
An Android Malware Detection Approach to Enhance Node Feature Differences in a Function Call Graph Based on GCNs


Abstract
1. Introduction
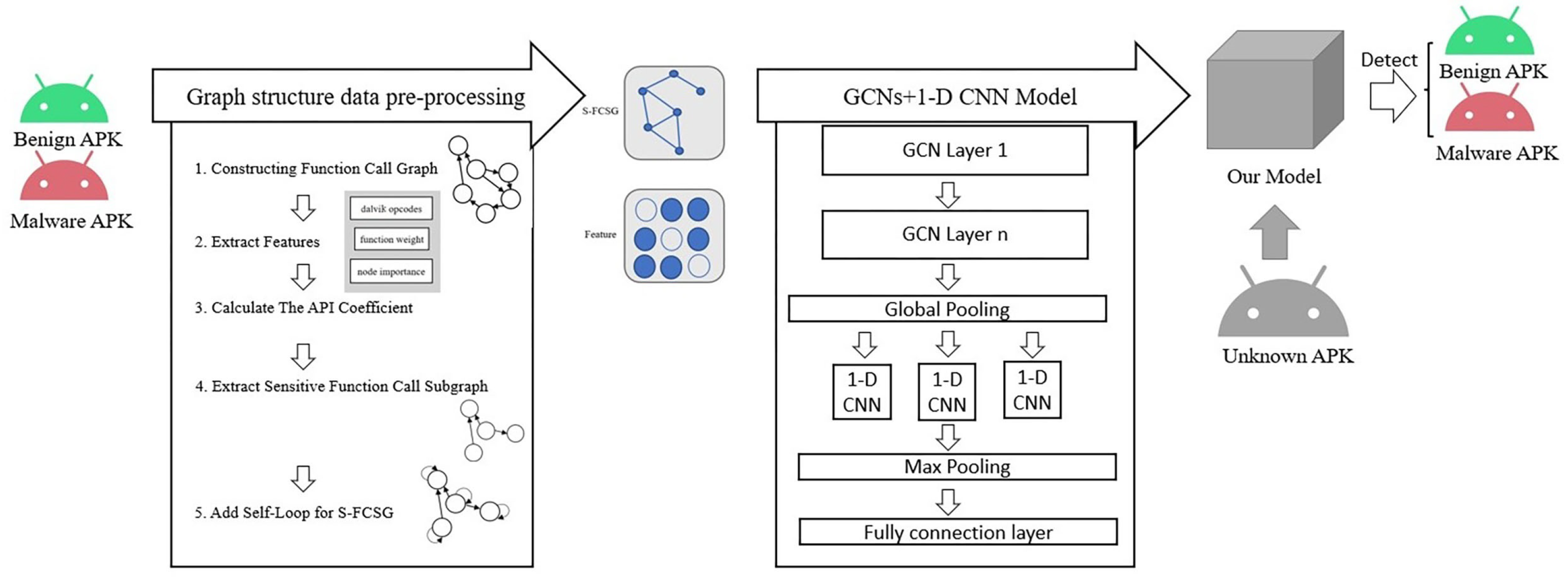
- The function call graph is a static feature that is often used because it captures the intent and behavior features of the function very well. We propose a subgraph extraction approach that effectively removes nonsensical nodes and maximizes the retention of node features. The function call subgraph avoids the interference of nonsense nodes and reduces the dimensionality of the adjacency matrix and feature matrix of the function call graph;
- We extracted the latest API protection level mapping relationship from the Android Open Source Project [11] instead of directly using the one in Pscout [12]. Based on the API protection level relationship, we proposed a function weight feature and demonstrated through experiments that embedding this feature into nodes can effectively help neural networks identify and detect Android malware;
- Since the model learning of GCNs is based on the features of low-pass filters, the node features in the graph structure will converge to similarity during the forward propagation and interfere with our detection. On the one hand, we extract the sensitive function call subgraph. On the other hand, inspired by the GCN formula, we propose an approach of aggregating the features of its nodes one more time to enhance the differences between the different node features;
- Traditional deep learning models cannot learn graph structure type data directly. We propose a GCN + 1-D CNN model using the GCN model to learn the behavior features between different nodes in the function call graph, and we use the 1-D CNN model with different convolutional kernel depths to extract the association relationships between important nodes. The experimental results show that our model has a high accuracy rate in Android malware detection methods.
