1. Introduction
Automatic speech recognition (ASR) uses algorithms implemented in devices such as computers or computer clusters to convert voice signals into a sequence of words or other linguistic entities [
1,
2]. Previous ASR applications were based on interactive voice response, device control by voice, content-based voice audio search, and robotics. However, ASR technology has improved significantly in recent years owing to the exponential increase in data and processing power, which makes it possible to perform difficult applications. Voice search using mobile devices, voice control in home, and numerous speech-centric information processing applications that benefit from the downstream processing of ASR outputs are some of the examples of advancements in ASR technology [
3]. Thus, noise robustness has become an essential core technology for large-scale, real-world applications given that OCSR APIs must exhibit improved functionality because of the significantly demanding acoustic scenarios.
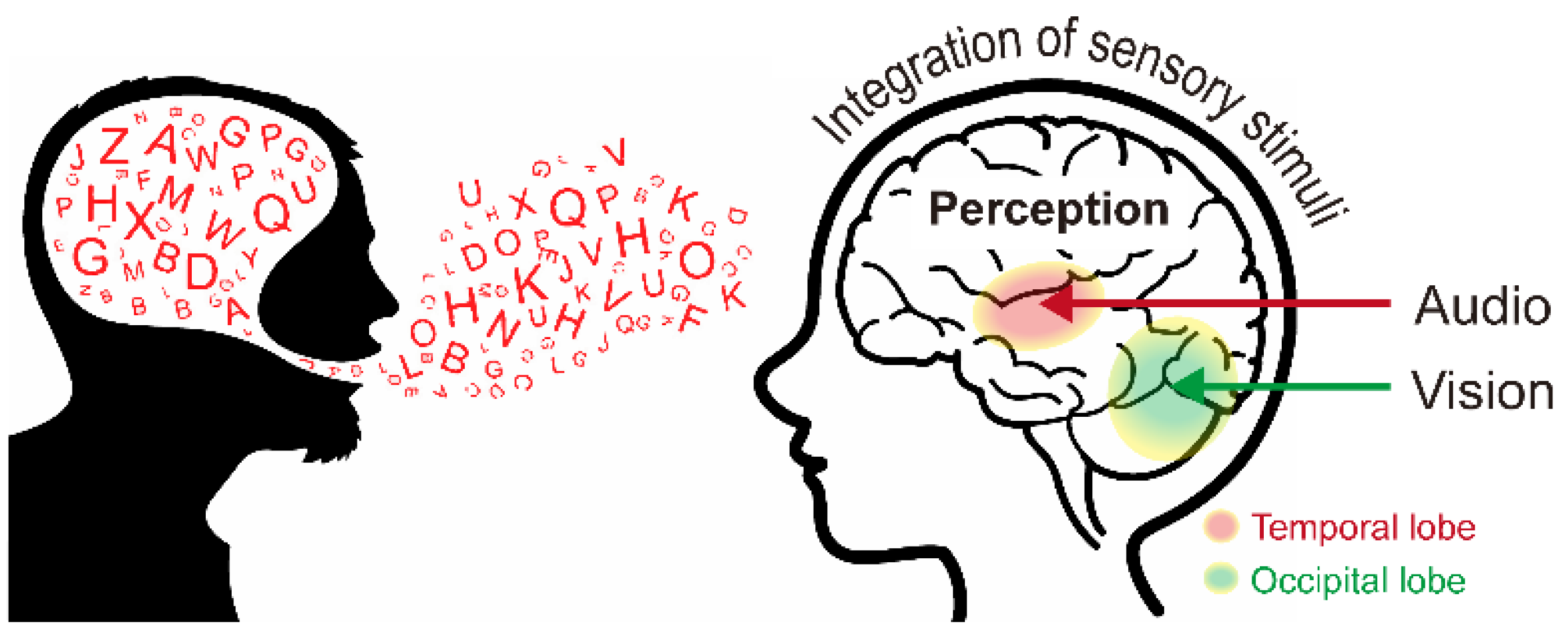
In this study, we propose a noise enhancement system that uses a multimodal interaction approach based on multisensory integration that refers to the interplay of information from several senses. Multisensory integration often influences the perception of human speech. The human nervous system comprises several specialized sensory organs, each of which conveys certain sensory information [
4]. The organization of sensory organs in the human body is advantageous considering that each organ serves as a non-redundant source of information, which allows organisms to detect critical sensory events with higher certainty by separately examining the input received from each sense. However, when several sources of information are merged, information from different senses can be linked [
5], and this can synergistically influence the capacity to notice, assess, and start reactions to sensory events (
Figure 1) [
6]. The brain is divided into four lobes;
Figure 1 shows the audio (red, temporal lobe) and visual (green, occipital lobe) information in multisensory integration.
Several studies have shown that the contemporaneous observation of visual speech, such as the movement around the speaker’s lips, significantly affects speech perception. Visual speech information improves the ability to understand speech in scenarios when words are spoken with an accent, or when the surrounding environment is noisy [
7,
8,
9]. For example, lip-reading can substantially improve the understanding of speech if the audio signal is unclear [
10,
11,
12]. The McGurk effect illustrates how mismatched auditory and visual speech information affects speech perception [
13]. For example, when we hear the sound “ba” while seeing a person’s face express “ga”, many people hear “da”, a third sound that is a combination of the two. This fusion approach contributes to the robustness of speech detection in a variety of real-world applications, such as human–machine interaction, by overcoming the problems of noise, auditory ambiguity, and visual ambiguity.
To the best of our knowledge, this is the first study that proposes a noise-robust OCSR API system based on an end-to-end lipreading architecture for practical applications in various environments. This system exhibits performance superior to those systems that comprise only audio or visual speech recognition technology. For auditory-based speech recognition, we evaluated the performance of four OCSR APIs (Google, Microsoft, Amazon, and Naver) using Google Speech Commands Dataset v2 and the collected dataset prepared by us to select the best API for our design. The word lists recognized in the highest-performance API were expressed as word vectors using the Google Word2Vec model, which was trained using the dataset of 1,791,232-word sentences. Similarly, we developed a new end-to-end lipreading architecture comprising two end-to-end neural subnetworks for visual-based speech recognition. The feature extraction method consists of the following components: a 3D convolutional neural network (CNN), 3D dense connection CNN for each time step to reduce the number of model parameters and avoid overfitting, and multilayer 3D CNN to capture multichannel information in the temporal dimension of the entire video to overcome insufficient visual information and obtain specific image features. A bi-directional gated recurrent unit (GRU) with two layers, followed by a linear layer, was used in the sequence processing module. Therefore, the integrated values of word vectors obtained from speech API and the integrated values of vectors obtained from the lip-reading model were concatenated to form vector matrix. After introducing a SoftMax layer at each time step with a concatenated vector matrix, the entire network was trained using the connectionist temporal classification (CTC) loss function to obtain probabilities. Furthermore, we compared the proposed system’s accuracy and efficiency with those of existing standalone techniques that extract the visual features and several OCSR APIs for the collected datasets. An extensive assessment revealed that the proposed system achieved an excellent performance and efficiency. Thus, we propose a noise-robust open cloud-based speech recognition API system based on an end-to-end lip-reading architecture for practical applications.
The remainder of this paper is organized as follows.
Section 2 examines relevant research on OCSR APIs and visual speech recognition VSR systems.
