
Exploring Artificial Neural Networks Efficiency in Tiny Wearable Devices for Human Activity Recognition



Abstract
:1. Introduction
2. Related Works
3. The Proposed Method
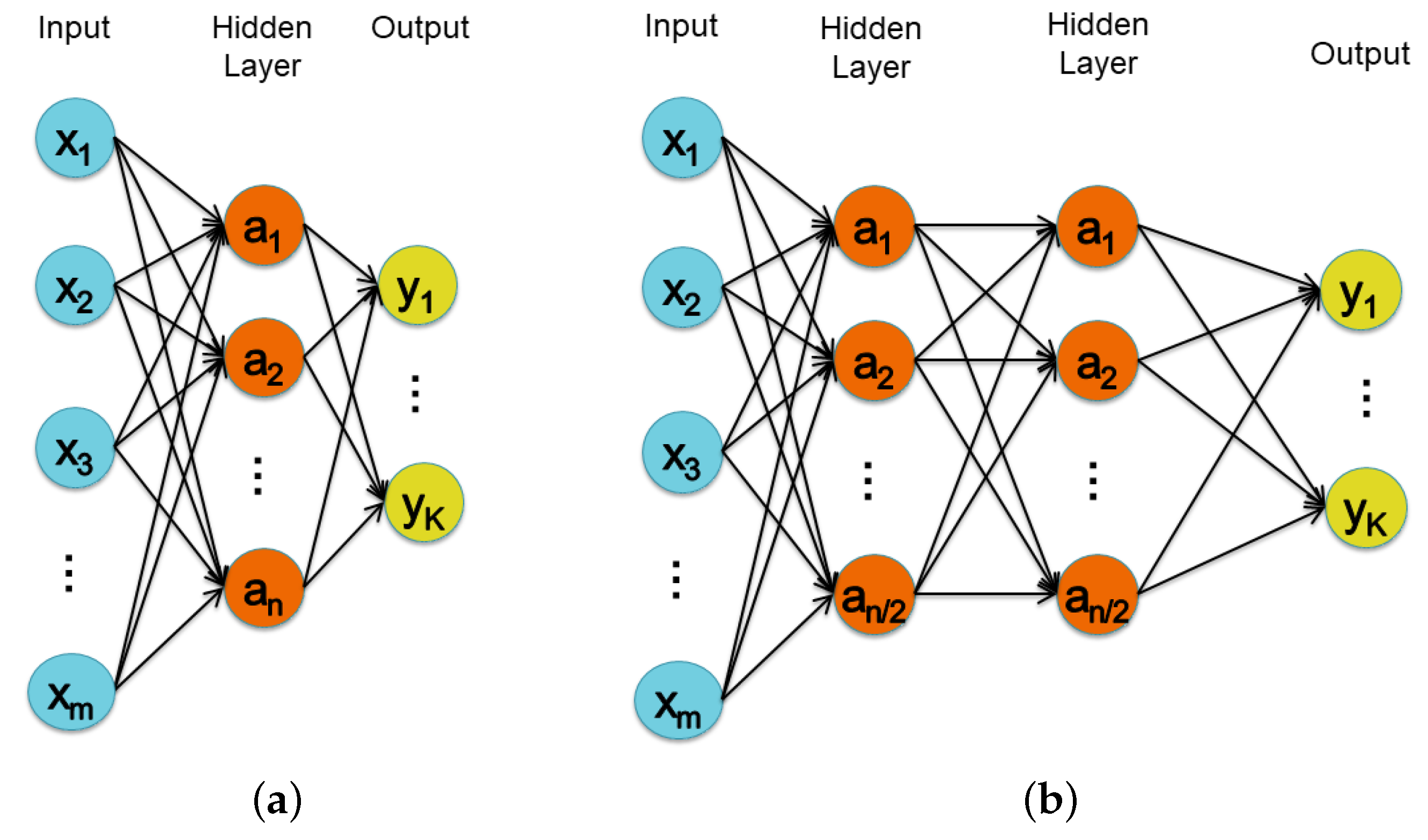
3.1. Perceptron Network
3.2. Convolutional Neural Network
3.3. Tuning Neural Networks Complexity
3.4. The Case Study
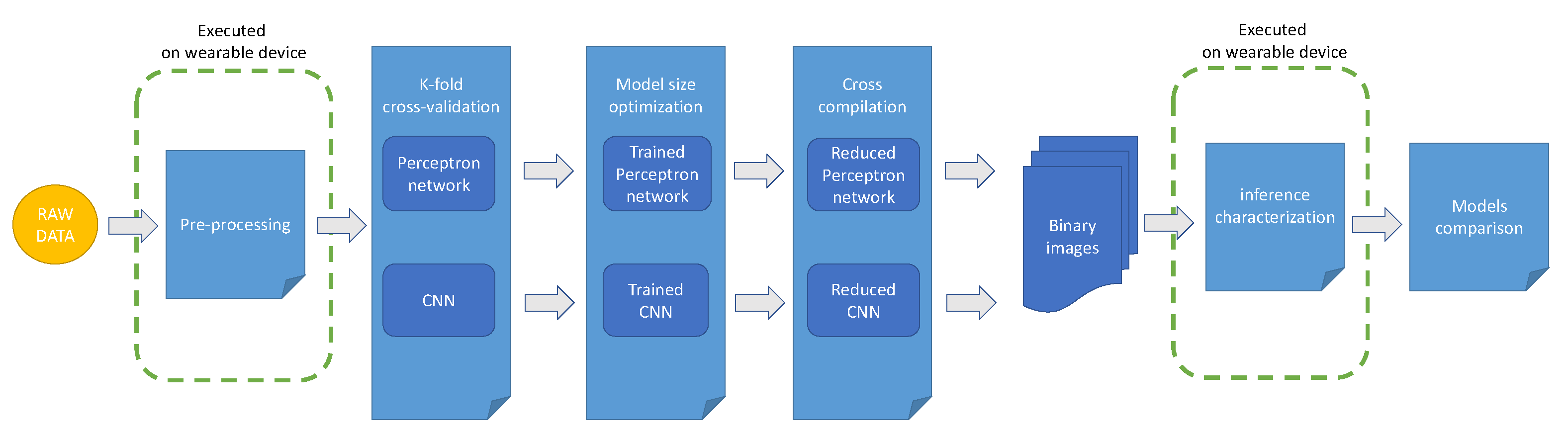
3.5. The Proposed Workflow
3.6. Signal Pre-Processing
4. Experimental Setup
4.1. The Software Platform
4.2. The Wearable Device
4.3. Energy Consumption Measurement Setup
4.4. Classification Performance Metrics
5. Experimental Results and Discussion
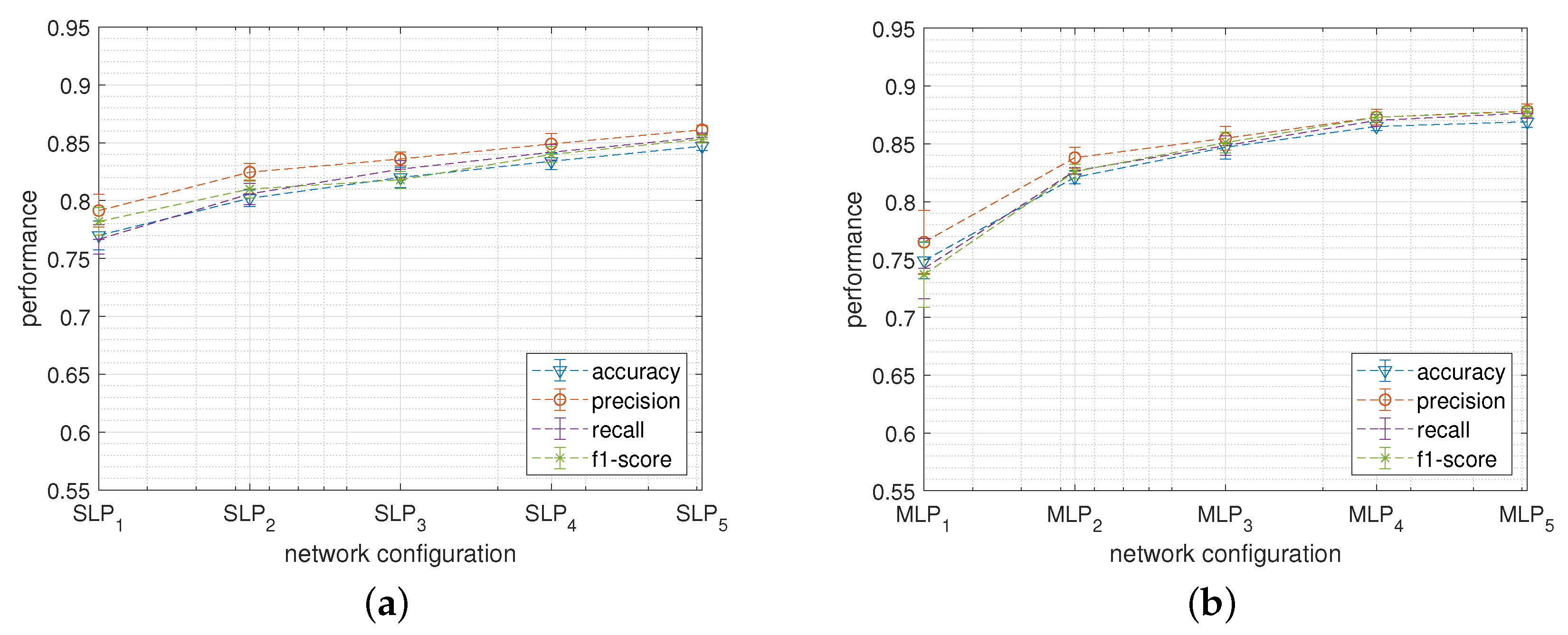
5.1. Perceptron Network
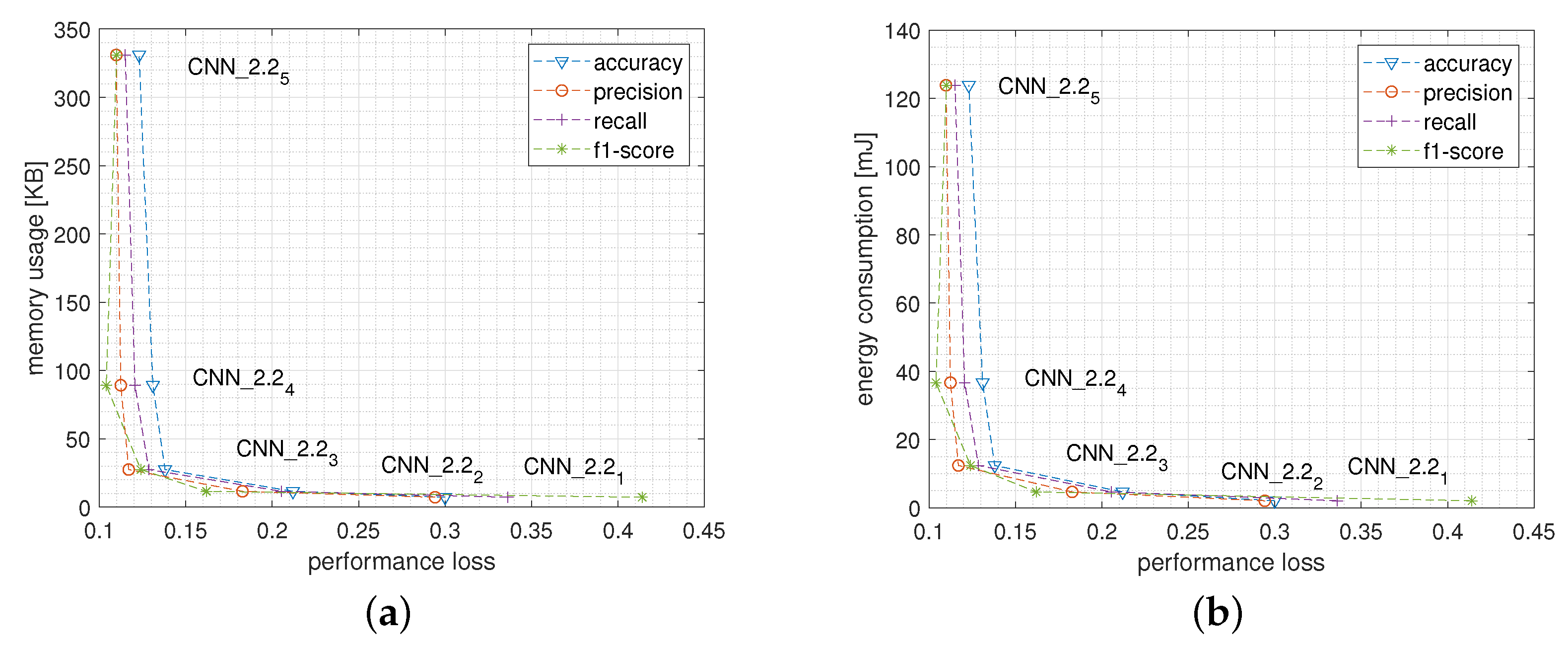
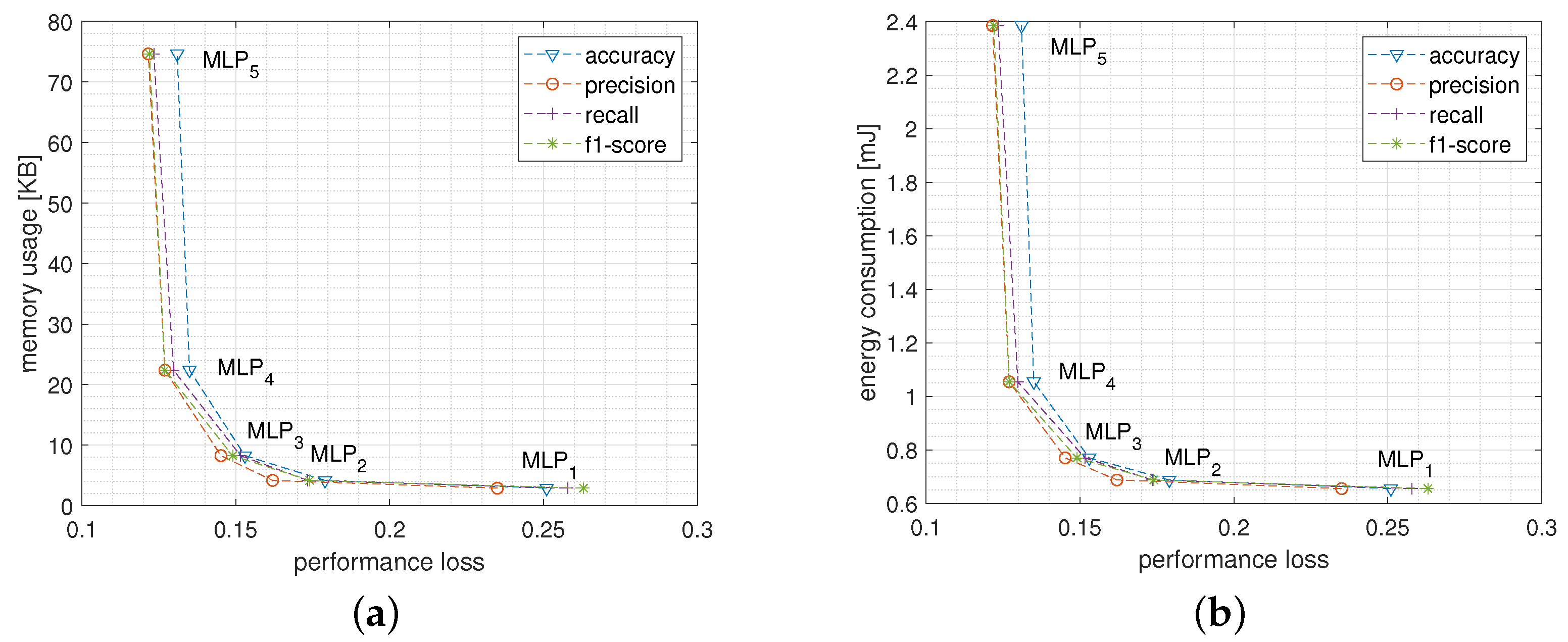
5.1.1. Network Size and Structure
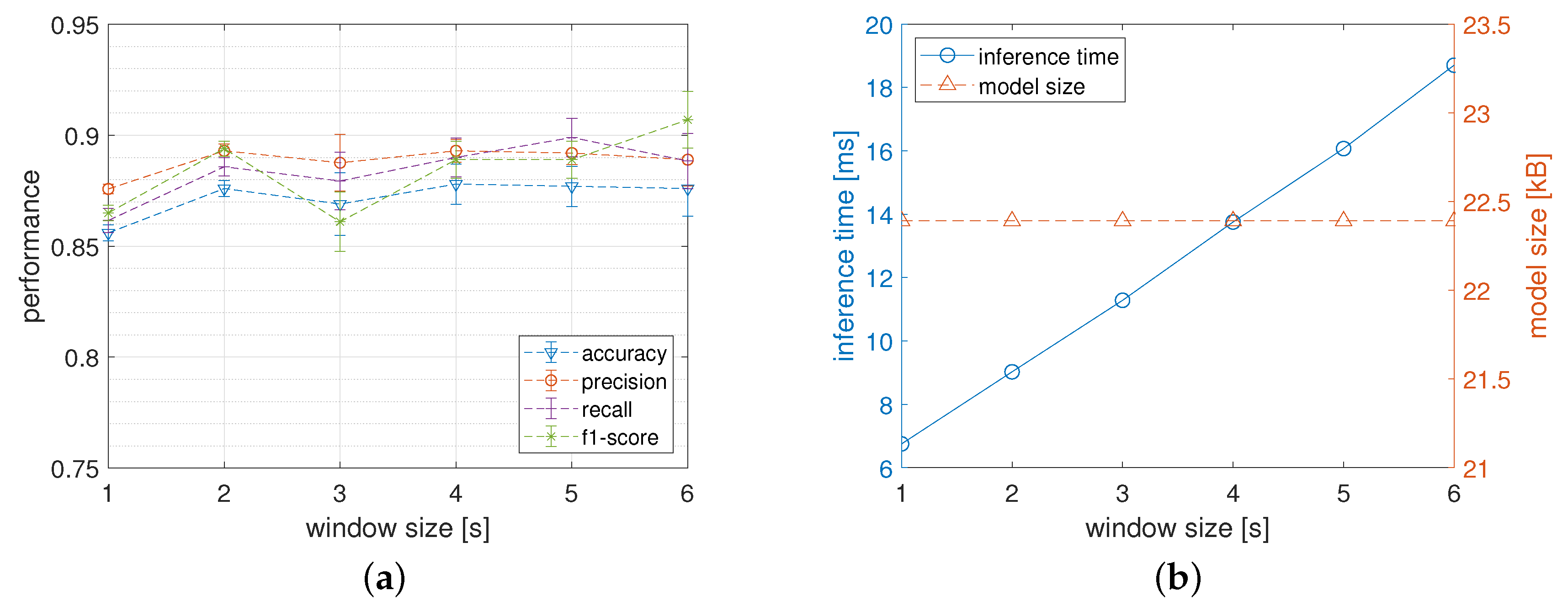
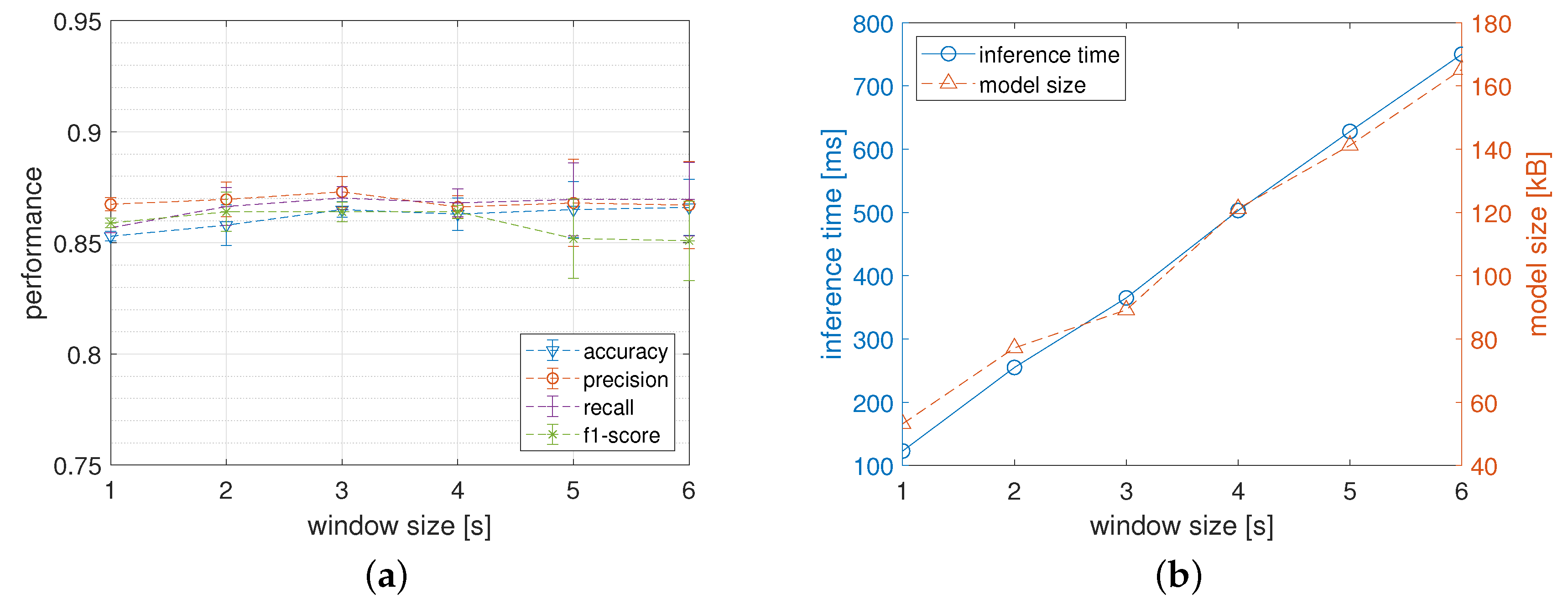
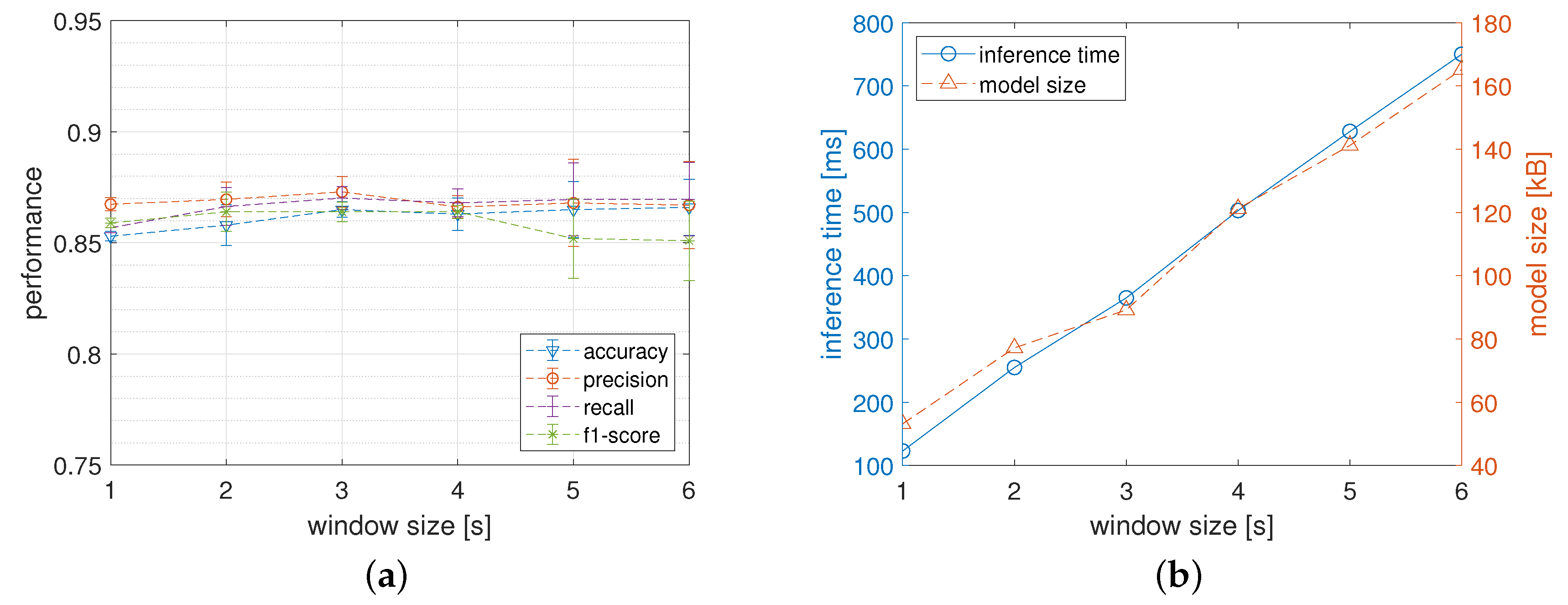
5.1.2. Window Size
5.1.3. Feature Selection
5.2. Convolutional Neural Network
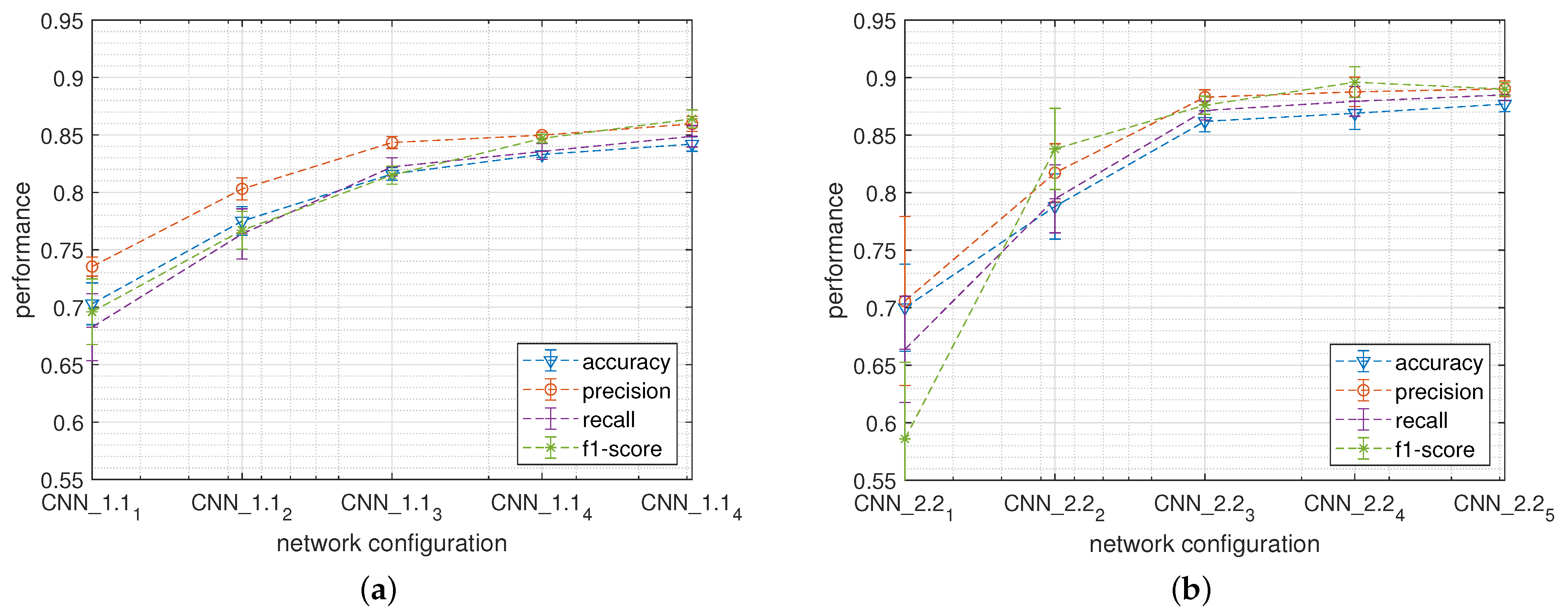
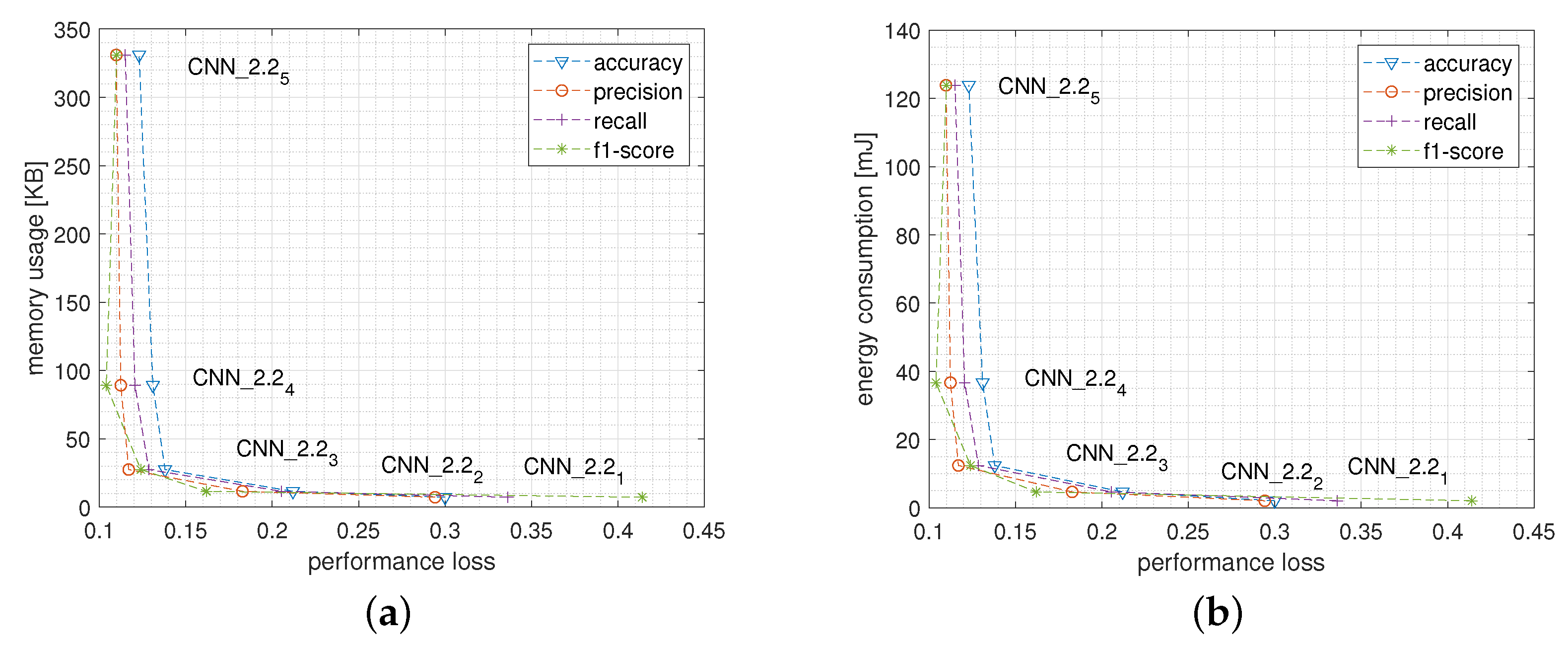
5.2.1. Network Size and Structure
5.2.2. Window Size
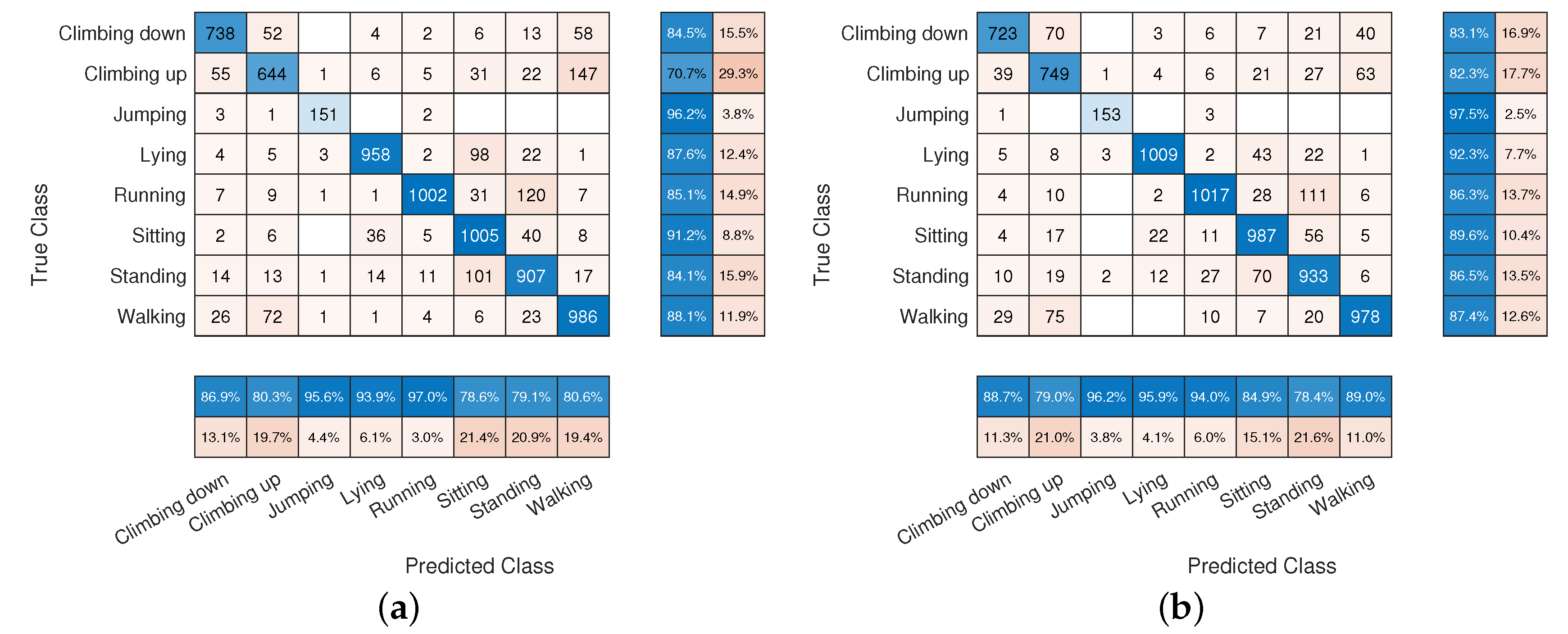
5.3. Network Comparison
