2.1. Hardware Platform
The MONOCULAR framework was embedded, optimized, characterized, and tested on a Pepper Y20 model by SoftBank Robotics (SoftBank Robotics, Tokyo, Japan).
Pepper is supplied with an Intel Atom E3845 (quad-core) 1.91 GHz processor, 4 GB DDR3 (2 GB dedicated to Operating System (OS)) of RAM, 8 GB eMMC (not available to user), and 16 GB of micro SDHC. All the routines proposed in the following execute on Pepper’s native operating system, NAOqi OS, which is a Gentoo-based GNU/Linux distribution [
10]. For the sake of readability, only the details related to the sensors that are involved in the routines proposed here will be described in the following.
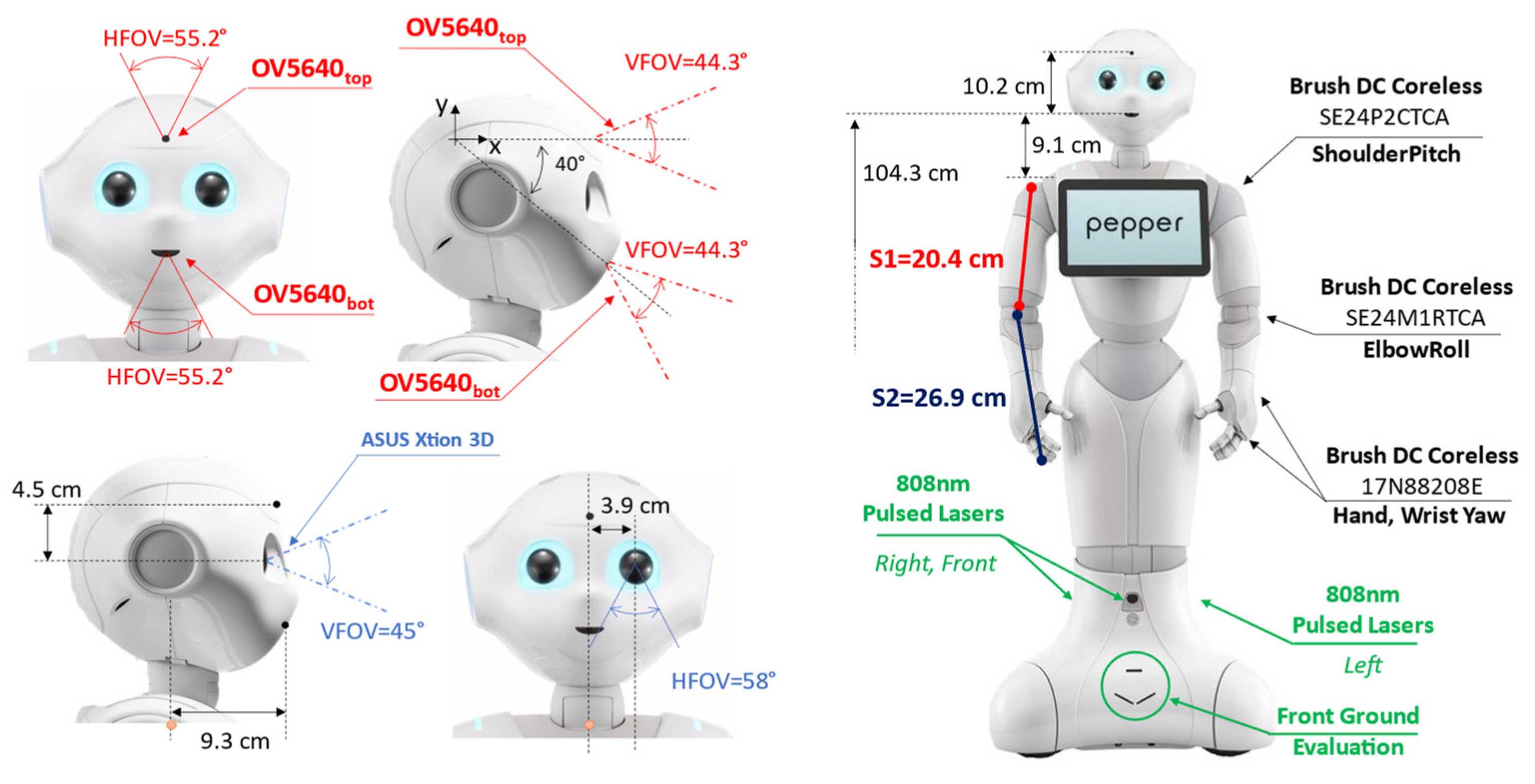
Pepper is provided with two RGB cameras and a 3D depth sensor as per
Figure 1. Both RGB cameras are OV5640 (OmniVision Technologies Inc., Santa Clara, CA, USA). The first one, identified as OV5640top is placed on the forehead with an angle of 90° with respect to the head frame axis (0° considering the X-axis reference in
Figure 1). The second camera, labeled OV5640bot, is placed on the robot mouth with an orientation of −40° with respect to the X-axis reference in
Figure 1. The OV5640 provides a maximum resolution of 5 Mp with 55.2° of the horizontal field of view (FOV), 44.3° of vertical FOV, and a diagonal FOV of 68.2°. The output frames are set to kQVGA (320 × 240 px) with 5 fps.
Pepper is also provided with an ASUS Xtion 3D (ASUSTeK Computer Inc., Taipei, Taiwan) sensor, located in the left eye of the robot, with 0.3 Mp of resolution. The Xtion provides 58° of horizontal FOV, 45° of vertical FOV, and a diagonal FOV of 70°. The depth camera output was set to be kQVGA (320 × 240 px) with 5 fps.
The navigation routines, for the object being approached, also involve motor management to move the arm segments, reported in
Figure 1 only for the right side as S1 and S2. Specifically, the routines manage six different motors for the different robot sections: head, arms, and hands. A brush DC coreless SE24PCTCA is driven for the head yaw and the shoulder pitch. A SE24M1RTCA is used to drive the head pitch and the elbow roll. Finally, the hands section is managed by two 17N88208E for the wrist yaw and the hand open and close. For navigation purposes, Pepper is also supplied with three holonomic wheels (spheric shape) placed at the base of the automaton.
