Abstract
Locomotion prediction for human welfare has gained tremendous interest in the past few years. Multimodal locomotion prediction is composed of small activities of daily living and an efficient approach to providing support for healthcare, but the complexities of motion signals along with video processing make it challenging for researchers in terms of achieving a good accuracy rate. The multimodal internet of things (IoT)-based locomotion classification has helped in solving these challenges. In this paper, we proposed a novel multimodal IoT-based locomotion classification technique using three benchmarked datasets. These datasets contain at least three types of data, such as data from physical motion, ambient, and vision-based sensors. The raw data has been filtered through different techniques for each sensor type. Then, the ambient and physical motion-based sensor data have been windowed, and a skeleton model has been retrieved from the vision-based data. Further, the features have been extracted and optimized using state-of-the-art methodologies. Lastly, experiments performed verified that the proposed locomotion classification system is superior when compared to other conventional approaches, particularly when considering multimodal data. The novel multimodal IoT-based locomotion classification system has achieved an accuracy rate of 87.67% and 86.71% over the HWU-USP and Opportunity++ datasets, respectively. The mean accuracy rate of 87.0% is higher than the traditional methods proposed in the literature.
1. Introduction
From simple hand movements to complex activities of daily living (ADL), it is now possible for intelligent systems to recognize human actions by collecting the action properties from multimodal IoT-based sensors [1,2,3]. These human actions are collectively known as locomotion and can be performed in different environmental setups, such as rehabilitation centers, smart homes, and healthcare facilities [4,5,6]. The industry has advanced towards the implementation of such locomotion prediction systems as fitness trackers or fall recognition systems [7,8]. Nonetheless, such devices are based on a single sensor type and do not serve the purpose as efficiently as required [9]. Thereby, this study will fulfill the two main needs of such ADL recognition and locomotion prediction systems: enhancing the system’s accuracy and enabling the system to deal with complex motion via multimodal IoT-based locomotion classification. The applications of this system include healthcare systems, smart homes, IoT-based facilities, robotic learning, ambient assistive living, and patient monitoring.
Locomotion prediction consists of multiple locomotive abilities in humans to perform daily routine activities. Most conventional systems have used one type of sensor to classify the locomotive activities of daily living. This novel technique has used a new way of multi-sensor fusion and a skeleton model to predict human locomotion, including motion data, ambient data, and videos. This fusion of multi-sensors for locomotion prediction is referred to as the multimodal approach and can help in creating predictions that are more accurate.
Two benchmarked IoT-based datasets have been selected to verify the proposed multimodal locomotion classification system. Three types of sensor data have been utilized from these two datasets, including wearable motion, ambient, and visual sensors. At the start, we propose that the multimodal IoT-based data be filtered through different techniques that will cater to the unique requirements of noise removal in each sensor’s nature. Next, the motion and ambient filtered signals are windowed, and video frame sequences are used to extract the skeleton model. Then, the features are extracted for each sensor type separately, followed by fusing them over time series. Further, the fused features have been optimized, and locomotion via ADL is recognized. Lastly, the HWU-USP (Heriot-Watt University/University of Sao Paulo) and Opportunity++ datasets are utilized for evaluation of the proposed multimodal IoT-based locomotion classification system. Following are the key contributions of our proposed locomotion prediction system:
- Fusing the three different types of sensor data features for multimodal locomotion prediction.
- Accurate skeleton modeling for the extracted human silhouette was validated through confidence levels and skeleton point accuracies.
- Major enhancement in the accuracy of locomotion classification with improved human skeleton point confidence levels by applying a combination of different feature extraction methods and feature fusion in the proposed system methodology.
A previous systems review has been offered in Section 2, and a thorough architecture discussion about the proposed multimodal IoT-based locomotion classification model has been given in Section 3. The experiments performed have also been mentioned in Section 4, and the paper’s conclusion, along with limitations and future work discussion, has been presented in Section 5.
2. Literature Review
There are several studies proposed by the researchers in the literature. Some are based on either sensor-based models or vision-based methods, while others consist of multimodal systems. Section 2.1 describes sensor- or vision-based systems, and Section 2.2 gives detail about multimodal systems presented by researchers.
2.1. Sensor or Vision-Based Systems
Vision-based data has been used as a methodology for IoT-based locomotion classification systems. Simple inertial data has also been utilized as a monomodal system for locomotion prediction. Different investigators have offered diverse systems for locomotion prediction in the literature. In [10], a locomotion prediction system has been proposed consisting of noise removal, feature extraction, pattern retrieval, and hidden Markov model (HMM)-based classification steps. However, the locomotion detected was based on limited environmental settings and activity diversity. A study based on kinematic motion sensors has been given in Figueiredo et al. [11]. Multiple ADLs have been recognized, such as ascend stairs, descend stairs, level-ground walking, descend stairs, ascend ramp, descend ramp, etc. They have utilized feature processing, machine learning, feature reduction, and classification methods. Though the proposed study achieved good accuracy results, it did not filter the noise from raw sensor data, causing problematic outcomes. In [12], Javeed et al. described a system for locomotion prediction by introducing a calibration-based filter and a pattern identification technique. Additionally, a sliding overlapping technique was used for window extraction, and two datasets were utilized to perform experiments on the system. However, the lack of good features caused lower accuracy rates. In Wang et al. [13], a study has explained the locomotion activity recognition method for different activities. They have used radio sensor data to recognize locomotion and transportation actions. Moreover, they faced technical challenges, such as sensor unavailability and data synchronization, causing the system F1 scores to be less than 80%.
