig individuals and improving the accuracy of multi-target recognition and tracking. Bhujel A et al. [
24] proposed a deep-learning-based pig individual and motion state detection and tracking algorithm and found that the YOLOv4 detector combined with the deep sorting tracking algorithm improves performance in pig multi-object detection and tracking. Zhang L et al. [
25] proposed a method for individual detection and tracking of live pigs that achieves a recognition accuracy of 94.72% and a recall rate of 94.74%, providing appearance features for the tracker.
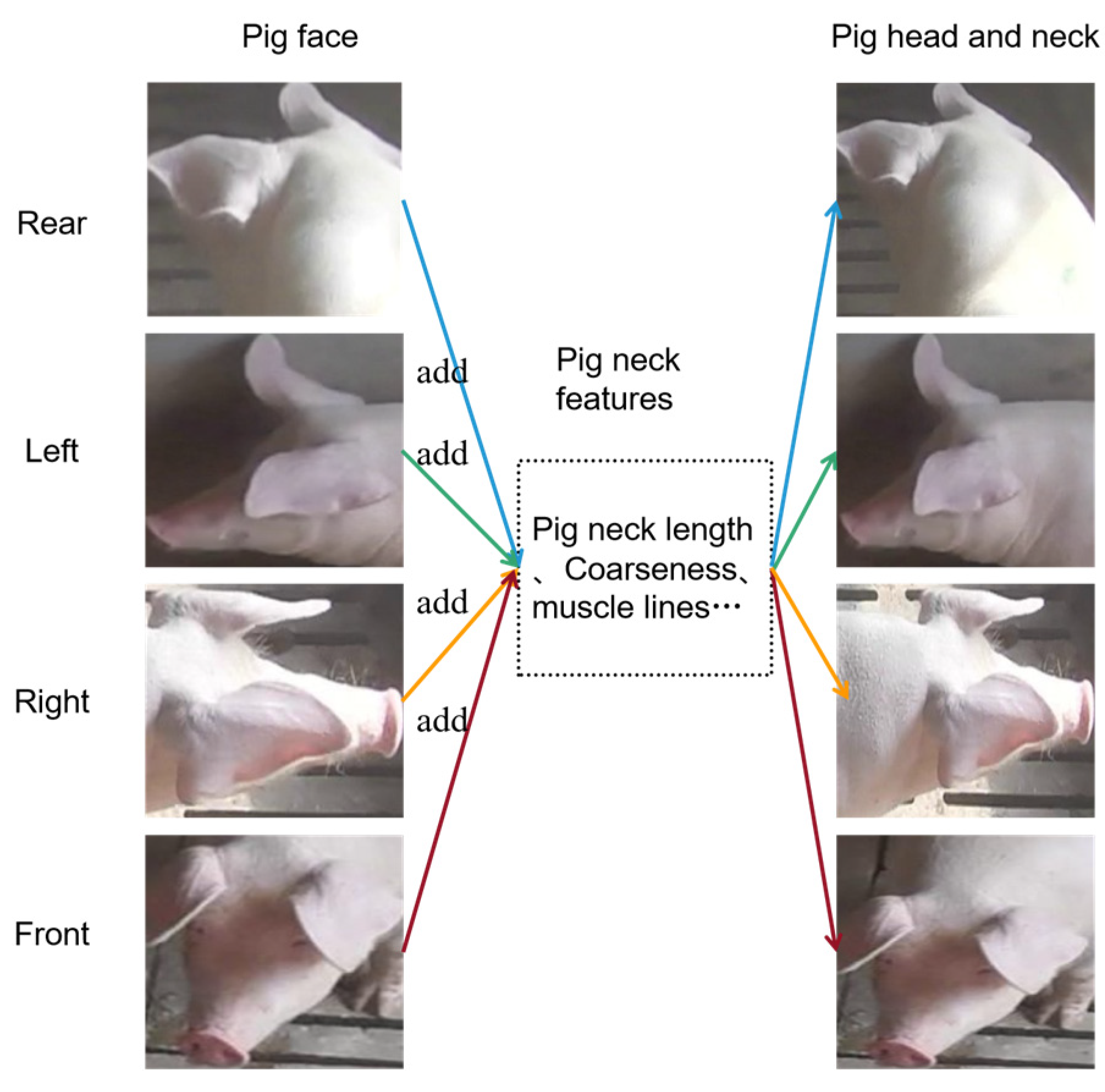
Despite the positive results achieved in various studies on pig identification, there are still certain limitations in practical pig farming, specifically with regards to identifying individual pigs from a distance. Evidently, most of these studies focus on pig faces, which are subject to occlusion and loss of features on the rear, left, and right sides during pig activities, leading to missed detections. To improve accuracy, this article proposes using pig heads and necks, which, taken together, contain more feature information for individual recognition. However, there is still room for improvement in terms of the robustness and accuracy of the algorithms mentioned above. Building upon the YOLOv5 algorithm, this article enhances the adaptability of the algorithm’s target frames, position feature extraction, and high-to-low-level feature fusion by optimizing target anchors, introducing CA attention mechanisms, and BiFPN feature fusion. These enhancements enable precise identification of individual pigs in practical farming settings.
The main contributions of this article are as follows:
(1) In terms of datasets, a new pig head and neck dataset has been created based on the pig face. Pig heads and necks are involved in the judgment criteria of pig recognition, which provides more information and improves accuracy.
