

YOLOv7-Peach: An Algorithm for Immature Small Yellow Peaches Detection in Complex Natural Environments

Abstract
:1. Introduction
- Anchor frame information for the new YOLOv7 model is generated by K-means clustering algorithm combined with yellow peach data labels.
- The CA (coordinated attention) module is added to the YOLOv7 backbone network for a better extraction of target features from various yellow peaches.
- The original CIoU loss function is replaced with EIoU to accelerate network convergence and improve model accuracy.
- The P2 module for shallow downsampling is added to the head structure of YOLOv7, and the P5 module for deep downsampling is removed, effectively improving the detection of small targets.
2. Data Acquisition and Preprocessing
2.1. Data Acquisition
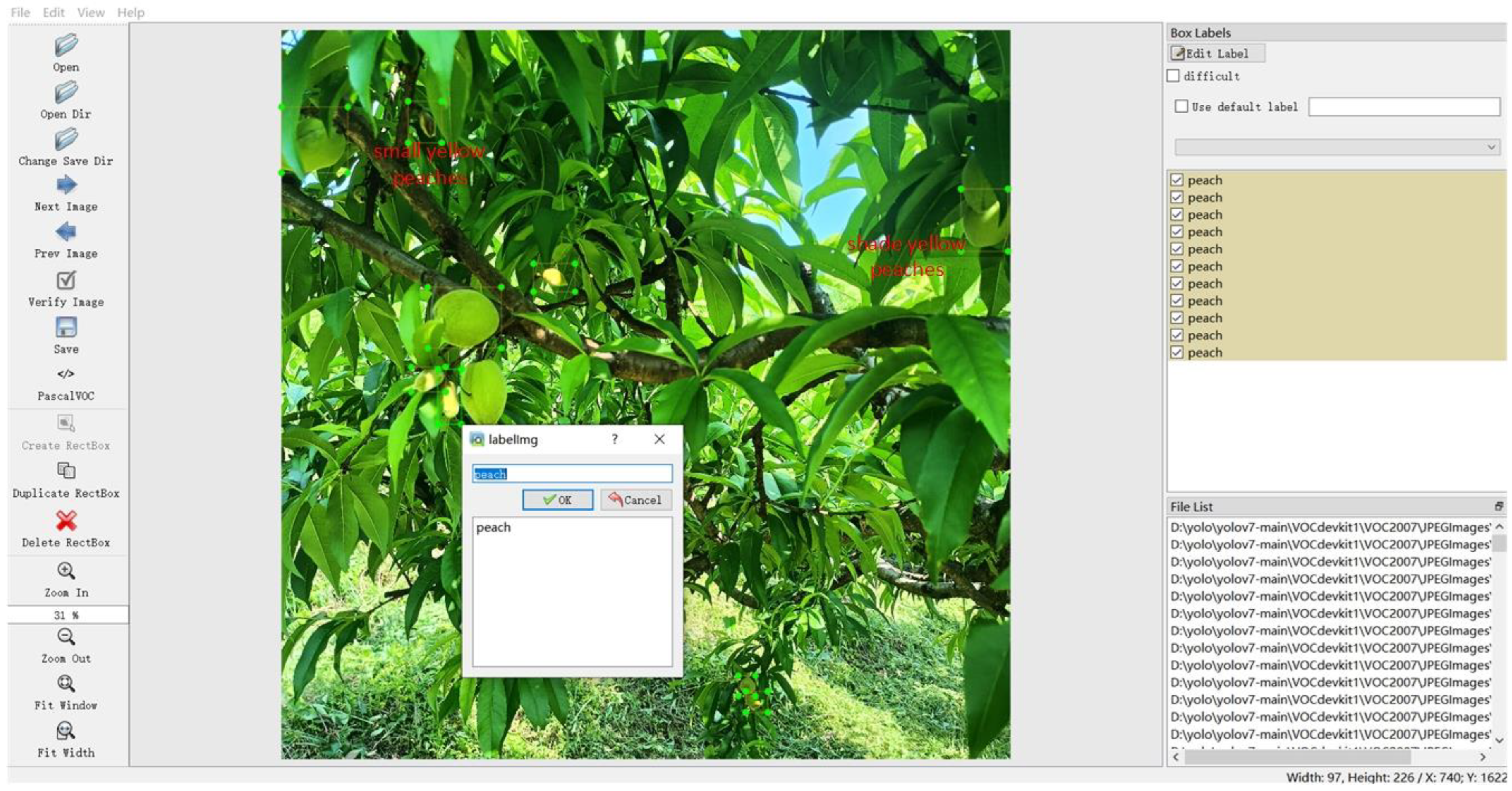
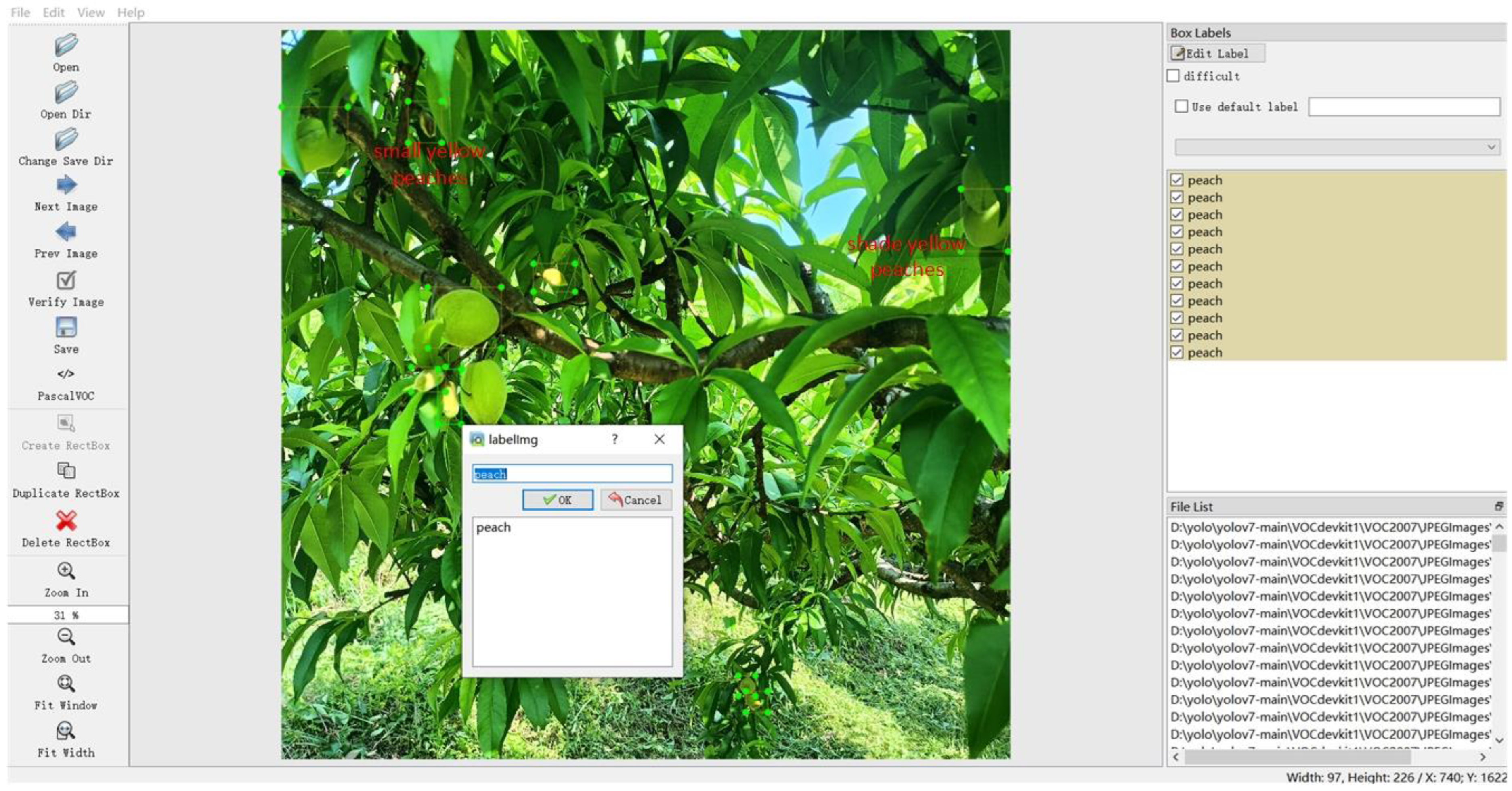
2.2. Data Annotation and Segmentation
2.3. Data Enhancement
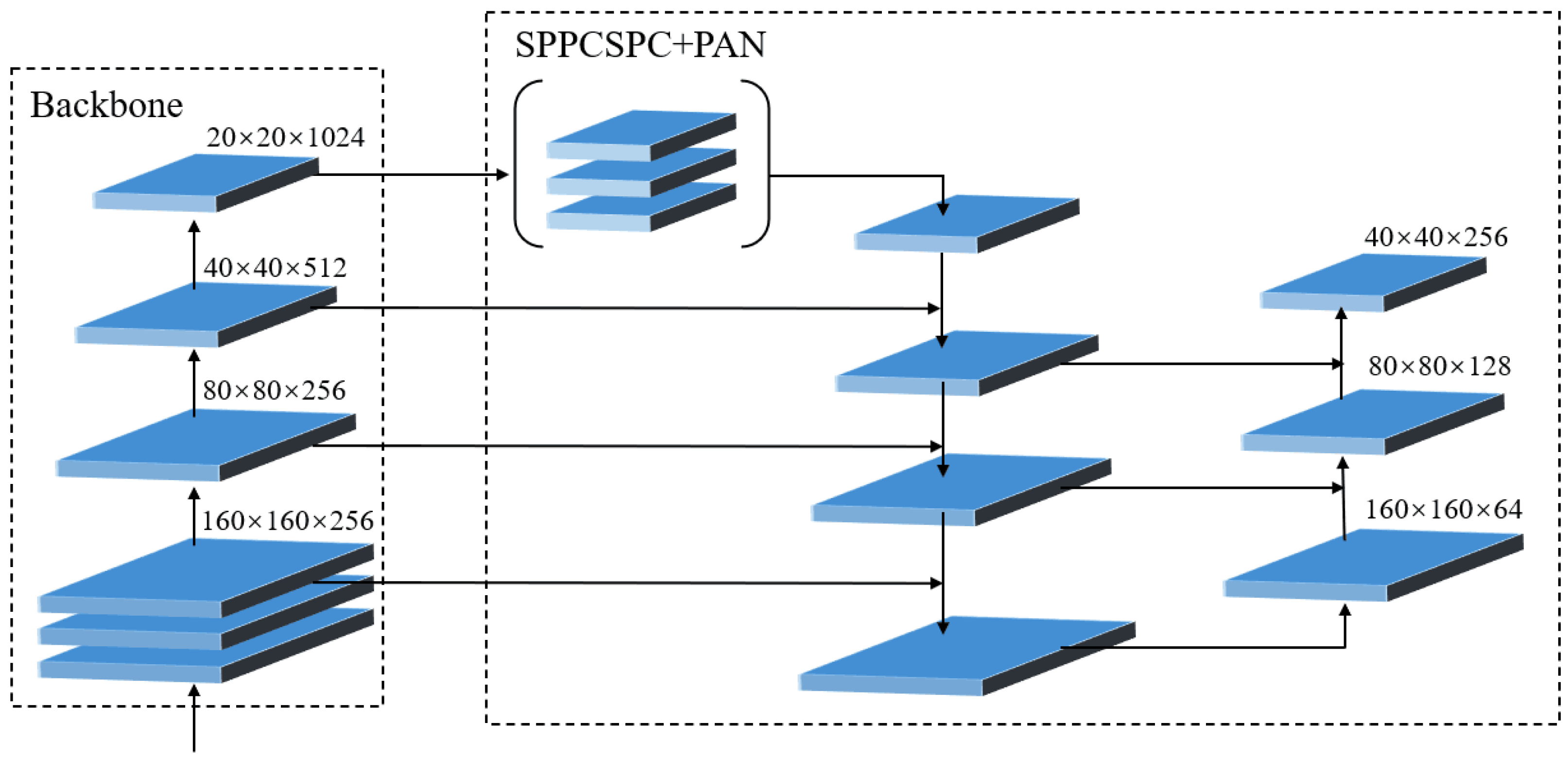
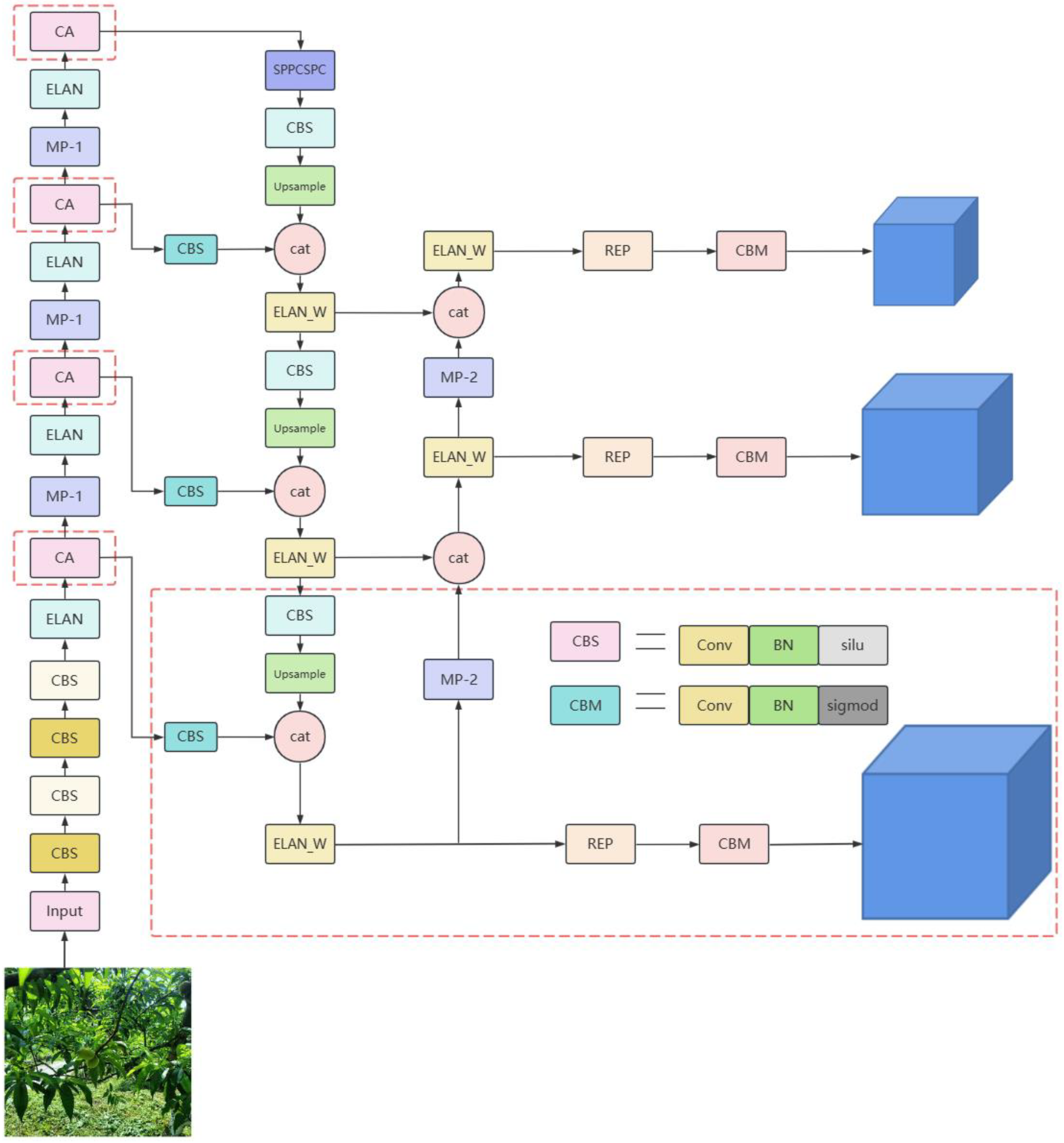
3. YOLOv7-Peach Detection Model
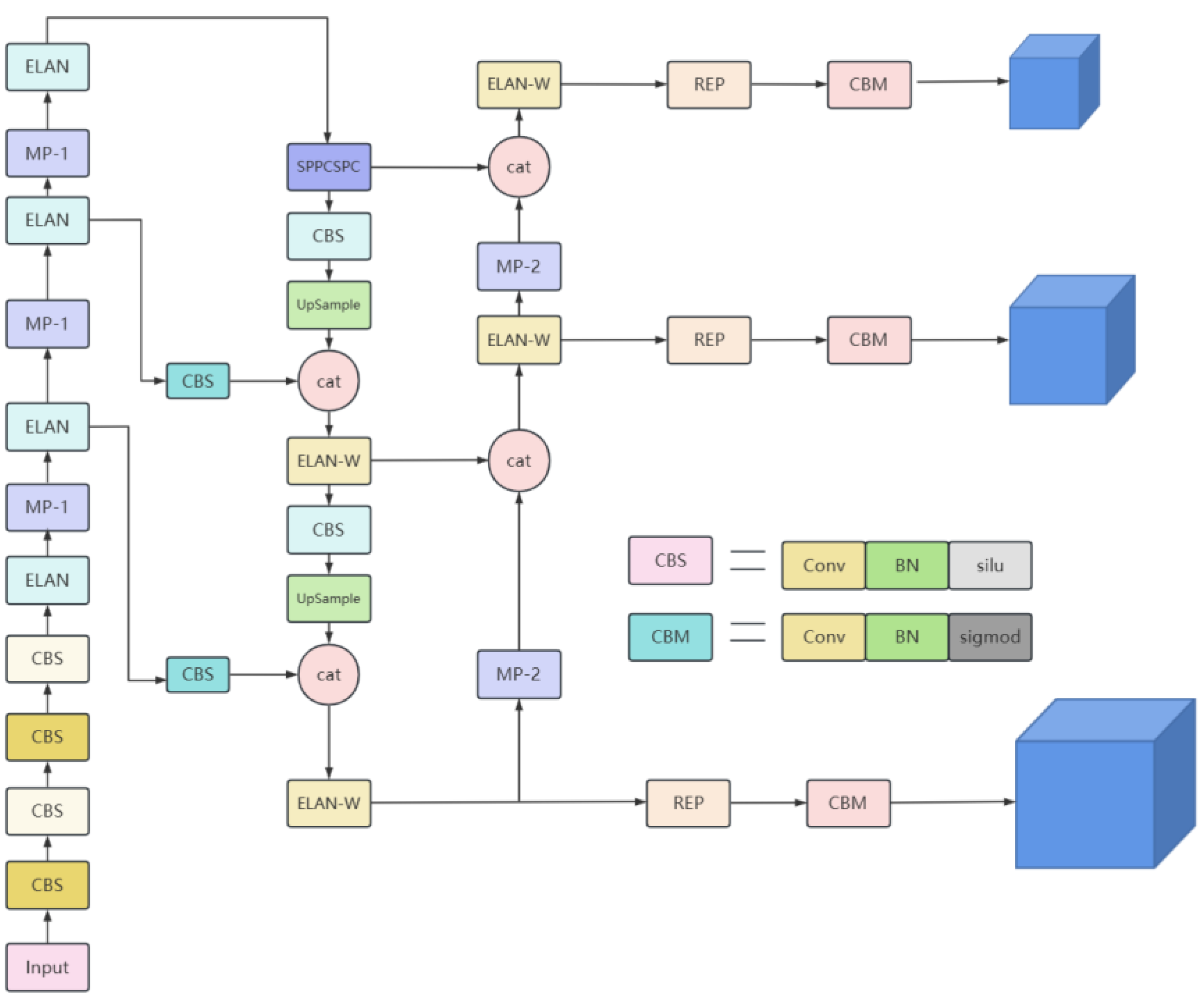
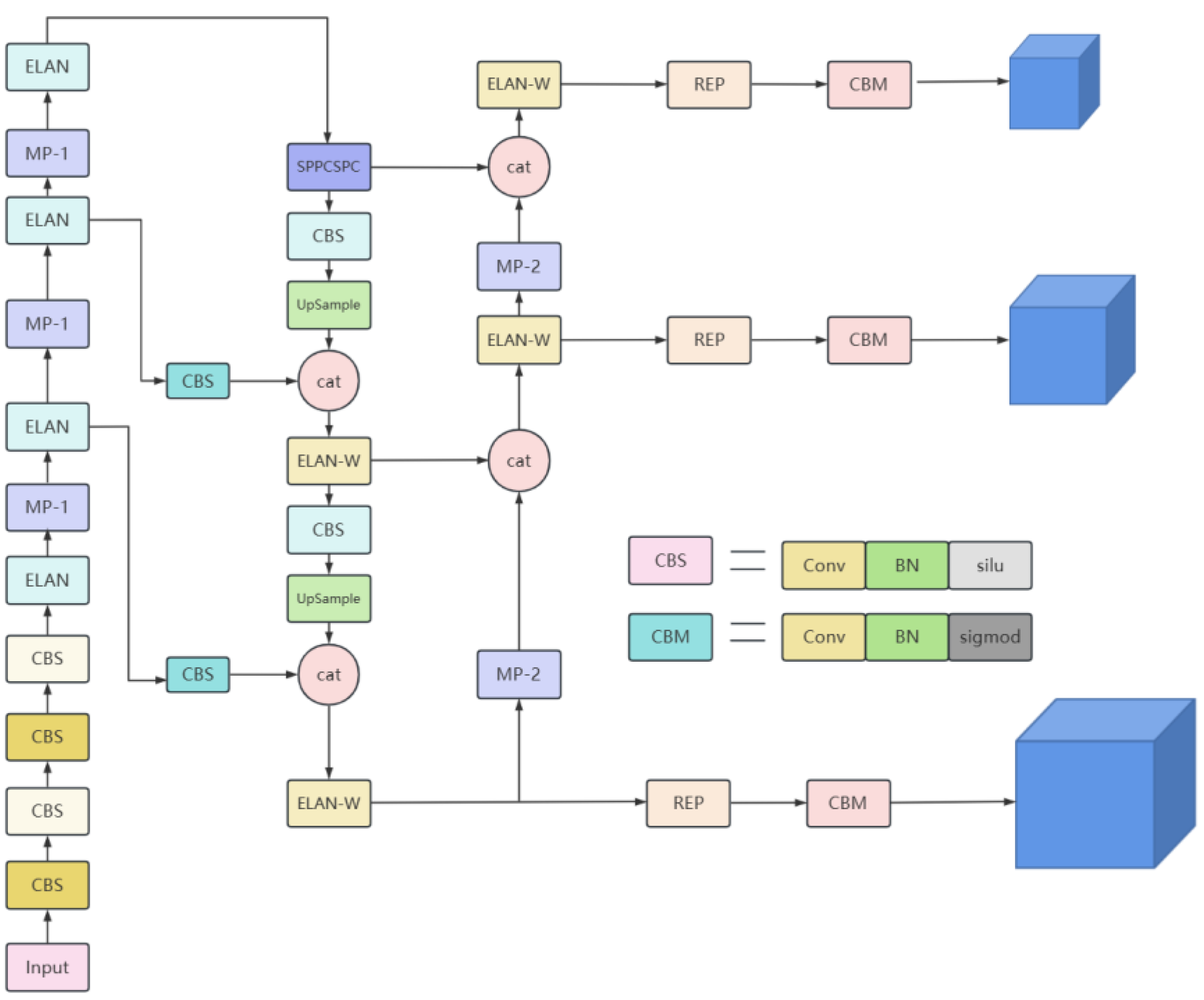
3.1. YOLOv7 Algorithm
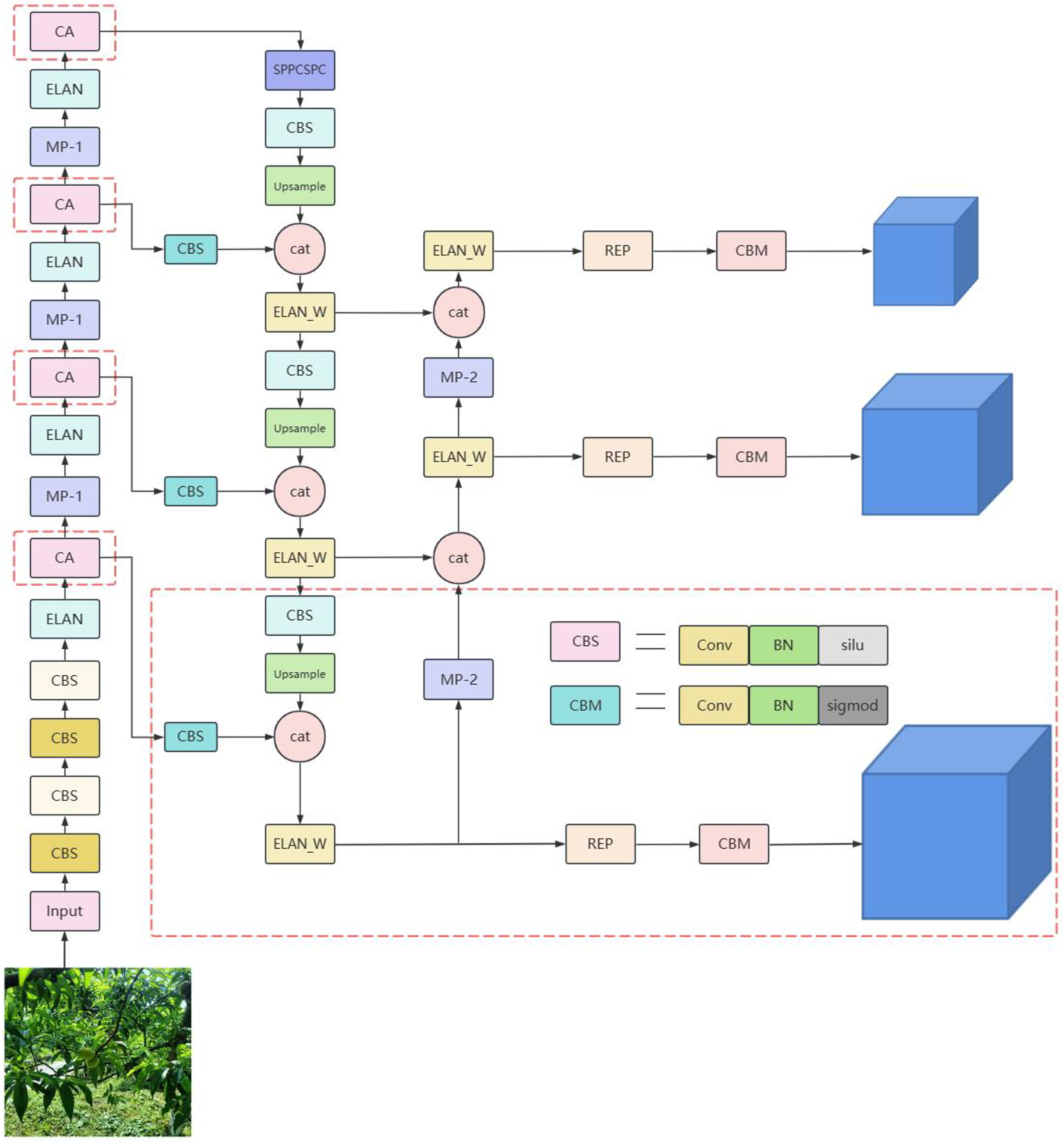
3.2. Improved YOLOv7 Algorithm: YOLOv7-Peach
3.2.1. Anchor Redesigning
- K points are randomly selected from the dataset as the centers of the initial clusters, with the centers
- For each sample in the dataset, the distance to the centroid of each cluster is calculated so as to assign it to the class of the corresponding cluster center if its distance to the centroid of the cluster is the smallest.
