
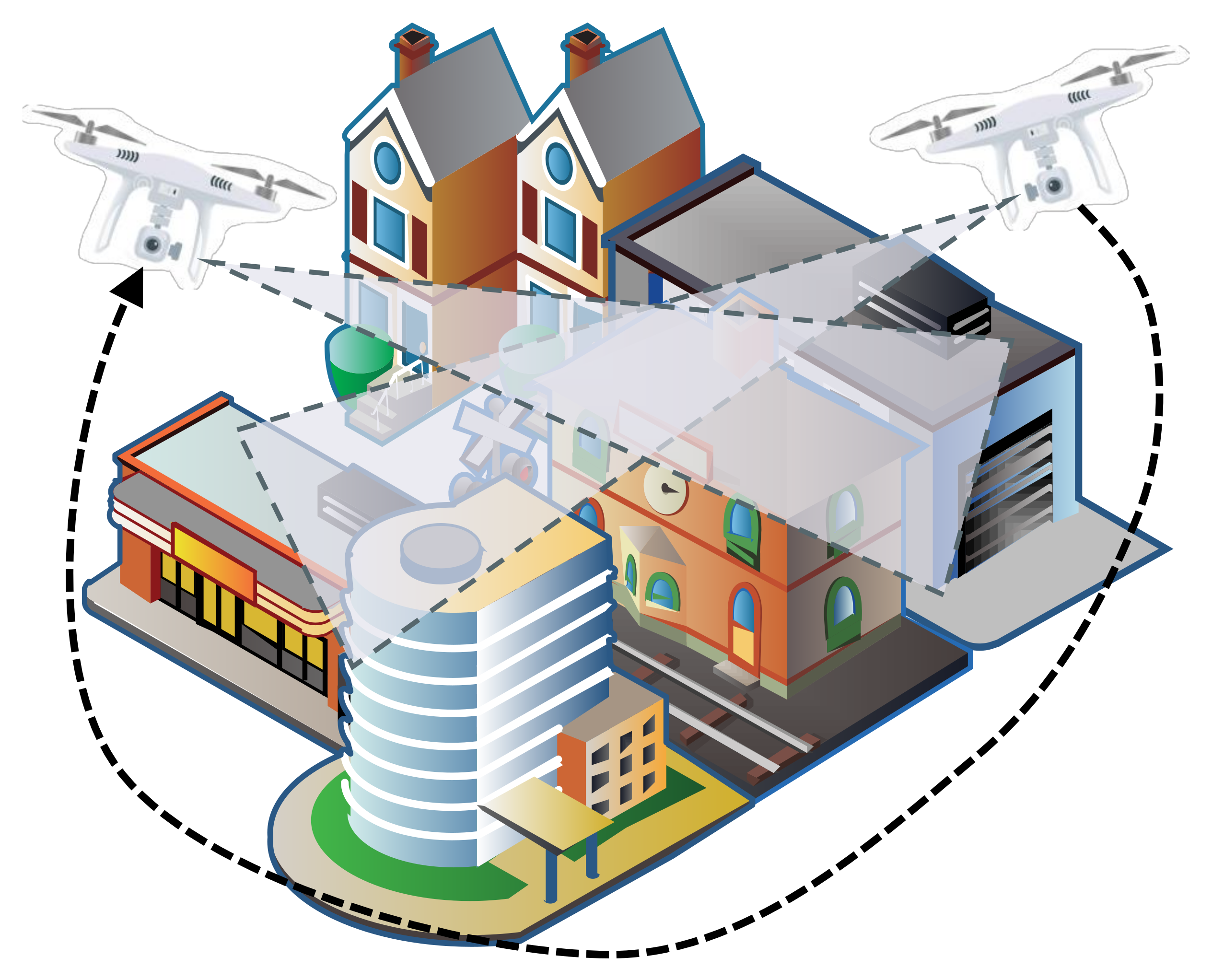
A Path Planning Method with Perception Optimization Based on Sky Scanning for UAVs



Abstract
:1. Introduction
- 1.
- A drone planning algorithm. In this algorithm, based on the traditional heuristic method, we introduce information density. The confidence of object detection can be extracted by a pre-trained detection model and optimized during route planning;
- 2.
- By using an object recognition deep learning model. For the video frames captured by drones, our method can simultaneously detect and locate pre-selected objects, such as buildings, pedestrians, and so forth. All the detected information will contribute to the route planning;
- 3.