2.2. Multimodal Systems
Multimodal systems have opened up more challenges for locomotion prediction models. In [14], Chavarriaga et al. proposed a multimodal system based on ambient and wearable sensors. They have recognized the ADL based on modes of locomotion and gestures. Further, dynamic multimodal data fusion has enabled the system to perform better. However, the system was not able to make use of the visual sensors. In a study proposed by Ordóñez et al., complex motor activity sequences have been recognized using convolutional and long short-term memory (LSTM) recurrent neural networks [15]. Multiple layers of convolution, dense, and softmax have been used. However, due to the lack of filtration techniques applied to multimodal data, the system’s performance was low. A multimodal approach for in-home, fine-grained locomotion detection has been proposed in [16]. A two-level supervised classifier and a modified conditional random field-based supervised classifier are being utilized to recognize 19 complex IoT-based ADL. Though the system did not use any hand-crafted features, resulting in low accuracy, in [17], multiple inertial measurement units (IMU) have been used at different positions on the body to recognize human actions. A LSTM network has been produced to support the training process, and multiple ADL have been used to test the performance of the system. However, due to the lack of proper filtration and feature extraction techniques applied, the system was not able to recognize the ADL correctly.
3. Materials and Methods
3.1. System Methodology
The section explains the methods used for a multimodal IoT-based locomotion classification system. The proposed locomotion prediction method first uses the multimodal raw data from two selected datasets. Next, the input data is pre-processed using three types of filters [18]. Then, the features for each sensor type are extracted using different techniques. Further, the extracted features are fused and optimized to reduce the vector dimensionality. Finally, the features are provided to the recursive neural network for locomotion classification. Figure 1 contributes to a detailed view of the architecture flow diagram proposed for this research paper.
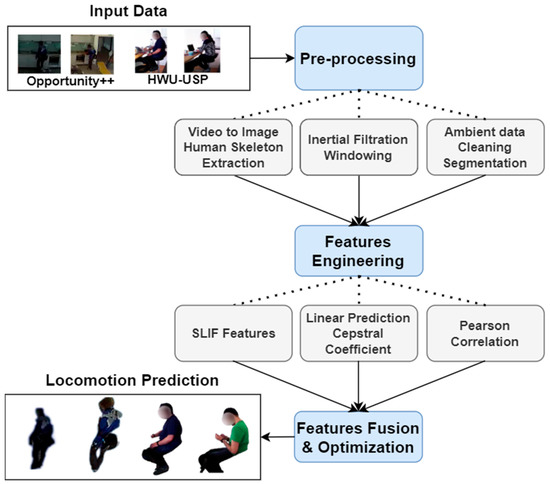
Figure 1.
Architecture flow diagram of the proposed IoT-based multimodal locomotion prediction.
3.2. IoT-Based Multimodal Data Pre-Processing
First, the ambient data has been pre-processed through the Butterworth [19] filter and displayed in Figure 2a. Then, we applied a wavelet quaternion-based filter [20] over the wearable motion sensor data and demonstrated the results in Figure 2b. Both ambient and motion sensor-filtered data are windowed for 4 s [21] each to further process the signals proficiently. Conversely, the visual data has been pre-processed by subtracting the common background [22] among all subjects, as shown in Figure 2c,d. It is further utilized to extract the skeleton model [23] from the human silhouette by extracting eleven skeleton points, including the head, neck, torso, elbows, wrists, knees, and ankles. Figure 3 describes the human skeleton modelling in detail over the HWU-USP dataset.
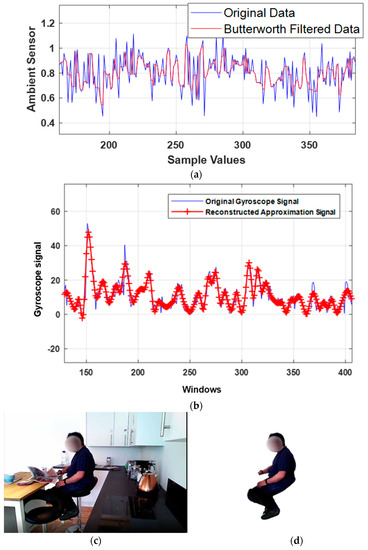
Figure 2.