- For each category , the study recalculates the cluster centre for that category (where is the total number of data in that category).
- Steps 2 and 3 are repeated until the position of the cluster centers no longer changes.
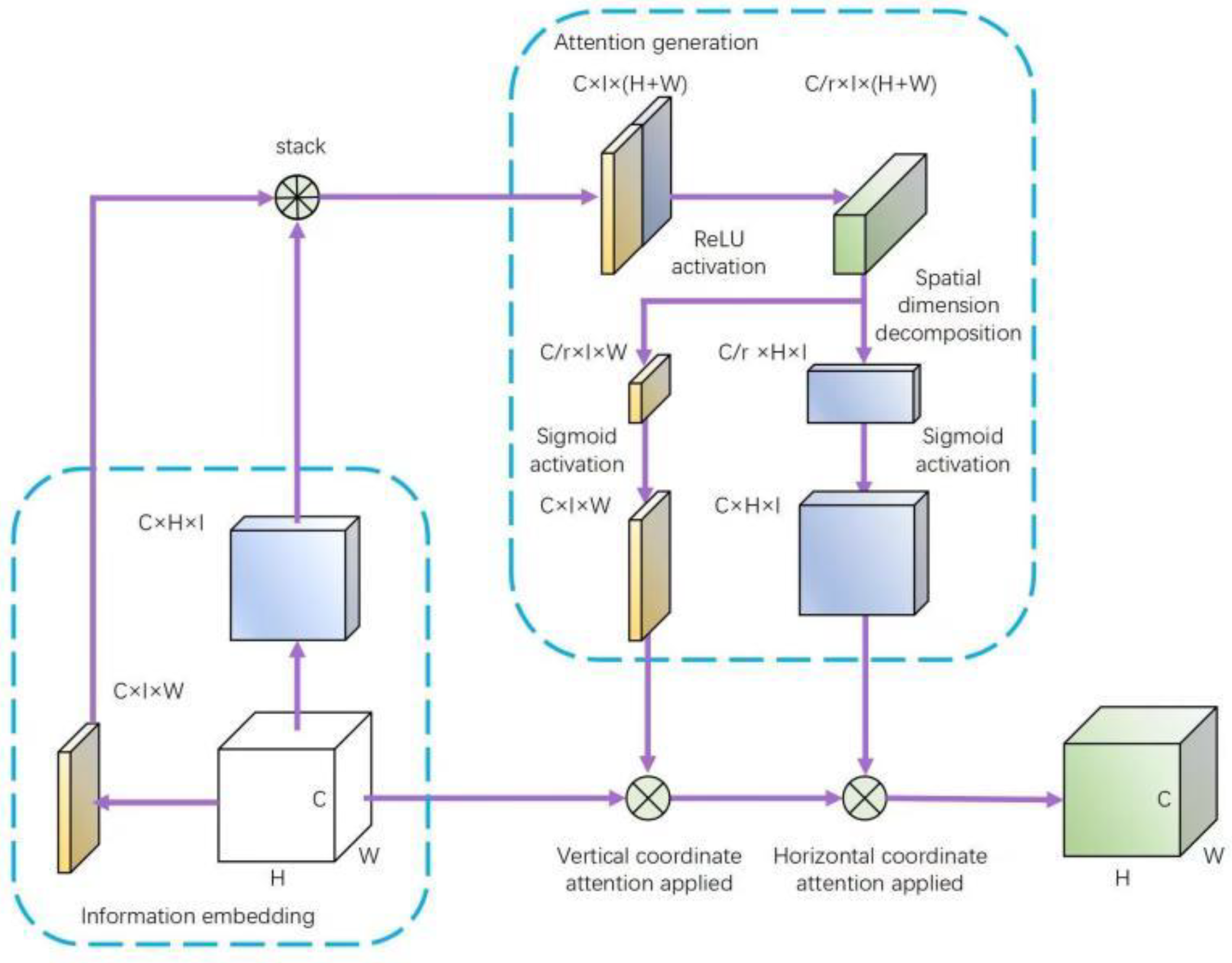
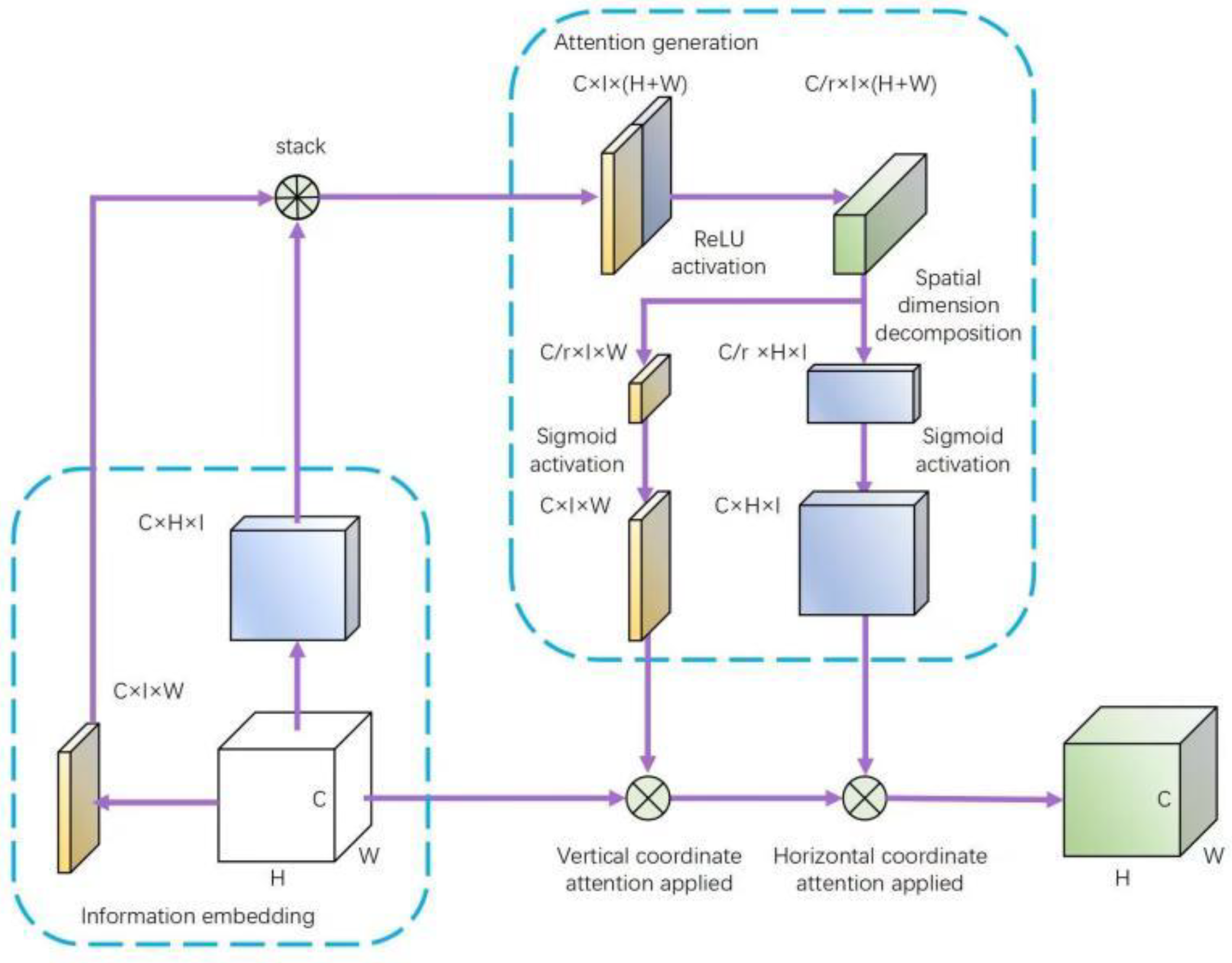
3.2.2. Attention Module
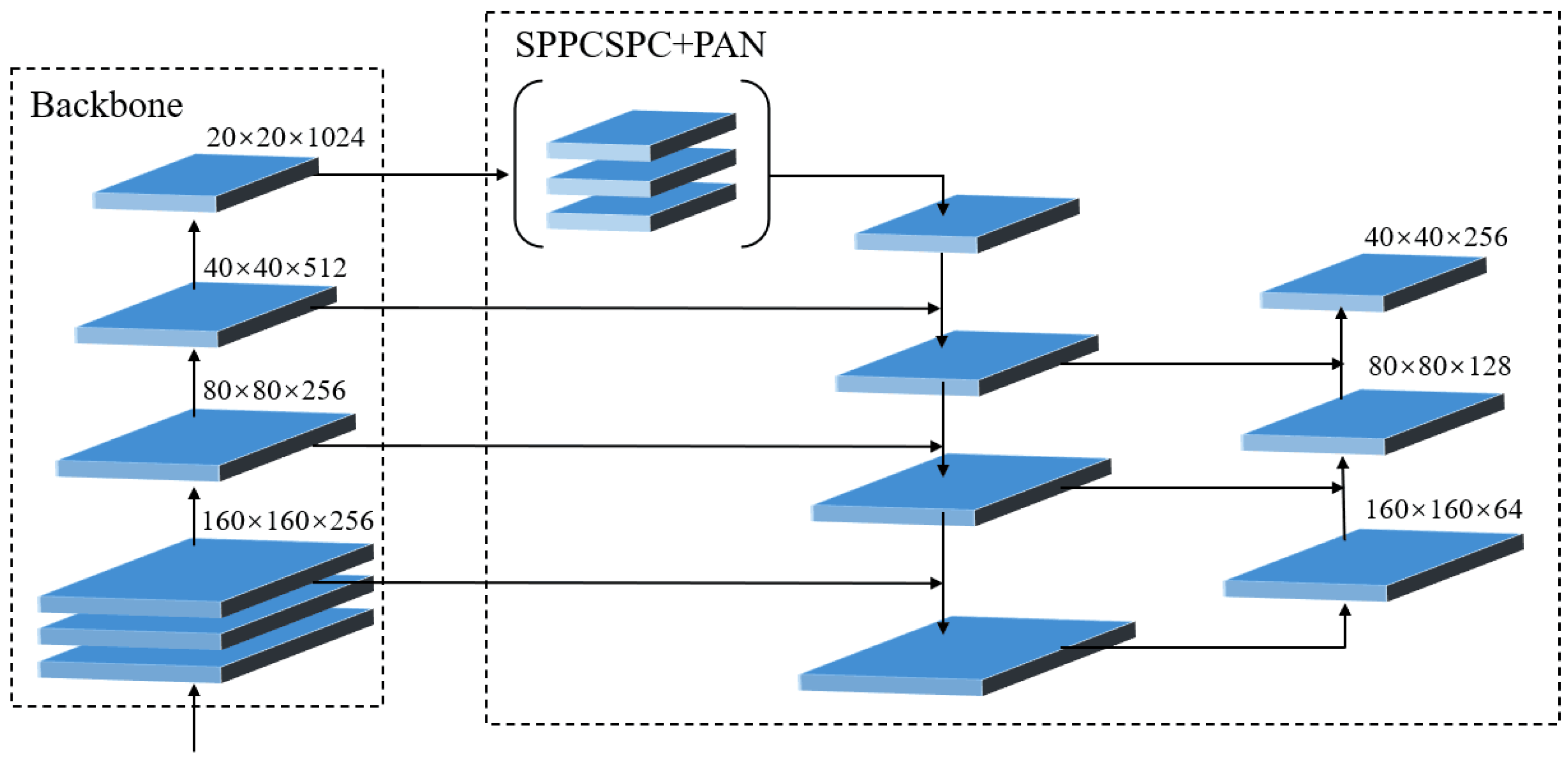
3.2.3. Replacement of the Detection Layer
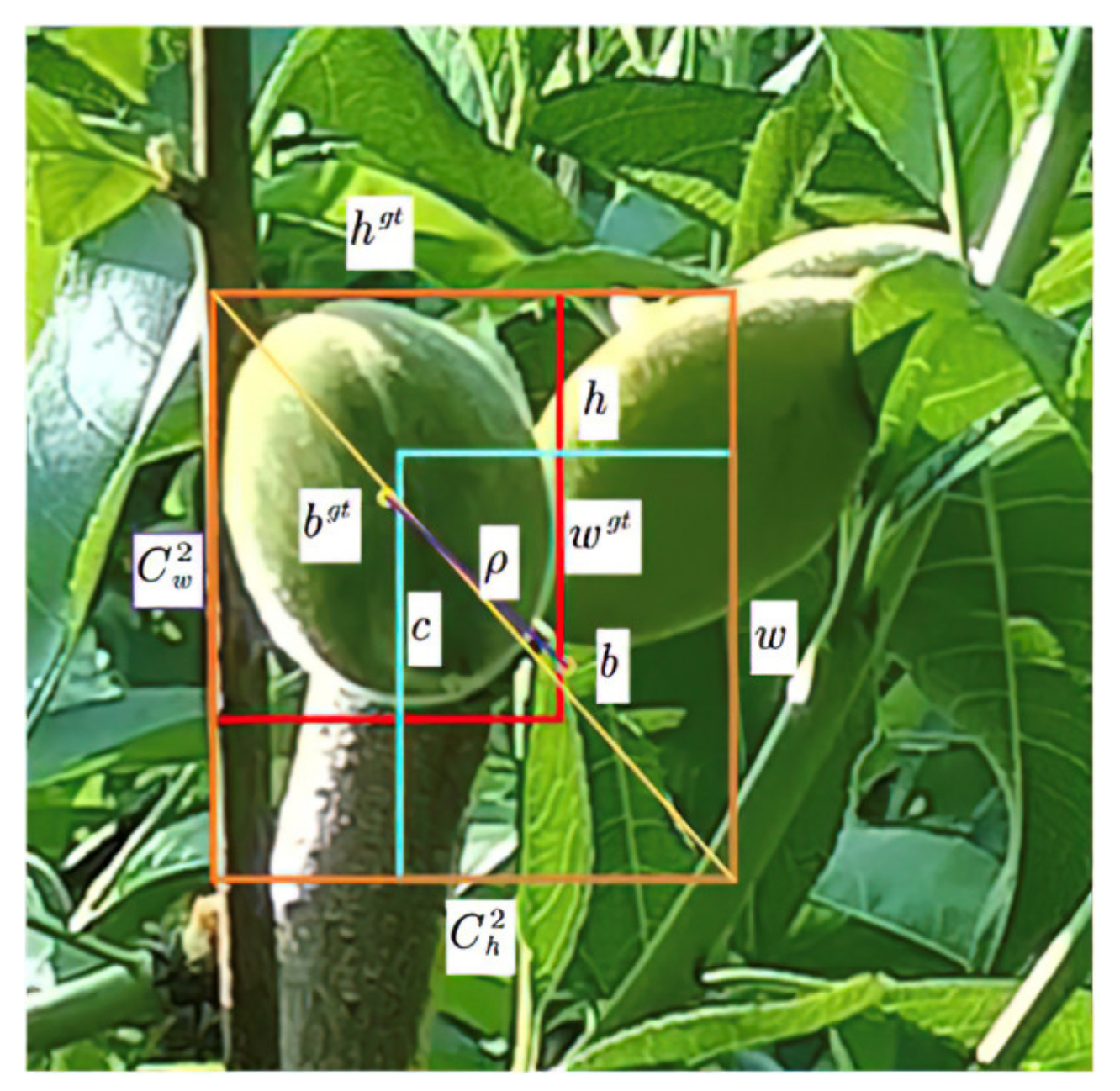
3.2.4. Loss Function Replacement with EIoU
4. Model Training and Evaluation
4.1. Experimental Environment and Parameters
4.2. Evaluation Indicators
5. Experimental Results
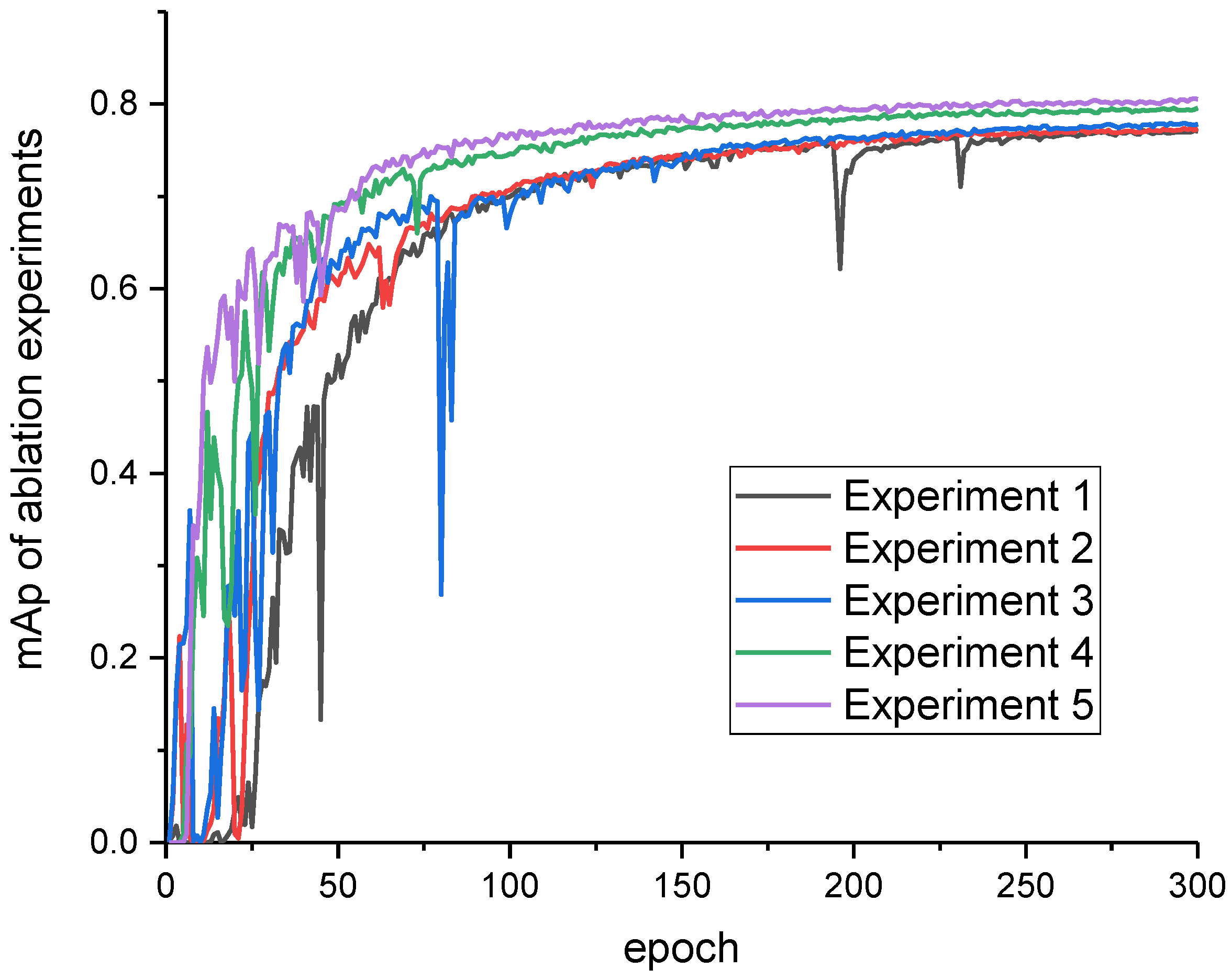
5.1. Ablation Experiments
5.2. Comparison of Different Networks
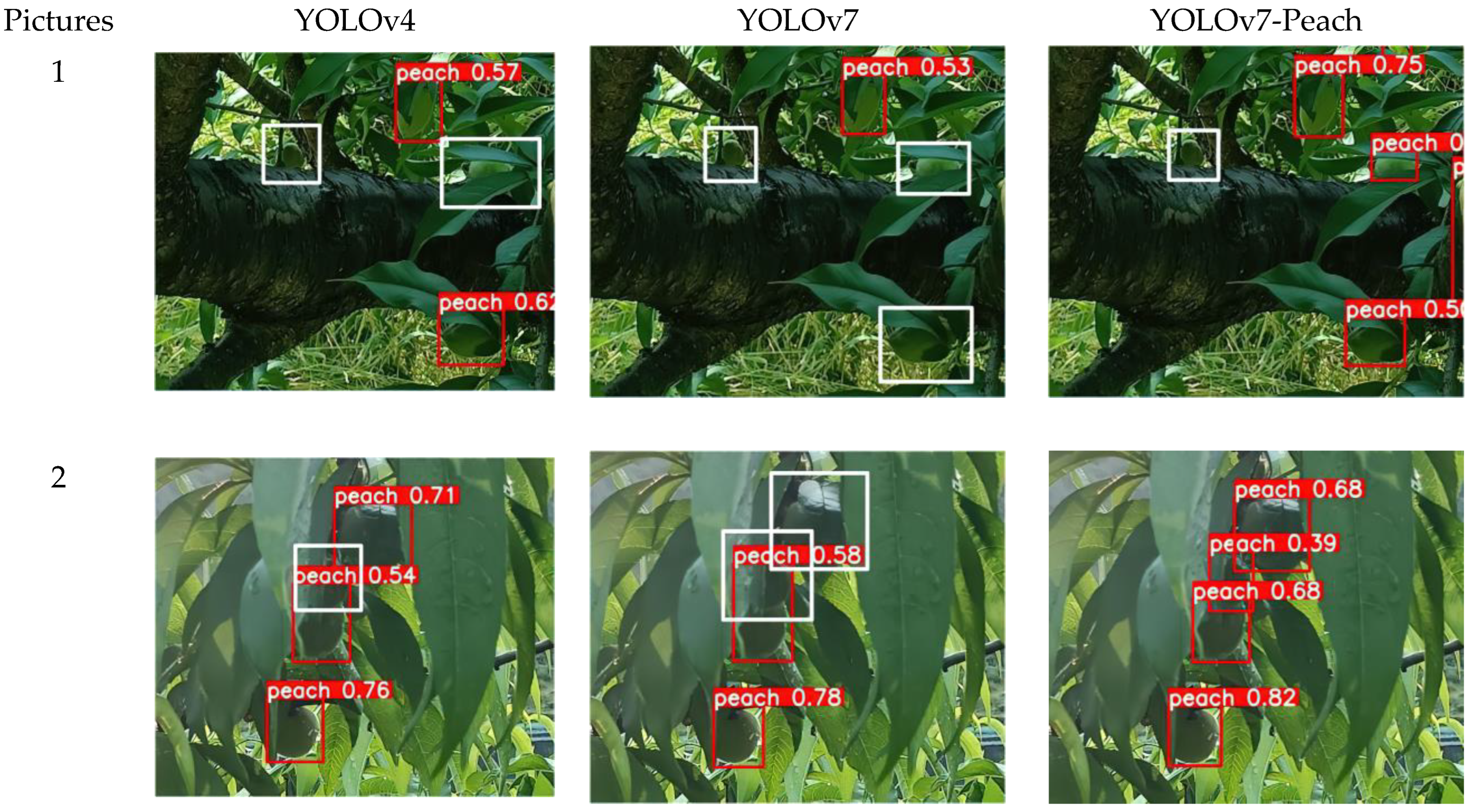
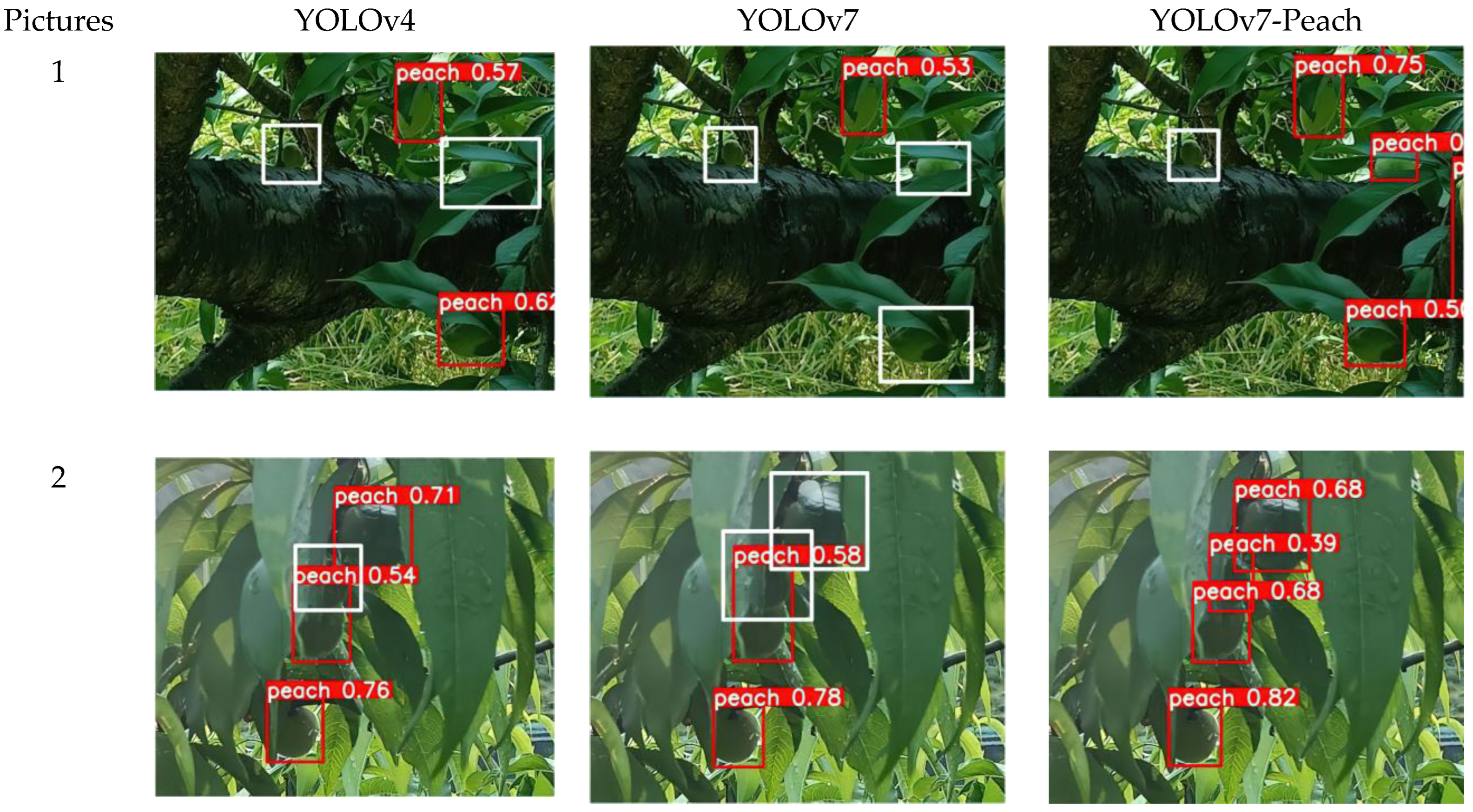
5.3. Comparison of Small Target Detection
5.4. Contrast Test of Occlusion Detection
5.5. Contrast Test of Algorithm Robustness
5.6. Application of Our Method
6. Discussion
- (1)
- The YOLOv7-Peach algorithm is proposed, which can be used for the yellow peach detection under different complex natural environments. In the ablation experiments, the YOLOv7-Peach algorithm improved the mAp by 3.5%, with an accuracy rate of 79.3%, and improved the recall by 3.3% and the F1 score by 1.8%, as well as the mAp@.5:.95 by 2.5%. It is clear that all evaluation metrics in the improved model worked better than those of the original YOLOv7 network. The YOLOv7-Peach had fewer missed detections and higher accuracy than other models, indicating that the YOLOv7-Peach could provide more reliable support for the yellow peach detection.
