
Fault Handling in Industry 4.0: Definition, Process and Applications


Abstract
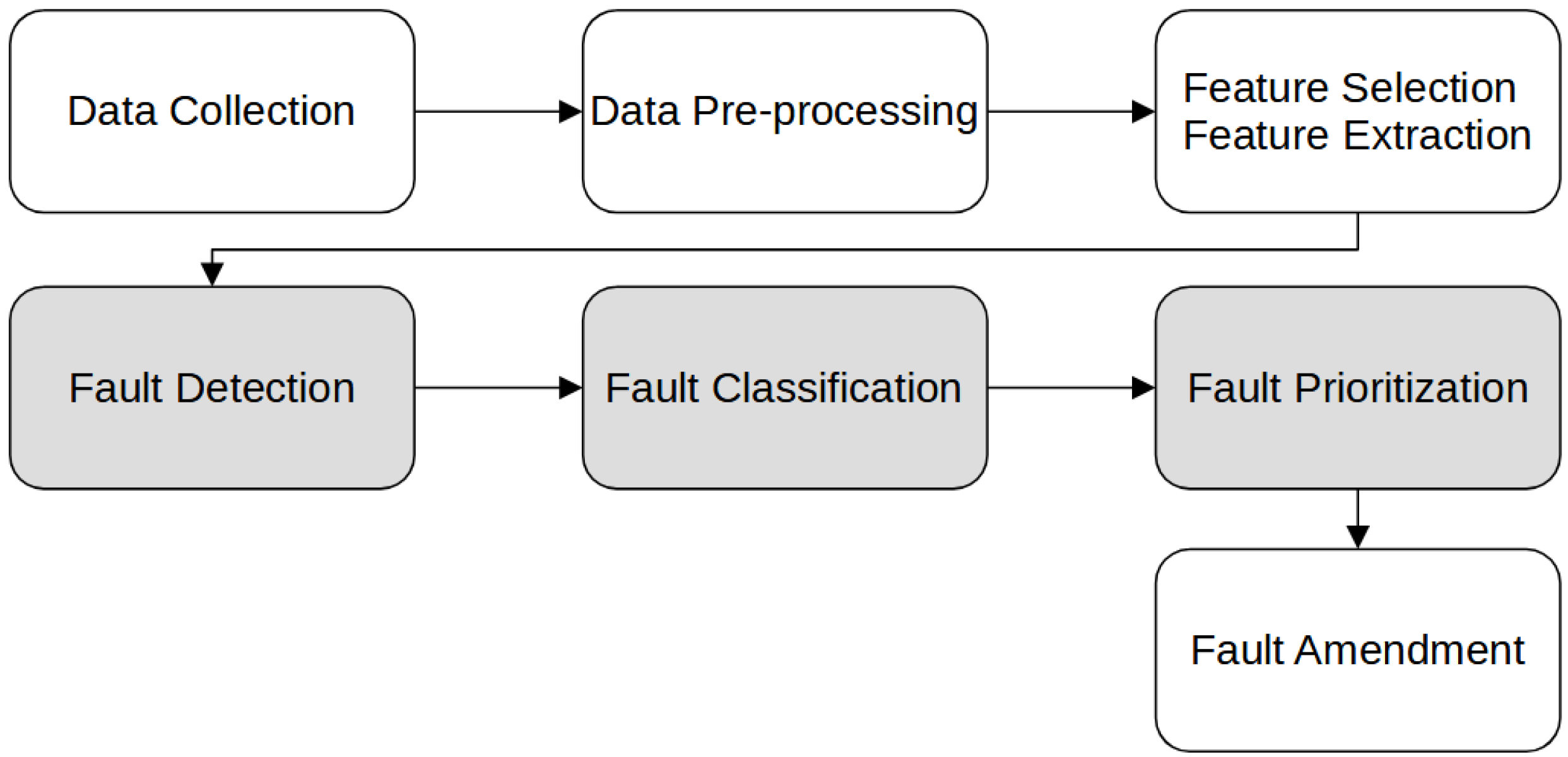
:1. Introduction
2. Requirements for Effective Fault Handling
3. Methods
3.1. Fault Detection
3.1.1. Neural Networks
3.1.2. Random Forests
3.1.3. k-Nearest Neighbors (kNN) and Naïve Bayes
3.1.4. Kernel Principal Component Analysis
3.1.5. Typicality and Eccentricity Data Analysis
3.1.6. Improved Support Vector Machines
3.2. Fault Classification
3.2.1. Fault Clustering Methods
3.2.2. Neural Networks
3.2.3. Sparse Representation Classification
3.2.4. Support Vector Machines
3.2.5. Decision Trees
3.2.6. Tree-Structured Fault Dependence Kernel
3.2.7. Linear Discriminant Analysis
3.3. Fault Prioritization
3.3.1. Failure Mode and Effects Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Amruthnath, N.; Gupta, T. Fault class prediction in unsupervised learning using model-based clustering approach. In Proceedings of the 2018 International Conference on Information and Computer Technologies (ICICT), Libertad City, Ecuador, 10–12 January 2018; pp. 5–12. [Google Scholar]
- Amruthnath, N.; Gupta, T. A research study on unsupervised machine learning algorithms for early fault detection in predictive maintenance. In Proceedings of the 2018 5th International Conference on Industrial Engineering and Applications (ICIEA), Singapore, 26–28 April 2018; pp. 355–361. [Google Scholar]
- Bezerra, C.G.; Costa, B.S.J.; Guedes, L.A.; Angelov, P.P. An evolving approach to unsupervised and Real-Time fault detection in industrial processes. Expert Syst. Appl. 2016, 63, 134–144. [Google Scholar] [CrossRef] [Green Version]
- Singh, M.; Gehin, A.-L.; Ould-Boaumama, B. Robust Detection of Minute Faults in Uncertain Systems Using Energy Activity. Processes 2021, 9, 1801. [Google Scholar] [CrossRef]
- Wedel, M.; Noessler, P.; Metternich, J. Development of bottleneck detection methods allowing for an effective fault repair prioritization in machining lines of the automobile industry. Prod. Eng. 2016, 10, 329–336. [Google Scholar] [CrossRef]
- Alippi, C.; Ntalampiras, S.; Roveri, M. Model-Free Fault Detection and Isolation in Large-Scale Cyber-Physical Systems. IEEE Trans. Emerg. Top. Comput. Intell. 2017, 1, 61–71. [Google Scholar] [CrossRef]
- Katipamula, S.; Brambley, M.R. Review Article: Methods for Fault Detection, Diagnostics, and Prognostics for Building Systems—A Review, Part II. HVAC&R Res. 2005, 11, 169–187. [Google Scholar]
- Ding, S.X. Model-Based Fault Diagnosis Techniques: Design Schemes, Algorithms and Tools; Springer: London, UK, 2013. [Google Scholar]
- Pérez, F.; Irisarri, E.; Orive, D.; Marcos, M.; Estevez, E. A CPPS Architecture approach for Industry 4.0. In Proceedings of the IEEE 20th Conference on Emerging Technologies & Factory Automation (ETFA), Luxembourg, 8–11 September 2015; pp. 1–4. [Google Scholar]
- Kaupp, L.; Beez, U.; Hülsmann, J.; Humm, B. Outlier Detection in Temporal Spatial Log Data Using Autoencoder for Industry 4.0. In Engineering Applications of Neural Networks, Proceedings of the 20th International Conference, EANN 2019, Xersonisos, Crete, Greece, 24–26 May 2019; Macintyre, J., Iliadis, L., Maglogiannis, I., Jayne, C., Eds.; Communications in Computer and Information Science, 1000; Springer: Cham, Switzerland; pp. 55–65.
- Alur, R. Principles of Cyber-Physical Systems; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Boi-Ukeme, J.; Ruiz-Martin, C.; Wainer, G. Real-Time Fault Detection and Diagnosis of CPS Faults in DEVS. In Proceedings of the 2020 IEEE 6th International Conference on Dependability in Sensor, Cloud and Big Data Systems and Application (DependSys), Nadi, Fiji, 14–16 December 2020; pp. 57–64. [Google Scholar]
