1. Introduction
The rapid development of novel sensor technology, powerful computing capabilities and methods using artificial intelligence has moved the prospect of autonomously driving vehicles into a potential candidate to transform the way people experience mobility. This development is a promising direction for traffic safety. Surveys [
1,
2,
3] reporting the causes of traffic crashes in manual driving, have identified cognitive and emotional load among others as a major factor. However, until fully autonomous driving is available, the operator still needs to observe and, in critical situations, take control of the vehicle. To measure the required degree of manual interaction with the vehicle, the Society of Automotive Engineers (SAE) defines 6 levels of automation ranging from 0 (fully manual) to 5 (fully autonomous) [
4]. While even lower level autonomous driving can reduce the complexity of traffic situations and therefore lead to task execution at levels with lower cognitive load [
5], recent studies suggest, that inattention or distraction through additional tasks performed by the driver can lead to accidents for vehicles of level 1 (assisted driving), level 2 (partial driving automation) and level 3 (conditional driving automation) [
6,
7]. When performing a secondary task, for example, talking to a car passenger while driving, inattention to the primary task, in this example, driving a car, can manifest itself on different levels: visual (not monitoring the road or the vehicle), manual (hands not on the steering wheel) or cognitive components [
6], while visual and manual inattentions are important components for driver monitoring, we study the detection of phases with high cognitive states.
These states are of special interest, since engaging in dual- or multitask settings, a driver’s attention is a finite resource and cognitive limitations are soon met [
8]. The research community describes a subject’s, cognitive state, with different terms like cognitive workload, mental workload, cognitive load or task load. We use Working Memory (WM), which is based on Baddeley’s model [
9], as storage of conscious information that is limited by the amount of information one can hold and process. Following this definition, we use Cognitive Load (CL) as a measurement to define the amount a subject puts on the WM during a task [
10]. The definition of CL by [
11] as a “… multidimensional construct representing the load that performing a particular task imposes…” indicates that the prediction of when a person can attend to information (or process additional workload) is challenging.
One can study the concept of CL empirically, through meaningful measurements from four categories [
12,
13].
Subjective measurements can capture Perceived Mental Workload (PMWL) as shown in early studies, that used a mental-effort rating scale with 9-grades as symmetrical categories from very, very low mental effort (1) to very, very high mental effort (9) [
14], while recent studies often use a multidimensional measure to evaluate perceived CL such as NASA-Task Load Index (TLX) [
15,
16,
17]. Even though researchers have put a lot of work into developing these Likert-scale-styled subjective rating systems for different tasks, major issues remain: (a) subjective ratings rely on the participants’ ability to introspect their current cognitive load [
18], (b) the current task needs to be interrupted to answer the questionnaire and (c) subjective feedback can not be measured in real-time and continuously.
Performance measurements are strongly related to the task imposed on the subject. Several metrics have been used in the past, such as the number of mistakes made during a complex learning task [
19] or more general accuracy metrics such as hit-rate or reaction time, when solving standardized tasks such as
n-back [
20]. Others have used a dual-task load paradigm and evaluated the performance on the secondary task as an indicator of the cognitive load induced by the primary task [
20]. In the area of driver monitoring, Engström et al. [
6] reviewed the literature and identified inconsistent and counterintuitive findings, with an increasing, as well as a decreasing number of accidents, as a performance metric under increased cognitive load imposed by secondary tasks such as speaking while driving or listing to the radio. The measurement of CL using performance metrics is therefore limited by being strongly selective and task-dependent. A major advantage of performance metrics, such as response time of braking on brake light onset of leading cars, is, that these can be continuously measured during real-world driving situations [
6].
Behavioral Measurements such as linguistic [
21], speech [
22,
23,
24], device inputs like pen [
25,
26] or computer-mouse movements [
27] are commonly used in various applications, while metrics computed from behaviors such as lane keeping, steering wheel activity, mean vehicle speed or the number of initiated speed changes are more specific to driving [
6]. A very prominent approach in the affective computing community is the extraction of action units from facial videos to detect emotions. These action units can also be useful to detect cognitive load while driving [
28,
29]. Another extensively researched modality is based on eye-tracking technology [
30,
31], that in addition to the behavioral dimension accounts to physiological measurements’ with parameters such as pupil diameter.
Physiological Measurements, include other properties of the eye, such as pupil diameter or pupil change responses [
32]. Other physiological processes of the heart, muscles, lung, skin (temperature or conductance) and brain can be measured using biosignal acquisitions [
33]. Both physiological and behavioral measurements have therefore the major advantage of being able to be recorded continuously. In addition to these biosignal recordings, biomarkers such as amylase or cortisol, commonly measured in stress studies, may help to detect phases of high cognitive load [
34].
Our attempt to measure cognitive load using multimodal data is influenced by other areas of research, that try to detect psychological states, especially contributions in the area of affective computing. Lisetti et al. have summarized early work in a review article, highlighting several contributions that show statistically significant changes in different elicited emotions [
35]. Wang et al. attempted to recognize five emotional states of various drivers in an automotive simulator application setting [
36]. With recent advances in machine learning over the last years, not only novel algorithms have been developed, but the requirement for high-quality data and therefore the collection and annotation process gained attention. Datasets such as DEAP [
37], DECAF [
38], cStress [
39], ASCERTAIN [
40], uulmMAC [
41], AMIGOS [
42] and WESAD [
43] have been published in the affective sensing community.
In addition to the study of emotions and stress, other researchers already studied the concept of cognitive load while driving using multidimensional measurements. Haapalainen et al. studied the effect of various elementary cognitive tasks while recording the psycho-physiological activity using wearables [
44]. Hussain et al. compared different modalities (videos of the face and electro-physiological measurements) for different cognitive load tasks and proposed a fusion technique of inputs [
45]. Closely related to our contribution is the distracted driver dataset published by Taamneh et al., that records various driving conditions in a simulated environment [
46]. CLAS [
47] and MAUS [
48] published datasets enabling the study of multidimensional data during different simulated cognitive load tasks. A noteworthy contribution, that shares a close relationship with our work on inducing cognitive load to drivers, is the eDREAM dataset [
49,
50]. A more practical approach for avoiding crashes through automatic measures is presented by Healey and Picard [
51], that analyze cognitive load during real-world driving tasks using physiological signals. Another real-world driving study, conducted by Friedman et al. [
52], tried to estimate cognitive load using only non-contact sensors during two experiments, a driving experiment and a version of an
n-back task based on datasets, that have been introduced in [
53,
54].
Aside from the research gaps, described below and answered throughout this study, the analysis of related datasets makes it apparent, that issues with current data acquisitions setups and datasets remain:
Some datasets are not publicly available to the research community. We release recordings of 30 subjects.
Related work collected combinations of input modalities from subsets of relevant measures, while our work combines a diverse set of modalities form physiological and behavioral measurements, subjective questionnaires and performance metrics.