- A drone image dataset. The dataset was collected from real drones. All buildings in each video frame were manually annotated and the exact location mask was marked. It is a first-released dataset for UAV route planning.
2. Related Works
2.1. Scene Understanding for UAVs
2.2. Path Planning of UAVs
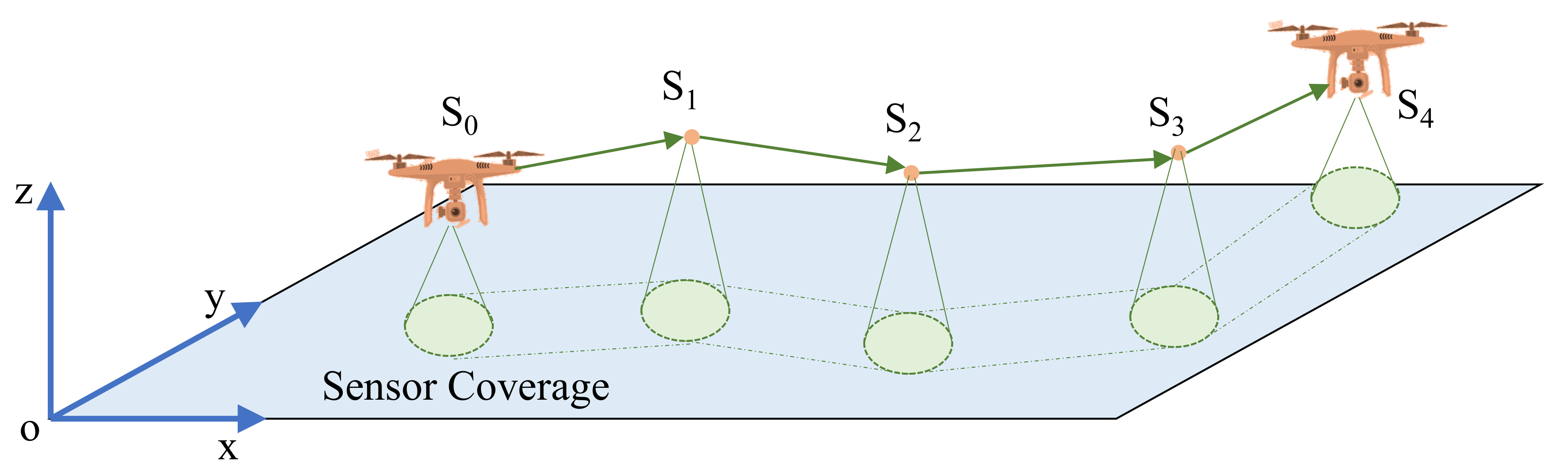
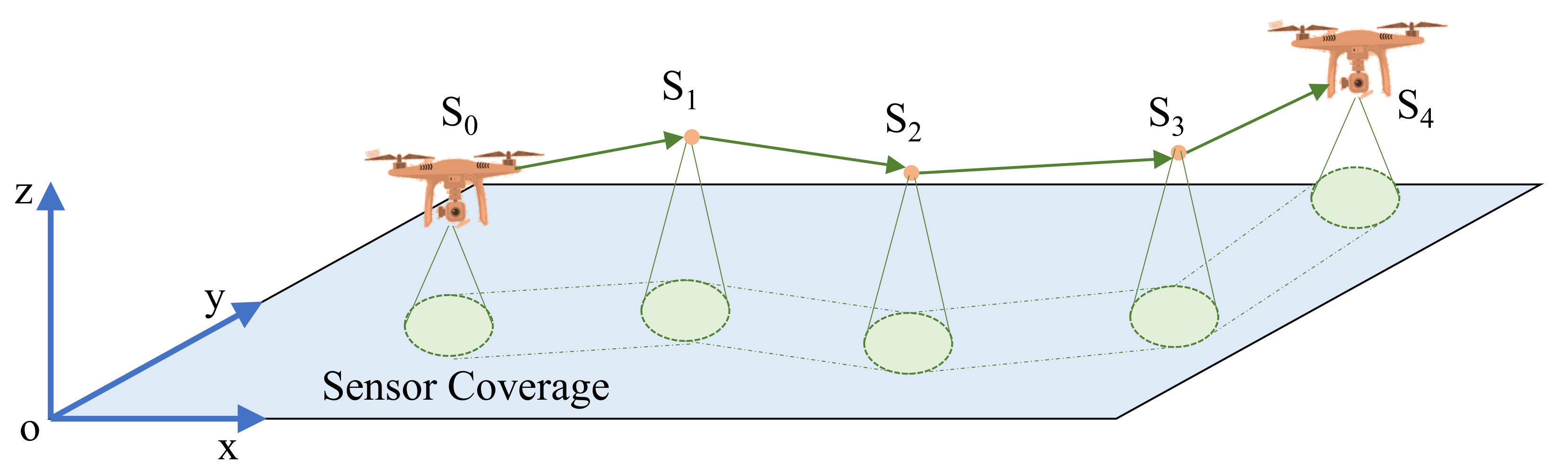
3. Path Planning
4. Perception Method
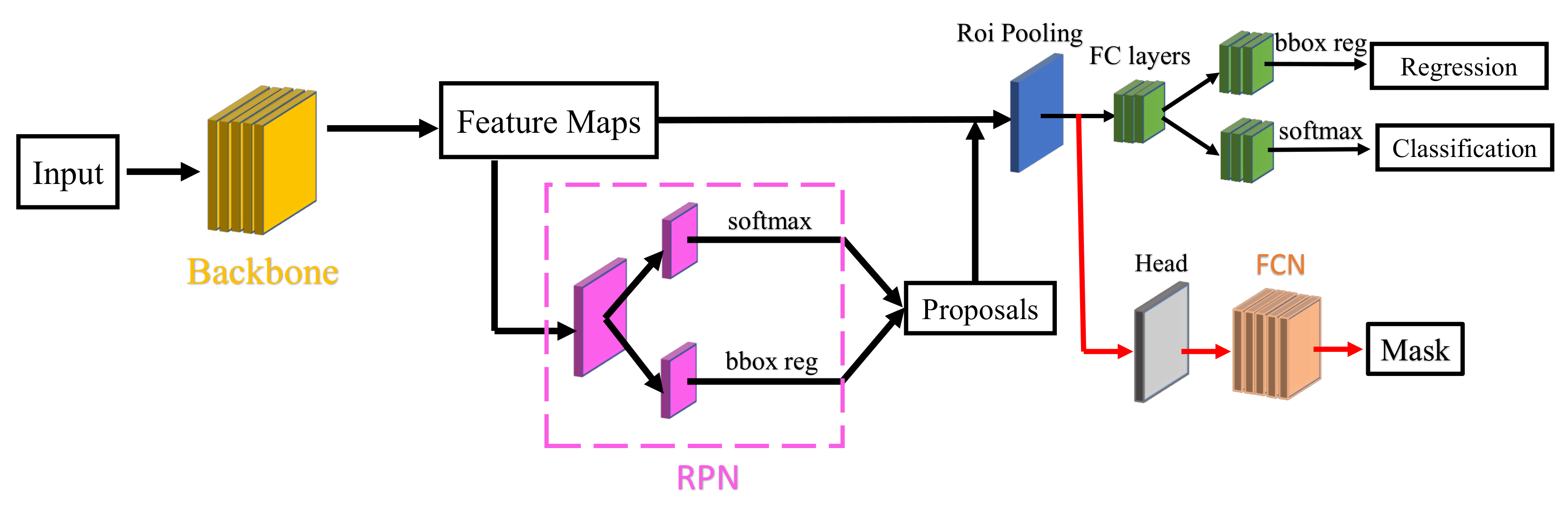
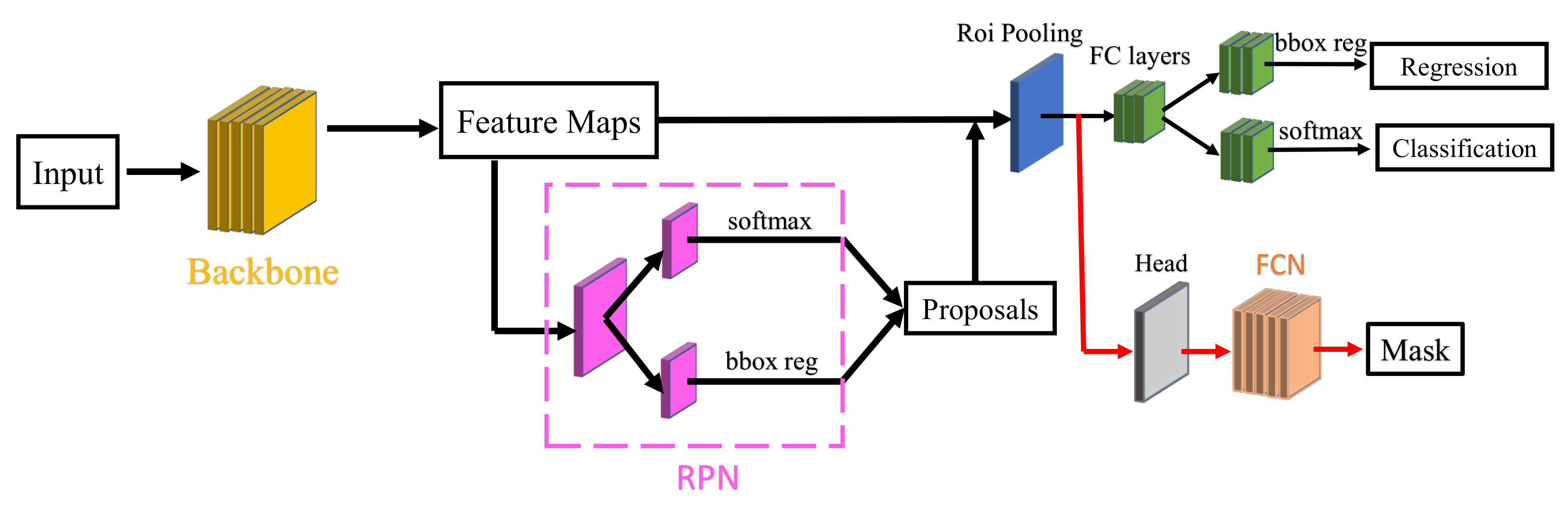
4.1. Deep Learning Model
4.2. UAV Image Dataset
5. Performance Evaluation
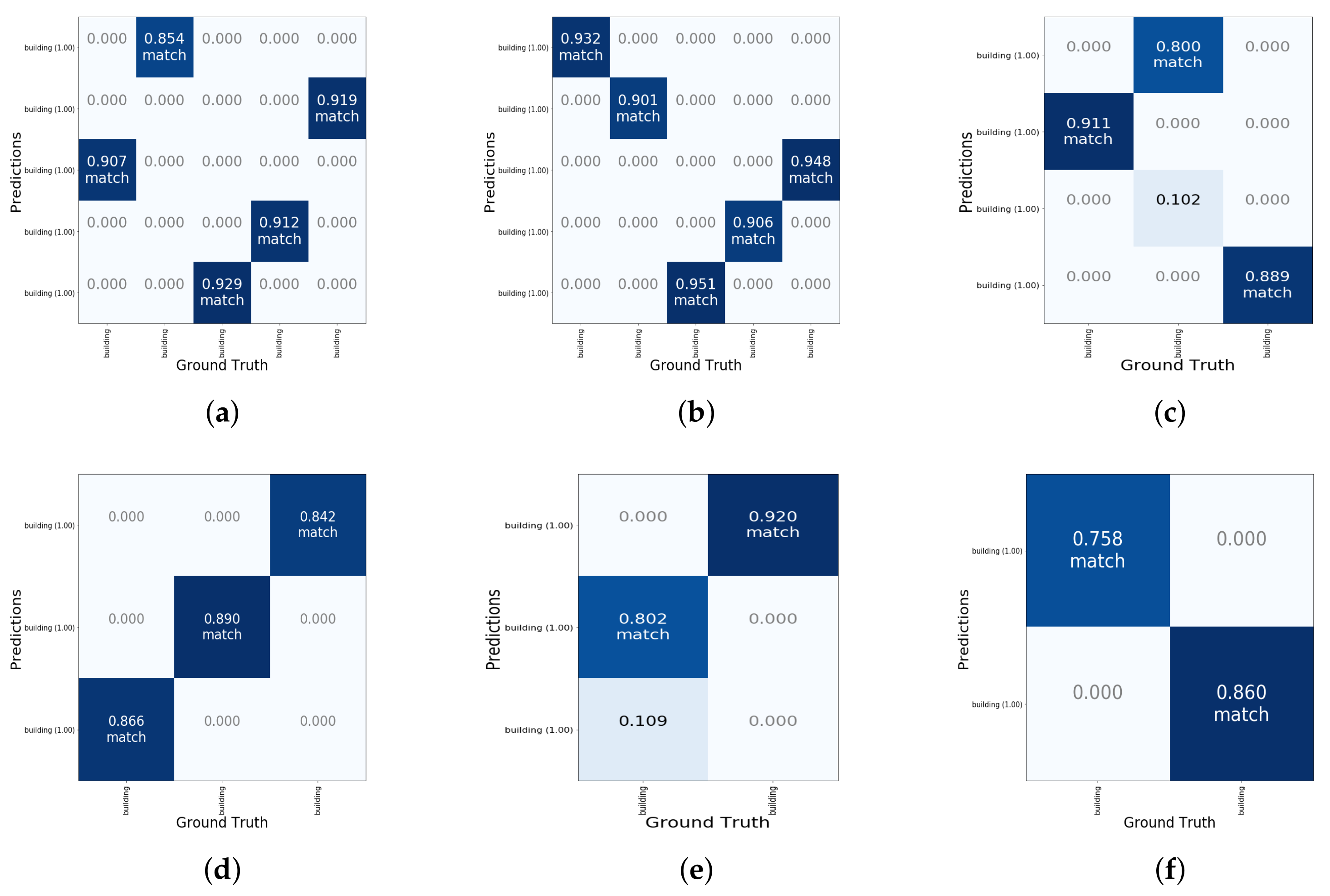
5.1. Recognition of Building Objects
5.2. Confidence Value
5.3. Visualization
6. Discussion
6.1. Analyse of Detection
6.2. Computing Cost and Possible Application
6.3. Limitation
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dong, M.; Ota, K.; Lin, M.; Tang, Z.; Du, S.; Zhu, H. UAV-assisted data gathering in wireless sensor networks. J. Supercomput. 2014, 70, 1142–1155. [Google Scholar] [CrossRef]
- Li, L.; Ota, K.; Dong, M.; Borjigin, W. Eyes in the Dark: Distributed Scene Understanding for Disaster Management. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 3458–3471. [Google Scholar] [CrossRef]
- Yang, X.; Wang, F.; Bai, Z.; Xun, F.; Zhang, Y.; Zhao, X. Deep learning-based congestion detection at urban intersections. Sensors 2021, 21, 2052. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Takeda, T.; Sugimoto, K.; Zhang, J.; Wada, S.; Konishi, S.; Manabe, S.; Okada, K.; Matsumura, Y. Automatic creation of annotations for chest radiographs based on the positional information extracted from radiographic image reports. Comput. Methods Programs Biomed. 2021, 209, 106331. [Google Scholar] [CrossRef] [PubMed]
