
Embedded Temporal Convolutional Networks for Essential Climate Variables Forecasting


Abstract
:1. Introduction
- We propose a novel deep learning architecture for forecasting future values which gracefully handles the high-dimensionality of observations.
- We introduce novel datasets of satellite derived geophysical parameters, namely land surface temperature and surface soil moisture, obtained on monthly periodicity over 17.5 years.
- We performed a detailed analysis of both state-of-the-art and proposed deep learning models for the problem of climate variables prediction.
2. Related Work
3. Materials and Methods
3.1. The E-TCN Framework
3.2. Analysis Ready Dataset
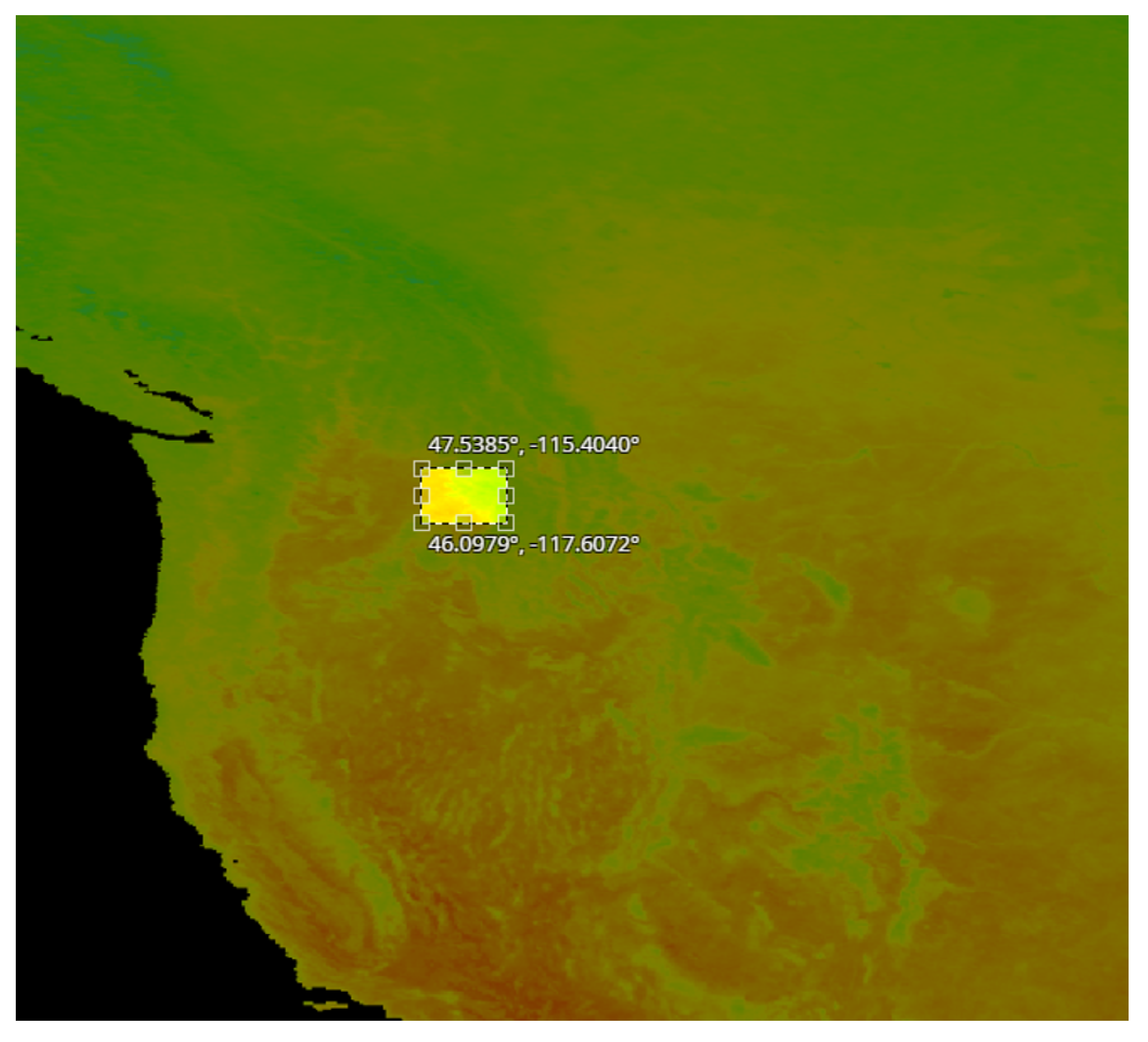
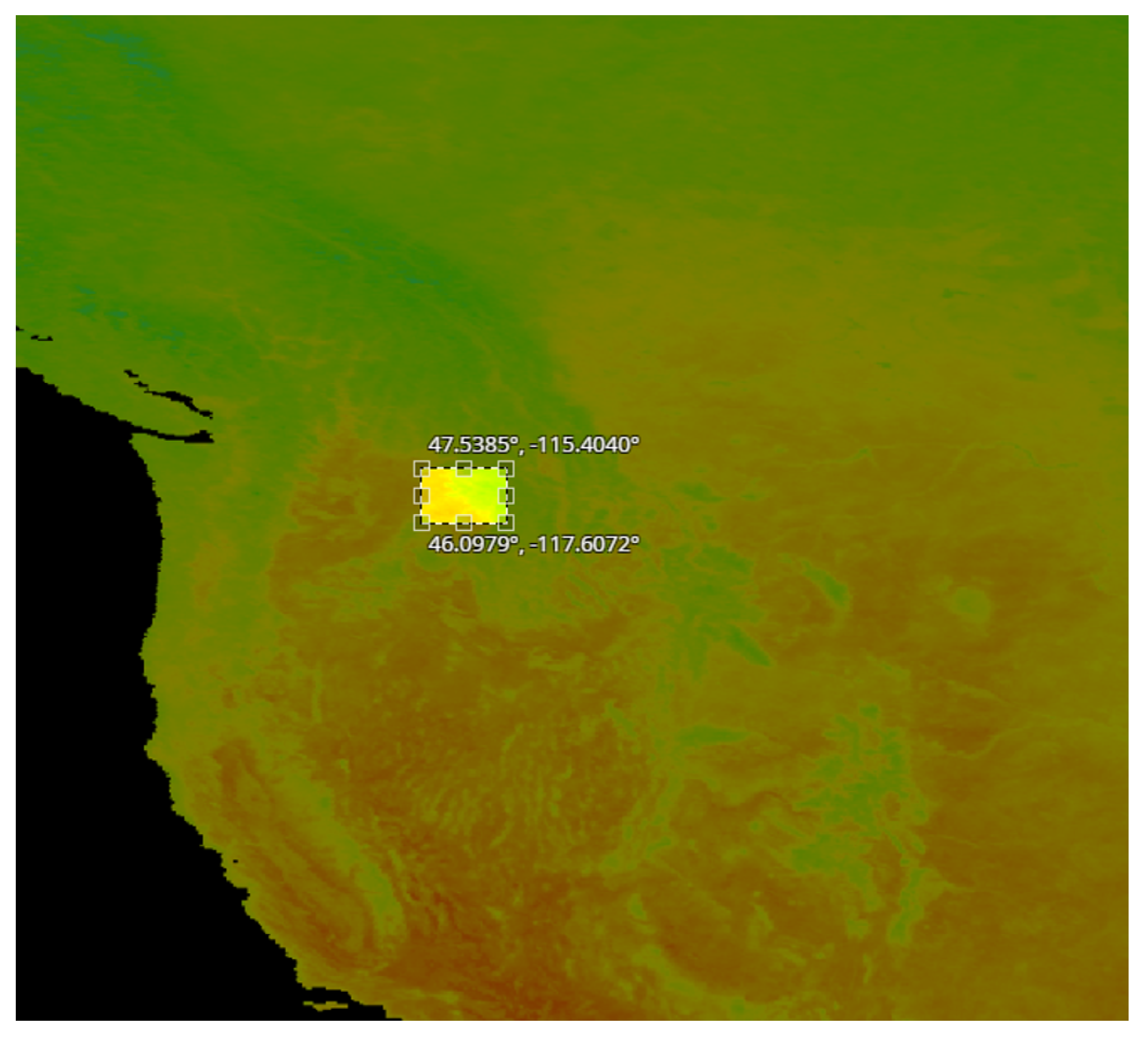
- A set of pixel images with per pixel resolution equal to 5 km. These images were acquired from the region in Idaho shown in Figure 2.
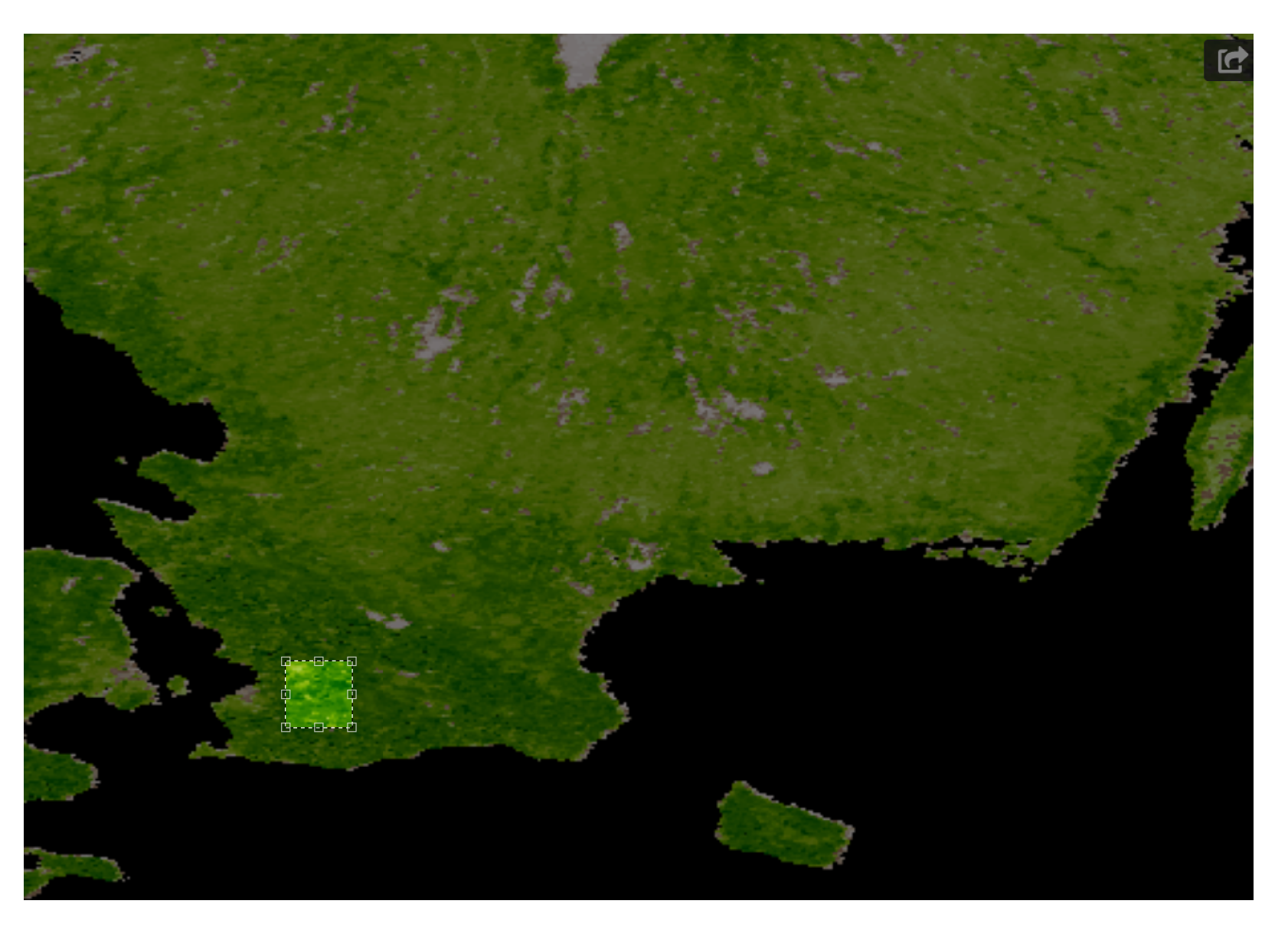
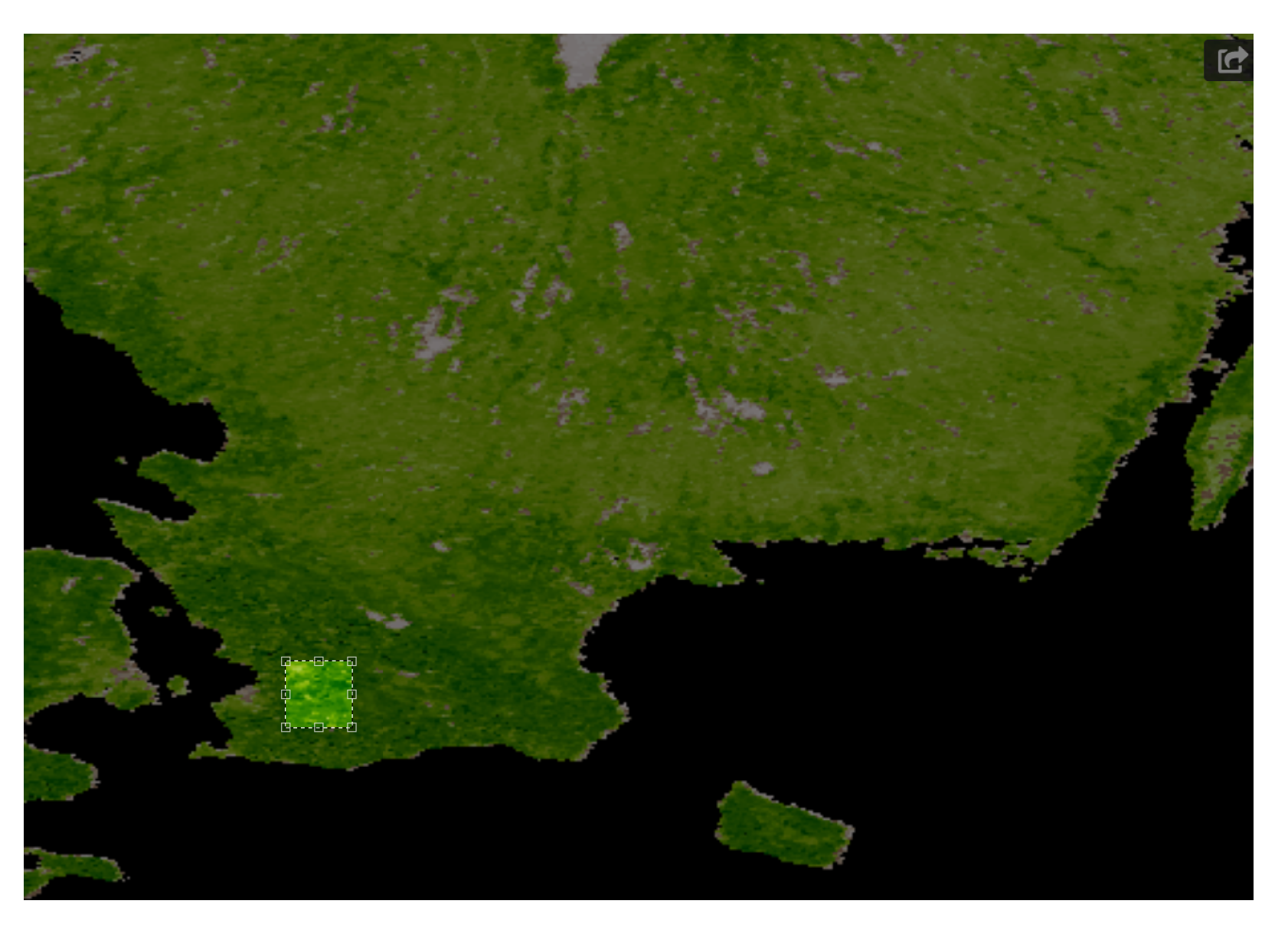
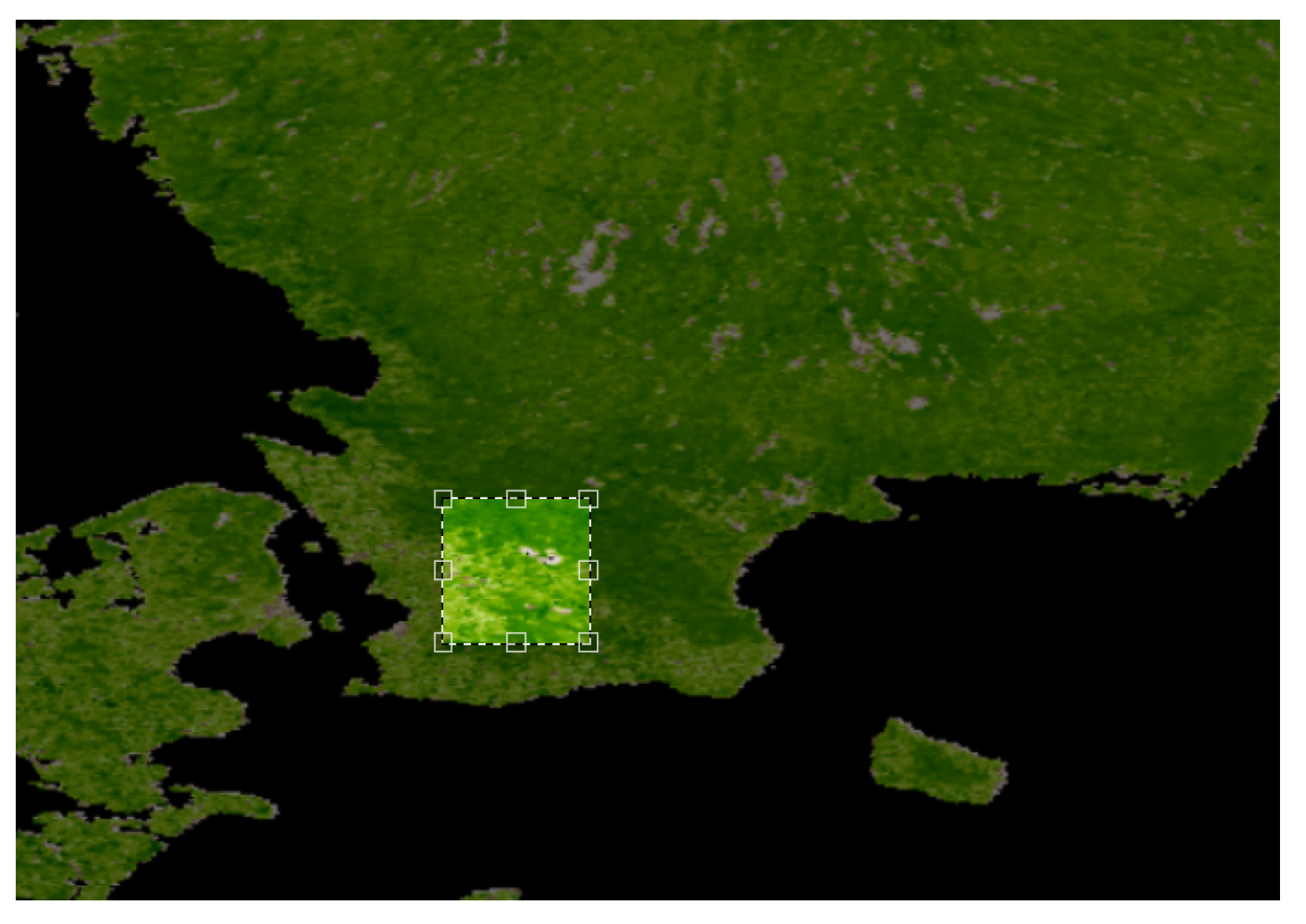
- A set of pixel images with per pixel resolution equal to 5 km. These images were acquired from the region in Sweden shown in Figure 3.
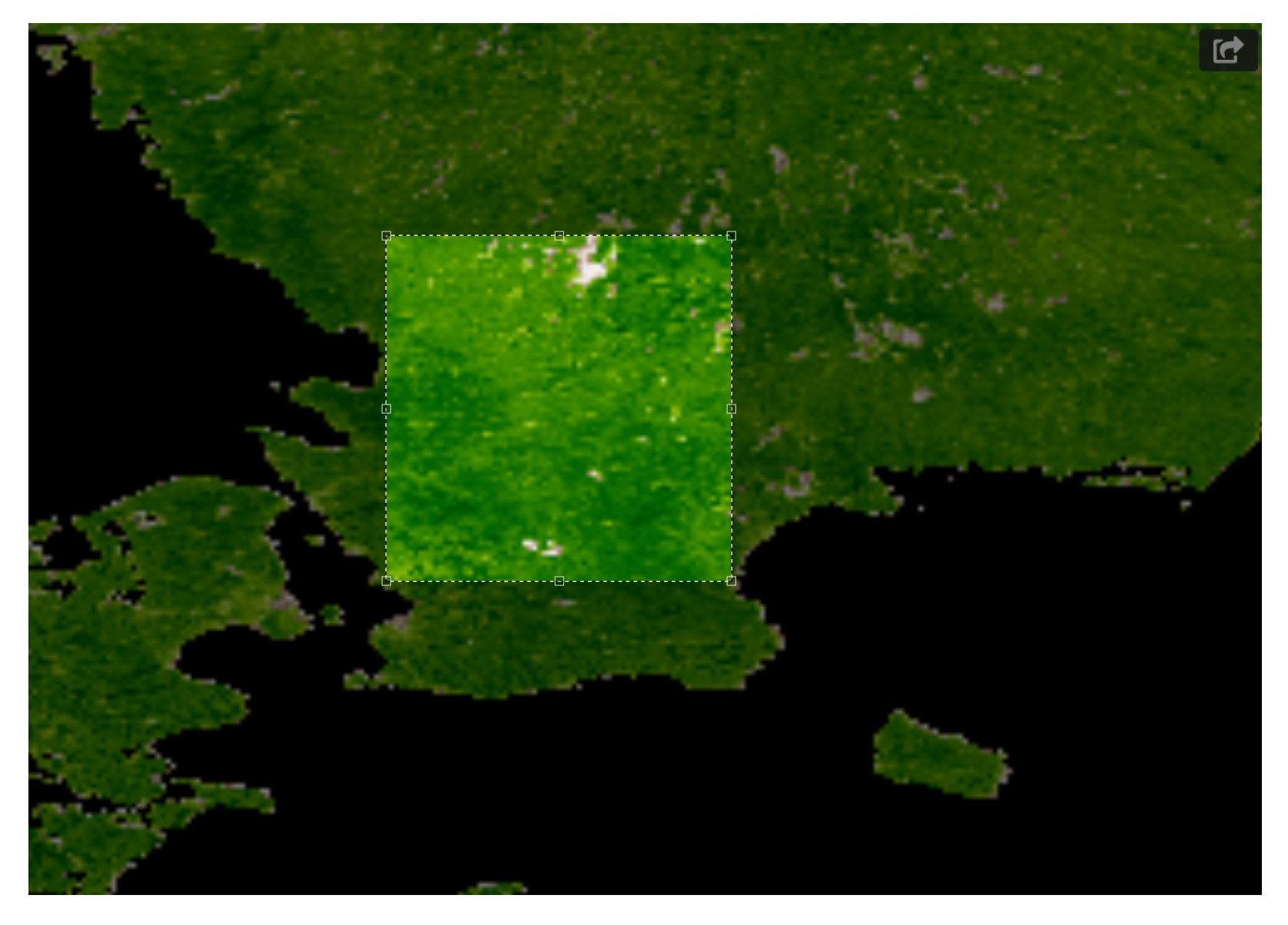
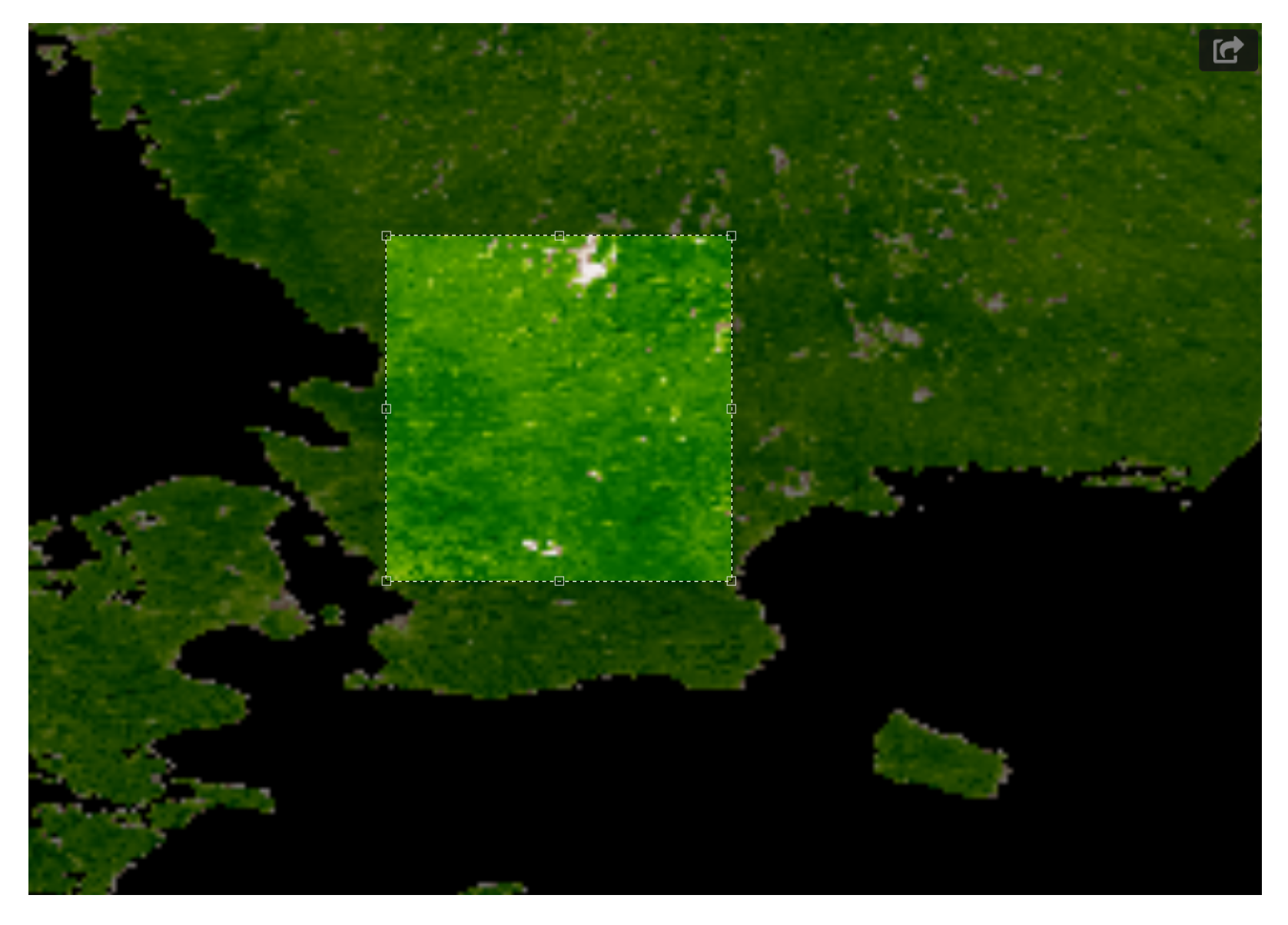
- A set of pixel images with per pixel resolution equal to 1 km. These images were acquired from the region in Sweden shown in Figure 4.
