
Research on a Traffic Sign Recognition Method under Small Sample Conditions
Abstract
1. Introduction
- The basic model structure is adjusted so that the network can pay more attention to the detail information and semantic information of the image, reduce the loss of image features, reduce the risk of overfitting, and improve the detection performance in the case of few samples.
- The ACBAM-RPN module combined with a multi-attention mechanism is proposed to make the model focus on the candidate boxes related to the target category, reduce the number of irrelevant candidate boxes, and improve the detection accuracy of the target category.
- The multi-scale FPN module is introduced to extract features, and the deep cross-correlation between support set image features and query set image features is calculated to obtain more accurate candidate boxes.
2. Methodology
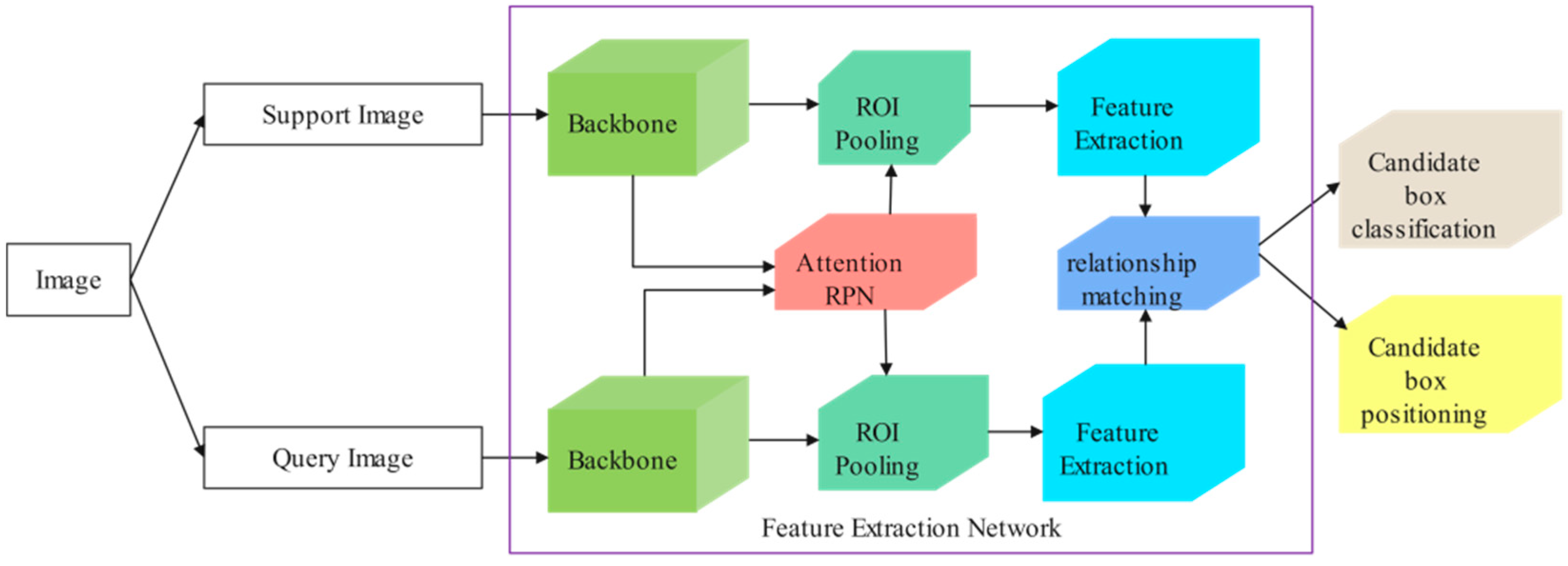
2.1. Background of FSOD
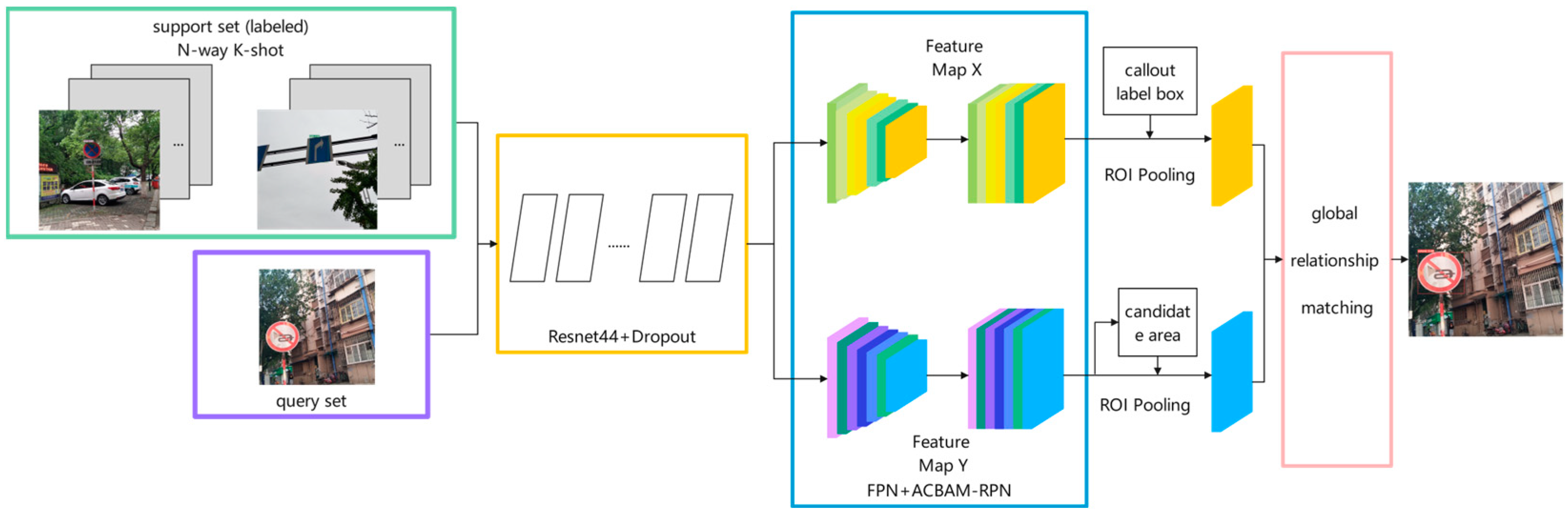
2.2. Improved Network Structure
3. Materials and Methods
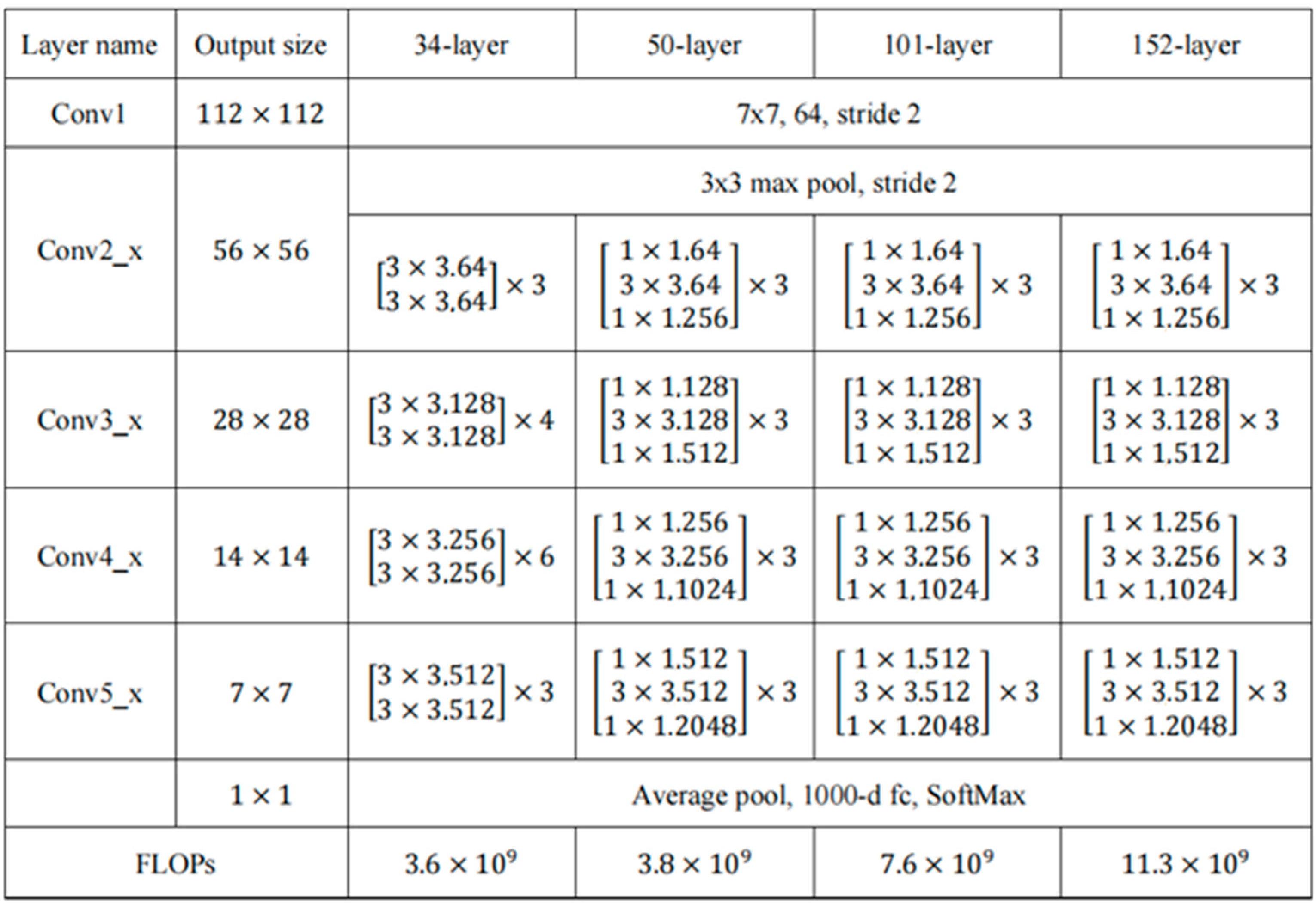
3.1. Adjustment of Backbone Network
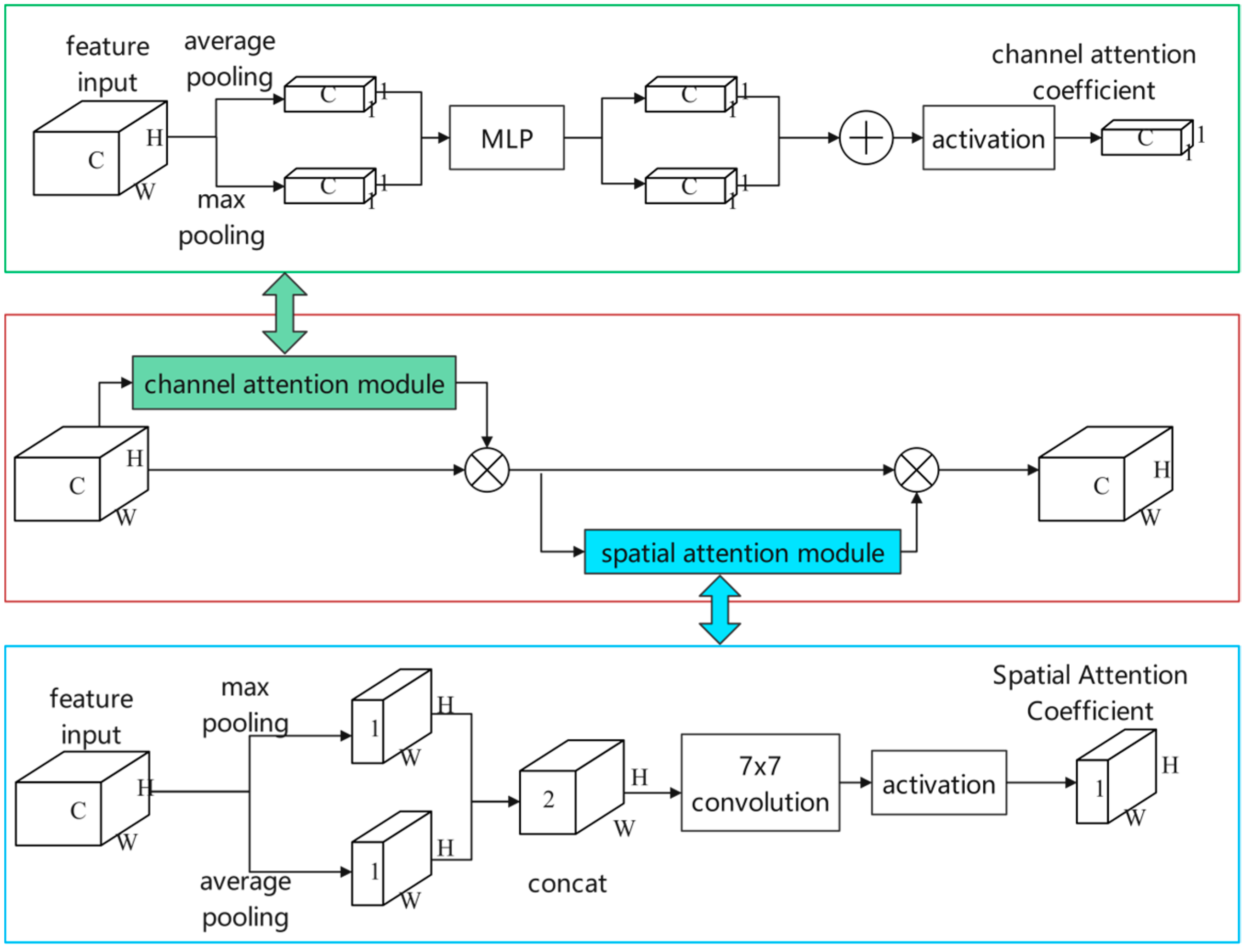
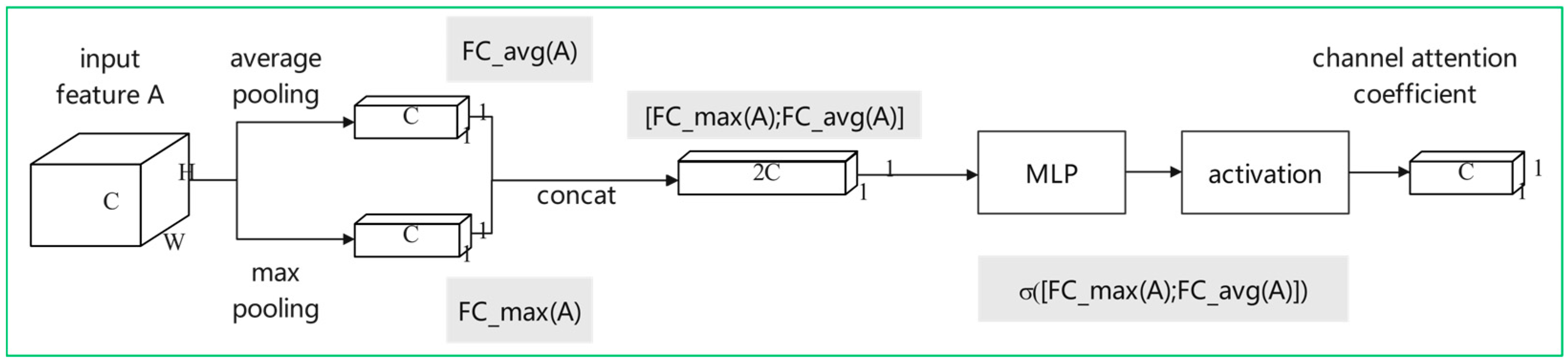
3.2. RPN Module with Multi-Attention Mechanism
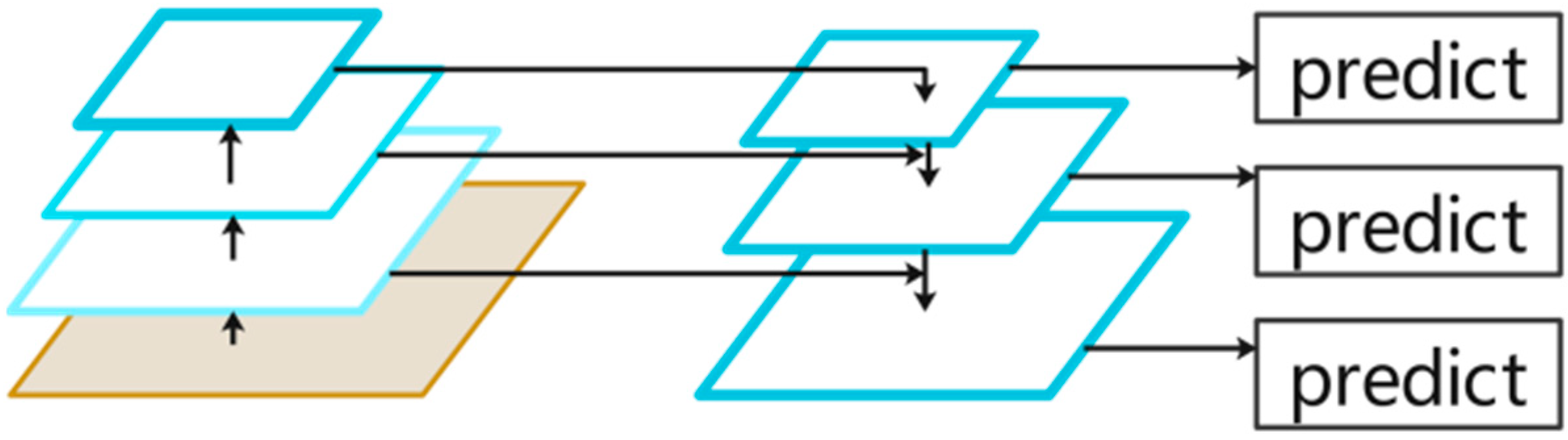
3.3. Multi-Scale Feature Fusion Module
4. Experiments
4.1. Data Preparation
4.1.1. Self-Made Dataset