- (2)
- The yellow peach dataset for this paper was produced by photographing yellow peaches in a complex natural environment by using various equipment in the natural environment of the yellow peach orchards. The YOLOv7-Peach model was compared with other networks of target detection algorithms, such as the SSD, Objectbox, and YOLO series. The test results showed that the YOLOv7-Peach algorithm achieved good results in terms of the mAp and the recall, reaching 80.4% and 73%, respectively. These two most important metrics were the most effective of the seven different network models.
- (3)
- Although the YOLOv7-Peach model could basically meet the needs of real-time detection in agriculture, the model still had wrong detections and missed detections due to the similar features of leaves and yellow peaches. In view of this, the feature extraction of the input picture information should be strengthened in the subsequent research process to reduce the loss of information caused by the increase in network layers and thus further improve the accuracy of the model.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xie, D.; Li, X.; Xu, J.; Qian, J.; Zhu, Z.; Dai, F. Nutritional quality evaluation of yellow peach from different producing areas. J. Zhejiang Agric. Sci. 2023, 64, 25–28. [Google Scholar]
- Wu, P.; Yuan, L.; Fan, Z.; Wu, E.; Chen, X.; Wang, Z. The introduction performance and supporting cultivation techniques of Jinxiu yellow peach in Hubei Huanggang. Fruit Tree Pract. Technol. Inf. 2022, 335, 17–19. [Google Scholar]
