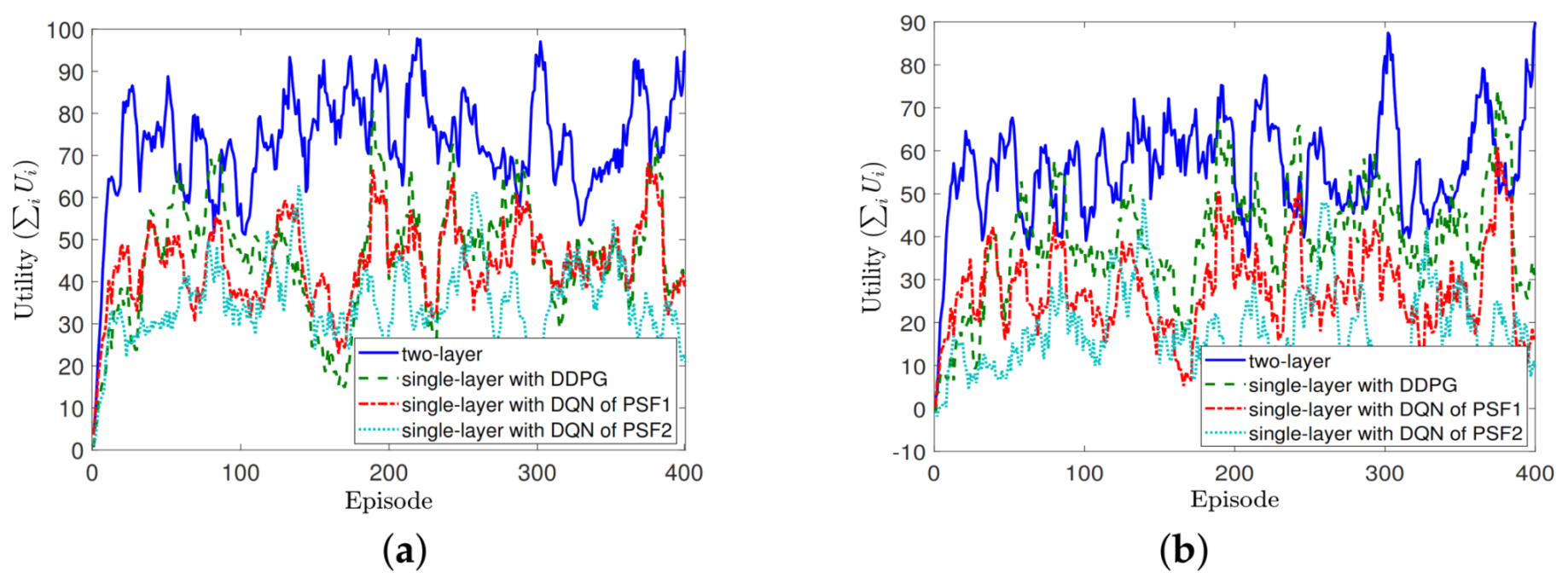
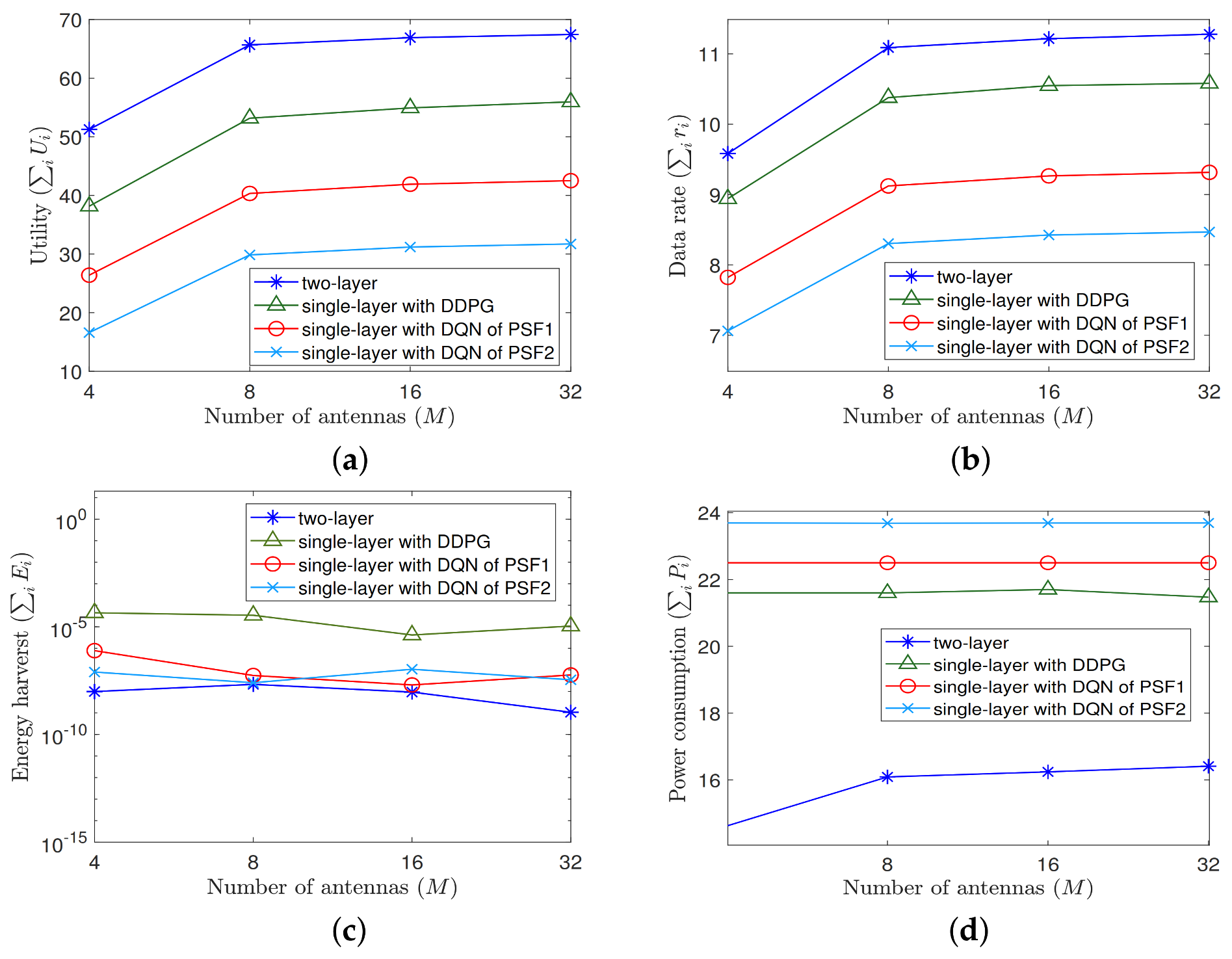
Determining an exact state transition model for (P1) through a model-based dynamic programming algorithm is challenging because the MRA problem on transmit power, power split ratio, and beamforming vector is location dependent. It is not trivial to list all the state–action pairs to be found in a state transition model predefined. Therefore, we design two single-layer learning-based algorithms derived from Markov decision process (MDP) to resolve this problem.
3.1. Q-Learning Approach
The Q-learning algorithm is based on the MDP that can be defined as a 4-tuple <
>, where
is the finite set of states, and
is the set of discrete actions.
is the function to provide reward
defined at state
, action
, and next state
.
is the transition probability of the agent at state
s taking action
a to migrate to state
. Given that, reinforcement learning is conducted to find the optimal policy
that can maximize the total expected discounted reward. Among the different approaches to this end, Q-learning is widely considered, which adopts a value function
for the expected value to be obtained by policy
from each
. Specifically, based on the infinite horizon discounted MDP, the value function in the following is formulated to show the goodness of
as
where
denotes the discount factor, and
is the expectation operation. Here, the optimal policy is defined to map the states to the optimal action in order to maximize the expected cumulative reward. In particular, the optimal action at each sate
s can be obtained with the Bellman equation [
61]:
Given that, the action–value function is in fact the expected reward of this model starting from state
s which takes action
a according to policy
; that is,
Let the optimal policy
be
. Then, we can obtain
The strength of Q-learning can now be revealed as it can learn
without knowing the environment dynamics or
, and the agent can learn it by adjusting the Q value with the following update rule:
where
denotes the learning rate.