6. Conclusions, Limitations, and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2012, 15, 1192–1209. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Bacciu, D.; Chessa, S.; Gallicchio, C.; Micheli, A. On the need of machine learning as a service for the internet of things. In Proceedings of the 1st International Conference on Internet of Things and Machine Learning, Liverpool, UK, 17–18 October 2017; pp. 1–8. [Google Scholar]
- Tahsien, S.M.; Karimipour, H.; Spachos, P. Machine learning based solutions for security of Internet of Things (IoT): A survey. J. Netw. Comput. Appl. 2020, 161, 102630. [Google Scholar] [CrossRef] [Green Version]
- Uma, S.; Eswari, R. Accident prevention and safety assistance using IOT and machine learning. J. Reliab. Intell. Environ. 2021, 1–25. [Google Scholar] [CrossRef]
- Jensen, U.; Kugler, P.; Ring, M.; Eskofier, B.M. Approaching the accuracy–cost conflict in embedded classification system design. Pattern Anal. Appl. 2016, 19, 839–855. [Google Scholar] [CrossRef]
- Cui, L.; Yang, S.; Chen, F.; Ming, Z.; Lu, N.; Qin, J. A survey on application of machine learning for Internet of Things. Int. J. Mach. Learn. Cybern. 2018, 9, 1399–1417. [Google Scholar] [CrossRef]
- Samie, F.; Bauer, L.; Henkel, J. From cloud down to things: An overview of machine learning in internet of things. IEEE Internet Things J. 2019, 6, 4921–4934. [Google Scholar] [CrossRef]
