1. Introduction
Skin cancer is caused by the abnormal growth of skin cells. Skin cancer cases have increased dramatically in recent years [
1]. The increase in skin cancer is because of the reduction in the ozone layer, which is protection against ultraviolet rays [
2]. Squamous cell carcinoma, actinic keratosis (solar keratosis), melanoma, and basal cell carcinoma are all types of skin cancer [
3]. Melanoma is the most dangerous type of skin cancer, out of all the others. Melanoma begins in the melanocyte cells, which resemble a mole and are brown or black in color [
4]. The occurrence rate of melanoma is 7%, but 75% of deaths are caused by this type of deadly cancer [
5].
In 2017, in the USA, 3590 deaths occurred from 95,360 cases. From these cases, 87,110 were melanoma cases. The reported deaths in 2018 are 13,460 from a total of 99,550 cases. The melanoma cases that occurred in 2018 are 91,270. In 2019, 104,350 cases of skin cancer were reported in the USA alone. The number of reported cases in men was 62,320 and in women was 42,030. The number of melanoma cases was 96,480 (reportedly 57,220 in men and 39,260 in women) of all skin cancer cases reported in 2019. The number of deaths in 2019 due to melanoma was 7320 [
6]. More than 15,000 people in the USA die every year from skin cancer lesions. In the next few decades, the mortality rate by melanoma infections could increase [
7].
Because of the differences in skin textures and injuries, detecting skin cancer is a difficult task. As a result, dermatologists employ a noninvasive technique known as dermoscopy to detect skin lesions at an early stage [
8]. The first step in dermoscopy is to apply the gel to the infected area. Then, a magnified image is acquired by using a magnifying tool. This magnified image provides a better visualization to examine the structure of the lesion area. The detection accuracy depends on the experience of the dermatologist [
9]. A study shows that the dermatologist’s detection accuracy can vary between 75% and 84% [
10]. Manual identification of skin lesions using dermoscopy, on the other hand, is a time-consuming procedure with a high risk of error, even for experienced dermatologists [
11]. Therefore, researchers have introduced different computer-aided diagnostic (CAD) techniques based on machine learning and deep CNN features [
12].
Dermatologists can use CAD systems to identify skin lesions more quickly and accurately. A CAD system’s key steps are skin image dataset acquisition, feature extraction and selection, and classification [
13]. The utilization of deep features for skin lesion detection and classification has been shown to be of immense importance in the last few years compared to the traditional feature extraction techniques [
14]. The deep features are extracted from the fully connected layers of a CNN model that was later employed for the classification [
15]. Deep features, as opposed to traditional methods, such as texture, color, and shape, include both local and global information about an image. An image’s local information is extracted from the convolutional layer, while the global information is captured from the 1D layers (global average pooling and fully connected) [
16]. In the traditional methods, shape features, such as HOG, color, and texture (LBP), are extracted separately [
17].
A few researchers faced the problem of redundant features that mislead the multiclass lesion classification. Therefore, it is essential to develop a feature selection technique that selects the most appropriate features for final classification [
18]. A few recently introduced feature selection techniques include grasshopper, binary whale optimization, among others [
19]. As compared to the binary class classification problem, the multiclass classification is more complex due to the similar nature of skin lesions. Moreover, the intraclass similarity is another problem for the multiclass classification.
In this work, a new framework is proposed based on the hybrid whale optimization deep feature selection that later fused with a modified canonical correlation approach. The contrast stretching method is proposed to improve the visibility quality of the lesion region. The deep learning model is trained on the contrast enhanced lesions instead of original dermoscopic images. Further, two feature selection techniques are utilized in order to improve the accuracy and reduce the computational time.
2. Related Work
Several techniques and methods have been developed for the robust segmentation and classification of skin lesions [
8]. The developed techniques utilized computer vision-based machine learning techniques [
20]. Machine learning algorithms utilized supervised learning and deep learning methods for robust detection, segmentation, and classification of skin lesions [
21]. Dorj et al. [
22] utilized the deep features from pre-trained AlexNet model and that had been given to SVM for classification. Their technique produced promising results for lesion classification. Ren et al. [
23] presented a fusion mechanism for the segmentation of a skin lesion. The spatial attention and channel attention modules extracted the information from channels of skin images. The implementation of serial network fusion for segmentation achieved competitive accuracy. Automated skin lesion segmentation [
24] and classification was performed using the deep CNN-based mutual boot strapping network. The segmentation and classification used learned information of both phases using a bootstrapping technique. The proposed method was implemented on challenging skin lesion datasets and achieved robust segmentation and classification performance. A deep learning [
25] technique was deployed to detect and classify the melanoma from dermoscopic images. A deep residual network was used to extract deep feature and fisher vectors utilized for image encoding. SVM classification was performed with chi-square to detect and classify the melanoma from discriminatory images of dermoscopy. The presented method achieved robust performance on the challenging ISBI 2016 dataset. Khan et al. [
26] came up with a novel deep learning-based methodology for efficient segmentation and classification of skin lesions. The segmentation was performed using mask recurrent neural network (Mask-RNN). A pyramid network feature was used with Resnet50 for feature extraction and lesion classification performed with the SoftMax classifier. The HAM10000 dataset was utilized for the presented deep learning method evaluation and achieved competitive performance. A deep learning-based novel cascaded architecture [
27] presented the ability for recognition of skin lesions. The diffusion of knowledge was required to perform analysis of the skin lesion and segmentation of lesions. The data augmentation was performed to remove the class disparity and implanted technique compared with the state-of-the-art (SOTA) technique of skin lesion classification and segmentation. The super pixel [
28] method adopted for efficient segmentation and recognition of skin lesions used a novel segmentation technique. Image registration and segmentation techniques were fused for feature derivation, in order to achieve the better lesion segmentation results. The deep learning-based techniques [
29] achieve robust performance in skin lesion segmentation, detection, and classification. Sikkandar et al. [
30] came up with a new GrabCut and neuro fuzzy algorithm for recognition and segmentation of skin lesion. Preprocessing performed using top hat filter, GrabCut method used for segmentation, feature extraction performed using deep CNN model inception, and images of skin lesions classified using neuro fuzzy classifier. The presented technique applied on ISIC dataset and achieved robust performance in terms lesion segmentation and classification. Researchers in [
31] used the transfer learning technique on the PH2 dataset for the classification of skin lesions. They performed transfer learning on the AlexNet network and achieved an accuracy of 98.61%.
The methods described above follow some standard steps for lesion classification, including preprocessing of lesion images, segmentation of skin lesions, extraction of deep learning features from segmented lesions, and, finally, classification using supervised learning methods. The accuracy of features extracted using pre-trained deep learning models is higher than that of features extracted using traditional techniques. The key limitation of the methods described above is the inclusion of redundant features, which not only reduces system accuracy but also increases computational time. Furthermore, the majority concentrated on the binary class classification problem. In this paper, we proposed a new framework for multiclass classification using deep learning and fusion of best selected features.
3. Datasets
Two datasets are utilized in this work for the experimental process, such as HAM10000 and ISIC2018. The detail of both datasets is given below.
HAM1000 Dataset: The HAM10000 “Human Against Machine with 10,000 training images” dataset is one of the largest datasets, which contains 10,015 total dermoscopy images, used for detecting pigmented skin lesions, that are publicly accessible through the ISIC repository [
32]. This dataset is grouped into seven different classes with a number of images, i.e., melanocytic nevus (nv = 6705), actinic keratosis (akiec = 327), dermatofibroma (df = 115), basal cell carcinoma (bcc = 514), vascular lesion (vacs = 115), benign keratosis (bkl = 1099), and melanoma (mel = 1113) [
33]. The dataset contains 54% male and 45% female skin lesion images. It is a complex dataset with many skin lesion images having low inter-class and high intra-class variation issues, therefore the classification of these skin classes is not an easy task, and the chances of a high misclassification rate are significant. A few sample images are shown in
Figure 1.
ISIC 2018 Dataset: The ISIC 2018 dataset was published by the International Skin Imaging Collaboration (ISIC) as a large-scale dataset of dermoscopy images that included over 12,500 images. The dataset performs three different tasks, i.e., lesion segmentation, attribute detection, and disease classification, respectively [
34]. For the classification task, this dataset consists of more than 10,000 images of seven type of classes [
35]. The sample images are illustrated in
Figure 2. The ISIC 2018 challenge has two main problems: first, the limited number of images in some classes; and, secondly, the imbalanced number of images in different classes makes the classifier difficult to correct classification.
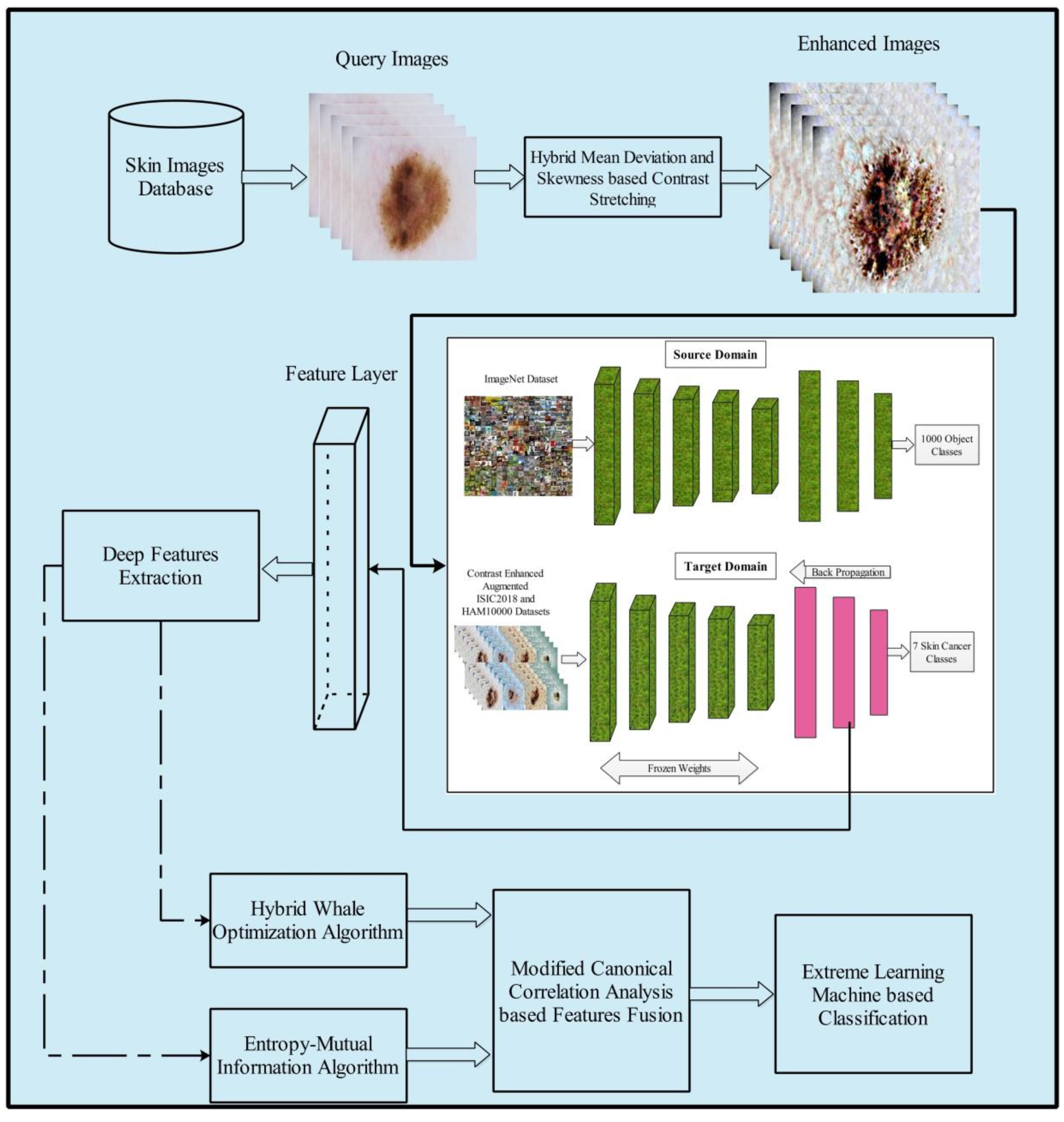
4. Proposed Methodology
The proposed method for multiclass skin cancer classification used deep learning and the fusion of the best selected features, and is presented in this section. The architecture of the proposed method is illustrated in
Figure 3. Five primary steps are performed in the proposed method: image acquisition and contrast enhancement; deep learning features extraction using transfer learning; selection of best features using hybrid whale optimization and entropy-mutual information (EMI) approach; fusion of selected features using modified canonical correlation based approach; and, finally, ELM-based classification. The detail of each step is given below subsections.
