
Towards Semantic Photogrammetry: Generating Semantically Rich Point Clouds from Architectural Close-Range Photogrammetry

 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
2. Literature Review
2.1. Notions on Photogrammetry
2.2. DEEP Learning for Semantic Segmentation
2.2.1. Projection-Based Methods
- Multiview representation: These methods project firstly the 3D shape or point cloud into multiple images or views, then apply existing models to extract feature from the 2D data. The results obtained on the image representation are compared and analysed, and then re-projected on the 3D shape to obtain the segmentation of the 3D scene. Two of the most popular works are MVCNN [64] which proposed the use of Convolutional Neural Networks (CNN) on multiple perspectives and SnapNet [65] which uses snapshots of the cloud to generate RGB and depth images to address the problem of information loss. These methods ensure excellent image segmentation performance, but the 3D features transposition remains a challenging task, producing large loss of spatial information.
- Volumetric representation: Volumetric representation consists in the transformation of the unstructured 3D cloud into a regular spatial grid, a process also called voxelisation. The information as distributed on the regular grid is then exploited to train a standard neural network to perform the segmentation task. The most popular architectures are VoxNet [66] which uses CNN to predict classes directly on the spatial grid, OctNET [67] and SEGCloud [68] which introduced the methods of spatial partition such as K-d tree or Octree. These methods require large amounts of computing memory and produce reasonable performance on small point clouds. They are therefore unfortunately still unsuitable for complex scenarios.
- Spherical representation: This type of representation retains more geometrical and spatial information compared to multiview representation. The most important works in this regard include SqueezeNet [69] and RangeNet++ [70] especially for application on real time lidar data segmentation. However, they still have to face several issues such as discretisation errors and occlusion problems.
- Lattice representation: Lattice representation converts a point cloud into discrete elements such as sparse permutohedral lattices. This representation can control the sparsity of the extracted features and it reduces memory requirement and computational cost compared to simple voxelisation. Some of the main studies include SPLATNet [71], LatticeNet [72] and MinkowskiNet [73].
2.2.2. Point-Based Methods
- Pointwise methods: The pioneering work for this method is PointNet [74] which learns per-point features using shared Multi-Layer Perceptrons (MLPs) and global features using symmetrical polling functions. Since MLP cannot capture local geometry, a lot of networks based on PointNet have been developed recently. These methods are generally based on neighbouring feature pooling such as PointNet++ [75].