- Lane, N.D.; Bhattacharya, S.; Georgiev, P.; Forlivesi, C.; Jiao, L.; Qendro, L.; Kawsar, F. Deepx: A software accelerator for low-power deep learning inference on mobile devices. In Proceedings of the 2016 15th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Vienna, Austria, 11–14 April 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–12. [Google Scholar]
- Kang, Y.; Hauswald, J.; Gao, C.; Rovinski, A.; Mudge, T.; Mars, J.; Tang, L. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge. ACM SIGARCH Comput. Archit. News 2017, 45, 615–629. [Google Scholar] [CrossRef] [Green Version]
- Xu, M.; Qian, F.; Zhu, M.; Huang, F.; Pushp, S.; Liu, X. Deepwear: Adaptive local offloading for on-wearable deep learning. IEEE Trans. Mob. Comput. 2019, 19, 314–330. [Google Scholar] [CrossRef] [Green Version]
- Osia, S.A.; Shamsabadi, A.S.; Sajadmanesh, S.; Taheri, A.; Katevas, K.; Rabiee, H.R.; Lane, N.D.; Haddadi, H. A hybrid deep learning architecture for privacy-preserving mobile analytics. IEEE Internet Things J. 2020, 7, 4505–4518. [Google Scholar] [CrossRef] [Green Version]
- Eshratifar, A.E.; Abrishami, M.S.; Pedram, M. JointDNN: An efficient training and inference engine for intelligent mobile cloud computing services. IEEE Trans. Mob. Comput. 2019, 20, 565–576. [Google Scholar] [CrossRef] [Green Version]
