In this section, the performance of predictor functions generated by machine learning is thoroughly investigated. In this study, we adopted ANNs and k-NN as methods for machine learning.
3.1. Conditions of Numerical Calculation
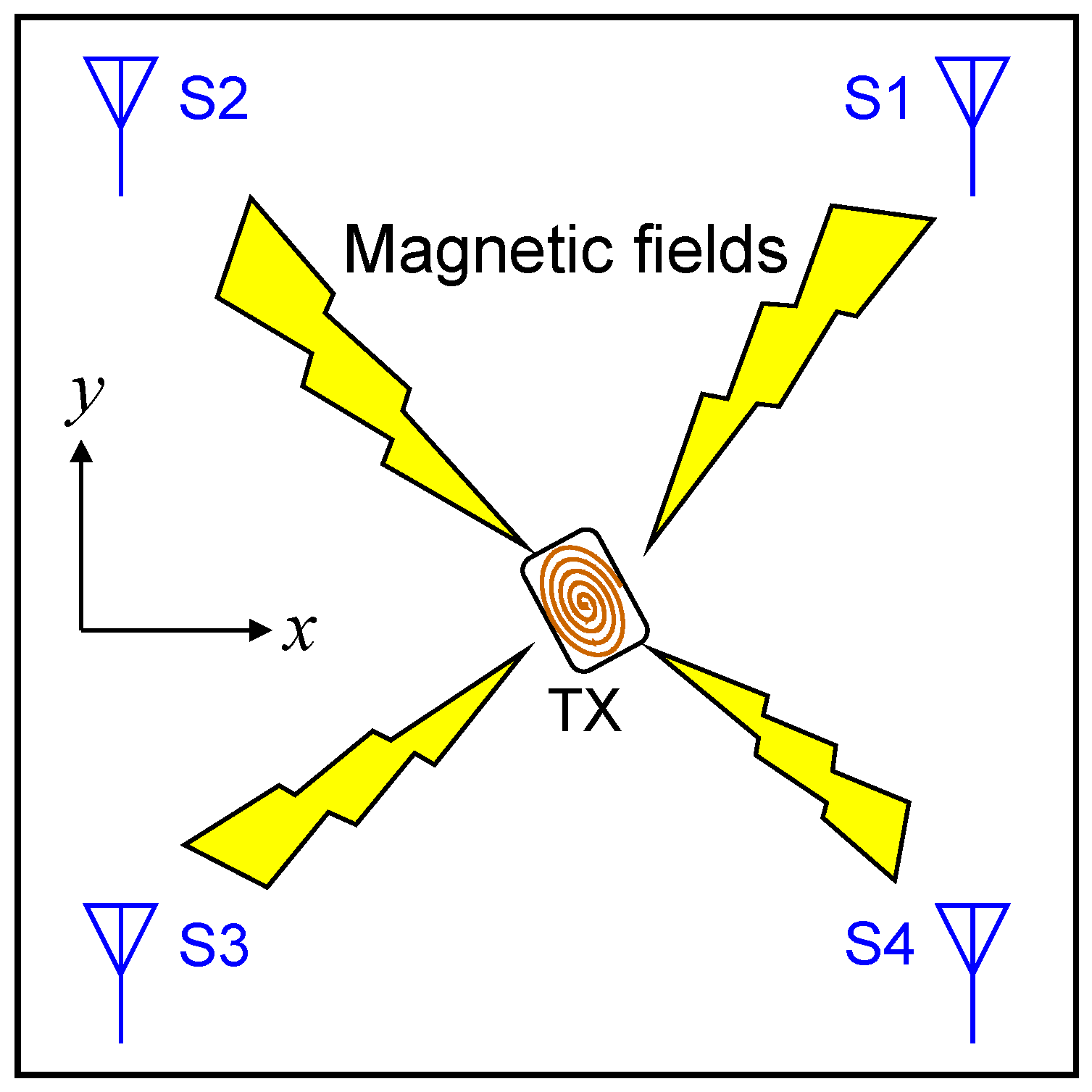
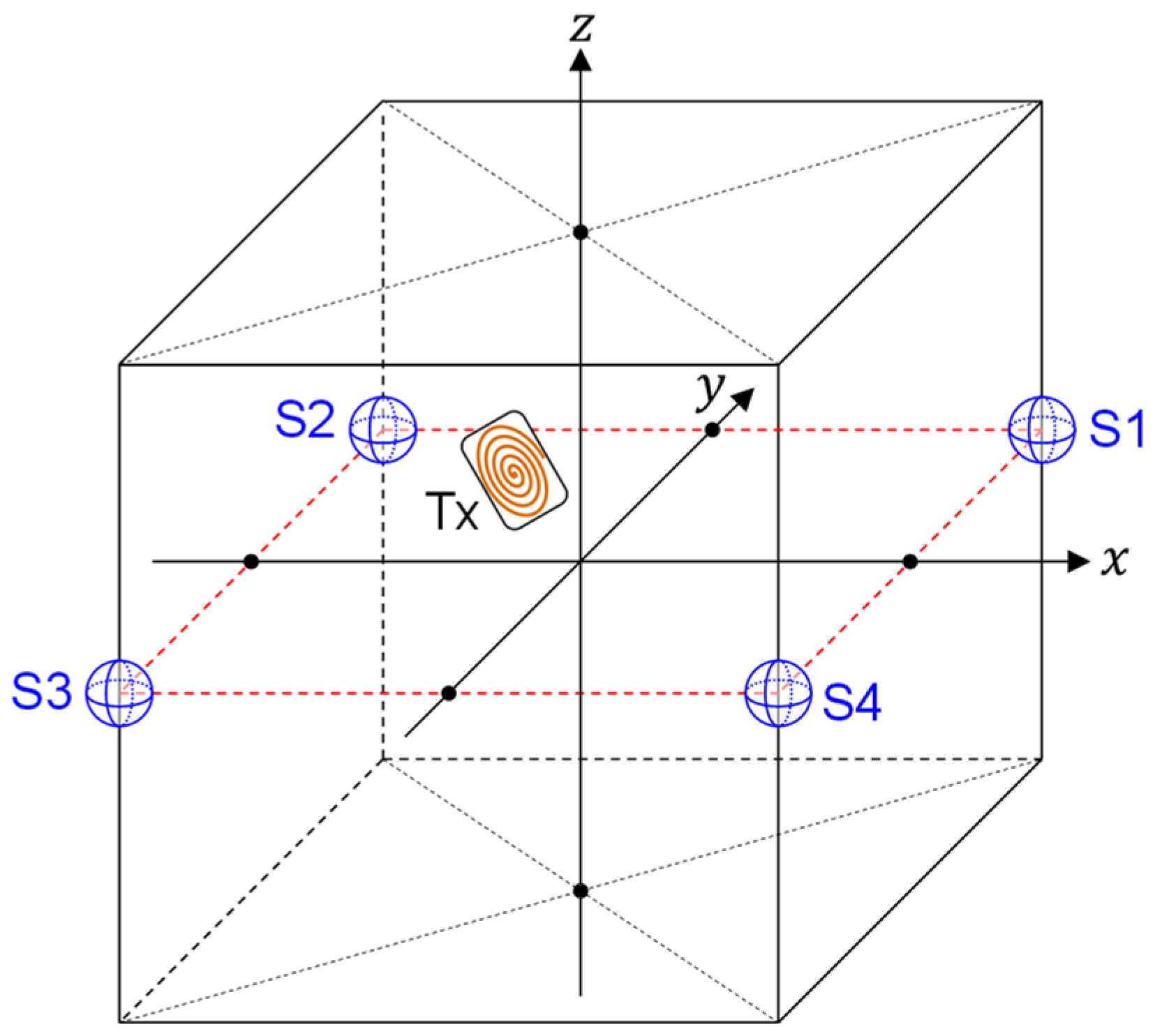
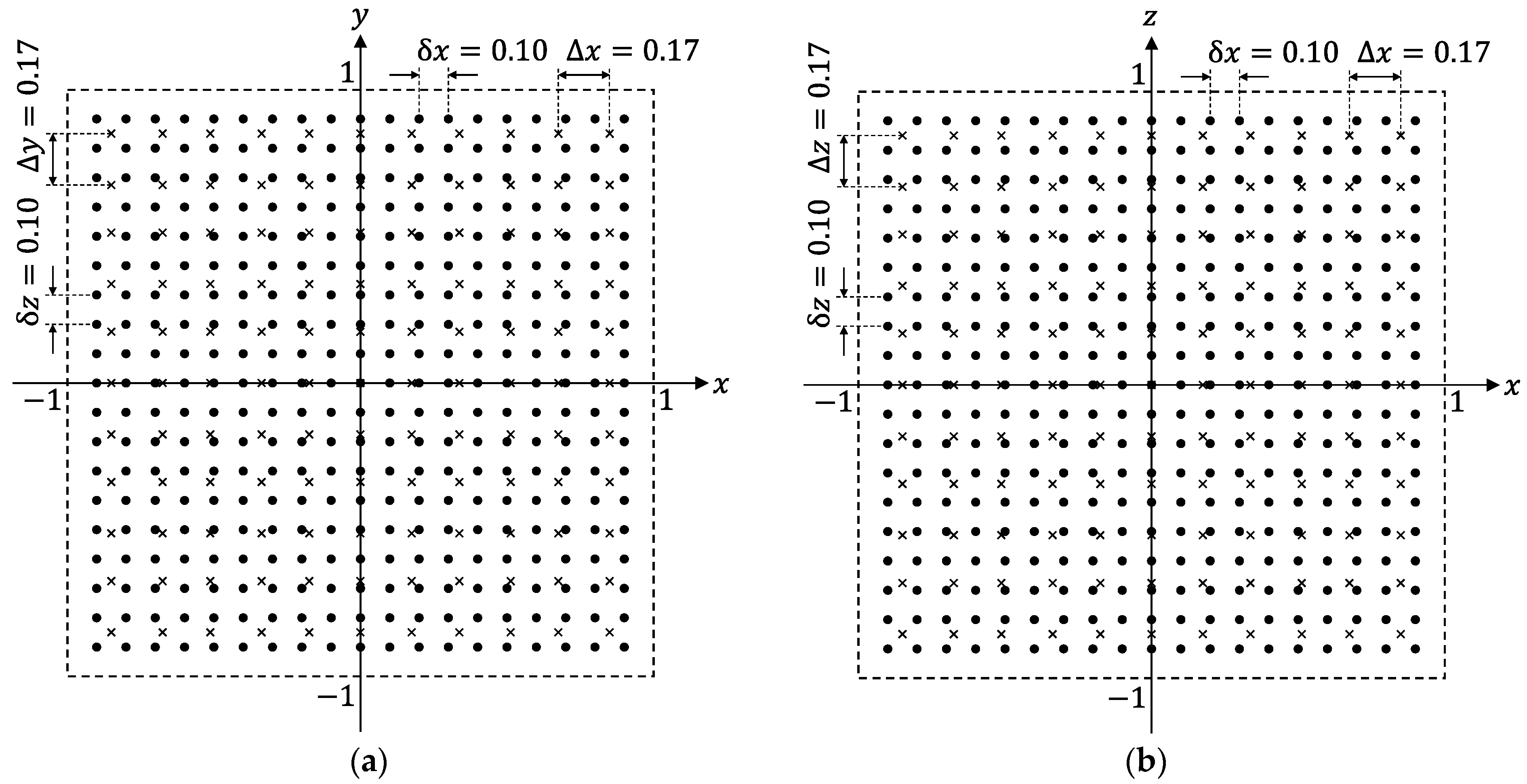
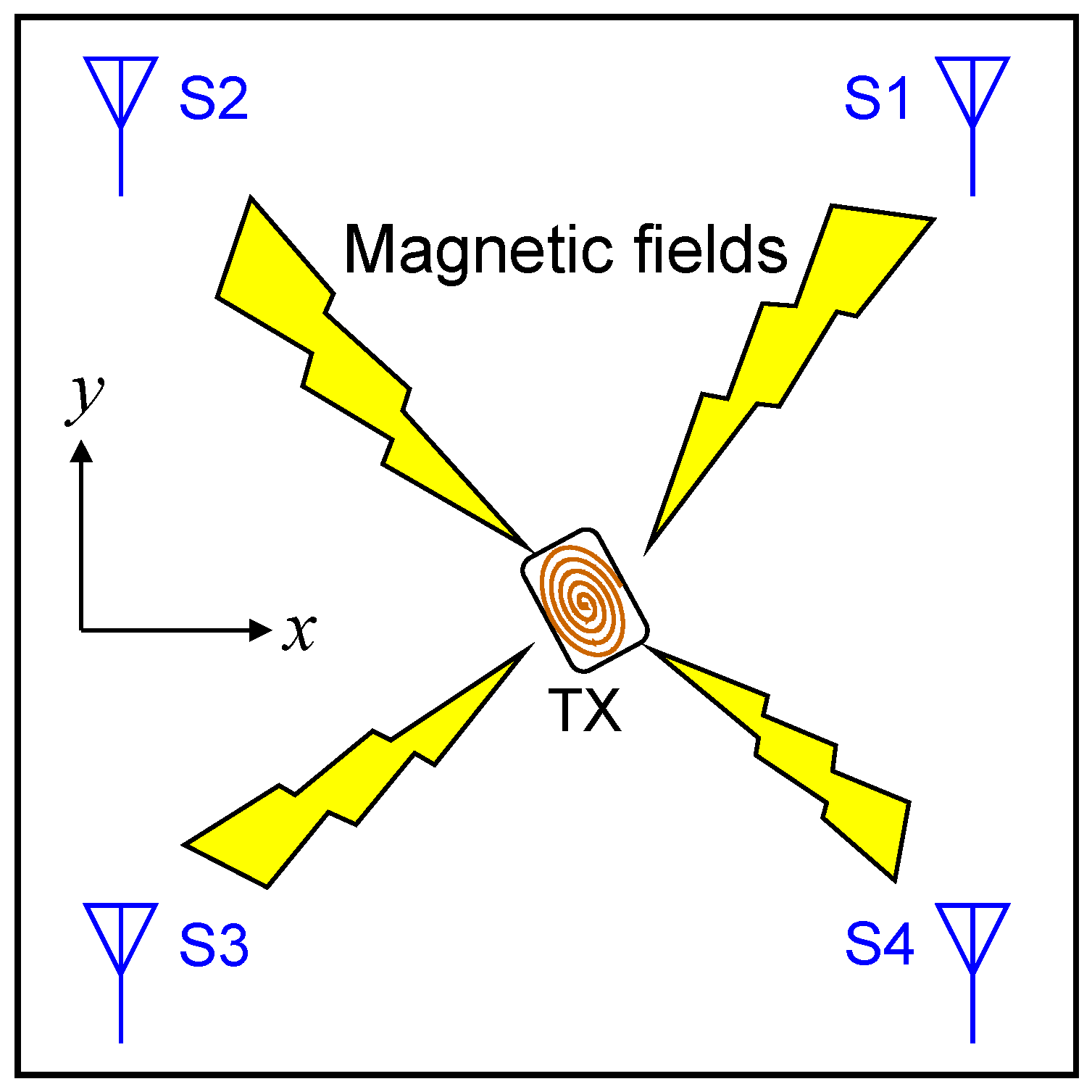
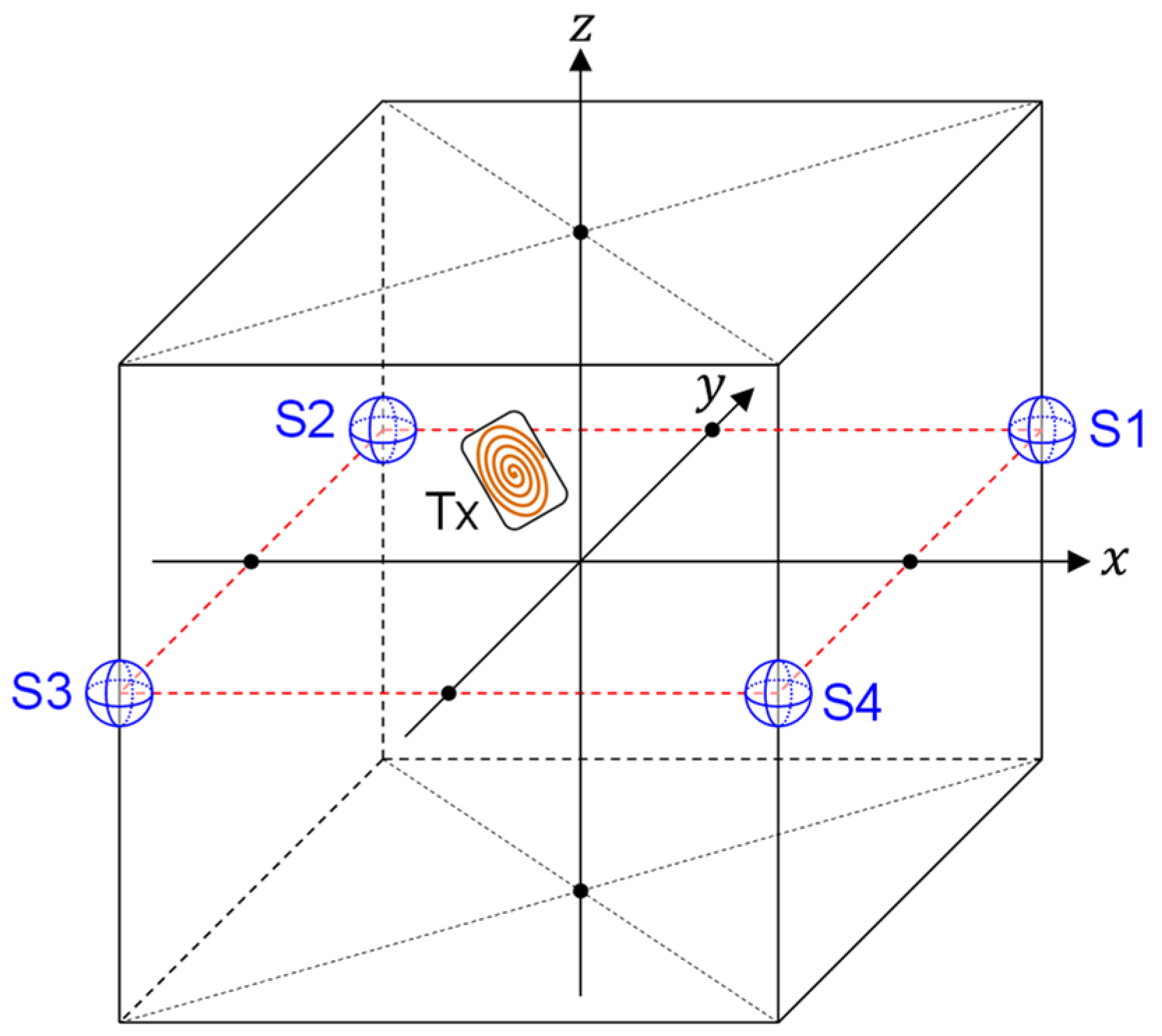
The scenarios and conditions of our investigation are shown in
Figure 1,
Figure 2 and
Figure 3. In this study, we assume that the target (TX) exists inside a cubic space of length (2 m) × height (2 m) × width (2 m). However, the dimensions of the cubic space are not fixed since the scaling law holds in localization with artificially generated magnetic fields. Therefore, the results obtained with the 2 m × 2 m × 2 m cubic space can be easily extended to cubic spaces with arbitrary dimensions. For example, it is possible to obtain a predictor function valid for a cubic space of length (4 m) × height (4 m) × width (4 m) by using the same model without increasing training data. Details on this topic are discussed in [
18].
