1. Introduction
In real life, many complex systems can be modeled into complex networks for analysis, such as power networks, traffic networks, routing networks, citation networks, 5G/6G space–air–ground communication networks, social networks, etc.
In link prediction tasks, nodes in the network always represent real entities, such as routers and switches in the network, and associations between entities represent edges. Link prediction is mainly based on current network structures and other information to complete the missing links in a current network or predict the possible new connections in a future network [
1], such as new routing links, which may occur in the 5G/6G space–air–ground communication networks around satellite MEC equipment (mobile edge computing) to transport data-dense computation. As an important research direction in complex networks, link prediction has extensive theoretical research value and practical application value.
In other theoretical research value aspects, link prediction can reveal the evolutionary mechanism of a network and provide a simple and fair comparison method for the evolutionary network [
2]. For example, for a certain type of network, many models provide evolutionary methods. The quality of evolutionary methods can be verified through real datasets, but these evolutionary methods are often limited by the scale of evolutionary time or the difficulty of real dataset collection. The link prediction algorithm provides a simple and fair comparison method. According to network structure at the moment
, the link prediction algorithm can be used to complete the missing link in the current network or to predict the network at time
when new links are generated in the future. Then, the accuracy of different evolution methods can be obtained via comparison with the network at the original moment. Additionally, the advantages and disadvantages of different evolutionary methods can be obtained by analyzing the accuracy of new generated links.
In other practical applications, for example, in social networks, the link prediction algorithm recommends users who have the same interests but are not friends to other online social users to improve user stickiness [
3]. In Weibo or Facebook, the link prediction algorithm can be used to recommend topics or short videos that users are interested in and to predict the popularity of certain special topics and short videos [
3]. In the field of e-commerce, the relationship graph between users and commodities can be established, and the link prediction algorithm can recommend relevant commodities to users, reduce the time of searching for commodities, and improve efficiency [
4]. In the protein network, there are many unknown links, and searching for these links requires many crossover experiments, which will waste much manpower and material resources. However, the link prediction algorithm will predict the most likely links, which provides guiding opinions for the experiment, shortens the scope of the experiment, and speeds up the identification process of unknown links. Additionally, the experimental cost is reduced [
5]. The research on link prediction in complex networks has wide theoretical and practical value.
2. Related Work
In reality, a large number of complex systems can be represented by networks, with nodes representing different entities and edges representing relationships between entities. Link prediction is the prediction of missing links in the current network and the generation of new links in a future network through the known network structure and other information [
1]. It has a wide range of practical value regarding friend recommendation [
3], product recommendation [
4], knowledge graph completion [
6], and other areas [
7,
8,
9].
The heuristic algorithms commonly used in link prediction are based on node similarity [
10]. This algorithm assigns a scoring function to each node pair, representing the similarity of node pair, and sorts the unobserved node pairs according to the scoring function. The node pairs with high similarity are more likely to generate new connections. This kind of algorithm can be classified according to the maximum hop number of the maximum neighbor node required to calculate the scoring function [
11]. For example, CN [
12] and JC [
13] link prediction algorithms only need the one-hop neighbor node of the target node pair to calculate the score function, so it belongs to the heuristic algorithm of one-hop node similarity. AA [
3] and RA [
14] link prediction algorithms need the target node to calculate the two-hop neighbor node when calculating the score function. Therefore, it belongs to the heuristic algorithm of two-hop node similarity. This form of similarity-based heuristic algorithm has become the most common algorithm in link prediction because of its simplicity and effectiveness. However, such algorithms need strong assumptions. When changing from one network structure to another network structure, the assumptions are not consistent with the other network structure. For example, the CN algorithm believes that the more common neighbors two nodes have, the more likely they will have links in the future, which is often correct in social networks. However, this is not true in protein interaction networks (the more common neighbors two nodes have, the less likely they are to generate links in the future) [
15]. Therefore, it is a significant disadvantage of heuristic algorithms based on node similarity to select appropriate scoring functions for different network structures.
The link prediction algorithm based on machine learning mainly transforms the link prediction task into a binary classification task, in which the node pairs with links are regarded as positive classes and the node pairs without links are regarded as negative classes. The key to this kind of algorithm mainly lies in the selection of features and classification algorithms. In 2004, Faloutsos et al. [
16] introduced a connection subgraph, which is able to capture the topology between two nodes in a social network. In 2006, Al et al. [
17] extracted the non-topological features of the network based on the extraction of the topological features of the network, which improved the algorithm’s accuracy. In 2007, Liben et al. [
18] extracted some network topology features from the citation network, such as CN, AA, Katz, etc., and input them into a supervised learning algorithm for learning and prediction. Their experimental results outperform link prediction algorithms based on individual network topologies. In 2010, Benchettara et al. [
19] used the enhanced decision tree algorithm and found that using topological features in the feature set is able to significantly improve the link prediction algorithm’s precision, recall, and F value. In 2014, Fire et al. [
20] proposed a set of easily computable graph-structured features and adopted two ensemble learning methods to predict missing links in the network. In 2018, Zhang et al. [
21] used the attribute features of nodes as non-topological features to input into supervised learning algorithms, improving the accuracy of the link prediction algorithms. In 2018, Mandal et al. [
22] used a variety of supervised learning algorithms for link prediction in a two-layer network composed of Twitter and Foursquare. In 2022, Kumar et al. [
23] introduced the value of node centrality as a sample feature, input it into various supervised learning algorithms for prediction, and achieved the best results on the LGBM (light gradient boosted machine) classifier. The key to link prediction algorithms based on machine learning lies in selecting feature sets. Such algorithms often extract some topological features of the network as feature sets. However, when solving domain-specific link prediction problems, corresponding domain knowledge is also required to construct its domain-specific features. Compared with the heuristic-based link prediction algorithm, the link prediction algorithm based on machine learning can improve its accuracy, but it also results in time costs for training models and feature selection.