- Elsts, A.; McConville, R.; Fafoutis, X.; Twomey, N.; Piechocki, R.J.; Santos-Rodriguez, R.; Craddock, I. On-Board Feature Extraction from Acceleration Data for Activity Recognition. In Proceedings of the EWSN, Madrid, Spain, 14–16 February 2018; pp. 163–168. [Google Scholar]
- Khan, A.; Hammerla, N.; Mellor, S.; Plötz, T. Optimising sampling rates for accelerometer-based human activity recognition. Pattern Recognit. Lett. 2016, 73, 33–40. [Google Scholar] [CrossRef]
- Lane, N.D.; Bhattacharya, S.; Mathur, A.; Georgiev, P.; Forlivesi, C.; Kawsar, F. Squeezing deep learning into mobile and embedded devices. IEEE Pervasive Comput. 2017, 16, 82–88. [Google Scholar] [CrossRef]
- Coelho, Y.L.; Santos, F.d.A.S.d.; Frizera-Neto, A.; Bastos-Filho, T.F. A Lightweight Framework for Human Activity Recognition on Wearable Devices. IEEE Sens. J. 2021, 21, 24471–24481. [Google Scholar] [CrossRef]
- Fedorov, I.; Adams, R.P.; Mattina, M.; Whatmough, P.N. SpArSe: Sparse architecture search for CNNs on resource-constrained microcontrollers. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 1–13. [Google Scholar]
- Haigh, K.Z.; Mackay, A.M.; Cook, M.R.; Lin, L.G. Machine Learning for Embedded Systems: A Case Study; BBN Technologies: Cambridge, MA, USA, 2015. [Google Scholar]
- Alam, F.; Mehmood, R.; Katib, I.; Albeshri, A. Analysis of eight data mining algorithms for smarter Internet of Things (IoT). Procedia Comput. Sci. 2016, 98, 437–442. [Google Scholar] [CrossRef] [Green Version]
