
Deep Learning Based SWIR Object Detection in Long-Range Surveillance Systems: An Automated Cross-Spectral Approach

 , , , and
, , , and
Abstract
:1. Introduction
2. SWIR Sensor Characteristics and Advantages Compared to Visible (VIS)
3. Related Work in SWIR Object Detection
4. Experiment Workflow
4.1. Problem Formulation
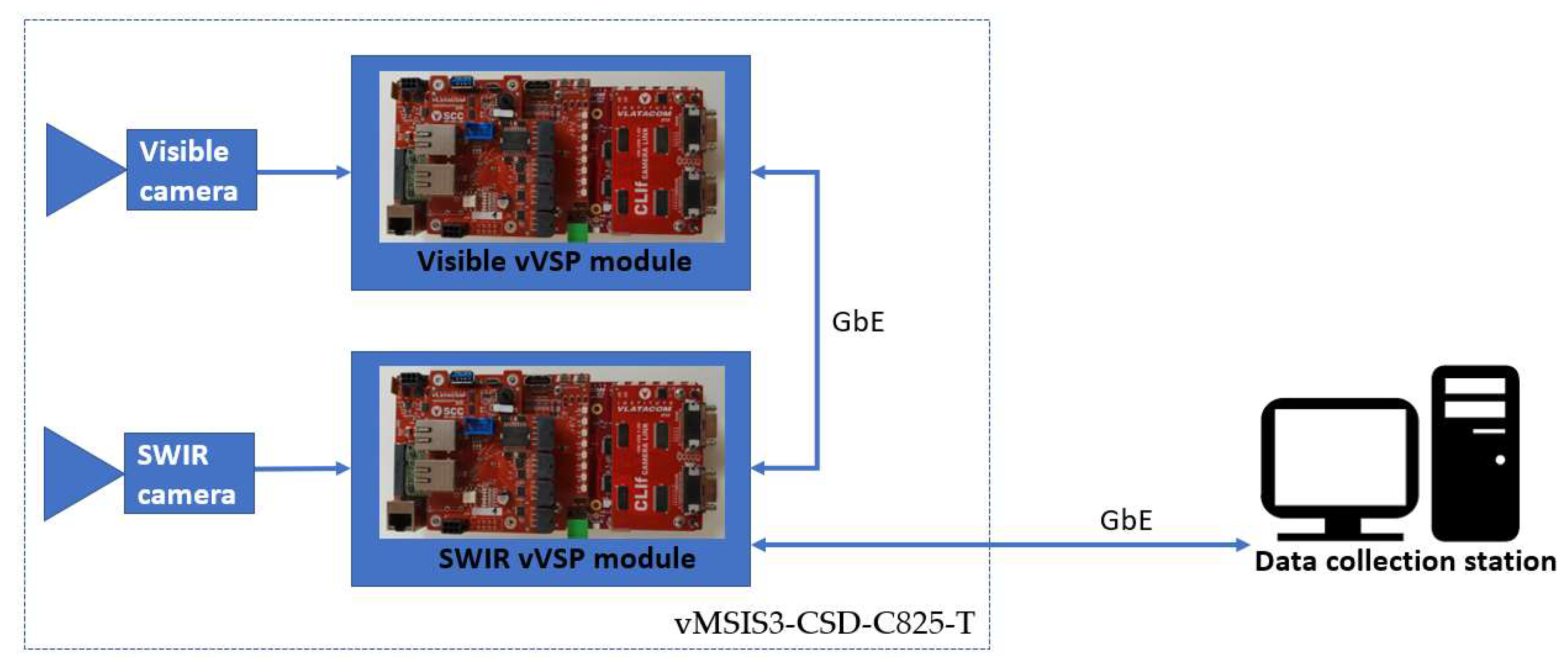
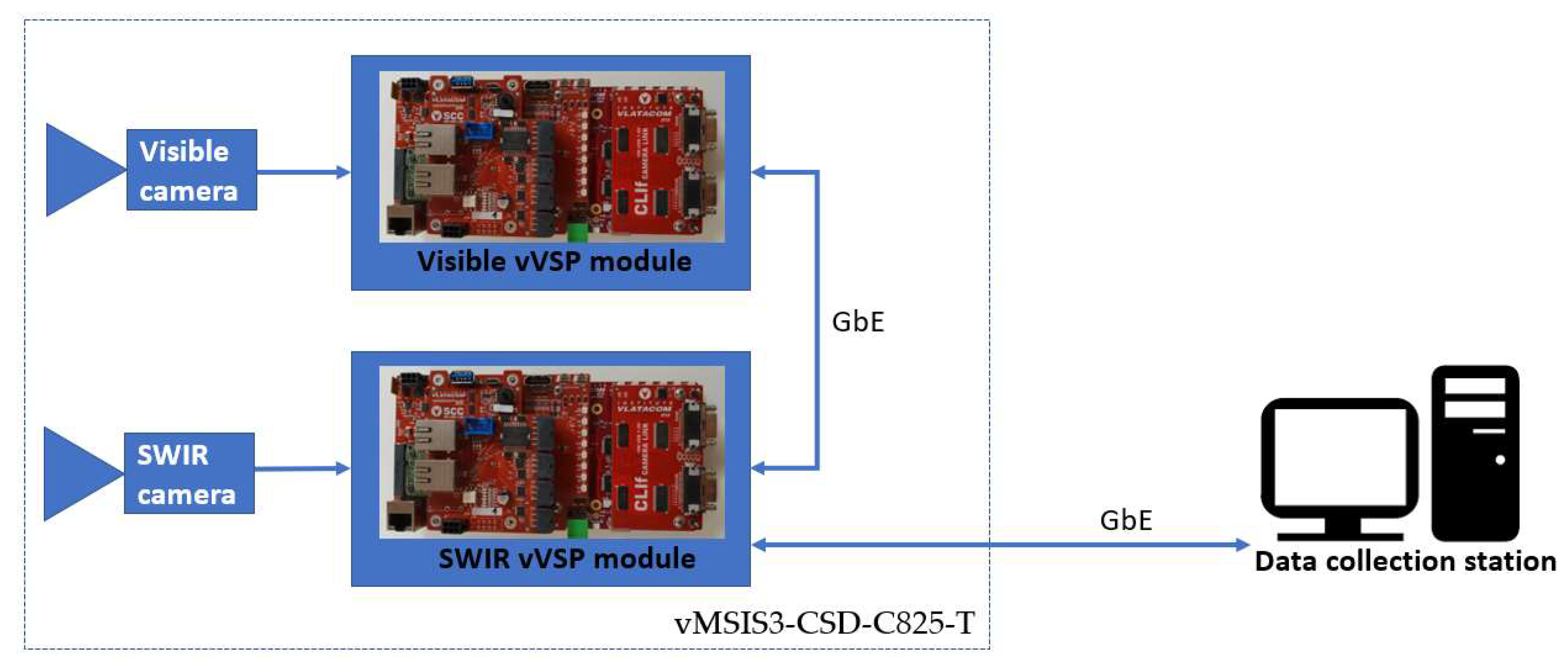
4.2. Multi-Sensor Imaging System
4.3. Cross-Spectral Data Annotation
4.4. Selection of Object Detection Models for Visible-Light Channel
5. Results and Discussion
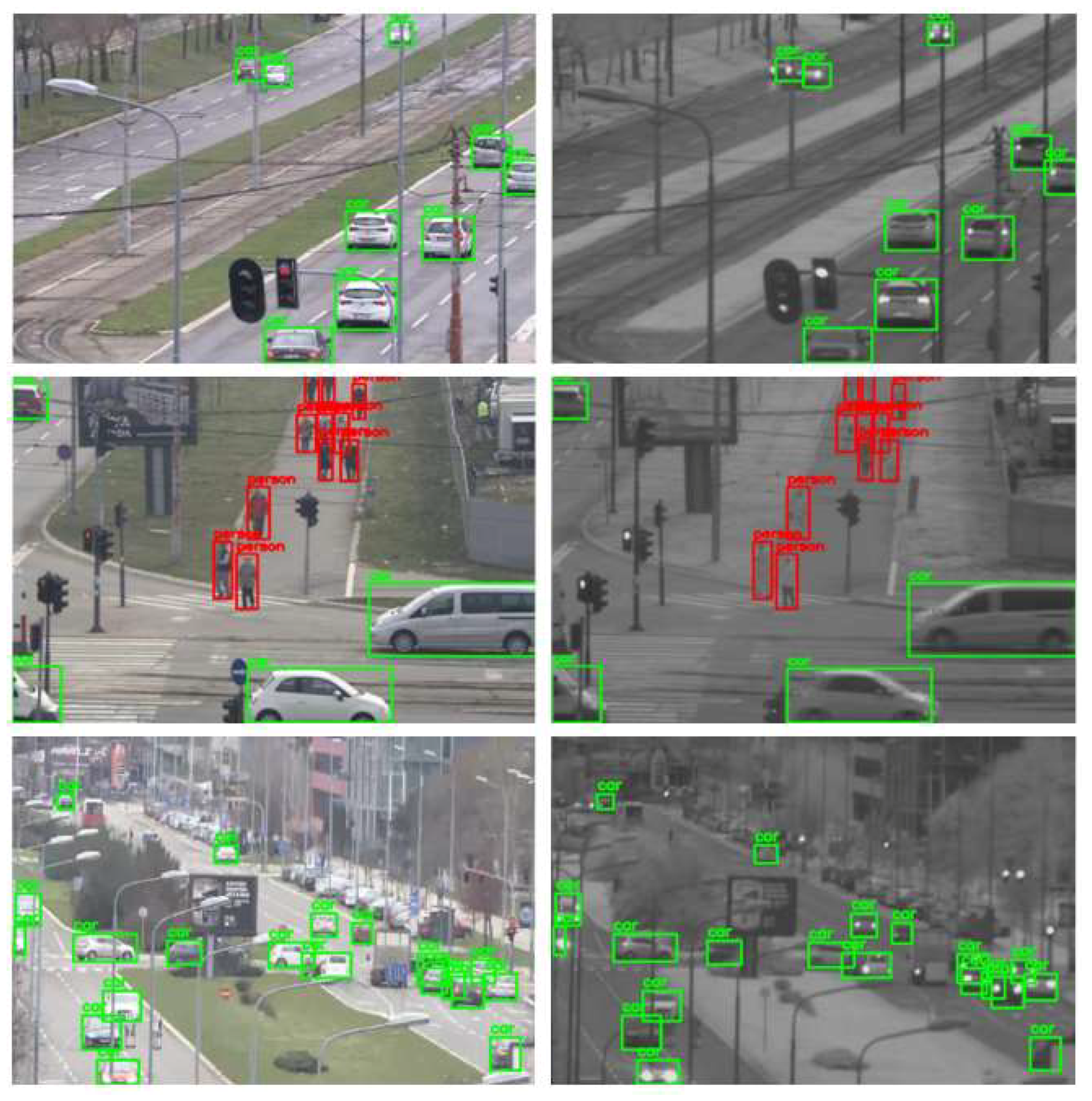
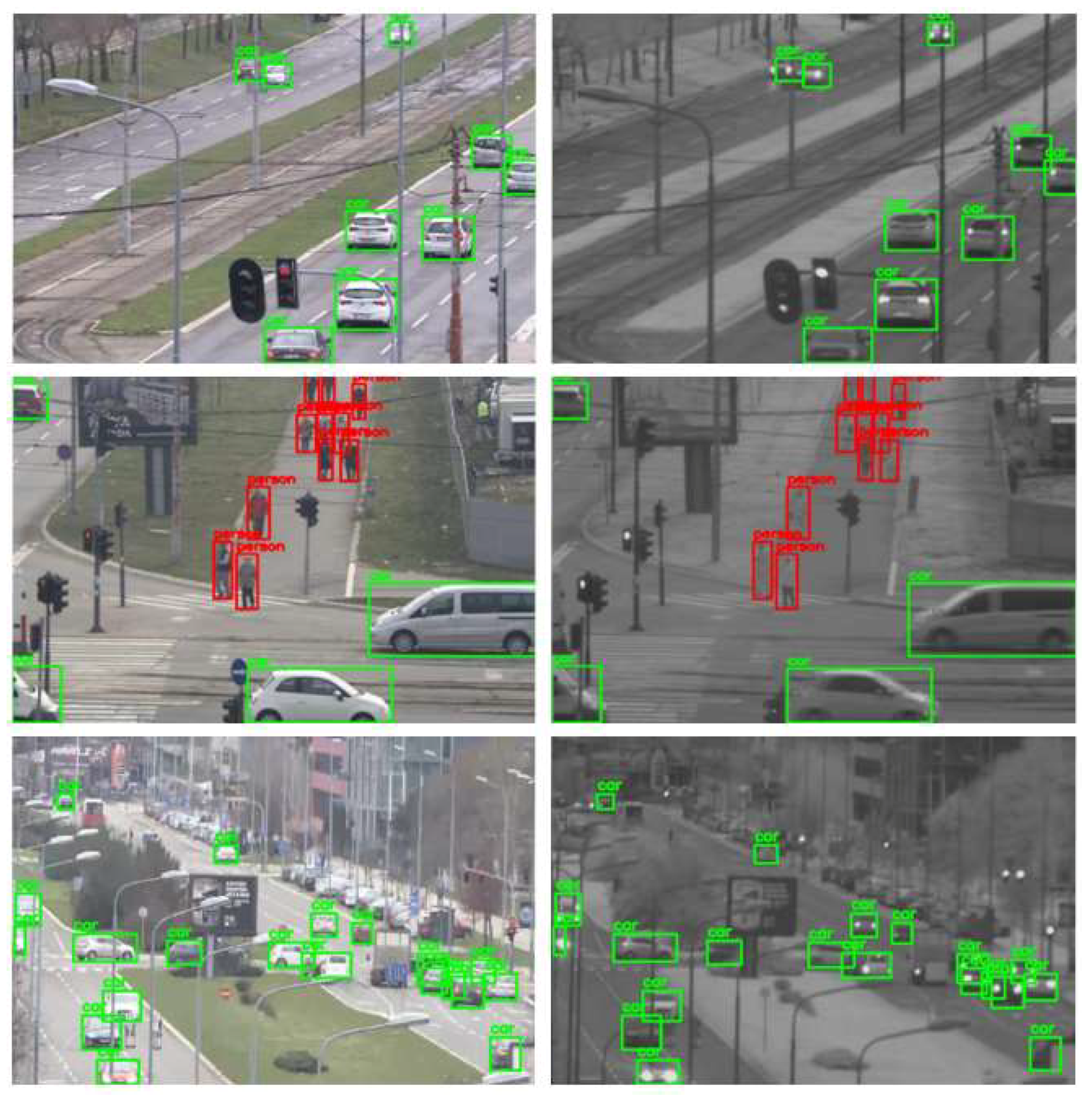
5.1. Detection Mapping from Visible-Light to SWIR Channel
- Missed detections on the color image—Figure 9. Due to partial occlusions, some objects remain undetected on the color image, although they are significantly visible and should have been part of the ground-truth SWIR dataset.