- Huang, Y.; Zhang, W.; Zhang, Q.; Li, G.; Shan, Y.; Su, D.; Zhu, X. Effects of Pre-harvest Bagging and Non-bagging Treatment on Postharvest Storage Quality of Yellow-Flesh Peach. J. Chin. Inst. Food Sci. Technol. 2021, 21, 231–242. [Google Scholar]
- Li, W.; Wang, D.; Ning, Z.; Lu, M.; Qin, P. Survey of Fruit Object Detection Algorithms in Computer Vision. Comput. Mod. 2022, 322, 87–95. [Google Scholar]
- Hao, J.; Bing, Z.; Yang, S.; Yang, J.; Sun, L. Detection of green walnut by improved YOLOv3. Trans. Chin. Soc. Agric. Eng. 2022, 38, 183–190. [Google Scholar]
- Song, Z.; Liu, Y.; Zheng, L.; Tie, J.; Wang, J. Identification of green citrus based on improved YOLOV3 in natural environment. J. Chin. Agric. Mech. 2021, 42, 159–165. [Google Scholar]
- Song, H.; Wang, Y.; Wang, Y.; Lv, S.; Jiang, M. Camellia oleifera Fruit Detection in Natural Scene Based on YOLO v5s. Trans. Chin. Soc. Agric. Mach. 2022, 53, 234–242. [Google Scholar]
- Zhang, Z.; Luo, M.; Guo, S.; Liu, G.; Li, S.; Zhang, Y. Cherry Fruit Detection Method in Natural Scene Based on Improved YOLO v5. Trans. Chin. Soc. Agric. Mach. 2022, 53, 232–240. [Google Scholar]
- Lv, J.; Li, S.; Zeng, M.; Dong, B. Detecting bagged citrus using a Semi-Supervised SPM-YOLOv5. Trans. Chin. Soc. Agric. Eng. 2022, 38, 204–211. [Google Scholar]
