
Monocular Depth Estimation with Self-Supervised Learning for Vineyard Unmanned Agricultural Vehicle

Abstract
:1. Introduction
- (i)
- A lightweight monocular depth estimation model which has competitive accuracy and lower color sensitivity.
- (ii)
- A novel depth estimation scoring method that comprehensively considers major evaluation metrics of depth estimation and models’ performance on NVIDIA JETSON TX2.
2. Methods
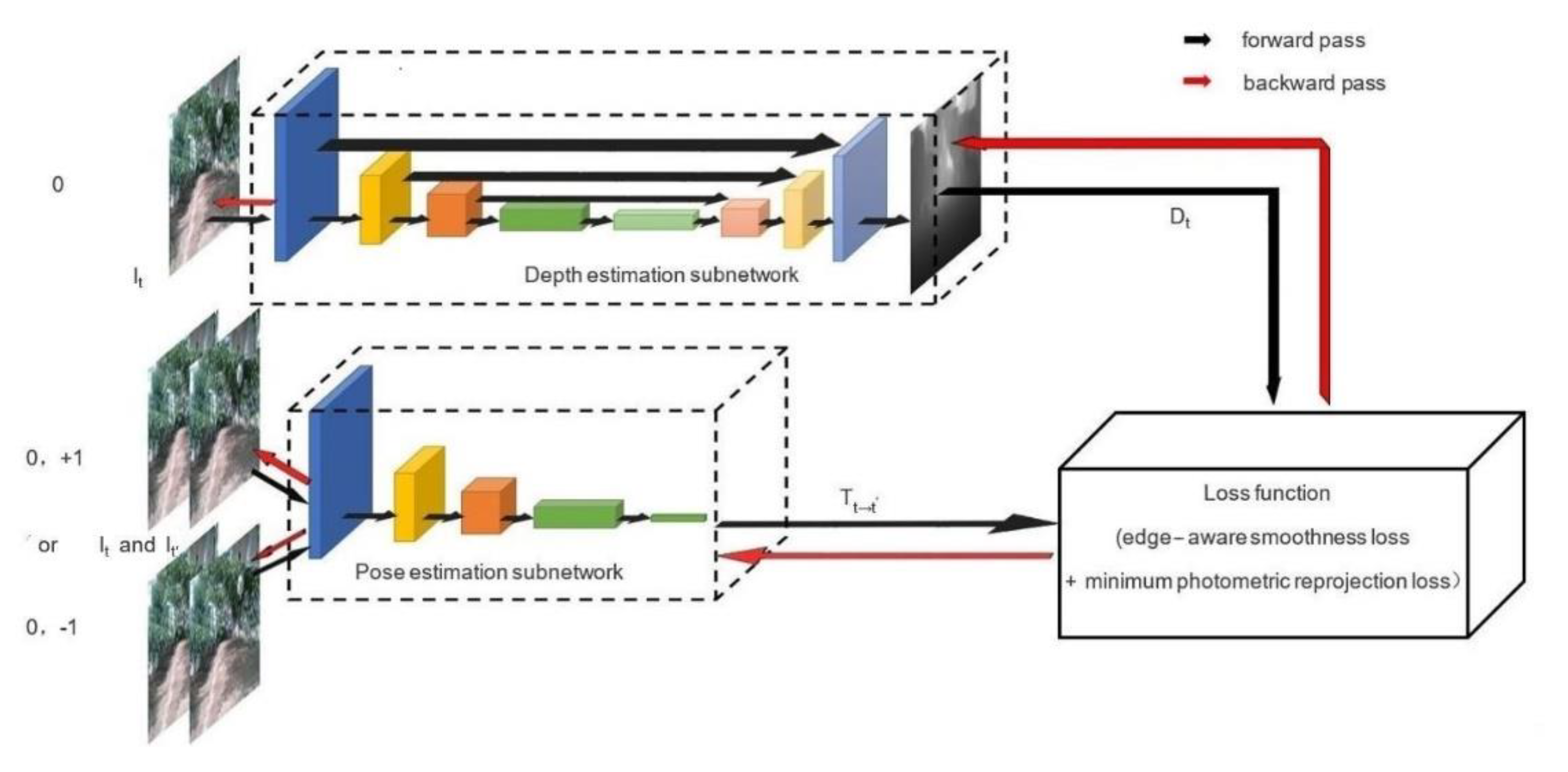
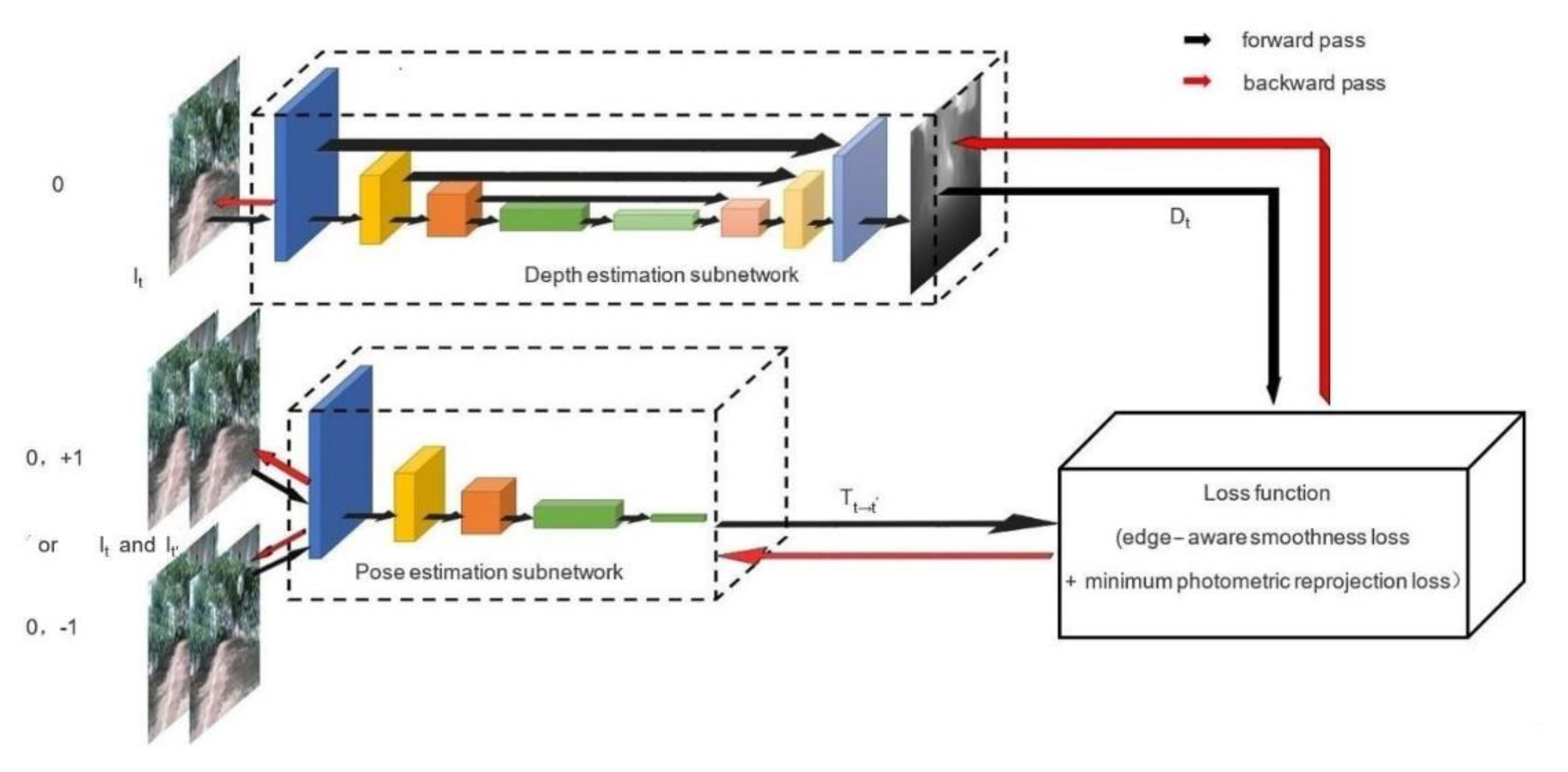
2.1. The Structure of MonoDA
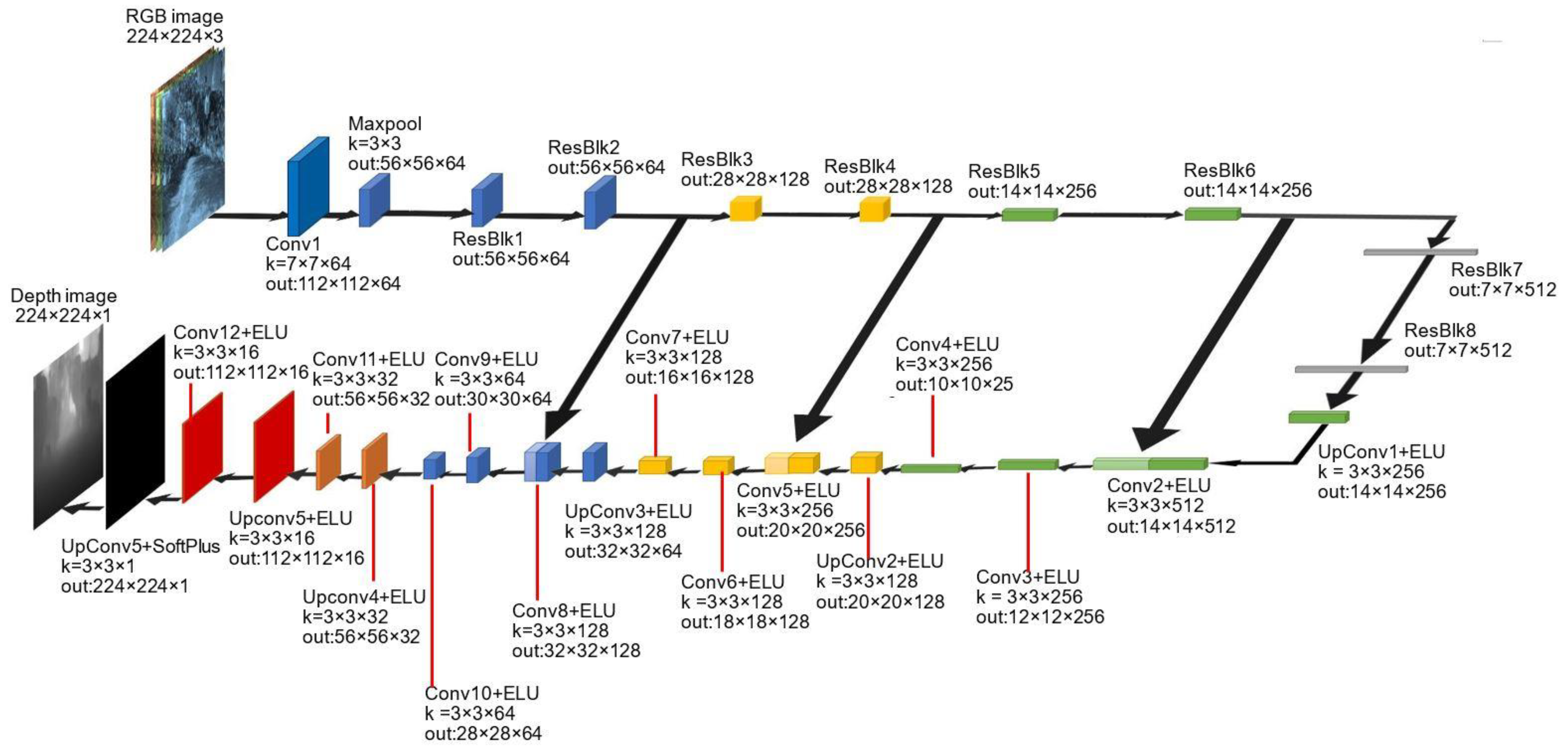
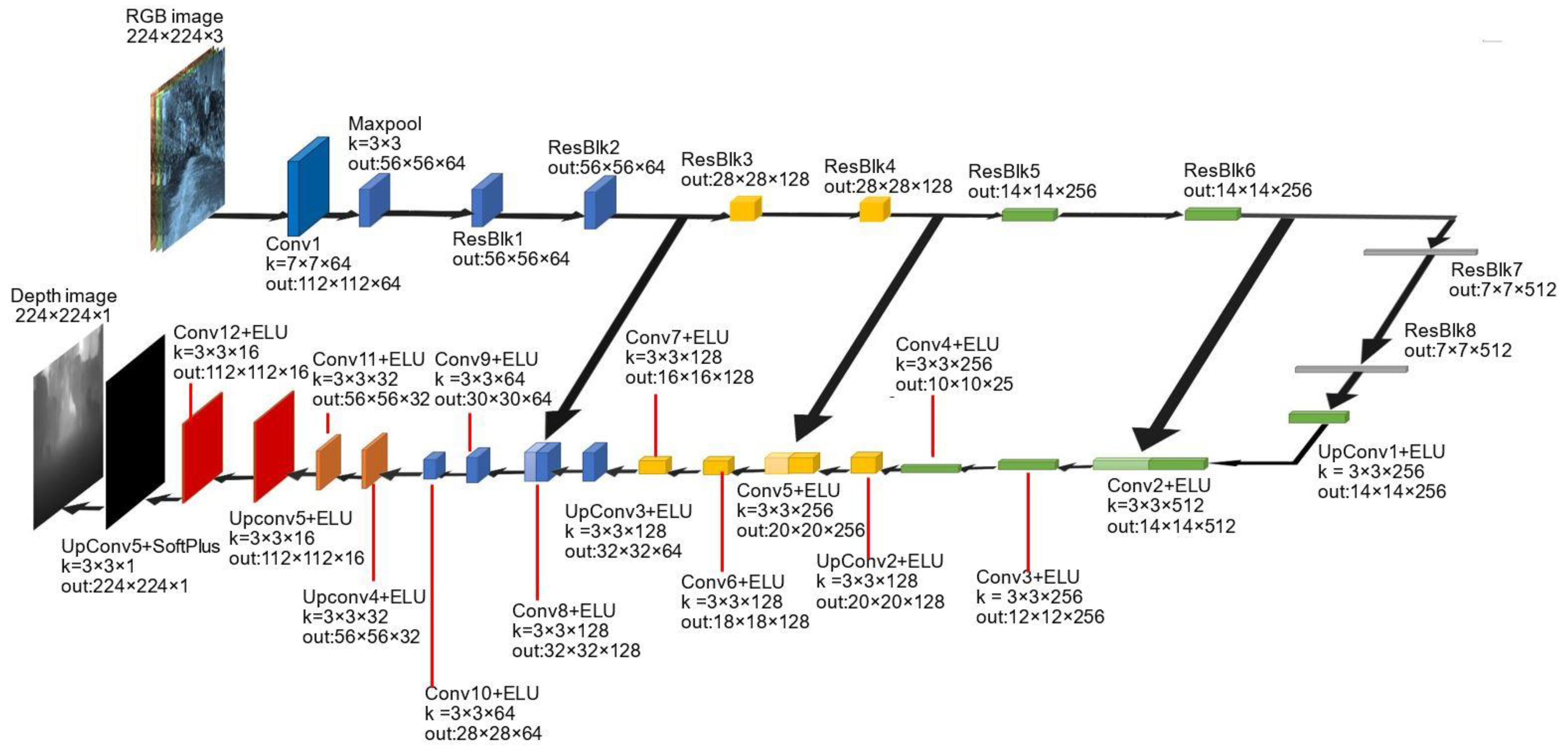
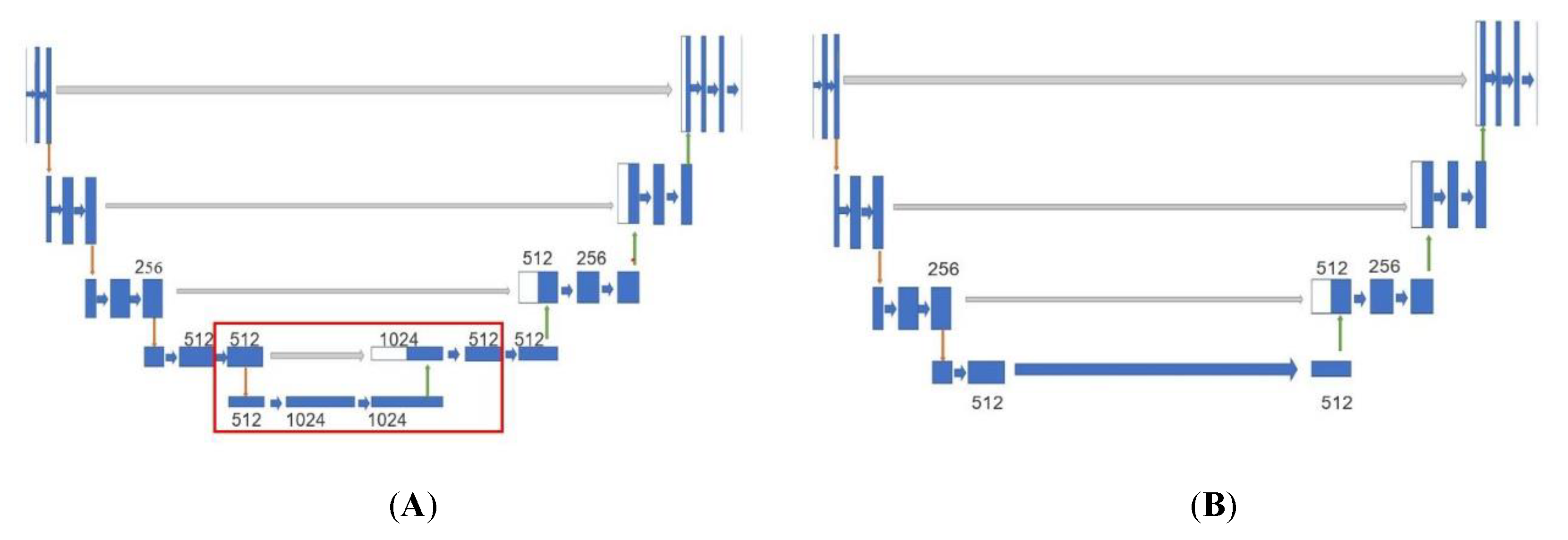
2.2. Depth Estimation Subnetwork
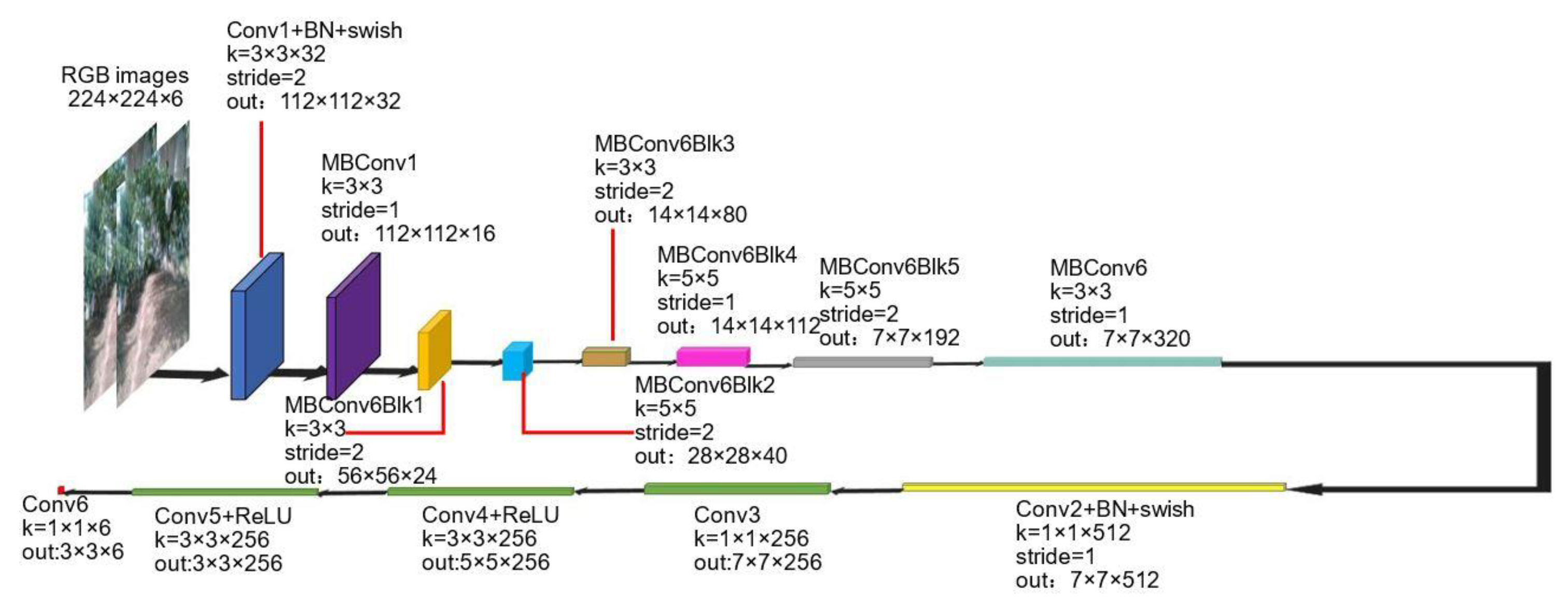
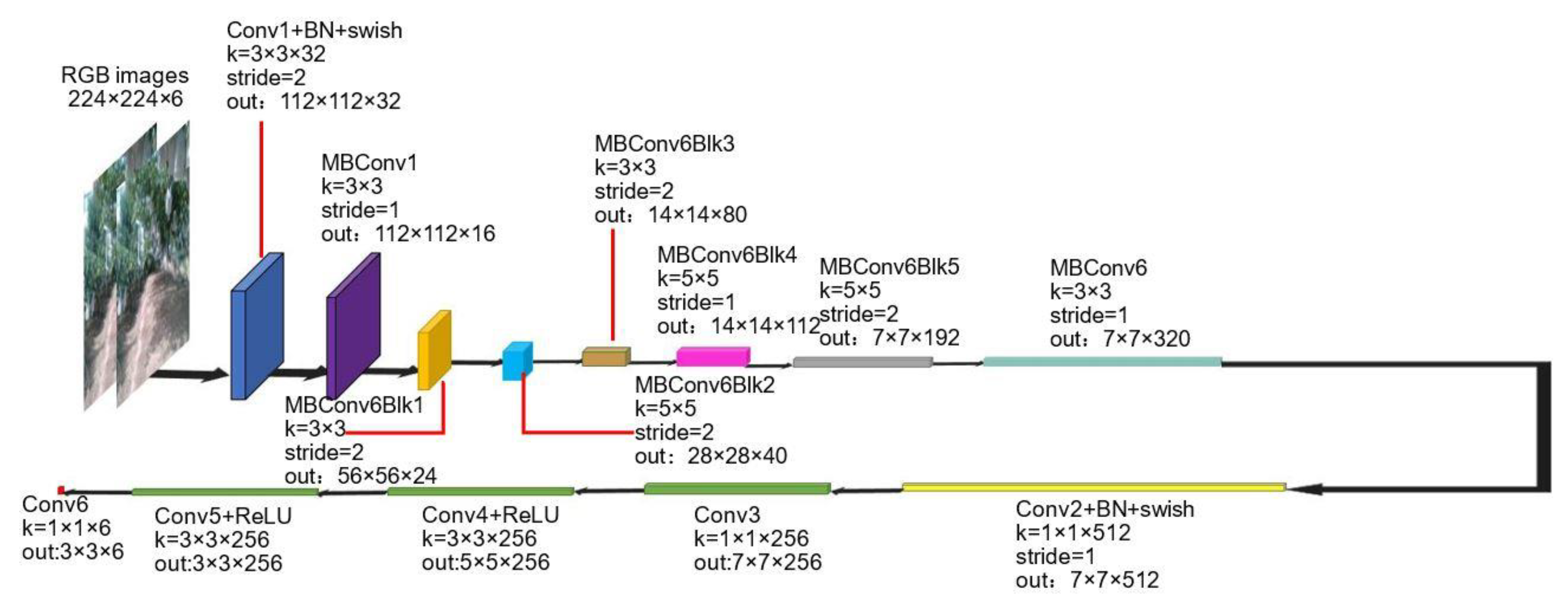
2.3. Pose Estimation Subnetwork
2.4. Training Method
3. Materials and Experiments
3.1. Platforms and Software Environments
3.2. Platforms and Software Environments
3.3. Experiments and Evaluation Metrics
3.3.1. Model Evaluation Metrics
3.3.2. Real Distance Test and Evaluation
3.3.3. Model Comprehensive Test and Scoring Method on TX2
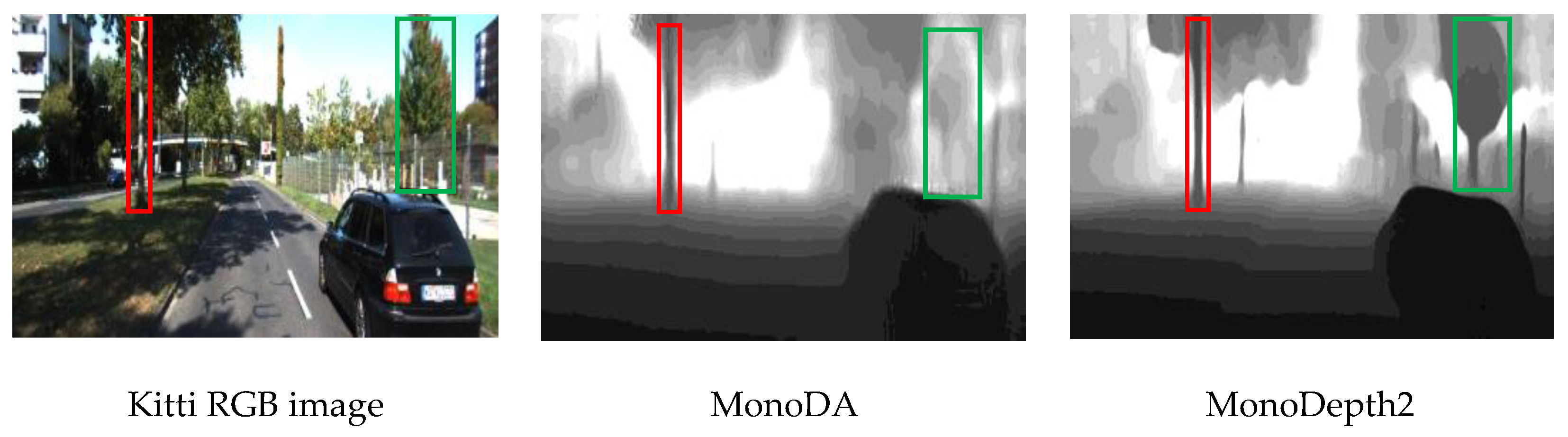
4. Results
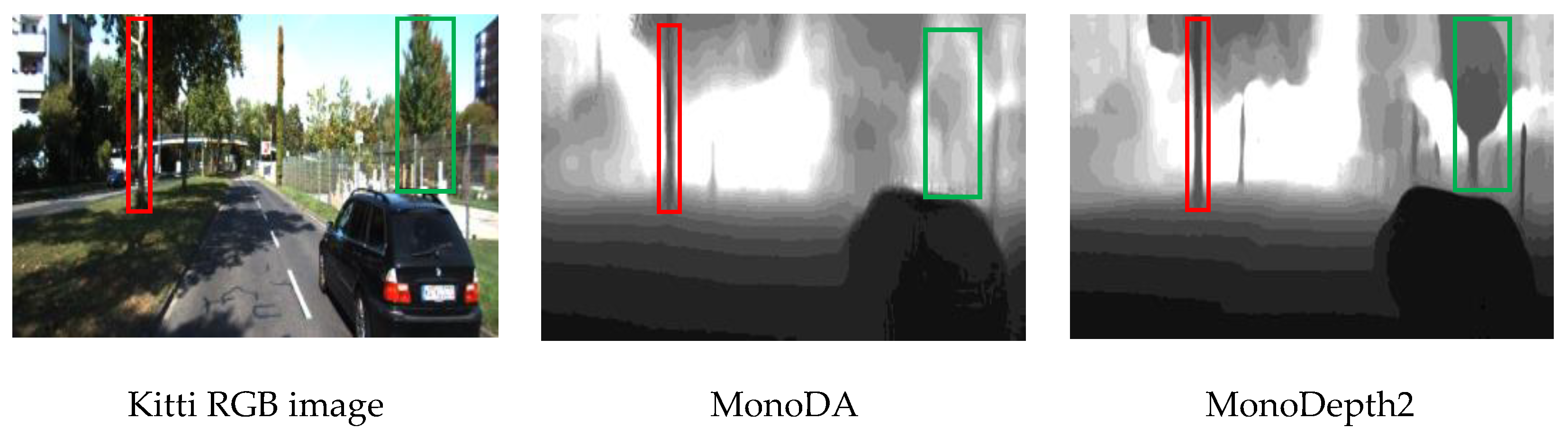
4.1. Accuracy Evaluation Results
4.2. Model Comprehensive Test Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Han, S.; He, Y.; Fang, H. Recent development in automatic guidance and autonomous vehicle for agriculture: A Review. Zhejiang. Univ. (Agric. Life. Sci.) 2018, 44, 381–391+515. [Google Scholar]
- Tian, R.; Chen, M.; Dong, D.; Li, W.; Jiao, L.; Wang, Y.; Li, M.; Sun, C.; Yang, X. Identification and counting method of orchard pests based on fusion method of infrared sensor and machine vision. Trans. Chin. Soc. Agric. Eng. 2016, 32, 196–201. [Google Scholar]