- Reppa, V.; Polycarpou, M.M.; Panayiotou, C.G. Sensor Fault Diagnosis. Found. Trends Syst. Control 2016, 3, 1–248. [Google Scholar] [CrossRef]
- Dowdeswell, B.; Sinha, R.; MacDonell, S.G. Finding faults: A scoping study of fault diagnostics for Industrial Cyber–Physical Systems. J. Syst. Softw. 2020, 168, 110638. [Google Scholar] [CrossRef]
- Isermann, R. Supervision, fault-detection and fault-diagnosis methods—An introduction. Control. Eng. Pract. 1997, 5, 639–652. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Kavuri, S.N.; Yin, K. A review of process fault detection and diagnosis: Part III: Process history based methods. Comput. Chem. Eng. 2003, 27, 327–346. [Google Scholar] [CrossRef]
- Kaupp, L.; Webert, H.; Nazemi, K.; Humm, B.; Simons, S. CONTEXT: An Industry 4.0 Dataset of Contextual Faults in a Smart Factory. Procedia Comput. Sci. 2021, 180, 492–501. [Google Scholar] [CrossRef]
- Oztemel, E.; Gursev, S. Literature review of Industry 4.0 and related technologies. J. Intell. Manuf. 2020, 31, 127–182. [Google Scholar] [CrossRef]
- Wang, T.; Qiao, M.; Zhang, M.; Yang, Y.; Snoussi, H. Data-driven prognostic method based on self-supervised learning approaches for fault detection. J. Intell. Manuf. 2020, 31, 1611–1619. [Google Scholar] [CrossRef]
- Park, Y.-J.; Fan, S.-K.S.; Hsu, C.-Y. A Review on Fault Detection and Process Diagnostics in Industrial Processes. Processes 2020, 8, 1123. [Google Scholar] [CrossRef]
- Milis, G.M.; Eliades, D.G.; Panayiotou, C.G.; Polycarpou, M.M. A cognitive fault-detection design architecture. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 2819–2826. [Google Scholar]
- Yen, I.; Zhang, S.; Bastani, F.; Zhang, Y. A Framework for IoT-Based Monitoring and Diagnosis of Manufacturing Systems. In Proceedings of the 2017 IEEE Symposium on Service-Oriented System Engineering (SOSE), San Francisco, CA, USA, 6–9 April 2017; pp. 1–8. [Google Scholar]
- Arrieta, A.; Wang, S.; Sagardui, G.; Etxeberria, L. Search-Based Test Case Selection of Cyber-Physical System Product Lines for Simulation-Based Validation. In Proceedings of the 20th International Systems and Software Product Line Conference, Online, 16 September 2016; pp. 297–306. [Google Scholar]
- Diedrich, A.; Balzereit, K.; Niggemann, O. First Approaches to Automatically Diagnose and Reconfigure Hybrid Cyber-Physical Systems; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Balzereit, K.; Niggemann, O. Automated Reconfiguration of Cyber-Physical Production Systems using Satisfiability Modulo Theories. In Proceedings of the 2020 IEEE Conference on Industrial Cyberphysical Systems (ICPS), Tampere, Finland, 10–12 June 2020; pp. 461–468. [Google Scholar]
- Balzereit, K.; Niggemann, O. Sound and Complete Reconfiguration for a Class of Hybrid Systems. In Proceedings of the 32nd International Workshop on Principle of Diagnosis, Hamburg, Germany, 13–15 September 2021. [Google Scholar]
- Chen, Z. Data-Driven Fault Detection for Industrial Processes: Canonical Correlation Analysis and Projection Based Methods; Springer Vieweg: Wiesbaden, Germany, 2017. [Google Scholar]
- Harirchi, F.; Ozay, N. Guaranteed model-based fault detection in cyber–physical systems: A model invalidation approach. Automatica 2018, 93, 476–488. [Google Scholar] [CrossRef] [Green Version]
- Djelloul, I.; Sari, Z.; Sidibe, I.D.B. Fault diagnosis of manufacturing systems using data mining techniques. In Proceedings of the 2018 5th IEEE International Conference on Control, Decision and Information Technologies (CoDIT), Thessaloniki, Greece, 10–13 April 2018; pp. 198–203. [Google Scholar]