Given this strength, the application of Q-learning is, however, limited because the optimal policy can be obtained only when the state-action spaces are discrete and the dimension is relatively small. Fortunately, after considerable investigations on the deep learning techniques, reinforcement learning has made significant progress to replace a Q-table with the neural network, leading to DQN that can approximate
. In particular, in DQN, the Q value in time
t is rewritten as
wherein
is the weight of a deep neural network (DNN). Given that, the optimal policy
in DQN can be represented by
, where
denotes the optimal Q value obtained through DNN. The goal of this approach is then to choose the approximated action
, and the approximated Q value is given by
In the above,
will be updated by minimizing the loss function:
Deep Q learning elements: Following the Q-learning design approach, we next define state, action, and reward function specific for solving (P1) as follows:
- (1)
State: First, if there are
n links in the network, the state at time
t is represented in the sequel by using the capital notations for their components and using the superscript such as “
” for the time index as follows:
where
,
,
, and
. In the above,
denotes the Cartesian coordinates of MN in link
i at time
t, while the others, i.e.,
,
, and
, denote the transmit power, power splitting ratio, and beamforming vector for link
i at time
t, respectively.
Among these variables, the transmit power is usually the only parameter to be considered in many previous works [
27,
62]. In the complex MRA problem also involving other types of resources, it is still a major factor affecting the system performance based on SINR in (
5) that would be significantly impacted by the power, and thus we consider two different state formulations for
as follows.
Power state formulation 1 (PSF1): First, to align with the industry standard [
33] which chooses integers for power increments, we consider a
dB offset representation similar to that shown in [
51], as the the first formulation for the power state. Specifically, given an initial value
, the transmit power
(despite
t), will be chosen from the set
where
=
and
=
.
Power state formulation 2 (PSF2): Next, as shown in [
27], the performance of a power-controllable network can be improved by quantizing the transmit power through a logarithmic step size instead of linear step size. Given that, the transmit power
could be selected from the set
Apart from the above, the other parameters, such as , can be chosen from the splitting ratio set with linear step size, and can be selected from the predefined codebook with finite vectors or elements.
- (2)
Action: The action of this process at time
t,
is selected from a set of binary decisions on the variables
where
,
, and
denote all the possible binary decisions on the three types of variables involved, respectively. That is, the agent can decide each link
i to increase or decrease each of the variables to the next quantized value according to
,
and
in
, respectively.
Note that, as the number of values of a variable is limited, when reaching the maximum or minimum value with a binary action chosen from , a modulo operation is used to decide the index for the next quantized value in the state space. For example, in PSF2, if with , and , then the modulo operation will lead to with in . As another example, with and to denote the first and the last vector in the codebook , respectively, the action of increasing or decreasing by 1 will choose the previous or the next vector of in as , and a similar modulo operation will also be applied to keep within , .
- (3)
Reward: To reduce the power consumption for green communication while maintaining the desired trade-off among the data rate and the energy harvesting, we introduce a reward function that can represent a trade-off among the three metrics properly normalized for link
i with parameters
,
, and
, at time
t, as
where
denotes the data rate of link
i obtained at time
t, which can be represented by
In addition,
is the energy harvested at MN of link
i at time
t, represented in the log scale as
wherein the harvested energy in its raw form is given by
In the above,
is the power conversion efficiency, and
is the price or cost for the power consumption
to be paid for link
i’s transmission. Note that the log representation is considered here to accommodate a normalization process in deep learning similar to the batch normalization in [
63]. Otherwise, the data rate
obtained with a log operation and the raw energy harvesting
without the (log) operation may be directly combined in the utility function. If so, with the metric values lying in very different ranges, such a raw representation could cause problems in the training process. Note also that, although
and
could be set to compensate the scale differences, a very high energy obtained in certain case can still happen to significantly vary the utility function and impede the learning process. By taking these into account, the system utility at time
t can be represented by the sum of these link rewards as
Policy selection: In general, Q-learning is an off-policy algorithm that can find a suboptimal policy even when its actions are obtained from an arbitrary exploratory selection policy [
64]. Following that, we conduct the DQN-based MRA algorithm to have a near-greedy action selection policy, which consists of (1) exploration mode and (2) exploitation mode. On the one hand, in exploration mode, the DQN agent would randomly try different actions at every time
t for getting a better state-action or Q value. On the other hand, in exploitation mode, the agent will choose at each time
t an action
that can maximize the Q value via DNN with weight
; that is,
. More specifically, we conduct the agent to explore with a probability
and to exploit with a probability
, where
denotes a hyperparameter to adjust the trade-off between exploration and exploitation, resulting in a
-greedy selection policy.