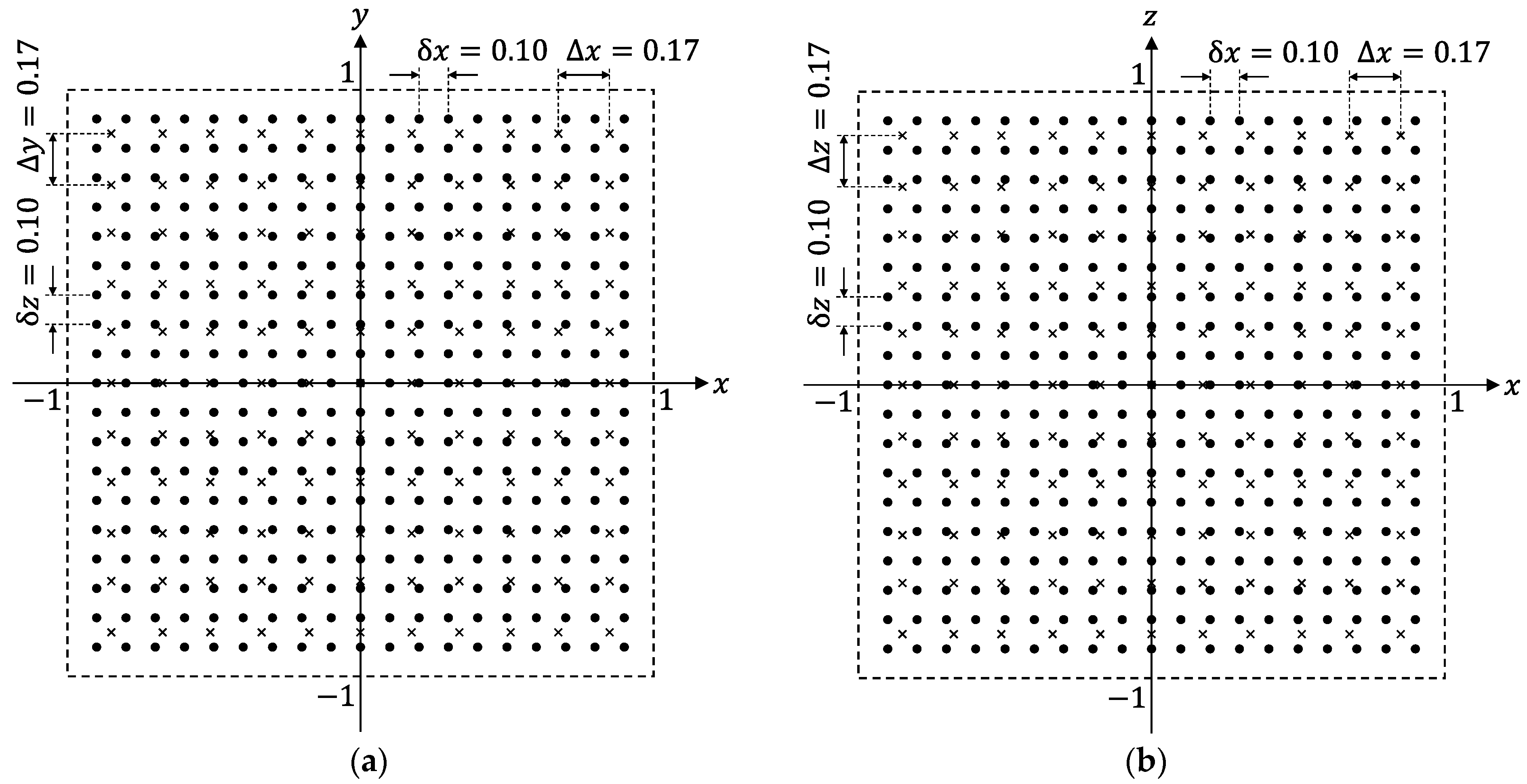
What we should do first is to generate sufficient numbers of training samples in the forms of Equations (10) or (15). Fortunately, we do not have to gather training samples by cumbersome measurement in real systems. It is possible to obtain numbers of training samples just by calculating
for many different TX-state parameters using Equation (5). The TX-positions chosen to calculate the training samples are indicated by black dots in
Figure 3a,b, depicting the
x-
y and
x-
z planes of the cubic space, respectively. The numerical values in
Figure 3 are in meter. Hence, the distance between the two adjacent dots is
. In this condition, the amount of TX positions for the training samples reaches
. It should be noted that
is dependent on both positions and angles of the TX. Hence, we must calculate
for various TX-angle sets
for each TX position. Here, we adopt
to calculate the training samples for different TX-angle sets. Therefore, the number of angle sets was
. Hence, the total number of TX states used for training data reached
.
In this study, Wolfram Mathematica 12.0 was used to execute machine learning [
18,
19]. Mathematica includes highly automated functions related to machine learning. We used the “Predict” command to generate predictor functions
and
. The command can be executed to automatically generate the predictor functions by inputting training data. We also selected “Quality” as an option command of Mathematica for setting a performance goal. Additionally, it is possible to select several algorithms for machine learning using Mathematica. In this study, we selected “Neural Network” and “Nearest Neighbors” for the algorithms and used a standard computer with Intel Xeon W-2223 and 64-GB RAM.
To evaluate generalization performances of predictor functions obtained by machine learning, we must calculate the EDF values (
) for various TX-state parameters that were not used for calculating training samples. The TX positions used for evaluating the generalization performances are indicated by crosses in
Figure 3. It can be confirmed that the positions of the crosses do not coincide with those of dots, which are used for training.
3.2. Performance Evaluation of Predictor Functions
We calculated the EDF values and plotted them within
x-
y planes for three different TX-state parameters to compare the performances of the predictor functions generated by
k-NN and ANNs, as shown below.
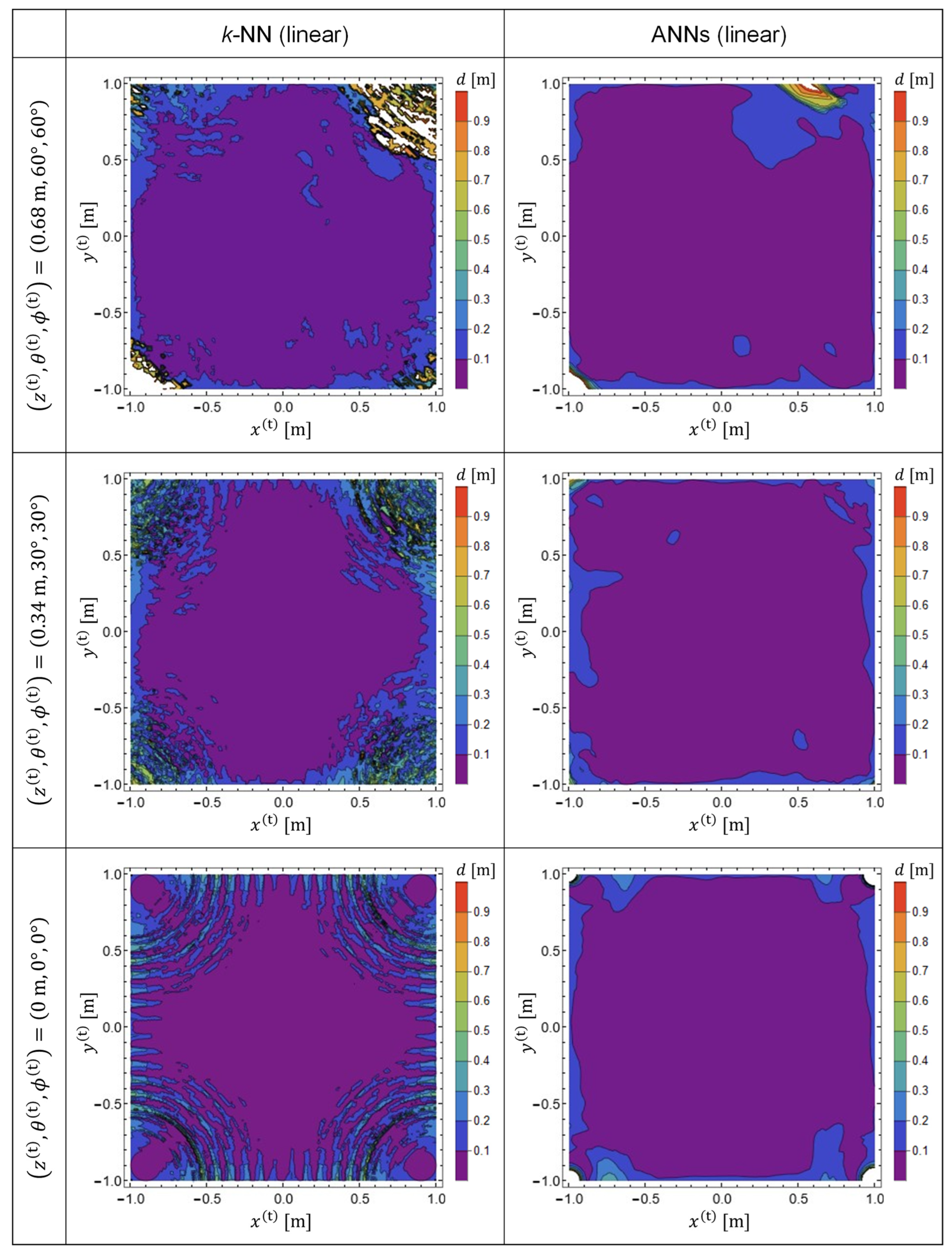
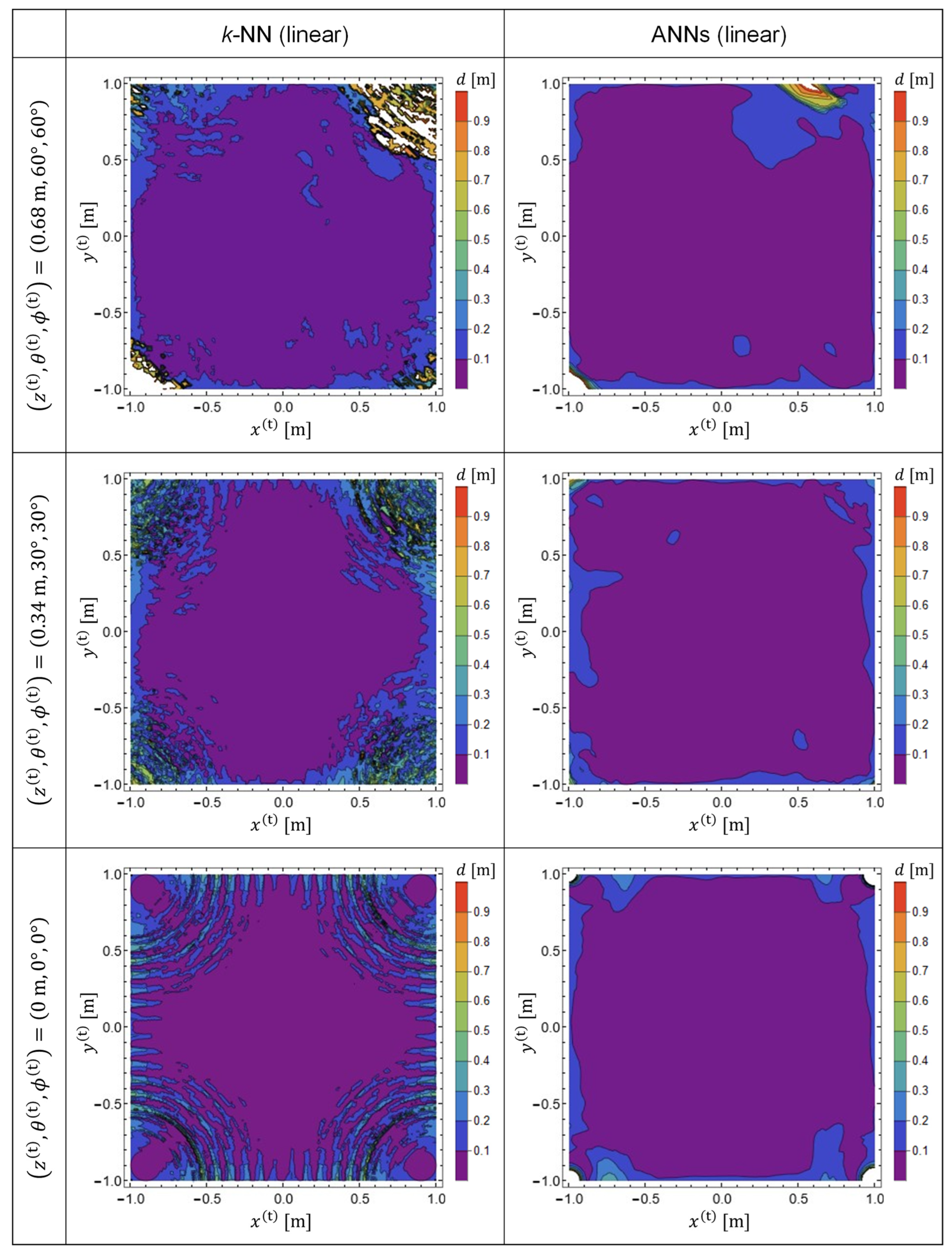
The results are presented in
Figure 4. The predictor functions used for plotting
Figure 4 are
, which were generated from the training data in a linear representation. Note that the TX-state parameters in Equation (21) were not used for the calculation of the training data. Therefore, the results plotted in
Figure 4 exhibit the generalization performance of the predictor functions generated by machine learning. The left and right columns indicate the EDF values obtained using
k-NN and ANNs, respectively. It was observed that, with
k-NN, the prediction accuracy is reduced in the vicinity of the four corners of the target space [
18,
19]. Meanwhile, it was confirmed that the prediction accuracy was significantly improved by adopting ANNs.
