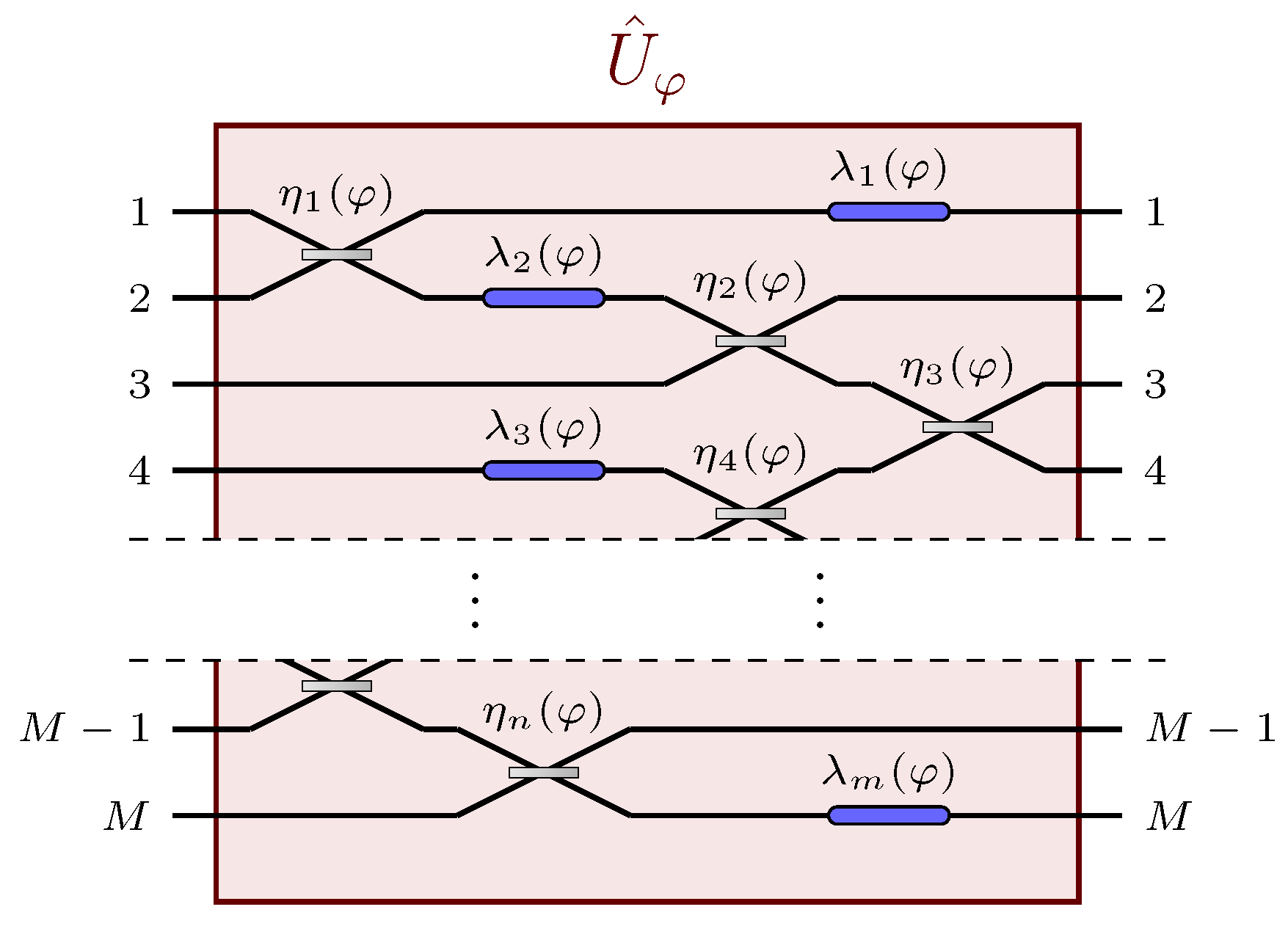
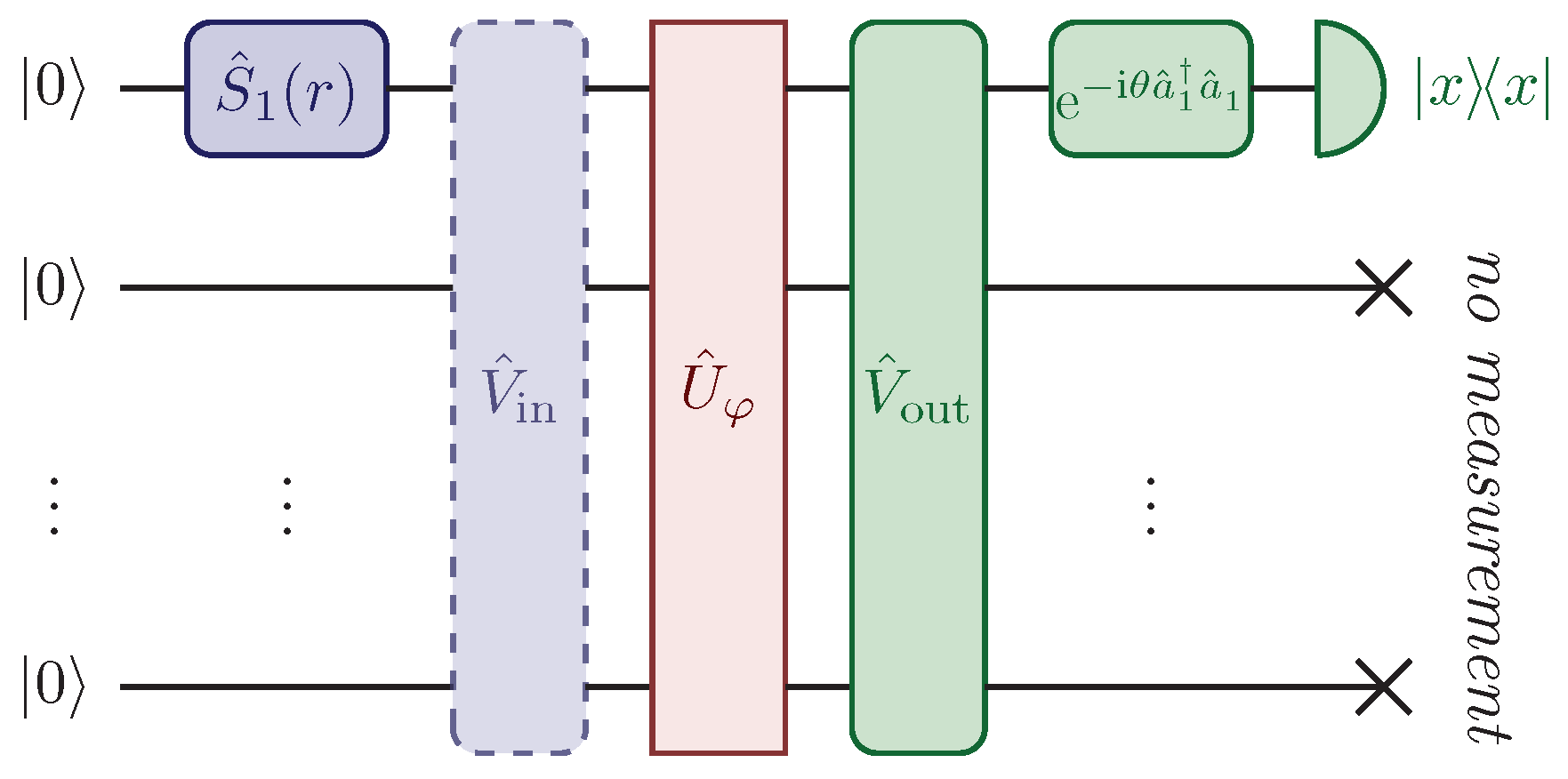
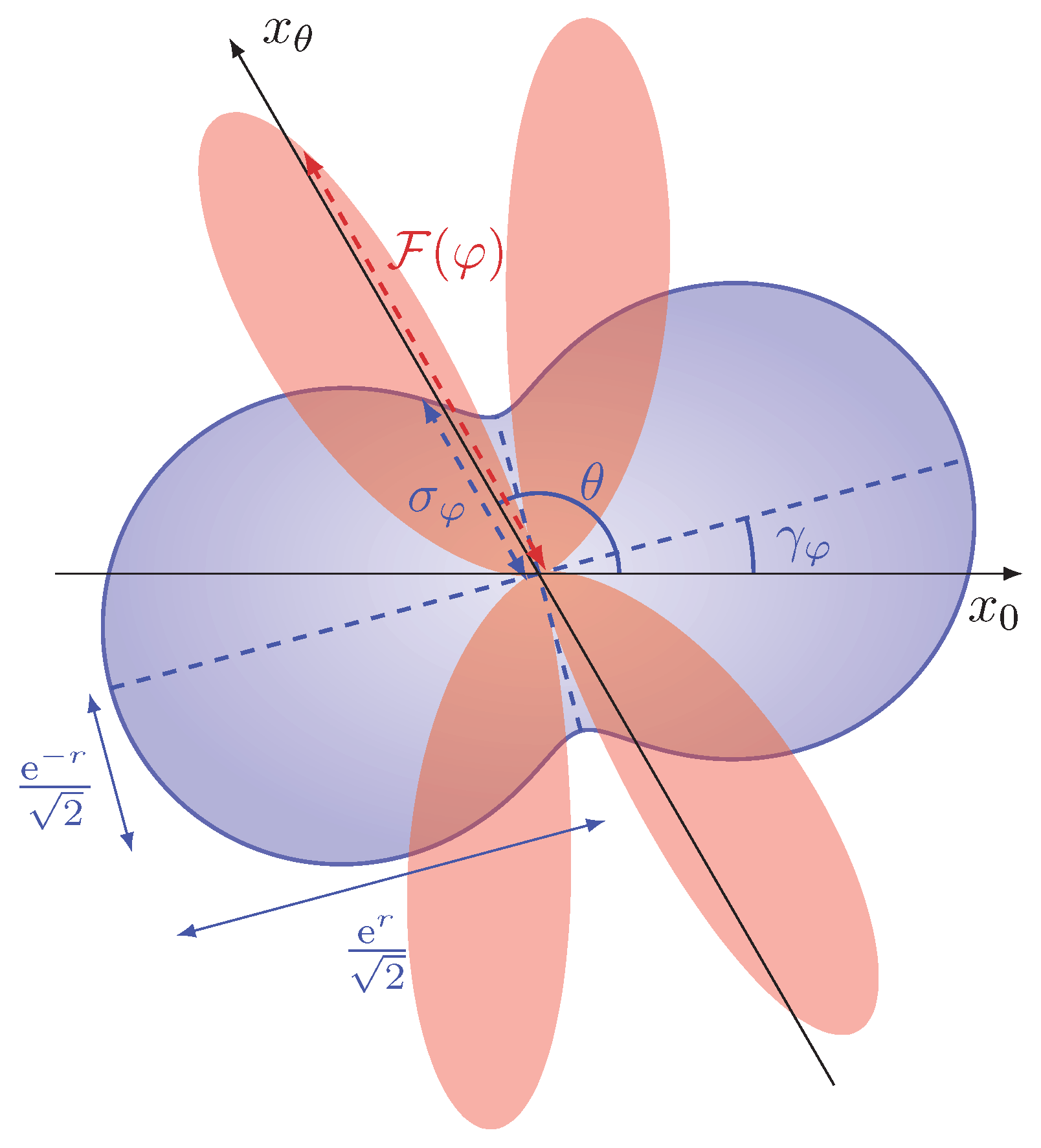
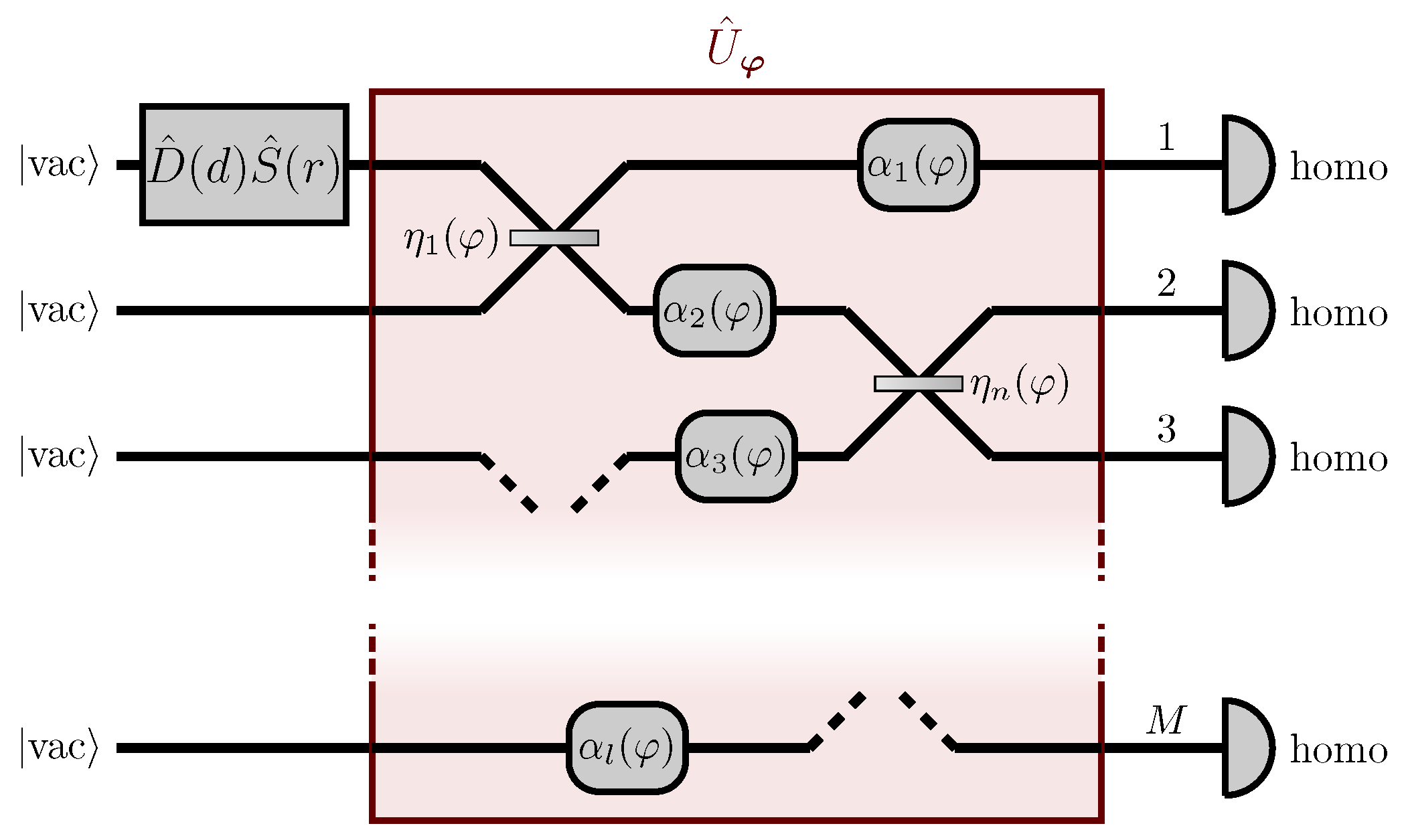
2.1. Setup
Let us consider a
M-channel passive linear network, whose action on the state of the probe is described by the unitary operator
,
being a single, generally distributed, unknown parameter we are interested to estimate. Due to its passive and linear nature, this network can be represented by a unitary matrix. Let then,
be the
unitary matrix representing the action of
on the annihilation operators
,
, associated with each channel of the network, satisfying the commutation relations
,
, where we denote with
the Kronecker delta. The matrix
is thus defined by the transformation
We will consider a single-mode squeezed state
as a probe, with
squeezing operator and
average number of photons, all injected in a single channel of the apparatus, i.e., the first one with the choice of squeezing parameters
in Equation (
2). In other words, the state
presents a non-vanishing number of photons only in the first mode. As discussed in
Section 1, the approach of squeezing-based estimation strategies is to infer the value of
from the transformation of the covariance matrix
of the state
after the interferometric evolution
. To do so, we will consider the model where a single output channel, say the first, is measured through homodyne detection. We will denote with
the phase of the local oscillator, which coincides with the phase of the measured quadrature
. We will assume that
without loss of generality. We notice that, with this assumption, the squeezed quadrature of the state
is
, with
, while the anti-squeezed quadrature field is
, with
. In terms of the creation and annihilation operators, the measured quadrature field can be expressed as
.
