

Corner-Point and Foreground-Area IoU Loss: Better Localization of Small Objects in Bounding Box Regression


Abstract
:1. Introduction
- Loss based on the -norm. The literature [1,7,8,9,10] calculates the -norm distance between the corresponding coordinate points of two boxes to measure the distance between the predicted box and the target box. However, the literature [11] argues that the -norm loss only considers the difference between two boxes and ignores their spatial relationship and containment relationship, thus proposing another loss based on Intersection over Union (IoU) between two boxes to measure the actual regression performance of the predicted box and the target box.
- Loss based on Broad IoU. The IoU loss function only considers the difference between the predicted box and the target box, without taking into account the intersection and anchor information between the two boxes. When the predicted box and the target box do not overlap, IoU cannot reflect the distance between them, and its corresponding loss function cannot calculate gradients, making it impossible to optimize the parameters of the predicted box in the next step. To address this issue, many researchers have proposed IoU-based loss functions that incorporate spatial information errors between the predicted box and the target box into the original IoU loss function, which can better improve the accurate positioning ability of the predicted box. These loss functions include the original IoU loss and various improved versions, which are collectively referred to as broad IoU losses. Due to their excellent performance in measuring the actual differences between two bounding boxes, BIoU losses have been widely used in object detection algorithms. Currently, the mainstream BIoU losses include GIoU loss [12], DIoU and CIoU loss [13], and EIoU loss [14]. Therefore, the BIoU losses can be defined as Equation (1)
- CFIoU loss is a loss function designed for bounding box regression, which provides faster and better regression performance than BIoU losses.
- To address the deficiency of BIoU losses when the predicted box approaches the target box, we propose a loss term based on the corner point distance deviation.
- To utilize target information in bounding box regression optimization, we propose an adaptive loss term. This approach is particularly effective for small targets with limited information.
- Our proposed method can be easily integrated into existing anchor-based and anchor-free object detection algorithms to achieve improved performance on small targets.
2. Related Works
2.1. BIoU Losses for Bounding Box Regression
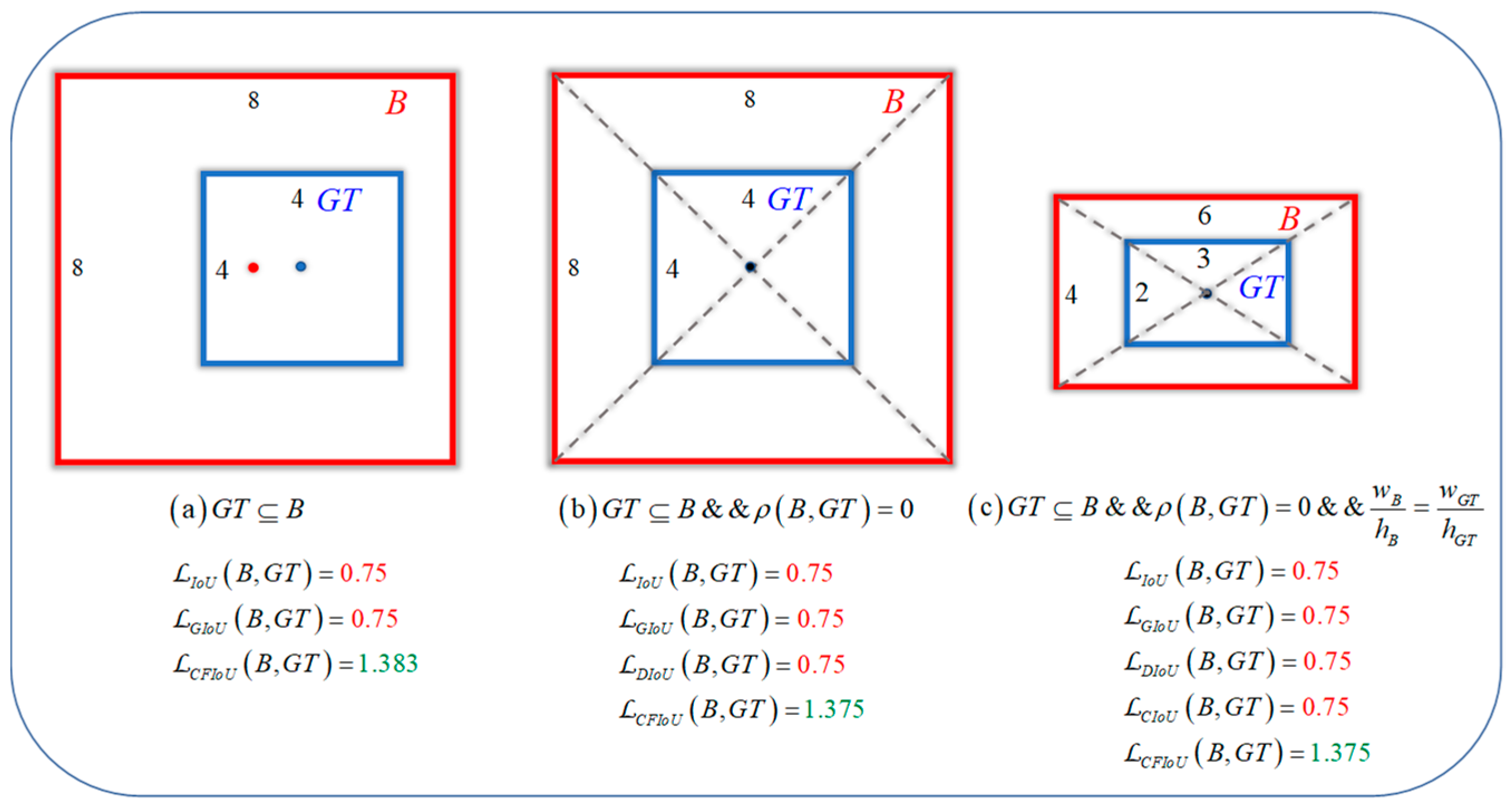
2.1.1. Limitations of IoU Loss
2.1.2. Limitations of Generalized IoU Loss (GIoU Loss)
2.1.3. Limitations of Distance IoU Loss (DIoU Loss)
2.1.4. Limitations of Complete IoU Loss (CIoU Loss)
2.1.5. Limitations of Efficient IoU Loss (EIoU Loss)