- Maldonado, J.; Giefer, L.A. A comparison of bottom-up models for spatial saliency predictions in autonomous driving. Sensors 2021, 21, 6825. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Ota, K.; Dong, M. Learning IoT in Edge: Deep Learning for the Internet of Things with Edge Computing. IEEE Netw. 2018, 32, 96–101. [Google Scholar] [CrossRef] [Green Version]
- Mottaghi, R.; Fidler, S.; Yuille, A.; Urtasun, R.; Parikh, D. Human-Machine CRFs for Identifying Bottlenecks in Scene Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 74–87. [Google Scholar] [CrossRef]
- Geiger, A.; Lauer, M.; Wojek, C.; Stiller, C.; Urtasun, R. 3D Traffic Scene Understanding From Movable Platforms. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1012–1025. [Google Scholar] [CrossRef] [Green Version]
- Lim, C.H.; Risnumawan, A.; Chan, C.S. A Scene Image is Nonmutually Exclusive? A Fuzzy Qualitative Scene Understanding. IEEE Trans. Fuzzy Syst. 2014, 22, 1541–1556. [Google Scholar] [CrossRef] [Green Version]
- Minaeian, S.; Liu, J.; Son, Y. Vision-Based Target Detection and Localization via a Team of Cooperative UAV and UGVs. IEEE Trans. Syst. Man Cybern. Syst. 2016, 46, 1005–1016. [Google Scholar] [CrossRef]
- Ye, N.; Wang, B.; Kita, M.; Xie, M.; Cai, W. Urban commerce distribution analysis based on street view and deep learning. IEEE Access 2019, 7, 162841–162849. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Q.; Zhuang, Y.; Hu, H. A Novel Trail Detection and Scene Understanding Framework for a Quadrotor UAV with Monocular Vision. IEEE Sens. J. 2017, 17, 6778–6787. [Google Scholar] [CrossRef]
