1. Introduction
Cognitive decline is a common health issue among aging populations [
1]. Memory loss and forgetfulness are part of the normal aging process; however, memory loss that affects daily life can be a symptom of dementia [
2]. Neurodegeneration is a common cause of dementia [
3]; its symptoms vary among individuals and include memory loss, deterioration of speech, motor skills, and cognitive function [
4]. Mild cognitive impairment (MCI) is a condition between normal age-associated memory impairment and dementia [
5]. It causes cognitive problems that are noticeable to individuals and those close to them, but does not impact daily life activities. MCI is believed to be a high-risk condition for the development of Alzheimer’s disease (AD) [
6], and the early detection of MCI allows for health professionals to better plan for and treat individuals at risk of developing AD or other types of dementia.
Numerous screening tools have been developed for detecting dementia. Among them, the mini-mental state examination (MMSE) [
7] is the most widely used, but difficulties have been reported in detecting early dementia. To address this problem, the Montreal cognitive assessment (MoCA) was developed to screen patients with MCI, while performing on a normal range of MMSE [
8]. The MoCA showed a sensitivity of 90% whereas the MMSE had a sensitivity of 18% in identifying MCI patients with memory loss [
9]. MoCA assesses several parts of brain function, such as short-term memory, visuospatial abilities, executive function, attention, concentration and working memory, language, and orientation; it is available in both paper and digital formats. However, data collection and scoring require extensive assistance by health professionals, and further data analysis is limited to text input only.
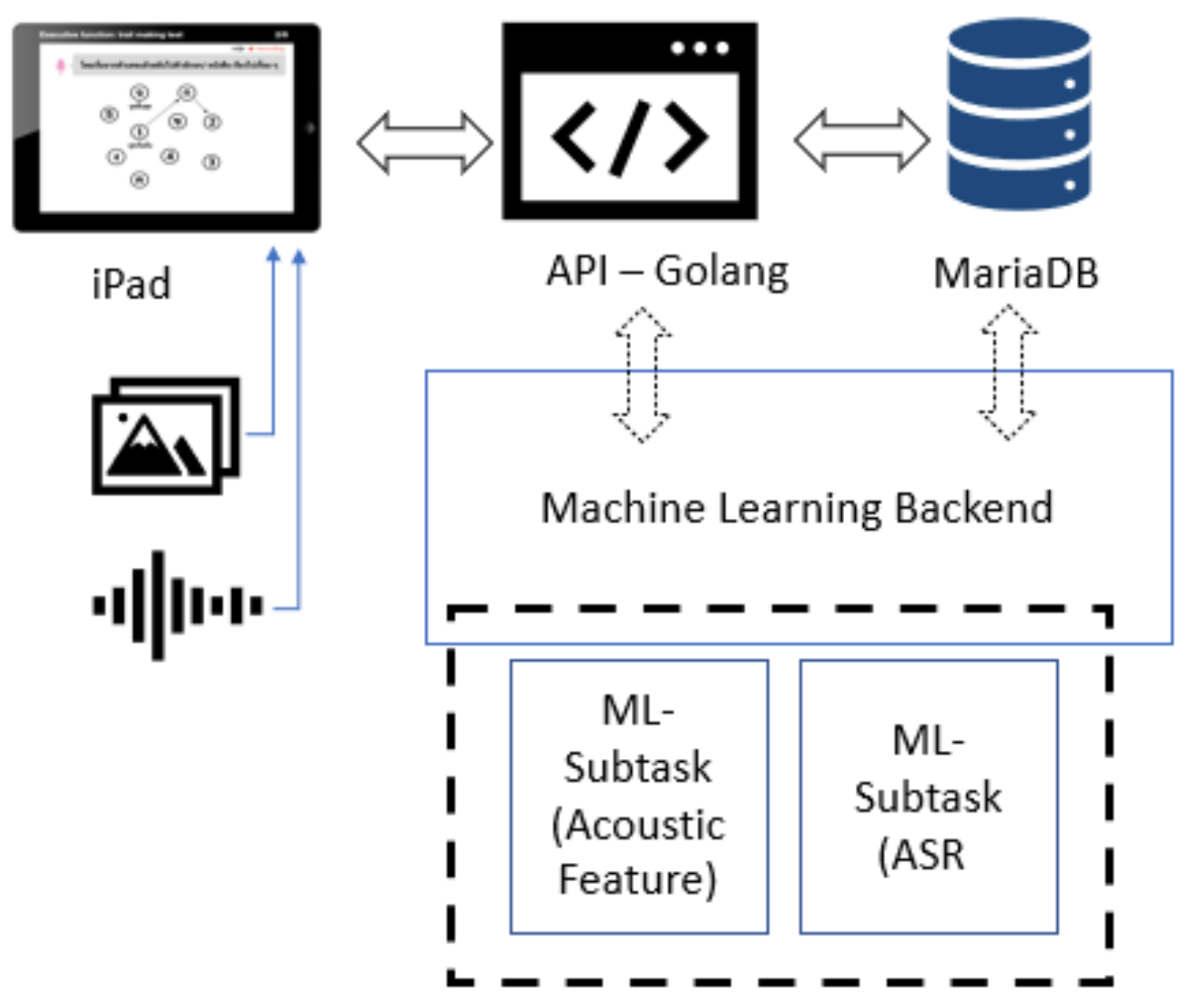
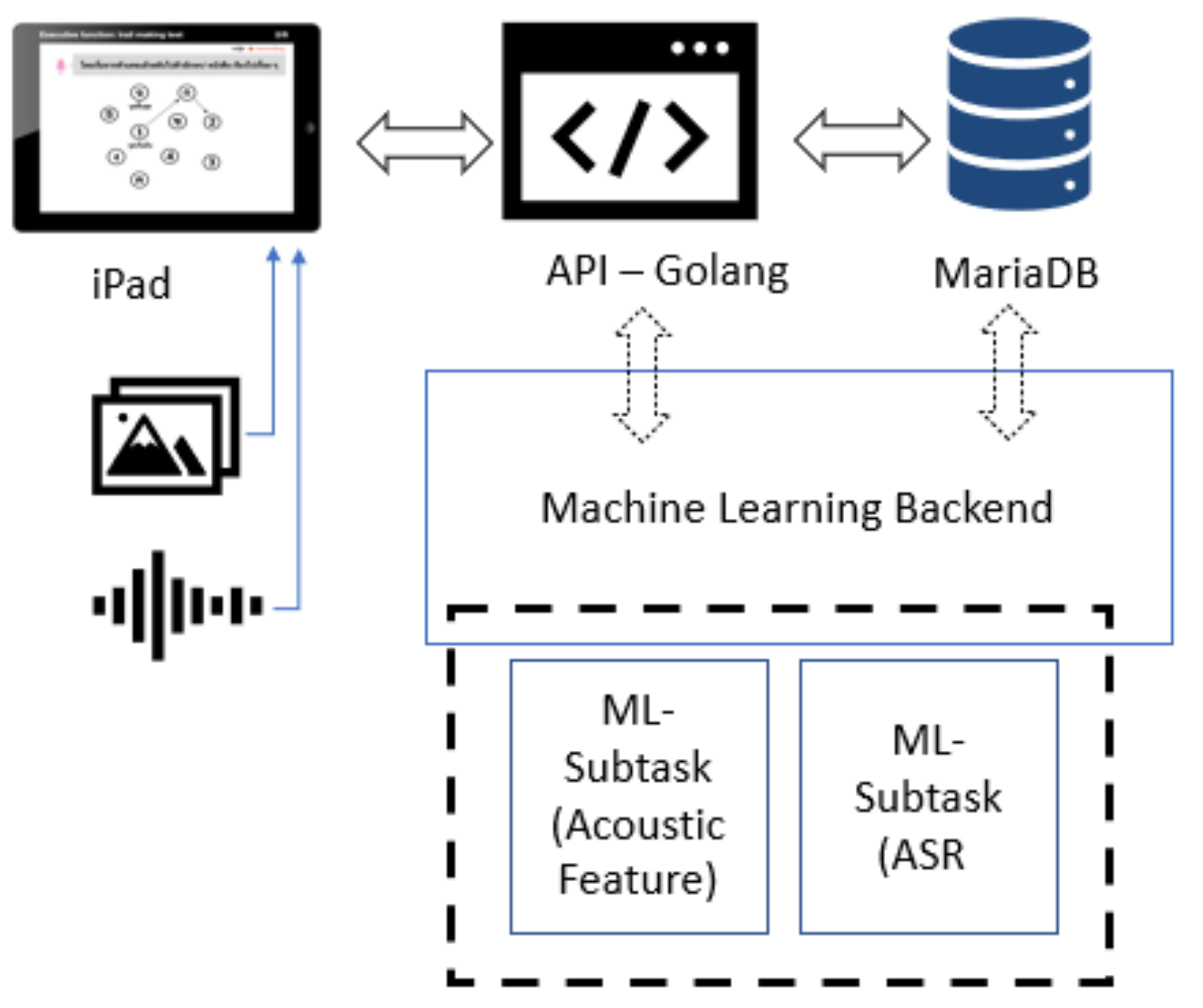
MoCA is available in two versions: a standard paper-and-pencil version and an electronic version. Using the electronic version enables opportunities for utilizing technology such as artificial intelligence (AI) to significantly improve the efficiency and quality of cognitive assessment. To address the limitations of the standard MoCA test procedure for Thai, researchers from the Faculty of Medicine in collaboration with the Department of Computer Engineering at Chulalongkorn University initiated a new project to develop a customized version of MoCA as an iPad application called “Digital MoCA”, which provides Thai language support. Their main goal was to enable automatic data collection and utilize machine learning techniques for the early detection of MCI patients in Thailand.
Digital MoCA is based on the standard MoCA test criteria with Thai language support, including automatic data collection and scoring with limited assistance from health professionals. The automatic data collection of voice recording and drawing input enable further data analysis using machine learning techniques for better understanding MCI risk factors. Since the composition of this paper, digital MoCA is still in the early phase of development with a prototype version under evaluation by a group of physicians and a health professional team. This study is a sub-project of the project initiative to utilize new AI techniques for MCI detection improvement.