2. Related Work
2.1. Static Features
2.1.1. Traditional Static Features
2.1.2. Function Call Graph
2.2. Dynamic Features
3. Method
3.1. Feature Extractor
3.1.1. Dalvik Opcodes
3.1.2. Node Importance
3.1.3. Function Weight
- Using Java annotation @requiresPermission to associate APIs with permissions;
- Using @link android.Manifest.permission# to describe an API’s required permissions.
3.2. Graph Extractor
3.2.1. Generate an Entire Function Call Graph (FCG)
3.2.2. Calculate the API Coefficient
- : the counts of is called in the APK;
- : the total counts of API called in the APK;
- : the counts of APKs of type c in the dataset. c indicates whether the category of the APK is malicious or benign;
- : the counts of APK which are called .
3.2.3. Extract the Function Call Subgraph (FCSG)
| Algorithm 1 Generate the Function Call Subgraph (FCSG) |
|
3.2.4. Generate the Sensitive Function Call Subgraph (S-FCSG)
| Algorithm 2 Generate the Sensitive Function Call Subgraph (S-FCSG) |
|
3.3. Neural Network Model
3.3.1. Graph Convolutional Networks
3.3.2. Global Pooling Layer
3.3.3. The 1-D Convolution Neural Networks and Fully Connected Layer
4. Experiment and Evaluation
4.1. Experimental Software and Environment
4.2. Dataset
4.3. Evaluation Indicator
4.4. Experimental Process and Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| GCNs | Graph Convolutional Networks |
| FCG | Function Call Graph |
| FCSG | Function Call Subgraph |
| S-FCSG | Sensitive Function Call Subgraph |
| AOSP | Android Open Source Project |
| 1-D CNN | 1-D Convolutional Neural Network |
References
- Google Play Annual App Downloads 2021. Available online: https://www.statista.com/statistics/734332/google-play-app-installs-per-year/ (accessed on 22 February 2022).
- Android Test 2019—250 Apps. Available online: https://www.av-comparatives.org/tests/android-test-2019-250-apps/ (accessed on 22 February 2022).
- Liu, K.; Xu, S.; Xu, G.; Zhang, M.; Sun, D.; Liu, H. A review of android malware detection approaches based on machine learning. IEEE Access 2020, 8, 124579–124607. [Google Scholar] [CrossRef]
- Bhat, P.; Dutta, K. A survey on various threats and current state of security in android platform. Acm Comput. Surv. (CSUR) 2019, 52, 1–35. [Google Scholar] [CrossRef]
- A Gentle Introduction to Graph Neural Networks. Available online: https://distill.pub/2021/gnn-intro (accessed on 22 March 2022).
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Gers, F.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. In Proceedings of the 1999 Ninth International Conference on Artificial Neural Networks ICANN 99. (Conf. Publ. No. 470), Edinburgh, UK, 7–10 September 1999; Volume 2, pp. 850–855. [Google Scholar] [CrossRef]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying Graph Convolutional Networks. In Machine Learning Research, Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Chaudhuri, K., Salakhutdinov, R., Eds.; MLR Press: Philadelphia, PA, USA, 2019; Volume 97, pp. 6861–6871. [Google Scholar]
- Li, Q.; Wu, X.M.; Liu, H.; Zhang, X.; Guan, Z. Label efficient semi-supervised learning via graph filtering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 10–20 June 2019; pp. 9582–9591. [Google Scholar]
- Bo, D.; Wang, X.; Shi, C.; Shen, H. Beyond low-frequency information in graph convolutional networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 3950–3957. [Google Scholar]
- Android Open Source Project. Available online: https://github.com/aosp-mirror (accessed on 22 June 2022).
