
An Experimental Safety Response Mechanism for an Autonomous Moving Robot in a Smart Manufacturing Environment Using Q-Learning Algorithm and Speech Recognition



Abstract
1. Introduction
1.1. Motivation of the Study
1.2. Contributions and Limitations
2. Previous Works Findings
Previous Researches Gaps Summary
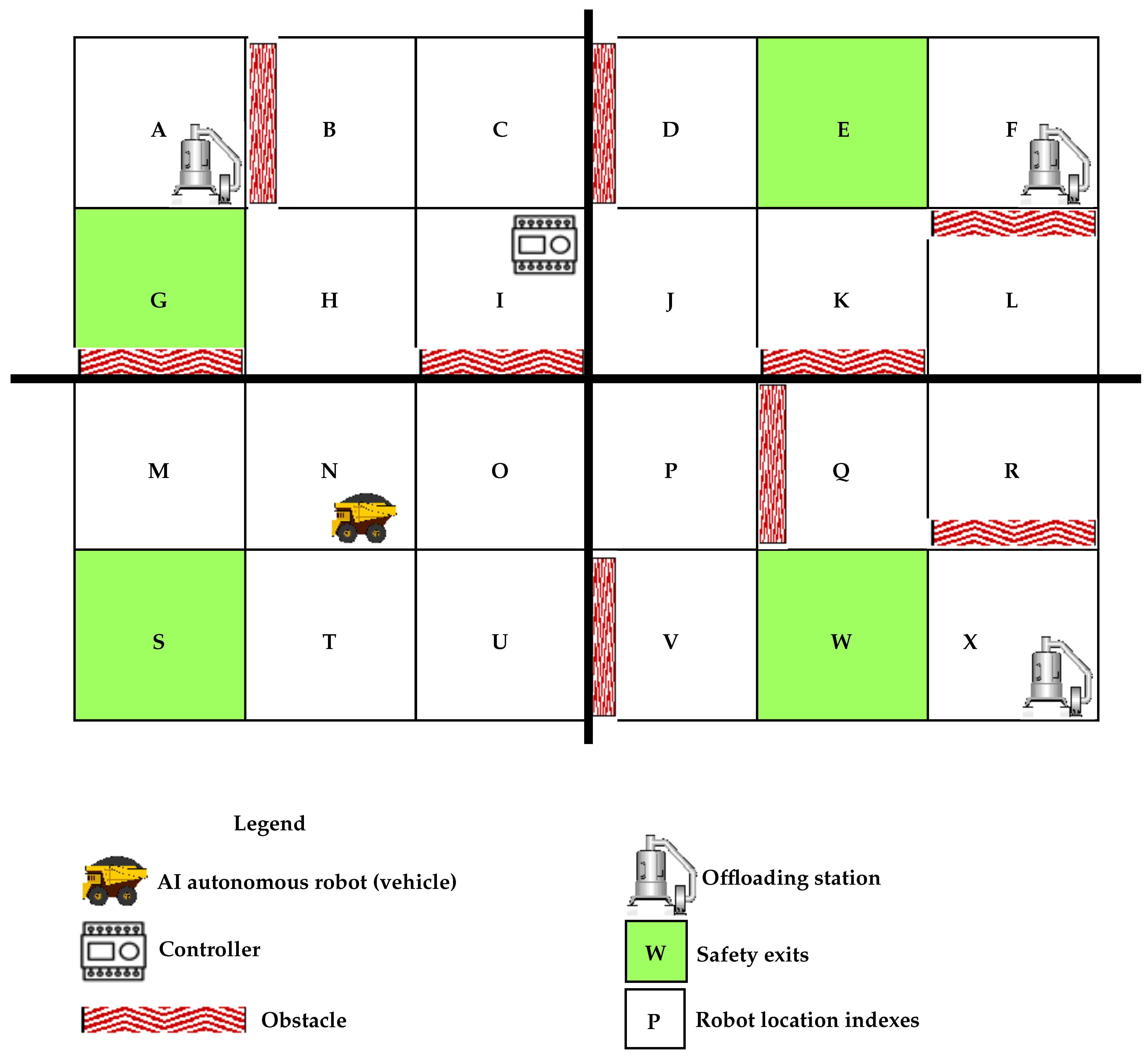
- Find an obstacle-free path to the closest safety exit based on its current location.
