
DFT-Net: Deep Feature Transformation Based Network for Object Categorization and Part Segmentation in 3-Dimensional Point Clouds

 , , , , and
, , , , and
Abstract
:1. Introduction
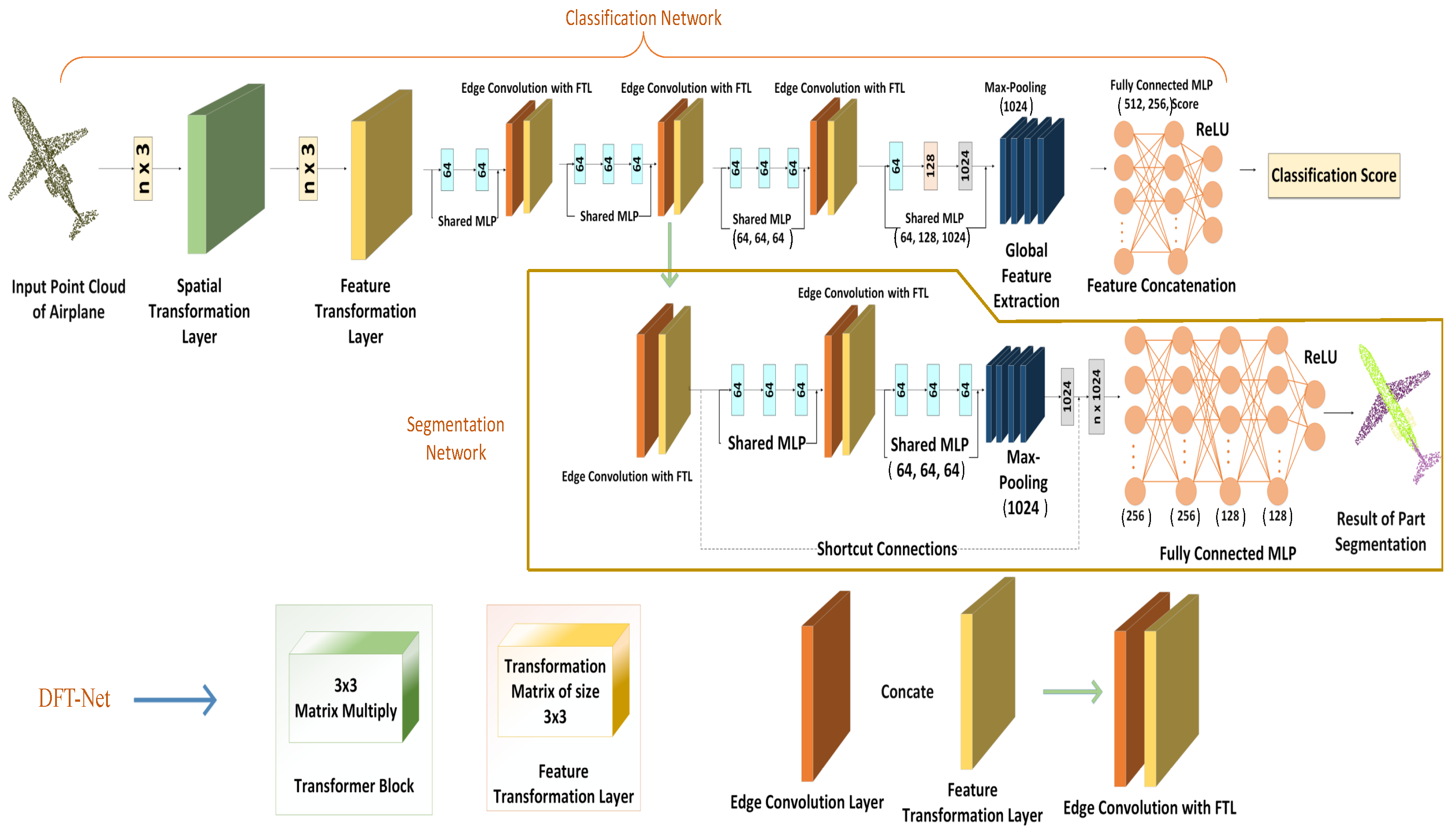
- The proposed Deep Feature Transformation Network (DFT-Net) consists of a cascading combination of edge convolution and feature transformation layers, capturing local geometric features by preserving adjacent relationships between points.
