
YOLOv5s-FP: A Novel Method for In-Field Pear Detection Using a Transformer Encoder and Multi-Scale Collaboration Perception


 ,
,  ,
,  ,
, 
Abstract
:1. Introduction
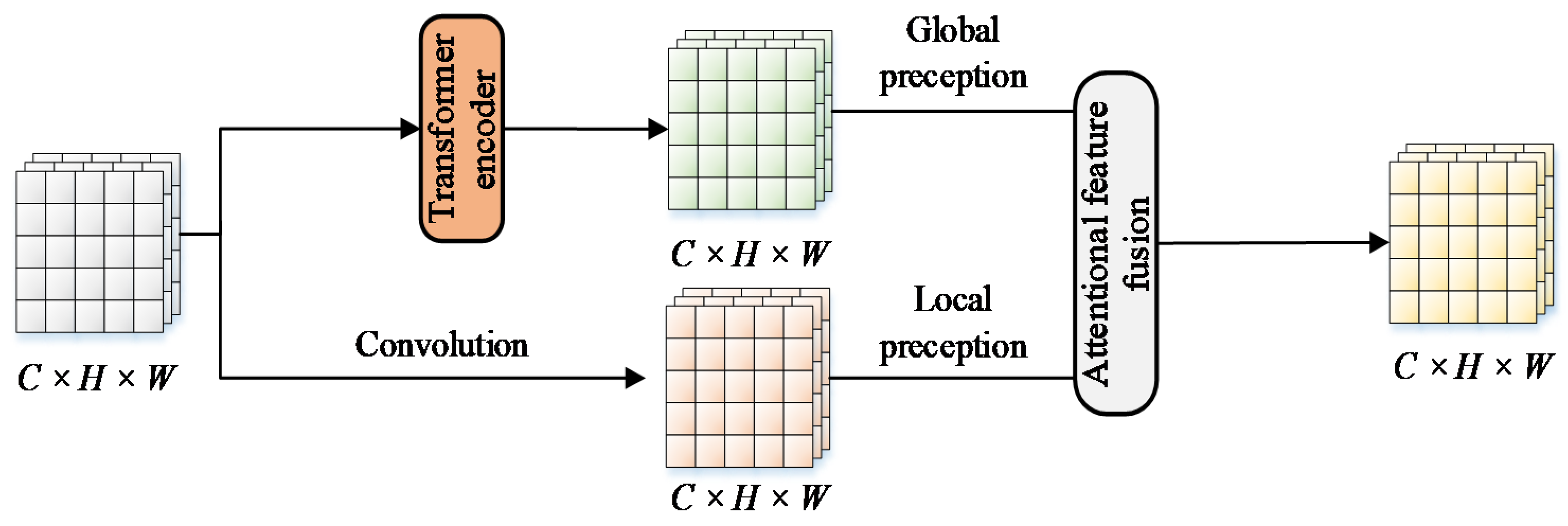
- The original cross-stage-partial module was optimized to extract non-local features through a transformer encoder, which was then fused with local features by an attentional feature fusion mechanism, achieving the mutual embedding of local features and global features.
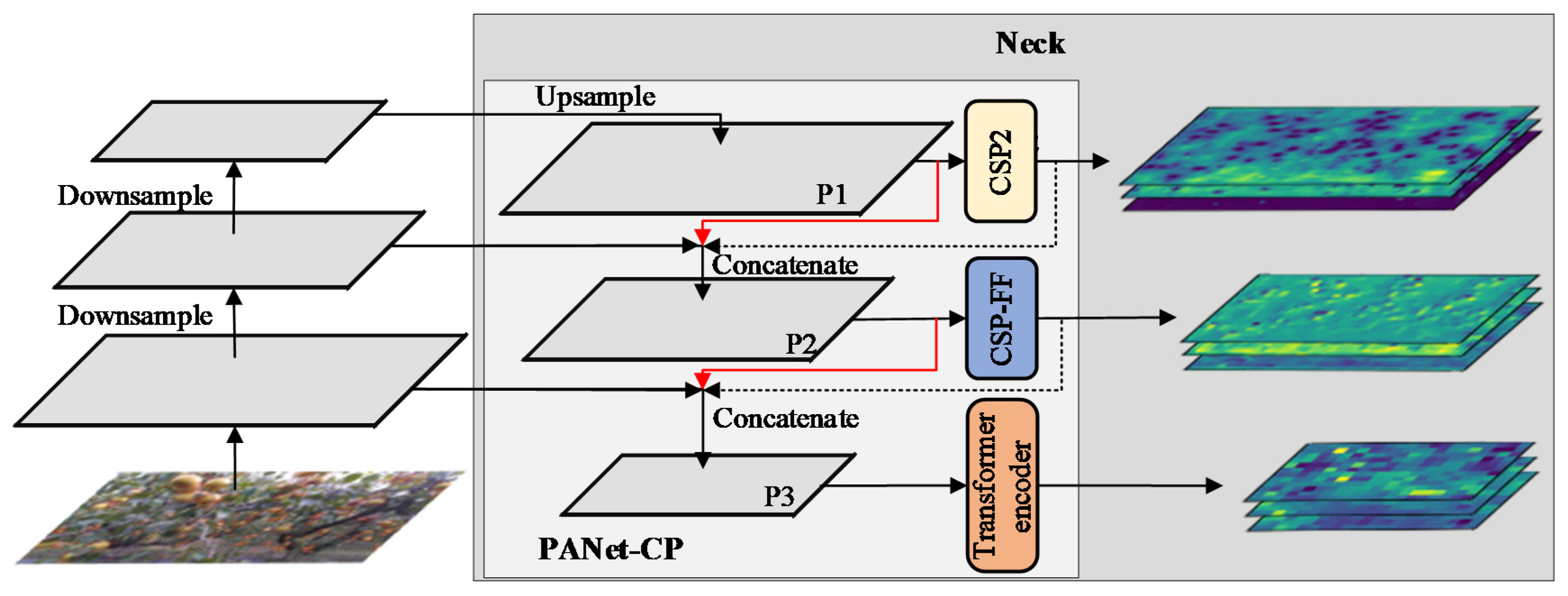
- A modified path aggregation network oriented to collaboration perception of multi-scale features was proposed by incorporating a transformer encoder and the optimized CSP module into the paths, and new skip connections were made to transfer information between paths to enhance information exchange and prevent network degradation [7].
- Quantitative and qualitative controlled experiments were carried out to compare the detection results of pears at a variety of sizes, illuminations, and viewpoints. The experimental results indicated the beneficial impacts of the improved network on pear detection tasks in natural environments, demonstrating the good potential in assisting pear growth monitoring and automatic harvesting.