- Fu, G.; Yang, C.; Zhang, S.; Huang, W.; Chen, T.; Zhu, L. Method on Ranging for Banana Tree with Laser and Ultrasonic Sensors Based on Fitting and Filtering. Trans. Chin. Soc. Agric. Mach. 2021, 52, 159–168. [Google Scholar]
- Hiroki, S.; Tomoo, S.; Naoshi, K.; Yuichi, O.; Nobuyoshi, T. Accurate Position Detecting during Asparagus Spear Harvesting using a Laser Sensor. Eng. Agric. Environ. Food. 2013, 6, 105–110. [Google Scholar]
- Wang, D.; Song, H.; He, D. Research advance on vision system of apple picking robot. Trans. Chin. Soc. Agric. Eng. 2017, 33, 59–69. [Google Scholar]
- Zhang, M. Study on Binocular Range Measurement in Information Collection of Paddy Field Culture Area. Master’s Thesis, Kunming University of Science and Technology, Chenggong District, Kunming, Yunnan, China, 1 May 2019. [Google Scholar]
- Zhai, G.; Zhang, W.; Hu, W.; Ji, Z. Coal mine rescue robots based on binocular vision: A review of the state of the art. IEEE Access 2020, 8, 130561–130575. [Google Scholar] [CrossRef]
- Han, Y.; Chu, Z.; Zhao, K. Target positioning method in binocular vision manipulator control based on improved canny operator. Multimed Tools Appl. 2020, 79, 9599–9614. [Google Scholar] [CrossRef]
- Barukčić, I.; Zheng, Y.; Ge, J. Binocular intelligent following robot based on YOLO–LITE. MATEC Web Conf. 2021, 336, 3002. [Google Scholar]
- Song, Z.; Peng, J.; Xiao, C. Obstacle Detection of Agricultural Vehicles Based on Millimeter Wave Radar and Camera. Modern. Inf. Technol. 2019, 3, 46–48. [Google Scholar]
- Sun, K. Research on Obstacle Avoidance Technology of Plant Protection UAV Based on Millimter Wave. Master’s Thesis, Hangzhou Dianzi University, Hangzhou Economic Development Zone, Hangzhou, Zhejiang, China, 1 May 2019. [Google Scholar]
- Niu, R.; Zhang, X.; Wang, J. Orchard Trunk Detection Algorithm for Agricultural Robot Based on Laser Radar. Trans. Chin. Soc. Agric. Mach. 2020, 51, 21–27. [Google Scholar]