Since the linear network
is arbitrary, the average number of photons that can be actually detected after the interferometric evolution ranges between 0 and
N. Naturally, if this number were to be small, or far from
N, we would expect a sub-optimal performance of the estimation scheme, since most of the photons would come out of the network
from channels that are not observed, and information on
would in this way be lost. Moreover, it may happen that the transformation that it imposes on the probe in the transition to the first output port is trivial, namely that the element
of the transition amplitude matrix
does not depend on
. This occurrence would preclude the probe from acquiring any observable information on the parameter. In order to prevent these conditions from happening, this model includes the presence of two auxiliary linear and passive networks acting on the probe,
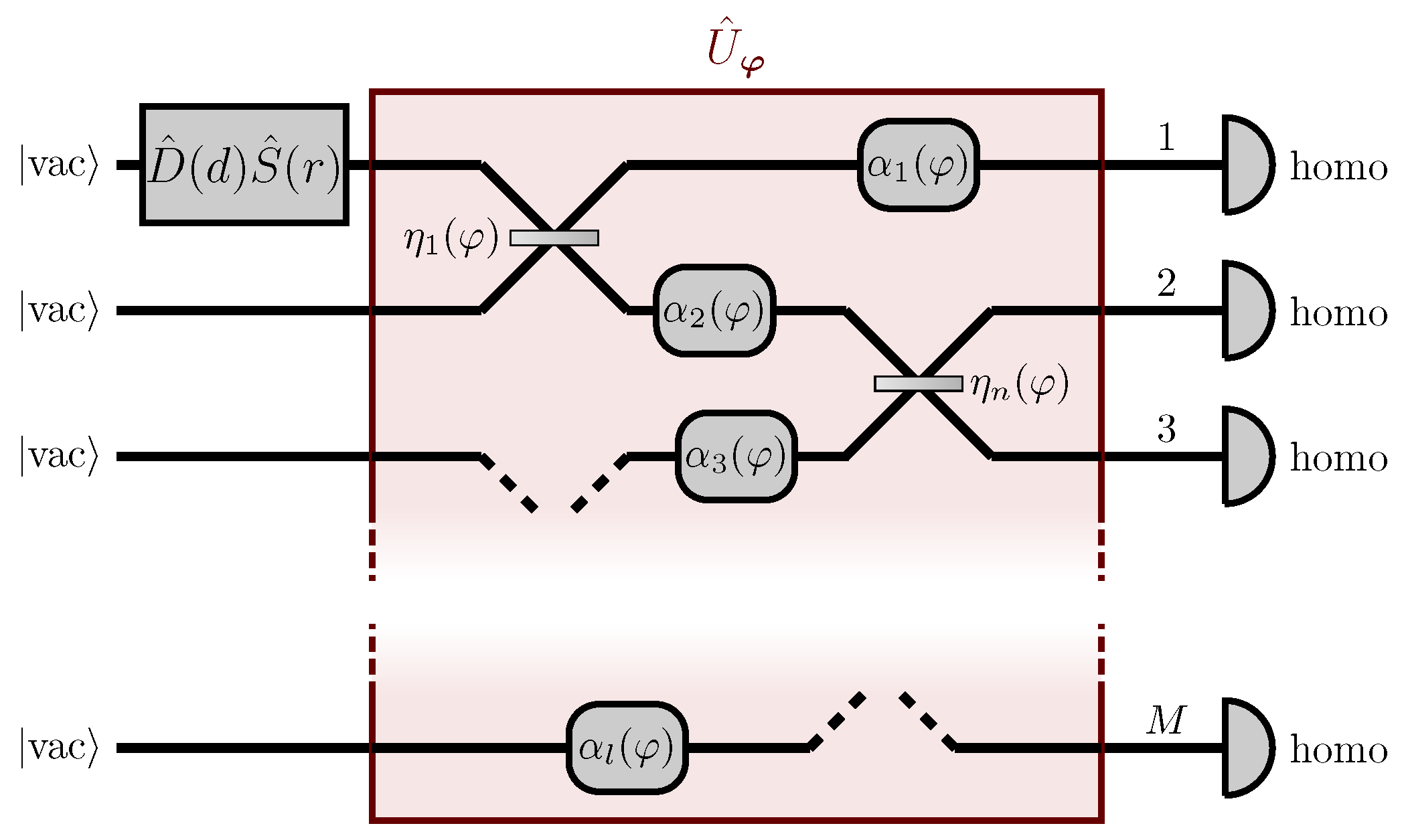
before and
after the linear network
(see
Figure 2). The first auxiliary stage
can be understood as network scattering, which distributes the probe through multiple input channels of the parameter-dependent network
. The purpose of the second stage
is instead to refocus the probe, after the interaction with
, into the only observed channel. The unitary matrix describing the overall network is thus
given by the matrix product of the three single matrix representations
,
and
.
Since in this model all the photons are injected in the first input channel, which is also the only channel observed at the output, the only relevant transition amplitude is the element
of the overall unitary matrix in Equation (
3). We can then rewrite
where
is the probability that a single photon injected in the first port is detected at the first output port of the overall network, and
is the phase acquired by the probe during the interferometric evolution. The Gaussian nature of the probe and of the homodyne measurements yield a Gaussian probability density function
which governs the outcomes of the homodyne detection [
18,
19,
20,
21]. The univariate Gaussian probability density function in Equation (
5) is centred at zero due to the absence of a displacement in the probe, while its variance is given by (see
Appendix A)
where
is the phase of the local oscillator.