For navigation purposes, Pepper is also equipped with six laser line generators emitting at 808 nm with a framerate of 6.25 Hz per laser. As per
Figure 1, three main laser scanners are pointing toward the front, right, and left directions. Each laser scanner is composed of 15 laser beams able to update the directive distance value in ~160 ms. According to the constructor directives, the Horizontal Field of View (HFOV) of each laser scanner is 60°, while the Vertical Field of View (VFOV) is 40°. This leads to an overall HFOV of 240° with 60° of blind angle equally distributed across 45° and −45°. There are also three laser scanners used for front-ground evaluation. The maximum distance of detection is defined as up to 10 m with a maximum height of 10 cm for the objects that the lasers can detect.
2.2. MONOCULAR Working Principle: Preparation Steps
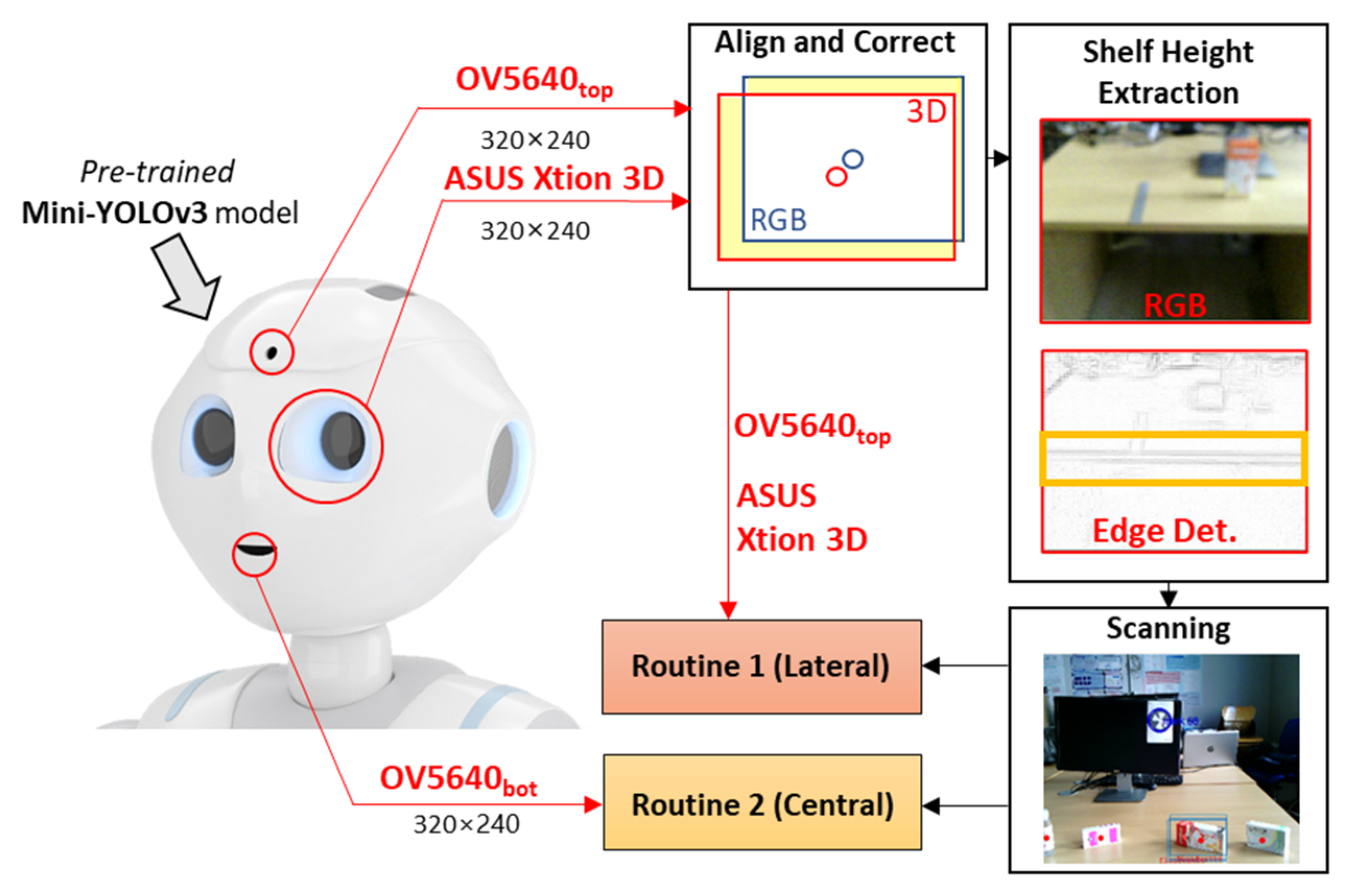
Figure 2 reports a schematic overview of the MONOCULAR framework. The workflow starts with the acquisition of a sequence of frames from the embedded top RGB camera (the forehead one) and the depth map frame from the 3D sensor placed in the left eye of the robot.
Align and Correct. The frames from the top RGB camera and the 3D sensors are displaced between them due to the mutual positioning and the dedicated field of view (FOV) as per
Figure 1. For this aim, a dedicated step for image alignment and a correction step were needed.
The procedure is composed of two main steps as proposed in our previous work [
16], i.e., (i) frame border correction, and (ii) frame extraction. Frame border correction operation consists of computing the FOV coverage of the top RGB camera (i.e., OV5640
top—
Figure 1) and the 3D sensor (i.e., ASUS Xtion 3D—
Figure 1). During this step, the frames from the two sources are overlapped and the parts that are not shared are removed from the analyzed frame. This cropping operation is named frame extraction. According to [
16], for a Pepper Y20 with the above-mentioned settings, 13 pixels should be removed on the top and 7 pixels on the right of the RGB frame.
Similarly, 13 pixels should be cropped on the left 3D sensor frame. Next, the cropped frames are resized (via bilinear interpolation) to match the closest multiple of 32 on both dimensions due to YOLO input constraint [
17].
Shelf Height Extraction. To properly adapt both manipulation routines, the proposed system must estimate, as precisely as possible, the height of the shelf on which the objects to be grabbed are placed. For this purpose, MONOCULAR embeds a dedicated processing step that exploits frames from the top RGB camera and the 3D sensor.