4.1.2. PASCAL VOC Dataset
4.2. Evaluation Methods
4.3. The Results of Ablation Experiments
4.3.1. RPN Module with Multi-Attention Mechanism
4.3.2. Multi-Scale Feature Fusion Module
4.3.3. Ablation Experiments
4.4. The Results of Comparative Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, Y.; Luo, H.; Xu, H.; Wu, F. Towards real-time traffic sign detection and classification. IEEE Trans. Intell. Transp. Syst. 2015, 17, 2022–2031. [Google Scholar] [CrossRef]
- Li, J.; Wang, Z. Real-time traffic sign recognition based on efficient CNNs in the wild. IEEE Trans. Intell. Transp. Syst. 2018, 20, 975–984. [Google Scholar] [CrossRef]
- Luo, X.; Zhu, J.; Yu, Q. Efficient convNets for fast traffic sign recognition. IET Intell. Transp. Syst. 2019, 13, 1011–1015. [Google Scholar] [CrossRef]
- Liu, Z.; Du, J.; Tian, F.; Wen, J. MR-CNN: A multi-scale region-based convolutional neural network for small traffic sign recognition. IEEE Access 2019, 7, 57120–57128. [Google Scholar] [CrossRef]
- Yuan, Y.; Xiong, Z.; Wang, Q. VSSA-NET: Vertical spatial sequence attention network for traffic sign detection. IEEE Trans. Image Process. 2019, 28, 3423–3434. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.H.; Kim, D.W.; Kang, T.K.; Lim, M.T. Traffic Sign Recognition in Harsh Environment Using Attention Based Convolutional Pooling Neural Network. Neural Process. Lett. 2020, 51, 2551–2573. [Google Scholar] [CrossRef]