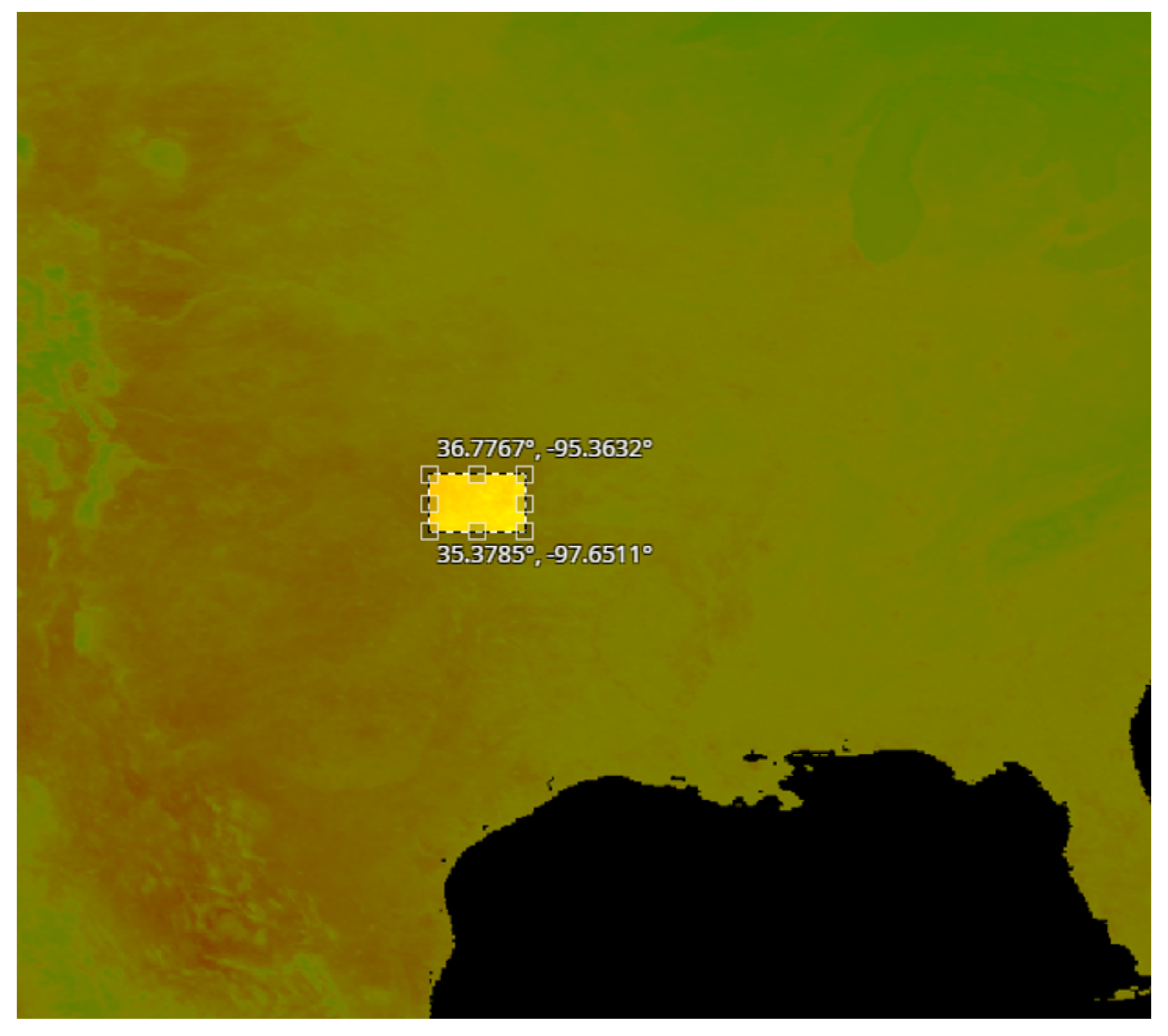
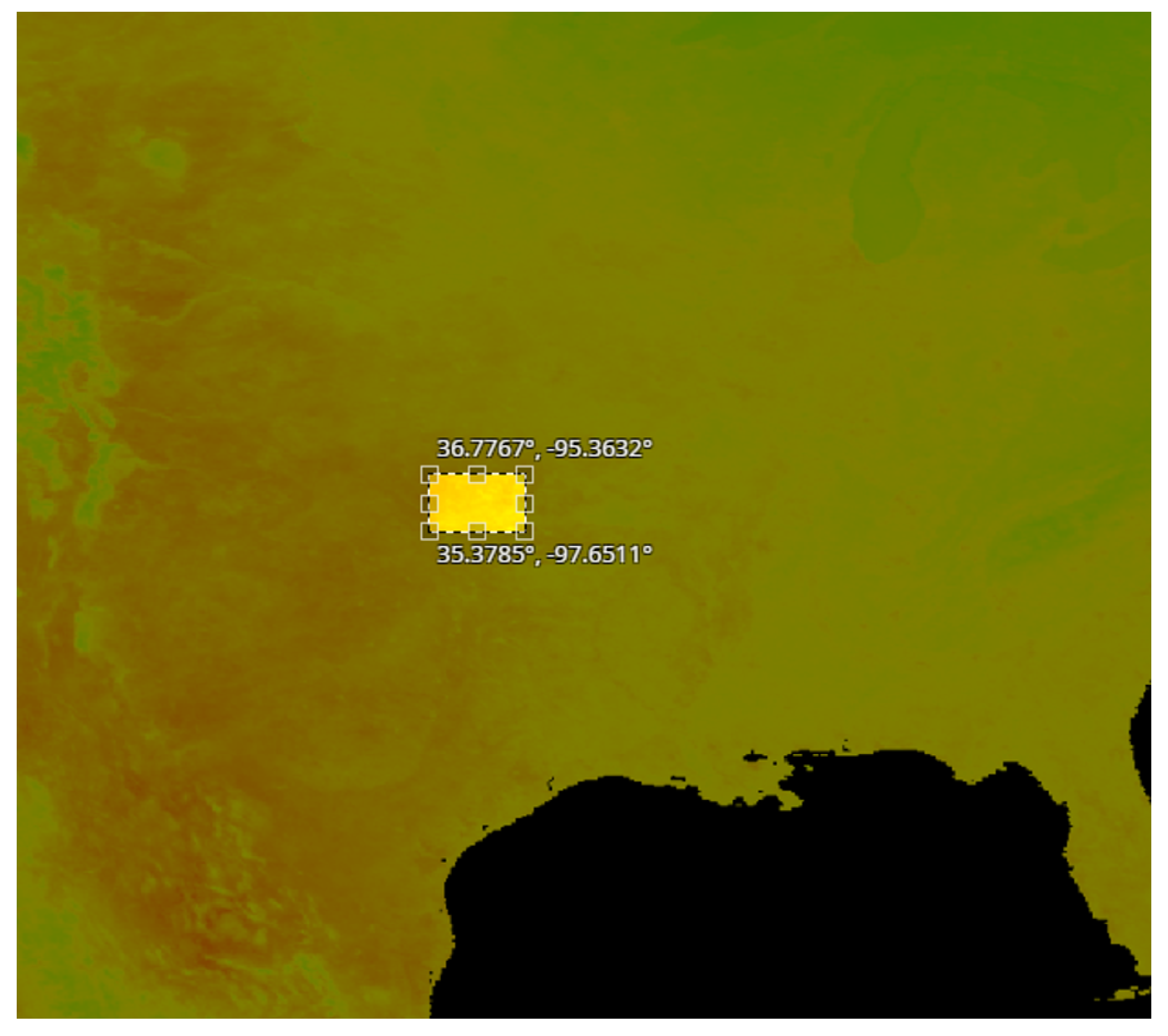
- A set of pixel images with per pixel resolution equal to 1 km. These images were acquired from the region in USA shown in Figure 5.
4. Results
4.1. Performance Evaluation Metrics