- DFT-Net guarantees an invariance point order and dynamically calculates the edges in each layer independently.
- DFT-Net can directly process unstructured raw 3D point clouds while achieving part segmentation and object classification simultaneously.
2. Related Work
3. Methodology
3.1. Brief Overview
3.2. Edge Convolution with Feature Transformation
3.3. Proposed Network Architecture
3.3.1. Object Categorization
3.3.2. Part Segmentation
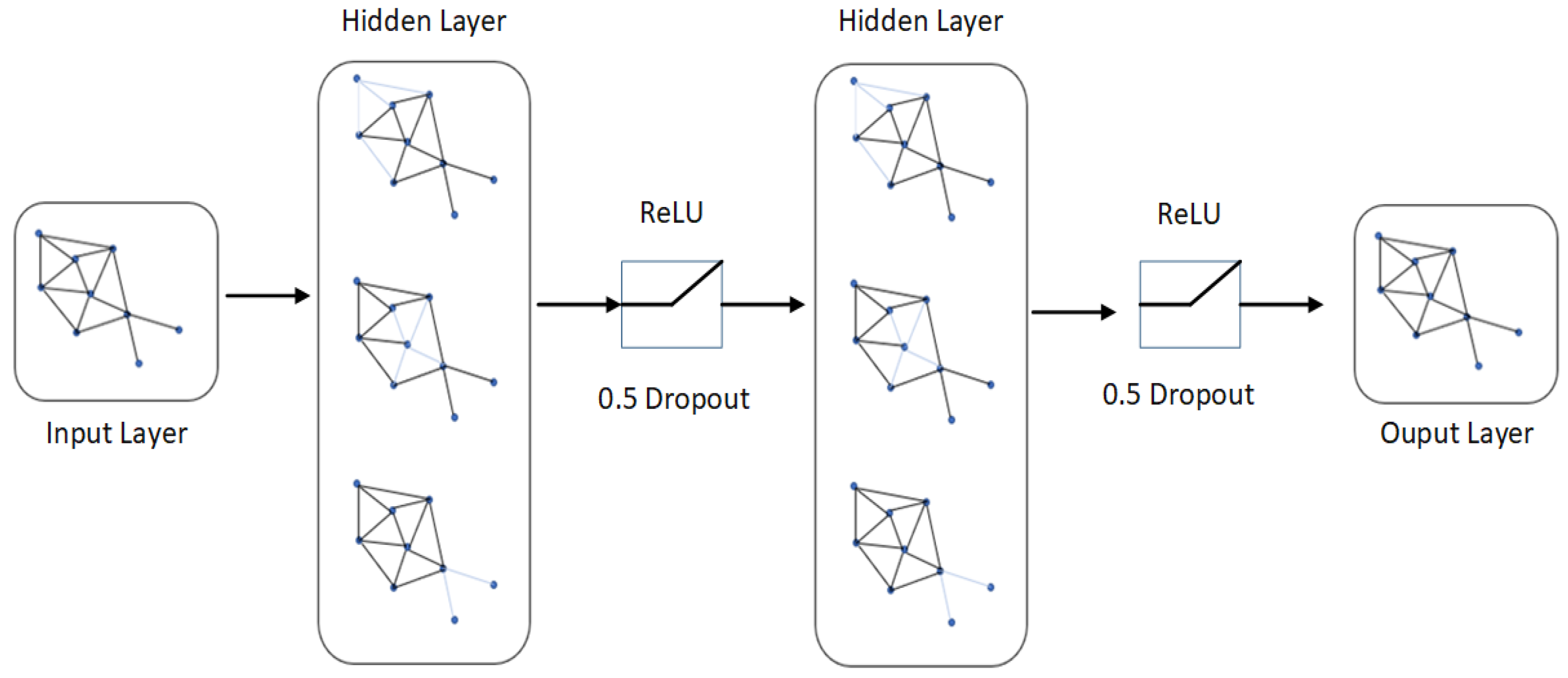
4. Implementation Details
4.1. Network Training
4.2. Training Time and Hardware
5. Experimental Evaluation
5.1. Materials
5.2. Object Categorization Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Avg. Class Accuracy | Overall Accuracy |
|---|---|---|
| 3D ShapeNets [24] | 77.3 | 84.7 |
| VoxNet [13] | 83.0 | 85.9 |
| Subvolumes [37] | 86.0 | 89.2 |
| Pointwise Convolution [21] | 81.4 | 86.1 |
| ECC [38] | 83.2 | 87.4 |
| Learning SO(3) [39] | 86.9 | 88.9 |
| DPRNet 8-Layers [22] | 81.9 | 86.1 |
| DPRNet 16-Layers [22] | 82.1 | 85.4 |
| Spherical CNN [40] | 85.2 | 89.7 |
| PointNet [29] | 86.0 | 89.2 |
| DGCNN [23] | 88.8 | 91.2 |
| kD-Net [41] | - | 90.6 |
| MRTNet-VAE [42] | - | 86.4 |
| 3DContextNet [43] | - | 91.1 |
| FoldingNet [34] | - | 88.4 |
| LearningRepresentations [44] | - | 84.5 |
| SRN-PointNet++ [35] | - | 91.5 |
| PAT (GSA only) [36] | - | 91.3 |
| PAT (FPS) [36] | - | 91.4 |
| PAT (FPS + GSS) [36] | - | 91.7 |
| LightNet [45] | - | 86.9 |
| PointNet++ [19] | - | 90.7 |
| FusionNet [27] | - | 90.8 |
| DFT-Net | 90.1 | 92.9 |
5.3. Part Segmentation Results
| Methods | Overall Accuracy |
|---|---|
| PointNet++ [19] | 85.1 |
| KD-Tree [41] | 82.3 |
| FPNN [47] | 81.4 |
| SSCNN [48] | 84.7 |
| PointNet [29] | 83.7 |
| LocalFeature [49] | 84.3 |
| DGCNN [23] | 85.1 |
| FCPN [50] | 84.0 |
| RSNet [51] | 84.9 |
| ASIS (PN) [52] | 84.0 |
| ASIS (PN++) [52] | 85.0 |
| DFT-Net | 85.2 |
5.4. Model Robustness
6. Conclusions and Future Work
- Fusion of Non-Spatial Attributes: In the proposed model, we only considered 3D coordinates of points to perform object categorization and part segmentation. Another exciting work might be to fuse traditional hand-crafted point cloud features (e.g., color, point density, surface normals, texture, curvature, etc.) together with extracted deep features or spatial coordinates for enhanced feature representation, consequently improve model performance.
- Distance-Based Neighborhood: Instead of capturing local relationships to build a dynamic graph, the distance-based neighbors may be used instead of k-nearest neighbors. This may allow for incorporating the semantics of being physically close in selecting the neighbors of the point of interest;
