1. Introduction
Originally designed to solve machine translation problems [
1,
2], the Transformer [
3,
4] model has been widely introduced into computer vision (CV) [
5,
6,
7], natural language processing (NLP) [
8], speech processing [
9,
10,
11], audio processing [
12,
13], chemistry [
14], and life sciences [
15] due to its powerful modelling capabilities and applicability. It has contributed significantly to the development of these fields.
In computer vision, Convolutional Neural Networks (CNNs) [
16,
17,
18] are traditionally used as the primary means of processing. Convolution is well suited for processing regular, high-dimensional data and allows for automatic feature extraction. However, convolution suffers from obvious localisation constraints. The conditional assumption is that points in the space are only associated with their neighbouring grids, whereas distant grids are not associated with each other. Although this limitation can be alleviated to some extent by expanding the convolution kernel, it still cannot solve the problem fundamentally. After introducing the Transformer, some researchers have tried to introduce the Transformer model architecture into the field of computer vision. Transformer has a larger field of perception than CNN, so it captures rich global information and can better understand the whole image. Ramachandran et al. [
19] constructed a vision model without using convolution, which uses a full-attention mechanism instead of convolution to improve the localisation constraint in convolution. In addition, Transformer has shown excellent performance in other CV areas such as image classification [
6,
20], object detection [
5,
21], semantic segmentation [
22], image processing [
22], and video understanding [
5].
Sequential data are more suitable for processing using Transformer than computer vision. In the traditional field of time series prediction, most of them rely on Recurrent Neural Network (RNN) [
23,
24] models, among which the more influential ones include Gated Recurrent Unit (GRU) [
25] and Long Short-term Memory (LSTM) [
26,
27] networks. For example, Mou et al. [
28] proposed a Time-Aware LSTM (T-LSTM) with temporal information enhancement, whose main idea is to divide memory states into short-term memory and long-term memory, adjust the influence of short-term memory according to the time interval between inputs (the longer the time interval, the smaller the influence of short-term memory), and then reorganise the adjusted short-term memory and long-term memory into a new memory state. However, the emergence of Transformer soon shook the dominance of RNN family models in the field of time series prediction because of the following bottlenecks of RNNs in dealing with long-time prediction problems.
(1) Parallelism bottleneck: The RNN family of models requires the input data to be arranged in temporal order and computed sequentially according to the order of arrangement. This serial structure has the advantage that it inherently contains the portrayal of positional relationships, but it also constrains the model from being computed in parallel. Especially when facing long sequences, the inability to parallelise means more time and cost.
(2) Gradient bottleneck [
29]: One performance bottleneck of RNN networks is the frequent problem of gradient disappearance or gradient explosion during training. Most neural network models optimise model parameters by computing gradients. Gradient disappearance or gradient explosion can cause the model to fail to converge or converge too slowly, which means that for the RNN family of networks, it is difficult to make the model better by increasing the number of iterations or increasing the size of the network.
(3) Memory bottleneck: For each moment, the RNN network requires a positional input and a hidden input , which will be fused within the model according to the inherent rules to produce a hidden state . Therefore, when the sequence length is too long, the almost no longer contains the earlier positional input; that is, the “forgetting” phenomenon occurs.
Compared with the RNN family of models, Transformer portrays the positional relationships between sequences by positional encoding without recursively feeding sequential data. This processing makes the model more flexible and provides the maximum possible parallelisation for time series data. The positional encoding also ensures that no forgetting occurs. The information at each location has an equal status for the Transformer. Additionally, using an attention mechanism to extract internal features allows the model to choose to focus on important information. The problem of gradient disappearance or gradient explosion can be avoided by ignoring irrelevant and redundant information. Therefore, based on the above advantages of Transformer models, many scholars are now trying to use Transformer models for time series tasks.
2. Research Background
Transformer is a typical encoder-decoder-based sequence-to-sequence [
30] model, and this structure is well suited for processing sequence data. Several researchers have tried to improve the Transformer model to meet the needs of more complex applications. For example, Kitaev et al. [
31] proposed a Reformer model that uses Locality Sensitive Hashing Attention (LSH) to reduce the complexity of the original model from
to
. Zhou et al. [
32] proposed an Informer model for Long Sequence Time Series Forecasting (LSTF), which accurately captures the long-term dependence between output and input and exhibits high predictive power. Wu et al. [
33] proposed the Autoformer model, which uses a deep decomposition architecture and an autocorrelation mechanism to improve LSTF accuracy. The Autoformer model achieves desirable results even when the series is predicted much longer than the length of the input series, i.e., it can predict the longer-term future based on limited information. Zhou et al. [
34] proposed the FEDformer model, which provides a way to apply the attention mechanism in the frequency domain and can be used as an essential complement to the time domain analysis.
