
Pix2Pix-Based Monocular Depth Estimation for Drones with Optical Flow on AirSim


Abstract
:1. Introduction
- This is the first paper to generate a depth image from a monocular image with optical flow for collision avoidance of drone flight.
- We verify that our proposed method can estimate high-quality depth images in real-time, and demonstrates that a drone can successfully fly avoiding objects in a flight simulator.
- In addition, our method is superior to previous method of depth estimation on accuracy and collision avoidance.
2. Related Work
3. AirSim
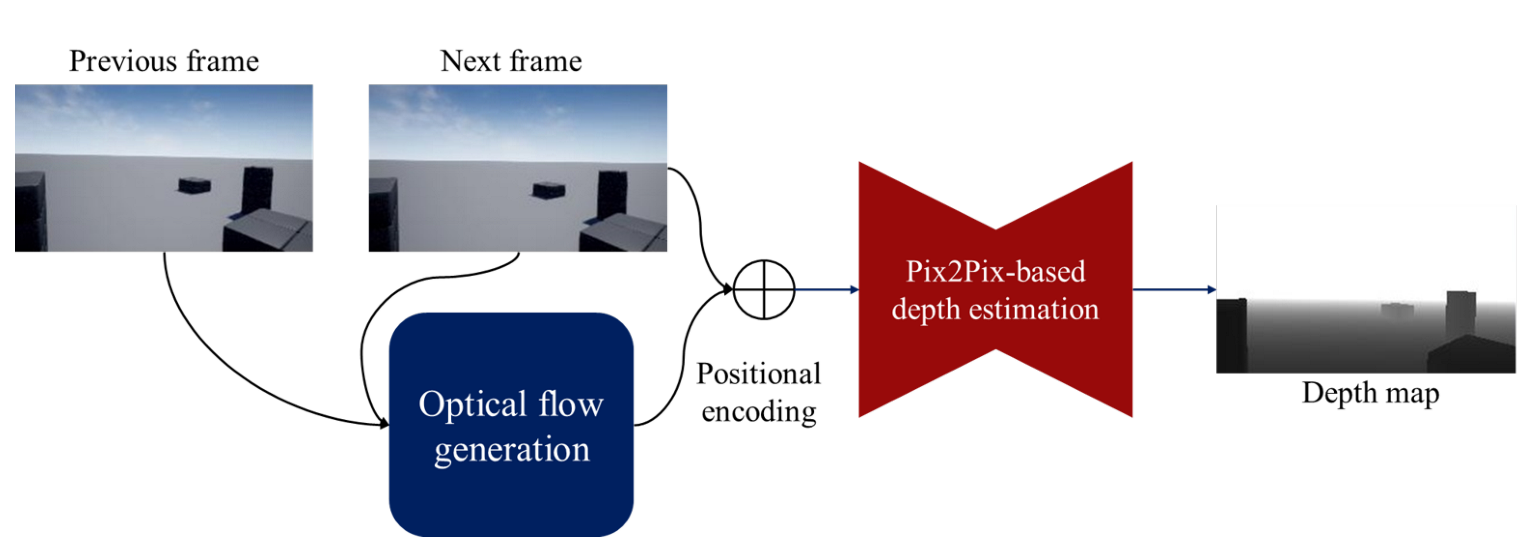
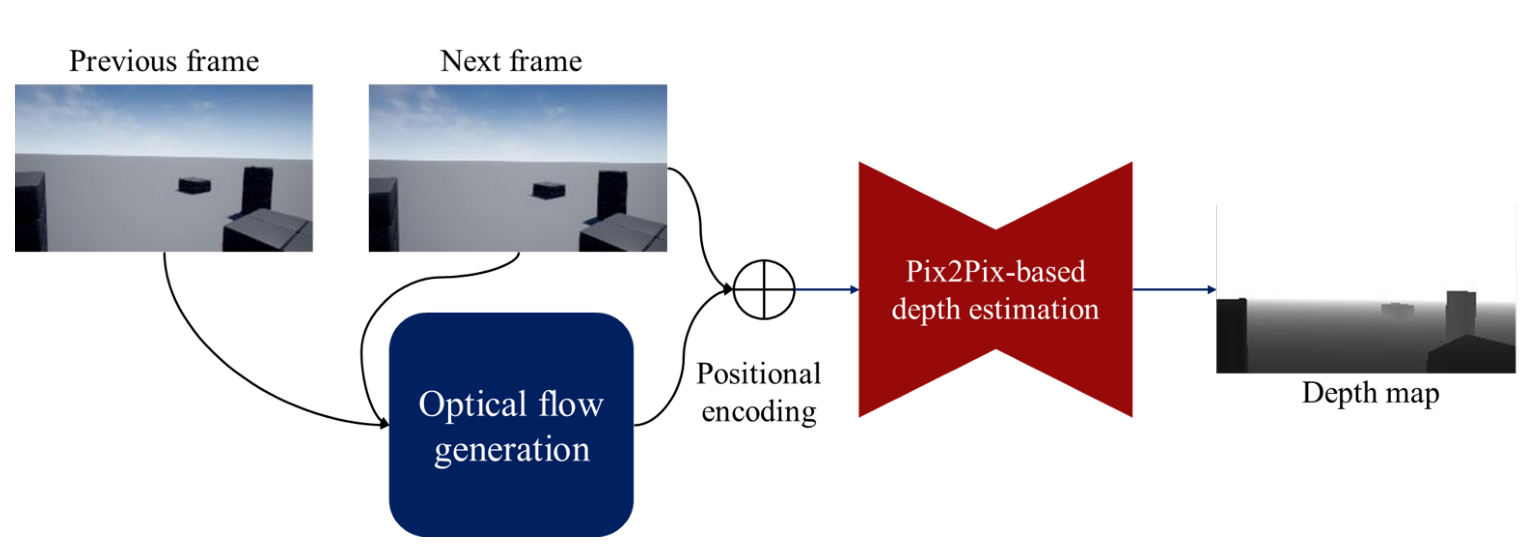
4. A Pix2Pix-Based Monocular Depth Estimation with Optical Flow
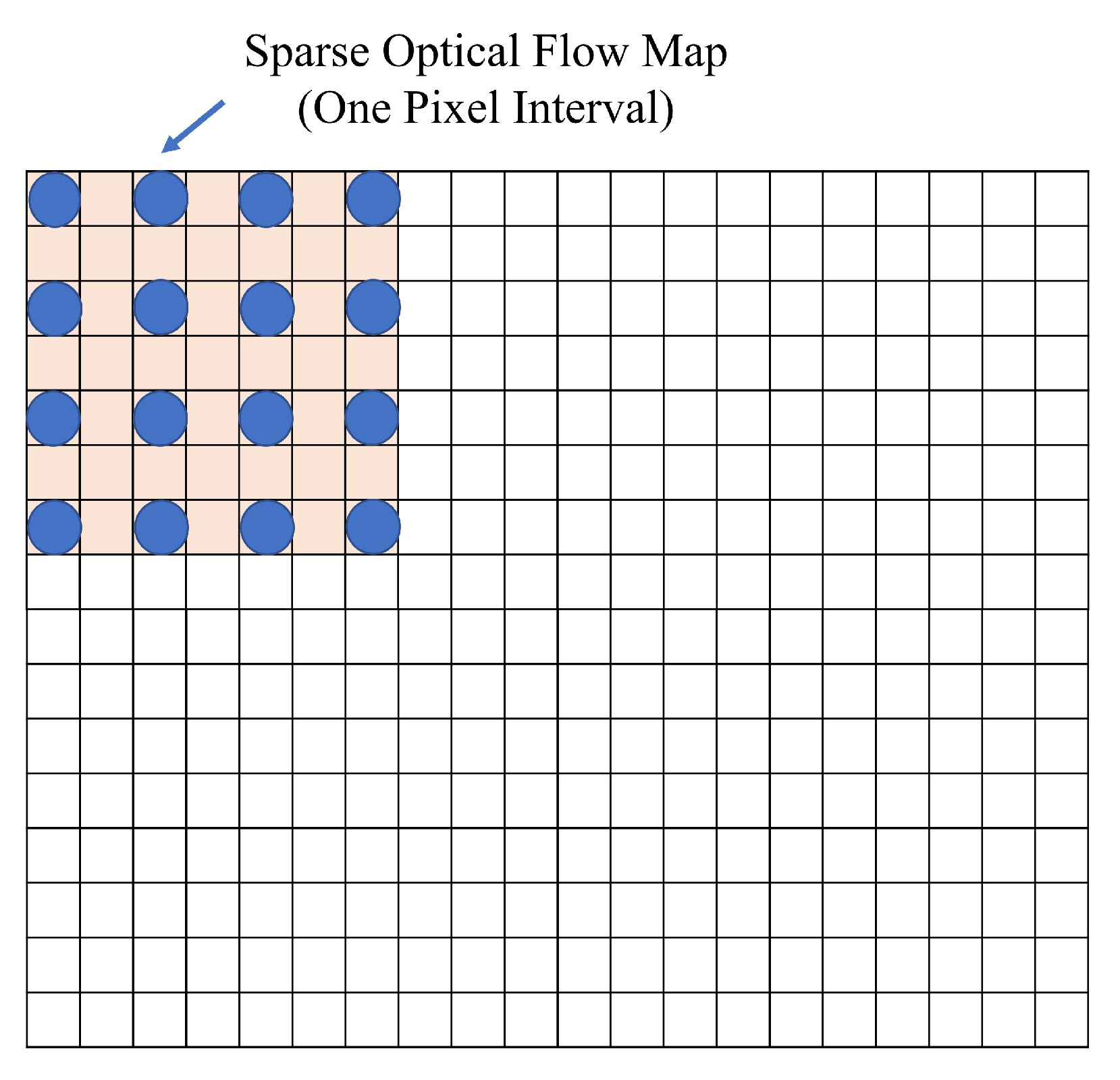
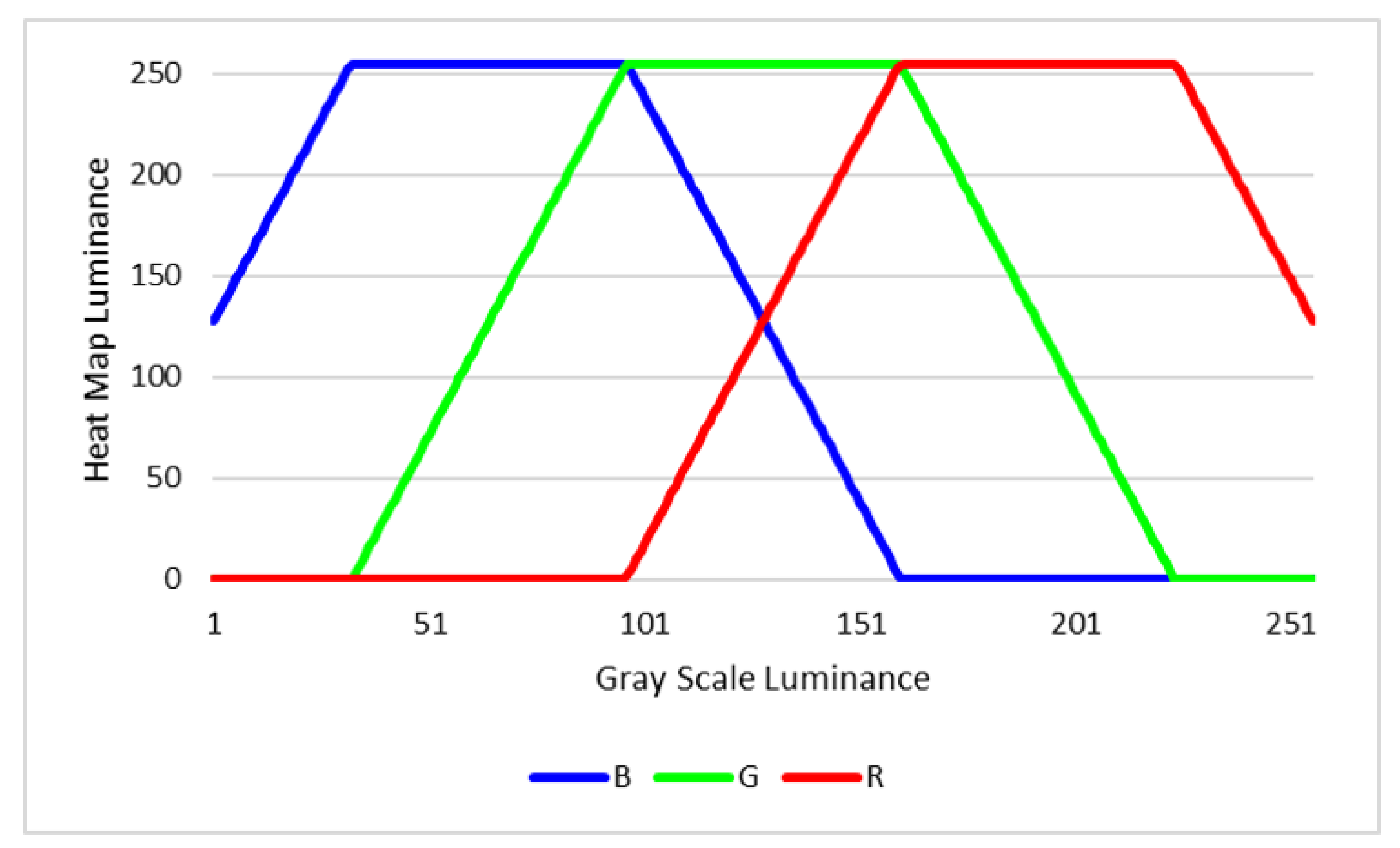
4.1. Optical Flow Map Generation
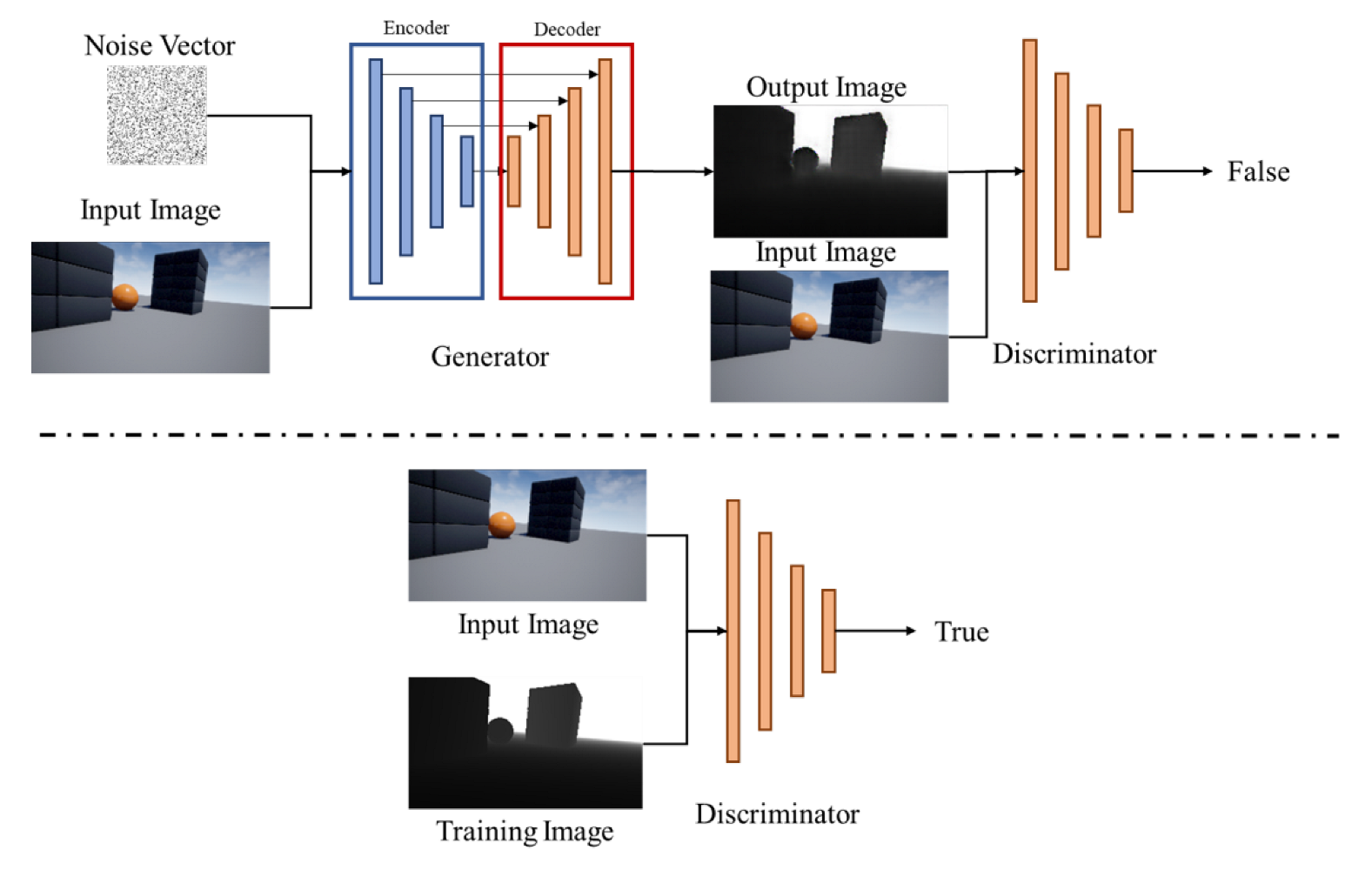
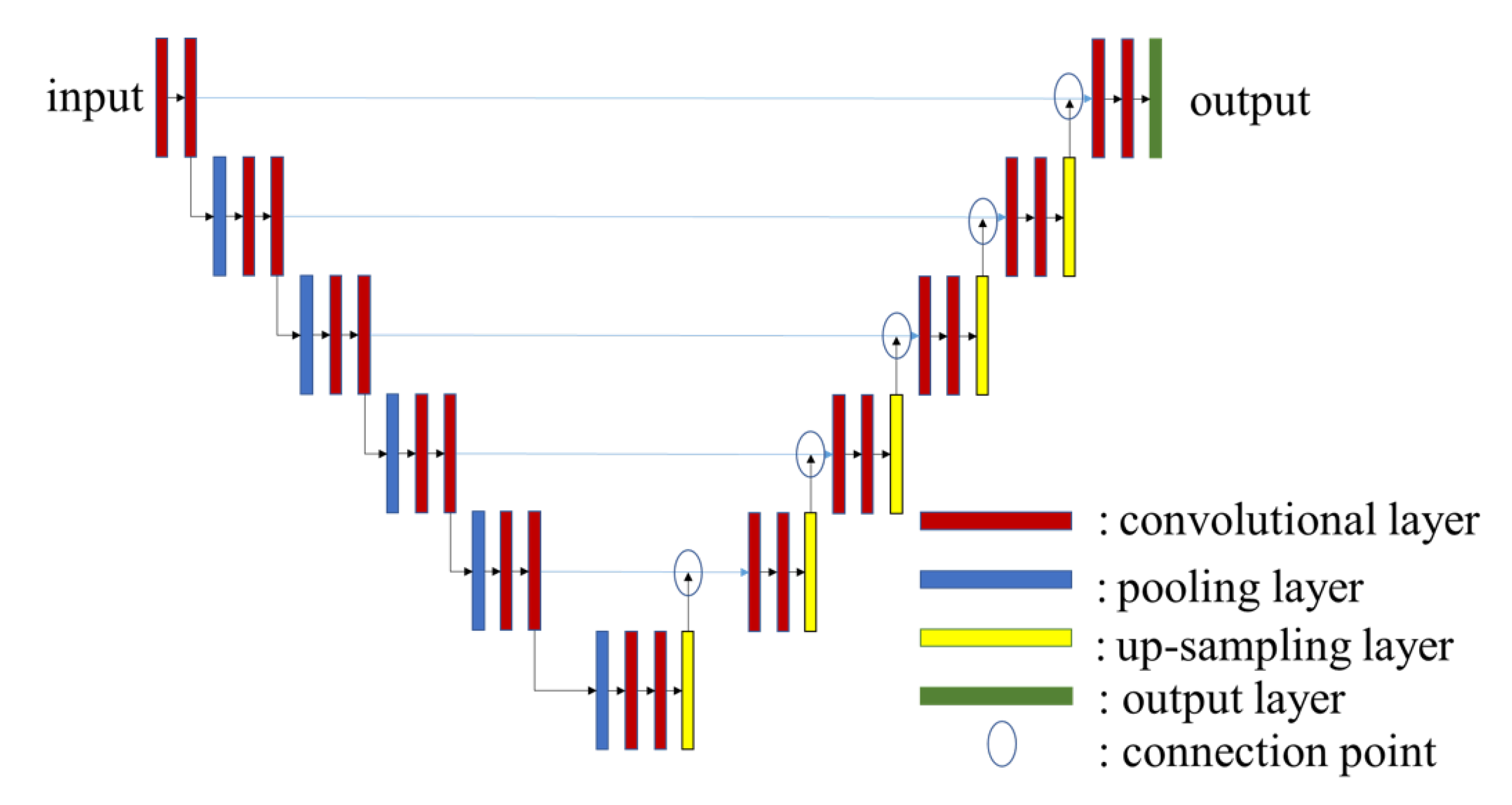
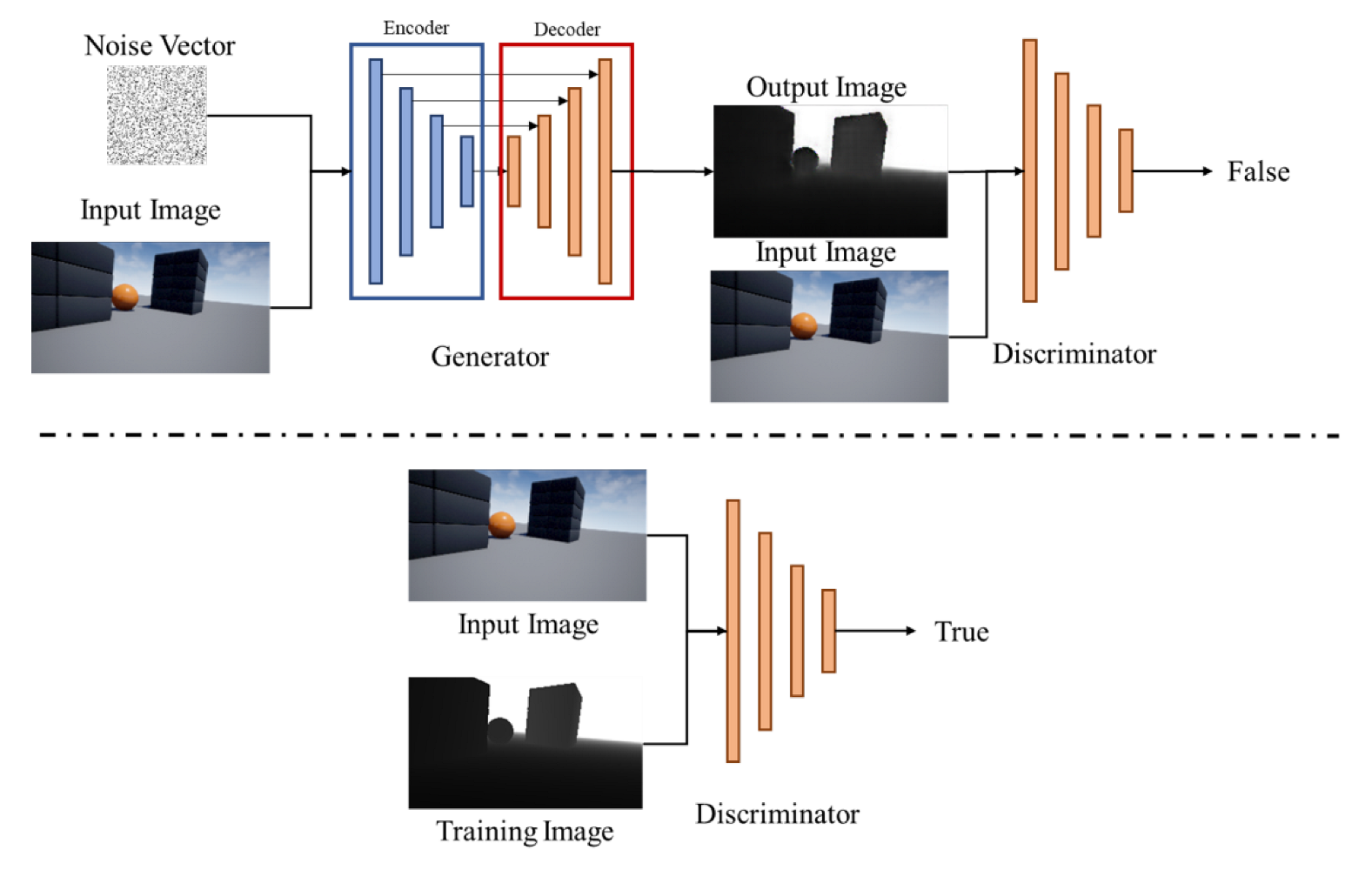
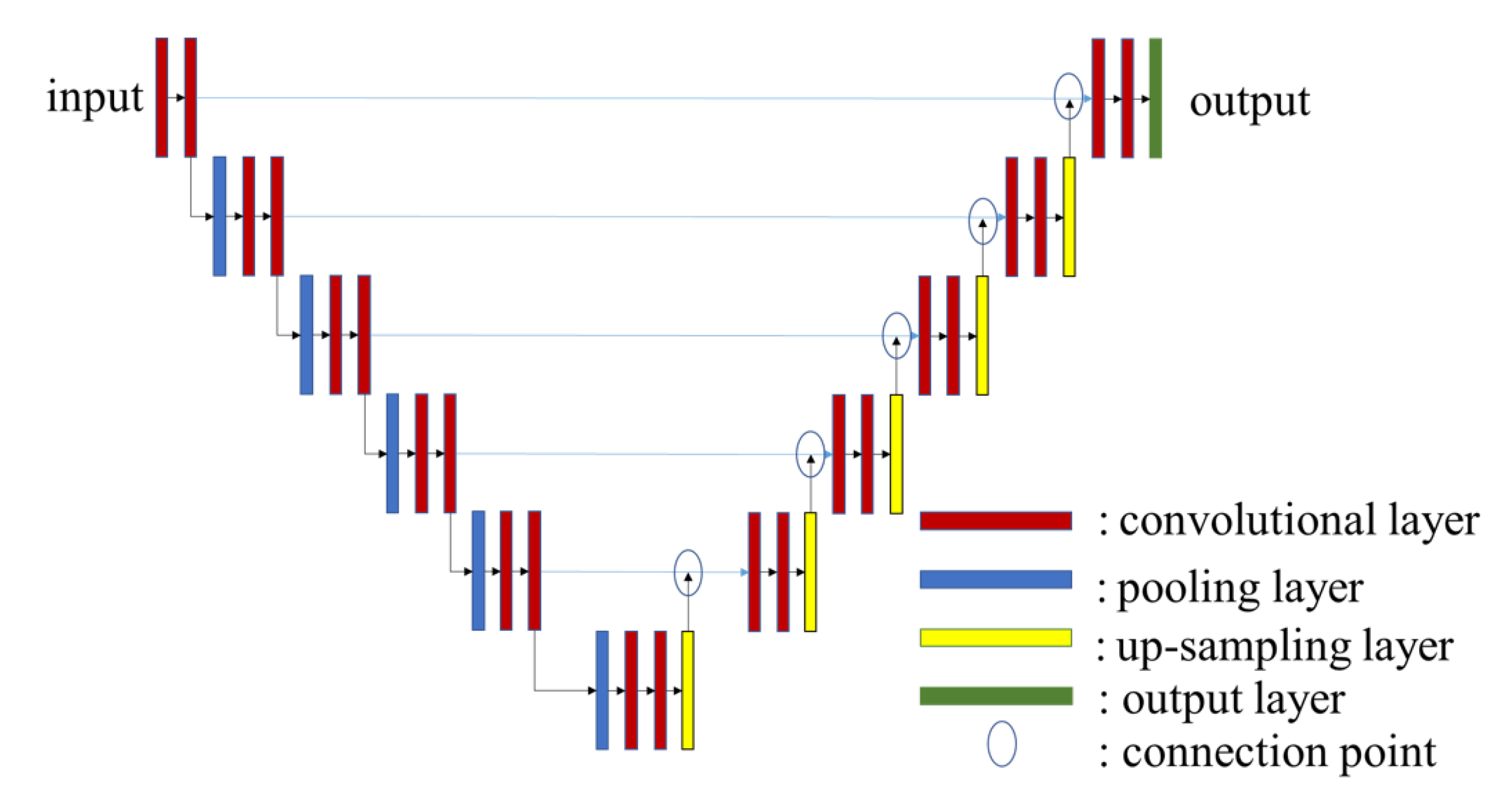
4.2. Pix2Pix
4.3. Depth Estimation Method
5. Experiments
5.1. Preliminary Evaluation with Different Pixels Interval of Optical Flow Maps
5.2. Comparison Accuracy between Proposed Method and Related Work
5.3. Run Time Evaluation
5.4. Collision Rate Evaluation in AirSim Environment
6. Discussion
6.1. Evaluation for Effects of Pixels Interval
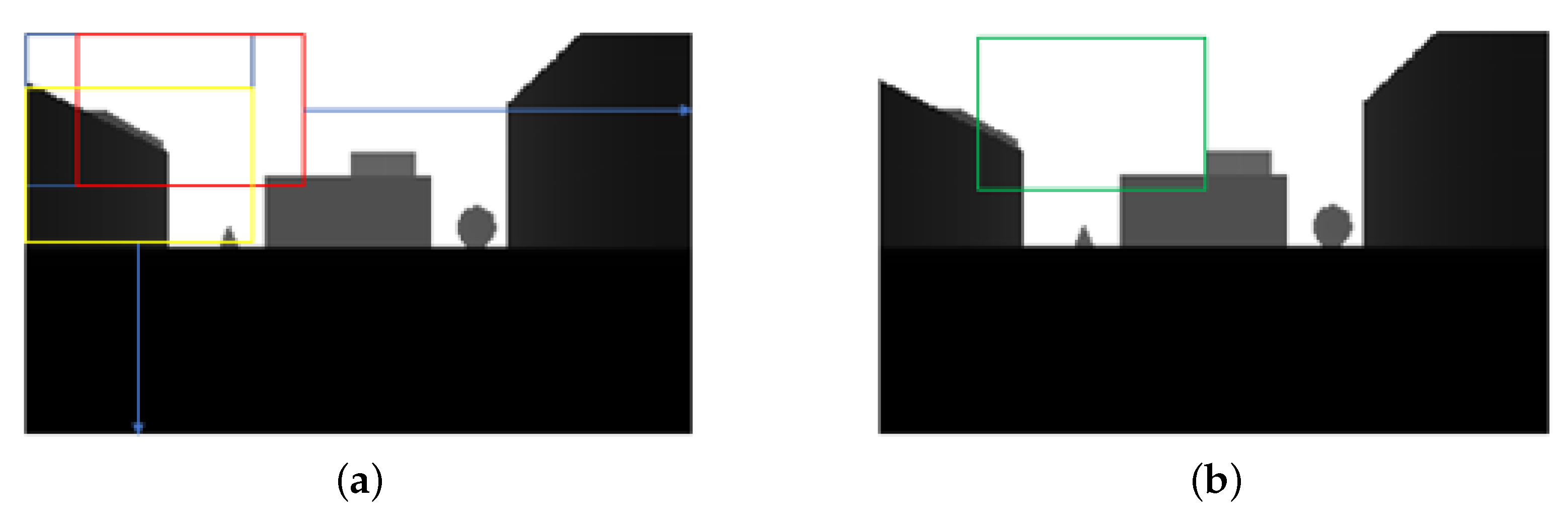
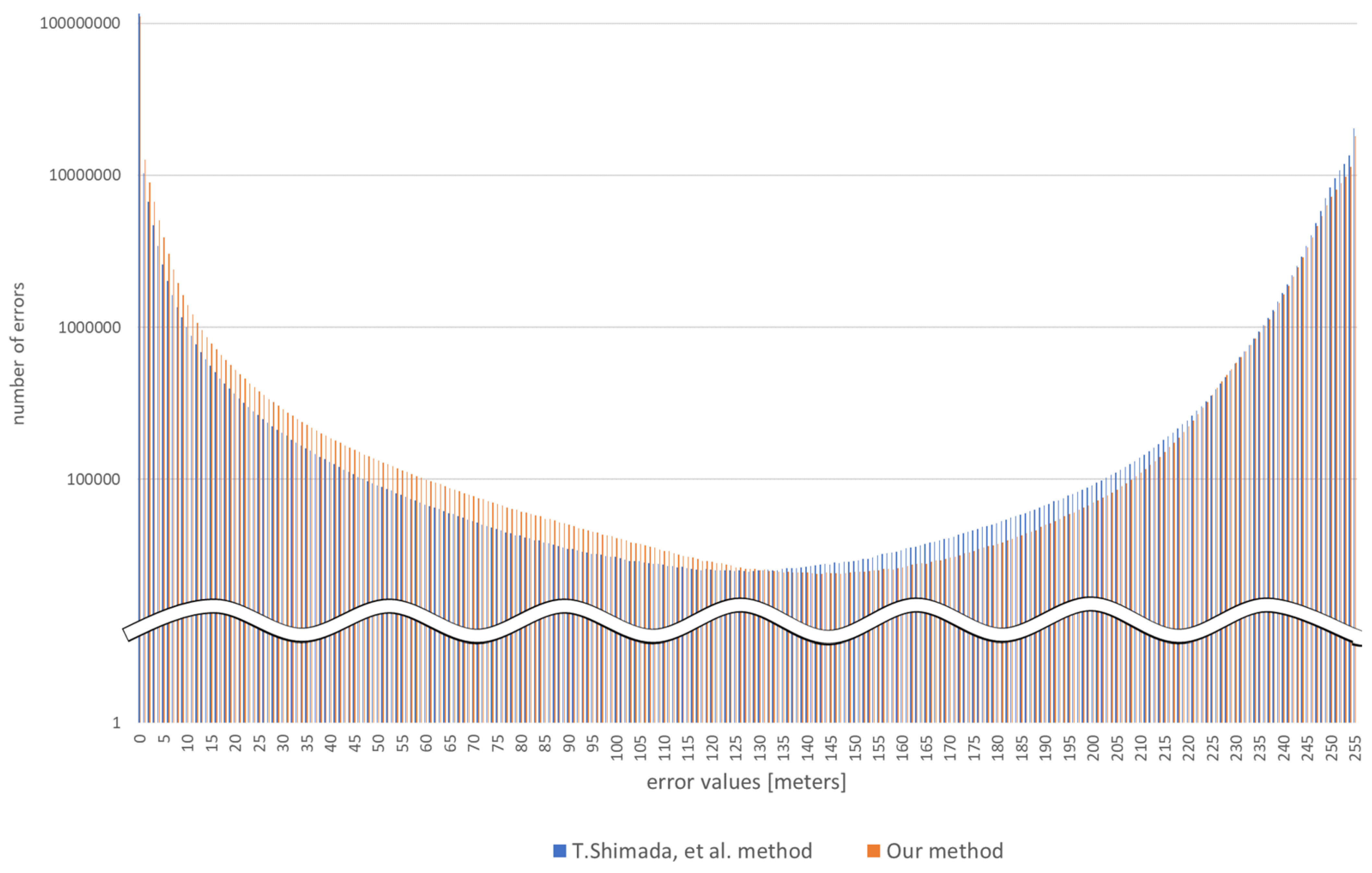
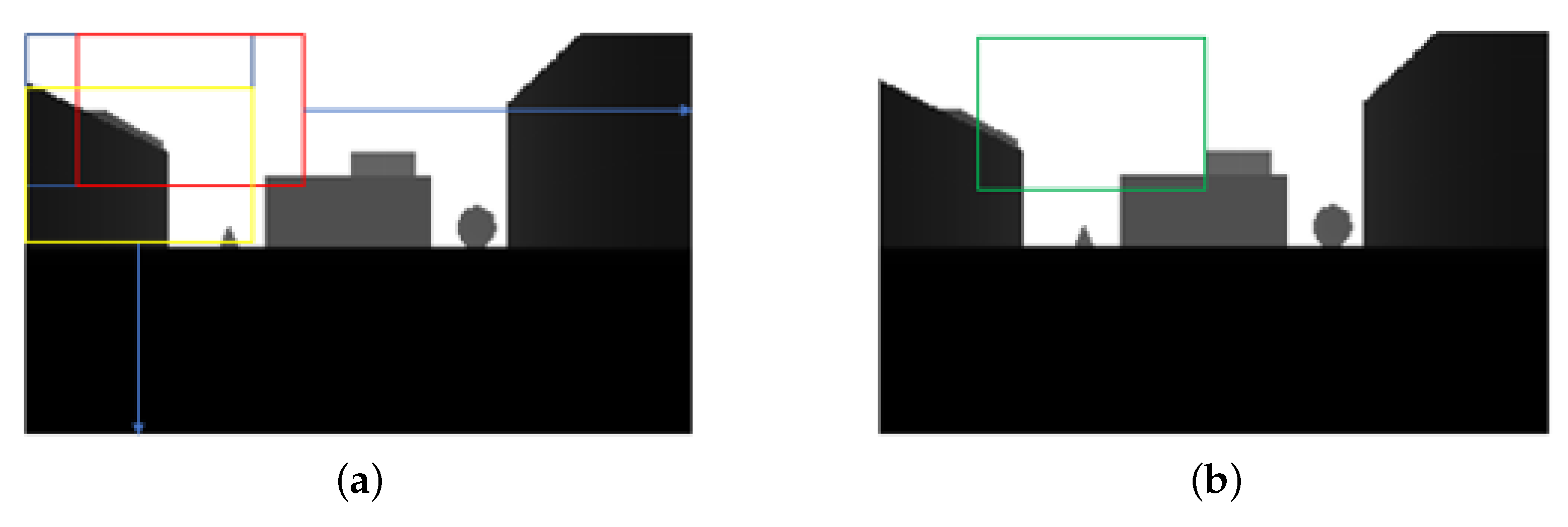