- Hu, Z. Research on Automatic Spraying Method of Fruit Trees. Master’s Thesis, Yantai University, Laishan District, Yantai, Shandong, China, 1 April 2017. [Google Scholar]
- Vitor, H.; Andres, V.; Daniel, M.; Marcelo, B.; Girish, C. Under canopy light detection and ranging-based autonomous navigation. J. Filed Robot 2019, 36, 547–567. [Google Scholar]
- Li, Q.; Ding, X.; Deng, X. Intra–row Path Extraction and Navigation for Orchards Based on LiDAR. Trans. Chin. Soc. Agric. Mach. 2020, 51, 334–350. [Google Scholar]
- Hou, J.; Pu, W.; Li, T.; Ding, X. Development of dual–lidar navigation system for greenhouse transportation robot. Trans. Chin. Soc. Agric. Eng. 2020, 36, 80–88. [Google Scholar]
- Sun, Z.; Lindell D, B.; Solgaard, O.; Wetzstein, G. SPADnet: Deep RGB–SPAD sensor fusion assisted by monocular depth estimation. Opt. Express 2020, 28, 14948–14962. [Google Scholar] [CrossRef] [PubMed]
- Saxena, A.; Chung, S.; Ng A, Y. Learning depth from single monocular images. In Proceedings of the 2006 Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 1161–1168. [Google Scholar]
- Konrad, J.; Wang, M.; Ishwar, P. 2d–to–3d image conversion by learning depth from examples. In Proceedings of the 2012 Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 16–22. [Google Scholar]
- Karsch, K.; Liu, C.; Kang S, B. Depth extraction from video using non–parametric sampling. In Proceedings of the 2006 European Conference on Computer Vision, Firenze, Italy, 7–13 October 2006; pp. 775–788. [Google Scholar]
- Liu, M.; Salzmann, M.; He, X. Discrete–continuous depth estimation from a single image. In Proceedings of the 2014 Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 20–24 June 2014; pp. 716–723. [Google Scholar]
