1. Introduction
A floor plan is a graphical representation of the top view of a house or building along with its necessary dimensions. Relevant studies make use of a plan’s extensive architectural information to aid their own research [
1,
2,
3]. For instance, ref. [
1] focuses on detecting walls from a floor plan based on an alternative patch-based segmentation approach working at a pixel level, concluding that the identified walls can be utilized for a variety of tasks, including three-dimensional (3D) reconstruction and the construction of building boundaries. On the other hand, ref. [
2] utilizes a two-dimensional (2D) floorplan to align panorama red-green-blue-depth (RGBD) scans, which can significantly reduce the number of necessary scans with the aid of a floorplan image. Finally, ref. [
3] proposes a method for understanding hand-painted planar graphs by using subgraph isomorphism and Hough transform—acknowledging that a plan consists of recognizing building elements (doors, windows, walls, tables, etc.) and their topological properties—so as to propose an alternative computer aided design (CAD) system input technique that allows for the storage and modification of paper-based plans. Two-dimensional floor plan evaluation and information retrieval can help in many applications, e.g., to count the number of rooms and their areas, as well as architectural information recovery. Moreover, indoor robot navigation [
4], indoor building area analysis, and position analysis [
5] all require analyses of floor plans.
Furthermore, the technique for detecting rooms in an architectural floor plan has been investigated by various scholars [
6,
7,
8,
9,
10,
11,
12]. For instance, a wall’s straight line is first detected based on an original coupling of classical Hough transform with image vectorization, and the door symbol is then discovered using the arc detection technique [
13]; in a final step, the detected door and wall are connected to detect the room [
9]. Ahmed et al. [
10] adopted and extended this method [
9] and introduced new processing steps such as wall edge extraction and boundary detection, and proposed a technique for automatically recognizing and labeling the rooms in a floor plan by combining the technology introduced in their own work [
11].
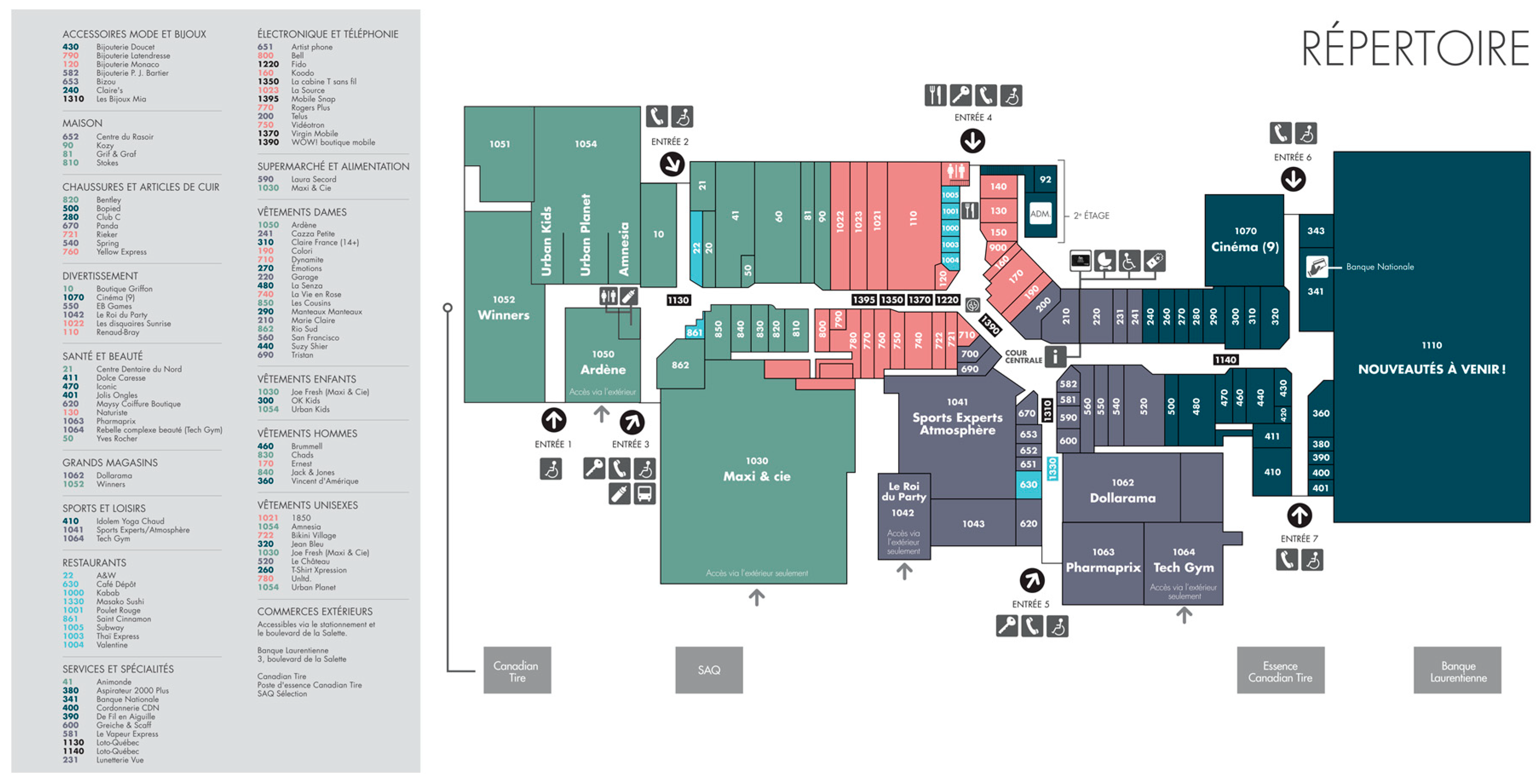
Numerous studies have been performed on architectural floor plans, while research on shopping mall plans differs greatly from this field. To close the final minor gap in an architectural floor plan, ref. [
12] employed speeded-up robust features (SURF) matching technology to recognize door symbols. This was not necessary in our research because a shop floor plan normally does not include an interval between sections, due to the door sign. That said, ref. [