In recent years, researchers introduced and studied various tasks, however, we as a research community failed to provide a database where the same subject participated in different tasks with different intensities of cognitive load in one recording session. Our setup fills this gap and therefore enables the analysis of distribution shifts and the evaluation of the robustness of predictors with representations that generalize across tasks and test the effects of subject-wise shifts during analysis.
Missing information about metadata of the sample population like age, sex and personality traits, as well as the potential inclusion of subjects with undetected medical conditions or medication treatments, that might interfere with some measurements.
In this work, we focus on the estimation of cognitive load, collecting measurements of all four groups: physiological measurements, performance measurements, subjective measures and behavioral measures. For our subjective measurements, we employ the multidimensional NASA-TLX test. For performance measurements, we measure based on correct and incorrect hits recall and precision for our tests, as well as the reaction time. Our physiological measurements include Electrocardiography (ECG), Electrodermal Activity (EDA), Electromyography (EMG) Photoplethysmogram (PPG), respiration and eye tracker data. For behavioral measurements, we use action units extracted from video recordings. We enrich these data records through a detailed analysis of our study cohort design. To explore the potential use of cortisol as a biomarker for CL, prominently used in stress studies, we collect salivary samples. Furthermore, our statistical analysis of various extracted statistical and medical-motivated expert features provides explainable measures of cognitive load. We train various machine learning models to predict CL of subjects while participating and observing a close-to real-world driving simulation of an autonomously driving car. This leads to our key major contributions:
We implemented a simulation environment for autonomous driving software to induce different levels of cognitive load and a fully synchronous network of recording devices for multimodal measurements.
We create a dataset that provides a wide range of physiological modalities, subjective ratings, performance metrics, behavioral data and biomarkers with precisely annotated phases of multiple levels of cognitive load.
We conduct a robust statistical evaluation, and present various statistical and expert features with significant changes for multiple modalities.
We identify several meaningful combinations of modalities to measure cognitive load using multimodal fusion techniques.
We propose a novel continuous cognitive load value, combining subjective and performance measurements as a target for training.
We release Autonomous Driving Cognitive Load Assessment Database (ADABase), containing 30 subjects to the public to enable the development of novel algorithms for multimodal machine learning.
In addition, research gaps in related works are clarified by providing a detailed analysis of 51 subjects with multimodal data recordings including modalities that are only briefly studied, such as action units and cortisol measurements at different levels of cognitive load. Furthermore, we combine multiple modalities that are until now, studied in subsets in related work, to a superset of modalities for cognitive load estimations, including remote measures such as eye tracking data and facial videos. We have created a new simulation with a close-to-real-world autonomous driving scenario, while also recording the extensively studied n-back test for easier alignment with related work.
2. Materials and Methods
To study the concept of cognitive load and develop machine learning algorithms, that utilize multimodal data for the detection of different cognitive load levels, this study focuses on the implementation of a fully integrated driving simulator. Our simulator includes the ability to record a wide range of physiological signals, face videos and eye tracker data, performance data, task-specific subjective feedback self-evaluations, personality traits and stress-related questionnaires while ensuring that all data points are synchronized across multiple acquisition platforms and modalities. In this study, we induce CL in two different ways. The first test is motivated by recent advances in the development of autonomously driving vehicles. We developed a test with subject/test-system interactions, that are similar to driver/vehicle interactions in lower-to-mid-level-autonomous vehicles. This test is introduced in
Section 2.3 and contains different levels of cognitive load and the addition of a secondary task in the form of controlling an entertainment system while observing the vehicle. The second test is well-established in the research community: The
n-back test introduced in
Section 2.4 is conducted at three levels of difficulty and with single (visual) and dual-task workloads. However, due to the basic concept of our scenario and the conducted psychological assessment (
n-back), commonly used in cognitive neuroscience to measure the working memory and its capacity, the results may generalize well to similar scenarios.
One of the many development contributions in this dataset is the usage of high-precision multimodal recordings and coordinated cognitive load simulation. The simulator for both tests is introduced in
Section 2.2. In
Section 2.1, we introduce statistics about our cohort design and relevant parameters such as driver experience. Our approach to measure the response of the hypothalamic-pituitary-adrenal (HPA) axis using salivary cortisol values is introduced in
Section 2.5. Methods to evaluate subjective feedback are introduced in
Section 2.6 and performance measures and metrics are described in
Section 2.7.
Section 2.8 describes our physiological measurements equipment and recording setup, including relevant references to current literature and a list of extracted expert and statistical features. The same information is provided for eye tracking data in
Section 2.9 and behavioral data extracted from videos in
Section 2.10. The handling of artifacts is described in
Section 2.11. Before using the extracted expert features, motivated by medical practitioners and affective sensing literature, for the detection of phases with different levels of cognitive load we introduce our statistical evaluation protocol in
Section 2.12. In
Section 2.13, we introduce machine learning tasks using different sets of modalities for simple binary classification between low and high levels of cognitive load. Additionally, to this simple binary classification, we propose a three-class under-to-overload classification task and use subjective feedback and performance metrics to develop machine learning algorithms with a continuous cognitive load level as output. Our machine learning pipeline and algorithms are introduced in
Section 2.14.