- Xie, J.; Peng, J.; Wang, J.; Chen, B.; Jing, T.; Sun, D.; Gao, P.; Wang, W.; Lu, J.; Yetan, R.; et al. Litchi Detection in a Complex Natural Environment Using the YOLOv5-Litchi Model. Agronomy 2022, 12, 3054. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, W.; Yu, J.; He, L.; Chen, J.; He, Y. Complete and accurate holly fruits counting using YOLOX object detection. Comput. Electron. Agric. 2022, 198, 107062. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, J.; Chen, J.; Yang, W.; Zhang, W.; He, Y. Real-time strawberry detection using deep neural networks on embedded system (rtsd-net): An edge AI application. Comput. Electron. Agric. 2022, 192, 106586. [Google Scholar] [CrossRef]
- Qi, C.; Murilo, S.; Jesper, C.; Ea, H.; Merethe, B.; Erik, A.; Gao, J. In-field classification of the asymptomatic biotrophic phase of potato late blight based on deep learning and proximal hyperspectral imaging. Comput. Electron. Agric. 2023, 205, 107585. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, J.; Shu, A.; Chen, Y.; Chen, J.; Yang, Y.; Tang, W. Study of convolutional neural network-based semantic segmentation methods on edge intelligence devices for field agricultural robot navigation line extraction. Comput. Electron. Agric. 2023, 209, 107811. [Google Scholar] [CrossRef]
- Ange, C.; Firozeh, S.; Giovanni, D.; Angelo, P.; Stephan, S.; Francesco, C.; Vito, R. Detection of tomato plant phenotyping traits using YOLOv5-based single stage detectors. Comput. Electron. Agric. 2023, 207, 107757. [Google Scholar]
- Wang, D.; He, D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 8, 15. [Google Scholar] [CrossRef]