Sample signals after filters applied for (a) ambient sensor data, (b) motion sensor data, (c) original visual frame sequence, and (d) background removed frame sequence over the HWU-USP dataset.
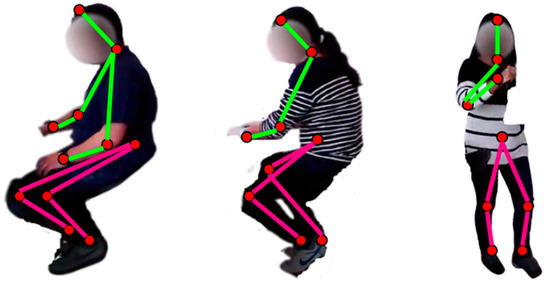
Figure 3.
Skeleton model extracted from different sample frame sequences over the HWU-USP dataset.
3.3. Features Engineering
This section will explain three different feature extraction methods used for three types of multimodal IoT-based data. Features are extracted according to the nature of the data and the characteristics required to be mined from all the multimodal data types [24,25]. Furthermore, to improve the correctness rate of the proposed method, the selection of the most efficient feature engineering techniques, such as Pearson correlation, linear prediction cepstral coefficients, and spider local image features, is significant. The following subsections will explain the three techniques in detail.
3.3.1. Pearson Correlation
The four-second windowed data from the ambient sensor has been used to get the actions performed features. If the average Pearson correlation [26] for a selected window is over a particular threshold of 0.04, then it is considered an action performed. Pearson correlation can be calculated as:
where gives the first variable value in a four second window, provides the second variable values in the window, and and are the mean of the first and second variable values. Figure 4 shows the Pearson correlation and a chosen threshold value with a red dashed line.
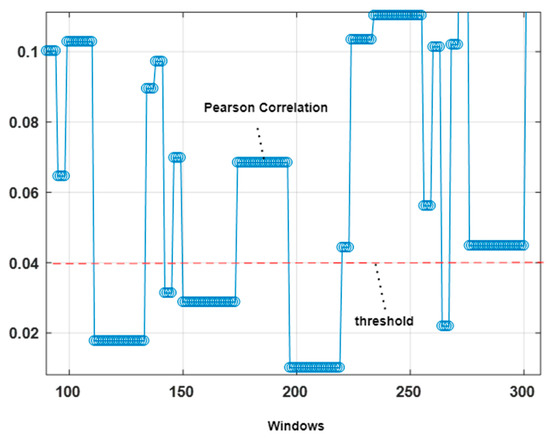
Figure 4.
Locomotion identification using Pearson correlation.
3.3.2. Linear Prediction Cepstral Coefficients (LPCC)
The motion signal and its transfer function can support the extraction of LPCC. The rate of change over different bands has been declared by the cepstrum calculation [27]. Linear prediction coefficients are used to calculate the LPCC as:
where is the linear prediction coefficient and presents the number of coefficients [28]. Figure 5 demonstrates the LPCC extracted for ADL, called setting the table, from the HWU-USP dataset.
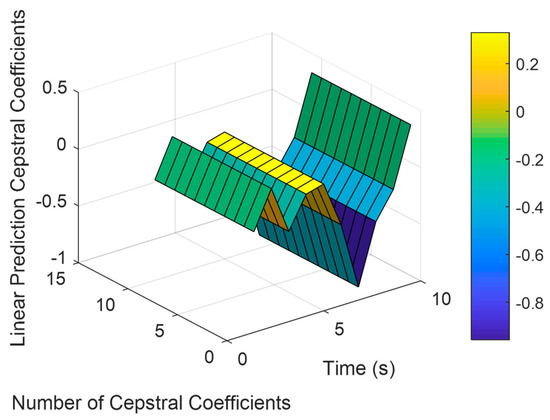
Figure 5.
Result of LPCC applied to motion sensor-filtered and windowed data over the HWU-USP dataset.
3.3.3. Spider Local Image Features
After the skeleton modeling from the human silhouette, we applied the technique called spider local image feature (SLIF). The skeleton points have been used as the web intersection points in an image [29]. The 2D coordinates are utilized to represent the coordinates as:
where and give the horizontal and vertical coordinates. Figure 6 displays the SLIF applied over 11 skeleton points.
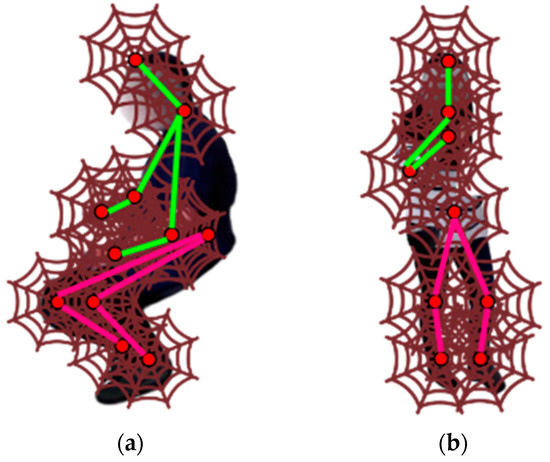
Figure 6.