Digital MoCA’s automatic data collection of voice recording and drawing input enable further data analysis using machine learning techniques to better understand MCI risk factors.
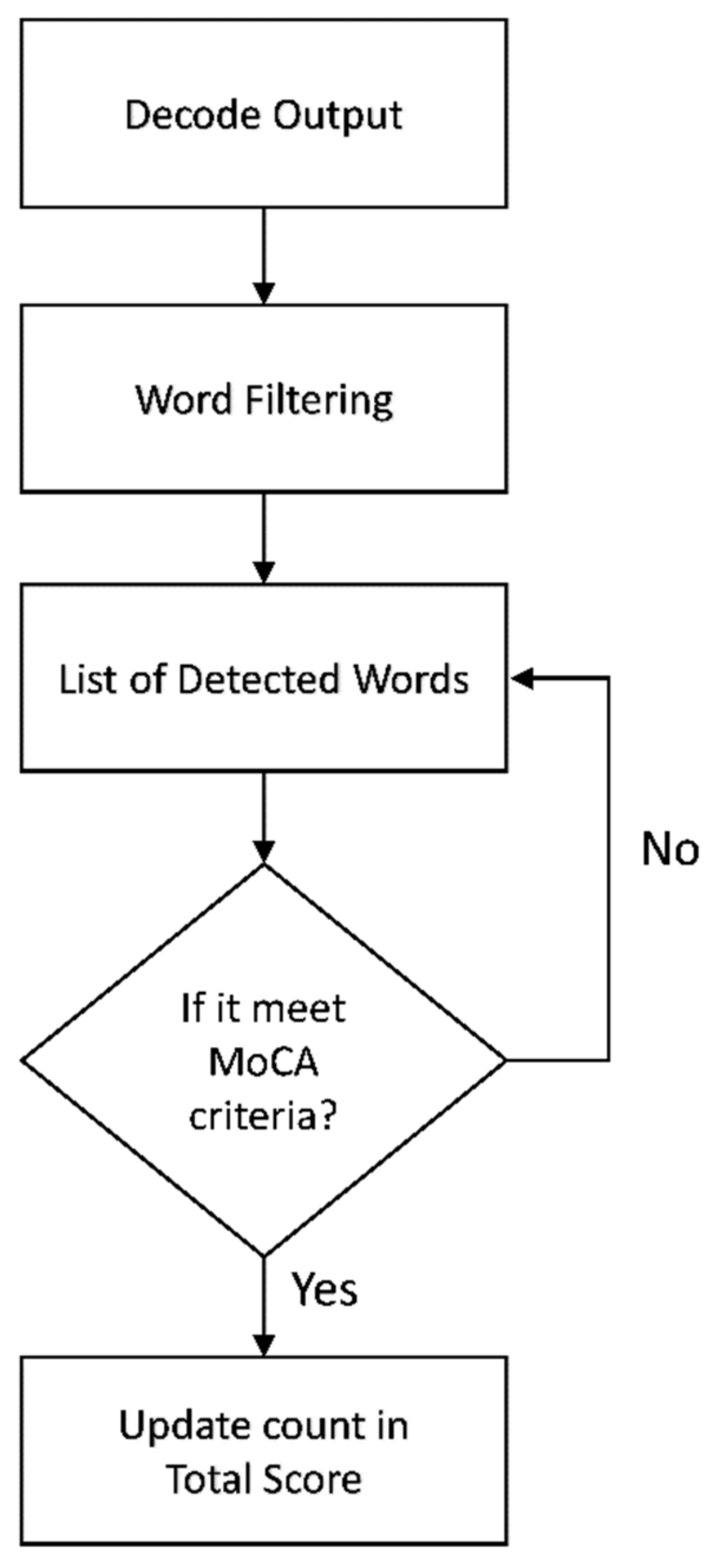
To achieve reliable results through digital MoCA, automated scoring is preferred for limiting the impacts of human error, personal judgment, and bias. Automatic speech recognition (ASR) can be adopted to translate voice recordings into word sequences for automated scoring and evaluation. This study focuses on applying ASR techniques to detect proper Thai words to assist the automated scoring system of the language fluency test of the MoCA and reduce the need for health professionals providing personal judgments during assessments; this will help to increase the overall reliability of MoCA scores. Developing ASR for intended functionalities in this situation comes with several challenges, such as the great variety of pronunciation, intonation, tone, and accent of the patients—all of which might differ from healthy controls. For example, many patients with MCI have slurred speech or a muffled voice, which are somewhat unintelligible to the human ear and have a direct impact on the quality of recognition. Thai is a tonal language in which the pronunciation of isolated words outside a specific context markedly increases the difficulty of detecting the correct tone, especially in older adults with MCI and unclear speech. Furthermore, Thai accents differ by region, and this may affect the accuracy of word detection when developing ASR with a small dataset. Additionally, background noises and conversations between patients and health professionals are recorded during the test. To overcome these challenges, several techniques need to be applied in combination with a special algorithm to differentiate between words that are eligible for MoCA scoring versus those that are not.
In our study, the ASR system plays an important role in enabling reliable word detection for the MoCA language fluency test scoring system. Since Thai is a tonal language, the accuracy of the ASR system depends highly on reliability of tone detection. Understanding tone in the Thai language system can help determine a proper tone mark in the lexical model of ASR system development.
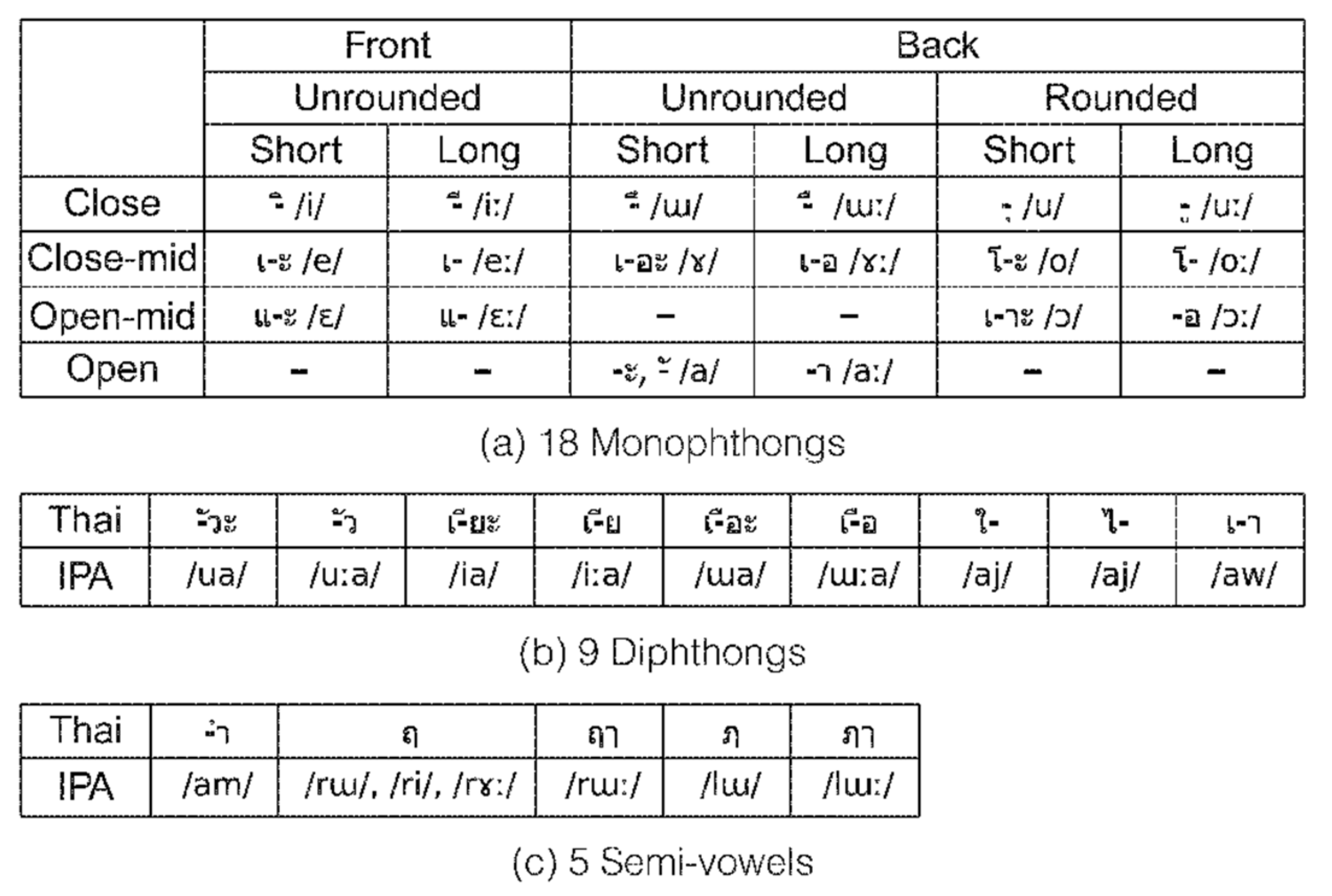
The Thai language system is composed of consonant, vowel, and tonal sounds. These are described in the form of/C
iVC
fT/or/C
iV
T/, where C
i is the initial consonant, V is a vowel, C
f is the final consonant, and T represents the tone level. C
i can either be a single or a clustered consonant, whereas V can either be a single vowel or a diphthong [
10].
There are 44 consonant symbols in Thai that represent 21 initial consonant and 8 final consonant sounds (
Table 1), wherein 18 vowel symbols in combination with 3 consonants are used to create 32 vowels (
Figure 1) [
11].