10]’s usage of room label information to assist with planar graph recognition is enlightening for our study. In a shopping mall plan, there are no sophisticated features, such as door symbols, to identify rooms, and there are numerous rooms on the plan that are tightly spaced and include a great deal of invalid information. As a result, the relevant approaches for an architectural floor plan are not applicable in shopping mall floor plans. Although a shopping mall plan does not have as much structural information as an architectural floor plan, it does include a great deal of semantic information: each room has a unique number that may be used to assist the study of the mall floor plan. Outdoor navigation technology has advanced dramatically in the last decade, but consumers are more likely to become disoriented in huge, enclosed structures such as stadiums, educational institutions, and shopping malls. Therefore, indoor plan analysis is crucial, but there has been no research on the segmentation and recognition of shopping mall plans. Therefore, this study focuses on two major issues: image segmentation and OCR.
Image segmentation plays a vital role in image processing. Image segmentation methods primarily include threshold, region, edge, and deep learning segmentation methods [
14,
15]. The key role of a threshold segmentation algorithm is to determine the threshold
for an image
, with 1 for target pixel
and 0 for the non-target pixel
; ref. [
16] introduced a local dynamic threshold image segmentation method that overcomes the drawbacks of the global Otsu algorithm, removes the block effect, and improves the effectiveness and adaptivity of complex background image segmentation. To achieve image segmentation, the region growing method [
17,
18] first selects a seed pixel and then continuously merges pixels with similar characteristics. In order to overcome the influence of seed selection and segmentation holes, simple linear iterative cluster (SLIC) is used to segment the raw image into several small pixel blocks according to the characteristics of similar pixel gray levels [
18]. The super pixel segmentation can eliminate the influence of image noise and uneven gray values. The edge-based segmentation method [
19] mainly uses differential operators to detect the edge of gray mutations to achieve the purpose of segmentation. Typical differential operators, including the Roberts operator [
20], the Sobel operator [
21], the Canny operator [
22], ref. [
22] developed the Canny edge detection algorithm by using band decomposition and the Otsu algorithm to adaptively select high and low thresholds based on picture gray level, and performed well for remote sensing image segmentation.
The deep learning segmentation method [
23,