4.1. Contrast Enhancement
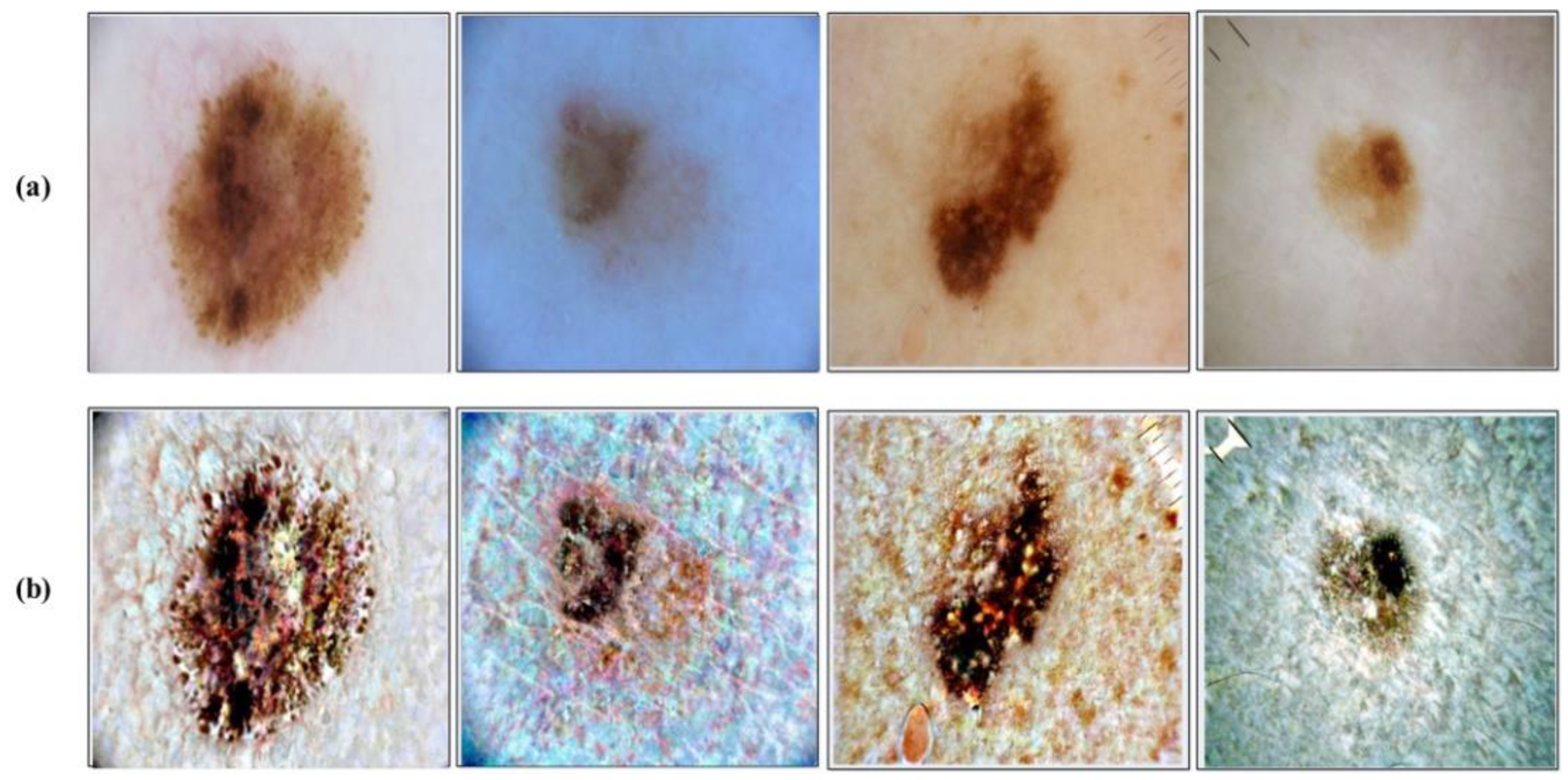
Contrast enhancement is an important step in the area of medical imaging to improve the local contrast of an image. In medical image processing, contrast stretching is usually applied for accurate skin lesion detection; however, in this step, contrast stretching is applied for the sake of more useful feature extraction. Many techniques are presented in the literature for global contrast enhancement, but a very few of them focused on local contrast stretching. In this work, a hybrid contrast stretching technique is proposed based on absolute mean deviation and a skewness function. This method increases the contrast of skin lesion region and makes the image more useful for the further processing. Mathematically, this process is defined as follows:
Consider
is dermoscopic database,
is an input image of dimension
. Let,
represent the total number of pixels in the image and
is the each image pixel. The absolute mean deviation (AMD) and skewness are formulated through Equations (1) and (2).
where the
is AMD of the image,
is average mean of the dataset (
), and
is the standard deviation, respectively. By employing these values, the final transformation image is obtained as follows:
where
is final transformed image and
denote the image pixel’s. This process is applied on the entire selected datasets before training of the deep learning models. A few sample results are illustrated in
Figure 4. In this figure, it is clearly illustrated that after the proposed transformation, the lesion region is more easy to identify.
4.2. Convolutional Neural Network
In the area of medical imaging, CNN showed promising performance for both segmentation and classification tasks. Generally, a CNN architecture consists of a number of layers, such as input layer, convolutional layer, activation layer, ReLu, pooling, fully connected, and SoftMax.
The first layer of a convolutional layer is the input layer. This layer is always in , where denotes the number of channels. In this layer, the whole image pixels are considered as input to the next layer. Through this layer, both low-level and high-level features are extracted.
The second layer is a convolutional layer, mainly utilized to extract feature information from the images using convolutional operation and dot product. This layer is defined as follows:
where,
denotes the output of the convolutional layer. The result of this layer returned into a matrix format, which consists of the number of positive and negative values. The negative values are not required for the next step; therefore, converting those pixel values into positive ones is essential. For this purpose, an activation layer, called the ReLu layer, is applied. This layer transforms the negative pixel values into zero and keeps positive values as it is. Mathematically, it is defined as follows:
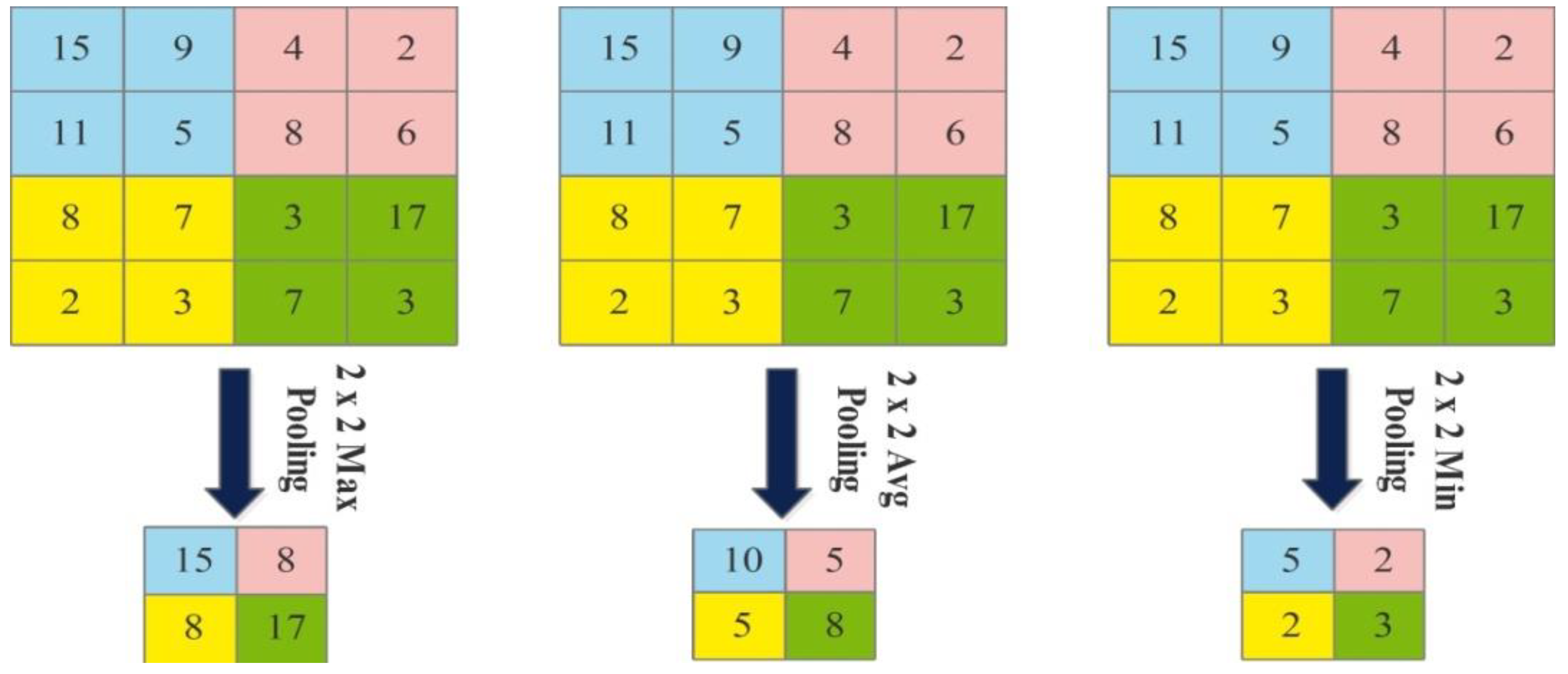
The next layer is the pooling layer, which reduces the spatial size of an image after the convolutional layer. This layer is usually applied between two convolutional layers. Visually, the pooling layer operations are illustrated in
Figure 5 and mathematical output is defined as follows:
The fully connected layer (FC) comprises neurons fully linked with all preceding layers of activations. After that, the activations can be calculated using matrix multiplication and bias offset. Finally, the performance of this layer is graded using the SoftMax classifier. Mathematically it is defined as:
A SoftMax function is used to take either positive, zero, or negative real value as input to all the values of . As an input vector, each value is subjected to an exponential equation.