2.2. Strategies for Utilizing Object Foreground Information
3. Methods
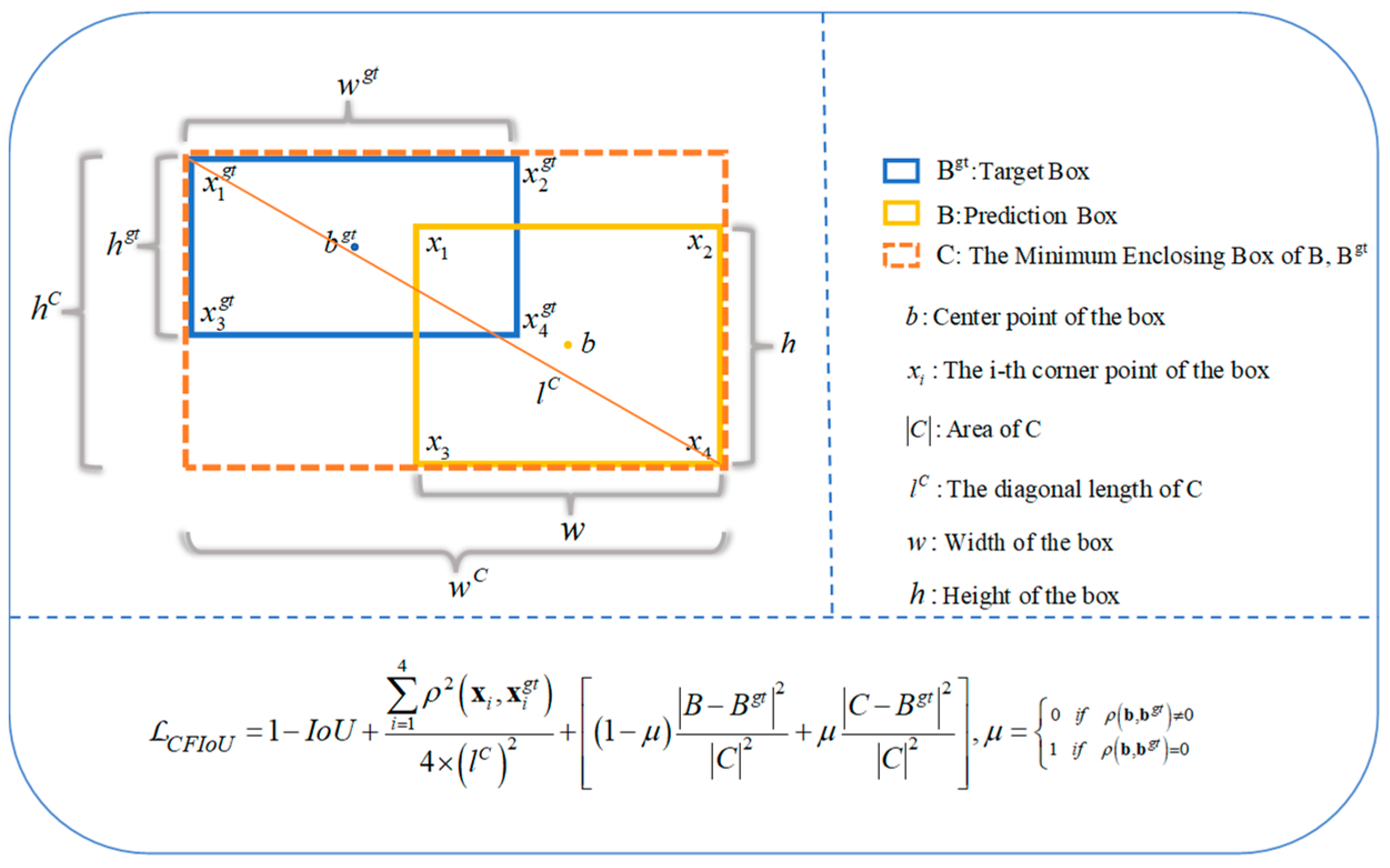
3.1. Penalty Term Based on Corner Point Distance
3.2. Penalty Term Based on Target Foreground Information
- When the geometric centers of the predicted and target bounding boxes do not coincide, we use the method of directly minimizing the size difference between the predicted box and the real target foreground to speed up the regression of the predicted box.
- When the geometric centers of the predicted and target bounding boxes coincide, we use the difference between the minimum enclosing region and the real target foreground region to distinguish the contributions of the foreground and background regions in the penalty function. If the proportion of the foreground region in the minimum enclosing region of the predicted and target bounding boxes is small (the proportion of the background region is large), it indicates that the regression effect of the current predicted box is not good, so the predicted box needs to be punished more severely. In particular, for small objects, which have limited foreground information and are prone to be missed, using the foreground information in the minimum enclosing region can help their bounding boxes obtain more advantageous gradient information for regression.
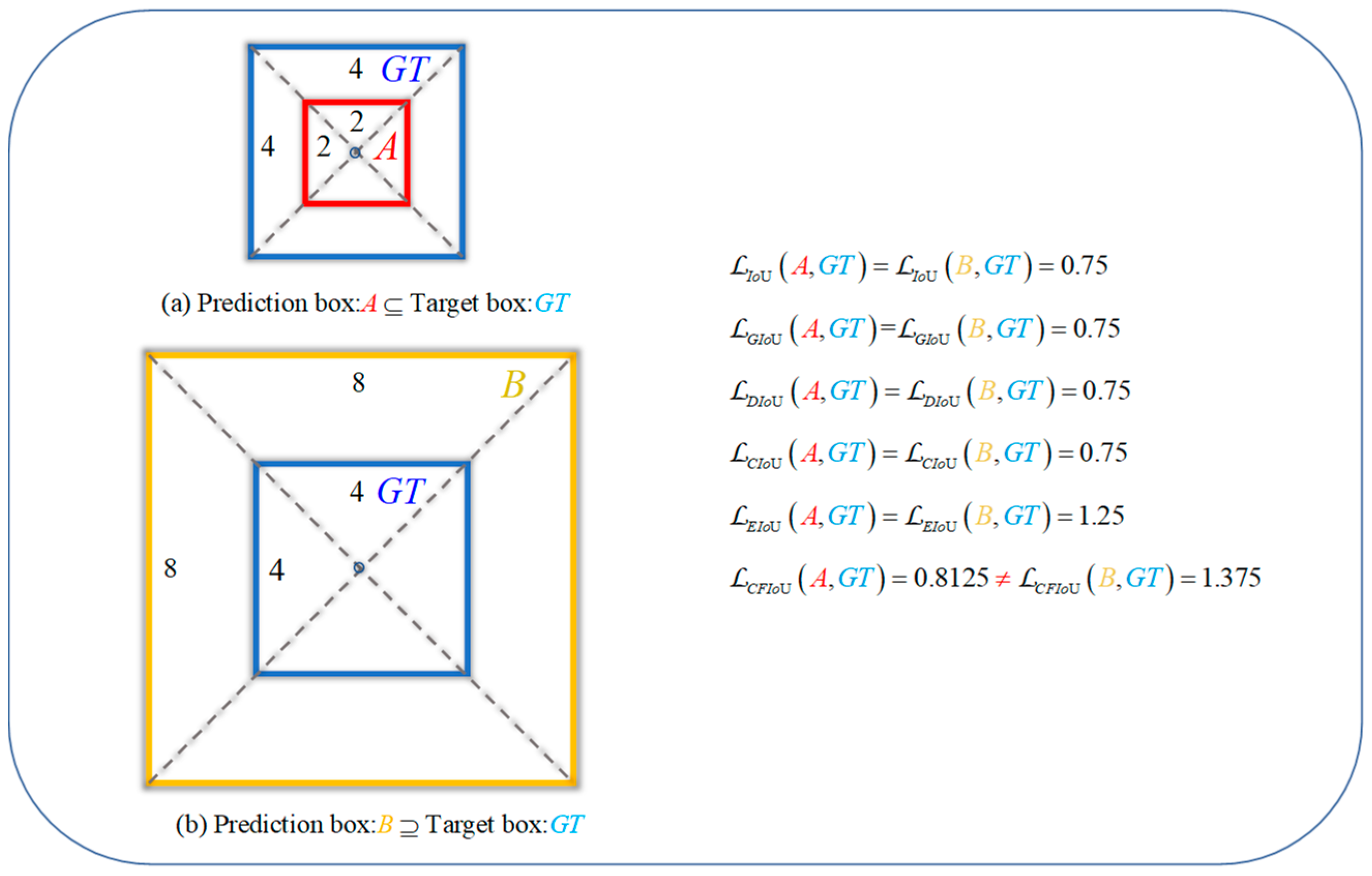
3.3. Corner-Point and Foreground-Area IoU Loss