- Taimoor, M.; Aijun, L. Lyapunov Theory Based Adaptive Neural Observers Design for Aircraft Sensors Fault Detection and Isolation. J. Intell. Robot. Syst. 2019, 98, 311–323. [Google Scholar] [CrossRef]
- Wu, Y.; Jiang, B.; Wang, Y. Incipient winding fault detection and diagnosis for squirrel-cage induction motors equipped on CRH trains. ISA Trans. 2020, 99, 488–495. [Google Scholar] [CrossRef] [PubMed]
- Boussif, A.; Ghazel, M.; Basilio, J.C. Intermittent fault diagnosability of discrete event systems: An overview of automaton-based approaches. Discret. Event Dyn. Syst. 2021, 31, 59–102. [Google Scholar] [CrossRef]
- Iqbal, R.; Maniak, T.; Doctor, F.; Karyotis, C. Fault Detection and Isolation in Industrial Processes Using Deep Learning Approaches. IEEE Trans. Ind. Inform. 2019, 15, 3077–3084. [Google Scholar] [CrossRef]
- Li, D.; Hu, G.; Spanos, C.J. A data-driven strategy for detection and diagnosis of building chiller faults using linear discriminant analysis. Energy Build. 2016, 128, 519–529. [Google Scholar] [CrossRef]
- Calabrese, F.; Regattieri, A.; Bortolini, M.; Gamberi, M.; Pilati, F. Predictive Maintenance: A Novel Framework for a Data-Driven, Semi-Supervised, and Partially Online Prognostic Health Management Application in Industries. Appl. Sci. 2021, 11, 3380. [Google Scholar] [CrossRef]
- von Birgelen, A.; Buratti, D.; Mager, J.; Niggemann, O. Self-Organizing Maps for Anomaly Localization and Predictive Maintenance in Cyber-Physical Production Systems. Procedia CIRP 2018, 72, 480–485. [Google Scholar] [CrossRef]
- Heo, S.; Lee, J.H. Fault detection and classification using artificial neural networks. IFAC-PapersOnLine 2018, 51, 470–475. [Google Scholar] [CrossRef]
- Waqar, T.; Demetgul, M. Thermal analysis MLP neural network based fault diagnosis on worm gears. Measurement 2016, 86, 56–66. [Google Scholar] [CrossRef]
- Yan, W.; Zhou, J.-H. Early Fault Detection of Aircraft Components Using Flight Sensor Data. In Proceedings of the 2018 IEEE 23rd International Conference on Emerging Technologies and Factory Automation (ETFA), Torino, Italy, 4–7 September 2018; Volume 1, pp. 1337–1342. [Google Scholar]
- Fan, S.-K.S.; Hsu, C.-Y.; Tsai, D.-M.; He, F.; Cheng, C.-C. Data-Driven Approach for Fault Detection and Diagnostic in Semiconductor Manufacturing. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1925–1936. [Google Scholar] [CrossRef]
- Yang, J.; Chen, Y.; Sun, Z. A real-time fault detection and isolation strategy for gas sensor arrays. In Proceedings of the 2017 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Turin, Italy, 22–25 May 2017; pp. 1–6. [Google Scholar]
- Kallas, M.; Mourot, G.; Anani, K.; Ragot, J.; Maquin, D. Fault detection and estimation using kernel principal component analysis. IFAC-PapersOnLine 2017, 50, 1025–1030. [Google Scholar] [CrossRef]
- Costa, B.S.J.; Bezerra, C.G.; Guedes, L.A.; Angelov, P.P. Online fault detection based on Typicality and Eccentricity Data Analytics. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–16 July 2015; pp. 1–6. [Google Scholar]
- Angelov, P. Anomaly detection based on eccentricity analysis. In Proceedings of the 2014 IEEE Symposium on Evolving and Autonomous Learning Systems (EALS), Orlando, FL, USA, 9–12 December 2014; pp. 1–8. [Google Scholar]
- Lou, C.; Li, X. Unsupervised Fault Detection Based on Laplacian Score and TEDA. In Proceedings of the 2018 IEEE 7th Data Driven Control and Learning Systems Conference (DDCLS), Enshi, China, 25–27 May 2018; pp. 267–270. [Google Scholar]
- Deng, F.; Guo, S.; Zhou, R.; Chen, J. Sensor Multifault Diagnosis With Improved Support Vector Machines. IEEE Trans. Autom. Sci. Eng. 2017, 14, 1053–1063. [Google Scholar] [CrossRef]