4.3. Deep Learning Features Extraction
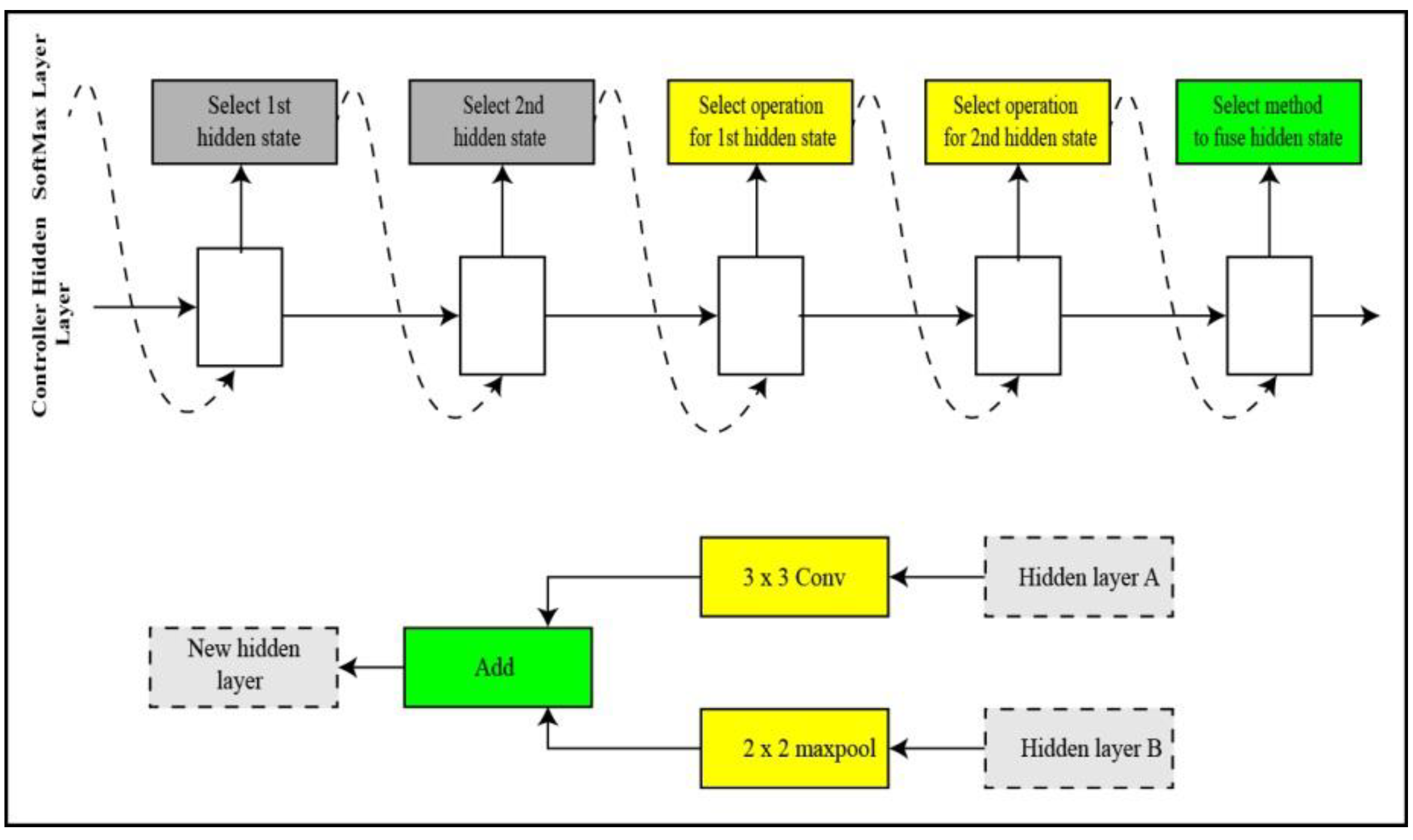
NASNET Large: A neural architecture search (NAS) [
36] deep network trained over a million images of the challenging image database ImageNet [
37]. The input size of image for the NasNet Large is 331-by-331. A child network of unique structure is created in NAS by the recurrent neural network (RNN). The child networks are trained using a holdout method to achieve accuracy. The controller is updated using the combined accuracy of child networks to create a better architecture for the network. The controller structure is represented in
Figure 6. The controller predictions are gathered into
blocks. Five unique SoftMax classifiers make five predictions at five steps of the block in accordance with the discrete choices of blocks.
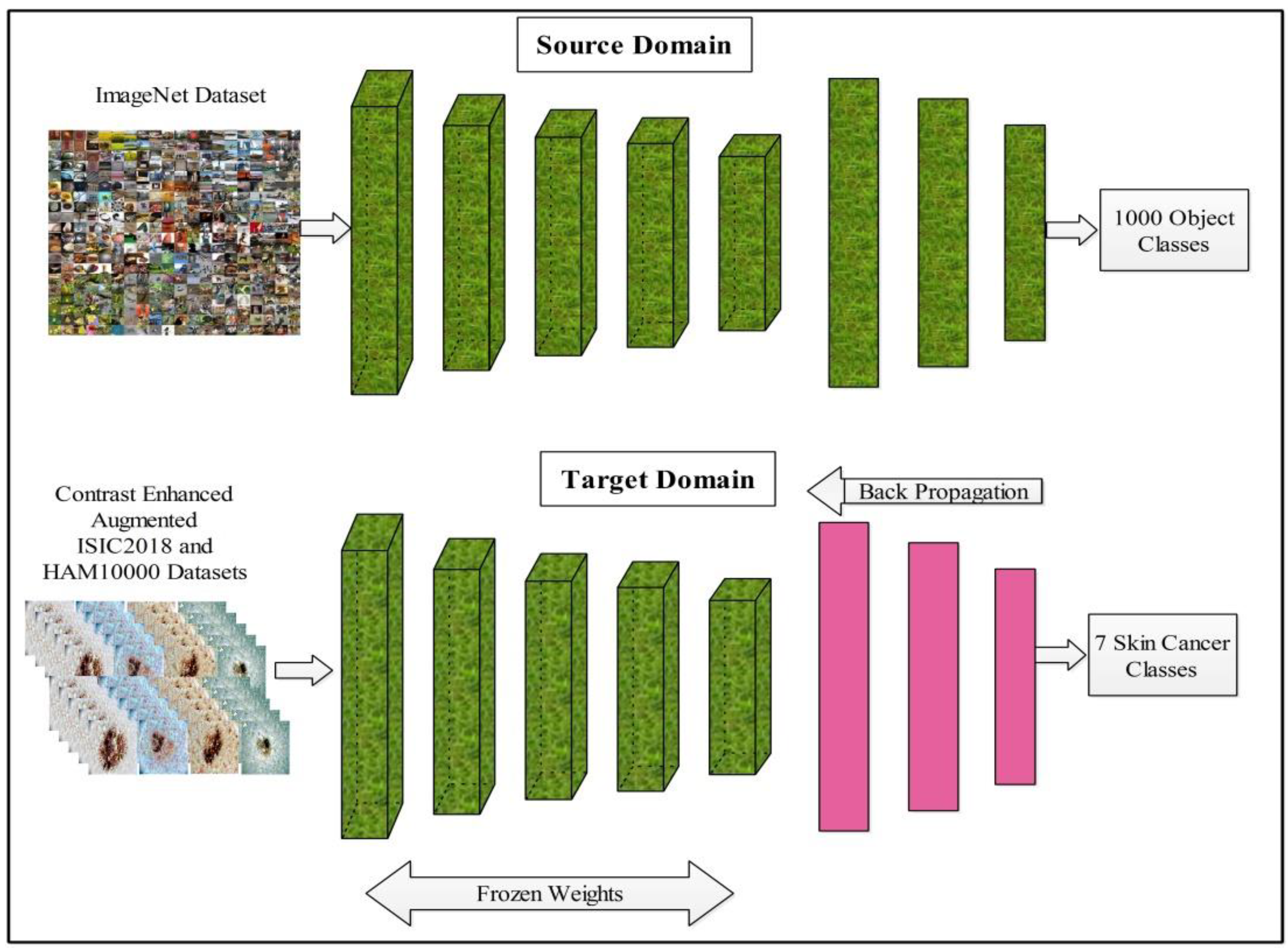
In the process of model fine-tuning, we first remove the last three layers of this model and add a new layer according to the number of dataset classes. After the fine-tuning process, transfer learning is employed for the training of the model. In the training process, several hyperparameters are selected, such as the learning rate of 0.001, epochs of 100, minimum batch size of 64, and SGD for learning. The transfer learning process is illustrated in
Figure 7. After the training of a finely tuned model on skin datasets, features are extracted from the average pool layer and utilized for the further processing, such as feature selection.
4.4. Optimal Feature Selection
The selection of the best features is an important step, with the advantage of improving the classification accuracy and reducing the computational time [
38]. In this work, two methods are applied for the selection of best features. In the first method, a hybrid whale optimization algorithm is proposed. HWO Algorithm: Originally, the WOA was introduced by Mirjalili [
39]. This algorithm is executed in two phases: (i) encircling prey and (ii) search for prey. In other words, two steps are performed: an exploitation phase and an exploration phase. Mathematically, these phases are formulated as:
where
is position vector,
is best solution,
and
are coefficient vectors,
is random vector of value [0, 1],
is decrease linearly from 2 to 0 over the iterations, and
is absolute value, respectively. The
update the positions according to the best known solutions
. The values
and
are located in the whale according to their best solutions. The shrinking behavior is updated through the following equation:
Later, the distance is computed among
and
to create the position of a neighbor search agent.
where
is a constant and value is 1, and
is a random number between −1 and 1. The final shrinking process is formulated through the following equation:
where the
is a random number of value between 0 and 1. In the exploration phase, a random search agent is selected to guide the search.
where
is a random search agent and
is selected agents (features). The extreme learning machine (ELM) classifier [
40] is adopted for the classification error and to make the balance among classification classes, the following fitness function is employed:
where
is classification error computed from ELM. The best solutions are picked and saved in
. These best solutions are further refined using the sorting and absolute mean deviation (AMD)-based function. AMD is computed through Equation (1) and final selection function is defined as follows:
EMI Selection Technique: Another technique, named Fuzzy Entropy Mutual Information (EMI), is proposed for features uncertainty handling. The fuzzy entropy is initially computed from the original feature vector and then embedded into the mutual information equation for the final selection. Fuzzy entropy is defined as follows:
Using this equation, the join entropy of two variables is computed as follows:
After that, the common information is computed among
and
, known as mutual information.
The resultant vector is finally fused with the HWOA-based selected feature vector using modified canonical correlation analysis (MdCAA).
4.5. Optimal Feature Fusion
The best selected features of HWO and EMI are finally fused in one matrix using modified canonical correlation analysis. Mathematically, the original CCA is formulated as follows:
where
j,
k, and
l represent dimensions of sample space, n denotes observation size. CCA aims to find projection directories.
That raises the correlation between
where
X = [
,
Y = [
and
Z = [
represents sample matrices. Formally, in CCA we solve:
where
define covariance matrix between feature sets and
,
,
represents covariance within three feature sets. When the matrices within feature sets are non-singular, then CCA can be obtained by computing generalized Eigen-problem.
Let
=
,
=
,
=
denote three projection directories matrices. Where the vector pairs
corresponds to the largest d generalized Eigen value. From the three modalities we can get the fused feature as termed below:
where
is the fused vector that later sorted into descending order and remove the redundant features by comparing approach. The final results features are finally classified using ELM classifier.