Section 3 introduces the architecture of the proposed system.
Section 4 presents information on the benchmark datasets, custom collected datasets, audio-visual information processing, augmentation technique, experimental setup, and evaluation. Finally,
Section 5 presents the discussion and conclusions.
2. Related Work
Google has published “Google Assistant” (an AI voice recognition assistant) and various speech recognition features for autos and consumer electronics as an open API. The technology, which supports more than 120 languages, includes various features, such as automatic punctuation, speaker distinction, automatic language identification, and enhanced voice adaptability. As part of Watson’s AI service package, which currently handles 11 languages, the company offers an ASR service. However, the custom acoustic and language model desired by the user must be initially trained using user data. In other words, to use a personalized acoustic model, the user’s own audio must be used, and a new corpus must be added to expand the language model. Further, Microsoft offers a cloud service package known as Azure, and speech-to-text is an API for speech recognition provided by Azure’s cognitive services. According to the official website, Azure employs “breakthrough voice technology” based on decades of study. Furthermore, their website alludes to a 2017 publication where Microsoft achieved the first-ever human-level accuracy on the switchboard test [
14]. Alexa by Amazon is a voice-activated artificial intelligence (AI) smart personal assistant that includes features such as voice interaction and the ability to ask and answer questions. Further, Alexa can control smart gadgets featured in intelligent home technology. Alexa is easily available on Amazon Echo, Echo Dot, Echo Plus, and other smart speakers. In South Korea, the Naver collaboration aggressively developed speech recognition by launching Clova speech recognition (CSR) on 12 May 2017 [
15]. The CSR now supports Korean, English, Japanese, and Chinese languages, although Korean has a better recognition rate.
Deep learning technology has recently demonstrated remarkable performance in a variety of applications, including VSR systems. Deep learning algorithms can achieve higher accuracy compared to older approaches with traditional predictions. For example, when a CNN is used in combination with conventional approaches, the CNN architecture can differentiate different visemes, and temporal information is added after obtaining CNN output using an HMM framework [
16,
17]. Furthermore, other studies [
18,
19] have integrated long short-term memory (LSTM) with histograms of oriented gradients (HOGs) and used the GRID dataset to input recognized short words. Similarly, word predictions were generated using an LSTM classifier with a discrete cosine transformation (DCT) trained with the OuluVS and AVLetters datasets [