2. Related Works
3. Materials and Methods
3.1. Datasets
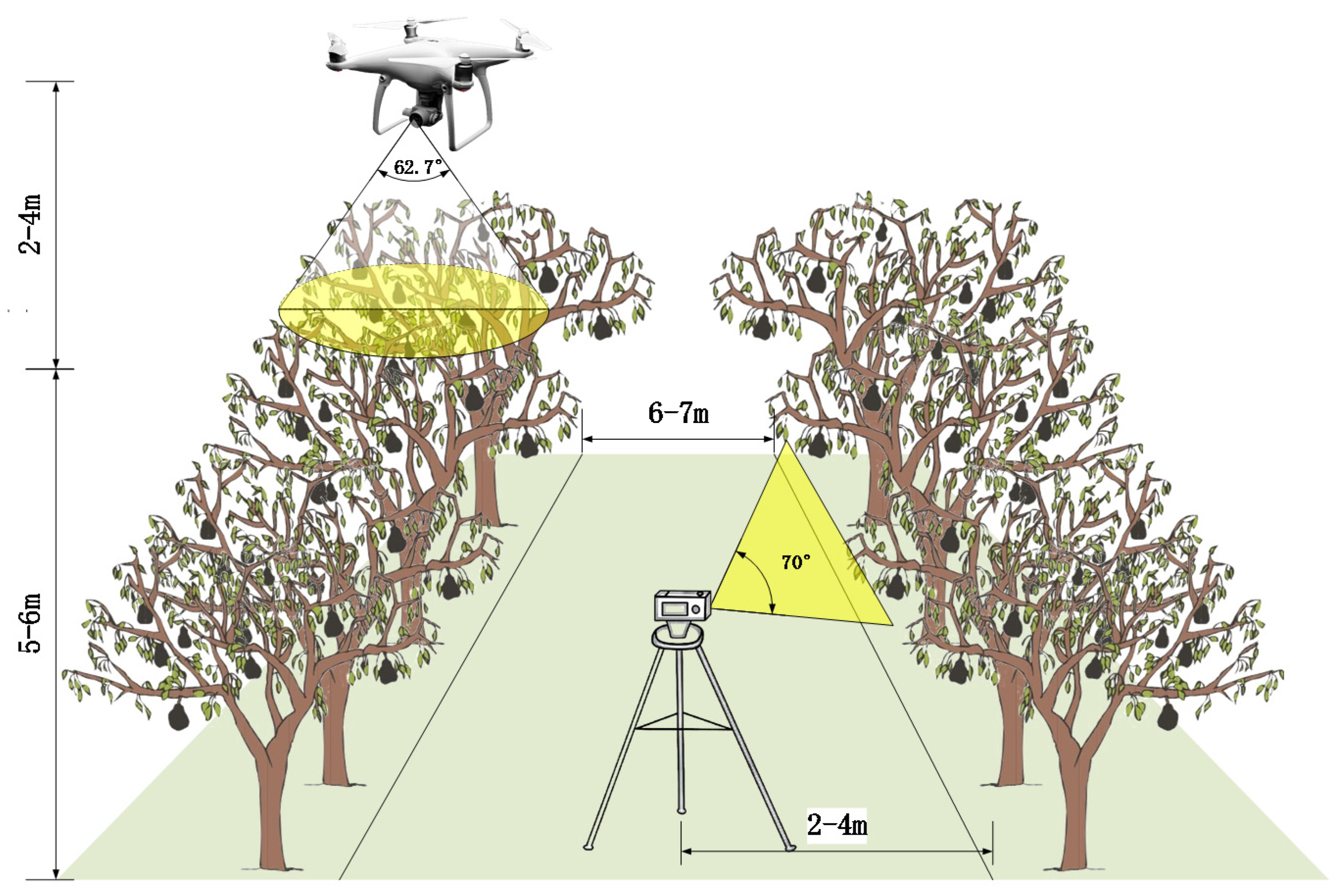
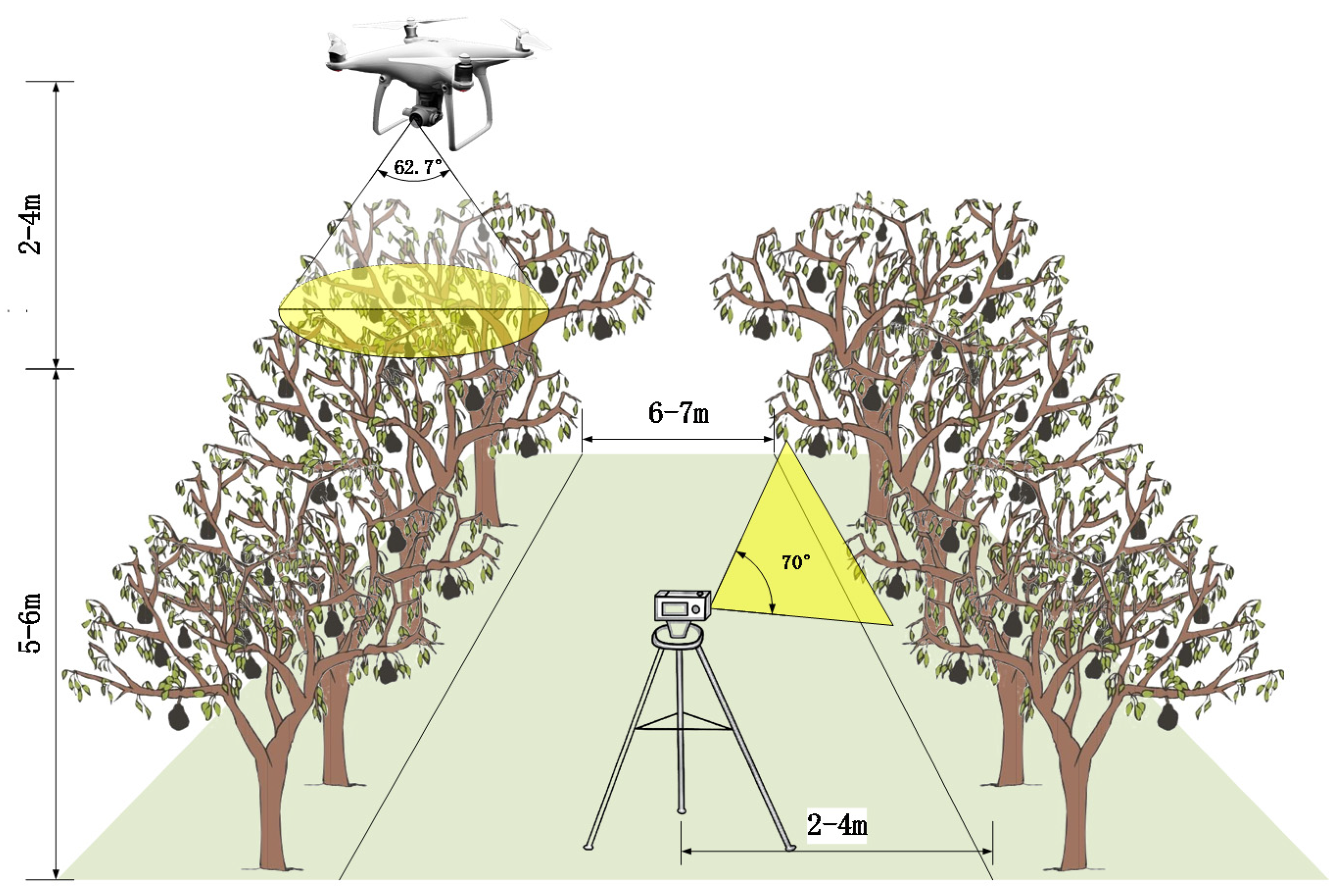
3.1.1. Data Acquisition and Analysis
3.1.2. Image Annotation and Data Enhancement
3.2. The Proposed YOLOv5s Improvement
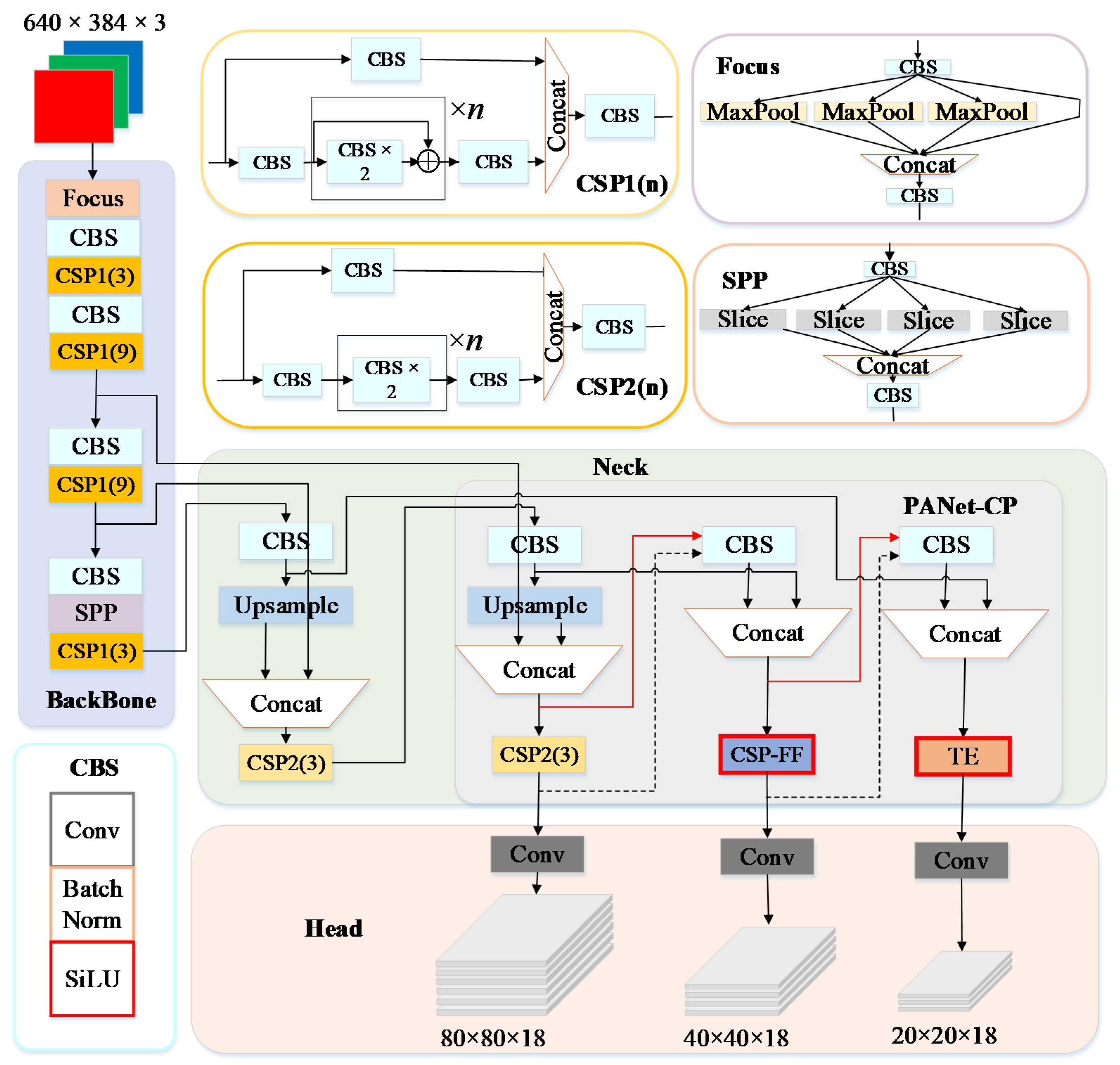
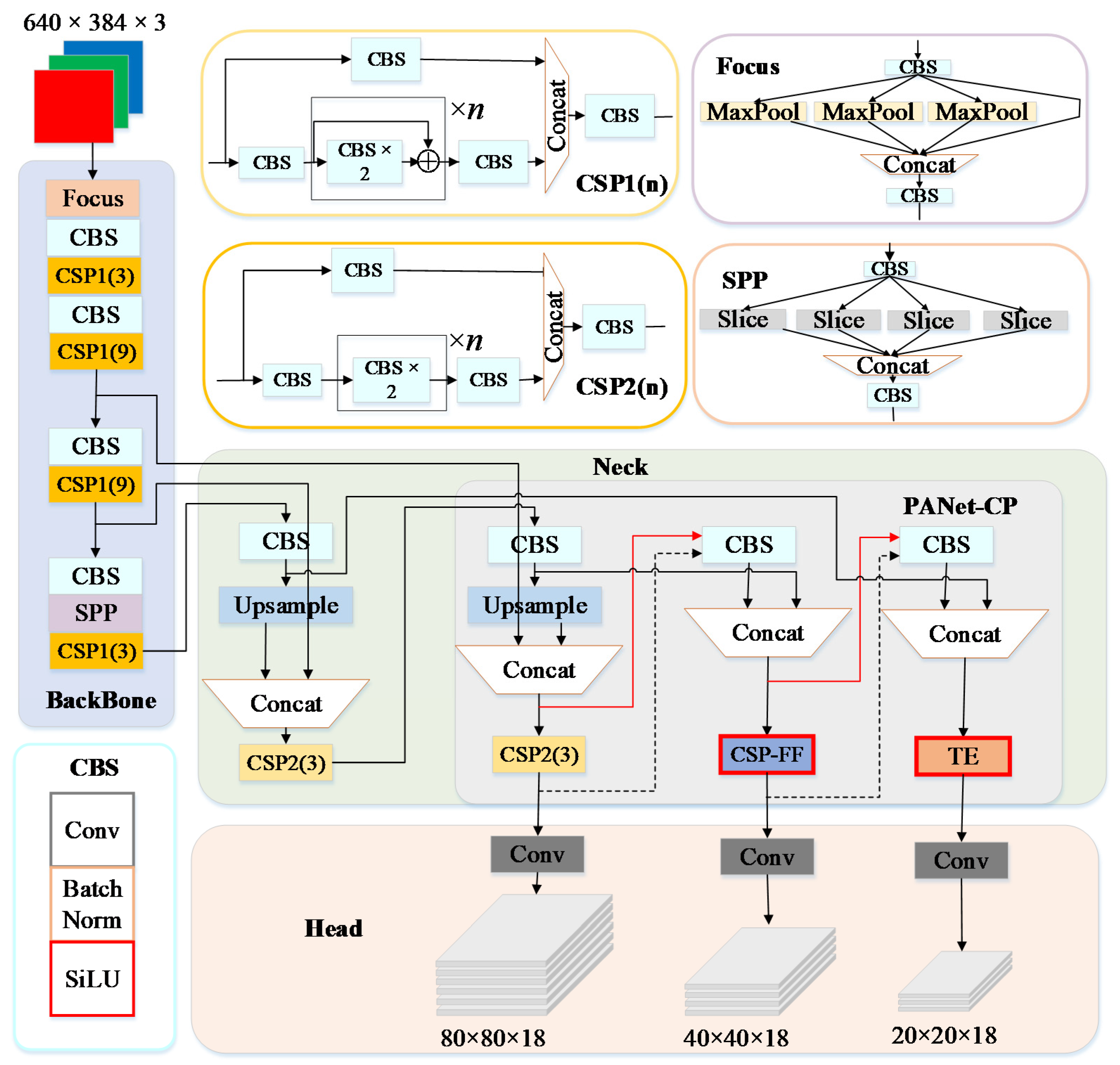
3.2.1. Network Architecture
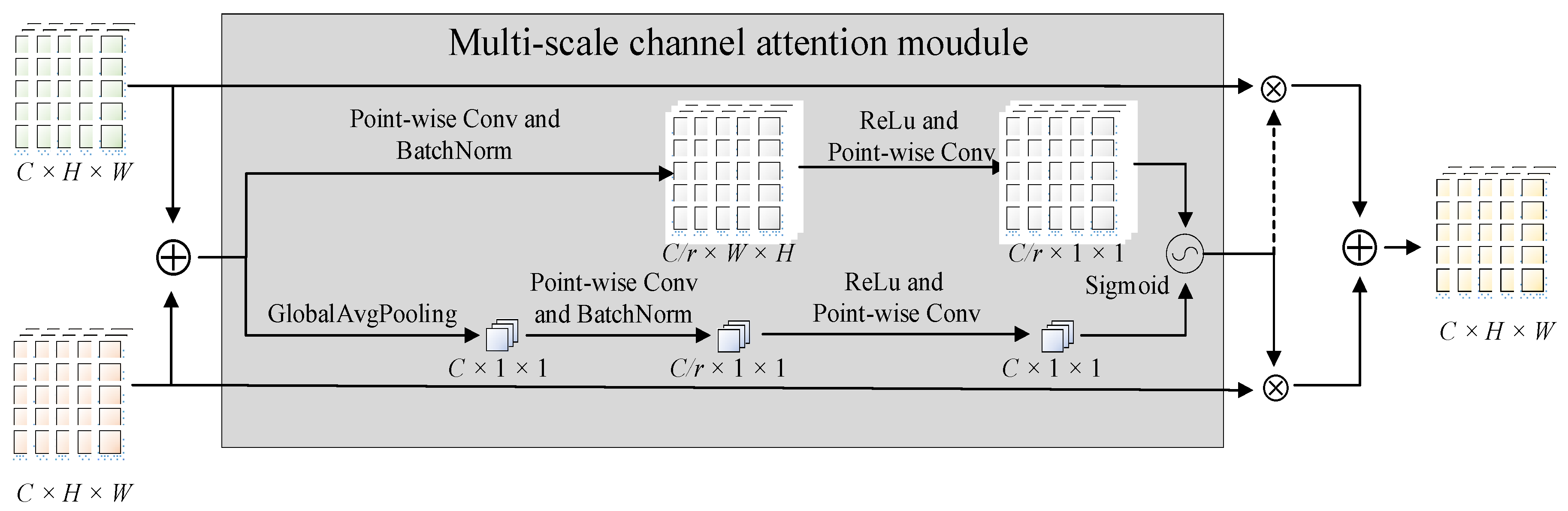
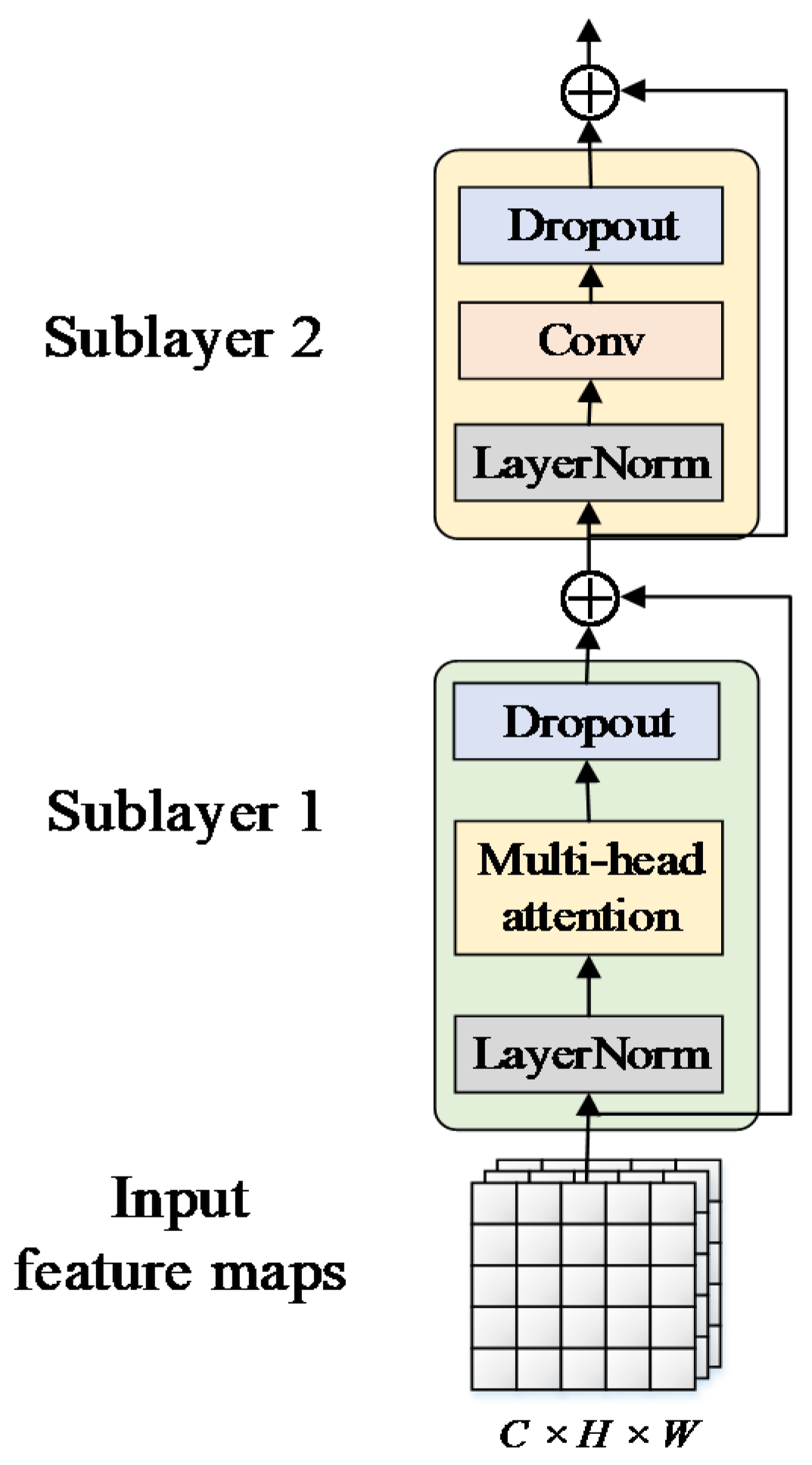
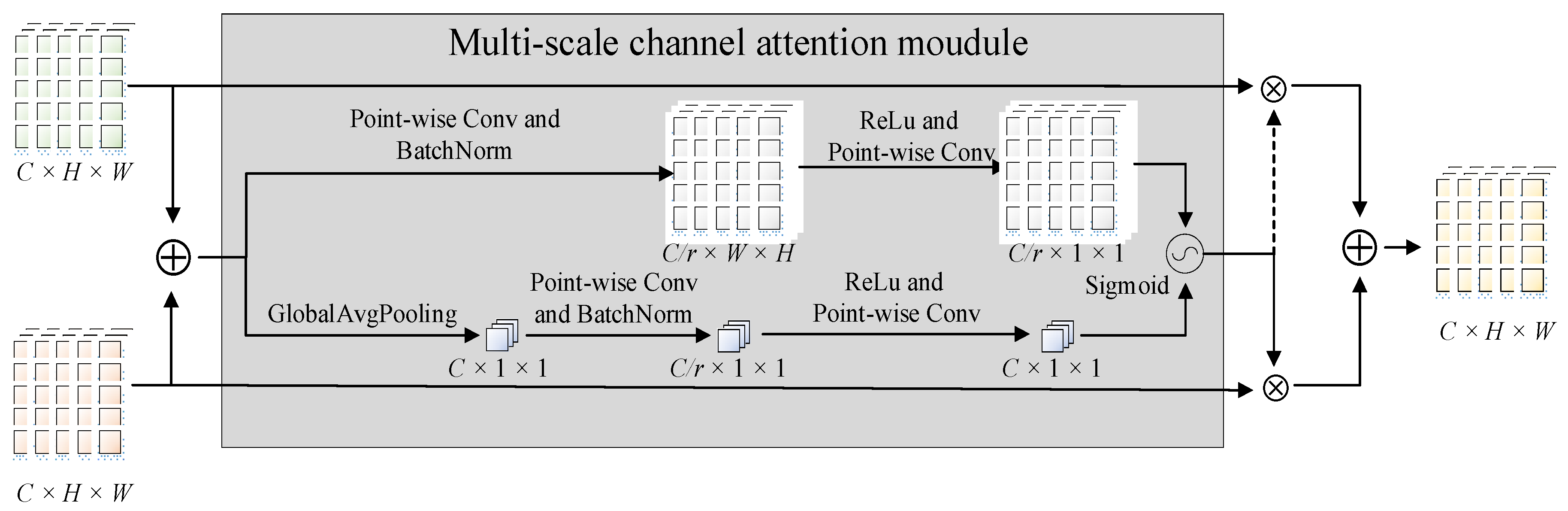
3.2.2. Feature Fusion-Based CSP
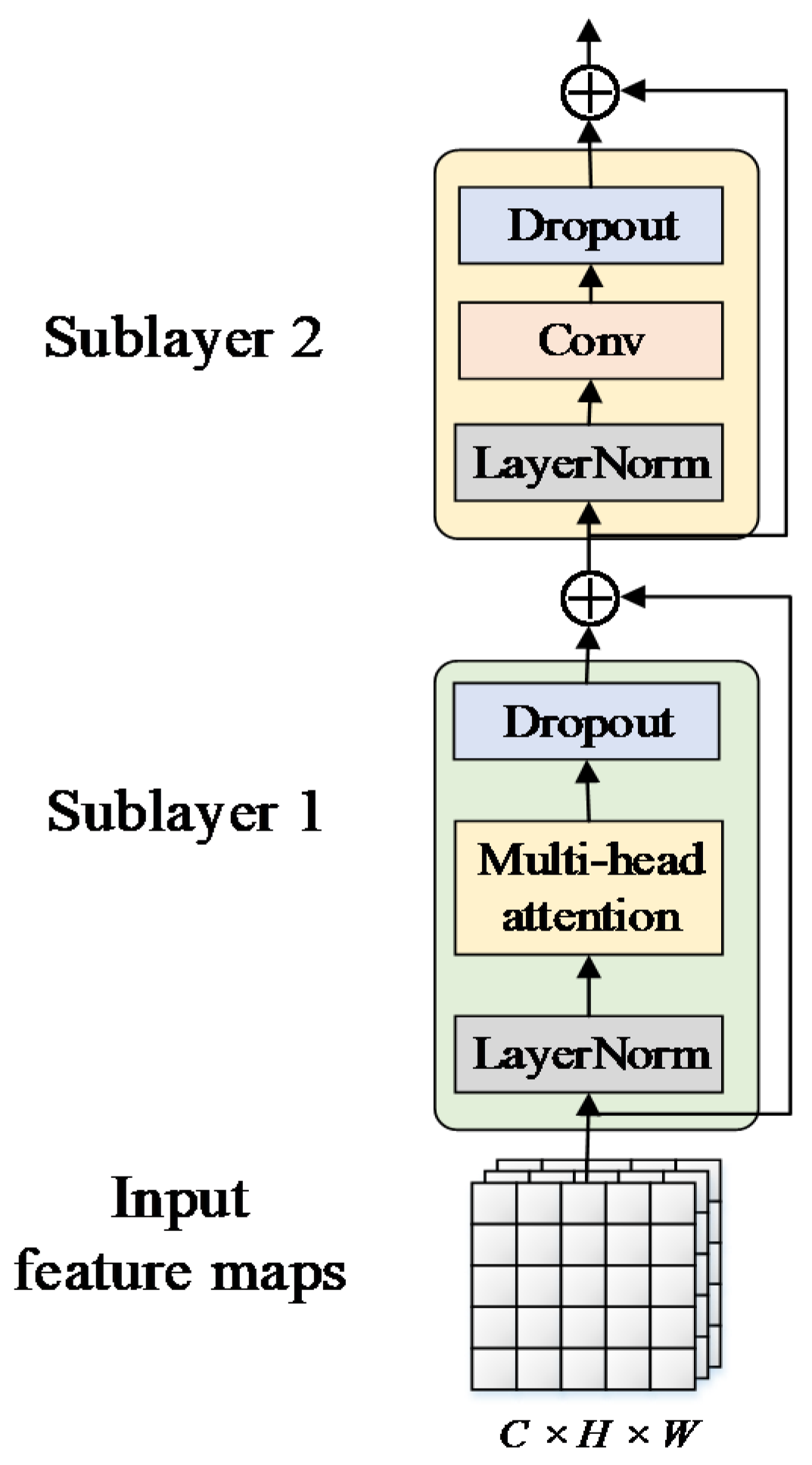
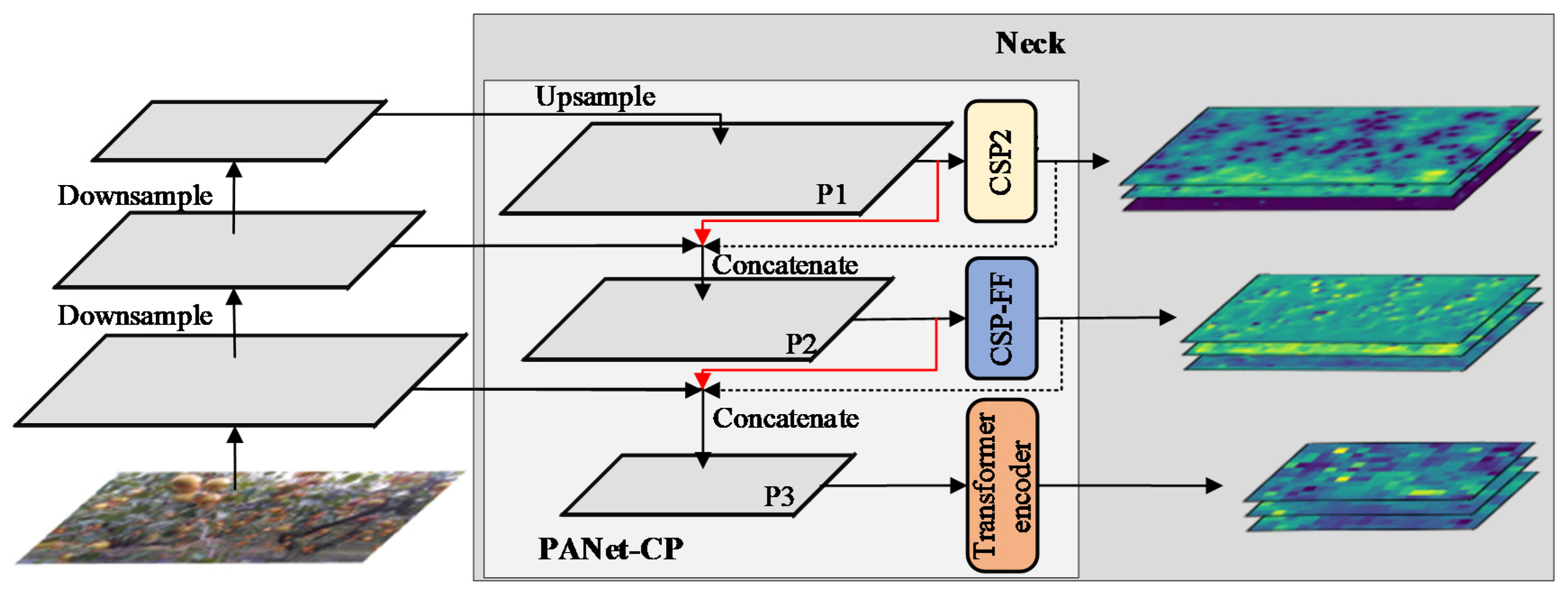
3.2.3. Collaboration Perception-Oriented PANet
4. Experimental Results and Analysis
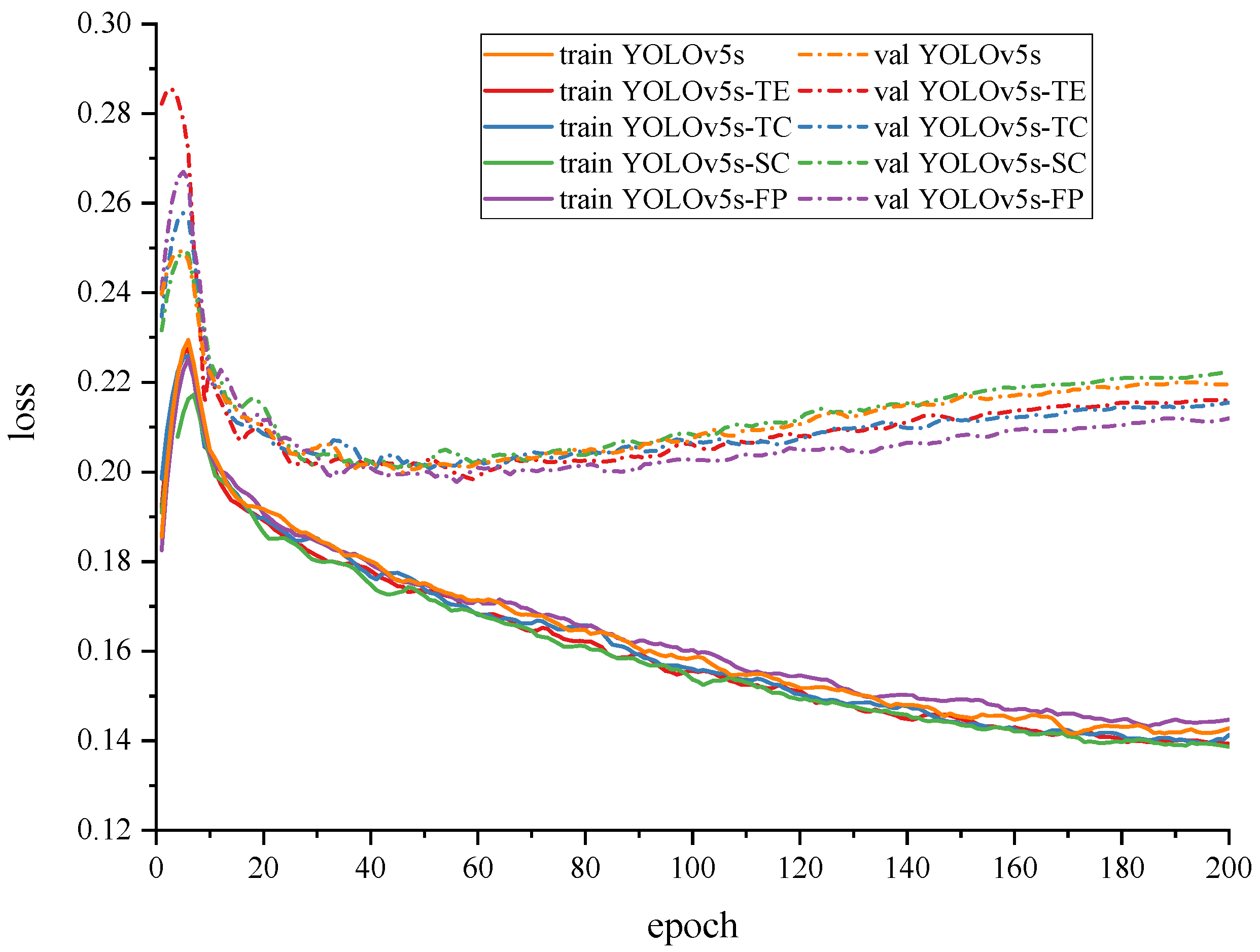
4.1. Network Training
4.2. Network Evaluation
4.3. Quantitative Performance of the YOLOv5s-FP
4.4. Comparison with the YOLO Series Networks
4.5. Ablation Experiments
4.6. Visual Performance Comparison
4.6.1. Comparison of Test Results at Different Pear Sizes
4.6.2. Comparison of Test Results under Different Illumination Conditions
4.6.3. Comparison of Test Results in Different Viewpoints of UAV
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, S.; Xie, Z. Current Status, Trends, Main Problems and the Suggestions on Development of Pear Industry in China. J. Fruit Sci. 2019, 36, 1067–1072. [Google Scholar]
- Yang, W.; Nigon, T.; Hao, Z.; Paiao, G.D.; Fernández, F.G.; Mulla, D.; Yang, C. Estimation of Corn Yield Based on Hyperspectral Imagery and Convolutional Neural Network. Comput. Electron. Agric. 2021, 184, 106092. [Google Scholar] [CrossRef]