Link prediction algorithms based on graph representation learning mainly map high-dimensional dense matrices (graph data) into low-dimensional dense vectors and then use the mapped vectors for downstream tasks, such as node classification [
24,
25], graph classification [
26,
27], link prediction [
28], etc. In 2014, Perozzi et al. [
29] first proposed the graph representation algorithm DeepWalk for unsupervised learning. The algorithm obtains the sequence of nodes through random walks and inputs the sequence of nodes as sentences into the Skip-Gram model in the Word2Vec algorithm to obtain the node vector representation. In 2015, Tang et al. [
30] proposed the LINE algorithm model, which proposed a method of edge sampling so that the vectors of the obtained nodes retain the first-order similarity and second-order similarity. In 2016, Grover et al. [
31] proposed the Node2Vec algorithm. Node2Vec is similar to DeepWalk, but Node2Vec uses a biased random walk method, which balances depth-first walk and breadth-first walk and obtains a higher-quality embedded representation. In 2016, Wang et al. [
32] proposed the SDNE (structural deep network embedding) model. SDNE is a semi-supervised deep learning model that uses a deep network structure to simultaneously optimize the first-order and second-order similarity objective functions and obtains vectors for preserving the graph’s local and global structure. In 2016, Cao et al. [
33] proposed the DNGR algorithm model. DNGR uses the random walk model (random surfing) to generate the probability co-occurrence matrix, calculates the PPMI matrix with the probability co-occurrence matrix, and uses the superimposed denoising automatic encoding machine to extract features to obtain the vector representation of the node. In 2016, Kipf et al. [
34] proposed the GCN (graph convolutional network) model. The algorithm considers the influence of neighbor nodes and continuously aggregates the characteristics of neighbor nodes. Embedding neighbor nodes can obtain scalability, and the global information can be described by aggregating the characteristics of neighbor nodes through multiple iterations. In 2016, Kipf et al. [
35] proposed the VGAE (variational graph auto-encoders) model, introducing variational autoencoders into graph data. The distribution of the node vector representation of the known graph is learned through GCN convolution, the representation of the node vector is sampled in the distribution and then decoded (link prediction) to reconstruct the graph. In 2017, Veličković et al. [
36] proposed the GAT (graph attention networks) model, which introduced an attention mechanism. When calculating the vector representation of nodes, the model’s generalization ability is improved by assigning different weights to the characteristics of nodes. At the same time, a multi-head attention mechanism is introduced and the features obtained by multiple attention mechanisms are spliced and averaged to obtain the final node representation. In 2017, Hamilton et al. [
