
Imitating Emergencies: Generating Thermal Surveillance Fall Data Using Low-Cost Human-like Dolls




Abstract
:1. Introduction
- Experimentally verifying the visual representation of a doll construct for thermal imaging.
- Analyzing the motion representation of the doll for falling visualization.
- Presenting a real world use case for the captured thermal footage for pedestrian detection.
2. Related Work
2.1. Fall Detection
2.2. Mannequins in Data Capture
2.3. Thermal Mannequins
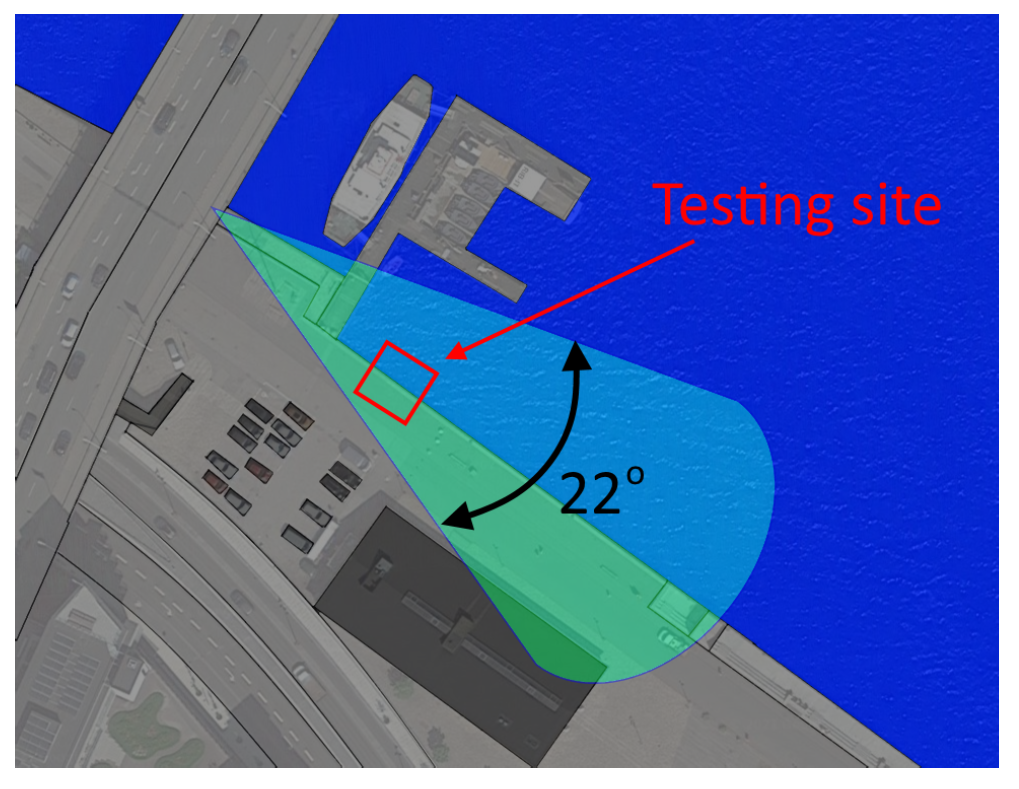
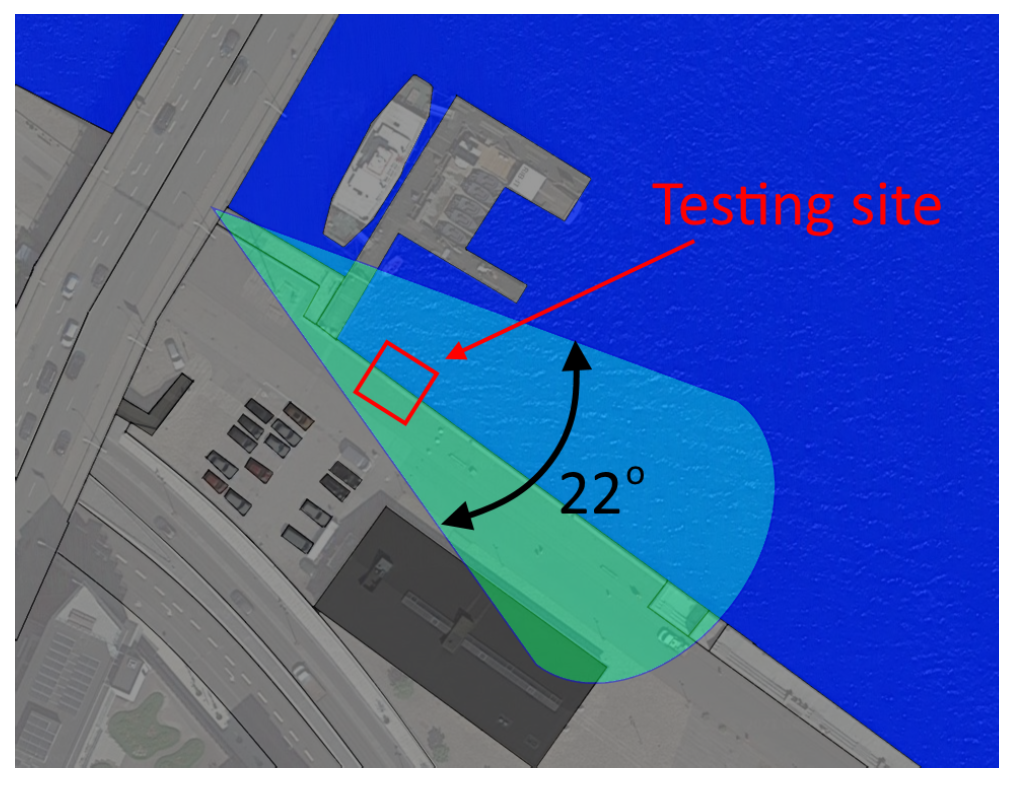
3. Capturing Cameras
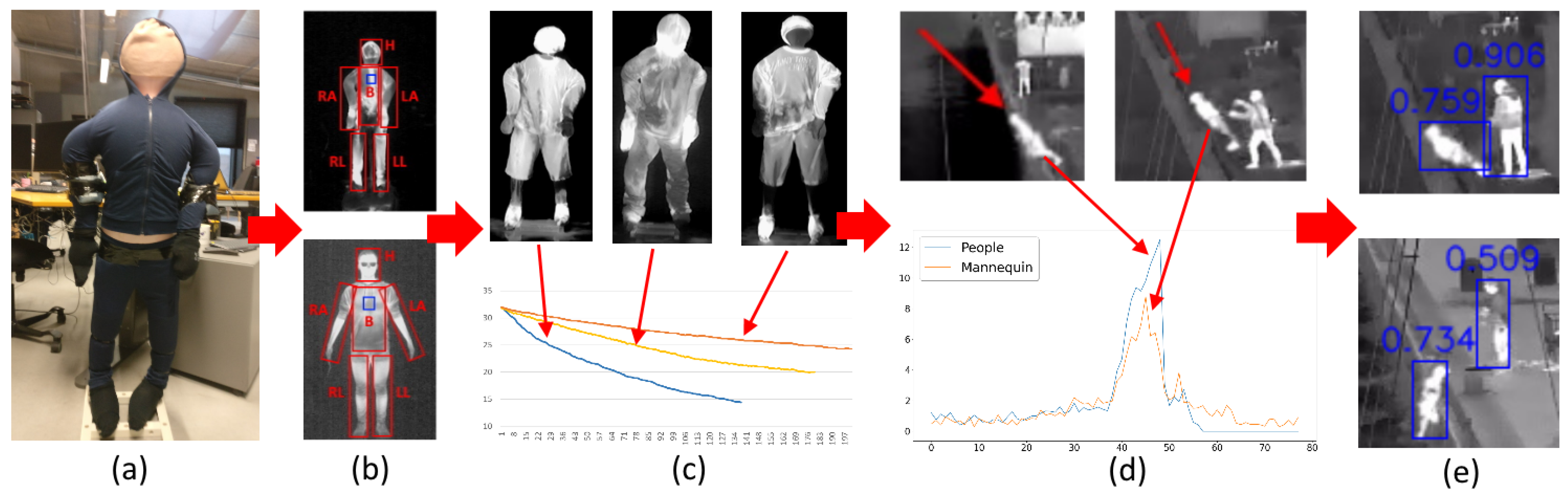
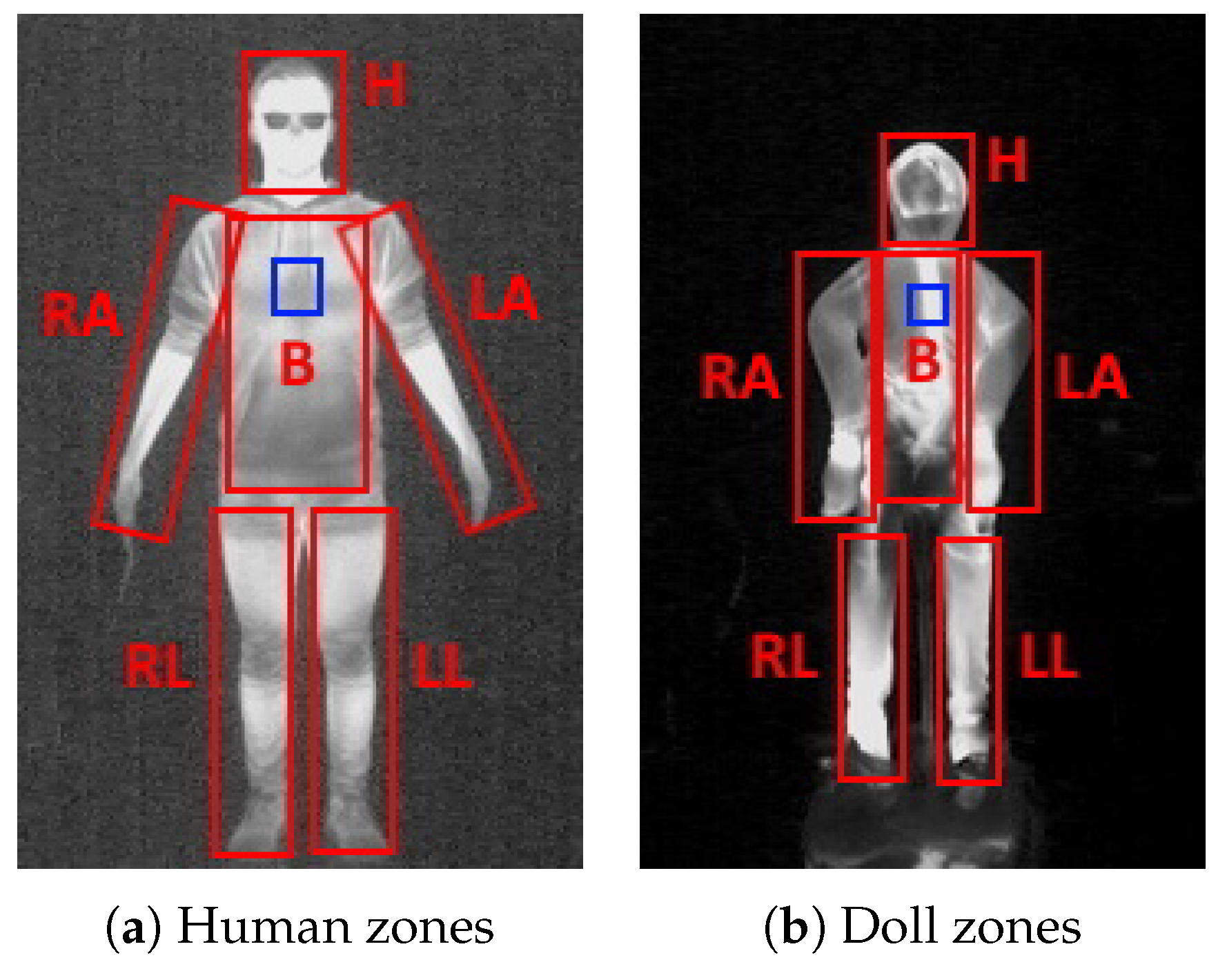
4. Thermal Doll Design