2.1. Participants and Cohort Description
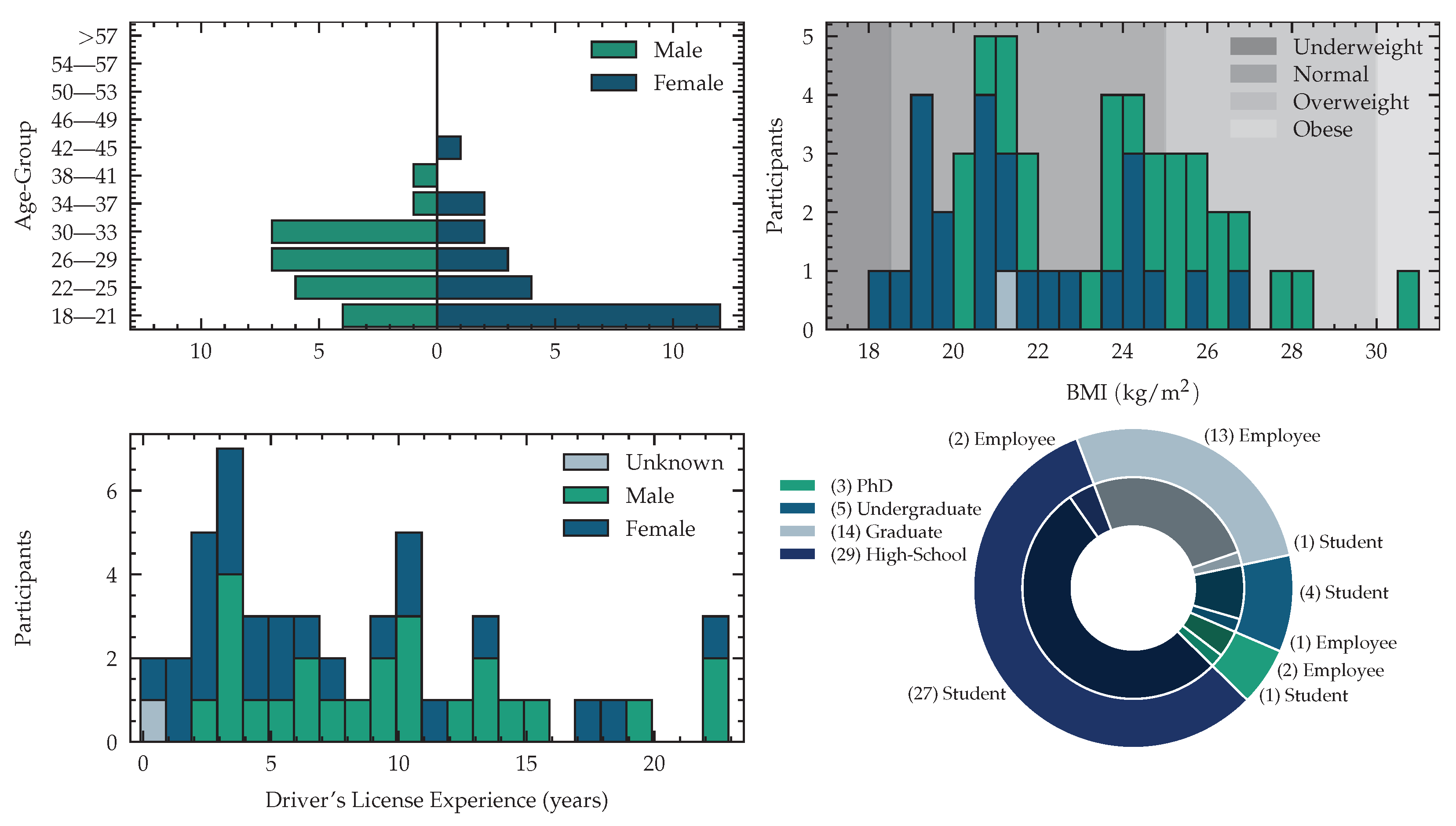
The demographic data of all participants was acquired through self-reporting. Reported parameters were age, sex, weight, height, the highest obtained educational degree, state of employment, first language, state of driving license, as well as the duration of driving experience and handedness. Subjects with medical conditions or subjects under medications, that are known to have an impact on behavior, cognition, physiology or the HPA axis analyzed in this experiment, have been excluded upfront.
The acquired dataset consists of 51 (24 female, 26 male subject and 1 subject that did not want to state gender and age) subjects with an average age of
years, where the youngest subject is 18 years and the oldest subject is 42 years old. The distribution of male and female participants is visualized in
Figure 1. We measured body weights between
and
kilogram, with a mean weight of
kg and a body height between
and
meters with a mean of
m. We computed the Body-Mass-Index (BMI) yielding
kg/m
in average, with a minimal value of
and a maximal value of
kg/m
. Following the World Health Organization (WHO) expert consultation classification recommendations for adults, described in [
55], we identify 1 subject as underweight (BMI
), 37 are in normal range (
BMI
), 12 subjects are pre-obese (
BMI
) and one participant was obese (BMI
). We publish this meta information with our dataset to enable future work to develop algorithms that take the subject meta information into account. Eight of 24 female subjects were on contraceptive medications. Two subjects were using Levothyroxin to treat hypothyroidism. As our study involves various driving scenarios, we asked the number of years, since the driving license was acquired. Subjects without driving licenses were set to zero years of experience, yielding an average driving experience of 8 years of all participants. The detailed distribution is shown in
Figure 1. Of 51 participants, 49 were right-handed and two left-handed. The experimentation setting was adjusted to match the handedness. The subjects were recruited from a diverse population of employees at the Fraunhofer Institute for Integrated Circuits and psychology students at Friedrich Alexander University Erlangen-Nuremberg. One complete session in our simulator, including preparation, measurements and debriefing took, depending on the subject’s compliance, around three hours, with an average signal recording time of
min per subject. The data was acquired on workdays from Monday to Friday at different times of the day. All subjects gave their informed consent for inclusion before they participated in the experiment. The study was approved by the Ethics Committee of the Friedrich-Alexander-University Erlangen Nuremberg. (Ethics-Code: 129_21 B) The complete experimentation recording was 135 h for 51 subjects. We acquire psychological profiles as suggested by Gjoreski et al. when evaluating mental workload through self-reported questionnaires [
56]. To analyze the impact of personality, we utilize the Big Five Inventory (BFI) as a model for the description of personality. To reduce testing time we use a short version, called Big Five Inventory-Kurz (BFI-K) introduced in [
57] as an assessment questionnaire. We report the results for all five traits: extraversion vs. introversion, agreeableness vs. antagonism, conscientiousness vs. lack of direction, neuroticism vs. emotional stability and openness vs. closeness.
2.2. Experiment Structure and Simulator Environment
The experimentation schedule consists of two main test phases, separated by a questionnaire phase to acquire self-reported subjective measures, targeting mental-well being, chronic stress and all demographic information reported in
Section 2.1. The study setup was conducted in a controlled environment, to ensure, that no interruptions occur. An approximately constant room temperature was held during the completion of the experiments. To mitigate the effects of different body positions on parameters like Heart Rate Variability (HRV), the subject was in a sitting position in a car seat. The light conditions were the same for all subjects and no windows were present in the room (no sunlight). Issues with the circadian rhythm of the test subjects are taken into account, as all tests were conducted in fixed time slots, starting either at approximately 9 a.m. or 1 p.m. During this study we conducted two main tasks, in a randomized order:
n-back Test: A established and commonly used continuous assessment of the wm, described in
Section 2.4 [
58].
k-drive Test: An application task with multiple levels of cognitive load with a primary and secondary task, while observing an autonomously driving vehicle, described in
Section 2.3.
During the complete experiment, the subjects were located in the center, sitting in an upright position in a simulator car seat (Playseat ®Evolution Pro Gran Turismo, Playseat B.V. Innovatieweg 18-19, 7007 CD Doetinchem, The Netherlands). The user inputs were entered using the button controls of a steering wheel (Logitech G29 Driving Force, 7700 Gateway Blvd. Newark, CA 94560, USA). The different tasks were visualized using a multi-monitor setup (four 4K 55inch monitors) to enable an immersive experience and a simulation environment that is motivated by real-world car cockpits. All commands, instructions and custom tests were shown on the top monitor, while the three monitors below were used to show the driving simulation. The tablet was located on the side of the dominant hand. The test system was running depending on the active study phase, several custom applications, which were written in PsychoPy [
59], exectued on a separate test system that is synchronized to the Biopac (BIOPAC Systems Inc., 42 Aero Camino, Goleta, CA 93117, USA) system, described in
Section 2.8 using a Universal Serial Bus (USB) to TTL connection. A camera system, described in
Section 2.10 and an eye tracking device, described in
Section 2.9 were located above the steering wheel. The camera system is synchronized using analog triggers from the Biopac system and the eye tracker was connected to and synchronized with the PsychoPy test system. Images documenting the test environment are shown in
Figure 2. An overview of the technical setup is shown in
Figure 3.