4.6. Extreme Learning Machine
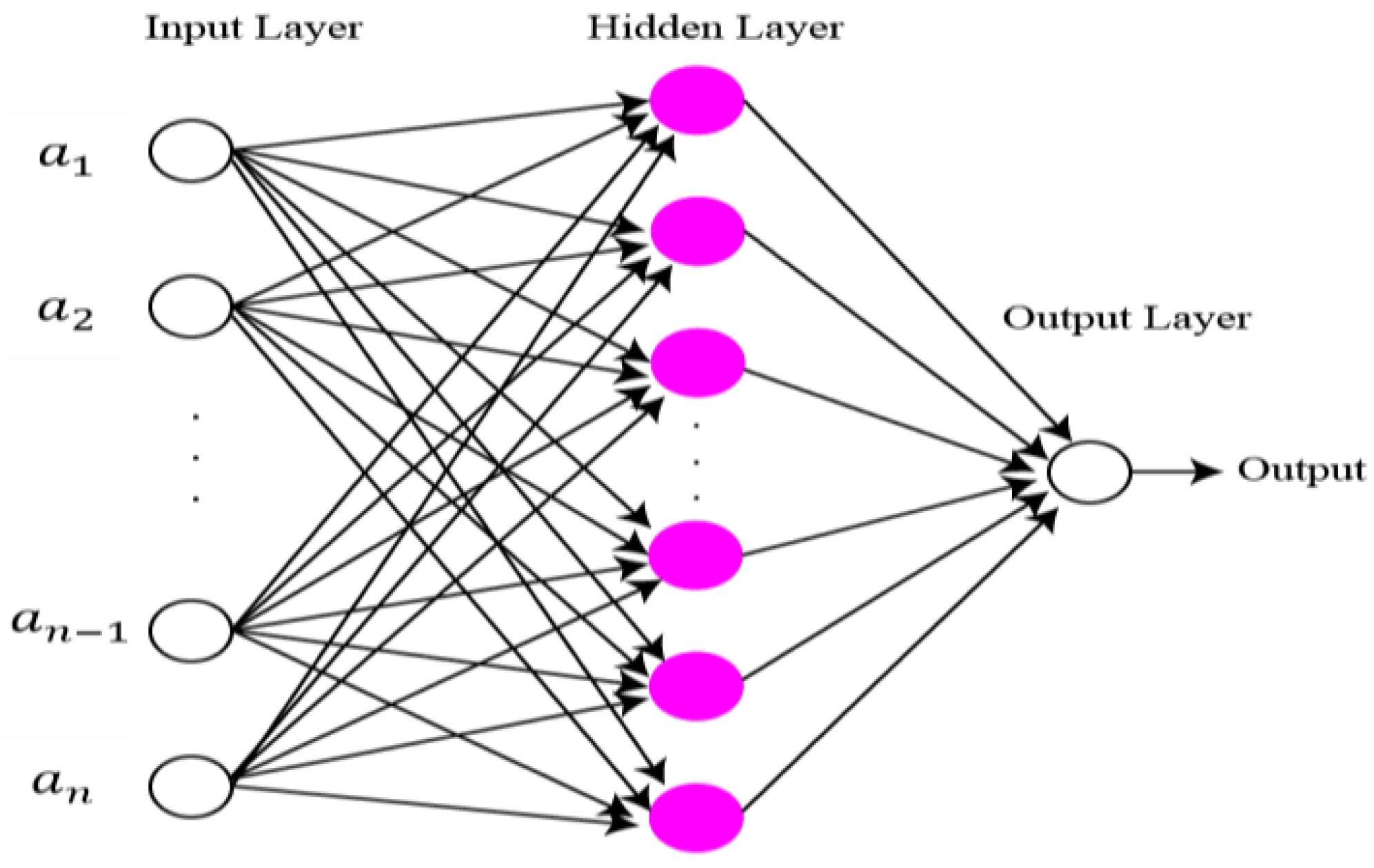
The final features are classified using extreme learning machine (ELM) [
41]. The structure of ELM is illustrated in
Figure 8. Compared to classical gradient-based neural networks (GBNN), the ELM rate of learning and generalization efficiency is better. In the case of the ELM algorithm, the assignment of weights and hidden biases are carried out randomly. Although a least square technique is used for the calculation of output weight. Mathematical representation of ELM is as follows:
Suppose ELM has
unique samples
from the fused feature set. The approximation of the desired output can be carried out with help of ELM having zero error which can be denoted as
where
is input samples and
is output samples. L refers to nodes of hidden layer,
are weights for output, activation function is referred to as
.
and
refer to input weights and input bias, respectively. The activation function for ELM is the radial basis function. The matrix of Equation (35) can be denoted as:
where the weights of matrix are represented as
, the target output is represented as
, the hidden layer output can be represented as
.
Practically, the nodes of hidden layer
are less than the total number of samples of training (
S). The matrix
of the output weight is not a singular matrix. The ELM approximation for target output cannot be with zero error. That is why the Moore Penrose (MP) generalization inverted method is utilized to obtain approximation and to express output weights.
where
refers the generalized inverse of hidden layer of output.
5. Results and Analysis
The proposed multiclass skin lesion classification framework results are presented in this section. Two publicly available datasets, named HAM10000 [
32] and ISIC2018 [
42], are employed for the experimental process. Both datasets consist of seven different skin lesion classes. As mentioned in
Section 4.1, the data augmentation process is employed in this work to handle the imbalanced issue. Therefore, the balanced datasets are considered for the experimentations. Several parameters are employed in this work during the training process, such as a training rate of 0.001; a mini batch size of 64, and max epochs of 500. The 50:50 is considered for the training and testing process for both datasets, whereas the cross validation value is 10. Several classifiers are utilized for the experimental process, such as multiclass SVM (MC-SVM), fine KNN (F-KNN), decision trees (DT), Naïve Bayes, ensemble tree (EBT), and single hidden layer extreme learning machine (ELM). The performance of each classifier is computed using accuracy, precision, FDR, and computational time. The simulations of proposed framework are performed on MATLAB2020b. Moreover, an 8GB graphics processing unit (GPU) is utilized for processing of the proposed framework.
Experiments: The following experiments are performed in this work for validation of the proposed framework:
- -
Classification using originally deep features;
- -
Classification using HWOA-based best features selection;
- -
Classification using EMI-based best features selection;
- -
Classification using best selected features fusion approach.
5.1. Results on HAM10000 Dataset
Table 1 presents the classification results of HAM10000 dataset using originally deep extracted features from fine-tuned NasNet large network. The features are extracted from the global average pool layer and the classification is performed. On this layer, the length of extracted deep features is
. The highest achieved accuracy noted in this table is 84.90%, for the ELM classifier. The precision and FDR values are 84.10 and 15.90%, respectively. Additionally, the computational time of ELM is 214.5536 (s). A few other classifiers are also implemented, such as MC-SVM, F-KNN, DT, Naïve Bayes, and EBT, and the accuracy value is 84.72, 80.90, 79.63, 81.50, and 82.96%, respectively. The accuracy and precision value of ELM is better, compared to these classifiers. Additionally, computationally, ELM is more efficient than rest of the classifiers.
After the experimentation on the originally deep features, two feature selection techniques are introduced, named HWOA and EMI.
Table 2 presents the classification results of the HWOA-based best features selection algorithm. The higher noted accuracy in this table is 85.10%. The precision and FDR values of this classifier are 84.86 and 15.14%, respectively. Computation time of ELM is 147.6329 (s), which is less as compared to the other mentioned classifiers, such as MC-SVM, F-KNN, to name a few. Compared to the results of HWOA-based feature selection with originally deep extracted (from
Table 1), it is noted that a minor improvement is occurred in the accuracy but there is significant change in the computational time.
Table 3 presents the classification accuracy using EMI-based best feature selection approach. In this table, the best noted accuracy value is 84.90, whereas the computational time is 90.3560 (s). This selection method has also shown slight improvement in the accuracy but there is a high change in the computational time (compared with
Table 1 and
Table 2). Based on these three experiments, it is analyzed that the selection of the best features shows slight improvement in the accuracy value but higher change in the computational time. After the process of best features selection, time is significantly reduced.
The best selected features through HWOA and EMI are finally fused using proposed fusion approach.