5. Doll Thermal Appearance
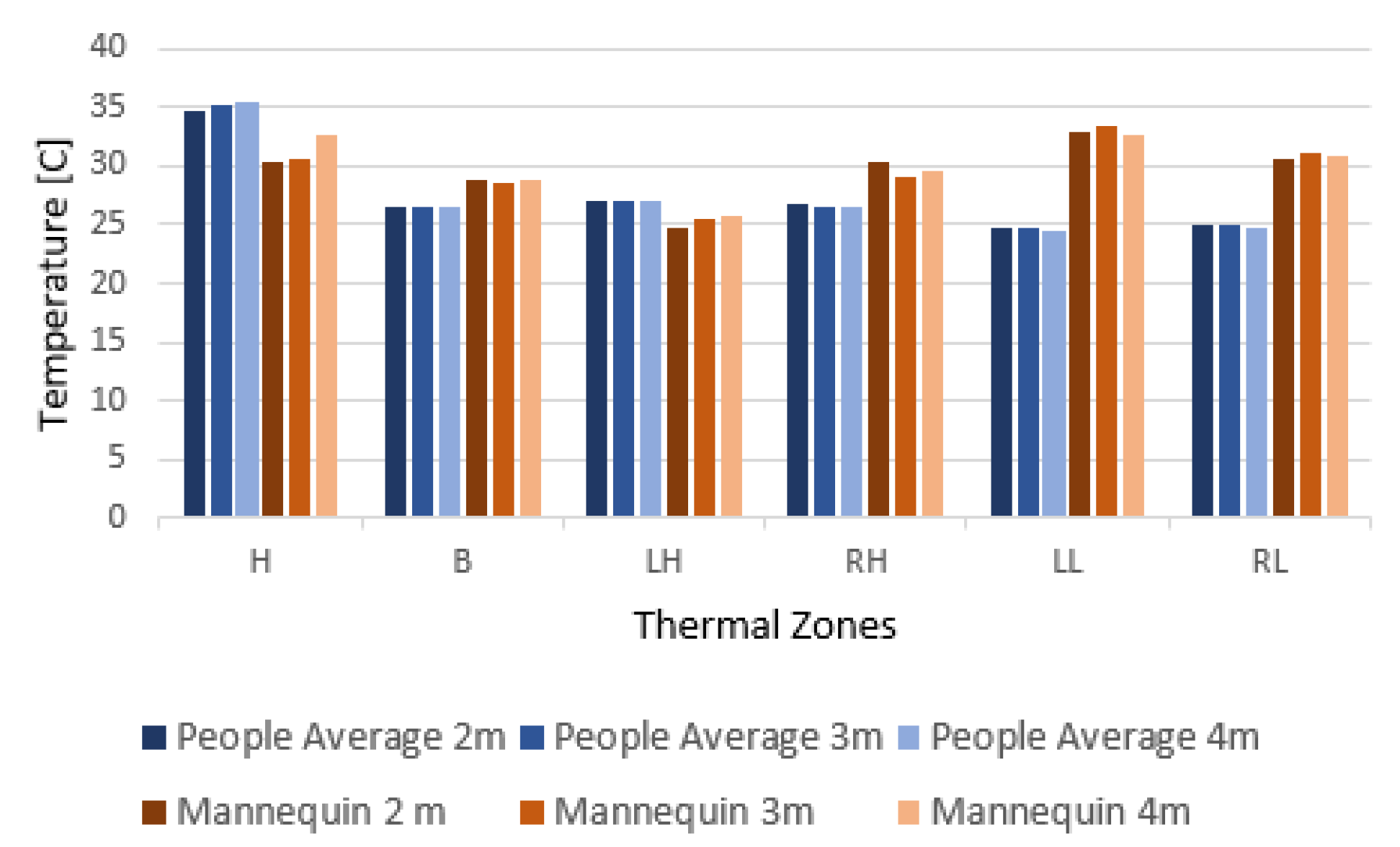
5.1. Comparing Temperature between the Doll and Real People
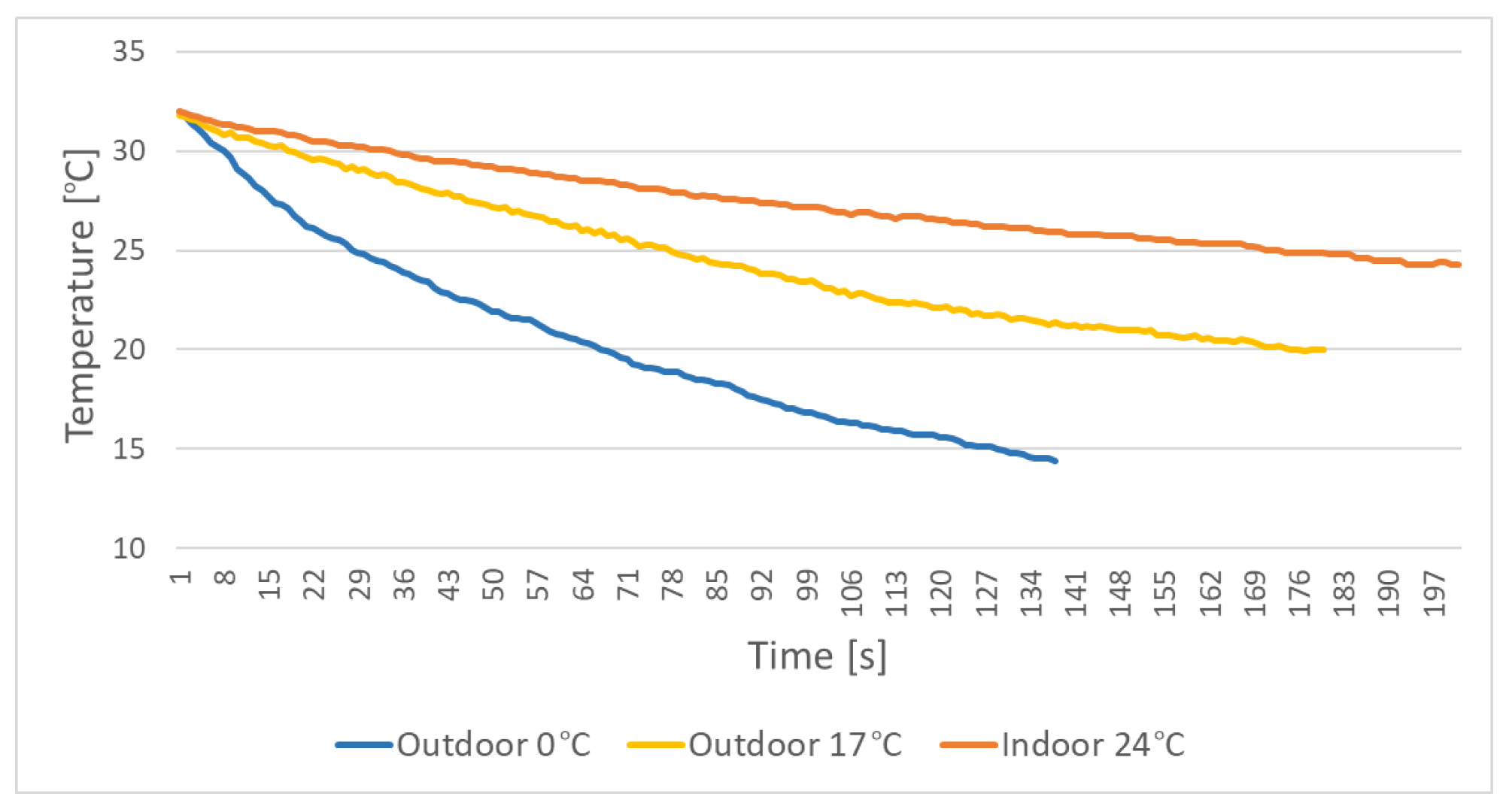
5.2. Doll Temperature Change over Time
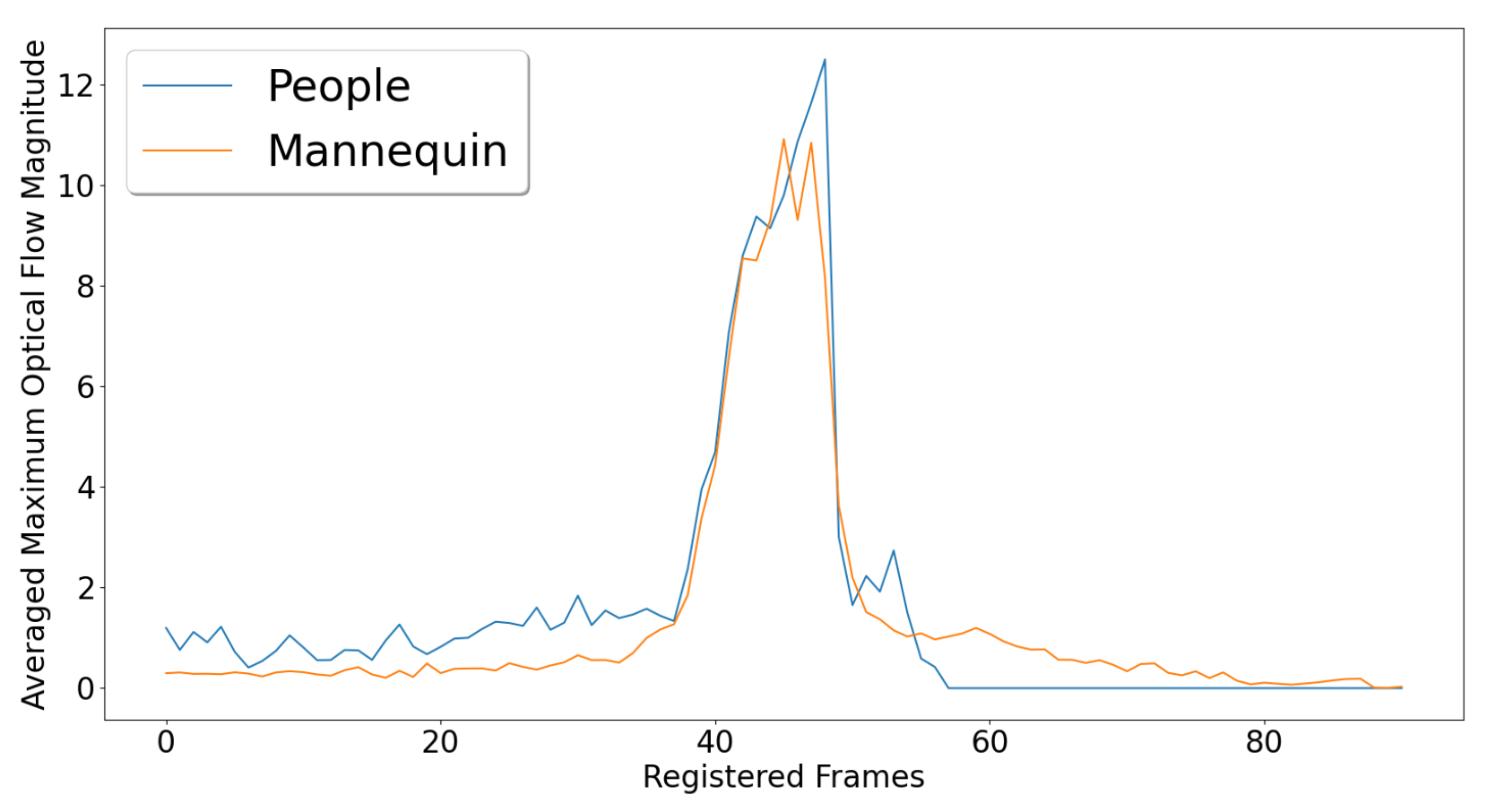
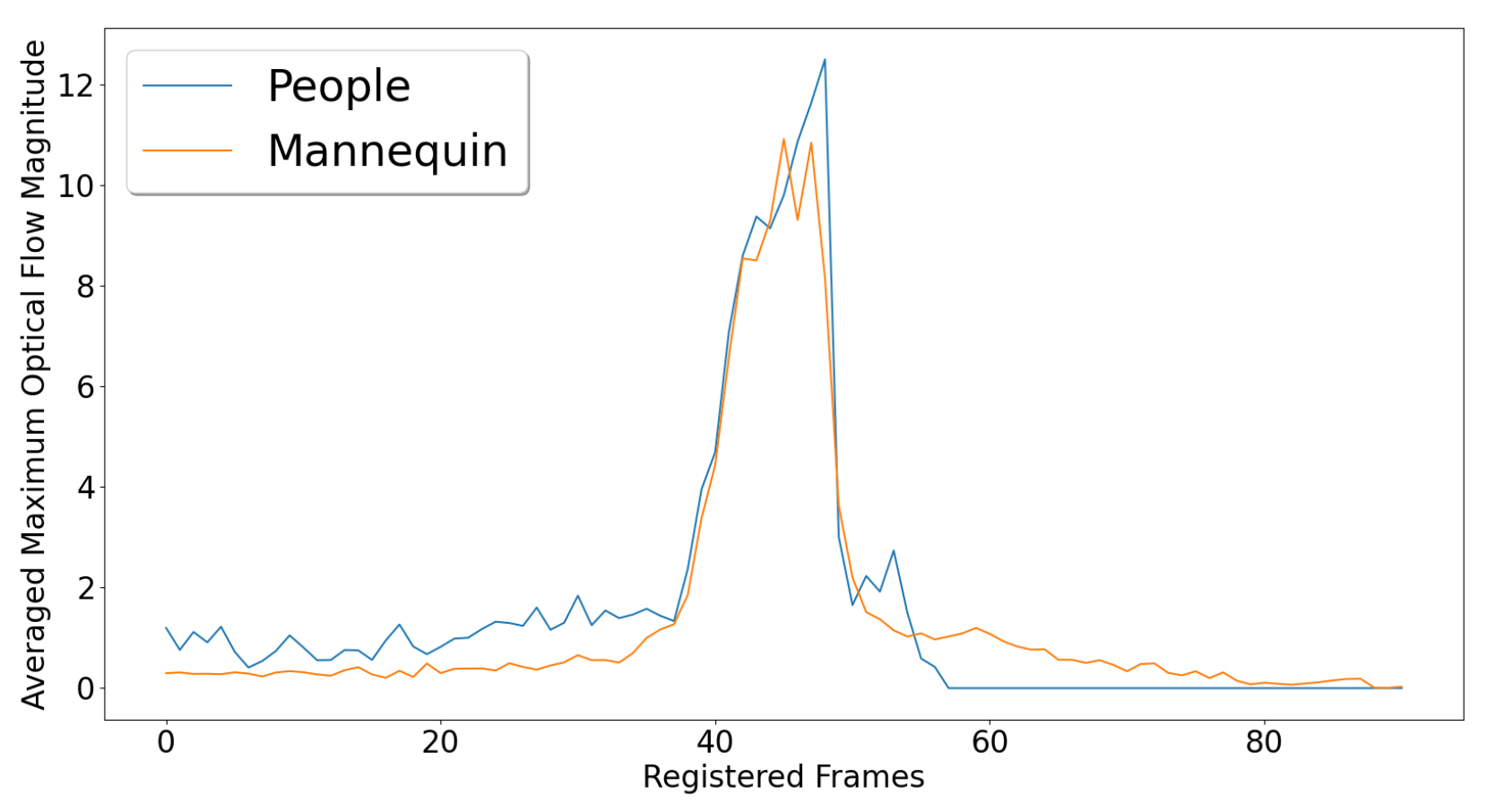
6. Fall Motion Comparison
7. Doll Detection Comparison
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| CNN | Convolutional Neural Network |
| LWIR | LOng Wavelength Infrared |
| NETD | Noise Equivalent Temperature Difference |
| DTW | Dynamic Time Warping |
References
- Manekar, R.; Saurav, S.; Maiti, S.; Singh, S.; Chaudhury, S.; Kumar, R.; Chaudhary, K. Activity recognition for indoor fall detection in 360-degree