- Li, G.; Chen, L.; Zhao, S.; Liu, Y. Efficient Aircraft Object Detection Based on Faster R-CNN in Remote Sensing Images. In Proceedings of the Second International Conference on Digital Signal and Computer Communications (DSCC 2022), SPIE, Changchun, China, 8–10 April 2022; Volume 12306, pp. 198–204. [Google Scholar]
- Sinnetta, A.; Malcolm, B.; Farquharson, R.; Ramilan, T. A Moveable Harvest: An Investigation into Using Mobile Platforms for Picking Apples. Aust. Farm Bus. Manag. J. 2020, 17, 1–19. [Google Scholar]
- Lombard, W.A. Labour Trends and Mechanisation: The Productivity Sum. FarmBiz 2019, 5, 7–9. [Google Scholar]
- Yan, Q.; Yang, B.; Wang, W.; Wang, B.; Chen, P.; Zhang, J. Apple Leaf Diseases Recognition Based on an Improved Convolutional Neural Network. Sensors 2020, 20, 3535. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Dai, Q.; Cheng, X.; Qiao, Y.; Zhang, Y. Agricultural Pest Super-Resolution and Identification with Attention Enhanced Residual and Dense Fusion Generative and Adversarial Network. IEEE Access 2020, 8, 81943–81959. [Google Scholar] [CrossRef]
- Zhang, W.; Ma, H.; Li, X.; Liu, X.; Jiao, J.; Zhang, P.; Gu, L.; Wang, Q.; Bao, W.; Cao, S. Imperfect Wheat Grain Recognition Combined with an Attention Mechanism and Residual Network. Appl. Sci. 2021, 11, 5139. [Google Scholar] [CrossRef]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using Channel Pruning-Based YOLO v4 Deep Learning Algorithm for the Real-Time and Accurate Detection of Apple Flowers in Natural Environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Li, Z.; Li, Y.; Yang, Y.; Guo, R.; Yang, J.; Yue, J.; Wang, Y. A High-Precision Detection Method of Hydroponic Lettuce Seedlings Status Based on Improved Faster RCNN. Comput. Electron. Agric. 2021, 182, 106054. [Google Scholar] [CrossRef]