- False detections on the color image—Figure 10.
- Detections of objects on the color image that are not visible on the SWIR image due to the nature of the SWIR sensor and should not be part of the SWIR training dataset—Figure 11.
- Poorer precision in detection mapping of moving objects, especially if they are moving at a higher speed, due to the nature of the image on the SWIR camera. The used SWIR camera is an interlaced camera, thus there is inaccuracy in detection mapping from the color image because the position of the object on the SWIR image at the time of sampling is not unambiguously determined. An example is shown in Figure 12.
5.2. Selection of the Object Detection Model for Development of SWIR Object Detection
5.3. Improved SWIR Object Detection by New Methodology Based on Cross-Spectral Data Annotaion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
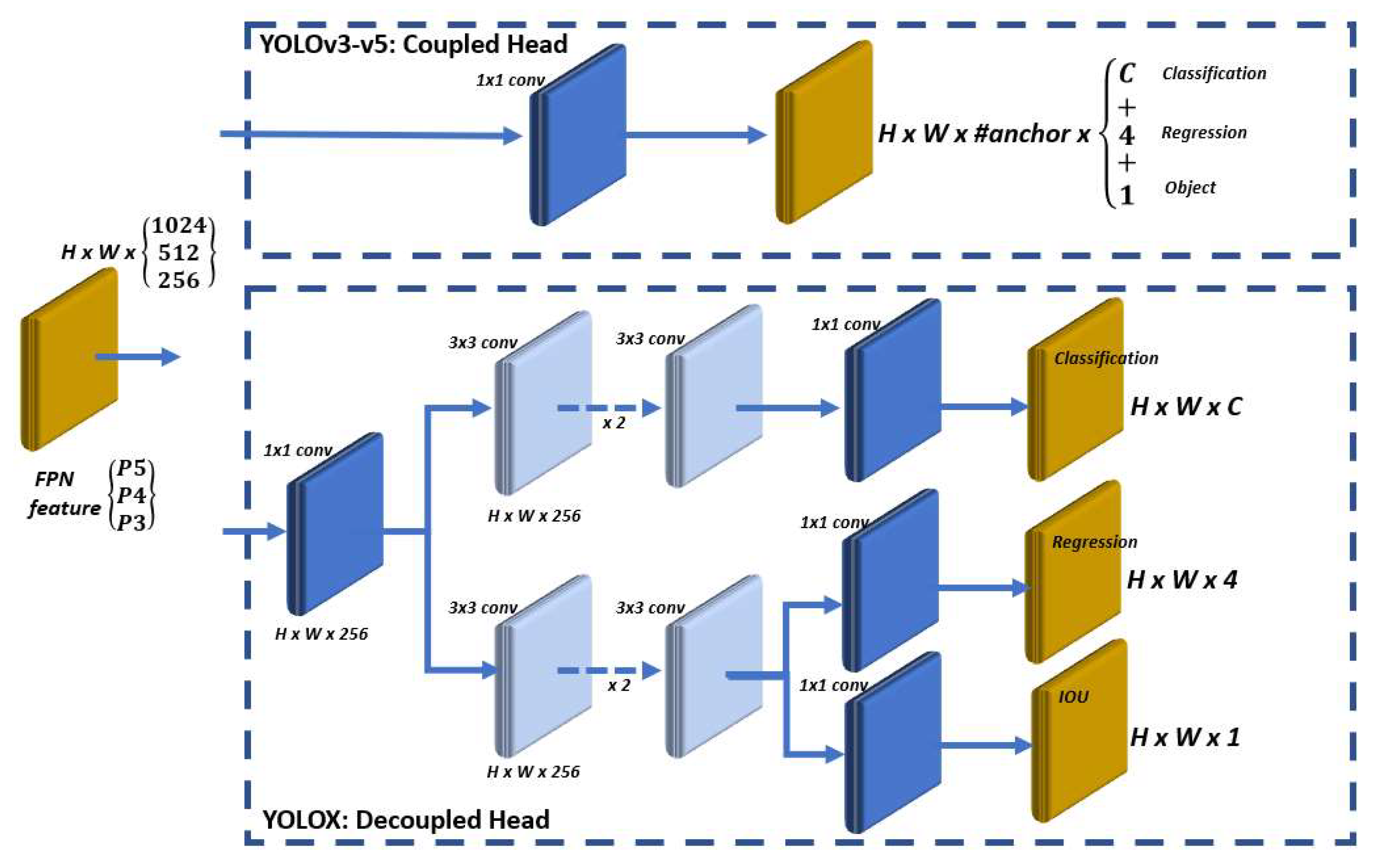