videos using deep-learning techniques. In Proceedings of the of 3rd International Conference on Computer Vision and Image Processing, Hong Kong, China, 22–24 May 2020; pp. 417–429. [Google Scholar]
- Sadreazami, H.; Bolic, M.; Rajan, S. TL-fall: Contactless indoor fall detection using transfer learning from a pretrained model. In Proceedings of the 2019 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Istanbul, Turkey, 26–28 June 2019; pp. 1–5. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Song, H.; Liang, H.; Li, H.; Dai, Z.; Yun, X. Vision-based vehicle detection and counting system using deep learning in highway scenes. Eur. Transp. Res. Rev. 2019, 11, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Santhosh, K.K.; Dogra, D.P.; Roy, P.P. Anomaly detection in road traffic using visual surveillance: A survey. ACM Comput. Surv. 2020, 53, 1–26. [Google Scholar] [CrossRef]
- Dèveloppement, Y. Thermal Imagers and Detectors 2020—COVID-19 Outbreak Impact—Preliminary Report. 2020. Available online: http://www.yole.fr/Thermal_Imagers_And_Detectors_Covid19_Outbreak_Impact.aspx (accessed on 11 August 2021).
- Research, A.M. Global Thermal Imaging Camera Market by 2030. 2021. Available online: https://www.globenewswire.com/news-release/2021/08/09/2277188/0/en/Global-Thermal-Imaging-Camera-Market-is-Expected-to-Reach-7-49-Billion-by-2030-Says-AMR.html (accessed on 11 August 2021).