- Karsch, K.; Liu, C.; Kang S, B. DepthTransfer: Depth Extraction from Video Using Non – parametric Sampling. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 99, 1. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth Map Prediction from a Single Image using a Multi–Scale Deep Network. In Proceedings of the 2014 Conference and Workshop on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2366–2374. [Google Scholar]
- Xu, D.; Ricci, E.; Ouyang, W. Sebe N. Monocular Depth Estimation using Multi–Scale Continuous CRFs as Sequential Deep Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1426–1440. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, H.; Gong, M.; Wang, C.; Tmanghelich, K.; Tao, D. Deep Ordinal Regression Network for Monocular Depth Estimation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2002–2011. [Google Scholar]
- Li, N.; Shen, N.; Dai, N.; Hengel, A.; He, N. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1119–1127. [Google Scholar]
- Cao, Y.; Wu, Z.; Shen, C. Estimating depth from monocular images as classification using deep fully convolutional residual networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 3174–3182. [Google Scholar] [CrossRef] [Green Version]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision, Stanford, CA, USA, 25–28October 2016; pp. 239–248. [Google Scholar]
- Wang, X.; Fouhey, D.; Gupta, A. Designing deep networks for surface normal estimation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 539–547. [Google Scholar]
- Garg, R.; Kumar, V.; Carneiro, G.; Reid, I. Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; p. 9912. [Google Scholar]
- Godard, C.; Aodha, O.; Brostow, G. Unsupervised monocular depth estimation with left–right consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Flynn, J.; Neulander, I.; Philbin, J.; Snavely, N. Deep Stereo: Learning to Predict New Views from the World’s Imagery. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5515–5524. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Deep3d: Fully automatic 2d–to–3d video conversion with deep convolutional neural networks. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 842–857. [Google Scholar]
