1. Introduction
Fault diagnosis (FDi) systems are essential components of many engineering systems. These systems play a very important role for accident prevention, service continuity, and cost minimization, ultimately leading to increased human safety in transportation systems. Due to the increasing availability of multi-source sensorial data along with the significant computational power and storage capacity of modern computers, today, there is an increasing research interest in developing data-driven (DD) algorithms to tackle complex monitoring and control problems [
1]. DD approaches are widely used in applications where a detailed physical knowledge of the system is unavailable or not readily available or in cases where system input-output relations are too complex or too uncertain. Typically, DD approaches applied to FD problems derive fault-sensitive signals (also known as diagnostic signals) directly from experimental models identified from sample datasets acquired from the monitored system during normal and faulty operations. The pioneers in this field are Isermann [
2,
3,
4], Basseville [
5,
6,
7], and Gertler [
8,
9,
10].
Today, multivariate statistical process monitoring (SPM) methods, such as principal component analysis (PCA) [
11] (and its variants) and parity space approaches [
12,
13,
14,
15], are widespread techniques used for system monitoring and fault diagnosis purposes. The widespread use of PCA-based monitoring techniques is due to its simplicity and its capability to efficiently manage large quantities of multivariate data. In this context, widespread approaches used for fault isolation (FI) are the so-called contribution plots methods, such as the reconstruction-based contributions method [
11,
13]. Although powerful and effective, this method might produce incorrect fault isolations due to the so-called smearing effect, i.e., the influence of a faulty sensor measurement on non-faulty sensors contributions. In a system characterized by a limited number of monitored variables, directional residuals methods have shown to be a valid alternative to SPM methods. Directional residual methods work by relating possible faulty sensors with the characteristic direction of the faults, isolating the faulty sensor as the one having the smallest distance between the residuals signal and the monitored sensor fault directions [
12,
13,
16]. An important variant of the directional residual method is the structured residual approach [
9].
A fundamental assumption underlying most SPM techniques is the linear dependence between modeling variables. While this assumption may be reasonable in some applications, in the case of strongly non-linear systems or significant variations in the operating range of the signals, these techniques could lead to inaccurate results. The direct consequence on fault diagnosis is that the linearity in covariate FD models may produce many false positives and false negatives in practical applications when applied to non-linear systems.
A typical approach to allow non-linear dependencies between the covariates is to augment their number by introducing several new terms derived by non-linear transformations of the original signals while retaining the linear dependence between the extended set of covariates. Although this approach is straightforward, it suffers from the problem that the set of extended non-linear functions cannot be defined ‘a priori’. Instead, a complex and time-consuming tuning phase is needed to select a suitable set of non-linear transformations. These problems have motivated the scientific community to go beyond the linear dependence assumptions of covariates, promoting the development of non-parametric models based on generic non-linear smooth functions, such as splines, neural networks, and kernel models, and implement specific data-driven tuning algorithms to reduce the mean and variance of the mapping error to identify best-fitting models [
17].
Another direction to deal with the problem of fault diagnosis in non-linear systems is related to the use of machine learning and deep learning techniques. The issue of Fault Isolation, in fact, can be easily set as a direct application of a classification or clustering problem. At the same time, ML regression techniques can also be employed for estimating the shape and amplitude of the fault (Fault Estimation (FE)) [
18,
19,
20,
21].
An interesting comparison of FI and FE performance of three popular classification algorithms, namely the support vector machine (SVM), K-nearest neighbor (KNN), and decision tree (DT), can be found in [
17]. The classification algorithms are trained using data from optimized and non-optimized sensor subsets and then validated with new data characterized by varying degrees of fault severity. In [
22], Erfani et al. present a hybrid model in which an unsupervised deep belief network (DBN) is trained to extract latent features. Then, a one-class support vector machine (SVM) based on the DBN features is trained to learn decision surfaces. In [
23], Revathi and Kumar proposed a deep-learning-based anomaly detection and classification system in video sequences, where the final module classifies the detected events as usual or suspect. In [
24], Pashazadeh et al. propose a data-driven fault detection and isolation (FDI) scheme based on the fusion of different classifiers for a wind turbine challenge system. Multi-layer perceptron (MLP), radial basis function (RBF), decision tree (DT), and K-nearest neighbor (KNN) classifiers are implemented in parallel, and the faulty sensor is identified using a majority voting method. Next, discrete-time up–down counters (UDCs) are used for each fault to reduce false alarms (FAs) and missed detections (MDs). In [
25], an efficient strategy for fault detection and isolation (FDI) for an industrial gas turbine based on ensemble learning methods is introduced; specifically, a fault isolation scheme based on ensemble bagged trees is developed to isolate faults in a steady-state runtime.
In this study, we considered a natural non-linear extension of linear regression models of the form
, i.e., the class of the so-called generalized additive models (GAM) [
26]
, where
are generic smooth functions to be identified from data. Due to the simple additive structure, GAMs are sufficiently versatile for capturing linear or non-linear relationships between response functions and covariates. The additive form is of particular interest for FDi problems because it allows the easy calculation of the fault sensitivity of the individual monitored variables. Although GAMs have been used extensively in many application fields, their employment in a data-driven FDi system has not been fully explored. In fact, to date, only a few studies have been presented, such as [
16,
27]. Motivated by the mentioned issues, in this paper, we propose GAMs to identify non-linear parity relationships in the monitored variables using cubic spline basis functions to characterize the non-linear functions
by exploiting the MARS modeling and estimation algorithm proposed in [
28].
Next, to exploit the consolidated tools available for the fault diagnosis of linear parity space models, a local linearization of the identified GAM parity relations is performed to achieve a time-dependent fault sensitivity matrix.
Indeed, unlike standard linear parity methods, the so-called fault signature matrix is not constant but, rather, it depends on the operating point, implying that the resulting fault directions are not constant but time-varying. A state-dependent fault sensitivity model can better capture the effects of faults in a non-linear system compared to a standard linear and fixed fault sensitivity matrix. The proposed GAM plus linearization approach can immediately fit the directional residual FI method developed in the linear contest and applied in [
14,
15]. In addition to this first key innovative aspect, this study aims to show the effectiveness of the proposed technique compared to machine learning techniques applied to the problems of fault isolation and fault estimation. In particular, the second main contribution of this research is related to the comparison of the proposed directional residual-based technique with ML fault diagnosis methods. This is performed by investigating the advantages and disadvantages of each approach, highlighting the benefits in terms of performance, memory occupancy and robustness to unexpected fault amplitudes.
The proposed novel method is applied to design a complete fault isolation and estimation (FIE) system based on real sensor data taken from a semi-autonomous aircraft where single additive faults are artificially injected on eight primary sensors.
2. Non-Linear Additive Models for Fault Diagnosis
The set of the monitored (potentially faulty) sensors measurements is concatenated in the vector
, while the set of control signals and other no monitored sensors (assumed not faulty) are included in the vector
. The integer
is the discrete-time index at sample time
(where
is the sampling interval). Occasionally in the article, the dependence on
is omitted to simplify the notation. The proposed FD technique is based on analytical redundancy (AR) concepts [
12,
13,
16]. It is assumed that a sensor measurement
is approximated by a non-linear additive model consisting of the linear combination of non-linear functions (
and
) defined as follows
where
and
are constant coefficients (to be estimated from data) and
and
are non-linear functions of the variables
and
, respectively, typically representing a rectified linear unit (ReLU) or Gaussians or polynomial splines [
26]. The functions
are assumed to be constant and equal to one in order to take into account possible constant offsets in the models. The actual signal
is
where
characterizes the modeling error and sensor noise associated with the
-th sensor. The primary residual associated to each sensor is defined as
At fault-free conditions, it results in the following:
i.e., the residual is equal to the modeling uncertainty. Typically,
is a small amplitude signal, and in the ideal perfect modeling noise-free case, this is equal to 0. In the present study, we considered the occurrence of single additive sensor faults
on the generic
-th sensor. In the presence of a sensor fault, the fault-free measurement
should be substituted by the faulty signal
, that is
where
is a generic fault modelling function that is zero in fault-free conditions and different from zero in the presence of the sensor fault. When a fault is present on the
-th sensor, the impact on the residuals can be evaluated by substituting (5) in (1) and (3). It is immediate to verify that
In the above Equation (6), the term
is not directly computable because the sensor reading is equal to
and not to
in the presence of a fault. For this reason, the Taylor approximation of
around
is computed, that is
where
is a fault increment and
contains higher-order terms of the Taylor expansion. In this study, we exploited model (7) to compute an approximation of
. This can be easily achieved by taking
in (7) (in fact, results
) resulting in:
Substituting Expression (8) for
in the residuals in (6) results in the following:
that is
Define:
then (10) becomes
the above expressions can be arranged in matrix form resulting in:
The matrix in (13) () is known as the fault sensitivity matrix and contains all the uncertain terms in (13). It is observed that the matrix is time-dependent; in other words, it depends on the current measurements at time k.
The occurrence of a single fault at a time on a generic
-th sensor is assumed here; therefore, in (13), only the component
is different from zero (that is
). This implies that (13) simplifies to
In vector form
where
is the primary residual vector and
(the
-th column vectors of the matrix
) defines the so-called fault direction. Assuming a sufficiently large fault
compared to
, the residual vector direction tends to be alienated to the known direction of the vector
. This directional information will be later exploited for sensor FI purposes. Unlike our previous papers in [
12,
13]—where the faults signature matrix is constant by construction—the fault signature matrix is time-varying in the present study.
2.1. Linear Model Case
In case the functions
and
are approximated by simple linear in the variables models, then Equation (1) simplifies to:
where
and
are constant weights, implying that the time-dependent matrix
becomes a constant matrix
[
12,
13] and the associated fault directions
are fixed and constant vectors.