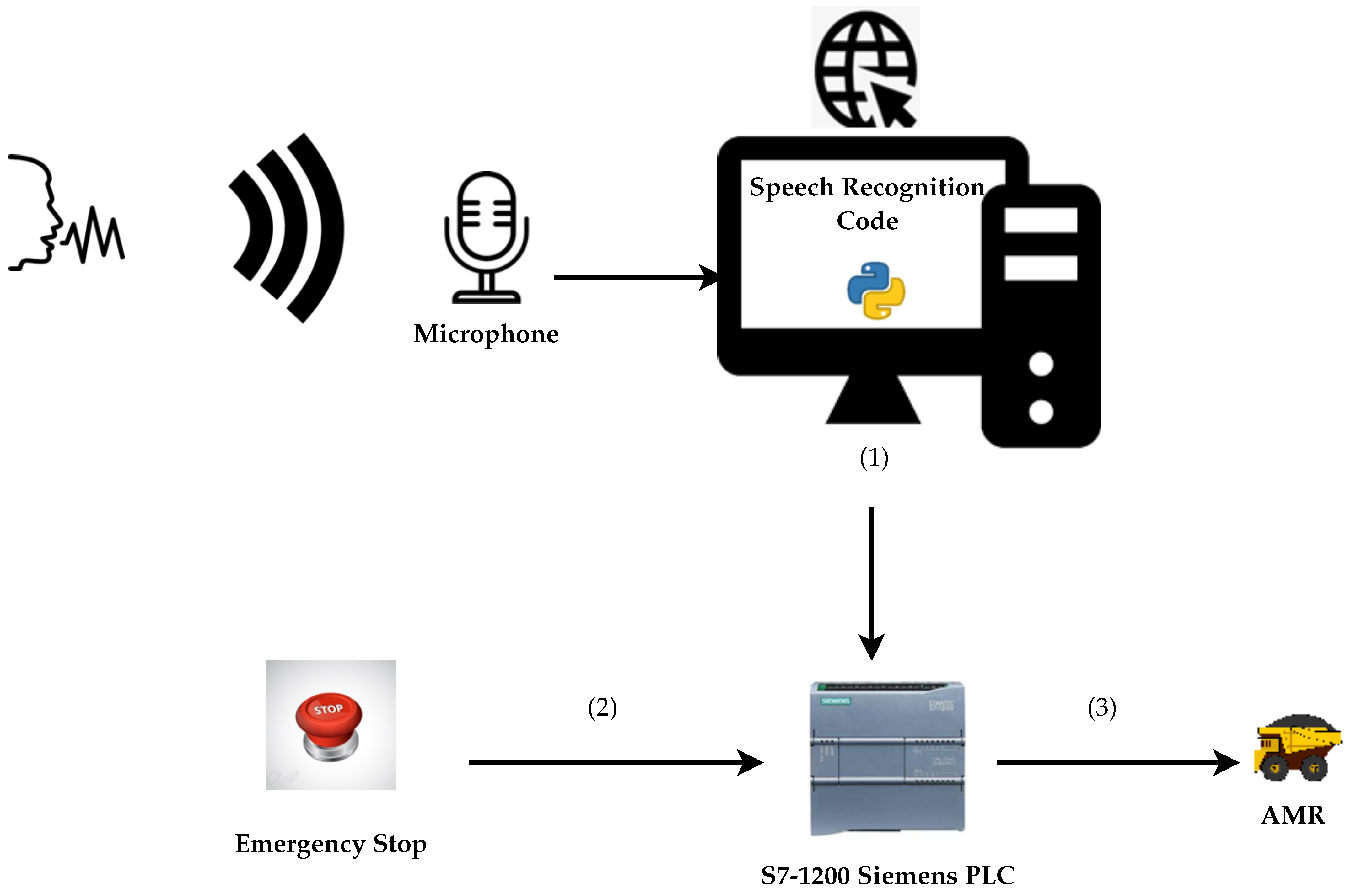
- Receive a voice command from the main plant PLC. The voice command is implemented as an additional stopping interlock for the PLC. It means that it can stop all ongoing plant operations in case of emergency.
3. Short Theory and Background Overview
3.1. Reinforcement Learning (RL)
Q-Learning Algorithm
3.2. Speech Recognition
3.3. Programmable Logic Controller (PLC) Functions in the Era of Industry 4.0
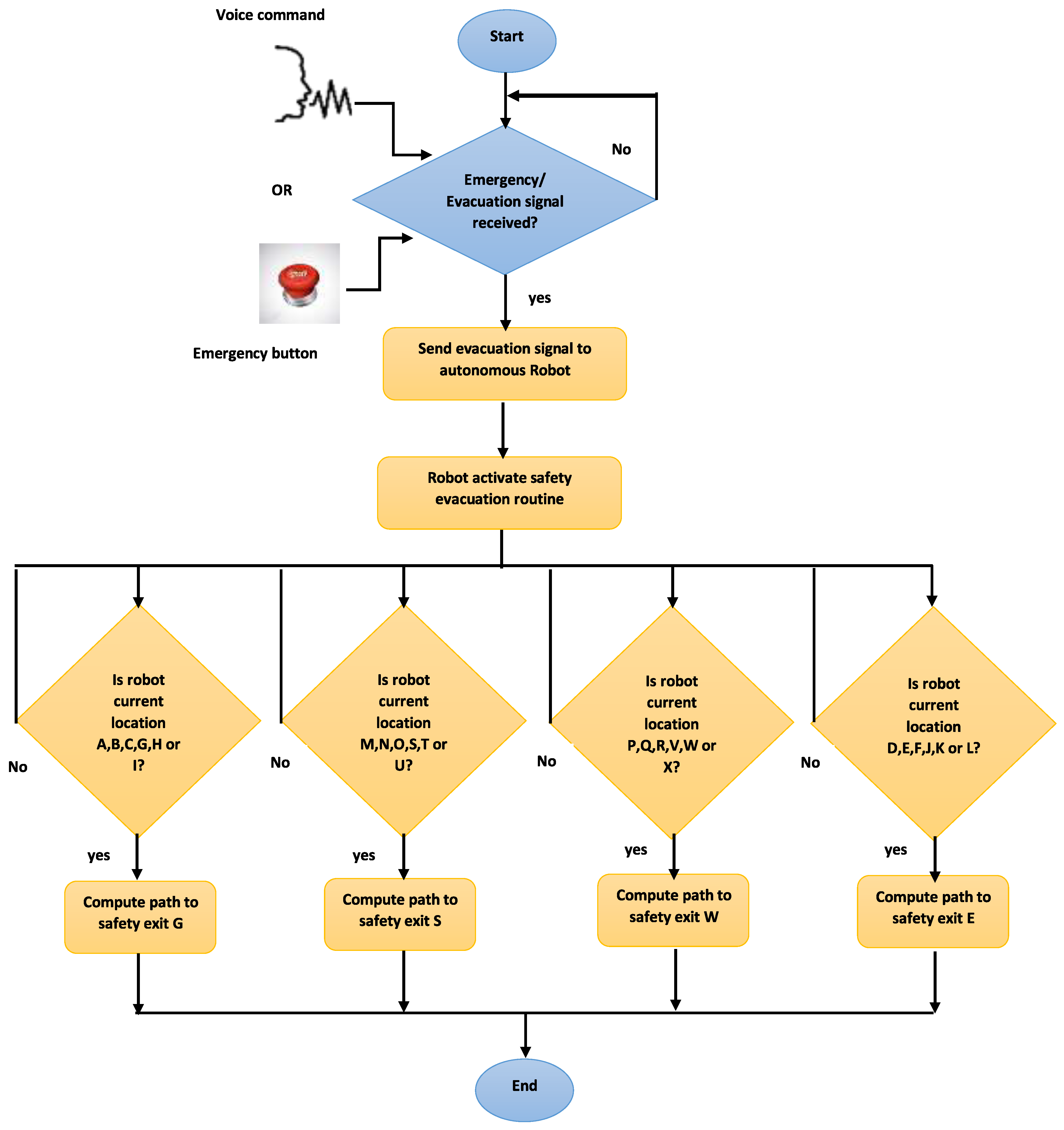
4. Safety Response Mechanism Methodology
- An automatic path finding section to safety exits in case of emergency: We build this section based on the Q-learning algorithm.
