
Posture Detection of Individual Pigs Based on Lightweight Convolution Neural Networks and Efficient Channel-Wise Attention


Abstract
:1. Introduction
- This paper proposes an intensive commercial weaned piglet all-weather posture data set, including multiple pigs, different pig colors, different piglet ages, and complex lighting environments, to benchmark the performance of state-of-the-art models.
- An optimized shuffle block is proposed based on model structure and parameter statistics. To further improve the accuracy of pig posture detection, we combine the block with the efficient channel attention module. The overall increase in the size of the model is negligible. The results of comparative experiments with state-of-the-art models show that the detection effects of the designed model are more accurate than the corresponding structure. The results show that this method provides higher detection accuracy and reduces the amount of model calculation. Finally, our model deployment plan meets the computer configuration requirements of intensive pig farm production (CPU = i7 and RAM = 8 G).
2. Materials and Methods
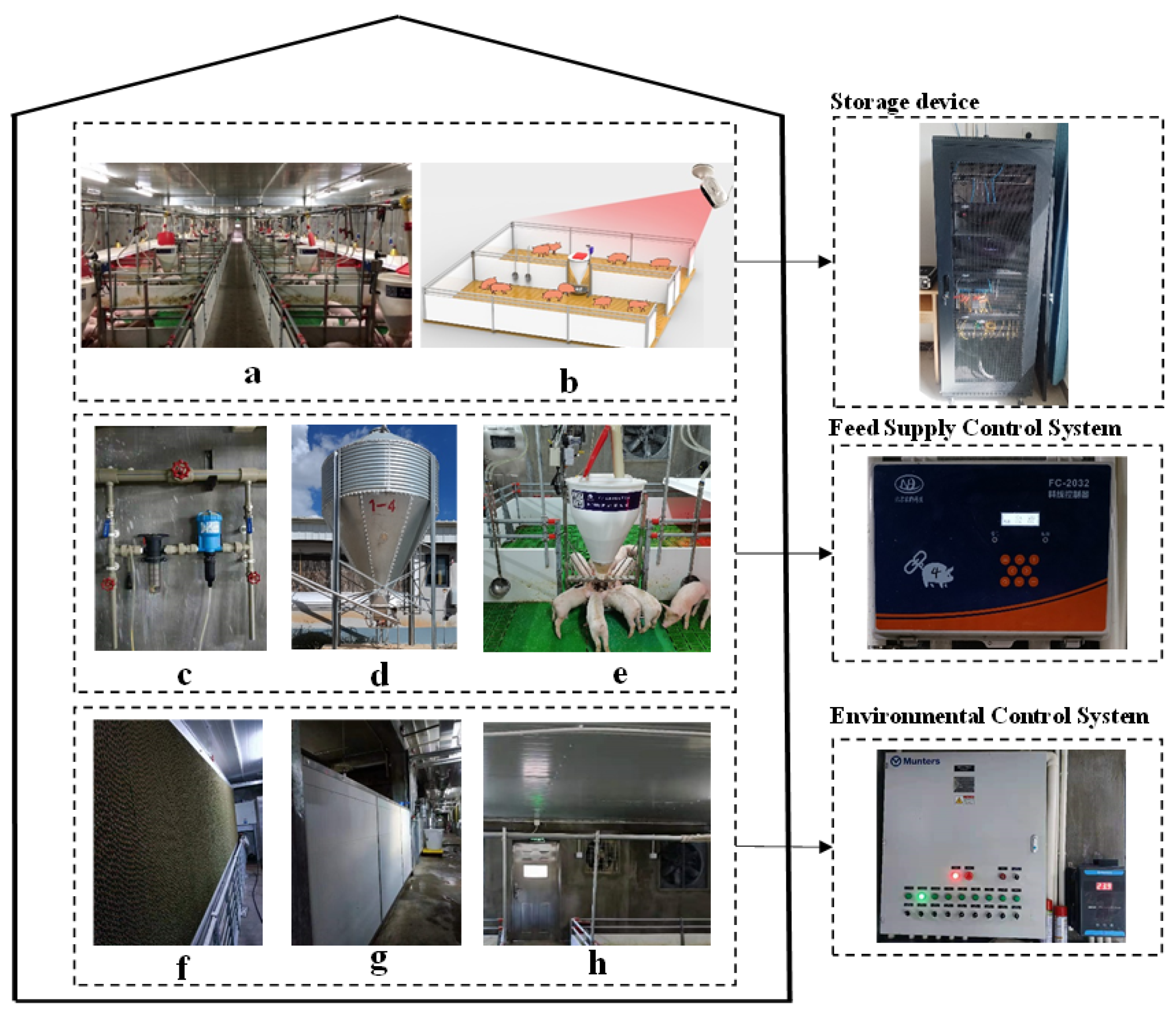
2.1. Animals, Housing and Management
2.2. Data Set
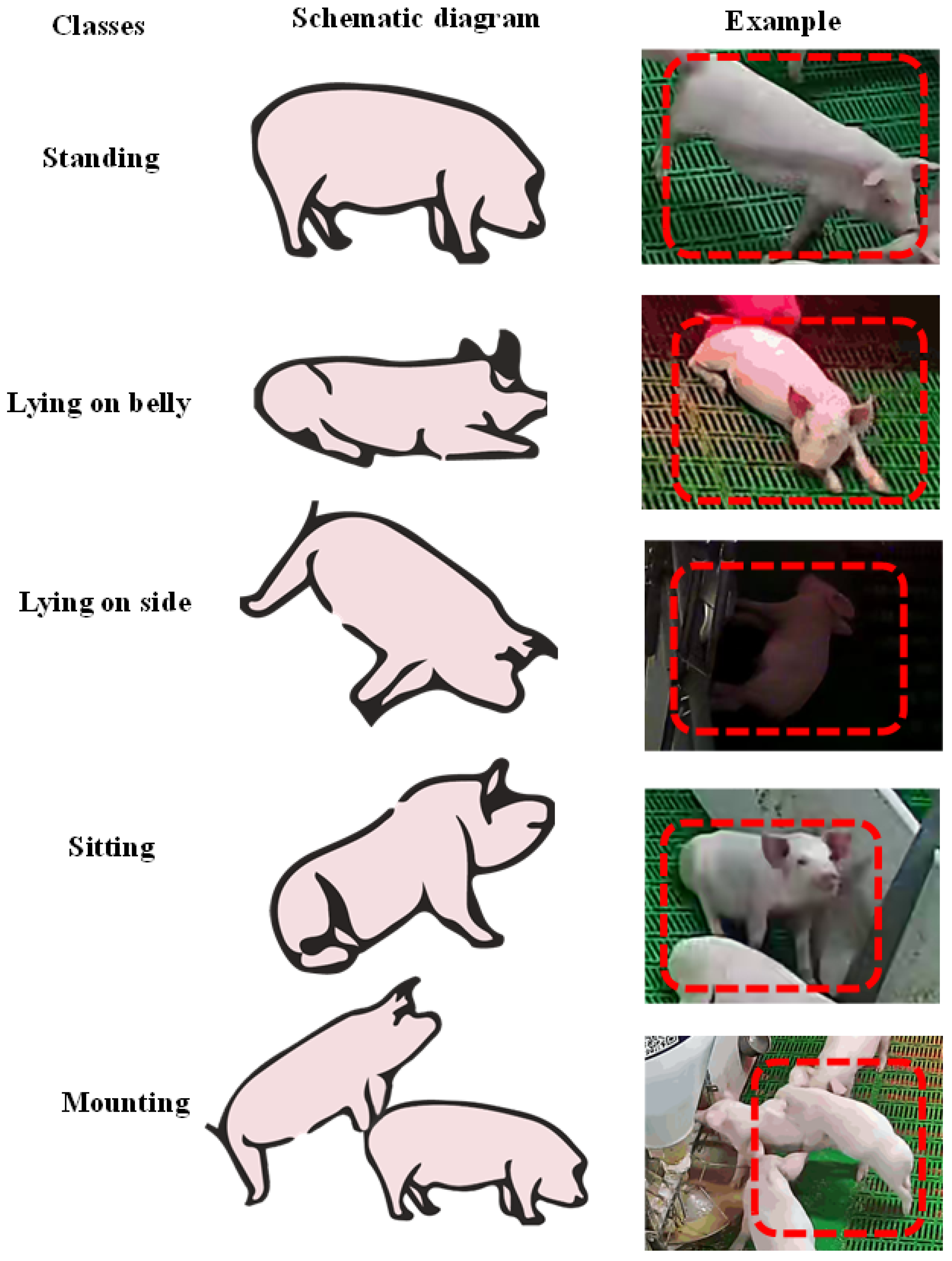
2.2.1. Definition of Pig Postures
2.2.2. Data Acquisition and Preprocessing
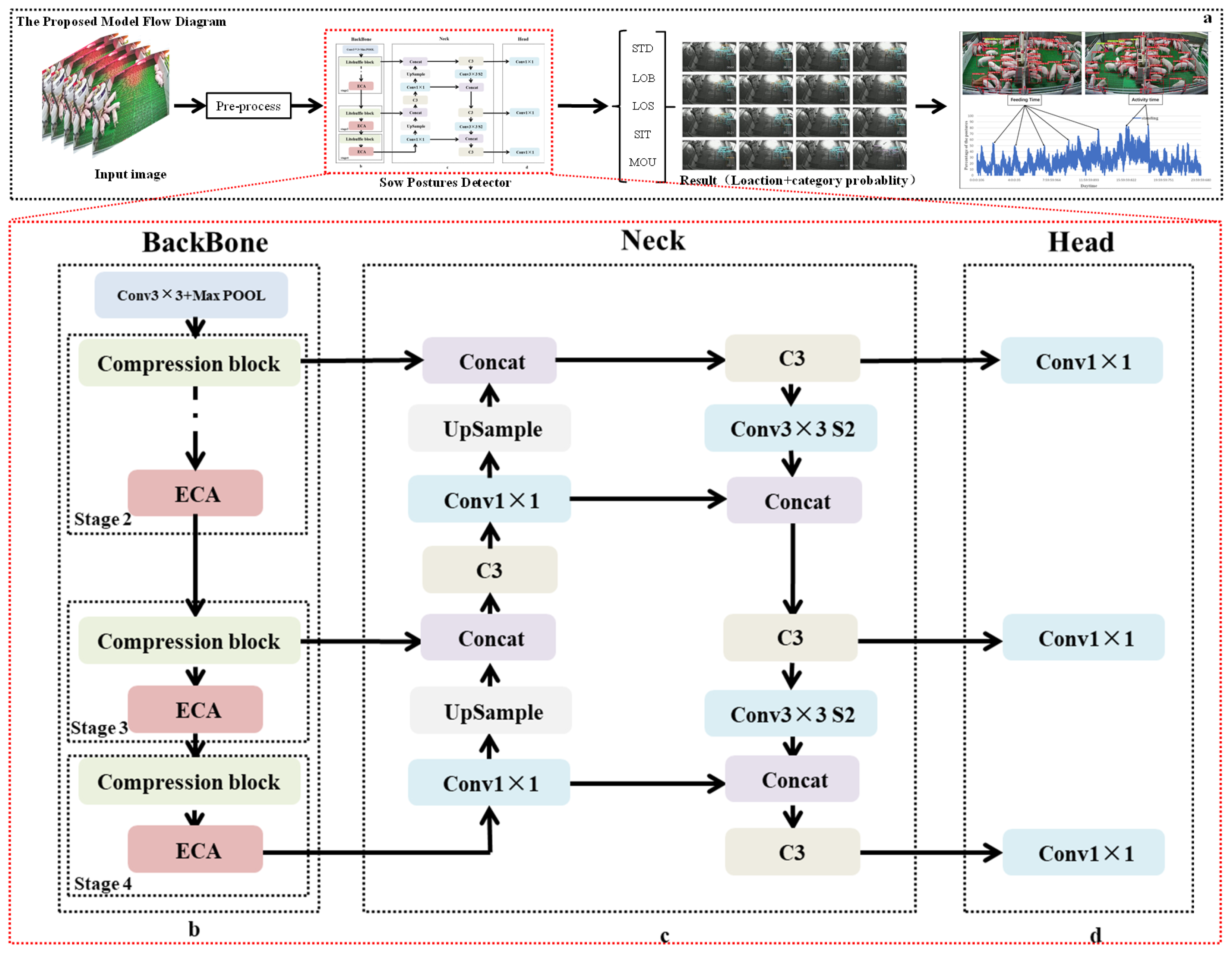
2.3. Light-SPD-YOLO Network Architecture
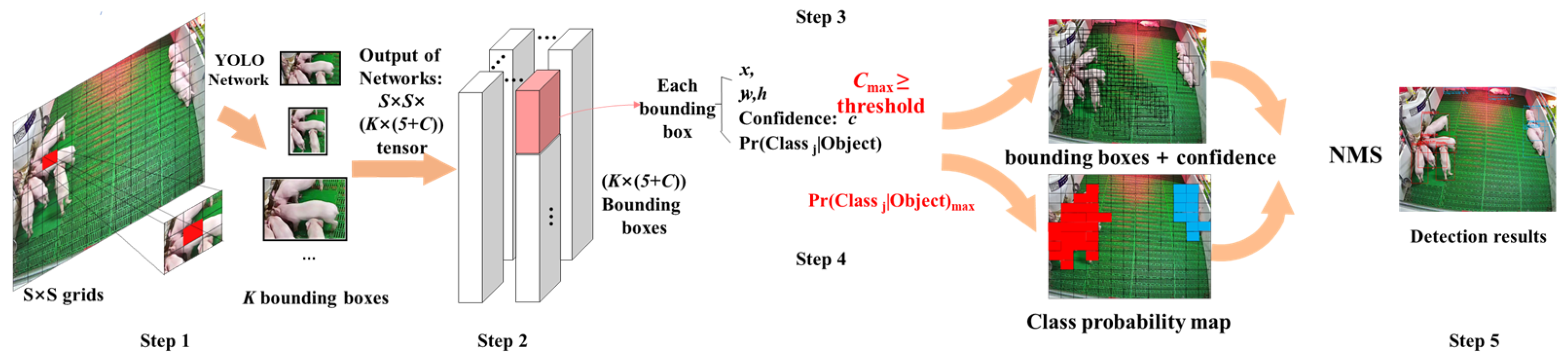
2.3.1. YOLO Principle
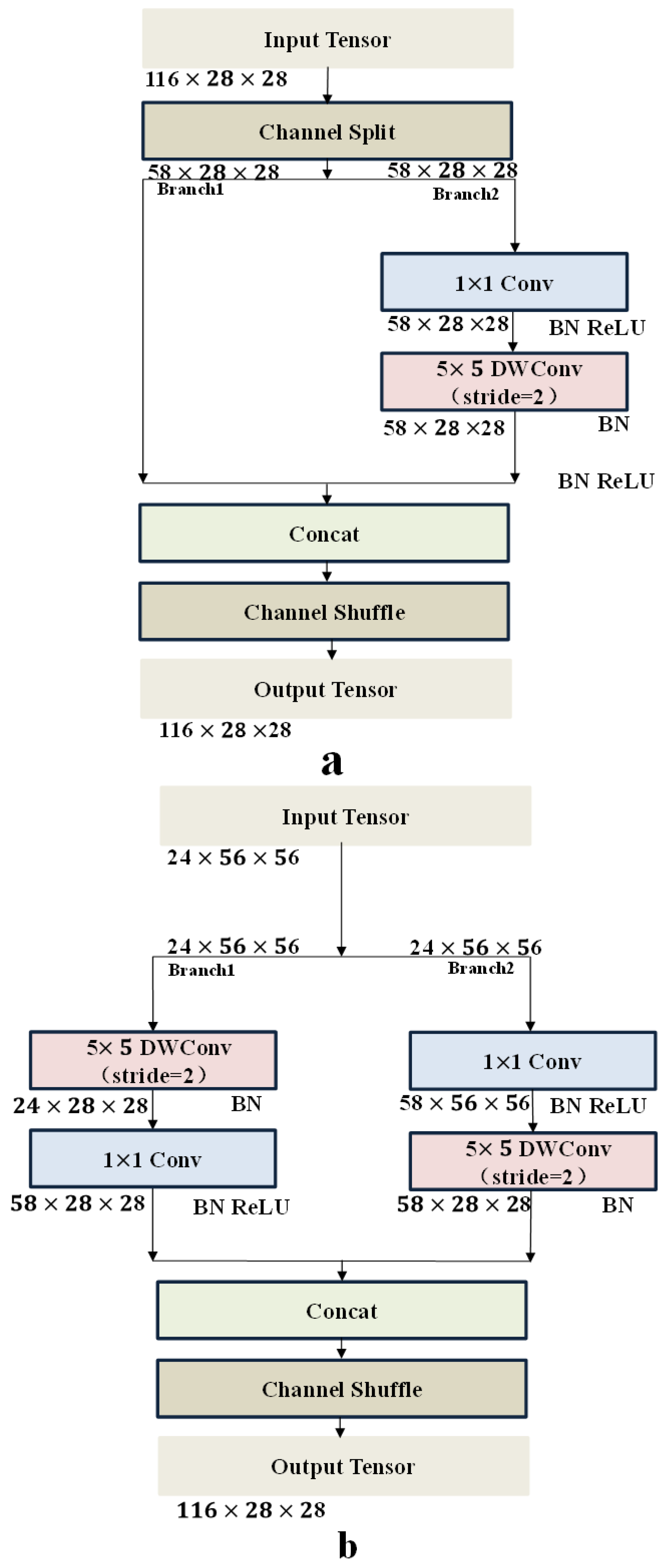
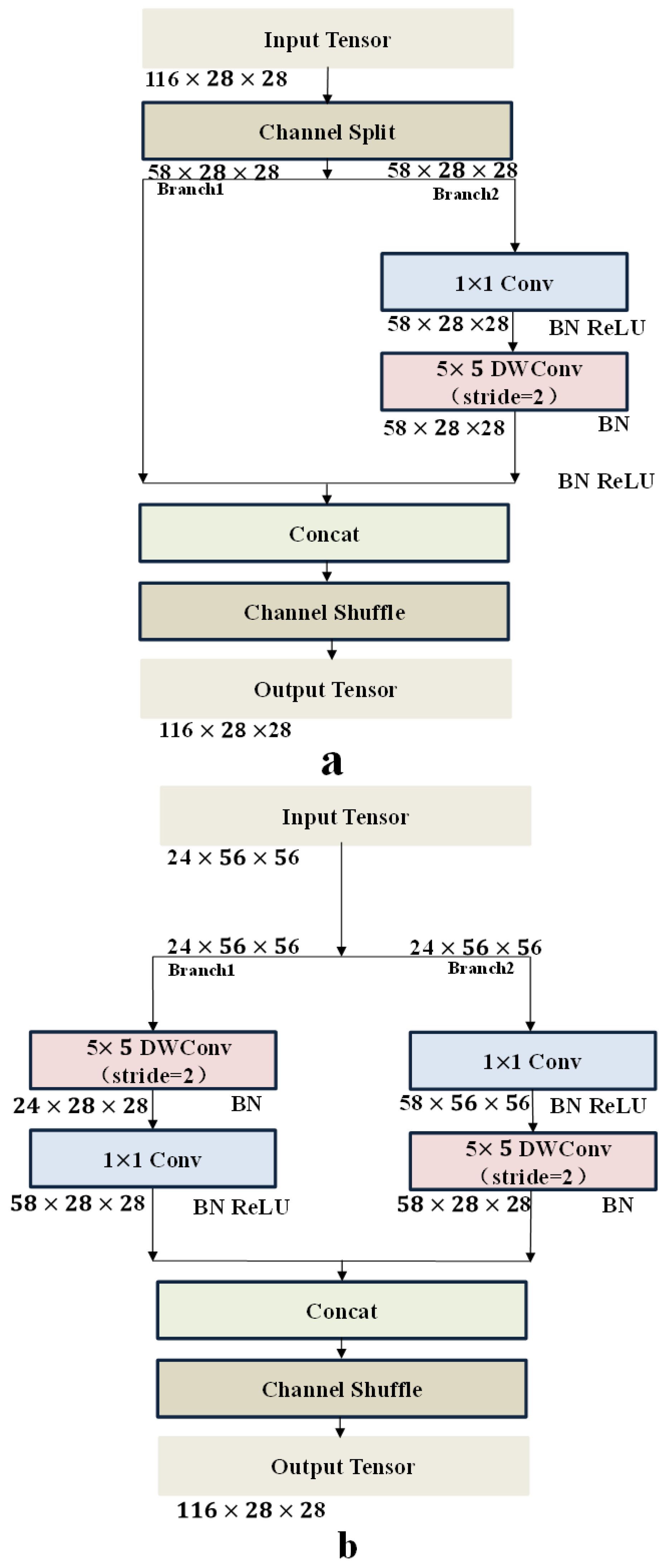
2.3.2. Compression Block
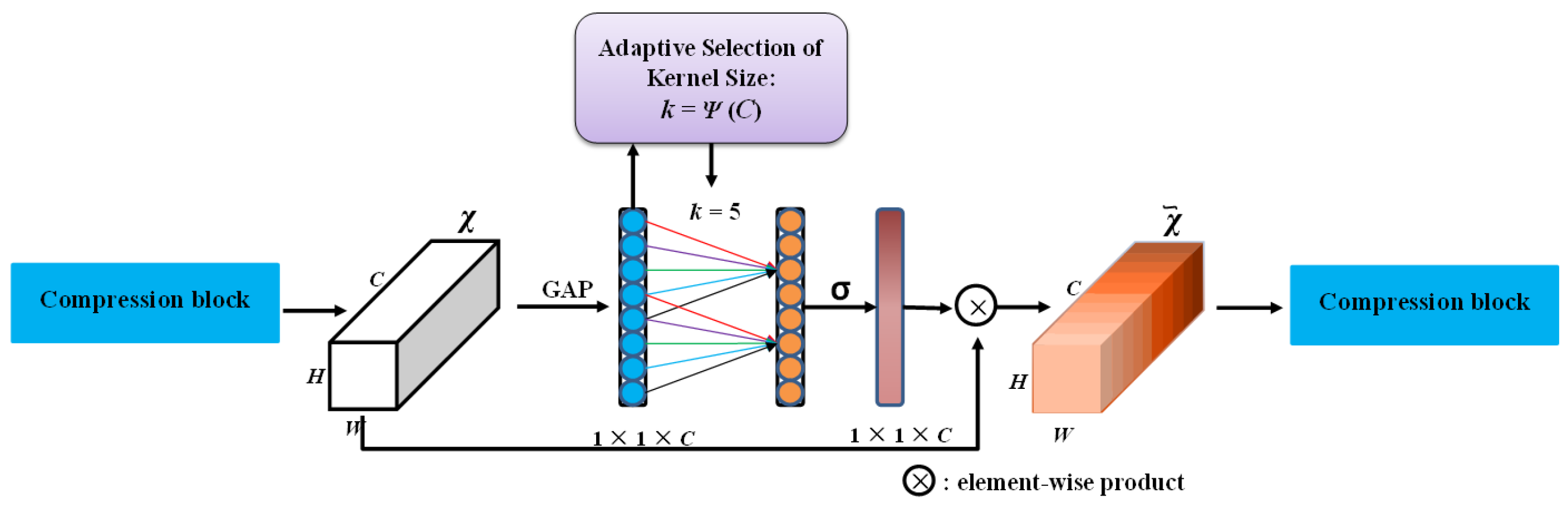
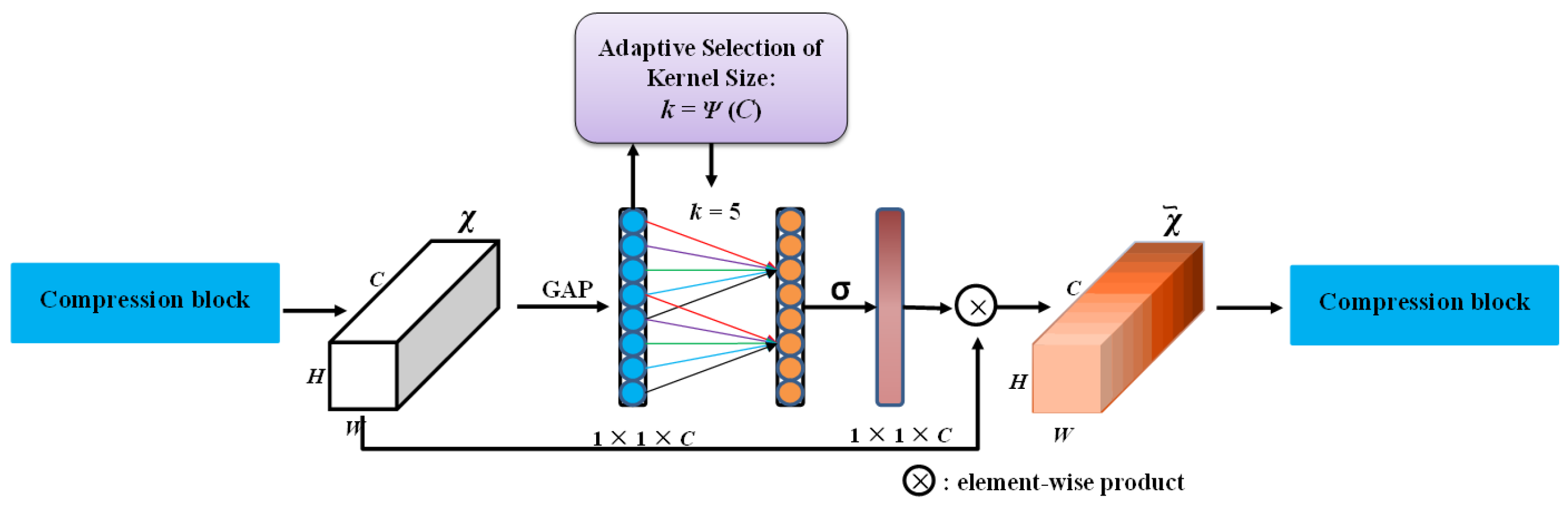
2.3.3. ECA-Net
2.4. Evaluation Index
2.5. Network Training
3. Results and Discussions
3.1. Performance Comparison of Different Models
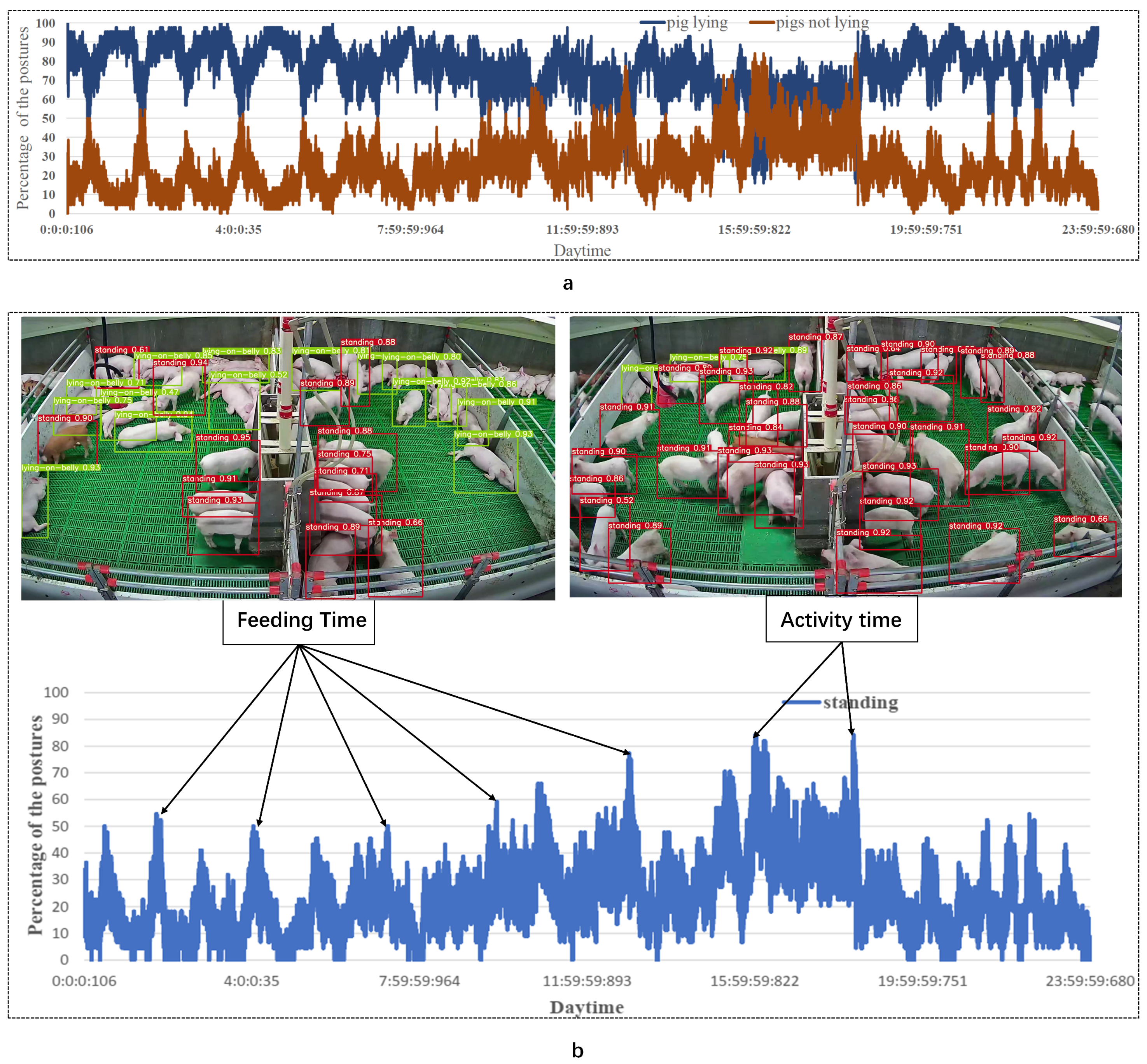
3.2. Statistics of Pigs Posture for 24 h
3.3. Application in Another Data Set
3.4. Limitation of Proposed Model
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| STD | standing |
| LOB | lying on the belly |
| LOS | lying on side |
| SIT | sitting |
| MOT | mounting |
| R-FCN | region-based fully convolution |