- Yang, Z.; Wang, P.; Xu, W.; Zhao, L.; Nevatia, R. Unsupervised learning of geometry from videos with edge–aware depth–normal consistency. In Proceedings of the 2018 Association for the Advance of Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; pp. 7493–7500. [Google Scholar]
- Yang, Z.; Wang, P.; Xu, W.; Wang, Y.; Zhao, L.; Nevatia, R. LEGO: Learning edge with geometry all at once by watching videos. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 225–234. [Google Scholar]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised learning of depth and ego–motion from monocular video using 3D geometric constraints. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5667–5675. [Google Scholar]
- Lin, R.; Lu, Y.; Lu, G. APAC–Net: Unsupervised Learning of Depth and Ego–Motion from Monocular Video. In Proceedings of the 2019 International Conference on Intelligent Science and Big Data Engineering, Nanjing, China, 17–20 October 2019; pp. 336–348. [Google Scholar]
- Yin, Z.; Shi, J. GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1983–1992. [Google Scholar]
- Wang, C.; Buenaposada, J.; Zhu, R.; Lucey, S. Learning depth from monocular videos using direct methods. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2022–2030. [Google Scholar]
- Zou, Y.; Luo, Z.; Huang, J. DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross–Task Consistency. ECCV Comput. Vis. 2018, 11209, 8–55. [Google Scholar]