- Zhou, J.; Yang, Y.; Ding, S.X.; Zi, Y.; Wei, M. A Fault Detection and Health Monitoring Scheme for Ship Propulsion Systems Using SVM Technique. IEEE Access 2018, 6, 16207–16215. [Google Scholar] [CrossRef]
- Xiao, Y.; Wang, H.; Zhang, L.; Xu, W. Two methods of selecting Gaussian kernel parameters for one-class SVM and their application to fault detection. Knowl.-Based Syst. 2014, 59, 75–84. [Google Scholar] [CrossRef]
- Lv, F.; Wen, C.; Bao, Z.; Liu, M. Fault diagnosis based on deep learning. In Proceedings of the 2016 American Control Conference (ACC), Boston, MA, USA, 6–8 July 2016; pp. 6851–6856. [Google Scholar]
- Gao, X.; Hou, J. An improved SVM integrated GS-PCA fault diagnosis approach of Tennessee Eastman process. Neurocomputing 2016, 174, 906–911. [Google Scholar] [CrossRef]
- Jing, C.; Hou, J. SVM and PCA based fault classification approaches for complicated industrial process. Neurocomputing 2015, 167, 636–642. [Google Scholar] [CrossRef]
- Yin, S.; Ding, S.X.; Haghani, A.; Hao, H.; Zhang, P. A comparison study of basic data-driven fault diagnosis and process monitoring methods on the benchmark Tennessee Eastman process. J. Process Control 2012, 22, 1567–1581. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhao, J. A deep belief network based fault diagnosis model for complex chemical processes. Comput. Chem. Eng. 2017, 107, 395–407. [Google Scholar] [CrossRef]
- Kohonen, T. The self-organizing map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Breiman, L. Using Random Forest to Learn Imbalanced Data; University of California: Berkeley, CA, USA, 2004. [Google Scholar]
- Arlot, S.; Genuer, R. Analysis of purely random forests bias. arXiv 2014, arXiv:1407.3939. [Google Scholar]
- Chen, X.; Ishwaran, H. Random forests for genomic data analysis. Genomics 2012, 99, 323–329. [Google Scholar] [CrossRef] [Green Version]
- Gul, A.; Perperoglou, A.; Khan, Z.; Mahmoud, O.; Miftahuddin, M.; Adler, W.; Lausen, B. Ensemble of a subset of kNN classifiers. Adv. Data Anal. Classif. 2016, 12, 827–840. [Google Scholar] [CrossRef] [Green Version]
- Ren, J.; Lee, S.D.; Chen, X.; Kao, B.; Cheng, R.; Cheung, D. Naive Bayes Classification of Uncertain Data. In Proceedings of the 2009 Ninth IEEE International Conference on Data Mining, Miami, FL, USA, 6–9 December 2009; pp. 944–949. [Google Scholar]
- Ji, Y.; Yu, S.; Zhang, Y. A novel Naive Bayes model: Packaged Hidden Naive Bayes. In Proceedings of the 2011 6th IEEE Joint International Information Technology and Artificial Intelligence Conference, Chongqing, China, 20–22 August 2011; Volume 2, pp. 484–487. [Google Scholar]
- Hoffmann, H. Kernel PCA for novelty detection. Pattern Recognit. 2007, 40, 863–874. [Google Scholar] [CrossRef]
- Kangin, D.; Angelov, P. Evolving clustering, classification and regression with TEDA. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–16 July 2015; pp. 1–8. [Google Scholar]
- Suykens, J.; Vandewalle, J. Multiclass least squares support vector machines. In Proceedings of the IJCNN’99, International Joint Conference on Neural Networks, Proceedings (Cat. No.99CH36339), Washington, DC, USA, 10–16 July 1999; Volume 2, pp. 900–903. [Google Scholar]
- Yiakopoulos, C.; Gryllias, K.; Antoniadis, I. Rolling element bearing fault detection in industrial environments based on a k-means clustering approach. Expert Syst. Appl. 2011, 38, 2888–2911. [Google Scholar] [CrossRef]
- Fang, H.; Shi, H.; Dong, Y.; Fan, H.; Ren, S. Spacecraft power system fault diagnosis based on DNN. In Proceedings of the 2017 Prognostics and System Health Management Conference (PHM-Harbin), Harbin, China, 9–12 July 2017; pp. 1–5. [Google Scholar]