- The proposed CFIoU loss inherits some properties of the BIoU loss:
- The CFIoU loss has the following advantages over the BIoU losses:
4. Experiments and Discussion
4.1. Datasets and Evaluation Metrics
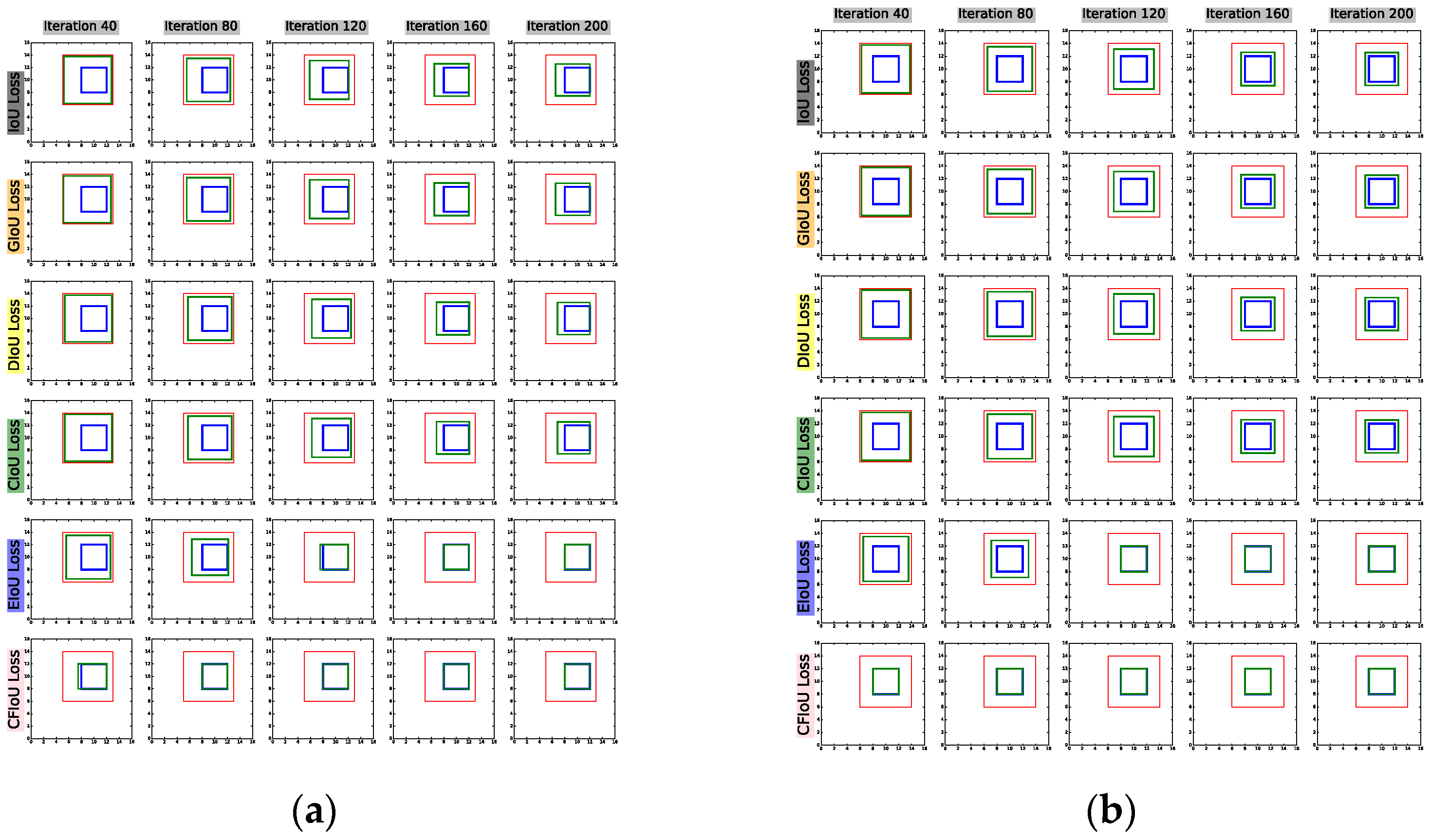
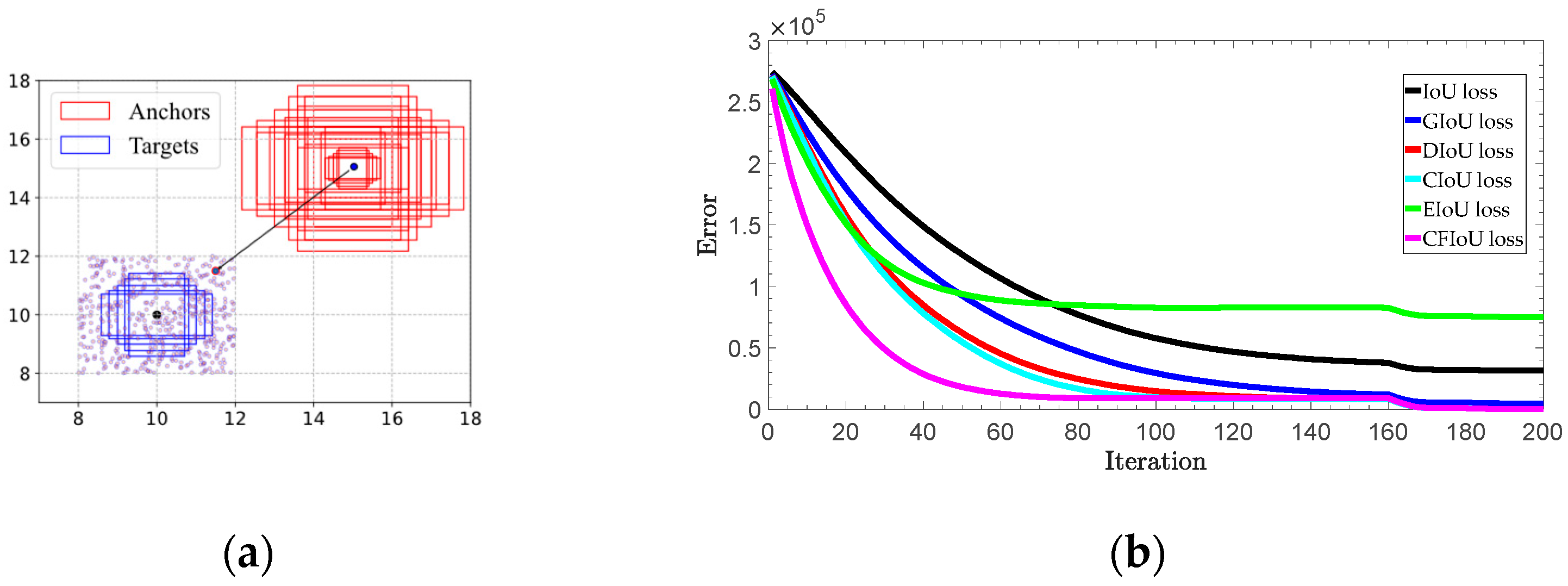
4.2. Simulation Experiment
| Algorithm 1 Simulation Experiment |
| Input: denotes all the anchors at points, where is the number of combinations of different areas and aspect ratios. is the set of target boxes that are fixed at (10, 10) with area 4, and have five aspect ratios. Output: Regression error 1: 2: Do bounding box regression: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: |
4.3. Ablation Study
4.4. Quantitative Results
4.4.1. YOLOv5 and YOLOv8 on VisDrone2019
4.4.2. YOLOv5 and YOLOv8 on SODA-D
4.4.3. SSD on VisDrone2019
4.5. Discussion
4.6. Further Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems 28, Proceedings of the Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Curran Associates, Inc.: Red Hook, NY, USA, 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ultralytics YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 20 January 2023).
- Law, H.; Deng, J. CornerNet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 20–26 October 2019; pp. 9627–9636. [Google Scholar]
- Ultralytics YOLOv8. Available online: https://github.com/ultralytics/ultralytics (accessed on 5 February 2023).