37] proposed the GraphSage algorithm model for large-scale graph data. By learning an aggregation function, the neighbor nodes are sampled and aggregated to obtain a new vector representation of the node. In 2018, Chen et al. [
38] proposed the HARP algorithm model. HARP selects the starting node by weight and combines it with DeepWalk and Node2Vec to obtain a better embedding representation. In 2018, Schlichtkrull et al. [
39] proposed the R-GCN (relational graph convolutional networks) algorithm model. R-GCN introduced weight sharing and parameter constraints to improve the performance of the link prediction algorithm. In 2018, Sam et al. [
40] learned the representation vectors of nodes in historical time slices through the Node2Vec algorithm, concatenated the vectors of nodes in historical time slices to obtain the representation of future time slice links, and finally used supervised learning algorithms to predict future time links state. In 2019, Lei et al. [
41] used GCN to learn the network topology features of each time slice, used LSTM (long short term memory) to capture the evolution pattern of multiple continuous time slice dynamic networks, and then used GAN (generative adversarial network) to generate a representation of links in future time slices. In 2017, Zhang et al. [
42] proposed the WLNM link prediction model, which extracts the h-hop closed subgraph of the target node pair and sends the adjacency matrix of the subgraph to the fully connected layer for learning, which improves the link prediction algorithm results. Link prediction methods based on graph representation learning capture deeper network structural relationships in complex networks and more complex relationship features between nodes with difficulty due to limited walk steps and aggregation methods, resulting in lower algorithm accuracy.
Considering that the existing link prediction algorithms are unsuitable for different network structures, capturing the deeper network structure relationships and the more complex relationship characteristics between nodes is difficult, this paper proposes a link prediction algorithm based on subgraph (PLAS, predicting links by analysis subgraph). The algorithm first obtains h-hop neighbor nodes of the target node pair to form a subgraph and then assigns labels to each node of the subgraph. The nodes in the subgraph are sorted according to labels. Finally, the nodes of the subgraph are input to the full connection layer in a consistent order for classification.
Additionally, our contributions are as follows:
A subgraph node labeling method is provided, which is able to automatically learn graph structure features and input nodes of subgraphs into the full connection layer in a consistent order.
A link prediction method (PLAS) based on subgraph is proposed, which can be applied to different network structures and is superior to other link prediction algorithms.
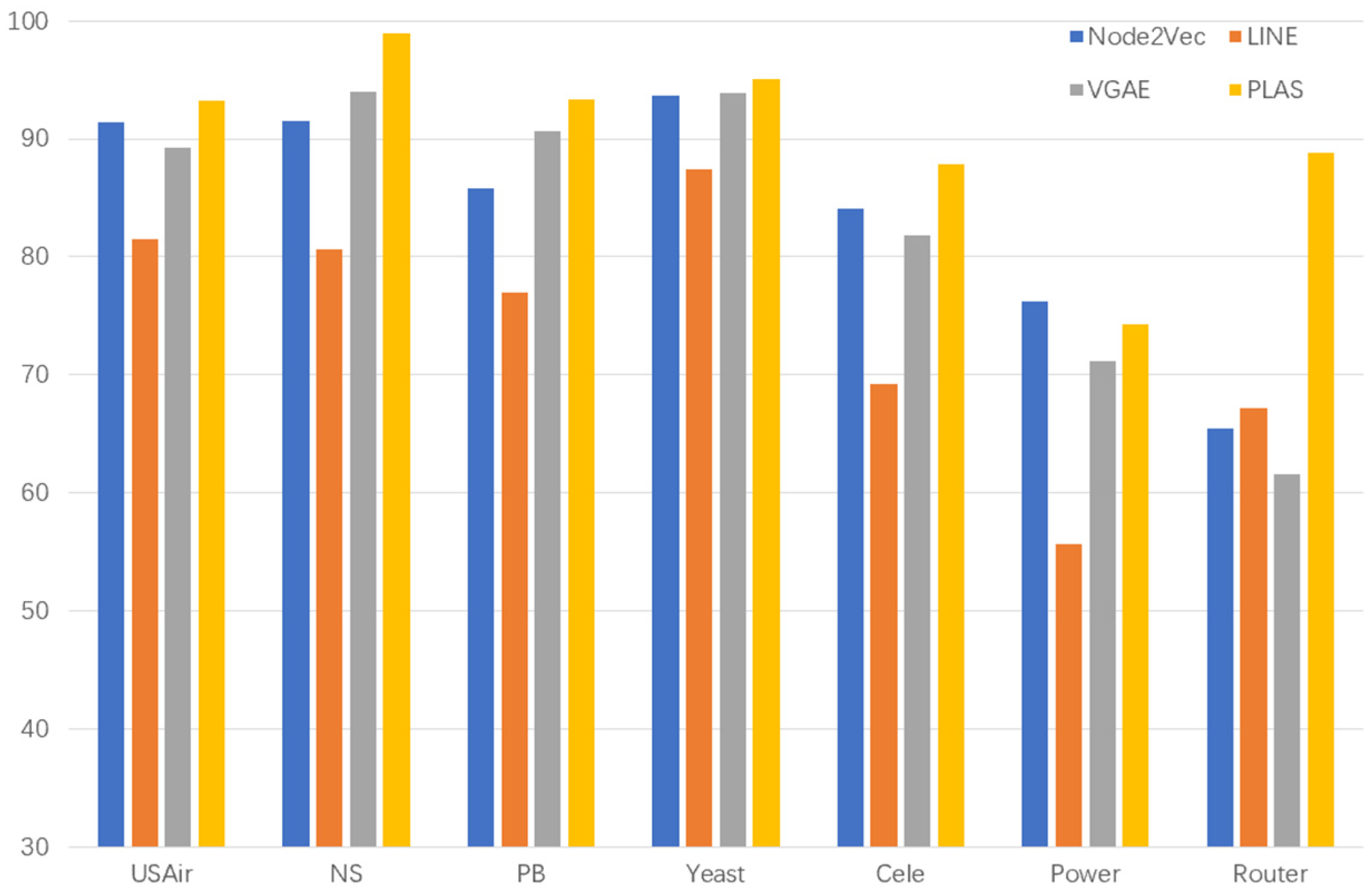
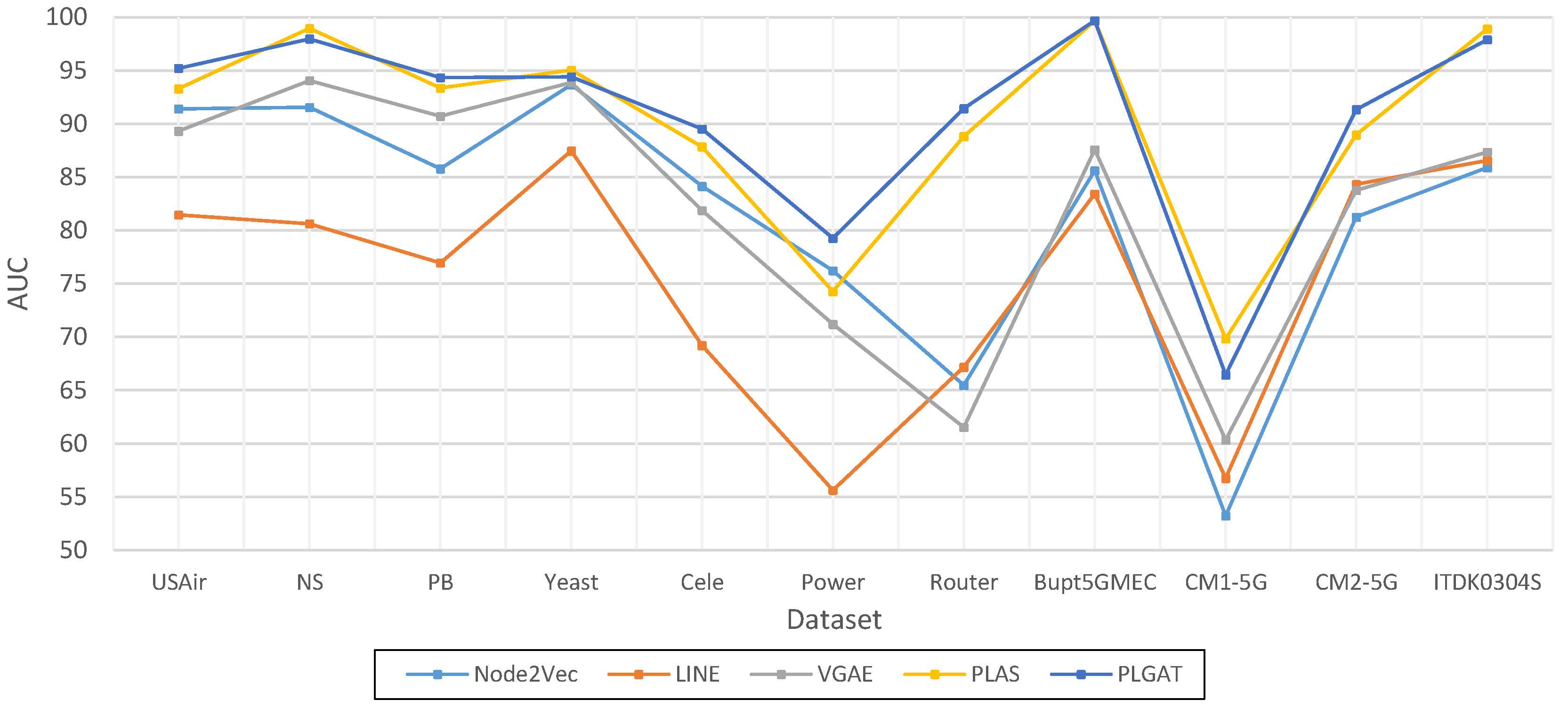
Based on a torch, the link prediction algorithm (PLAS) model based on subgraph is implemented and verified using seven real datasets. Experimental results show that PLAS algorithm is superior to other link prediction algorithms.