Table 4 presents the results of features fusion. In this table, the best noted accuracy value is 93.40% that is improved than the accuracy values given in
Table 1,
Table 2 and
Table 3. After the fusion process, the change in the accuracy value is approximately 8%. The values of precision and FDR is 93.10 and 6.90%, respectively. Additionally, the computational time is reduced and reached to 69.2036 (s). The recent best time was 90.3560 (s) for EMI-based features selection approach. For the rest of the classifiers, such as MC-SVM, F-KNN, DT, Naïve Bayes, and Ensemble trees, also showed the improved performance after the fusion process. The accuracy value of ELM is further verified by
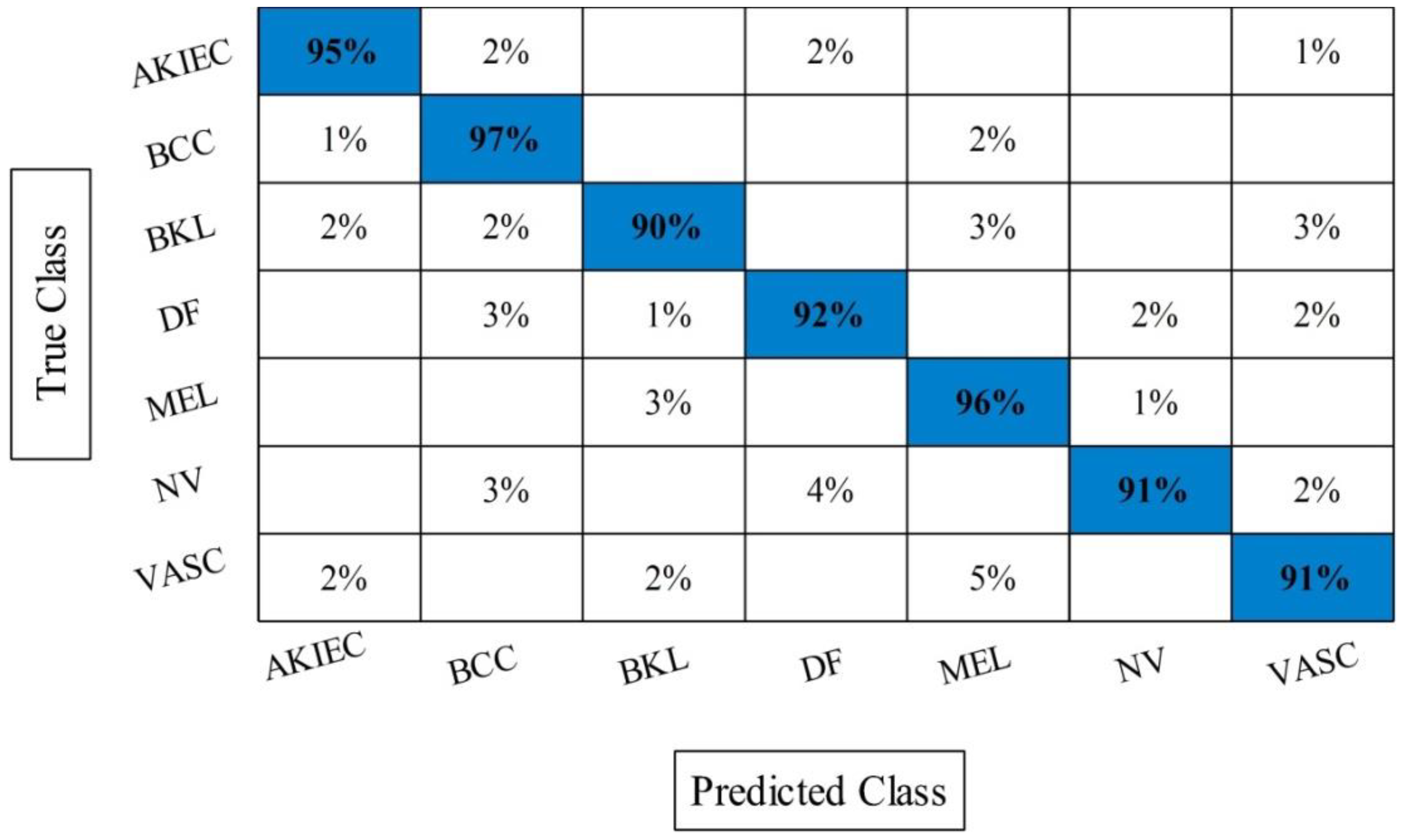
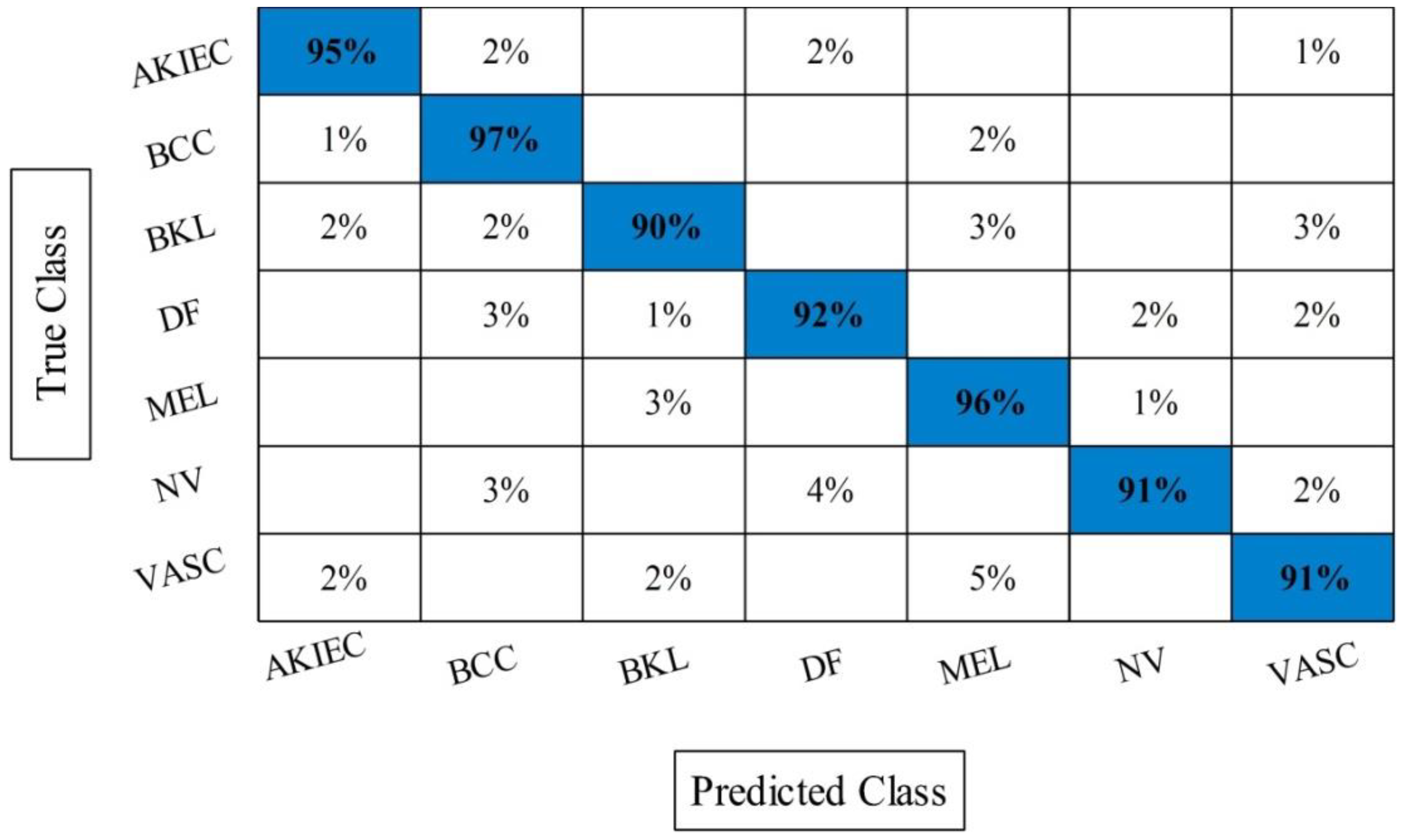
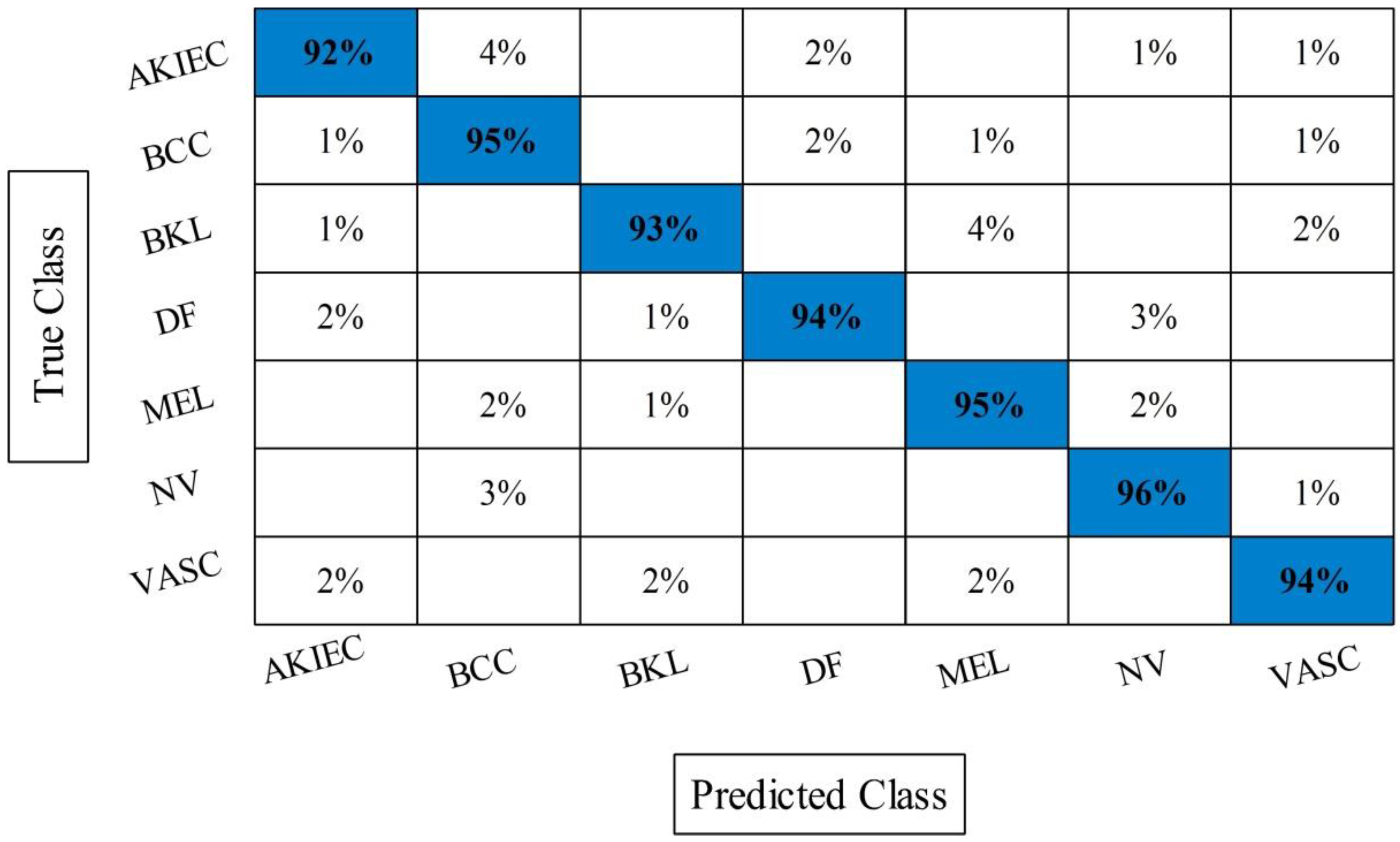
Figure 9 in the form of confusion matrix. In this figure, the diagonal value represents the correct prediction rate.