- Non-Shared Feature Transformer: Another extension would be to design a non-shared feature transformer network that may work on the local patch level, consequently adding more flexibility to the proposed model.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Link to the Code
Abbreviations
| 2D | 2-Dimensional |
| 3D | 3-Dimensional |
| CNN | Convolutional Neural Networks |
| CRF | Conditional Random Field |
| DFT-Net | Deep Feature Transformation Network |
| DGCNN | Dynamic Grapgh Convolutional Neural Networks |
| DNN | Deep neural Networks |
| ECL | Edge Convolutional Layer |
| FTL | Feature Transformation Layer |
| IoU | Intersection over Union |
| LiDAR | Light Detection Furthermore, Ranging |
| mIoU | mean Intersection over Union |
| MLP | Multi-Layer Perceptrons |
| ReLU | Rectified Linear Unit |
References
- Ullman, S. The interpretation of structure from motion. Proc. R. S. Lond. Ser. B Biol. Sci. 1979, 203, 405–426. [Google Scholar]
- Westoby, M.J.; Brasington, J.; Glasser, N.F.; Hambrey, M.J.; Reynolds, J.M. ‘Structure-from-motion’ photogrammetry: A low-cost, effective tool for geoscience applications. Geomorphology 2012, 179, 300–314. [Google Scholar] [CrossRef] [Green Version]
- Schwarz, B. Lidar: Mapping the world in 3d. Nat. Photonics 2010, 4, 429–430. [Google Scholar] [CrossRef]
- Shahzad, M.; Zhu, X.X. Automatic detection and reconstruction of 2-d/3-d building shapes from spaceborne tomosar point clouds. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1292–1310. [Google Scholar] [CrossRef] [Green Version]
- Shahzad, M.; Zhu, X.X. Robust reconstruction of building facades for large areas using spaceborne tomosar point clouds. IEEE Trans. Geosci. Remote Sens. 2014, 53, 752–769. [Google Scholar] [CrossRef] [Green Version]
- Vo, A.V.; Truong-Hong, L.; Laefer, D.F.; Bertolotto, M. Octree-based region growing for point cloud segmentation. ISPRS J. Photogramm. Remote Sens. 2015, 104, 88–100. [Google Scholar] [CrossRef]
- Pauly, M.; Gross, M.; Kobbelt, L.P. Efficient simplification of point-sampled surfaces. In Proceedings of the Conference on Visualization’02, Boston, MA, USA, 27 October–1 November 2002; pp. 163–170. [Google Scholar]
- Rabbani, T.; Van Den Heuvel, F.; Vosselmann, G. Segmentation of point clouds using smoothness constraint. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2006, 36, 248–253. [Google Scholar]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient ransac for point-cloud shape detection. Comput. Graph. Forum 2007, 26, 214–226. [Google Scholar] [CrossRef]