- Luo, C.; Yang, Z.; Peng, W.; Yang, W.; Yuille, A. Every Pixel Counts ++: Joint Learning of Geometry and Motion with 3D Holistic Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2624–2641. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Casser, V.; Pirk, S.; Mahjourian, R.; Angelova, A. Depth prediction without the sensors: Leveraging structure for unsupervised learning from monocular videos. In Proceedings of the 2019 Association for the Advance of Artificial Intelligence, Honolulu, HI, USA, 27 January–1February 2019; pp. 8001–8008. [Google Scholar]
- Godard, C.; Aodha, O.; Firman, M.; Brostow, G. Digging Into Self–Supervised Monocular Depth Estimation. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3827–3837. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton G, E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 2012 International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large–Scale Image Recognition. In Proceedings of the 2015 International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 44–59. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real–time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 429–442. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R–CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. Solov2: Dynamic and fast instance segmentation. arXiv 2020, arXiv:2003.10152. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U–Net:Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 2015 International Conference on Medical Image Computing and Computer–Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 237–241. [Google Scholar]
- Xu, D.; Wang, W.; Tang, H.; Liu, H.; Sebe, N.; Ricci, E. Structured Attention Guided Convolutional Neural Fields for Monocular Depth Estimation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3917–3925. [Google Scholar]