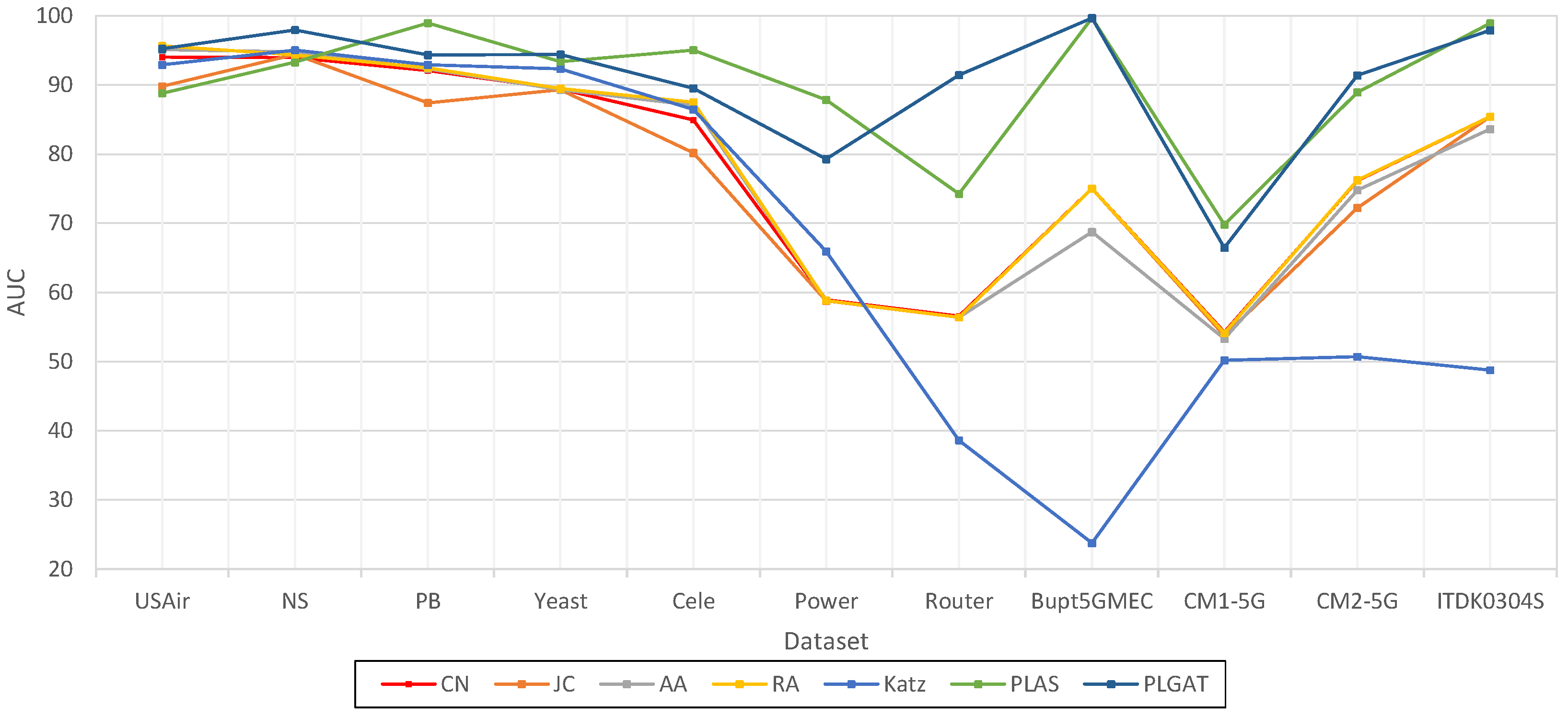
The existing algorithm PLAS is improved by introducing a graph attention network, and a link prediction algorithm (PLGAT) is proposed, which was verified using seven real datasets and two 5G/6G space–air–ground communication networks. The experimental results show that the PLGAT algorithm is superior to other link prediction algorithms. Furthermore, our proposed PLGAT algorithm for link prediction can precisely find out the new links on the Mobile MEC equipment network in 5G/6G to provide better QoS for data transportation.
3. PLAS Model Framework
This paper proposed a link prediction algorithm PLAS (predicting links by analysis subgraph) based on subgraphs. The PLAS algorithm transforms the link prediction task into a graph classification task, with the target node taking the linked subgraph as a positive sample and the target node taking the unlinked subgraph as a negative sample. Compared with the link prediction algorithm based on machine learning, it uses node labels to learn the graph features of the subgraph automatically and integrates the potential features of the subgraph nodes and node attribute features. The subgraph with multiple features has more comprehensive information, which is able to improve link prediction accuracy.
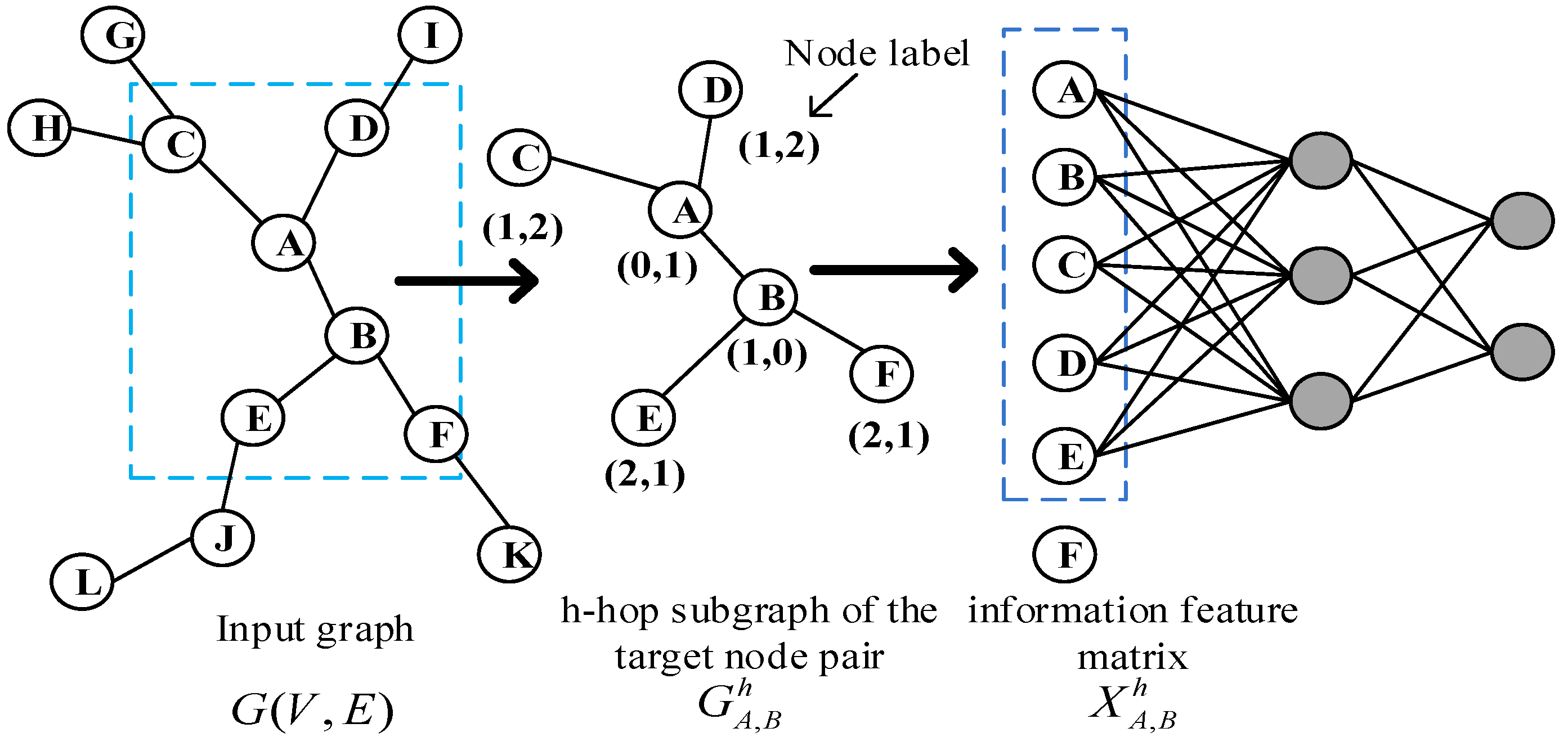
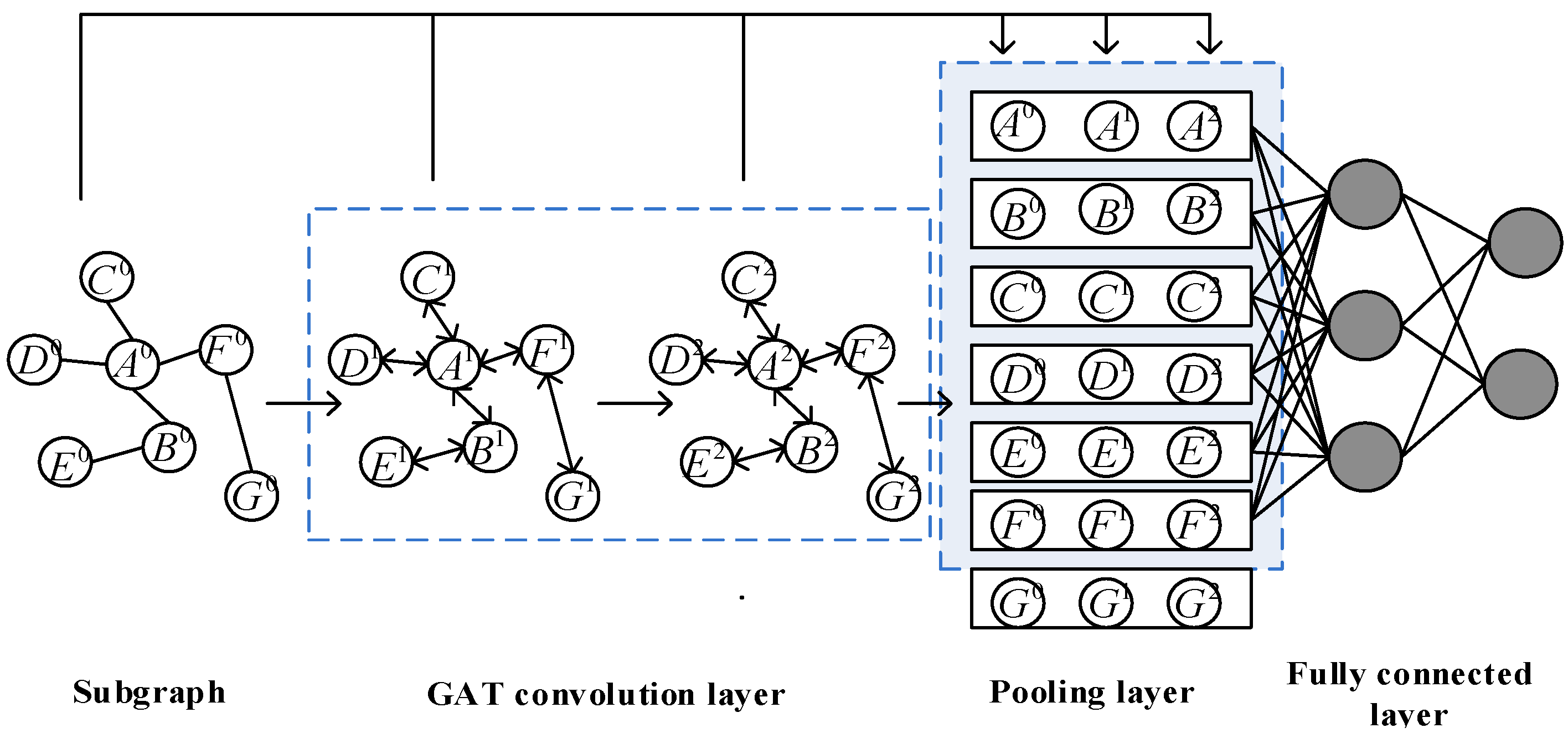
Figure 1 is the frame diagram of the model, which is mainly divided into four modules: 1. extraction of subgraphs; 2. graph labeling algorithm; 3. subgraph encoding; and 4. fully connected layer learning.
The principle of the PLAS algorithm is shown in
Figure 1. Given the undirected and unweighted graph
at the input time
, the subgraph of the h-hop of the target node
,
is first extracted, namely
(1-hop in the graph), and then labels are assigned to each node in the subgraph through the graph-labeling algorithm. The nodes in the subgraph are sorted according to labels and the information characteristic matrix
is constructed according to their order. Then, the first
node is selected, splicing the corresponding features of the first
node in the information matrix
