
Multi-Label Classification in Anime Illustrations Based on Hierarchical Attribute Relationships


Abstract
:1. Introduction
- We propose a GCN-based model for the multi-label attribute classification suitable for anime illustrations.
- Considering the hierarchical relationships between attributes, we use hierarchical clustering and organize the attribute representations of anime illustrations by hierarchical label assignments to generate a feature with rich hierarchical relationships between labels that can be imported into the GCN-based classification model.
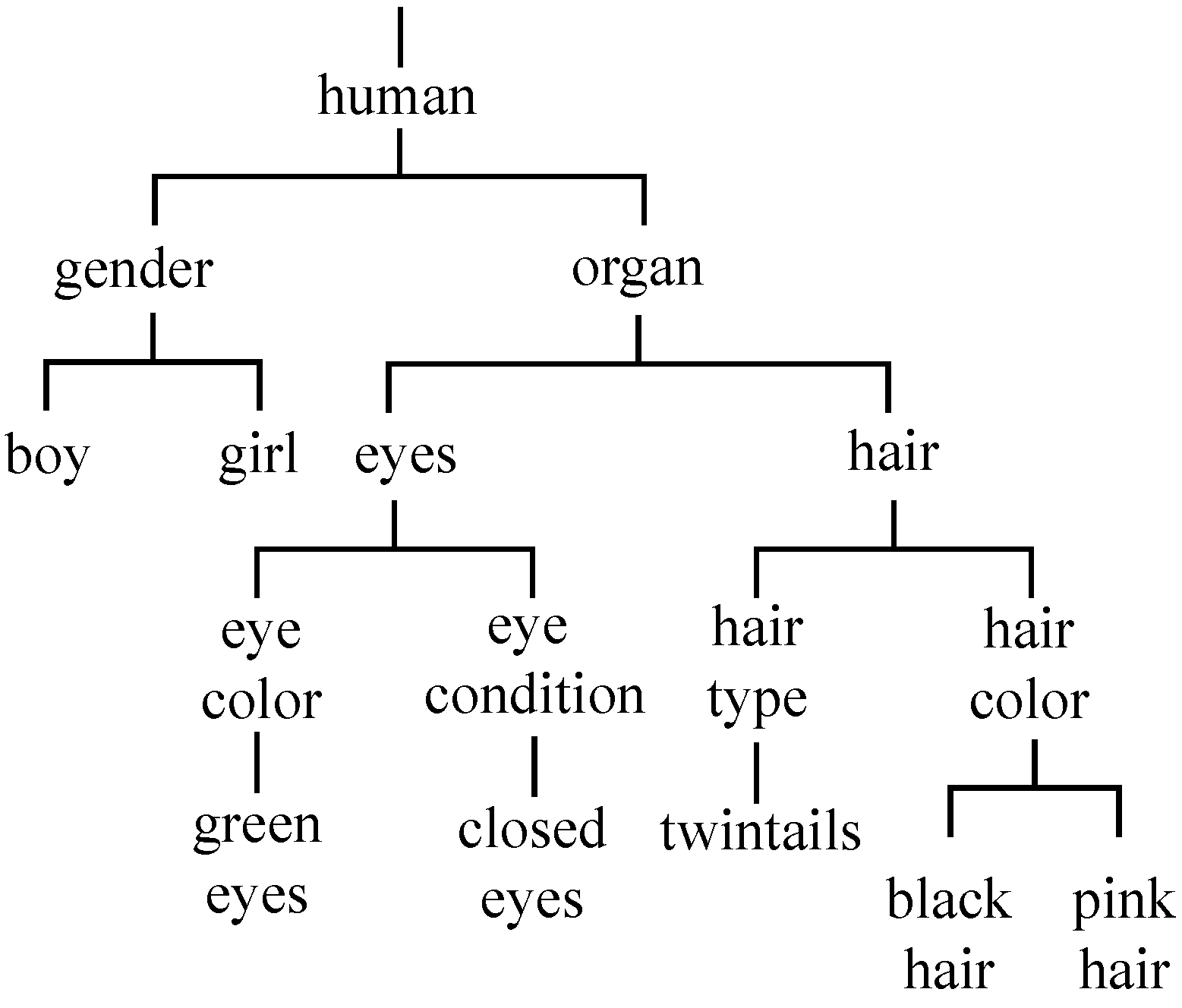
- We construct a hierarchical structure of attributes in the anime illustration datasets based on the defined logical relationships between words, which helps better reflect the relationships between different attributes in the classification process.
2. Related Works
2.1. Attribute Classification
2.2. Hierarchical Classification
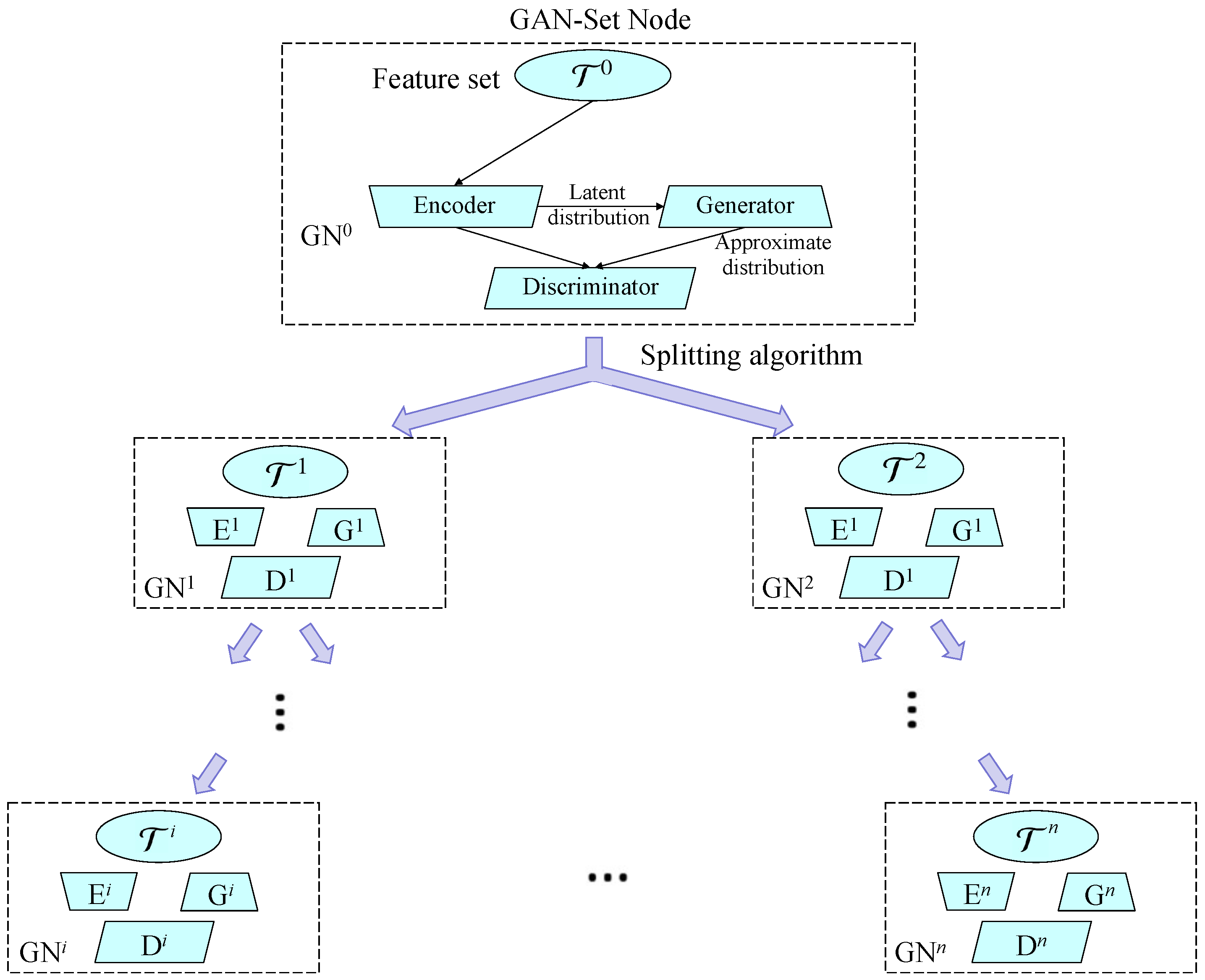
2.3. Clustering Based on the Generative Adversarial Network (GAN)
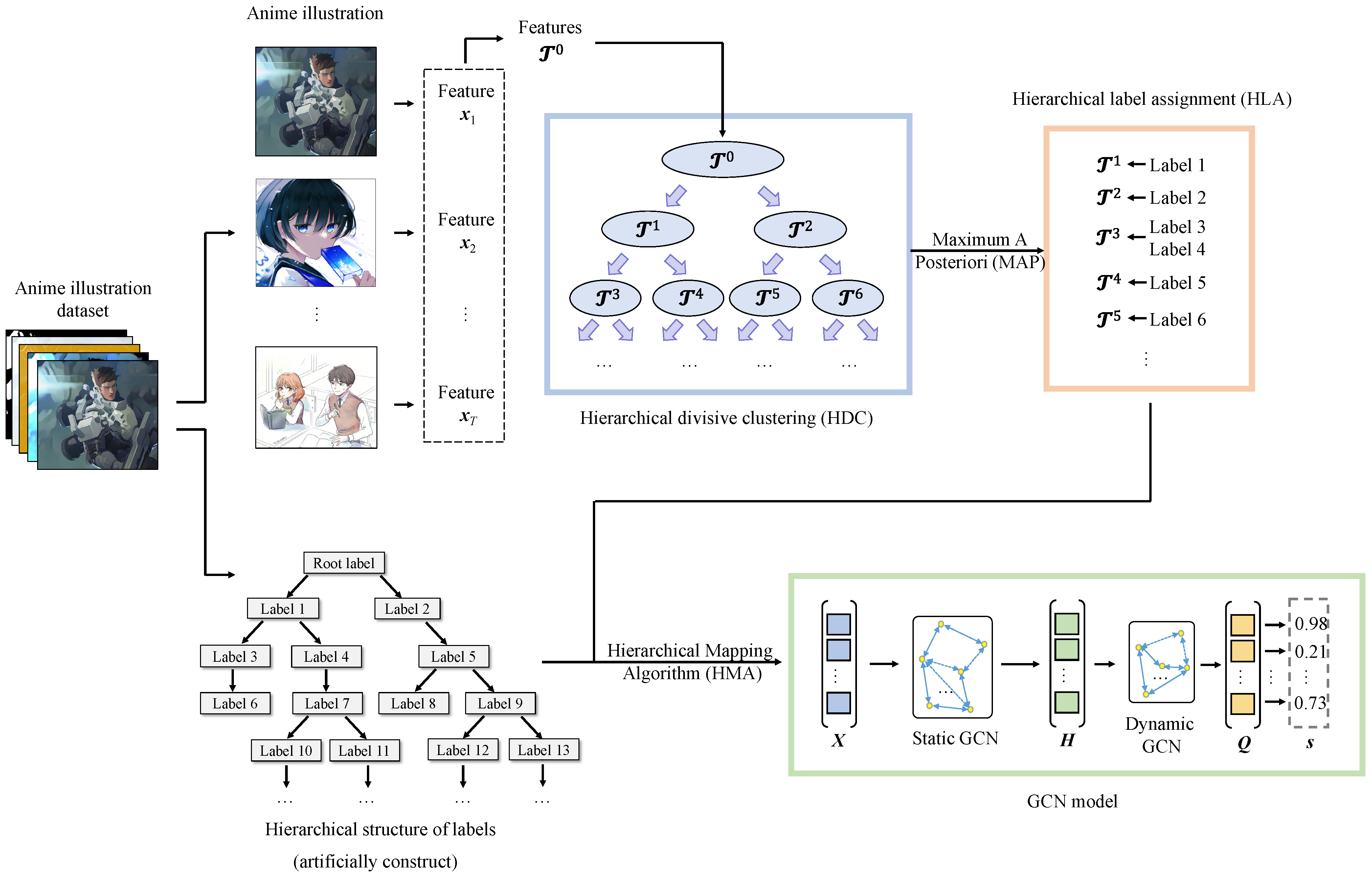
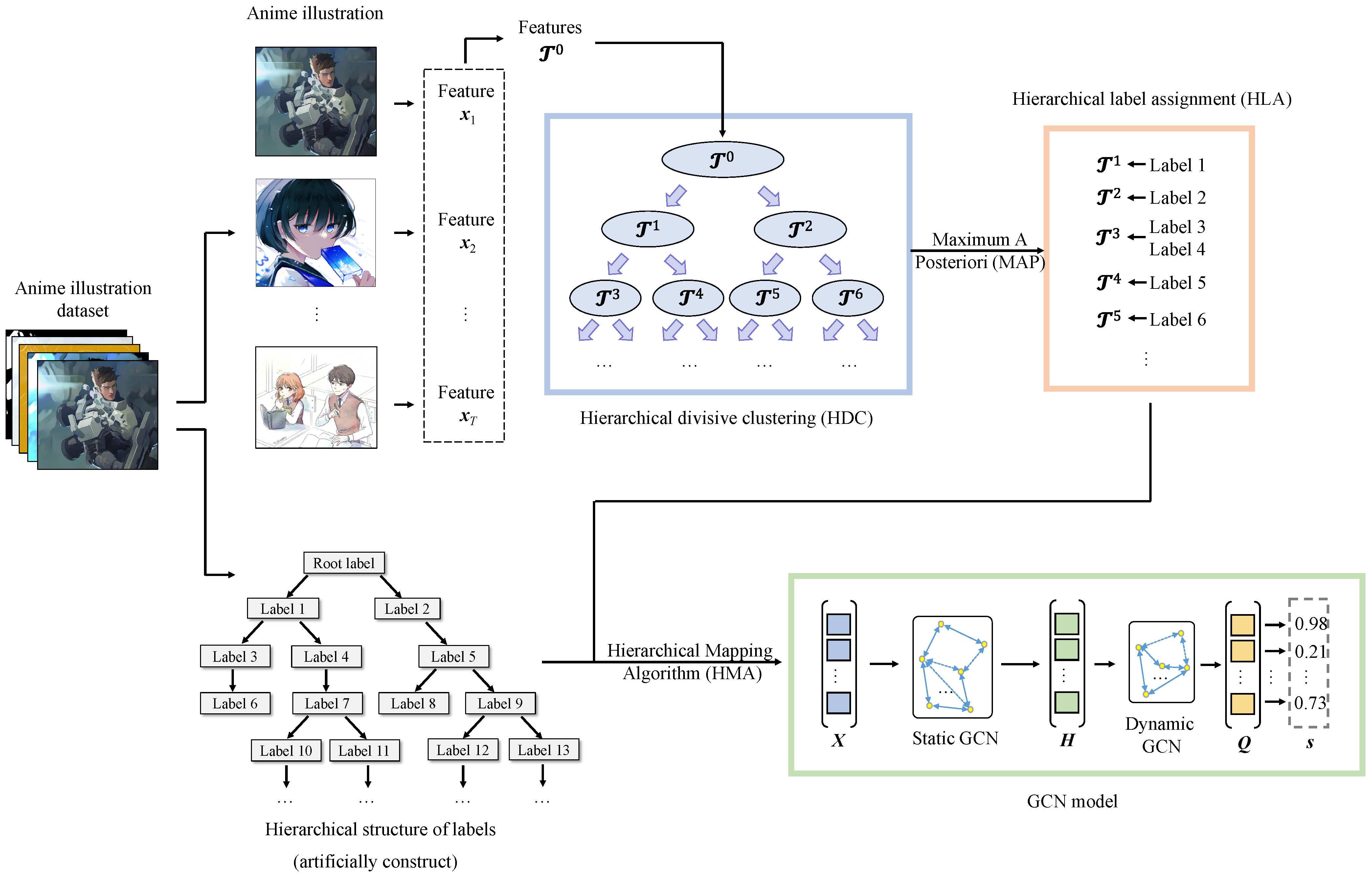
3. Proposed Method
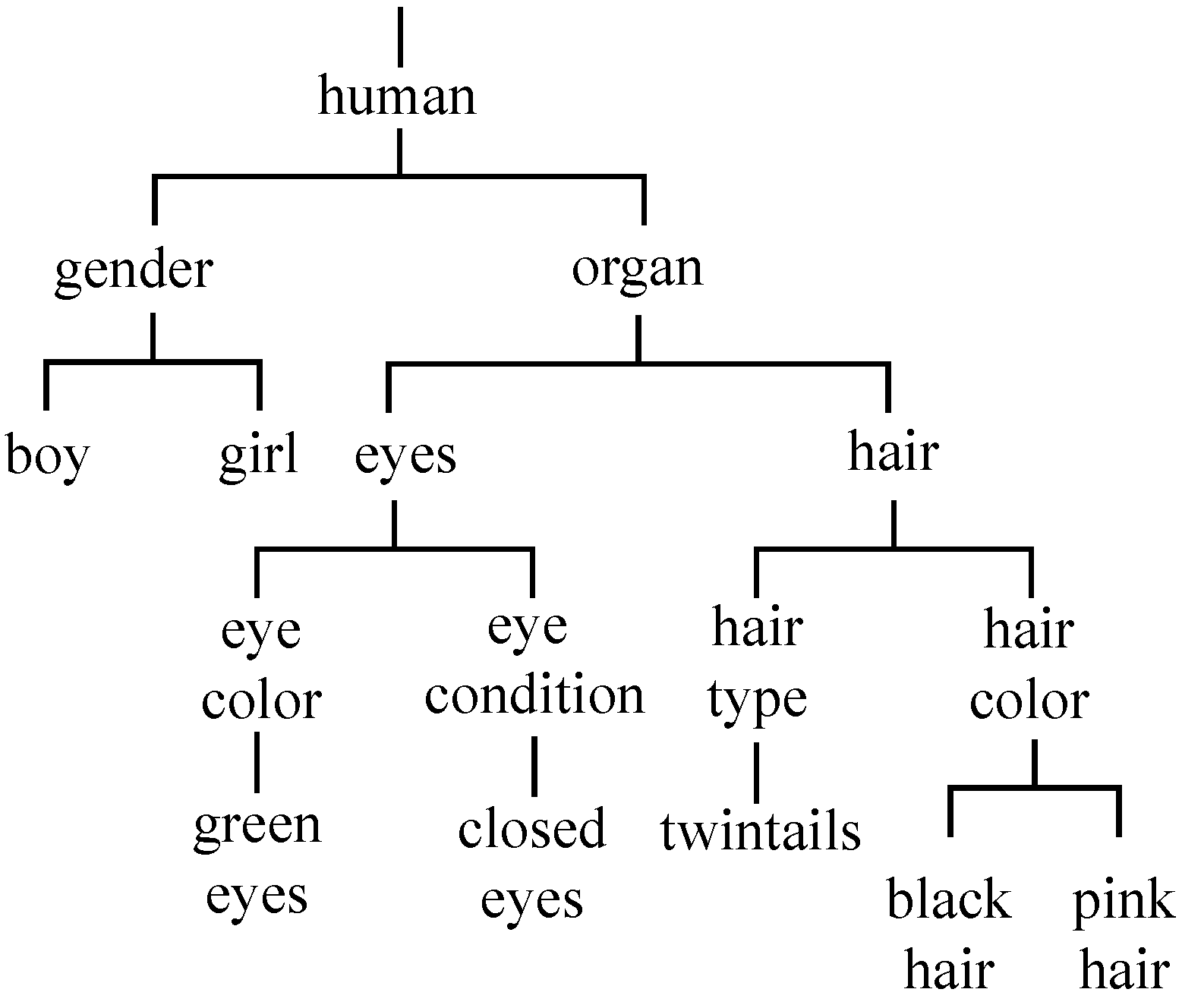
3.1. Hierarchical Divisive Clustering (HDC)
3.2. Hierarchical Label Assignment (HLA)
3.3. GCN-Based Classification
4. Comparison Experiments