The experimentation software is developed using PsychoPy version 2021.1.0. All experiments and user instructions are described in German language within the software. To mitigate any effects that can arise from personal interactions between the examiner and the subject only a few interactions are required during the experimentation phase. At the beginning/end of the experiment, the subject is connected/disconnected to the Biopac system. During the questionnaire phase or before the driving test starts, the tablet is positioned by the examiner to ensure ergonomic accessibility. In addition to these interactions, the salivary samples are collected given the described schedule in
Section 2.5. Deviations from the schedule are documented by the examiner on a predefined template.
2.3. Autonomous Driving Simulation
We are simulating a semi-autonomous driving experiment, where only little interaction of the subject with the vehicle is required and increasing levels of single- and dual-task load is put onto the subject. The steering, gas and brake control as well as gear shifting is autonomously controlled by the simulator. The subject’s interaction is limited to three buttons, located on the steering wheel to detect three different maneuvers as a primary task. During level 1, the subject can use the

button to indicate that the autonomously driving car is passing another car (overtaking). In level 2, the subject is additionally asked to indicate that the car is being overtaken, which can be detected by pushing the

button. For the last level (3), events of high acceleration and deceleration need to be detected by pushing the

button. All driving sessions were simulated using the playback of a pre-recorded Assetto Corsa (Assetto Corso v.1.16,
https://www.assettocorsa.it/en/, (accessed on 25 November 2022) KUNOS Simulazioni s.r.l., Via Degli Olmetti 39/B, 00060 Formello (RM), Italy) screen capture and were presented on the three lower monitors shown on the left side of
Figure 4. During every session, the participant’s car was driving on a racetrack (Assetto Corso Tracks:
https://www.assettocorsa.it/tracks/ (accessed on 25 November 2022)), with twelve other cars that followed the road. The selected racetracks contained curvy and straight street segments without two-way traffic to simulate one-way highways. For easier reference, we are using the notation:
k-drive, where
k indicates the number of actions the user needs to react to and set
(Levels/Actions for reference:
:

:

/

:

/

/

).
Similar to our dual-task
n-back test (see
Section 2.4), the subject is asked to solve a secondary task during level two and level three while observing the vehicle’s actions. For our secondary driving task, we ask the subject to search and add songs to a playlist using a mobile music application (Spotify App v8.6.12, 03/2021, Spotify AB, Regeringsgatan 19, SE-111 53 Stockholm, Sweden), that is presented on an iPad (iPad version 2021 Apple Inc., 1 Infinite Loop, Cupertino, CA 95014) next to the steering wheel. The songs that need to be added are shown on the top screen in our multi-monitor setup shown on the right side of
Figure 4. To ensure a correct understanding we provide a detailed description of every task to the subject upfront and propose solution strategies, such as using the current race position, the presence of rearview mirrors or a tachometer. In addition to these instructions presented in advance, the subject will have at least one training session of 50 s before the test level starts, which can be repeated if that is requested by the subject. Similar to the
n-back training sessions the positive and negative hits are reported after every training session. Before starting the driving experiments, the subject will run through three different baselines. During the first baseline, the subject will rest for five minutes and does not interact with the driving simulator, followed by a second baseline of two minutes, where the subject is observing the autonomously driving car in the test simulator without interaction or any imposed tasks. The third and last baseline phase (two minutes) is used to familiarize the subject with the music application, presented on the IPad. We run these baselines to ensure an ergonomic and familiar setting and record baselines for task-specific shifts, such as moving your eyes from the on-road screen to the iPad music application. We record positive (action was detected correctly) and negative hits (the wrong button was pressed, or no event occurred) as well as reaction time for our primary task. Additionally, we count the number of added songs that were added to the playlist for levels 2 and 3 for our dual-task experiment.
2.4. n-Back Test
In addition to our driving simulation, we conducted an
n-back test [
58] that is extensively used in the literature as a working memory paradigm. The experimentation scenario is inspired by [
20]. In our single task schedule, we presented visuospatial stimuli as a blue square appearing at one of eight possible locations equally spaced and symmetrically around a white cross in the center on a black background. For dual-task tests, we additionally played recorded German consonants from the set {c, g, h, k, p, q, t, w} spoken by a male native speaker. Both versions are visualized in
Figure 5. We repeated the test 6 times: 1-back to 3-back for visual-only stimuli and 1-back to 3-back for visual and audio-verbal stimuli, which were presented simultaneously for our dual-task workload paradigm. Prior to the complete
n-back test run, the subject had different baseline phases. The schedule for the complete test run and the baseline phases is visualized in
Figure 6. Each test was preceded by a short period of training that could be repeated on request by the subject, shown in
Figure 7. Similar to Jaeggi et al. the stimuli were presented for 500 ms followed by an inter-stimulus-interval of 2500 ms [
20]. The subjects were asked to react to repetitions using the buttons on the steering wheel. For a positive visual event, the subject was asked to press the

and for an auditive event the

, respectively.
We recorded both, positive hits (when the reaction to a stimulus was correct) and negative hits (no stimulus was played, or the wrong button was pressed). For positive hits, we recorded the reaction time from the beginning of the stimuli until the button was pressed. The evaluation protocol for positive/negative hits and reaction time is described in
Section 2.7. The subject received performance feedback (number of correct and incorrect hits) automatically after each training session, visualized on the monitor, to ensure that the task was understood correctly, before starting the actual test. The system feedback was formulated neutrally, while the supervisor did not give any feedback during the complete study, to reduce the effects of perceived social stress.
The appendix of this publication provides an overview of the experimentation sequence in
Figure A2 of both conducted experiments.
2.5. Salivary Cortisol Responses
The measurement of glucocorticoids has proven to be a significant auxiliary value to detecting acute social stress responses using salivary samples [
60,
61]. Early studies identified an increase of cortisol, as a response to acute stress, transmitted by the HPA axis as a pathway to send signals to the organism. Cortisol is therefore a promising non-invasive biomarker for stress [
62,
63]. As our study does not impose any social evaluative thread but various levels of cognitive load, we are analyzing cortisol as a biomarker for our
k-drive and
n-back levels. Woody et al. have bisected the cognitive component and social evaluative component of stress and found that social evaluative thread in absence of cognitive load led to greater cortisol values while increased cognitive load had no main or additive effect [
34] on cortisol. Contrary, Veltman and Gailard [
64] have identified a high impact of different mental workload tasks and cortisol levels, while low task performance leads to higher cortisol levels. To capture the complete cortisol response [
60,
65], we measure four points in time for both tasks: Right before the test start (Pre-00), After finishing the test (Post-00), 10 min (Post-10) and 20 min (Post-20) after the test finishes.