- Au, K.W.Y.; Zhou, Y.F.; Huang, Z.; Lie, D. PScout: Analyzing the Android Permission Specification. In Proceedings of the CCS ’12, 2012 ACM Conference on Computer and Communications Security, New York, NY, USA, 16–18 October 2012; pp. 217–228. [Google Scholar] [CrossRef]
- Wu, D.J.; Mao, C.H.; Wei, T.E.; Lee, H.M.; Wu, K.P. DroidMat: Android Malware Detection through Manifest and API Calls Tracing. In Proceedings of the 2012 Seventh Asia Joint Conference on Information Security, Tokyo, Japan, 9–10 August 2012; pp. 62–69. [Google Scholar] [CrossRef]
- Li, D.; Wang, Z.; Xue, Y. DeepDetector: Android Malware Detection using Deep Neural Network. In Proceedings of the 2018 International Conference on Advances in Computing and Communication Engineering (ICACCE), Paris, France, 22–23 June 2018; pp. 184–188. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, L.; Huang, X. Using G Features to Improve the Efficiency of Function Call Graph Based Android Malware Detection. Wirel. Pers. Commun. 2018, 103, 2947–2955. [Google Scholar] [CrossRef]
- Fan, M.; Liu, J.; Wang, W.; Li, H.; Tian, Z.; Liu, T. DAPASA: Detecting Android Piggybacked Apps Through Sensitive Subgraph Analysis. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1772–1785. [Google Scholar] [CrossRef]
- Feng, P.; Ma, J.; Li, T.; Ma, X.; Xi, N.; Lu, D. Android Malware Detection Based on Call Graph via Graph Neural Network. In Proceedings of the 2020 International Conference on Networking and Network Applications (NaNA), Haikou, China, 10–13 December 2020; pp. 368–374. [Google Scholar] [CrossRef]
- Vinayaka, K.V.; Jaidhar, C.D. Android Malware Detection using Function Call Graph with Graph Convolutional Networks. In Proceedings of the 2021 2nd International Conference on Secure Cyber Computing and Communications (ICSCCC), Jalandhar, India, 21–23 May 2021; pp. 279–287. [Google Scholar] [CrossRef]
- Cai, M.; Jiang, Y.; Gao, C.; Li, H.; Yuan, W. Learning features from enhanced function call graphs for Android malware detection. Neurocomputing 2021, 423, 301–307. [Google Scholar] [CrossRef]
- Garg, S.; Peddoju, S.K.; Sarje, A.K. Network-based detection of Android malicious apps. Int. J. Inf. Secur. 2017, 16, 385–400. [Google Scholar] [CrossRef]
- Cai, H.; Meng, N.; Ryder, B.; Yao, D. DroidCat: Effective Android Malware Detection and Categorization via App-Level Profiling. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1455–1470. [Google Scholar] [CrossRef]
- John, T.S.; Thomas, T.; Emmanuel, S. Graph Convolutional Networks for Android Malware Detection with System Call Graphs. In Proceedings of the 2020 Third ISEA Conference on Security and Privacy (ISEA-ISAP), Guwahati, India, 27 February–1 March 2020; pp. 162–170. [Google Scholar] [CrossRef]
- Taheri, L.; Kadir, A.F.A.; Lashkari, A.H. Extensible Android Malware Detection and Family Classification Using Network-Flows and API-Calls. In Proceedings of the 2019 International Carnahan Conference on Security Technology (ICCST), Chennai, India, 1–3 October 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Dalvik Opcodes. Available online: http://pallergabor.uw.hu/androidblog/dalvik_opcodes.html (accessed on 10 June 2022).
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef]
- Android Developers. Available online: https://developer.android.com/reference/android/Manifest.permission (accessed on 12 June 2022).
- Improve Code Inspection with Annotations. Available online: https://developer.android.com/studio/write/annotations (accessed on 12 June 2022).
- Welcome to Androguard’s Documentation. Available online: https://androguard.readthedocs.io/en/latest/index.html (accessed on 17 March 2022).