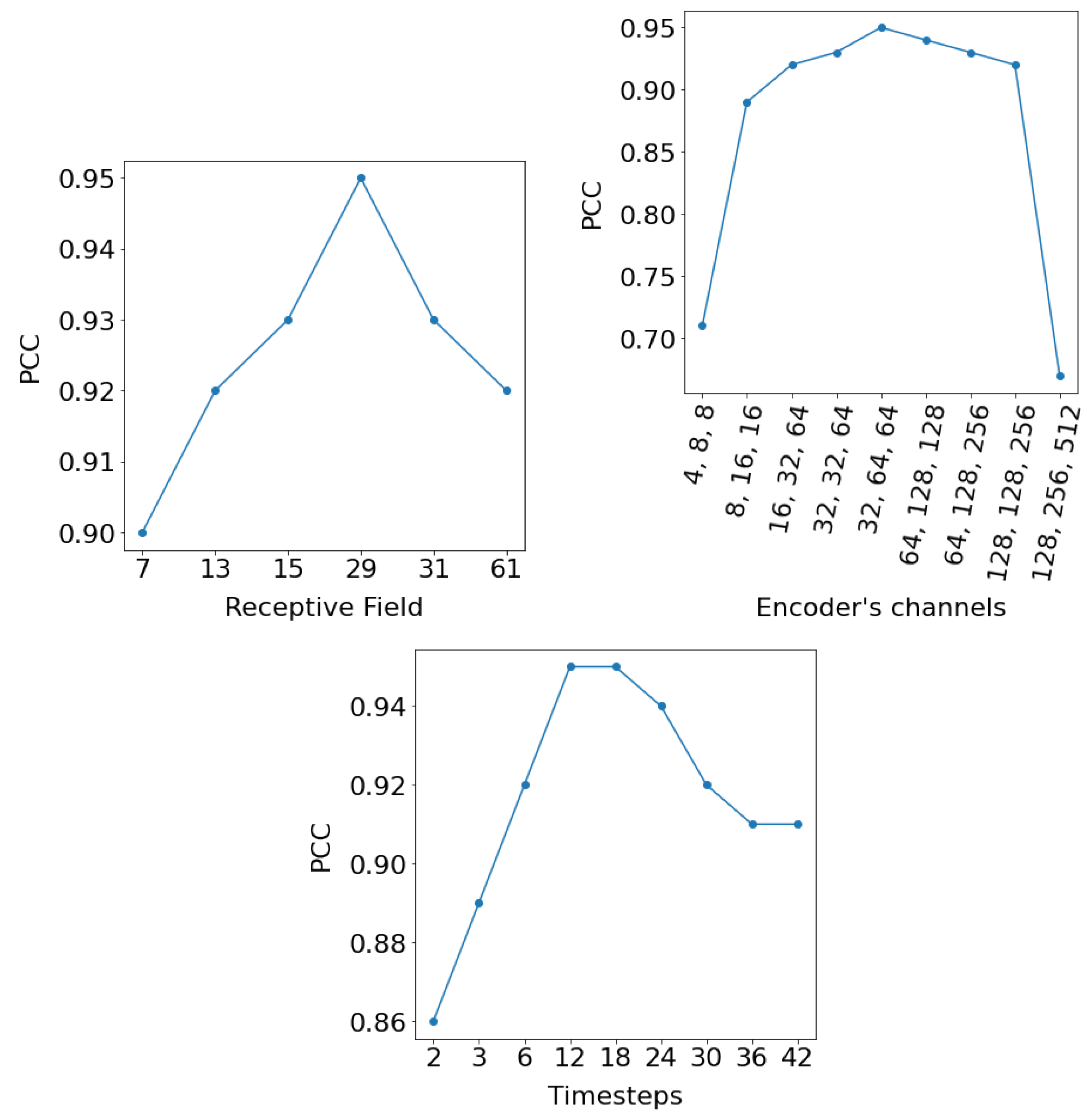
4.2. Ablation Study
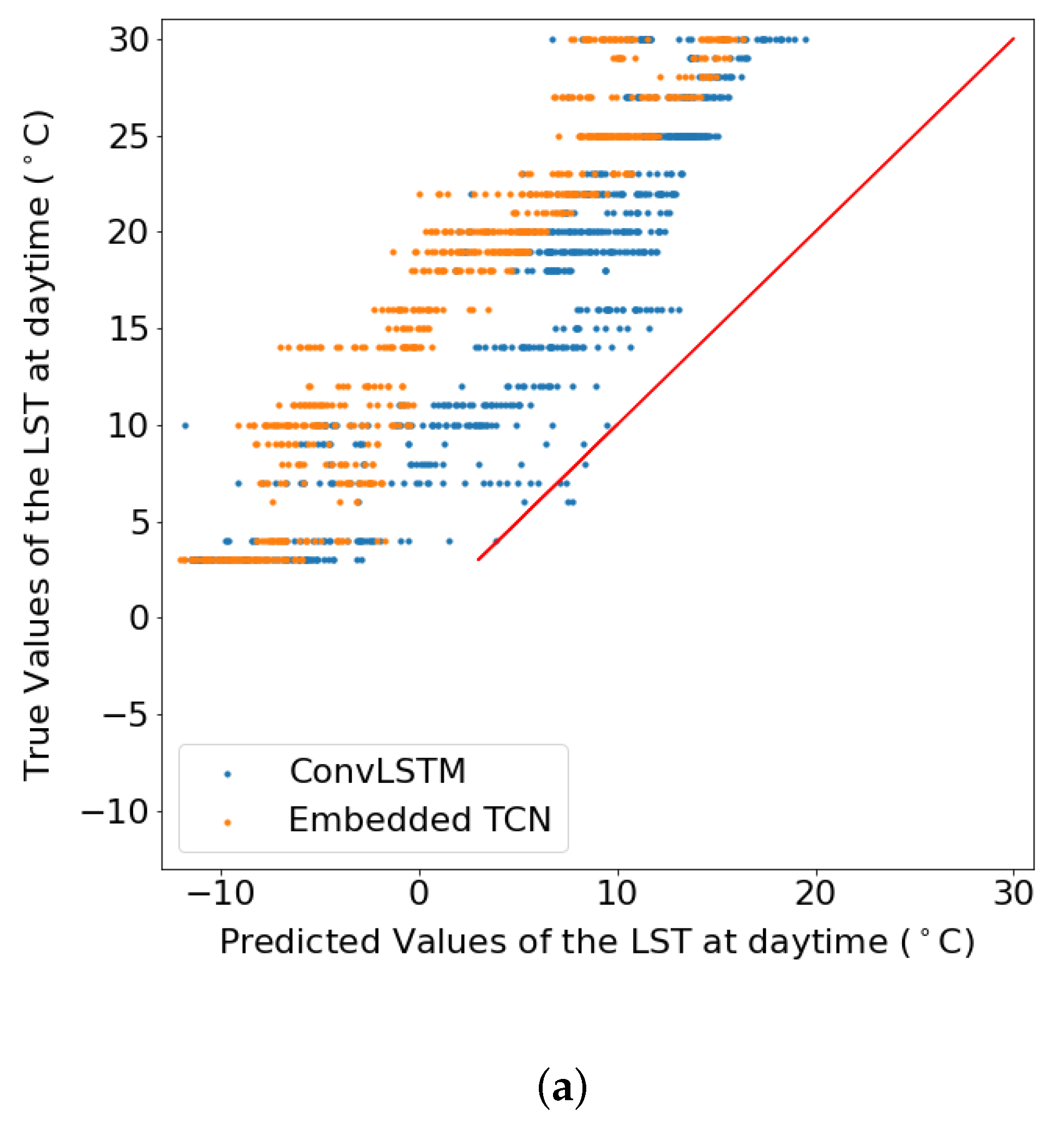
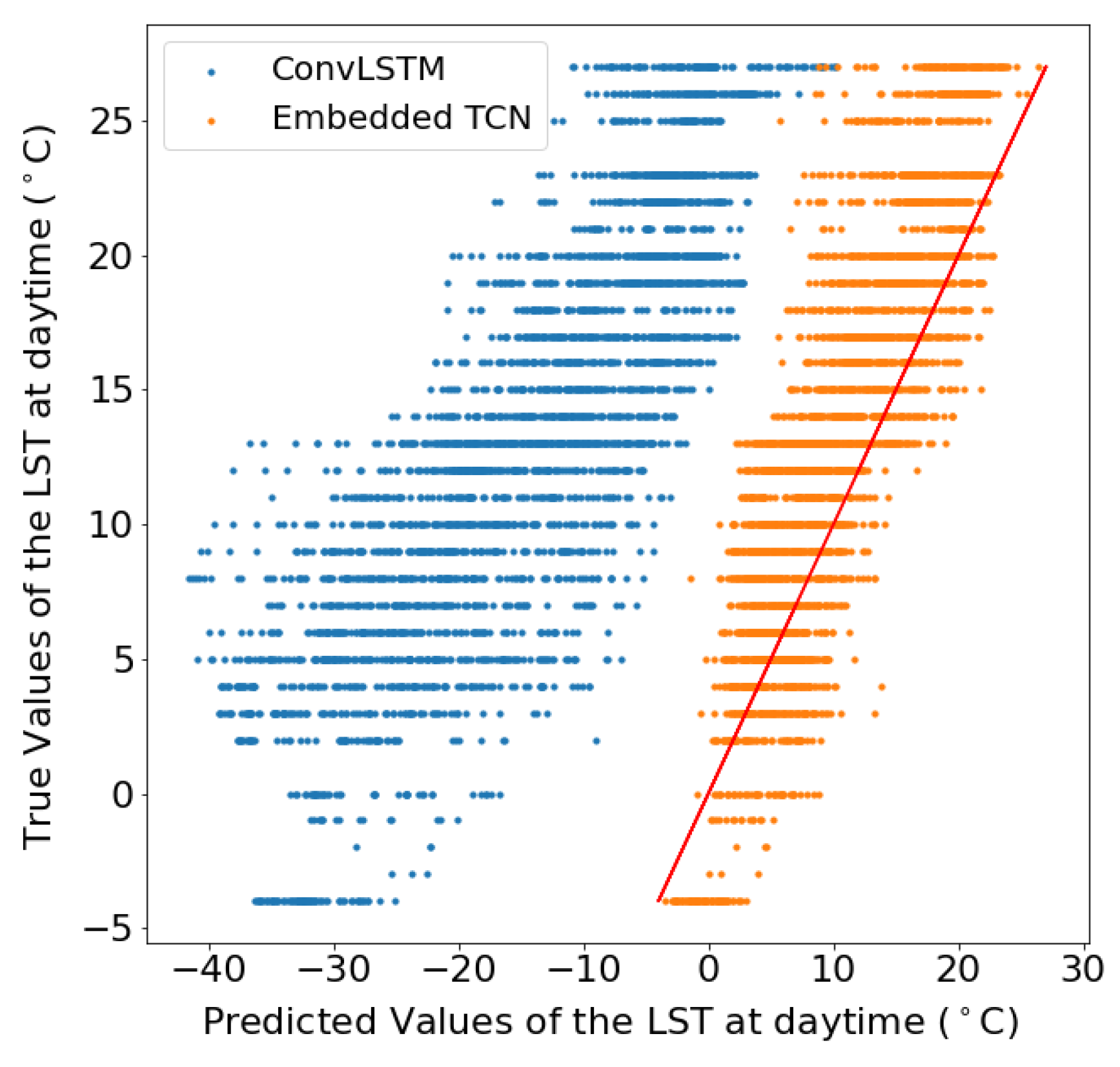
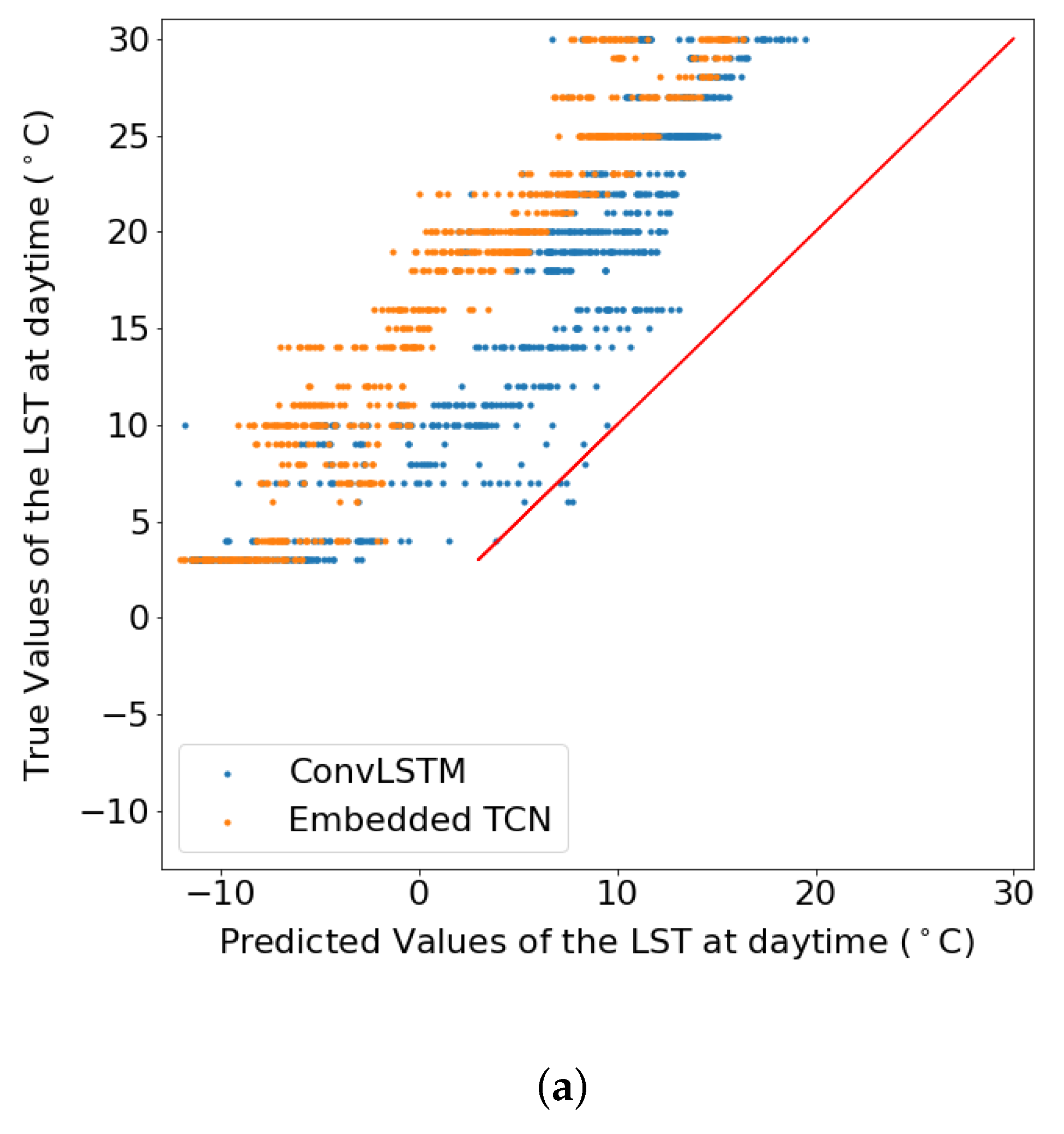
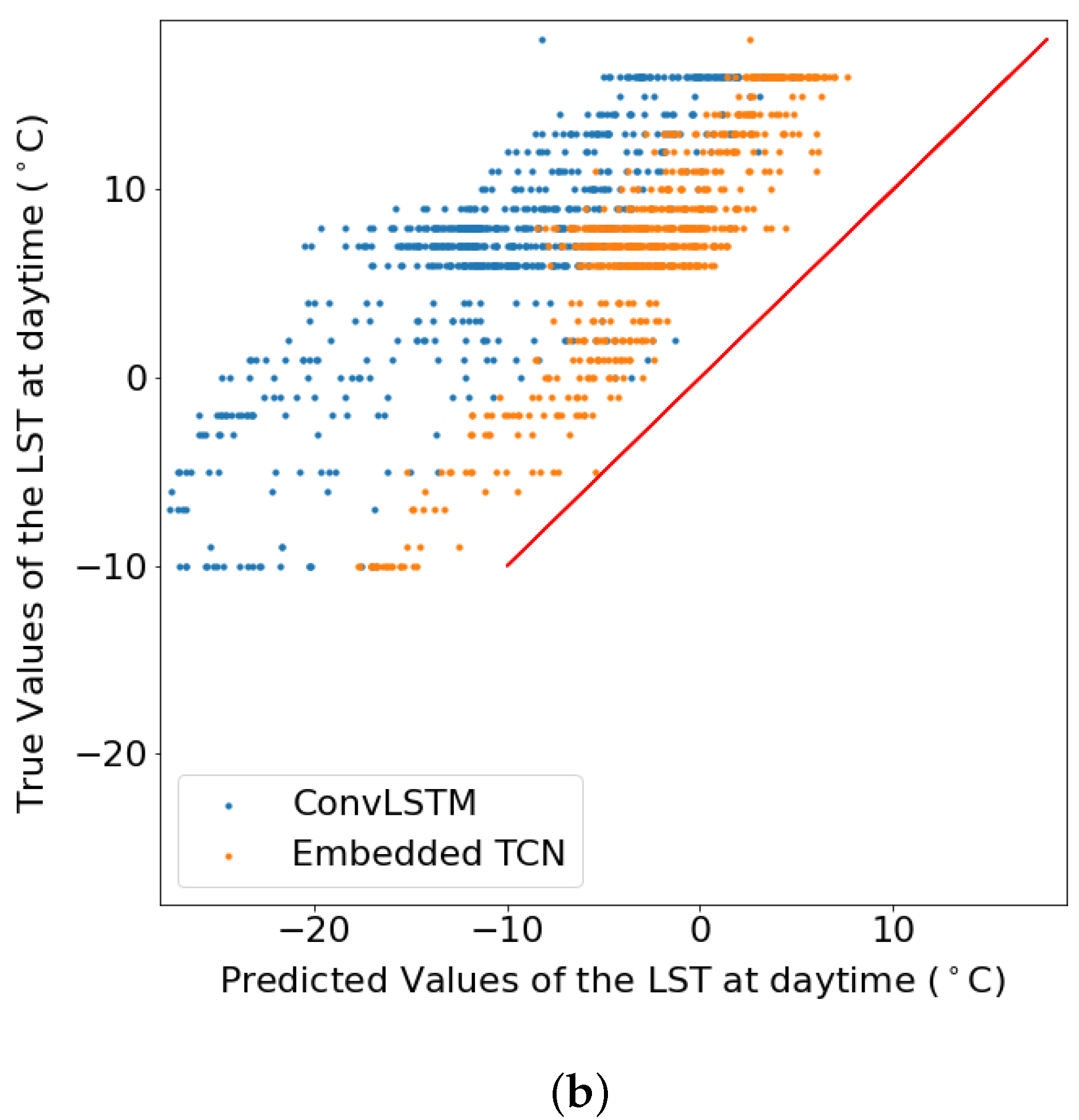