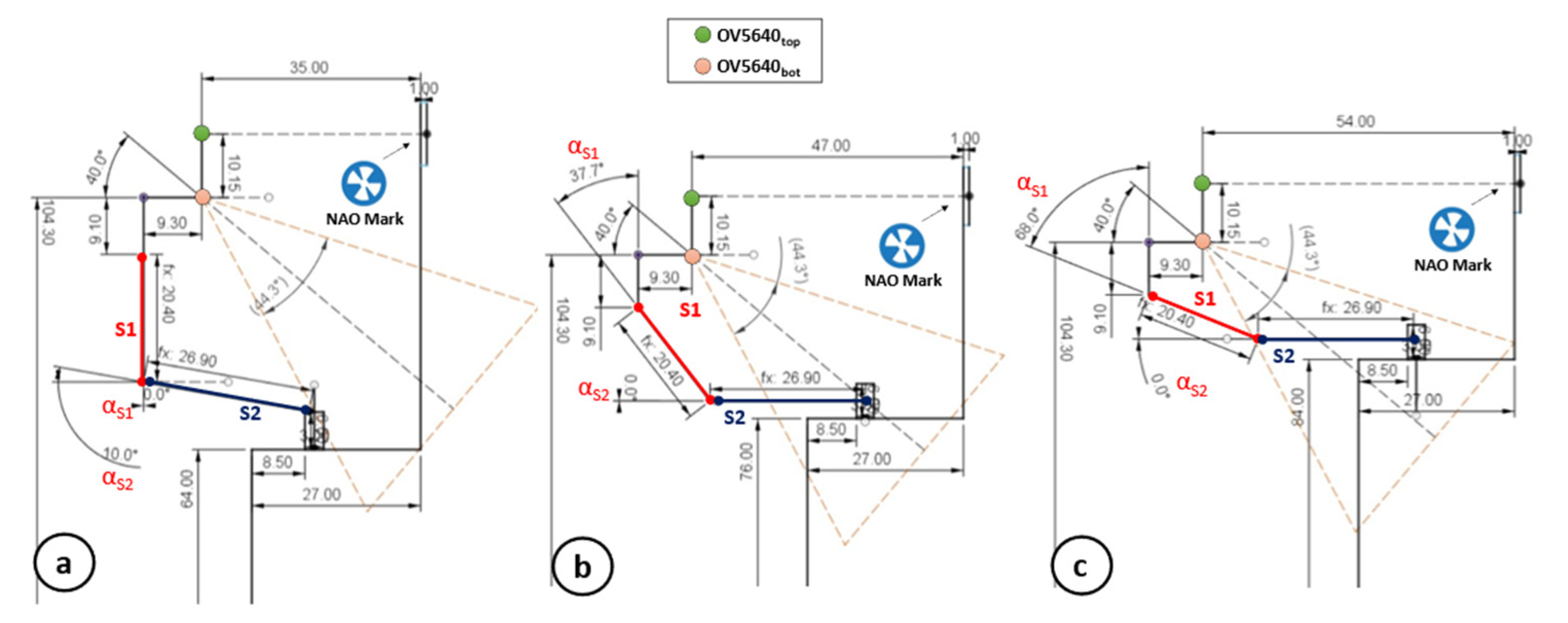
Figure 3a shows the height estimation setup. The first step of this procedure consists of acquiring the distance between the 3D camera coordinates and the center point of an NAO mark placed on a frontal surface via depth map data. This distance is named d
T,NM in
Figure 3b. To maximize the accuracy of the estimation, the NAO mark should be roughly placed at the same height of the 3D sensor.
Once d
T,NM is extracted, the pitch value for the head frame is increased up to α
HP = 36° (max allowed: 36.5°). Next, MONOCULAR queries the robot for a top RGB camera photo, which is analyzed via an embedded and low-complexity edge detection algorithm considering a 3 × 3 convolution mask [
18]. Specifically, an edge detection with a 2nd derivative using a Laplacian of Gaussian (LoG) filter and zero-crossing (with σ = 3 for the Laplacian of Gaussian kernel) was implemented as Python script on NAOqi.
Figure 3d shows an example of the LoG filtering application starting from the camera frame in
Figure 3c.
If the central area of the resulting image (
Figure 3d) is occupied for >70% by edge pixels, it means that the shelf edge is centered with the FOV of the camera. If <70% is detected, the robot starts moving toward the shelf with preset steps. Optimal positioning is reported in
Figure 3a,b, where the center of the RGB camera frame coincides with the shelf edge. In the proposed application, the central area is defined as the whole frame width (i.e., 320) and a restricted area of the frame height that corresponds to the range of pixels 120 ± n
px, where n
px are the limits of the area (n
px = 15 pixels in the proposed application).
Since the distance between the NAO mark and the shelf edge is known a priori (d
1 in
Figure 3b), the height of the shelf can be estimated as per the following equation:
where
is the shelf height,
is the height of the top RGB camera (i.e., 114.45 cm),
is the distance between the camera and the NAO mark as per
Figure 3b, while
is the head pitch angle. The distance between the NAO mark and the shelf edge,
, is preset due to the employment of a positioning grid that allows the placement of the object only in specific areas.
Scanning. Once the shelf height is estimated, the cropped and resized RGB acquisition is then sent to an object detection routine based on the Mini-YOLOv3 method [
14,
15]. The Mini-YOLOv3 model must be pretrained offline to recognize specific objects. Generally, the YOLO method oversees extracting a number of bounding boxes returning; for each of these, the probability that the box contains an object and the probability that the object belongs to a specific class. Since all the objects are placed at specific coordinates on the shelf, the MONOCULAR framework decides the manipulation routine to be carried out. It can be Routine 1 if the objects are laterally placed from the robot’s point of view, or Routine 2 if the object is centrally placed. Routine 1 involves the top RGB camera and the 3D sensor, while Routine 2 mainly involves frames from the bottom RGB camera. Routine 1’s design idea was investigated in our previous work [
16], but no considerations about the shelf height, object characteristics and dynamic parameters’ adaption were provided.
2.3. MONOCULAR Working Principle: Object Detection
The MONOCULAR object detection engine was entrusted to the portable version of YOLOv3, the Mini-YOLOv3 by [
15]. Mini-YOLOv3 proposes a lightening of the YOLOv3 backbone network (i.e., darknet-53), employing only 16% of the initial parameters. This reduction led to the degradation of the network’s accuracy. To improve the performance of multi-scale object detection, a Multi-Scale Feature Pyramid network based on a simple U-shaped structure was employed according to [
15]. The above-mentioned structures (lightweight backbone and Multi-Scale Feature Pyramid network) are used to extract the features maps from the input image, and to produce bounding boxes based on the learned features. Specifically, the Multi-Scale Feature Pyramid network is composed of three main parts: (i) the Concatenation module; (ii) the Encoder-Decoder module; and (iii) the Feature Fusion module. The Concatenation module is used to connect each feature generated by the backbone network and the Encoder-Decoder module is used to generate multi-scale features. The Feature Fusion module is used to aggregate features for the final prediction. The Non-Maximum Suppression (NMS) approach is used to produce the classification results.