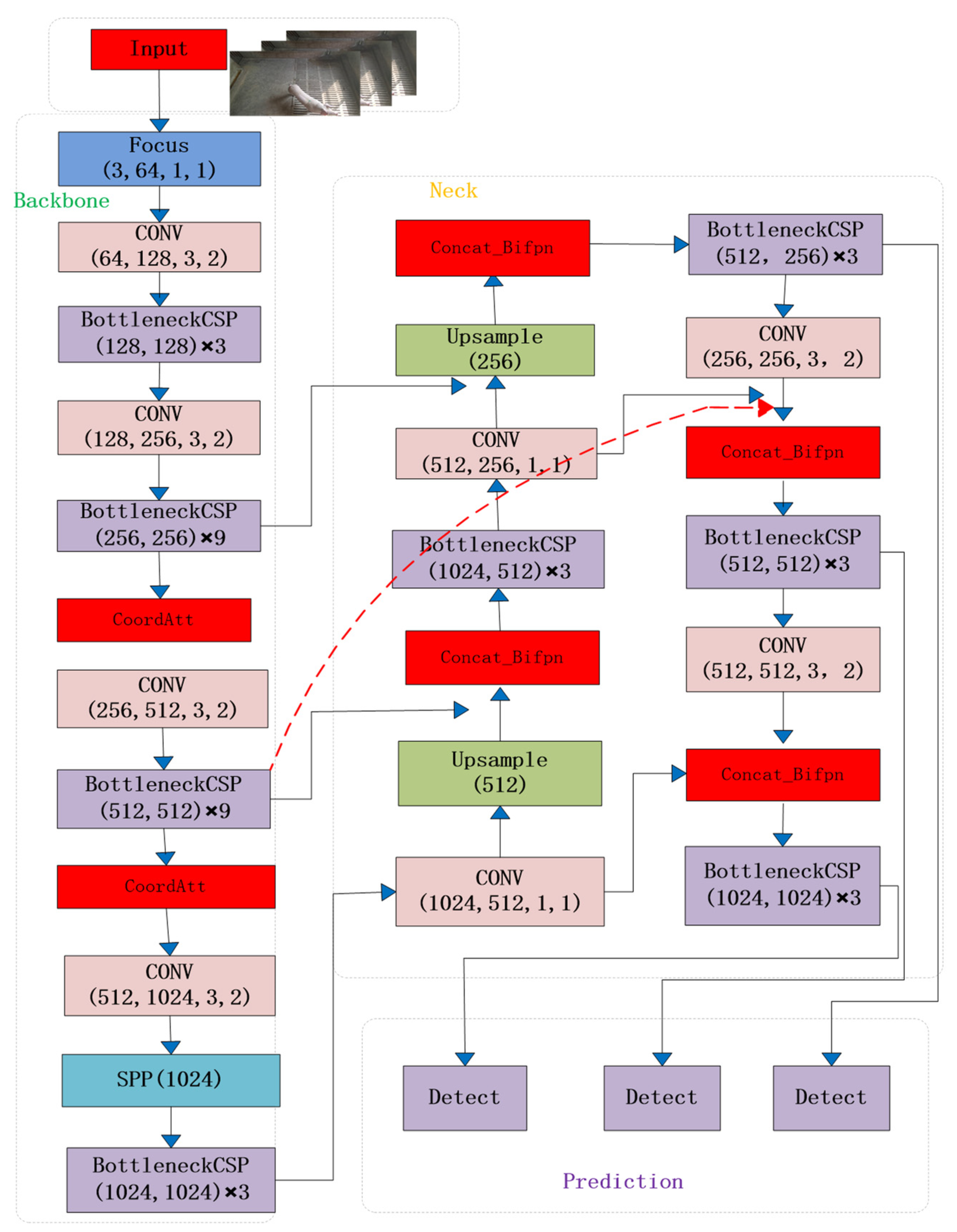
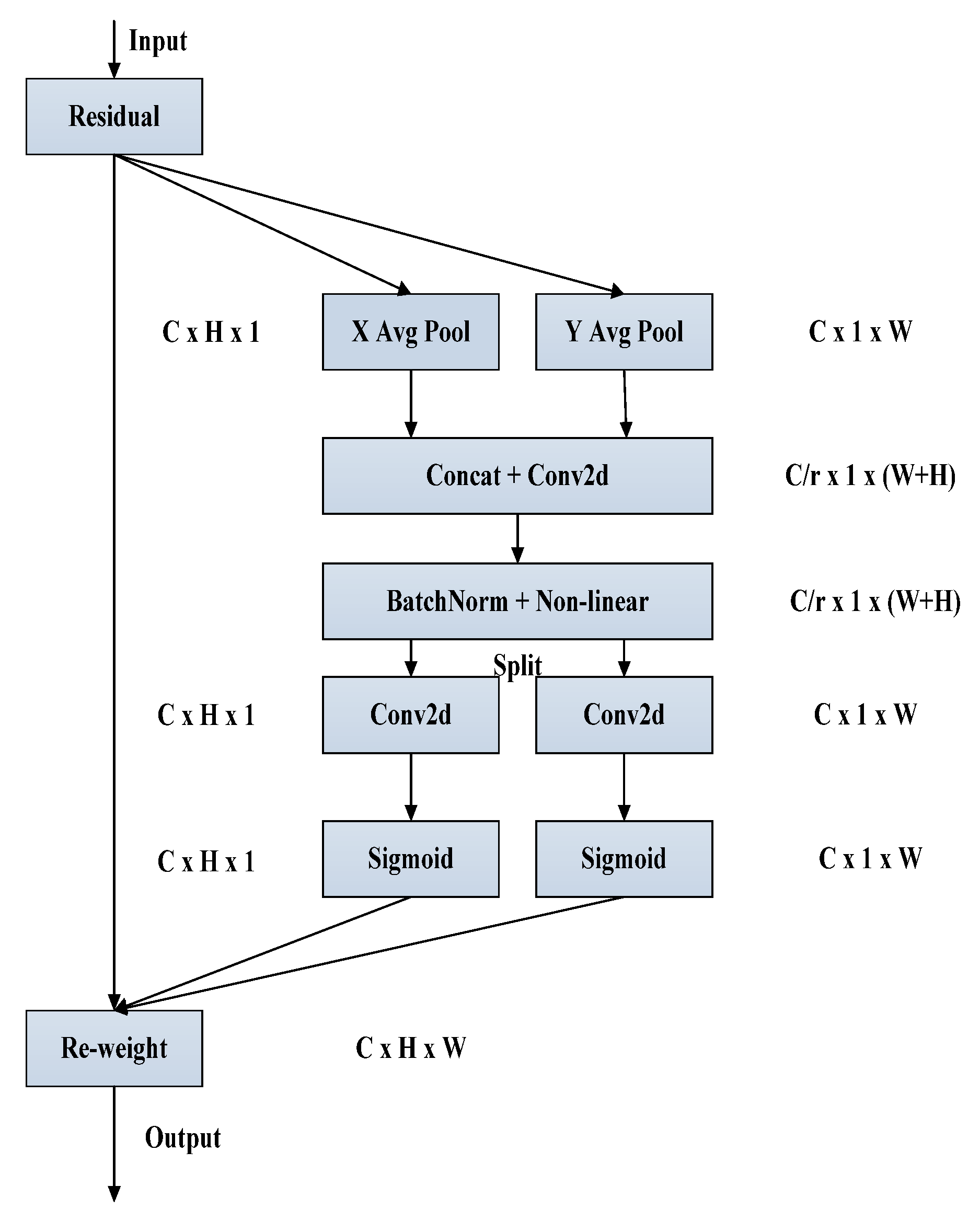
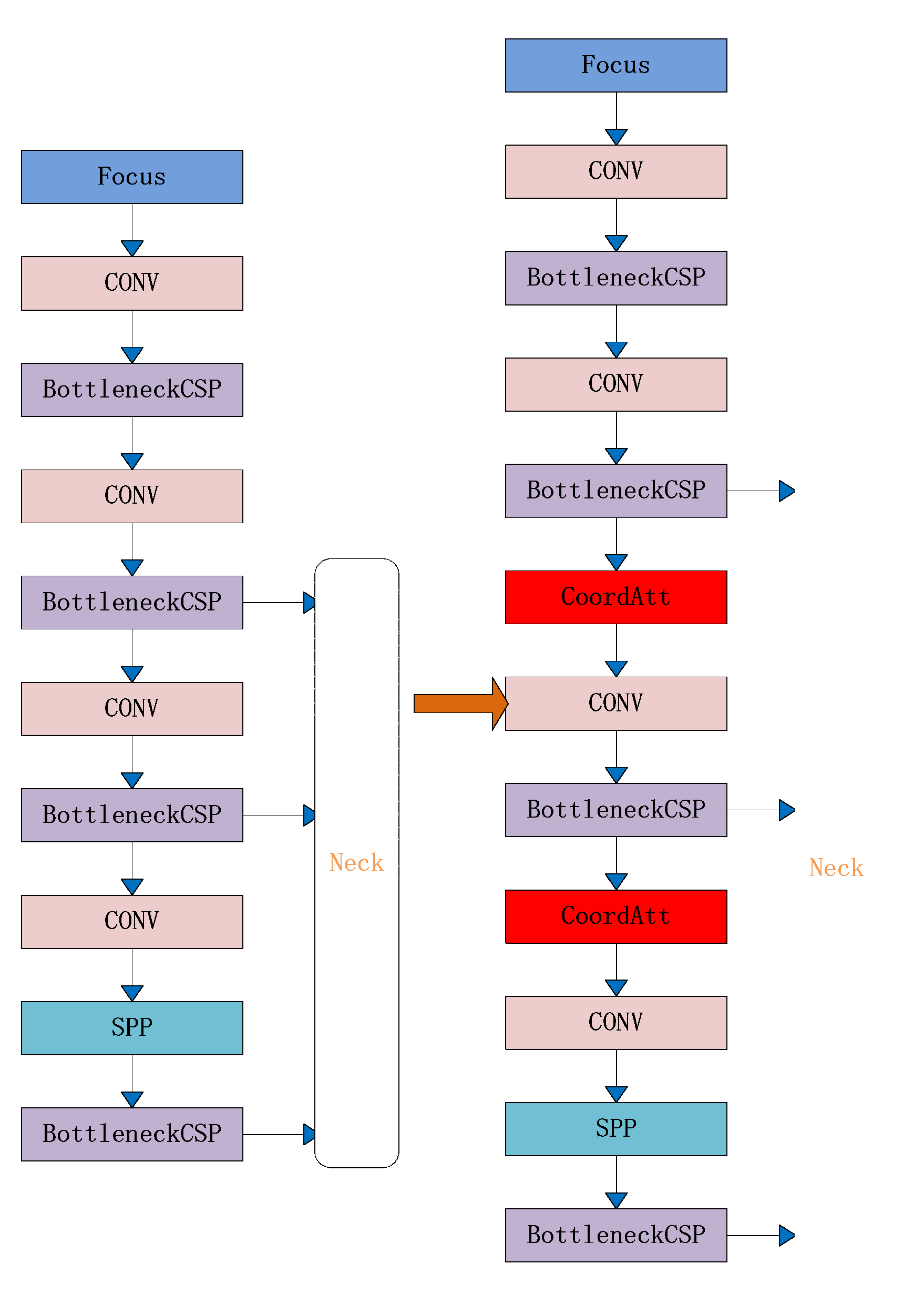
(2) In terms of algorithms, this article intends to use the YOLOv5 algorithm, which has higher recognition accuracy, as the basis for improvement. Firstly, we will change the Euclidean distance of K-means clustering to 1-IOU to improve the adaptability of the algorithm’s target box. Then we will introduce coordinate attention mechanism to more effectively learn the features of small targets and target positions. Finally, we will improve the feature fusion method by introducing BiFPN feature fusion, which expands the algorithm’s receptive field and enhances multi-scale learning of multiple interfering targets. This will improve the accuracy of general pig individual identification, as well as the missed detection in dense pig scenes and the missed detection, false detection, and low confidence in classifying small targets at long distances.
(3) In terms of actual breeding, experiments have shown that the improved algorithm for pig recognition performs well in scenarios with single or multiple pigs, small targets, high density, and obstacles. This lays the foundation for intelligent, health-encouraging, and precise breeding of pigs.
3. Results and Analysis
3.1. Experimental Environment
Due to the significant size of parameters and high level of computational complexity in most target detection algorithms, this paper utilizes GPUs, which offer much greater computational power than CPUs, to reduce training time and improve speed. The experimental setup in this study includes an Intel i7 9700F 3.0 GHz processor with 16 GB of memory and a 16 GB graphics card (NVIDIA GeForce RTX 2080Ti). The tabulated data presented in
Table 1 provides specific details.
To maximize the overall goal, the algorithm was trained using the SGD optimizer with a batch size of 16, an initial learning rate of 0.001, a momentum of 0.92, and a weight-decay coefficient of 0.001. The learning rate was changed using the cosine annealing method, and the algorithm went through 100 iterations. All algorithms used in this research employed the same hyperparameters mentioned above.
3.2. Model Evaluation
In this article, we will use common evaluation metrics in deep learning [
43,
44], including recall (
R), precision (
P), average precision (
AP), and mAP, which is the average of
AP values across all categories.