The Transformer model described above focuses on reducing its temporal and spatial complexity, but needs to enhance the diversity of the information it captures. The attention mechanism is the core part of the Transformer used for feature extraction. It is designed to allow the model to focus on more important information, which means there is a certain amount of information loss. The multi-head attention mechanism can compensate for this. However, since each attention head captures similarly, there is no way to ensure that each attention head is capturing different vital features. Since the multi-head attention mechanism essentially divides multiple mutually independent subspaces, this approach completely cuts off the connection between each subspace, which leads to a lack of interaction between the information captured by multiple heads. Based on these problems, this paper proposes a hierarchical attention mechanism that features each layer using a different attention mechanism to capture features. The higher layers will use the information captured by the lower layers, thus enhancing the Transformer’s ability to perceive deeper information.
3. Research Methodology
3.1. Problem Description
Initially, the Transformer model was proposed by Waswani et al. to solve the machine translation problem, so Vanilla Transformer is more suitable for processing textual data. For example, the primary processing unit of the Vanilla Transformer model is a word vector, and each word vector is called a token. In contrast, in the time series prediction problem, our basic processing unit becomes a timestamp. If we want to apply Transformer to a time series problem, the reasonable idea is to encode the multivariate sequence information of each timestamp into a token vector. This modelling approach is also the treatment of many mainstream Transformer-like models.
Here, for the convenience of the subsequent description, we define the dimension of the token as
d, the input length of the model as
I, and the output length as
O. Further, the model’s input can be defined as
, and the model’s output as
. Therefore, this paper aims to learn a mapping
from the input space to the output space.
3.2. Model Architecture
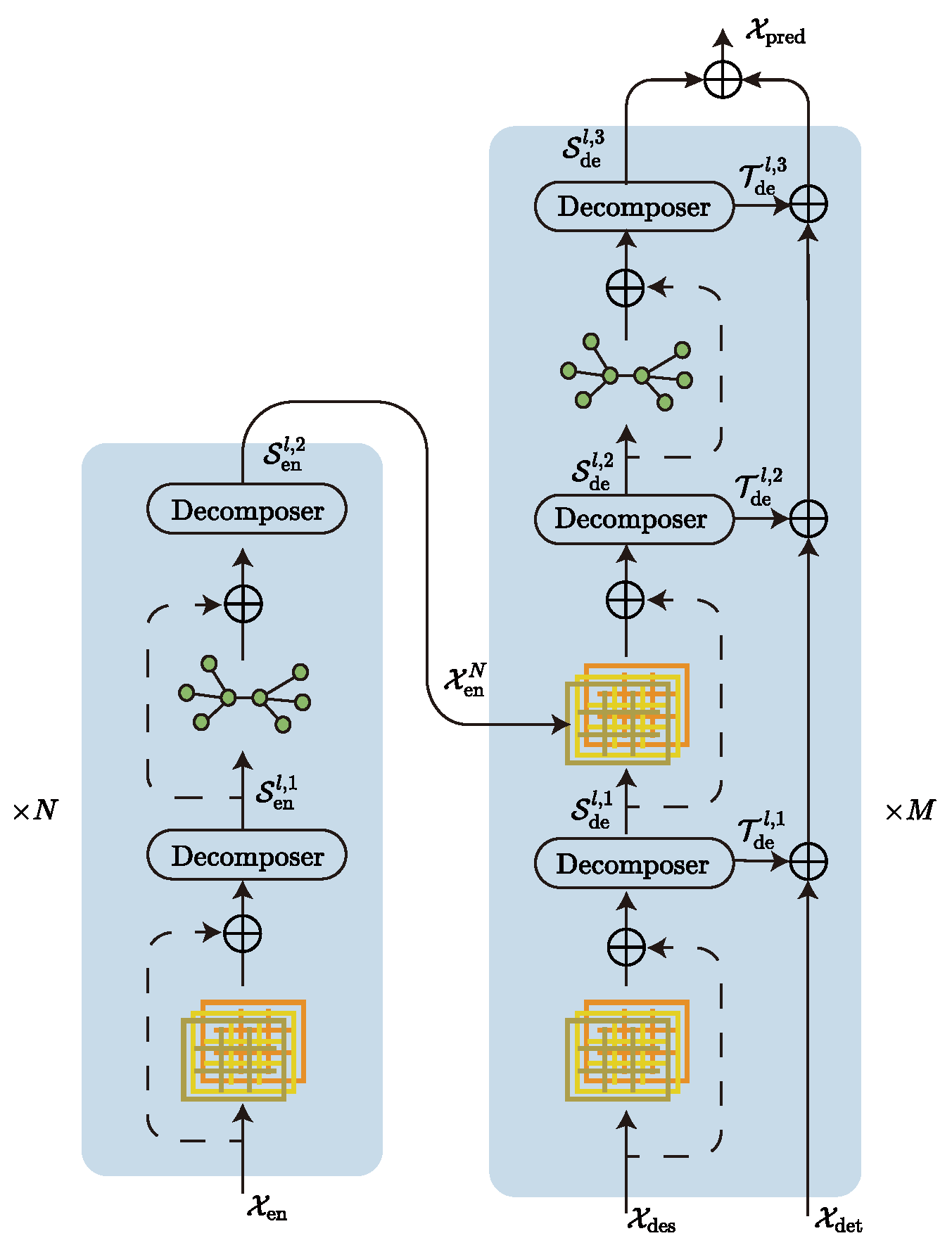
Our model (
Figure 1) continues the Transformer architecture in the main body, and we also added a decomposer to the model by referring to Autoformer’s sequence decomposition model. The function of the decomposer is to filter trend-cyclical and seasonal parts. The advantage is that removing trend parts from the series allows the model to focus better on the hidden periodic information of the series, and Wu et al. [