- Hu, W.; Tao, J.; Ma, X.; Zhou, W.; Zhao, S.; Han, T. MIGDroid: Detecting APP-Repackaging Android malware via method invocation graph. In Proceedings of the 2014 23rd International Conference on Computer Communication and Networks (ICCCN), Shanghai, China, 4–7 August 2014; pp. 1–7. [Google Scholar] [CrossRef]
- Aizawa, A. An information-theoretic perspective of tf–idf measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the NIPS’17, 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Zhang, M.; Cui, Z.; Neumann, M.; Chen, Y. An End-to-End Deep Learning Architecture for Graph Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Deep Graph Library. Available online: https://www.dgl.ai (accessed on 18 July 2022).
- Joblib: Running Python Functions as Pipeline Jobs. Available online: https://joblib.readthedocs.io (accessed on 4 July 2022).
- Allix, K.; Bissyandé, T.F.; Klein, J.; Le Traon, Y. AndroZoo: Collecting Millions of Android Apps for the Research Community. In Proceedings of the MSR’16, 13th International Conference on Mining Software Repositories, New York, NY, USA, 14–22 May 2016; pp. 468–471. [Google Scholar] [CrossRef]
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K.; Siemens, C. Drebin: Effective and explainable detection of android malware in your pocket. NDSS 2014, 14, 23–26. [Google Scholar]
- Mahdavifar, S.; Kadir, A.F.A.; Fatemi, R.; Alhadidi, D.; Ghorbani, A.A. Dynamic android malware category classification using semi-supervised deep learning. In Proceedings of the 2020 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 17–22 August 2020; pp. 515–522. [Google Scholar]
- Onwuzurike, L.; Mariconti, E.; Andriotis, P.; Cristofaro, E.D.; Ross, G.; Stringhini, G. MaMaDroid: Detecting Android Malware by Building Markov Chains of Behavioral Models (Extended Version). ACM Trans. Priv. Secur. 2019, 22. [Google Scholar] [CrossRef]
- Sun, X.; Zhongyang, Y.; Xin, Z.; Mao, B.; Xie, L. Detecting Code Reuse in Android Applications Using Component-Based Control Flow Graph. In IFIP Advances in Information and Communication Technology, Proceedings of the ICT Systems Security and Privacy Protection, Marrakech, Morocco, 2–4 June 2014; Cuppens-Boulahia, N., Cuppens, F., Jajodia, S., Abou El Kalam, A., Sans, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 142–155. [Google Scholar]
- Ge, X.; Pan, Y.; Fan, Y.; Fang, C. AMDroid: Android Malware Detection Using Function Call Graphs. In Proceedings of the 2019 IEEE 19th International Conference on Software Quality, Reliability and Security Companion (QRS-C), Sofia, Bulgaria, 22–26 July 2019; pp. 71–77. [Google Scholar] [CrossRef]
- Huang, H.; Sun, L.; Du, B.; Liu, C.; Lv, W.; Xiong, H. Representation Learning on Knowledge Graphs for Node Importance Estimation. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 646–655. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Year | Feature | Algorithm Model | Contribution and Future Work |
|---|---|---|---|---|
| Wu et al. [13] | 2012 | Static feature (requested permissions, intent messages passed, and component) | kNN algorithm | Takes half the time of Androguard to analyze the same number of samples. |
| Li et al. [14] | 2018 | Static feature (hardware components, requested permissions, app components, filtered intents, restricted API calls, used permissions, suspicious API calls, and network addresses) | deep neural network (DNN) | In the future, they will consider combining static and dynamic features to characterize Android applications. |