6.2. Comparison of the Error of Depth Information
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moffatt, A.; Platt, E.; Mondragon, B.; Kwok, A.; Uryeu, D.; Bhandari, S. Obstacle Detection and Avoidance System for Small UAVs Using A LiDAR. In Proceedings of the IEEE International Conference on Unmanned Aircraft Systems, Athens, Greece, 1–4 September 2020. [Google Scholar]
- Hou, Y.; Zhang, Z.; Wang, C.; Cheng, S.; Ye, D. Research on Vehicle Identification Method and Vehicle Speed Measurement Method Based on Multi-rotor UAV Equipped with LiDAR. In Proceedings of the IEEE International Conference on Advanced Electronic Materials, Computers and Software Engineering, Shenzhen, China, 24–26 April 2020. [Google Scholar]
- Borenstein, J.; Koren, Y. The Vector Field Histogram-Fast Obstacle Avoidance for Mobile Robots. IEEE Trans. Robot. Autom. 1991, 7, 278–288. [Google Scholar] [CrossRef] [Green Version]
- Ma, C.; Zhou, Y.; Li, Z. A New Simulation Environment Based on AirSim, ROS, and PX4 for Quadcopter Aircrafts. In Proceedings of the International Conference on Control, Automation and Robotics, Singapore, 20–23 April 2020. [Google Scholar]
- Ma, D.; Tran, A.; Keti, N.; Yanagi, R.; Knight, P.; Joglekar, K.; Tudor, N.; Cresta, B.; Bhandari, S. Flight Test Validation of Collision Avoidance System for a Multicopter using Stereoscopic Vision. In Proceedings of the International Conference on Unmanned Aircraft Systems, Atlanta, GA, USA, 11–14 June 2019. [Google Scholar]