TP (true positives) is the number of correctly identified individual pigs, while
FN (false negatives) is the number of missed individual pigs, and
FP (false positives) is the number of falsely identified individual pigs. The formulas for these metrics are shown below:
3.3. Experimental Comparison of Improved Target Anchors
This new approach has been shown to be feasible by the introduction of the average IOU as an evaluation metric. Average IOU represents the average maximum IOU between the previous box and the actual target box. The higher the average IOU, the better the previous frame obtained by the improved algorithm.
The experimental hardware is displayed above. The previous boxes were clustered using the K-means algorithm, utilizing both its original form (referred to as Cluster SSE) and an enhanced method (referred to as Cluster IOU).
It is evident that the original clustering algorithm performs better than the manual design method in determining the previous frame from
Table 2. However, the improved clustering algorithm outperforms both the original clustering algorithm and the manual design method, with improvements of 6.1% and 2.1% in the average IOU, respectively. This demonstrates that the enhanced K-means algorithm surpasses the previously-used adaptive prior frame determination methods and enhances the detection of multi-scale pig face images in the model.
To further evaluate the performance of optimizing the target anchor box improvement for individual pig identification and detection, experiments were conducted using the same experimental setup and parameters on a homemade dataset of pig faces and live pigs’ heads and necks.
Table 3 shows the details of the experiments, where “-” indicates the addition of a module in YOLOv5 (as shown in the following tables) except for the CBAM and CARAFE modules, which are represented by the last letter of their names.
The experimental findings demonstrate that the YOLOv5-K algorithm, which enhances the target anchor box through K-means clustering, has considerably increased accuracy, recall, and average precision, as compared to the original YOLOv5 algorithm. Additionally, it supports the improved YOLOv5 algorithm in multi-scale live-pig individual identification.
In comparing the datasets of pig faces and live pig heads and necks, the data from the latter resulted in varying degrees of improvement in accuracy, recall, and average precision in both the original YOLOv5 and YOLOv5-K algorithms. This suggests that the head and neck dataset is better suited for discerning individual pigs.
3.4. Experimental Comparison with Attention Mechanisms
