
Human Activity Recognition for AI-Enabled Healthcare Using Low-Resolution Infrared Sensor Data



Abstract
1. Introduction
- LRIR datasets for community: For the first time, our synchronized multichannel LRIR dataset, referred to as Coventry-2018 [19], is utilized as the main dataset in this paper for activity recognition. In addition, another existing dataset, the Infra-ADL2018, is used in order to verify models based on two different datasets. These are the first two LRIR datasets that include multiple view angles, single, and multiple subjects in the scene. The datasets will help the researchers in the community to identify the optimum experimental settings in terms of the number of required sensors for highest accuracy, the optimum sensor position, noise removal, model generalization, and sensitivity to sensor layouts.
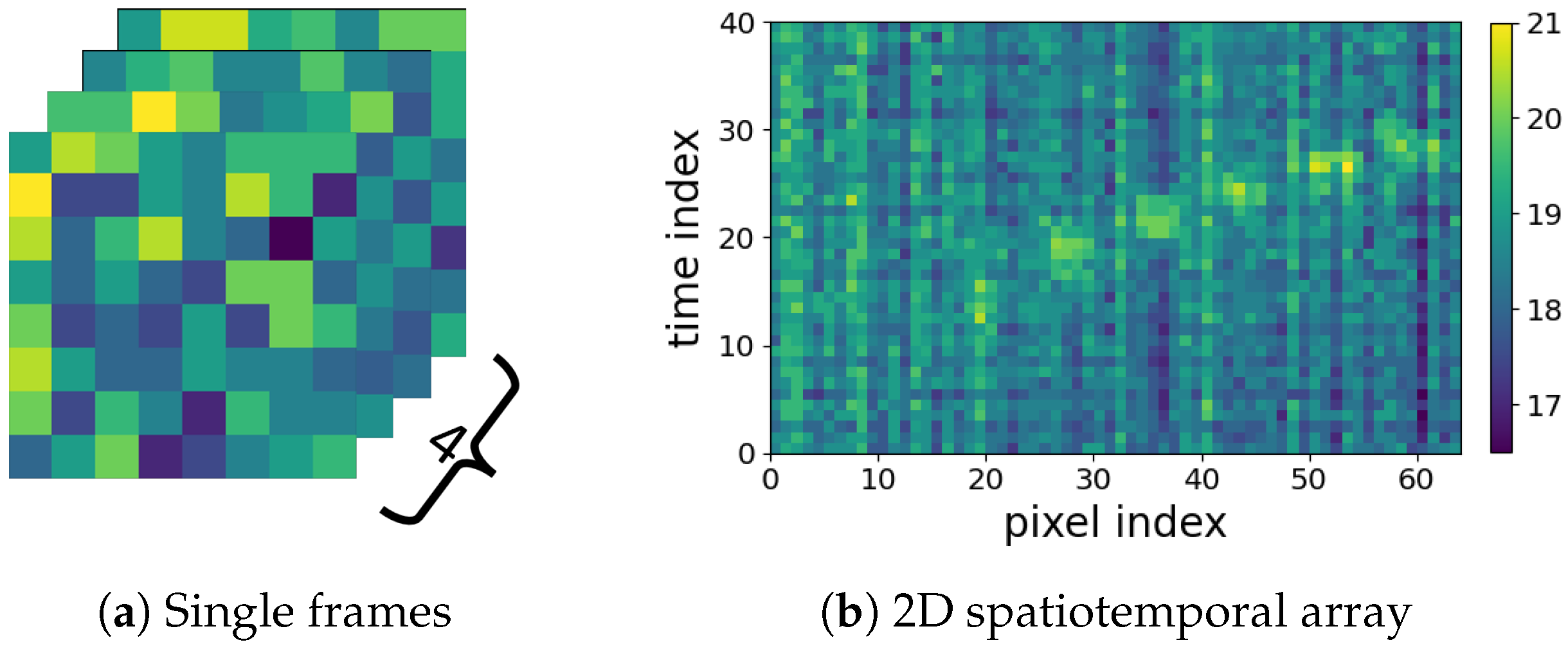
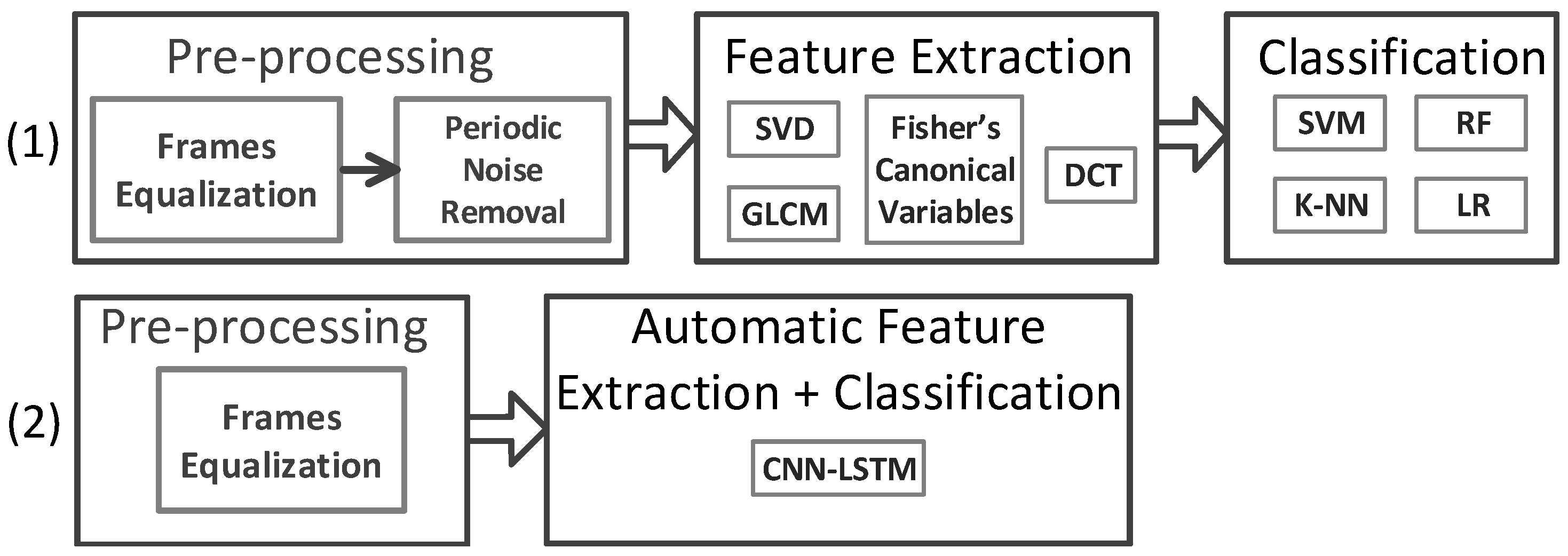
- Comprehensive comparison and verification of main analysis strategies: Two main groups of analysis strategies are considered: (1) the 2D spatiotemporal maps shown in Figure 1b are used for applying different feature extraction strategies to achieve deep insight about the new LRIR data. These include (i) orthogonal transformation based on the singular-value decomposition (SVD) and the Fisher’s canonical variables, (ii) two texture feature extraction techniques, including spectral domain analysis using 2D DCT and the gray-level co-occurrence matrix (GLCM). Then, the extracted features are fed to a selected group of classifiers including SVM, k-NN, random forest (RF), and logistic regression (LR) for activity recognition. (2) The series of LRIR frames are used as video streams to train a deep convolutional LSTM model for activity detection.