- Thakur, N.; Han, C.Y. Country-Specific Interests towards Fall Detection from 2004–2021: An Open Access Dataset and Research Questions. Data 2021, 6, 92. [Google Scholar] [CrossRef]
- Mubashir, M.; Shao, L.; Seed, L. A survey on fall detection: Principles and approaches. Neurocomputing 2013, 100, 144–152. [Google Scholar] [CrossRef]
- Katsamenis, I.; Protopapadakis, E.; Voulodimos, A.; Dres, D.; Drakoulis, D. Man overboard event detection from RGB and thermal imagery: Possibilities and limitations. In Proceedings of the 13th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 30 June–3 July 2020; pp. 1–6. [Google Scholar]
- Lu, N.; Wu, Y.; Feng, L.; Song, J. Deep learning for fall detection: Three-dimensional CNN combined with LSTM on video kinematic data. IEEE J. Biomed. Health Inform. 2018, 23, 314–323. [Google Scholar] [CrossRef] [PubMed]
- Gutiérrez, J.; Rodríguez, V.; Martin, S. Comprehensive review of vision-based fall detection systems. Sensors 2021, 21, 947. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Li, W.; Wang, L.; Hu, J.; Ye, M. Vision-based fall event detection in complex background using attention guided bi-directional LSTM. IEEE Access 2020, 8, 161337–161348. [Google Scholar] [CrossRef]
- Feng, Q.; Gao, C.; Wang, L.; Zhao, Y.; Song, T.; Li, Q. Spatio-temporal fall event detection in complex scenes using attention guided LSTM. Pattern Recognit. Lett. 2020, 130, 242–249. [Google Scholar] [CrossRef]
- Tsai, T.H.; Hsu, C.W. Implementation of fall detection system based on 3D skeleton for deep learning technique. IEEE Access 2019, 7, 153049–153059. [Google Scholar] [CrossRef]
- Nogas, J.; Khan, S.S.; Mihailidis, A. Fall detection from thermal camera using convolutional lstm autoencoder. In Proceedings of the 2nd workshop on Aging, Rehabilitation and Independent Assisted Living, IJCAI Workshop, Stockholm, Sweden, 13–15 July 2018. [Google Scholar]
- Asif, U.; Von Cavallar, S.; Tang, J.; Harrer, S. Sshfd: Single shot human fall detection with occluded joints resilience. arXiv 2020, arXiv:2004.00797. [Google Scholar]
- Asif, U.; Mashford, B.; Von Cavallar, S.; Yohanandan, S.; Roy, S.; Tang, J.; Harrer, S. Privacy preserving human fall detection using video data. In Proceedings of the Machine Learning for Health Workshop, PMLR, Virtual Event, 7–8 August 2020; pp. 39–51. [Google Scholar]
- Bowen, M.E.; Craighead, J.; Wingrave, C.A.; Kearns, W.D. Real-time locating systems (RTLS) to improve fall detection. Gerontechnology 2010, 9, 464. [Google Scholar] [CrossRef]
- Sahin, Y.G.; Eren, A.; Seker, A.R.; Okur, E. A personalized fall detection system for older people. In Proceedings of the 2013 International Conference on Biology and Biomedicine, Rhodes, Greece, 21–27 September 2013; pp. 43–48. [Google Scholar]
- WHO. Drowning Accidents Report. 2021. Available online: https://www.who.int/news-room/fact-sheets/detail/drowning (accessed on 29 November 2021).
- Du, J. Characteristics and Function Analysis of Swimming Life Saving System Based on Machine Vision Technology. J. Phys. Conf. Ser. 2021, 1881, 042079. [Google Scholar] [CrossRef]
- Alshbatat, A.I.N.; Alhameli, S.; Almazrouei, S.; Alhameli, S.; Almarar, W. Automated Vision-based Surveillance System to Detect Drowning Incidents in Swimming Pools. In Proceedings of the 2020 Advances in Science and Engineering Technology International Conferences (ASET), Dubai, United Arab Emirates, 4 February–9 April 2020; pp. 1–5. [Google Scholar]
- Park, J.; Chen, J.; Cho, Y.K.; Kang, D.Y.; Son, B.J. CNN-based person detection using infrared images for night-time intrusion warning systems. Sensors 2020, 20, 34. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bonderup, S.; Olsson, J.; Bonderup, M.; Moeslund, T.B. Preventing Drowning Accidents Using Thermal Cameras. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 12–14 December 2016; pp. 111–122. [Google Scholar]
- Simulaids. TI Rescue Randy. Available online: https://www.aedsuperstore.com/simulaids-ti-rescue-randy-thermal-imaging-mankin.html (accessed on 20 September 2021).
- Thermetrics. Newton Thermal Manikin. Available online: https://thermetrics.com/products/manikin/newton-thermal-manikin/ (accessed on 20 September 2021).
- Lion. SmartDummy Thermal Manikin. Available online: https://www.lionprotects.com/smartdummy-thermal-manikin (accessed on 20 September 2021).
- Bhattacharya, A.; Vaughan, R. Deep learning radar design for breathing and fall detection. IEEE Sens. J. 2020, 20, 5072–5085. [Google Scholar] [CrossRef]
- Jokanović, B.; Amin, M. Fall detection using deep learning in range-Doppler radars. IEEE Trans. Aerosp. Electron. Syst. 2017, 54, 180–189. [Google Scholar] [CrossRef]
- Mauldin, T.R.; Canby, M.E.; Metsis, V.; Ngu, A.H.; Rivera, C.C. SmartFall: A smartwatch-based fall detection system using deep learning. Sensors 2018, 18, 3363. [Google Scholar] [CrossRef] [Green Version]
- Santos, G.L.; Endo, P.T.; Monteiro, K.H.d.C.; Rocha, E.d.S.; Silva, I.; Lynn, T. Accelerometer-based human fall detection using convolutional neural networks. Sensors 2019, 19, 1644. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, S.C.; Tripathi, R.K.; Jalal, A.S. Human-fall detection from an indoor video surveillance. In Proceedings of the 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Delhi, India, 3–5 July 2017; pp. 1–5. [Google Scholar]
- Huang, Z.; Liu, Y.; Fang, Y.; Horn, B.K. Video-based fall detection for seniors with human pose estimation. In Proceedings of the 2018 4th International Conference on Universal Village (UV), Boston, MA, USA, 21–24 October 2018; pp. 1–4. [Google Scholar]
- Wang, T.; Snoussi, H. Detection of abnormal visual events via global optical flow orientation histogram. IEEE Trans. Inf. Forensics Secur. 2014, 9, 988–998. [Google Scholar] [CrossRef]
- Adhikari, K.; Bouchachia, H.; Nait-Charif, H. Activity recognition for indoor fall detection using convolutional neural network. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 81–84. [Google Scholar]
- Elshwemy, F.A.; Elbasiony, R.; Saidahmed, M.T. A New Approach for Thermal Vision based Fall Detection Using Residual Autoencoder. Int. J. Intell. Eng. Syst. 2020, 13, 250–258. [Google Scholar] [CrossRef]
- Harrou, F.; Zerrouki, N.; Sun, Y.; Houacine, A. An integrated vision-based approach for efficient human fall detection in a home environment. IEEE Access 2019, 7, 114966–114974. [Google Scholar] [CrossRef]