- Wofk, D.; Ma, F.; Yang, T.; Karaman, S.; Sze, V. FastDepth: Fast Monocular Depth Estimation on Embedded Systems. In Proceedings of the 2019 International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 6101–6108. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 2019 International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DEE 1 | AFPS 2 | HRO 3 | |||||
|---|---|---|---|---|---|---|---|
| EI 4 | AI 5 | ARE 6 | A1 7 | A2 8 | A3 9 | ||
| 5 | ≤1.5 | 1.50< | 0~5% | 30.0< | ≤30.0% | cores full ≤ 1 | ≤1.5 GB |
| 4 | 1.5~1.625 | 1.35~1.50 | 5~10% | 24.0~30.0 | 30.0~36.0% | 2 cores full | 1.5 GB~1.8 GB |
| 3 | 1.625~1.750 | 1.20~1.35 | 10~15% | 18.0~24.0 | 36.0~42.0% | 3 cores full | 1.8 GB~2.1 GB |
| 2 | 1.750~1.875 | 1.05~1.20 | 15~20% | 12.0~18.0 | 42.0~48.0% | 4 cores full | 2.1 GB~2.4 GB |
| 1 | 1.875~2.00 | 0.90~1.05 | 20~25% | 6.0~12.0 | 48.0~54.0% | 5 cores full | 2.4 GB~2.7 GB |
| 0 | 2.00< | <0.90 | 25%< | <6.0 | 54.0%< | 6 cores full | 2.7 GB< |
| Model | Error items | Accuracy items | |||||
|---|---|---|---|---|---|---|---|
| Abs Rel | Sq Rel | RMSE | LG RMSE | ||||
| GeoNet [38] | 0.149 | 1.060 | 5.567 | 0.226 | 0.796 | 0.935 | 0.975 |
| DDVO [39] | 0.151 | 1.257 | 5.583 | 0.228 | 0.810 | 0.936 | 0.974 |
| DF-Net [40] | 0.150 | 1.124 | 5.507 | 0.223 | 0.806 | 0.933 | 0.973 |
| EPC++ [41] | 0.141 | 1.029 | 5.350 | 0.216 | 0.816 | 0.941 | 0.976 |
| Struct2depth [42] | 0.141 | 1.026 | 5.291 | 0.215 | 0.816 | 0.945 | 0.979 |
| MonoDepth2 NP 1 | 0.132 | 1.044 | 5.142 | 0.210 | 0.845 | 0.948 | 0.977 |
| MonoDA (our) | 0.126 | 1.035 | 5.105 | 0.203 | 0.857 | 0.955 | 0.979 |
| MonoDepth2 [43] | 0.115 | 0.903 | 4.863 | 0.193 | 0.877 | 0.959 | 0.981 |
| Model | Error Items | Accuracy Items | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Abs Rel | Sq Rel | RMSE | LG RMSE | Average 1 | Average | ||||
| MonoDA | 0.134 | 1.083 | 5.306 | 0.214 | 1.684 | 1.118 | 1.271 | 1.453 | 1.281 |
| MonoDepth2 | 0.144 | 1.075 | 5.415 | 0.232 | 1.717 | 1.113 | 1.243 | 1.375 | 1.244 |