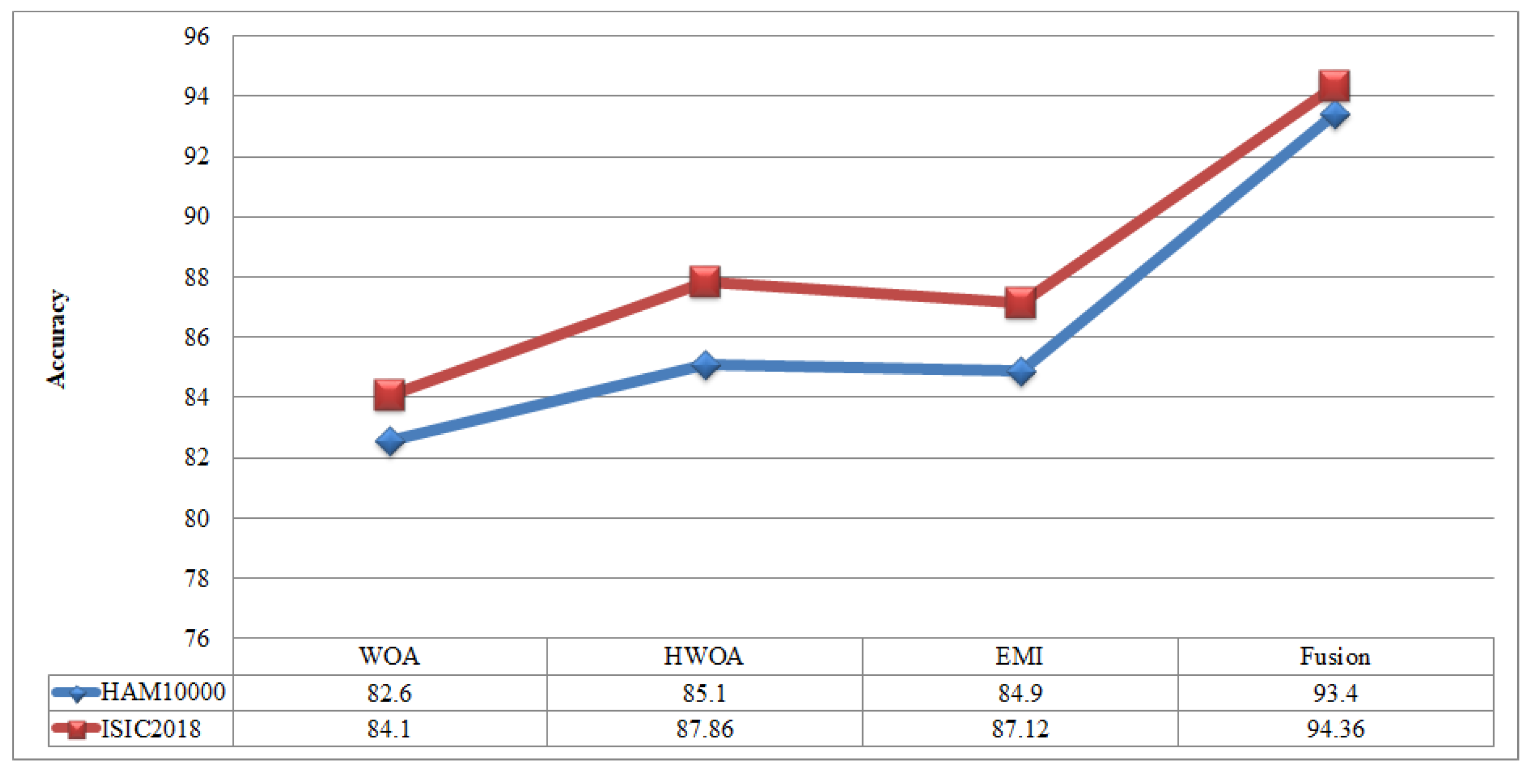
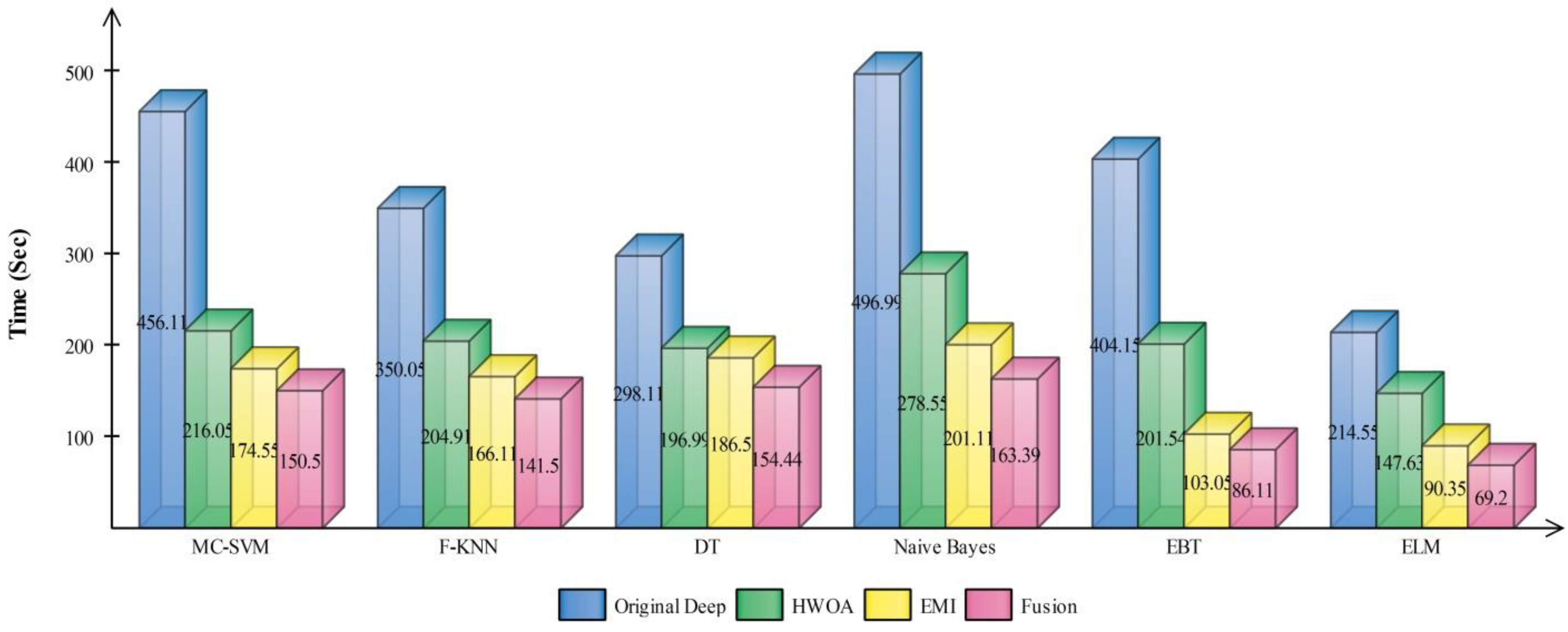
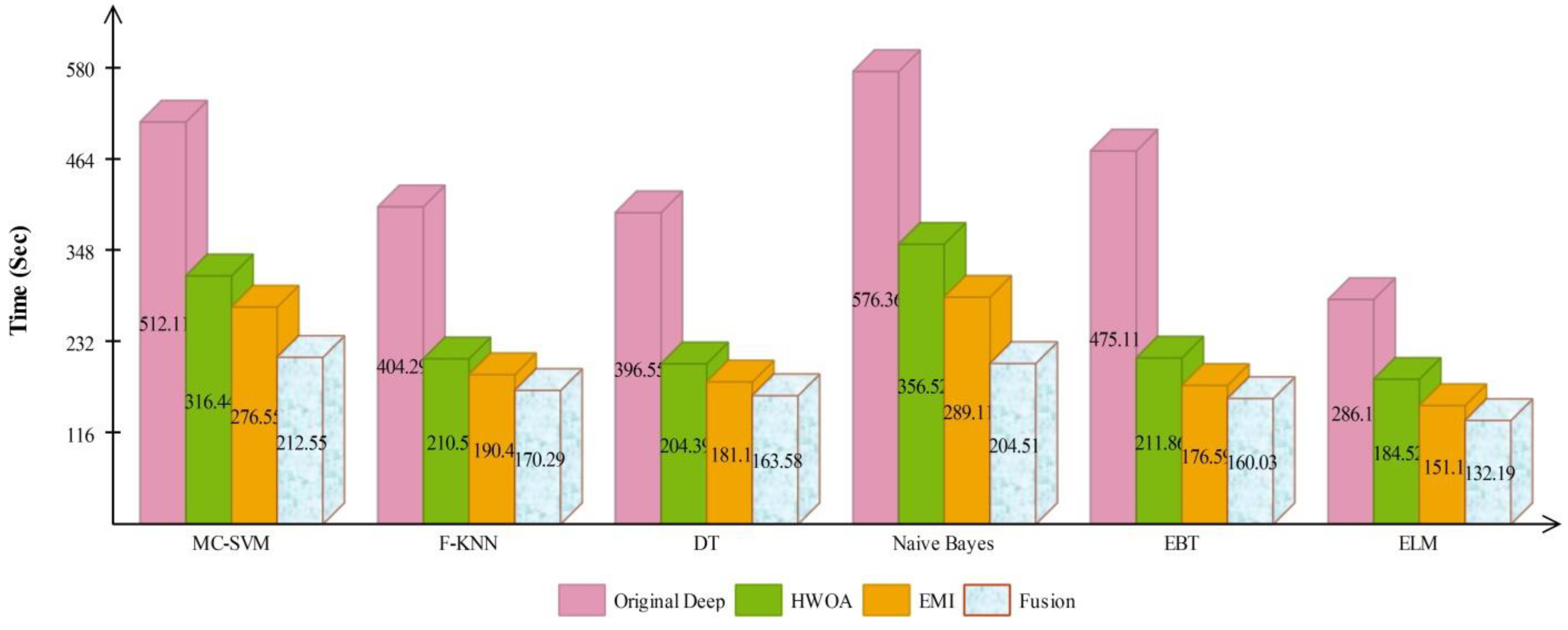
Figure 10 illustrated the overall depiction of computational time for all four experiments using HAM10000 dataset. Based on this figure, it is clearly analyzing that the fusion process is computationally less expensive than original deep features, HWOA, and EMI. The fusion process reduced some features that are not meet the criteria, given in Equation (33). Moreover, the ELM is performed overall better than rest of the classifiers.
5.2. Results on ISIC2018 Dataset
The classification results on ISIC2018 dataset are presented in this section. Several experiments are performed to validate the propose results.
Table 5 presents the classification results of ISIC2018 dataset using originally deep extracted features. The ELM classifier achieved a highest accuracy of 85.96%, whereas the precision value is 85.52%. The rest of the classifiers achieved an accuracy of 83.90, 81.40, 82.56, 83.50, and 82.16%, respectively. The computational time of each classifier is also noted and minimum noted time is 286.1009 (s). To overcome the problem of higher computational time and improved accuracy, a hybrid WOA is proposed. The results of HWOA are given in
Table 6. This table presents the best accuracy of 87.86%, whereas the computational time is 184.5294 (s). The computed accuracies of other classifiers are 85.14, 82.96, 84.60, 85.36, and 83.90%, respectively. This results in this table showing that the use of HWOA improved in the accuracy and minimizes the computational time. To further reduce the computational time, another feature selection technique is proposed named EMI. The results of this approach are given in
Table 7. This table showed that the accuracy is almost consistent but the computational time is minimized.
The accuracy of HWOA- and EMI-based feature selection is not improved as compared to the existing techniques; therefore, a fusion technique is proposed.
Table 8 presents the results of features fusion. In this table, the best noted accuracy value is 94.36% that is improved than the accuracy values given in
Table 5,
Table 6 and
Table 7. After the fusion process, the change in the accuracy value is approximately 7%. The computational time is also reduced after the fusion process and reached to 132.1990 (s). The recent best time was 184.5294 (s) for EMI-based features selection approach. For the rest of the classifiers accuracy is also improved (91.84, 90.60, 92.56, 92.80, and 90.46%, respectively).
Figure 11 illustrated the confusion matrix of ELM classifier for ISIC2018 dataset. Through this figure, the ELM accuracy can be verified.
Figure 12 illustrated the overall depiction of computational time for all four experiments using ISIC2018 dataset. Based on this figure, it is clearly analyzed that the fusion process is computationally less expensive. Moreover, ELM classifier is computationally less expensive than other listed classifiers in this table.