17]. The sequence-to-sequence model (seq2seq) is a deep speech recognition architecture that can read and predict the output of an entire input sequence. For longer sequences, it takes advantage of global information. These studies [
20,
21] demonstrated the recognition of audio-visual speech in a dataset based on real words using the first seq2seq model that incorporates both audio and visual information. The initial model is LipNet to use the end-to-end model and be trained using sentence-level datasets (GRID corpus) for performance evaluation [
22]. The overlapped and unseen-speaker databases had word error rates of 4.8% and 11.4%, respectively, whereas human lip-readers had a success rate of 47.7% for the same database. In [
23,
24,
25], digit sequence prediction using 18 phonemes and 11 terms, and other similar architectures such as the CTC cascade model were implemented to evaluate the convergence of audio-visual features. Therefore, deep learning techniques can extract more detailed information from experimental data, which demonstrates their high level of resiliency against big data and visual ambiguity.
Several previous studies [
26,
27,
28] focused on evaluating the recognition performance of existing disclosed OCSR APIs and aimed to apply them to applications such as robots. However, this study focused on improving the system using visual information in the existing OCSR API system and showed a low error rate in a noisy environment; as a result, a high recognition performance was demonstrated. This study presents a model that achieves a low error rate even in noisy environments using deep learning-based audio and visual information compared to the existing OCSR APIs that rely solely on audio information.
3. Architecture of the Proposed Model
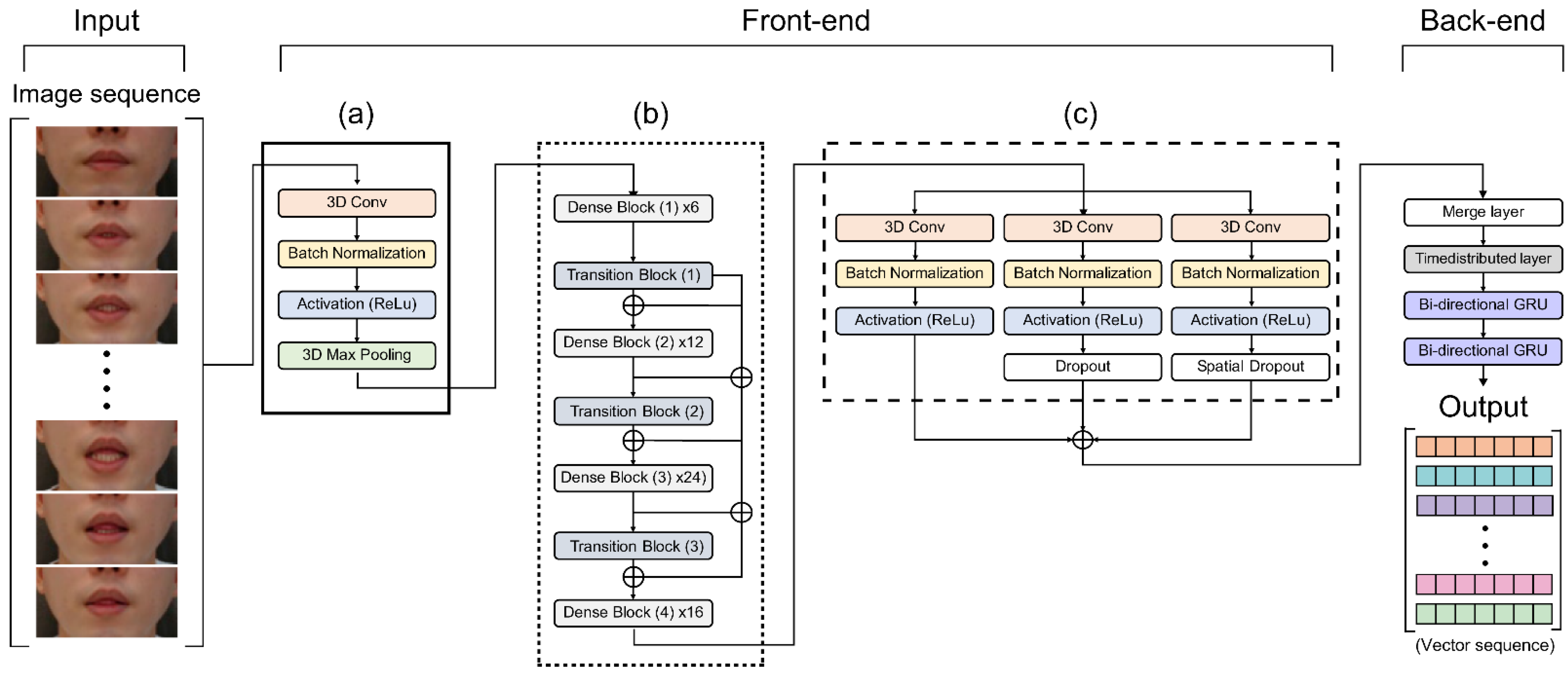
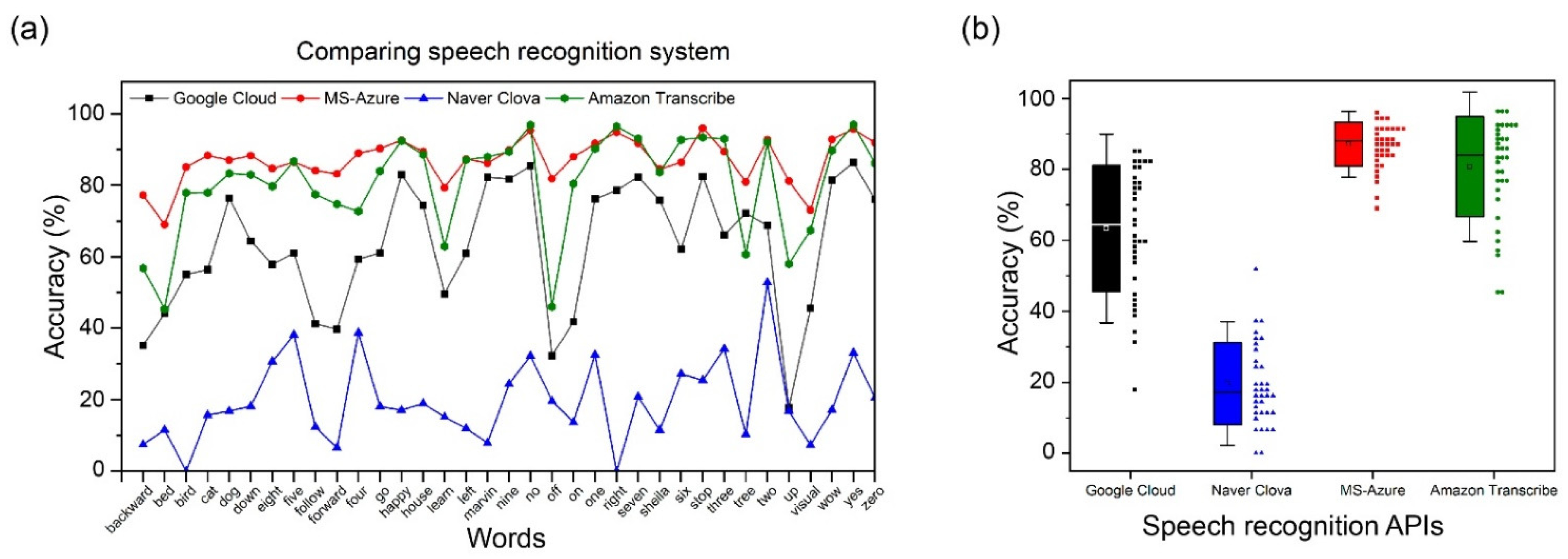
Our lipreading system is combined with existing cloud-based speech recognition systems, and the proposed audio-visual speech recognition system is shown in
Figure 2. The audio architecture among Microsoft, Google, Amazon, and Naver was compared to select and combine the best performing OCSR API. The vision architecture of the proposed model was combined with the following feature extraction methods: LipNet (used as the baseline method), LeNet-5, Autoencoder, ResNet-50, DenseNet-121, and multi-layer CNN, all of which exhibit exceptional feature performance.
In all speech recognition engines, the user’s voice is transmitted to the recognition system using a microphone (
Figure 2). To this end, we used two generic algorithms. The voice was processed on a local device, and the recorded voice was forwarded to a cloud server provided by Google or Microsoft for additional processing. Microsoft Cortana and Google are commercial engines that simultaneously separate speech recognition systems into closed and open-source code systems [