YOLOX

References
- Kolekar, M.H. Intelligent Video Surveillance Systems: An Algorithmic Approach; CRC Press/Taylor & Francis Group: Boca Raton, FL, USA, 2019. [Google Scholar]
- Perić, D.; Livada, B.; Perić, M.; Vujić, S. Thermal Imager Range: Predictions, Expectations, and Reality. Sensors 2019, 19, 3313. [Google Scholar] [CrossRef] [Green Version]
- Gade, R.; Moeslund, T.B. Thermal cameras and applications: A survey. Mach. Vis. Appl. 2013, 25, 245–262. [Google Scholar] [CrossRef] [Green Version]
- Simić, M.; Perić, M.; Popadić, I.; Perić, D.; Pavlović, M.; Vučetić, M.; Stanković, M.S. Big Data and development of Smart City: System Architecture and Practical Public Safety Example. Serb. J. Electr. Eng. 2020, 17, 337–355. [Google Scholar] [CrossRef]
- Kristo, M.; Ivasic-Kos, M.; Pobar, M. Thermal Object Detection in Difficult Weather Conditions Using YOLO. IEEE Access 2020, 8, 125459–125476. [Google Scholar] [CrossRef]
- Hansen, M.P.; Malchow, D.S. Overview of SWIR Detectors, Cameras, and Applications. In Thermosense Xxx; International Society for Optics and Photonics: Orlando, FL, USA, 2008; Volume 6939, p. 69390I. [Google Scholar]
- Driggers, R.G.; Hodgkin, V.; Vollmerhausen, R. What Good Is SWIR? Passive Day Comparison of VIS, NIR, and SWIR. In Proceedings of the Infrared Imaging Systems: Design, Analysis, Modeling, and Testing XXIV, Baltimore, MD, USA, 30 April–2 May 2013; Volume 8706. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Available online: https://pytorch.org/hub/nvidia_deeplearningexamples_ssd/ (accessed on 2 February 2022).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Available online: https://github.com/ultralytics/yolov5 (accessed on 2 February 2022).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Iwata, S.; Kawanishi, Y.; Deguchi, D.; Ide, I.; Murase, H.; Aizawa, T. LFIR2Pose: Pose Estimation from an Extremely Low-resolution FIR image Sequence. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2597–2603. [Google Scholar] [CrossRef]
- Le, H.; Smailis, C.; Shi, L.; Kakadiaris, I. EDGE20: A Cross Spectral Evaluation Dataset for Multiple Surveillance Problems. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 2685–2694. [Google Scholar]
- Kim, M.; Joung, S.; Park, K.; Kim, S.; Sohn, K. Unpaired Cross-Spectral Pedestrian Detection Via Adversarial Feature Learning. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1650–1654. [Google Scholar] [CrossRef]
- Arnulf, A.; Bricard, J.; Curé, E.; Véret, C. Transmission by Haze and Fog in the Spectral Region 035 to 10 Microns. J. Opt. Soc. Am. 1957, 47, 491–497. [Google Scholar] [CrossRef]
- Available online: https://www.vlatacominstitute.com/_files/ugd/510d2b_ab410776328144979064c9cfa9bda036.pdf (accessed on 2 February 2022).