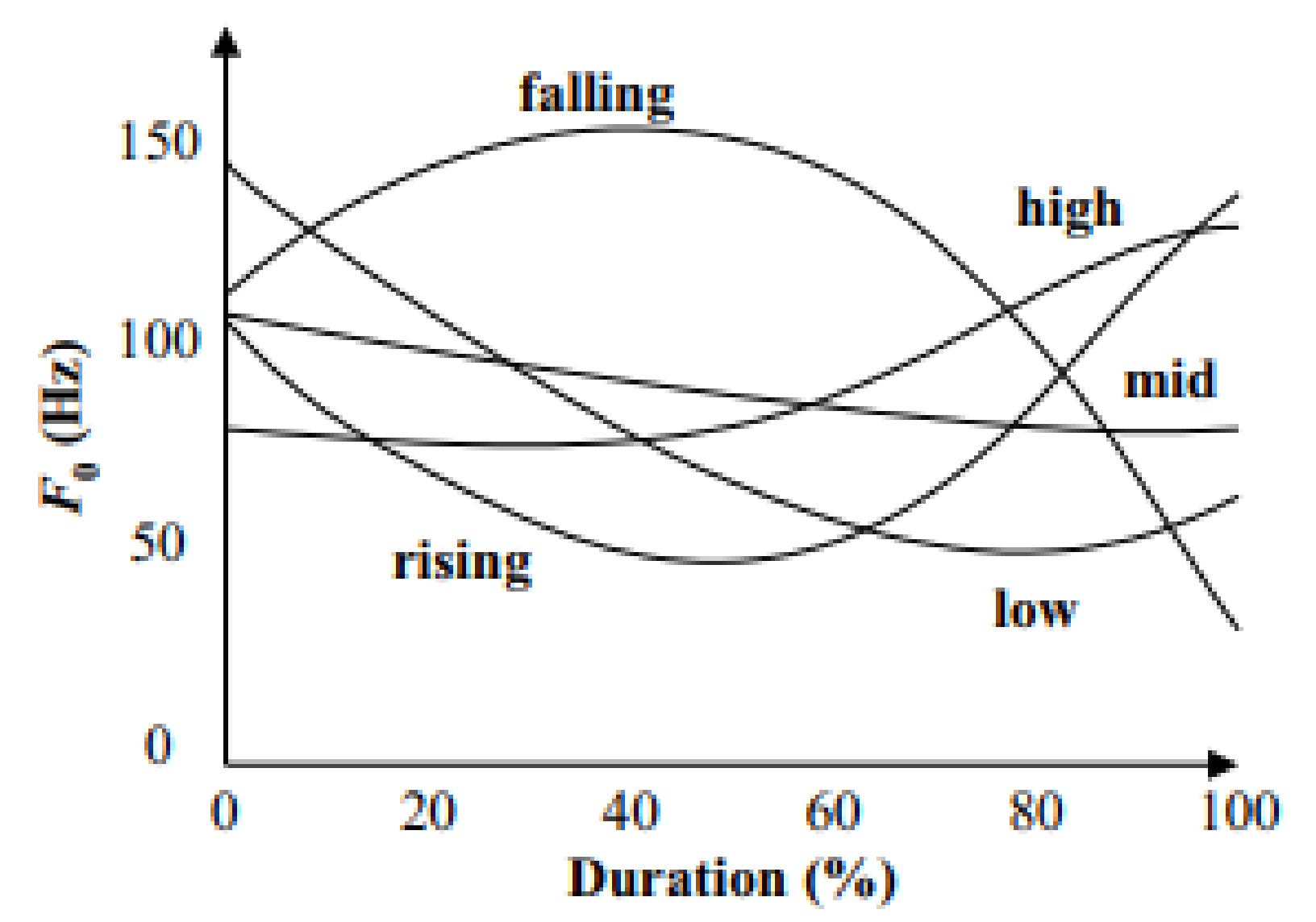
There are five lexical tones in Thai as follows: mid/M/, low/L/, high/H/, falling/F/, and rising/R/. The identification of tone relies on the shape of the fundamental frequency (F0) contour (
Figure 2) [
10]. A change in the tone will change the meaning of a word. For example, khaa has five meanings according to the effect of the tone (
Table 2).
Our study aims to develop an ASR model for MCI patients that can work well with a limited amount of training data. The key contributions of this research are the techniques that we used to develop an ASR model that can support the Thai speech data of MCI patients from a very small sample dataset with an acceptable word error rate (WER). Achieving similar accuracy would normally require a very large amount of MCI patient speech data for training using the standard ASR technique. We discovered that using a phonetically distributed dataset from the LOTUS corpus with MCI speech data helped the ASR to learn the speech features of all the basic phone units in Thai as part of the TDNN-HMM model training. Consequently, the ASR model could successfully recognize Thai words outside the training dataset and reduce the need for manual data collection to build a large MCI patient training dataset. The main novelty of this study is the decoding, where a new algorithm was developed for the detection of eligible Thai words to automate the fluency score calculation. This may be extended and used to support other languages in the near future.
The remainder of this paper is organized as follows:
Section 2 reviews the related works on ASR systems for speech analysis, verbal fluency assessment, and tonal language support.
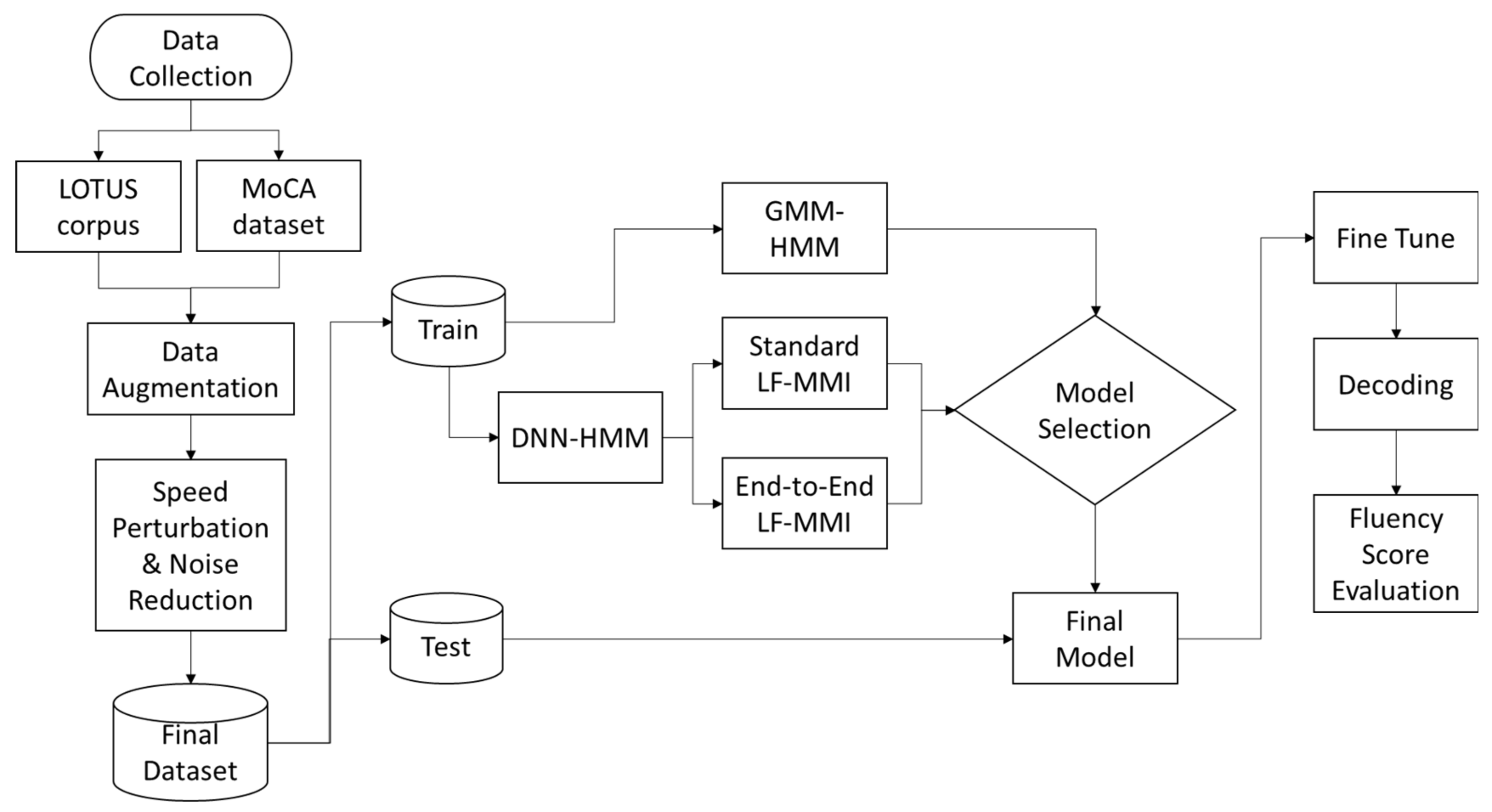
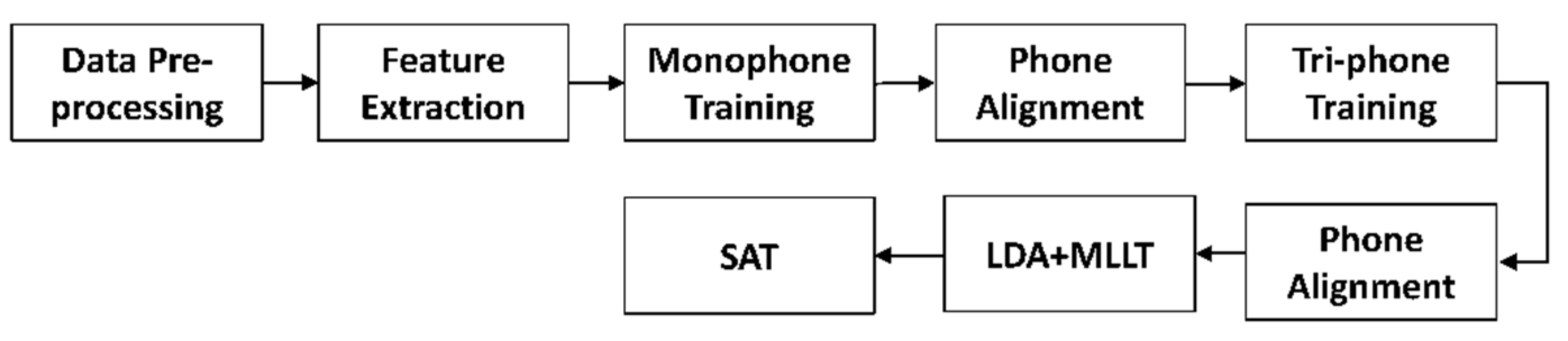
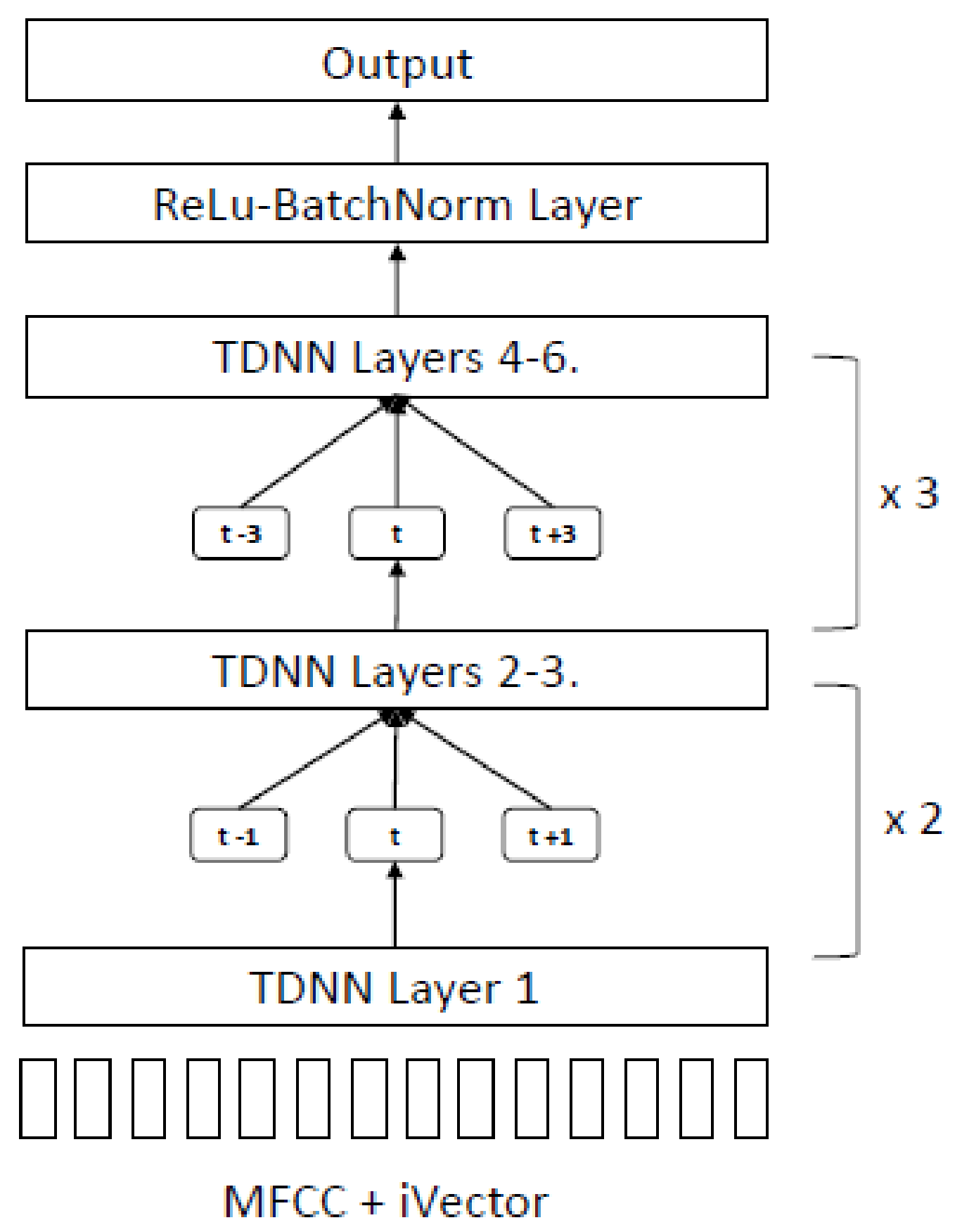
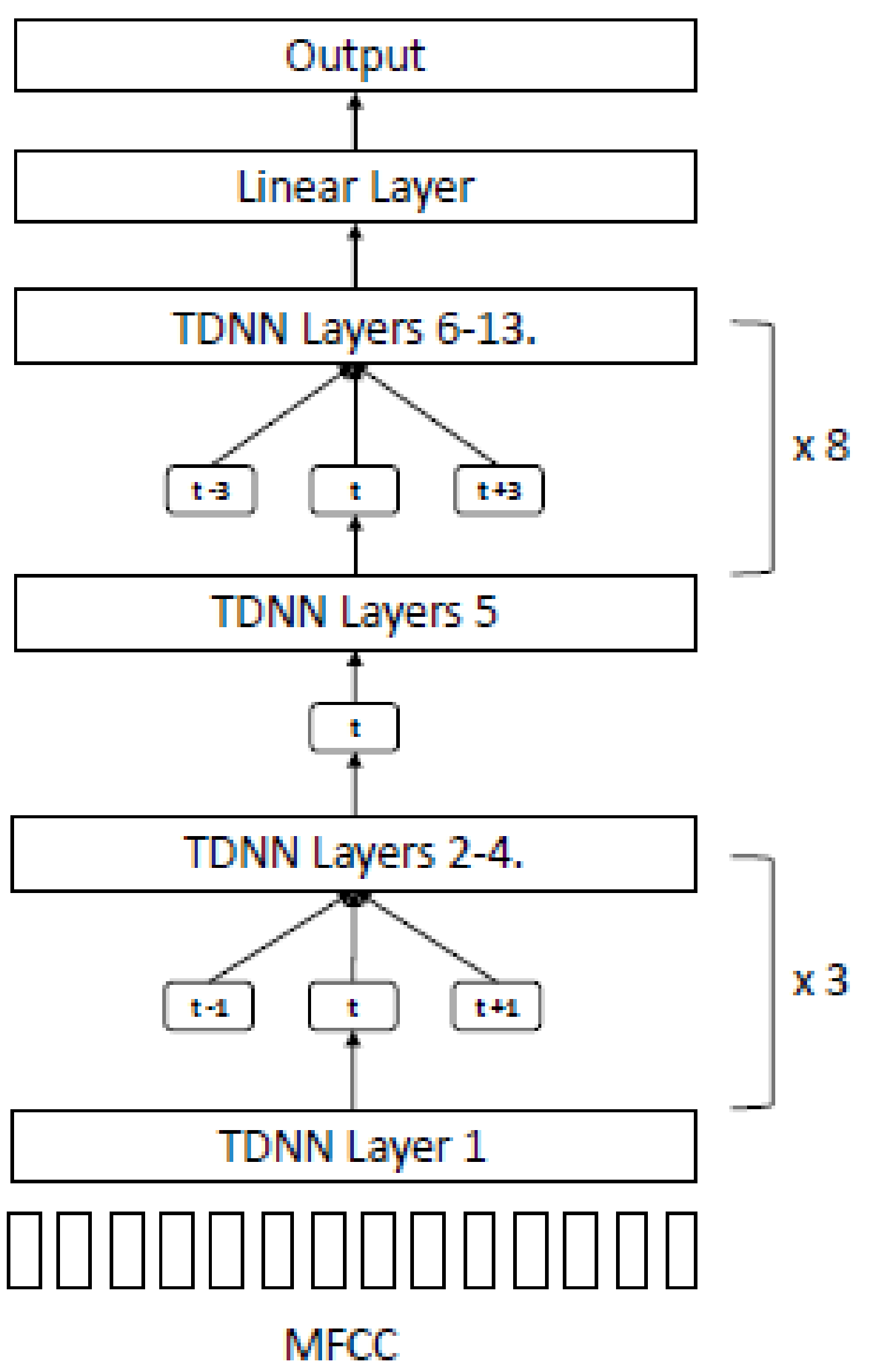
Section 3 describes the data pre-processing and augmentation procedure with the experiment setup using several GMM-HMM model training approaches as the baseline. The TDNN model architecture for end-to-end LF-MMI is proposed with evaluation metrics.