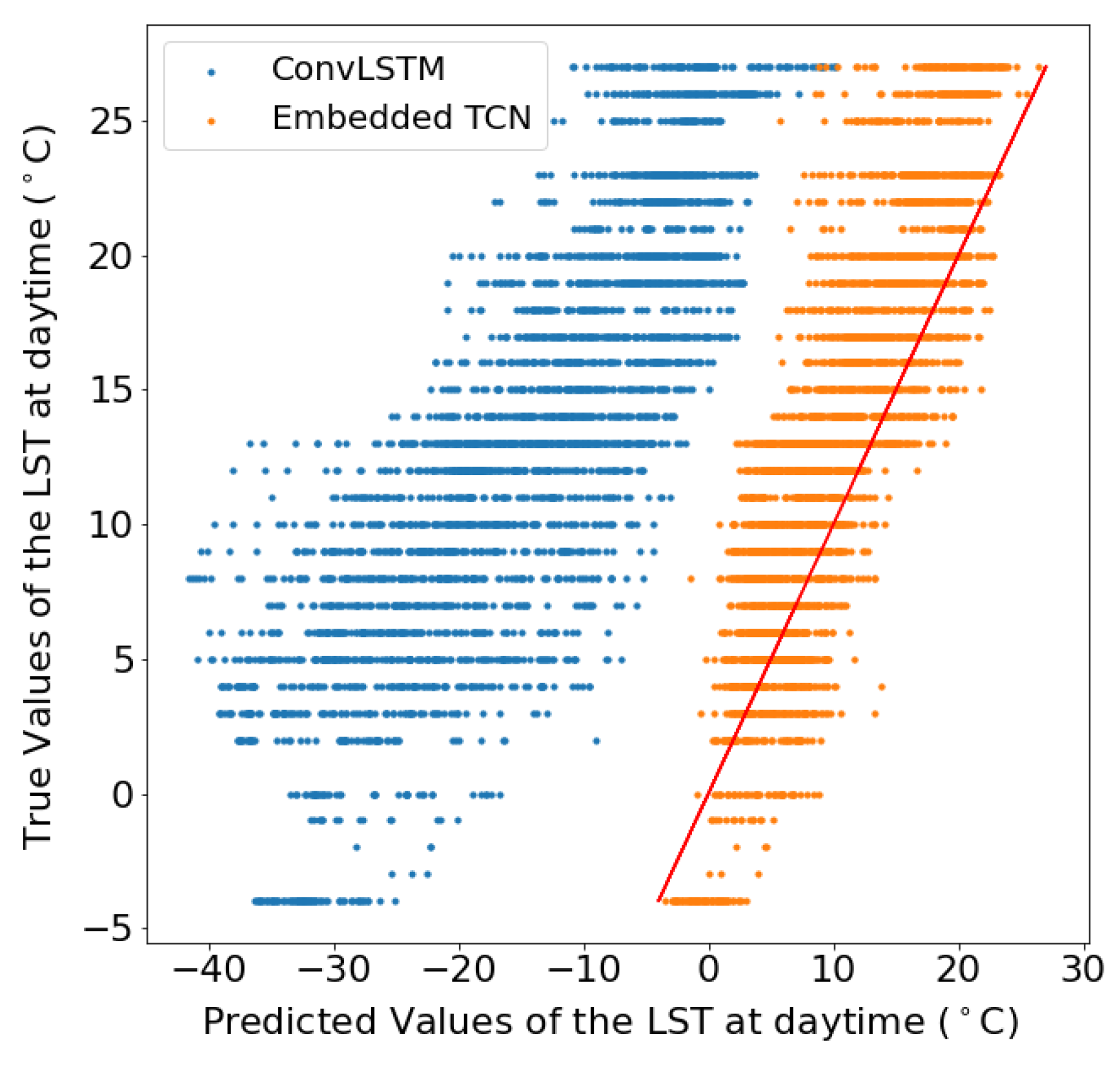
4.3. Prediction of Land Surface Temperature at Various Resolutions
4.4. Dependence on the Number of Training Examples
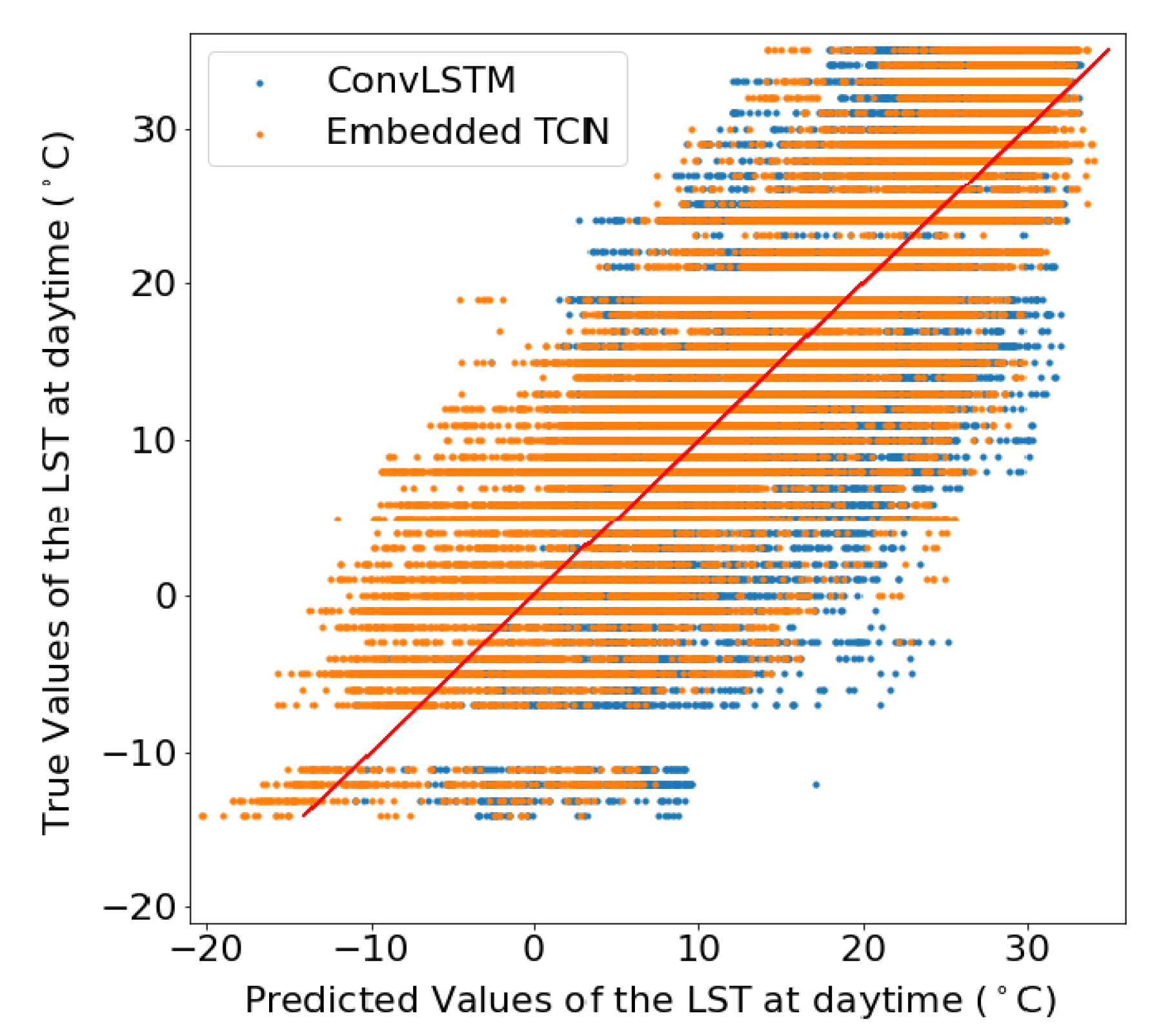
4.5. Impact of Region Size
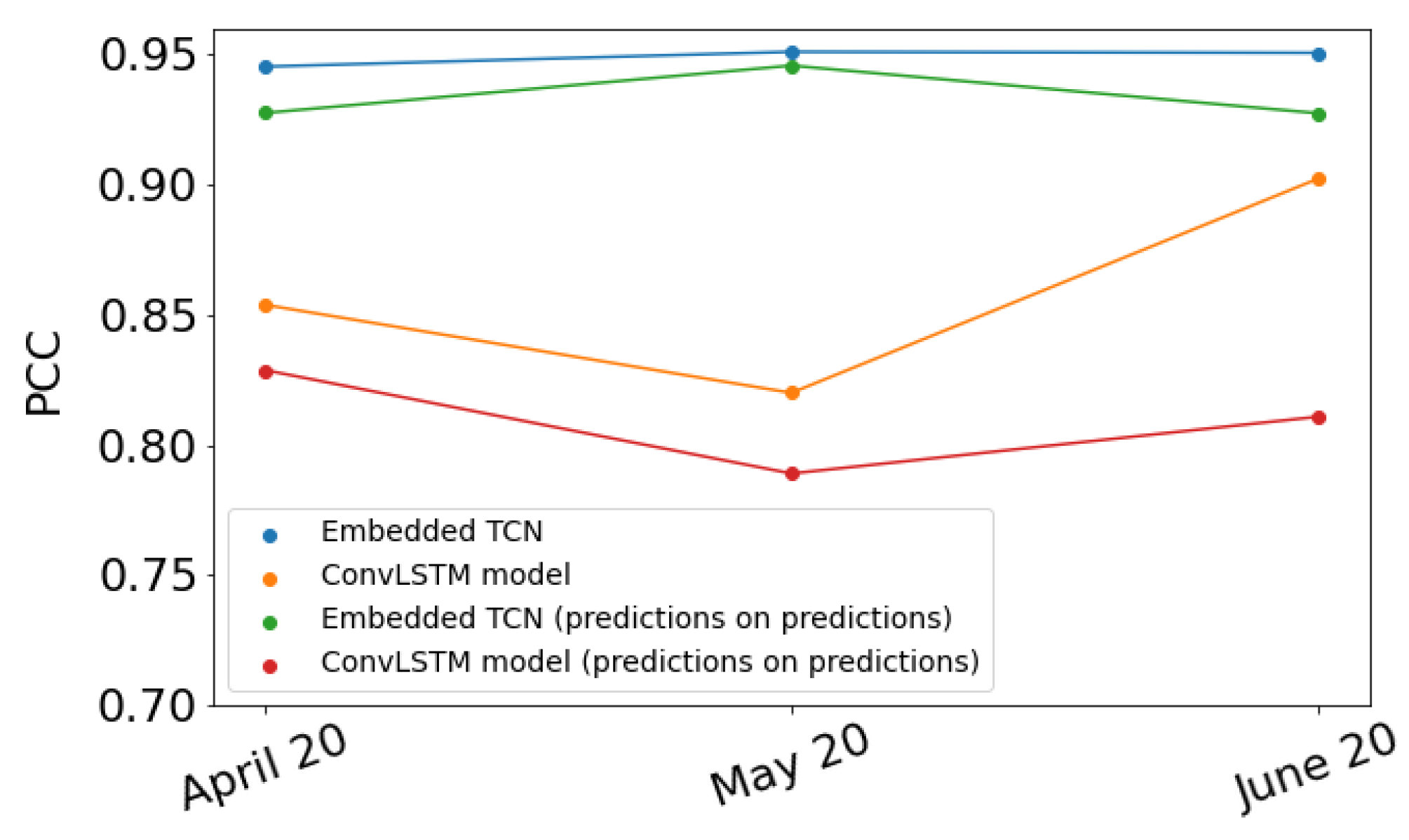