29]. Speech recognition in OCSR APIs, which is a type of closed source, allows the rapid and easy construction of application speech recognition systems. Application speech recognition systems can be developed easily using OCSR APIs and are therefore gaining traction in a variety of sectors. Thus, developers of application speech recognition systems need to select suitable OCSR APIs based on the function and performance of the system. Furthermore, the performance of OCSR APIs varies depending on the date of the research and the type of learning data. Words output from the OCSR API are represented by word vectors using Google’s pre-trained Google’s Word2Vec model. Word2Vec is a set of shallow neural network models developed by Mikolov et al. to build “high-quality distributed vector representations that capture a large number of exact syntactic and semantic word associations” [
30,
31]. The dimensions of these word vector representations, also known as word embeddings, can be in the hundreds. To represent a document, word embeddings can be concatenated. Google has provided a Word2Vec model that has been pre-trained on the 100 billion words in the Google News corpus, resulting in 3 million 300-dimension word embeddings for academics. Therefore, five-word list were outputted and converted into 300-dimensional vectors and summed into one single vector (
Figure 2).
As mentioned above, we present a deep-learning-based VSR architecture and propose a new feature extraction method (
Figure 2).
Figure 3 and
Supplementary Table S1 shows the detailed hyperparameters of the proposed architecture.
3.1. Convolutional Layer
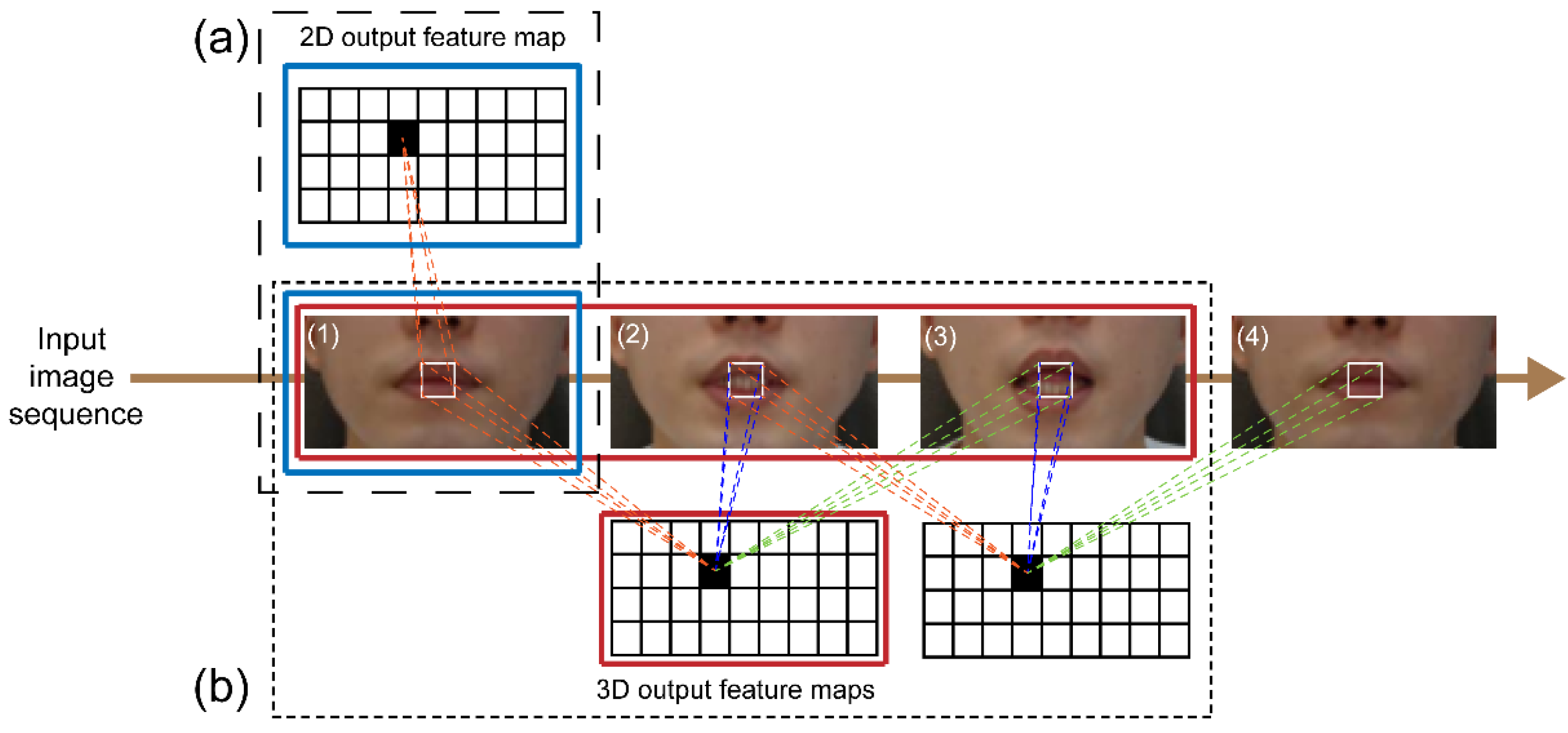
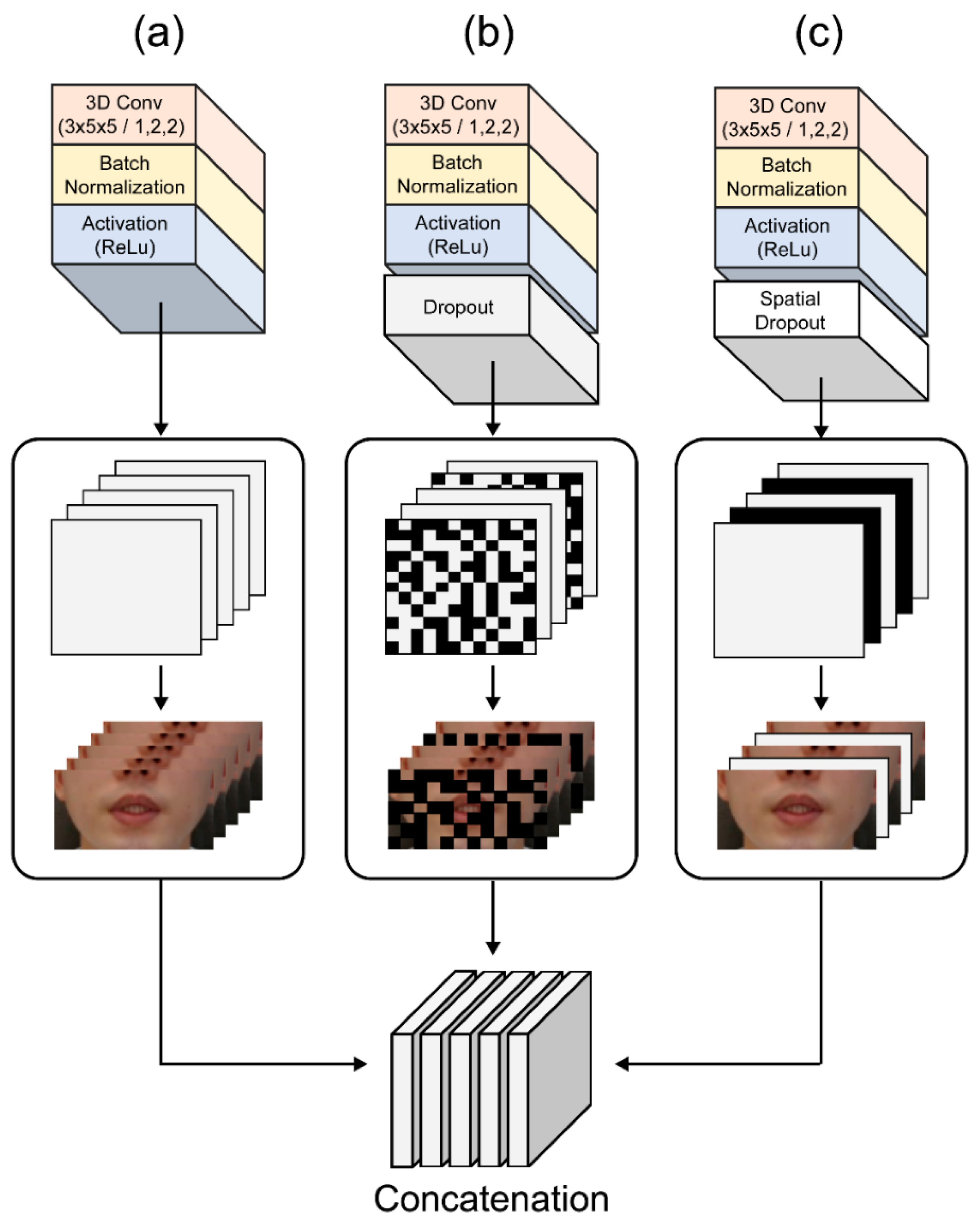
CNNs use raw input data directly, which results in the automation of the feature development process. For image recognition, a 2D CNN is used to collect encoded information for a single picture dataset and to convert that information to 2D feature maps for computing features from spatial dimensions. However, the motion information contained in numerous contiguous frames fails when utilizing a 2D CNN for video recognition (
Figure 4a). We used a spatial-temporal 3D CNN to calculate spatial and temporal features to capture distinct lip-reading actuations around the lips, such as tongue and teeth movements. When spatial and temporal information from following frames is considered, 3D CNNs have been found to be effective in extracting attributes from video frames in several experiments [
16,
22] (
Figure 4b).
In this experiment, all consecutive frames input to encode the visual information of the lips were transmitted to the CNN layers in 64 3D kernels with a size of 3 × 7 × 7 to obtain feature information, as shown in
Figure 3a. We reduced the internal covariate transformation using a batch normalization (BN) layer and ReLU to accelerate the training process. Additionally, a max-pooling 3D layer was added to reduce the spatial scale of the 3D feature maps (
Supplementary Figure S1a).