- Xu, W.; Thomasson, J.A.; Su, Q.; Ji, C.; Shi, Y.; Zhou, J.; Chen, H. A Segmentation Algorithm Incorporating Superpixel Block and Holistically Nested Edge for Sugarcane Aphids Images under Natural Light Conditions. Biosyst. Eng. 2022, 216, 241–255. [Google Scholar] [CrossRef]
- Li, H.; Li, C.; Li, G.; Chen, L. A Real-Time Table Grape Detection Method Based on Improved YOLOv4-Tiny Network in Complex Background. Biosyst. Eng. 2021, 212, 347–359. [Google Scholar] [CrossRef]
- Xia, H.; Yang, B.; Li, Y.; Wang, B. An Improved CenterNet Model for Insulator Defect Detection Using Aerial Imagery. Sensors 2022, 22, 2850. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Li, X.; Pan, J.; Xie, F.; Zeng, J.; Li, Q.; Huang, X.; Liu, D.; Wang, X. Fast and Accurate Green Pepper Detection in Complex Backgrounds via an Improved Yolov4-Tiny Model. Comput. Electron. Agric. 2021, 191, 106503. [Google Scholar] [CrossRef]
- Lu, S.; Chen, W.; Zhang, X.; Karkee, M. Canopy-Attention-YOLOv4-Based Immature/Mature Apple Fruit Detection on Dense-Foliage Tree Architectures for Early Crop Load Estimation. Comput. Electron. Agric. 2022, 193, 106696. [Google Scholar] [CrossRef]
- Fu, L.; Feng, Y.; Wu, J.; Liu, Z.; Gao, F.; Majeed, Y.; Al-Mallahi, A.; Zhang, Q.; Li, R.; Cui, Y. Fast and Accurate Detection of Kiwifruit in Orchard Using Improved YOLOv3-Tiny Model. Precis. Agric. 2021, 22, 754–776. [Google Scholar] [CrossRef]