- A voice command input to a Siemens S7-1200 PLC to activate the emergency signal: Speech recognition is the key feature of this segment.
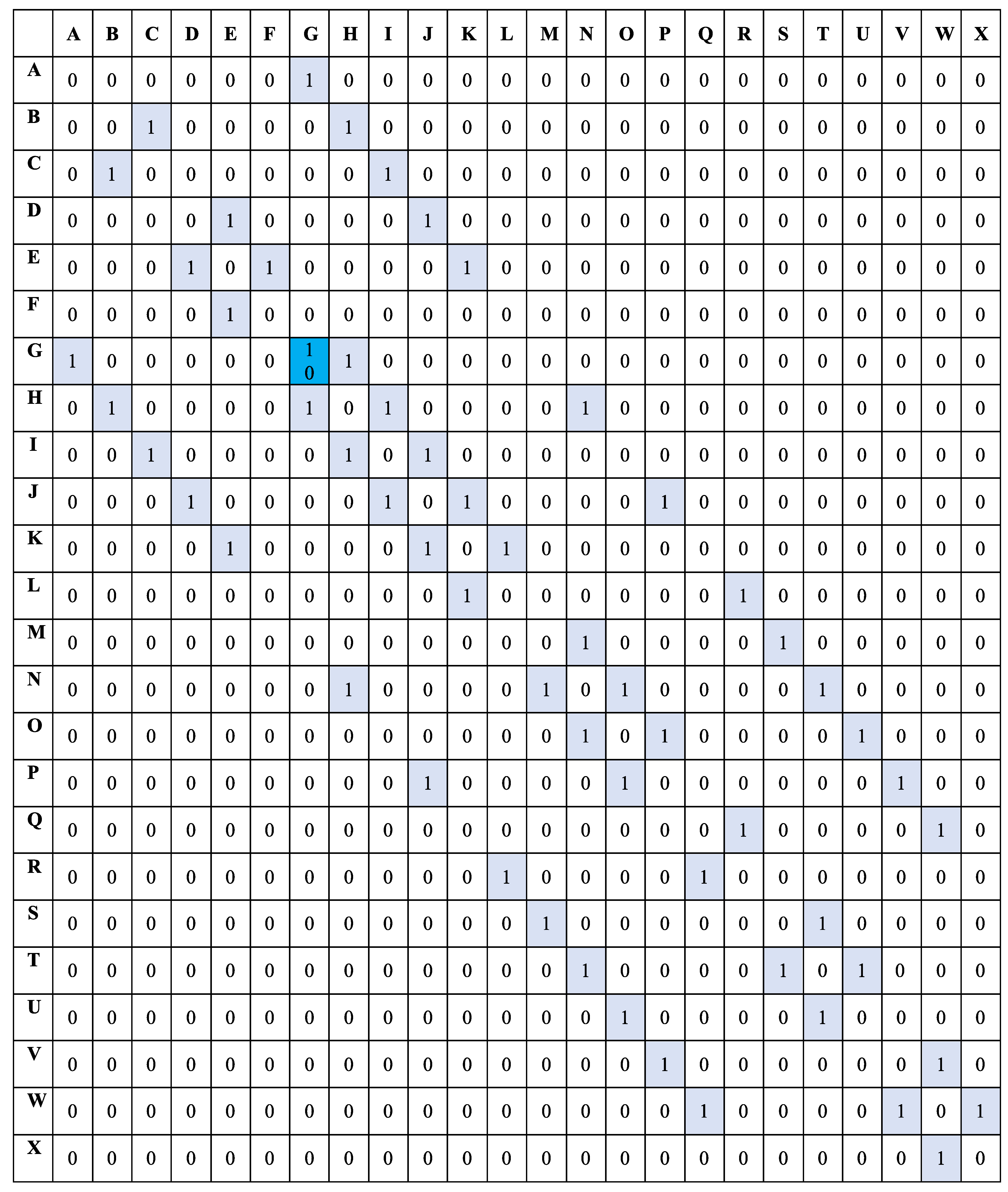
4.1. Q-Learning Algorithm to Find Obstacle Free Paths
| Algorithm 1 Q-learning general algorithm for operation summary |
|
4.2. Speech Recognition Process to Activate a Voice Command Input to the PLC
| Algorithm 2 Finding the obstacle free path from the current location to the safety exit |
|
- is the emergency/evacuation signal.
- X is the autonomous robot.
- is a safety exit.
| Algorithm 3 Voice command to PLC input via speech recognition |
|
| Algorithm 4 Safety mechanism procedure summary |
|
5. Experimental Environment Architecture and Workflow Diagram
6. Experimental Results
6.1. Experimental Background and Assumptions
- Every industrial plant has or should have a safety protocol to activate in case of emergency. It could lead to evacuating the plant and pressing one of the emergencies stop interlocks (ESTOP or Stop buttons depending on the disaster’s severity) that usually halts the whole system. The stop interlocks are wired inputs of the plant controller (a PLC for this experiment) that are programmed to control several outputs. These stop buttons (including ESTOPS) are connected to the control panels and sometimes on different strategic locations.How to palliate to emergencies where none of the operators is nowhere near to the stop buttons?We answer this problem by incorporating a voice command as an additional stop interlock programmed in the PLC. The operator can use the command “emergency” to alt to the system via a microphone. We apply a speech recognition algorithm to convert the operator’s voice command to a PLC’s instruction. A Siemens S7-1200 PLC is used for testing the program via the TIA portal software. We develop the speech recognition code in a python integrated development environment (IDE).