- Kankar, P.; Sharma, S.C.; Harsha, S. Fault diagnosis of ball bearings using machine learning methods. Expert Syst. Appl. 2011, 38, 1876–1886. [Google Scholar] [CrossRef]
- Zhou, F.; Gao, Y.; Wen, C. A Novel Multimode Fault Classification Method Based on Deep Learning. J. Control Sci. Eng. 2017, 2017, 1–14. [Google Scholar] [CrossRef]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional Neural Network Based Fault Detection for Rotating Machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Chen, Z.; Li, C.; Sanchez, R.-V. Gearbox Fault Identification and Classification with Convolutional Neural Networks. Shock Vib. 2015, 2015, 390134. [Google Scholar] [CrossRef] [Green Version]
- Ince, T.; Kiranyaz, S.; Eren, L.; Askar, M.; Gabbouj, M. Real-Time Motor Fault Detection by 1-D Convolutional Neural Networks. IEEE Trans. Ind. Electron. 2016, 63, 7067–7075. [Google Scholar] [CrossRef]
- Wu, L.; Chen, X.; Peng, Y.; Ye, Q.; Jiao, J. Fault detection and diagnosis based on sparse representation classification (SRC). In Proceedings of the 2012 IEEE International Conference on Robotics and Biomimetics (ROBIO), Guangzhou, China, 11–14 December 2012; pp. 926–931. [Google Scholar]
- Laouti, N.; Sheibat-Othman, N.; Othman, S. Support Vector Machines for Fault Detection in Wind Turbines. IFAC Proc. Vol. 2011, 44, 7067–7072. [Google Scholar] [CrossRef] [Green Version]
- Yan, K.; Shen, W.; Mulumba, T.; Afshari, A. ARX model based fault detection and diagnosis for chillers using support vector machines. Energy Build. 2014, 81, 287–295. [Google Scholar] [CrossRef]
- Demetgul, M. Fault diagnosis on production systems with support vector machine and decision trees algorithms. Int. J. Adv. Manuf. Technol. 2013, 67, 2183–2194. [Google Scholar] [CrossRef]
- Widodo, A.; Yang, B.-S.; Han, T. Combination of independent component analysis and support vector machines for intelligent faults diagnosis of induction motors. Expert Syst. Appl. 2007, 32, 299–312. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, Y.; Zhu, Y. Intelligent fault diagnosis of rolling element bearing based on SVMs and fractal dimension. Mech. Syst. Signal Process. 2007, 21, 2012–2024. [Google Scholar] [CrossRef]
- Hu, Q.; He, Z.; Zhang, Z.; Zi, Y. Fault diagnosis of rotating machinery based on improved wavelet package transform and SVMs ensemble. Mech. Syst. Signal Process. 2007, 21, 688–705. [Google Scholar] [CrossRef]
- Yang, B.-S.; Di, X.; Han, T. Random forests classifier for machine fault diagnosis. J. Mech. Sci. Technol. 2008, 22, 1716–1725. [Google Scholar] [CrossRef]
- Li, D.; Zhou, Y.; Hu, G.; Spanos, C.J. Fault detection and diagnosis for building cooling system with a tree-structured learning method. Energy Build. 2016, 127, 540–551. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Springer: Boston, MA, USA, 1981. [Google Scholar]
- Eslamloueyan, R. Designing a hierarchical neural network based on fuzzy clustering for fault diagnosis of the Tennessee–Eastman process. Appl. Soft Comput. 2011, 11, 1407–1415. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, W.; Chellappa, R.; Krishnaswamy, A. Discriminant analysis of principal components for face recognition. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 336–341. [Google Scholar]
- Gopalakrishnan, M.; Skoogh, A. Machine criticality based maintenance prioritization: Identifying productivity improvement potential. Int. J. Product. Perform. Manag. 2018, 67, 654–672. [Google Scholar] [CrossRef] [Green Version]
- Umer, Q.; Liu, H.; Sultan, Y. Emotion Based Automated Priority Prediction for Bug Reports. IEEE Access 2018, 6, 35743–35752. [Google Scholar] [CrossRef]