- Liu, Z.; Li, D.; Ge, S.S. Small Traffic Sign Detection From Large Image. Appl. Intell. 2020, 50, 1–13. [Google Scholar] [CrossRef]
- Liu, Z.; Shen, C.; Qi, M.; Fan, X. SADANet: Integrating scale-aware and domain adaptive for traffic sign detection. IEEE Access 2020, 8, 77920–77933. [Google Scholar] [CrossRef]
- Shen, L.; You, L.; Peng, B.; Zhang, C. Group multi-scale attention pyramid network for traffic sign detection. Neurocomputing 2021, 452, 1–14. [Google Scholar] [CrossRef]
- Dubey, U.; Chaurasiya, R.K. Efficient Traffic Sign Recognition Using CLAHE-Based Image Enhancement and ResNet CNN Architectures. Int. J. Cogn. Inform. Nat. Intell. (IJCINI) 2021, 15, 1–19. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster RCNN:Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Lin, Y.; Dong, X.; Yan, Y.; Ouyang, W.; Yang, Y. Exploit the Unknown Gradually: One-Shot Video-Based Person Re-identification by Stepwise Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5177–5186. [Google Scholar]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. LSTD: A Low-Shot Transfer Detector for Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Li, A.; Li, Z. Transformation invariant few-shot objectdetection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3094–3102. [Google Scholar]