To thoroughly evaluate how attention mechanisms affect individual pig detection, we conducted experiments on our own dataset of pig faces and head–neck data. Under the same experimental conditions, we compared CA, SE, and CBAM attention mechanisms against the original YOLOv5 algorithm.
The results in
Table 4 illustrate that the YOLOv5-S, YOLOv5-M, and YOLOv5-C algorithms with the introduced attention mechanisms are all more effective than the original algorithm in terms of accuracy, recall rate, and mean precision. Therefore, this paper introduces the CA attention mechanism to enhance the algorithm’s anti-interference ability and target feature extraction, improving individual pig detection results.
In addition, the pig head–neck dataset has more individual pig feature information than the pig face dataset, which allows YOLOv5-S, YOLOv5-M, and YOLOv5-C to extract individual pig information better. This, in turn, boosts the algorithm’s accuracy, recall rate, and average accuracy, while also strengthening the robustness of its individual pig detection algorithm.
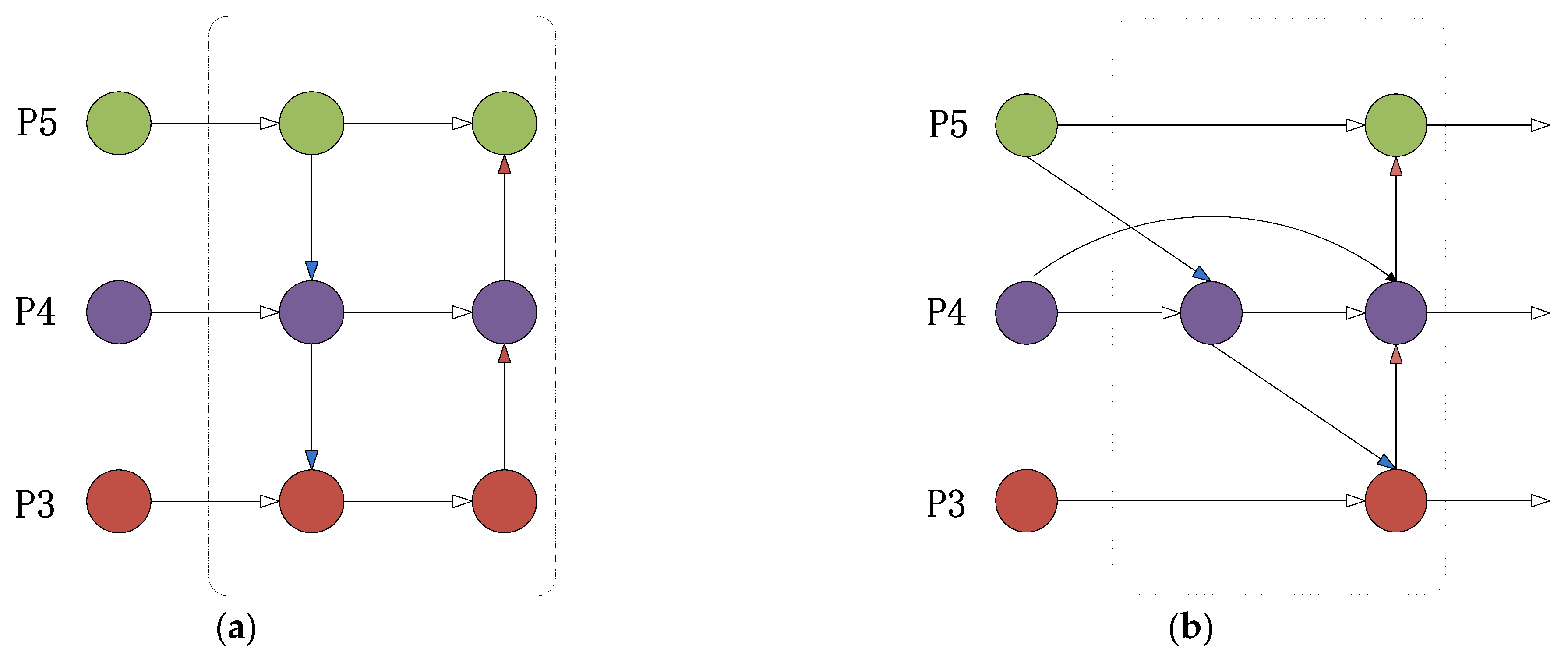
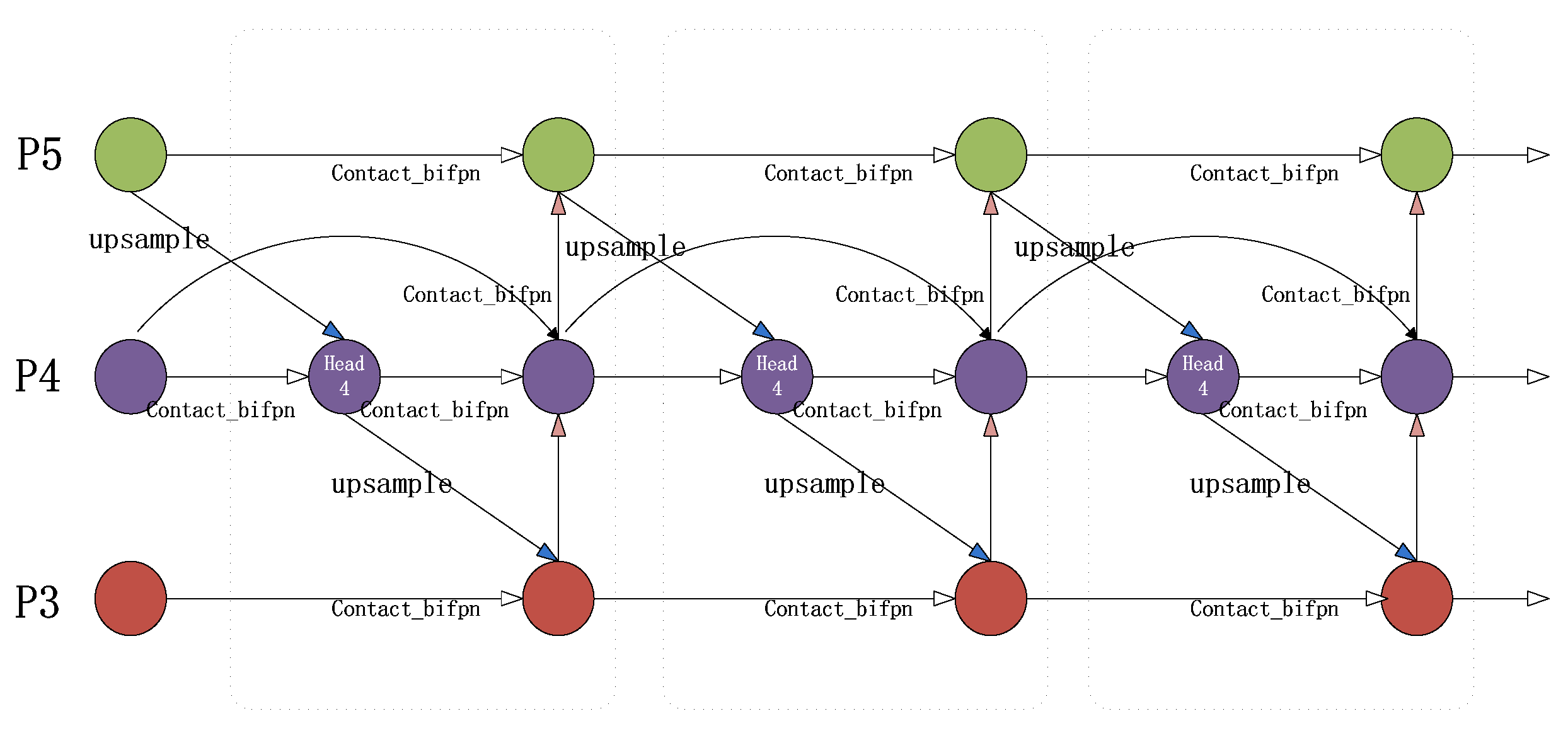
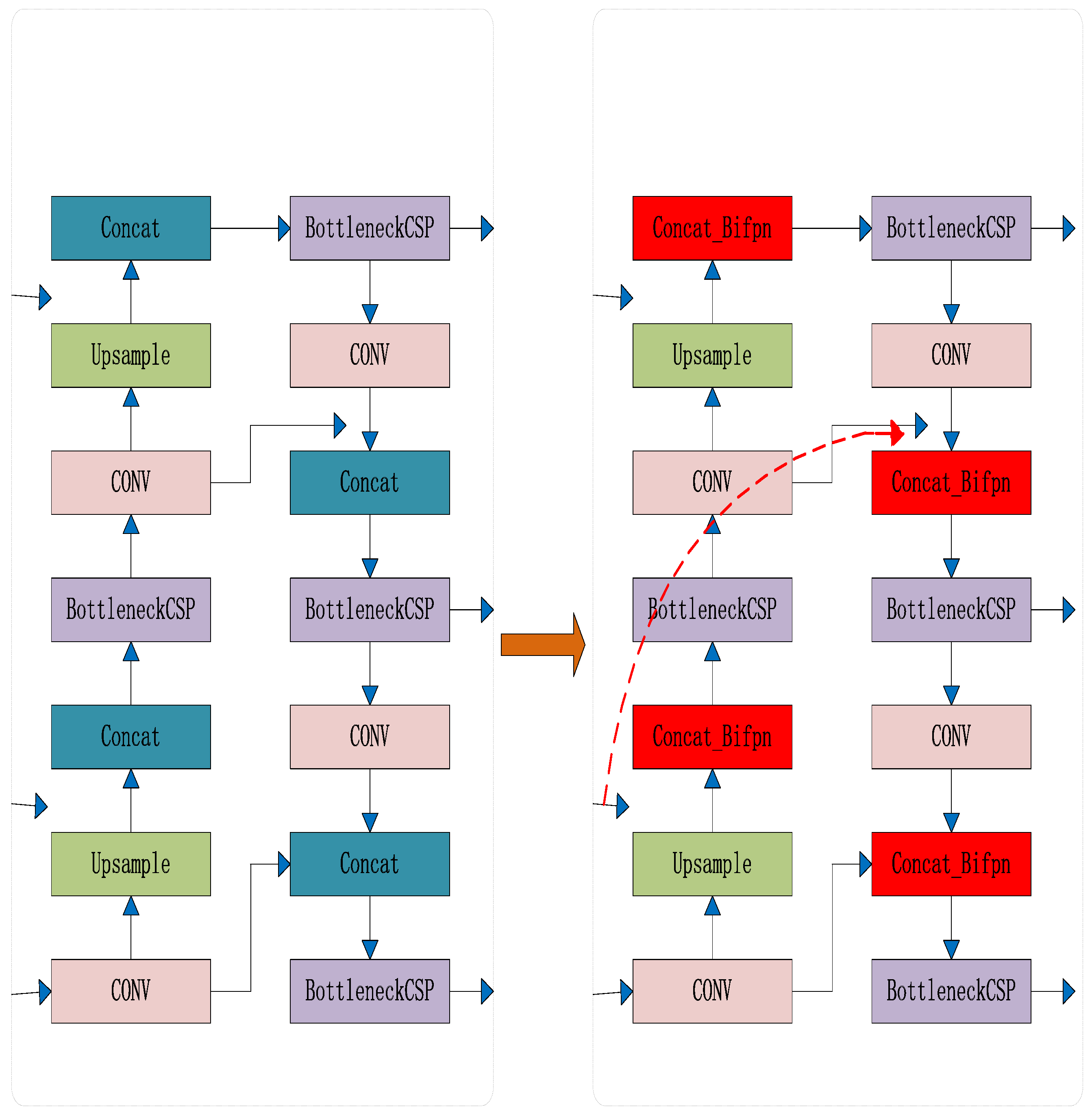
3.5. Experimental Comparison of Improved Feature Fusion
To gain a deeper understanding of the effectiveness of enhanced feature fusion algorithms for individual pig detection, a consistent dataset of pig faces and head–neck images was utilized under the same experimental conditions. The evaluated feature fusion algorithms included lightweight common up-sampling operator (CARAFE), adaptive spatial feature fusion (ASFF), bidirectional feature pyramid network (BiFPN), and the original YOLOv5 algorithm, which were compared and analyzed in
Table 5.
In terms of algorithm optimization, YOLOv5-E with CARAFE, YOLOv5-A with ASFF, and YOLOv5-B with BiFPN feature fusion all showed improvements in accuracy, average precision, and recall compared to the original YOLOv5 algorithm. However, YOLOv5-B demonstrated significantly better performance in average precision and accuracy compared to the previous two improvements. As a result, this study utilized the YOLOv5-B approach with BiFPN feature fusion to extract high-level and low-level features from the backbone network in a biased manner, broaden the receptive field, and establish a stronger foundation for identifying individual pigs.
When comparing the pig face and pig head–neck datasets, it was found that the pig head–neck dataset is better suited for feature extraction and fusion. YOLOv5-A, YOLOv5-E, and YOLOv5-B all showed varying degrees of improvement in accuracy, recall, and average precision on this dataset. Notably, YOLOv5-B performed much better in feature fusion on the pig head–neck dataset compared to the pig face dataset, with a 1% improvement in average precision, making it more beneficial for individual pig identification.