- Bae, S.-H. Object detection based on region decomposition and assembly. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8094–8101. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Cheng, G.; Yuan, X.; Yao, X.; Yan, K.; Zeng, Q.; Han, J. Towards large-scale small object detection: Survey and benchmarks. arXiv 2022, arXiv:2207.14096. [Google Scholar]
- Qin, Z.; Li, Z.; Zhang, Z.; Bao, Y.; Yu, G.; Peng, Y.; Sun, J. ThunderNet: Towards real-time generic object detection on mobile devices. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6718–6727. [Google Scholar]
- Cao, Y.; Chen, K.; Loy, C.C.; Lin, D. Prime sample attention in object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11583–11591. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. Varifocalnet: An iou-aware dense object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]
- Chen, K.; Li, J.; Lin, W.; See, J.; Wang, J.; Duan, L.; Chen, Z.; He, C.; Zou, J. Towards Accurate One-Stage Object Detection with Ap-Loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5119–5127. [Google Scholar]
- Qian, Q.; Chen, L.; Li, H.; Jin, R. Dr loss: Improving object detection by distributional ranking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12164–12172. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Loss | IoU | Centroids | Corner Points | Foreground Areas | Recall | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|---|---|
| (a) | √ | √ | 31.2 | 28.9 | 15.7 | ||
| (b) | √ | √ | 32.3 (↑3.53%) | 29.3 (↑1.38%) | 15.8 (↑0.64%) | ||