- Tarsha-Kurdi, F.; Landes, T.; Grussenmeyer, P. Hough-transform and extended ransac algorithms for automatic detection of 3d building roof planes from lidar data. In Proceedings of the ISPRS Workshop on Laser Scanning 2007 and SilviLaser 2007, Espoo, Finland, 12–14 September 2007; Volume 36, pp. 407–412. [Google Scholar]
- Zhang, R.; Candra, S.A.; Vetter, K.; Zakhor, A. Sensor fusion for semantic segmentation of urban scenes. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1850–1857. [Google Scholar]
- Wolf, D.; Prankl, J.; Vincze, M. Fast semantic segmentation of 3d point clouds using a dense crf with learned parameters. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 4867–4873. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. Segcloud: Semantic segmentation of 3d point clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar]
- Sitzmann, V.; Thies, J.; Heide, F.; Nießner, M.; Wetzstein, G.; Zollhofer, M. Deepvoxels: Learning persistent 3d feature embeddings. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 2437–2446. [Google Scholar]
- Shin, D.; Fowlkes, C.C.; Hoiem, D. Pixels, voxels, and views: A study of shape representations for single view 3d object shape prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3061–3069. [Google Scholar]
- Moon, G.; Chang, J.Y.; Lee, K.M. V2v-posenet: Voxel-to-voxel prediction network for accurate 3d hand and human pose estimation from a single depth map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5079–5088. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 4. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2017; pp. 5099–5108. [Google Scholar]
- Shen, Y.; Feng, C.; Yang, Y.; Tian, D. Mining point cloud local structures by kernel correlation and graph pooling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4548–4557. [Google Scholar]
- Hua, B.S.; Tran, M.K.; Yeung, S.K. Pointwise convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 984–993. [Google Scholar]
- Arshad, S.; Shahzad, M.; Riaz, Q.; Fraz, M.M. Dprnet: Deep 3d point based residual network for semantic segmentation and classification of 3d point clouds. IEEE Access 2019, 7, 68892–68904. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. arXiv 2018, arXiv:1801.07829. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3 shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Yang, B.; Luo, W.; Urtasun, R. Pixor: Real-time 3d object detection from point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7652–7660. [Google Scholar]