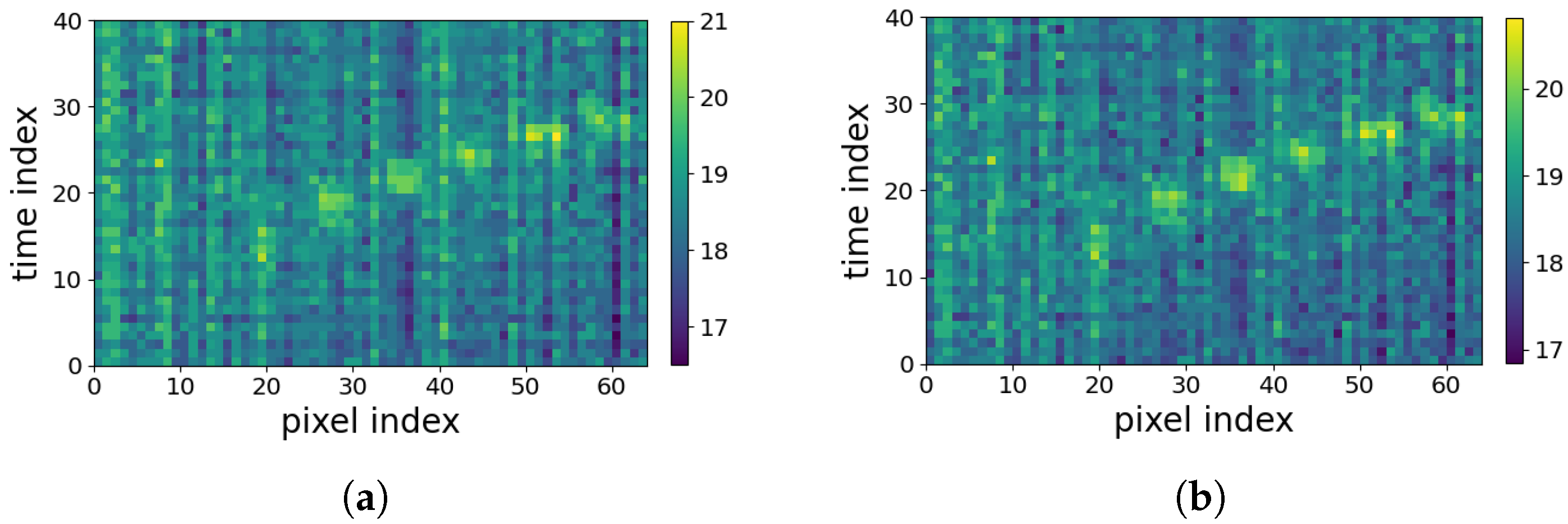
- Novel periodic noise reduction technique: To alleviate the horizontal and vertical periodic noise in 2D spatiotemporal maps shown in Figure 1b, a new supervised noise removal algorithm based on Fourier transform is proposed to improve the quality of 2D profiles before feature extraction and activity classification. To the best of our knowledge, no previous research addressed the periodic noise issue for such 2D spatiotemporal maps.
- Model sensitivity and generalization interpretation: Leveraging rich sensor settings during data collection, including multiple sensors and layouts, comprehensive interpretations are derived. This includes the following: (1) Feature robustness and model sensitivity and generalization against different layout properties, such as geometry size, prospects, and environmental factors, as well as the recommended optimal room setup and sensor subset; (2) model sensitivity against the number and diversity of the subjects under test, even unseen subjects.
2. Data Collection and Data Description
2.1. Coventry-2018 Dataset Collection and Description
2.1.1. Sensor and Processing System Design
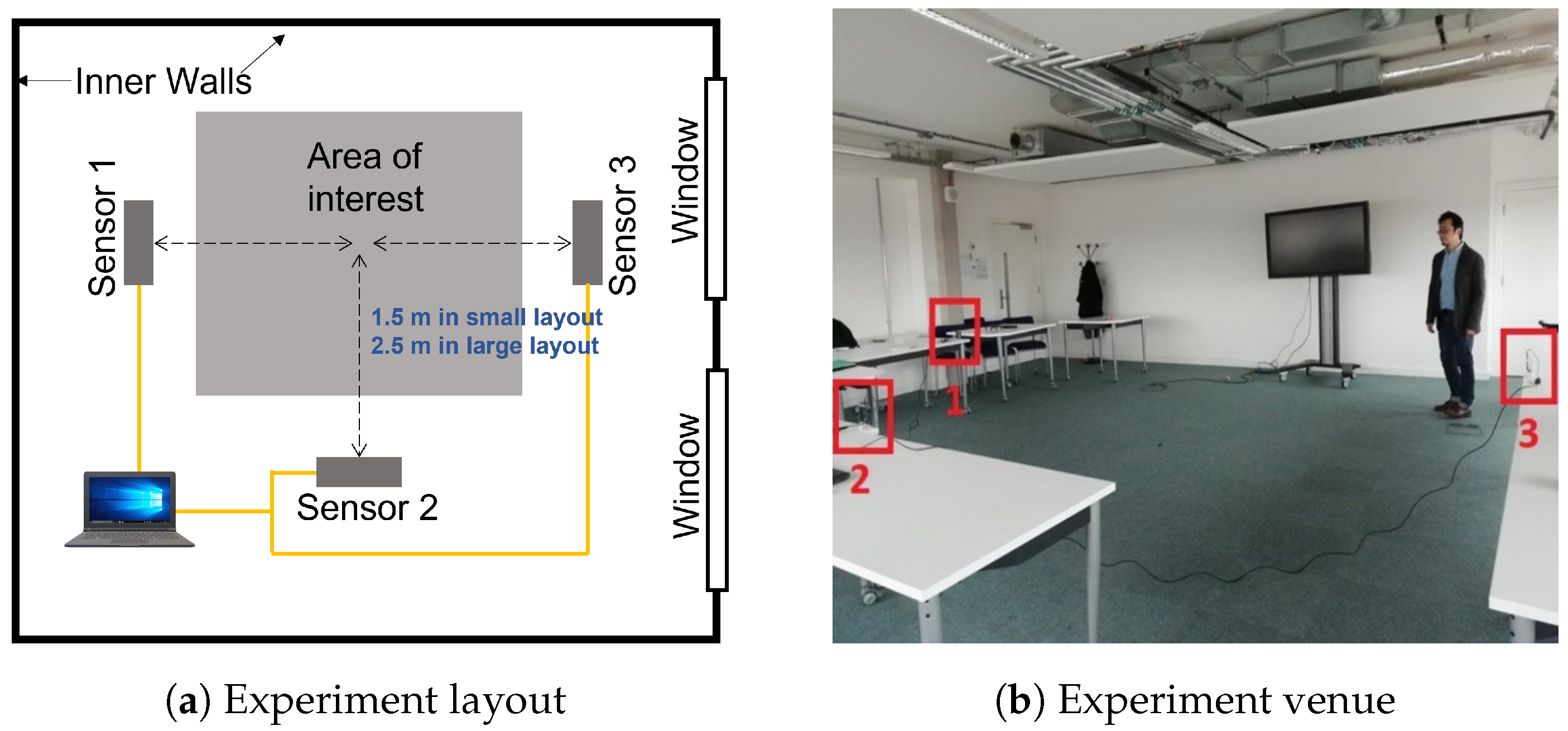
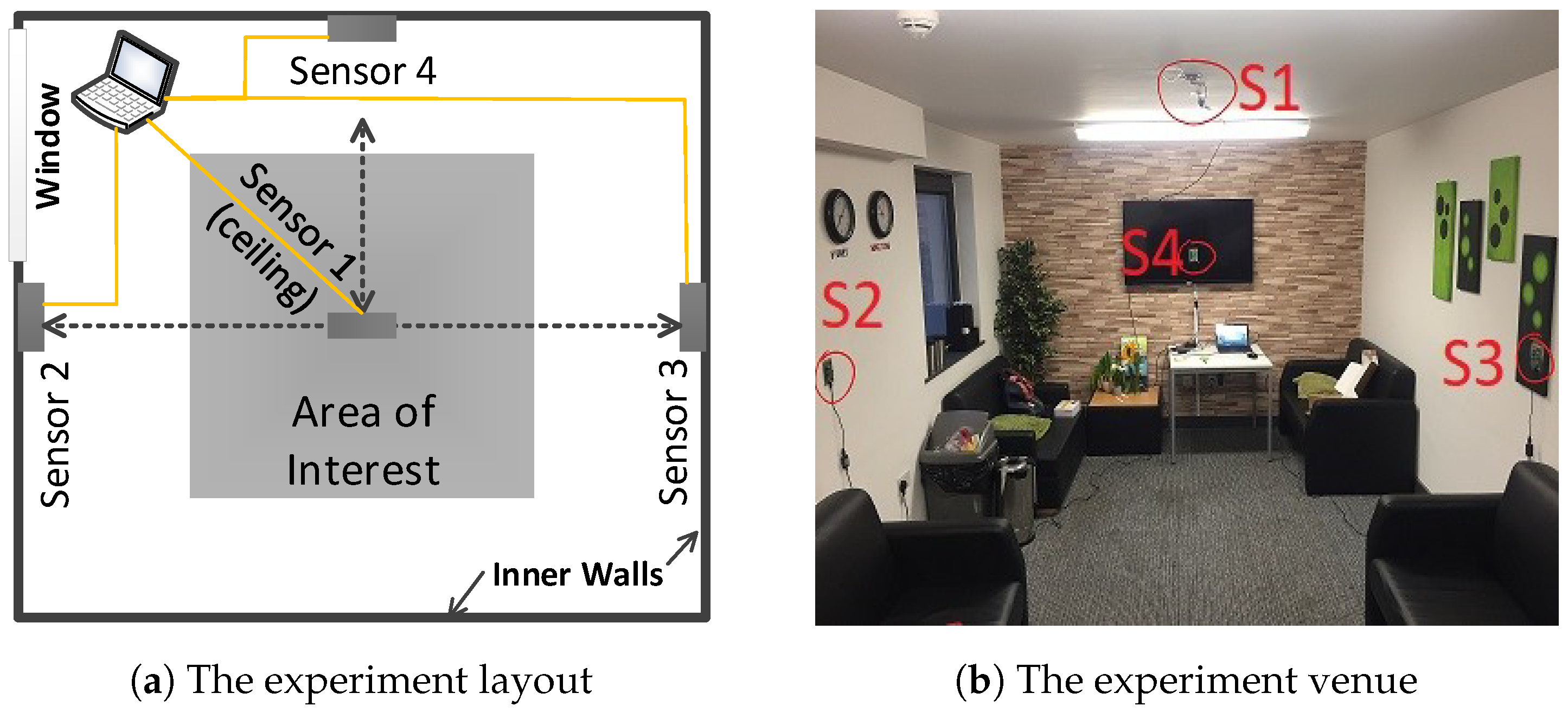
2.1.2. Sensors Layout