- Convolution methods: These methods propose an effective convolution operator directly for point clouds. PointCNN [76] is an example of a network based on parametric continuous convolution layers and kernel function as parameterised by MLPs. Another example is ConvPoint [77] which proposed a point-wise convolution operator and convolution weights determined by the Euclidean distances to kernel points.
- RNN-based methods: Recurrent Neural Network (RNN) are used recently for the segmentation of point clouds, in particular to capture inherent context features. Based on PointNet, they first transform a block of points into multi-scale blocks or grid blocks. Then the features extracted by PointNet are fed into a Recurrent Consolidation Units (RCU) to obtain the output-level context. One of the most popular networks in this regard is 3DCNN-DQN-RNN [78].
- Graph-based methods: Graph Neural Network (GNN) is a type of network which directly operates on graph structure. Several methods leverage on graphs to capture richer geometrical information, for example DGCNN [79].
2.3. Reprojection of 2D Semantic Segmentation into the 3D Space
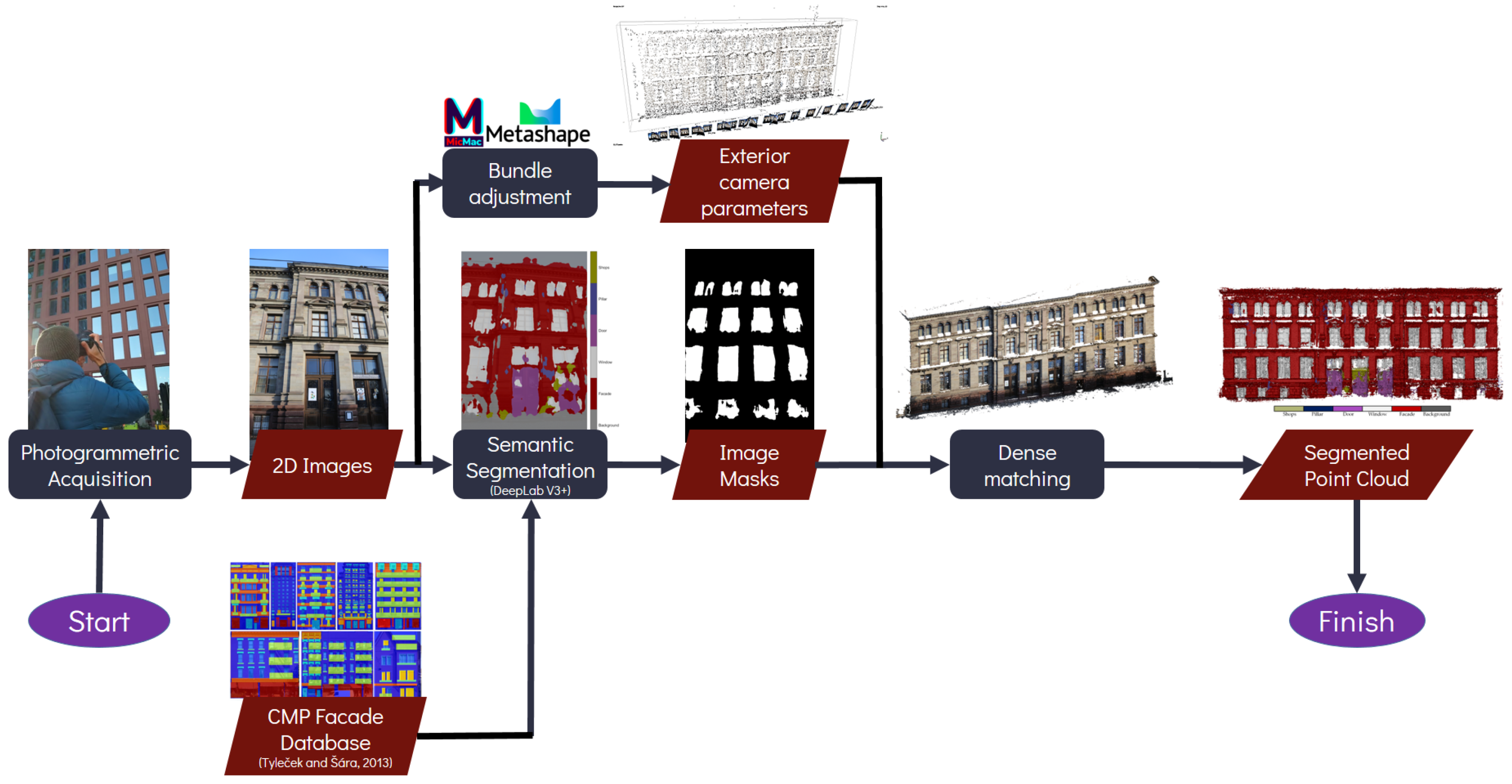
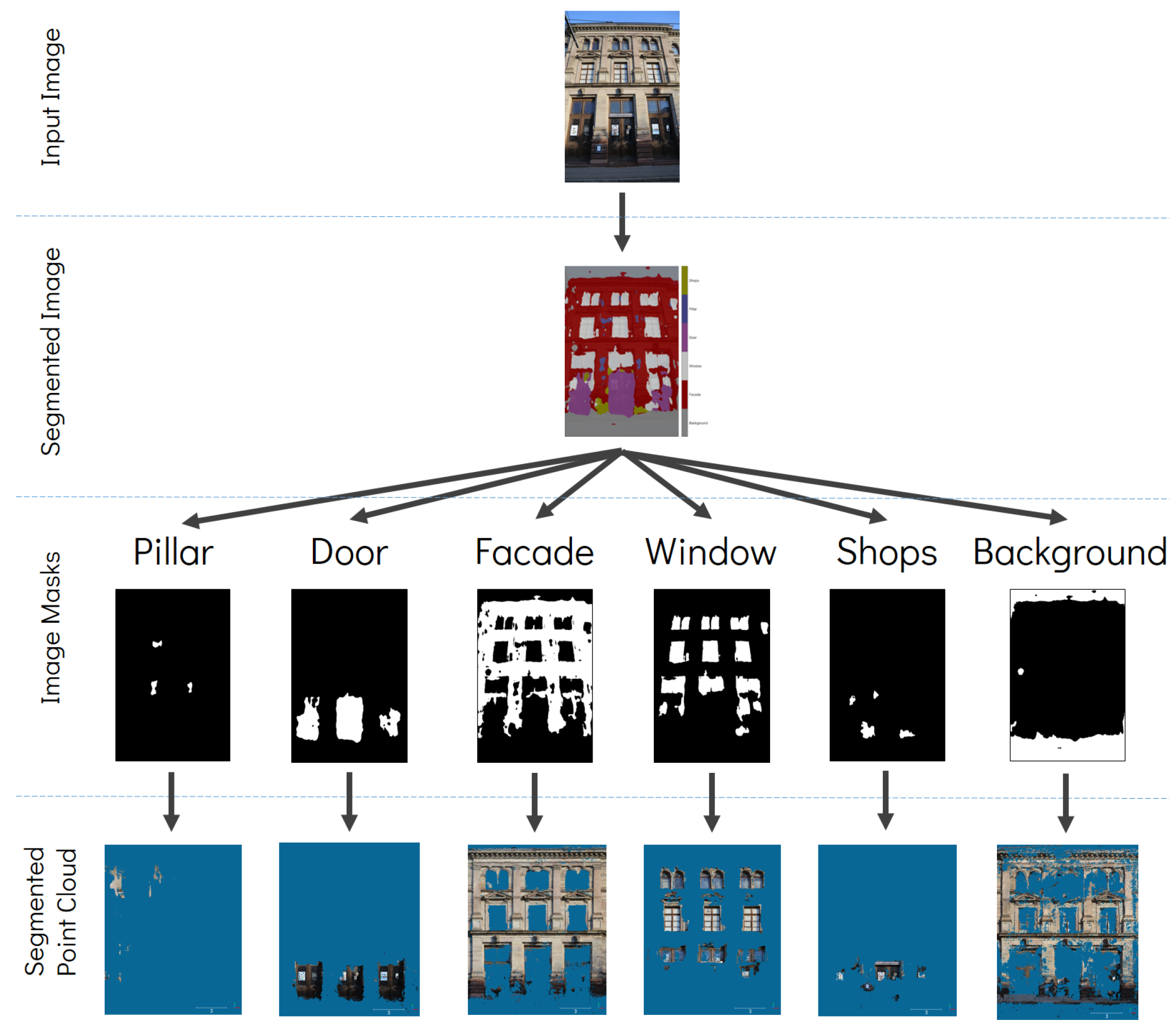
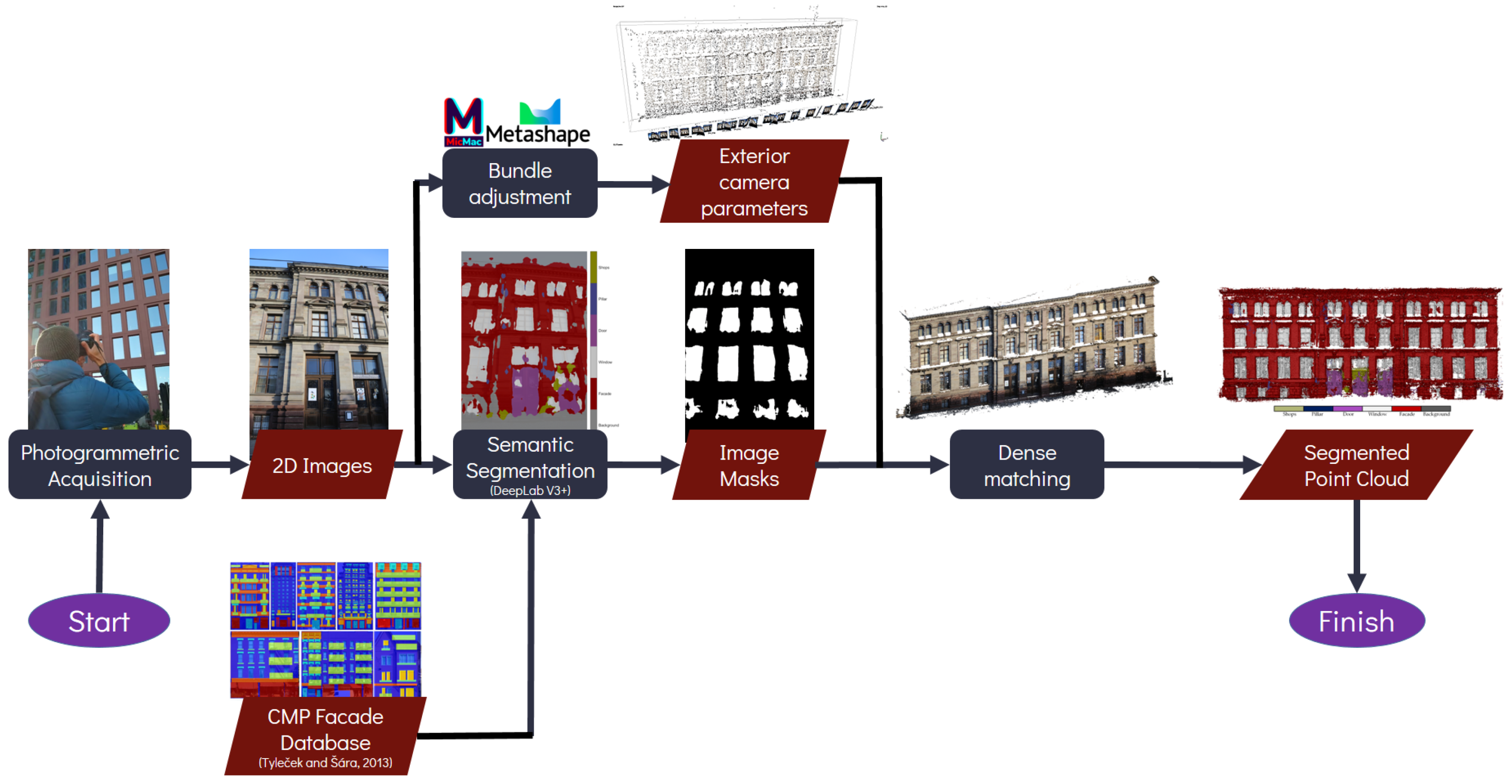
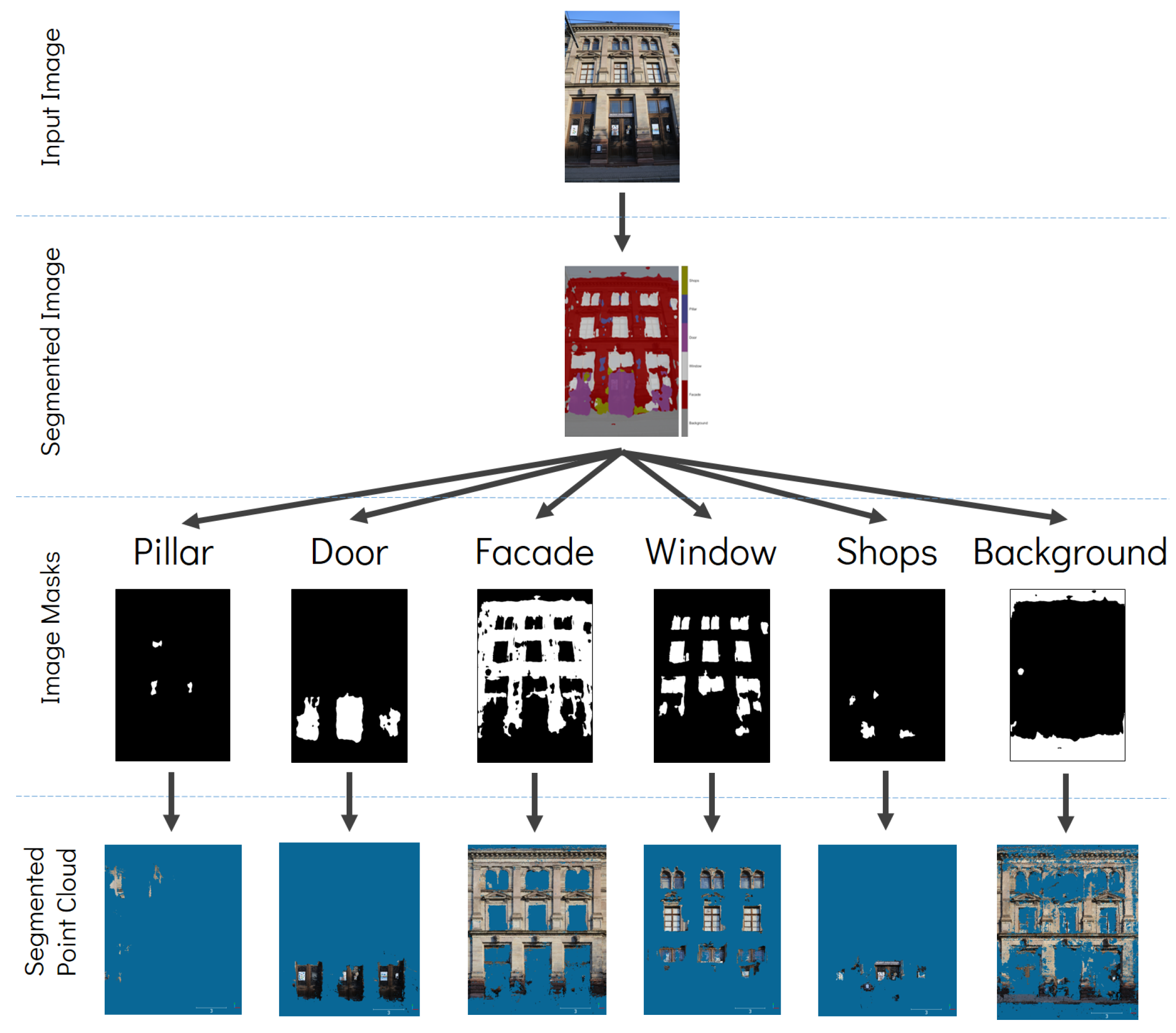
3. Proposed Method
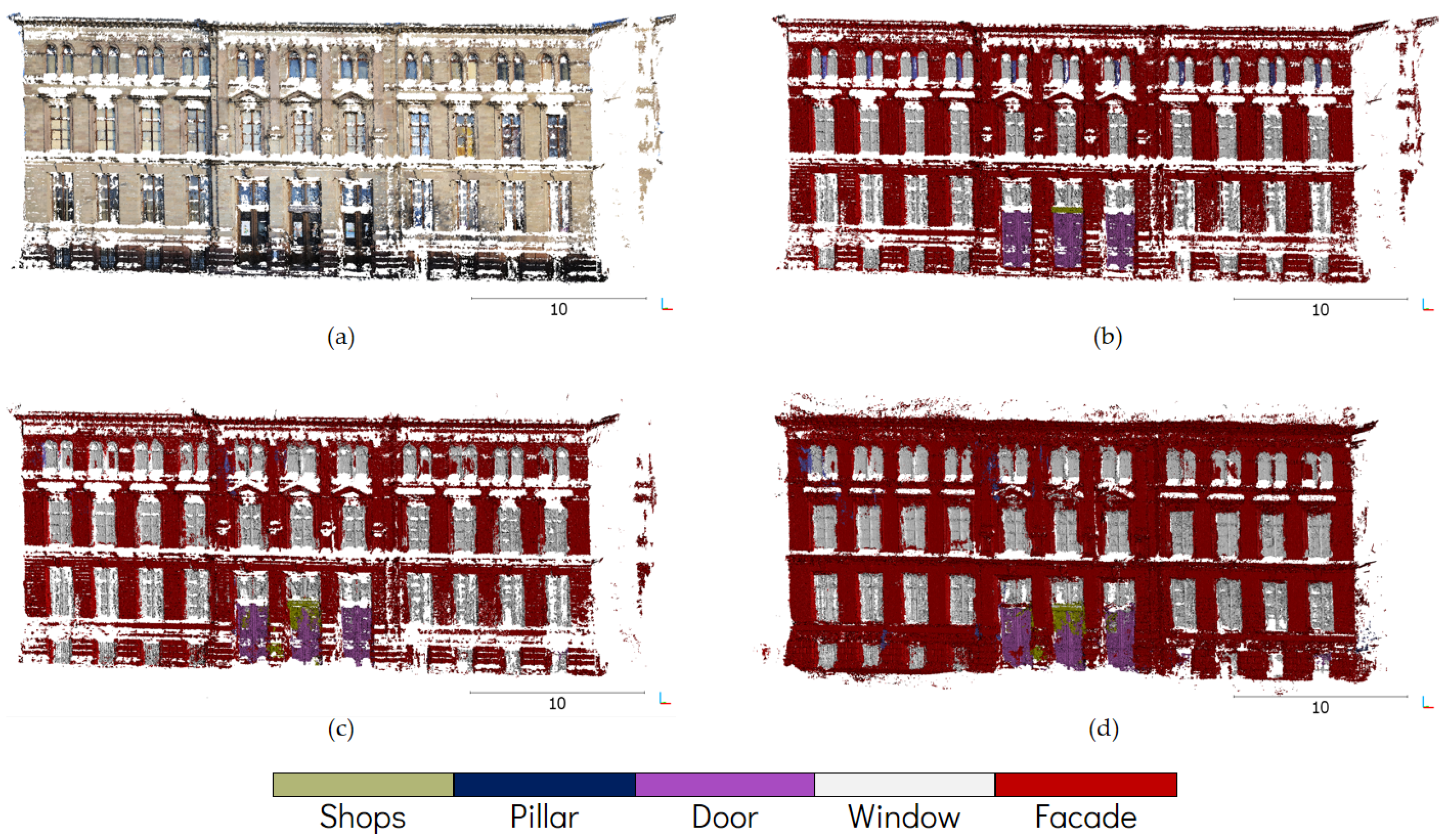
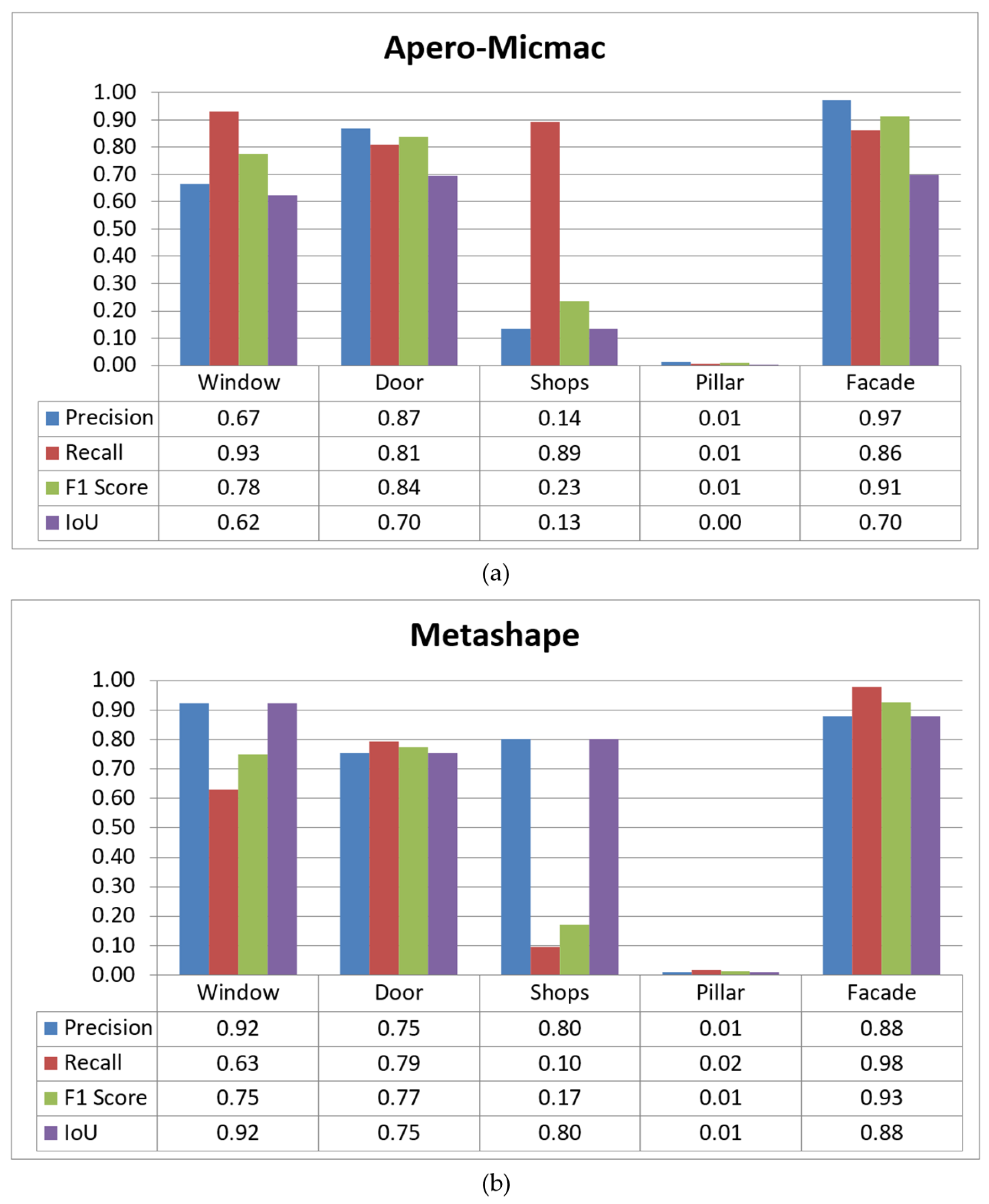
4. Experimental Results and Assessments
5. Discussion
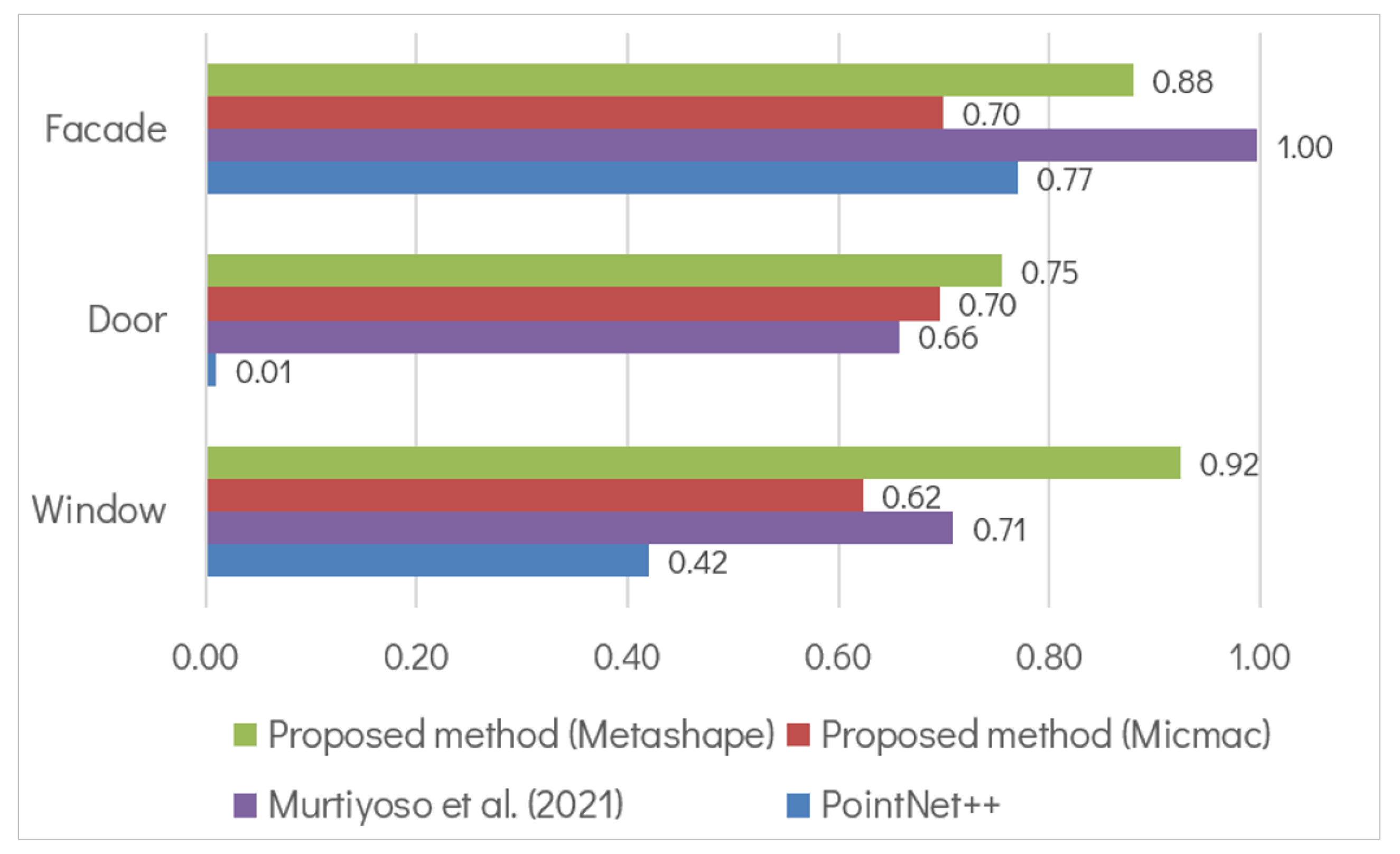
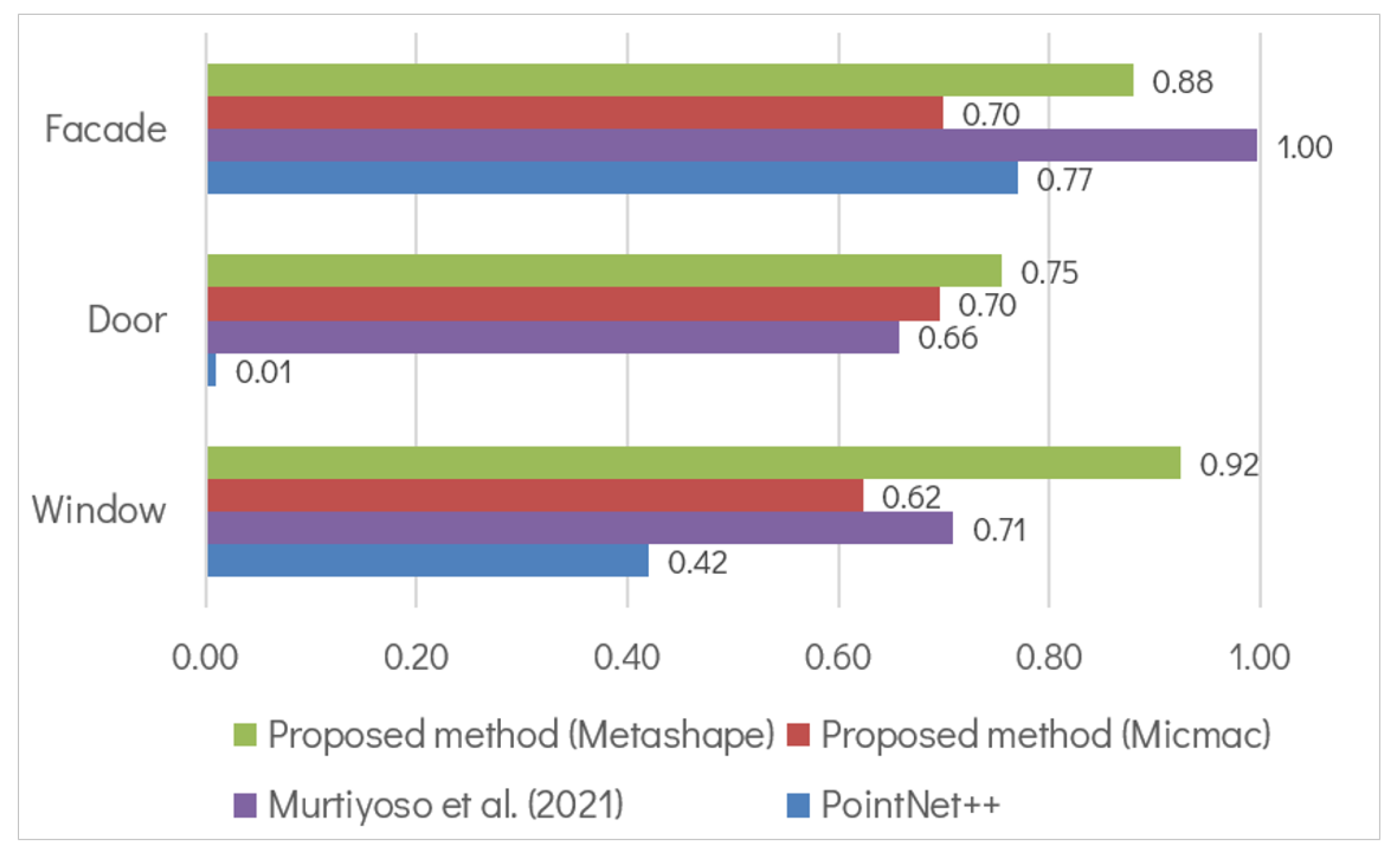
5.1. Comparison to Previous Work
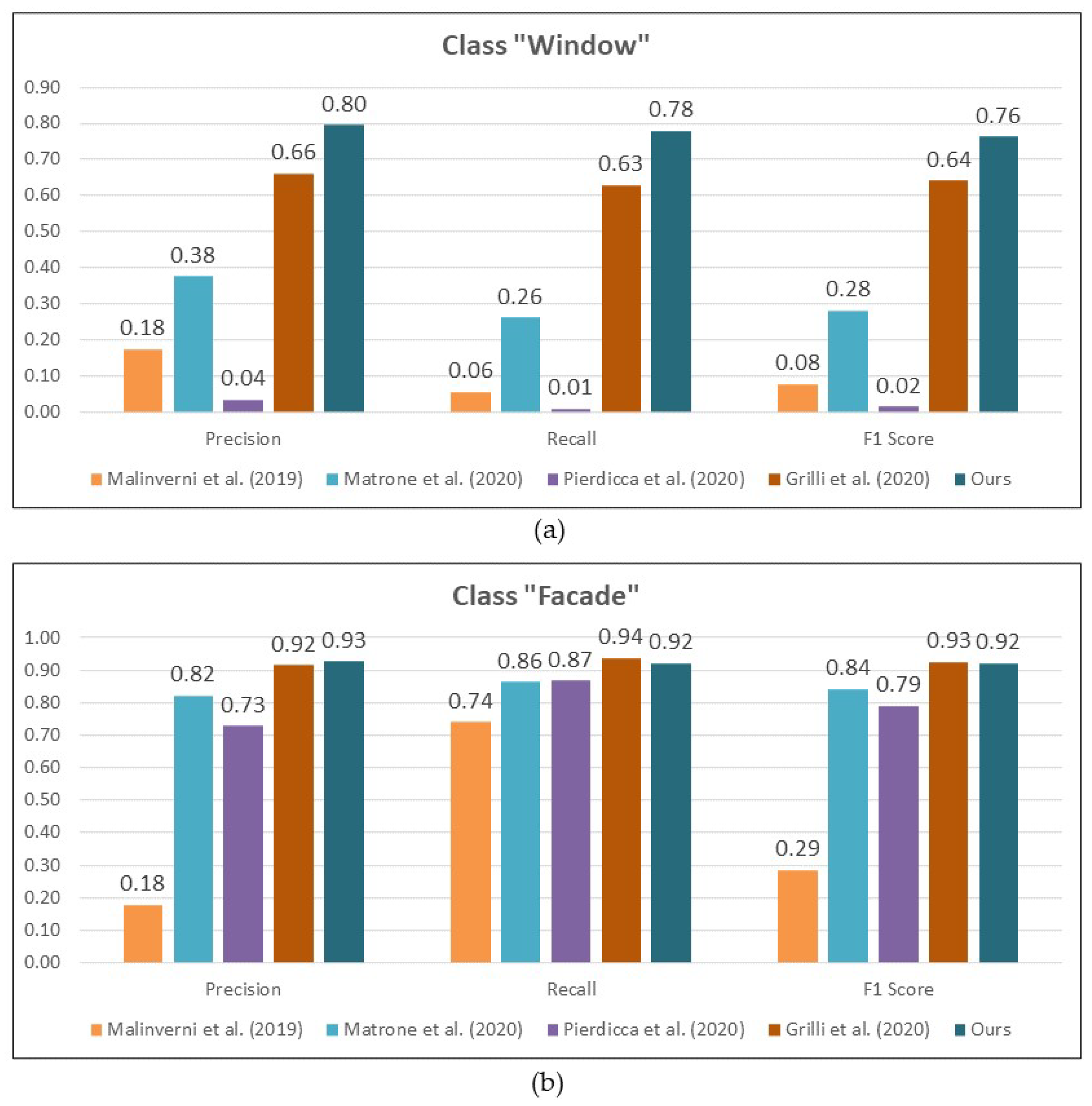
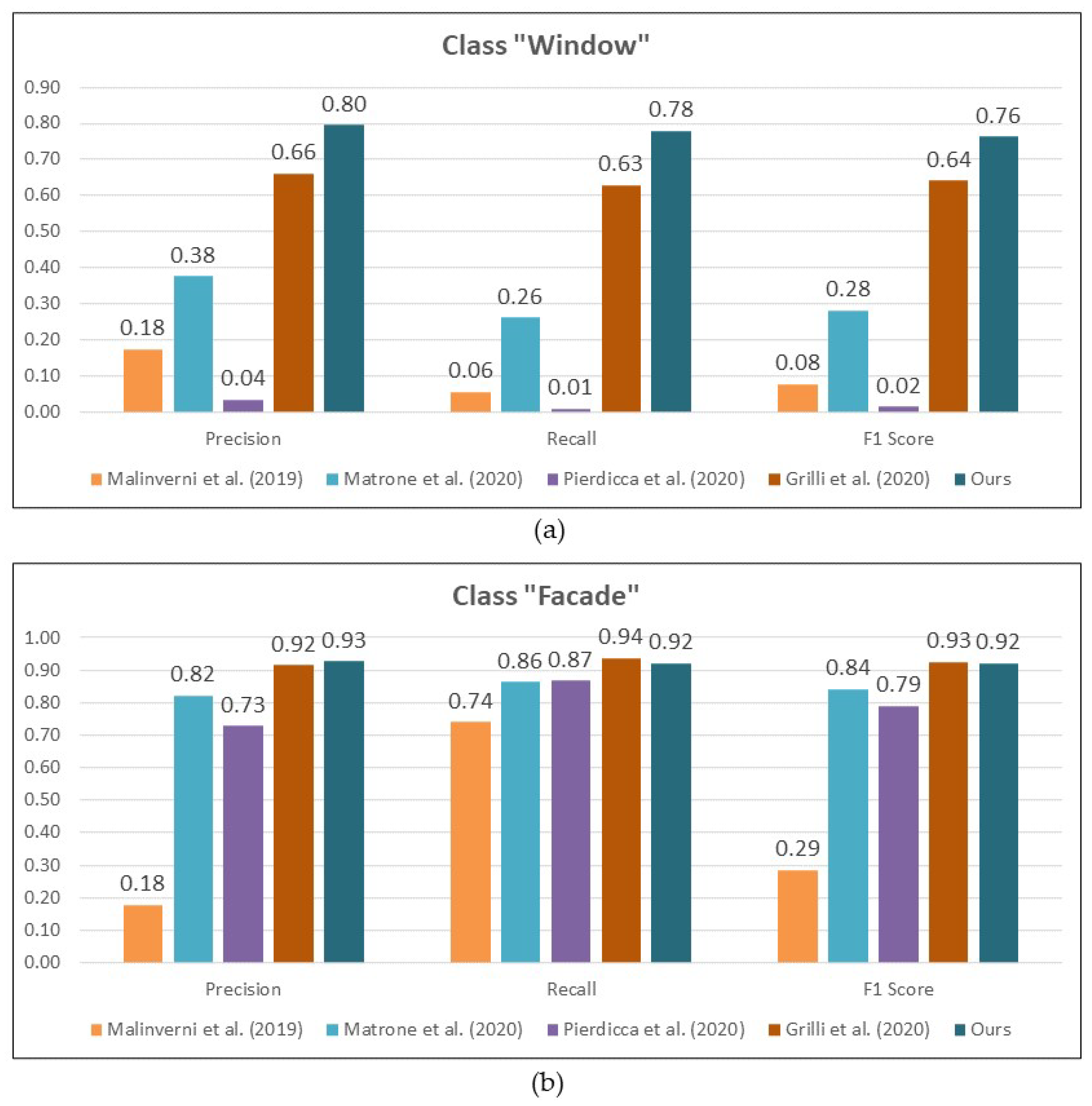
5.2. Comparison to Other Studies
5.3. Example of Direct Application: Point Cloud Cleaning
6. Conclusions and Future Investigations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Grilli, E.; Menna, F.; Remondino, F. A Review of Point Clouds Segmentation and Classification Algorithms. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-2/W3, 339–344. [Google Scholar] [CrossRef] [Green Version]
- Mölg, N.; Bolch, T. Structure-from-motion using historical aerial images to analyse changes in glacier surface elevation. Remote Sens. 2017, 9, 1021. [Google Scholar] [CrossRef] [Green Version]
- Abate, D.; Murtiyoso, A. Bundle adjustment accuracy assessment of unordered aerial dataset collected through Kite platform. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W17, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Grussenmeyer, P.; Hanke, K.; Streilein, A. Architectural Photogrammetry. In Digital Photogrammetry; Kasser, M., Egels, Y., Eds.; Taylor and Francis: London, UK, 2002; pp. 300–339. [Google Scholar]
- Granshaw, S.I. Bundle Adjustment Methods in Engineering Photogrammetry. Photogramm. Rec. 1980, 10, 181–207. [Google Scholar] [CrossRef]
- Grussenmeyer, P.; Al Khalil, O. Solutions for exterior orientation in photogrammetry: A review. Photogramm. Rec. 2002, 17, 615–634. [Google Scholar] [CrossRef]
- Gruen, A. Adaptive least squares correlation: A powerful image matching technique. S. Afr. J. Photogramm. Remote Sens. Cartogr. 1985, 14, 175–187. [Google Scholar]