3.6. Ablation Experiment
To verify the effectiveness of the proposed combination of modules to enhance individual pig identification, an ablation experiment was conducted. The results are presented in
Table 6, and use the same pig face and pig head neck datasets while maintaining consistent experimental conditions. Compared with the original algorithm, the algorithm incorporating improved K-means clustering, CA coordinate attention mechanism, and BiFPN feature fusion showed varying degrees of improvement in accuracy, recall, and mean precision. This suggests that improved K-means clustering effectively improves the algorithm’s efficiency in learning target detection boxes. Moreover, CA’s long-term dependence on both location and channel relationships enhances the algorithm’s efficiency in learning position information and enhances prediction accuracy. Finally, BiFPN feature fusion simplifies nodes that contribute less to feature fusion, strengthens nodes that contribute more through weight allocation, and effectively combines low-level and high-level feature maps for optimal detection results.
In terms of algorithm optimization, the comparison in
Table 6 shows that the YOLOv5-KCB used in this paper outperformed other algorithms in all aspects except recall, which was slightly lower than that of YOLOv5-C and YOLOv5-B, which incorporated CA alone, and CA and BiFPN together, respectively. In terms of average precision (mAP), the increase in performance was in the following order: adding one improved point (YOLOv5-K, YOLOv5-C, and YOLOv5-B), adding two improved points (YOLOv5-KC, YOLOv5-KB, and YOLOv5-CB), and adding three improved points (YOLOv5-KCB), with the improvement gradually increasing compared to the original YOLOv5 algorithm. This indicates that the three improvements in this paper are not only effective when used individually, but also have a positive correlation when used together. Overall, the YOLOv5-KCB with three improvements still performed best, with the highest average accuracy and precision, although the recall rate was lower than some individual algorithms. The average accuracy and precision for pig face recognition were 95.5% and 92.6%, respectively, 2.2% and 13.2% higher than those of the original YOLOv5, while for pig head–neck recognition, they were 98.4% and 95.1%, respectively, 4.8% and 13.8% higher than those of the original YOLOv5, further demonstrating the feasibility of YOLOv5-KCB.