- Gené-Mola, J.; Gregorio, E.; Guevara, J.; Auat, F.; Sanz-Cortiella, R.; Escolà, A.; Llorens, J.; Morros, J.-R.; Ruiz-Hidalgo, J.; Vilaplana, V. Fruit Detection in an Apple Orchard Using a Mobile Terrestrial Laser Scanner. Biosyst. Eng. 2019, 187, 171–184. [Google Scholar] [CrossRef]
- Underwood, J.P.; Hung, C.; Whelan, B.; Sukkarieh, S. Mapping Almond Orchard Canopy Volume, Flowers, Fruit and Yield Using Lidar and Vision Sensors. Comput. Electron. Agric. 2016, 130, 83–96. [Google Scholar] [CrossRef]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral Image Classification with Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in neural information processing systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Event, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Yang, Y.; Jiao, L.; Liu, X.; Liu, F.; Yang, S.; Feng, Z.; Tang, X. Transformers Meet Visual Learning Understanding: A Comprehensive Review. arXiv 2022, arXiv:2203.12944. [Google Scholar] [CrossRef]
- D’Ascoli, S.; Touvron, H.; Leavitt, M.L.; Morcos, A.S.; Biroli, G.; Sagun, L. Convit: Improving Vision Transformers with Soft Convolutional Inductive Biases. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18−24 July 2021; pp. 2286–2296. [Google Scholar]
- Srinivas, A.; Lin, T.-Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck Transformers for Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Event, 11–17 October 2021; pp. 16519–16529. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Bench, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO: Transformer-Based YOLO for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Event, 11–17 October 2021; pp. 2799–2808. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, IEEE, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, New York, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. arXiv 2021, arXiv:2101.08158. [Google Scholar] [CrossRef]