Section 4 and
Section 5 present the experimental results and discuss them, respectively. Finally, the Conclusions are presented in
Section 6.
2. Related Work
Many studies have applied speech processing to cognitive assessment. The common approach used for analysis relies on acoustic features from speech data and text features extracted through ASR. König et al. [
13] analyzed dementia-related characteristics from voice and speech patterns by developing a classifier using a support vector machine (SVM), with features extracted from spoken tasks. These tasks were characterized by the continuity of speech using the duration of contiguous voice and silent segments as well as the length of contiguous periodic and aperiodic segments to derive statistical values as vocal features. For the semantic fluency task, the vocal feature was defined as the distance in time from the first detected word to each following word. The evaluation results show the following classification accuracy: healthy control (HC) versus MCI, 79%; HC versus AD, 87%; and MCI versus AD, 80%. These findings suggest that automatic speech analyses could be an additional assessment tool for older patients with cognitive decline.
Spontaneous speech can provide valuable information about the cognitive state of individuals [
14]; however, to retrieve useful clinical information, it needs to be transcribed manually. Zhou et al. [
14] proposed an ASR system for generating transcripts automatically and extracting text features to identify AD with an SVM classifier. They used an open-source Kaldi ASR toolkit [
15] to optimize performance for the speakers with and without dementia based on the dementia bank (DB) corpus through insertion penalty and language model weight adjustment. They obtained an average WER of 38.24%, showing an improvement over their previous work, which had employed commercial ASR. However, their results were limited by the poor quality of audio in the DB corpus, thus necessitating further exploration.