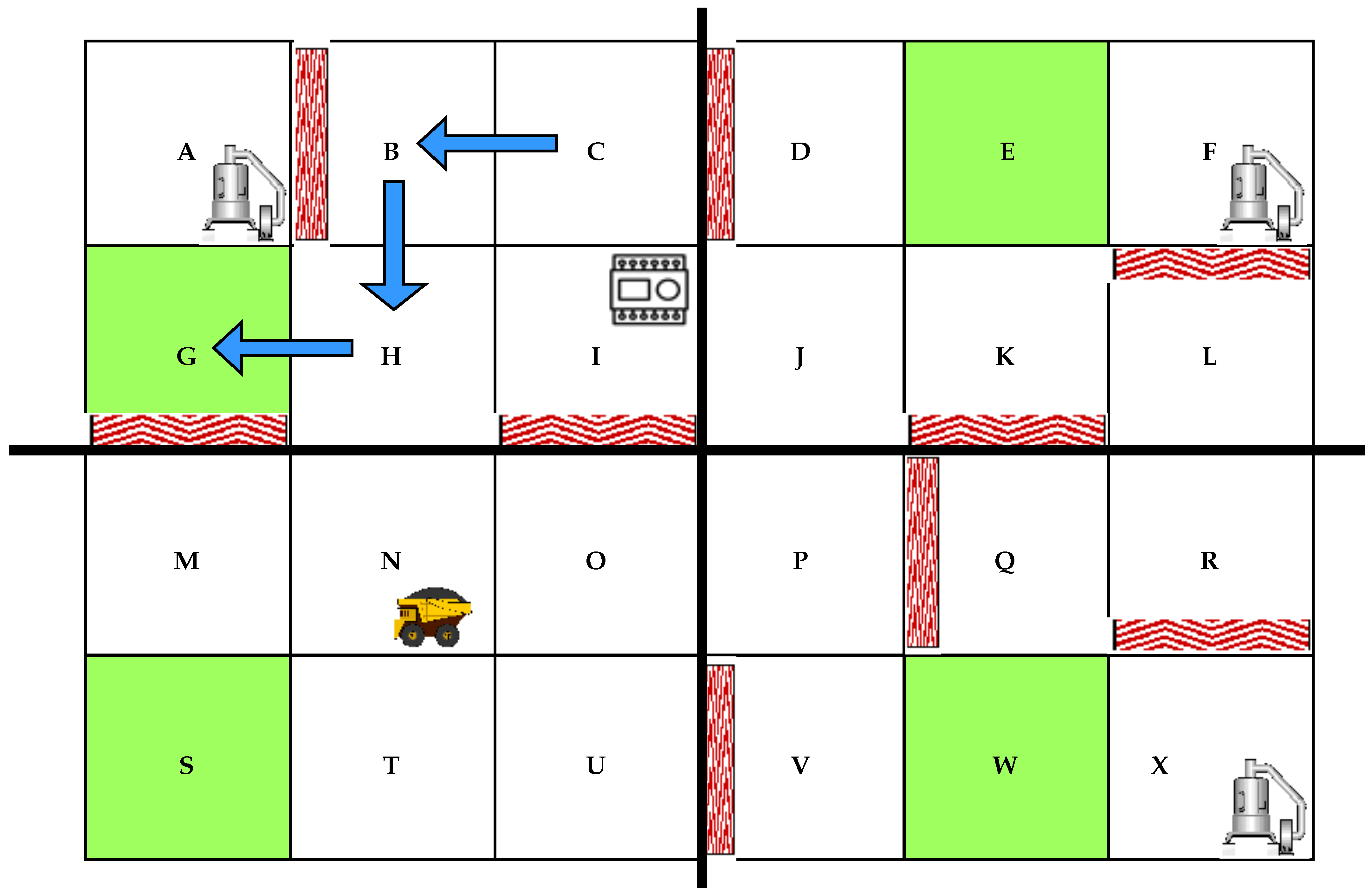
- Significant modern buildings are constructed with different safety exits located at different areas to ensure smooth and efficient evacuations in case of emergencies. It could be more dangerous for people to always go out through a single safety exit that could be far away from their current location, risking getting more injured on the way.What happens to autonomous robots in a smart manufacturing environment when a signal to evacuate the plant has been given, and they were busy performing one of their tasks at the plant’s location?We address this problem by implementing the same principle of decentralized safety exits for an autonomous robot. We simulate different safety exits for the autonomous robot based on its current location, and we apply the Q-learning algorithm for the robot to learn the obstacle-free path to the closest safety exit when an evacuation signal is received. We, therefore, reduce the risk of undesired incidents on the robot in an emergency evacuation. We use python to program our Q-learning method for safety exits.
- In the design of our safety procedure response system, we assume that the autonomous robot has been equipped with onboard means like sensors and cameras to interact with other field components (such as the main plant PLC) and knowledge of its current location.
- We also presume that the microphone used to capture the voice command is powerful enough (wide range) to detect the operator’s emergency command from a long distance and has a noise suppression scheme.
- Another assumption we make in this research is that the autonomous robot has a designated route that does not interfere with human operators’ paths.
- We assume that during the evacuation procedure, the AMR only encounters static obstacles. All other moving obstacles have been stopped accordingly due the state of emergency.