This approach was selected due to the optimal trade-off between two main discrimination metrics for the object detection algorithms: the number of floating-point operations (FLOPs) and the mean average precision with Intersection over Union (IoU) of 0.5, typically identified as mAP@0.5, as declared by dedicated works considering a standard dataset (i.e., COCO test-dev2017) [
15,
17]. The object detection speed, in frames per second (FPS), was excluded by this analysis due to the RGB camera setting for the streaming speed (i.e., 5 fps). Moreover, only object detection algorithms that provide the weights of the backbone network were considered for further investigation. This constraint was needed due to the limited number of images related to the object to be classified for the proof of concept. As per the previous constraints, the employment of a four object detection algorithm (i.e., Mini-YOLOv3, YOLOv3-tiny, YOLOv3- tiny pruned and YOLOv4-tiny) was investigated. According to data reported in [
15,
17], Mini-YOLOv3 achieves the highest mAP@0.5, even executing a high number of FLOPs with respect to other solutions. Indeed, Mini-YOLO executes 10.81 billion FLOPs for an mAP of 52.1%, YOLOv3-tiny employs 5.57 billion FLOPs for an mAP of 33.1%, 3.47 billion FLOPs are executed by YOLOv3-tiny pruned with an mAP of 33.1% and, finally, 6.91 billion FLOPs and an mAP of 40.2% are the parameters of the YOLOv4-tiny.
The object detection model pre-training was carried out offline and consisted of data collection and preparation, model training, inference testing, and model extraction. During the data collection, images were captured both via the forehead and mouth camera, with different operative angles (repeating the approach routine every time).
Four classes of pharmaceutical packages were considered for the proof of concept:
{Fluifort, Aciclovir, Antipyretic, Hand Sanitizer}. Overall, 2496 images were collected for a total of 9984 annotations (4 per image). The labeling was manually realized via Labellmg software. As per the guidelines in [
16], during the labeling, the bounding boxes were drawn including the entirety of the object and a small amount of space between the object and the bounding box. Extracted data were further pre-processed via a Roboflow framework to implement data augmentation and auto-orienting on the gathered data [
19]. The above-mentioned preparation steps were carried out on Google Colab. The same online notebook was employed for the Mini-YOLOv3 implementation via Keras with TensorFlow backend, running a repetitive fine-tuning approach, by freezing and unfreezing the backbone body. Specifically, new data were uploaded via the Roboflow setting with a batch size of 32, epochs at 500, and an Adam optimizer with a learning rate of 10
−3 with the reduced darknet body full-freeze and 10
−4 for unfreezing and fine-tuning. The fitted model, with the custom weights, was exported as a .py script on NAOqi OS and implemented on the Pepper robot.
2.4. MONOCULAR Working Principle: Routine 1
The MONOCULAR Routine 1 concerns the laterally placed objects according to [
16]. Briefly, it consists of two main steps: (i) Tag Extraction, and (ii) Object-vs.-Hand Coverage Routine.
Tag Extraction. During this step, the robot moves towards the object by keeping the selected YOLO tag in the center of the image and progressively adjusting the head frame.
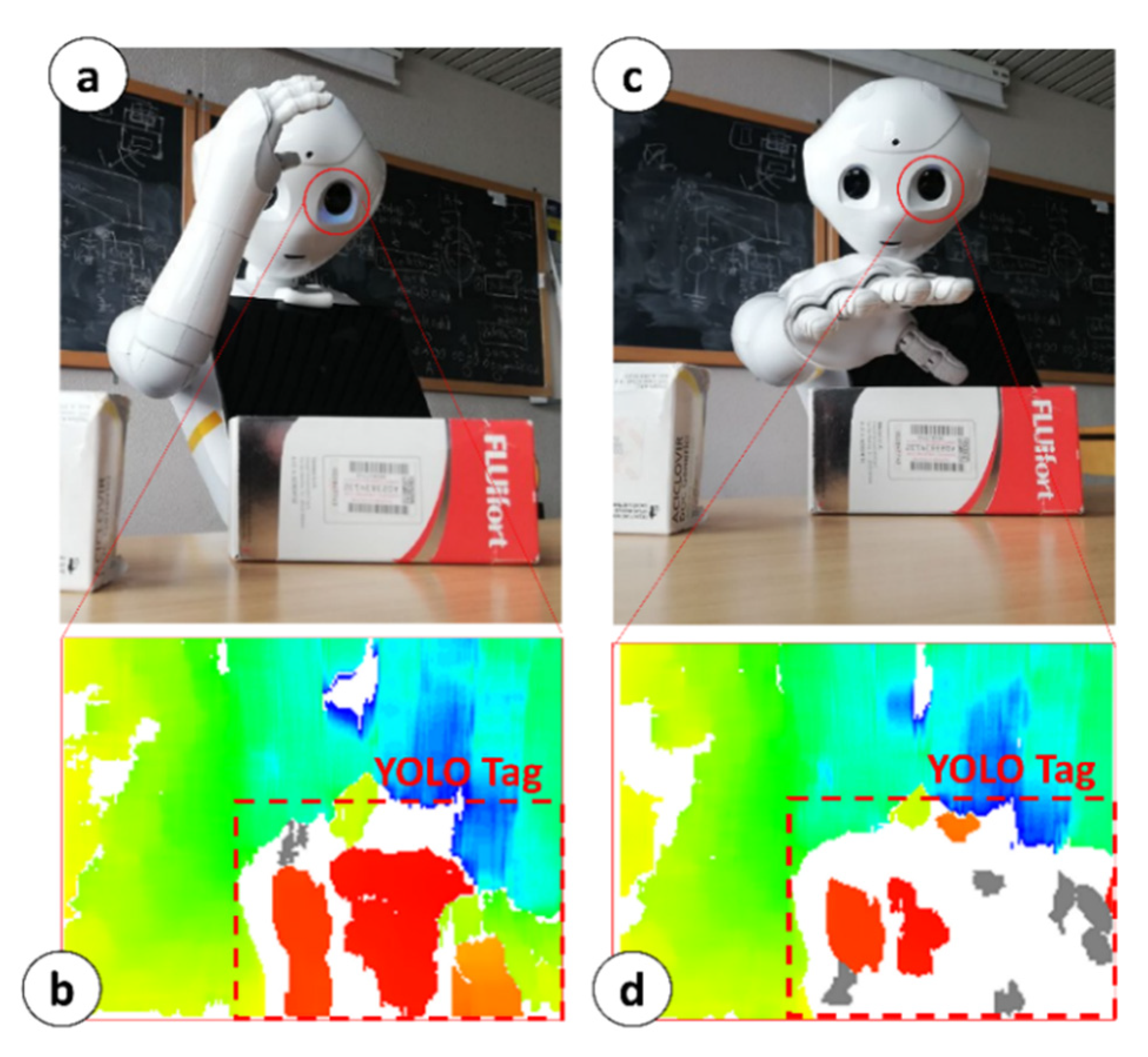
According to the object’s position with respect to the robot’s torso frame, MONOCULAR selects the arm to be used for grabbing and manipulation. During the object’s approach, the arm selected for grabbing is led to the position shown in
Figure 4a. The aligned RGB image from the top camera and the 3D image are used to extract the area covered by the YOLO tag (
Figure 4b) to proceed with further analysis. The central anchor point of the YOLO Tag is used to define a reference distance from the depth map of the 3D sensor.