- Gupta, C.; Suggala, A.S.; Goyal, A.; Simhadri, H.V.; Paranjape, B.; Kumar, A.; Goyal, S.; Udupa, R.; Varma, M.; Jain, P. Protonn: Compressed and accurate knn for resource-scarce devices. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 1331–1340. [Google Scholar]
- Wang, X.; Magno, M.; Cavigelli, L.; Benini, L. FANN-on-MCU: An Open-Source Toolkit for Energy-Efficient Neural Network Inference at the Edge of the Internet of Things. IEEE Internet Things J. 2020, 7, 4403–4417. [Google Scholar] [CrossRef]
- Lane, N.D.; Bhattacharya, S.; Georgiev, P.; Forlivesi, C.; Kawsar, F. An early resource characterization of deep learning on wearables, smartphones and internet-of-things devices. In Proceedings of the 2015 International Workshop on Internet of Things towards Applications, New York, NY, USA, 1 November 2015; pp. 7–12. [Google Scholar]
- Disabato, S.; Roveri, M. Incremental On-Device Tiny Machine Learning. In Proceedings of the 2nd International Workshop on Challenges in Artificial Intelligence and Machine Learning for Internet of Things, Virtual Event, 16–19 November 2020; pp. 7–13. [Google Scholar]
- Wang, Z.; Wu, Y.; Jia, Z.; Shi, Y.; Hu, J. Lightweight Run-Time Working Memory Compression for Deployment of Deep Neural Networks on Resource-Constrained MCUs. In Proceedings of the 26th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 18–21 January 2021; pp. 607–614. [Google Scholar]