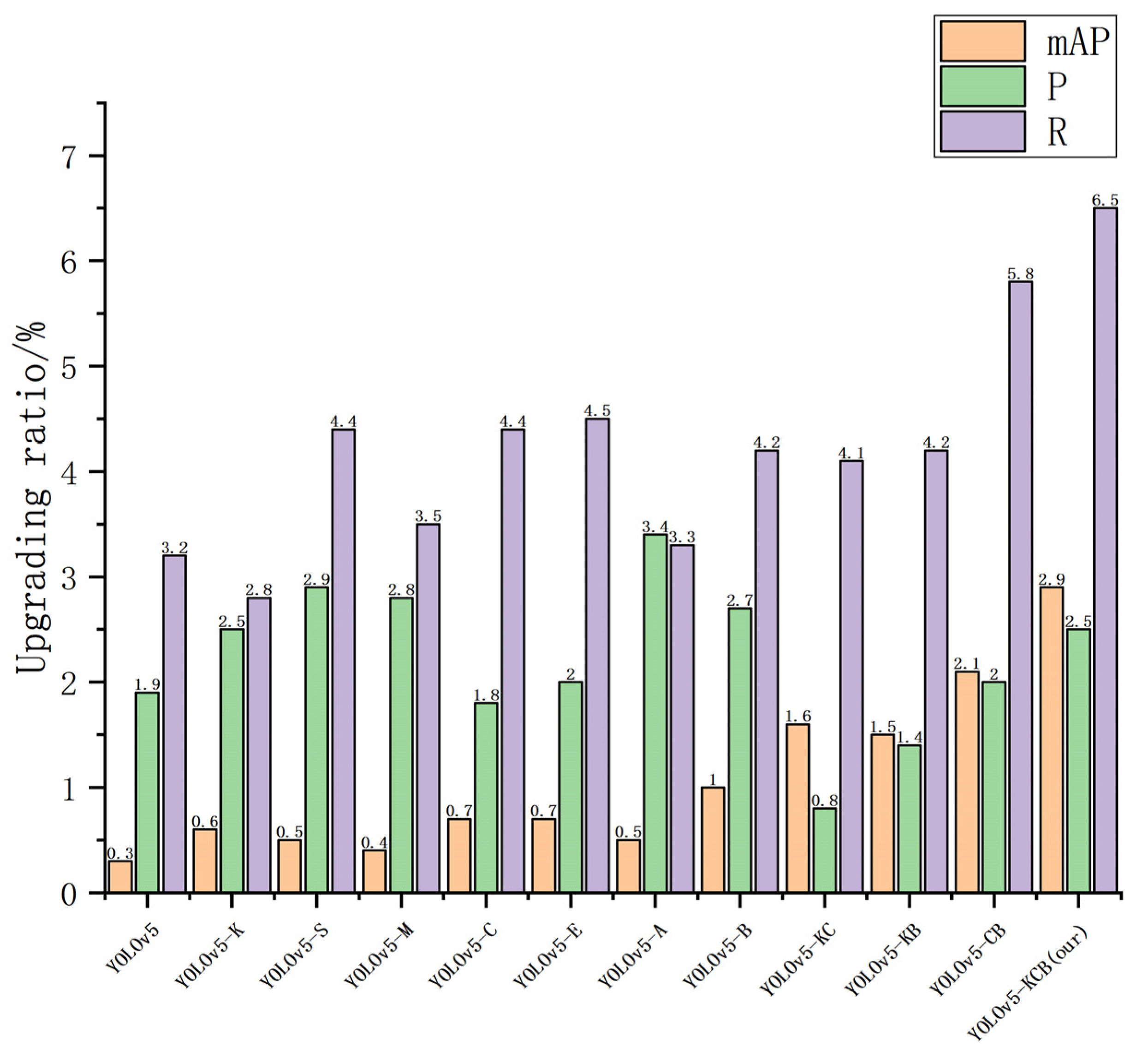
The X-axis in
Figure 14 below represents various algorithms, and the Y-axis represents the percentage improvement in pig head and neck recognition compared to pig face recognition (unit: %).
Regarding the comparison of the pig face and pig head–neck datasets, the use of the pig head–neck dataset improved the average precision, accuracy, and recall rate to varying degrees. The YOLOv5-KCB used in this paper had a lower increase in accuracy than some individual improved algorithms, but it still achieved a 2.5% increase and had the greatest improvement in average accuracy (mAP) and recall rate (R), reaching 2.9% and 6.5%, respectively, indicating that using the pig head–neck dataset for recognition is more conducive to identifying individual pigs than is using the pig face dataset.
3.7. Results of Ablation Experiment
The pig face, pig head and neck datasets were used for individual pig identification, with better pig head and neck identification highlighted as an example.
Figure 15 illustrates the results of ablation experiments on various algorithms in terms of test-set loss. The figure shows that the value of the loss decreases rapidly in the range 0 to 15, followed by a gradual decline in the range 15 to 75. Finally, when the epoch is between 75 and 100, the loss of various algorithms drops to a stable level, and the loss value stabilizes at about 0.015–0.03 on convergence. The training process does not exhibit underfitting or overfitting.
3.8. Detection Results of YOLOv5-KCB
In actual pig farming, there are multiple feeding environments. This study verifies the effect of YOLOv5-KCB on individual pig identification in three environments: single-headed, multi-headed, and dense and long-distance.
Figure 16,
Figure 17 and
Figure 18 show the detection results of the original YOLOv5 algorithm and the improved YOLOv5-KCB algorithm on pig face and pig head–neck datasets.
In
Figure 16, under single-pig breeding, the original image has only background interference information and no other pig obstruction or interference. Therefore, both the YOLOv5 algorithm and the YOLOv5-KCB algorithm can detect individual pigs using either the pig’s face or the pig’s head and neck. However, the classification confidence detected by the YOLOv5-KCB algorithm is higher, and the fitting effect of the detection box is more significant. In addition, the recognition effect of the pig head–neck dataset in the two datasets is better. This suggests that the YOLOv5-KCB algorithm still maintains strong robustness and accuracy under interference backgrounds and is suitable for multiple datasets.
In the case, from
Figure 17, of raising multiple pigs in a pigsty, the YOLOv5 algorithm missed pig 8 under strong lighting conditions and pig 5 with few facial features, while the YOLOv5-KCB algorithm successfully detected pigs 8 and 5, but with lower classification confidence and poorer detection box alignment for pig 5. This indicates that the YOLOv5-KCB algorithm still exhibits high robustness in strong lighting conditions and situations with fewer feature points.
In the case of identifying individual pigs based on their head and neck, both the YOLOv5 algorithm and the YOLOv5-KCB algorithm detected all individual pigs, but the YOLOv5-KCB algorithm showed significant improvements in classification confidence and detection box alignment for all individual pigs. This indicates that the accuracy and robustness of the YOLOv5-KCB algorithm for identifying individual pigs in a dataset with more head and neck feature points will be further improved.
In the case, from
Figure 18, of raising pigs in dense and long distance pig farms, in pig face recognition of individual pigs, the YOLOv5 algorithm missed pigs 6, 7, and 8 in dense, obstructed, and long distance small target recognition, while the YOLOv5-KCB algorithm successfully detected all individual pigs, but due to blurred facial features and obstruction of small target pigs 6 and 7, the effective facial feature information was limited and the detection boxes were offset. This indicates that the YOLOv5-KCB algorithm further enhances feature extraction of location information and fusion of high-level and low-level information. In the identification of individual pigs based on their head and neck, the YOLOv5 algorithm produced a false detection for pig 6, while the YOLOv5-KCB algorithm successfully detected pig 6. This indicates that the YOLOv5-KCB algorithm has a strong generalization ability in scenes with small, dense, and obstructed targets.