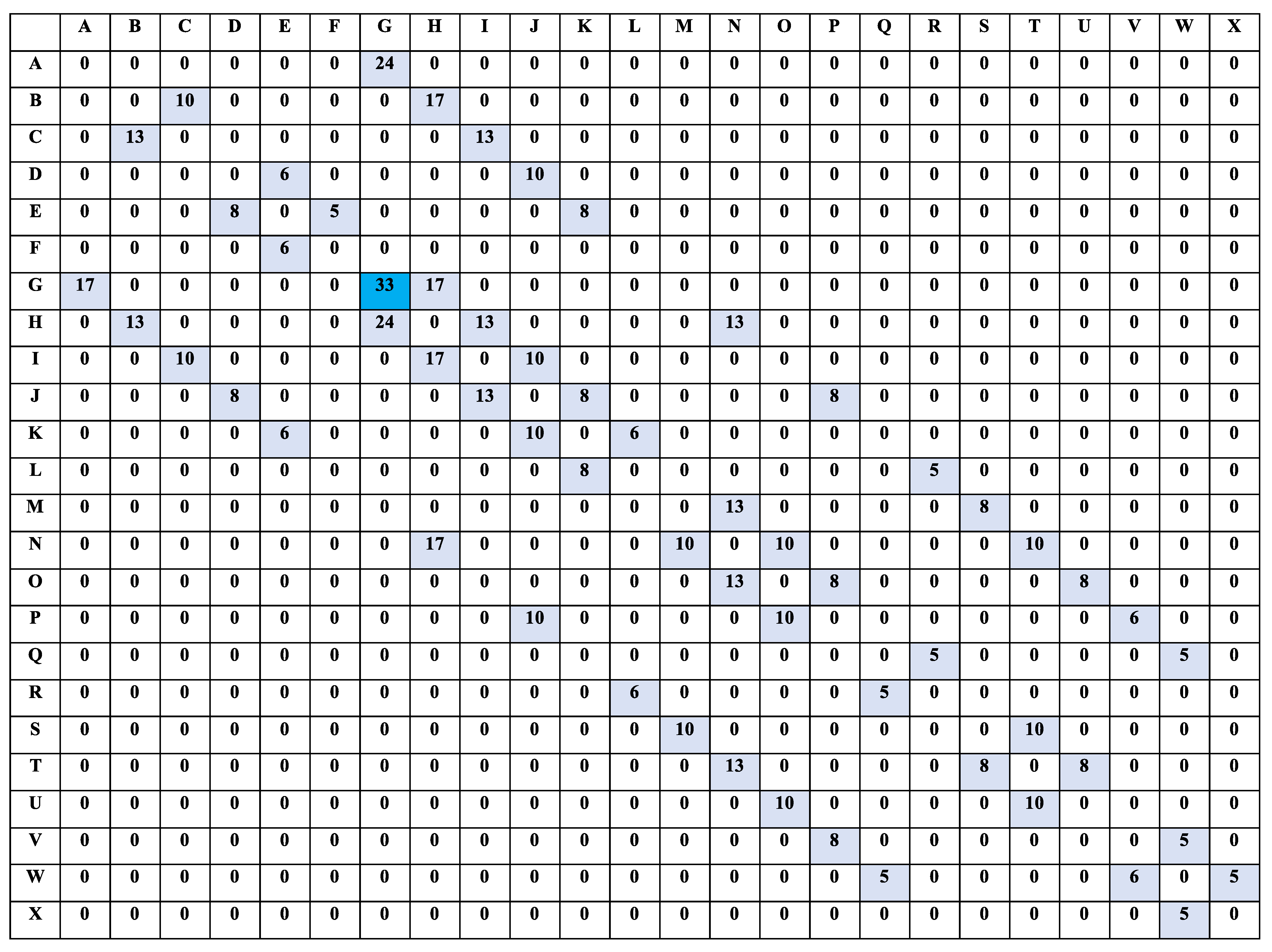
6.2. Finding Robot Paths to the Closest Safety Exits Using Q-Learning
- For segment 1—locations A, B, C, G, H and I: safety exit G
- For segment 2—locations M, N, O, S, T and U: safety exit S
- For segment 3—locations P, Q, R, V, W and X: safety exit W
- For segment 4—locations D, E, F, J, K and L: safety exit E
- From A to B or from B to A—Reward value 0. The reward value is 0 because of the obstacle between the two locations
- From A to G—Reward value 24.
- From G to A—Reward value 17. The difference in reward is because going from G to A, the robot moves away from the safety location (G) but from A to G, it moves closer hence a higher reward.
- From B to C—Reward value 0.
- From C to B—The difference in reward is because going from B to C, the robot moves away from the safety location (G) but from C to B, it moves closer hence a higher reward.
- From C to D—Reward value 0. The reward value is 0 because of the obstacle between the two locations.
- From C to I—Reward value 13.
- From I to C—Reward value 10. the difference in reward is because going from I to C, the robot moves away from the safety location (G) but from C to I, it moves closer hence a higher reward.
- From I to J—Reward value 10.
- From I to O—Reward value 0. The reward value is 0 because of the obstacle between the two locations.
- From I to H—Reward value 17.
- From H to I—Reward value 13. The difference in reward is because going from H to I, the robot moves away from the safety location (G) but from I to H, it moves closer hence a higher reward.
- From H to N—Reward value 13.
- From H to G—Reward value 24.
- From G to H—Reward value 13. The difference in reward is because going from G to H, the robot moves away from the safety location (G) but from H to G, it moves closer hence a higher reward.
- From G to M—Reward value 0. The reward value is 0 because of the obstacle between the two locations.
| Listing 1. The programming code portion of the robot path from C to G. |
| if loc == ’A’ or loc == ’B’ or loc == ’C’ |
| or loc == ’G’ or loc == ’H’ or loc == ’I’: |
| print(route(loc,’G’)) |
| elif loc == ’M’ or loc == ’N’ or loc == ’O’ |
| or loc == ’S’ or loc == ’T’ or loc == ’U’: |
| print(route(loc,’S’)) |
| elif loc == ’P’ or loc == ’Q’ or loc == ’R’ |
| or loc == ’V’ or loc == ’W’ or loc == ’X’: |
| print(route(loc,’W’)) |
| else: |
| print(route(loc,’E’)) |
| [’C’, ’B’, ’H’, ’G’] |
6.3. Using a Voice Command to Control a Siemens S7-1200 PLC Emergency Stop Interlock
6.4. Results Summary and Discussion
6.5. Research Implications
- In society: Some studies [59,60] highlighted that safety measures and procedures in a manufacturing environment have a direct impact on the frequency of accidents in the plant, to the overall production performance (which in return affects the economy) and to the workers’ well-being. Operators are performant in an environment where they feel safe and comfortable working. Our research offers additional practical strategies for manufacturing plants to enhance their safety procedures in an intelligent manufacturing scenario where human operators and intelligent equipment such as autonomous robots are at risk in emergencies.