33] have shown that this decomposition is effective. In addition, the model uses a coder–decoder structure, where the encoder is responsible for mapping the information from the input space to the feature space, and the decoder is responsible for mapping the information from the feature space to the target space. The model is a typical sequence-to-sequence model, since both the input and output of the model are sequence-type data. In addition, we try to use a hierarchical attention mechanism instead of the original multi-head attention mechanism and a graph network instead of the original feedforward neural network inside the codec, which can improve the diversity of captured information and the mitigate token-uniformity inductive bias [
35,
36] of the model, respectively.
3.2.1. Decomposer
The main difficulty of time series forecasting lies in discovering the hidden trend-cyclical and seasonal parts information from the historical series. The trend-cyclical records the overall trend of the series, which has an essential influence on the long-term trend-cyclical of the series. The seasonal parts record the hidden cyclical pattern of the series, which mainly shows the regular fluctuation of the series in the short term. It is generally difficult to predict these two pieces of information simultaneously. The basic idea is to decompose the two, extracting the trend-cyclical from the sequence using average pooling and filtering the seasonal period using the trend-cyclical, which is how Decomposer implements the decomposed information, as shown in Algorithm 1.
| Algorithm 1 Decomposer |
| Require: |
| Ensure: |
- 1:
- 2:
|
Here, is the input sequence of length L. is the decomposed trend-cyclical and seasonal parts where the role of padding is to ensure that the decomposed series remains equal in dimension to the input sequence.
The decomposer module has a relatively simple structure. However, it can decompose the forecasting task into two subtasks, i.e., mining hidden periodic patterns and forecasting overall trends. This decomposition can reduce the difficulty of prediction to a certain extent and, thus, improve the final prediction results.
3.2.2. Encoder
The encoder is mainly responsible for encoding the input data and realizing the transformation from the input space to the feature space. The decomposer in the encoder is more like a filter because, in the encoder, we focus more on the seasonal parts of the sequence and ignore the trend-cyclical. The input data are passed through a hierarchical attention layer for initial key feature extraction. After which, the decomposer extracts the seasonal part’s features in the sequence and they are further fed into the graph network to mitigate inductive bias. After stacking
N layers, The seasonal parts features thus obtained will be auxiliary inputs to the decoder. Algorithm 2 describes the computation procedure.
| Algorithm 2 Encoder |
| Require: |
| Ensure: |
- 1:
for
do - 2:
if then - 3:
- 4:
end if - 5:
- 6:
- 7:
- 8:
end for
|
Here, denotes the historical observation sequence. N denotes the number of stacked layers of the encoder. denotes the output of the N-th layer encoder. denotes the decomposer operator. denotes the graph network operator and denotes the hierarchical attention mechanism, the concrete implementation of which will be described later.