- Perić, D.; Livada, B. Analysis of SWIR Imagers Application in Electro-Optical Systems. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Kladovo, Serbia, 5–8 June 2017. [Google Scholar]
- Ni, Y.; Bouvier, C.; Arion, B.; Noguier, V. Wide Dynamic Logarithmic InGaAs Sensor Suitable for Eye-Safe Active Imaging. In Proceedings of the SPIE Commercial + Scientific Sensing and Imaging, Baltimore, MD, USA, 17–21 April 2016. [Google Scholar]
- Rankin, A.L.; Matthies, L.H. Daytime Mud Detection for Unmanned Ground Vehicle Autonomous Navigation; Jet Propulsion Laboratory, California Institute of Technology: Pasadena, CA, USA, 2008. [Google Scholar]
- Rankin, A.L.; Matthies, L.H. Passive sensor evaluation for unmanned ground vehicle mud detection. J. Field Robot. 2010, 27, 473–490. [Google Scholar] [CrossRef]
- DeCann, B.; Ross, A.; Dawson, J. Investigating Gait Recognition in the Short-Wave Infrared (SWIR) Spectrum: Dataset and Challenges. In Biometric and Surveillance Technology for Human and Activity Identification X; International Society for Optics and Photonics: Baltimore, MD, USA, 2013; Volume 8712, p. 87120J. [Google Scholar]
- Lemoff, B.E.; Martin, R.B.; Sluch, M.; Kafka, K.M.; McCormick, W.; Ice, R. Long-range Night/Day Human Identification Using Active-SWIR Imaging. In Infrared Technology and Applications XXXIX; International Society for Optics and Photonics: Baltimore, MD, USA, 2013; Volume 870487042J. [Google Scholar]
- Bertozzi, M.; Fedriga, R.I.; Miron, A.; Reverchon, J.L. Pedestrian Detection in Poor Visibility Conditions: Would SWIR Help? In Proceedings of the International Conference on Image Analysis and Processing, Naples, Italy, 11–13 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 229–238. [Google Scholar]
- Miron, A.; Bensrhair, A.; Fedriga, R.I.; Broggi, A. SWIR Images Evaluation for Pedestrian Detection in Clear Visibility Conditions. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013; pp. 354–359. [Google Scholar]
- Lemoff, B.E.; Martin, R.B.; Sluch, M.; Kafka, K.M.; Dolby, A.; Ice, R. Automated, Long-Range, Night/Day, Active-SWIR Face Recognition System. In Infrared Technology and Applications XL; International Society for Optics and Photonics: Baltimore, MD, USA, 2014; Volume 9070, p. 90703I. [Google Scholar]
- Besbes, B.; Rogozan, A.; Rus, A.-M.; Bensrhair, A.; Broggi, A. Pedestrian Detection in Far-Infrared Daytime Images Using a Hierarchical Codebook of SURF. Sensors 2015, 15, 8570–8594. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adler-Golden, S.; Sundberg, R. Identifying Vehicles with VNIR-SWIR Hyperspectral Imagery: Sources of Distinguishability and Confusion. In Imaging Spectrometry XXI; International Society for Optics and Photonics: San Diego, CA, USA, 2016; Volume 9976, p. 99760K. [Google Scholar]
- Kwan, C.; Chou, B.; Echavarren, A.; Budavari, B.; Li, J.; Tran, T. Compressive Vehicle Tracking Using Deep Learning. In Proceedings of the 2018 9th IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 8–10 November 2018; pp. 51–56. [Google Scholar]
- Kwan, C.; Chou, B.; Yang, J.; Tran, T. Compressive Object Tracking and Classification Using Deep Learning for Infrared Videos. In Pattern Recognition and Tracking XXX; International Society for Optics and Photonics: Baltimore, MD, USA, 2019; Volume 10995, p. 1099506. [Google Scholar]
- Kwan, C.; Chou, B.; Yang, J.; Rangamani, A.; Tran, T.; Zhang, J.; Etienne-Cummings, R. Target tracking and classification using compressive sensing camera for SWIR videos. Signal Image Video Process. 2019, 13, 1629–1637. [Google Scholar] [CrossRef]