- In research: On one hand, our study converts the theoretical concept of the Q-learning algorithm into a practical application directed in the area of safety where much more applications can be developed. On the other hand, we make a traditional controller (a PLC) more intelligent by enabling its ability to receive external voice commands using the Speech-recognition algorithm. The research area of speech recognition for PLCs is still quite open and presents many opportunities for the enhancement of traditional processes in an era of smart manufacturing. Reference [60] states that there is a crucial need for more practical research in manufacturing safety in the way people and external factors or situations can influence the overall safety. Our study is a new addition to this research area.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bajic, B.; Rikalovic, A.; Suzic, N.; Piuri, V. Industry 4.0 Implementation Challenges and Opportunities: A Managerial Perspective. IEEE Syst. J. 2021, 15, 546–559. [Google Scholar] [CrossRef]
- Ou, X.; Chang, Q.; Arinez, J.; Zou, J. Gantry Work Cell Scheduling through Reinforcement Learning with Knowledge-guided Reward Setting. IEEE Access 2018, 6, 14699–14709. [Google Scholar] [CrossRef]
- Matheson, E.; Minto, R.; Zampieri, E.G.G.; Faccio, M.; Rosati, G. Human–Robot Collaboration in Manufacturing Applications: A Review. Robotics 2019, 8, 100. [Google Scholar] [CrossRef]
- Hasan, R.; Asif Hussain, S.; Azeemuddin Nizamuddin, S.; Mahmood, S. An autonomous robot for intelligent security systems. In Proceedings of the 9th IEEE Control System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, 29–31 May 2018; pp. 201–206. [Google Scholar]
- Prianto, E.; Kim, M.; Park, J.H.; Bae, J.H.; Kim, J.S. Path Planning for Multi-Arm Manipulators Using Deep Reinforcement Learning: Soft Actor-Critic with Hindsight Experience Replay. Sensors 2020, 20, 5911. [Google Scholar] [CrossRef]
- Colgate, J.E.; Edward, J.; Peshkin, M.A.; Wannasuphoprasit, W. Cobots: Robots for Collaboration withHuman Operators. In Proceedings of the 1996 ASME International Mechanical Engineering Congress and Exposition, Atlanta, GA, USA, 17–22 November 1996; pp. 433–439. [Google Scholar]
- Muhammad, J.; Bucak, I.O. An improved Q-learning algorithm for an autonomous mobile robot navigation problem. In Proceedings of the 2013 The International Conference on Technological Advances in Electrical, Electronics and Computer Engineering (TAEECE), Konya, Turkey, 9–11 May 2013; pp. 239–243. [Google Scholar]
- Zhao, M.; Lu, H.; Yang, S.; Guo, F. The Experience-Memory Q-Learning Algorithm for Robot Path Planning in Unknown Environment. IEEE Access 2020, 8, 47824–47844. [Google Scholar] [CrossRef]
- Ribeiro, T.; Gonçalves, F.; Garcia, I.; Lopes, G.; Ribeiro, A.F. Q-Learning for Autonomous Mobile Robot Obstacle Avoidance. In Proceedings of the 2019 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Porto, Portugal, 24–26 April 2019. [Google Scholar]
- Peres, R.S.; Jia, X.; Lee, J.; Sun, K.; Colombo, A.W.; Barata, J. Industrial Artificial Intelligence in Industry 4.0—Systematic Review, Challenges and Outlook. IEEE Access 2020, 8, 220121–220139. [Google Scholar] [CrossRef]
- Shvets, A.A.; Rakhlin, A.; Kalinin, A.A.; Iglovikov, V.I. Automatic instrument segmentation in robot-assisted surgery using deep learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 624–628. [Google Scholar]
- Graves, A.; Abdel-rahman, M.; Geoffrey, H. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Xie, Q.; Zhou, X.; Wang, J.; Gao, X.; Chen, X.; Liu, C. Matching Real-World Facilities to Building Information Modeling Data Using Natural Language Processing. IEEE Access 2019, 7, 119465–119475. [Google Scholar] [CrossRef]
- Wang, D.; Su, J.; Yu, H. Feature Extraction and Analysis of Natural Language Processing for Deep Learning English Language. IEEE Access 2020, 8, 46335–46345. [Google Scholar] [CrossRef]
- Yu, D.; Deng, L. Deep Learning and Its Applications to Signal and Information Processing [Exploratory DSP]. IEEE Signal Process. Mag. 2011, 28, 145–154. [Google Scholar] [CrossRef]
- Varchacskaia, P.; Fitzpatrick, P.; Breazeal, C. Characterizing and processing robot-directed speech. In Proceedings of the International IEEE/RSJ Conference on Humanoid Robotics, Tokyo, Japan, 30 August 2001; pp. 229–237. [Google Scholar]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech Recognition Using Deep Neural Networks: A Systematic Review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Krejsa, J.; Vechet, S. Mobile Robot Motion Planner via Neural Network. In Proceedings of the 17th International Conference on Engineering Mechanics, Svratka, Czech Republic, 14–17 May 2011; pp. 327–330. [Google Scholar]
- Dhounchak, D.; Biban, L.K. Applications of Safety in Manufacturing Industry. Int. J. Sci. Res. Sci. Eng. Technol. 2017, 3, 498–500. [Google Scholar]
- Verl, A.; Lechler, A.; Schlechtendahl, J. Globalized cyber physical production systems. Prod. Eng. 2012, 6, 643–649. [Google Scholar] [CrossRef]