| LDA | linear discriminant analysis |
| ANNs | artificial neural networks |
| RF | random forest |
| SVM | support vector machine |
| Faster R-CNN | faster region-based convolutional network |
| ZFNet | Zeiler and Fergus Net |
| YOLOv5 | You Look Only Once version five |
References
- Mumm, J.M.; Calderón Díaz, J.A.; Stock, J.D.; Kerr Johnson, A.; Ramirez, A.; Azarpajouh, S.; Stalder, K.J. Characterization of the lying and rising sequence in lame and non-lame sows. Appl. Anim. Behav. Sci. 2020, 226, 104976. [Google Scholar] [CrossRef]
- Neethirajan, S. Measuring animal emotions-and why it matters. Pig Progr. 2021, 37, 10–12. [Google Scholar]
- Gómez, Y.; Stygar, A.H.; Boumans, I.J.; Bokkers, E.A.; Pedersen, L.J.; Niemi, J.K.; Pastell, M.; Manteca, X.; Llonch, P. A systematic review on validated Precision Livestock Farming technologies for pig production and its potential to assess animal welfare. Front. Vet. Sci. 2021, 8, 660565. [Google Scholar] [CrossRef] [PubMed]
- Nasirahmadi, A.; Sturm, B.; Olsson, A.C.; Jeppsson, K.H.; Müller, S.; Edwards, S.; Hensel, O. Automatic scoring of lateral and sternal lying posture in grouped pigs using image processing and Support Vector Machine. Comput. Electron. Agric. 2019, 156, 475–481. [Google Scholar] [CrossRef]
- Tzanidakis, C.; Simitzis, P.; Arvanitis, K.; Panagakis, P. An overview of the current trends in precision pig farming technologies. Livest. Sci. 2021, 249, 104530. [Google Scholar] [CrossRef]
- Pol, F.; Kling-Eveillard, F.; Champigneulle, F.; Fresnay, E.; Ducrocq, M.; Courboulay, V. Human–animal relationship influences husbandry practices, animal welfare and productivity in pig farming. Animal 2021, 15, 100103. [Google Scholar] [CrossRef]
- Thompson, R.; Matheson, S.M.; Plötz, T.; Edwards, S.A.; Kyriazakis, I. Porcine lie detectors: Automatic quantification of posture state and transitions in sows using inertial sensors. Comput. Electron. Agric. 2016, 127, 521–530. [Google Scholar] [CrossRef] [Green Version]
- Tassinari, P.; Bovo, M.; Benni, S.; Franzoni, S.; Poggi, M.; Mammi, L.M.E.; Mattoccia, S.; Di Stefano, L.; Bonora, F.; Barbaresi, A.; et al. A computer vision approach based on deep learning for the detection of dairy cows in free stall barn. Comput. Electron. Agric. 2021, 182, 106030. [Google Scholar] [CrossRef]