- Perez, E.; Winger, A.; Tran, A.; Garcia-Paredes, C.; Run, N.; Keti, N.; Bhandari, S.; Raheja, A. Autonomous Collision Avoidance System for a Multicopter using Stereoscopic Vision. In Proceedings of the IEEE International Conference on Unmanned Aircraft Systems, Dallas, TX, USA, 12–15 June 2018. [Google Scholar]
- Tsuichihara, S.; Akita, S.; Ike, R.; Shigeta, M.; Takemura, H.; Natori, T.; Aikawa, N.; Shindo, K.; Ide, Y.; Tejima, S. Drone and GPS Sensors-Based Grassland Management Using Deep-Learning Image Segmentation. In Proceedings of the International Conference on Robotic Computing, Naples, Italy, 25–27 February 2019. [Google Scholar]
- Huang, Z.Y.; Lai, Y.C. Image-Based Sense and Avoid of Small Scale UAV Using Deep Learning Approach. In Proceedings of the International Conference on Unmanned Aircraft Systems, Athens, Greece, 1–4 September 2020. [Google Scholar]
- Bipin, K.; Duggal, V.; Madhava Krishna, K. Autonomous Navigation of Generic Monocular Quadcopter in Natural Environment. In Proceedings of the IEEE International Conference on Robotics and Automation, Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Lin, Y.H.; Cheng, W.H.; Miao, H.; Ku, T.H.; Hsieh, Y.H. Single Image Depth Estimation from Image Descriptors. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Kyoto, Japan, 25–30 March 2012. [Google Scholar]