- Odema, M.; Rashid, N.; Al Faruque, M.A. Energy-Aware Design Methodology for Myocardial Infarction Detection on Low-Power Wearable Devices. In Proceedings of the 26th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 18–21 January 2021; pp. 621–626. [Google Scholar]
- Rashid, N.; Dautta, M.; Tseng, P.; Al Faruque, M.A. HEAR: Fog-Enabled Energy-Aware Online Human Eating Activity Recognition. IEEE Internet Things J. 2021, 8, 860–868. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Hawash, H.; Chang, V.; Chakrabortty, R.K.; Ryan, M. Deep learning for Heterogeneous Human Activity Recognition in Complex IoT Applications. IEEE Internet Things J. 2020, 1. [Google Scholar] [CrossRef]
- Novac, P.E.; Castagnetti, A.; Russo, A.; Miramond, B.; Pegatoquet, A.; Verdier, F. Toward unsupervised human activity recognition on microcontroller units. In Proceedings of the 2020 23rd Euromicro Conference on Digital System Design (DSD), Kranj, Slovenia, 26–28 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 542–550. [Google Scholar]
- Alessandrini, M.; Biagetti, G.; Crippa, P.; Falaschetti, L.; Turchetti, C. Recurrent Neural Network for Human Activity Recognition in Embedded Systems Using PPG and Accelerometer Data. Electronics 2021, 10, 1715. [Google Scholar] [CrossRef]