- Kwan, C. Object Tracking and Classification in Videos Using Compressive Measurements. In Proceedings of the 3rd International Conference on Vision, Image and Signal Processing, Vancouver, BC, Canada, 26–28 August 2019; pp. 1–6. [Google Scholar]
- Kandylakis, Z.; Vasili, K.; Karantzalos, K. Fusing Multimodal Video Data for Detecting Moving Objects/Targets in Challenging Indoor and Outdoor Scenes. Remote Sens. 2019, 11, 446. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Processing Syst. 2015, 28, 2969239–2969250. [Google Scholar] [CrossRef] [Green Version]
- Vishnyakov, B.; Blokhinov, Y.; Sgibnev, I.; Sheverdin, V.; Sorokin, A.; Nikanorov, A.; Masalov, P.; Kazakhmedov, K.; Brianskiy, S.; Andrienko, E.; et al. Semantic scene understanding for the autonomous platform. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B2-2, 637–644. [Google Scholar] [CrossRef]
- Latinović, N.; Popadić, I.; Tomić, B.; Simić, A.; Milanović, P.; Nijemčević, S.; Perić, M.; Veinović, M. Signal Processing Platform for Long-Range Multi-Spectral Electro-Optical Systems. Sensors 2022, 22, 1294. [Google Scholar] [CrossRef] [PubMed]
- Livada, B.; Peric, D.; Peric, M. Challenges of Laser Range Finder Integration in Electro-Optical Surveillance System. In Proceedings of the 4th International Conference on Electrical, Electronic, and Computing Engineering (IcETRAN 2017), Kladovo, Serbia, 5–8 June 2017. [Google Scholar]
- Mambo, S. Optimisation and Performance Evaluation in Image Registration Technique. Ph.D. Thesis, Université Paris-Est, Créteil, France, Tshwane University of Technology, Pretoria, South Africa, 2018. [Google Scholar]
- Available online: https://github.com/AlexeyAB/Yolo_mark (accessed on 2 February 2022).
- Available online: https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocotools/cocoeval.py (accessed on 2 February 2022).
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1405. Available online: https://cocodataset.org/ (accessed on 8 February 2022).
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that Can Enhance Learning Capability of CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR Workshop), Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Guo, Y.; Wang, R. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, S. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Dewi, C.; Chen, R.-C.; Yu, H.; Jiang, X. Robust detection method for improving small traffic sign recognition based on spatial pyramid pooling. J. Ambient Intell. Humaniz. Comput. 2021, 1–18. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Yao, J.; Qi, J.; Zhang, J.; Shao, H.; Yang, J.; Li, X. A Real-Time Detection Algorithm for Kiwifruit Defects Based on YOLOv5. Electronics 2021, 10, 1711. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, X.; Yan, J.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W. A Wheat Spike Detection Method in UAV Images Based on Improved YOLOv5. Remote Sens. 2021, 13, 3095. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. Cornernet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Ge, Z.; Liu, S.; Li, Z.; Yoshie, O.; Sun, J. OTA: Optimal Transport Assignment for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 303–312. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Daytime Considerations | VIS | NIR | SWIR |
|---|---|---|---|
| Maritime haze penetration | bad | moderate | good |
| Fog penetration | bad | bad | bad |
| Atmospheric transmission | bad | moderate | good |
| Cloud penetration | bad | bad | bad |
| Forrest fire and fog oil penetration | bad | moderate | good |
| “See” laser designator spot | moderate | moderate | good |