Once the probability density function
is known, it is possible to evaluate the Fisher information [
44,
45]
of the estimation scheme, which in turn fixes the ultimate precision
achievable in the estimation of
through
iteration of the measurement, given by the Cramer-Rao bound [
44,
45]
For a Gaussian distribution centred on zero, the Fisher information reads (see
Appendix B)
where
. We notice from Equation (
6) that all the information on the parameter
is encoded in the variance
of the measured quadrature
through the two quantities
and
. Thus, we can split
into two contributions, one containing the derivative of
, the other the derivative of
, namely
where
and
are derivatives with respect to
and
, respectively, so that
2.2. Heisenberg Scaling
Generally, without imposing any condition on the setup, this model does not achieve the Heisenberg scaling in the precision for the estimation of
. In fact, we can explicitly rewrite the variance
in Equation (
6) in terms of the average number of photons
in the probe
where
is a term of order equal to or smaller than 1, negligible in the asymptotic regime of
N large (We will say that given two functions
and
,
when
). We can also rewrite the derivatives
and
in terms of
NPlugging the asymptotics shown in Equations (
12) and (
13) into the expression of the Fisher information in Equation (
9), we notice that the numerator of
can be of the order
at most. Since the denominator is in general of the order
as well, it yields an overall general scaling of the Fisher information of
—i.e., even lower than the SQL.
In order for this setup to reach the Heisenberg scaling, we thus need to impose some constraints which prevent the denominator of the Fisher information, i.e., the variance
, to grow with
N. We show in
Appendix C that the asymptotic conditions (Given a function
and a finite sum
of powers of
N, we will say that
when they show the same asymptotic behaviour. In formulas,
when
,
, with
s exponent of the smallest power of
N appearing in the sum
)
need to be satisfied for large
N, with
and
arbitrary constant independent of
N. We will discuss more in detail the physical meaning of these conditions in
Section 2.3, and we will see that Equation (
14) is a minimum-resolution requirement on the tuning of the local oscillator, while Equation (15) is the condition on the refocusing of the probe. Intuitively, Equations (
14) and (15) assure that
at the denominator of
does not grow as fast as
at the numerator: instead, we can see in
Appendix C that, when these conditions hold, the variance
becomes of the order
, while its derivative
remains constant for large
N. In particular, we show in
Appendix C that the Fisher information in Equation (
9) asymptotically reads
proving the achievement of the Heisenberg scaling, with
positive factor reaching its maximum value for
and
, namely
.
Compared with the conditions found in the literature for single-parameter Gaussian estimation schemes based on squeezed-vacuum probes which, adjusted to the notation employed so far, can be translated into
and
[
26,
27], we see that Equations (
14) and (15) achieve two important further results
It is possible to loosen the optimal conditions found in literature, which still allow us to reach the Heisenberg scaling, at the price of a multiplying factor which does not depend on N and hence does not ruin the scaling of the precision;
These conditions are explicitly expressed in terms of the average number
N of photons in the probe and, therefore, in terms of the precision we want to achieve. In
Section 2.3, we will discuss how this allows us to assess the precision needed to engineer suitable auxiliary stages
and
to reach the Heisenberg scaling, showing that it is possible to avoid an iterative adaptation of the optical network.
Lastly, we recall that it is always possible to asymptotically saturate the Cramér-Rao bound in Equation (
8) in the limit
of samples with a large number
of observations. In particular, the maximum-likelihood estimator
is an asymptotically efficient and Gaussian estimator which can be obtained through the maximisation of the Likelihood function
associated with the set
of the
measurement outcomes of the quadrature field
[
44,
45]. In
Appendix D we see that the non-trivial solution which maximises the Likelihood function
in Equation (
18) is simply given by the estimator
satisfying
where
is the variance
in Equation (
6) as a function of
, and
is the usual sample variance
Generally, Equation (
19) cannot be solved analytically, so that numerical methods need to be employed to find non-trivial solutions. Nevertheless, it is possible to find some exceptions, particularly for elementary functional dependencies of
and
on the unknown parameter
. For example, in the case for which
is independent of
, and the functional dependence of
on
of the phase acquired by the probe is invertible, the function
in Equation (
19) can be easily inverted as well, and the maximum-likelihood estimator reads
We can notice how, due to the presence of the cosine in
in Equation (
6), some prior knowledge on the parameter
is required in order to correctly choose the invertibility interval for
—i.e., to choose the correct value of
and the sign of the arccos function in Equation (
21). In the next section, we will see how a classical prior knowledge of the parameter
is required to satisfy condition (15), achievable with a prior coarse estimation reaching an uncertainty of the order of
. Such prior knowledge on the parameter, for a large enough
N, can be employed to choose the correct invertibility interval.