This reference distance is used to fix a reference useful to calibrate the segmentation blob during the 3D reconstruction as per
Figure 4b. This reference can be identified in
Figure 4b as a red blob. The depth threshold for the segmentation is set to 5 mm, and the colormap limits are restricted in the proximity of the reference value.
Figure 4b shows the initial blob vision from Position #1. The area included in the red blob determines 100% of the uncovered object. MONOCULAR stores the number of “red pixels” from the depth map.
Object-vs.-Hand Coverage Routine. Once the initial number of pixels is set, the hand moves onto the selected object, partially covering it, from the point of view of the 3D sensor (see
Figure 4c). MONOCULAR evaluates the difference between the initial number of red pixels, and the final one (after moving the hand). If the difference falls within an experimentally derived range (i.e., ~40–45% for right hand manipulation, 25–32% for left hand), the hand stops moving, and the grabbing routine starts running. More details about the Object-vs.-Hand Coverage Routine and its characterization are available in [
16].
Once the robot’s hand is in the position shown by
Figure 4c, the shoulder pitch is progressively adapted to press against the shelf plane to ensure a good grabbing force on the object. Since the shelf height,
, is derived from the Shelf Height Extraction step, MONOCULAR can extract a desired shoulder pitch angle to ensure it can extract the desired shoulder pitch, which ensures the correct pressure on the plane without overloading the mechanical shoulder joint. The actual degrees read by the shoulder motor are compared with the desired ones extracted by MONOCULAR. If the actual degrees stop decreasing, it means that the object has been blocked and no additional pressure needs to be applied, preserving the joint from overloading. This step ends with a full-hand closing.
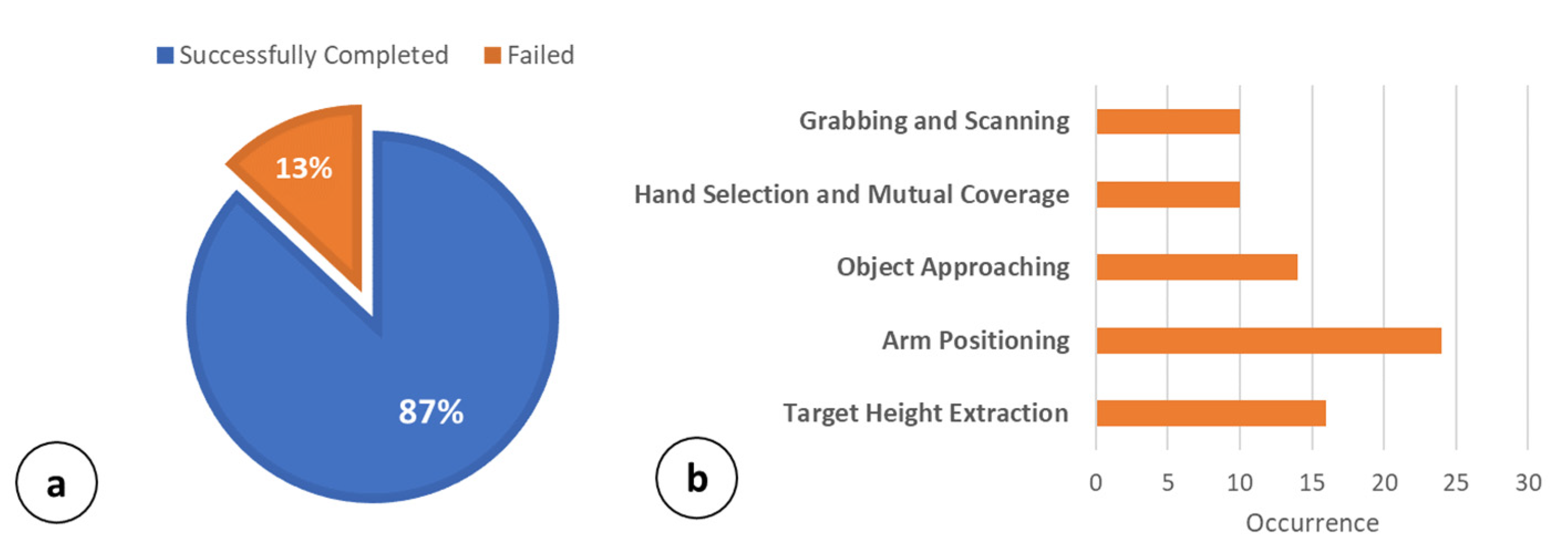
The object is—finally—scanned through the image recognition engine to confirm the request matches. The robot is now ready to deliver the pharmaceutical envelope.