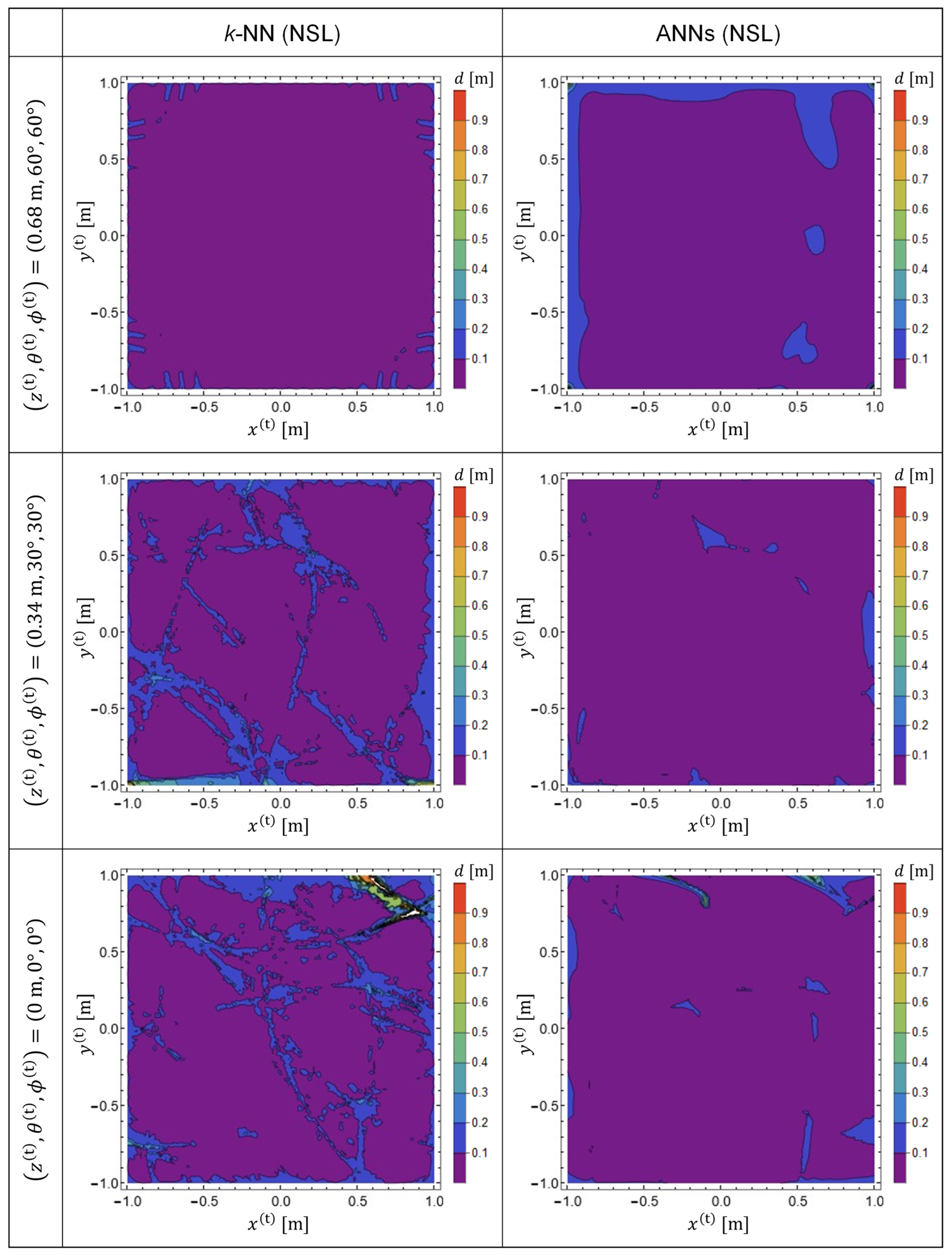
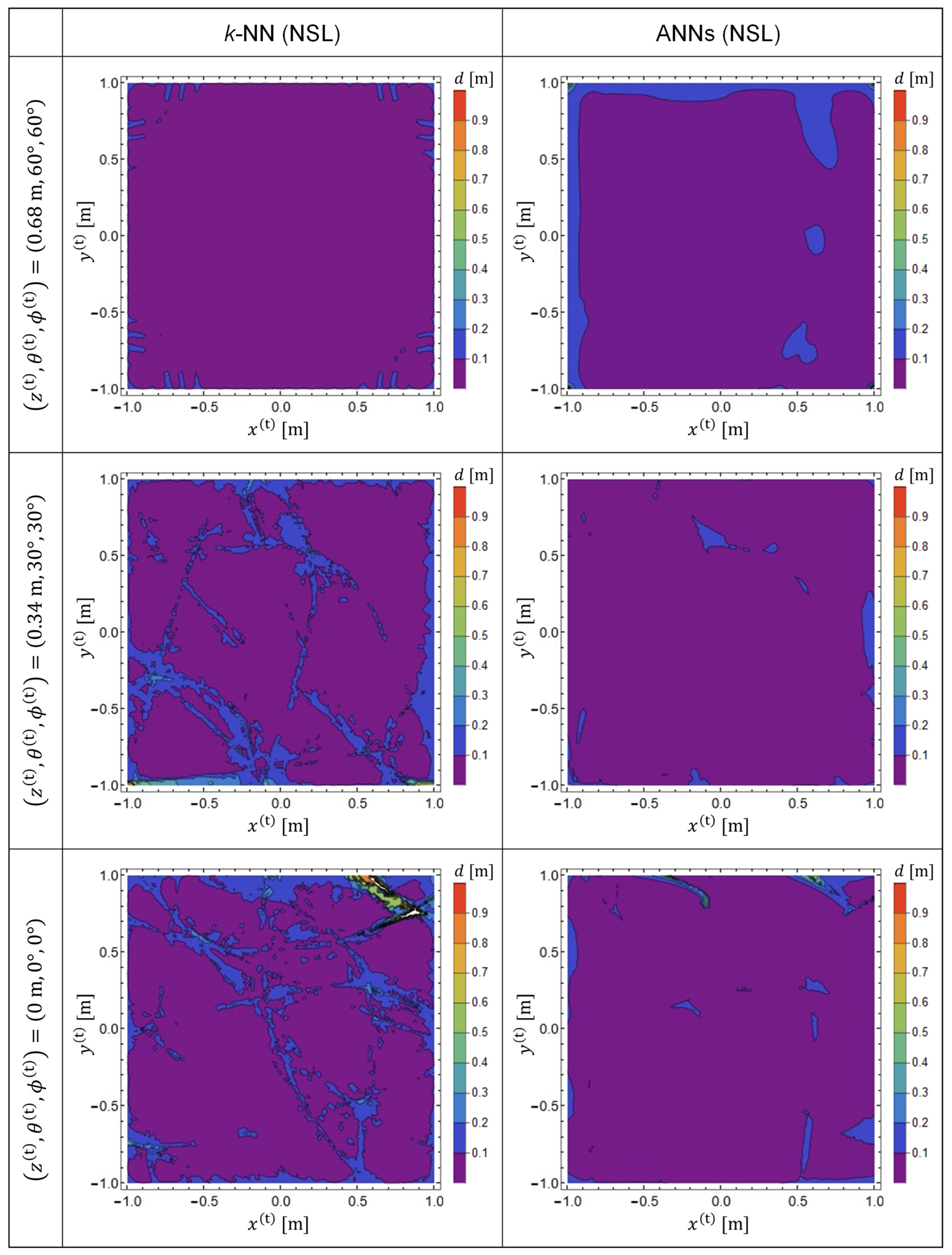
Figure 5 shows the EDF patterns obtained with the predictor functions
, which were generated from training data in the NSL representation. By comparing
Figure 4 and
Figure 5, it is evident that the prediction accuracy is improved for both ANNs and for
k-NN by using training data in NSL representation. However, it was observed that ANNs showed better performance for both representations of the training data.
Although it has been demonstrated in
Figure 4 and
Figure 5 that ANNs and NSL representation show better performances, quantitative assessments of the predictor functions have not yet been carried out. Hence, we quantitatively evaluated the performances of the predictor functions via a statistical approach. To do this, we calculated the EDF values at TX positions indicated by crosses in
Figure 3 and analyzed the statistical distribution of the values for predictor functions generated from different combinations of the learning algorithms and training-data representations. As shown in
Figure 3, the distance between the two adjacent crosses was 0.17 m (
). The EDF values were calculated for various angles (
) for each cross point. As a result, the number of TX states used for the quantitative evaluation of the predictor functions reached 82,522. Since the TX states used to generate the training samples were not included in the 82,522 states, the statistical distribution of the EDF values reflects generalization performances of the predictor functions.
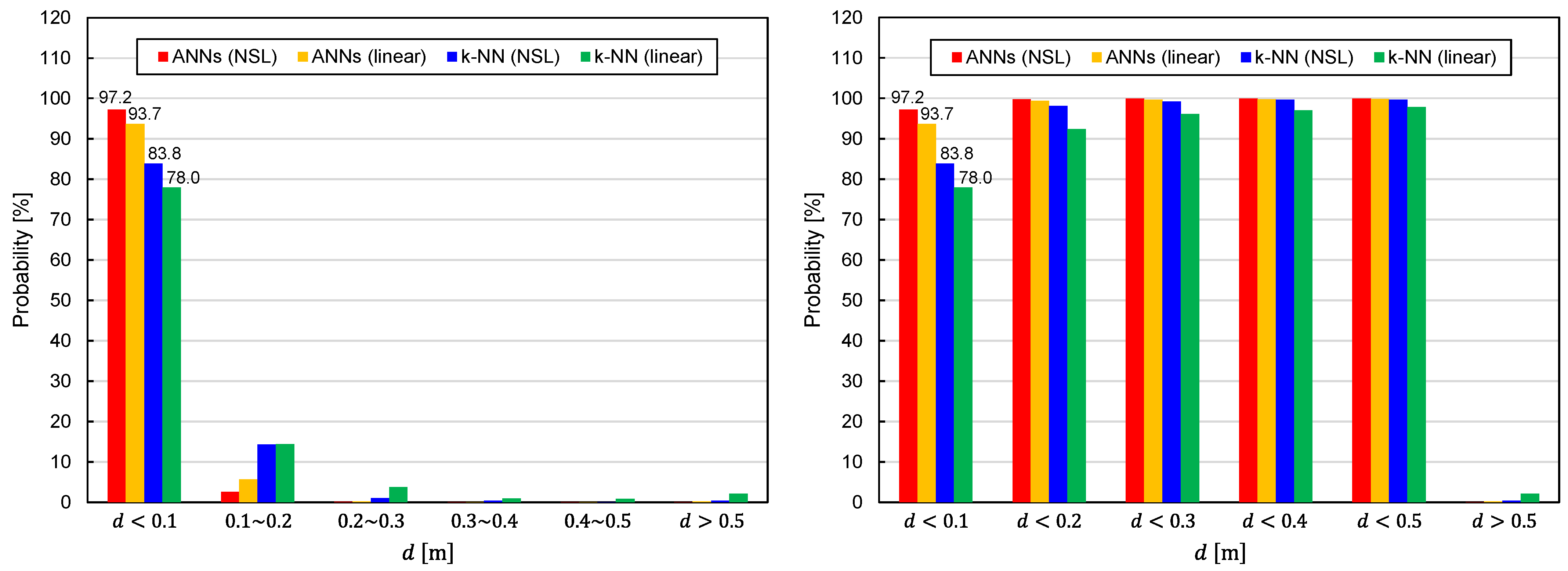
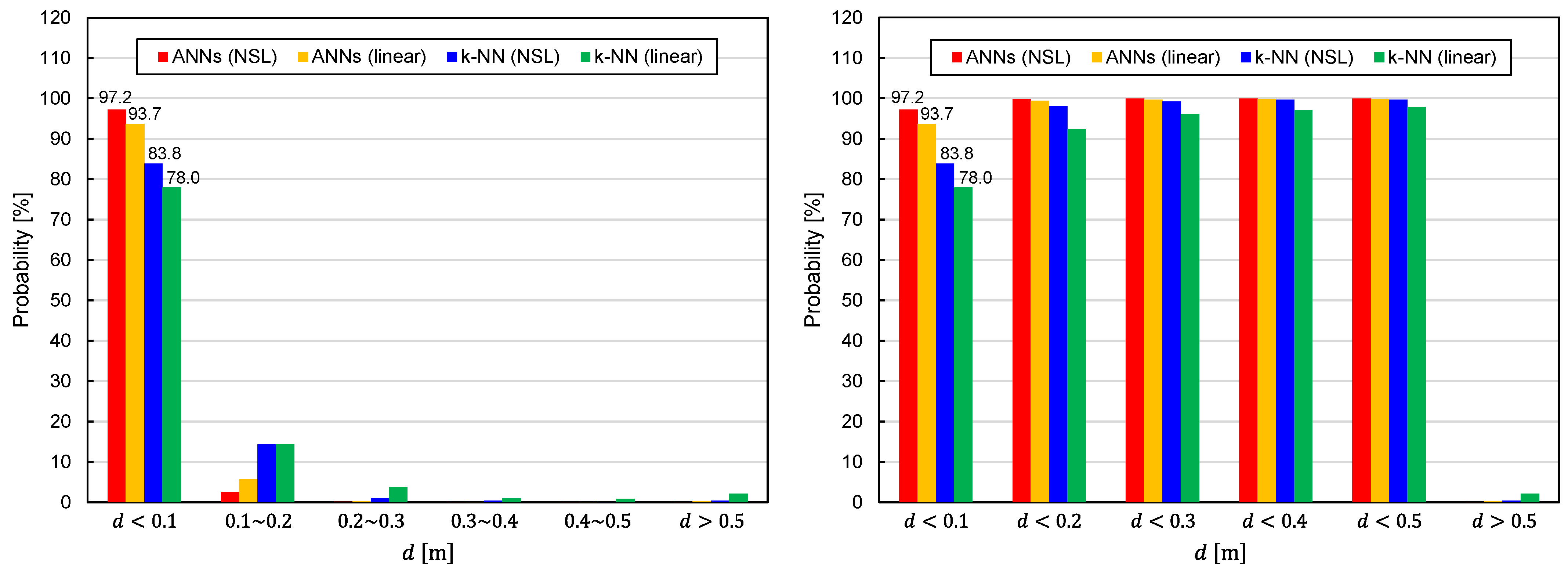
The statistical distributions of the EDF values are shown in
Figure 6. It can be seen that the predictor functions generated by ANNs exhibit better performance for both representations of the training data (NSL and linear). With regard to the training-data representations, the NSL representation is superior to the linear representation, regardless of the learning algorithms.