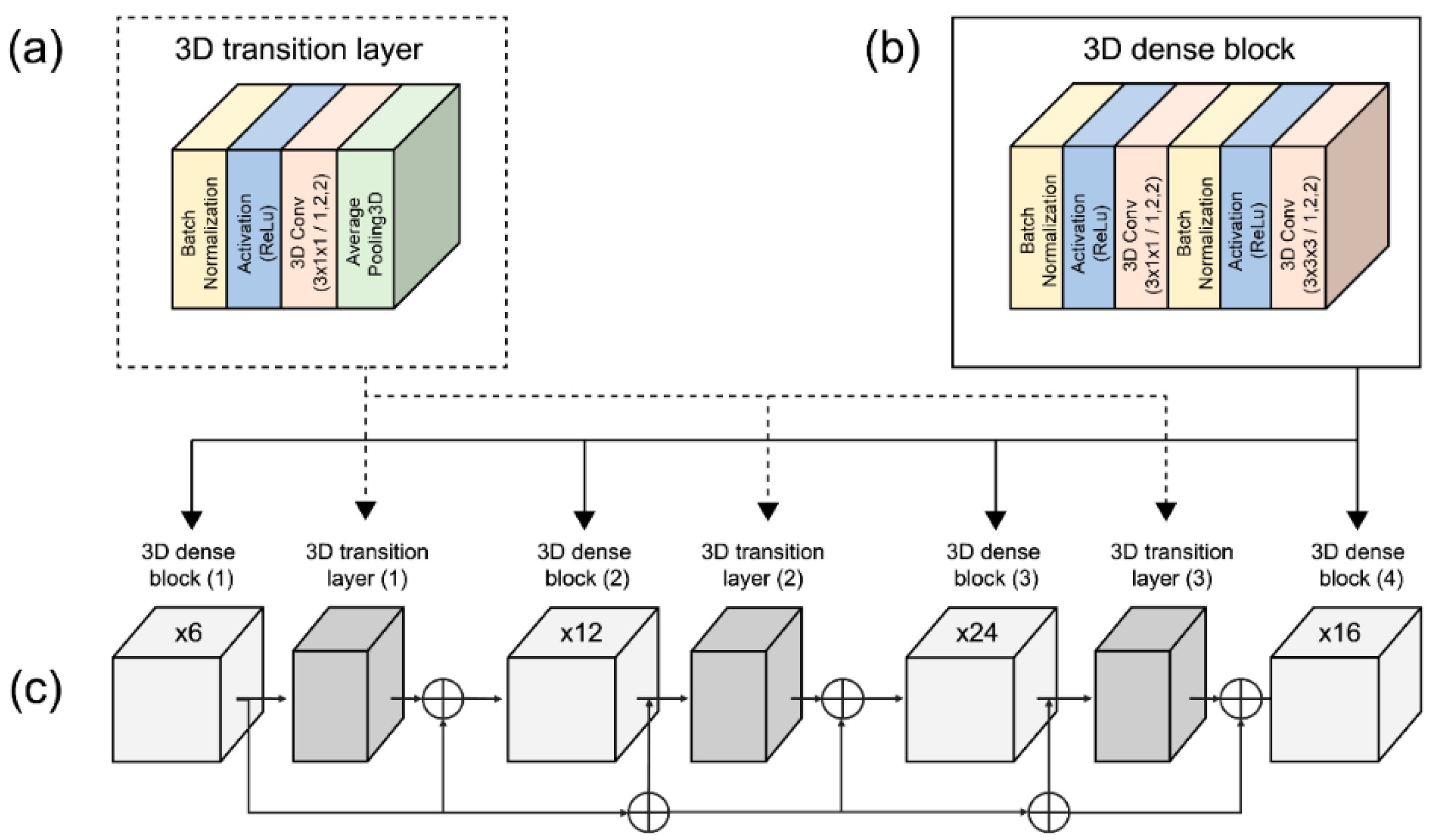
A dense connection CNN generates relationships between multiple connected layers, allowing for full feature usage, vanishing gradient, and network depth. The input features are decreased by the bottleneck layer placed prior to the convolution layer. As a result, following the bottleneck layer operation, multichannel feature volumes are fused. Because the previous features are still present, the subsequent layer is only applied to a small number of feature volumes. Transition layers are also incorporated to increase model compactness due to the hyperparameter theta that controls the degree of compression. A decreased growth rate was achieved by using bottleneck and transition layers, resulting in a narrower network, reduced model parameters, efficiently controlled overfitting, and reduced processing resources.
We implemented the 3D dense connection CNN architecture comprising transition layers and dense blocks, as shown in
Figure 5. The transition layers (
Figure 5a) are connected in the following order: BN layer, ReLU, 3D convolution layer (3 × 1 × 1), and average pooling 3D layer (2 × 2 × 2). The dense blocks (
Figure 5b) are organized in the following order: BN layer, ReLU, 3D convolution layer (3 × 1 × 1), BN layer, ReLU, 3D convolution layer, and 3D convolution layers (3 × 3 × 3).
To date, image classification tasks handled with various CNN models have demonstrated exceptional performance. For example, using the fusion of several CNNs for feature aggregation, it is feasible to extract diverse spatial and temporal information by building different scales and depths [
32]. In addition, a different convolutional layer can extract different features for the multilayer 3D CNN training phase to obtain more diverse feature information. Furthermore, by using different depths and filters of varying sizes, multiple features may be created from this training process. Certain associated qualities that were lost in the layered design can be chosen using this strategy, resulting in a richer final feature. The suggested multilayer 3D CNN architecture is shown in
Figure 3c. The first module follows the 3D dense connection convolution layer output feature in the order of a 3D convolution layer (64 3D kernels of size 3 × 5 × 5) and then a BN-ReLU layer (
Figure 6a). The second module (
Figure 6b) includes a dropout layer to prevent overtraining and overfitting that improves and generalizes the CNN’s performance by preventing strongly correlated activations. This is important because of the small size of the benchmark dataset compared to other image datasets [
24]. The structure of the third module drops the entire feature map by adding a spatial dropout layer to the structure of the first module (
Figure 6c). Unlike the traditional dropout method that removes pixels at random, this method uses CNN models with significant spatial correlation to provide superior picture categorization [
33]. As a result, we used a spatial dropout layer to efficiently extract the shape of the lips, teeth, and tongue, which are fine movements around the mouth, with a significant spatial correlation.
3.2. Structure of Comparative Feature Extraction Methods
We compared the proposed method to other feature extraction methods, such as LipNet, LeNet-5, CNN Autoencoder, and ResNet-50, which all exhibit an outstanding feature extraction performance. The feature extraction method of LipNet as a baseline comprises 3 × (spatiotemporal convolutions, channel-wise dropout, and spatial max-pooling) [
22]. LeNet-5 is the earliest model of deep learning and uses a gradient-based CNN structure for handwritten digital recognition [
34]. The input layer of a typical LeNet-5 structure diagram is a handwritten digital image of 0 with a size of 32 × 32, whereas the output layer comprises 10 nodes corresponding to 0. LeNet-5 comprises six layers in total, namely the input and output layers: three convolutional layers, two pooling levels, and one fully connected layer. Convolutional core sizes in the convolutional and pooling layers were set to 5 × 5 and 2 × 2, respectively. However, the training parameters were reduced when the connection layer decreased the number of neurons from 120 to 84. Thus, an unsupervised model that learns to rebuild the input is used as a typical autoencoder [
35].
In several domains, such as speech recognition and computer vision, deep learning models can learn intricate hierarchical nonlinear features that can provide superior representations of original data [
36]. Encoder, hidden, and decoder layers comprise the autoencoder. The hidden layer’s input is the encoder layer’s output, and the decoder layer’s input is the encoder layer’s output. We created an autoencoder model using LipNet’s feature extraction method for experimental comparison. ResNet-50, a convolutional neural network with 50 layers, is a ResNet [
37] version comprising 48 convolution layers, a MaxPool layer, and an average pool layer. The deep residual learning architecture lies at the heart of ResNet. ResNet-50 is substantially smaller than other current designs, with 50 layers and over 23 million trainable parameters; extremely deep neural networks can be employed to circumvent the vanishing gradient problem.