SLIF feature extraction: (a) reading the newspaper, (b) making tea over the HWU-USP dataset.
3.4. Features Fusion and Optimization
This section will explain the fusion between three types of multimodal data fusion along with the optimization technique applied to reduce the dimensionality for a large number of features.
3.4.1. Features Fusion
The featured data from ambient and motion sensors has been fused using the windows. Then, the features extracted from visual frame sequences have been fused with the ambient and motion data using skeleton points detected over the time windows in the motion data [30]. Figure 7 exhibits the feature fusion technique applied to the proposed multimodal IoT-based locomotion prediction system.
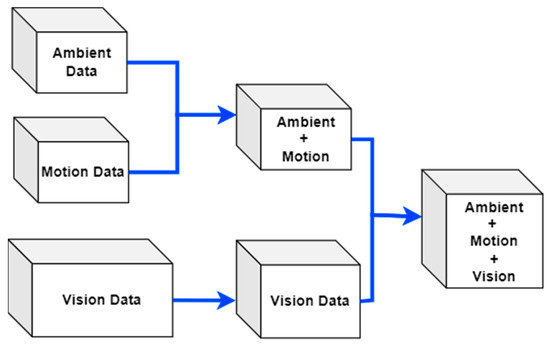
Figure 7.
Multimodal IoT-based data feature fusion for locomotion prediction.
3.4.2. Features Optimization
A cross entropy-based optimization has been applied to the large feature vector. It has selected the correlated features from the fused feature vector and reduced the vector size for deep learning-based classifier training. The mechanism is based on fuzzy logic over type-2 and a logical hierarchy procedure based additive ratio valuation [31]. Figure 8 shows the process to obtain an optimized vector for selected features.
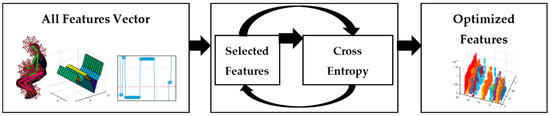
Figure 8.
Process to obtain an optimized vector of selected features.
3.5. Locomotion Classification via Recursive Neural Network
A recursive neural network (RvNN) [32] is a deep learning-based neural network where we apply the same set of weights recursively over ambient, motion, and vision data features. We have applied this network because RvNN can be used to learn distributed, structured data. Therefore, it is ideal for our proposed multimodal IoT-based locomotion prediction system. The parent n-dimensional vector can be calculated as:
where represents the weight matrix and gives the first hidden layer of RvNN. Figure 9 demonstrates the architecture used for RvNN in detail.
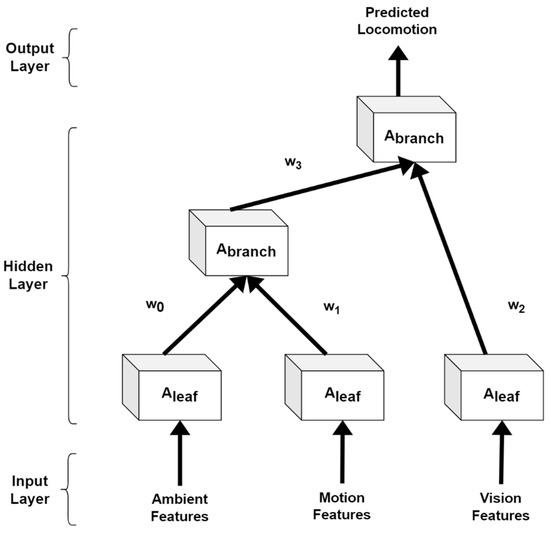
Figure 9.
Architecture diagram for a recursive neural network.
4. Experimental Setup and Evaluation
We have explained the details of the experiments performed and the validation techniques utilized in this section. Locomotion classification accuracy has been used for the performance validation of the proposed multimodal IoT-based locomotion classification system from the chosen challenging indoor datasets. The software Matlab, hardware Intel Core i7 at 2.4 GHz along with 24 GB of RAM are utilized to assess the proposed system. Two indoor activities-based datasets known as HWU-USP [33] and Opportunity++ [34] are utilized for system performance measurement. A 10-fold cross-validation technique has been used over the dataset for training purposes. Following is a description of the datasets used, their investigational outcomes, and a comparison of our proposed multimodal IoT-based locomotion classification system with conventional approaches.