to represent the embedding of the subgraph of target node pair, and finally input it to the fully connection layer for learning.
is the closed subgraph of the h-hop of the target node pair
, including all the first-order, second-order, and h-order nodes and the edges of corresponding nodes.
is an information feature matrix that sorts nodes in the subgraph and builds in accordance with their order, which is described as follows:
where
,
, and
are the explicit attribute feature, implicit attribute feature, and graph label of the first node in the information feature matrix. Additionally, each row in information feature matrix
represents the feature of a node in the subgraph
. The feature of each node is composed of explicit attributes (attributes of the node itself, such as interest, position, gender, etc.), implicit attributes (Node2Vec [
31] embedding nodes in the graph) and the label of each node in the subgraph (network structure features).
3.1. Extraction of Subgraphs
In order to learn the topological features of the network, the PLAS algorithm extracts its h-hop closed subgraph for each target node pair. In a natural system, the connection between nodes is affected by neighbor nodes, and the more intermediate nodes on the node path, the weaker the relationship between two nodes. Although more node structure may lead to more link information, whether the node pair will generate a link is primarily affected by 1-hop or 2-hop neighbor nodes. In this paper, the parameter is set to 1 or 2, according to the sparseness of the network structure. When the average number of neighbor nodes of each node in the network is greater than 10, parameter is selected as 1; when the average number of neighbor nodes of each node in the network is less than 10, parameter is selected as 2. This ensures that the value of will not be set too small, resulting in insufficient neighbor information and thus significantly impacting the prediction results. Moreover, with the decrease of the parameter, the number of neighbor nodes extracted from the target node pairs will decrease exponentially, indicating that the dimension of the feature vector of subgraph decreases, which can significantly reduce the training time of the model.