3.3. Recurrent Layer
The GRU is one of the recurrent neural networks and is a method of governing and propagating information flow across many time stages [
25]. GRUs are derived from LSTM units that determine what information should be carried forward and which should be disregarded. Given that the 3D CNN only captures brief viseme-level data, it may be able to comprehend wider temporal contexts, which is beneficial for ambiguity detection. Because the GRU uses update and reset gates, the gradient vanishing problem can also be overcome. A bi-directional GRU is used as a sequence processing module in the proposed architecture. Compared to typical GRU deployment, a bi-directional GRU provides information in both forward and backward directions to two distinct neural network topologies coupled to the same output layer, allowing both networks to gain full knowledge of the input.
3.4. Transcription Layer
We used the CTC method, which employs a loss function to parameterize the distribution of a label token sequence without requiring the alignment of the input sequence to an end-to-end deep neural network. CTC is conditionally independent of the marginal distributions established at each time step of the temporal module as it restricts the usage of autoregressive connections to manage the inter-time-step dependencies of the label sequence. Therefore, CTC models are decoded using a beam search procedure to restore label temporal dependence, and the language model’s probabilities are mixed.
6. Discussion
In recent years, the ASR technology has significantly improved because of the exponential increase in large data and processing power, which has made it possible to create complex applications such as voice search and interactions with mobile devices, voice control in home entertainment systems, and various speech-centric information processing applications that benefit from the downstream processing of ASR outputs [
3]. Considering that OCSR APIs must function appropriately in demanding acoustic scenarios compared to those in the past, noise robustness has become an essential core technology for large-scale, real-world applications.