- Atapour-Abarghouei, A.; Breckon, T.P. Monocular Segment-Wise Depth: Monocular Depth Estimation Based on a Semantic Segmentation Prior. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019. [Google Scholar]
- Shimada, T.; Nishikawa, H.; Kong, X.; Tomiyama, H. Pix2Pix-Based Depth Estimation from Monocular Images for Dynamic Path Planning of Multirotor on AirSim. In Proceedings of the International Symposium on Advanced Technologies and Applications in the Internet of Things, Kusatsu, Japan, 23–24 August 2021. [Google Scholar]
- Fraga-Lamas, P.; Ramos, L.; Mondéjar-Guerra, V.; Fernández-Caramés, T.M. A Review on IoT Deep Learning UAV Systems for Autonomous Obstacle Detection and Collision Avoidance. Remote Sens. 2019, 11, 2144. [Google Scholar] [CrossRef] [Green Version]
- Valisetty, R.; Haynes, R.; Namburu, R.; Lee, M. Machine Learning for US Army UAVs Sustainment: Assessing Effect of Sensor Frequency and Placement on Damage Information in The Ultrasound Signals. In Proceedings of the IEEE International Conference on Machine Learning and Applications, Orlando, FL, USA, 17–20 December 2018; pp. 165–172. [Google Scholar]
- Figetakis, E.; Refaey, A. UAV Path Planning Using on-Board Ultrasound Transducer Arrays and Edge Support. In Proceedings of the IEEE International Conference on Communications Workshops, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- McGee, T.G.; Sengupta, R.; Hedrick, K. Obstacle Detection for Small Autonomous Aircraft using Sky Segmentation. In Proceedings of the IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 4679–4684. [Google Scholar]