24] relies on a neural network to extract features, and outputs labels of each pixel end-to-end. Shelhamer et al. [
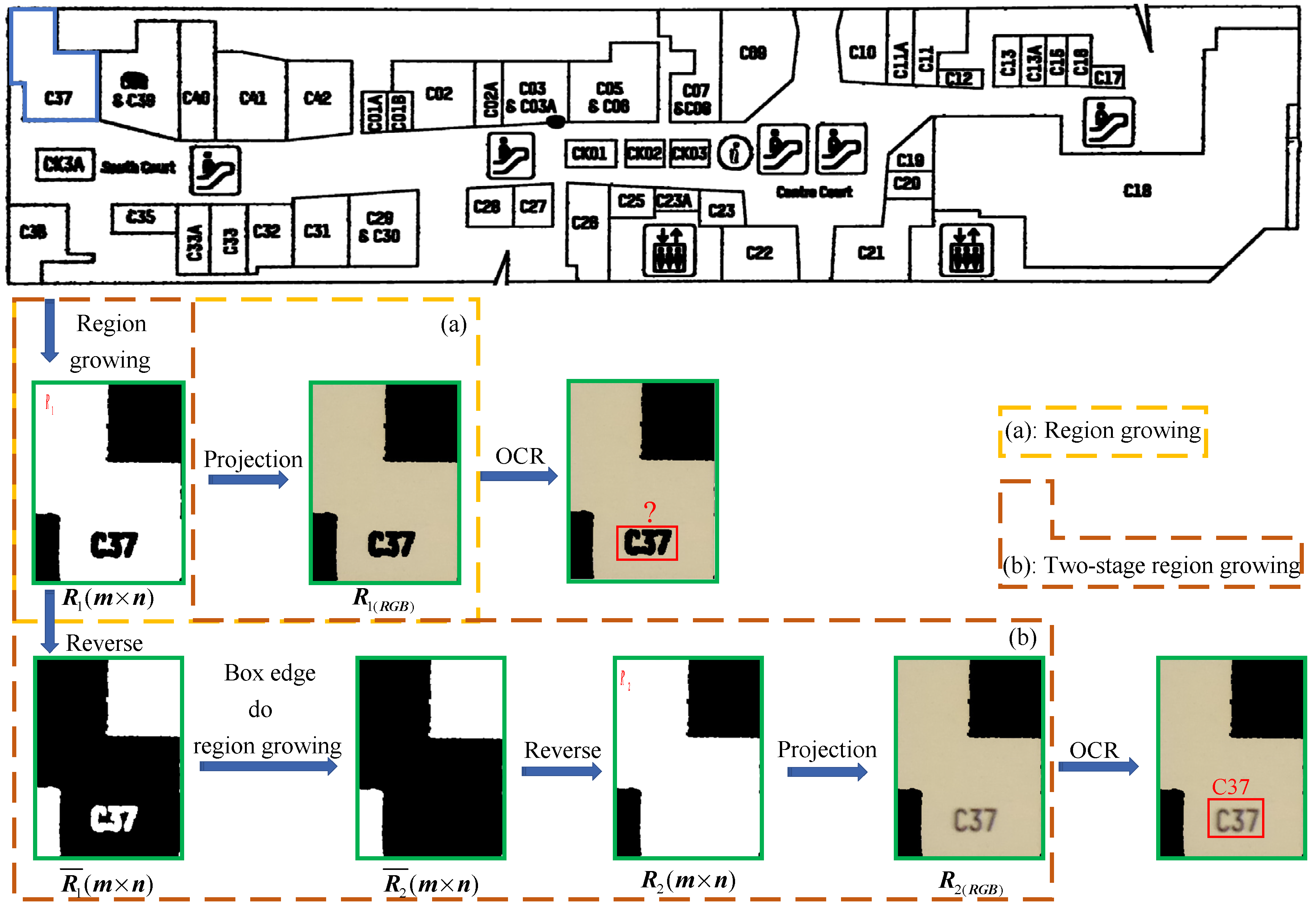
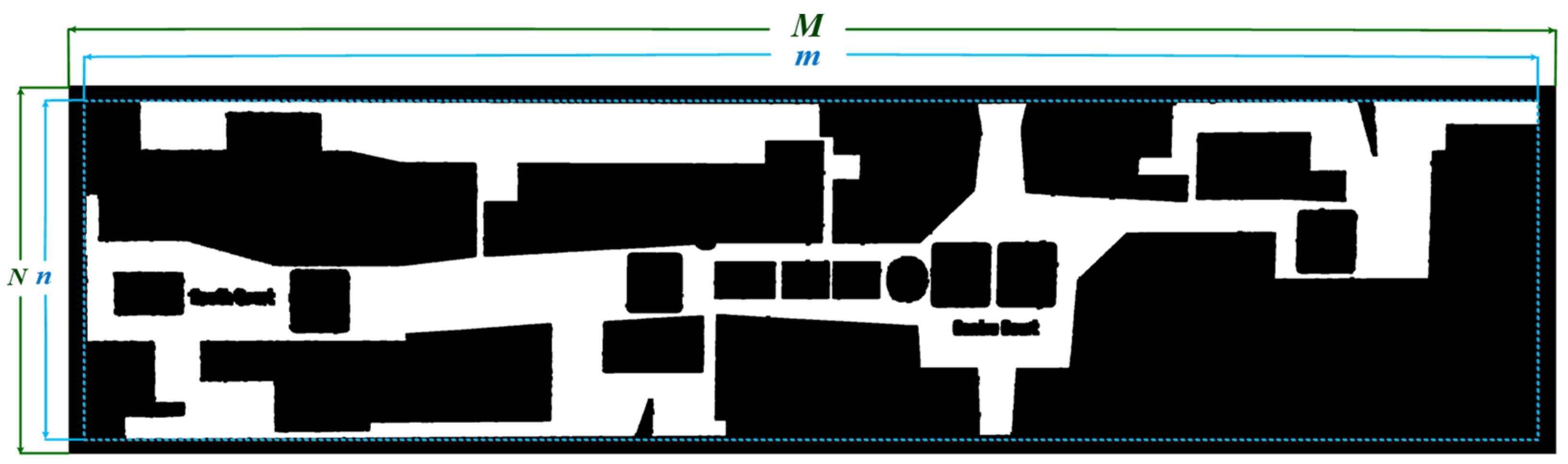
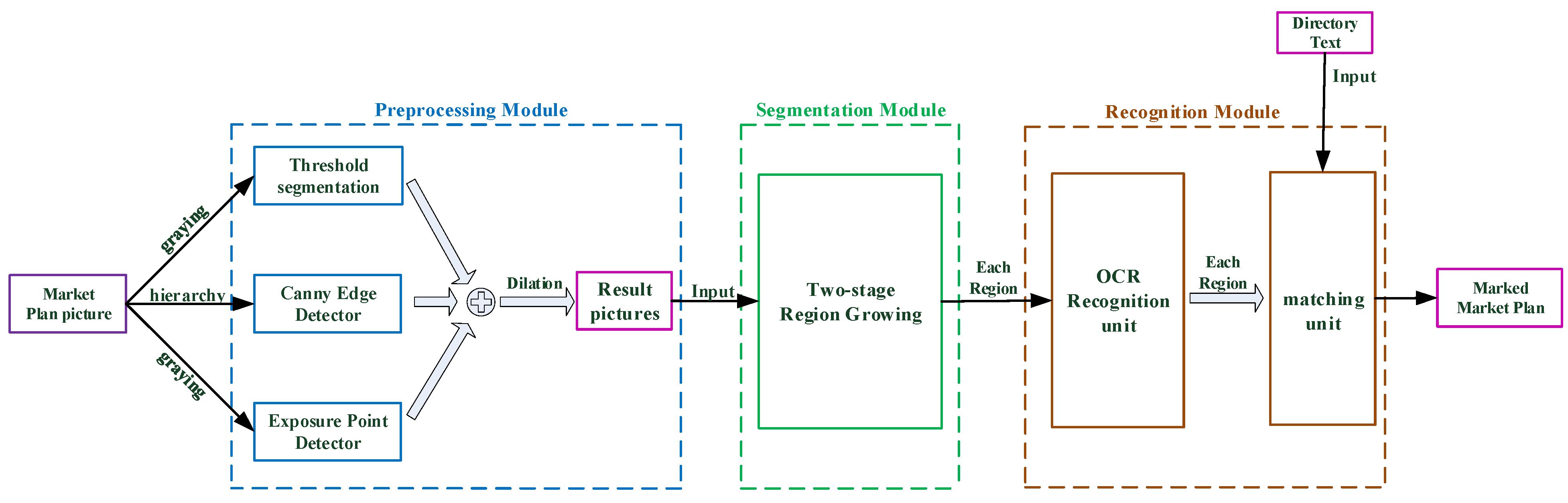
24] proposed a full convolution neural network (FCN) semantic segmentation approach, which has demonstrated significant progress in this field. It not only solves the problem of how CNN achieves end-to-end semantic segmentation training, but it also effectively solves the problem of generating pixel level output semantic prediction for any size input. The two-stage region growth approach we propose is utilized to segment the plan to obtain each individual area to fulfill our objective in this article, i.e., the segmentation and recognition of each individual part of a mall plan. In addition, the preprocessing step employs threshold segmentation and edge detection technology.
OCR [
25,
26] takes in images containing text optical character information and outputs text information corresponding to those images. Currently, the mainstream OCR system is divided into two modules: text detection and text recognition. Recently, researchers have concentrated their efforts on developing techniques for digitizing handwritten documents, which are largely based on deep learning [
27]. The use of cluster computing and GPUs, as well as the improved performance by deep learning architectures [