2.3. Conditions for the Heisenberg Scaling
We can see that both conditions in Equations (
14) and (15) are
-dependent, suggesting that an adaptive procedure must take place in order to employ the estimation scheme described in
Section 2.1, as it is customary for ab-initio Gaussian estimation strategies [
24,
27,
35,
36,
37]. However, some considerations can be made in this regard.
Condition (
14) fixes the phase of the quadrature
which needs to be measured. The quantity
is in fact the phase acquired by the squeezed vacuum during the interferometric evolution from the first input port to the first output port, and for
Equation (
14) resembles the condition
found in the literature for single-phase estimation [
24]. On the other hand, condition (
14) is a looser condition to reach the Heisenberg scaling, and it puts in relation the precision with which we are able to choose the phase
of the local oscillator—given by the resolution of the homodyne detection apparatus—with the precision achievable in the estimation of
. In particular, it is evident how the minimum resolution for the homodyne detector required to reach an uncertainty
of order
must be, in turn, of order
. This is in agreement with the common notion in metrology for which a sensor cannot detect changes in the quantity that is being measured which are smaller than its resolution.
Interestingly, we notice from Equation (
14) that the constant
k cannot be equal to zero. Counterintuitively, the value
coincides with the choice of measuring the quadrature
, namely the minimum-variance quadrature after the squeezed vacuum undergoes a phase-shift of magnitude
, i.e., after the interferometric evolution given by
in Equation (
3). This apparent incongruity can be explained by observing the expression of
in Equation (
10). Differently from displacement-encoding approaches—in which the information on the parameter is obtained from the transformation of the displacement of the probe, and thus minimizing the noise of the signal is always the optimal choice—here the value of
is encoded in the variance of the quadrature itself. For us to be able to extract information on the parameter, the variance of the signal needs to be sensitive to small variations in
—i.e., the derivative
must be non-vanishing. Of the two contributions of
in Equation (
10), the one originating from the variations in
is identically vanishing when condition (15) is satisfied, since
for
close to its maximum. The remaining contribution derives from the variations in the overall phase
, and the variance of the maximally squeezed quadrature
is a stationary point with respect to variations in the phase
and is thus insensitive to
, namely
for
in Equation (
11) (See
Figure 3).
Condition (15) is the requirement that most of the photons injected into the network end up in the observed output channel. In fact, this condition can be rewritten in terms of the average number of photons that are not correctly refocused
. Thus, condition (15) tells us that the number of photons which are not observed must be a constant
ℓ, not growing with
N. In other words, this condition assures that most of the information on
encoded in the probe is not lost in channels that are not observed. As a matter of fact, we can see from Equation (
6) that the variance of the observed quadrature
after the interferometric evolution is the convex combination of the variances of a squeezed vacuum and the pure vacuum, with coefficients
and
, respectively. In order for this variance to be ‘squeezed’, in the sense that it is of order
, the contribution from the pure vacuum must be of order
, namely
.
This condition can also be seen as a requirement of the performance of the refocusing stage
. In fact, in order to satisfy condition (15) for a given choice of
, the auxiliary stage
must be chosen so that
. As discussed earlier, this implies that, in general, the auxiliary stage
which satisfies this condition depends on the value of the parameter itself, requiring an adaptive approach to find an optimal refocusing stage to reach the Heisenberg scaling. We show now that the information on
required to engineer an adequate refocusing stage to reach the Heisenberg scaling can be obtained through a classical estimation strategy, namely that which achieves the scaling
typical of the shot-noise limit. This result is due to the structure of
, which is essentially a transition probability
between the unitary vectors
and
, with
. Hence, a small tilt of order
between the unit vectors
and
yields a quadratic reduction in their transition probability. To prove this, we will call
the rough guess of the value of
that is sufficiently precise to engineer a refocusing stage
which satisfy condition (15), and we will show that the estimation strategy to obtain this rough estimate of
is classical, namely that the error
associated with the prior rough estimation is allowed to be of order
. For a given choice of
and
ℓ, we will call
a solution of Equation (15). The single-photon transition probability
appearing in this condition can be written as the squared complex modulus of the scalar product of two
M-dimensional complex vectors
and
, with
. We can then write
where the transition probability
is a smooth function of
and
, with a locus of points of maxima along the condition
, since, for a perfect knowledge of the parameter the auxiliary stage,
would satisfy
. If the prior estimation
slightly deviates from the real value of the parameter
, we can write the expansion
where the derivative of
is zero along the condition
. We can see, comparing Equations (
23) and (15), that an error
of order
suffices to correctly engineer a refocusing stage
that allows for the Heisenberg scaling. It is then possible to conceive two-step ab initio protocols exploiting the model presented in this section: a first, coarse, classical estimation of the parameter
is performed and the rough estimate
is obtained, with an error
of the same order of the shot-noise limit. Then, the classical information obtained on
can be employed to engineer the refocusing stage
, once
is fixed, so that the overall network satisfies condition (15), allowing us to reach the Heisenberg scaling through the quantum strategy described in
Section 2.1.