- Li, Y.; Zhu, H.; Cheng, Y.; Wang, W.; Teo, C.S.; Xiang, C.; Vadakkepat, P.; Lee, T.H. Few-shot objectdetection via classification refinement and distractor retreatment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 395–403. [Google Scholar]
- Xiao, Z.; Zhong, P.; Quan, Y.; Yin, X.; Xue, W. Few-shot object detection with feature attention highlight module in remote sensing images. In Proceedings of the 2020 International Conference on Image, Video Processing and Artificial Intelligence, Xi’an China, 25–27 December 2020; pp. 217–223. [Google Scholar]
- Fan, Q.; Zhuo, W.; Tang, C.K.; Tai, Y.W. Few-shot object detection with attention-RPN and multi-relation detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2020; pp. 4013–4022. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D. Cascade object detection with deformable part models. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2241–2248. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9577–9586. [Google Scholar]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly Simple Few-Shot Object Detection. In Proceedings of the International Conference on Machine Learning. PMLR, Online, 26–28 August 2020; pp. 9919–9928. [Google Scholar]
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-scale positive sample refinement for few-shot object detection. In Proceedings of the Computer Vision–ECCV 2020, 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVI 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 456–472. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Number of Data before Enhancement | Number of Data after Enhancement |
|---|---|---|
| Straight | 15 | 329 |
| Nohook | 18 | 368 |
| Stop | 16 | 336 |
| Left | 18 | 374 |
| Slow | 17 | 365 |
| Crosswalk | 15 | 312 |
| Right | 16 | 351 |
| Method | Self-Made Dataset (5-Way 3-Shot) | Self-Made Dataset (5-Way 5-Shot) | ||||
|---|---|---|---|---|---|---|
| A | B | C | AP50 (%) | AP75 (%) | AP50 (%) | AP75 (%) |
| 14.39 | 14.39 | 19.70 | 15.15 | |||
| √ | 14.85 | 14.39 | 19.92 | 15.14 | ||
| √ | 15.34 | 14.72 | 21.15 | 15.28 | ||
| √ | 14.75 | 14.41 | 19.83 | 14.67 | ||
| √ | √ | 15.11 | 14.43 | 20.27 | 15.71 | |
| √ | √ | 16.26 | 15.32 | 22.19 | 16.22 | |
| Method | Self-Made Dataset (5-Way 3-Shot) | Self-Made Dataset (5-Way 5-Shot) | |||
|---|---|---|---|---|---|
| A | B | AP50 (%) | AP75 (%) | AP50 (%) | AP75 (%) |
| 14.39 | 14.39 | 19.70 | 15.15 | ||
| √ | 16.19 | 14.43 | 21.37 | 15.72 | |
| √ | 16.60 | 14.44 | 21.21 | 15.21 | |
| √ | √ | 17.12 | 14.96 | 22.95 | 16.82 |
| Model | Method | Self-Made Dataset (5-Way 3-Shot) | Self-Made Dataset (5-Way 5-Shot) | |||
|---|---|---|---|---|---|---|
| Improved RPN | FPN | AP50 (%) | AP75 (%) | AP50 (%) | AP 75(%) | |
| Baseline | 14.39 | 14.39 | 19.70 | 15.15 | ||