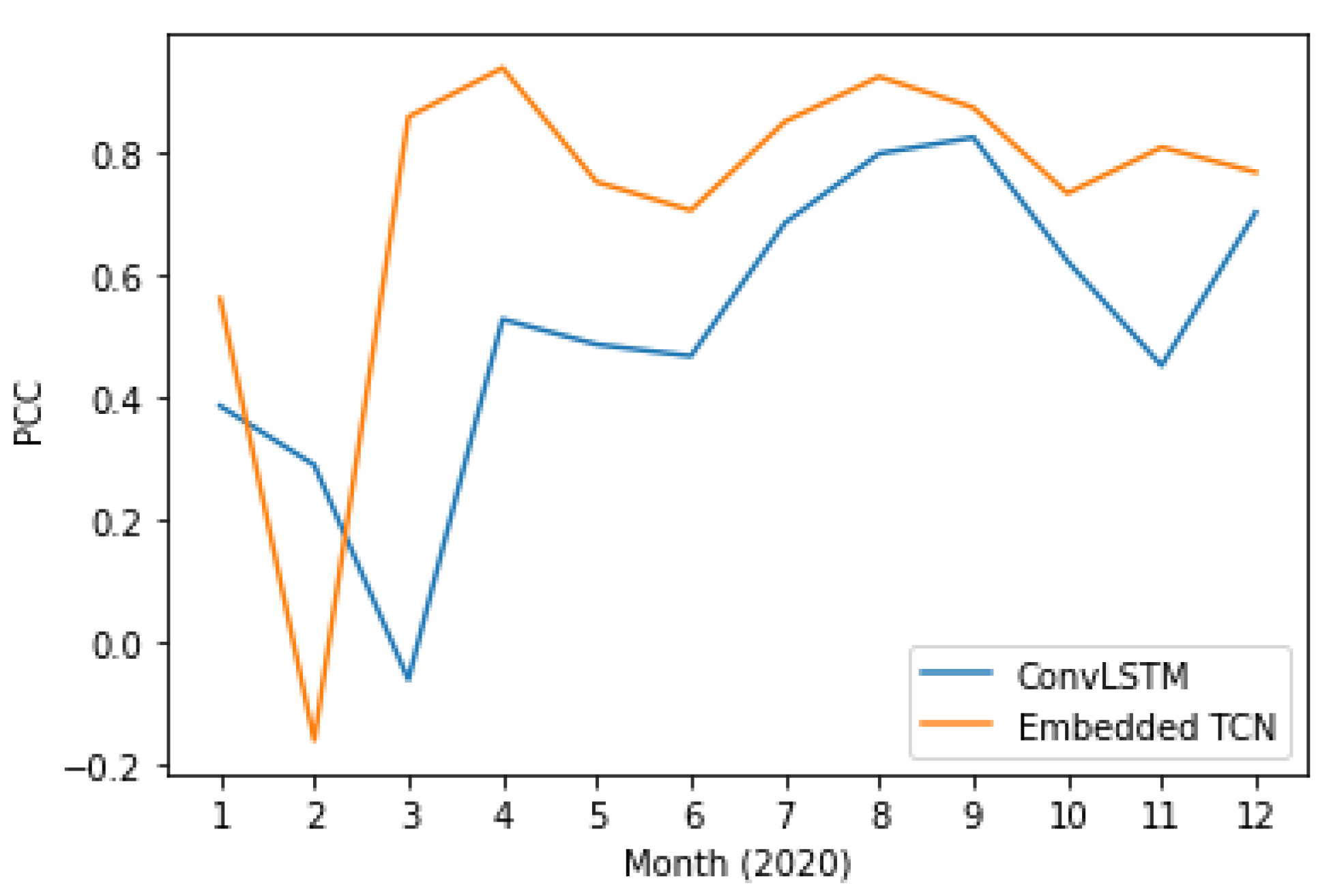
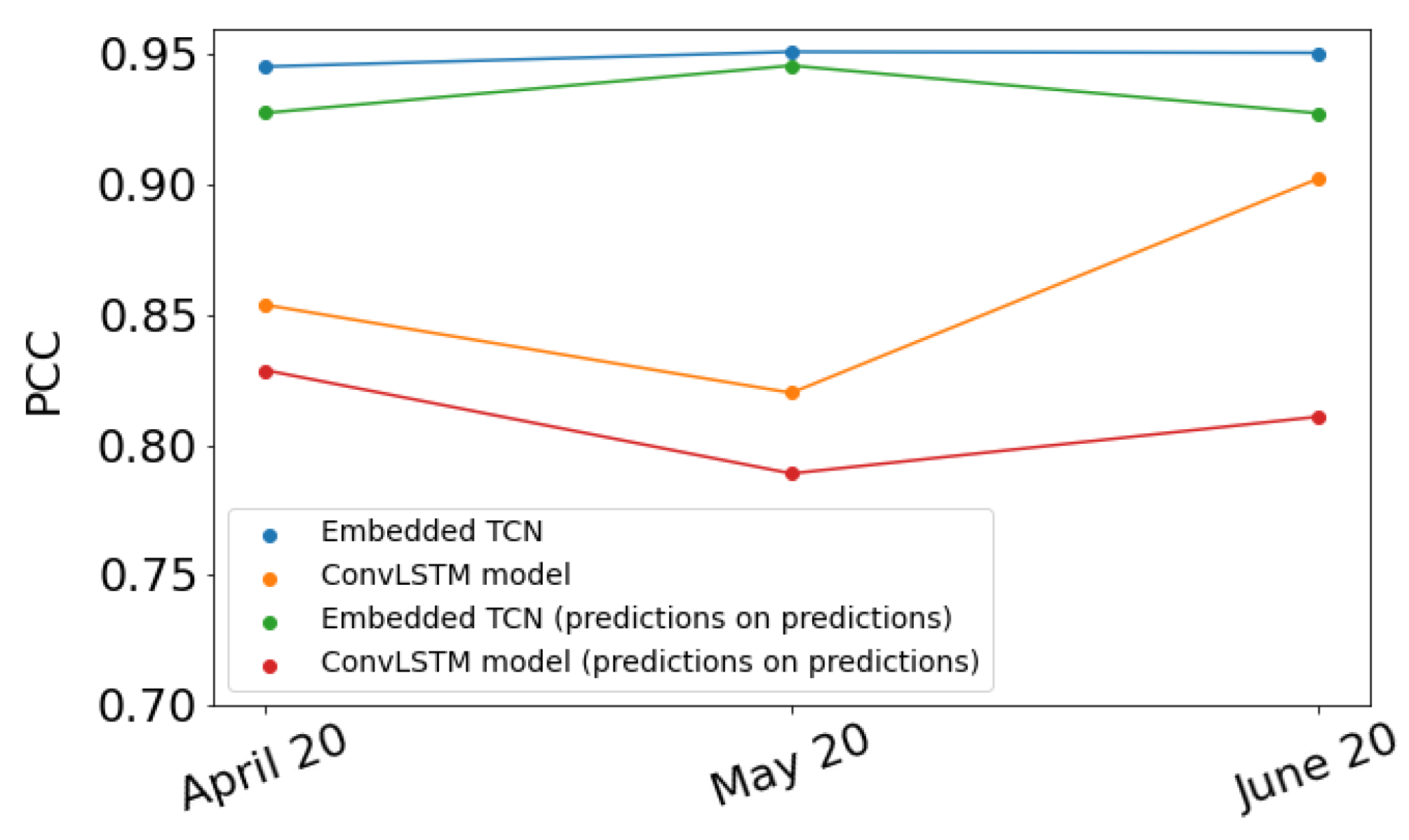
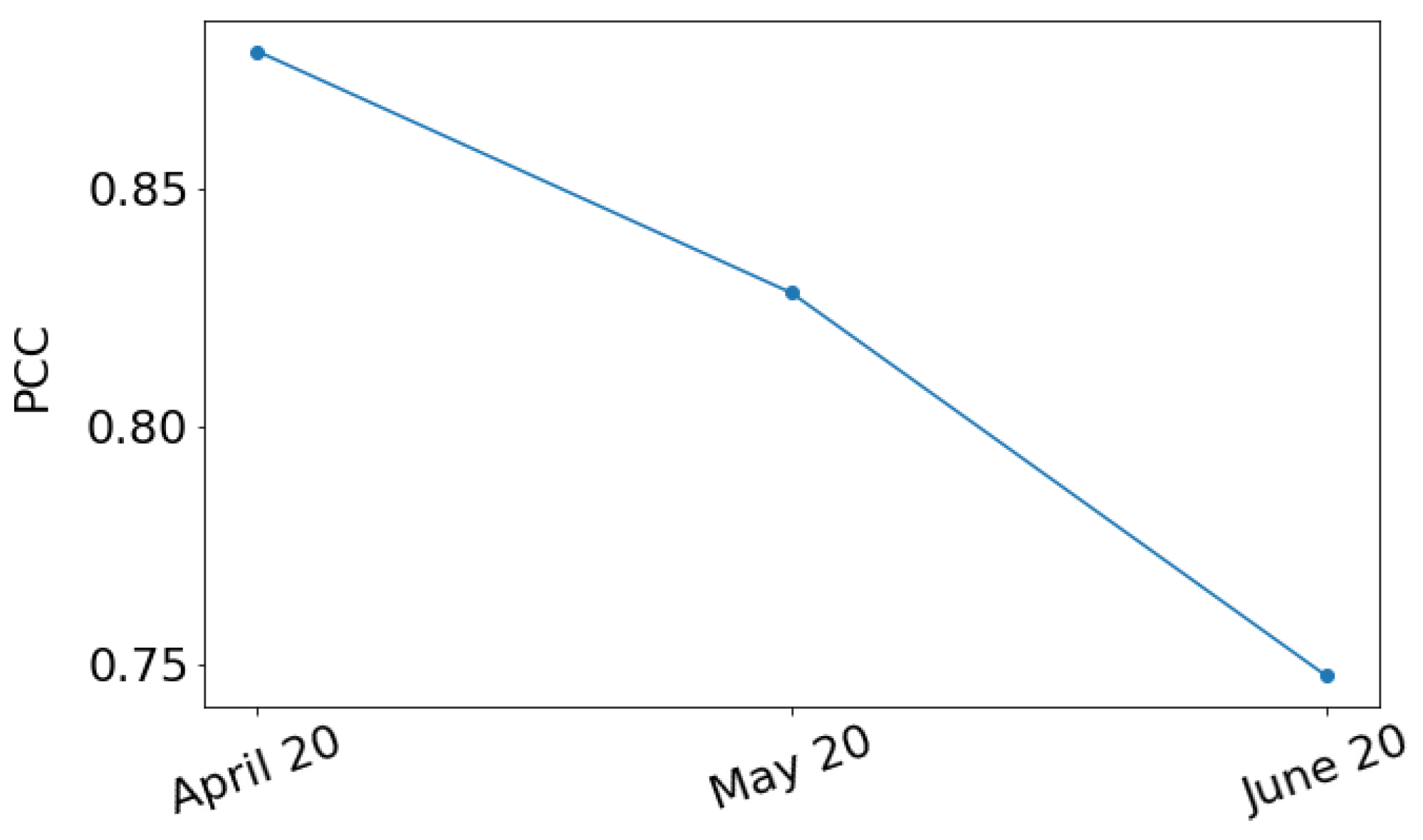
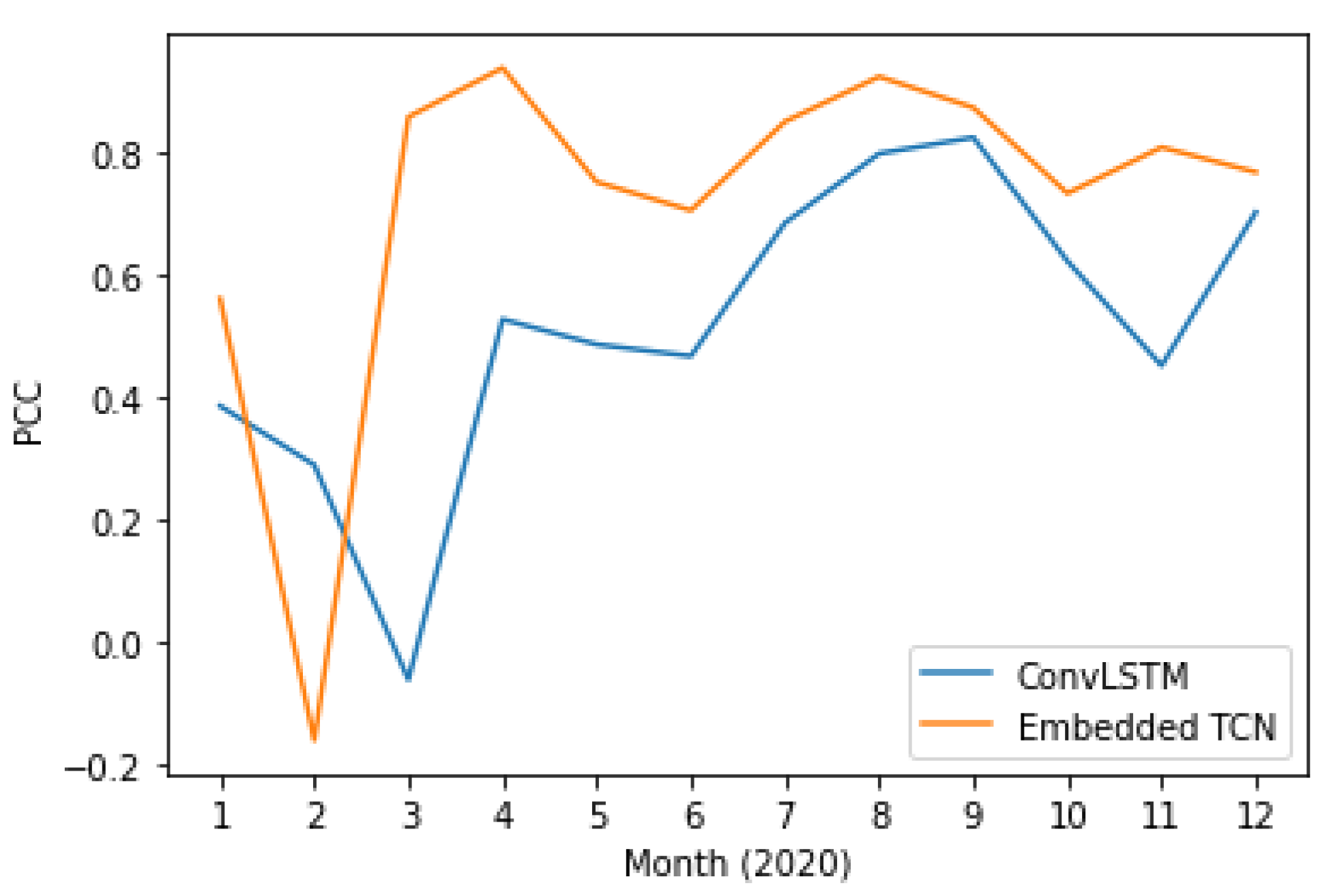
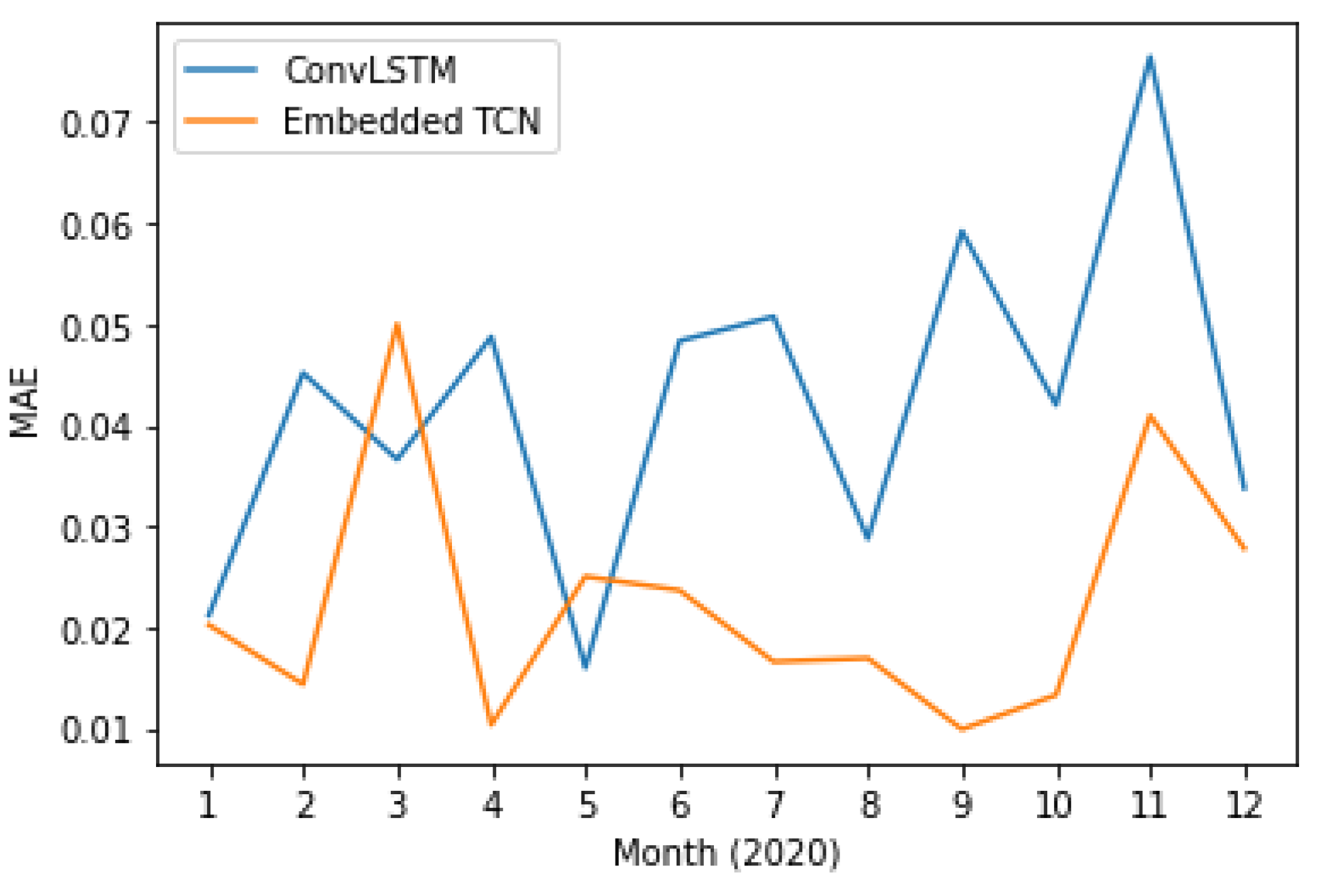
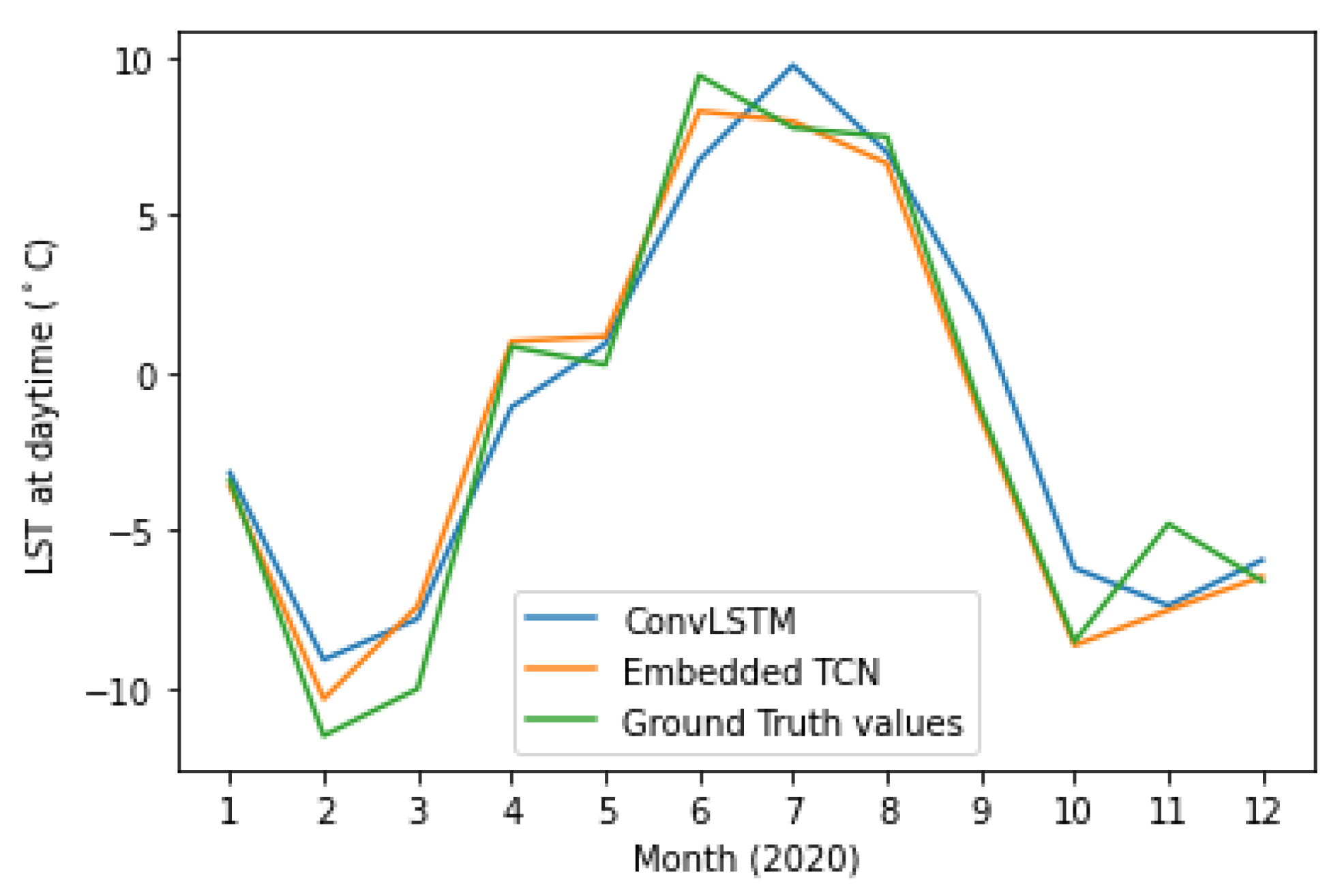