- Börlin, N.; Grussenmeyer, P. Bundle adjustment with and without damping. Photogramm. Rec. 2013, 28, 396–415. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.; Agarwal, S.; Curless, B.; Seitz, S.M. Multicore bundle adjustment. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; Volume 1, pp. 3057–3064. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer: Berlin/Heidelberg, Germany, 2010; Volume 5, p. 832. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Hirschmüller, H. Semi-Global Matching Motivation, Developments and Applications. In Proceedings of the Photogrammetric Week, Stuttgart, Germany, 9–13 September 2011; pp. 173–184. [Google Scholar]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multi-view stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1362–1376. [Google Scholar] [CrossRef]
- Barazzetti, L.; Previtali, M.; Roncoroni, F. Can we use low-cost 360 degree cameras to create accurate 3D models? Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-2, 69–75. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Lee, S.; Ahn, H.; Seo, D.; Park, S.; Choi, C. Feasibility of employing a smartphone as the payload in a photogrammetric UAV system. ISPRS J. Photogramm. Remote Sens. 2013, 79, 1–18. [Google Scholar] [CrossRef]
- Wand, M.; Berner, A.; Bokeloh, M.; Jenke, P.; Fleck, A.; Hoffmann, M.; Maier, B.; Staneker, D.; Schilling, A.; Seidel, H.P. Processing and interactive editing of huge point clouds from 3D scanners. Comput. Graph. 2008, 32, 204–220. [Google Scholar] [CrossRef]
- Meng, F.; Zha, H. An Easy Viewer for Out-of-core Visualization of Huge Point-sampled Models. In Proceedings of the IAN Proceedings 2nd International Symposium on 3D Data Processing, Visualization and Transmission 2004, Thessaloniki, Greece, 9 September 2004; pp. 207–214. [Google Scholar] [CrossRef]
- Murtiyoso, A.; Grussenmeyer, P. Documentation of heritage buildings using close-range UAV images: Dense matching issues, comparison and case studies. Photogramm. Rec. 2017, 32, 206–229. [Google Scholar] [CrossRef] [Green Version]
- Campanaro, D.M.; Landeschi, G.; Dell’Unto, N.; Leander Touati, A.M. 3D GIS for cultural heritage restoration: A ‘white box’ workflow. J. Cult. Herit. 2016, 18, 321–332. [Google Scholar] [CrossRef]
- Murtiyoso, A.; Veriandi, M.; Suwardhi, D.; Soeksmantono, B.; Harto, A.B. Automatic Workflow for Roof Extraction and Generation of 3D CityGML Models from Low-Cost UAV Image-Derived Point Clouds. ISPRS Int. J. Geo-Inf. 2020, 9, 743. [Google Scholar] [CrossRef]
- Barsanti, S.G.; Remondino, F.; Fenández-Palacios, B.J.; Visintini, D. Critical factors and guidelines for 3D surveying and modelling in Cultural Heritage. Int. J. Herit. Digit. Era 2014, 3, 141–158. [Google Scholar] [CrossRef] [Green Version]
- Nex, F.; Gerke, M.; Remondino, F.; Przybilla, H.J.; Bäumker, M.; Zurhorst, A. ISPRS benchmark for multi-platform photogrammetry. Isprs Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-3/W4, 135–142. [Google Scholar] [CrossRef] [Green Version]