5.3. Discussion
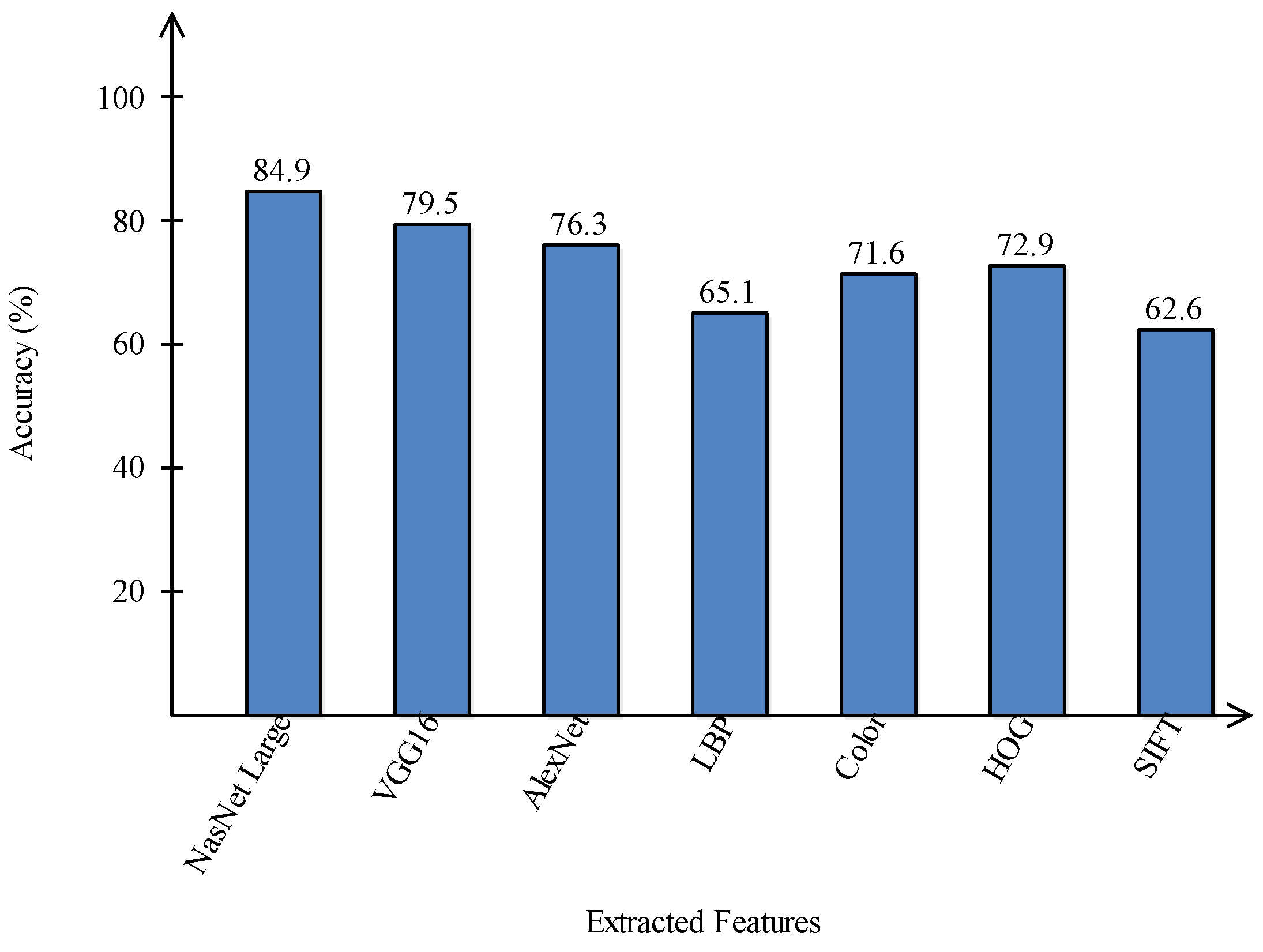
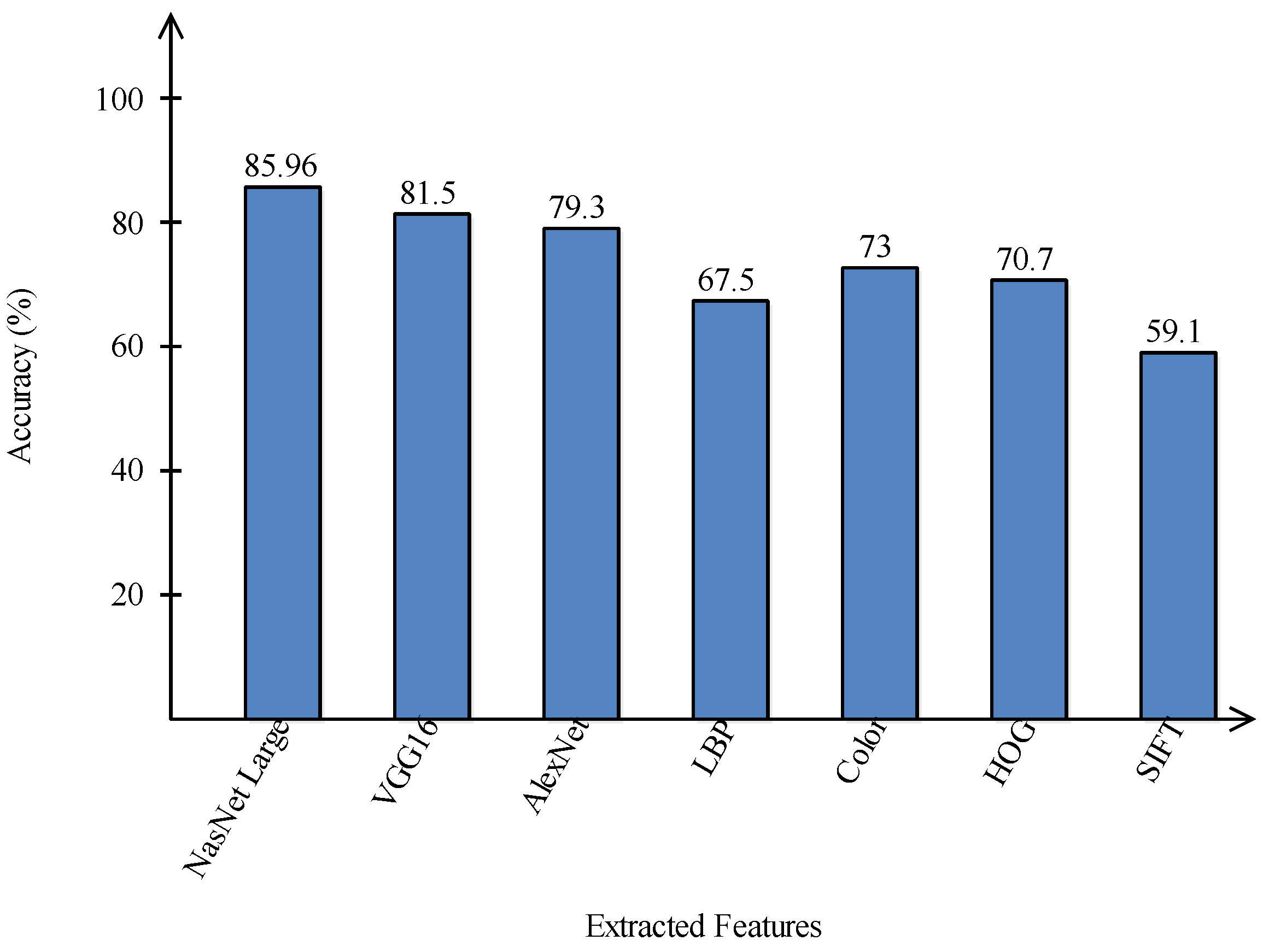
A comparison is conducted among extracted deep features and traditional features, as illustrated in
Figure 13 and
Figure 14. In these figures, it is illustrated that the deep learning-based extracted features (i.e., NAsNet Large, VGG16, Alexnet) give better results than traditional features (i.e., HOG, LBP, SIFT, and Color) on selected datasets. In the traditional features, HOG and color give better results than SIFT and LBP. In addition,
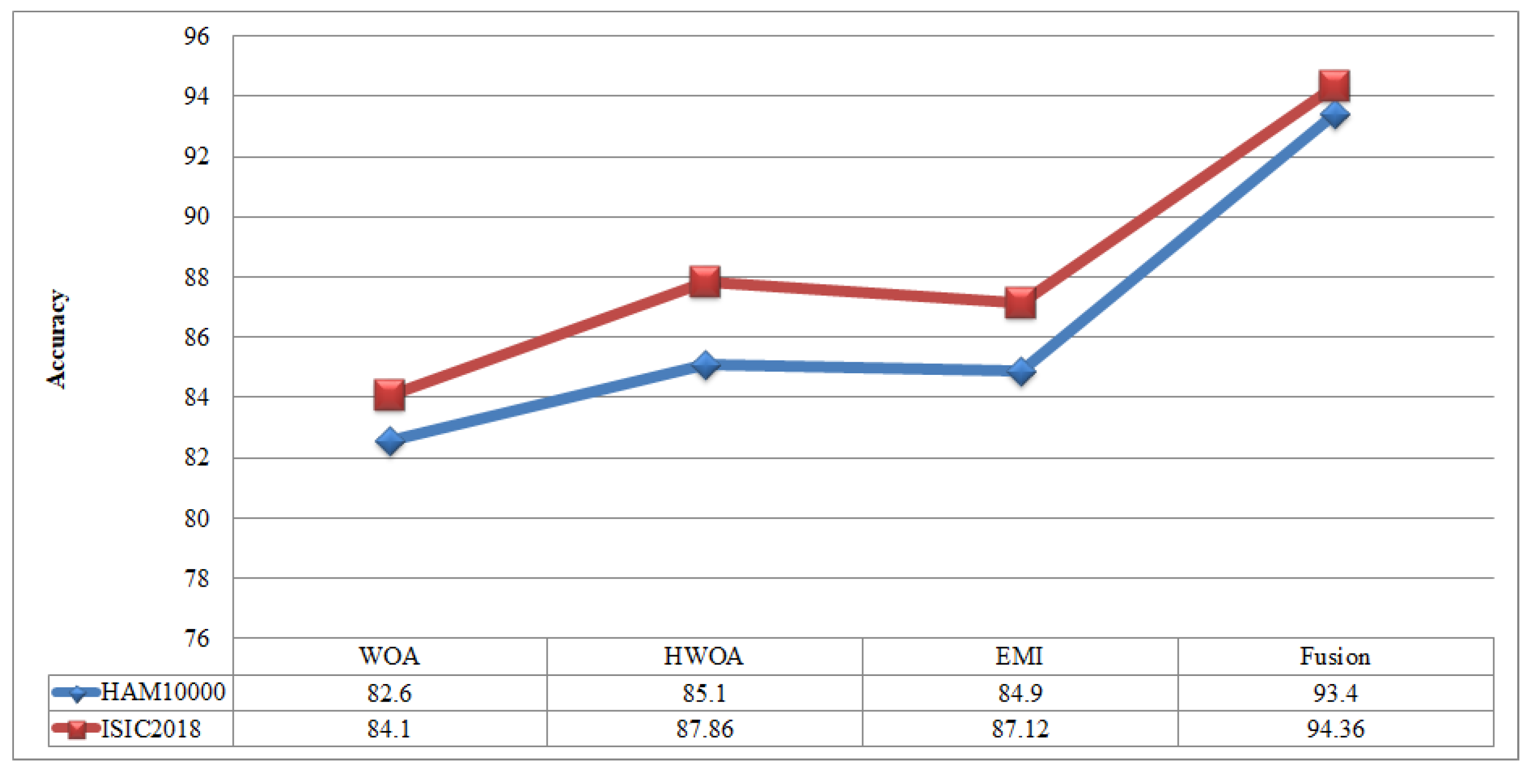
Figure 15 showing the comparison among original WOA-, HWOA-, and EMI-based best feature selection.
A comprehensive analysis of different contrast enhancement techniques is also performed, with the proposed enhancement technique as the chosen enhancement technique. In place of the proposed enhancement technique, three well-known techniques, such as HE [
43], BBHE [
44], and DSIHE [
45], are chosen and included in the proposed framework.