4.6. Evaluation on Different Time Instances
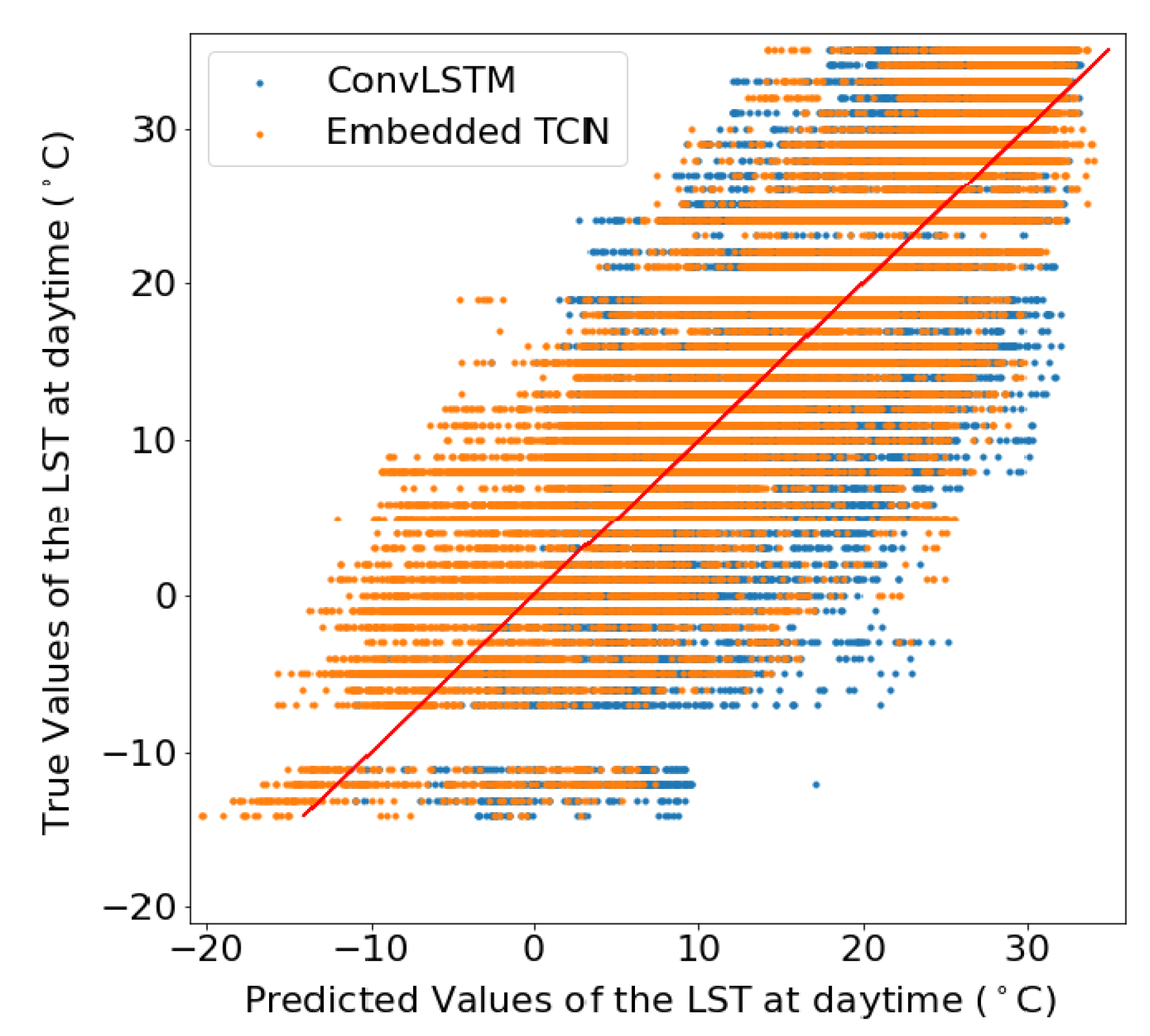
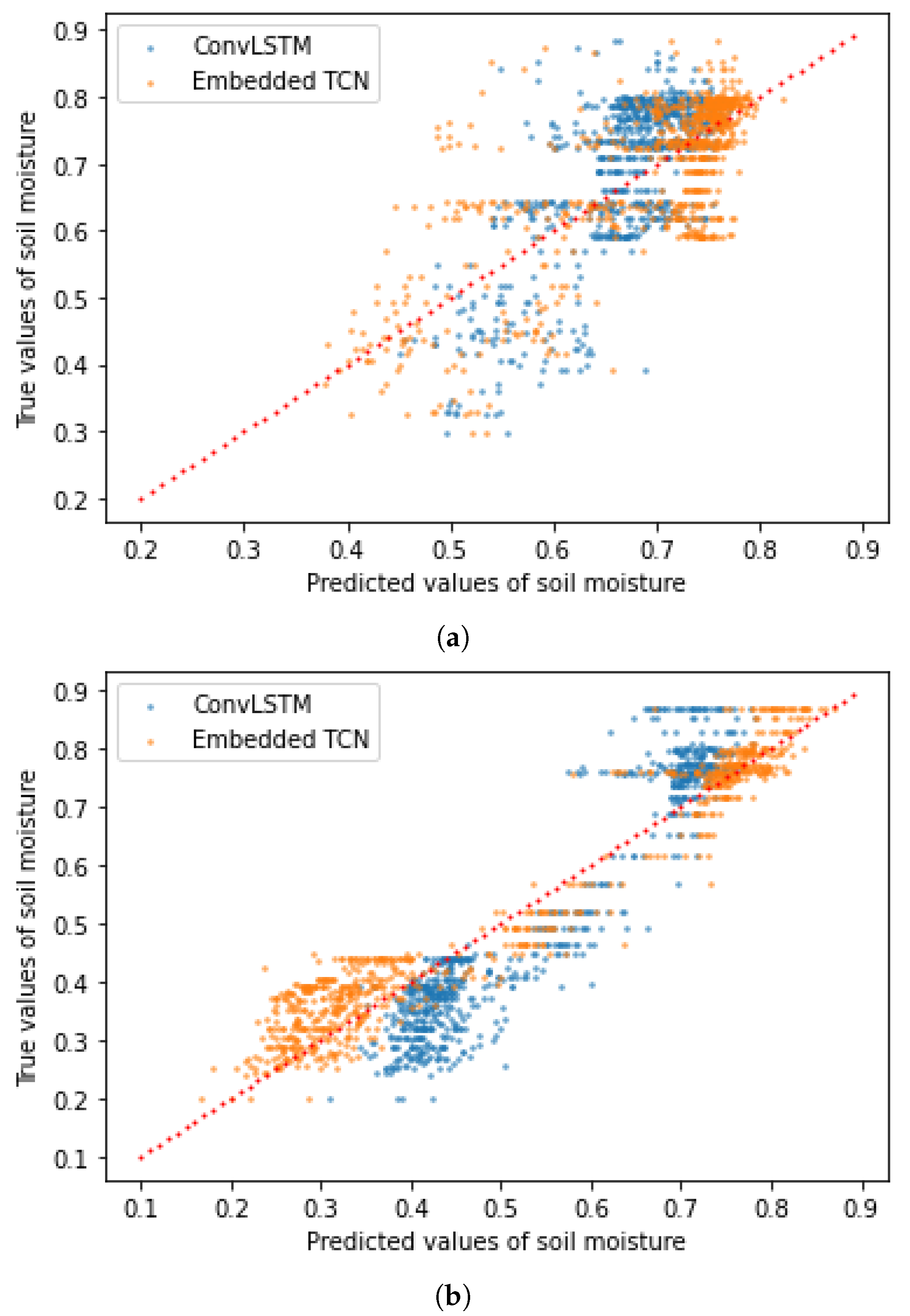
4.7. Prediction of Soil Moisture
5. Discussion
- Higher spatial resolution makes the problem more challenging.