2.5. MONOCULAR Working Principle: Routine 2
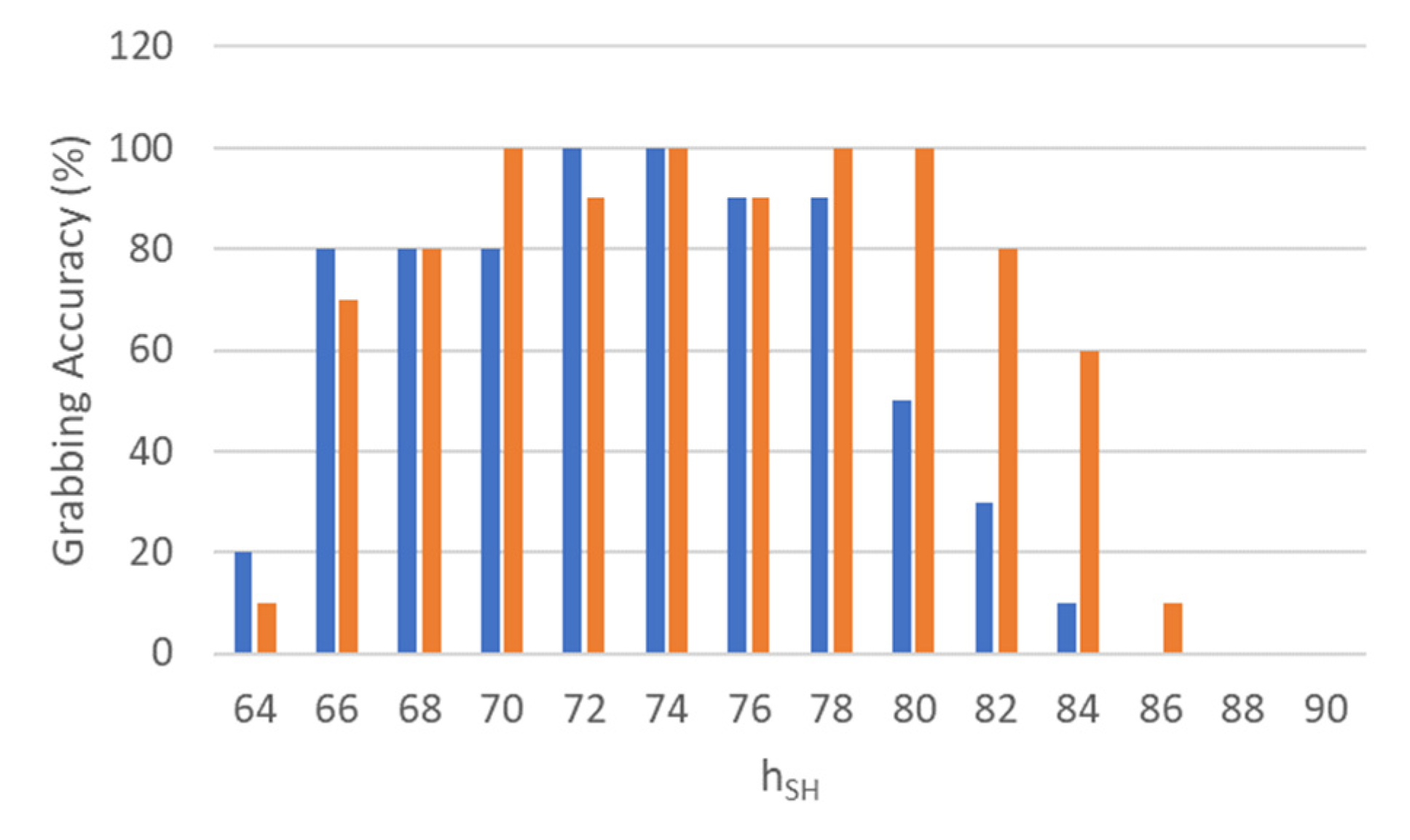
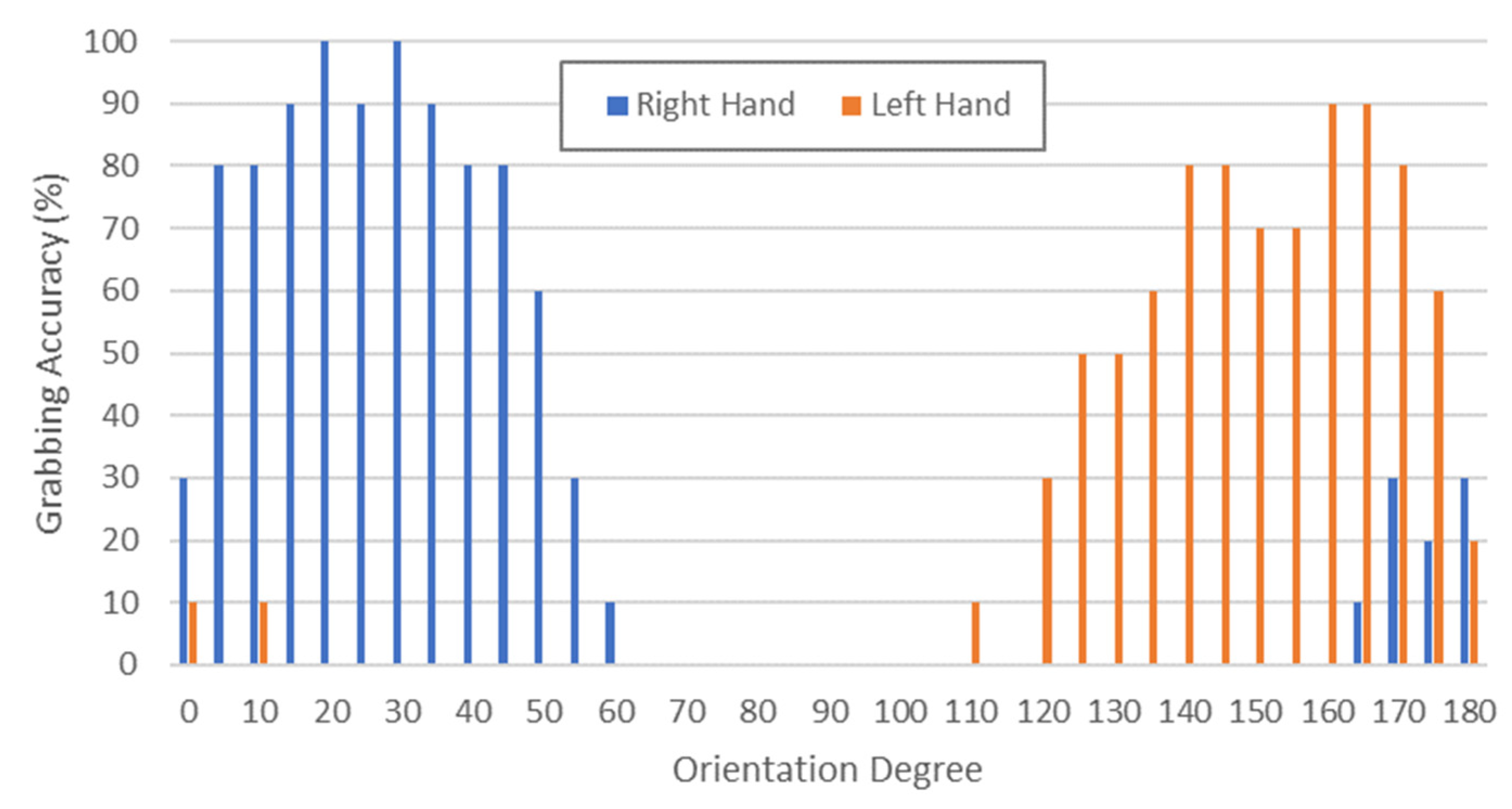
Routine 2 of the MONOCULAR framework involves the objects that are placed centrally on the shelf. The procedure is realized by means of five main steps: (i) Target Height Extraction, (ii) Arms Positioning, (iii) Object Approaching, (iv) Hand Selection and Mutual Coverage, and (v) Grabbing and Scanning.