- Matrone, F.; Lingua, A.; Pierdicca, R.; Malinverni, E.S.; Paolanti, M.; Grilli, E.; Remondino, F.; Murtiyoso, A.; Landes, T. A benchmark for large-scale heritage point cloud semantic segmentation. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 1419–1426. [Google Scholar] [CrossRef]
- Poux, F.; Neuville, R.; Nys, G.A.; Billen, R. 3D point cloud semantic modelling: Integrated framework for indoor spaces and furniture. Remote Sens. 2018, 10, 1412. [Google Scholar] [CrossRef] [Green Version]
- Fabbri, K.; Zuppiroli, M.; Ambrogio, K. Heritage buildings and energy performance: Mapping with GIS tools. Energy Build. 2012, 48, 137–145. [Google Scholar] [CrossRef]
- Seker, D.Z.; Alkan, M.; Kutoglu, H.; Akcin, H.; Kahya, Y. Development of a GIS Based Information and Management System for Cultural Heritage Site; Case Study of Safranbolu. In Proceedings of the FIG Congress 2010, Sydney, Australia, 11–16 April 2010. [Google Scholar]
- Gröger, G.; Plümer, L. CityGML—Interoperable semantic 3D city models. ISPRS J. Photogramm. Remote Sens. 2012, 71, 12–33. [Google Scholar] [CrossRef]
- Biljecki, F.; Stoter, J.; Ledoux, H.; Zlatanova, S.; Çöltekin, A. Applications of 3D city models: State of the art review. ISPRS Int. J. Geo-Inf. 2015, 4, 2842–2889. [Google Scholar] [CrossRef] [Green Version]
- Volk, R.; Stengel, J.; Schultmann, F. Building Information Modeling (BIM) for existing buildings—Literature review and future needs. Autom. Constr. 2014, 38, 109–127. [Google Scholar] [CrossRef] [Green Version]
- Macher, H.; Landes, T.; Grussenmeyer, P. Point clouds segmentation as base for as-built BIM creation. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-5/W3, 191–197. [Google Scholar] [CrossRef] [Green Version]
- Macher, H.; Landes, T.; Grussenmeyer, P. From Point Clouds to Building Information Models: 3D Semi-Automatic Reconstruction of Indoors of Existing Buildings. Appl. Sci. 2017, 7, 1030. [Google Scholar] [CrossRef] [Green Version]
- Bassier, M.; Bonduel, M.; Genechten, B.V.; Vergauwen, M. Octree-Based Region Growing and Conditional Random Fields. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-2/W8, 25–30. [Google Scholar] [CrossRef] [Green Version]
- Murtiyoso, A.; Grussenmeyer, P. Virtual disassembling of historical edifices: Experiments and assessments of an automatic approach for classifying multi-scalar point clouds into architectural elements. Sensors 2020, 20, 2161. [Google Scholar] [CrossRef] [Green Version]
- Matrone, F.; Grilli, E.; Martini, M.; Paolanti, M.; Pierdicca, R.; Remondino, F. Comparing machine and deep learning methods for large 3D heritage semantic segmentation. ISPRS Int. J. Geo-Inf. 2020, 9, 535. [Google Scholar] [CrossRef]
- Granshaw, S.I. Photogrammetric terminology: Fourth edition. Photogramm. Rec. 2020, 35, 143–288. [Google Scholar] [CrossRef]
- Jinqiang, W.; Basnet, P.; Mahtab, S. Review of machine learning and deep learning application in mine microseismic event classification. Min. Miner. Depos. 2021, 15, 19–26. [Google Scholar] [CrossRef]