- Redding, J.; Amin, J.; Boskovic, J.; Kang, Y.; Hedrick, K.; Howlett, J.; Poll, S. A Real-Time Obstacle Detection and Reactive Path Planning System for Autonomous Small-Scale Helicopters. In Proceedings of the AIAA Guidance, Navigation and Control Conference and Exhibit, Hilton Head, SC, USA, 20–23 August 2007. [Google Scholar]
- Trinh, L.A.; Thang, N.D.; Vu, D.H.N.; Hung, T.C. Position Rectification with Depth Camera to Improve Odometry-based Localization. In Proceedings of the International Conference on Communications, Management and Telecommunications (ComManTel), DaNang, Vietnam, 28–30 December 2015; pp. 147–152. [Google Scholar]
- Zhang, S.; Li, N.; Qiu, C.; Yu, Z.; Zheng, H.; Zheng, B. Depth Map Prediction from a Single Image with Generative Adversarial Nets. Multimed. Tools Appl. 2020, 79, 14357–14374. [Google Scholar] [CrossRef]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning Depth from Single Monocular Images Using Deep Convolutional Neural Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mancini, M.; Costante, G.; Valigi, P.; Ciarfuglia, T.A. J-MOD2: Joint Monocular Obstacle Detection and Depth Estimation. IEEE Robot. Autom. Lett. 2018, 3, 1490–1497. [Google Scholar] [CrossRef] [Green Version]
- Hatch, K.; Mern, J.; Kochenderfer, M. Obstacle Avoidance Using a Monocular Camera. arXiv 2020, arXiv:2012.01608. [Google Scholar]