- Sharma, M.; Bedi, P.; Chaturvedi, K.; Singh, V. Predicting the priority of a reported bug using machine learning techniques and cross project validation. In Proceedings of the 2012 12th International Conference on Intelligent Systems Design and Applications (ISDA), Kochi, India, 27–29 November 2012; pp. 539–545. [Google Scholar]
- Bani-Salameh, H.; Sallam, M.; Al shboul, B. A Deep-Learning-Based Bug Priority Prediction Using RNN-LSTM Neural Networks. E-Inform. Softw. Eng. J. 2021, 15, 29–45. [Google Scholar] [CrossRef]
- Ramay, W.Y.; Umer, Q.; Yin, X.C.; Zhu, C.; Illahi, I. Deep Neural Network-Based Severity Prediction of Bug Reports. IEEE Access 2019, 7, 46846–46857. [Google Scholar] [CrossRef]
- Rezaee, M.J.; Salimi, A.; Yousefi, S. Identifying and managing failures in stone processing industry using cost-based FMEA. Int. J. Adv. Manuf. Technol. 2017, 88, 3329–3342. [Google Scholar] [CrossRef]
- Oliveira, J.; Carvalho, G.; Cabral, B.; Bernardino, J. Failure Mode and Effect Analysis for Cyber-Physical Systems. Futur. Internet 2020, 12, 205. [Google Scholar] [CrossRef]
- Sharma, K.; Srivastava, S. Failure mode and effect analysis (FMEA) implementation: A literature review. J. Adv. Res. Aeronaut. Space Sci. 2018, 5, 1–17. [Google Scholar]
- Wu, Z.; Liu, W.; Nie, W. Literature review and prospect of the development and application of FMEA in manufacturing industry. Int. J. Adv. Manuf. Technol. 2021, 112, 1409–1436. [Google Scholar] [CrossRef]
- Liu, H.-C.; Chen, X.-Q.; Duan, C.-Y.; Wang, Y.-M. Failure mode and effect analysis using multi-criteria decision making methods: A systematic literature review. Comput. Ind. Eng. 2019, 135, 881–897. [Google Scholar] [CrossRef]
- Huang, J.; You, J.-X.; Liu, H.-C.; Song, M.-S. Failure mode and effect analysis improvement: A systematic literature review and future research agenda. Reliab. Eng. Syst. Saf. 2020, 199, 106885. [Google Scholar] [CrossRef]
- Choley, J.-Y.; Mhenni, F.; Nguyen, N.; Baklouti, A. Topology-based Safety Analysis for Safety Critical CPS. Procedia Comput. Sci. 2016, 95, 32–39. [Google Scholar] [CrossRef]
- Biffl, S.; Lüder, A.; Meixner, K.; Rinker, F.; Eckhart, M.; Winkler, D. Multi-view-Model Risk Assessment in Cyber-Physical Production Systems Engineering. In Proceedings of the 9th International Conference on Model-Driven Engineering and Software Development—MODELSWARD, Online, 8–10 February 2021; pp. 163–170. [Google Scholar]
- Thoppil, N.M.; Vasu, V.; Rao, C.S.P. Failure Mode Identification and Prioritization Using FMECA: A Study on Computer Numerical Control Lathe for Predictive Maintenance. J. Fail. Anal. Prev. 2019, 19, 1153–1157. [Google Scholar] [CrossRef]
- Liu, H.-C.; Liu, L.; Liu, N. Risk evaluation approaches in failure mode and effects analysis: A literature review. Expert Syst. Appl. 2013, 40, 828–838. [Google Scholar] [CrossRef]
- Ardeshir, A.; Mohajeri, M.; Amiri, M. Evaluation of Safety Risks in Construction Using Fuzzy Failure Mode and Effect Analysis (FFMEA). Sci. Iran. 2016, 23, 2546–2556. [Google Scholar] [CrossRef] [Green Version]
- Chang, K.-H. Generalized multi-attribute failure mode analysis. Neurocomputing 2016, 175, 90–100. [Google Scholar] [CrossRef]
- Ciani, L.; Guidi, G.; Patrizi, G. A Critical Comparison of Alternative Risk Priority Numbers in Failure Modes, Effects, and Criticality Analysis. IEEE Access 2019, 7, 92398–92409. [Google Scholar] [CrossRef]
- Liu, H.-C.; Wang, L.-E.; You, X.-Y.; Wu, S.-M. Failure mode and effect analysis with extended grey relational analysis method in cloud setting. Total Qual. Manag. Bus. Excel. 2019, 30, 745–767. [Google Scholar] [CrossRef]