4.1. Anime Illustration Datasets and Construction of Label Hierarchy
- Safebooru [36]: The Safebooru dataset is a comprehensive anime illustration dataset with over 1.0 million illustrations and 30 million labels. It is a subset of the Danbooru dataset, the largest dataset in the field of anime illustration, where illustrations tend to be non-pornographic and non-violent, and each illustration is accompanied by metadata, such as content labels and the names of the artists. We randomly selected 25,000 anime illustrations from the dataset, of which 75% were used as the training set and 25% as the test set, following the division of the original dataset.
- DAF:re [40]: The DAF:re (DanbooruAnimeFaces:revamped) dataset is a crowd-sourced, long-tailed dataset with almost 50,000 images spread across more than 3000 classes. It is also a subset of the Danbooru dataset, and is mainly used for animated character recognition, but unlike the usual dataset for character recognition, each image in this dataset is labeled with attributes other than the label indicating the character names. According to the description by the authors of this dataset in [40], the proportion of images in the training set, validation set, and test set are 70%, 10%, and 20%, respectively.
- FG-BG [41]: The FG-BG dataset is a dataset of anime illustrations used for character background segmentation. It consists of 18,500 illustrations from the Danbooru dataset, including illustrations with transparent backgrounds that only contain characters, illustrations with pure backgrounds that do not contain characters, and ordinary illustrations with characters and backgrounds. Following the previous study [41], we divided this dataset into a training set containing 75% of the images and a test set containing 25% of the images, and it should be noted that the proportions of the three types of images mentioned above in the subset are the same as the whole dataset.
- iCartoonFace [42]: The iCartoonFace is a benchmark dataset of 389,678 images of 5013 characters annotated with character names and other auxiliary attributes. In character recognition of anime illustrations, this dataset is exceptional due to its large-scale nature, high quality, rich annotations, and coverage of multiple occurrences, including near-duplications, occlusions, and appearance changes. The difference with the DAF:re dataset, which is also used for character recognition, is that this dataset is not a subset of the Danbooru dataset. In our experiments, we randomly selected 25,000 anime illustrations from the dataset, of which 75% were used as the training set and 25% as the test set following the division of the original dataset.