In summary: (1) Recognizing individual pigs based on their head and neck can obtain more pig features and is more beneficial in real-world scenarios than the correlative performance of pig face recognition. (2) The YOLOv5-KCB algorithm can still maintain high recognition accuracy and robustness under the differing conditions of single or multiple heads, and dense and long-distance pigs.
3.9. Experimental Comparison of Other Improved Algorithms
To provide a better analysis of the strengths and weaknesses of the improved algorithm presented in this article, we conducted experiments on other improved algorithms under the same dataset and experimental conditions, as shown in
Table 7. Experimental results show that the YOLOv5-KCB used in this paper outperforms other algorithms in all aspects, except for slightly lower accuracy and recall rates in pig face recognition and head–neck recognition when compared to YOLOv5-M and YOLOv5-A, respectively. In particular, the YOLOv5-KCB algorithm shows a significant advantage in average accuracy, with a 2% and 4.4% improvement in pig face recognition and head–neck recognition, respectively, over the lower-performing YOLOv5-S algorithm. There was also an improvement of 1.6% and 3.8% over the highest performing YOLOv5-E. These results further confirm the feasibility of the YOLOv5-KCB algorithm proposed in this paper for individual recognition of live pigs.
3.10. Experimental Comparison with Other SOTA Algorithms
To further demonstrate the feasibility of the YOLOv5-KCB algorithm, a comparison experiment was conducted with the YOLOv5, YOLOX [
45], and YOLOv7 [
46] algorithms. The objective of the experiment was to evaluate three metrics: mAP, P, and R. The experimental results, presented in
Table 8, maintained consistency in the dataset and experimental conditions to ensure reliability.
The results demonstrate that the YOLOv5-KCB algorithm used in this study showed varying degrees of improvement across the three metrics in pig face and head–neck recognition compared to YOLOv5, YOLOX, and YOLOv7. Notably, significant improvements were observed in the YOLOv5 and YOLOX algorithms. When compared to YOLOv7, the YOLOv5-KCB algorithm showed a minor increase in accuracy, but significantly improved recall and average precision, with respective increases of 1.8% and 1% in pig head–neck recognition. These findings suggest that the YOLOv5-KCB algorithm, which incorporates optimized K-means, CA attention mechanism, and bidirectional feature pyramid networks, is highly feasible in individual pig detection.
4. Discussion
Traditional ear tag identification in pig farming is prone to the falling-off of tags, causing infections, and having difficulties in identification and low accuracy. More and more practitioners are turning to non-invasive identification based on deep learning algorithms, reducing manual labor in pig individual identification, and providing new possibilities for realizing welfare, systematization, and intelligence in pig production management. Wutke M et al. [
47] proposed using a CNN network to detect individual pigs and provide their location and motion direction, laying the foundation for subsequent pig tracking. Chen J et al. [
48] proposed a lightweight YOLOv5 network and applied it to an embedded platform for pig individual identification and early warning, achieving a detection accuracy of up to 93.5%. Wang X et al. [
49] proposed a pig individual detection method based on HRNet and Swin transform, which improved the average precision by 6.8%.The above studies all used non-invasive identification and achieved certain results in pig individual identification, but did not innovate and improve specific single, multiple, small targets, dense, and occluded pig farming scenes. This paper uses the YOLOv5-KCB algorithm to optimize the target anchor box, enhance the extraction of position features, and improve the fusion of high and low-level features, improving the robustness and accuracy of pig individual identification in different scenarios. The average precision is 98.4%, which is a 4.8% improvement over the original model.
Experimental results show that the YOLOv5-KCB algorithm can accurately identify multiple pig individuals in different scenarios, with fast identification speed and high accuracy, to some extent, solving the problems of traditional pig farming ear tag identification being prone to falling off, causing infections, difficult identification, and low accuracy. In the future, combined with pig detection platforms, pig farmers can observe pigs around the clock, which is beneficial for statistics and prediction of the growth of breeding pigs, piglets, and other important pigs, and can timely deal with a series of sudden problems such as biting and climbing. In this article, the YOLOv5-KCB algorithm is highlighted as a leading comparative detection algorithm, giving rise to the expectation that it is proficient in other livestock identification beyond doubt.
However, this paper only used nine types of pig individual samples for experimentation, which has certain limitations. In order to better apply the YOLOv5-KCB algorithm in modern pig farming, the next step will be to collect more pig individual images and further improve and adjust the model to improve the practicality and accuracy of pig individual image recognition.
5. Conclusions
To address the challenges and limited accuracy associated with individual pig identification in pig farming, this paper presents a novel non-intrusive recognition algorithm named YOLOv5-KCB. By optimizing the adaptability of target anchor boxes, enhancing the algorithm’s feature extraction capabilities, and effectively integrating high-level and low-level information, the algorithm expands its receptiveness. Consequently, the YOLOv5-KCB algorithm achieves an average precision of 0.984 in identifying regions of pig heads and necks. Compared to the traditional manual individual pig identification method, which suffers from low efficiency, poor accuracy, and inadequate security, the non-intrusive recognition provided by the YOLOv5-KCB algorithm is both safer and more efficient, with greater accuracy. Furthermore, in comparison to existing deep learning-based individual pig identification methods, the YOLOv5-KCB algorithm demonstrates superior performance, with average precision, recall, and accuracy values of 0.984, 0.962, and 0.951, respectively. In addition, the YOLOv5-KCB algorithm has a broader recognition range, enabling convenient individual pig identification in a variety of settings such as single and multiple pig environments, as well as densely populated and long-distance pig farming environments. These findings emphasize the essential role that YOLOv5-KCB plays in monitoring pig farming and individual recognition. The introduction of YOLOv5-KCB provides a viable solution for modernizing individual pig identification technology. Future work will aim at collecting more pig head and neck data in various scenarios to validate the algorithm’s performance, increase its robustness, and establish a solid basis for intelligent recognition and management of individual pigs.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}