4. Multivariate Adaptive Regression Splines (MARS)
In this study, the data-driven identification of the non-linear functions (
and
) defined in (1) is performed using Friedman’s multivariate adaptive regression Splines algorithm [
28] which is a well-known procedure used to identify non-parametric additive models from data. The MARS algorithm can be easily set to fit the structure of the non-linear additive models in (1). In practice, the identification of the primary residuals is performed by exploiting the adaptive regression splines toolbox [
31] (ARESLab). MARS is a non-parametric regression technique and can be viewed as a non-linear extension of linear regression models that can be used to model non-linear dependencies in high-dimensional data. Technically, MARS models consist of the linear combination of spline basis functions; in ARESLab, the number of basis functions and the parameters characterizing their shape is inferred directly from data through a forward–backward iterative approach [
28,
31]. Starting from (1), the considered MARS functions have the following form:
where
is the number of basis functions that are selected by the MARS forward–backward iterative approach to identify the
function. The
are constant coefficients and
is the
-th basis function that depends only on the
variable. Similar definitions can be attributed to
,
, and
.
The ARESLab allows the selection of different classes of basis functions, such as piecewise ReLU and piecewise cubic splines. We used piecewise continuous cubic splines with continuous first derivatives to estimate the non-linear functions. An in-depth discussion and comparison between piecewise cubic models and piecewise linear models can be found in [
28].
The considered piecewise cubic spline basis functions consist of one or two “complementary” basis functions
. These are defined as follows:
for
is a scalar,
and
The shape parameters , , and represent the lower side knot, the upper side knot, and the central knot, respectively. The first two knots define the change point between the functions, while the last influences the cubic and the linear functions. The ARESLab procedure automatically estimates the slope parameter and the number of Basis Functions to build the model. In particular, the design does not necessarily use both “complementary” basis functions; only the positive one or the negative one could be used in the estimation model.
In this study, the MARS algorithm for each sensor model in (1) is applied separately using the same data segment. Once the MARS spline basis functions are identified for all the monitored sensors, the local fault sensitivity matrix
is analytically computed following the linearization procedure described in
Section 2.
NOTE-2: Since there are no iterations (multiplications) between the sensor measurements, the fault diagnosis method based on the MARS algorithm could be implemented exclusively through the matrix product between suitably defined matrices and the values measured by the sensors. In particular, combining Equations (1), (3), and (19)–(22), it is possible to calculate the residual where , , , and . Similarly, the matrix can also be calculated through the matrix product between some matrices appropriately defined and the values measured by the sensors. In particular, the column vector where and . The matrices , and depend on the shape parameters , of each basis function of the model and the values of the sensor measurements. Therefore, the implementation complexity of the proposed approach is related to the matrix multiplication algorithm that results, as known, in the worst case .
5. Machine Learning-Based Fault Isolation and Estimation
The proposed directional residual-based FI and FE scheme can be compared with machine learning (ML) solutions. ML techniques are extensively applied to FD problems; an extensive literature exists on this issue [
32,
33]. In this study, ML structures with different complexity are built and compared using the same data used to identify and test the directional residual-based technique. Specifically, FI and FE are addressed separately. First, a ML classifier is used to estimate the faulty sensor index. Then, a second ML approximator is used to estimate the fault amplitude. The first is a typical classification problem, while the second is a typical regression problem. Classification and regression structures are built by exploiting the dedicated MATLAB toolboxes in more detail. For example, support vector machines (SVMs) [
17,
22], neural networks (NNs) [
23,
24], decision trees [
17,
24], and ensemble of decision trees [
25] structures have been considered.
5.1. Dataset Preparation for ML Algorithms
In contrast to the primary residual-based FI techniques that are based only on fault-free data and on fault directions, the ML technique requires faulty data samples which are representative of each possible sensor fault for a wide range of fault amplitudes.
Since real sensor flight data with sensor faults are not easily available, additive faults are artificially injected on the fault-free data to simulate the occurrence of a sensor fault (this approach of generating artificial faulty data is widely used in the FDi community, see for instance [
11,
12,
13,
14,
15,
16]).
For this reason, a new ‘ad-hoc’ data set is produced based on the fault-free dataset used to identify the MARS models. This is performed by adding a random amplitude fault at each sampling time on a randomly selected sensor. Random amplitude fault on a random sensor is clearly not a realistic fault scenario; this approach is used only to generate a rich set of training data to promote generalization capacity and robustness in the ML schemes.
It is observed that this simple fault generation method is possible thanks to the fact that, in this study, our approach is “memoryless”. Indeed, the estimation at the time depends only on other signals at the same time ; therefore, serial temporal correlation of data has not been considered in the model. If the estimations at time depend on signals at previous time instants (), the above faulty data generation procedure can be easily extended by considering data segments of appropriate length. Next, the fault-free mean and standard deviation of the data are normalized, and two new labels (signals) are added to the data. The first is the index identifying the sensor where the fault is injected, while the second is the normalized amplitude of the fault.
5.2. ML Classifier for FI
The FI classifiers input is the vector
of the current sensors and inputs measurements, and the corresponding output is the label of the faulty sensors
. The data set described in
Section 6 is used for the training. The set of classifiers that are evaluated and the main design parameters are reported in
Table 1.
5.3. ML Estimator for FE
The FE estimator input is the vector
of the current sensors and inputs measurements plus the index of the faulty sensor. The corresponding output is the amplitude of the normalized fault
injected on the fault-free measurements. The data set described in
Section 6 is used for the training. The set of estimators and the main design parameters are shown in
Table 1.
5.4. Online Operation of ML Algorithms
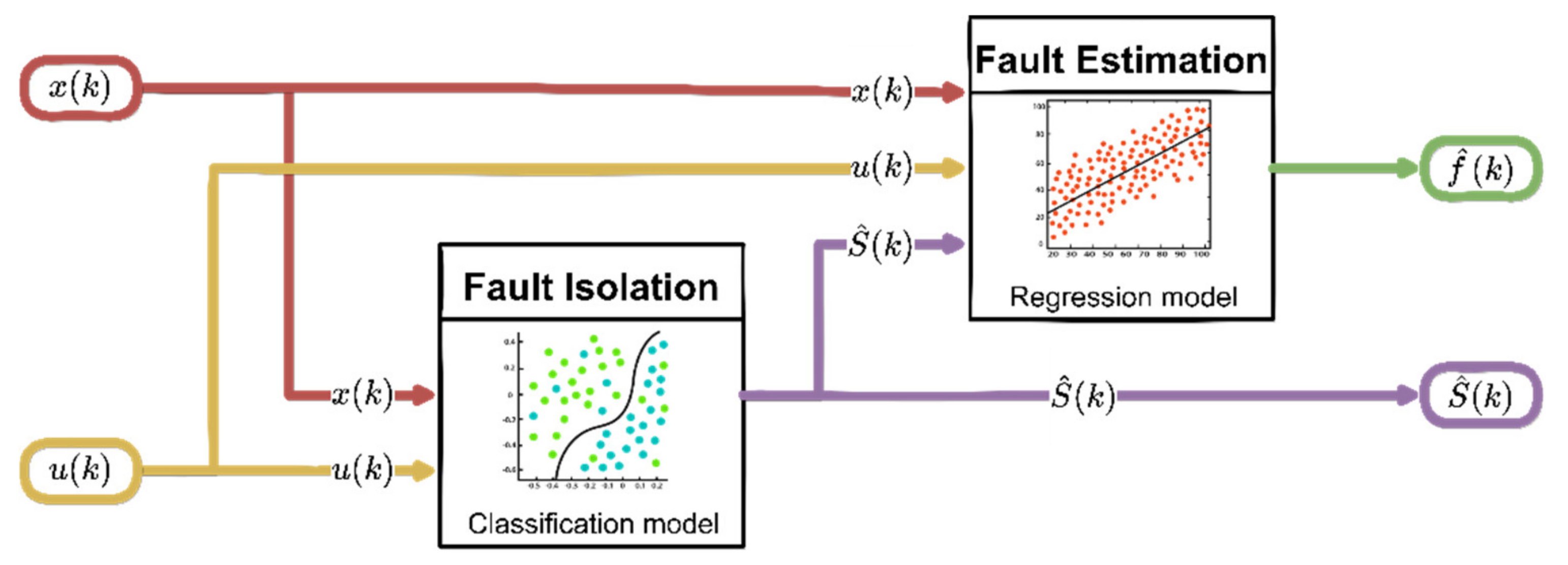
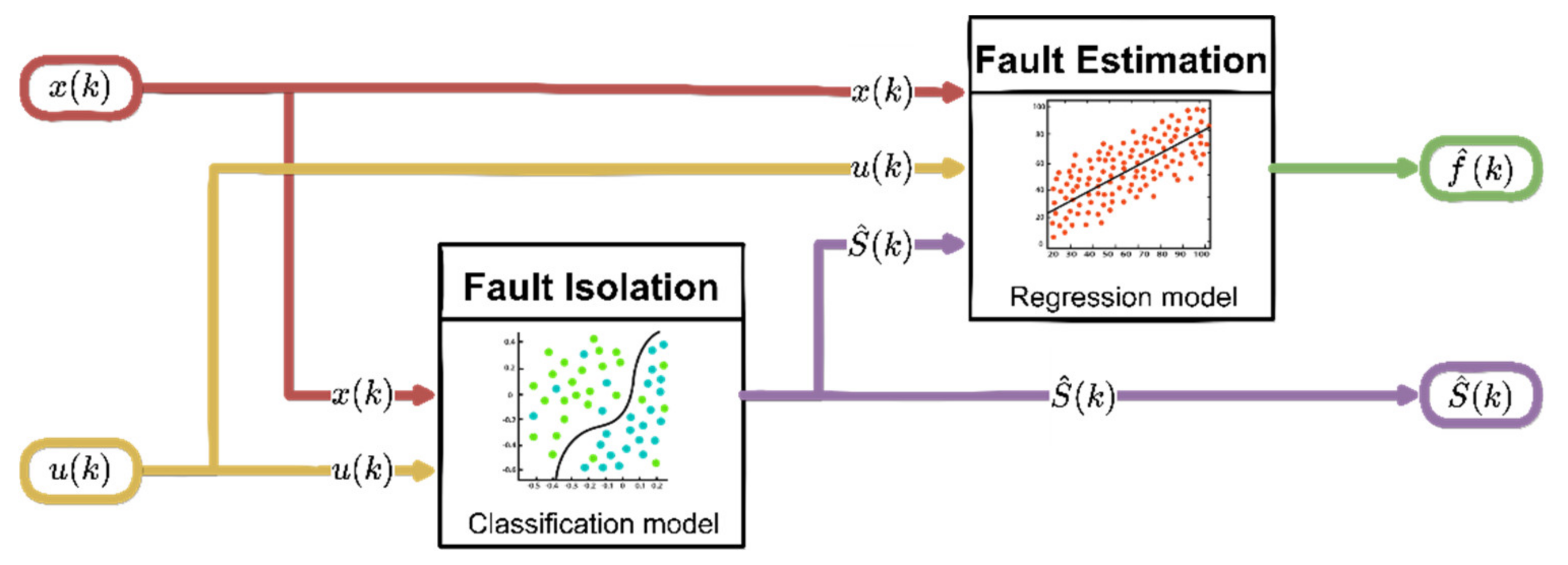
The previously trained ML structures are then used for FI and FE purposes in the online operation phase according to the scheme shown in
Figure 1. Following the failure detection, the FI block processes the current input
and provides the estimation of the sensor fault index
in the output. This information, as well as the measured current signals
, is then processed by the FE block that provides the estimation
of fault amplitude at time k.