- Labels of the title of the work, the name of the character, the name of the illustrator, etc. (e.g., hatsune miku).
- Labels describing information about the illustration, not the content of the illustration (e.g., absurdres).
- Labels describing the art style to which the illustration belongs (e.g., traditional media, monochrome, sketch).
- Labels describing the character’s facial expression, movement, or pose (e.g., happy, standing).
- Labels describing the layout of the illustration (e.g., upper body, cowboy shot).
4.2. Experimental Conditions and Implementation Details
4.3. Comparison Methods and Evaluation Metrics
- ResNet-101 [43], an extensively used CNN for image classification tasks.
- DAN [12], a method that uses CNNs to learn discriminative features for multi-label attribute classification on real-world images.
- SSGRL [45], a method that uses CNNs and a graph propagation mechanism to improve the multi-label classification performance.
- ML-GCN [11], a method that uses GCNs to model the correlations between labels in the multi-label classification task.
- ADD-GCN [14], a method that constructs dynamic graphs to describe label relationships in images and uses an attention mechanism in the feature extraction to improve the GCN-based multi-label classification performance.
- DSGCN [39], a method that uses domain-specific semantic features from the image in the multi-label classification task for anime illustrations.
- P-GCN [38], a state-of-the-art method that uses a GCN to improv the multi-label classification performance, which is an extended version of ML-GCN.
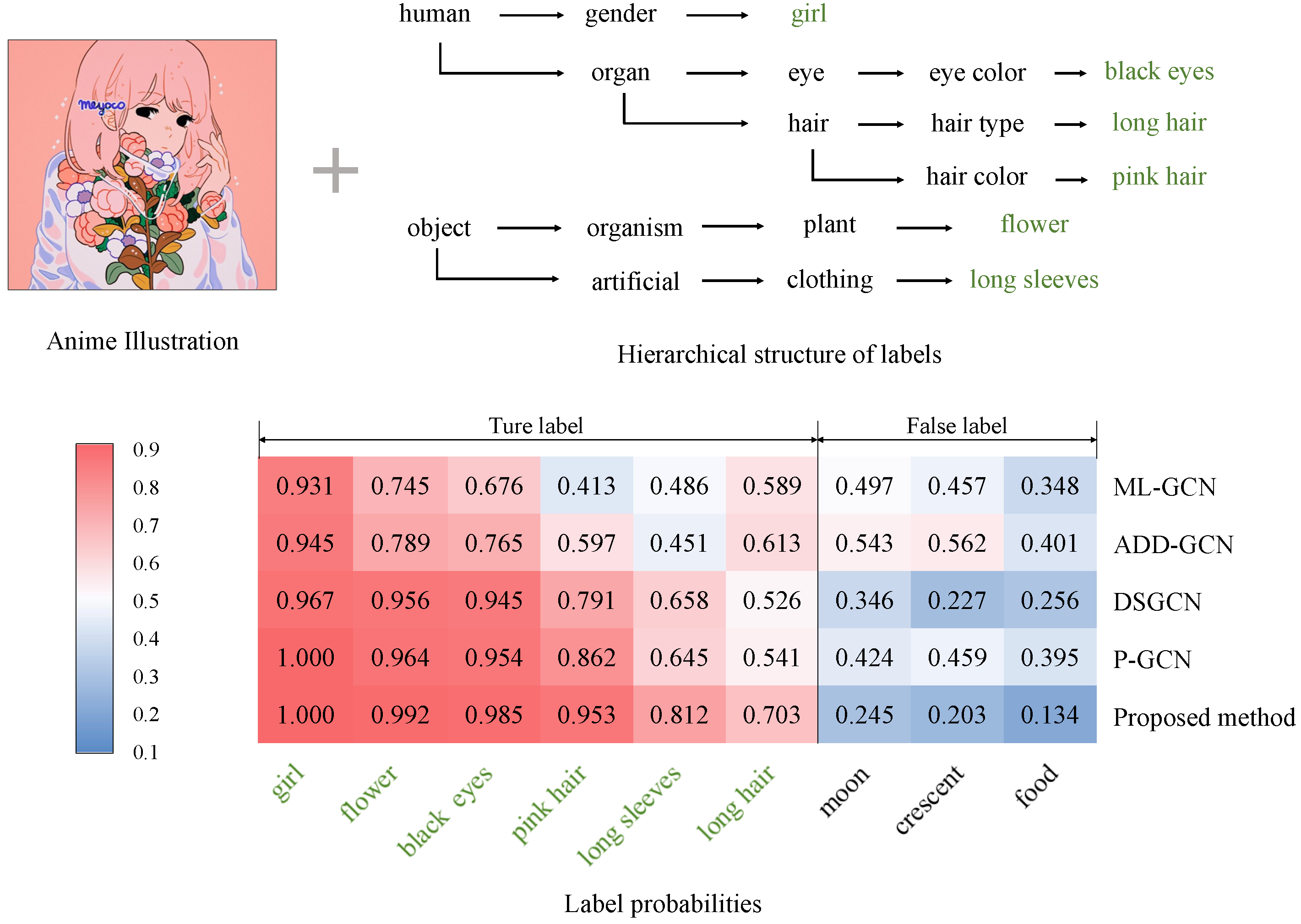
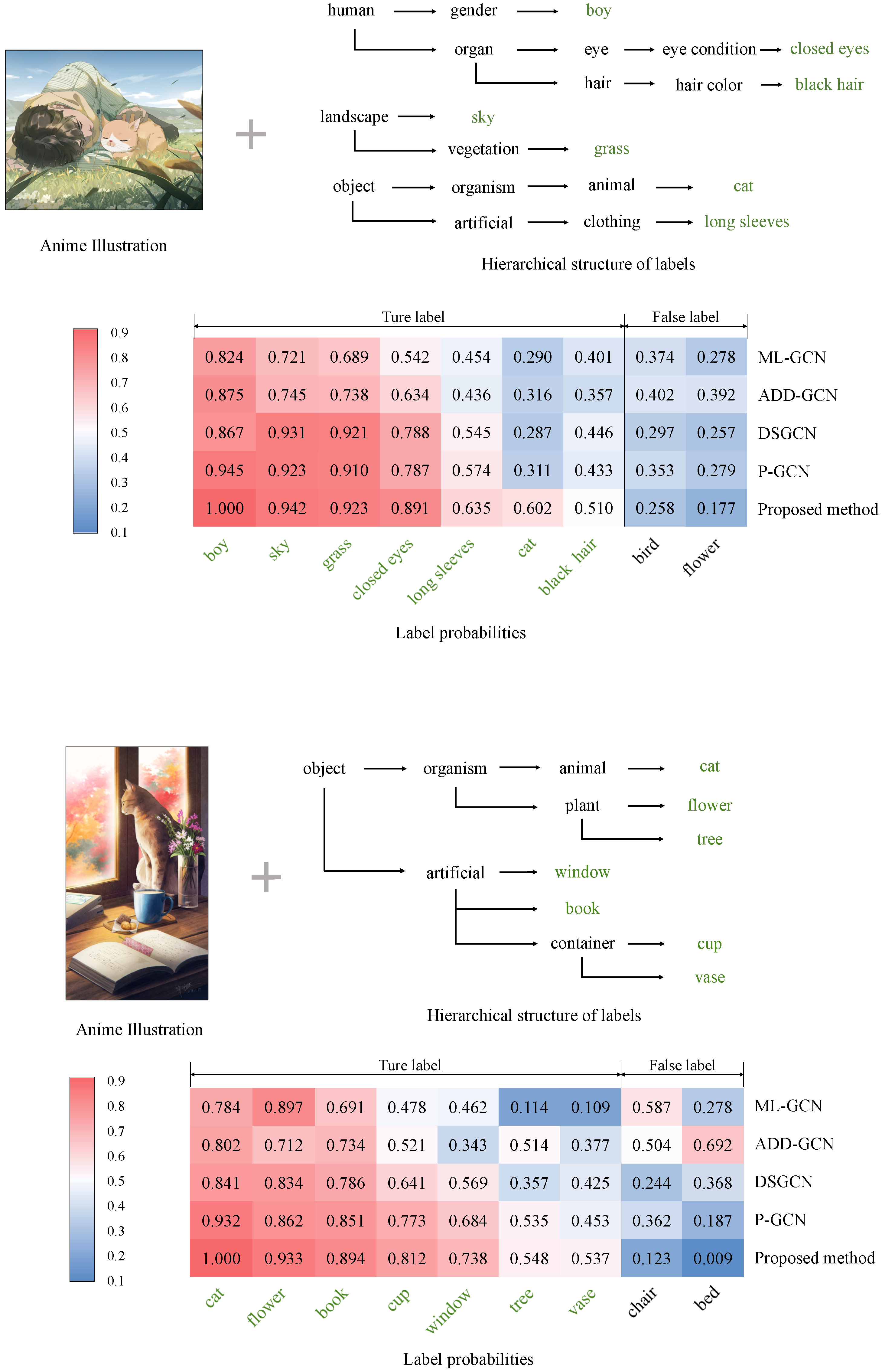
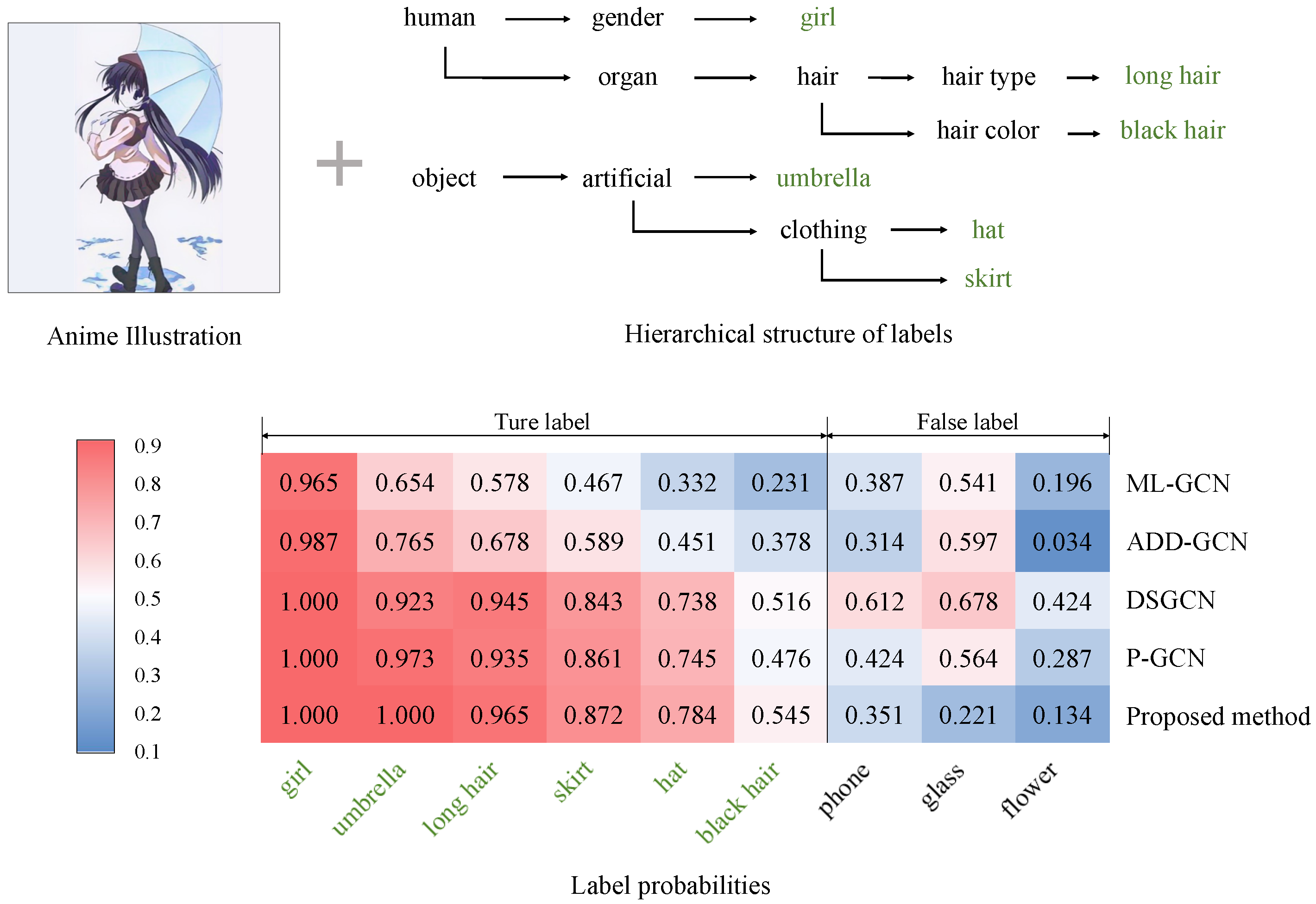
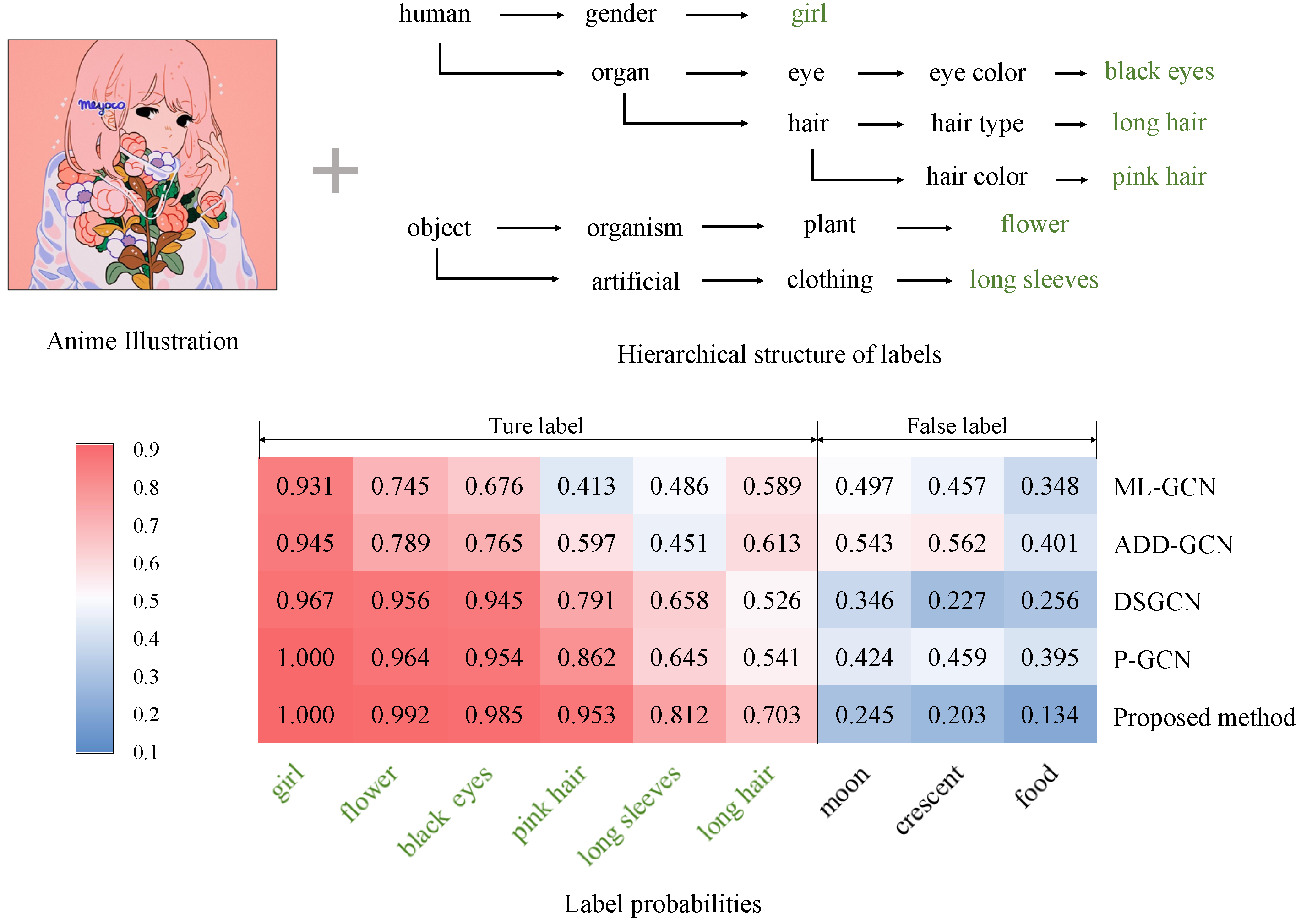
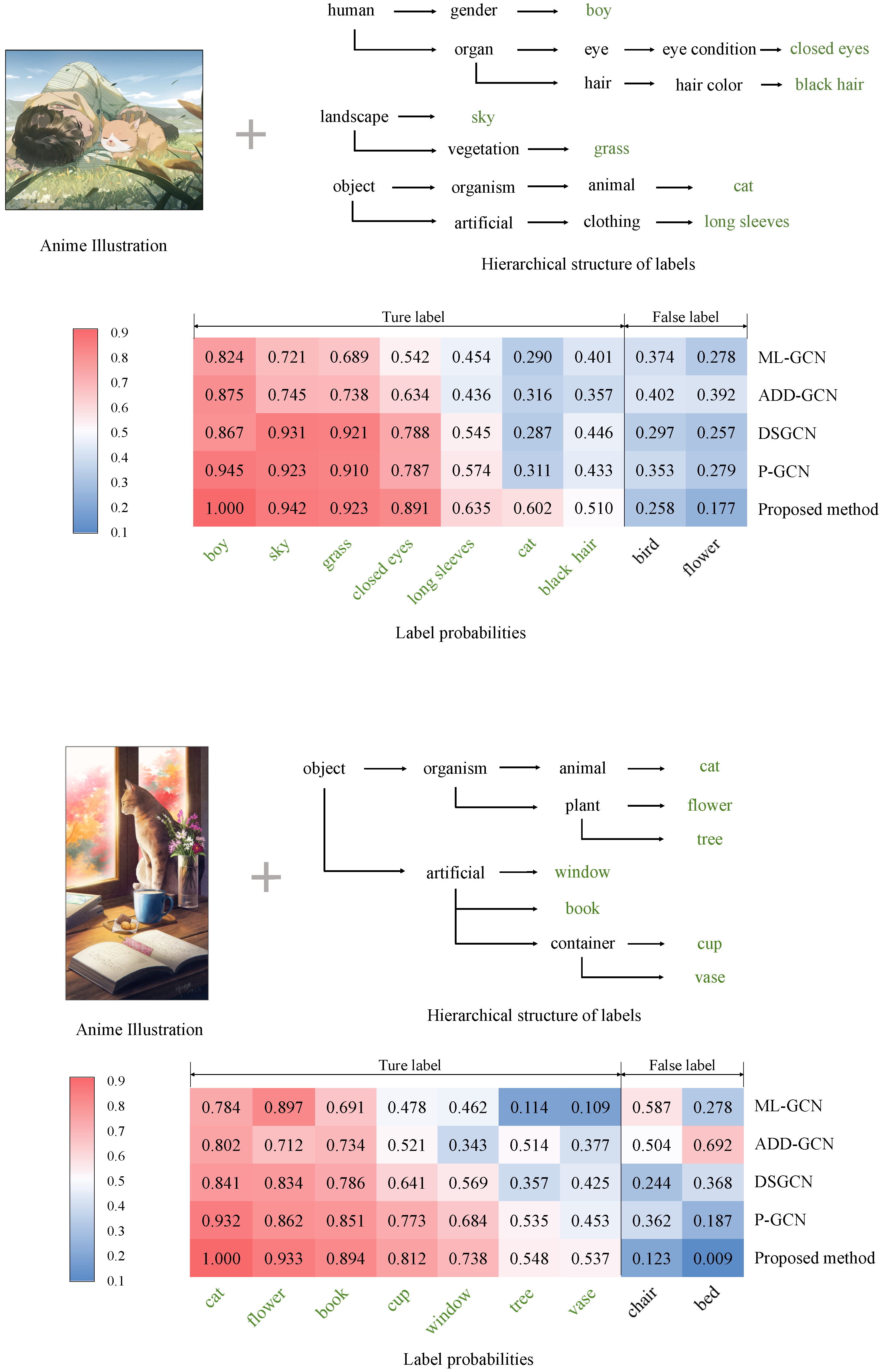
4.4. Experimental Results and Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, G.; Fei, N.; Ding, M.; Liu, G.; Lu, Z.; Xiang, T. L2M-GAN: Learning To Manipulate Latent Space Semantics for Facial Attribute Editing. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2951–2960. [Google Scholar]