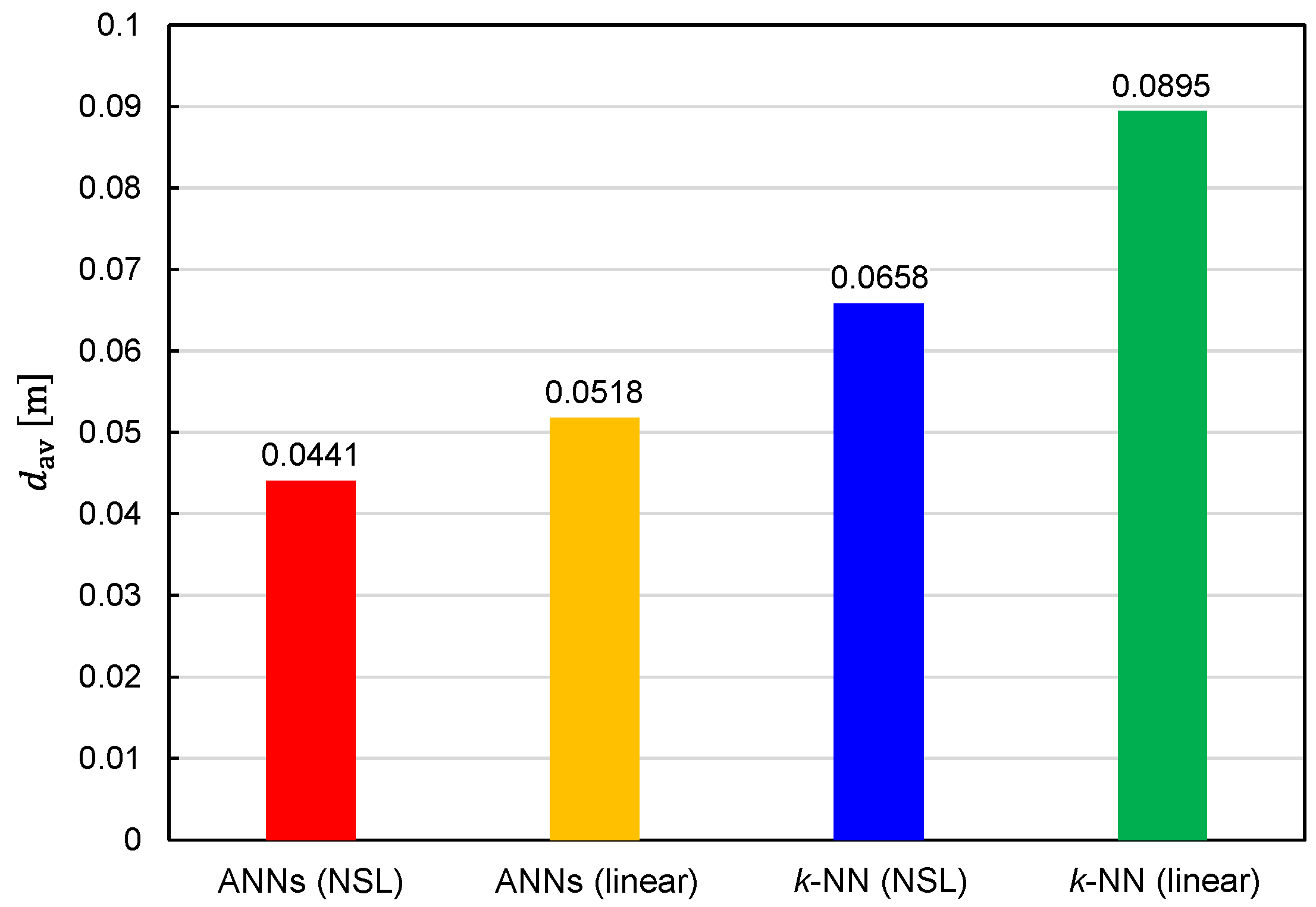
Figure 7 illustrates the EDF values averaged over 82,522 TX states. The average EDF value is denoted by
. The benefits of using ANNs and NSL representation are again confirmed by
Figure 7.
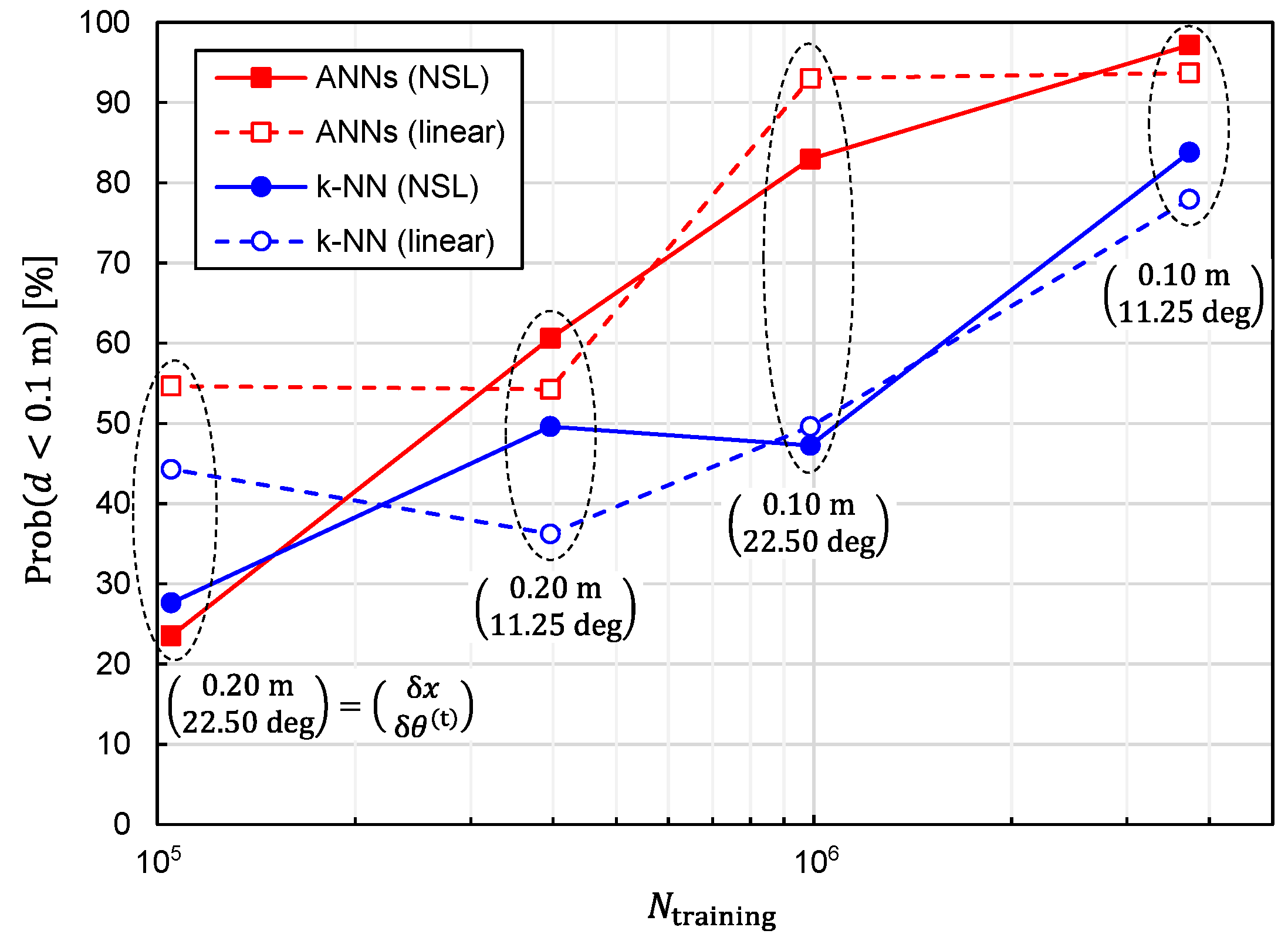
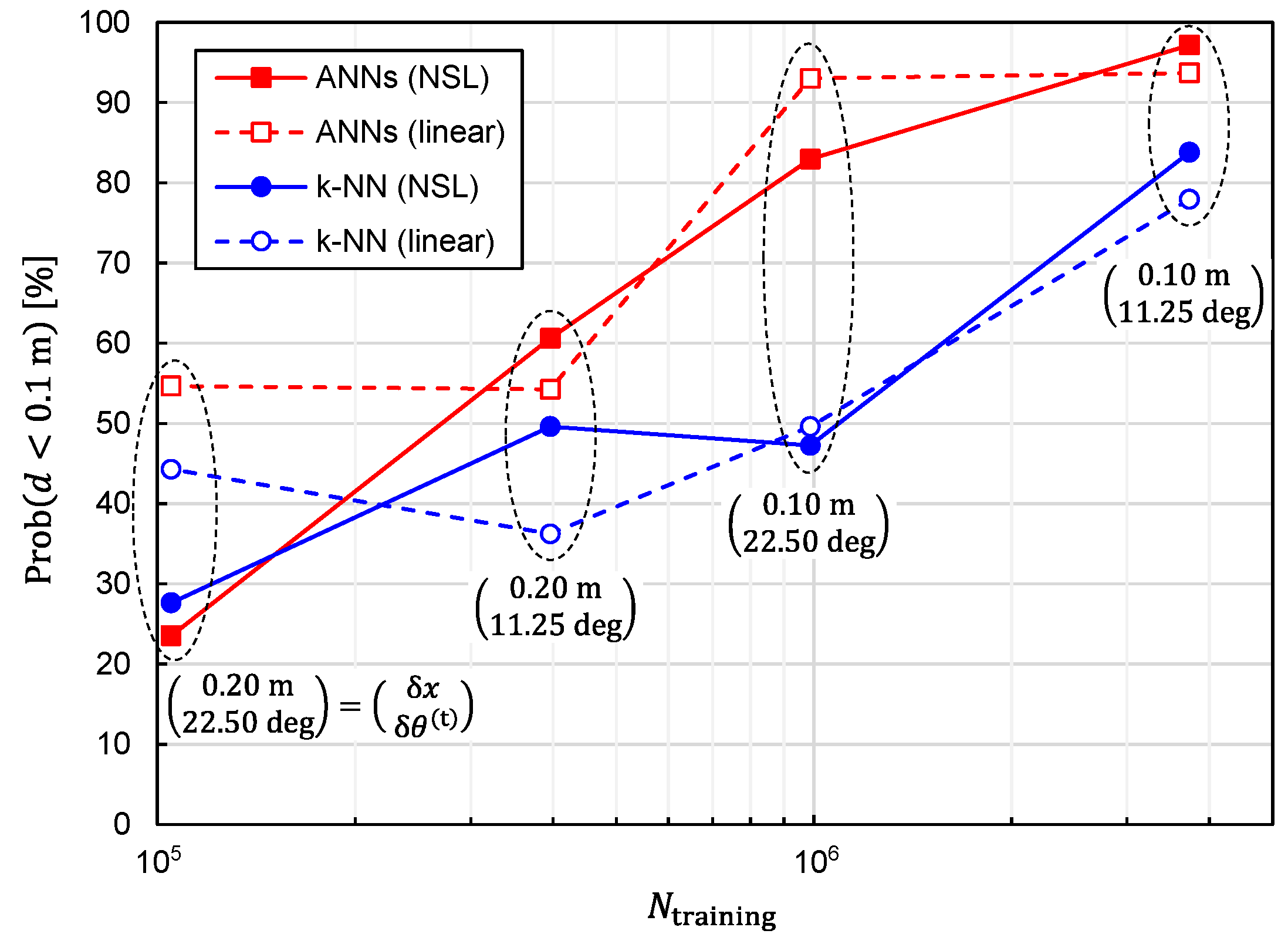
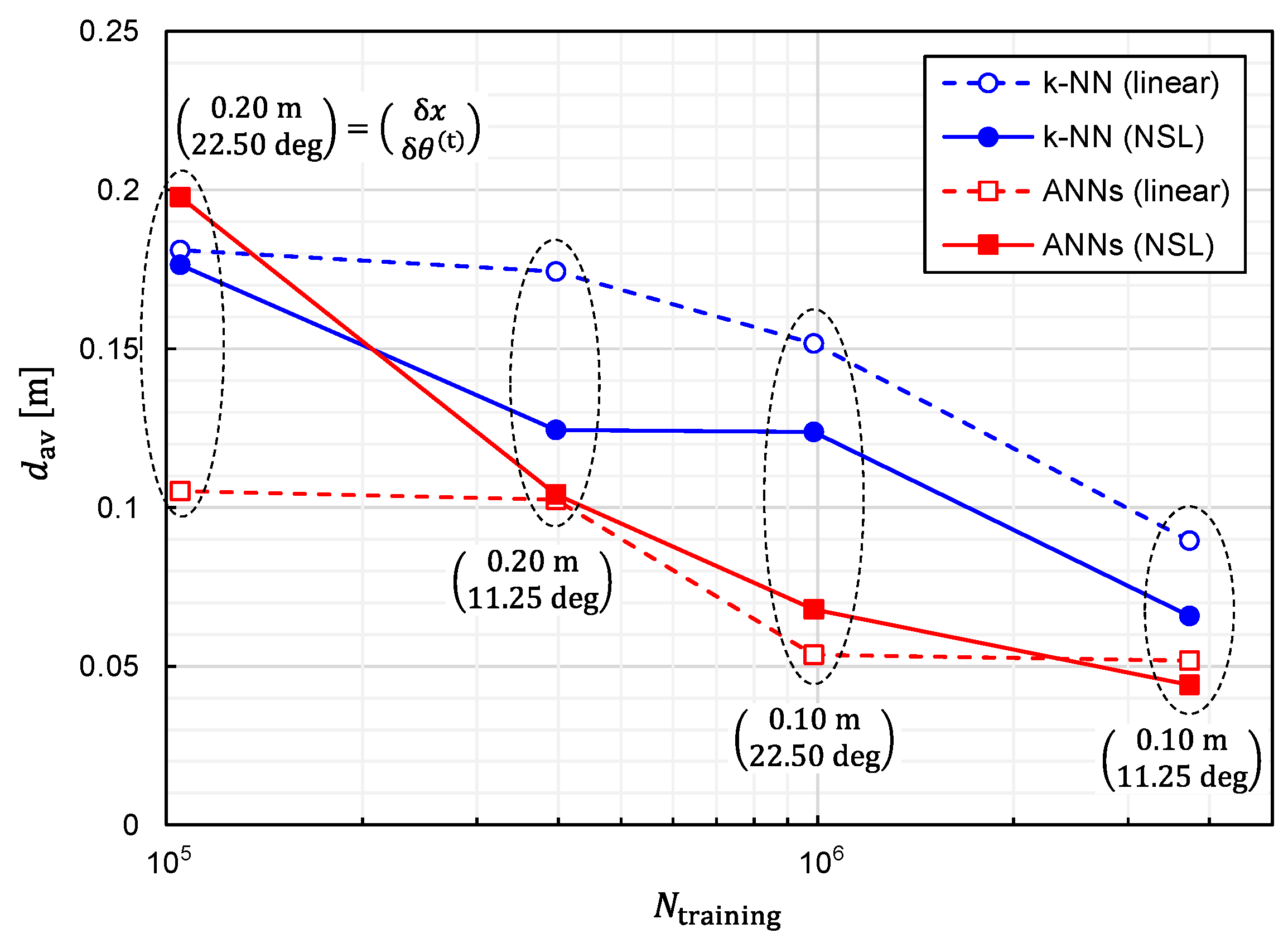
It is also critical to investigate the relationship between the prediction accuracy and the number of training samples,
. We plotted
and
as functions of
in
Figure 8 and
Figure 9, respectively, to investigate the relationship. Since reducing
is equivalent to reducing
and
, the simulations have been executed for different combinations of
. It can be observed from these figures that the prediction accuracy was improved by increasing
. Moreover, it is expected that the prediction accuracy will be further improved by increasing
except for the combinatorial use of ANNs and linear representation. In other words, the situation of overfitting has not yet occurred for
.