NOTE-3: The ML classification and regression schemes introduced in
Section 5.2 and
Section 5.3 have the same hyperparameters but differ in the inner architecture. For example, in the case of neural networks, the structure of the inner layers is the same, except the output layer, specifically in the case of a neural network classification, and the SoftMax activation function is applied. In contrast, linear activation functions are used in the regression neural network.
8. Design of Machine-Learning-Based FI Schemes
This section describes the design of ML-based FI schemes. First, the FI classifiers are trained. The input of the classifiers is the
vector of the eight monitored sensors and four inputs signals reported in
Table 1. For each of the eight monitored sensors, single random amplitude faults are added to the fault-free signals at random time instants sampled from the training data. Positive and negative fault amplitudes are generated in the range
, whose values are reported in
Table 5. The corresponding out at time
k is the label of the faulty sensors
. A total of
random samples are generated for the training. The training of the 16 FI classifiers (the first column in
Table 6) is then performed using MATLAB.
Table 6 shows the accuracy [
36] of the models obtained from cross-validation of the training data with the
-fold validation taking
. The neural network FI classifiers achieved the highest accuracies compared to the other family of models; in particular, the wide neural network scores provided a 78.1%.
Next, the 16 FI estimators are trained. The input vector
coincides with
augmented with the index
indicating the faulty sensor, and the output is the amplitude of the normalized fault amplitude
. A total of
training samples are generated using the same procedure used for the training of the FI classifiers. The second column of
Table 6 reports the root mean square error (RMSE),
, of the models achieved, cross-validating the training data with the
-fold method (
). Once again, the wide neural network provides the lowest RMSE compared to the other family of models.
9. Metrics for Validating Fault Diagnosis Schemes
For validation and comparison purposes, additive constant bias faults of amplitude () are considered. The constant fault is applied at time and is maintained for the entire duration of the validation flight. The following FI and FE metrics are used.
9.1. Fault Isolation Percentage (FIP)
The FI performance is measured in terms of the fault isolation percentage (FIP), defined as:
: Given a fault of amplitude
on the sensor
, the fault isolation percentage is the percent ratio between the number of samples the FI block which correctly isolates the faulty sensor and the number of samples in the validation flight.
The index is calculated for each considered technique, for different fault amplitude and for each monitored sensor . The rest of the paper will refer to the average of for the considered fault amplitudes injected on the monitored sensor , i.e., . Similarly, will refer to the average of the values evaluated over the eight monitored sensors, that is: .
9.2. Fault Estimation Percentage (FEP)
The primary residuals in models (1) and (16) for the non-linear and linear models, respectively, allow direct estimation (see Equation (15)) of the fault amplitude
that is computed as the difference between the measured and predicted signal. In contrast, the ML models estimate the fault amplitude
as a regression problem (see
Section 5.3). The fault estimation percentage (FEP) is defined as:
: Given a fault amplitude
, the fault estimation percentage ratio is the absolute value of the percent ratio between the fault amplitude reconstruction. The
is calculated as the difference between the actual fault amplitude
and the mean of the reconstructed fault amplitude throughout the validation flight.
Furthermore, the index is calculated for each technique, a different fault amplitude , and a monitored sensor . In addition, refers to the average of for the different fault amplitudes injected on the monitored sensor , while refers to the average of evaluate over the eight monitored sensors.
9.3. Complementary Fault Estimation Percentage (cFEP)
In order to achieve a performance metric that is 100% when the FE performance is perfect and 0% when it is completely unsatisfactory, the complementary
FEP (
cFEP) is defined as:
From the
index, the
,
, and
indices are derived. In addition, to produce an overall performance ranking that takes into account both the FI and FE performance, the overall performance index
is defined:
Perfect performance is archived when , i.e., in the case of perfect fault isolation and perfect fault reconstruction.
10. Comparison between Directional Residual and Machine Learning Techniques
This section compares the fault diagnosis performance provided by the directional residuals and machine-learning-based methods. This study is performed using the data of the validation flight. Positive and negative constant faults are added to the fault-free data, considering, for each sensor, fault amplitudes
A equal to ±17%, ±33%, ±50%, ±67%, ±83%, and ±100% of the maximum fault amplitude taken from
Table 5. The faults are added at time
to the faulty sensor and maintained constant for the entire flight duration. This procedure is repeated for all eight sensors and all the considered fault amplitudes, resulting in a total of about
validation samples. The mean performance for all the sensors and fault amplitudes is evaluated using
,
, and
indices already in
Section 9. The results are reported in the first two columns of
Table 7.
It is observed that the non-Linear technique (NL-DR) provides 71% in terms of . Although satisfactory, it is also observed that medium neural network (M-NN) and the wide neural network (W-NN) methods perform slightly better. On the other side, considering the performance, the NL-DR achieves an excellent 18% while M-NN and the W-NN provides a significant performance degradation equal to 35%.
These facts are relevant because the NL-DR provides a high-level FI performance while maintaining an excellent capability for fault reconstruction. This fact does not apply to any one of the 16 ML techniques that provide a performance lower than 72%.
In summary, the best resulting method in terms of FI performance is the W-NN, and the worst is the F-SVM. Considering the FE performance, the best is provided by our proposed NL-DR method, and the worst is the L-SVM.
10.1. Overall Performance Comparison
The fourth column of
Table 7 reports the index
for all the techniques. It is now evident that the resulting method with the best overall performance index is given by the proposed NL-DR (77%), followed by 3-NN (71%) and M-NN (69%) and by 2-NN (69%).
The last column of
Table 7 also shows the combined memory occupancy of the isolation and estimation models. The SVM models have the highest memory occupation, up to about 50 MB, while the most parsimonious architectures are those based on directional residuals and neural networks.
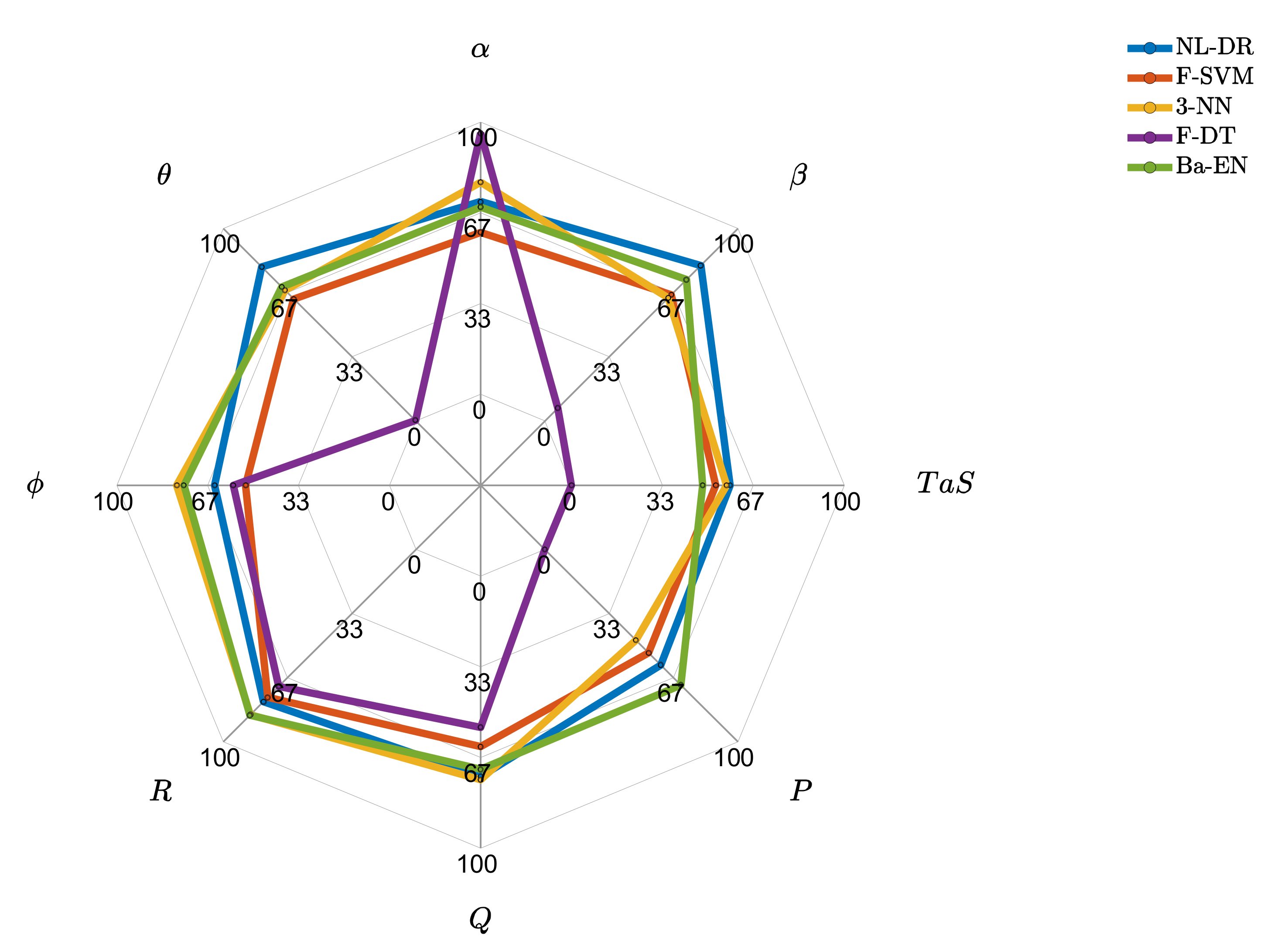
10.2. In-Depth Performance Comparison of the Best Techniques
This section shows the
and
indices for the best performing techniques explicitly evaluated for the eight monitored sensors.