- Chen, Z.; Xie, L.; Niu, J.; Liu, X.; Wei, L.; Tian, Q. Visformer: The Vision-Friendly Transformer. arXiv 2021, arXiv:2104.12533. [Google Scholar] [CrossRef]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional Feature Fusion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3560–3569. [Google Scholar]
- Silva, L.A.; Sanchez San Blas, H.; Peral García, D.; Sales Mendes, A.; Villarubia González, G. An Architectural Multi-Agent System for a Pavement Monitoring System with Pothole Recognition in UAV Images. Sensors 2020, 20, 6205. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Architecture | Strengths | Weaknesses |
|---|---|---|
| Based on CNNs | Low computational cost, strong real-time performance, and easy to deploy. | The detection accuracy of small and occluded objects can be improved. |
| Based on the ViT | It is beneficial to the detection of small and occluded pears, and the accuracy can be significantly improved. | The computational cost and memory usage are too high, which is not conducive to real-time detection. |
| Based on a combination of CNNs and the ViT | Taking into account both accuracy and computational cost, it is helpful in the detection of small and occluded pears. | An inappropriate combination can still result in a significant increase in computational cost and memory usage. |
| Networks | (%) | (%) | F1-Score (%) | Detection Time (ms) | Memory Usage (MB) | FLOPs (G) |