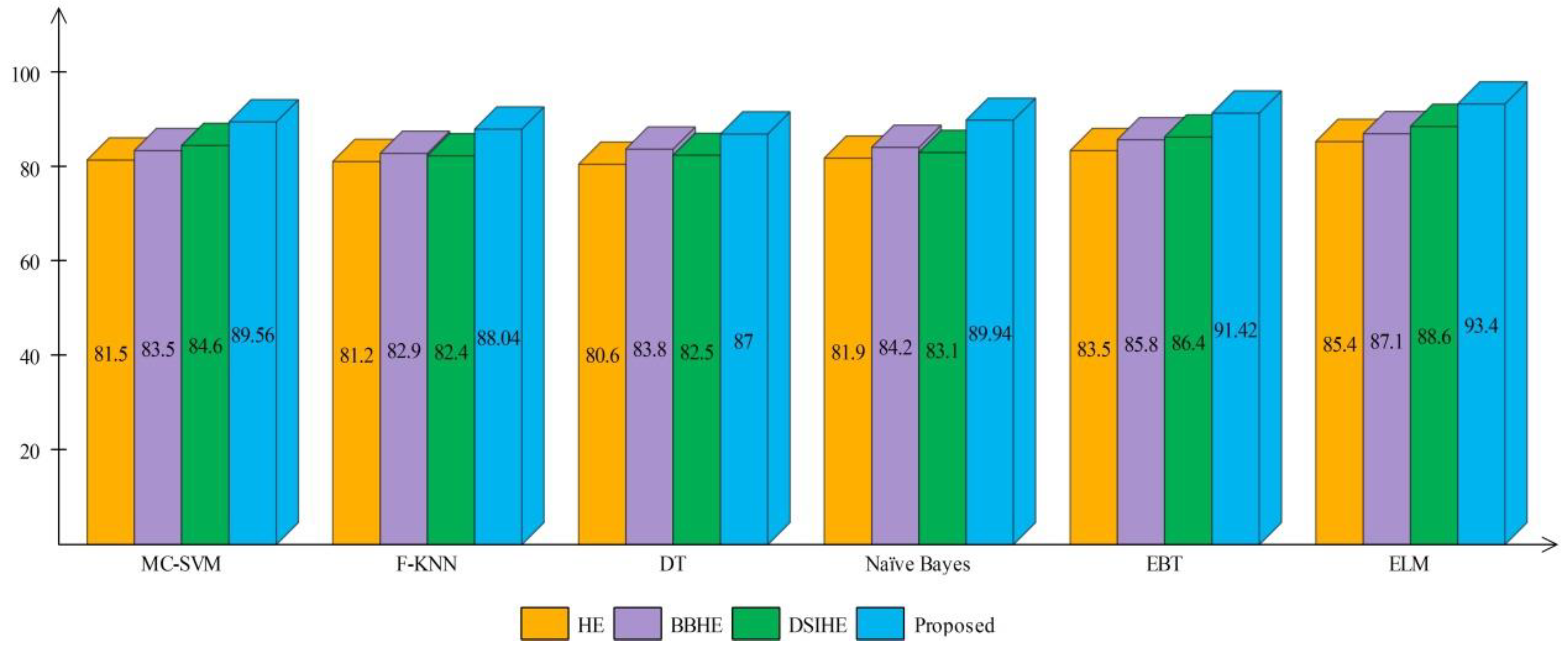
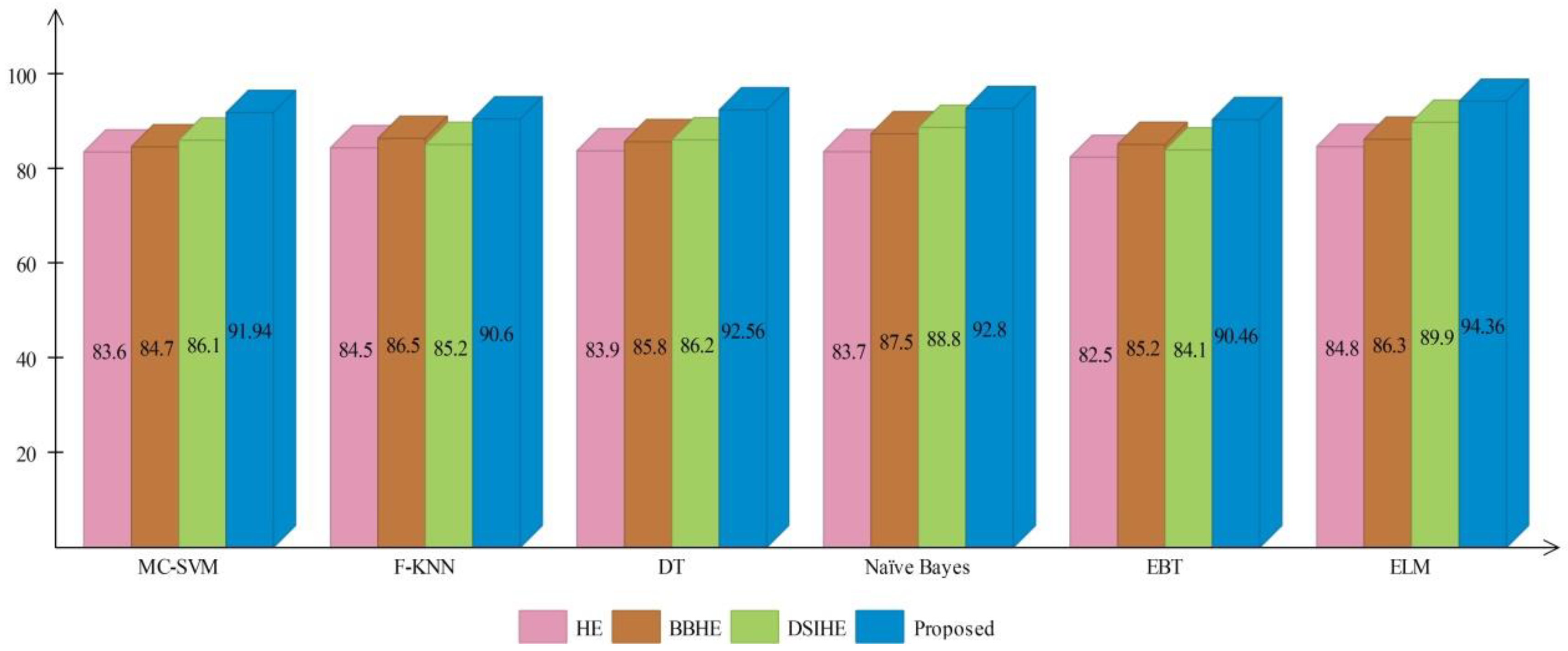
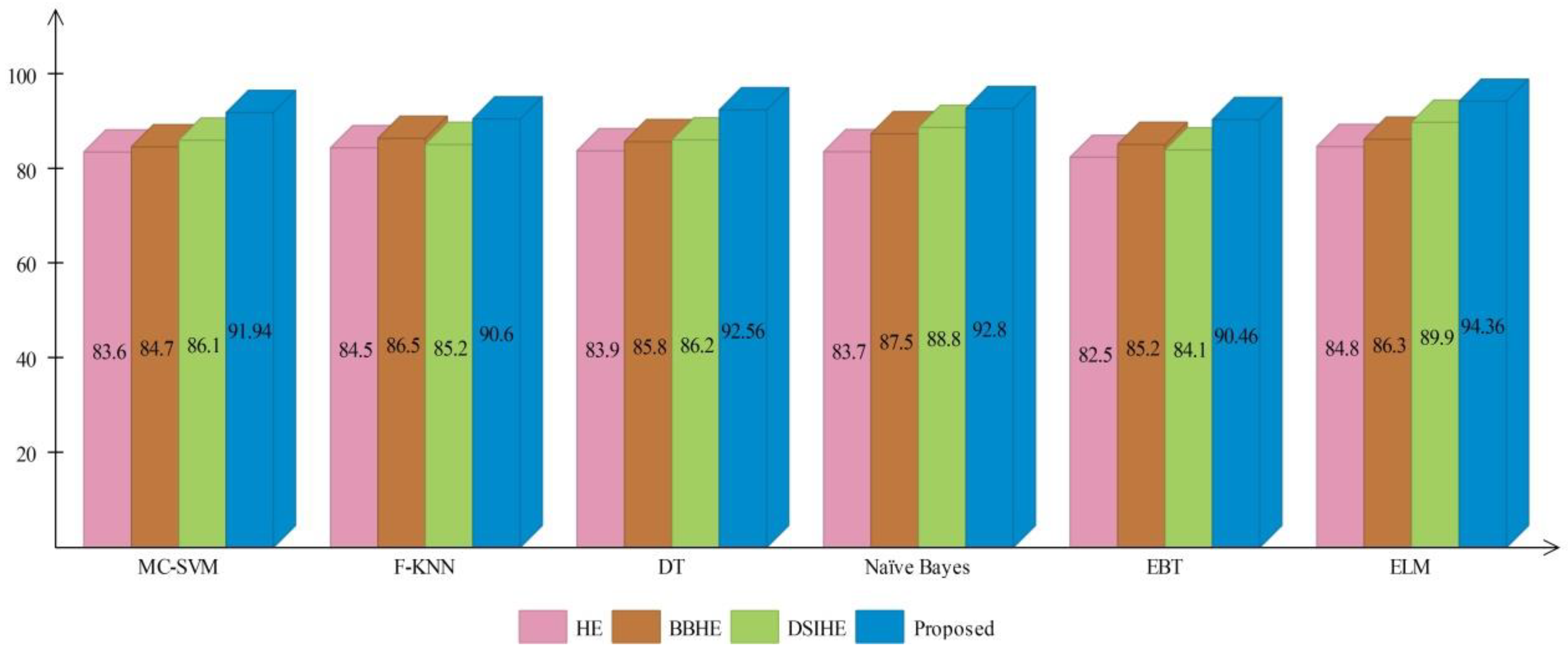
Figure 16 and
Figure 17 show the computed and plotted results after the addition of these techniques. Based on these figures, it is clear that the proposed contrast enhancement technique produces superior results. The second best accuracy is provided by the DSIHE contrast enhancement technique.
Finally, a comparison is also conducted with state of the art (SOTA) techniques, as shown in
Table 9. In this table, Huang et al. [
46] used the HAM10000 dataset for the experimental process and achieved an accuracy of 85.80%. Hamsi et al. [
47] achieved an accuracy of 87.70% for the HAM10000 dataset. Chaturvedi et al. [
48] improved accuracy on Ham10000 and reached to 92.83%. Recently, Khan et al. [
26] introduced a deep learning framework and obtained an accuracy of 86.50% on the Imbalanced HAM10000 dataset. Authors in [
49,
50] introduced a deep learning-based framework and achieved an accuracy of 92.40% and 93.4%. In the proposed method, the obtained accuracy is 93.40% on HAM10000 dataset and 94.36% on ISIC2018 dataset. This showed that the proposed method outperformed than SOTA.
The key strength of this work is the selection of optimal features. The fusion process of optimal features shows better results. The key limitation of this work is high computational time due to more number of steps. In the future, the lesion segmentation step will be adopted and utilized for the direct deep learning features extraction process. Moreover, the ISIC2019 and ISIC2020 datasets will be employed for the experimental process.
6. Conclusions
This paper proposes an automated deep learning-based framework for multiclass skin lesion classification. The proposed method includes a number of important steps, including contrast enhancement of the skin lesion using a new function, deep learning model learning via TL using enhanced images, best feature selection via two techniques—HWO and EMI, fusion of selected features via a modified CCA approach, and finally ELM-based classification. The experimental process demonstrates that the proposed method outperformed the other methods on the chosen datasets. Overall, it is concluded that:
The contrast enhancement step improve the quality of lesion region that later extracts the more relevant features;
The selection of optimal features improves the classification accuracy and reduces the computational time;
The fusion process further helps in the improvement of classification accuracy and reduces some redundant features through comparing approach.
In the future, the recent deep learning models shall be considers and refine in the middle layers [
51,
52,
53]. Augmentation of datasets is important step and it can be refining through more up-to-date methods [
54,
55]. Moreover, the optimization through some latest techniques should be opted [
56,
57].


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}