| (c) | √ | 32.1 | 29.2 | 15.7 | |||
| (d) | √ | √ | 32.7 | 29.8 | 16.0 | ||
| (e) | √ | √ | √ | 33.1 | 30.1 | 16.0 |
| Loss/Evaluation | YOLOv5s | YOLOv8s | ||||
|---|---|---|---|---|---|---|
| Recall | mAP@0.5 | mAP@0.5:0.95 | Recall | mAP@0.5 | mAP@0.5:0.95 | |
| 32.1 | 29.3 | 15.7 | 34.9 | 33.4 | 19.3 | |
| 31.7 | 29.1 | 15.7 | 34.1 | 32.5 | 18.7 | |
| R I.% 1 | −1.25% | −0.68% | - | −2.29% | −2.69% | −3.11% |
| 31.2 | 28.9 | 15.7 | 35.2 | 33.5 | 19.1 | |
| R I.% 1 | −2.80% | −1.37% | - | +0.86% | +0.30% | −1.04% |
| 31.5 | 29.2 | 15.7 | 35.0 | 33.2 | 19.0 | |
| R I.% 1 | −1.87% | −0.34% | - | −0.29% | −0.60% | −1.55% |
| 32.6 | 29.9 | 16.0 | 35.2 | 33.1 | 19.0 | |
| R I.% 1 | +1.56% | +2.05% | +1.91% | +0.86% | −0.90% | −1.55% |
| 33.1 | 30.1 | 16.0 | 35.5 | 33.6 | 19.3 | |
| R I.% 1 | +3.12% | +2.73% | +1.91% | +1.72% | +0.60% | - |
| Loss/ Evaluation | YOLOv5s | YOLOv8s | ||||
|---|---|---|---|---|---|---|
| Recall | mAP@0.5 | mAP@0.5:0.95 | Recall | mAP@0.5 | mAP@0.5:0.95 | |
| 15.00 | 10.70 | 3.64 | 11.90 | 8.46 | 3.21 | |
| 13.10 | 9.56 | 3.33 | 11.80 | 8.48 | 3.27 | |
| R I.% 1 | −12.67% | −10.65% | −8.52% | −8.40% | +0.24% | +1.87% |
| 13.80 | 10.00 | 3.40 | 11.90 | 8.53 | 3.24 | |
| R I.% 1 | −8.00% | −6.54% | −6.59% | - | +0.83% | +0.93% |
| 14.10 | 10.30 | 3.33 | 11.80 | 8.52 | 3.25 | |
| R I.% 1 | −6.00% | −3.74% | −8.52% | −8.40% | +0.71% | +1.25% |
| 15.6 | 11.6 | 3.91 | 12.1 | 8.62 | 3.29 | |