28], such as recurrent neural networks (RNN), convolutional neural networks (CNN), and long short-term memory (LSTM) networks, has sparked this paradigm shift. Tencent Cloud [
29] and Baidu Cloud [
30], for example, have developed powerful and easy-to-use OCR technologies to allow user calls via application programming interfaces (APIs) to satisfy the needs of text extraction and analysis in production and real-life scenarios. Baidu OCR also offers multilingual recognition in a variety of scenarios with great robustness and accuracy. Furthermore, many academics have made common OCR projects open source, such as AdvancedEAST [
31] (which is based on the Keras framework), PixelLink [
32,
33], and the connectionist text proposal network (CTPN) [
34,
35], which are implemented using the TensorFlow framework; EasyOCR [
36], however, is built with the Pytorch framework. EasyOCR’s detection model employs the character-region awareness for text detection (CRAFT) network [
37], while the identification model employs the convolutional recurrent neural network (CRNN) network [
38]. EasyOCR has an advantage over other open-source programs in that it supports more than 80 languages, including English, Chinese (both simple and sophisticated), Arabic, Japanese, and other forms of identification. Due to language differences in the identification of catalogs and shopping mall plans in different countries, Baidu OCR and EasyOCR are primarily used as OCR identification modules in this paper to adapt to different language scenarios.