- Zhang, L.; Li, C.; JI, Y.; Liu, C.; Wong, T.T. Erasing Appearance Preservation in Optimization-based Smoothing. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Xu, S.; Dutta, V.; He, X.; Matsumaru, T. A Transformer-Based Model for Super-Resolution of Anime Image. Sensors 2022, 22, 8126. [Google Scholar] [CrossRef] [PubMed]
- Back, J. Fine-Tuning StyleGAN2 For Cartoon Face Generation. arXiv 2021, arXiv:2106.12445. [Google Scholar]
- Back, J.; Kim, S.; Ahn, N. WebtoonMe: A Data-Centric Approach for Full-Body Portrait Stylization. arXiv 2022, arXiv:2210.10335. [Google Scholar]
- Lee, J.; Kim, E.; Lee, Y.; Kim, D.; Chang, J.; Choo, J. Reference-Based Sketch Image Colorization Using Augmented-Self Reference and Dense Semantic Correspondence. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, L.; Li, C.; Simo-Serra, E.; Ji, Y.; Wong, T.T.; Liu, C. User-Guided Line Art Flat Filling with Split Filling Mechanism. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Ge, Z.; Mahapatra, D.; Sedai, S.; Garnavi, R.; Chakravorty, R. Chest X-rays classification: A multi-label and fine-grained problem. arXiv 2018, arXiv:1807.07247. [Google Scholar]
- Jain, H.; Prabhu, Y.; Varma, M. Extreme multi-label loss functions for recommendation, tagging, ranking and other missing label applications. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 935–944. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Chen, Z.; Wei, X.S.; Wang, P.; Guo, Y. Multi-label image recognition with graphconvolutional network. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5177–5186. [Google Scholar]
- Banik, S.; Lauri, M.; Frintrop, S. Multi-label Object Attribute Classification using a Convolutional Neural Network. arXiv 2018, arXiv:1811.04309. [Google Scholar]
- Russakovsky, O.; Li, F.F. Attribute Learning in Large-scale Datasets. In Proceedings of the Proc. European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 1–14. [Google Scholar]
- Ye, J.; He, J.; Peng, X.; Wu, W.; Qiao, Y. Attention-Driven Dynamic Graph Convolutional Network for Multi-Label Image Recognition. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 649–665. [Google Scholar]