- Mayer, P.; Magno, M.; Benini, L. Energy-Positive Activity Recognition—From Kinetic Energy Harvesting to Smart Self-Sustainable Wearable Devices. IEEE Trans. Biomed. Circuits Syst. 2021, 15, 926–937. [Google Scholar] [CrossRef] [PubMed]
- Haykin, S.; Network, N. A comprehensive foundation. Neural Netw. 2004, 2, 41. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Neural Networks and Deep Learning; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Bashiri, M.; Geranmayeh, A.F. Tuning the parameters of an artificial neural network using central composite design and genetic algorithm. Sci. Iran. 2011, 18, 1600–1608. [Google Scholar] [CrossRef] [Green Version]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Domhan, T.; Springenberg, J.; Hutter, F. Speeding up Automatic Hyperparameter Optimization of Deep Neural Networks by Extrapolation of Learning Curves; AAAI Press: Palo Alto, CA, USA, 2015; Volume 2015-January, pp. 3460–3468. [Google Scholar]
- Cui, H.; Bai, J. A new hyperparameters optimization method for convolutional neural networks. Pattern Recognit. Lett. 2019, 125, 828–834. [Google Scholar] [CrossRef]
- Mikroe. Hexiwear: Complete IOT Development Solution. Available online: https://www.mikroe.com/hexiwear (accessed on 19 July 2020).