3.2.3. Decoder
The structure of the decoder is more complex than that of the encoder. However, its internal modules are identical to the encoder’s, but use a multi-input structure. It goes through two hierarchical attention calculations and three sequence decompositions in turn. Assuming that the model’s encoder is a feature catcher, the decoder is a feature fuser that fuses and corrects the inputs from different sources to obtain the correct prediction sequence. The decoder has three primary input sources: the seasonal parts
and the trend-cyclical
extracted from the original series, and the seasonal parts
captured by the decoder. The computation of the trend-cyclical and seasonal parts is kept relatively independent throughout the computation process. Only at the final output is a linear layer used to fuse the two to obtain the final prediction
. The computation process is described in Algorithm 3.
| Algorithm 3 Decoder |
| Require: |
| Ensure: |
- 1:
- 2:
- 3:
- 4:
for
do - 5:
if then - 6:
- 7:
- 8:
end if - 9:
- 10:
- 11:
- 12:
- 13:
- 14:
end for - 15:
|
Here, denotes the original sequence, which is also the input to the encoder. It is decomposed into trend-cyclical and season parts before feeding into the decoder as the initial input.
3.3. Hierarchical Attention Mechanism
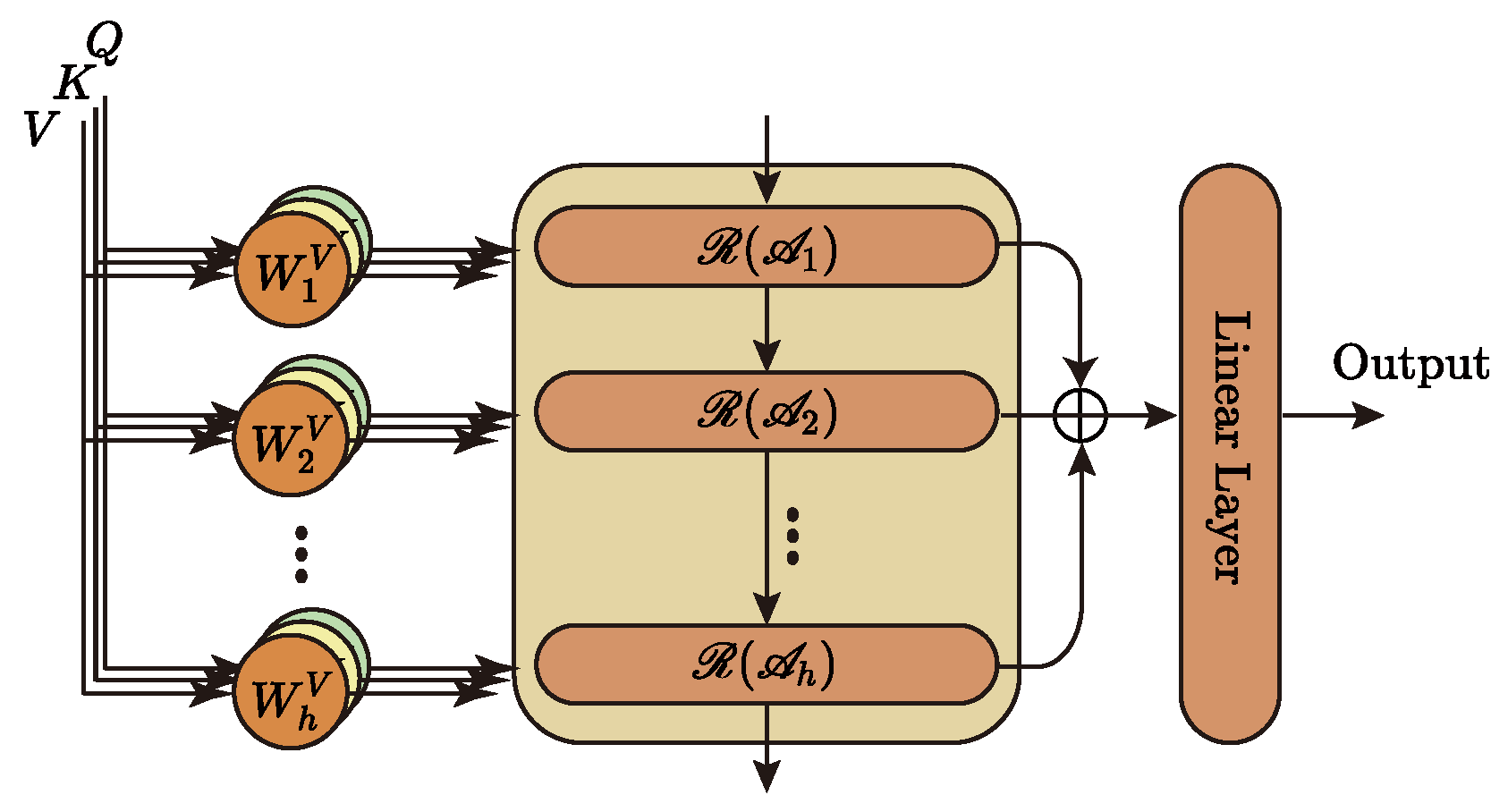
The hierarchical attention mechanism, as the first feature capture unit of Metaformer, is at the model’s core and, therefore, has a significant impact on the subsequent work. Most Transformer-like models use the multi-head attention mechanism to complete the first step of feature extraction. However, the multi-head attention mechanism itself has significant drawbacks: (1) each head uses the exact attention mechanism, which cannot guarantee the diversity of captured information and may even miss some critical information. (2) Each head belongs to a separate subspace, and the lack of information interaction between heads is not conducive to the deep understanding of information by the model. Therefore, we propose a hierarchical attention mechanism for the first time. First, a hierarchical structure is used, where each layer uses a different attention mechanism to capture features separately, which ensures the diversity of information circulating in the network; second, a cascading interaction is used, where the information captured by the lower layer will be reused by the upper layer, which will deepen the depth of information understanding by the model. We know that when we humans understand language, we not only focus on the surface meaning of words, but can also understand the metaphors behind the words. Inspired by this, we use a hierarchical structure to model this phenomenon and, thus, improve the network’s ability to perceive information in three dimensions.