- Kundu, J.N.; Gor, M.; Agrawal, D.; Babu, R.V. GAN-Tree: An Incrementally Learned Hierarchical Generative Framework for Multi-Modal Data Distributions. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8191–8200. [Google Scholar]
- Fellbaum, C. WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Zhang, N.; Paluri, M.; Ranzato, M.; Darrell, T.; Bourdev, L. Panda: Pose aligned Networks for Deep Attribute Modeling. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 1637–1644. [Google Scholar]
- Huang, S.; Elhoseiny, M.; Elgammal, A.; Yang, D. Learning Hypergraph-regularized Attribute Predictors. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 409–417. [Google Scholar]
- Wu, F.; Wang, Z.; Lu, W.; Li, X.; Yang, Y.; Luo, J.; Zhuang, Y. Regularized Deep Belief Network for Image Attribute Detection. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1464–1477. [Google Scholar] [CrossRef]
- Pham, K.; Kafle, K.; Lin, Z.L.; Ding, Z.; Cohen, S.D.; Tran, Q.; Shrivastava, A. Learning to Predict Visual Attributes in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 13013–13023. [Google Scholar]
- Sakib, S.; Deb, K.; Dhar, P.; Kwon, O. A Framework for Pedestrian Attribute Recognition Using Deep Learning. Appl. Sci. 2022, 12, 622. [Google Scholar] [CrossRef]
- Silla, C.N.; Freitas, A.A. A survey of hierarchical classification across different application domains. Data Min. Knowl. Discov. 2010, 22, 31–72. [Google Scholar] [CrossRef]
- Wehrmann, J.; Barros, R.C.; Dôres, S.N.d.; Cerri, R. Hierarchical Multi-Label Classification with Chained Neural Networks. In Proceedings of the the Symposium on Applied Computing, Marrakech, Morocco, 3–7 April 2017; pp. 790–795. [Google Scholar]
- Gopal, S.; Yang, Y. Hierarchical Bayesian Inference and Recursive Regularization for Large-Scale Classification. ACM Trans. Knowl. Discov. Data 2015, 9, 1–23. [Google Scholar] [CrossRef]
- Huang, W.; Chen, E.; Liu, Q.; Chen, Y.; Huang, Z.; Liu, Y.; Zhao, Z.; Zhang, D.; Wang, S. Hierarchical Multi-Label Text Classification: An Attention-Based Recurrent Network Approach. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1051–1060. [Google Scholar]