- Yu, L.; Yeung, S.; Terzopoulos, D. The Clutterpalette: An Interactive Tool for Detailing Indoor Scenes. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1138–1148. [Google Scholar] [CrossRef] [PubMed]
- Gu, Y.; Wang, Q.; Kamijo, S. Intelligent Driving Data Recorder in Smartphone Using Deep Neural Network-Based Speedometer and Scene Understanding. IEEE Sens. J. 2019, 19, 287–296. [Google Scholar] [CrossRef]
- Di, S.; Zhang, H.; Li, C.; Mei, X.; Prokhorov, D.; Ling, H. Cross-Domain Traffic Scene Understanding: A Dense Correspondence-Based Transfer Learning Approach. IEEE Trans. Intell. Transp. Syst. 2018, 19, 745–757. [Google Scholar] [CrossRef]
- Zitnick, C.L.; Vedantam, R.; Parikh, D. Adopting Abstract Images for Semantic Scene Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 627–638. [Google Scholar] [CrossRef]
- Zhang, L.; Deng, F.; Chen, J.; Bi, Y.; Phang, S.K.; Chen, X.; Chen, B.M. Vision-Based Target Three-Dimensional Geolocation Using Unmanned Aerial Vehicles. IEEE Trans. Ind. Electron. 2018, 65, 8052–8061. [Google Scholar] [CrossRef]
- Zhu, J.; Sun, K.; Jia, S.; Li, Q.; Hou, X.; Lin, W.; Liu, B.; Qiu, G. Urban Traffic Density Estimation Based on Ultrahigh-Resolution UAV Video and Deep Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4968–4981. [Google Scholar] [CrossRef]
- Fan, Z.; Lu, J.; Gong, M.; Xie, H.; Goodman, E.D. Automatic Tobacco Plant Detection in UAV Images via Deep Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 876–887. [Google Scholar] [CrossRef]
- Liu, X.; Chen, S.; Song, L.; Woźniak, M.; Liu, S. Self-attention negative feedback network for real-time image super-resolution. J. King Saud-Univ.-Comput. Inf. Sci. 2021, in press. [Google Scholar] [CrossRef]