2.6. Subjective Feedback
After every phase of the aforementioned
n-back tests and drive scenarios, we ask the subject to self-evaluate and report the effort required to complete the given task. These subjective measures often vary. However, to a certain degree the self-reported ratings can reliably determine the CL put on a certain task [
14,
17,
66]. In this work, we use the NASA-TLX, a well-established tool to analyze CL on a multidimensional, weighted scale [
16]. We kept the dimensions as described by Hart [
17]: mental, physical and temporal demand, performance, effort and frustration. The dimensions and associated questions were translated into German. Each dimension is also accompanied by a weighting factor through pairwise comparisons regarding their perceived importance. The final score is computed by a summation of the scores on each dimension times the corresponding weights (the number of times it was rated more important). The NASA-TLX score is then scaled to be between 0 and 100. In addition to the weighted version, we report the NASA-Raw Task Load Index (RTLX) without applying the weights. The overall score is computed using the average of all scores [
15]. We collect three ratings for our single
n-back test, three ratings for our dual workload
n-back test and three ratings for our driving experiments. In addition, we evaluate perceived stress over the last month and therefore set a baseline for our evaluations. We utilized the Perceived Stress Scale (PSS) by Cohen et al. [
67] to enable respondents to indicate how stressful their life is. Analog to the work by Cohen et al. [
67] the 5-scale ratings (from “Never” to “Very Often”) are computed by summing scores of all items (including inversion for some questions). The respondents were able to express their positive and negative affect after the driving phase and the
n-back test. Utilizing a 5-scale Positive and Negative Affect Schedule (PANAS) introduced in work by Watson et al. [
68] with 10 positive feelings and 10 negative feelings, we report the affective state of the corresponding subject. The evaluation of affective states was conducted after both phases of this study. As PSS and PANAS questionnaires are used to measure a baseline stress level and affective states, but are not directly relate to specific phases of our experiment, we report the result in
Appendix E.
2.7. Performance
Performance is commonly used to measure cognitive load as introduced in
Section 1. Metrics to measure performance are highly task-dependent: We collect true positives (correct button pressed,
), false positives (no event occurred, but the button is pressed,
) and false negatives (the event occurred, but no input was recorded,
) as well as reaction time for true positives. Both, for our
n-back test, and our
k-drive test, the maximal time between the beginning of an event and the time when the user could react to this event was set to 3 s. Similar to the nomenclature used in classification tasks we compute and report recall, precision and
-score. For this experiment we use:
The same metrics are also computed for the secondary auditive n-back task. For the secondary tasks during levels 2 and 3 of k-drive we only collect the correctly added songs to the playlist (false positives are not recorded) and report only our recall-motivated performance metric.
2.8. Physiological Features
For data acquisition, we used a Biopac MP160 system and specialized Biopac modules ECG100C, EGG100C, EMG100C, EDA100C, PPG100C, RSP100C and SKT100C for the corresponding modalities. We used a sampling frequency of 2000 Hz for all modalities, as storage was not an issue in this simulator setting and the analog synchronization across multiple devices, modalities and time stamps is ensured to be consistent. For ECG recordings, we use the Einthoven, Lead I and Lead II with a limp sensor placed below the shoulder and lower torso using Ag-AgCl electrodes (torso limp positions: right arm, left arm, left leg and right leg as neutral). The skin was prepared with an isopropyl solution. The surface EMG was recorded to capture the activation of the trapezius muscle using three electrodes. The reference electrode is placed on the seventh cervical vertebra (C7), and the other two electrodes for measuring the activation are placed at the right lateral trapezius muscle. The EDA electrodes were placed on the palmar side of the index and middle fingers (digitus manus 2 and 3) at the medial phalanges. To compensate for changes in conductance at the beginning of the recording, the placement of the electrodes was done at least 10 min before the recording started. For skin preparation, only warm water was used. The PPG signal was measured on the tip of the middle finger (digitus manus 3). Skin Temperature (SKT) was measured using a sensor placed on the tip of the index finger (digitus manus 2). All, EDA, PPG and SKT were measured on the non-dominant hand, which was placed on the leg and could rest without movement as no interaction was required. Respiration cycles were recorded using the BIOPAC MP3X respiratory effort transducer, measuring the change in thoracic circumference. During the early stages of our experimentation development, we recorded electroencephalographic recordings using a Mobita ConfiCab with 32 channels. We stopped the acquisition of these recordings during this experiment, as some subjects, reported headaches after the long duration of wearing the electrode cap.
We opted to extract features based on statistical signal properties and medical expert features for all biosignal modalities. Features extracted from electrocardiography recordings, reflecting the electrical activity of the human heart, are, except the heart rate itself, based on the concept of Heart Rate Variability (HRV). The HRV is impacted by modulations of biochemical processes, that correspond to the activation of the parasympathetic and sympathetic nervous systems. In addition to recordings of the electrical activity of the heart, we measure the mechanical activity using PPG sensors. Studies have extracted features based on the variability of the pulse waves, so call Pulse Rate Variability (PRV) features. In this publication, we are not interested in the estimation and computation of PRV features, because they have a strong correlation with HRV features, but are more sensitive to movement artifacts in our acquisition setup [
69]. Recording PPG features as part of this database is still a valuable addition, as this modality enables the study of early fusion techniques reflecting measures like Pulse-Transit Time (PTT) [
70] or detecting cognitive load using only wearable devices, sensing the activity of the heart using pulse waves in the extremities in the future. Based on Pham et al. [
71], we solely use features reflecting the activity of the human heart on rhythmic scales and use the R-peaks for stable detection [
72]. Our features are based on state-of-the-art techniques from the literature analyzing affective states, cognitive load, stress [
33] and other biopsychosocial states. Our features are described in
Table 1 and are among other techniques computed using time-based (RMSSD, SDNN, etc.) or frequency-based (HF, LF, etc.) methods. Another physiological response triggered by the Sympathetic Nervous System (SNS) is the activation of sweat glands. This electrodermal activity can be measured on the skin surface through conductance changes, that are caused by sweat and ionic permeability changes in and on the skin surface [
73]. Current literature decomposes EDA signals into phasic and tonic components for the analysis of psycho-physiological responses [
74]. We capture the tonic activation by computing the change in Skin Conductance Level (SCL) within a given interval and extract features of the faster-changing phasic component also interval-related by measuring Skin Conductance Response (SCR) and do not conduct any direct-stimuli related analysis of SCR events for our level-based experimentation setup. Both SCL and SCR based features are shown in
Table 1. Past studies have also found a correlation between the activation of trapezius muscle activity using EMG recordings and cognitive load [
75,
76]. We have computed features based on the overall activity within a timeframe, e.g., by computing the root-mean-square of the preprocessed signal within a given interval, as well as features based on task-specific changes, such as the number of activations within that interval. To extract information from varying skin temperatures, that are associated with the cognitive load, we extract standard statistical features such as an increase or a decrease in temperature within a time window or mean and standard deviation and follow the methodology used in past studies, that found a correlation for both stress [
33] and cognitive load [
56]. We extract respiration features from our effort transducer values, by detecting lows (exhalation) and highs (inhalations) and use the amplitude difference between inhalation and exhalation, as well as the mean and standard deviation of respiration rates within a fixed window, as a measure for cognitive load [
77]. All features used in this publication, are provided in
Table 1. We compute all features with a rolling window with a predefined window size
W.