4.1. Dataset Descriptions
4.1.1. HWU-USP Dataset
A synthetic living-lab-based environment was used to capture the daily living activities of sixteen participants. In total, nine different ADLs have been performed in an assisted living facility inside Heriot-Watt University. The ADL performed include making a sandwich, making a bowl of cereal, making a cup of tea, setting the table, using a phone, reading a newspaper, using a laptop, cleaning the dishes, and tidying the kitchen. The data for each activity was recorded using three types of sensors, including IMU devices, ambient sensors, and videos. The ambient sensors, including four binary switches and PIR sensors, were placed in different places in the kitchen, such as switches, doors, mugs, dishes, and drawers. Inertial sensors, including MetaMotionR by MbientLab, were placed over the subjects’ dominant hands, wrist, and waist. For videos, a RGBD camera placed on the head of the TIAGo robot at VGA 640 × 480 and 25 fps has been used [33]. Figure 10 displays a few sample frame sequences from the selected dataset where a subject is (a) making a cup of tea; (b) preparing a sandwich; (c) preparing a bowl with cereals; (d) setting up the table; (e) using a laptop; (f) manipulating the cell phone; (g) reading a newspaper; (h) washing dishes; and (i) cleaning the kitchen. The dataset consists of multiple videos and inertial signals obtained from a waist clip and wristband.

Figure 10.
Sample frame sequences from the HWU-USP dataset.
4.1.2. Opportunity++ Dataset
This novel dataset is an addition to the previously proposed Opportunity [14] dataset. A total of 12 participants performed two types of activity drills. Two kinds of activities have been recognized through this dataset, such as locomotion-level and low-level activities. This system focused on 17 activities performed in different drills, including close door, open fridge, open door, close fridge, open dishwasher, open drawer, drink from cup, close drawer, close dishwasher, clean table, and toggle switch. The dataset was recorded using seven body worn IMU sensors, 12 object sensors, 13 ambient sensors, and videos. The body-worn sensors, including InertiaCube3 and Xsens MT9, were placed over the subject’s shoulders, wrists, elbows, waist, knees, and ankles. Whereas the ambient sensors, including 13 switches and 8 3D acceleration sensors, were attached to objects like milk, spoons, water bottles, glasses, drawers, and doors. Videos were recorded at 640 × 480 pixels and 10fps [34]. Figure 11 presents a few sample images captured during video recordings where a subject is (a) cleaning the table; (b) opening the door; (c) opening the drawer; (d) closing the door; (e) opening the door; and (f) closing the dishwasher.

Figure 11.
Sample frame sequences from Opportunity++.
4.2. Experimental Results
Locomotion prediction accuracy and skeleton point confidence levels for multimodal systems have been evaluated through the experiments. The proposed system attained sufficient outcomes due to robust multimodal IoT-based locomotion classification that shows significant improvement in the classification of ADL in terms of accuracy.
4.2.1. Experiment 1: Via HWU-USP Dataset
The suggested methodology has been applied to the HWU-USP dataset. Table 1 displays the main ADL of the HWU-USP dataset, yielding a notable improvement in classification accuracy. The mean accuracy achieved for this experiment was 87.67%. Table 2 provides the confidence levels [35] calculated for each skeleton point extracted from the human silhouette. The distance is measured from the ground truth [36] for the HWU-USP and Opportunity++ datasets as:
where gives the skeleton point position and denotes the ground truth for both datasets. We chose a threshold of 15 to determine the recognition accuracy.

Table 1.
Confusion matrix for locomotion classification for the proposed approach and the HWU-USP dataset.
Table 2.
Human skeleton points confidence level using the HWU-USP dataset.
4.2.2. Experiment 2: The Opportunity++ Dataset
The Opportunity++ dataset is utilized to test the experiments over the proposed multimodal IoT-based locomotion prediction system and is displayed using Table 3 in the form of a confusion matrix [37]. It is evident from the table that the offered methodology was able to attain an accuracy rate of 86.71% in this experiment. Table 4 explains the confidence levels and recognition accuracy measured against each skeleton point for the human silhouette extracted in our proposed methodology.
Table 3.
Confusion matrix for locomotion classification for the proposed approach and the Opportunity++ dataset.
Table 4.
Human skeleton points confidence level using the Opportunity++ dataset.
4.2.3. Experiment 3: Evaluation Using Other Conventional Systems
Using the HWU-USP and Opportunity++ datasets, we have compared the proposed IoT-based multimodal locomotion prediction system with other similar multimodal systems present in the literature. The comparison of our approach with conventional multimodal state-of-the-art techniques is given in Table 5 [38]. An enhanced mean accuracy rate of 87.0% has been achieved through the proposed system when compared to the other conventional models.
Table 5.
Comparison of the proposed method with conventional systems.