| R I.% 1 | +4.00% | +8.41% | +7.42% | +1.68% | +1.89% | +2.49% |
| 15.9 | 12.1 | 4.16 | 12.3 | 8.77 | 3.34 | |
| R I.% 1 | +6.00% | +13.08% | +14.29% | +3.36% | +3.66% | +4.05% |
| Loss/Evaluation | AP | AP75 |
|---|---|---|
| 7.382 | 7.453 | |
| 7.247 | 7.519 | |
| Relative improv. % | −1.83% | +0.89% |
| 7.214 | 7.331 | |
| Relative improv. % | −2.28% | −1.64% |
| 7.155 | 7.095 | |
| Relative improv. % | −3.08% | −4.80% |
| 7.340 | 7.037 | |
| Relative improv. % | −0.57% | −5.58% |
| 7.795 | 7.853 | |
| Relative improv. % | +5.59% | +5.37% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, D.; Zhang, Z.; Zhang, Z. Corner-Point and Foreground-Area IoU Loss: Better Localization of Small Objects in Bounding Box Regression. Sensors 2023, 23, 4961. https://doi.org/10.3390/s23104961
Cai D, Zhang Z, Zhang Z. Corner-Point and Foreground-Area IoU Loss: Better Localization of Small Objects in Bounding Box Regression. Sensors. 2023; 23(10):4961. https://doi.org/10.3390/s23104961
Chicago/Turabian StyleCai, Delong, Zhaoyun Zhang, and Zhi Zhang. 2023. "Corner-Point and Foreground-Area IoU Loss: Better Localization of Small Objects in Bounding Box Regression" Sensors 23, no. 10: 4961. https://doi.org/10.3390/s23104961
APA StyleCai, D., Zhang, Z., & Zhang, Z. (2023). Corner-Point and Foreground-Area IoU Loss: Better Localization of Small Objects in Bounding Box Regression. Sensors, 23(10), 4961. https://doi.org/10.3390/s23104961