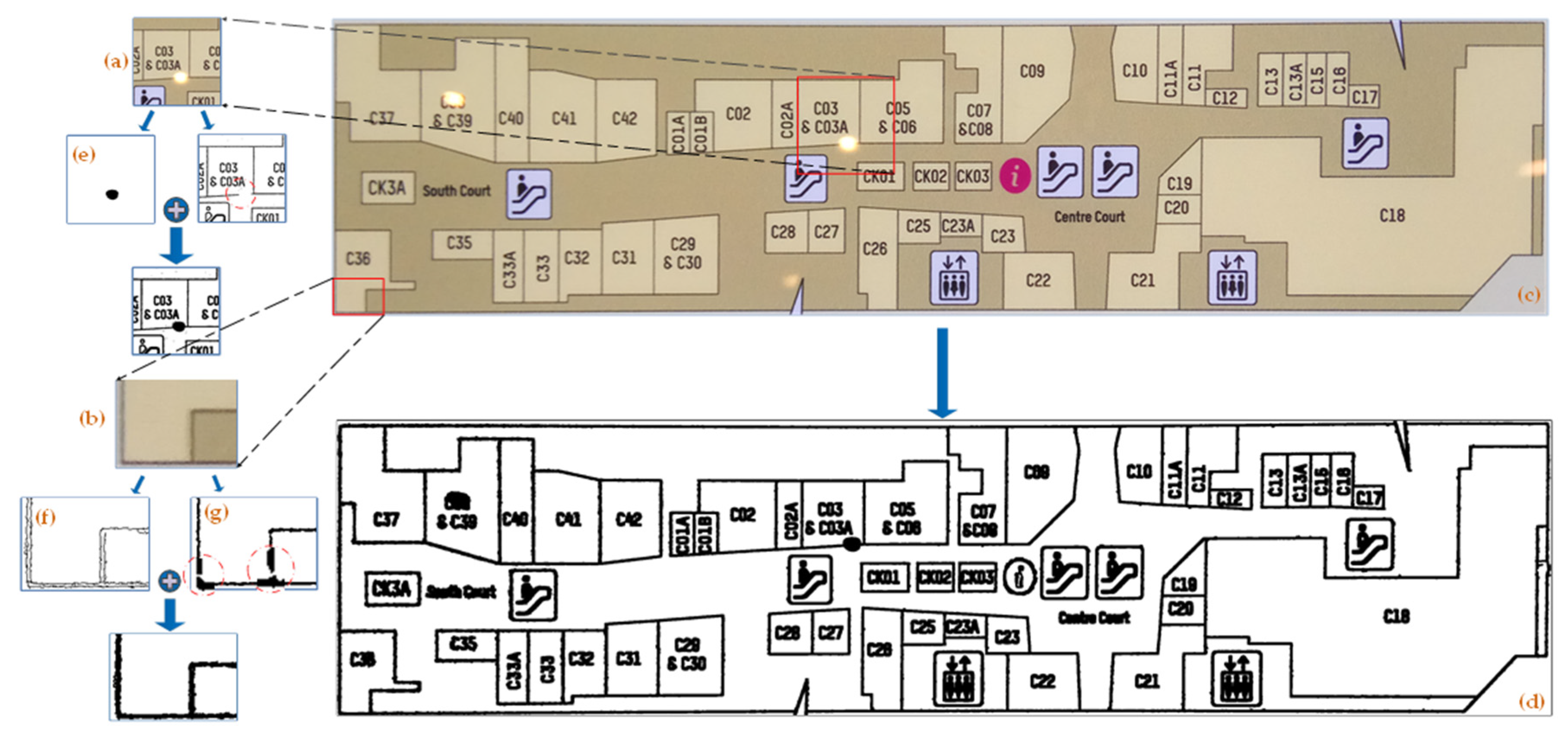
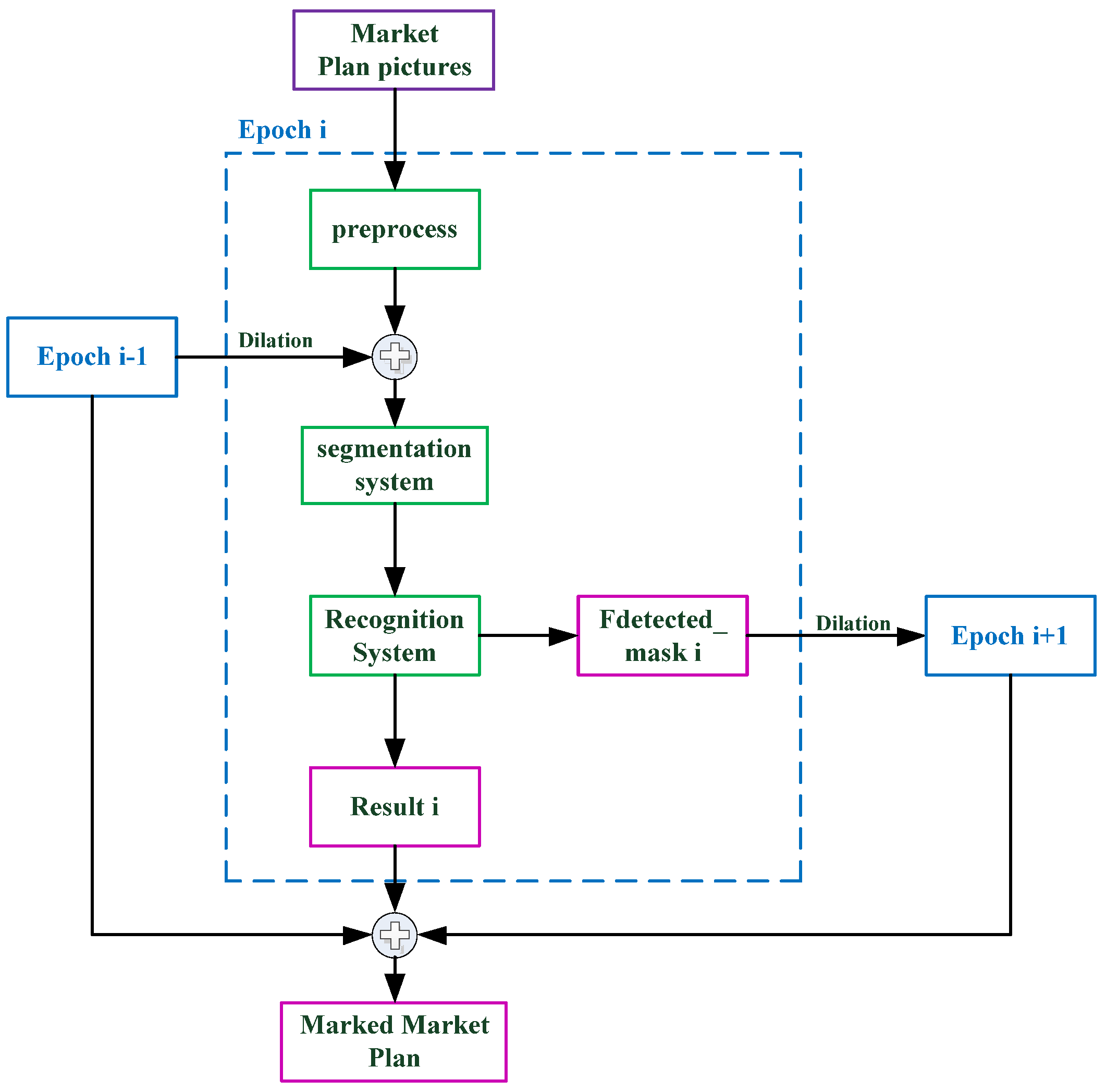
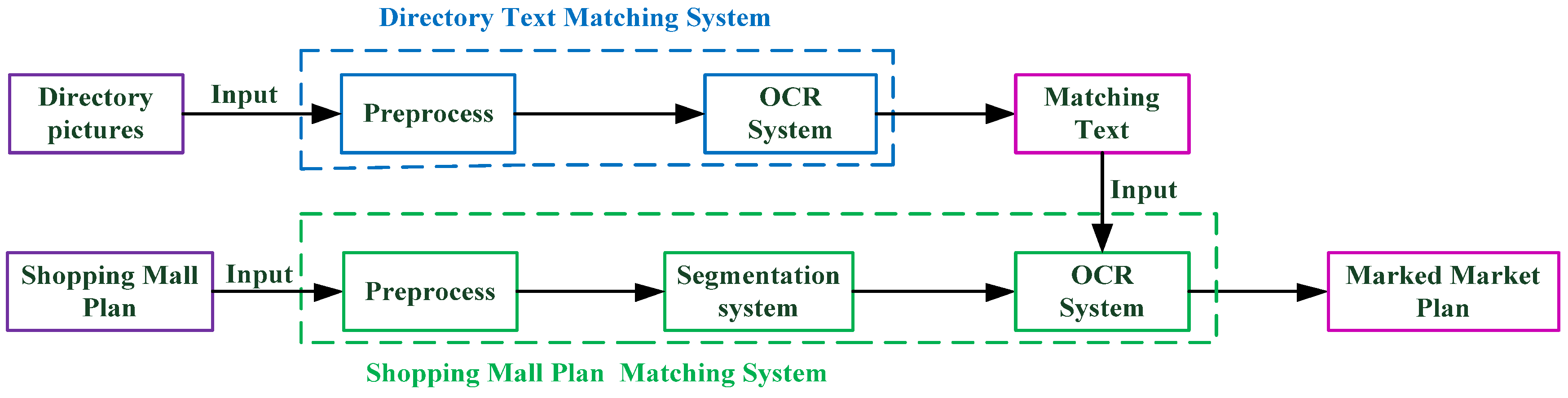
Each room number on the plan corresponds to an independent room region; although OCR can recognize the overall room numbers, it cannot judge which room number relates to which room region, nor can it determine the exact location of each room. We propose a method to segment a room by the two-stage region growth method, and then recognize the room by OCR to solve this problem. The remainder of this article is organized as follows.
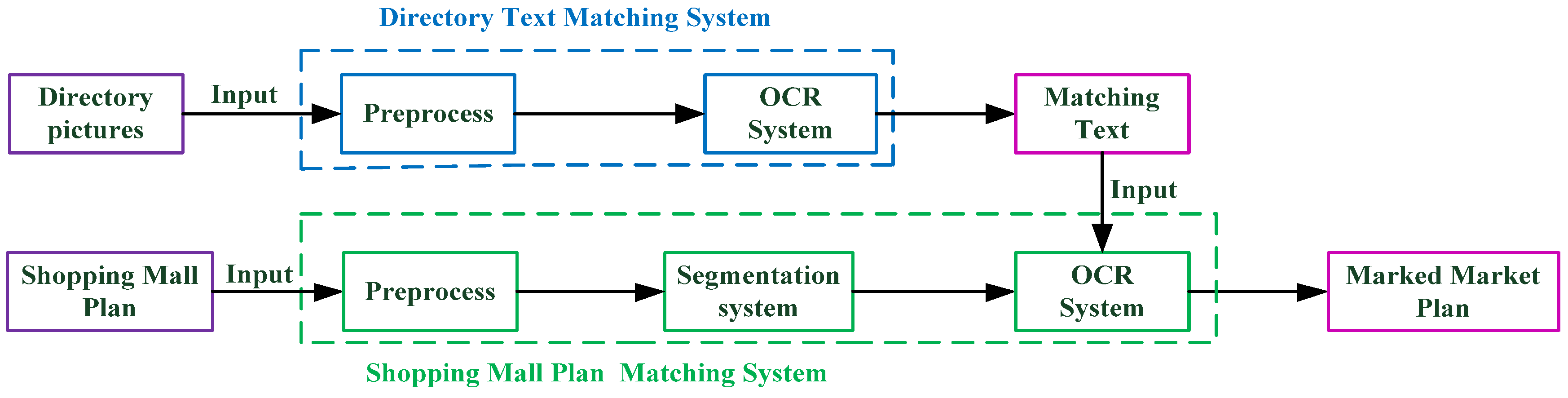
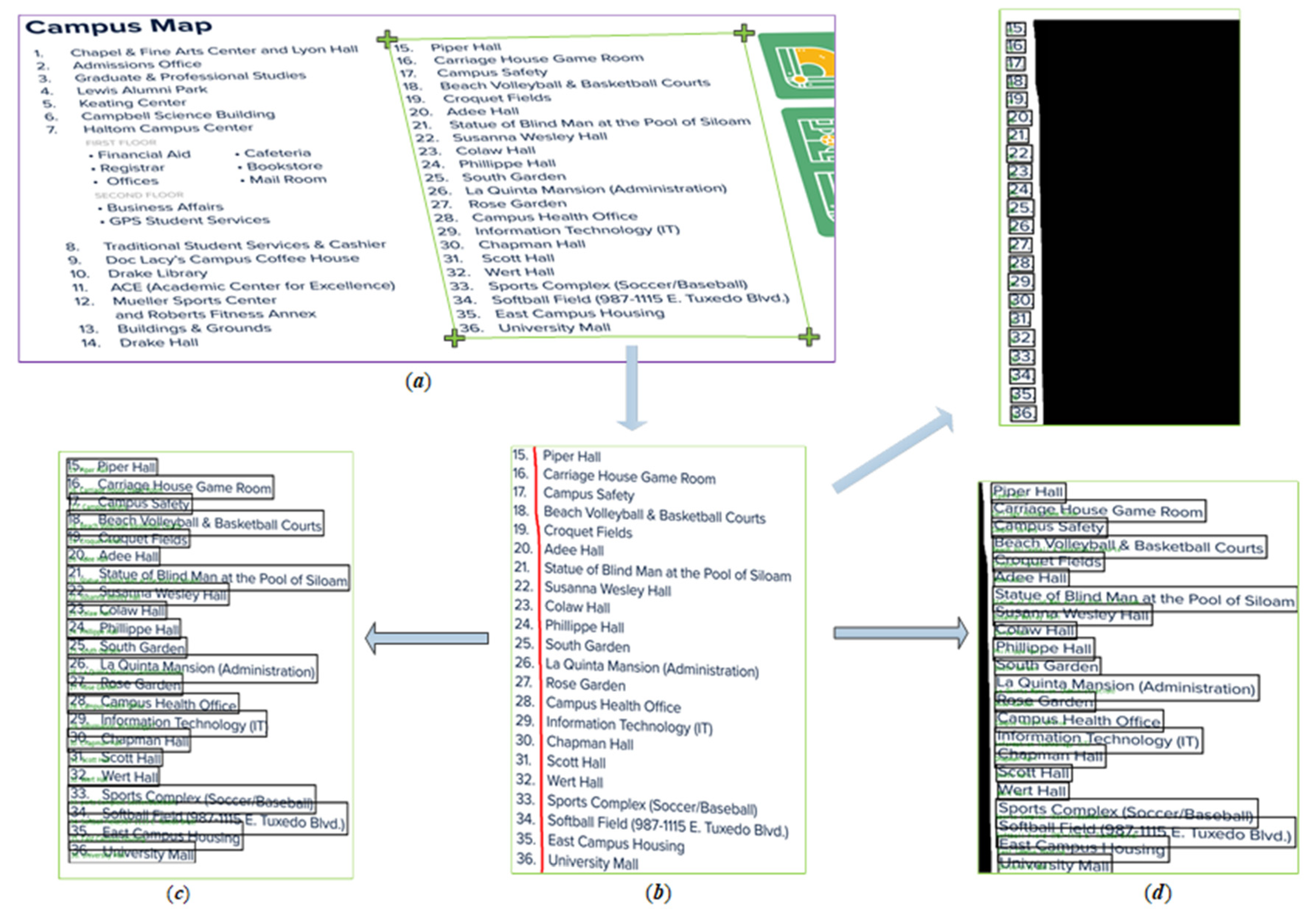
Section 2.1 describes the shopping center directory text matching system method.
Section 2.2 describes the shopping mall room matching system’s processes in detail, including the preprocessing steps and the detailed content of the two-stage region growth algorithm, and introduces the use of an OCR system in the recognition module and region labeling.
Section 3.1 outlines the experimental details and assessment criteria, followed by a large number of experiments to validate the algorithm’s effectiveness. Finally, discussion is provided in
Section 4 and the conclusion is provided in
Section 5.