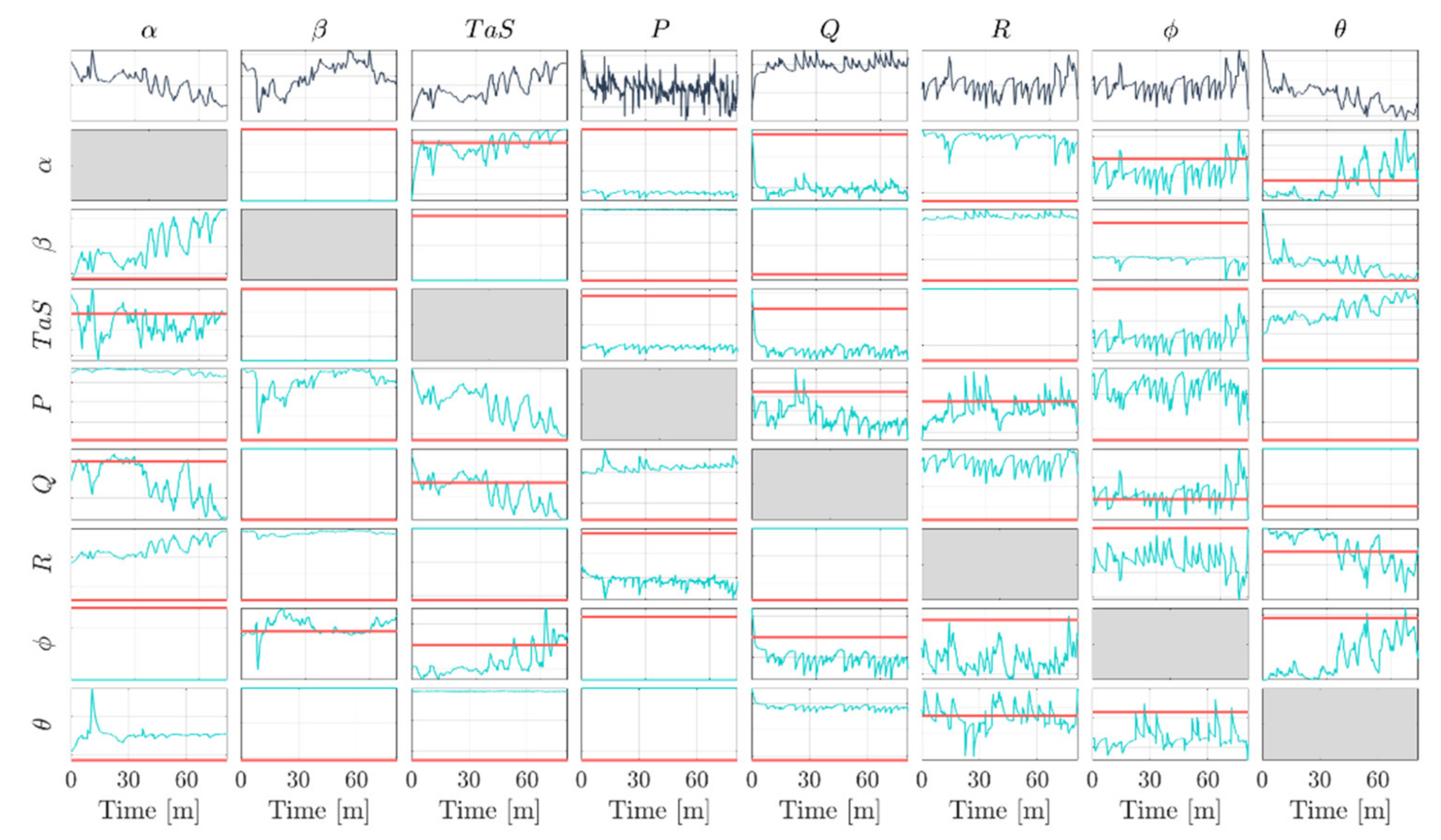
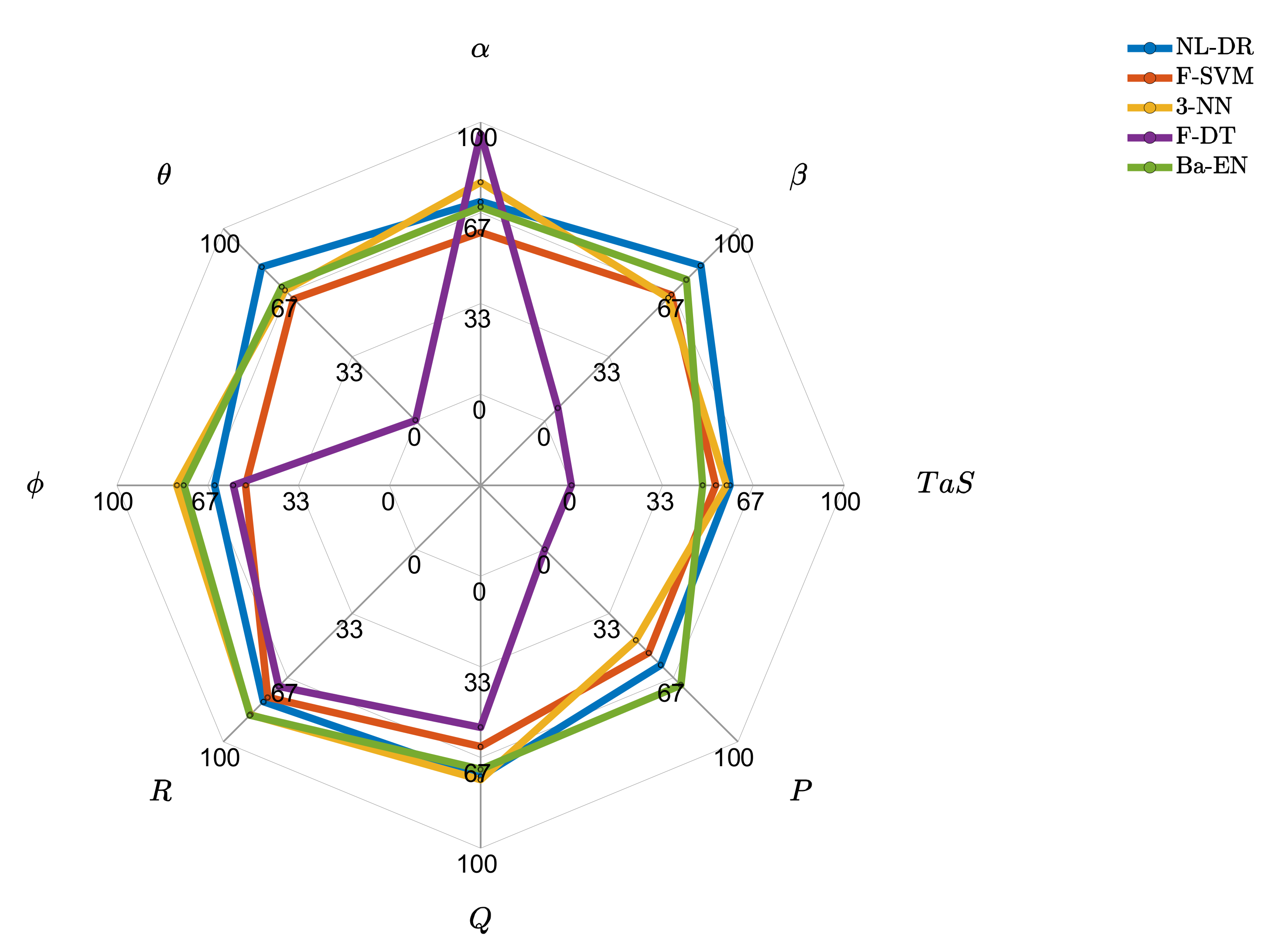
Figure 3 shows that the F-DT approach is biased toward the
sensor at the expense of the others. It perfectly isolates the faults on the
sensor, but it cannot correctly isolate any fault occurring on
,
,
, and
sensors. It is also observed that the NL-DR technique performs better than the other techniques for four of the eight monitored sensors.