- Wan, B.; Jiang, W.; Fang, Y.; Luo, Z.; Ding, G. Anomaly detection in video sequences: A benchmark and computational model. arXiv 2021, arXiv:2106.08570. [Google Scholar] [CrossRef]
- Ko, M.; Kim, S.; Kim, M.; Kim, K. A novel approach for outdoor fall detection using multidimensional features from a single camera. Appl. Sci. 2018, 8, 984. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Wu, C.; Wang, Y. Human fall detection based on body posture spatio-temporal evolution. Sensors 2020, 20, 946. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, J.; Philipsen, M.P.; Moeslund, T.B. Supervised Versus Self-Supervised Assistant for Surveillance of Harbor Fronts. In Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2021); SciTePress: Setúbal, Portugal, 2021; pp. 610–617. [Google Scholar]
- Xu, T.; Sheng, X.; Zhang, T.; Liu, H.; Liang, X.; Ding, A. Development and validation of dummies and human models used in crash test. Appl. Bionics Biomech. 2018, 2018, 3832850. [Google Scholar] [CrossRef] [PubMed]
- Belaid, M.K.; Rabus, M.; Krestel, R. CrashNet: An encoder–decoder architecture to predict crash test outcomes. Data Min. Knowl. Discov. 2021, 35, 1688–1709. [Google Scholar] [CrossRef]
- Bertocci, G.E.; Pierce, M.C.; Deemer, E.; Aguel, F.; Janosky, J.E.; Vogeley, E. Using test dummy experiments to investigate pediatric injury risk in simulated short-distance falls. Arch. Pediatr. Adolesc. Med. 2003, 157, 480–486. [Google Scholar] [CrossRef] [Green Version]
- Martinez-Maldonado, R.; Power, T.; Hayes, C.; Abdiprano, A.; Vo, T.; Axisa, C.; Buckingham Shum, S. Analytics meet patient manikins: Challenges in an authentic small-group healthcare simulation classroom. In Proceedings of the Seventh International Learning Analytics & Knowledge Conference, Vancouver, BC, Canada, 13–17 March 2017; pp. 90–94. [Google Scholar]
- Di Mitri, D.; Schneider, J.; Specht, M.; Drachsler, H. Detecting mistakes in CPR training with multimodal data and neural networks. Sensors 2019, 19, 3099. [Google Scholar] [CrossRef] [Green Version]
- Genovese, A.; Roginska, A. Hmdir: An hrtf dataset measured on a mannequin wearing xr devices. In Proceedings of the Audio Engineering Society Conference: 2019 AES International Conference on Immersive and Interactive Audio. Audio Engineering Society, York, UK, 27–29 March 2019. [Google Scholar]
- Spagnol, S.; Purkhús, K.B.; Unnthórsson, R.; Björnsson, S.K. The Viking HRTF Dataset. In Proceedings of the 16th Sound and Music Computing Conference, Malaga, Spain, 28–31 May 2019; pp. 55–60. [Google Scholar]
- Alhammami, M.; Ooi, C.P.; Tan, W.H. Violent actions against children. Data Brief 2017, 12, 480–484. [Google Scholar] [CrossRef]
- Liu, S.; Yin, Y.; Ostadabbas, S. In-bed pose estimation: Deep learning with shallow dataset. IEEE J. Transl. Eng. Health Med. 2019, 7, 1–12. [Google Scholar] [CrossRef]
- Satat, G.; Tancik, M.; Gupta, O.; Heshmat, B.; Raskar, R. Object classification through scattering media with deep learning on time resolved measurement. Opt. Express 2017, 25, 17466–17479. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Christiansen, P.; Nielsen, L.N.; Steen, K.A.; Jørgensen, R.N.; Karstoft, H. DeepAnomaly: Combining background subtraction and deep learning for detecting obstacles and anomalies in an agricultural field. Sensors 2016, 16, 1904. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kragh, M.F.; Christiansen, P.; Laursen, M.S.; Larsen, M.; Steen, K.A.; Green, O.; Karstoft, H.; Jørgensen, R.N. Fieldsafe: Dataset for obstacle detection in agriculture. Sensors 2017, 17, 2579. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, Y.; Kuklane, K.; Gao, C. Types of thermal manikin. In Manikins for Textile Evaluation; Elsevier: Amsterdam, The Netherlands, 2017; pp. 25–54. [Google Scholar]
- Farrington, R.B.; Rugh, J.P.; Bharathan, D.; Burke, R. Use of a thermal manikin to evaluate human thermoregulatory responses in transient, non-uniform, thermal environments. SAE Trans. 2004, 113, 548–556. [Google Scholar]
- Fan, J. Recent developments and applications of sweating fabric and applications of sweating fabric manikin—Walter. Therm. Manikins Model. 2006, 2006, 202–209. [Google Scholar]
- Chen, Y.; Xu, J.; Fan, J. Passive and active water supply to perspiring manikin. In Proceedings of the 6th International Thermal Manikin and Modeling Meeting, Hong Kong, China, 16–18 October 2006; pp. 16–18. [Google Scholar]
- Yu, W.; Fan, J.; Ng, S.; Gu, H. Female torso mannequins with skeleton and soft tissue for clothing pressure evaluation. In Proceedings of the Thermal manikins and modeling, Sixth International Thermal Manikin and Modeling Meeting, Hong Kong, China, 16–18 October 2006. [Google Scholar]
- Nilsson, H.O. Comfort Climate Evaluation with Thermal Manikin Methods and Computer Simulation Models. Ph.D. Thesis, Byggvetenskap, Stockholm, Sweden, 2004. [Google Scholar]
- Miura, J.; Demura, M.; Nishi, K.; Oishi, S. Thermal comfort measurement using thermal-depth images for robotic monitoring. Pattern Recognit. Lett. 2020, 137, 108–113. [Google Scholar] [CrossRef]
- Fitzgerald, S.; Atkins, H.; Leknys, R.; Kelso, R. A thermal test system for helmet cooling studies. Multidiscip. Digit. Publ. Inst. Proc. 2018, 2, 272. [Google Scholar] [CrossRef] [Green Version]
- Hikvision. DS-2TD2235D-25/50. 2015. Available online: https://us.hikvision.com/en/products/more-products/discontinued-products/thermal-camera/thermal-network-bullet-camera-ds (accessed on 27 September 2021).
- AXIS. Q1921. 2018. Available online: https://www.axis.com/en-us/products/axis-q1921-e (accessed on 27 September 2021).
- Schuster, N.; Franks, J. Depth of field in modern thermal imaging. Infrared Imaging Syst. Des. Anal. Model. Test. 2015, 9452, 94520J. [Google Scholar]
- Iino, A.; Annaka, T.; Iino, Y.; Ohba, M. Visualization of sensible heat on thermal mannequin’s surface by image analysis of infrared animation. In Proceedings of the The Fourth International Conference on Advances in Wind and Structures (AWAS2008), Jeju, Korea, 29–31 May 2008. [Google Scholar]
- Bhushan, B.; Basu, S.; Panigrahi, P.K.; Dutta, S. Exploring the Thermal Signature of Guilt, Shame, and Remorse. Front. Psychol. 2020, 11, 2874. [Google Scholar] [CrossRef]
- Salvador, S.; Chan, P. Toward accurate dynamic time warping in linear time and space. Intell. Data Anal. 2007, 11, 561–580. [Google Scholar] [CrossRef] [Green Version]
- Ultralytics. Yolov5, 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 25 October 2021).