|---|---|---|---|---|---|---|
| YOLOv5s-FP | 96.12 | 68.22 | 89.73 | 13.2 | 50.01 | 18.2 |
| Networks | (%) | (%) | F1-Score (%) | Detection Time (ms) | Memory Usage (MB) | FLOPs (G) |
|---|---|---|---|---|---|---|
| YOLOv3s | 86.51 | 59.42 | 83.72 | 16.1 | 120.32 | 157.1 |
| YOLOv4s | 89.98 | 62.83 | 85.62 | 20.2 | 246.34 | 137.2 |
| YOLOv5s | 89.09 | 63.09 | 84.35 | 11.2 | 13.70 | 16.4 |
| YOLOXs | 92.62 | 64.31 | 86.23 | 14.3 | 64.23 | 26.8 |
| YOLOv5s-FP | 96.12 | 68.22 | 89.73 | 13.2 | 50.01 | 18.2 |
| Networks | (%) | (%) | F1-Score (%) | Detection Time (ms) | Memory Usage (MB) | FLOPs (G) |
|---|---|---|---|---|---|---|
| YOLOv5s | 89.09 | 63.09 | 84.35 | 11.2 | 13.7 | 16.3 |
| YOLOv5s-SC | 89.56 | 63.39 | 84.48 | 11.2 | 13.9 | 16.8 |
| YOLOv5s-TE | 92.92 | 63.07 | 84.61 | 11.7 | 42.2 | 17.8 |
| YOLOv5s-TC | 94.58 | 64.33 | 86.45 | 12.4 | 21.2 | 17.9 |
| YOLOv5s-FP | 96.12 | 68.22 | 89.73 | 13.2 | 50.0 | 18.2 |
| Networks | Small | Medium | Large | ||||||
|---|---|---|---|---|---|---|---|---|---|
| F1-Score (%) | F1-Score (%) | F1-Score (%) | |||||||
| YOLOv5 | 82.8 | 51.3 | 84.2 | 95.1 | 65.2 | 87.1 | 96.2 | 88.6 | 89.2 |
| YOLOv5s-FP | 87.9 | 55.1 | 89.5 | 97.5 | 69.3 | 90.2 | 97.3 | 89.5 | 92.1 |
| Illumination Conditions | YOLOv5s-FP | YOLOv5s | Count of Images | Count of Annotated Pears | ||||
|---|---|---|---|---|---|---|---|---|
| F1-Score (%) | F1-Score (%) | |||||||
| Strong illumination | 95.8 | 66.2 | 89.3 | 90.2 | 62.3 | 84.2 | 80 | 2066 |
| Normal illumination | 97.5 | 73.2 | 93.1 | 95.3 | 71.9 | 91.9 | 124 | 3690 |
| Weak illumination | 96.4 | 69.9 | 92.2 | 92.2 | 66.2 | 89.5 | 96 | 2630 |