- Subramani, P.; Sattar, K.N.A.; de Prado, R.P.; Girirajan, B.; Wozniak, M. Multi-Classifier Feature Fusion-Based Road Detection for Connected Autonomous Vehicles. Appl. Sci. 2021, 11, 7984. [Google Scholar] [CrossRef]
- Yu, H.; Meier, K.; Argyle, M.; Beard, R.W. Cooperative Path Planning for Target Tracking in Urban Environments Using Unmanned Air and Ground Vehicles. IEEE/ASME Trans. Mechatron. 2015, 20, 541–552. [Google Scholar] [CrossRef]
- He, Z.; Zhao, L. The Comparison of Four UAV Path Planning Algorithms Based on Geometry Search Algorithm. In Proceedings of the 2017 9th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 26–27 August 2017; Volume 2, pp. 33–36. [Google Scholar] [CrossRef]
- Morita, T.; Oyama, K.; Mikoshi, T.; Nishizono, T. Decision Making Support of UAV Path Planning for Efficient Sensing in Radiation Dose Mapping. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 1, pp. 333–338. [Google Scholar] [CrossRef]
- Wen, N.; Zhao, L.; Su, X.; Ma, P. UAV online path planning algorithm in a low altitude dangerous environment. IEEE/CAA J. Autom. Sin. 2015, 2, 173–185. [Google Scholar] [CrossRef]
- Yin, C.; Xiao, Z.; Cao, X.; Xi, X.; Yang, P.; Wu, D. Offline and Online Search: UAV Multiobjective Path Planning Under Dynamic Urban Environment. IEEE Internet Things J. 2018, 5, 546–558. [Google Scholar] [CrossRef]
- Imran, M.A.; Onireti, O.; Ansari, S.; Abbasi, Q.H. Autonomous Airborne Wireless Networks; Wiley-IEEE Press: Piscataway, NJ, USA, 2021. [Google Scholar]
- Just, G.E.; E Pellenz, M.; Lima, L.A.; S Chang, B.; Demo Souza, R.; Montejo-Sánchez, S. UAV Path Optimization for Precision Agriculture Wireless Sensor Networks. Sensors 2020, 20, 6098. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Liu, P.; Zhang, T.; Sun, J. The Adaptive Vortex Search Algorithm of Optimal Path Planning for Forest Fire Rescue UAV. In Proceedings of the 2018 IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 October 2018; pp. 400–403. [Google Scholar] [CrossRef]