- Tan, K.; Lee, W.S.; Gan, H.; Wang, S. Recognising blueberry fruit of different maturity using histogram oriented gradients and colour features in outdoor scenes. Biosystems. Eng. 2018, 176, 59–72. [Google Scholar] [CrossRef]
- Kim, D.W.; Yun, H.; Jeong, S.J.; Kwon, Y.S.; Kim, S.G.; Lee, W.; Kim, H.J. Modeling and Testing of Growth Status for Chinese Cabbage and White Radish with UAV-Based RGB Imagery. Remote Sens. 2018, 10, 563. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Lee, W.S.; Ampatzidis, Y.; Chen, Y.; Peres, N.; Fraisse, C. Strawberry Maturity Classification from UAV and Near-Ground Imaging Using Deep Learning. Smart. Agric. Technol. 2021, 1, 100001. [Google Scholar] [CrossRef]
- Yun, C.; Kim, H.J.; Jeon, C.W.; Gang, M.; Lee, W.S.; Han, J.G. Stereovision-based ridge-furrow detection and tracking for auto-guided cultivator. Comput. Electron. Agric. 2021, 191, 106490. [Google Scholar] [CrossRef]
- Kim, W.S.; Lee, D.H.; Kim, Y.J.; Kim, T.; Lee, W.S.; Choi, C.H. Stereo-vision-based crop height estimation for agricultural robots. Comput. Electron. Agric. 2021, 181, 105937. [Google Scholar] [CrossRef]
- Woo, S.; Uyeh, D.D.; Kim, J.; Kim, Y.; Kang, S.; Kim, K.C.; Lee, S.Y.; Ha, Y.; Lee, W.S. Analyses of Work Efficiency of a Strawberry-Harvesting Robot in an Automated Greenhouse. Agronomy 2020, 10, 1751. [Google Scholar] [CrossRef]
- Li, Z.; Guo, R.; Li, M.; Chen, Y.; Li, G. A review of computer vision technologies for plant phenotyping. Comput. Electron. Agric. 2020, 176, 105672. [Google Scholar] [CrossRef]
- Zheng, C.; Zhu, X.; Yang, X.; Wang, L.; Tu, S.; Xue, Y. Automatic recognition of lactating sow postures from depth images by deep learning detector. Comput. Electron. Agric. 2018, 147, 51–63. [Google Scholar] [CrossRef]
- Riekert, M.; Klein, A.; Adrion, F.; Hoffmann, C.; Gallmann, E. Automatically detecting pig position and posture by 2D camera imaging and deep learning. Comput. Electron. Agric. 2020, 174, 105391. [Google Scholar] [CrossRef]