- Marco, S.; Silvia, C.; Alessia, C.; Ahmed, K.; Francesco, M. Automatic Bunch Detection in White Grape Varieties Using YOLOv3, YOLOv4, and YOLOv5 Deep Learning Algorithms. Agronomy 2022, 12, 319. [Google Scholar]
- Yi, S.; Li, J.; Zhang, P.; Wang, D. Detecting and counting of spring-see citrus using YOLOv4 network model and recursive fusion of features. Trans. Chin. Soc. Agric. Eng. 2021, 37, 161–169. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wu, Z.; Chen, M. Lightweight detection method for microalgae based on improved YOLO v7. J. Dalian Ocean. Univ. 2023, 38, 11. [Google Scholar]
- He, D.; Liu, J.; Xiong, H.; Lu, Z. Individual Identification of Dairy Cows Based on Improved YOLO v3. Trans. Chin. Soc. Agric. Mach. 2020, 51, 250–260. [Google Scholar]
- Gao, Y.; Mosalam, K. Deep transfer learning for image-based structural damage recognition. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 748–768. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Zhan, W.; Sun, C.; Wang, M.; She, J.; Zhang, Y.; Zhang, Z.; Sun, Y. An improved Yolov5 real-time detection method for small objects captured by UAV. Springer Nat. Exp. 2022, 26, 361–373. [Google Scholar] [CrossRef]
- Zhang, Y.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Wu, H.; Wu, H.; Sun, Y.; Yan, C. Pilot Workload Assessment Based on Improved KNN Algorithms. Aeronaut. Comput. Tech. 2022, 52, 77–81. [Google Scholar]
- Zhang, X.; Jing, M.; Yuan, Y.; Yin, Y.; Li, K.; Wang, C. Tomato seedling classification detection using improved YOLOv3-Tiny. Trans. Chin. Soc. Agric. Eng. 2022, 38, 221–229. [Google Scholar]