- Lifen, L.; Ruoxin, S.; Shuandao, L.; Jiang, W. Path planning for UAVS based on improved artificial potential field method through changing the repulsive potential function. In Proceedings of the 2016 IEEE Chinese Guidance, Navigation and Control Conference (CGNCC), Nanjing, China, 12–14 August 2016; pp. 2011–2015. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, J.; Li, J.; Wang, X. UAV path planning based on receding horizon control with adaptive strategy. In Proceedings of the 2017 29th Chinese Control And Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 843–847. [Google Scholar] [CrossRef]
- Kumar, P.; Garg, S.; Singh, A.; Batra, S.; Kumar, N.; You, I. MVO-Based 2-D Path Planning Scheme for Providing Quality of Service in UAV Environment. IEEE Internet Things J. 2018, 5, 1698–1707. [Google Scholar] [CrossRef]
- Chen, J.; Ye, F.; Jiang, T. Path planning under obstacle-avoidance constraints based on ant colony optimization algorithm. In Proceedings of the 2017 IEEE 17th International Conference on Communication Technology (ICCT), Chengdu, China, 27–30 October 2017; pp. 1434–1438. [Google Scholar] [CrossRef]
- Yang, X.; Zhou, W.; Zhang, Y. On collaborative path planning for multiple UAVs based on Pythagorean Hodograph curve. In Proceedings of the 2016 IEEE Chinese Guidance, Navigation and Control Conference (CGNCC), Nanjing, China, 12–14 August 2016; pp. 971–975. [Google Scholar] [CrossRef]
- Yang, P.; Tang, K.; Lozano, J.A.; Cao, X. Path Planning for Single Unmanned Aerial Vehicle by Separately Evolving Waypoints. IEEE Trans. Robot. 2015, 31, 1130–1146. [Google Scholar] [CrossRef] [Green Version]