| Liu et al. [15] | 2018 | Static feature (function call graph) | machine learning algorithm | Avoids collapsing issues induced by the high-dimension vectors of traditional FCGs. |
| Fan et al. [16] | 2017 | Static feature (sensitive function call subgraph) | machine learning algorithm | Complements permission-based and API-based approaches from a new perspective of the invocation structure. |
| Feng et al. [17] | 2020 | Static feature (approximate call graph) | graph neural network (GNN) | Constructed traditional static features into novel graph structure data. |
| Vinayaka et al. [18] | 2021 | Static feature (function call graph) | graph convolutional network (GCN) | Proposed a balanced technique to make the number of nodes similar. |
| Cai et al. [19] | 2021 | Static feature (enhanced function call graph) | graph convolutional network (GCN) | Overcomes the inability to understand the behavioral characteristics of the app due to missing function properties. |
| Garg et al. [20] | 2017 | Dynamic feature (four different traffic categories of network features) | machine learning algorithm | Future work will focus on improving the detection rate of unknown applications. |
| Cai et al. [21] | 2019 | Dynamic feature (method calls and inter-component communication (ICC) intents) | machine learning algorithm | Found that features capturing the app execution structure are much more important than typical security features. |
| John et al. [22] | 2020 | Dynamic feature (system calls) | graph convolutional network (GCN) | The first application of a GCN for dynamic Android malware detection. |
| Taheri et al. [23] | 2019 | Hybrid feature (permissions, intents, and network-flow) | machine learning algorithm | Plans to generate an Android dataset with more captured features and with a massive sample size. |
| i | Opcode (hex) | Opcode Keywords | Explanation |
|---|---|---|---|
| 1 | 00 | nop | Empty operation instruction: aligns the code and has no actual operation. |
| 2 | 01-0D | move | Data operation instruction. |
| 3 | 0E-11 | return | Method return instruction: returns the result of the current working function. |
| 4 | 12-1C | const | Data definition instruction. |
| 5 | 1D-1E | monitor | Lock instruction: used in multithreaded programs to operate on the same object. |
| 6 | 1F/20/22 | check | Object operation instruction: used to transform, check, and new instances. |
| 7 | 21/23-26 | array | Array operation instruction. |
| 8 | 27 | throw | Exception instruction. |
| 9 | 28-2C/32-3D | goto/switch/if | Jump instruction: jump from the current address to the specified offset. |
| 10 | 2D-31 | cmpl/cmpg/cmp | Compare instruction: compare the values of two registers. |
| 11 | 44-6D/F2-F7 | iget/iput/sget/sput | Field operation instruction: read or write the fields of the object instance. |
| 12 | 6E-72/74-78/F0/F8-FB | invoke | Function call instruction: calls the method of other class instances. |
| 13 | 7B-E2 | neg-/not-/int-to/long-to/float-to/double-to/-int/-long/-float/-double | Datatype transfer instruction. |
| The Type of Annotation | The Meaning of the Fields | Fields | Explanation |
|---|---|---|---|
| Java annotation sign | @requiresPermission | A kind of annotation in Java. | |
| Number of required permissions | allOf | There are two categories: allOf and anyOf. allOf: all permissions are required. anyOf: only one of the permissions is required. | |
| @RequiresPermission Annotation | Permission name | android.Manifest.permission. MANAGE_DEVICE_ADMINS, android.Manifest.permission. INTERACT_ACROSS_USERS_FULL | MANAGE_DEVICE_ADMINS and INTERACT_ACROSS_USERS_FULL are the required permission names. |