Target Height Extraction. This step starts with the assessment of the shelf height parameter, , and the height of the object to be grabbed, namely . This latter parameter is stored in the object dictionary accessible via Pepper’s memory recall.
As a first step, MONOCULAR estimates the maximum height that the whole arm, given by the combination of S1 and S2 segments with proper orientation, should have. For this purpose, a target height is extracted according to the equation:
where
is the target height defined as the maximum height that the arm (S1 + S2) should have to properly approach the object,
is the shoulder joint height (i.e., 95.2 cm in this application), while
is a coefficient related to the height of the object,
. The coefficient
is provided by the dictionary of objects stored in the Pepper memory and is related to the mass distribution of the package. Experimental analysis showed that a general height of approach of
(i.e., with
= 2) allows the robot to achieve high grabbing accuracy with most of the packages involved in the proof of concept.
Arms Positioning. Once the
is estimated, MONOCULAR compares
with the length of the segment S1 (
= 20.4 cm in our application). If
, according to
Figure 5, MONOCULAR computes the angle that the S1 segment should keep with respect to the torso axis (
in
Figure 5), according to the following equation:
In this configuration, the second segment, S2, remains perpendicular to the torso axis as per
in
Figure 5.
Nevertheless, if
, the second segment S2 must be moved, by increasing
in
Figure 5 to compensate for the difference between
and
, according to the equation:
where
represents the length of the second arm segment S2. The combination of
and
is mirrored on the opposite arm.
Object Approaching. Once Pepper assumes the correct posture in a safe area (with no collision), the MONOCULAR framework starts driving the robot toward the object, keeping the achieved grabbing position as per
Figure 5. The movement considers the distance between the robot and the NAO mark (through 3D sensor) and the distance between the object and the shelf edge (preset).
All those approaching movements are carried out slowly to avoid its omnidirectional wheels slipping. In addition, every movement is controlled by a dedicated odometric algorithm to compensate for incomplete movement errors [
20,
21]. When in the grabbing position, MONOCULAR runs an object position check step. This consists of taking a frame of the bottom RGB camera perspective that is sent to YOLO for stable labeling.
As a first step, the proposed system extracts the distance between the camera and the object’s position, calculating the parameter
as follows:
where 9.3 cm corresponds to the horizontal distance between the bottom camera and the shoulder joint position according to the robot mechanics in
Figure 5. The projection of
on the bottom camera axis is given by:
where 40° is the mutual angle of the OV5640 cameras (bottom camera axis). Starting from the above-presented parameter,
, it is possible to define the vertical field of view of the camera.
This vertical field of the view projection is mathematically defined as:
where
is the projection of the vertical field of view of the camera (
) in correspondence with the object. The extraction of the
parameter allows MONOCULAR to assess the correct robot–object alignment.
For this purpose, the framework considers only the central vertical column of the taken frame (480 rows from the column with index 320). Then, it extracts the minimum number of pixels that should belong to the object in a specific zone of the frame. This zone depends on the object height, , shelf height, , and robot arms’ position.
Specifically, considering an object placed on the shelf, it is possible to derive the position of its base as:
where
is the height of the bottom camera (i.e., 104.3 cm in this application), while 50° is derived by 90°–40° with 40° being the mutual angle of the OV5640 cameras.
The
can be expressed in pixels considering the following relationship:
MONOCULAR also extracts the upper limit starting from
, as per:
If the desired object is recognized, at least, in the vertical range [] as defined by Equations (9) and (10). The grabbing can start, otherwise, the robot should adjust its position to fit the range.
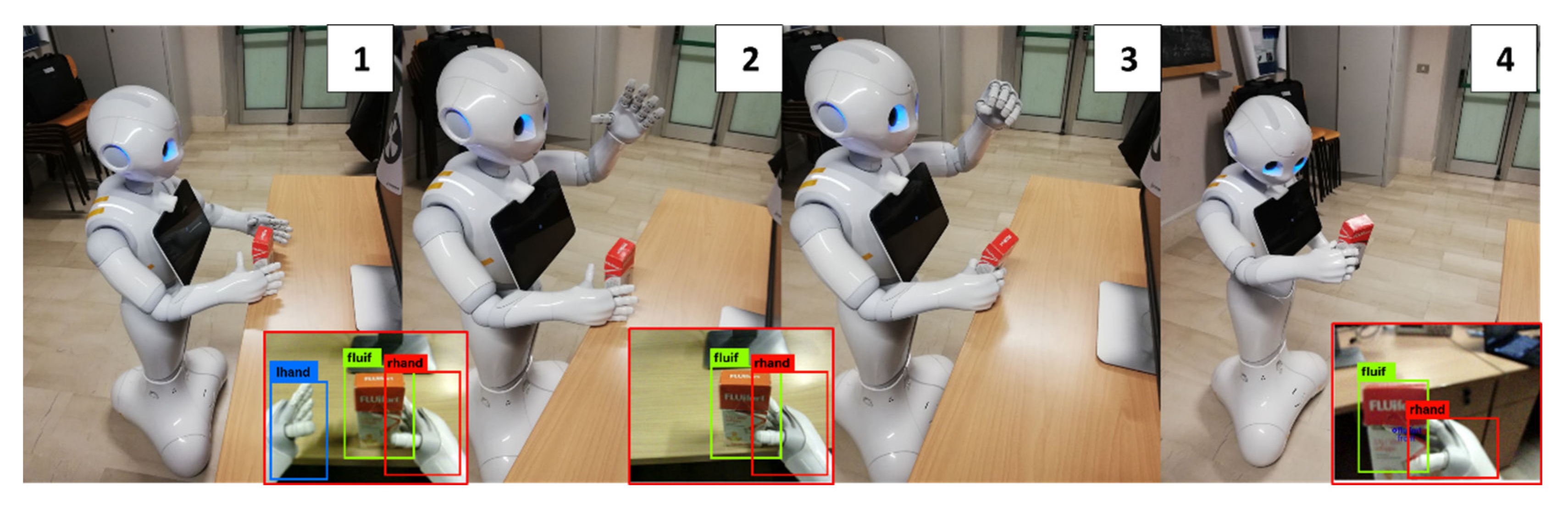
Hand Selection and Mutual Coverage. When the object position check is completed (
Figure 6—step 1), the MONOCULAR framework starts assessing the overlapping degree among the hands bounding boxes by YOLO and the recognized object to be grabbed.