- Hegde, V.; Zadeh, R. Fusionnet: 3D object classification using multiple data representations. arXiv 2016, arXiv:1607.05695. [Google Scholar]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J. 3d object recognition in cluttered scenes with local surface features: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 270–2287. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Garcia, A.; Gomez-Donoso, F.; Garcia-Rodriguez, J.; Orts-Escolano, S.; Cazorla, M.; Azorin-Lopez, J. Pointnet: A 3d convolutional neural network for real-time object class recognition. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1578–1584. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on χ-Transformed Points. arXiv 2018, arXiv:1801.07791. [Google Scholar]
- Sheshappanavar, S.V.; Singh, V.V.; Kambhamettu, C. PatchAugment: Local Neighborhood Augmentation in Point Cloud Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2118–2127. [Google Scholar]
- Zhang, J.; Chen, L.; Ouyang, B.; Liu, B.; Zhu, J.; Chen, Y.; Meng, Y.; Wu, D. PointCutMix: Regularization Strategy for Point Cloud Classification. arXiv 2021, arXiv:2101.01461. [Google Scholar]
- Qiu, S.; Anwar, S.; Barnes, N. Geometric back-projection network for point cloud classification. IEEE Trans. Multimed. 2021. [Google Scholar] [CrossRef]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. Foldingnet: Point cloud auto-encoder via deep grid deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; Volume 3. [Google Scholar]
- Duan, Y.; Zheng, Y.; Lu, J.; Zhou, J.; Tian, Q. Structural relational reasoning of point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 949–958. [Google Scholar]
- Yang, J.; Zhang, Q.; Ni, B.; Li, L.; Liu, J.; Zhou, M.; Tian, Q. Modeling point clouds with self-attention and gumbel subset sampling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and multi-view cnns for object classification on 3d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]
- Simonovsky, M.; Komodakis, N. Dynamic edgeconditioned filters in convolutional neural networks on graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Esteves, C.; Allen-Blanchette, C.; Makadia, A.; Daniilidis, K. Learning so (3) equivariant representations with spherical cnns. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 52–68. [Google Scholar]
- Lei, H.; Akhtar, N.; Mian, A. Spherical convolutional neural network for 3d point clouds. arXiv 2018, arXiv:1805.07872. [Google Scholar]
- Klokov, R.; Lempitsky, V. Escape from cells: Deep kd-networks for the recognition of 3d point cloud models. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 863–872. [Google Scholar]
- Gadelha, M.; Wang, R.; Maji, S. Multiresolution tree networks for 3d point cloud processing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 103–118. [Google Scholar]