Language fluency tests are a main task in cognitive tests; in the literature, they are also known as verbal fluency (VF) tasks, which refer to short tests of verbal functioning where patients are given 1 min to produce as many unique words as possible within a sematic category (semantic fluency) or start with a given letter (phonemic fluency) [
16]. In clinical practice, VF tests are administered manually; few studies have evaluated computerized VF administration and scoring. Pakhomov et al. [
17] applied ASR to speech data collected during VF tasks to obtain an approximate count of legitimate words. They implemented an ASR system based on Kaldi’s [
15] work using a speaker-independent acoustic model with a specially trained animal fluency language model and applied confidence scoring to the post-process ASR output. Standard manual scoring was performed, including transcribing all responses during the VF task to be used for evaluating the ASR decoder performance. They achieved a WER of 56%, which was relatively high; however, the results suggested that the combination of speaker adaptation and confidence scoring improved overall accuracy and was able to produce a VF estimated score that was very close to the ones yielded by human assessment.
Tröger et al. [
18] proposed telephone-based dementia screening with automated semantic verbal fluency (SVF) assessment. Speech was recorded through a mobile tablet built-in microphone and downsampled to 8 KHz to simulate telephone conditions. SVF sound segments were analyzed using Google’s ASR service for possible transcriptions. Various features were extracted from generated transcripts and evaluated using an SVM classifier. The overall error rate of the automatic transcripts was 33.4%, and the automated ASR classifier reached results comparable with those of the classifier that utilized manual transcriptions. Lauraitis et al. [
19] proposed neural impairment screening and self-assessment using a mobile application for MCI detection based on the self-administered gerocognitive examination (SAGE) screening. They developed a mobile application to collect data from different tasks. A VF task was conducted by instructing participants to write down 12 different items in a given category as text field in the mobile application for calculating the SAGE score. Voice recording was performed as an additional task to evaluate speech impairment by extracting several features, including pitch, mel-frequency cepstral coefficients (MFCC), gammatone cepstral coefficients, and spectral skewness, for further speech analysis with an SVM and a bidirectional long short-term memory classifier that had 100% and 94.29% accuracy, respectively.
Various approaches have been proposed for ASR with Thai language support over the years. For instance, Chaiwongsai et al. [
12] proposed HMM-based isolated word speech recognition with a tone detection function to improve the accuracy of ASR for tonal languages. The tone detection function was added as a parallel computation process to detect tone level and map the results from speech recognition to obtain the final results. Experimental results revealed that the accuracy of Thai word detection improved by 4.94% for TV remote control commands and by 10.75% for Thai words that had different meanings with each tone.
One approach to avoid new training steps whenever new words are added into the dictionary is the phoneme recognition approach. To this end, Theera-Umpon et al. [
20] proposed a new method to classify the tonal accents of syllables using soft phoneme segmentation techniques for Thai speech, which was better than the hard-threshold approach for phoneme classification. Hu et al. [
21] conducted an experiment with Mandarin and Thai words by incorporating tonal information from fundamental frequency (F0) and fundamental frequency variation into the convolution neural network (CNN) architecture and compared CNN with DNN. The WER for Thai was 33.19% and 35.16% for CNN and DNN.
5. Discussion
5.1. Automatic Speech Recognition
The results of the GMM-HMM baseline analysis support our hypothesis that incorporating the LOTUS corpus could help to improve the accuracy of our model. However, an improvement in accuracy over the combined dataset produced an observation about the imbalance between the LOTUS and digital MoCA data. To enhance the reliability and generalizability of our model, an up-sampling of digital MoCA data was performed through augmentation by deploying the noise reduction and pitch shift techniques (
Table 5). From the experiments, we observed that the implementation of the pitch shift algorithm on the digital MoCA data helped to reduce the deviation of cross-validation results. We used high-frequency steps to create pitch variety and simulated artificial speech as uttered by different participants in our dataset, while applying noise reduction to populate a cleaner version of speech that could improve the balance of our total dataset. This was performed to enable our model to learn and work in both noisy and quiet room environments, which helps to improve accuracy in general.
We further analyzed the results and found that the main reason for the poor results from the GMM-HMM model was a phone alignment issue that occurred during training. We used the phone alignment results from the GMM-HMM training with the LOTUS + MoCA dataset for the LF-MMI model, and the results confirm that we could not obtain a high level of accuracy because of the bad quality of input. Decoded output from the EE-LF-MMI obtained a WER of 30.77%, which was relatively high; it showed significant improvement over the other two models.
Considering that one of our main research constraints is the small amount of training data—as we are still in the developmental phase and only possess 1–2 h of speech data from MCI patients for the experiment—the initial focus was to select a method that did not require a large training dataset, coupled with the flexibility to adapt to domain-specific tasks. Therefore, based on the number of studies, GMM-HMM and DNN-HMM offer greater flexibility compared to the end-to-end approach. Furthermore, the LF-MMI achieved an optimal result over several speech recognition tasks on a relatively small corpus [
29]. Therefore, we chose to apply the LF-MMI model in this study.
The end-to-end LF-MMI can obtain a comparable performance with regular LF-MMI but with a simplified training pipeline, and it works well with a small dataset. In our study, the LF-MMI approach obtained better accuracy than GMM-HMM, but the model architecture required alignment data from the previous training owing to very poor results from GMM-HMM. Thus, phone alignment information significantly affected the quality and accuracy of the TDNN layers. Meanwhile, the EE-LF-MMI approach demonstrated a high potential for future ASR development where domain-specific data are scarce with minimum effort needed for feature engineering.
5.2. Data Augmentation
Owing to the limited corpus of sample data from digital MoCA in our study, data augmentation emerged as the main factor for the development of our ASR model. A combination of techniques were used to populate data with a greater variety of pitch; however, the key factor involves the incorporation of the LOTUS corpus into our dataset as it contains a PD set of data for Thai phonemes that enables our acoustic model to learn the majority of the basic phone units and predict unseen words outside of the training data. The results confirm that our model can predict words outside of the training data, as shown in
Table 11, which helps reduce the need for collecting a large amount of speech sample data from patients, to develop an acoustic model for a speech recognition task. To the best of our knowledge, this study was the first attempt to utilize the LOTUS corpus for supporting data augmentation and the provision of basic phone units with a limited sample of Thai speech data within the medical domain. We believe our method can contribute to the future development of Thai ASR tasks where domain-specific data are scarce.
5.3. Word Detection Error Analysis
We observed a slightly better accuracy rate for male speakers (70.31% correct words) compared to female speakers (69.91% correct words). We listened to the original audio recordings and found that the voice quality of male speakers seemed to be better. However, because of the small sample size, we could not draw any meaningful conclusions about the impact of model accuracy from the variation of voice quality observed between genders.
As the audio samples contained both long utterances and single words, to attain a better understanding of the sequence of errors for long utterances, we filtered out the results from single words and analyzed only long utterances. By doing so, we found that major mismatches were caused by deletion and substitution errors, as shown in
Figure 15.
This result suggest that our ASR model could detect words correctly from the majority of the long utterances because of the support of the language model, while the detection of single words indicates a greater error (
Table 10).
5.3.1. Substitution Error
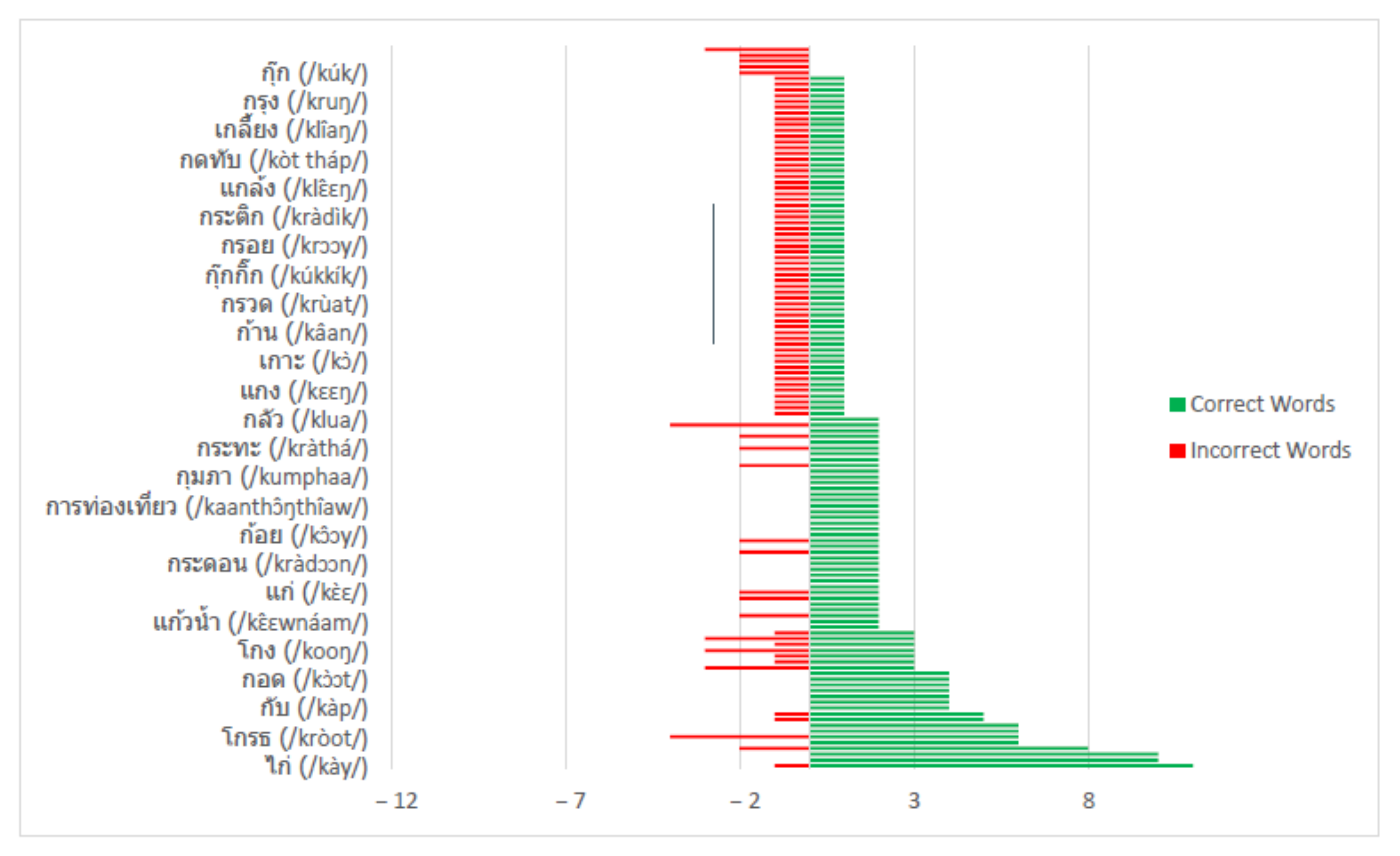
The data suggested that several of the detected words have a strikingly similar pronunciation to the test utterance. Therefore, we performed a detailed analysis of the most frequent incorrect words detected by our ASR model and found that the majority of the errors, which came from substitution errors, were caused by words of similar tone and pronunciation (
Table 11 and
Table 12).