- Maalek, R.; Lichti, D.D.; Ruwanpura, J.Y. Automatic recognition of common structural elements from point clouds for automated progress monitoring and dimensional quality control in reinforced concrete construction. Remote Sens. 2019, 11, 1102. [Google Scholar] [CrossRef] [Green Version]
- Murtiyoso, A.; Grussenmeyer, P. Automatic heritage building point cloud segmentation and classification using geometrical rules. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-ISPRS Arch. 2019, XLII-2/W15, 821–827. [Google Scholar] [CrossRef] [Green Version]
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollar, P. Panoptic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9396–9405. [Google Scholar] [CrossRef]
- Murtiyoso, A.; Lhenry, C.; Landes, T.; Grussenmeyer, P.; Alby, E. Semantic Segmentation for Building Façade 3D Point Cloud From 2D Orthophoto Images Using Transfer Learning. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, XLIII-B2-2, 201–206. [Google Scholar] [CrossRef]
- Pierdicca, R.; Paolanti, M.; Matrone, F.; Martini, M.; Morbidoni, C.; Malinverni, E.S.; Frontoni, E.; Lingua, A.M. Point Cloud Semantic Segmentation Using a Deep Learning Framework for Cultural Heritage. Remote Sens. 2020, 12, 1005. [Google Scholar] [CrossRef] [Green Version]
- Stathopoulou, E.K.; Remondino, F. Semantic photogrammetry—Boosting image-based 3D reconstruction with semantic labeling. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W9, 685–690. [Google Scholar] [CrossRef] [Green Version]
- Heipke, C.; Rottensteiner, F. Deep learning for geometric and semantic tasks in photogrammetry and remote sensing. Geo-Spat. Inf. Sci. 2020, 23, 10–19. [Google Scholar] [CrossRef]
- Stathopoulou, E.K.; Remondino, F. Multi-view stereo with semantic priors. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-SPRS Arch. 2019, XLII-2/W15, 1135–1140. [Google Scholar] [CrossRef] [Green Version]
- Grilli, E.; Battisti, R.; Remondino, F. An advanced photogrammetric solution to measure apples. Remote Sens. 2021, 13, 3960. [Google Scholar] [CrossRef]
- Kernell, B. Improving Photogrammetry Using Semantic Segmentation. Ph.D. Thesis, Linköping University, Linköping, Sweden, 2018. [Google Scholar]
- Rupnik, E.; Daakir, M.; Pierrot Deseilligny, M. MicMac—A free, open-source solution for photogrammetry. Open Geospat. Data Softw. Stand. 2017, 2, 14. [Google Scholar] [CrossRef]
- Schenk, T. Introduction to Photogrammetry; Department of Civil and Environmental Engineering and Geodetic Science, The Ohio State University: Columbus, OH, USA, 2005; pp. 79–95. [Google Scholar]
- Murtiyoso, A.; Grussenmeyer, P.; Börlin, N.; Vandermeerschen, J.; Freville, T. Open Source and Independent Methods for Bundle Adjustment Assessment in Close-Range UAV Photogrammetry. Drones 2018, 2, 3. [Google Scholar] [CrossRef] [Green Version]
- Wolf, P.; DeWitt, B.; Wilkinson, B. Elements of Photogrammetry with Applications in GIS, 4th ed.; McGraw-Hill Education: New York, NY, USA, 2014; p. 696. [Google Scholar]