- Zand, M.; Etemad, A.; Greenspan, M. ObjectBox: From Centers to Boxes for Anchor-Free Object Detection. In Computer Vision–ECCV 2022, Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022, Part X.; Springer Nature: Cham, Switzerland, 2022; pp. 390–406. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Map Level/Downsampling Multiple | P5/32 | P4/16 | P3/8 | P2/4 |
|---|---|---|---|---|
| (142, 110) | (36, 75) | (12, 16) | - | |
| COCO anchor size | (192, 243) | (76, 55) | (19, 36) | - |
| (459, 401) | (72, 146) | (40, 28) | - | |
| - | (20, 17) | (10, 13) | (6, 6) | |
| Yellow peach anchor size | - | (21, 25) | (14, 13) | (7, 9) |
| - | (33, 39) | (14, 19) | (10, 9) |
| Experiment Number | Anchor Redesigning | EIoU | Attention Module | Detection Head Replacement | mAp |
|---|---|---|---|---|---|
| 1 | 76.9% | ||||
| 2 | √ | 77.3% | |||
| 3 | √ | √ | 77.8% | ||
| 4 | √ | √ | √ | 79.6% | |
| 5 | √ | √ | √ | √ | 80.4% |
| Target Detection Model | mAp | P | R | F1 | mAp@.5:95 |
|---|---|---|---|---|---|
| SSD-VGG | 0.5401 | 0.9332 | 0.17 | 0.29 | 0.225 |
| YOLOv3 | 0.739 | 0.82 | 0.665 | 0.734 | 0.37 |
| YOLOv4 | 0.749 | 0.813 | 0.65 | 0.722 | 0.364 |
| YOLOv5 | 0.685 | 0.787 | 0.61 | 0.687 | 0.312 |
| YOLOv7 | 0.769 | 0.793 | 0.697 | 0.742 | 0.371 |
| ObjectBox | 0.699 | 0.838 | 0.614 | 0.709 | 0.339 |
| YOLOv7-Peach(ours) | 0.804 | 0.793 | 0.73 | 0.76 | 0.396 |
| Training Time | Time Spent in Detection (ms) | Detection Speed (FPS) | Size of Model (MB) |
|---|---|---|---|
| 22.5 h | 47 | 21 | 51.9 |
| Models | Pictures | Real Numbers | Predicted Numbers | Missed Numbers | Average Confidence |