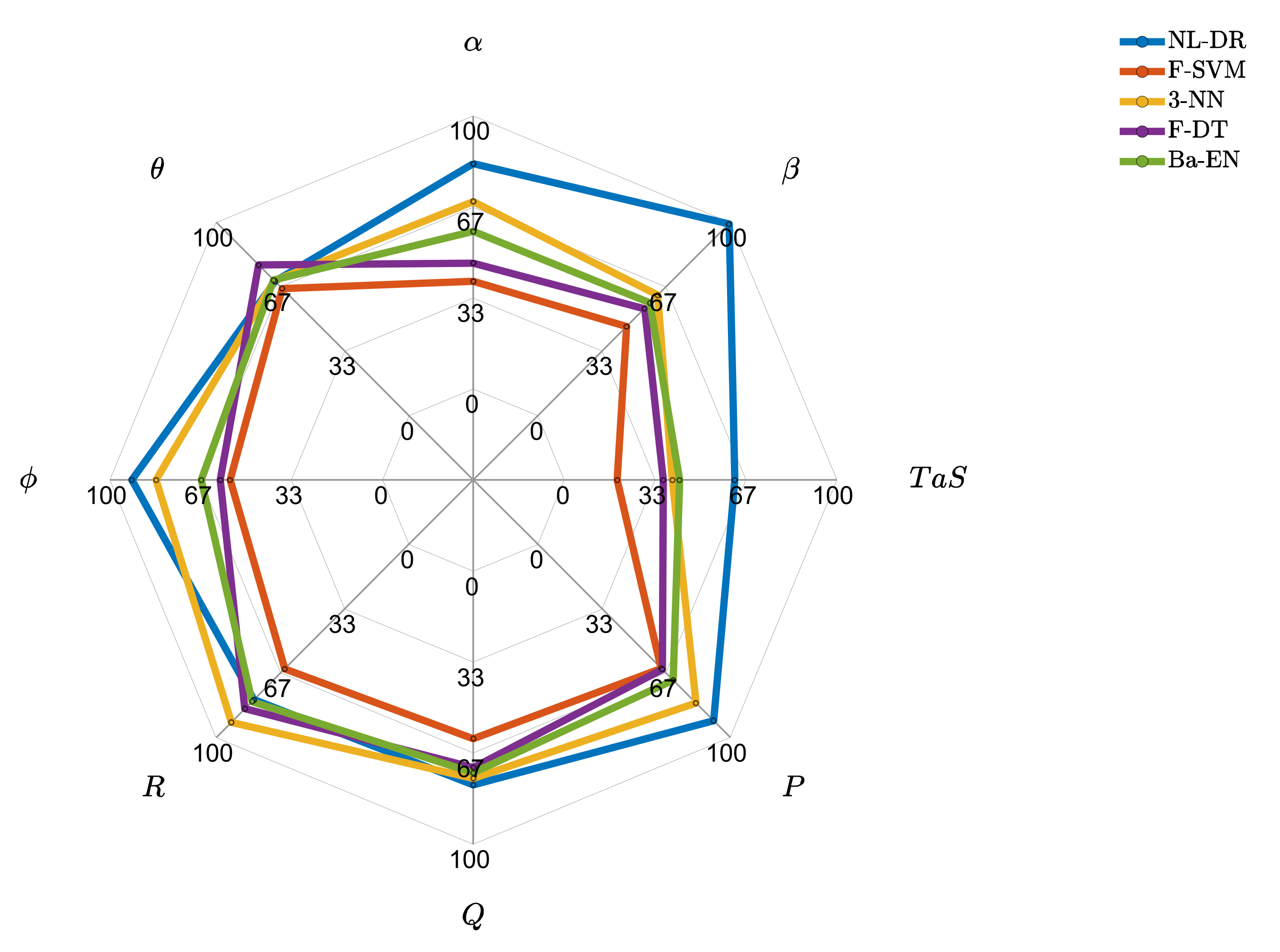
In
Figure 4, it can be deduced that ML techniques have much lower FE performance than those provided by the NL-DR method for all the sensors. In fact, the proposed NL-DR scheme performs significantly better than the others for six of the eight monitored sensors.
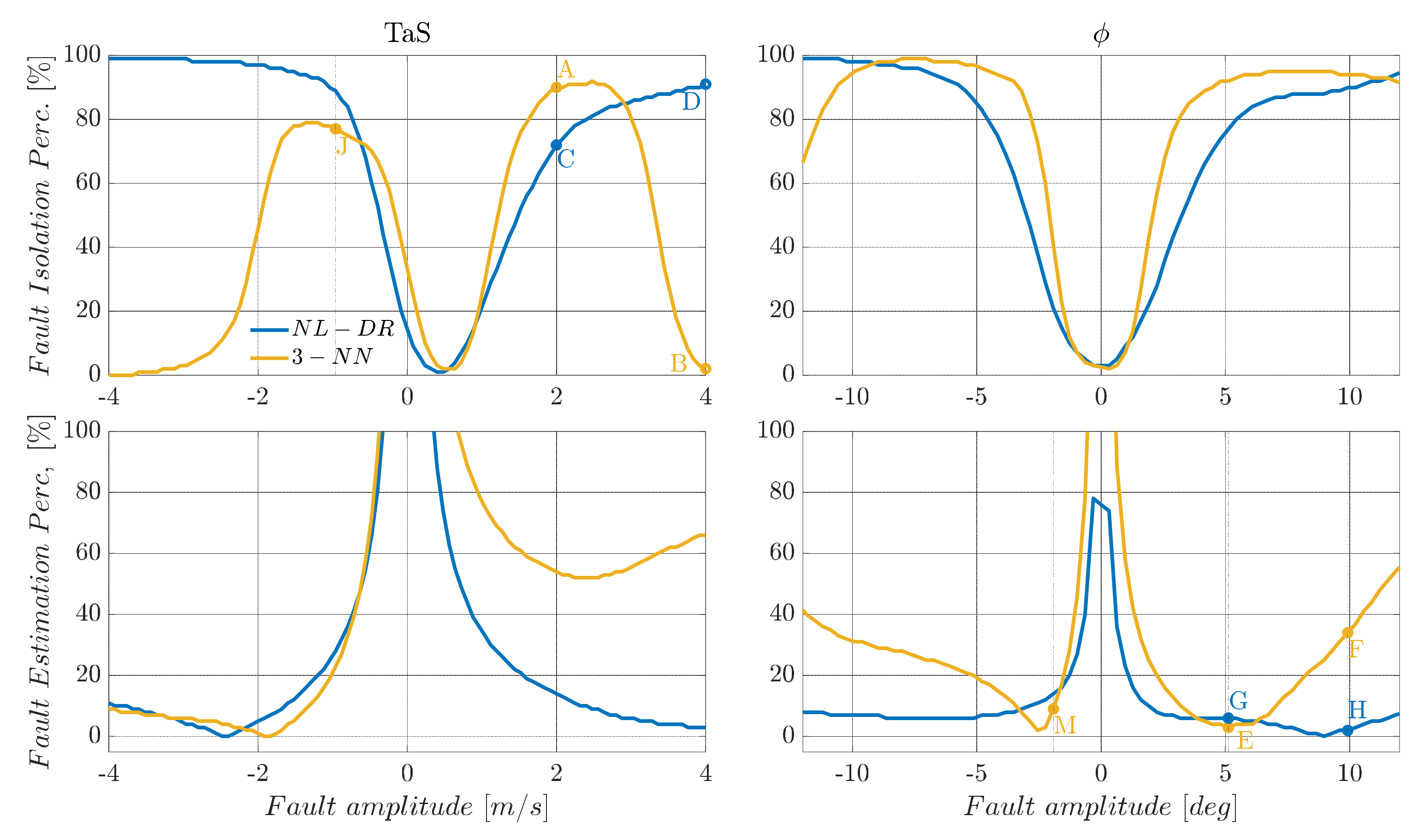
10.3. Performance Comparison Evaluated over a Wider Fault Range
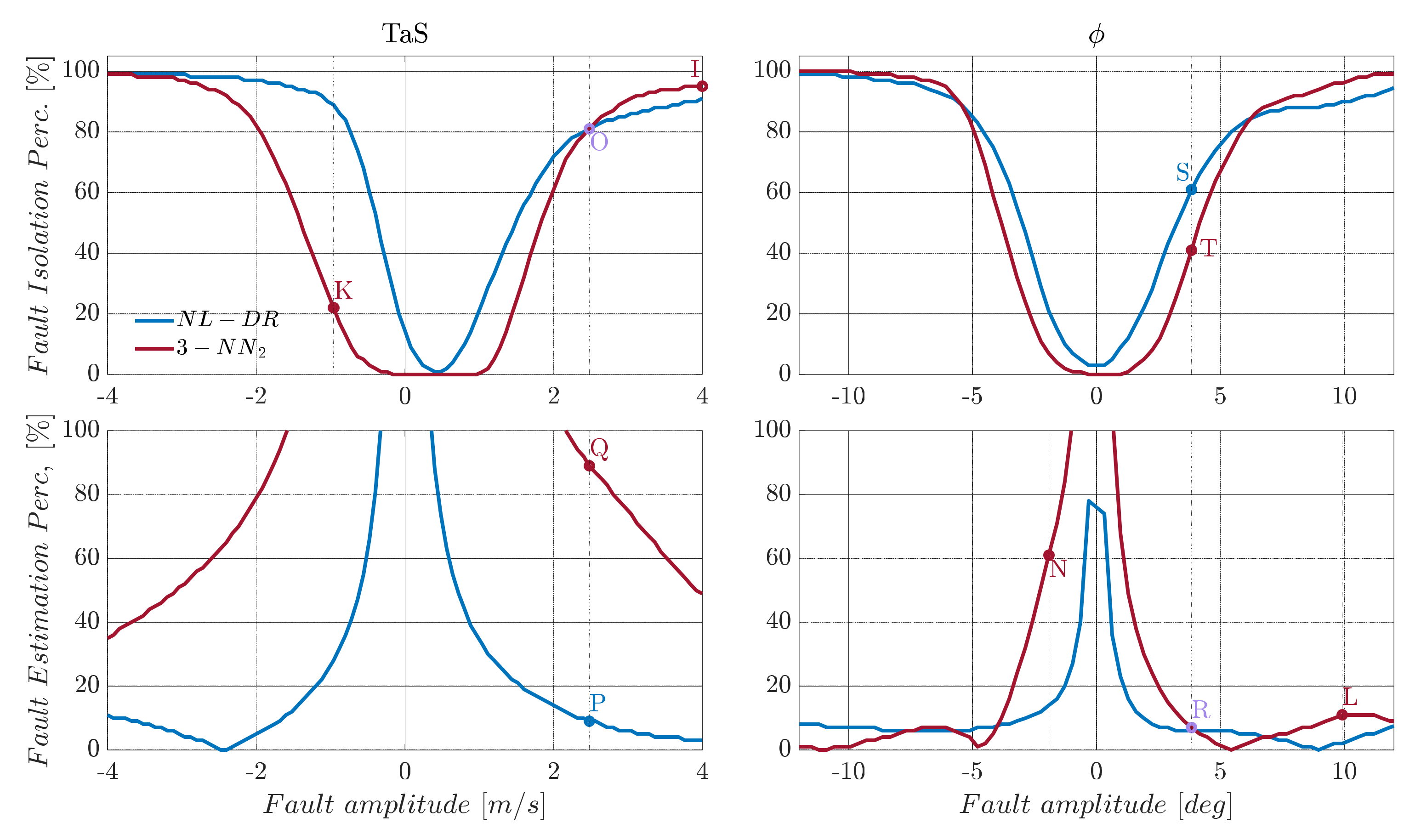
The performance of any machine learning technique is strongly influenced by the data used for training. This implies that the available set training data strongly influences ML-based FIE methods in our specific case. In contrast, the proposed residual-based approach is virtually independent from the fault amplitude. In fact, in the primary residual modelling phase, no assumption is made about the magnitude of the faults, which leads to significant benefits in case the range of potential faults is under- or over-estimated. A clear example of this potential problem can be observed in
Figure 5, where the response of
and
indices for
and
sensors are compared for NL-DR and neural-network-based methods.