Further analysis showed that the model could not accurately predict words with similar tones; for example, ไกล/klay/vs. ใกล้/klây/, ไกล/klay/vs. ไก่/kày/, เกี้ยว/kîaw/vs. เกี่ยว/kìaw, as shown in
Figure 16.
5.3.2. Deletion Error
Deletion errors occur randomly with both single words and long utterances (
Table 13). We listened to the audio recordings of those words that the ASR recognizer was unable to detect and found that the majority of them contained a high level of noise, while several had issues with unclear pronunciation.
5.3.3. Insertion Error
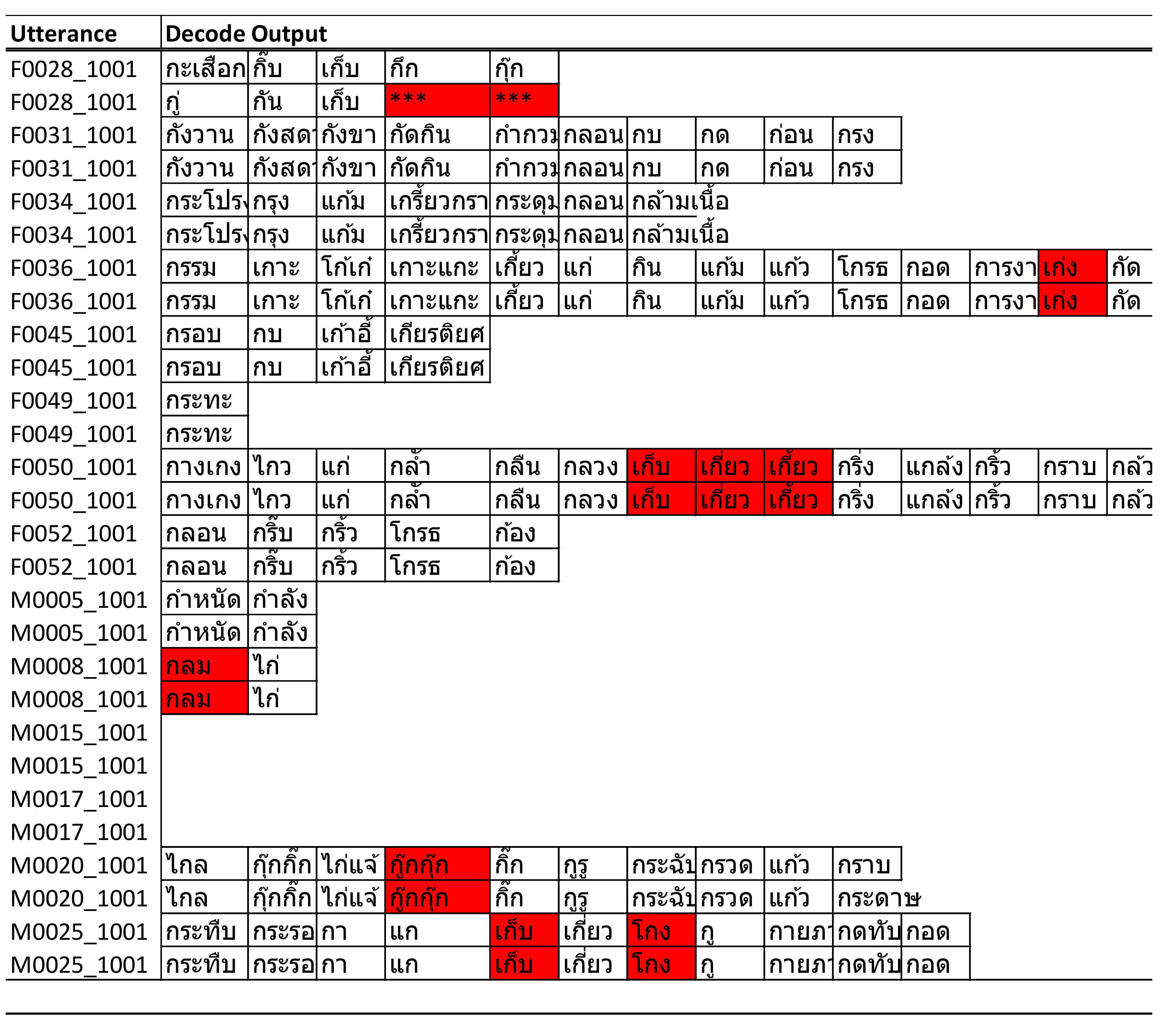
The results indicate that insertion errors occur with multiple-syllable words, where the ASR recognizer detects those syllables as separate words (
Figure 17). As a consequence of the insertion error, the remaining syllables were detected as another word and caused an additional substitution error in those utterances.
5.4. Language Fluency Assessment
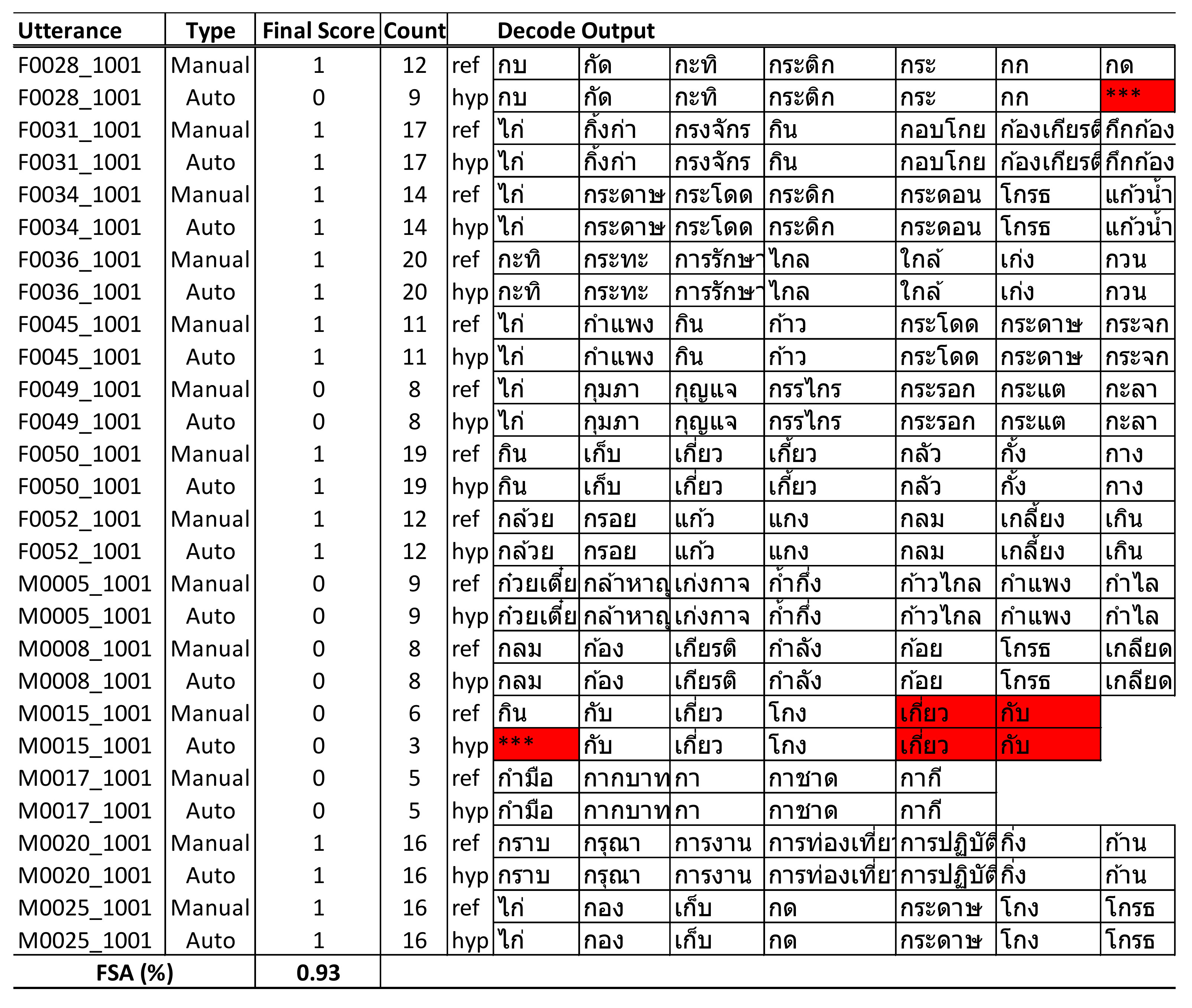
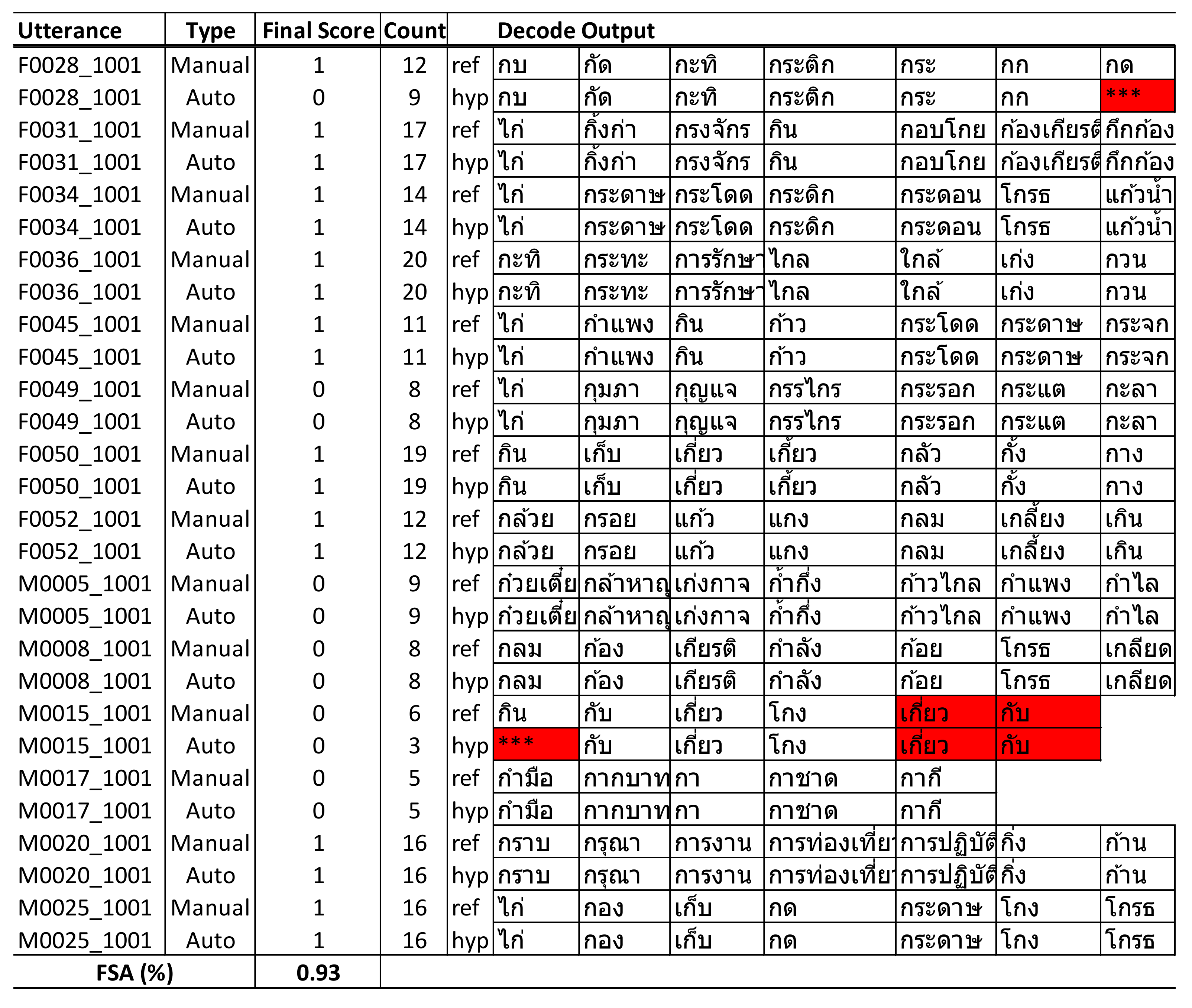
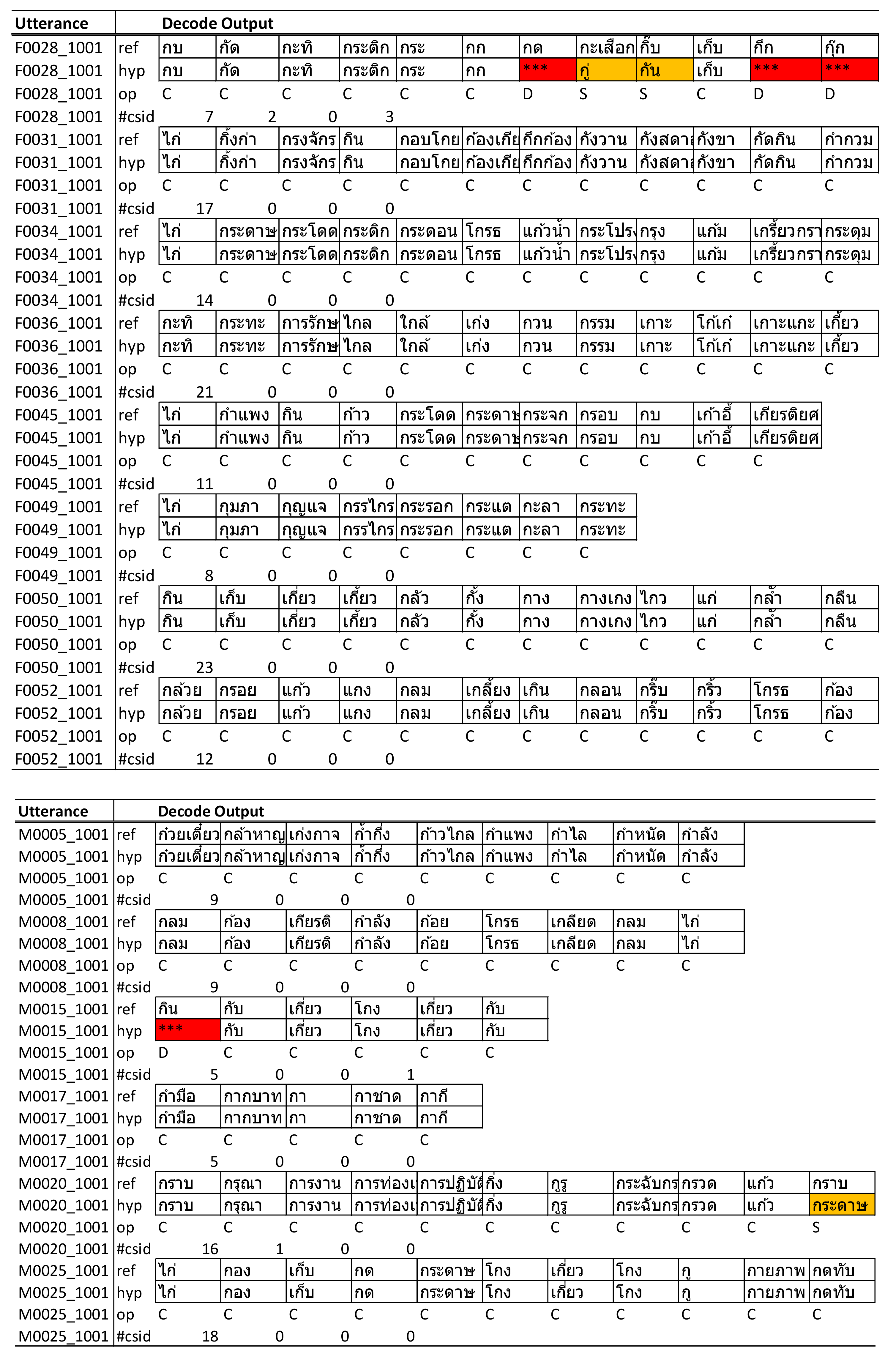
We compared the results of automated scoring with manual scoring and found that for utterances with substitution errors, the ASR recognizer attempted to predict the closest words where the initial phone started with “ก” (/k/) that were still within the dictionary. For example, the word “กราบ” (/kràap/) was incorrectly detected as “กระดาษ” (/kràdàat/); however, because of “กระดาษ”—also a valid Thai word starting with “ก” (which fully met the assessment criteria)—the scoring algorithm would count this word as eligible and result in no big deviation from the total count of words, although several of them were detected incorrectly but with no impact to the overall score for that utterance. Utterances with deletion errors would cause some words to be skipped and had a direct impact on the total word count and the overall score. However, because our ASR model had a low percentage of deletion errors in the test utterances, it had less of a negative impact on the final score.