2.1.3. Environmental Temperature of Coventry-2018 Dataset
2.1.4. Coventry-2018 Dataset Description
2.2. Infra-ADL2018 Dataset
3. Data Analysis
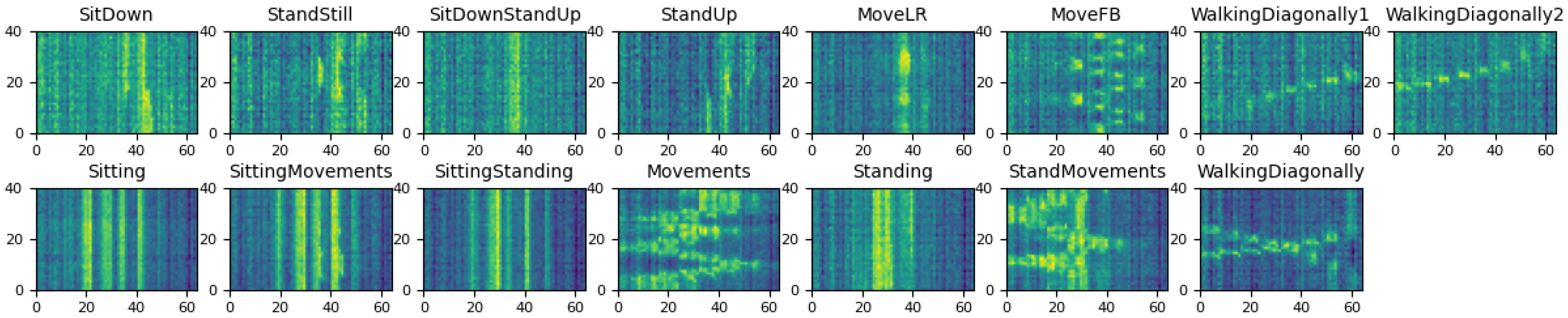
3.1. Data Preprocessing
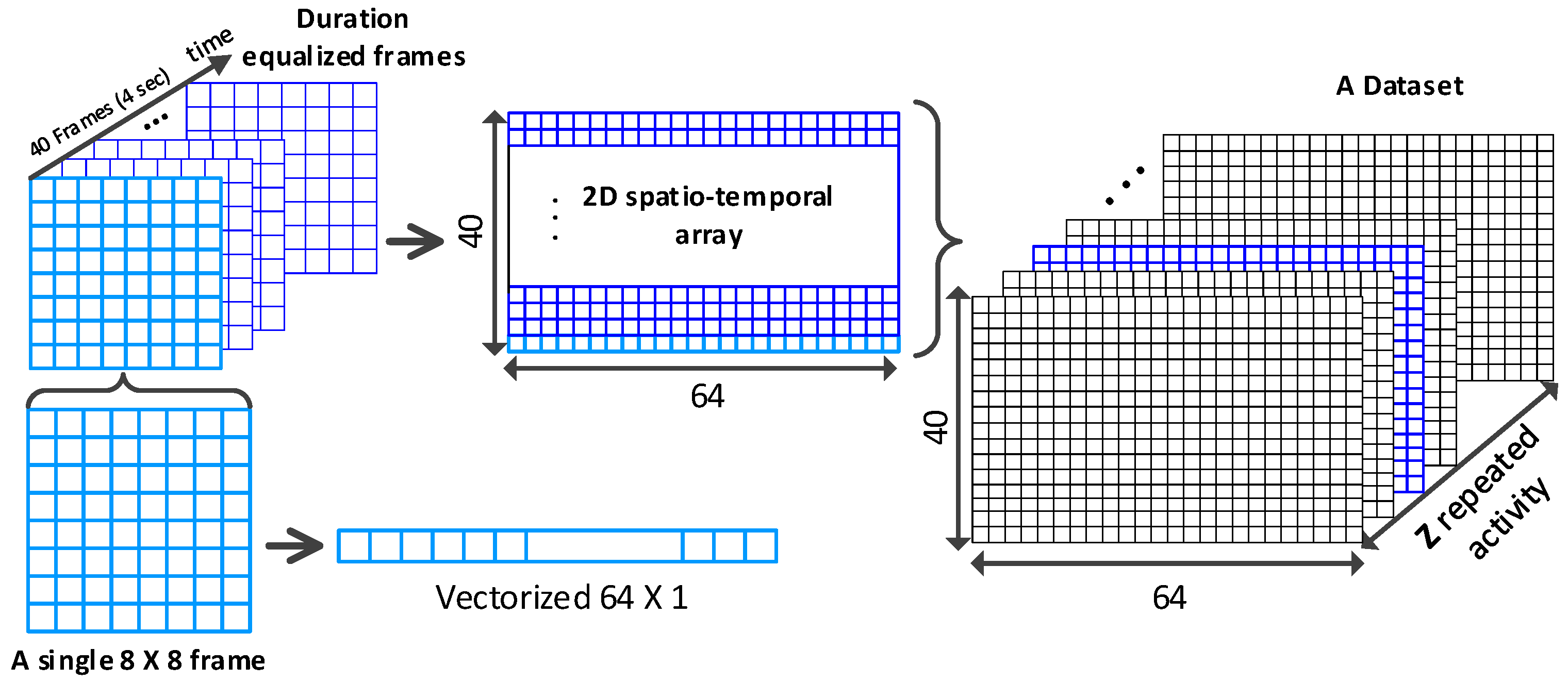
3.1.1. Frames Equalization and Vectorization
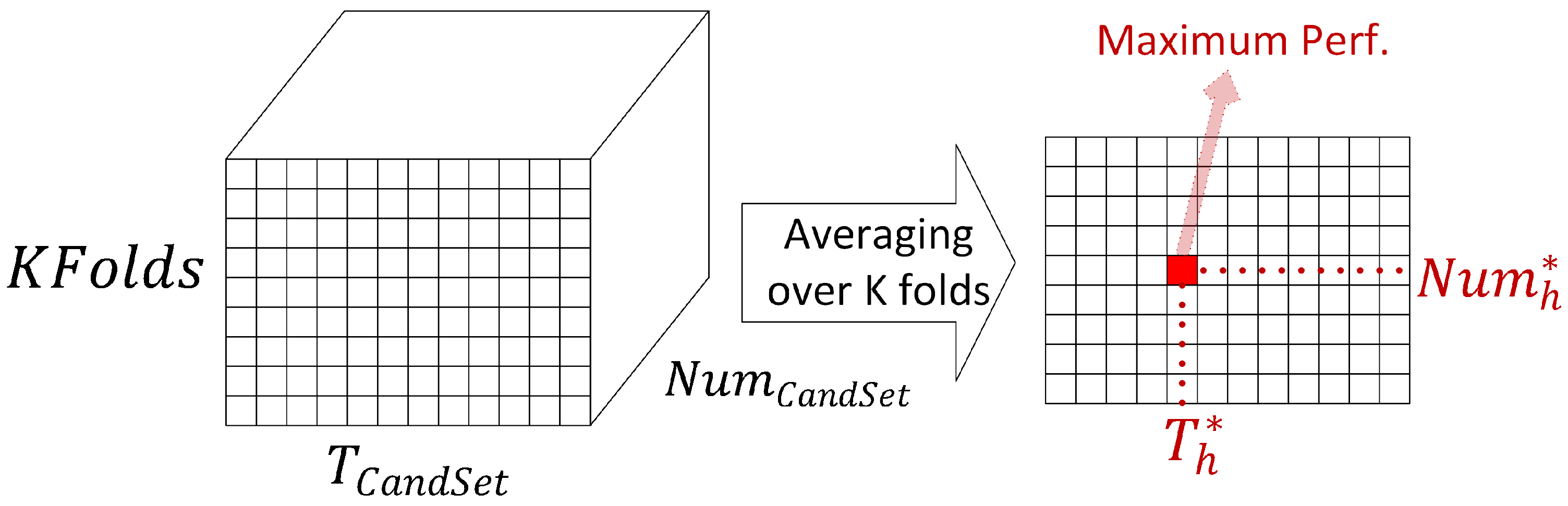
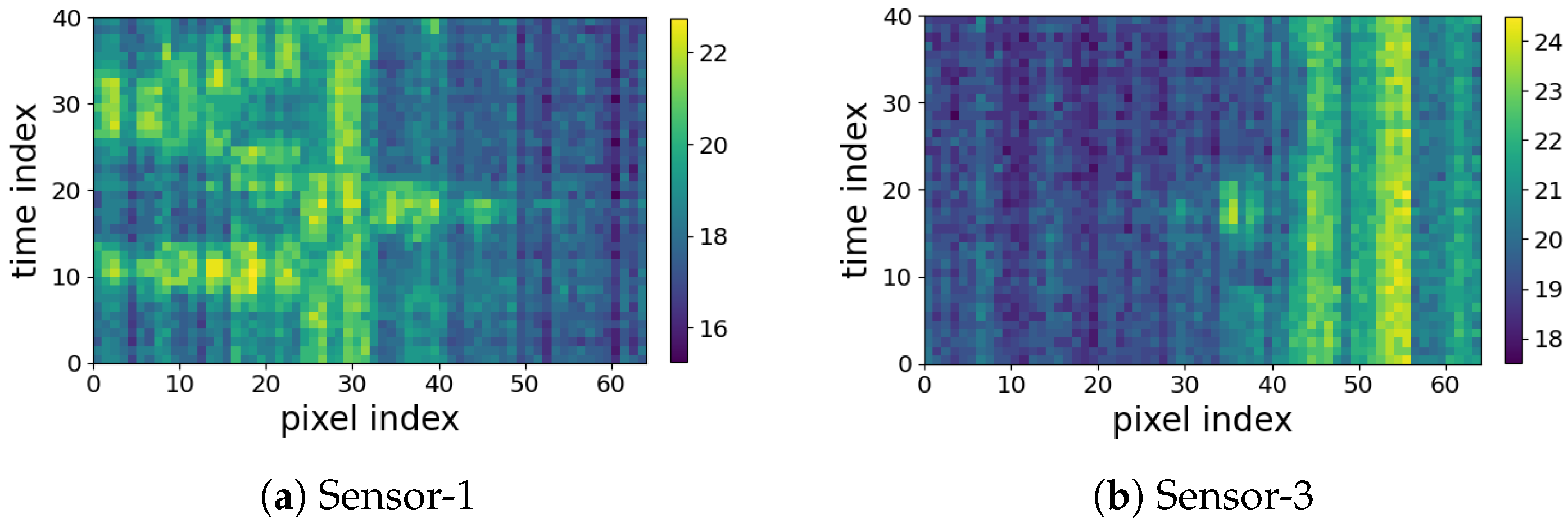
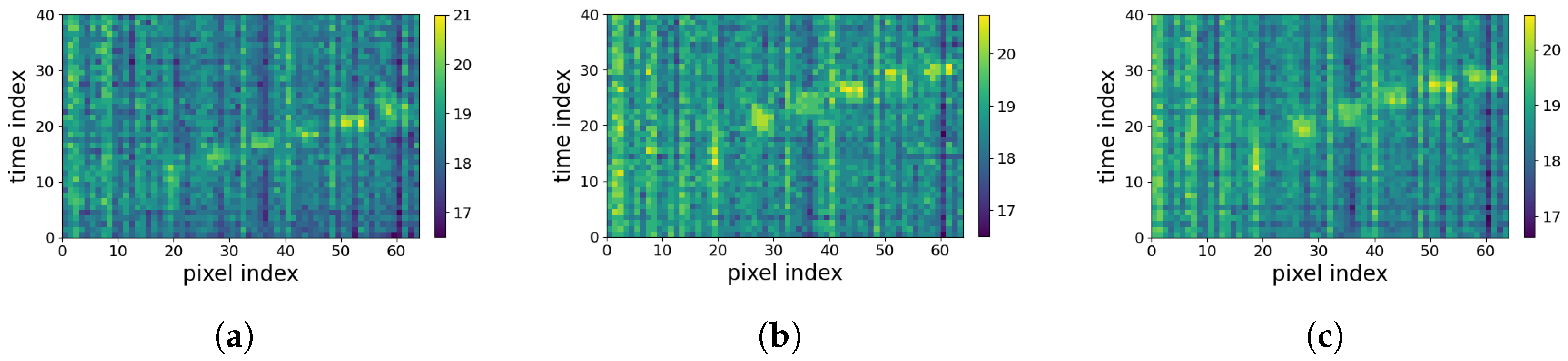
3.1.2. The Proposed Periodic Noise Removal Algorithm
| Algorithm 1: DFT-based periodic noise removal. |
| Input: Training data (), Number of folds K. 1. Divide data into K training and validation sets: , , , . 2. Repeat the following steps for both horizontal and vertical stripes represented as horizontal/vertical for showing all parameters. 3. Form the and 1,…, Maximum number of pixel pairs. 4. (1) For k = 1, …, K (2) For (3) For (4) For j = 1, …, number of images in and -Compute the power spectrum coefficients of the image, -Compute /, / -Find pixel pairs in horizontal/vertical stripes / , -Reduce the first greatest pixel pair values to /, -Compute the denoised image using 2D iDFT, End Loop 4 -Use the denoised image sets and to classify the activities and calculate the element () in the training and validation performance arrays, and . End Loop 3,2,1 5. Average the and arrays over the K-folds 6. Find the highest validation accuracy corresponding to the optimum threshold / and number of pixel pairs /. Output: / and / |
3.2. Feature Extraction Methods
3.3. Classification Methods for Activity Detection
3.4. Deep Neural Networks (DNNs) for Activity Recognition
4. Evaluation and Results
- Noise-reduction test—the test is performed on the Coventry-2018 dataset to compare the models’ performances on noisy data and noise-reduced data.
- Comprehensive model comparison test—all combinations of feature extraction and classification methods, as well as CNN-LSTM, are compared based on the Coventry-2018 dataset to discover the most optimum modeling strategy. Then, the best model is applied to different scenarios of the Infra-ADL2018 dataset.
- Layout-sensitivity test—the test is performed on the Coventry-2018 dataset to compare the effect of sensor distance to the subject using the small-layout and large-layout data.
- Model-generality in terms of layout—the test is performed to evaluate the generalization of a model trained on one layout datum (large or small), when tested on another layout datum. In addition, a mixture of small-layout and large-layout samples is applied as the second scenario evaluation. The Coventry-2018 dataset is used for this test.