- Zeng, W.; Gevers, T. 3dcontextnet: Kd tree guided hierarchical learning of point clouds using local and global contextual cues. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lin, C.H.; Kong, C.; Lucey, S. Learning efficient point cloud generation for dense 3d object reconstruction. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhi, S.; Liu, Y.; Li, X.; Guo, Y. Lightnet: A lightweight 3d convolutional neural network for real-time 3d object recognition. In Proceedings of the Eurographics Workshop on 3D Object Retrieval, Lyon, France, 23–24 April 2017. [Google Scholar]
- Monti, F.; Boscaini, D.; Masci, J.; Rodola, E.; Svoboda, J.; Bronstein, M.M. Geometric deep learning on graphs and manifolds using mixture model cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 3. [Google Scholar]
- Li, Y.; Pirk, S.; Su, H.; Qi, C.R.; Guibas, L.J. Fpnn: Field probing neural networks for 3d data. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2016; pp. 307–315. [Google Scholar]
- Yi, L.; Su, H.; Guo, X.; Guibas, L.J. Syncspeccnn: Synchronized spectral cnn for 3d shape segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2282–2290. [Google Scholar]
- Shen, Y.; Feng, C.; Yang, Y.; Tian, D. Neighbors do help: Deeply exploiting local structures of point clouds. arXiv 2017, arXiv:1712.06760. [Google Scholar]
- Rethage, D.; Wald, J.; Sturm, J.; Navab, N.; Tombari, F. Fully-convolutional point networks for large-scale point clouds. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 596–611. [Google Scholar]
- Huang, Q.; Wang, W.; Neumann, U. Recurrent slice networks for 3d segmentation of point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2626–2635. [Google Scholar]
- Wang, X.; Liu, S.; Shen, X.; Shen, C.; Jia, J. Associatively segmenting instances and semantics in point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4096–4105. [Google Scholar]
- Gomez-Donoso, F.; Escalona, F.; Cazorla, M. Par3dnet: Using 3dcnns for object recognition on tridimensional partial views. Appl. Sci. 2020, 10, 3409. [Google Scholar] [CrossRef]



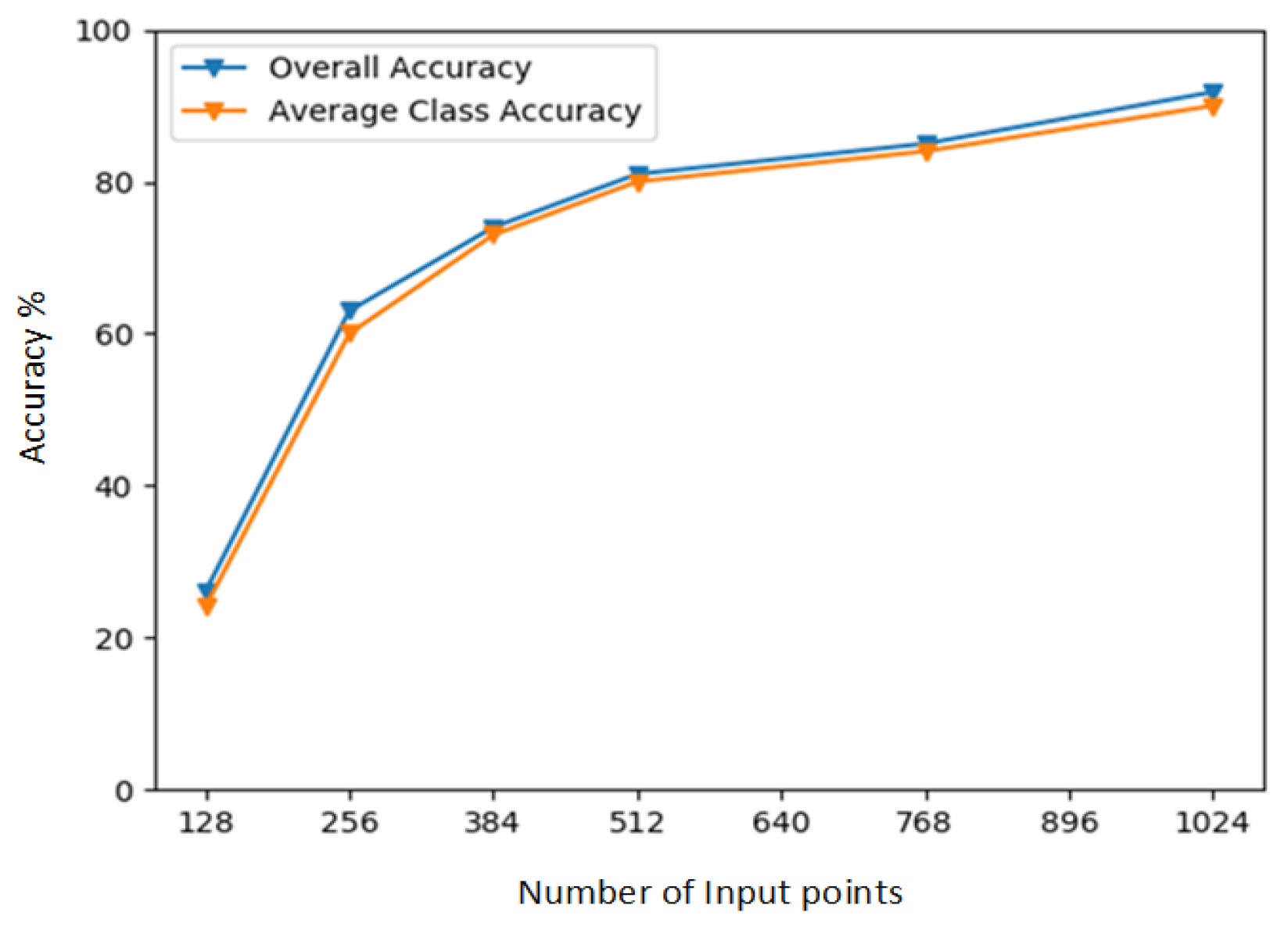


| Different Values of k-Nearest Neighbors | Average Class Accuracy | Overall Accuracy |
|---|---|---|
| 10 | 87.5% | 89.2% |
| 15 | 89.2% | 91.5% |
| 20 | 90.1% | 92.9% |
| 25 | 88.2% | 91.2% |
| 30 | 88.6% | 91.2% |
| 35 | 80.3% | 89.2% |
| 40 | 80.0% | 85.2% |
| Methods | Aero | Bag | Cap | Car | Chair | Guitar | Knife |
|---|---|---|---|---|---|---|---|
| No. of Shapes | 2690 | 76 | 55 | 898 | 3758 | 787 | 392 |
| PointNet++ [19] | 82.4 | 79.0 | 87.7 | 77.3 | 90.8 | 91.0 | 85.9 |