- Wang, Z.; Wang, P.; Huang, L.; Sun, X.; Wang, H. Incorporating Hierarchy into Text Encoder: A Contrastive Learning Approach for Hierarchical Text Classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 7109–7119. [Google Scholar]
- Dai, Y.; Wang, S.; Chen, X.; Xu, C.; Guo, W. Generative adversarial networks based on Wasserstein distance for knowledge graph embeddings. Knowl.-Based Syst. 2020, 190, 105–165. [Google Scholar] [CrossRef]
- Gu, J.; Shen, Y.; Zhou, B. Image processing using multi-code gan prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3012–3021. [Google Scholar]
- Metz, L.; Poole, B.; Pfau, D.; Sohl-Dickstein, J. Unrolled generative adversarial networks. arXiv 2016, arXiv:1611.02163. [Google Scholar]
- Srivastava, A.; Valkov, L.; Russell, C.; Gutmann, M.U.; Sutton, C. Veegan: Reducing mode collapse in gans using implicit variational learning. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Bang, D.; Shim, H. Mggan: Solving mode collapse using manifold-guided training. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2347–2356. [Google Scholar]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Lamb, A.; Arjovsky, M.; Mastropietro, O.; Courville, A. Adversarially Learned Inference. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Han, K.J.; Narayanan, S.S. A robust stopping criterion for agglomerative hierarchical clustering in a speaker diarization system. In Proceedings of the Interspeech, Antwerp, Belgium, 27–31 August 2007; pp. 1853–1856. [Google Scholar]
- Hu, Y.; Gripon, V.; Pateux, S. Leveraging the Feature Distribution in Transfer-Based Few-Shot Learning. In Proceedings of the Artificial Neural Networks and Machine Learning, Bratislava, Slovakia, 14–17 September 2021; pp. 487–499. [Google Scholar]
- Community, T.D.; Branwen, G. Danbooru2020: A Large-Scale Crowdsourced and Tagged Anime Illustration Dataset. 2021. Available online: https://www.gwern.net/Danbooru2020 (accessed on 12 January 2023).