2.9. Eye Tracking Features
Many studies have shown the relevance of eye-related characteristics for the prediction of a person’s cognitive state [
85]. For eye tracking, we utilize the Tobii Pro Fusion (Tobii Pro Fusion I5S, Tobii AB, Karlsrovägen 2D, S-182 53 Danderyd, Sweden) eye tracker, a stereoscopic system with two eye-tracking cameras for the left and right eye, respectively, that records the subject’s eye movements and pupil size at a sampling rate of 250 Hz. We use the PyGaze library [
86] to extract fixations (the activity of an eye looking at the same region for a certain duration), saccades (rapid eye movements between fixations), and blinks (defined by the absence of the signal for a certain time) from the acquired eye-tracking data. The fixation detection is based on a dispersion-duration method: if the dispersion of gaze data on the screen is below a certain threshold and has a duration of at least 100 ms, the data is considered a fixation. We select the dispersion threshold within an exploratory analysis as suggested by Salvucci et al. [
87]. The duration threshold of 100 ms is a common choice [
87,
88,
89]. Following Negi et al., we calculate fixations of three non-overlapping temporal ranges: 66–150 ms (short ambient), 300–500 ms (longer focal), and above 1000 ms (very long). This distinction allows us to gain additional insights into an individual’s conscious perception of objects [
90]. Despite the strong dependence between pupil dilation and light reflexes, pupil size can provide information about the commitment of greater effort and the expectation of a difficult task [
91,
92]. High-frequency oscillations, also called hippus, can also indicate increased cognitive load [
93].
In accordance with the literature, we extract multiple features based on fixations, saccades, blinks, and pupil dilation. An overview can be found in
Table 2. For a window length
W we extract the number and duration of fixations, saccades, and blinks as well as the mean saccade amplitude, thus the mean distance for a saccadic movement. As pupil-related features, we select the mean pupil size and two other features that take pupil change into account. To calculate the index of pupillary activity (IPA) we follow [
93,
94].
2.10. Videos
One of many indices in this study is the analysis of facial cues. These facial cues are sometimes closely related to messages, that express emotion, such as anger, fear, disgust, happiness, sadness or surprise. As we are highly interested in such behavioral expressions and their relationship to cognitive load, we record the subject’s face during the complete experiment. A BASLER acA1920 155 μm (Basler AG, An der Strusbek 60–62, 22926 Ahrensburg, Germany) camera was used to record a video stream with a resolution of 1920 × 1080 at 25 frames per second, which was triggered using the BIOPAC analog output, to ensure a fully synchronized recording. Depending on the position of the subject, we extracted 1024 × 1024 pixels as a region of interest and resampled it to a 512 × 512 frame. For action unit extraction we used the SVM model developed by Cheong et al. [
95], using Deng et al. [
96] as face detection model, Albiero et al. Img2Pose [
97] as pose correction model and Chen et al. MobileFaceNets [
98] to extracted landmarks. To mitigate effects, such as many-to-one correspondences of certain behaviors and emotions, or varying interpretations across subjects, we opted to use a sign-judgment-based action unit system instead. The Facial Action Coding System (FACS) system, introduced by Ekman and Friesen [
99] and improved by Ekman and Rosenberg [
100] specifies different action units. Martinez et al. present the current state of research and its application [
101], while predicting cognitive load using visual facial cues has been studied in Li and Busso [
102], Yuce et al. [
29] and Viegas et al. [
28], on which we base our decision to extract the action units presented in
Table 3. For our statistical analysis and machine learning experiments, we count the frames with active actions unit within the given window and denote the number of action units similar to our physiological features with # as count.
2.11. Preprocessing, Artifacts and Data Collection
The recording of biosignals is prone to various artifacts, while we designed our recording environment with great care, in some situations it is not evitable that artifacts degrade signal quality. Due to the complex nature of our environment, we were not able to prevent 50 Hz power line noise and removed this frequency component, if applicable, and all higher harmonics from the recorded signals using a notch filter. For our ECG feature extraction pipeline it is crucial to detect the R-peaks with high sensitivity and specificity. To ensure only sequences with sufficient quality are used during evaluation, we have computed Signal Quality Index (SQI)’s based on work by Zaho and Zhang of both leads and selected the lead with better SQI’s or if both leads are corrupted, we exclude those intervals from the evaluation [
104]. For video, we removed frames from evaluation if the subject’s head moved outside the recording region. For eye tracker measurements we removed samples with a Tobii Fusion Pro system code indicating the detection of both eyes. For all other modalities, our artifact rejection was integrated by information from the examiner that noted events to the protocol during acquisition. These time intervals were manually removed. Otherwise, we computed features over a two-minute rolling window with a step size of five seconds of our continuous signal. We employed subject-wise z-score normalization (subtracted mean and scaled to standard deviation) using every feature computed within the complete phase of our
k-drive and
n-back test, including baselines, training and testing phases. For statistical evaluation and machine learning, we used the window that was in the center of the respective phase described in
Section 2.3 and
Section 2.4 and removed outliers using the Median Absolute Deviation (MAD)-rule [
105].
To summarize our feature-extraction and preprocessing protocol, for all records used in our statistical evaluation and machine learning pipeline, we start by rejecting artifacts as described above in this section and exclude corrupted parts of the signal. If the examiner reported recording issues during acquisition (e.g., ECG lead fall-off), we removed the corrupted parts from the sequence. Given the recorded, fully synchronized trigger signals, we define the windows of the baselines and levels. Following that, we computed all features for each modality using a rolling window over the complete experiments of
n-back and
k-drive and normalize the extracted trials using subject-wise z-score normalization. We used the MAD-rule to remove outliers of our features. When working with combinations of multiple features, we drop the complete instance (feature vector) that contains a missing value from our dataset and therefore out machine learning experiments. We do not employ any imputation technique, for missing data, but remove the entire sample that contains a missing feature value. We report the percentages of available records after these steps in
Appendix H for reference.
2.12. Statistical Evaluation
To analyze the effect of different experimentation levels (factors), on our extracted expert features (values) we conduct a one-way Analysis of Variance (ANOVA) for repeated measurements, observing if there are significant changes. We determine if the data is distributed normally, using a Shapiro–Wilk test. If the criterion of normality for ANOVA is not met, we conduct a non-parametric Friedman test as omnibus test instead. The assumption of sphericity was controlled by a Mauchly’s test. Whenever necessary, we employ a Greenhouse-Geisser correction. As we conduct multiple comparisons we adjust our
p-values using Holm–Bonferroni correction for our experiments (
k-drive and
n-back) separately. For features that changed significantly according to our repeated measures ANOVA, we conducted post hoc-tests. If the post hoc-test results show a
p-value below our level of significance
we report if the mean value is increasing or decreasing for that specific feature. If the conditions for normality are met, we use a two-sided paired t-test, otherwise, we use the non-parametric Wilcoxon test as a post hoc-test. These tests are executed for our features described in
Section 2.8,
Section 2.9 and
Section 2.10.