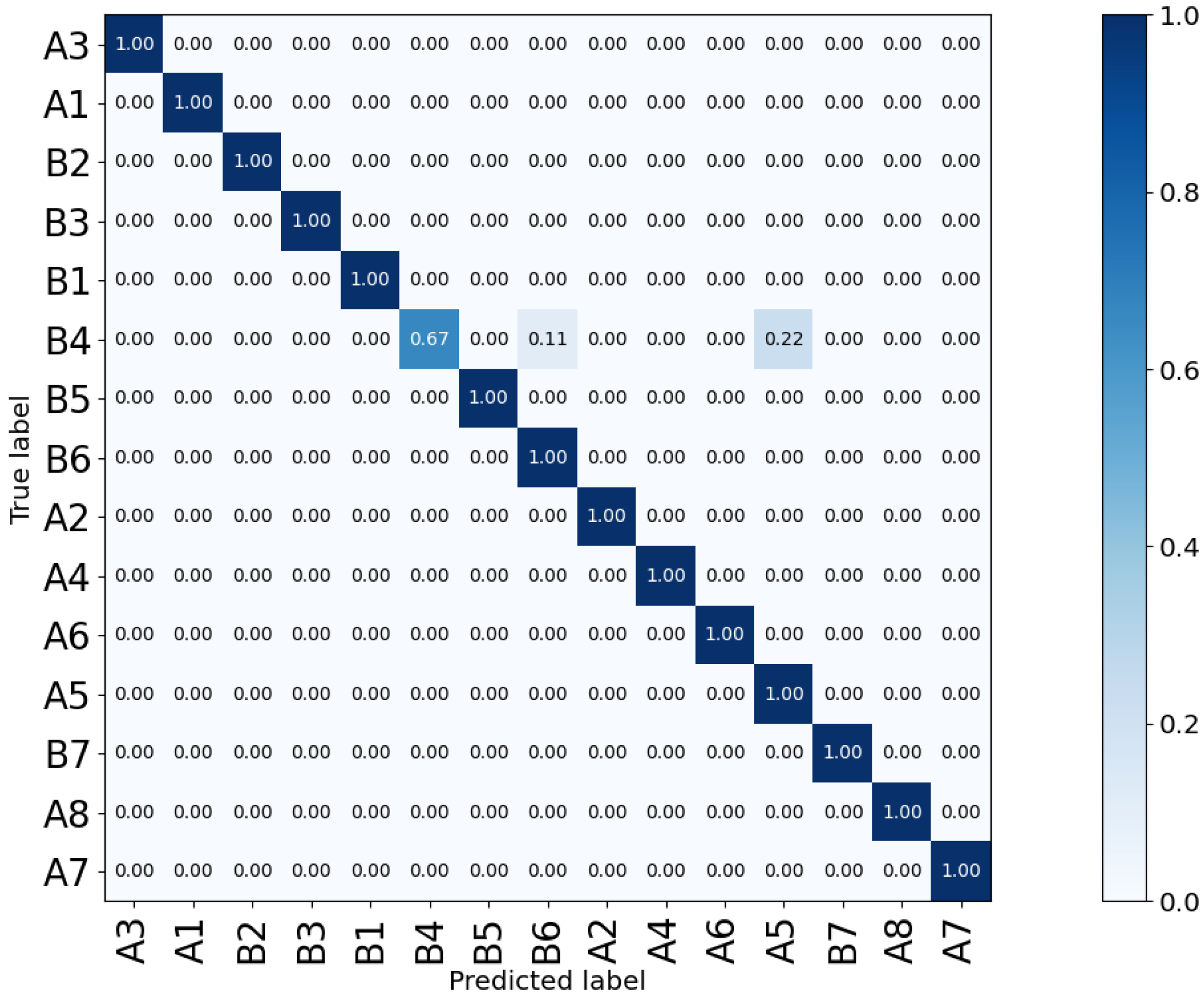
- Subject-sensitivity test—the test is performed to evaluate the effect of number of subjects (one or more) on the performance of the models. The Coventry-2018 dataset and Infra-ADL2018 dataset are used for this experiment.
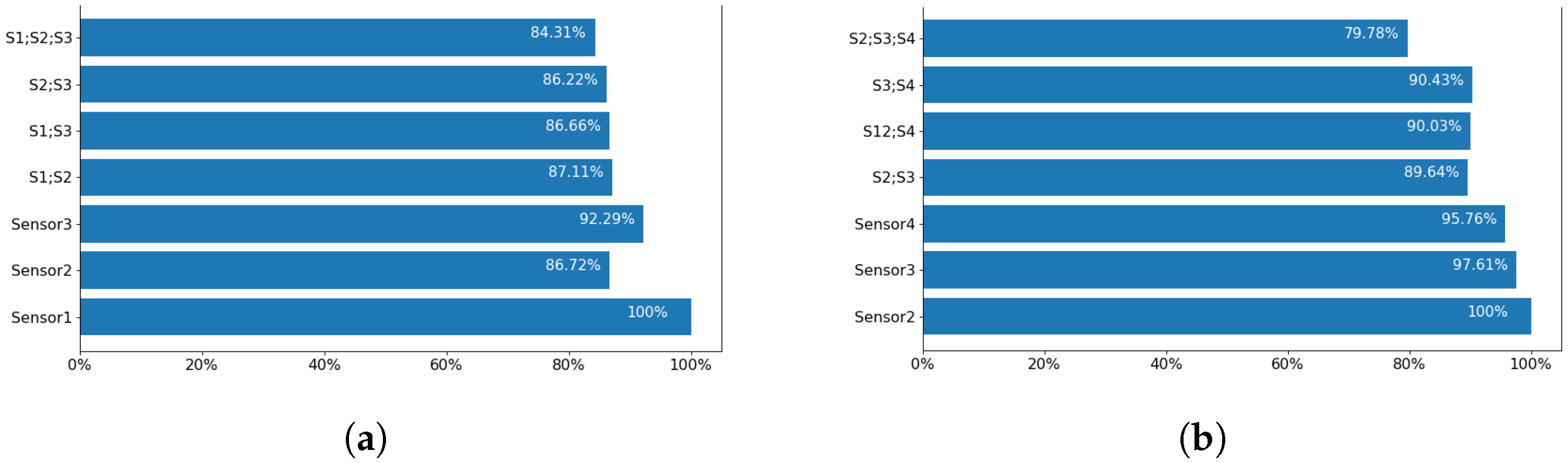
- Optimum sensor test—the test is performed to identify the optimum number and position of sensor(s) that can give the highest performance. All individual sensors and combinations of them are used for this experiment using the Coventry-2018 and Infra-ADL2018 datasets.