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013. [Google Scholar]
- Chen, Z.; Wei, X.S.; Wang, P.; Guo, Y. Learning Graph Convolutional Networks for Multi-Label Recognition and Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 45, 6969–6983. [Google Scholar] [CrossRef] [PubMed]
- Lan, Z.; Maeda, K.; Ogawa, T.; Haseyama, M. GCN-Based Multi-modal Multi-label Attribute Classification in Anime Illustration Using Domain-Specific Semantic Features. In Proceedings of the IEEE International Conference on Image Processing, Bordeaux, France, 16–19 October 2022; pp. 2021–2025. [Google Scholar]
- Rios, E.A.; Cheng, W.H.; Lai, B.C.C. DAF: Re: A Challenging, Crowd-Sourced, Large-Scale, Long-Tailed Dataset For Anime Character Recognition. arXiv 2021, arXiv:2101.08674. [Google Scholar]
- Chen, S.; Zwicker, M. Transfer Learning for Pose Estimation of Illustrated Characters. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022. [Google Scholar]
- Zheng, Y.; Zhao, Y.; Ren, M.; Yan, H.; Lu, X.; Liu, J.; Li, J. Cartoon Face Recognition: A Benchmark Dataset. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2264–2272. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Chen, T.; Xu, M.; Hui, X.; Wu, H.; Lin, L. Learning semantic-specific graph representation for multi-label image recognition. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 522–531. [Google Scholar]
- Kiritchenko, S.; Matwin, S.; Nock, R.; Famili, A.F. Learning and Evaluation in the Presence of Class Hierarchies: Application to Text Categorization. In Proceedings of the 19th International Conference on Advances in Artificial Intelligence: Canadian Society for Computational Studies of Intelligence, Quebec City, QC, Canada, 7–9 June 2006; pp. 395–406. [Google Scholar]
- Borges, H.B.; Silla, C.N.; Nievola, J.C. An evaluation of global-model hierarchical classification algorithms for hierarchical classification problems with single path of labels. Comput. Math. Appl. 2013, 66, 1991–2002. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | OP | OR | OF1 | CP | CR | CF1 | HP | HR | HF1 | mAP |
|---|---|---|---|---|---|---|---|---|---|---|
| ResNet-101 [43] | 61.0 | 56.5 | 59.3 | 60.4 | 55.2 | 58.1 | 59.1 | 40.8 | 48.3 | 60.4 |
| SSGRL [45] | 69.0 | 57.2 | 64.2 | 70.2 | 58.2 | 61.3 | 60.9 | 47.2 | 53.2 | 68.6 |
| DAN [12] | 64.9 | 51.0 | 58.1 | 66.5 | 56.8 | 61.2 | 51.0 | 38.8 | 44.1 | 64.6 |
| ML-GCN [11] | 63.8 | 60.5 | 62.4 | 60.1 | 54.2 | 58.0 | 60.8 | 52.1 | 56.1 | 62.3 |
| ADD-GCN [14] | 69.6 | 64.1 | 67.2 | 66.4 | 60.2 | 62.0 | 61.7 | 52.8 | 56.9 | 68.1 |
| DSGCN [39] | 73.1 | 66.8 | 70.2 | 69.9 | 57.1 | 66.3 | 61.4 | 59.8 | 60.6 | 71.1 |
| P-GCN [38] | 69.1 | 58.9 | 63.1 | 72.8 | 58.9 | 64.2 | 65.3 | 58.8 | 61.9 | 70.2 |
| Ours | 73.4 | 68.3 | 71.1 | 69.8 | 56.4 | 65.9 | 67.9 | 62.9 | 65.3 | 71.3 |
| Method | OP | OR | OF1 | CP | CR | CF1 | HP | HR | HF1 | mAP |
|---|---|---|---|---|---|---|---|---|---|---|
| ResNet-101 [43] | 63.4 | 52.3 | 57.3 | 58.1 | 53.2 | 55.5 | 45.9 | 43.1 | 44.5 | 56.2 |
| SSGRL [45] | 69.1 | 54.6 | 61.0 | 64.8 | 54.8 | 59.4 | 51.0 | 42.3 | 46.2 | 60.1 |
| DAN [12] | 62.7 | 51.9 | 56.8 | 59.5 | 52.3 | 55.7 | 52.9 | 45.6 | 49.0 | 57.4 |
| ML-GCN [11] | 64.5 | 56.8 | 60.4 | 62.3 | 56.4 | 59.2 | 53.6 | 44.6 | 48.7 | 59.8 |
| ADD-GCN [14] | 65.2 | 54.0 | 59.1 | 61.9 | 54.4 | 57.9 | 55.0 | 47.4 | 50.9 | 58.9 |
| DSGCN [39] | 69.6 | 57.6 | 63.0 | 66.0 | 58.1 | 61.8 | 54.7 | 44.6 | 49.2 | 62.7 |
| P-GCN [38] | 67.7 | 60.1 | 63.7 | 64.3 | 56.5 | 60.1 | 57.1 | 49.2 | 52.9 | 62.0 |
| Ours | 72.1 | 59.7 | 65.3 | 68.4 | 56.1 | 61.7 | 60.8 | 52.4 | 56.3 | 63.5 |
| Method | OP | OR | OF1 | CP | CR | CF1 | HP | HR | HF1 | mAP |
|---|---|---|---|---|---|---|---|---|---|---|
| ResNet-101 [43] | 53.2 | 49.9 | 51.5 | 49.2 | 42.1 | 45.4 | 41.1 | 39.5 | 40.3 | 48.5 |
| SSGRL [45] | 60.2 | 51.3 | 55.4 | 56.5 | 51.9 | 54.1 | 45.6 | 37.3 | 41.0 | 54.6 |
| DAN [12] | 58.5 | 54.9 | 56.6 | 54.1 | 46.3 | 49.9 | 45.2 | 43.5 | 44.3 | 53.4 |
| ML-GCN [11] | 61.2 | 56.3 | 58.7 | 59.2 | 52.1 | 55.4 | 50.2 | 44.0 | 46.9 | 60.1 |
| ADD-GCN [14] | 62.6 | 58.7 | 60.6 | 57.9 | 49.6 | 53.4 | 48.4 | 46.5 | 47.4 | 57.1 |
| DSGCN [39] | 63.7 | 58.6 | 61.0 | 61.5 | 54.2 | 57.6 | 52.2 | 45.8 | 48.8 | 59.5 |
| P-GCN [38] | 68.5 | 56.5 | 61.9 | 62.7 | 57.6 | 60.0 | 49.6 | 46.5 | 51.9 | 60.7 |
| Ours | 67.9 | 59.8 | 63.6 | 62.5 | 58.1 | 60.2 | 59.4 | 50.4 | 54.5 | 61.8 |
| Method | OP | OR | OF1 | CP | CR | CF1 | HP | HR | HF1 | mAP |
|---|---|---|---|---|---|---|---|---|---|---|
| ResNet-101 [43] | 49.6 | 46.9 | 48.2 | 47.0 | 33.3 | 39.0 | 28.2 | 18.2 | 22.1 | 44.3 |
| SSGRL [45] | 51.4 | 50.0 | 50.7 | 51.5 | 39.3 | 44.6 | 30.3 | 19.3 | 23.6 | 46.1 |
| DAN [12] | 58.0 | 55.5 | 56.7 | 57.2 | 44.1 | 49.8 | 32.7 | 21.4 | 25.9 | 52.5 |
| ML-GCN [11] | 61.3 | 56.1 | 58.6 | 60.3 | 46.5 | 52.5 | 34.2 | 25.6 | 29.3 | 54.8 |
| ADD-GCN [14] | 60.5 | 54.8 | 57.5 | 59.1 | 45.3 | 51.3 | 35.7 | 25.1 | 29.5 | 53.6 |
| DSGCN [39] | 62.3 | 54.7 | 58.3 | 61.7 | 49.9 | 55.2 | 40.5 | 30.4 | 34.7 | 56.8 |
| P-GCN [38] | 63.9 | 57.8 | 60.7 | 59.9 | 53.0 | 56.2 | 48.9 | 34.1 | 40.2 | 58.7 |
| Ours | 65.4 | 59.8 | 62.5 | 60.9 | 52.4 | 56.3 | 53.8 | 42.4 | 47.5 | 60.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lan, Z.; Maeda, K.; Ogawa, T.; Haseyama, M. Multi-Label Classification in Anime Illustrations Based on Hierarchical Attribute Relationships. Sensors 2023, 23, 4798. https://doi.org/10.3390/s23104798
Lan Z, Maeda K, Ogawa T, Haseyama M. Multi-Label Classification in Anime Illustrations Based on Hierarchical Attribute Relationships. Sensors. 2023; 23(10):4798. https://doi.org/10.3390/s23104798
Chicago/Turabian StyleLan, Ziwen, Keisuke Maeda, Takahiro Ogawa, and Miki Haseyama. 2023. "Multi-Label Classification in Anime Illustrations Based on Hierarchical Attribute Relationships" Sensors 23, no. 10: 4798. https://doi.org/10.3390/s23104798
APA StyleLan, Z., Maeda, K., Ogawa, T., & Haseyama, M. (2023). Multi-Label Classification in Anime Illustrations Based on Hierarchical Attribute Relationships. Sensors, 23(10), 4798. https://doi.org/10.3390/s23104798