- Krišto, M.; Ivasic-Kos, M.; Pobar, M. Thermal Object Detection in Difficult Weather Conditions Using YOLO. IEEE Access 2020, 8, 125459–125476. [Google Scholar] [CrossRef]
- Huda, N.U.; Hansen, B.D.; Gade, R.; Moeslund, T.B. The Effect of a Diverse Dataset for Transfer Learning in Thermal Person Detection. Sensors 2020, 20, 1982. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nikolov, I.A.; Philipsen, M.P.; Liu, J.; Dueholm, J.V.; Johansen, A.S.; Nasrollahi, K.; Moeslund, T.B. Seasons in Drift: A Long-Term Thermal Imaging Dataset for Studying Concept Drift. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems, Virtual, 6–14 December 2021. [Google Scholar]
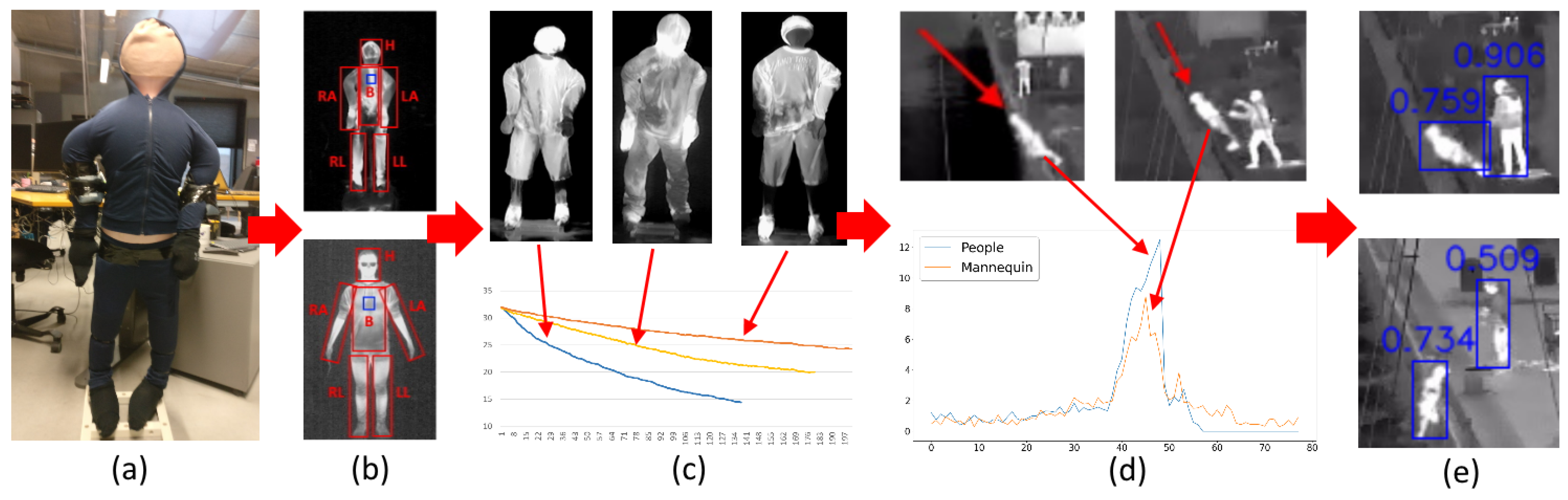

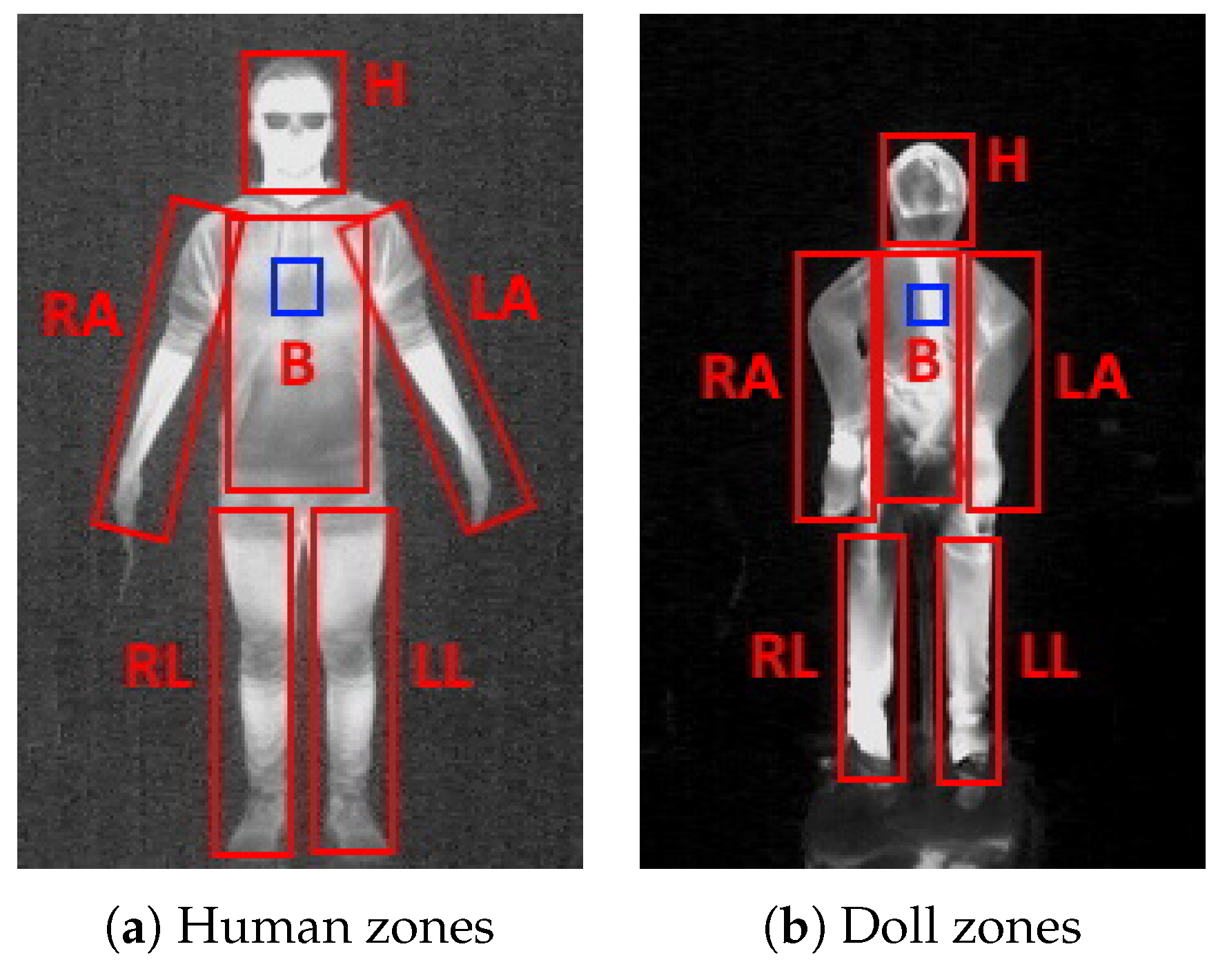
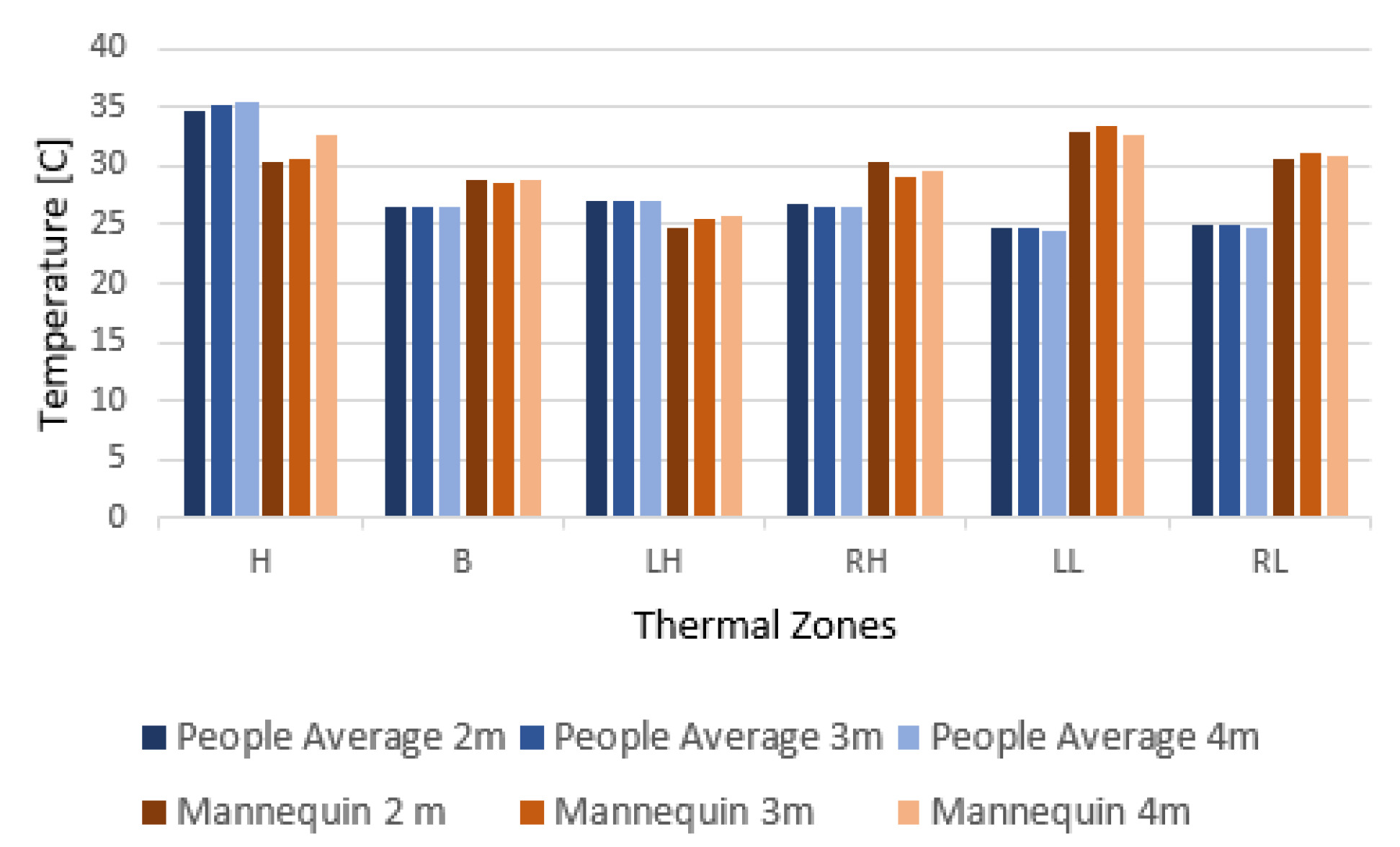
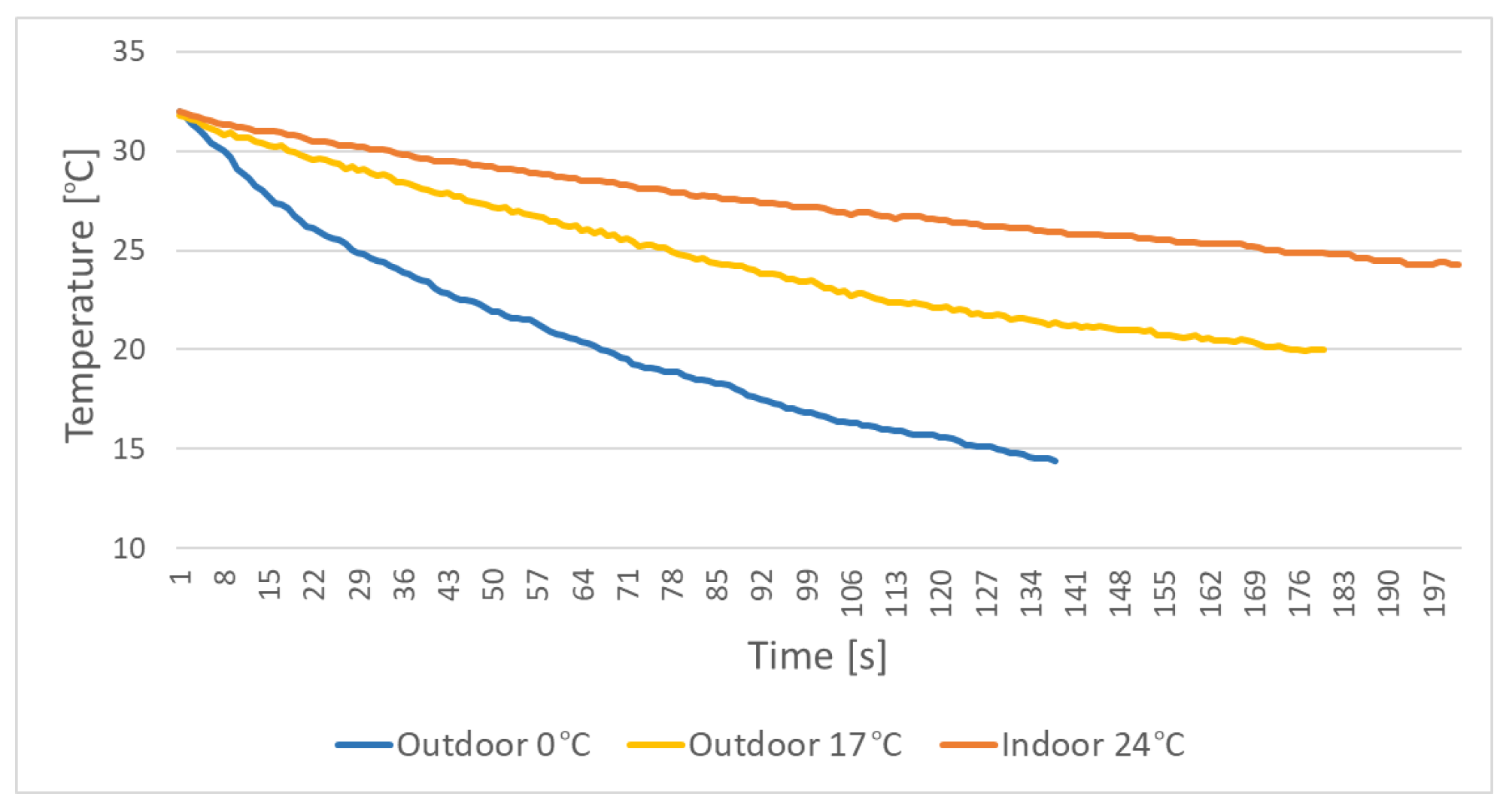




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AXIS Q1921 | Hikvision DS-2TD2235D | |
|---|---|---|
| Resolution | 384 × 288 | 384 × 288 |
| Image sensor | Uncooled | Vanadium Oxide Uncooled |
| Response Waveband | 8–13 m | 8–14 m |
| FoV | 19 | 25 |