- Luhmann, T.; Robson, S.; Kyle, S.; Boehm, J. Close-Range Photogrammetry and 3D Imaging, 2nd ed.; De Gruyter: Berlin, Germany, 2014; p. 684. [Google Scholar]
- Hirschmüller, H. Accurate and efficient stereo processing by semi-global matching and mutual information. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 807–814. [Google Scholar]
- Remondino, F.; Spera, M.G.; Nocerino, E.; Menna, F.; Nex, F. State of the art in high density image matching. Photogramm. Rec. 2014, 29, 144–166. [Google Scholar] [CrossRef] [Green Version]
- Murtiyoso, A.; Grussenmeyer, P.; Suwardhi, D.; Awalludin, R. Multi-Scale and Multi-Sensor 3D Documentation of Heritage Complexes in Urban Areas. ISPRS Int. J. Geo-Inf. 2018, 7, 483. [Google Scholar] [CrossRef] [Green Version]
- Bedford, J. Photogrammetric Applications for Cultural Heritage; Historic England: Swindon, UK, 2017; p. 128. [Google Scholar]
- Kalinichenko, V.; Dolgikh, O.; Dolgikh, L.; Pysmennyi, S. Choosing a camera for mine surveying of mining enterprise facilities using unmanned aerial vehicles. Min. Miner. Depos. 2020, 14, 31–39. [Google Scholar] [CrossRef]
- Wenzel, K.; Rothermel, M.; Fritsch, D.; Haala, N. Image acquisition and model selection for multi-view stereo. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-5/W1, 251–258. [Google Scholar] [CrossRef] [Green Version]
- Verhoeven, G.; Taelman, D.; Vermeulen, F. Computer Vision-Based Orthophoto Mapping of Complex Archaeological Sites: The Ancient Quarry of Pitaranha (Portugal-Spain). Archaeometry 2012, 54, 1114–1129. [Google Scholar] [CrossRef]
- Bassier, M.; Vergauwen, M.; Van Genechten, B. Automated Classification of Heritage Buildings for As-Built BIM using Machine Learning Techniques. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, IV-2/W2, 25–30. [Google Scholar] [CrossRef] [Green Version]
- Poux, F.; Hallot, P.; Neuville, R.; Billen, R. Smart Point Cloud: Definition and Remaining Challenges. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, IV-2/W1, 119–127. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.; Tian, J.; Zhu, X.X. Linking Points with Labels in 3D: A Review of Point Cloud Semantic Segmentation. IEEE Geosci. Remote Sens. Mag. 2020, 8, 38–59. [Google Scholar] [CrossRef] [Green Version]
- Pellis, E.; Masiero, A.; Tucci, G.; Betti, M.; Grussenmeyer, P. Towards an Integrated Design Methodology for H-Bim. In Proceedings of the Joint International Event 9th ARQUEOLÓGICA 2.0 and 3rd GEORES, Valencia, Spain, 26–28 April 2021; pp. 389–398. [Google Scholar] [CrossRef]
- Zhang, K.; Hao, M.; Wang, J.; de Silva, C.W.; Fu, C. Linked dynamic graph CNN: Learning on point cloud via linking hierarchical features. arXiv 2019, arXiv:1904.10014. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar] [CrossRef] [Green Version]
- Boulch, A.; Guerry, J.; Le Saux, B.; Audebert, N. SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks. Comput. Graph. (Pergamon) 2018, 71, 189–198. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Detection. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Sustems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Riegler, G.; Ulusoy, A.O.; Geiger, A. OctNet: Learning deep 3D representations at high resolutions. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 6620–6629. [Google Scholar] [CrossRef] [Green Version]