- Nguyen, T.-L.; Shu, M.-H.; Hsu, B.-M. Extended FMEA for Sustainable Manufacturing: An Empirical Study in the Non-Woven Fabrics Industry. Sustainability 2016, 8, 939. [Google Scholar] [CrossRef]
- Nguyen, T.L.; Tai, D.H.; Shu, M.H. Modifying risk priority number in failure modes and effects analysis. Int. J. Adv. Appl. Sci. 2016, 3, 76–81. [Google Scholar]
- Zhou, D.; Tang, Y.; Jiang, W. A Modified Model of Failure Mode and Effects Analysis Based on Generalized Evidence Theory. Math. Probl. Eng. 2016, 2016, 4512383. [Google Scholar] [CrossRef]
- Di Bona, G.; Silvestri, A.; Forcina, A.; Petrillo, A. Total efficient risk priority number (TERPN): A new method for risk assessment. J. Risk Res. 2016, 21, 1384–1408. [Google Scholar] [CrossRef]
- Kmenta, S.; Ishii, K. Scenario-Based FMEA: A Life Cycle Cost Perspective. In Proceedings of the ASME 2000 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Baltimore, MD, USA, 10–13 September 2000; pp. 163–173. [Google Scholar]
- Li, Y.; Kang, R.; Ma, L.; Li, L. Application and improvement study on FMEA in the process of military equipment maintenance. In Proceedings of the 2011 9th International Conference on Reliability, Maintainability and Safety, Guiyang, China, 12–15 June 2011; pp. 803–810. [Google Scholar]
- Kirkire, M.S.; Rane, S.B.; Jadhav, J.R. Risk management in medical product development process using traditional FMEA and fuzzy linguistic approach: A case study. J. Ind. Eng. Int. 2015, 11, 595–611. [Google Scholar] [CrossRef] [Green Version]
- Gargama, H.; Chaturvedi, S.K. Criticality Assessment Models for Failure Mode Effects and Criticality Analysis Using Fuzzy Logic. IEEE Trans. Reliab. 2011, 60, 102–110. [Google Scholar] [CrossRef]
- Kolios, A.J.; Umofia, A.; Shafiee, M. Failure mode and effects analysis using a fuzzy-TOPSIS method: A case study of subsea control module. Int. J. Multicriteria Decis. Mak. 2017, 7, 29–53. [Google Scholar] [CrossRef]
- Carpitella, S.; Certa, A.; Izquierdo, J.; La Fata, C.M. A combined multi-criteria approach to support FMECA analyses: A real-world case. Reliab. Eng. Syst. Saf. 2018, 169, 394–402. [Google Scholar] [CrossRef] [Green Version]
- Lo, H.-W.; Shiue, W.; Liou, J.J.H.; Tzeng, G.-H. A hybrid MCDM-based FMEA model for identification of critical failure modes in manufacturing. Soft Comput. 2020, 24, 15733–15745. [Google Scholar] [CrossRef]
- Wang, L.-E.; Liu, H.-C.; Quan, M.-Y. Evaluating the risk of failure modes with a hybrid MCDM model under interval-valued intuitionistic fuzzy environments. Comput. Ind. Eng. 2016, 102, 175–185. [Google Scholar] [CrossRef]
- Kutlu, A.C.; Ekmekçioğlu, M. Fuzzy failure modes and effects analysis by using fuzzy TOPSIS-based fuzzy AHP. Expert Syst. Appl. 2012, 39, 61–67. [Google Scholar] [CrossRef]
- Apriliana, A.F.; Sarno, R.; Effendi, Y.A. Risk analysis of IT applications using FMEA and AHP SAW method with COBIT 5. In Proceedings of the 2018 International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 6–7 March 2018; pp. 373–378. [Google Scholar]
- Liu, H.-C.; You, J.-X.; Shan, M.-M.; Shao, L.-N. Failure mode and effects analysis using intuitionistic fuzzy hybrid TOPSIS approach. Soft Comput. 2015, 19, 1085–1098. [Google Scholar] [CrossRef]
- Jato-Espino, D.; Castillo-Lopez, E.; Rodriguez-Hernandez, J.; Canteras-Jordana, J.C. A review of application of multi-criteria decision making methods in construction. Autom. Constr. 2014, 45, 151–162. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, H.; Yuan, X.; Shardt, Y.A.; Yang, C.; Gui, W. Deep learning for fault-relevant feature extraction and fault classification with stacked supervised auto-encoder. J. Process Control 2020, 92, 79–89. [Google Scholar] [CrossRef]