5. Conclusions
A novel multimodal IoT-based state-of-the-art locomotion prediction system has been proposed in this article to reduce the errors caused by motion-related complexities and achieve an acceptable accuracy rate. Ambient, motion, and vision-based data have been retrieved from two publicly available datasets. Raw ambient data is pre-processed using a Butterworth filter; motion data is filtered through a Quaternion-based filter [44], and vision data is used to subtract background and extract the human silhouette. Next, we segmented the ambient and motion data along with extracting the skeleton points from the human silhouette for feature engineering over vision data. Then, we extracted Pearson correlation, LPCC, and SLIF features from ambient, motion, and vision data, respectively. Furthermore, the huge feature vector has been optimized using cross entropy and classified the data via RvNN. The system has been validated using confusion matrices, confidence levels, and skeleton point accuracies. The proposed multimodal IoT-based locomotion prediction model was able to achieve a mean accuracy rate of 87.0%. The results from these experiments have shown that our proposed system has outperformed several conventional multimodal approaches in the literature.
The proposed system did not perform well for complex motion patterns, such as tidying the kitchen or reading a newspaper. Therefore, we intend to further utilize more feature extraction methodologies and apply pattern recognition over motion and ambient sensor data to identify the static and dynamic motion signals before the feature extraction stage. It will be helpful in improving the proposed system for real-time applications.
Author Contributions
Conceptualization: M.J., N.A.M. and B.I.A.; methodology: M.J.; software: M.J.; validation: M.J., B.I.A. and W.K.; formal analysis: M.J. and W.K.; resources: A.J. and W.K.; writing—review and editing: N.A.M. and B.I.A.; funding acquisition: N.A.M., B.I.A. and W.K. All authors have read and agreed to the published version of the manuscript.
Funding
The authors are thankful to the Deanship of Scientific Research at Najran University for funding this work under the Research Group Funding program grant code (NU/RG/SERC/12/40). Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2023R440), the Technology development Program (No. G21S2861919) funded by the Ministry of SMEs and Startups (MSS, Republic of Korea).
Institutional Review Board Statement
The study was conducted according to the guidelines of the Declaration of Helsinki, and approved by the Institutional Review Board (or Ethics Committee) of the Heriot-Watt University (17 November 2019).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data presented in this study are openly available in the Dryad Digital Repository, at https://doi.org/10.5061/dryad.v6wwpzgsj.
Conflicts of Interest
The authors declare no conflict of interests.
References
- Ahmad, J.; Nadeem, A.; Bobasu, S. Human Body Parts Estimation and Detection for Physical Sports Movements. In Proceedings of the 2019 2nd International Conference on Communication, Computing and Digital Systems (C-CODE), Islamabad, Pakistan, 6–7 March 2019; pp. 104–109. [Google Scholar] [CrossRef]
- Pervaiz, M.; Ahmad, J. Artificial Neural Network for Human Object Interaction System Over Aerial Images. In Proceedings of the 2023 4th International Conference on Advancements in Computational Sciences (ICACS), Lahore, Pakistan, 20–22 February 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Quaid, M.A.K.; Ahmad, J. Wearable sensors based human behavioral pattern recognition using statistical features and reweighted genetic algorithm. Multimed. Tools Appl. 2020, 79, 6061–6083. [Google Scholar] [CrossRef]
- Danyal; Azmat, U. Human Activity Recognition via Smartphone Embedded Sensor using Multi-Class SVM. In Proceedings of the 2022 24th International Multitopic Conference (INMIC), Islamabad, Pakistan, 21–22 October 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Ahmad, J.; Batool, M.; Kim, K. Stochastic Recognition of Physical Activity and Healthcare Using Tri-Axial Inertial Wearable Sensors. Appl. Sci. 2020, 10, 7122. [Google Scholar] [CrossRef]
- Ahmad, J.; Mahmood, M. Students’ behavior mining in e-learning environment using cognitive processes with information technologies. Educ. Inf. Technol. 2019, 24, 2797–2821. [Google Scholar] [CrossRef]