In real-world applications, signals detected by sensors are affected by noise and irregularities of fabricated coils. Therefore, it is important to estimate the influences of these factors on prediction accuracy. Here we first discuss the influences of noise.
Since the amplitude of received signals depends on TX-state parameters, it is valid to define the reference magnetic-field amplitude for quantitatively discussing the influences of noise. Thus, we introduce the reference magnetic-field amplitude defined by
It is understood that
means the magnetic-field amplitude generated at the sensor positions by the TX directed toward
z-axis at a coordinate origin. Note that
is independent of
k when the sensors are located at the corners of a cubic space as shown in
Figure 2. We also define the signal-to-noise ratio (SNR) of sensors as
where
denotes amplitude of equivalent-input noise associated with each coil of the sensor. By considering the noise, the signal amplitude detected by the sensor can be written as
where
and
denote the amplitudes of detected signals with and without noise, respectively.
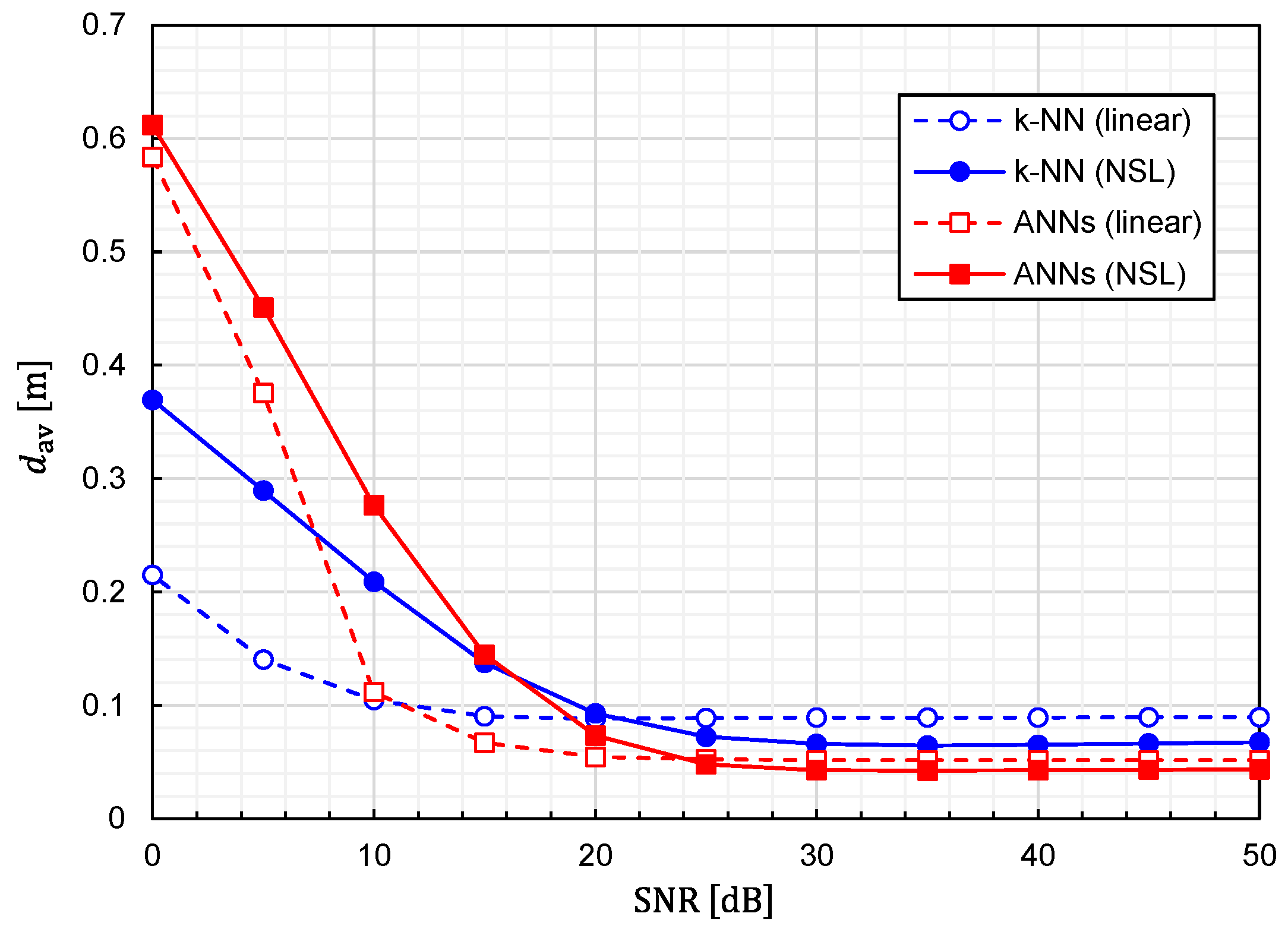
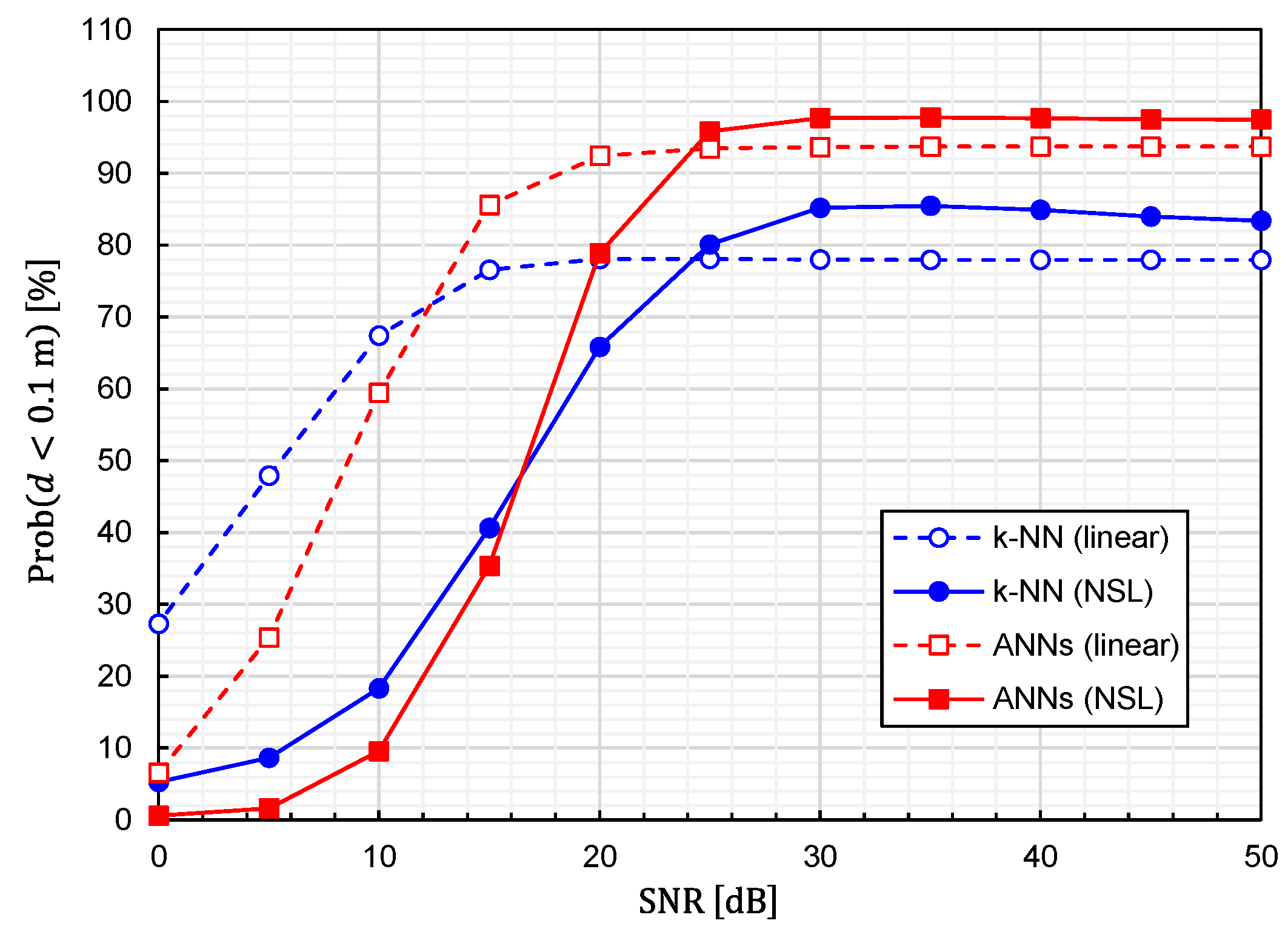
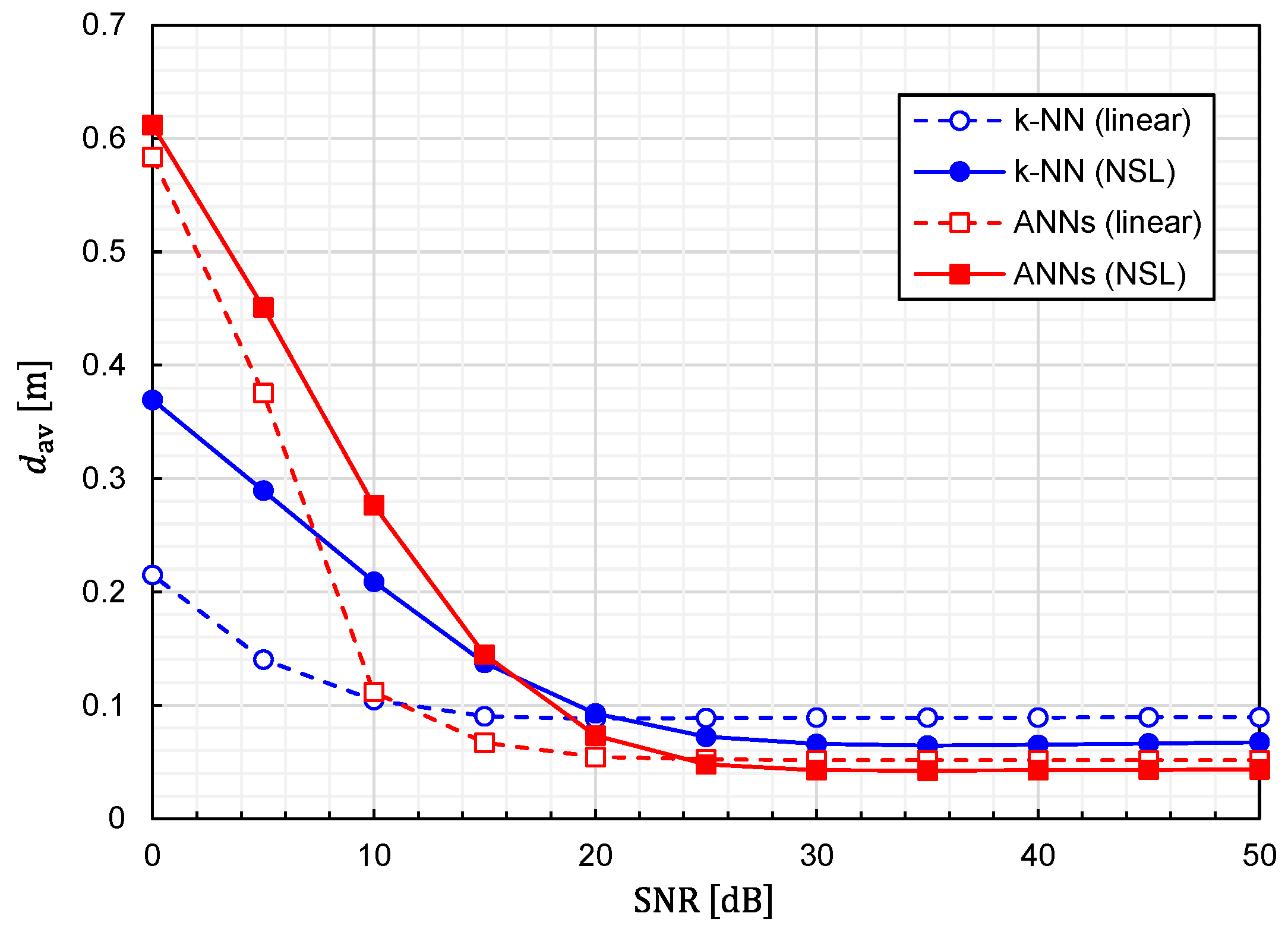
Using Equation (24), we calculated the prediction accuracy as functions of the SNR. The results for
and
are plotted in
Figure 10 and
Figure 11, respectively. It is observed that noise immunity depends on training-data representations. For NSL representation, the prediction accuracy is almost constant for
. On the other hand, for linear representation, it is kept constant for
. It is interesting to see that linear representation is superior to NSL representation in terms of noise immunity.