3.3.1. Traditional Multi-Head Attention Mechanism
In the multi-head attention mechanism, only one type of attention computation scaled dot-product attention is used. The multi-head attention mechanism first takes as input three vectors of queries, keys, and values with
dimension, and each head is projected to
and
dimensions using a linear layer. The attention function is then computed to produce a
dimensional output value. Finally, the output of each attention head is stitched together and passed through a linear layer to obtain the final output.
Equation (
2) calculates the multi-headed attention mechanism, where
denotes the linear layer with projection parameter matrix
, respectively.
h denotes the number of heads of attention.
denotes scaled dot-product attention. ∐ denotes sequential cascade.
3.3.2. Hierarchical Attention Mechanism
We propose a hierarchical attention mechanism to address the shortcomings in the multi-head attention mechanism, aiming to enhance the model’s deep understanding of the information.
Figure 2 depicts the central architecture of the hierarchical attention mechanism, and Algorithm 4 describes its implementation.
| Algorithm 4 Hierachical Attention |
| Require: |
| Ensure: |
- 1:
for
do - 2:
if then - 3:
- 4:
end if - 5:
- 6:
- 7:
end for - 8:
|
Here,
has the same meaning as in Equation (
2).
denotes the GRU unit.
records the information of each layer and finally maps it to the specified dimension as the model’s output by a linear layer.
denotes different attention calculation methods. This paper mainly uses four common attention mechanisms: Vanilla Attention, ProbSparse Attention, LSH Attention, and AutoCorrelation. AutoCorrelation is not, strictly speaking, part of the attention mechanism family. However, its effect is similar to or even better than attention mechanisms, so it is introduced into our model and involved in feature extraction.
Attention is the core building block of Transformer and is considered an essential tool for information capture in both CV and NLP domains. Many researchers have worked on designing more efficient attention, so many variants based on Vanilla Attention have been proposed in succession. The following briefly describes the four attention mechanisms used in our model.
3.3.3. Vanilla Attention
Vanilla Attention was first proposed in the Transformer [
3], and its input consists of three vectors: queries, keys, and values (
), whose dimensions are
, respectively. Vanilla Attention is also known as Scaled Dot Product Attention because it is computed by dot product using
and
and then scaled by
. The specific calculation process is shown in Equation (
3).