- Kang, I.; Molinaro, D.D.; Duggal, S.; Chen, Y.; Kunapuli, P.; Young, A.J. Real-Time Gait Phase Estimation for Robotic Hip Exoskeleton Control During Multimodal Locomotion. IEEE Robot. Autom. Lett. 2021, 6, 3491–3497. [Google Scholar] [CrossRef]
- Mahmood, M.; Ahmad, J.; Kim, K. WHITE STAG model: Wise human interaction tracking and estimation (WHITE) using spatio-temporal and angular-geometric (STAG) descriptors. Multimed. Tools Appl. 2020, 79, 6919–6950. [Google Scholar] [CrossRef]
- Batool, M.; Alotaibi, S.S.; Alatiyyah, M.H.; Alnowaiser, K.; Aljuaid, H.; Jalal, A.; Park, J. Depth Sensors-Based Action Recognition using a Modified K-Ary Entropy Classifier. IEEE Access 2013. [Google Scholar] [CrossRef]
- Ghadi, Y.Y.; Javeed, M.; Alarfaj, M.; Al Shloul, T.; Alsuhibany, S.A.; Jalal, A.; Kamal, S.; Kim, D.-S. MS-DLD: Multi-Sensors Based Daily Locomotion Detection via Kinematic-Static Energy and Body-Specific HMMs. IEEE Access 2022, 10, 23964–23979. [Google Scholar] [CrossRef]
- Figueiredo, J.; Carvalho, S.P.; Gonçalve, D.; Moreno, J.C.; Santos, C.P. Daily Locomotion Recognition and Prediction: A Kinematic Data-Based Machine Learning Approach. IEEE Access 2020, 8, 33250–33262. [Google Scholar] [CrossRef]
- Madiha, J.; Shorfuzzaman, M.; Alsufyani, N.; Chelloug, S.A.; Jalal, A.; Park, J. Physical human locomotion prediction using manifold regularization. PeerJ Comput. Sci. 2022, 8, e1105. [Google Scholar] [CrossRef]
- Wang, L.; Ciliberto, M.; Gjoreski, H.; Lago, P.; Murao, K.; Okita, T.; Roggen, D. Locomotion and Transportation Mode Recognition from GPS and Radio Signals: Summary of SHL Challenge 2021. In Proceedings of the Adjunct Proceedings of the 2021 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2021 ACM International Symposium on Wearable Computers (UbiComp ‘21), Association for Computing Machinery, New York, NY, USA, 21–26 September 2021; pp. 412–422. [Google Scholar] [CrossRef]
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.T.; Tröster, G.; Millán, J.D.R.; Roggen, D. The Opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recognit. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef]
- Ordóñez, F.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- De, D.; Bharti, P.; Das, S.K.; Chellappan, S. Multimodal Wearable Sensing for Fine-Grained Activity Recognition in Healthcare. IEEE Internet Comput. 2015, 19, 26–35. [Google Scholar] [CrossRef]
- Chung, S.; Lim, J.; Noh, K.J.; Kim, G.; Jeong, H. Sensor Data Acquisition and Multimodal Sensor Fusion for Human Activity Recognition Using Deep Learning. Sensors 2019, 19, 1716. [Google Scholar] [CrossRef]
- Ahmad, J.; Kim, Y. Dense depth maps-based human pose tracking and recognition in dynamic scenes using ridge data. In Proceedings of the 2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Seoul, Republic of Korea, 26–29 August 2014; pp. 119–124. [Google Scholar] [CrossRef]
- Muneeb, M.; Rustam, H.; Ahmad, J. Automate Appliances via Gestures Recognition for Elderly Living Assistance. In Proceedings of the 2023 4th International Conference on Advancements in Computational Sciences (ICACS), Lahore, Pakistan, 20–22 February 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Madiha, J.; Ahmad, J. Body-worn Hybrid-Sensors based Motion Patterns Detection via Bag-of-features and Fuzzy Logic Optimization. In Proceedings of the 2021 International Conference on Innovative Computing (ICIC), Lahore, Pakistan, 9–10 November 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Shloul, T.A.; Javeed, M.; Gochoo, M.; Alsuhibany, S.A.; Ghadi, Y.Y.; Jalal, A.; Park, J. Student’s health exercise recognition tool for E-learning education. IASC Intell. Autom. Soft Comput. 2023, 35, 149–161. [Google Scholar] [CrossRef]
- Gochoo, M.; Akhter, I.; Jalal, A.; Kim, K. Stochastic remote sensing event classification over adaptive posture estimation via multifused data and deep belief network. Remote Sens. 2021, 13, 912. [Google Scholar] [CrossRef]
- Azmat, U.; Ahmad, J. Smartphone Inertial Sensors for Human Locomotion Activity Recognition based on Template Matching and Codebook Generation. In Proceedings of the 2021 International Conference on Communication Technologies (ComTech), Rawalpindi, Pakistan, 21–22 September 2021; pp. 109–114. [Google Scholar] [CrossRef]
- Ahmad, J.; Quaid, M.A.K.; Hasan, A.S. Wearable Sensor-Based Human Behavior Understanding and Recognition in Daily Life for Smart Environments. In Proceedings of the 2018 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 17–19 December 2018; pp. 105–110. [Google Scholar] [CrossRef]