- Robla-Gómez, S.; Becerra, V.M.; Llata, J.R.; González-Sarabia, E.; Torre-Ferrero, C.; Pérez-Oria, J. Working Together: A Review on Safe Human-Robot Collaboration in Industrial Environments. IEEE Access 2017, 5, 26754–26773. [Google Scholar] [CrossRef]
- Babu, V.M.; Krishna, U.V.; Shahensha, S.K. An autonomous path finding robot using Q-learning. In Proceedings of the 2016 10th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 7–8 January 2016. [Google Scholar]
- Wiedemann, T.; Vlaicu, C.; Josifovski, J.; Viseras, A. Robotic Information Gathering with Reinforcement Learning Assisted by Domain Knowledge: An Application to Gas Source Localization. IEEE Access 2021, 9, 13159–13172. [Google Scholar] [CrossRef]
- Bae, H.; Kim, G.; Kim, J.; Qian, D.; Lee, S. Multi-Robot Path Planning Method Using Reinforcement Learning. Appl. Sci. 2019, 15, 3057. [Google Scholar] [CrossRef]
- Mannucci, T.; van Kampen, E.; de Visser, C.; Chu, Q. Safe Exploration Algorithms for Reinforcement Learning Controllers. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1069–1081. [Google Scholar] [CrossRef]
- Erol, B.A.; Majumdar, A.; Benavidez, P.; Rad, P.; Choo, K.R.; Jamshidi, M. Toward Artificial Emotional Intelligence for Cooperative Social Human–Machine Interaction. IEEE Trans. Comput. Soc. Syst. 2020, 7, 234–246. [Google Scholar] [CrossRef]
- Rahat, S.A.; Imteaj, A.; Rahman, T. An IoT based Interactive Speech Recognizable Robot with Distance control using Raspberry Pi. In Proceedings of the 2018 International Conference on Innovations in Science, Engineering and Technology (ICISET), Chittagong, Bangladesh, 27–28 October 2018; pp. 480–485. [Google Scholar]
- Jevtić, A.; Valle, A.F.; Alenya, G.; Chance, G.; Caleb-Solly, P.; Dogramadzi, S.; Torras, C. Personalized Robot Assistant for Support in Dressing. IEEE Trans. Cogn. Dev. Syst. 2019, 11, 363–374. [Google Scholar] [CrossRef]
- Jung, S.W.; Sung, K.W.; Park, M.Y.; Kang, E.U.; Hwang, W.J.; Won, J.D.; Lee, W.S.; Han, S.H. A study on precise control of autonomous driving robot by voice recognition. In Proceedings of the IEEE ISR, Seoul, Korea, 24–26 October 2013. [Google Scholar]
- Chan, K.Y.; Yiu, C.K.F.; Dillon, T.S.; Nordholm, S.; Ling, S.H. Enhancement of Speech Recognitions for Control Automation Using an Intelligent Particle Swarm Optimization. IEEE Trans. Ind. Inform. 2012, 8, 869–879. [Google Scholar] [CrossRef]
- Wang, Y.C.; Usher, J.M. Application of reinforcement learning for agent-based production scheduling. Eng. Appl. Artif. Intell. 2005, 18, 73–82. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Jiang, J.; Kamel, M.; Chen, L. Reinforcement learning and aggregation. In Proceedings of the IEEE International Conference on Systems, Man & Cybernetics, The Hague, The Netherlands, 10–13 October 2004; pp. 1303–1308. [Google Scholar]
- Wang, N.; Hsu, W. Energy Efficient Two-Tier Data Dissemination Based on Q-Learning for Wireless Sensor Networks. IEEE Access 2020, 8, 74129–74136. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, X.; Zare, R.N. Optimizing chemical reactions with deep reinforcement learning. ACS Central Sci. 2017, 3, 337–1344. [Google Scholar] [CrossRef] [PubMed]
- Mao, H.; Alizadeh, M.; Menache, I.; Kandula, S. Resource management with deep reinforcement learning. In Proceedings of the ACM Workshop on Hot Topics in Networks, Atlanta, GA, USA, 9–10 November 2016; pp. 50–56. [Google Scholar]
- El-Tantawy, S.; Abdulhai, B.; Abdelgawad, H. Multiagent Reinforcement Learning for Integrated Network of Adaptive Traffic Signal Controllers (MARLIN-ATSC): Methodology and Large-Scale Application on Downtown Toronto. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1140–1150. [Google Scholar] [CrossRef]
- Leurent, E.; Mercat, J. Social attention for autonomous decision-making in dense traffic. arXiv 2019, arXiv:1911.12250. [Google Scholar]
- Wang, R.Y.; Xu, L. Multi-Agent Dam Management Model Based on Improved Reinforcement Learning Technology. Appl. Mech. Mater. 2012, 198–199, 922–926. [Google Scholar] [CrossRef]
- Hashimoto, D.A.; Rosman, G.; Rus, D.; Meireles, O.R. Artificial intelligence in surgery: Promises and perils. Ann. Surg. 2018, 268, 70–76. [Google Scholar] [CrossRef]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Nguyen, H.; La, H. Review of deep reinforcement learning for robot manipulation. In Proceedings of the 3rd IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 590–595. [Google Scholar]
- Watkins, C.J.; Dayan, P. Technical note: Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Wicaksono, H. Q learning behavior on autonomous navigation of physical robot. In Proceedings of the 8th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Incheon, Korea, 23–26 November 2011; pp. 50–54. [Google Scholar]
- Jat, D.S.; Limbo, A.S.; Singh, C. Chapter 11—Speech-based automation system for the patient in orthopedic trauma ward. In Advances in Ubiquitous Sensing Applications for Healthcare, Smart Biosensors in Medical Care; Chaki, J., Dey, N., De, D., Eds.; Academic Press: Cambridge, MA, USA, 2020; pp. 201–214. [Google Scholar]
- Guo, L.; Zhou, D.; Zhou, J.; Kimura, S.; Goto, S. Lossy Compression for Embedded Computer Vision Systems. IEEE Access 2018, 6, 39385–39397. [Google Scholar] [CrossRef]