Here, denotes the attention or autocorrelation mechanism. denotes the softmax activation function.
3.3.4. ProbSparse Attention
This attention mechanism, first proposed in Informer, considers the attention coefficients’ sparsity and specifies the query matrix
using the exact query sparsity measurement method (Algorithm 5). Equation (
4) gives the ProbSparse Attention calculation method.
Here,
is the sparse matrix obtained by the sparsity measure. The prototype of
is Kullback–Leibler (KL) divergence, see Equation (
5).
| Algorithm 5 Explicit Query Sparisity Measurement |
| Require: |
| Ensure: |
- 1:
Define
- 2:
Define
- 3:
for
do - 4:
if then - 5:
- 6:
else - 7:
- 8:
end if - 9:
end for
|
3.3.5. LSH Attention
Like ProbSparse Attention, LSH Attention also uses a sparsification method to reduce the complexity of Vanilla Attention. The main idea is that for each query, only the nearest keys are focused on, where the nearest neighbour selection is achieved by locally sensitive hashing. The specific attentional process of LSH Attention is given in Equation (
6), where the hash function used is Equation (
7):
where
denotes the set of key vectors that the
i-th query focuses on.
is used to measure the association of nodes
i and
j.
3.3.6. AutoCorrelation
AutoCorrelation mechanisms are different from the types of attention mechanisms above. Whereas the self-attentive family focuses on the correlation between points, the AutoCorrelation mechanism focuses on the correlation between segments. Therefore, AutoCorrelation mechanisms are an excellent complement to self-attentive mechanisms.
Equation (
8) gives the procedure of calculating the AutoCorrelation mechanism, where Equation (
9) is used to measure the correlation between two sequences, and
denotes the order of the lag term.
denotes the vector of
-order lagged terms of vector
obtained in a self-looping manner. Equation (
10) is the Topk algorithm used to filter the set
of
k lagged terms with the highest correlation.
3.4. GAT Network
The Vanilla Transformer model embeds a Feedforward Network (FFN) [
37] layer at the end of each encoder–decoder layer. The FFN plays a crucial role in mitigating token-uniformity inductive bias. Inductive bias can be considered a learning algorithm as a heuristic or “value” for selecting hypotheses in ample hypothesis space. For example, convolutional networks assume that information is spatially local, spatially invariant, and translational equivalent, so that the parameter space can be reduced by sliding convolutional weight sharing; recurrent neural networks assume that information is sequential and invariant to temporal transformations, so that weight sharing is also possible. Similarly, the attention mechanism also has some assumptions, such as the uselessness of some information. If the attention mechanism is stacked, some critical information will be lost, so adding a layer of FNN can somehow alleviate the accumulation of inductive bias and avoid network collapse. Of course, not only does the FFN layer have a mitigating effect, but we find that a similar effect can be achieved using a Graph Neural Network (GNN) [
38,
39,
40]. Here, we use a two-layer GAT [
41,
42] network instead of the original FFN layer. The graph network has the property of aggregating the information of neighbouring nodes, i.e., through the aggregation of the graph network, each node will fuse some features of its neighbouring nodes. Additionally, we use random sampling to reduce the complexity. The reason is that our goal is not feature aggregation, but to mitigate the loss of crucial information. In particular, when the number of samples per node is 0, the graph network can be considered to ultimately degenerate into an FFN layer with a similar role to the original FFN.
Here, we model each token as a node in the graph and mine the dependencies between nodes using the graph attention algorithm. The input to GAT is defined as . Here, denotes the input vector of the i-th node, N denotes the number of nodes in the graph, and F denotes the dimensionality of the input vector. Through the computation of the GAT network, this layer generates a new set of node features . Similarly, here denotes the output vector of the i-th node, and denotes the dimensionality of the output vector.