- Hou, Q.; Jung, C. Occlusion Robust Light Field Depth Estimation Using Segmentation Guided Bilateral Filtering. In Proceedings of the IEEE International Symposium on Multimedia, Taichung, Taiwan, 11–13 December 2017. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision Meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Proceedings of the ECCV 2012, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Bhat, S.F.; Alhashim, I.; Wonka, P. Adabins: Depth Estimation Using Adaptive Bins. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4009–4018. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Field and Service Robotics; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981. [Google Scholar]
- Farnebäck, G. Two-frame Motion Estimation Based on Polynomial Expansion. In Proceedings of the Scandinavian Conference on Image Analysis, Halmstad, Sweden, 29 June–2 July 2003; pp. 363–370. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Chen, J.; Zhou, M.; Zhang, D.; Huang, H.; Zhang, F. Quantification of Water Inflow in Rock Tunnel Faces via Convolutional Neural Network Approach. Autom. Constr. 2021, 123, 103526. [Google Scholar] [CrossRef]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G. Deep Convolutional Neural Fields for Depth Estimation from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5162–5170. [Google Scholar]
- Kuznietsov, Y.; Stuckler, J.; Leibe, B. Semi-supervised Deep Learning for Monocular Depth Map Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6647–6655. [Google Scholar]
- Lidar, V. Velodyne Lidar Products. Available online: https://velodynelidar.com/products/ (accessed on 1 March 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OS | Windows 10 pro |
|---|---|
| RAM | 32 GB 2666 MHz |
| CPU | Intel Core i7-9700K 3.60 GHz |
| GPU | NVIDIA GeForce RTX 2070 SUPER 8 GB |
| Pixel Interval | Error (Lower Is Better) | Accuracy (Higher Is Better) | |||
|---|---|---|---|---|---|
| RMSE | Rel. | ||||
| Optical flow only | 7.6786 | 0.3886 | 0.7416 | 0.8604 | 0.9129 |
| 1 pixel | 6.6258 | 0.1675 | 0.8634 | 0.9376 | 0.9621 |
| 3 pixels | 6.0947 | 0.1397 | 0.8878 | 0.9554 | 0.9758 |
| 5 pixels | 6.0050 | 0.1230 | 0.8923 | 0.9608 | 0.9797 |
| 7 pixels | 6.5064 | 0.1240 | 0.8910 | 0.9605 | 0.9795 |
| 9 pixels | 6.7068 | 0.1335 | 0.8947 | 0.9573 | 0.9762 |
| Method | Error (Lower Is Better) | Accuracy (Higher Is Better) | |||
|---|---|---|---|---|---|
| RMSE | Rel. | ||||
| Shimada [12] | 5.942 | 0.1338 | 0.8871 | 0.9562 | 0.9772 |
| Proposed method | 6.005 | 0.1230 | 0.8923 | 0.9608 | 0.9796 |
| Method | Error (Lower Is Better) | Accuracy (Higher Is Better) | |||
|---|---|---|---|---|---|
| RMSE | Rel. | ||||
| Eigen et al. [34] | 7.156 | 1.515 | 0.692 | 0.899 | 0.967 |
| Liu et al. [35] | 6.986 | 0.217 | 0.647 | 0.882 | 0.961 |
| Kuznietsov et al. [36] | 4.621 | 0.113 | 0.862 | 0.960 | 0.986 |