| Output | 8-bit grayscale | 8-bit grayscale |
| NETD | <100 milli-Kelvin | <50 milli-Kelvin |
| Results | Volunteers | Doll |
|---|---|---|
| Avg. Confidence Score | 0.761 | 0.730 |
| Avg. Detected Frames [%] | 77.7 | 62.1 |
| Avg. Lost Frames before Water Hit | 1 | 2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nikolov, I.; Liu, J.; Moeslund, T. Imitating Emergencies: Generating Thermal Surveillance Fall Data Using Low-Cost Human-like Dolls. Sensors 2022, 22, 825. https://doi.org/10.3390/s22030825
Nikolov I, Liu J, Moeslund T. Imitating Emergencies: Generating Thermal Surveillance Fall Data Using Low-Cost Human-like Dolls. Sensors. 2022; 22(3):825. https://doi.org/10.3390/s22030825
Chicago/Turabian StyleNikolov, Ivan, Jinsong Liu, and Thomas Moeslund. 2022. "Imitating Emergencies: Generating Thermal Surveillance Fall Data Using Low-Cost Human-like Dolls" Sensors 22, no. 3: 825. https://doi.org/10.3390/s22030825
APA StyleNikolov, I., Liu, J., & Moeslund, T. (2022). Imitating Emergencies: Generating Thermal Surveillance Fall Data Using Low-Cost Human-like Dolls. Sensors, 22(3), 825. https://doi.org/10.3390/s22030825