In the upper part of
Figure 5, it can be observed that by injecting faults with amplitudes twice than the nominal ranges used for training (nominal range:
m/s for the
sensor and
for the
sensor), the FI performance of the 3-NN deteriorates quickly with the increase in the fault amplitude.
Considering a failure on equal to 2 m/s, the index for the 3-NN is 90% (Point A), while a failure of 4 m/s the descends to 2% (Point B). On the other hand, using the NL-DR technique, the performance constantly increases with the fault amplitude (Points C and D), avoiding the paradox response provided by the ML methods. Similar considerations apply to the index trend for faults on sensor .
In terms of FE performance, it is observed that both the and the NL-DR approaches provide a suitable monotone decreasing trend for the index with an increase in the failure amplitude. At the same time, there is a rapid degradation of the performance outside the nominal training range in the NN case. Specifically, a constant failure on produces a of 3% (Point E), while a failure of 10° produces a of 35% (Point F). Using the NL-DR approach, the index increases from 6% for a failure of (Point G) to 2% in the case of a failure of (Point H). The above issue is a typical effect known as “Unseen Data Problem” or “generalization problem”. It refers to the inability to make reliable predictions in regions outside those explored in the training data.
In our study, a simple method to limit this important problem is to provide the ML algorithms with a broader range of fault amplitudes to cover the unexplored regions in the training phase. However, on the other side, the excessive widening of the fault ranges used in the training data can lead to the inability to discriminate accurately small faults.
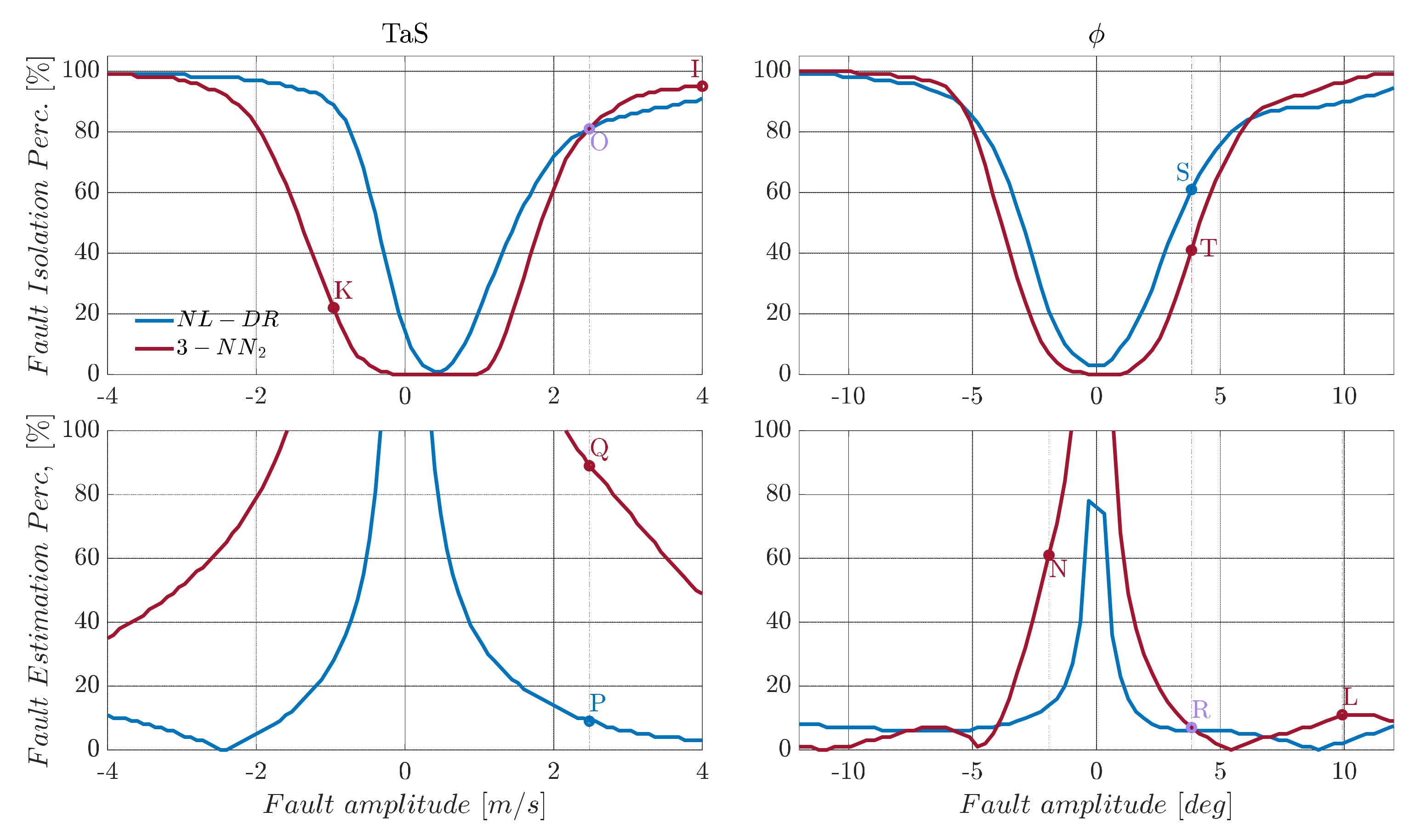
A direct example of this can be observed in
Figure 6, where the tri-layer neural network is retrained (3-NN
2), considering a range of fault amplitudes which are twice the size of the nominal range, as shown in
Table 5. Using the retrained network, a relevant increase in the FI performance is achieved for large fault amplitudes, but at the expense of performance degradation for medium and small amplitude faults.
In more detail, consider the case of a failure of 4 m/s on
. In this case, the
provided by the retrained neural network (3-NN
2) is now 95% (Point I), which is 93% more than the previous network (3-NN). Vice versa, in the case of a fault of −1 m/s, the 3-NN isolates the fault with an accuracy of 77% (Point J) while the 3-NN
2 of 25% (Point K) confirms what is previously conjectured. Moreover, by analyzing the
index for the sensor
, a similar conclusion can be drawn: that the
for
goes from 35% for 3-NN (Point F) to 9% for 3-NN
2 (Point L), while a failure of
goes from 8% for 3-NN (Point M) to 60% for 3-NN
2 (Point N), as shown in
Figure 5 and
Figure 6.
10.4. Overall Performance Evaluation for All the Monitored Sensors
To better compare the overall performance,
Table 8,
Table 9,
Table 10,
Table 11,
Table 12,
Table 13,
Table 14 and
Table 15 report, for each monitored sensor, the percentage ratio between the actual area below the
function (as those in
Figure 5 and
Figure 6) and the perfect performance area (
). The ideal area ratio is obviously 100%. The same process is also applied to the
functions. The last column of the tables reports the mean between the
area ratio and the
area ratio.
For almost all sensors, the area under the curve generated by 3-NN2 is larger than that under the curve generated by 3-NN, indicating a generalized performance improvement. However, in most cases, the performance improvement is only achieved for large amplitude faults, at the expense of performance degradation for small amplitude faults. This fact indicates the need to find a compromise on the magnitude of the faults used to train the neural network. This issue substantially limits the applicability of ML techniques, especially in a real-world context where an ‘a priori’ knowledge of the fault amplitude range cannot be established. Moreover, analyzing the results obtained for all the monitored sensors, the performance of the proposed NL-DR technique is almost always better than both the 3-NN and 3-NN2 techniques.
10.5. Time-Domain Performance Comparison with Same FIP/cFEP
This section evaluates and compares time domain FI and FE responses for the NL-DR and 3-NN
2 techniques. In order to achieve a meaningful comparison, the tests are performed by selecting faults whose amplitudes are such that the two methods provide the same value for the
or the
indices in
Figure 5 and
Figure 6, resulting in the selection of a fault of the amplitude of 2.5 m/s on
, and of
on
, respectively (as expected, the faults are injected at
and the constants for the whole flight are maintained).