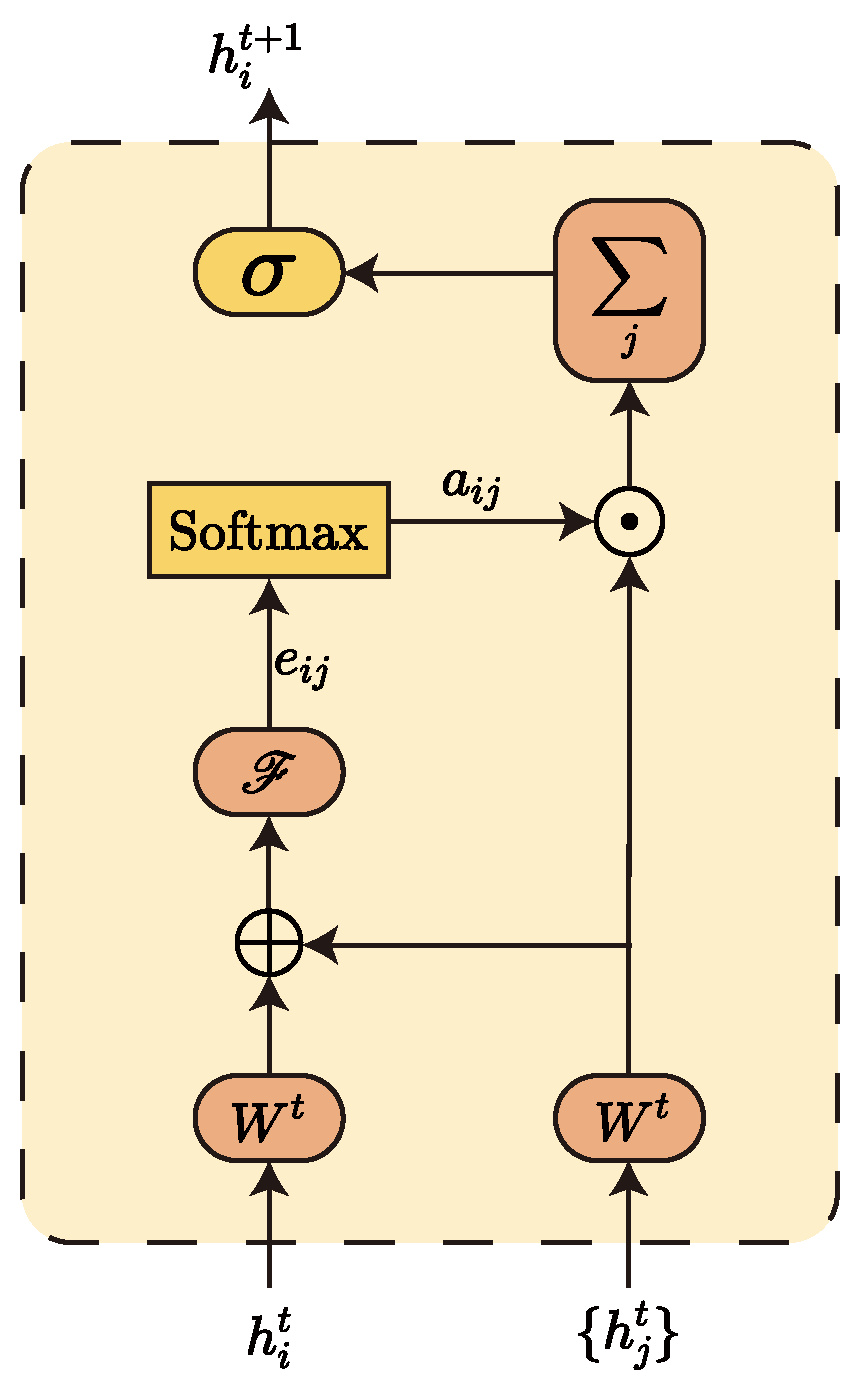
Figure 3 gives the general flow of information aggregation for a single node. Equation (
11) is a concrete implementation of calculating the attention coefficient
for the
i-th node and its neighbour node
j one by one. Equation (
12) is used to calculate the normalised attention factor
:
Here, denotes the set of all neighbouring nodes of the i-th node, and is a shared parameter for linear mapping of node features. is a single-layer feedforward neural network for mapping the spliced high-dimensional features into a real number . is the attention coefficient of node , and is its normalised value.
Finally, the new feature vector
of the current node
i is obtained by weighting and summing the feature vectors of each neighbouring node according to the calculated attention coefficients, where
records the neighbourhood information of the current node.
Here, represents applying a non-linear activation function logistic sigmoid at the end.
Furthermore, if information aggregation is accomplished through the
K head attention mechanism, the final output vector can be obtained by taking the average.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}