| KD-Tree [41] | 80.1 | 74.6 | 74.3 | 70.3 | 88.6 | 90.2 | 87.2 |
| FPNN [47] | 81.0 | 78.4 | 77.7 | 75.7 | 87.6 | 92.0 | 85.4 |
| SSCNN [48] | 81.6 | 81.7 | 81.9 | 75.2 | 90.2 | 93.0 | 86.1 |
| PointNet [29] | 83.4 | 78.7 | 82.5 | 74.9 | 89.6 | 91.5 | 85.9 |
| LocalFeature [49] | 86.1 | 73.0 | 54.9 | 77.4 | 88.8 | 90.6 | 86.5 |
| DGCNN [23] | 84.2 | 83.7 | 84.4 | 77.1 | 90.9 | 91.5 | 87.3 |
| FCPN [50] | 84.0 | 82.8 | 86.4 | 88.3 | 83.3 | 93.4 | 87.4 |
| RSNet [51] | 82.7 | 86.4 | 84.1 | 78.2 | 90.4 | 91.4 | 87.0 |
| DFT-Net | 97.0 | 99.2 | 98.4 | 97.7 | 99.1 | 96.0 | 99.7 |
| Methods | Lamp | Laptop | Bike | Mug | Pistol | Table | Skate Board |
| No. of Shapes | 1547 | 451 | 202 | 184 | 283 | 5271 | 152 |
| PointNet++ [19] | 83.7 | 95.3 | 71.6 | 94.1 | 81.3 | 82.6 | 76.4 |
| KD-Tree [41] | 81.0 | 94.9 | 57.4 | 86.7 | 78.1 | 80.3 | 69.9 |
| FPNN [47] | 82.5 | 95.7 | 70.6 | 91.9 | 85.9 | 75.3 | 69.8 |
| SSCNN [48] | 84.7 | 95.6 | 66.7 | 92.7 | 81.6 | 82.1 | 82.9 |
| PointNet [29] | 80.8 | 95.3 | 65.2 | 93.0 | 81.2 | 80.6 | 72.8 |
| LocalFeature [49] | 75.2 | 96.1 | 57.3 | 91.7 | 83.1 | 83.8 | 72.5 |
| DGCNN [23] | 82.9 | 96.0 | 67.8 | 93.3 | 82.6 | 82.0 | 75.5 |
| FCPN [50] | 77.4 | 97.7 | 81.4 | 95.8 | 87.7 | 73.4 | 83.6 |
| RSNet [51] | 83.5 | 95.4 | 66.0 | 92.6 | 81.8 | 82.2 | 75.8 |
| DFT-Net | 99.7 | 99.7 | 89.5 | 99.6 | 97.9 | 99.8 | 100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheikh, M.; Asghar, M.A.; Bibi, R.; Malik, M.N.; Shorfuzzaman, M.; Mehmood, R.M.; Kim, S.-H. DFT-Net: Deep Feature Transformation Based Network for Object Categorization and Part Segmentation in 3-Dimensional Point Clouds. Sensors 2022, 22, 2512. https://doi.org/10.3390/s22072512
Sheikh M, Asghar MA, Bibi R, Malik MN, Shorfuzzaman M, Mehmood RM, Kim S-H. DFT-Net: Deep Feature Transformation Based Network for Object Categorization and Part Segmentation in 3-Dimensional Point Clouds. Sensors. 2022; 22(7):2512. https://doi.org/10.3390/s22072512
Chicago/Turabian StyleSheikh, Mehak, Muhammad Adeel Asghar, Ruqia Bibi, Muhammad Noman Malik, Mohammad Shorfuzzaman, Raja Majid Mehmood, and Sun-Hee Kim. 2022. "DFT-Net: Deep Feature Transformation Based Network for Object Categorization and Part Segmentation in 3-Dimensional Point Clouds" Sensors 22, no. 7: 2512. https://doi.org/10.3390/s22072512
APA StyleSheikh, M., Asghar, M. A., Bibi, R., Malik, M. N., Shorfuzzaman, M., Mehmood, R. M., & Kim, S.-H. (2022). DFT-Net: Deep Feature Transformation Based Network for Object Categorization and Part Segmentation in 3-Dimensional Point Clouds. Sensors, 22(7), 2512. https://doi.org/10.3390/s22072512