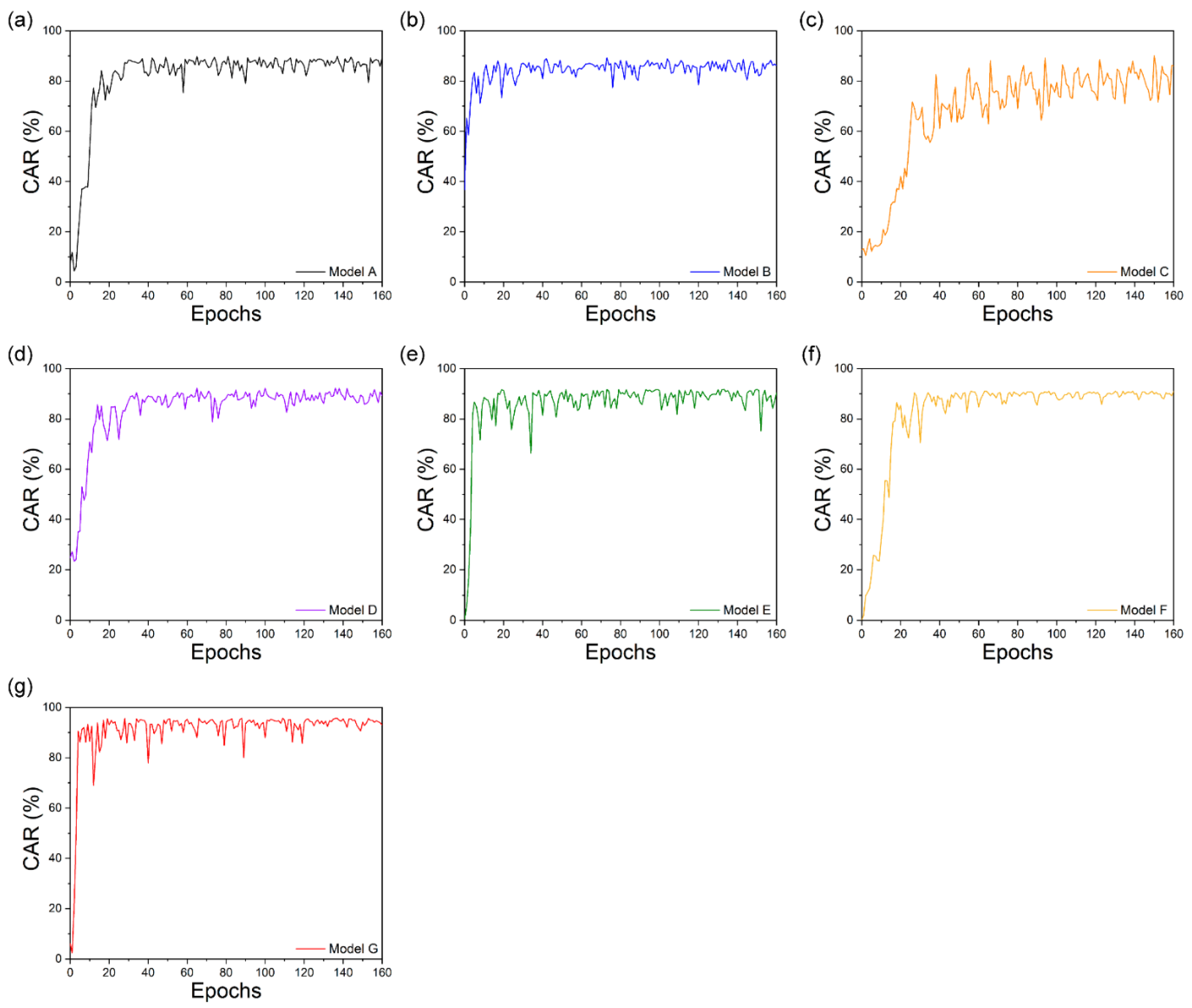
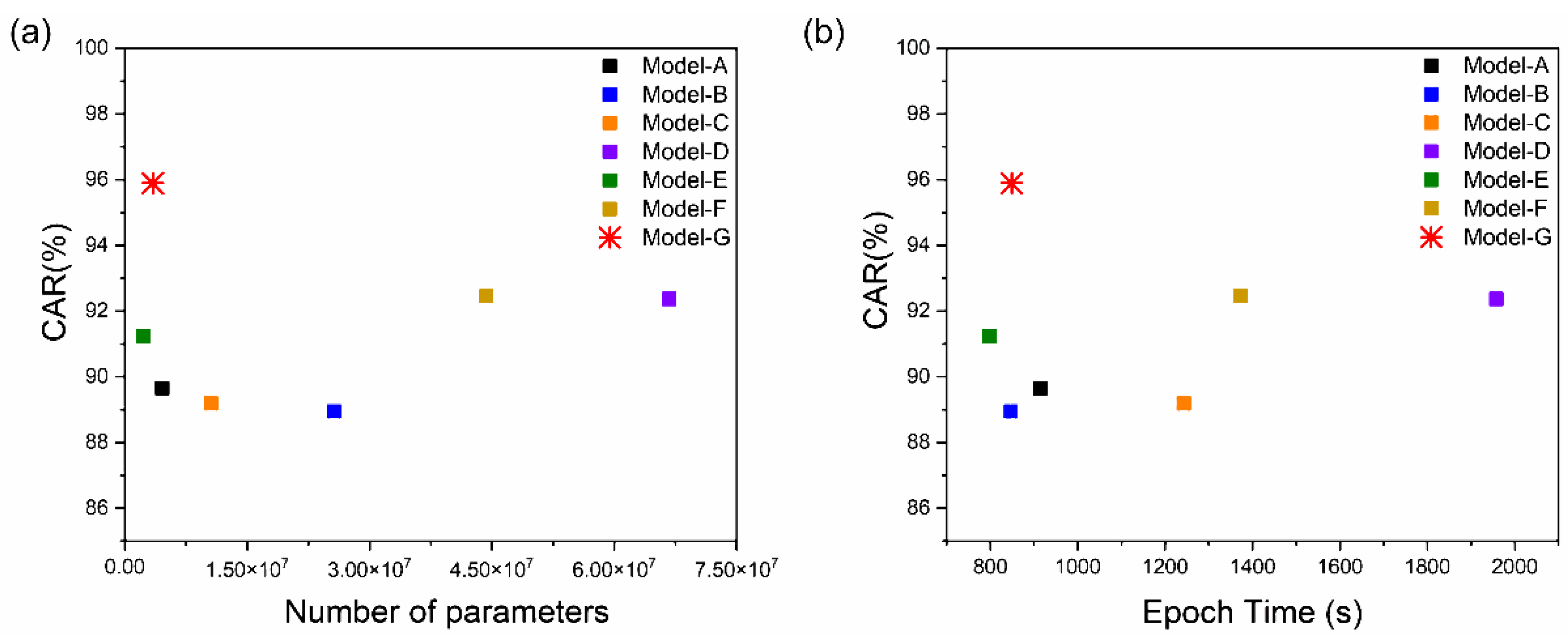
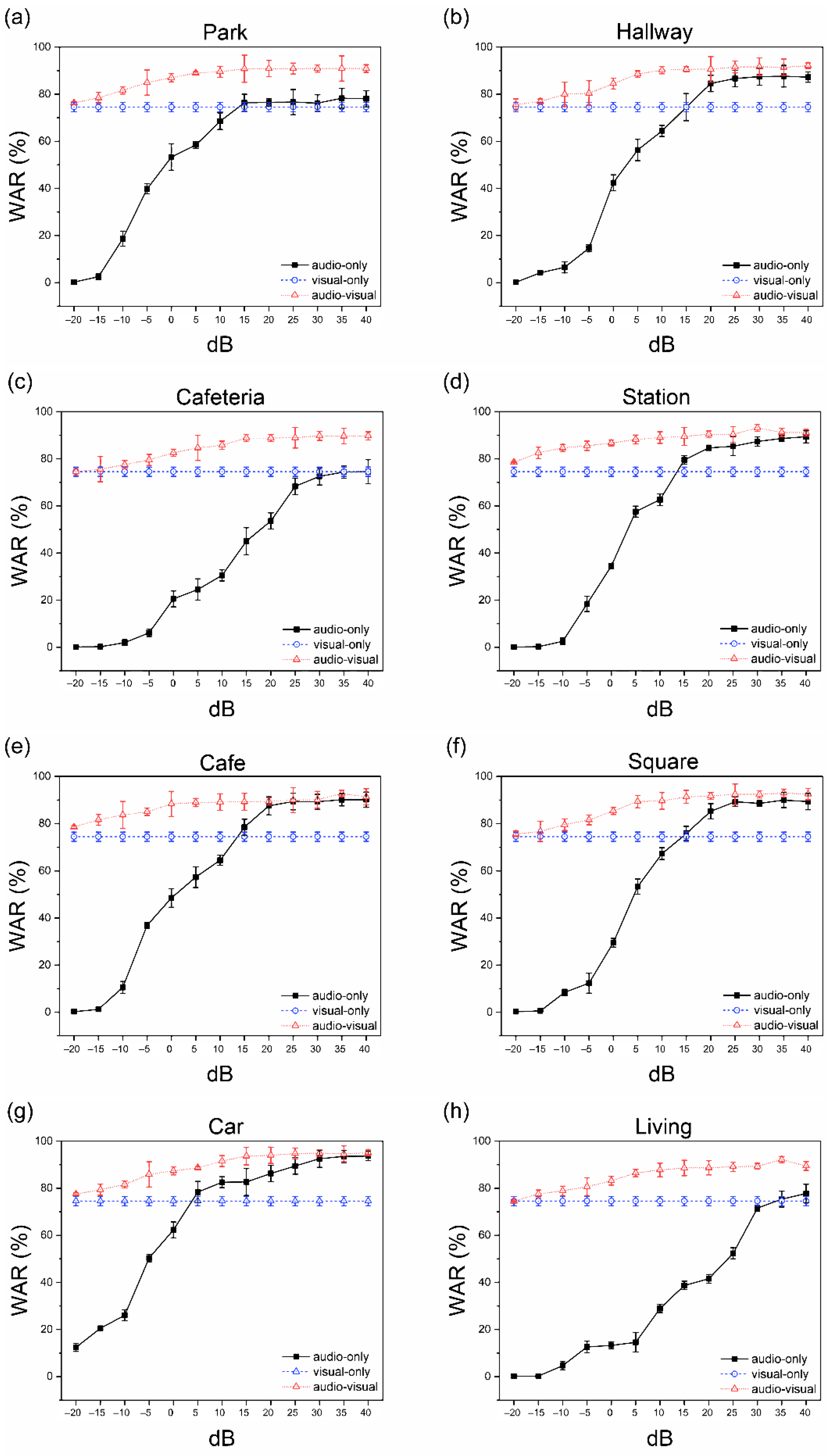
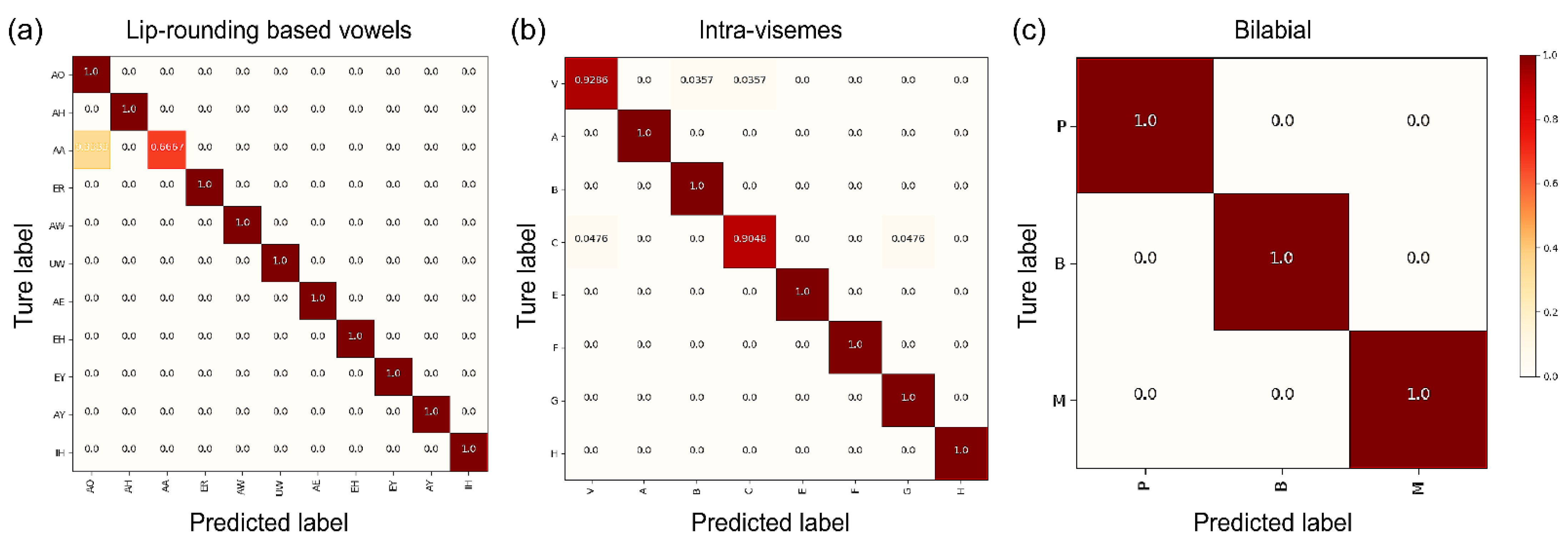
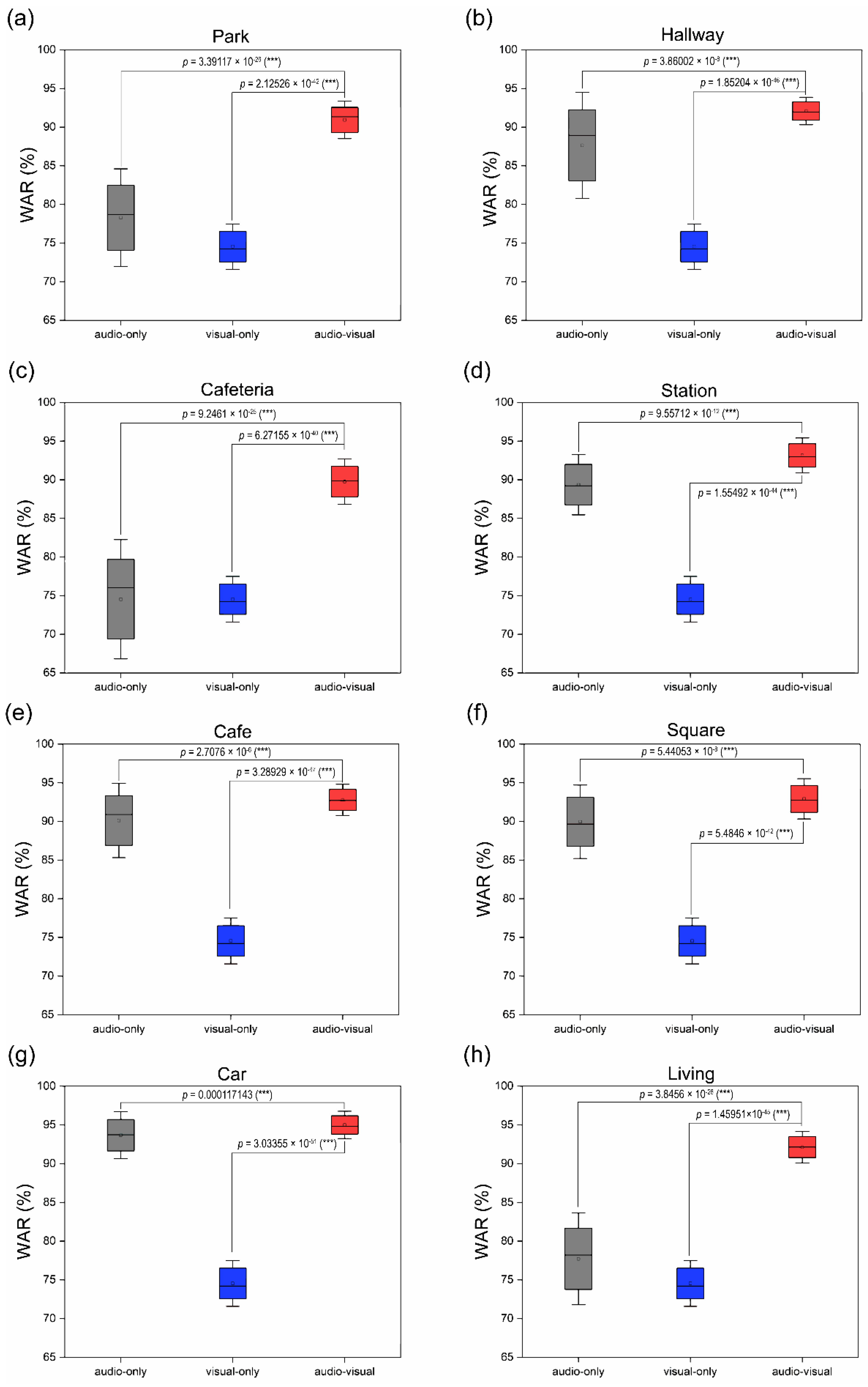
This study proposes noise-robust OCSR APIs based on an end-to-end lip-reading architecture for practical applications in various environments. We compared the performance of five OCSR APIs with excellent performance ability. Among all OCSR APIs, Microsoft’s API achieved the best performance on the Google Speech Command Dataset V2. Further, we evaluated the performance of several deep-learning models that analyzed visual information to predict keyword sequences. The results show that the proposed architecture achieves the best performance. Moreover, the proposed system requires fewer parameters and provides faster training times than those of the existing models. Compared to the baseline model, the proposed model decreased the number of parameters by 11.2 M and increased the accuracy by 6.239%.
We measured the SNR of the combined proposed system by synthesizing eight noise data and OCSR API outputs to compare the performance for various noise environments. Audio-based speech recognition systems, which showed excellent performance in only specific environment such as a car, demonstrated stable and excellent performance in all environments using visual information.
Supplementary Table S6 shows the highest word accuracy and standard deviation values for each of the eight environments. The lowest and highest recognition rates of audio-based speech recognition were calculated as 74.53% and 95.01%, respectively, with a difference of 19.15%, which indicates a significant performance difference based on the specific environment. However, the difference between the two performances was reduced from 19.15% to 5.25% by adding visual information using multimodal interaction methods, and the same performance was achieved in several environments. To solve problems based on the type of environment, two sets of experiments (A, V, and AV) were conducted; stable performances were observed in all environments. The proposed system showed consistent performance in various environments compared to the performance of conventional audio-based speech recognition, which showed excellent performance in only specific environments.