Experience replay: This algorithm also includes a buffer memory
D as a replay memory to store transactions
, where reward
is obtained by (
23) at time
t. Given that, at each learning step, a mini-batch is constructed by randomly sampling the memory pool and then a stochastic gradient descent (SGD) is used to update
. By reusing the previous experiences, the experience replay makes the stored samples to be exploited more efficiently. Furthermore, by randomly sampling the experience buffer, a more independent and identically distributed data set could be obtained for training.
As a summary of these key points introduced above, we formulate the single-layer DQN-based MRA training algorithm with a pseudo code representation shown in Algorithm 1 for easy reference.
| Algorithm 1 The single-layer DQN-based MRA training algorithm. |
- 1:
(Input) , batch size , learning rate , minimum exploration rate , discount factor , and exploration decay rate d; - 2:
(Output) Learned DQN to decide , for (7); - 3:
Initialize action and replay buffer ; - 4:
for episode = 1 to do - 5:
Initialize state ; - 6:
for time to do - 7:
Observe current state ; - 8:
; - 9:
if random number then - 10:
Select at random; - 11:
else - 12:
Select ; - 13:
end if - 14:
Observe next state ; - 15:
Store transition in D, where is obtained with ( 23); - 16:
Select randomly stored samples from D for experience; - 17:
Obtain for all j samples with ( 13); - 18:
Perform SGD to minimize the loss in ( 14) for finding the optimal weight of DNN, ; - 19:
Update in the DQN; - 20:
; - 21:
end for - 22:
end for
|
3.2. DDPG-Based Approach
Similar to that found in the literature [
28,
29], as a deep reinforcement learning algorithm, DQN would be superior to the classical Q-learning algorithm because it can handle the problems with high-dimensional state spaces that can hardly be done with the former. However, DQN still works on a discrete action space, and suffers the curse of dimensionality when the action space becomes large. For this, we next develop a deep deterministic policy gradient (DDPG)-based algorithm that can find optimal actions in a continuous space to solve this MRA optimization problem without quantizing the actions that should be done for the DQN-based algorithm.
Specifically, with DDPG, we aim to determine an action
a to maximize the action–value function
for a given state
s. That is, our goal is to find
as that done with DQN introduced previously. However, unlike DQN, there are two neural networks for DDPG, namely actor network and critic network, and each contains two subnets, namely online net and target net, with the same architecture. First, the actor network with the weight of DNN,
, which is called “actor parameter”, will take state
s to output a deterministic action
a, denoted by
. Second, the critic network with the weight of DNN,
, which is called “critic parameter” will take state
s and
a as its inputs to produce the state–value function, denoted by
, to simulate a table for Q-learning or Q-table that would get rid of the curse of dimensionality. Given that, two key features of DDPG can be summarized as follows:
- (1)
Exploration: As defined, the actor network is conducted to provide solutions to the problem, playing a crucial role in DDPG. However, as it is designed to produce only deterministic actions, additional noise,
n, is added to the output so that the actor network can explore the solution space. That is,
- (2)
Updating the networks: Next, with the notation to denote the transaction wherein reward is obtained by taking action a at state s to migrate to as that in DQN, the update procedures for the critic and actor networks can be further summarized in the following.