The final score calculated by the system indicated an accuracy of 93% compared with manual scoring, as reported in
Table 12. This indicates a high potential for further development and use in clinical practice to automate the scoring process of language fluency assessment.
5.5. Limitations and Future Directions
In this study, we developed and evaluated a new approach to integrate ASR techniques into a MoCA assessment tool for conducting a language fluency test with Thai language support. Most previous studies focus on utilizing ASR to assess verbal semantic fluency tasks in English, for which ample speech data are publicly available. This novel method is proposed to utilize ASR for assisting a phonemic fluency task in Thai, which is the first attempt of its kind. Several challenges still need to be addressed, starting from the data collection process, which directly affected the quality of voice recordings and had major impacts on the overall accuracy of ASR. Acoustic model training with low resources—that is, no domain-specific data available—was one of the biggest challenges in the speech recognition task.
The main limitation of this study is the small size of the dataset. We are in the early developmental phase of the new digital MoCA system; therefore, the Thai speech data of MCI patients are unavailable because it is the first attempt to collect data from the MoCA assessment in digital format for the Thai language. Additionally, limited numbers of iPad devices were used for the trial run; therefore, we could obtain only 1 h 40 min of data that could be used for our experiment. Consequently, it was difficult to utilize this small amount of data for the development of good ASR in general terms. Therefore, we believe that an increase in sample data will improve the overall accuracy and generalizability of our proposed ASR model. Once the digital MoCA system reaches its production stage and can be deployed for clinical use in broader communities, we will be able to collect more data for future work enhancement.