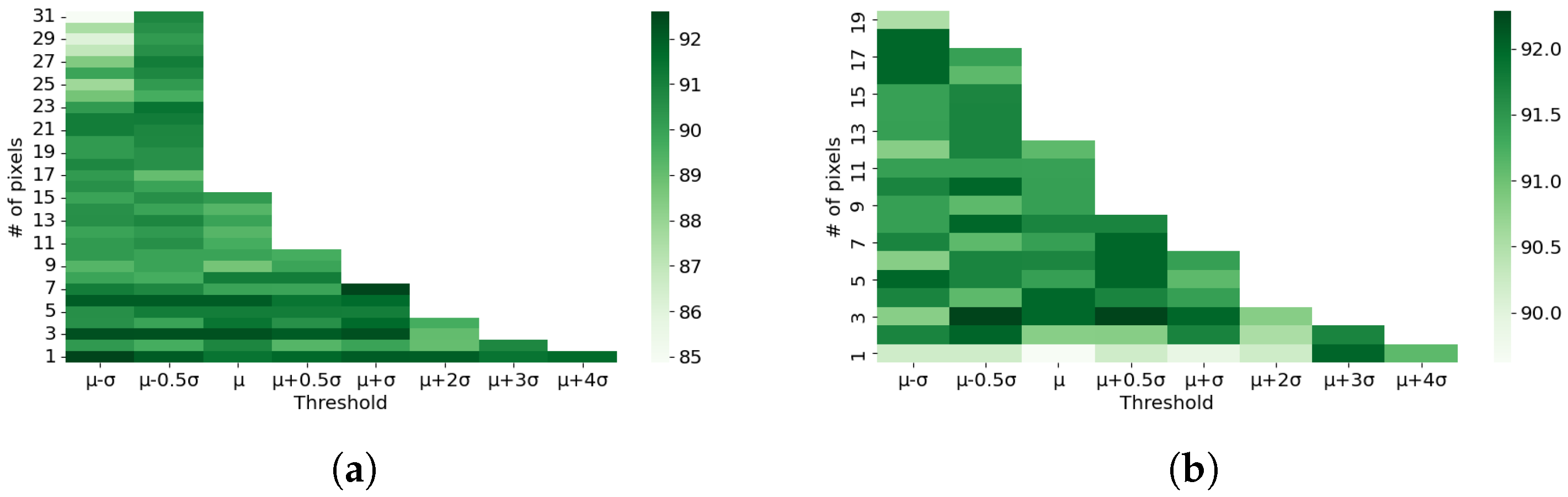
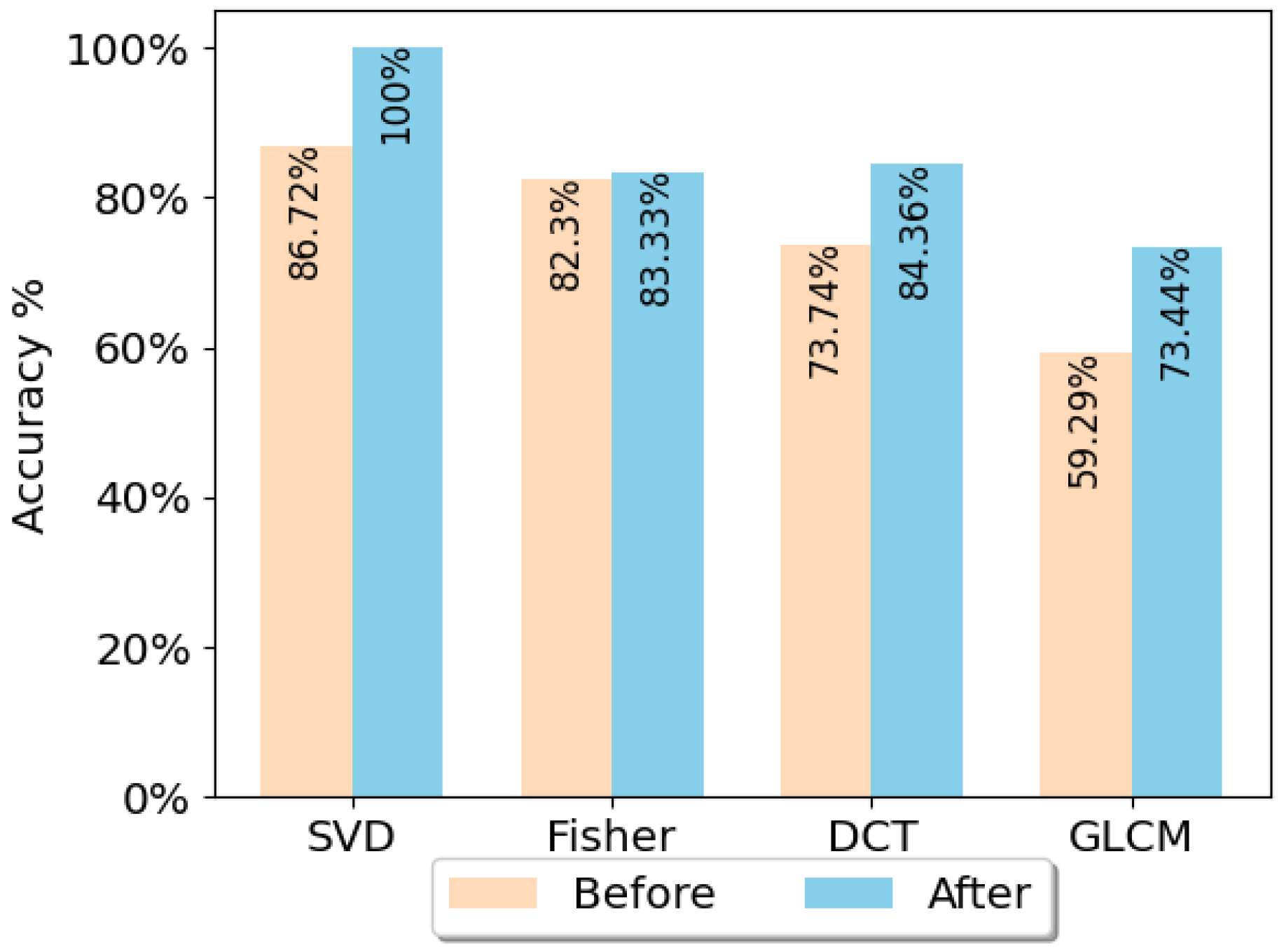
4.1. Result of Periodic Noise Removal
4.2. Comprehensive Comparison of Activity Recognition Techniques
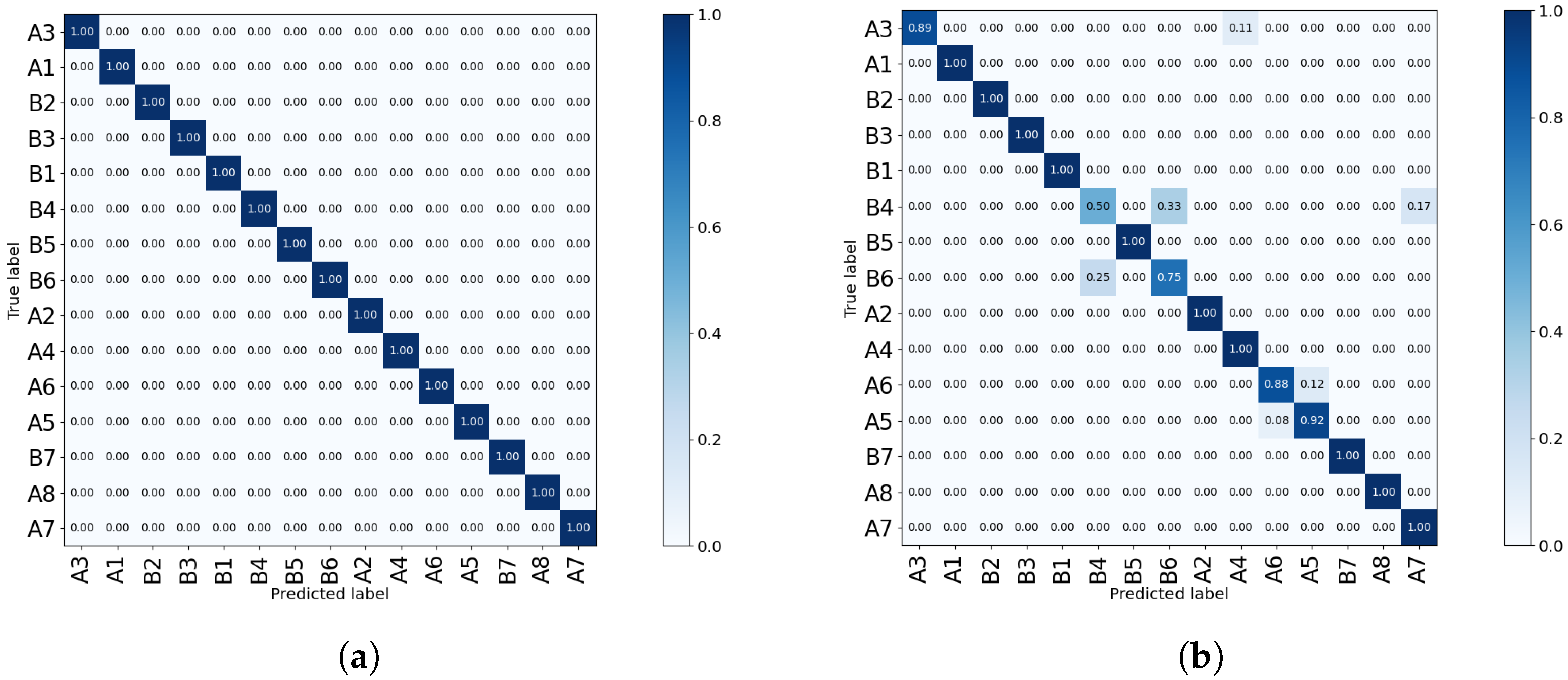
4.3. Layout-Sensitivity Test Results
4.4. Model-Generality in Terms of Layouts
- In the first experiment of the first scenario, the model which was trained using the single-subject Sensor-1 data in small layout was tested on the single-subject Sensor-1 data in large layout. The second experiment was also repeated for the large layout as train and small layout as test. The distances from sensors to the subjects are different. In addition, the average and standard deviation of the pixels for the small layout are , while for the large layout, they are . All combinations of feature extraction and classification methods as well as CNN-LSTM were tested. GLCM for feature extraction with LR for classification achieved the best accuracy in both experiments using Sensor-1. In the first experiment, the accuracy was 71%. In the opposite scenario, where the large layout is used for training and the model is evaluated on the small layout, the testing accuracy was 64.58% using the same feature extraction and classification strategy. This shows that the (GLCM + LR) can still generalize and show intermediate levels of results of 71% for small-layout training and large-layout testing. This is a positive indication that such systems still work in the case of changes in the original settings such as displacement, etc.