- Husnjak, S.; Perakovic, D.; Jovovic, I. Possibilities of Using Speech Recognition Systems of Smart Terminal Devices in Traffic Environment. Procedia Eng. 2014, 69, 778–787. [Google Scholar] [CrossRef][Green Version]
- Sehr, M.A.; Lohstroh, M.; Weber, M.; Ugalde, I.; Witte, M.; Neidig, J.; Hoeme, S.; Niknami, M.; Lee, E.A. Programmable Logic Controllers in the Context of Industry 4.0. IEEE Trans. Ind. Inform. 2021, 17, 3523–3533. [Google Scholar] [CrossRef]
- Zhang, Q.; Lin, J.; Sha, Q.; He, B.; Li, G. Deep Interactive Reinforcement Learning for Path Following of Autonomous Underwater Vehicle. IEEE Access 2020, 8, 24258–24268. [Google Scholar] [CrossRef]
- Li, L.; Li, S.; Zhao, S. QoS-aware scheduling of services-oriented Internet of Things. IEEE Trans. Ind. Inform. 2014, 10, 1497–1505. [Google Scholar]
- Da Xu, L.; He, W.; Li, S. Internet of Things in industries: A survey. IEEE Trans. Ind. Inform. 2014, 10, 2233–2243. [Google Scholar]
- Tang, J.; Song, J.; Ou, J.; Luo, J.; Zhang, X.; Wong, K. Minimum Throughput Maximization for Multi-UAV Enabled WPCN: A Deep Reinforcement Learning Method. IEEE Access 2020, 8, 9124–9132. [Google Scholar] [CrossRef]
- Oviatt, S.; Cohen, P. Perceptual user interfaces: Multimodal interfaces that process what comes naturally. Commun. ACM 2000, 43, 45–53. [Google Scholar] [CrossRef]
- Gorecky, D.; Schmitt, M.; Loskyll, M.; Zühlke, D. Human–machine-interaction in the industry 4.0 era. In Proceedings of the 12th IEEE INDIN, Porto Alegre, RS, Brazil, 27–30 July 2014; pp. 289–294. [Google Scholar]
- Garcia, M.A.R.; Rojas, R.; Gualtieri, L.; Rauch, E.; Matt, D. A human-in-the-loop cyber-physical system for collaborative assembly in smart manufacturing. Procedia CIRP 2019, 81, 600–605. [Google Scholar] [CrossRef]
- Li, J.; Deng, L.; Haeb-Umbach, R.; Gong, Y. Chapter 2—Fundamentals of speech recognition. In Robust Automatic Speech Recognition; Li, J., Deng, L., Haeb-Umbach, R., Gong, Y., Eds.; Academic Press: Cambridge, MA, USA, 2016; pp. 9–40. [Google Scholar]
- Dabous, S.A.; Ibrahim, F.; Feroz, S.; Alsyouf, I. Integration of failure mode, effects, and criticality analysis with multi-criteria decision-making in engineering applications: Part I—Manufacturing industry. Eng. Fail. Anal. 2021, 122, 105264. [Google Scholar] [CrossRef]
- Rajkumar, I.; Subash, K.; Raj Pradeesh, T.; Manikandan, R.; Ramaganesh, M. Job safety hazard identification and risk analysis in the foundry division of a gear manufacturing industry. Mater. Today Proc. 2021, 46, 7783–7788. [Google Scholar] [CrossRef]
- Hald, K.S. Social influence and safe behavior in manufacturing. Saf. Sci. 2018, 109, 1–11. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Address | Variable Function |
|---|---|
| M0.0 | This is the start signal for the system. It is usually a ON-OFF action directly |
| wired to a PLC input IX.X. For this simulation, we use a memory bit M. | |
| When the memory bit is ON the system starts if M0.1 and M0.2 are OFF. | |
| M0.1 | This is the memory bit controlled externally by our python speech |
| recognition code that converts the voice command to a ‘ON’ bit value. | |
| When M0.1 is ON the system is in stop mode. | |
| M0.2 | This is the memory bit controlled by an emergency stop signal. In real |
| plant applications it is usually an input signal IX.X. For simulation, | |
| we use a memory bit variable M. | |
| Q0.0 | This is a physical PLC output that controls the plant. |
| Q0.2 | This is a physical PLC output that controls the plants robots. |
| Variables | Values | Comment |
|---|---|---|
| M0.0 | 0 | Because of the latch programming format. M0.0 does not have to remain |
| ON (‘1’) for the system to run continuously. | ||
| M0.1 | 1 | An external voice command is received to stop the system. |
| M0.2 | 0 | No stop signal has been sent by the emergency stop button. |
| Q0.0 | 0 | The plant control signal is stopped. |
| Q0.2 | 0 | The robot control signal is stopped. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kiangala, K.S.; Wang, Z. An Experimental Safety Response Mechanism for an Autonomous Moving Robot in a Smart Manufacturing Environment Using Q-Learning Algorithm and Speech Recognition. Sensors 2022, 22, 941. https://doi.org/10.3390/s22030941
Kiangala KS, Wang Z. An Experimental Safety Response Mechanism for an Autonomous Moving Robot in a Smart Manufacturing Environment Using Q-Learning Algorithm and Speech Recognition. Sensors. 2022; 22(3):941. https://doi.org/10.3390/s22030941
Chicago/Turabian StyleKiangala, Kahiomba Sonia, and Zenghui Wang. 2022. "An Experimental Safety Response Mechanism for an Autonomous Moving Robot in a Smart Manufacturing Environment Using Q-Learning Algorithm and Speech Recognition" Sensors 22, no. 3: 941. https://doi.org/10.3390/s22030941
APA StyleKiangala, K. S., & Wang, Z. (2022). An Experimental Safety Response Mechanism for an Autonomous Moving Robot in a Smart Manufacturing Environment Using Q-Learning Algorithm and Speech Recognition. Sensors, 22(3), 941. https://doi.org/10.3390/s22030941