4. Discussion
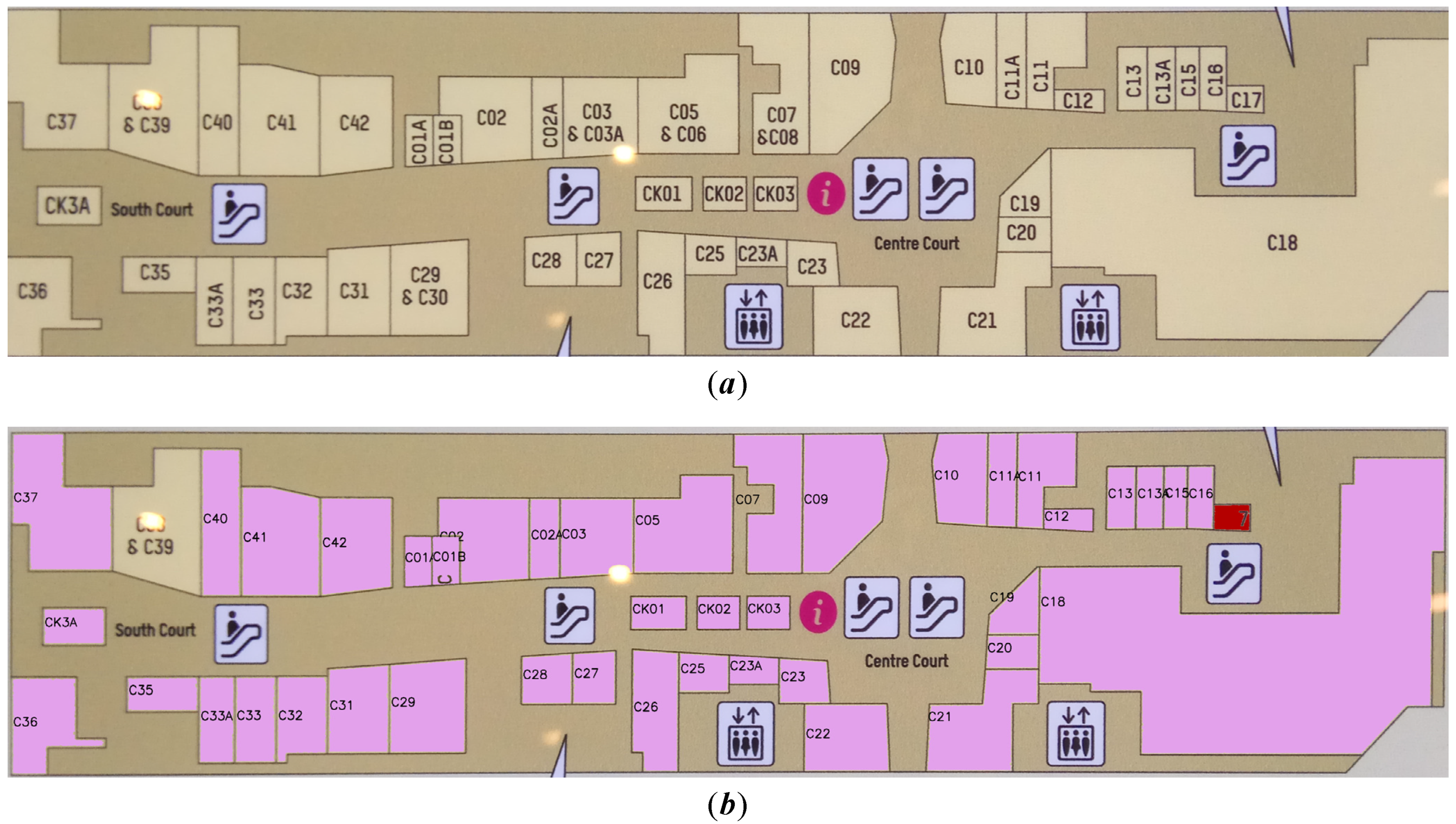
To validate the system’s efficacy, we ran a significant number of tests on the dataset including 1340 rooms. The segmentation accuracy was 92.54%, the recognition accuracy was 90.56%, and the overall detection rate was 83.81%. The two-stage region growing method we proposed can successfully segment all effective regions in the room and is favorable to OCR recognition, thus improving the overall detection accuracy. Our multi-epoch segmentation and recognition method effectively improves the system’s segmentation accuracy. Our system separates each room individually before identifying the segmented room and extracting the room’s semantic content. However, in a special case, where a room area is too tiny to display the room number (
Figure 13a, “49” in Case 1), our system cannot properly segment and identify it, which is the main drawback of our approach in such a circumstance. However, after further investigation, we discovered that nearly all of the plan’s room numbers are included in the room area. Since Case 1 accounts for less than 5% of all rooms, our approach is effective in the majority of them. Furthermore, if the position of the room number and other irrelevant characters is close (
Figure 13b, “C06” and “&” in Case 2), the OCR system will recognize the irrelevant characters and the room number as a string, and the “& C06” in Case 2 cannot be retrieved in the directory; thus, it cannot be successfully matched. In essence, this issue is still caused by OCR recognition errors, as it is easy for OCR to recognize characters that are close together. Case 2 may exist if two room numbers are present in the same room, although this only accounts for a minor fraction of the overall picture.
Finally, we presented the plan with the lowest precision in the dataset (
Figure 13c, Case 3). The challenge of this plan is that it has numerous lines, many invalid regions, and the room number is contained in a circle, all of which make the OCR system’s recognition more difficult. Furthermore, the number’s location is quite close to the room’s edge, making room segmentation more difficult. Despite this, our algorithm detected 46 rooms (out of a total of 67) with a total accuracy of 68.65%. Our algorithm still needs to be developed to increase the detection accuracy of complex images and to adapt to more special circumstances (such as most numbers being outside the room) in order to tackle the challenges mentioned above. The recognition accuracy of the system’s OCR module has the largest effect on the overall system’s recognition accuracy. Follow-up research should examine better OCR technology to enhance the mall plan’s overall accuracy.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

