However, for large-scale networks, such as social networks, where a superstar has millions of fans, the number of first-order neighbor nodes is very large, which will lead to a memory explosion when the subgraph is extracted. This paper sets a threshold to prevent the problem of oversampling of subgraphs. When extracting the subgraph of the target node pair, if the number of subgraph nodes exceeds the threshold value , the current h-order neighbor nodes will be randomly sampled to equal , prioritizing sampling nodes with closer hops. For example, we need to extract 2-hop neighbor node subgraphs, while setting the threshold N value with 100, extract first-order neighbor nodes to 50 and extract second-order neighbor nodes to 250, and the sum of first-order neighbor nodes and second-order neighbor nodes is thus greater than the threshold . Therefore, we need to randomly sample second-order neighbor nodes (randomly select 50 nodes from 250 nodes) so that the number of summary points in the subgraph is equal to the threshold .
The subgraph extraction algorithm is described as Algorithm 1:
| Algorithm 1: Subgraph extraction |
| Input: , graph , h-hops neighbor nodes, threshold |
| Output: |
|
|
The target node h-hop neighbor node subgraph extraction algorithm process is as follows: for the target node pair in graph , first add the target node pair to the subgraph node set , and then add the node pair , the first-order neighbors, and the second-order neighbors to the h-order neighbors to the set . The relationship between all nodes and nodes in the set constitutes a subgraph S.
3.2. Graph Labeling Algorithm
The graph is an unordered data structure. We need a graph labeling algorithm to sort the nodes in the graph according to their labels to form an ordered sequence so that the fully connected layer can read node feature in a consistent order.
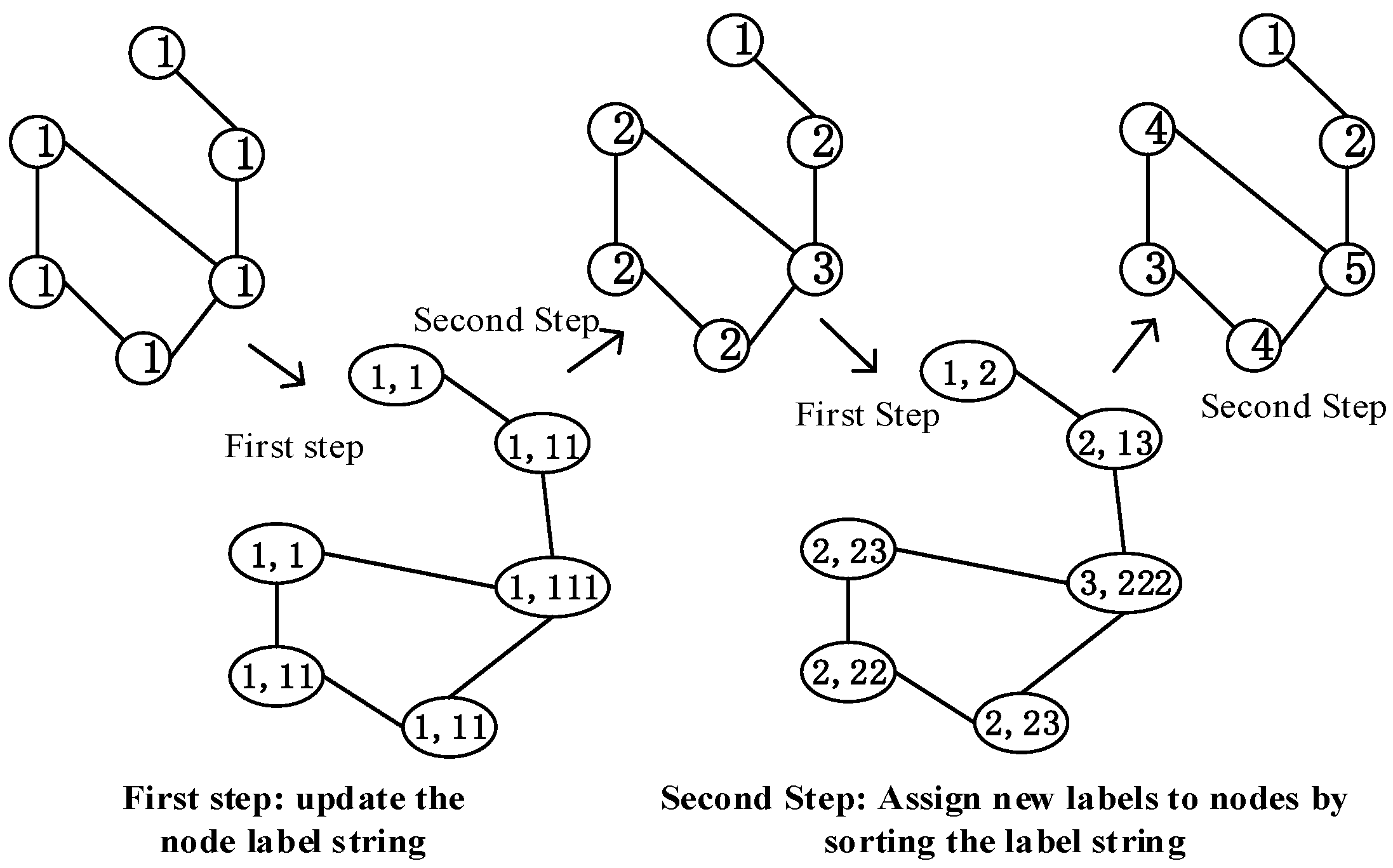
The Weisfeiler–Lehman (WL) algorithm [
43] is widely used in graph classification, and it is a classic graph labeling algorithm. The main idea of WL algorithm is to use the labels of neighbor nodes to update their own labels iteratively and compress the updated labels into new ones until they converge. The primary process of the WL algorithm is as follows:
It initializes all nodes in the graph to the same label 1, and each node aggregates its label and the labels of neighbor nodes to construct a label string.
The nodes in the graph are sorted in ascending order of label strings, and according to the sorting update to new labels 1, 2, 3, ... nodes with the same label string will receive the same new label. For example, suppose that the label of node is 2, its neighbor label is {3,1,2}, the label of node is 2, and its neighbor label is {2,1,2}. The label strings of and are < 2123 > and < 2122 >, respectively. Because < 2122 > is less than < 2123 > in the dictionary order, will be assigned a smaller label than in the next iteration.
This process is repeated until the node label stops changing.
Figure 2 shows updating the nodes’ labels from 1 to (1, ... 5).