| Model | Distance/m | ARE 1 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1.60 | 2.40 | 3.20 | 4.00 | 4.80 | 6.40 | 7.20 | 8.00 | 8.80 | ||
| MonoDepth2 | 1.81 | 2.07 | 2.84 | 3.31 | 2.74 | 4.92 | 7.29 | 8.24 | 8.62 | 17% |
| MonoDA | 1.34 | 1.94 | 3.51 | 3.03 | 3.25 | 5.42 | 6.85 | 8.45 | 8.93 | 14% |
| Model | Detection of Real-Time Video | Comprehensive Evaluation | ||||
|---|---|---|---|---|---|---|
| Average Frame Rate | A1 1 | A2 2 | A3 3 | |||
| MonoDepth2 | 16.84 | 51.92% | c1:4–20% c3:26–76% c5: 2–24% | c2:24–78% c4:5–16% c6:3–16% | 1.8 GB | Medium speed High GPU occupied Low CPU occupied |
| MonoDA | 18.92 | 45.42% | c1:6–27% c3:32–82% c5:4–25% | c2:26–78% c4:5–24% c6:3–22% | 1.8 GB | Relatively smooth Medium GPU occupied Low CPU occupied |
| Model | Items Score | Total Score | ||||||
|---|---|---|---|---|---|---|---|---|
| MonoDepth2 | 3 | 3 | 2 | 2 | 1 | 5 | 4 | 2.4 |
| MonoDA | 3 | 3 | 3 | 3 | 2 | 5 | 4 | 3.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, X.-Z.; Feng, Q.; Wang, S.-Z.; Zhang, J.-H. Monocular Depth Estimation with Self-Supervised Learning for Vineyard Unmanned Agricultural Vehicle. Sensors 2022, 22, 721. https://doi.org/10.3390/s22030721
Cui X-Z, Feng Q, Wang S-Z, Zhang J-H. Monocular Depth Estimation with Self-Supervised Learning for Vineyard Unmanned Agricultural Vehicle. Sensors. 2022; 22(3):721. https://doi.org/10.3390/s22030721
Chicago/Turabian StyleCui, Xue-Zhi, Quan Feng, Shu-Zhi Wang, and Jian-Hua Zhang. 2022. "Monocular Depth Estimation with Self-Supervised Learning for Vineyard Unmanned Agricultural Vehicle" Sensors 22, no. 3: 721. https://doi.org/10.3390/s22030721
APA StyleCui, X.-Z., Feng, Q., Wang, S.-Z., & Zhang, J.-H. (2022). Monocular Depth Estimation with Self-Supervised Learning for Vineyard Unmanned Agricultural Vehicle. Sensors, 22(3), 721. https://doi.org/10.3390/s22030721