The hand with the bounding box mostly overlapped with the object is selected for the grabbing procedure, while the other hand is raised to avoid interference in lateral adjusting movements (
Figure 6—step 2).
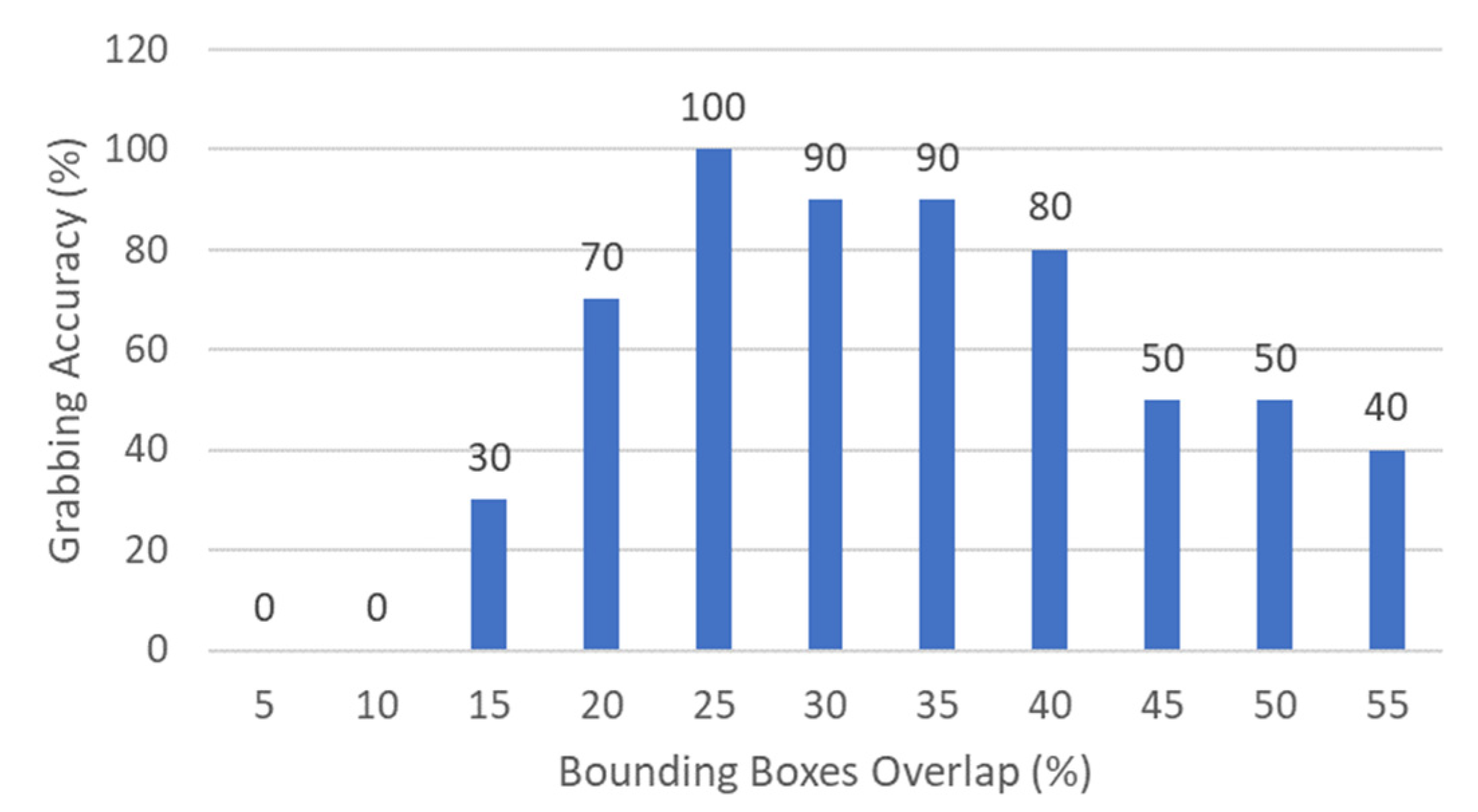
If the overlap involves less than 25% of the hand box, the robot is laterally moved to cover at least this limit.
Grabbing and Scanning. Once the alignment is over the object, MONOCULAR commands the hand to close (
Figure 6—step 3). The routine ends with scanning, which is carried out utilizing the image recognition system.
Figure 6.
MONOCULAR Routine 2: four-frame demonstrative sequence for grabbing and scanning centrally placed objects. Frames are numbered from 1 to 4. Step 1: Object approaching, Step 2: Hand Selection and Mutual Coverage step with body adjustments. Step 3: Grabbing procedure. Step 4: Scanning.
Figure 6.
MONOCULAR Routine 2: four-frame demonstrative sequence for grabbing and scanning centrally placed objects. Frames are numbered from 1 to 4. Step 1: Object approaching, Step 2: Hand Selection and Mutual Coverage step with body adjustments. Step 3: Grabbing procedure. Step 4: Scanning.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