2.13. Classification Tasks and Evaluation Protocol
Autonomous Driving Cognitive Load Assessment Database (ADABase) was recorded to study subjects under different levels of cognitive load while observing an autonomously driving vehicle, using multi-modal representations of physiological-, behavioral-, subjective- and performance-based measurements. We create various downstream tasks for classification and regression. As a first task, we separate our recording into two levels of cognitive load:
A Low Load Class, without any task or undemanding tasks imposed on the subject.
A High Load Class with tasks of high demand introducing high cognitive load.
Using this setup we evaluate three different experiments: For the visual-only n-back task we select the observation-only-baseline and the 1-back level as low load class and the 2-back and 3-back levels as high load class. The same phases are used for audiovisual classification. For complete n-back classification we used both baselines (resting and no-task observation), 1-back visual-only, 1-back audiovisual testing phase as low load class and 2-back and 3-back visual-only and audiovisual for high load. Using this classification scheme has several advantages of having a balanced class distribution, being able to evaluate single-only and dual-only vs. single-and-dual task loads, and capturing different levels of the load imposed by the given tasks. We propose to use this labeling scheme for k-drive, too. For our low load class, we use the baseline with an observation-only driving example as low load class and 1-drive as high load class. For our dual-task-load classification of k-drive, we use the baseline with observation-only driving and the baseline with secondary-task observation only as low load and 2 and 3-drive dual task as high load. We also train a classifier on the combination of n-back and k-drive schemes, leading to a single-task, dual-task and a combination of both binary classifications. It is important to note that these classification groups have been carefully selected to include similar tasks (e.g., only observation of n-back tests in baseline instead of simple rest periods) to mitigate the effects of distribution shifts, like not looking to the monitor or infotainment system and light patterns that influence the pupil dilation.
In addition to this very coarse-grained experiment of low vs. high load [
48], we create an experiment with three classification levels, low-load, medium-load and high-load. We do not differentiate between a single and a dual classification task but study the combination of both tasks for
n-back and
k-drive. For
k-drive, we use the observing-only-baseline and 1-drive for low load, 2-drive for medium load and 3-drive for high load. For
n-back we use the observation-only baseline and visual-only 1-back as low load, 2-back visual only and 1-back dual task for medium workload and 3-back visual-only and 2-back and 3-back audiovisual for high load. It is noteworthy that the records collected during the specific phases, using these splits are not equally distributed.
We propose several targets for our regression tasks. The first task is to use performance metrics only, averaging a score based on the recall of the primary task (scaled between 0 and 1, where 0 is the best score (highest recall) and 1 is the worst of the complete study population) and the reaction time of the primary task (scaled to be between 0 and 1, where 0 is an instant reaction and 1 is a reaction within 3 s as the maximal possible reaction time). As a second target, we use the NASA-RTLX score, scaled between 0 and 1, where 1 is the highest task load reported by the specific subject and 0 is the lowest reported task load of that subject. We drop all baselines from this dataset. For our third task, we compute the average of both targets and therefore use performance and subjective rating as a continuous target between 0 and 1 for our regression algorithms.
For evaluation, we conduct several experiments. We group our features modality-wise and train a classifier using the binary-task-classification to train and evaluate classifiers for all sub-tasks: single-
n-back, dual-
n-back, single-
k-drive, dual-
k-drive the combinations of both, single and dual-task load, and both experiments,
n-back and
k-drive. Using this experimentation schedule we can as an extension to our statistical evaluation in
Section 2.12 determine the predictive power of unimodal and multimodal models.
2.14. Machine Learning Algorithms and Training
Past studies in the affective sensing multimodal human sensing community have shown promising results using eXtreme Gradient Boosting (XGBoost) as a machine learning technique for classification [
106]. We follow their finding of using XGBoost and verify this approach, by training and evaluating a Support Vector Machine (SVM) with a linear and a radial kernel, as well as a k-Nearest-Neighbors (kNN) classifier using data from our experiment. To prevent data leakage in our machine learning pipeline, we use nested k-fold cross-validation with 10 inner folds as the validation set and 10 outer folds as the testing set [
107], taking bias and variance of our models into account [
108] and therefore provide reliable results. The data is split subject-wise. For our binary-classification task, we report Area Under the Receiver Operating Characteristic Curve (AUC) and F1-score. For our three-level classification task, we provide a confusion matrix. The predictive power of our regression task is expressed as
and Mean Squared Error (MSE). For hyperparameter optimization, we run a tree-structured parzen estimator on the validation of every inner fold [
109] and optimize for maximal AUC for our classification tasks and maximize
for our regression task. We optimize for the number of estimators, depth, lambda and learning rate for XGBoost, gamma and C for radial basis SVM, C for linear SVM and neighbors and weight function for kNN. As input for our classification, we use the same windows used for our statistical tests, described in
Section 2.12 and
Section 2.11. For training, validation and testing we use feature windows only recorded within the phases described in
Section 2.13. In addition to our experiment, using different groups of unimodal and multimodal inputs, we report the feature importance of our XGBoost classifier to explain our model behavior. We use gain, weight and coverage for every feature and report the importance of the top-5 features for every modality.
4. Discussion
The presented results compiled in the previous chapter of this study provide a valuable addition to the research community assessing the effect of cognitive load using multimodal measurements.
With a carefully designed study population and a detailed cohort description, we conducted two experiments with various levels of cognitive load. As a reference experiment, that is comparable to experiments on cognitive load in related work, we asked the subjects to participate in a single- and dual-task load n-back test with visual-only stimuli and audiovisual stimuli inducing cognitive load. As an application-motivated test, we developed the k-drive test, which is inspired by the observations of semi-autonomously driving cars with only a few driver-car interactions required. This test imposes cognitive load by an increasing number of events the subject needs to respond to. In addition, a secondary task of interacting with a car infotainment system needs to be executed for dual-task load tests.
Our study compiled a recording setup for multiple modalities. Our
physiological measurements include biosignals such as ECG, PPG, EDA, EMG, skin temperature and respiration recordings as well as eye tracker data. We found significant changes in established expert and statistical features during both,
n-back and
k-drive, which revealed an increasing heart rate, decreasing heart rate variability, an increasing number of peaks in the electrodermal activity, a decreasing mean skin temperature, a decreasing respiration rate and an increasing eye tracker IPA during cognitive load compared to non-load baselines, to name only a few. Our findings of a positive correlation between IPA and cognitive load align with previous research that has reported promising results using IPA in cognitive load measurement [
93,
110,
111]. Additionally, our omnibus test has shown the statistical significance of fixation features which also prove to be relevant in cognitive load prediction. This finding complies with literature [
30,
85,
112,
113,
114] In addition, we recorded
behavioral measurements based on facial videos. Using simple features based on the number of activated action units within a certain time frame, we found several action units that changed significantly for increasing levels of task demand of
n-back and
k-drive levels. These observations are supported by the findings of Yuce et al. who analyzed the link between action units and cognitive load while driving [
29]. We measured several
performance metrics for all conducted
n-back and
k-drive tests and levels for both secondary and primary task loads, including precision and recall. In combination with the
subjective feedback, acquired through NASA-TLX questionnaires following every test, we found properties of human responses, that are statistically significant across all analyzed dimensions:
physiological,
behavioral,
performance and
subjective measurements. Comparing our collected dataset with work analyzed by a recent review of related data collections by Seitz et al., confirms the validity of our multimodal approach for the computerized detection of cognitive load, differentiating our setup with a combination of multiple modalities, that all have been used in subsets, but not as a combination during the same protocol [
115]. The review of Seitz et al. further helps to highlight our contributions, as we provide multiple potential targets for model training and evaluation: subjective ratings, performance-based measurements and task-specific level information, which all have been studied independently in related work and are presented as alternatives in this work [
115].