- Tchapmi, L.P.; Choy, C.B.; Armeni, I.; Gwak, J.; Savarese, S. SEGCloud: Semantic Segmentation of 3D Point Clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar] [CrossRef]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.H.; Kautz, J. SPLATNet: Sparse Lattice Networks for Point Cloud Processing. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2530–2539. [Google Scholar] [CrossRef] [Green Version]
- Rosu, R.A.; Schütt, P.; Quenzel, J.; Behnke, S. LatticeNet: Fast Point Cloud Segmentation Using Permutohedral Lattices. arXiv 2020, arXiv:1912.05905. [Google Scholar]
- Choy, C.B.; Gwak, J.; Savarese, S. 4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks. arXiv 2019, arXiv:1904.08755. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–7 December 2017; pp. 5099–5108. [Google Scholar]
- Wang, S.; Suo, S.; Ma, W.C.; Pokrovsky, A.; Urtasun, R. Deep Parametric Continuous Convolutional Neural Networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2589–2597. [Google Scholar] [CrossRef]
- Boulch, A. ConvPoint: Continuous Convolutions for Point Cloud Processing. Comput. Graph. 2020, 88, 24–34. [Google Scholar] [CrossRef] [Green Version]
- Liu, F.; Li, S.; Zhang, L.; Zhou, C.; Ye, R.; Wang, Y.; Lu, J. 3DCNN-DQN-RNN: A Deep Reinforcement Learning Framework for Semantic Parsing of Large-Scale 3D Point Clouds. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5679–5688. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph Cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Ji, R.; Chang, S.F. Label propagation from imagenet to 3D point clouds. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3135–3142. [Google Scholar] [CrossRef] [Green Version]
- Tasaka, K.; Yanagihara, H.; Lertniphonphan, K.; Komorita, S. 2D TO 3D Label Propagation for Object Detection in Point Cloud. In Proceedings of the 2018 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Reza, M.A.; Zheng, H.; Georgakis, G.; Kosecka, J. Label propagation in RGB-D video. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; pp. 4917–4922. [Google Scholar] [CrossRef]
- Xie, J.; Kiefel, M.; Sun, M.T.; Geiger, A. Semantic Instance Annotation of Street Scenes by 3D to 2D Label Transfer. arXiv 2016, arXiv:1511.03240. [Google Scholar]
- Babahajiani, P.; Fan, L.; Kämäräinen, J.K.; Gabbouj, M. Urban 3D segmentation and modelling from street view images and LiDAR point clouds. Mach. Vis. Appl. 2017, 28, 679–694. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tyleček, R.; Šára, R. Spatial pattern templates for recognition of objects with regular structure. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2013, 8142 LNCS, 364–374. [Google Scholar] [CrossRef] [Green Version]