Lastly, we notice that, in order to satisfy condition (15), it is also possible to optimize the input auxiliary stage
while arbitrarily fixing the refocusing stage
. In such a case, identical considerations can be made regarding the possibility of a two-step protocol, since the optimization
still requires only a classical coarse estimation
of the parameter. Interestingly, only one of the auxiliary stages needs to be optimized, and thus depends on
, whether it is
or
. This leaves the choice of the second auxiliary stage completely arbitrary, notwithstanding that the pre-factor
appearing in the Fisher information in Equation (
16) is not vanishing. Indeed, the condition
corresponds to the situation in which the optimized network
acts trivially, namely without imprinting any information about
, on the probe. Remarkably, it has been shown that, for a random choice of the non-optimized auxiliary network, sampled uniformly within the set of all the possible linear networks, the pre-factor
multiplying the scaling
in the Fisher information is typically different from zero [
34]. In other words, within certain non-restrictive regularity conditions and for linear networks with a large enough number of channels, the value of the pre-factor becomes essentially unaffected by the choice of the non-optimised auxiliary network. This important feature can be exploited for experimental applications, for example, employing the arbitrary non-optimised stage to manipulate the information encoded into the probe regarding the structure of a linear network with multiple unknown parameters, ultimately allowing the choice of functions of such parameters to be estimated at the Heisenberg scaling sensitivity [
46].
2.4. A Two-Channel Network
In this section, we will apply our model for the estimation of distributed parameters to a particular example of a 2-channel network, in which the unknown parameter
influences the reflectivity
of a beam-splitter and the magnitudes
and
of two phase-shifts (see
Figure 4). We can think of the global parameter
as an external physical property, such as the temperature or the magnitude of the electromagnetic field, affecting the components of the network
. We will suppose that the functional dependence of the phase-shifts
,
and of the reflectivity
on the true value of the parameter
are known and smooth, whether given by some law of nature or opportunely engineered. With reference to
Figure 4, we can write the matrices representing the action of the beam-splitter and the phase-shifts as
respectively, where
,
, is the
i-th Pauli matrix and
is the
identity matrix, so that the network
is represented by the matrix
We easily notice that
, which, in general, is different from one and thus does not satisfy the condition (15), with the exception of the two values
which correspond to the absence of the mixing between the two modes. As described in the model earlier, we then add two auxiliary stages
and
, of which only one depends on a prior coarse estimation
of
realised with a classical strategy, so that
. In particular we choose as input stage
and as output stage
where
is a quantity which can be obtained through a classical estimation
of
. A straightforward calculation of
yields
where
and
are the error in the estimates of
and
due to the imprecision of the classical estimation
. We can then easily see that
in Equation (
28) satisfies condition (15), since both the errors
and
are of order
,—i.e.,
, and similarly for
—and thus we obtain from Equation (
28)
In order to evaluate the Fisher information in Equation (
16), we need to calculate both the phase acquired by the probe throughout the whole interferometric evolution
, and the coefficient
ℓ. The phase
is easily obtained as the complex phase of
Since
, we call
h the finite
N-independent constant such that
. The transition probability
can then be written as
so that the factor
appearing in the Fisher information in Equation (
16) is easily evaluated comparing Equations (15) and (
31). The Fisher information can be obtained from Equation (
16), with
given by Equation (
30), and
given by Equation (
17), with
k given by the condition on the local oscillator phase and
.
We notice from the expression of
that the unknown reflectivity of the beam splitter
does not influence the refocusing stage
, but it appears in the phase
acquired by the probe in Equation (
30). In particular, if the two phases
and
are vanishing, the dependence of
, and thus of the refocusing stage
, on the classical estimation
of the parameter disappears completely. In other words, this network for
transforms the reflectivity
of a beam splitter into the magnitude of a phase shift, independently from
.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}