| Camouflage detection/identification | moderate | moderate | moderate |
| Urban and rural background contrast | good | good | moderate |
| Maritime and ground target contrast | moderate | good | good |
| Skin detection | moderate | moderate | moderate |
| Spectral discrimination | moderate | moderate | good |
| Turbulence | moderate | moderate | good |
| Long-range identification (3 inch aperture soldier) | moderate | moderate | good |
| Long-range identification (6 inch aperture platform) | bad | moderate | good |
| Camera Properties | Visible | SWIR |
|---|---|---|
| Resolution | 1920 × 1080 | 576 × 504 |
| Frame rate | 30 | 25 |
| Minimal FOV [deg] | 0.73 | 0.581 |
| Maximum FOV [deg] | 26.61 | 6.126 |
| Optics | Motorized continuous zoom lens | Motorized continuous zoom lens |
| Minimal focal length [mm] | 12 | 100 |
| Maximum focal length [mm] | 550 | 1000 |
| Model | All Objects (Person and Car) |
|---|---|
| SSD | 0.3% |
| Mask RCNN | 23.7% |
| YOLOv3 | 24.9% |
| YOLOv4 | 21.6% |
| YOLOv5 | 20.9% |
| YOLOX | 27.6% |
| AP (0.5:0.95) | All Sizes | Small | Medium | Large |
|---|---|---|---|---|
| All objects | 89.2% | 83.5% | 91.3% | 89.7% |
| Person | 83.9% | 72.1% | 87.1% | 100% |
| Car | 94.5% | 95.0% | 95.6% | 89.7% |
| Model | All Objects (Person and Car) | Person | Car | Inference Time [ms] |
|---|---|---|---|---|
| SSD | 1.2% | 0.4% | 2% | 5.956 |
| Mask RCNN | 28.1% | 28.3% | 28.0% | 85.034 |
| YOLOv3 | 36.0% | 34.8% | 37.1% | 33.727 |
| YOLOv4 | 20.4% | 19.3% | 21.5% | 38.686 |
| YOLOv5 | 28.3% | 29.1% | 27.5% | 53.889 |
| YOLOX | 55.9% | 48.6% | 63.2% | 87.294 |
| AP [%] | All Sizes | Small | Medium | Large | |||||
|---|---|---|---|---|---|---|---|---|---|
| Original | Trained on SWIR | Original | Trained on SWIR | Original | Trained on SWIR | Original | Trained on SWIR | ||
| YOLOX Nano | All | 19.4 | 58.9 | 8.9 | 45.7 | 25.0 | 64.8 | 35.1 | 68.2 |
| Person | 17.5 | 53.7 | 5.2 | 36.6 | 22.9 | 60.2 | 34.0 | 58.9 | |
| Car | 21.2 | 64.1 | 12.7 | 54.8 | 27.2 | 69.4 | 36.3 | 77.4 | |
| YOLOX Tiny | All | 28.4 | 62.3 | 18.5 | 52.2 | 33.8 | 67.0 | 50.1 | 73.1 |
| Person | 25.9 | 57.6 | 17.1 | 45.1 | 29.6 | 62.3 | 50.0 | 68.5 | |
| Car | 30.9 | 67.1 | 19.9 | 59.3 | 38.1 | 71.8 | 50.2 | 77.6 | |
| YOLOX x | All | 55.9 | 66.2 | 51.0 | 57.3 | 58.1 | 70.3 | 86.5 | 67.6 |
| Person | 48.6 | 61.8 | 43.6 | 50.6 | 50.0 | 66.2 | 93.3 | 58.6 | |
| Car | 63.2 | 70.5 | 58.5 | 64.1 | 65.7 | 74.5 | 79.7 | 76.7 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pavlović, M.S.; Milanović, P.D.; Stanković, M.S.; Perić, D.B.; Popadić, I.V.; Perić, M.V. Deep Learning Based SWIR Object Detection in Long-Range Surveillance Systems: An Automated Cross-Spectral Approach. Sensors 2022, 22, 2562. https://doi.org/10.3390/s22072562
Pavlović MS, Milanović PD, Stanković MS, Perić DB, Popadić IV, Perić MV. Deep Learning Based SWIR Object Detection in Long-Range Surveillance Systems: An Automated Cross-Spectral Approach. Sensors. 2022; 22(7):2562. https://doi.org/10.3390/s22072562
Chicago/Turabian StylePavlović, Miloš S., Petar D. Milanović, Miloš S. Stanković, Dragana B. Perić, Ilija V. Popadić, and Miroslav V. Perić. 2022. "Deep Learning Based SWIR Object Detection in Long-Range Surveillance Systems: An Automated Cross-Spectral Approach" Sensors 22, no. 7: 2562. https://doi.org/10.3390/s22072562
APA StylePavlović, M. S., Milanović, P. D., Stanković, M. S., Perić, D. B., Popadić, I. V., & Perić, M. V. (2022). Deep Learning Based SWIR Object Detection in Long-Range Surveillance Systems: An Automated Cross-Spectral Approach. Sensors, 22(7), 2562. https://doi.org/10.3390/s22072562