- Malinverni, E.S.; Pierdicca, R.; Paolanti, M.; Martini, M.; Morbidoni, C.; Matrone, F.; Lingua, A. Deep learning for semantic segmentation of point cloud. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W15, 735–742. [Google Scholar] [CrossRef] [Green Version]
- Assi, R.; Landes, T.; Murtiyoso, A.; Grussenmeyer, P. Assessment of a Keypoints Detector for the Registration of Indoor and Outdoor Heritage Point Clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W15, 133–138. [Google Scholar] [CrossRef] [Green Version]
- Landes, T.; Macher, H.; Murtiyoso, A.; Lhenry, C.; Alteirac, V.; Lallement, A.; Kastendeuch, P. Detection and 3D Reconstruction of Urban Trees and Façade Openings by Segmentation of Point Clouds: First Experiment with PointNet++. In Proceedings of the International Symposium on Applied Geoinformatics, Riga, Latvia, 2–3 December 2021. [Google Scholar]
- Grilli, E.; Remondino, F. Machine Learning Generalisation across Different 3D Architectural Heritage. ISPRS Int. J. Geo-Inf. 2020, 9, 379. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ground Truth | |||||||
| Class | Window | Door | Shops | Pillar | Facade | Total | |
| Predicted | Window | 548,886 | 3920 | 688 | 14,927 | 254,941 | 823,362 |
| Door | 1566 | 152,538 | 0 | 0 | 21,483 | 175,587 | |
| Shops | 682 | 25,738 | 6216 | 0 | 13,326 | 45,962 | |
| Pillar | 15 | 0 | 0 | 124 | 9535 | 9674 | |
| Facade | 38,903 | 6121 | 66 | 6910 | 1,876,172 | 1,928,172 | |
| Total | 590,052 | 188,317 | 6970 | 21,961 | 2,175,457 | 2,982,757 | |
| Ground Truth | |||||||
| Class | Window | Door | Shops | Pillar | Facade | Total | |
| Predicted | Window | 3,104,942 | 22,286 | 6467 | 6697 | 217,949 | 3,358,341 |
| Door | 42,294 | 819,405 | 179,411 | 87 | 44,619 | 1,085,816 | |
| Shops | 6427 | 0 | 28,283 | 0 | 531 | 35,241 | |
| Pillar | 181,417 | 0 | 0 | 2621 | 54,961 | 238,999 | |
| Facade | 1,595,515 | 190,429 | 82,260 | 130,134 | 14,612,534 | 16,610,872 | |
| Total | 4,930,595 | 1,032,120 | 296,421 | 139,539 | 14,930,594 | 21,329,269 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Murtiyoso, A.; Pellis, E.; Grussenmeyer, P.; Landes, T.; Masiero, A. Towards Semantic Photogrammetry: Generating Semantically Rich Point Clouds from Architectural Close-Range Photogrammetry. Sensors 2022, 22, 966. https://doi.org/10.3390/s22030966
Murtiyoso A, Pellis E, Grussenmeyer P, Landes T, Masiero A. Towards Semantic Photogrammetry: Generating Semantically Rich Point Clouds from Architectural Close-Range Photogrammetry. Sensors. 2022; 22(3):966. https://doi.org/10.3390/s22030966
Chicago/Turabian StyleMurtiyoso, Arnadi, Eugenio Pellis, Pierre Grussenmeyer, Tania Landes, and Andrea Masiero. 2022. "Towards Semantic Photogrammetry: Generating Semantically Rich Point Clouds from Architectural Close-Range Photogrammetry" Sensors 22, no. 3: 966. https://doi.org/10.3390/s22030966
APA StyleMurtiyoso, A., Pellis, E., Grussenmeyer, P., Landes, T., & Masiero, A. (2022). Towards Semantic Photogrammetry: Generating Semantically Rich Point Clouds from Architectural Close-Range Photogrammetry. Sensors, 22(3), 966. https://doi.org/10.3390/s22030966