| API function name and parameters | setActiveAdmin(@NonNull ComponentName policyReceiver, boolean refreshing, int) | Extract the mapping relationship between the API function name and parameters and permission name based on those fields. | |
| Permission name | android.Manifest.permission #MASTER_CLEAR | Explanation as above. | |
| @link android.Manifest. permission#XXX Annotation | API function name and parameters | getFactoryResetProtectionPolicy(@Nullable ComponentName admin) |
| Number of Sensitive APIs That Began to Be Extracted | The Average Number of Nodes in the FCG | The Average Number of Nodes in the FCSG | Average Node Reduction Rate | The Total of the Feature Weight in the FCG | The Total of the Feature Weight in the FCSG | Node Feature Reduction Rate |
|---|---|---|---|---|---|---|
| Top 1 | 12,189 | 7303 | 40.1% | 1,884,584 | 1,663,770 | 11.7% |
| Top 3 | 7776 | 36.2% | 1,733,300 | 8.0% | ||
| Top 5 | 7914 | 35.0% | 1,766,982 | 6.2% | ||
| Top 7 | 7986 | 34.5% | 1,776,055 | 5.8% | ||
| Top 10 | 8170 | 33.0% | 1,789,436 | 5.0% | ||
| Top 15 | 8531 | 30.0% | 1,802,242 | 4.4% | ||
| Top 20 | 9115 | 25.2% | 1,822,036 | 3.3% | ||
| Top 30 | 10,094 | 17.1% | 1,866,399 | 1.0% |
| GCN Layers | K | Accuracy | Precision | F1 Score | TPR | FPR | AUC |
|---|---|---|---|---|---|---|---|
| 20 | 0.9534 | 0.9696 | 0.9527 | 0.9362 | 0.029 | 0.9908 | |
| 2 | 40 | 0.9593 | 0.9644 | 0.9597 | 0.9539 | 0.035 | 0.9879 |
| 60 | 0.9719 | 0.9820 | 0.9716 | 0.9614 | 0.017 | 0.9962 | |
| 20 | 0.9687 | 0.9620 | 0.9688 | 0.9757 | 0.038 | 0.9922 | |
| 3 | 40 | 0.9828 | 0.9890 | 0.9827 | 0.9765 | 0.011 | 0.9968 |
| 60 | 0.9652 | 0.9625 | 0.9653 | 0.9681 | 0.037 | 0.9936 | |
| 20 | 0.9631 | 0.9623 | 0.9631 | 0.9640 | 0.037 | 0.9930 | |
| 4 | 40 | 0.9476 | 0.9635 | 0.9467 | 0.9304 | 0.035 | 0.9867 |
| 60 | 0.9661 | 0.9688 | 0.9660 | 0.9631 | 0.031 | 0.9946 |
| Approaches | Accuracy | Precision | F1 Score | TPR | FPR | AUC |
|---|---|---|---|---|---|---|
| Derbin [37] | 0.9651 | 0.9542 | 0.9431 | 0.9565 | 0.043 | 0.9765 |
| MaMaDroid [39] | 0.9681 | 0.8909 | 0.8489 | 0.9371 | 0.063 | 0.9599 |
| DAPASA [16] | 0.9432 | 0.9356 | 0.9422 | 0.9279 | 0.072 | 0.9578 |
| DroidSim [40] | 0.9336 | 0.9124 | 0.8930 | 0.8878 | 0.108 | 0.9141 |
| AMDroid [41] | 0.9749 | 0.9787 | 0.9729 | 0.9739 | 0.027 | 0.9748 |
| V et al. proposed [18] | 0.9229 | 0.9242 | 0.9205 | 0.9223 | N/A | N/A |
| Ours | 0.9828 | 0.9890 | 0.9827 | 0.9765 | 0.011 | 0.9968 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Luktarhan, N.; Tian, G.; Song, Y. An Android Malware Detection Approach to Enhance Node Feature Differences in a Function Call Graph Based on GCNs. Sensors 2023, 23, 4729. https://doi.org/10.3390/s23104729
Wu H, Luktarhan N, Tian G, Song Y. An Android Malware Detection Approach to Enhance Node Feature Differences in a Function Call Graph Based on GCNs. Sensors. 2023; 23(10):4729. https://doi.org/10.3390/s23104729
Chicago/Turabian StyleWu, Haojie, Nurbol Luktarhan, Gaoqi Tian, and Yangyang Song. 2023. "An Android Malware Detection Approach to Enhance Node Feature Differences in a Function Call Graph Based on GCNs" Sensors 23, no. 10: 4729. https://doi.org/10.3390/s23104729
APA StyleWu, H., Luktarhan, N., Tian, G., & Song, Y. (2023). An Android Malware Detection Approach to Enhance Node Feature Differences in a Function Call Graph Based on GCNs. Sensors, 23(10), 4729. https://doi.org/10.3390/s23104729