- Prediction of large areas leads to better prediction accuracy.
- E-TCN achieved higher overall performance for both soil moisture and surface temperature.
- E-TCN achieved better performance in term of prediction quality with respect to training set size.
- E-TCN are characterized by a smaller number of parameters, and thus less prone to overfitting.
- E-TCN is a more compact network (in term of network parameters), making it more appealing for real-time/large-scale applications.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Frieler, K.; Lange, S.; Piontek, F.; Reyer, C.P.; Schewe, J.; Warszawski, L.; Zhao, F.; Chini, L.; Denvil, S.; Emanuel, K.; et al. Assessing the impacts of 1.5 C global warming–simulation protocol of the Inter-Sectoral Impact Model Intercomparison Project (ISIMIP2b). Geosci. Model Dev. 2017, 10, 4321–4345. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Gong, P.; Fu, R.; Zhang, M.; Chen, J.; Liang, S.; Xu, B.; Shi, J.; Dickinson, R. The role of satellite remote sensing in climate change studies. Nat. Clim. Chang. 2013, 3, 875–883. [Google Scholar] [CrossRef]
- Bojinski, S.; Verstraete, M.; Peterson, T.C.; Richter, C.; Simmons, A.; Zemp, M. The concept of essential climate variables in support of climate research, applications, and policy. Bull. Am. Meteorol. Soc. 2014, 95, 1431–1443. [Google Scholar] [CrossRef]
- Massonnet, F.; Bellprat, O.; Guemas, V.; Doblas-Reyes, F.J. Using climate models to estimate the quality of global observational data sets. Science 2016, 354, 452–455. [Google Scholar] [CrossRef]
- Huntingford, C.; Jeffers, E.S.; Bonsall, M.B.; Christensen, H.M.; Lees, T.; Yang, H. Machine learning and artificial intelligence to aid climate change research and preparedness. Environ. Res. Lett. 2019, 14, 124007. [Google Scholar] [CrossRef] [Green Version]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Stivaktakis, R.; Tsagkatakis, G.; Tsakalides, P. Deep learning for multilabel land cover scene categorization using data augmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1031–1035. [Google Scholar] [CrossRef]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of deep-learning approaches for remote sensing observation enhancement. Sensors 2019, 19, 3929. [Google Scholar] [CrossRef] [Green Version]
- Kaur, G.; Saini, K.S.; Singh, D.; Kaur, M. A comprehensive study on computational pansharpening techniques for remote sensing images. Arch. Comput. Methods Eng. 2021, 28, 4961–4978. [Google Scholar] [CrossRef]
- Syariz, M.A.; Lin, C.H.; Nguyen, M.V.; Jaelani, L.M.; Blanco, A.C. WaterNet: A convolutional neural network for chlorophyll-a concentration retrieval. Remote Sens. 2020, 12, 1966. [Google Scholar] [CrossRef]
- Tsagkatakis, G.; Moghaddam, M.; Tsakalides, P. Deep multi-modal satellite and in-situ observation fusion for Soil Moisture retrieval. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 6339–6342. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Gers, F.A.; Schmidhuber, J. Recurrent nets that time and count. In Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks. IJCNN 2000. Neural Computing: New Challenges and Perspectives for the New Millennium, Como, Italy, 27 July 2000; Volume 3, pp. 189–194. [Google Scholar]
- Schmidhuber, J.; Wierstra, D.; Gomez, F.J. Evolino: Hybrid Neuroevolution/Optimal Linear Search for Sequence Learning. In Proceedings of the 19th International Joint Conference on Artificial intelligence, IJCAI, Edinburgh, UK, 30 July–5 August 2005. [Google Scholar]
- Graves, A.; Mohamed, A.-R.; Hinton, G.E. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Aspri, M.; Tsagkatakis, G.; Tsakalides, P. Distributed Training and Inference of Deep Learning Models for Multi-Modal Land Cover Classification. Remote Sens. 2020, 12, 2670. [Google Scholar] [CrossRef]
- Bittner, K.; Cui, S.; Reinartz, P. Building extraction from remote sensing data using fully convolutional networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-ISPRS Arch. 2017, 42, 481–486. [Google Scholar] [CrossRef] [Green Version]
- Tsagkatakis, G.; Moghaddam, M.; Tsakalides, P. Multi-Temporal Convolutional Neural Networks for Satellite-Derived Soil Moisture Observation Enhancement. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 4602–4605. [Google Scholar]
- Tan, J.; NourEldeen, N.; Mao, K.; Shi, J.; Li, Z.; Xu, T.; Yuan, Z. Deep learning convolutional neural network for the retrieval of land surface temperature from AMSR2 data in China. Sensors 2019, 19, 2987. [Google Scholar] [CrossRef] [Green Version]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.k.; Woo, W.c. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. arXiv 2015, arXiv:1506.04214. [Google Scholar]
- Kim, S.; Hong, S.; Joh, M.; Song, S.k. DeepRain: ConvLSTM Network for Precipitation Prediction using Multichannel Radar Data. arXiv 2017, arXiv:1711.02316. [Google Scholar]
- Xiao, C.; Chen, N.; Hu, C.; Wang, K.; Xu, Z.; Cai, Y.; Xu, L.; Chen, Z.; Gong, J. A spatiotemporal deep learning model for sea surface temperature field prediction using time-series satellite data. Environ. Model. Softw. 2019, 120, 104502. [Google Scholar] [CrossRef]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks for Action Segmentation and Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1003–1012. [Google Scholar]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.W.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Kalchbrenner, N.; Espeholt, L.; Simonyan, K.; van den Oord, A.; Graves, A.; Kavukcuoglu, K. Neural Machine Translation in Linear Time. arXiv 2016, arXiv:1610.10099. [Google Scholar]
- Bai, S.; Zico Kolter, J.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Allan, M.; Williams, C.K.I. Harmonising Chorales by Probabilistic Inference. In Proceedings of the 17th International Conference on Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2004; pp. 25–32. [Google Scholar]
- Paperno, D.; Kruszewski, G.; Lazaridou, A.; Pham, Q.N.; Bernardi, R.; Pezzelle, S.; Baroni, M.; Boleda, G.; Fernández, R. The LAMBADA dataset: Word prediction requiring a broad discourse context. arXiv 2016, arXiv:1606.06031. [Google Scholar]
- Vega-Márquez, B.; Rubio-Escudero, C.; Nepomuceno-Chamorro, I.A.; Arcos-Vargas, Á. Use of Deep Learning Architectures for Day-Ahead Electricity Price Forecasting over Different Time Periods in the Spanish Electricity Market. Appl. Sci. 2021, 11, 6097. [Google Scholar] [CrossRef]
- Srivastava, N.; Mansimov, E.; Salakhutdinov, R. Unsupervised Learning of Video Representations using LSTMs. arXiv 2015, arXiv:1502.04681. [Google Scholar]
- Salimans, T.; Kingma, D.P. Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks. arXiv 2016, arXiv:1602.07868. [Google Scholar]
- Wan, Z. New refinements and validation of the collection-6 MODIS land-surface temperature/emissivity product. Remote Sens. Environ. 2014, 140, 36–45. [Google Scholar] [CrossRef]
- Oses, N.; Azpiroz, I.; Marchi, S.; Guidotti, D.; Quartulli, M.; G Olaizola, I. Analysis of Copernicus’ ERA5 climate reanalysis data as a replacement for weather station temperature measurements in machine learning models for olive phenology phase prediction. Sensors 2020, 20, 6381. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | W | Encoder’s Filters | 2D Conv Kernel | 1D Conv Kernel | TCN | Drop |
|---|---|---|---|---|---|---|
| 1 | 12 | 32, 64 & 64 | (4, 4) | 3 | 3 residual blocks of 64, 49 & 49 filters | 0.3 |
| 2 | 8 | 48, 48 & 96 | (4, 4) | 2 | 3 residual blocks of 96, 49 & 49 filters | 0.3 |
| 3 | 12 | 8, 16 & 16 | (6, 6) | 2 | 3 residual blocks of 225, 225 & 225 filters | 0.3 |
| 4 | 10 | 32, 64 & 64 | (4, 4) | 4 | 3 residual blocks of 64, 49 & 49 filters | 0.3 |
| 5 | 18 | 32, 64 & 64 | (4, 4) | 4 | 3 residual blocks of 64, 64 & 49 filters | 0.4 |
| Model | S.R. | PCC | MSE | ubRMSE | Parameters | Training Time |
|---|---|---|---|---|---|---|
| E-TCN | 1 km | 0.95 | 0.00091 | 0.0053 | 258,659 | 50–70 |
| ConvLSTM | 1 km | 0.90 | 0.00052 | 0.0072 | 446,913 | 430–450 |
| E-TCN | 5 km | 0.89 | 0.00038 | 0.0053 | 291,136 | 40–60 |
| ConvLSTM | 5 km | 0.82 | 0.00120 | 0.0077 | 366,701 | 340–360 |
| Number of Training Images | PCC (E-TCN) | PCC (ConvLSTM Model) |
|---|---|---|
| 89 | 0.94 | 0.85 |
| 149 | 0.93 | 0.87 |
| 209 | 0.95 | 0.90 |
| Model | PCC | MSE | ubRMSE | Parameters | Training Time |
|---|---|---|---|---|---|
| E-TCN | 0.85 | 0.000092 | 0.0078 | 926,920 | 100–130 |
| ConvLSTM | 0.83 | 0.0032 | 0.012 | 1,087,101 | 2000 |
| Model | PCC | MSE | unRMSE | Parameters | Training Time |
|---|---|---|---|---|---|
| E-TCN | 0.78 | 0.0018 | 0.028 | 277,190 | 50–60 |
| ConvLSTM | 0.59 | 0.0026 | 0.039 | 446,913 | 350–390 |
| Model | PCC | MSE | ubRMSE | Parameters |
|---|---|---|---|---|
| E-TCN (Idaho) | 0.74 | 0.0062 | 0.0828 | 343,814 |
| ConvLSTM (Idaho) | 0.71 | 0.0076 | 0.0669 | 446,913 |
| E-TCN (Arkansas) | 0.97 | 0.0431 | 0.0030 | 343,814 |
| ConvLSTM (Arkansas) | 0.95 | 0.0738 | 0.0078 | 446,913 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villia, M.M.; Tsagkatakis, G.; Moghaddam, M.; Tsakalides, P. Embedded Temporal Convolutional Networks for Essential Climate Variables Forecasting. Sensors 2022, 22, 1851. https://doi.org/10.3390/s22051851
Villia MM, Tsagkatakis G, Moghaddam M, Tsakalides P. Embedded Temporal Convolutional Networks for Essential Climate Variables Forecasting. Sensors. 2022; 22(5):1851. https://doi.org/10.3390/s22051851
Chicago/Turabian StyleVillia, Maria Myrto, Grigorios Tsagkatakis, Mahta Moghaddam, and Panagiotis Tsakalides. 2022. "Embedded Temporal Convolutional Networks for Essential Climate Variables Forecasting" Sensors 22, no. 5: 1851. https://doi.org/10.3390/s22051851
APA StyleVillia, M. M., Tsagkatakis, G., Moghaddam, M., & Tsakalides, P. (2022). Embedded Temporal Convolutional Networks for Essential Climate Variables Forecasting. Sensors, 22(5), 1851. https://doi.org/10.3390/s22051851