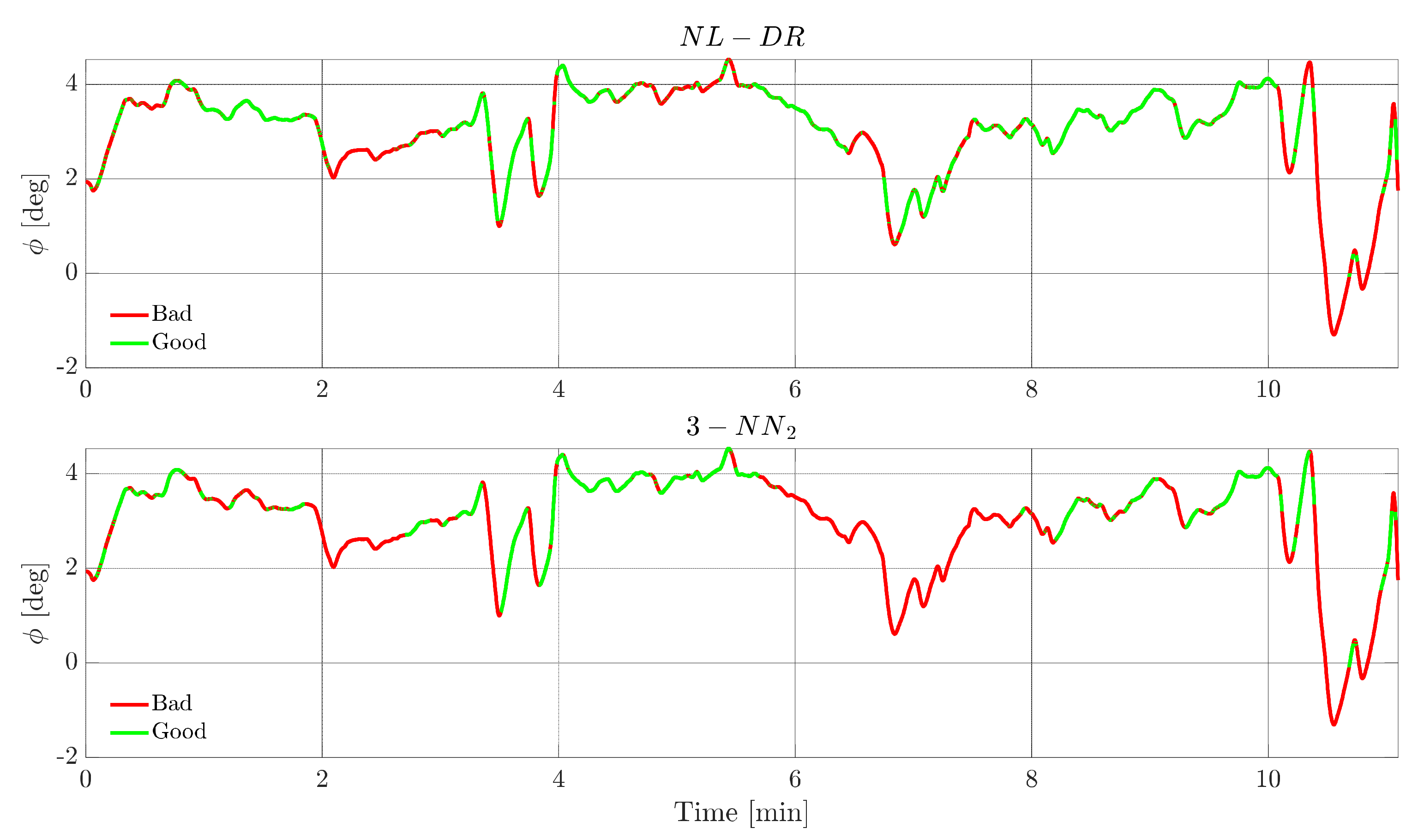
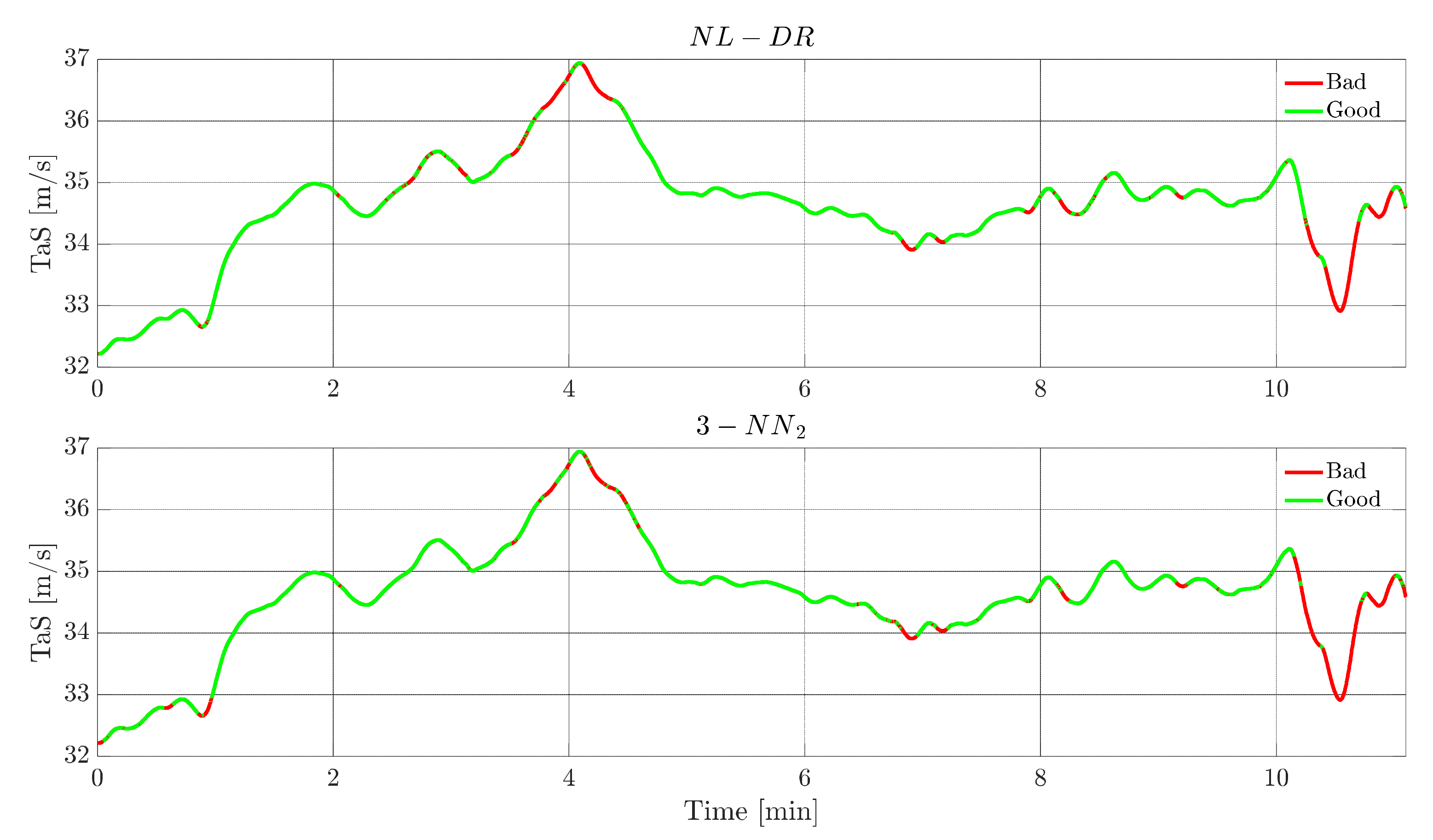
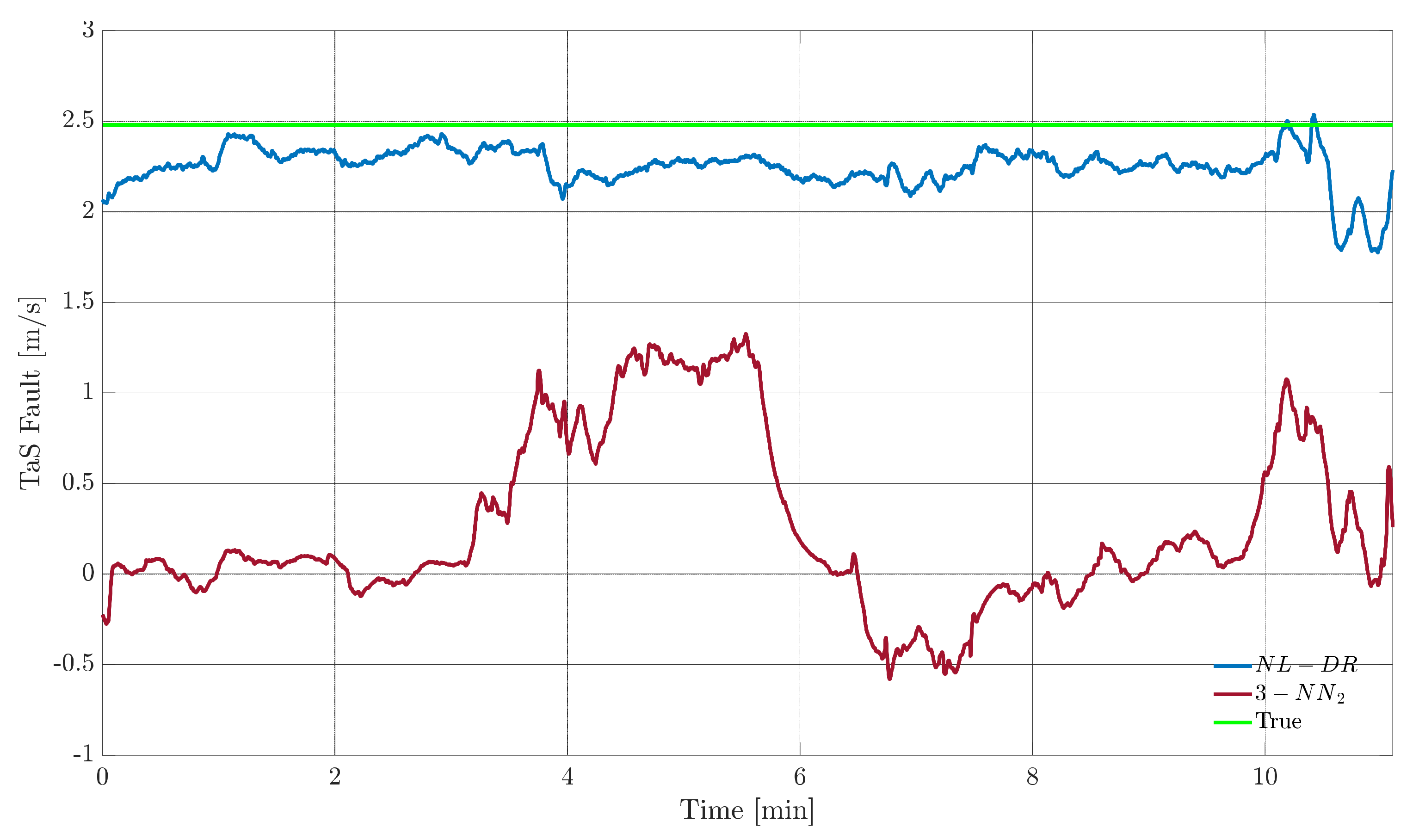
Figure 7 shows, for a failure on
TaS, the evolution of this signal. The green portions indicate the instants in which the FI is correct, while the red portions indicate when the failure is incorrectly attributed to a ‘wrong’ sensor. The upper plot refers to the NL-DR technique, while the lower plot refers to the 3-NN
2 technique. For hypothesis, both methods isolate the fault with the same percentage (82%, Point O in
Figure 6); the remarkable aspect is that the zones of wrong isolation are practically the same for the two techniques.