| Proposed method | 7.605 | 0.154 | 0.813 | 0.958 | 0.985 |
| Device | Runtime (s) | |
|---|---|---|
| Non Optical Flow | Optical Flow | |
| NVIDIA RTX 2070 SUPER | 0.031 | 0.134 |
| Intel Core i7 9700K | 0.181 | 0.273 |
| Jetson Xavier NX | 0.193 | 0.297 |
| Map | Collision Rate (%) | |||
|---|---|---|---|---|
| 10 m | 200 m | Shimada [12] | Our Method | |
| Blocks | 58.75 | 7.000 | 17.50 | 14.50 |
| City environment | 73.50 | 26.00 | 34.75 | 34.00 |
| Coastline | 70.50 | 0.250 | 1.500 | 1.250 |
| Neighborhood | 82.00 | 7.000 | 2.500 | 1.000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shimada, T.; Nishikawa, H.; Kong, X.; Tomiyama, H. Pix2Pix-Based Monocular Depth Estimation for Drones with Optical Flow on AirSim. Sensors 2022, 22, 2097. https://doi.org/10.3390/s22062097
Shimada T, Nishikawa H, Kong X, Tomiyama H. Pix2Pix-Based Monocular Depth Estimation for Drones with Optical Flow on AirSim. Sensors. 2022; 22(6):2097. https://doi.org/10.3390/s22062097
Chicago/Turabian StyleShimada, Tomoyasu, Hiroki Nishikawa, Xiangbo Kong, and Hiroyuki Tomiyama. 2022. "Pix2Pix-Based Monocular Depth Estimation for Drones with Optical Flow on AirSim" Sensors 22, no. 6: 2097. https://doi.org/10.3390/s22062097
APA StyleShimada, T., Nishikawa, H., Kong, X., & Tomiyama, H. (2022). Pix2Pix-Based Monocular Depth Estimation for Drones with Optical Flow on AirSim. Sensors, 22(6), 2097. https://doi.org/10.3390/s22062097