As shown in (
24), the actor network is updated by maximizing the state–value function. In terms of the parameters
and
, this maximization problem can be rewritten to find
. Here, as the action space is continuous and the state–value function is assumed to be differentiable, the actor parameter,
, would be updated by using the gradient ascent method. Furthermore, as the gradient depends on the derivative of the objective function with respect to
, the chain rule can be applied as
Then, as the actor network would output to be the action adopted by the critic network, the actor parameter can be updated by maximizing the critic network’s output with the action obtained from the actor network, while fixing the critic parameter .
Apart from the actor network to generate the needed actions, the critic network is also crucial to ensure that the actor network is well trained. To update the critic network, there are two aspects to be considered. First, with
from the target actor network to be an input of the target critic network, the state–value function would produce
Second, the output of the critic network,
, can be regarded as another source to estimate the state–value function. Based on these aspects, the critic network can be updated by minimizing the following loss function:
Given that, the critic parameter, , can be obtained by finding the parameter to minimize this loss function.
Finally, the target nets in both critic and actor networks can be updated with the soft update parameter,
, on their parameters
and
, as follows:
Action representation for the MRA problem: As defined, the actor network outputs the deterministic action
. Due to the deterministic, a dynamic
-greedy policy is used to determine the action by adding a noise term
to explore the action space. Here, as the state of this work involves different types of variables, the action resulting at time
t in fact consists of three parts as
. When added with the corresponding noises, the exploration action
would be specified as
where the different parts of
are clipped to the intervals
, according to the different types of variables, and the added noises are obtained with a normal distribution also based on the different types as
where
denotes the exploration decay rate at time
t.
State normalization and quantization: As shown in the previous works [
32,
63,
65], a state normalization to preprocess the training sample sets would lead to a much easier and faster training process. In our work, the three types of variables,
, and
(shown in vector forms) in
may have their values lying in very different ranges, which could cause problems in a training process. To prevent them, we normalize the coordinates with the cell radius, and these variables with the scale factors
,
, and
, as
In the above,
is an integer variable rounded from its real counterpart to denote which element in the codebook
to be used because the output of DDGP is a continuous action. Specifically, given
=
where
=
is obtained by (
30), its value at time
t will be
Note that, after the rounding operation (represented here by the floor function), the value may still be out of its feasible range, and thus a modulo operation similar to that for DQN is also applied here to keep it in
. For the other types of variables, the corresponding modulo operations are required to keep them in their feasible ranges as well. Still, due to their continuous nature, a rounding operation is avoided. Specifically, with
and
, each
and
at time
t would be updated by
Apart from the above, the critic network
is conducted to transfer gradient in learning, which is not involved in action generation. In particular, the critic network evaluates the current control action based on the performance index (
23) while the parameters
, and
of
U in (
23) are obtained by the actor network. Apart from these networks, the DDPG-based algorithm also includes an experience replay mechanism as the DQN counterpart. That is, when the experience buffer is full, the current transition
will replace the oldest one in the buffer
D where reward
, and then the algorithm would randomly choose
stored transitions to form a mini-batch for updating the networks. Given these sampled transitions, the critic network can update its online net by minimizing the loss function represented by
where
. Similarly, the actor network can update its online net with
Finally, we summarize the single-layer DDPG-based MRA training algorithm in Algorithm 2 to be referred to easily.
| Algorithm 2 The single-layer DDPG-based MRA training algorithm. |
- 1:
(Input) , batch size , actor learning rate , critic learning rate , decay rate d, discount factor , and soft update parameter ; - 2:
(Output) Learned actor/critic to decide , for (7); - 3:
Initialize actor , critic , action , replay buffer D, and set initial decay rate ; - 4:
for episode = 1 to do - 5:
Initialize state and ; - 6:
for time to do - 7:
Normalize state with ( 32); - 8:
Execute action in ( 30), obtain reward with ( 23), and observe new state ; - 9:
if replay buffer D is not full then - 10:
Store transition in D; - 11:
else - 12:
Replace the oldest one in buffer D with ; - 13:
Set ; - 14:
Randomly choose stored transitions from D; - 15:
Update the critic online network by minimizing the loss function in ( 36); - 16:
Update the actor online network with the gradient obtained by ( 37); - 17:
Soft update the target networks with their parameters updated by ( 29); - 18:
; - 19:
end if - 20:
end for - 21:
end for
|







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}