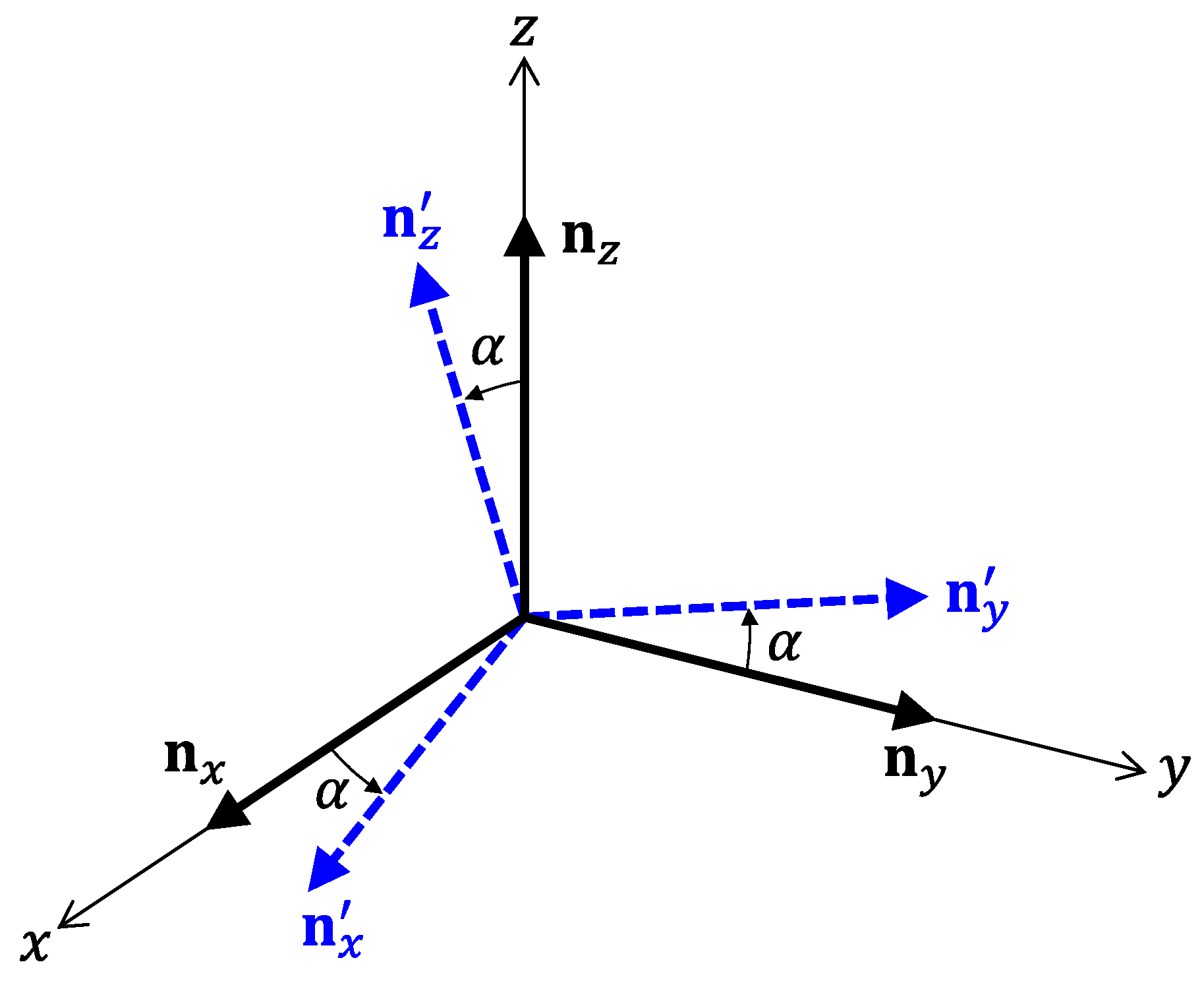
Next, we consider the influences of misalignment of receiving coils. In this study, we suppose that each sensor is equipped with the three coils. Let us denote unit vectors perpendicular to the three coils by
,
, and
. It is obvious that
,
, and
must be parallel to
x,
y, and
z-axes fixed to a target space, respectively. However, it is difficult to align the coils so that
,
, and
become completely parallel to the coordinate axes. As shown in
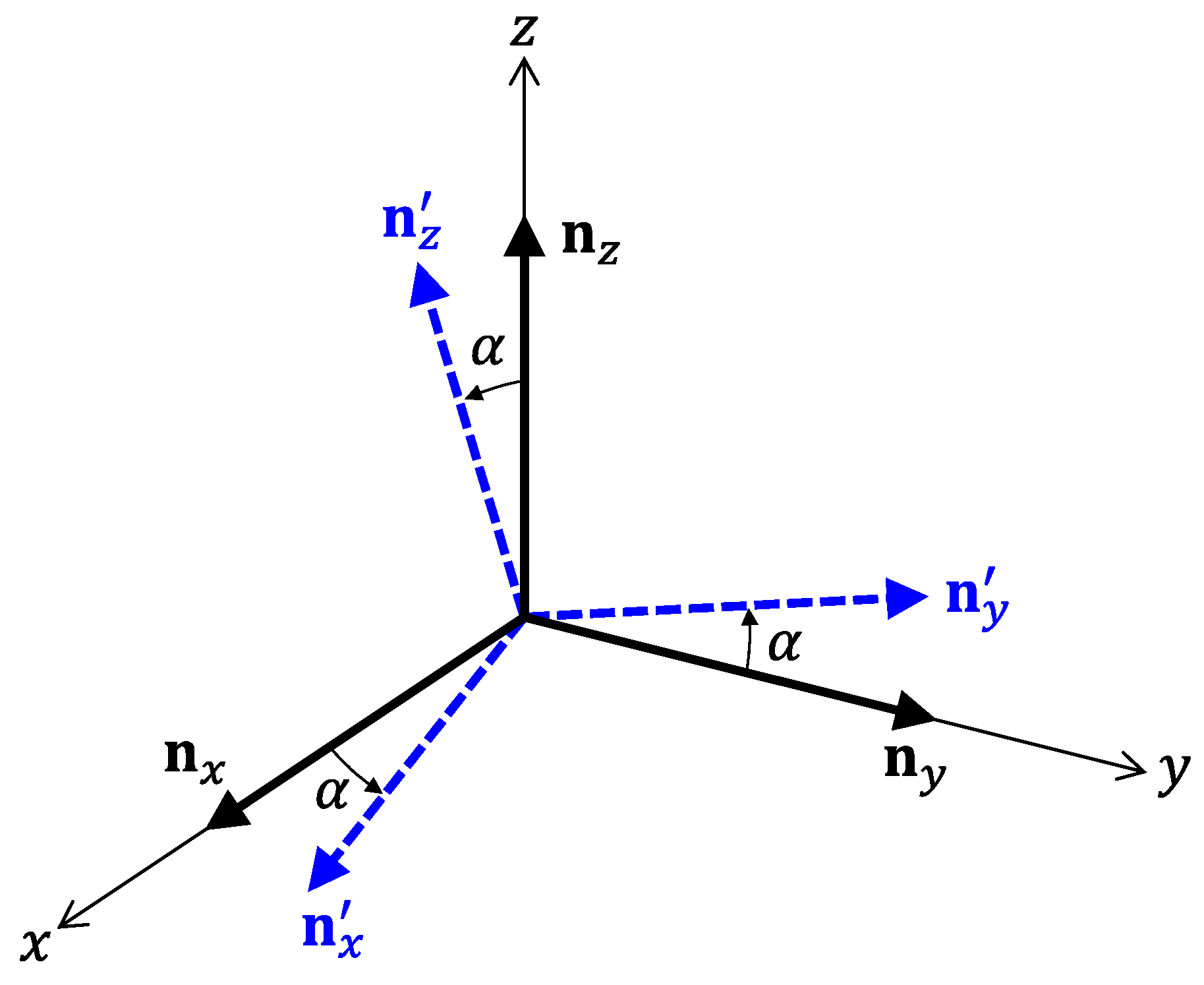
Figure 12, we consider the situation of the misalignment, where the wrongly directing unit vectors are denoted by
,
, and
. For simplicity, let the error angle
be common for all unit vectors. Moreover, we assume that
,
, and
are parallel to
x-
y,
y-
z, and
z-
x planes, respectively. In this situation, the influences of the misalignment can be written as
where
and
denote amplitudes of the detected signals with and without the misalignment, respectively.
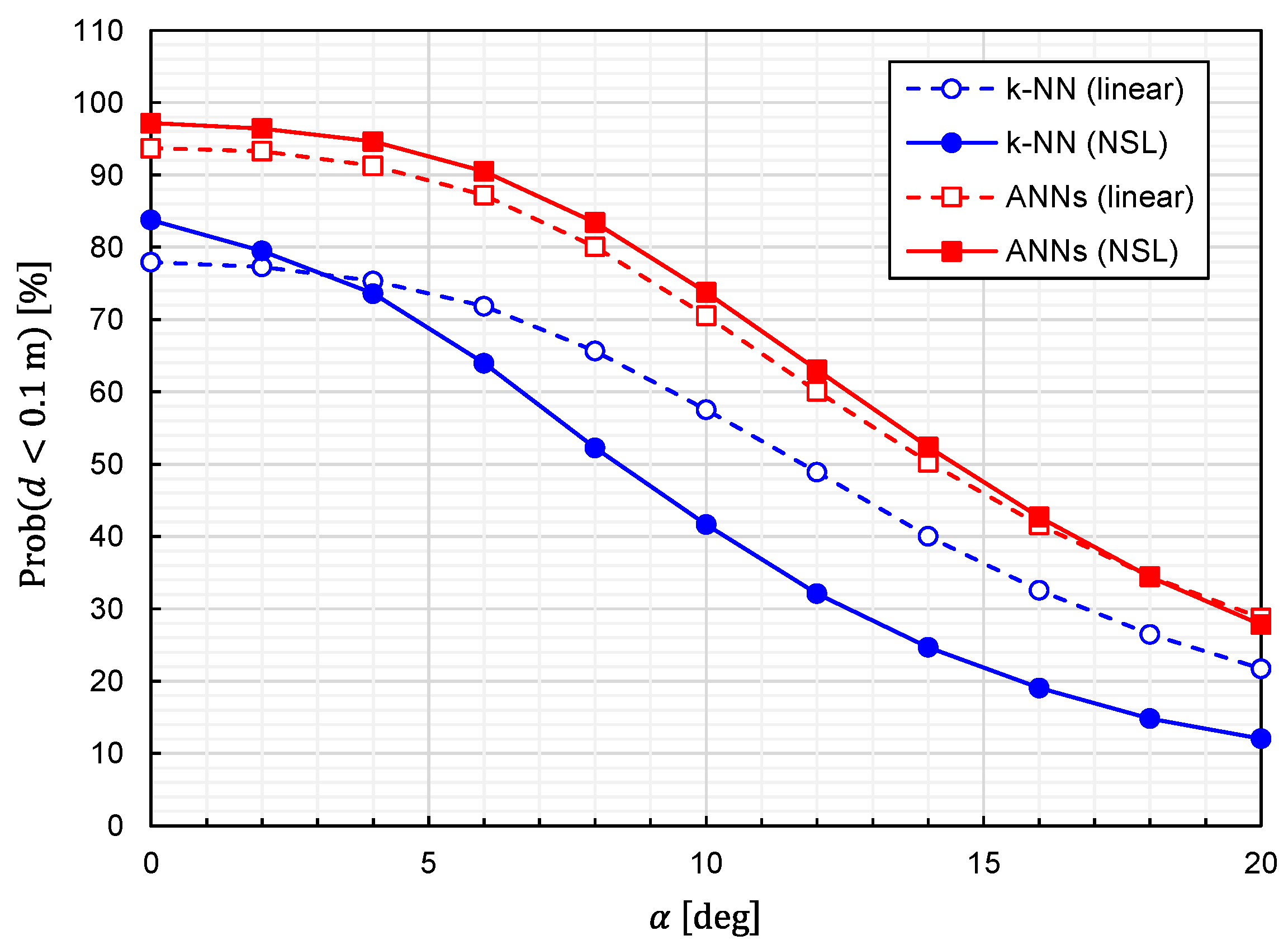
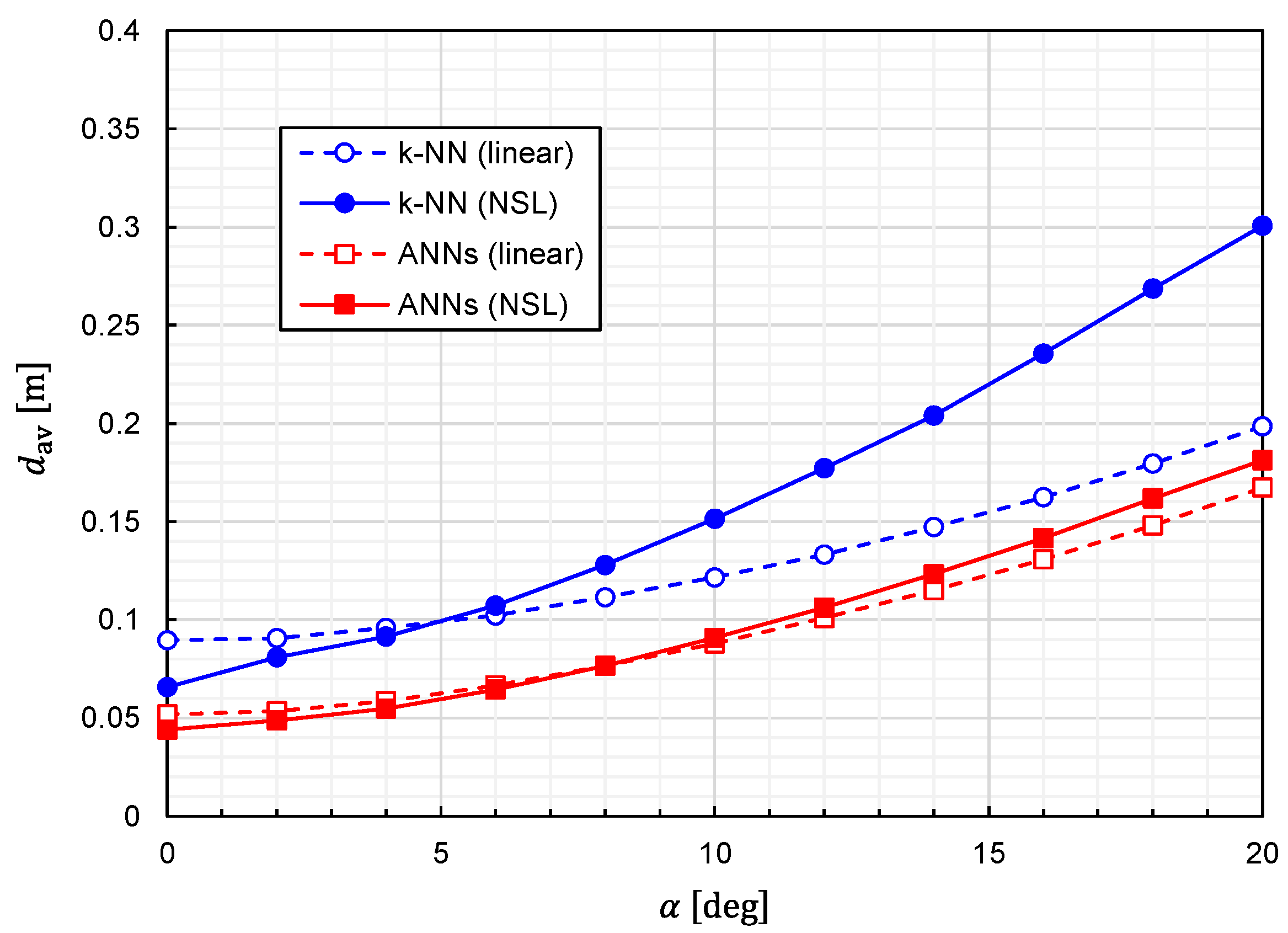
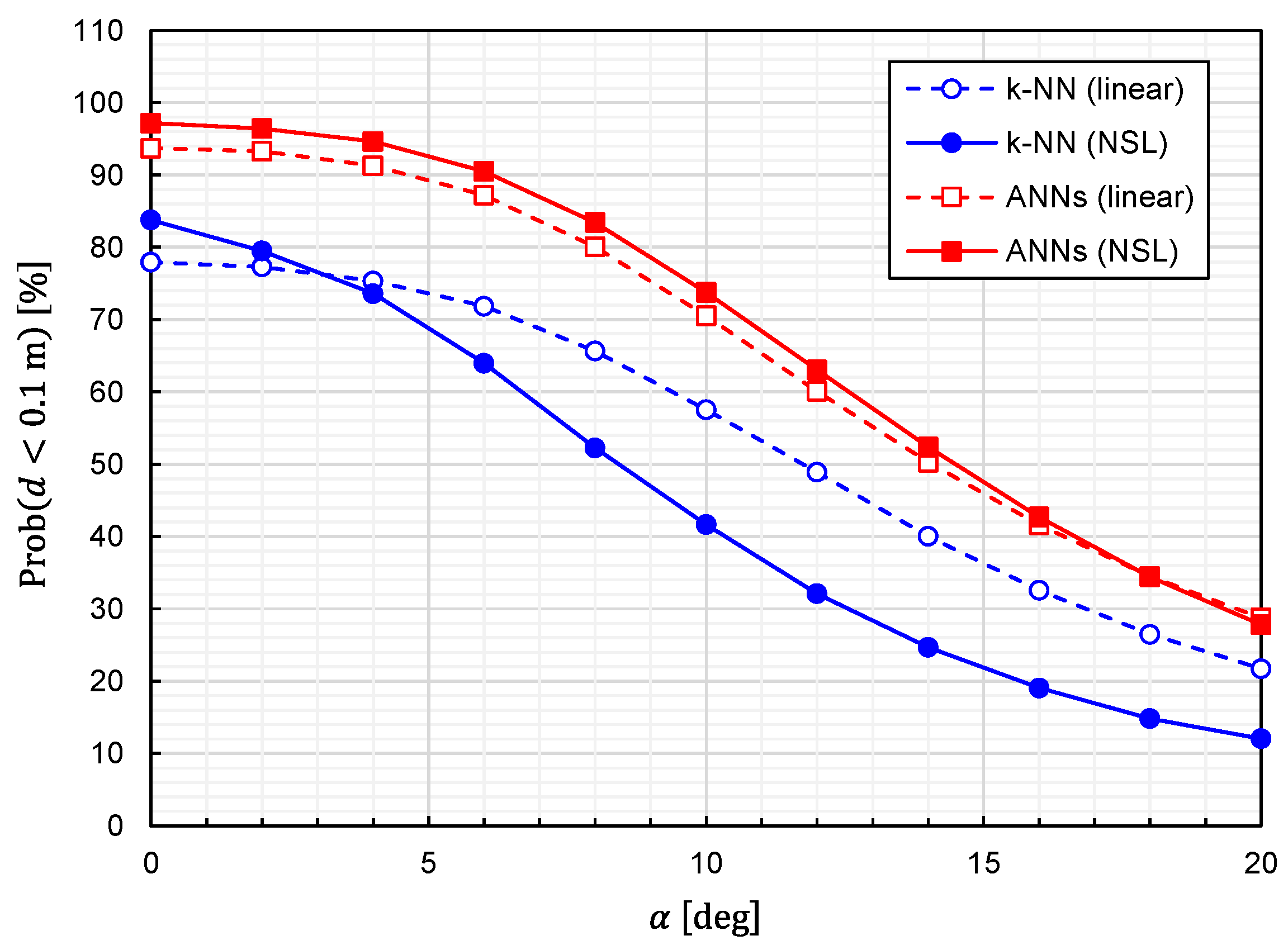
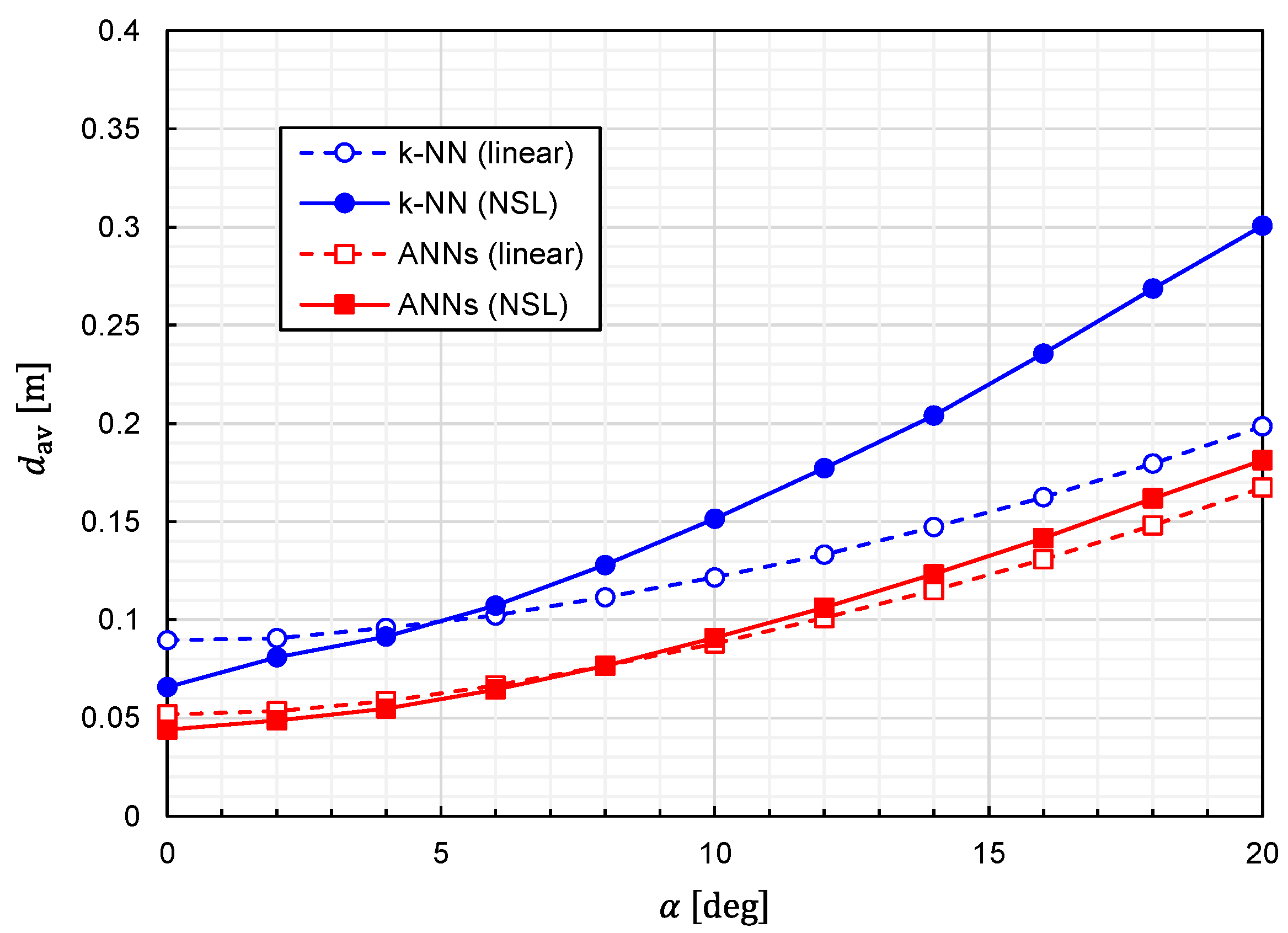
Using Equation (25), we calculated the prediction accuracy as functions of
. The results for
and
are plotted in
Figure 13 and
Figure 14, respectively. It is observed that the predictor function generated from the combination of