| Artificial illumination | 90.8 | 65.1 | 88.8 | 85.4 | 61.4 | 82.1 | 68 | 784 |
| Viewpoint of UAV | YOLOv5s-FP | YOLOv5s | Count of Images | Count of Annotated Pears | ||||
|---|---|---|---|---|---|---|---|---|
| F1-Score (%) | F1-Score (%) | |||||||
| Side viewpoint | 96.8 | 71.4 | 92.8 | 93.4 | 69.4 | 91.2 | 1392 | 262,624 |
| Bird’s-eye viewpoint | 83.3 | 61.0 | 82.1 | 80.5 | 59.5 | 80.3 | 648 | 185,722 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property re-sulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Rao, Y.; Jin, X.; Jiang, Z.; Wang, Y.; Wang, T.; Wang, F.; Luo, Q.; Liu, L. YOLOv5s-FP: A Novel Method for In-Field Pear Detection Using a Transformer Encoder and Multi-Scale Collaboration Perception. Sensors 2023, 23, 30. https://doi.org/10.3390/s23010030
Li Y, Rao Y, Jin X, Jiang Z, Wang Y, Wang T, Wang F, Luo Q, Liu L. YOLOv5s-FP: A Novel Method for In-Field Pear Detection Using a Transformer Encoder and Multi-Scale Collaboration Perception. Sensors. 2023; 23(1):30. https://doi.org/10.3390/s23010030
Chicago/Turabian StyleLi, Yipu, Yuan Rao, Xiu Jin, Zhaohui Jiang, Yuwei Wang, Tan Wang, Fengyi Wang, Qing Luo, and Lu Liu. 2023. "YOLOv5s-FP: A Novel Method for In-Field Pear Detection Using a Transformer Encoder and Multi-Scale Collaboration Perception" Sensors 23, no. 1: 30. https://doi.org/10.3390/s23010030
APA StyleLi, Y., Rao, Y., Jin, X., Jiang, Z., Wang, Y., Wang, T., Wang, F., Luo, Q., & Liu, L. (2023). YOLOv5s-FP: A Novel Method for In-Field Pear Detection Using a Transformer Encoder and Multi-Scale Collaboration Perception. Sensors, 23(1), 30. https://doi.org/10.3390/s23010030