- Zhu, X.; Chen, C.; Zheng, B.; Yang, X.; Gan, H.; Zheng, C.; Yang, A.; Mao, L.; Xue, Y. Automatic recognition of lactating sow postures by refined two-stream RGB-D faster R-CNN. Biosyst. Eng. 2020, 189, 116–132. [Google Scholar] [CrossRef]
- Too, E.C.; Yujian, L.; Njuki, S.; Yingchun, L. A comparative study of fine-tuning deep learning models for plant disease identification. Comput. Electron. Agric. 2019, 161, 272–279. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. Available online: https://arxiv.org/abs/1704.04861 (accessed on 9 November 2021).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Tang, Z.; Yang, J.; Li, Z.; Qi, F. Grape disease image classification based on lightweight convolution neural networks and channel-wise attention. Comput. Electron. Agric. 2020, 178, 105735. [Google Scholar] [CrossRef]
- Seo, J.; Ahn, H.; Kim, D.; Lee, S.; Chung, Y.; Park, D. EmbeddedPigDet—Fast and Accurate Pig Detection for Embedded Board Implementations. Appl. Sci. 2020, 10, 2878. [Google Scholar] [CrossRef]
- Wada, K. Labelme: Image Polygonal Annotation with Python. 2016. Available online: https://github.com/wkentaro/labelme (accessed on 8 June 2020).