k-NN and NSL is the most sensitive to
. The other three predictor functions show similar characteristics against
. We can say that the influences of the misalignment are limited for
.
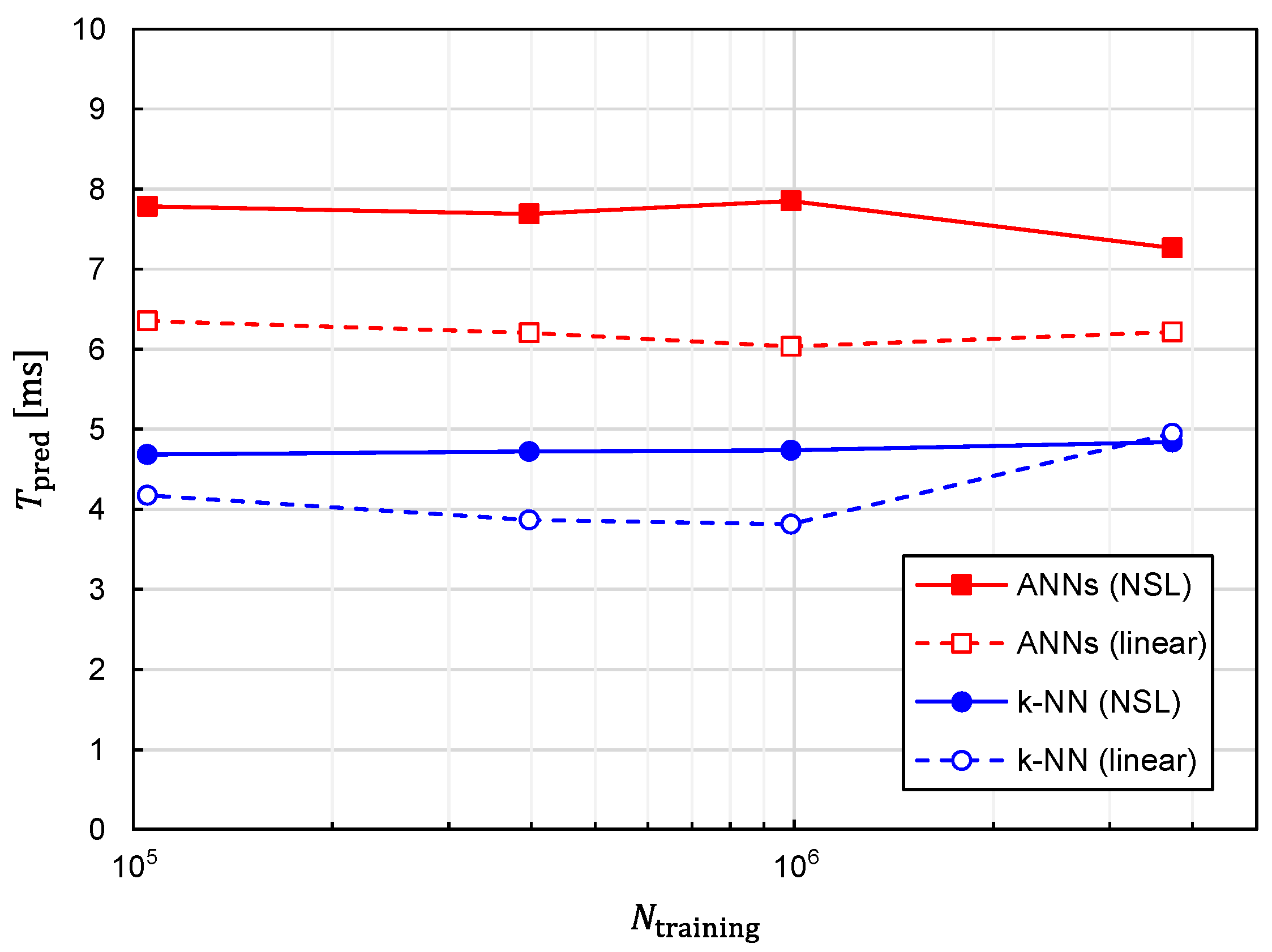
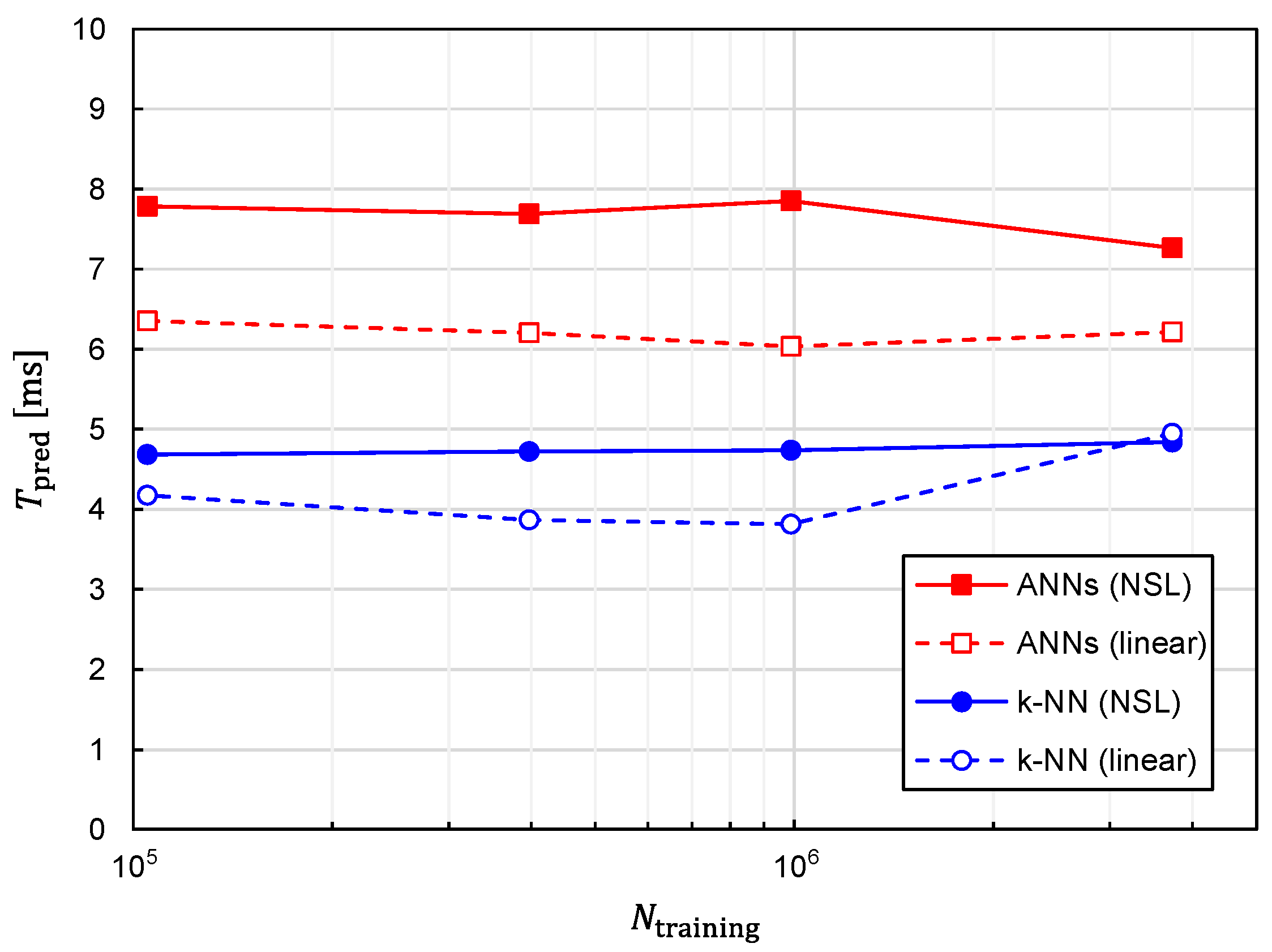
In addition to prediction accuracy, the computational speed is another critical aspect that needs to be evaluated. Since one of the advantages of machine learning to the conventional optimization method is the speed of predicting target positions, it is imperative to evaluate the time required for the prediction with machine learning, which we denote as
. The relationship between
and
is plotted in
Figure 15. The following three features can be observed in
Figure 15.
- 1.
is almost independent of ;
- 2.
is increased by approximately 1.5 times with ANNs in comparison with k-NN;
- 3.
is increased by approximately 1.2 times with training data of NSL representation in comparison with those of linear representation.
In terms of prediction accuracy, the best combination of the algorithm and training-data representation is that of the ANNs and NSL. Fortunately, considered with the best combination is kept less than 10 ms and is not drastically increased in comparison with the other combinations. Therefore, real-time tracking is possible with the best combination.