The WL algorithm has two key advantages: 1. The final label coding represents the structural role of nodes in the graph. Nodes with similar structures have similar labels in different graphs. 2. It defines the relative order of nodes in the graph, which is also consistent in different subgraphs. However, the WL algorithm treats all nodes in the subgraph equally during initialization and assigns the same label. After multiple rounds of iterations, the final node label encoding makes it impossible to distinguish the target node pair from other nodes in the subgraph, resulting in untargeted model training. Therefore, we designed a new graph labeling algorithm combined with the shortest distance, which can ensure that the nodes in different subgraphs are sorted in a consistent order and distinguish the target node pair from other nodes in the subgraph.
| Algorithm 2: subgraph labeling |
| Input:, subgraph node list , subgraph S |
Output: Ordered list with labels
|
The process of the subgraph labeling algorithm is as Algorithm 2. The label string for each node consists of the shortest distance from that node to the target link node pair , where and are the shortest distances from this node to the target nodes and , respectively. After extracting the subgraph, we put all the extracted nodes into set . For each node in set , we calculate the shortest distance from each node to the target node pair as the label string and add it to the sequence list for uniform sorting. Additionally, we allocate the label strings and for the target link node pair , respectively. The sequence list is sorted first using the value of and then using the value of .
Since the shortest distance from other nodes to the target node pair is always greater than or equal to 1, according to the sorting rules of the sequence list, the label string , of the target link node pair is always smaller than the label string of other nodes. Therefore, the first two elements in the sequence list are always target node pairs , which can well distinguish the target link node from other nodes in the subgraph. The label string of a node defines the structural role in the subgraph centered on the target link node pair. Additionally, in the subgraph centered on different links, nodes with the same structural role have similar label strings. Compared with the WL algorithm, the graph labeling algorithm in this paper only needs to calculate the shortest distance from the node in the subgraph to the target node, and there is no iterative process of updating the node label of the sub graph, so it has low time complexity.
3.3. Subgraph Encoding
The purpose of subgraph encoding is to represent the subgraph centered on the target node pair as a node information feature matrix with a specific order. We construct the information feature matrix according to the order of nodes in the sequence list . The information feature of each node is composed of an explicit attribute, implicit attribute, and node label.
Explicit attribute: The attribute of the node itself is the attribute feature of the dataset. For example, in the social network, the attribute feature of the node is interest, hobby, gender, etc.
Implicit attribute: Forming node embeddings in a graph using a graph embedding algorithm. Node2vec is a common node embedding algorithm. It first obtains a series of node sequences via random walk in the network, and then obtains models, such node sequences, by processing word vectors to obtain the representation of node vectors in the network.
The label of each node in the subgraph: The node label is represented by the function , which assigns a label string to each node in the subgraph. Node labels have three main functions:
They can represent different nodes playing different roles in the subgraph. The shorter the shortest path of other nodes in the subgraph relative to the target node pair, the greater its impact regarding whether the target node will generate links in the future, so it plays a more important role in the subgraph.
The graph is an unordered data structure, which has no fixed order. Therefore, it is necessary to sort the nodes in the subgraph through labels and then input them to the fully connection layer in a consistent order for learning.
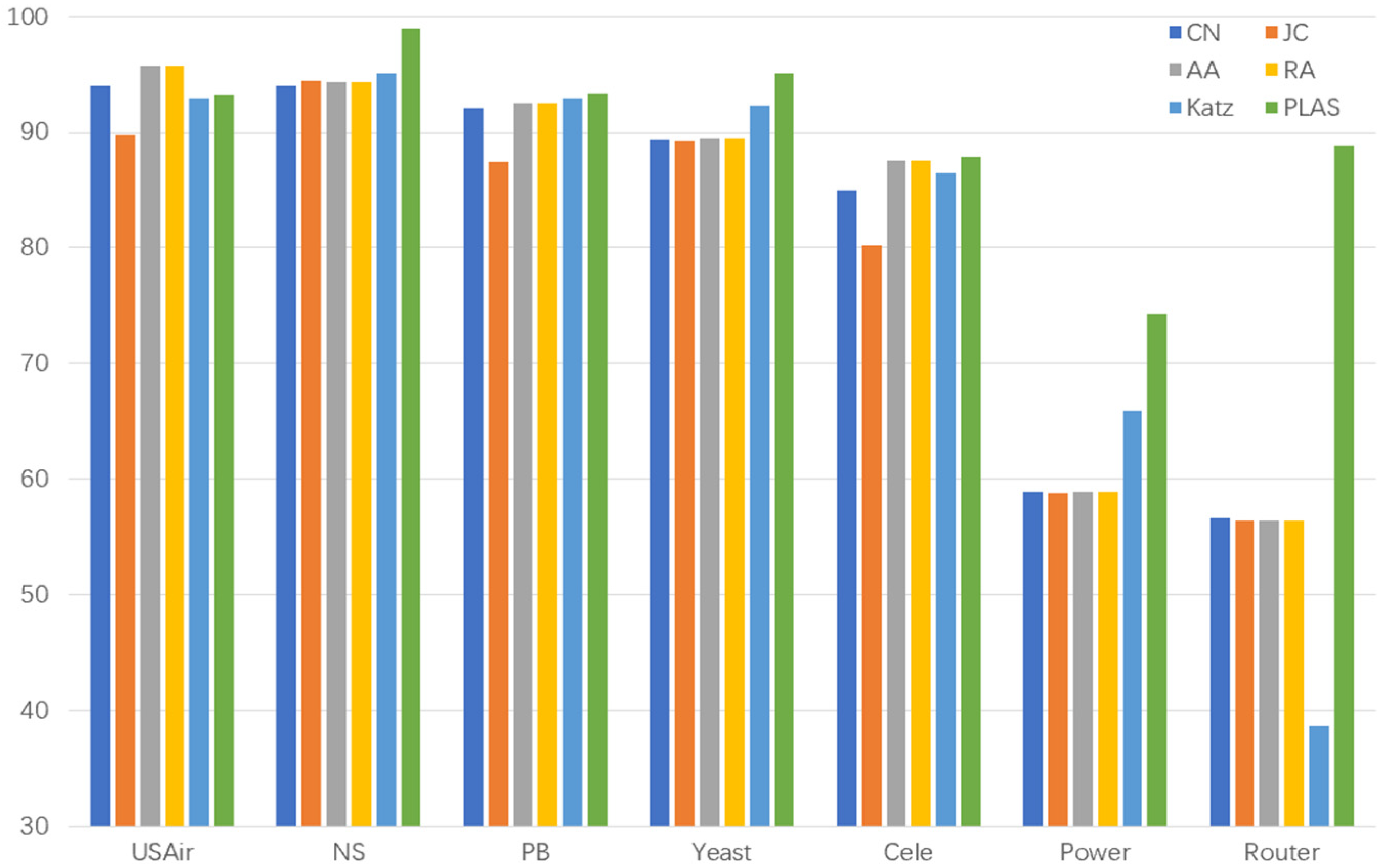
After extracting the hop subgraph of the target link node pair , we calculate the shortest path from other nodes in the subgraph to the target node pair and assign a label string to each node in the subgraph. When all node features in the subgraph are spliced and sent to the fully connected layer for learning, the fully connected layer will automatically learn the graph structure features suitable for the current network, including the discovered graph structure features or the undiscovered graph structure features. For example, the CN algorithm calculates the number of common neighbor nodes of the target node pair. The full connection layer only needs to find the number of nodes with node label . By assigning a node label string to each node in the graph through the icon algorithm, our algorithm model can automatically learn the graph structure characteristics of the network, so it can be applied to different network structures. The later experimental results show that our algorithm is better in the AUC (area under curve) than other link prediction algorithms.