- Mandal, S.; Santhi, B.; Sridhar, S.; Vinolia, K.; Swaminathan, P. Nuclear Power Plant Thermocouple Sensor Fault Detection and Classification using Deep Learning and Generalized Likelihood Ratio Test. IEEE Trans. Nucl. Sci. 2017, 64, 1526–1534. [Google Scholar] [CrossRef]

{kind=link}
| Method | Details | References |
|---|---|---|
| Neural Network | Self-organizing map | [36] |
| ANN | [37,38] | |
| Random Forest | Classification Problem (normal, fault) | [39] |
| k-Nearest Neighbors (kNN) | Ensemble method based on kNN with random forest k-means for feature selection | [40] |
| Naïve Bayes classifier | Ensemble method based on Naïve Bayes classifier with random forest k-means for feature selection | [40] |
| Kernel PCA | Training on only normal data points and using threshold for fault detection | [19,41,42] |
| TEDA (Typicality and Eccentricity Data Analytics) | Unsupervised algorithm, no previous knowledge needed; detects outliers as faulty data samples | [3,43,44,45] |
| Improved Support Vector Machines (SVM) | OS-LSSVM uses a sparsity component to increase the prediction speed of sensor values; fault is detected in case of high residual error | [46,47,48] |
| Method | Details | References |
|---|---|---|
| k-means | Clustering method to identify fault types | [1,2,65] |
| Gaussian Mixture Model | Clustering method to identify different distributions | [1,2] |
| Fuzzy-c-means | Extension of K-means with fuzzy variables | [2] |
| Autoencoder | [49,66] | |
| Neural Network | ANN with softmax layer | [37,67,68] |
| CNN-based feature learning | [69,70,71] | |
| Sparse Representation Classification (SRC) | Performs classification based on sparse representation of training data | [72] |
| SVM | Two-class classifier or pair-wise classifiers for multi-class classification | [51,67,69,70,73,74,75,76,77,78] |
| Decision Tree | Classification with QUEST, C&RT, C5.0, and CHAID methods | [75] |
| Random Forest | Random Forest with feature extraction | [69,79] |
| Tree-structured fault dependence kernel | Hierarchical large margin SVM | [80] |
| Linear Discriminant Analysis | Uses distance metrics to assign classes | [34] |
| Extension | Details | References |
|---|---|---|
| Additional risk factors | e.g., expected cost, cost of failures, weight of corrective actions, uncertain risk factors, environmental factors, economic safety | [91,92,105,107,108,109,110] |
| Usage of sub-risk factors | e.g., severity levels from various perspectives like technical or economical | [104,105,106] |
| Fuzzy variables | Fuzziness used in variables to represent uncertainty and imprecise risk factors | [111,112,113] |
| Multi-criteria decision methods | Defining risk based on multiple conflicting criteria | [108,113,114,115,116,117,118,119] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Webert, H.; Döß, T.; Kaupp, L.; Simons, S. Fault Handling in Industry 4.0: Definition, Process and Applications. Sensors 2022, 22, 2205. https://doi.org/10.3390/s22062205
Webert H, Döß T, Kaupp L, Simons S. Fault Handling in Industry 4.0: Definition, Process and Applications. Sensors. 2022; 22(6):2205. https://doi.org/10.3390/s22062205
Chicago/Turabian StyleWebert, Heiko, Tamara Döß, Lukas Kaupp, and Stephan Simons. 2022. "Fault Handling in Industry 4.0: Definition, Process and Applications" Sensors 22, no. 6: 2205. https://doi.org/10.3390/s22062205
APA StyleWebert, H., Döß, T., Kaupp, L., & Simons, S. (2022). Fault Handling in Industry 4.0: Definition, Process and Applications. Sensors, 22(6), 2205. https://doi.org/10.3390/s22062205