- Sivamani, S.; Choi, S.H.; Lee, D.H.; Park, J.; Chon, S. Automatic posture detection of pigs on real-time using Yolo framework. Int. J. Res. Trends Innov. 2020, 5, 81–88. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Guha Roy, A.; Navab, N.; Wachinger, C. Concurrent Spatial and Channel Squeeze & Excitation in Fully Convolutional Networks. arXiv 2018, 11070, arXiv-1803. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 21–25 June 2021; pp. 13713–13722. [Google Scholar]
- Paisitkriangkrai, S.; Shen, C.; Van Den Hengel, A. Efficient Pedestrian Detection by Directly Optimizing the Partial Area under the ROC Curve. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Chen, C.; Zhu, W.; Norton, T. Behaviour recognition of pigs and cattle: Journey from computer vision to deep learning. Comput. Electron. Agric. 2021, 187, 106255. [Google Scholar] [CrossRef]
- Mekhalfi, M.L.; Nicolò, C.; Bazi, Y.; Al Rahhal, M.M.; Alsharif, N.A.; Al Maghayreh, E. Contrasting YOLOv5, Transformer, and EfficientDet Detectors for Crop Circle Detection in Desert. IEEE Geosci. Remote Sens. Lett. 2021, 1–5. Available online: https://ieeexplore.ieee.org/abstract/document/9453822 (accessed on 9 November 2021). [CrossRef]
- Han, J.H.; Choi, D.J.; Park, S.; Hong, S.K. Hyperparameter optimization using a genetic algorithm considering verification time in a convolutional neural network. J. Electr. Eng. Technol. 2020, 15, 721–726. [Google Scholar] [CrossRef]
- Zheng, C.; Yang, X.; Zhu, X.; Chen, C.; Wang, L.; Tu, S.; Yang, A.; Xue, Y. Automatic posture change analysis of lactating sows by action localisation and tube optimisation from untrimmed depth videos. Biosystems. Eng. 2018, 194, 227–250. [Google Scholar] [CrossRef]
- Shao, H.; Pu, J.; Mu, J. Pig-Posture Recognition Based on Computer Vision: Dataset and Exploration. Animals 2021, 11, 1295. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pig Posture Category | Abbreviation | Posture Description |
|---|---|---|
| Standing | STD | Upright body position on extended legs with hooves only in contact with the floor [16]. |
| Lying on belly | LOB | Lying on abdomen/sternum with front and hind legs folded under the body; udder is obscured [16]. |
| Lying on side | LOS | Lying on either side with all four legs visible (right side, left side); udder is visible [16]. |
| Sitting | SIT | Partly erected on stretched front legs with caudal end of the body contacting the floor [16]. |
| Mounting | MOT | Stretch the hind legs and standing on the floor with the front legs in contact with the body of another pig. |
| Configuration | Parameter |
|---|---|
| CPU | Intel(R) Core(TM)4210 |
| GPU | NVIDIA GeForce RTX 2080Ti |
| Operating system | Ubuntu 18.04 system |
| Accelerated environment | CUDA11.2 CUDNN 7.6.5 |
| Development environment | Vscode |
| Detector | Backbone | mAP | Parameters | GFLOPS | fps(CPU = i7) | AP | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Standing | Lying-on-Belly | Lying-on-Side | Sitting | Mounting | ||||||
| Faster R-CNN | ResNet50 | 68.6% | 28.306 M | 909.623 | 528 ms | 83% | 72% | 69% | 60 % | 59% |
| YOLOv3 | Darknet53 | 81.66% | 61.539 M | 154.9 | 321 ms | 90.7% | 90.1 | 85.9% | 77.3% | 64.3% |
| YOLOv5 | CSPDarknet53 | 81.96% | 0.706 M | 16.4 | 111 ms | 90.4% | 90.4% | 84.8% | 75.2% | 69% |
| YOLOv5 | MobileNetV3-large | 78.48% | 0.521 M | 10.2 | 127 ms | 90.7% | 90.1% | 83.8% | 63.3% | 64.5% |
| YOLOv5 | MobileNetV3-small | 76.76% | 0.357 M | 6.3 | 82 ms | 91.2% | 90% | 85.2% | 63.1% | 54.3% |
| YoloV5 | Light-SPD-YOLO (proposed model) | 92.04% | 0.358 M | 1.2 | 63 ms | 97.7% | 95.2% | 95.7% | 87.5% | 84.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Y.; Zeng, Z.; Lu, H.; Lv, E. Posture Detection of Individual Pigs Based on Lightweight Convolution Neural Networks and Efficient Channel-Wise Attention. Sensors 2021, 21, 8369. https://doi.org/10.3390/s21248369
Luo Y, Zeng Z, Lu H, Lv E. Posture Detection of Individual Pigs Based on Lightweight Convolution Neural Networks and Efficient Channel-Wise Attention. Sensors. 2021; 21(24):8369. https://doi.org/10.3390/s21248369
Chicago/Turabian StyleLuo, Yizhi, Zhixiong Zeng, Huazhong Lu, and Enli Lv. 2021. "Posture Detection of Individual Pigs Based on Lightweight Convolution Neural Networks and Efficient Channel-Wise Attention" Sensors 21, no. 24: 8369. https://doi.org/10.3390/s21248369
APA StyleLuo, Y., Zeng, Z., Lu, H., & Lv, E. (2021). Posture Detection of Individual Pigs Based on Lightweight Convolution Neural Networks and Efficient Channel-Wise Attention. Sensors, 21(24), 8369. https://doi.org/10.3390/s21248369