- Lo, L.Y.; Yiu, C.H.; Tang, Y.; Yang, A.S.; Li, B.; Wen, C.Y. Dynamic Object Tracking on Autonomous UAV System for Surveillance Applications. Sensors 2021, 21, 7888. [Google Scholar] [CrossRef]
- Muñoz, J.; López, B.; Quevedo, F.; Monje, C.A.; Garrido, S.; Moreno, L.E. Multi UAV Coverage Path Planning in Urban Environments. Sensors 2021, 21, 7365. [Google Scholar] [CrossRef]
- Melo, A.G.; Pinto, M.F.; Marcato, A.L.; Honório, L.M.; Coelho, F.O. Dynamic Optimization and Heuristics Based Online Coverage Path Planning in 3D Environment for UAVs. Sensors 2021, 21, 1108. [Google Scholar] [CrossRef]
- Santin, R.; Assis, L.; Vivas, A.; Pimenta, L.C. Matheuristics for Multi-UAV Routing and Recharge Station Location for Complete Area Coverage. Sensors 2021, 21, 1705. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 13 December 2020).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, S.; Ota, K.; Dong, M.; Zhao, J. A Path Planning Method with Perception Optimization Based on Sky Scanning for UAVs. Sensors 2022, 22, 891. https://doi.org/10.3390/s22030891
Yuan S, Ota K, Dong M, Zhao J. A Path Planning Method with Perception Optimization Based on Sky Scanning for UAVs. Sensors. 2022; 22(3):891. https://doi.org/10.3390/s22030891
Chicago/Turabian StyleYuan, Songhe, Kaoru Ota, Mianxiong Dong, and Jianghai Zhao. 2022. "A Path Planning Method with Perception Optimization Based on Sky Scanning for UAVs" Sensors 22, no. 3: 891. https://doi.org/10.3390/s22030891
APA StyleYuan, S., Ota, K., Dong, M., & Zhao, J. (2022). A Path Planning Method with Perception Optimization Based on Sky Scanning for UAVs. Sensors, 22(3), 891. https://doi.org/10.3390/s22030891