| A | √ | 16.26 | 15.32 | 21.37 | 15.72 | |
| B | √ | 17.12 | 14.96 | 21.21 | 15.21 | |
| ACBAM-FSOD | √ | √ | 18.66 | 15.91 | 22.95 | 16.82 |
| Method/Shot | Split1 | Split2 | Split3 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 5 | 10 | 1 | 3 | 5 | 10 | 1 | 3 | 5 | 10 | |
| Meta RCNN | 19.9 | 35.0 | 45.7 | 51.5 | 10.4 | 29.6 | 34.8 | 45.4 | 14.3 | 27.5 | 41.2 | 48.1 |
| TFA2 | 39.8 | 44.7 | 55.7 | 56 | 23.5 | 34.1 | 35.1 | 39.1 | 30.8 | 42.8 | 49.5 | 49.8 |
| MPSR 3 | 41.7 | 51.4 | 55.2 | 61.8 | 24.4 | 39.2 | 39.9 | 47.8 | 35.6 | 42.3 | 48.0 | 49.7 |
| Ours | 45.8 | 54.3 | 56.9 | 62.1 | 27.9 | 40.0 | 40.4 | 47.6 | 34 | 43.2 | 48.5 | 49.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Zhang, Z. Research on a Traffic Sign Recognition Method under Small Sample Conditions. Sensors 2023, 23, 5091. https://doi.org/10.3390/s23115091
Zhang X, Zhang Z. Research on a Traffic Sign Recognition Method under Small Sample Conditions. Sensors. 2023; 23(11):5091. https://doi.org/10.3390/s23115091
Chicago/Turabian StyleZhang, Xiao, and Zhenyu Zhang. 2023. "Research on a Traffic Sign Recognition Method under Small Sample Conditions" Sensors 23, no. 11: 5091. https://doi.org/10.3390/s23115091
APA StyleZhang, X., & Zhang, Z. (2023). Research on a Traffic Sign Recognition Method under Small Sample Conditions. Sensors, 23(11), 5091. https://doi.org/10.3390/s23115091