7. Conclusions
We demonstrated a speech recognition system robust to noise using multimodal interaction based on visual information. Our system consisted of an architecture that combines audio and visual information, and its performance was evaluated under eight noise environments. Unlike conventional speech recognition, which shows high performance only in specific environments, we showed the same stable high performance in various noise environments, and simultaneously showed that visual information contributed to improving speech recognition. Therefore, our method showed a stable and high performance in various noise environments by combining lip-reading, a technology that can enhance the speech recognition system, with existing cloud-based speech recognition systems. This system has potential in various applications, such as IoT and robot applications, that use speech recognition in noise and can be useful in various real-life applications where speech recognition is frequently used, particularly indoors, including hallways, cars, and stations, and outdoors, such as parks, cafés, and squares.
Future Work
Multimodal interactions based on visual information must be used to produce noise-resistant ASR. The proposed system may be helpful for patients who have difficulty in conversation owing to problems with speech recognition in noisy environments. However, applying this technology to conversation recognition is problematic. Therefore, we will seek to expand the system’s capabilities to identify phrases rather than individual words in the future. We will also examine the performance of the suggested system in real-world settings involving humans and machines. Despite the intense effort invested into the development of an accurate speech recognition system, the development of a lightweight system that is robust with respect to real-life circumstances while accounting for all uncertainties is still challenging.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}