- In the second scenario, the single-subject data from both small layout (240 samples) and large layout (240 samples) were mixed, which represents the moderate scenario. Similar to the previous experiment, all classification models were tested in the pursuit of the most optimum model. As a result, the most accurate model was the automatic feature extraction and classification with the deep CNN-LSTM architecture, achieving average testing accuracy. Considering the very high accuracy, this experiment shows that having approximately equal distribution of data from both layouts in the training phase provides a very rich representation of the data, leading to a strong generalized model.
4.5. Sensitivity to the Number of Subjects
4.6. Optimum Room Setup and Sensor Selection
5. Discussion
5.1. Optimum Sensor Selection
5.2. Analysis of Model Accuracy
5.3. Data Augmentation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Woznowski, P.; Burrows, A.; Diethe, T.; Fafoutis, X.; Hall, J.; Hannuna, S.; Camplani, M.; Twomey, N.; Kozlowski, M.; Tan, B.; et al. SPHERE: A sensor platform for healthcare in a residential environment. In Designing, Developing, and Facilitating Smart Cities; Angelakis, V., Tragos, E., Pöhls, H., Kapovits, A., Bassi, A., Eds.; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Li, W.; Tan, B.; Piechocki, R.J.; Craddock, I. Opportunistic physical activity monitoring via passive WiFi radar. In Proceedings of the IEEE 18th International Conference on e-Health Networking, Applications and Services (Healthcom), Munich, Germany, 14–17 September 2016; pp. 1–6. [Google Scholar]
- Jalal, A.; Kamal, S.; Kim, D. Human depth sensors-based activity recognition using spatiotemporal features and hidden markov model for smart environments. J. Comput. Netw. Commun. 2016, 2016, 8087545. [Google Scholar] [CrossRef]
- Li, W.; Tan, B.; Piechocki, R. Passive Radar for Opportunistic Monitoring in E-Health Applications. IEEE J. Transl. Eng. Health Med. 2018, 6, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Majumder, S.; Mondal, T.; Deen, M.J. Wearable Sensors for Remote Health Monitoring. Sensors 2017, 17, 130. [Google Scholar] [CrossRef] [PubMed]
- Arshad, M.H.; Bilal, M.; Gani, A. Human Activity Recognition: Review, Taxonomy and Open Challenges. Sensors 2022, 22, 6463. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Tan, B.; Xu, Y.; Piechocki, R.J. Log-Likelihood Clustering-Enabled Passive RF Sensing for Residential Activity Recognition. IEEE Sens. J. 2018, 18, 5413–5421. [Google Scholar] [CrossRef]
- Serpush, F.; Menhaj, M.B.; Masoumi, B.; Karasfi, B. Wearable Sensor-Based Human Activity Recognition in the Smart Healthcare System. Comput. Intell. Neurosci. 2022, 2022, 1391906. [Google Scholar] [CrossRef] [PubMed]
- Uddin, M.Z.; Soylu, A. Human activity recognition using wearable sensors, discriminant analysis, and long short-term memory-based neural structured learning. Sci. Rep. 2021, 11, 16455. [Google Scholar] [CrossRef] [PubMed]
- Karayaneva, Y.; Baker, S.; Tan, B.; Jing, Y. Use of low-resolution infrared pixel array for passive human motion movement and recognition. In Proceedings of the 32nd International BCS Human Computer Interaction Conference, Belfast, UK, 4–6 July 2018; pp. 1–2. [Google Scholar]
- Mashiyama, S.; Hong, J.; Ohtsuki, T. Activity recognition using low-resolution infrared array sensor. In Proceedings of the IEEE ICC 2015 SAC—Communication for E-Health, London, UK, 8–12 June 2015; pp. 495–500. [Google Scholar]
- Mashiyama, S.; Hong, J.; Ohtsuki, T. A fall detection system using low resolution infrared array sensor. In Proceedings of the IEEE International Symposium on PIMRC, Washington, DC, USA, 30 August–2 September 2015; pp. 2109–2113. [Google Scholar]
- Trofimova, A.; Masciadri, A.; Veronese, F.; Salice, F. Indoor human detection based on thermal array sensor data and adaptive background estimation. J. Comput. Commun. 2017, 5, 16–28. [Google Scholar] [CrossRef]
- Basu, C.; Rowe, A. Tracking Motion and Proxemics Using Thermal-Sensor Array; Carnegie Mellon University: Pittsburgh, PA, USA, 2014; Available online: https://arxiv.org/pdf/1511.08166.pdf (accessed on 25 November 2022).
- Savazzi, S.; Rampa, V.; Kianoush, S.; Minora, A.; Costa, L. Occupancy pattern recognition with infrared array sensors: A bayesian approach to multi-body tracking. In Proceedings of the ICASSP, Brighton, UK, 12–17 May 2019; pp. 4479–4483. [Google Scholar]
- Tao, L.; Volonakis, T.; Tan, B.; Jing, Y.; Chetty, K.; Smith, M. Home Activity Monitoring using Low Resolution Infrared Sensor. arXiv 2018, arXiv:1811.05416. [Google Scholar]
- Yin, C.; Chen, J.; Miao, X.; Jiang, H.; Chen, D. Device-Free Human Activity Recognition with Low-Resolution Infrared Array Sensor Using Long Short-Term Memory Neural Network. Sensors 2021, 21, 3551. [Google Scholar] [CrossRef] [PubMed]
- Hosono, T.; Takahashi, T.; Deguchi, D.; Ide, I.; Murase, H.; Aizawa, T.; Kawade, M. Human tracking using a far-infrared sensor array and a thermo-spatial sensitive histogram. In Proceedings of the ACCV, Singapore, 1–5 November 2014; pp. 262–274. [Google Scholar]
- Karayaneva, Y.; Sharifzadeh, S.; Jing, Y.; Tan, B. Infrared Human Activity Recognition dataset—Coventry-2018. IEEE Dataport 2020. [Google Scholar] [CrossRef]
- Reddy, H.C.; Khoo, I.-H.; Rajan, P.K. 2-D Symmetry: Theory and Filter Design Applications. IEEE Circuits Syst. Mag. 2003, 3, 4–33. [Google Scholar] [CrossRef]
- Ketenci, S.; Gangal, A. Design of Gaussian star filter for reduction of periodic noise and quasi-periodic noise in gray level images. In Proceedings of the INISTA, Trabzon, Turkey, 2–4 July 2012; pp. 1–5. [Google Scholar]
- Yadav, V.P.; Singh, G.; Anwar, M.I.; Khosla, A. Periodic noise removal using local thresholding. In Proceedings of the CASP, Pune, India, 9–11 June 2016; pp. 114–117. [Google Scholar]
- Sur, F.; Grédiac, M. Automated Removal of Quasi-Periodic Noise through Frequency Domain Statistics. J. Electron. Imaging 2015, 24, 013003. [Google Scholar] [CrossRef]
- Weisstein, E. Singular Value Decomposition, MathWorld. 2012. Available online: https://mathworld.wolfram.com/ (accessed on 25 November 2022).
- Sharifzadeh, S.; Ghodsi, A.; Clemmensen, L.H.; Ersbøll, B.K. Sparse supervised principal component analysis (SSPCA) for dimension reduction and variable selection. Eng. Appl. Artif. Intell. 2017, 65, 168–177. [Google Scholar] [CrossRef]
- Sharifzadeh, S.; Skytte, J.L.; Clemmensen, L.H.; Ersbøll, B.K. DCT-based characterization of milk products using diffuse reflectance images. In Proceedings of the ICDSP, Fira, Greece, 1–3 July 2013; pp. 1–6. [Google Scholar]
- Sharifzadeh, S.; Biro, I.; Lohse, N.; Kinnell, P. Abnormality detection strategies for surface inspection using robot mounted laser scanners. Mechatronics 2018, 51, 59–74. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. Linear Methods for Classification, in the Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009; pp. 113–119. Available online: https://hastie.su.domains/Papers/ESLII.pdf (accessed on 26 November 2022).