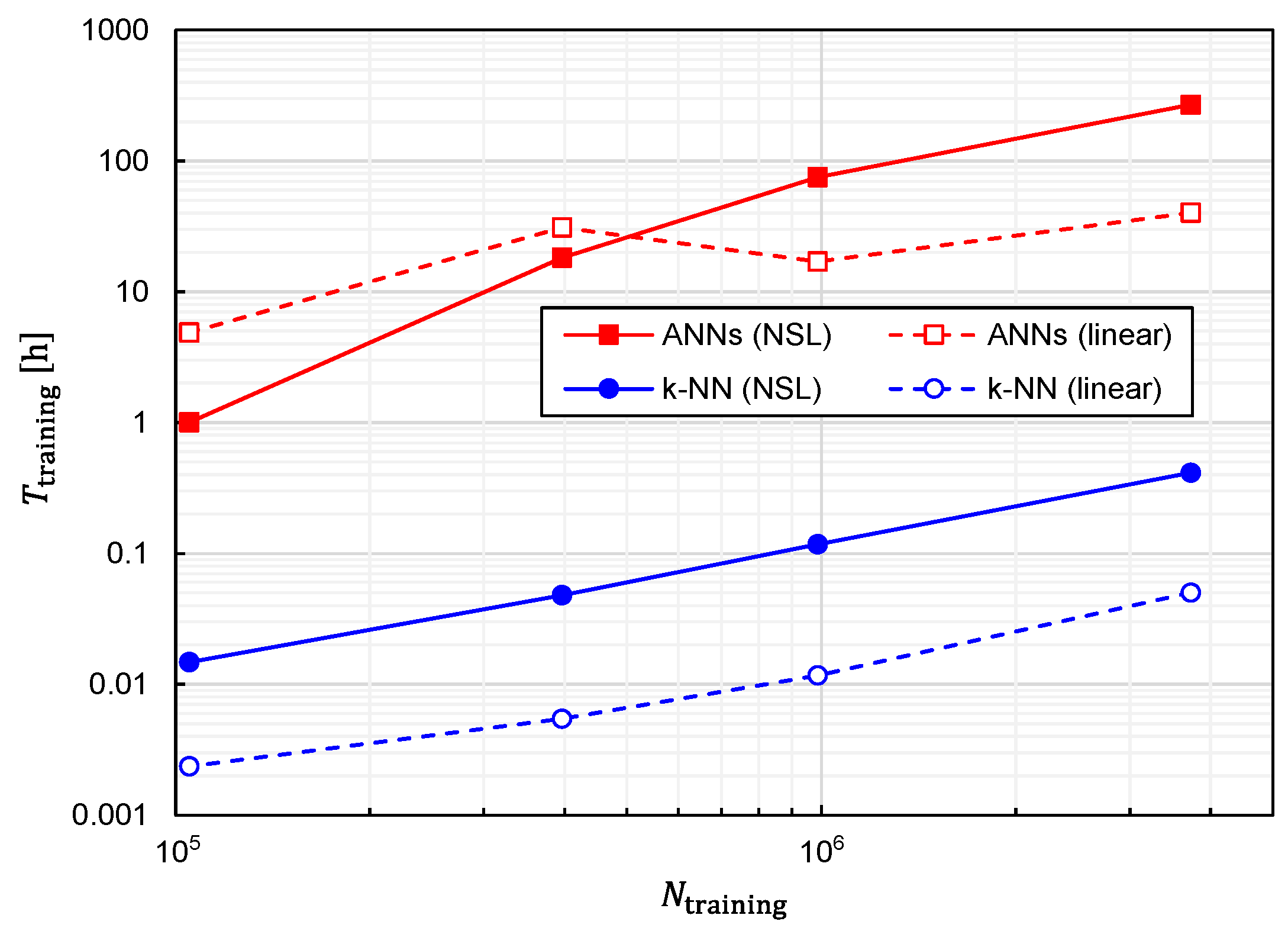
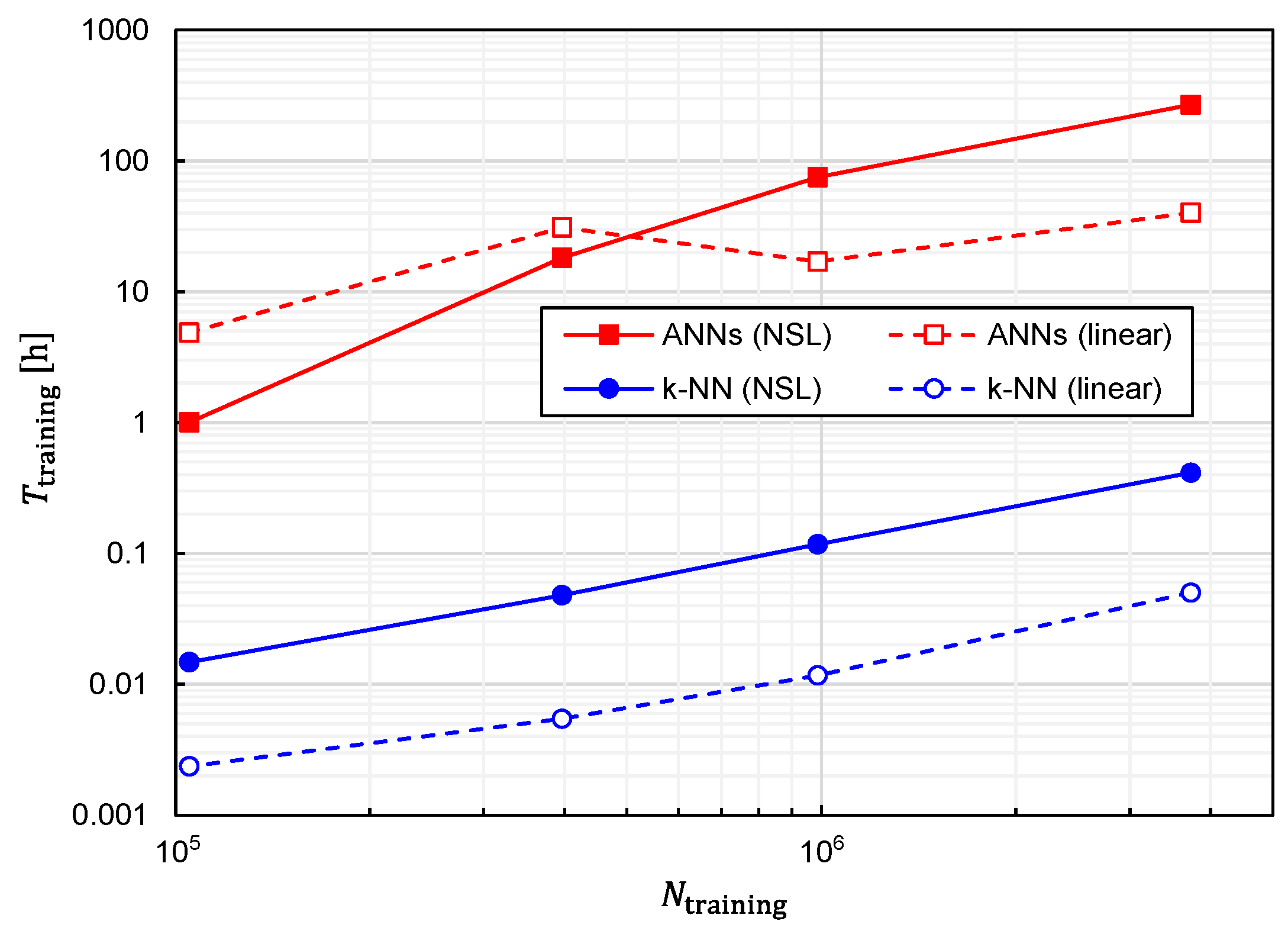
Regarding the computational speed, another critical index is the time required to generate a predictor function from training data, which we denote as
. Therefore, we also investigated the relationship between
and
, which is plotted in
Figure 16. The following three features can be observed in
Figure 16.
- 1.
is an almost monotonically increasing function of ;
- 2.
For large , is increased by approximately 500 to 1000 times with ANNs in comparison with k-NN;
- 3.
For large , is increased by approximately 5 to 10 times with training data of NSL representation in comparison with those of linear representation.
From a practical viewpoint, the only drawback of the best combination is that
becomes considerably longer. In fact, it takes 269 h for
with the computer used in this study (Intel Xeon W-2223 and 64-GB RAM). The considerably large
is primarily due to the adoption of ANNs. However, as shown in
Figure 8 and
Figure 9, a better prediction accuracy is obtained with ANNs. Therefore, there is a trade-off relationship between
and prediction accuracy. The performances obtained thus far are summarized in
Table 1.
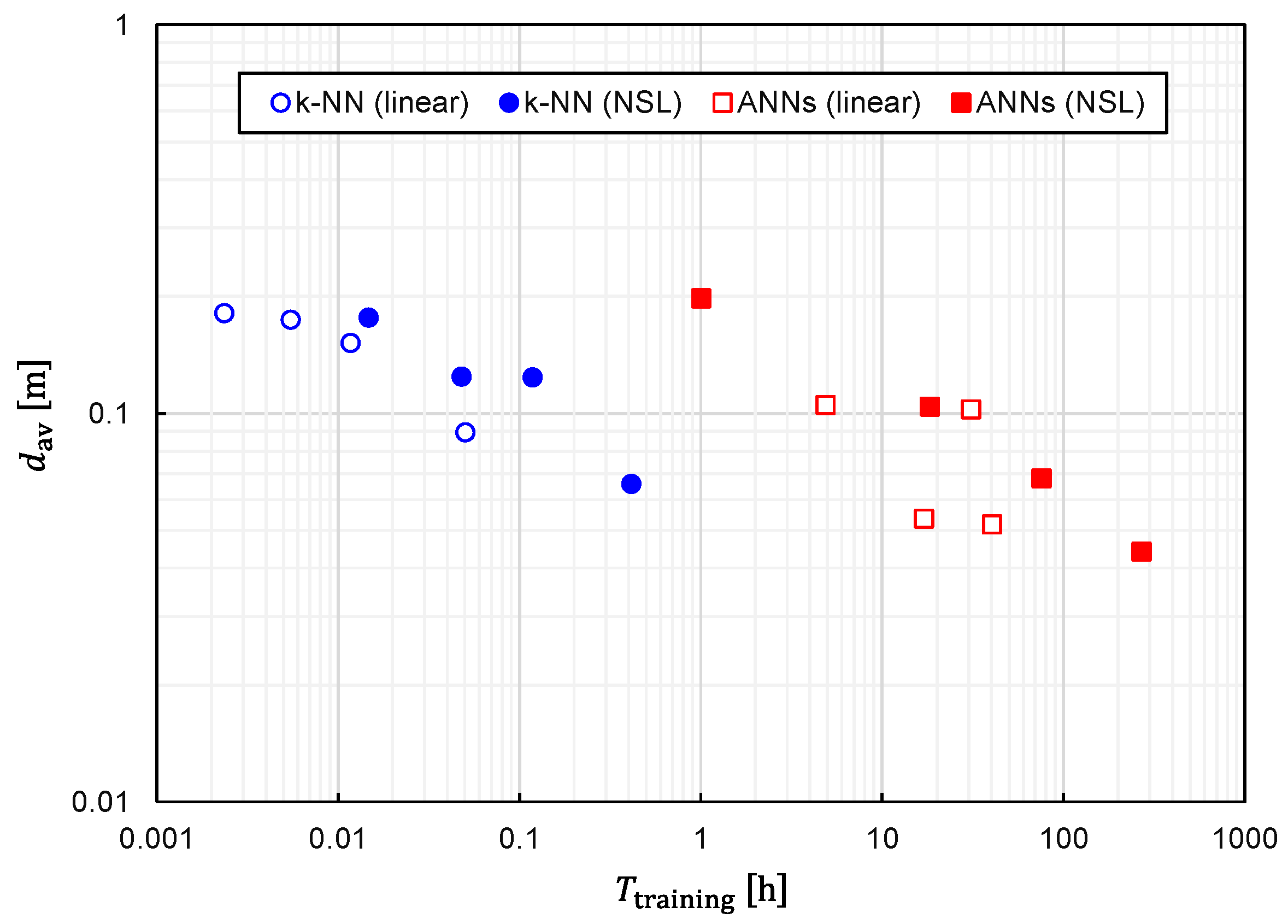
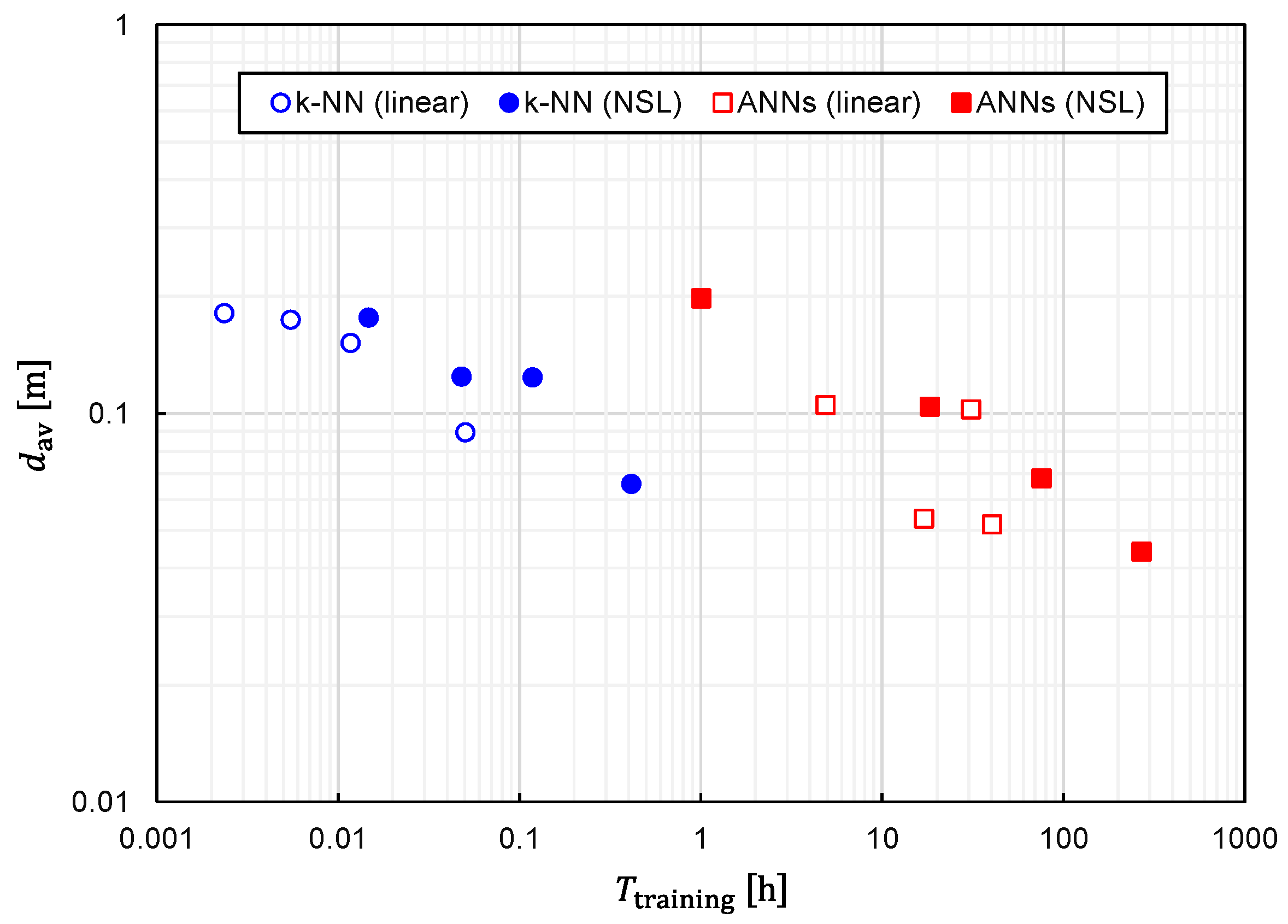
We plotted the relationship between
and
for several different values of
in
Figure 17 to clearly establish the trade-off relationship. As expected, the trade-off relationship can be seen as a whole. However, it was also observed that
k-NN and ANNs formed different clusters. The right cluster composed of squares suggests that ANNs are suitable for obtaining the best prediction accuracy, although
becomes considerably long. Meanwhile, the left cluster composed of circles implies that a fairly good prediction accuracy is obtainable with
k-NN while keeping
fairly short.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}