When we obtain the explicit attribute, implicit attribute, and label of each node in the subgraph, we splice the characteristics (explicit attribute, implicit attribute, and node label) of each node in the order of the sequence list and construct an information feature matrix to represent the whole subgraph.
3.4. Fully Connected Layer Learning
The fully connected layer is used to integrate the information feature matrix of the hop subgraph of different target link node pairs for learning. Since the number of nodes in the h-hop subgraph of each node pair is different, the training of the fully connected layer will be significantly affected by the subgraph with a large number of nodes, while the impact of the node information with a small number of subgraphs will be affected by neglect. Therefore, it is necessary to set a unified node number threshold to balance the feature dimension input of different subgraphs. We sort each node in the subgraph using a graph-labeling algorithm. When the number of nodes in the subgraph is greater than , the nodes ranked after are discarded. When the number of nodes in the subgraph is less than , we construct virtual nodes so that the number of nodes equals , and zero vectors represent the feature of the virtual nodes in . We set the specific value according to the overall network topology. We sort the number of each subgraph node in a training set in ascending order and take the value of the corresponding element at the 0.6 scale index as . If the value is set too small, too many nodes need to be deleted, resulting in too much information loss; if the value is set too large, we need to construct a large number of virtual nodes that do not contain any information, and this will also cause the input feature dimension to be too large, increasing the training time. Therefore, we have compromised selecting the value according to the network topology.
The neural network structure of the fully connected layer consists of an input layer, a hidden layer, and an output layer. The number of neurons in the input layer is determined by the dimension of each node feature vector multiplied by , and the number of neurons in the hidden layer is set to 128. Additionally, the number of neurons in the output layer is 2, because we converted link prediction into a graph classification problem (two classes), where the subgraph with linked node pairs represents one class and the subgraph without linked node pairs represents the other class. In this paper, the ReLU function was used for activation function and cross entropy loss function for the loss function.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
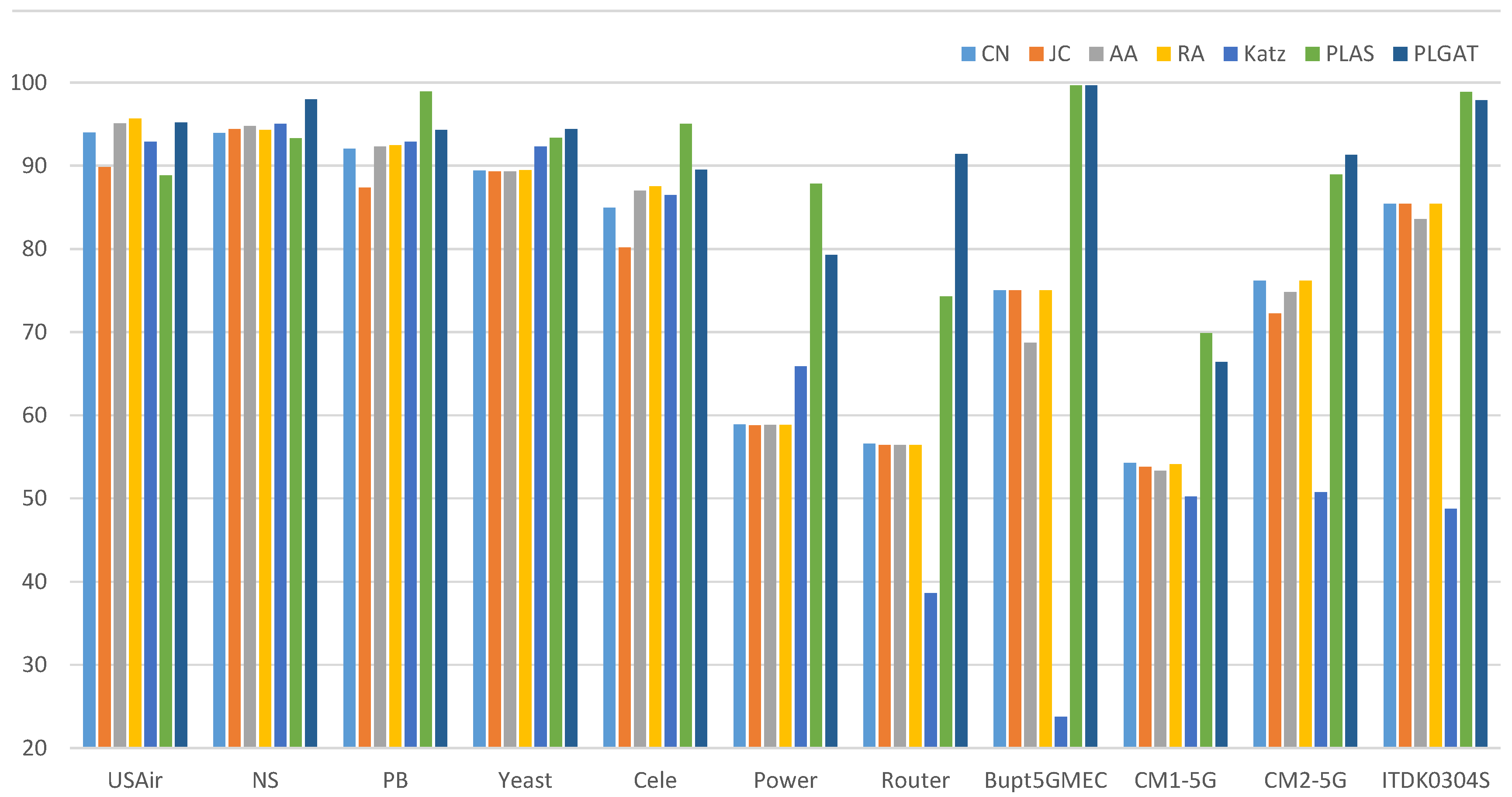{kind=link}
{kind=link}
{kind=link}