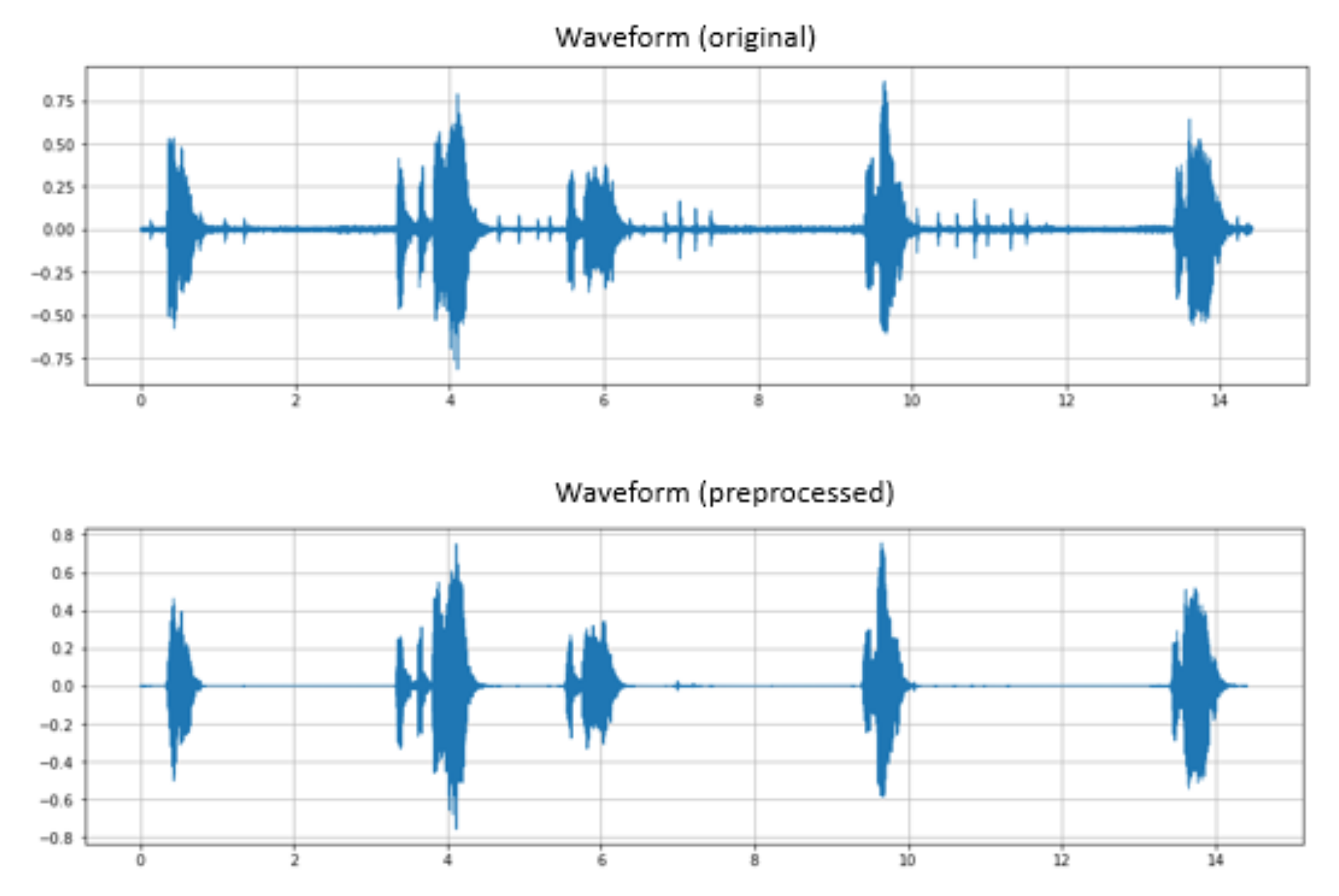
Additionally, the voice quality and control of the recording condition present challenges to our data processing steps. The data collection is performed in an open environment without the control of background noise and has a direct impact on the quality of speech recording. The majority of the utterances recorded from digital MoCA require manual data cleansing to remove the part of the conversation between health professionals and patients to ensure it contains only speech uttered by patients before its use for the training of the model. Furthermore, the current design of the digital MoCA system uses the built-in iPad microphone for voice recording; therefore, it is hard to control the voice quality and noise level. The integration of a dedicated microphone to differentiate the voices of patients from healthcare professionals facilitates the improvement of the quality of the voice recordings and reduces the need to perform the data cleansing step.
Furthermore, another limitation involves tone detection. Thai is a tonal language, and although our study implements the tone mark in the lexicon model, we observed that our ASR, in some cases, cannot accurately predict words with a similar tone. Therefore, an insufficient pitch difference can result in lower accuracy of word detection with incorrect tone, which can alter word meanings and lower the accuracy of the ASR. However, if we consider the overall language fluency score, it will not negatively impact the assessment because those detected words are approved according to the stated criteria even if they produce a different meaning. Consequently, the implementation of an algorithm for tone detection should be considered to improve the accuracy of the ASR model in the near future.
6. Conclusions
MoCA is a widely used tool of assessment for MCI detection, but data analysis options for the current paper-and-pencil-based version are limited and require great manual efforts in data collection. Therefore, we sought to develop digital MoCA in Thailand. This study is a sub-project of the larger digital MoCA project; the study aimed to create technology to support automatic data collection and analysis in order to enable physicians and other health professionals in Thailand to conduct reliable cognitive assessments for a broader range of patients.
This study demonstrated the possibilities of utilizing ASR techniques for word detection to assist the MoCA language fluency test scoring system for Thai. The proposed method yields acceptable accuracy under a number of constraints where domain-specific data are not publicly available. However, more data need to be collected for digital MoCA, which is still in the early phase of development. Additionally, several other challenges emerged in this study, mainly from data quality issues.
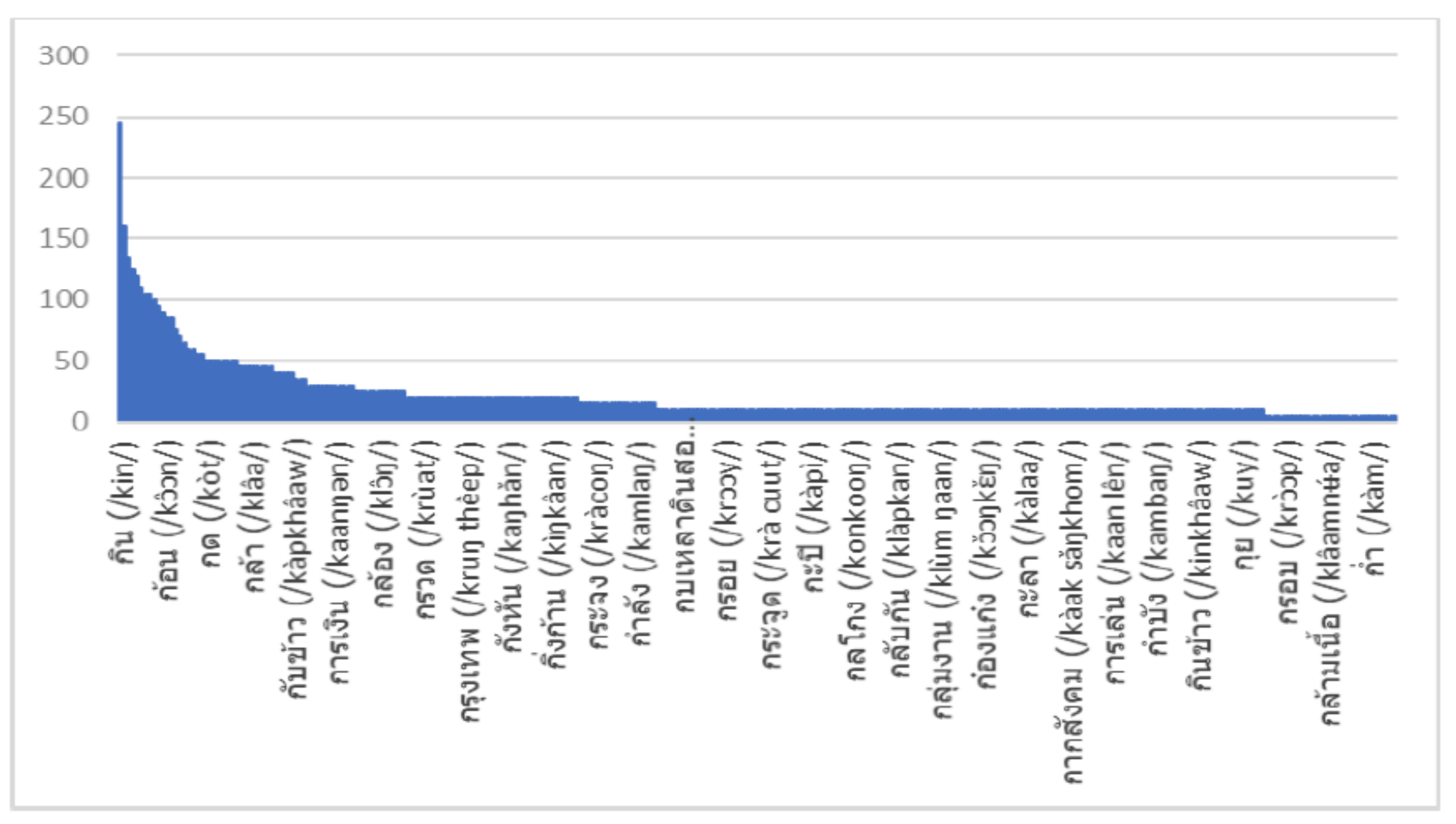
We see great potential for further improving the accuracy of the system, such as by enhancing the acoustic model with more data from patients, increasing the accuracy of the Thai tone detection with a better algorithm, and integrating a dedicated microphone system into the iPad. These points will assist in differentiating the voices of patients from health professionals, which will help to improve the quality of the voice recording. In addition to benefits within the medical domain, the techniques developed from this study, such as isolated word recognition of Thai words beginning with “ก,” can be used as a baseline for future expansion of complex ASR system integration in various speech recognition domains.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}