- Ahmad, J.; Quaid, M.A.K.; Kim, K. A Wrist Worn Acceleration Based Human Motion Analysis and Classification for Ambient Smart Home System. J. Electr. Eng. Technol. 2019, 14, 1733–1739. [Google Scholar] [CrossRef]
- Zhuo, S.; Sherlock, L.; Dobbie, G.; Koh, Y.S.; Russello, G.; Lottridge, D. Real-time Smartphone Activity Classification Using Inertial Sensors—Recognition of Scrolling, Typing, and Watching Videos While Sitting or Walking. Sensors 2020, 20, 655. [Google Scholar] [CrossRef]
- Pazhanirajan, S.; Dhanalakshmi, P. EEG Signal Classification using Linear Predictive Cepstral Coefficient Features. Int. J. Comput. Appl. 2013, 73, 28–31. [Google Scholar] [CrossRef]
- Fausto, F.; Cuevas, E.; Gonzales, A. A New Descriptor for Image Matching Based on Bionic Principles. Pattern Anal. Appl. 2017, 20, 1245–1259. [Google Scholar] [CrossRef]
- Madiha, J.; Jalal, A.; Kim, K. Wearable Sensors based Exertion Recognition using Statistical Features and Random Forest for Physical Healthcare Monitoring. In Proceedings of the 2021 International Bhurban Conference on Applied Sciences and Technologies (IBCAST), Islamabad, Pakistan, 12–16 January 2021; pp. 512–517. [Google Scholar] [CrossRef]
- Sen, B.; Hussain, S.A.I.; Gupta, A.D.; Gupta, M.K.; Pimenov, D.Y.; Mikołajczyk, T. Application of Type-2 Fuzzy AHP-ARAS for Selecting Optimal WEDM Parameters. Metals 2020, 11, 42. [Google Scholar] [CrossRef]
- Zhang, X.; Jiang, R.; Wang, T.; Wang, J. Recursive Neural Network for Video Deblurring. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3025–3036. [Google Scholar] [CrossRef]
- Murad, A.; Pyun, J.-Y. Deep Recurrent Neural Networks for Human Activity Recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef]
- Ranieri, C.M.; MacLeod, S.; Dragone, M.; Vargas, P.A.; Romero, R.F. Activity Recognition for Ambient Assisted Living with Videos, Inertial Units and Ambient Sensors. Sensors 2021, 21, 768. [Google Scholar] [CrossRef]
- Ciliberto, M.; Rey, V.F.; Calatroni, A.; Lukowicz, P.; Roggen, D. Opportunity++: A Multimodal Dataset for Video- and Wearable, Object and Ambient Sensors-based Human Activity Recognition. Front. Comput. Sci. 2021, 3. [Google Scholar] [CrossRef]
- Akhter, I.; Jalal, A.; Kim, K. Pose Estimation and Detection for Event Recognition using Sense-Aware Features and Adaboost Classifier. In Proceedings of the 2021 International Bhurban Conference on Applied Sciences and Technologies (IBCAST), Islamabad, Pakistan, 12–16 January 2021; pp. 500–505. [Google Scholar] [CrossRef]
- Javeed, M.; Jalal, A. Deep Activity Recognition based on Patterns Discovery for Healthcare Monitoring. In Proceedings of the 2023 International Conference on Advancements in Computational Sciences (ICACS), Lahore, Pakistan, 20–22 February 2023. [Google Scholar]
- Nadeem, A.; Ahmad, J.; Kim, K. Automatic human posture estimation for sport activity recognition with robust body parts detection and entropy markov model. Multimed. Tools Appl. 2021, 80, 21465–21498. [Google Scholar] [CrossRef]
- Hajjej, F.; Javeed, M.; Ksibi, A.; Alarfaj, M.; Alnowaiser, K.; Jalal, A.; Alsufyani, N.; Shorfuzzaman, M.; Park, J. Deep Human Motion Detection and Multi-Features Analysis for Smart Healthcare Learning Tools. IEEE Access 2022, 10, 116527–116539. [Google Scholar] [CrossRef]
- Memmesheimer, R.; Theisen, N.; Paulus, D. Gimme Signals: Discriminative signal encoding for multimodal activity recognition. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 10394–10401. [Google Scholar] [CrossRef]
- Martínez-Villaseñor, L.; Ponce, H.; Brieva, J.; Moya-Albor, E.; Núñez-Martínez, J.; Peñafort-Asturiano, C. UP-Fall Detection Dataset: A Multimodal Approach. Sensors 2019, 19, 1988. [Google Scholar] [CrossRef]
- Piechocki, R.J.; Wang, X.; Bocus, M.J. Multimodal sensor fusion in the latent representation space. Sci. Rep. 2023, 13, 2005. [Google Scholar] [CrossRef]
- Al-Amin, M.; Tao, W.; Doell, D.; Lingard, R.; Yin, Z.; Leu, M.C.; Qin, R. Action Recognition in Manufacturing Assembly using Multimodal Sensor Fusion. Procedia Manuf. 2019, 39, 158–167. [Google Scholar] [CrossRef]
- Gao, W.; Zhang, L.; Teng, Q.; He, J.; Wu, H. DanHAR: Dual Attention Network for multimodal human activity recognition using wearable sensors. Appl. Soft Comput. 2021, 111, 107728. [Google Scholar] [CrossRef]
- Ahmad, J.; Batool, M.; Kim, K. Sustainable Wearable System: Human Behavior Modeling for Life-Logging Activities Using K-Ary Tree Hashing Classifier. Sustainability 2020, 12, 10324. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).