- Math Works. “Discrete Cosine Transform—MATLAB & Simulink”. 2019. Available online: https://www.mathworks.com/help/images (accessed on 26 November 2022).
- Math Works. Texture Analysis Using the Gray-Level Co-Occurrence Matrix (GLCM)—MATLAB & Simulink- MathWorks United Kingdom. 2019. Available online: https://uk.mathworks.com/help/images/texture-analysis-using-the-gray-level-co-occurrence-matrix-glcm.html (accessed on 26 November 2022).
- Donahue, J.; Hendricks, L.A.; Rohrbach, M.; Venugopalan, S.; Guadarrama, S.; Saenko, K.; Darrell, T. Long-term Recurrent Convolutional Networks for Visual Recognition and Description. arXiv 2014, arXiv:1411.4389. [Google Scholar]
- Geron, A. Convolutional Neural Networks, In Hands-on Machine Learning with Scikit-learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. O’Reilly Media 2017, 361–373. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
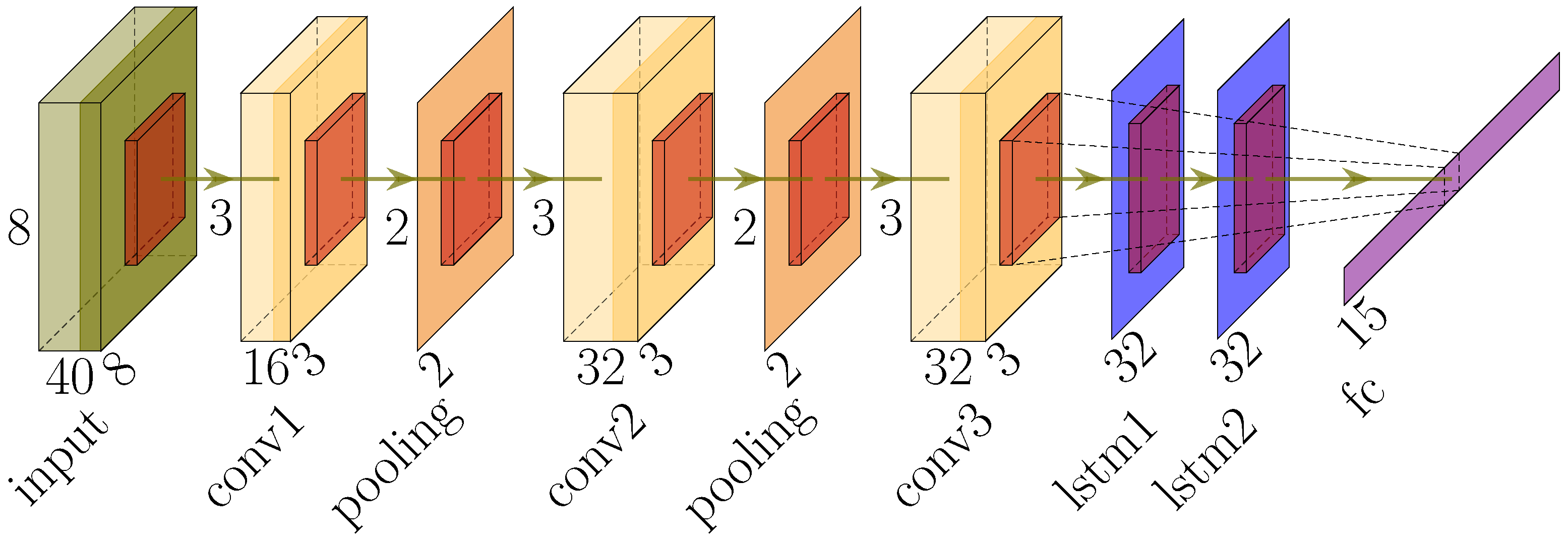{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1-Subject | 2-Subject | |||
|---|---|---|---|---|
| Activities | Small | Large | Activities | Large |
| Sit-Down | AS1 | AL1 | Both Sitting | B1 |
| Stand-Still | AS2 | AL2 | Sitting & Moving | B2 |
| Sit-Down & Stand-Up | AS3 | AL3 | Sitting & Standing | B3 |
| Stand-Up | AS4 | AL4 | Random Moving | B4 |
| Left & Right Move | AS5 | AL5 | Both Standing | B5 |
| For-backward Move | AS6 | AL6 | Standing & Moving | B6 |
| Walking-Diagonally 1 | AS7 | AL7 | Walking Across | B7 |
| Walking-Diagonally 2 | AS8 | AL8 | ||
| 1-Subject | Walking LR; Walking RL; Walking Away; Walking Toward; Falling; Stand to Sit; Sit to Stand; Sitting Still; Standing Still. |
| 2-Subject | Walking Opp Direction; Walking Same Direction; Sitting;
Standing; Sitting+Walking Front; Sitting+Walking Behind; Standing+Walking Front; Standing+Walking Behind; Sitting+Standing; Falling+Walking. |
| 3-Subject | Free Movement; Stand Still. |
| SVM | RF | k-NN | LR | CNN-LSTM | |
|---|---|---|---|---|---|
| SVD | 96.66 ± 0.9% | 97.02 ± 1.04% | 88.88 ± 1.57% | 100 ± 0% | — |
| Fisher | 87.03 ± 2.28% | 88.14 ± 0.52% | 86.29 ± 1.04% | 83.33 ± 1.6% | — |
| DCT | 84.95 ± 0.72% | 94.1 ± 0.83% | 79.97 ± 0.39% | 84.36 ± 1.66% | — |
| GLCM | 77.39 ± 2.09% | 82.22 ± 1.81% | 73.7 ± 2.09% | 73.44 ± 1.91% | — |
| CNN-LSTM | — | — | — | — | 95.88 ± 1.1% |
| Data | Single-Subject Activity | Double-Subject Activity | All Activities (21 Classes) | |
|---|---|---|---|---|
| Sensor-1 | 93.44 ± 0% | 100 ± 0% | 93.91 ± 0.37% | |
| Sensor-2 | 95.08 ± 0% | 100 ± 0% | 100 ± 0% | |
| Sensor-3 | 100 ± 0% | 100 ± 0% | 97.61 ± 0% | |
| Sensor-4 | 90.16 ± 0% | 100 ± 0% | 95.76± 0.37% | |
| Coventry-2018 | Infra-ADL2018 | |||
|---|---|---|---|---|
| Single | Double | Single | Double | |
| SVD | 88.33 ± 0% | 98.11 ± 0% | 97.90 ± 1.6% | 100 ± 0% |
| Fisher | 86.67 ± 0% | 91.82 ± 0.89% | 83.05 ± 2.78% | 97.21 ± 0.78% |
| DCT | 78.33 ± 0% | 94.33 ± 0% | 89.34 ± 0.82% | 100 ± 0% |
| GLCM | 78.33 ± 2.71% | 80.49 ± 2.35% | 66.11 ± 3.36% | 97.77 ± 0.78% |
| CNN-LSTM | 90.74 ± 1.31% | 95.83 ± 2.94% | 95.13 ± 5.77% | 96.66 ± 6.66% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karayaneva, Y.; Sharifzadeh, S.; Jing, Y.; Tan, B. Human Activity Recognition for AI-Enabled Healthcare Using Low-Resolution Infrared Sensor Data. Sensors 2023, 23, 478. https://doi.org/10.3390/s23010478
Karayaneva Y, Sharifzadeh S, Jing Y, Tan B. Human Activity Recognition for AI-Enabled Healthcare Using Low-Resolution Infrared Sensor Data. Sensors. 2023; 23(1):478. https://doi.org/10.3390/s23010478
Chicago/Turabian StyleKarayaneva, Yordanka, Sara Sharifzadeh, Yanguo Jing, and Bo Tan. 2023. "Human Activity Recognition for AI-Enabled Healthcare Using Low-Resolution Infrared Sensor Data" Sensors 23, no. 1: 478. https://doi.org/10.3390/s23010478
APA StyleKarayaneva, Y., Sharifzadeh, S., Jing, Y., & Tan, B. (2023). Human Activity Recognition for AI-Enabled Healthcare Using Low-Resolution Infrared Sensor Data. Sensors, 23(1), 478. https://doi.org/10.3390/s23010478