- Sprager, S.; Juric, M.B. Inertial Sensor-Based Gait Recognition: A Review. Sensors 2015, 15, 22089–22127. [Google Scholar] [CrossRef] [PubMed]
- Banos, O.; Galvez, J.M.; Damas, M.; Pomares, H.; Rojas, I. Window size impact in human activity recognition. Sensors 2014, 14, 6474–6499. [Google Scholar] [CrossRef] [Green Version]
- Sztyler, T.; Stuckenschmidt, H.; Petrich, W. Position-Aware Activity Recognition with Wearable Devices. Pervasive Mob. Comput. 2017, 38, 281–295. [Google Scholar] [CrossRef]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Kim, T.H.; White, H. On more robust estimation of skewness and kurtosis. Financ. Res. Lett. 2004, 1, 56–73. [Google Scholar] [CrossRef]
- Tapia, E.M.; Intille, S.S.; Haskell, W.; Larson, K.; Wright, J.; King, A.; Friedman, R. Real-time recognition of physical activities and their intensities using wireless accelerometers and a heart rate monitor. In Proceedings of the 2007 11th IEEE International Symposium on Wearable Computers, Boston, MA, USA, 11–13 October 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 37–40. [Google Scholar]
- Reddy, S.; Mun, M.; Burke, J.; Estrin, D.; Hansen, M.; Srivastava, M. Using mobile phones to determine transportation modes. ACM Trans. Sens. Netw. (TOSN) 2010, 6, 1–27. [Google Scholar] [CrossRef]
- Cheng, J.; Amft, O.; Lukowicz, P. Active capacitive sensing: Exploring a new wearable sensing modality for activity recognition. In Proceedings of the International Conference on Pervasive Computing, Helsinki, Finland, 17–20 May 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 319–336. [Google Scholar]
- Hassan, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Future Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Hou, C. A study on IMU-Based Human Activity Recognition Using Deep Learning and Traditional Machine Learning. In Proceedings of the 2020 5th International Conference on Computer and Communication Systems (ICCCS), Shanghai, China, 15–18 May 2020; pp. 225–234. [Google Scholar] [CrossRef]
- Ketkar, N. Introduction to keras. In Deep Learning with Python; Springer: Berlin/Heidelberg, Germany, 2017; pp. 97–111. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Google Brain Team. TensorFlow Lite for Microcontrollers. Available online: https://www.tensorflow.org/lite/microcontrollers (accessed on 15 February 2021).
- Arm Ltd. Mbed, Rapid IoT Device Development. Available online: https://os.mbed.com/ (accessed on 15 February 2021).
- Rohde & Schwarz. NGMO2 Datasheet. Available online: https://www.rohde-schwarz.com/it/brochure-scheda-tecnica/ngmo2/ (accessed on 19 July 2020).
- National Instruments. PC-6251 Datasheet. Available online: http://www.ni.com/pdf/manuals/375213c.pdf (accessed on 19 July 2020).
- National Instruments. Installation Guide BNC-2120. Available online: http://www.ni.com/pdf/manuals/372123d.pdf (accessed on 19 July 2020).
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Liu, H.; Yu, L. Toward integrating feature selection algorithms for classification and clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar]
- McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | n | p (SLP) | p (MLP) |
|---|---|---|---|
| 1 | 32 | 872 | 712 |
| 2 | 64 | 1736 | 1928 |
| 3 | 128 | 3464 | 5896 |
| 4 | 256 | 6920 | 19,976 |
| 5 | 512 | 13,832 | 72,712 |
| Features | Accuracy | Precision | Recall | f1-Score |
|---|---|---|---|---|
| A | 0.761 | 0.758 | 0.758 | 0.755 |
| A + S | 0.859 | 0.873 | 0.868 | 0.869 |
| A + S + X | 0.865 | 0.873 | 0.870 | 0.870 |
| A + S + X + M | 0.863 | 0.872 | 0.870 | 0.870 |
| A + S + X + M + K | 0.862 | 0.870 | 0.867 | 0.867 |
| A + S + X + M + K + W | 0.859 | 0.871 | 0.866 | 0.867 |
| ID | n | j | p () | p () |
|---|---|---|---|---|
| 1 | 32 | 4 | 6644 | 1512 |
| 2 | 64 | 8 | 25,824 | 5544 |
| 3 | 128 | 16 | 101,816 | 21,192 |
| 4 | 256 | 32 | 404,328 | 82,824 |
| 5 | 512 | 64 | 1,611,464 | 327,432 |
| - | - | - | - | - | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Run | H0 | p | H0 | p | H0 | p | H0 | p | H0 | p |
| #1 | true | false | 0.12134 | false | 0.09187 | false | 0.36484 | false | 0.26438 | |
| #2 | true | true | true | 0.00003 | false | 0.24403 | false | 0.51975 | ||
| #3 | true | false | 0.13615 | true | 0.00003 | false | 0.36831 | true | 0.00239 | |
| #4 | true | true | 0.00024 | false | 0.16356 | true | 0.00001 | false | 0.05891 | |
| #5 | true | true | true | 0.00077 | false | 0.05528 | false | 0.10078 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lattanzi, E.; Donati, M.; Freschi, V. Exploring Artificial Neural Networks Efficiency in Tiny Wearable Devices for Human Activity Recognition. Sensors 2022, 22, 2637. https://doi.org/10.3390/s22072637
Lattanzi E, Donati M, Freschi V. Exploring Artificial Neural Networks Efficiency in Tiny Wearable Devices for Human Activity Recognition. Sensors. 2022; 22(7):2637. https://doi.org/10.3390/s22072637
Chicago/Turabian StyleLattanzi, Emanuele, Matteo Donati, and Valerio Freschi. 2022. "Exploring Artificial Neural Networks Efficiency in Tiny Wearable Devices for Human Activity Recognition" Sensors 22, no. 7: 2637. https://doi.org/10.3390/s22072637
APA StyleLattanzi, E., Donati, M., & Freschi, V. (2022). Exploring Artificial Neural Networks Efficiency in Tiny Wearable Devices for Human Activity Recognition. Sensors, 22(7), 2637. https://doi.org/10.3390/s22072637