|---|---|---|---|---|---|
| 1 | 22 | 20 | 2 | 0.639 | |
| YOLOv4 | 2 | 13 | 12 | 1 | 0.653 |
| 3 | 10 | 5 | 5 | 0.598 | |
| 1 | 22 | 20 | 2 | 0.701 | |
| YOLOv7 | 2 | 13 | 11 | 2 | 0.661 |
| 3 | 10 | 4 | 6 | 0.688 | |
| 1 | 22 | 22 | 0 | 0.691 | |
| YOLOv7-Peach | 2 | 13 | 13 | 0 | 0.663 |
| 3 | 10 | 7 | 3 | 0.619 |
| Models | Pictures | Real Numbers | Predicted Numbers | Missed Numbers | Average Confidence |
|---|---|---|---|---|---|
| 1 | 4 | 2 | 2 | 0.595 | |
| YOLOv4 | 2 | 4 | 3 | 1 | 0.67 |
| 3 | 8 | 5 | 3 | 0.668 | |
| 1 | 4 | 1 | 3 | 0.530 | |
| YOLOv7 | 2 | 4 | 2 | 2 | 0.68 |
| 3 | 8 | 5 | 3 | 0.676 | |
| 1 | 4 | 3 | 1 | 0.5 | |
| YOLOv7-Peach | 2 | 4 | 4 | 0 | 0.643 |
| 3 | 8 | 6 | 2 | 0.693 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, P.; Yin, H. YOLOv7-Peach: An Algorithm for Immature Small Yellow Peaches Detection in Complex Natural Environments. Sensors 2023, 23, 5096. https://doi.org/10.3390/s23115096
Liu P, Yin H. YOLOv7-Peach: An Algorithm for Immature Small Yellow Peaches Detection in Complex Natural Environments. Sensors. 2023; 23(11):5096. https://doi.org/10.3390/s23115096
Chicago/Turabian StyleLiu, Pingzhu, and Hua Yin. 2023. "YOLOv7-Peach: An Algorithm for Immature Small Yellow Peaches Detection in Complex Natural Environments" Sensors 23, no. 11: 5096. https://doi.org/10.3390/s23115096
APA StyleLiu, P., & Yin, H. (2023). YOLOv7-Peach: An Algorithm for Immature Small Yellow Peaches Detection in Complex Natural Environments. Sensors, 23(11), 5096. https://doi.org/10.3390/s23115096