Starting with a unimodal input we train several machine learning models and present the predictive power of each biosignal modality, eye tracker data and facial action units separating low and high levels of cognitive load. By combining features of various modalities, we present the predictive power of all biosignals, biosignals and eye tracker data and the combination of eye tracker data, biosignal and action units, leading to an overall AUC, using the complete dataset consisting of collected single- and dual-task load
-back and
-drive test of
. In general, we can observe that combining modalities leads to an improvement in classification accuracy. This is especially evident in the case of using data from both tasks and emphasizes the importance of a multimodal approach, given that other publications report similar results [
116,
117,
118]. In addition, we report the gain feature importance values of our
XGBoost classifier, showing important contributions of features like heart rate, heart rate variability, change of skin conductance within a given time interval, IPA, fixations and saccades of our eye tracker data as features with strong predictive power in our binary low-vs-high cognitive load classification task. During
n-back we were able to control the lighting conditions to be more stable, compared to the application-motivated
k-drive test. This could be a reason, why IPA is the most important feature for the detection of cognitive load for one task while losing importance for the other task. Nonetheless, we found eye-tracking-based features to have a high contribution (see
Appendix G) for the detection of cognitive load in this publication. This finding is in line with work by Ahmed et al. [
119], who observed, that pupil-related features have the highest feature importance in comparison to ECG and respiration for multimodal classification. We evaluate several machine learning techniques using kNN, SVM with linear and radial kernel and find that XGBoost performs best using our complete set of features. We introduced a new task separating three levels of cognitive load: low, medium and high and found a high true positive rate for the detection of tasks that imposed only low loads onto the subject. The separation of levels with medium and high cognitive load leaves room for improvement in future work. It has also been observed in other publications that separation with more than 2 classes is challenging [
56,
117]. One possible reason for this could be a strong inter-subject variability, making fine-grained classification difficult.
In addition to our classification tasks, that separate the different levels of CL imposed onto the subject based on the task difficulty of each level, we introduced a regression task, that used performance metrics, subjective ratings and the linear combination of both measures as targets, resulting in a score of for all levels and tasks. To summarize our work, this work contributes:
The introduction of k-drive, a novel and close-to-real-world autonomous driving task to study cognitive load.
The collection of physiological, behavioral, subjective and performance measurement from 51 subjects while participating in levels of increasing task difficulty with single and dual workload scenarios.
The extraction and evaluation of features from ECG, PPG, EMG, EDA, respiration belt, skin temperature, eye tracker data, facial video recordings using a detailed statistical evaluation protocol.
The validation of the collected data using statistical methods before training and testing of machine learning models.
The training and evaluation of machine learning models using unimodal and multimodal inputs for cognitive load estimation.
The analysis of feature importance for models trained with multiple inputs.
The introduction of novel machine learning tasks and training of baseline models as reference for future contributions by the affective sensing and machine learning community.
Accompanying this publication we release a subset of 30 subjects, containing the recorded and unprocessed sensor data, questionnaires, performance metrics and NASA-TLX scores, enabling the research community to develop and evaluate novel algorithms for cognitive load estimation. We encourage the research community to build novel algorithms and machine-learning methods using the released data.
Our future work will include the analysis of distribution shifts of machine learning models that are trained on one task and evaluated on another task. An important next step before deploying these algorithms in the wild is the analysis of the robustness and stability of fusion techniques for multimodal machine learning when one or more modalities are corrupted or perturbed. In direct line with this work will be the study of models trained in an end-to-end manner such as deep neural networks using the raw input signals for CL prediction. Another important factor is the inclusion of the reported personality traits as input to machine learning models to improve model performances using personalized information. In this publication, we have selected a constant window length of two minutes for all features and all inputs, based on results from literature introduced in
Section 2.8. However, physiological responses manifest themselves on different timescales and the optimization of both latency and window length of all extracted features during or after phases with high CL may further improve the detection rate using computerized machine learning models. Given the precise measurements of time with a resolution of only
ms for events and phases of different levels of CL and the results of this study this is a promising direction that will be explored and described in future work.




 and
and  button to indicate that the autonomously driving car is passing another car (overtaking). In level 2, the subject is additionally asked to indicate that the car is being overtaken, which can be detected by pushing the
button to indicate that the autonomously driving car is passing another car (overtaking). In level 2, the subject is additionally asked to indicate that the car is being overtaken, which can be detected by pushing the  button. For the last level (3), events of high acceleration and deceleration need to be detected by pushing the
button. For the last level (3), events of high acceleration and deceleration need to be detected by pushing the  button. All driving sessions were simulated using the playback of a pre-recorded Assetto Corsa (Assetto Corso v.1.16, https://www.assettocorsa.it/en/, (accessed on 25 November 2022) KUNOS Simulazioni s.r.l., Via Degli Olmetti 39/B, 00060 Formello (RM), Italy) screen capture and were presented on the three lower monitors shown on the left side of Figure 4. During every session, the participant’s car was driving on a racetrack (Assetto Corso Tracks: https://www.assettocorsa.it/tracks/ (accessed on 25 November 2022)), with twelve other cars that followed the road. The selected racetracks contained curvy and straight street segments without two-way traffic to simulate one-way highways. For easier reference, we are using the notation: k-drive, where k indicates the number of actions the user needs to react to and set (Levels/Actions for reference: :
button. All driving sessions were simulated using the playback of a pre-recorded Assetto Corsa (Assetto Corso v.1.16, https://www.assettocorsa.it/en/, (accessed on 25 November 2022) KUNOS Simulazioni s.r.l., Via Degli Olmetti 39/B, 00060 Formello (RM), Italy) screen capture and were presented on the three lower monitors shown on the left side of Figure 4. During every session, the participant’s car was driving on a racetrack (Assetto Corso Tracks: https://www.assettocorsa.it/tracks/ (accessed on 25 November 2022)), with twelve other cars that followed the road. The selected racetracks contained curvy and straight street segments without two-way traffic to simulate one-way highways. For easier reference, we are using the notation: k-drive, where k indicates the number of actions the user needs to react to and set (Levels/Actions for reference: : 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