On the other side, there is a marked difference in
performance between the two techniques, see
Figure 8. The fault amplitude estimated by the NL-DR method is much closer to the true value than the estimate provided by the 3-NN
2 technique, as deduced from
Figure 6 in Points P and Q, respectively.
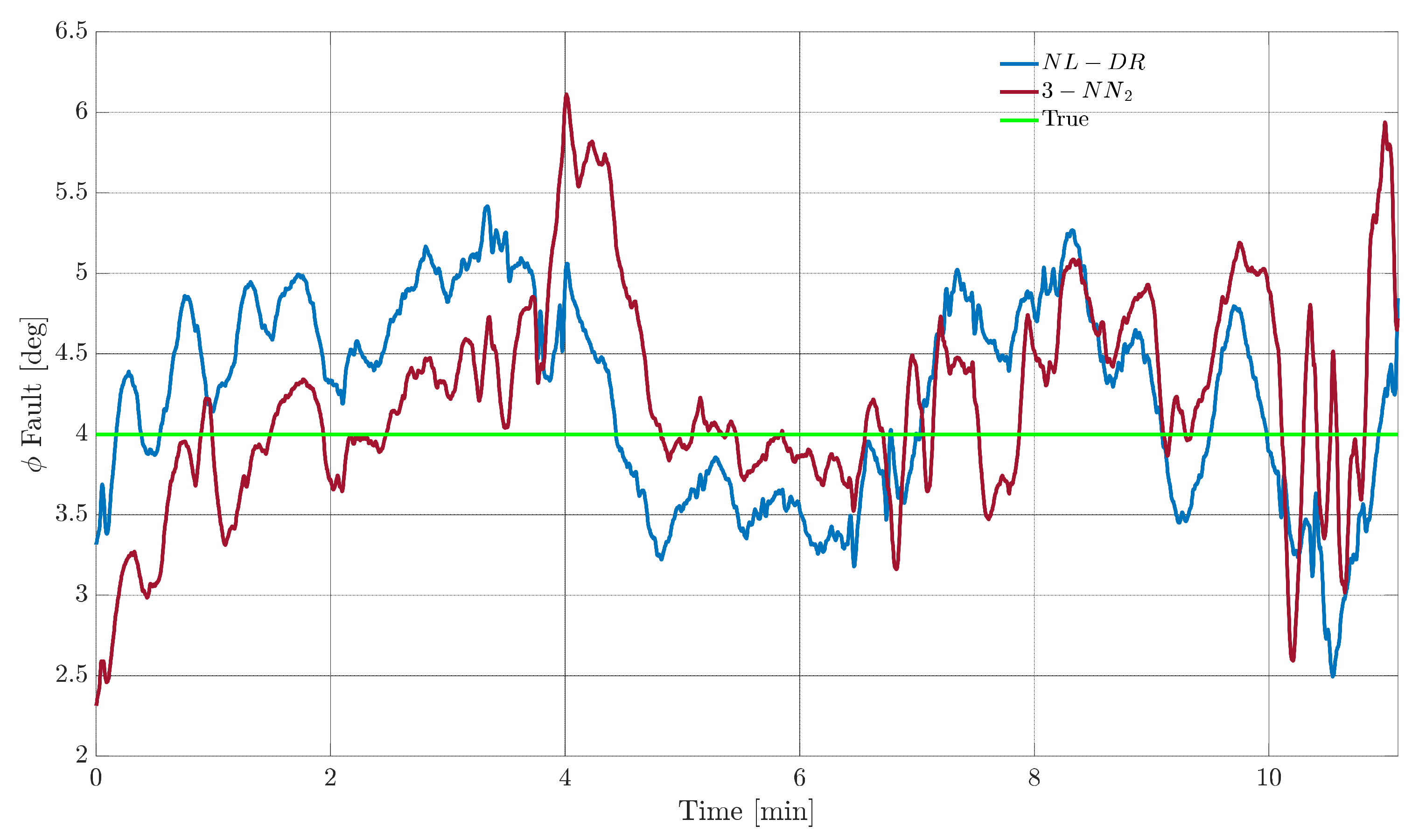
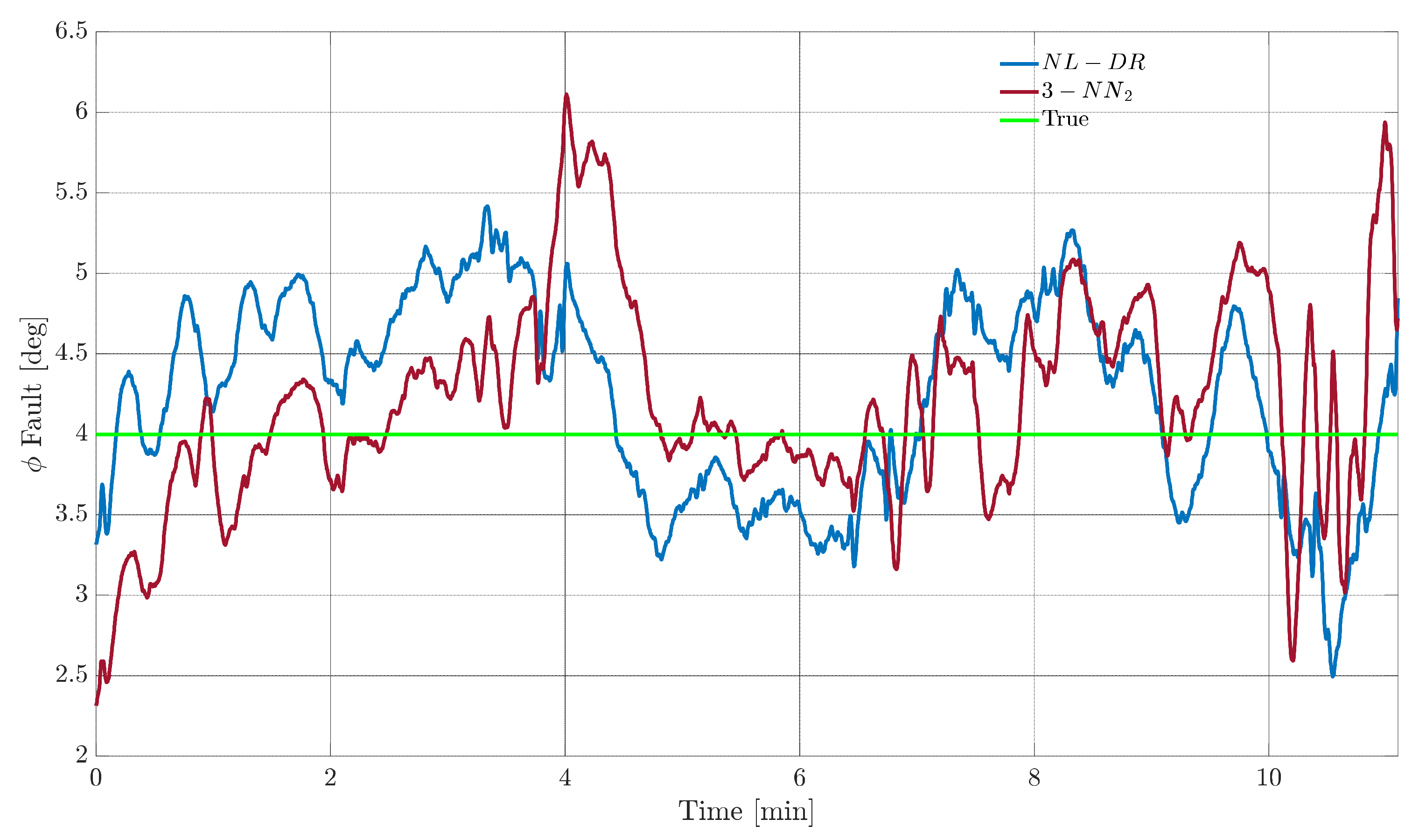
A similar analysis is then performed for the fault on the sensor
. In this case, however, the fault amplitude is selected to be 4°, i.e., the point R of
Figure 6 where the
index is equal to 6% for the two techniques.
Figure 9 shows the evolution of the estimation of the fault amplitude for the two techniques, where it is confirmed that the performances are equivalent for all practical purposes. On the other side, from
Figure 10, it can be observed that the
performance of the NL-DR technique is significantly better than that of the 3-NN
2 technique (Points S and T in
Figure 6).


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}