
A Hierarchical Spatial-Temporal Embedding Method Based on Enhanced Trajectory Features for Ship Type Classification


Abstract
:1. Introduction
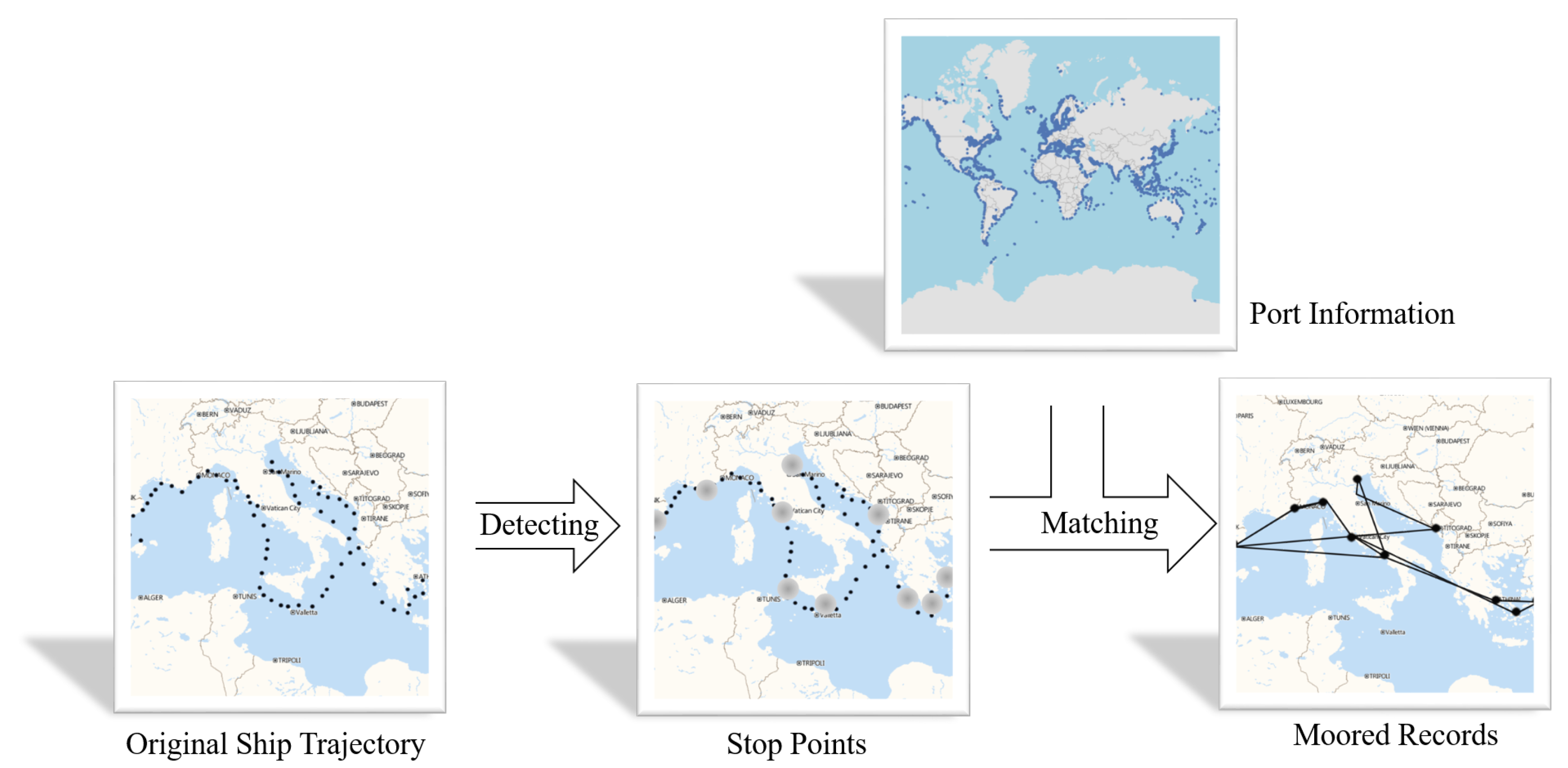
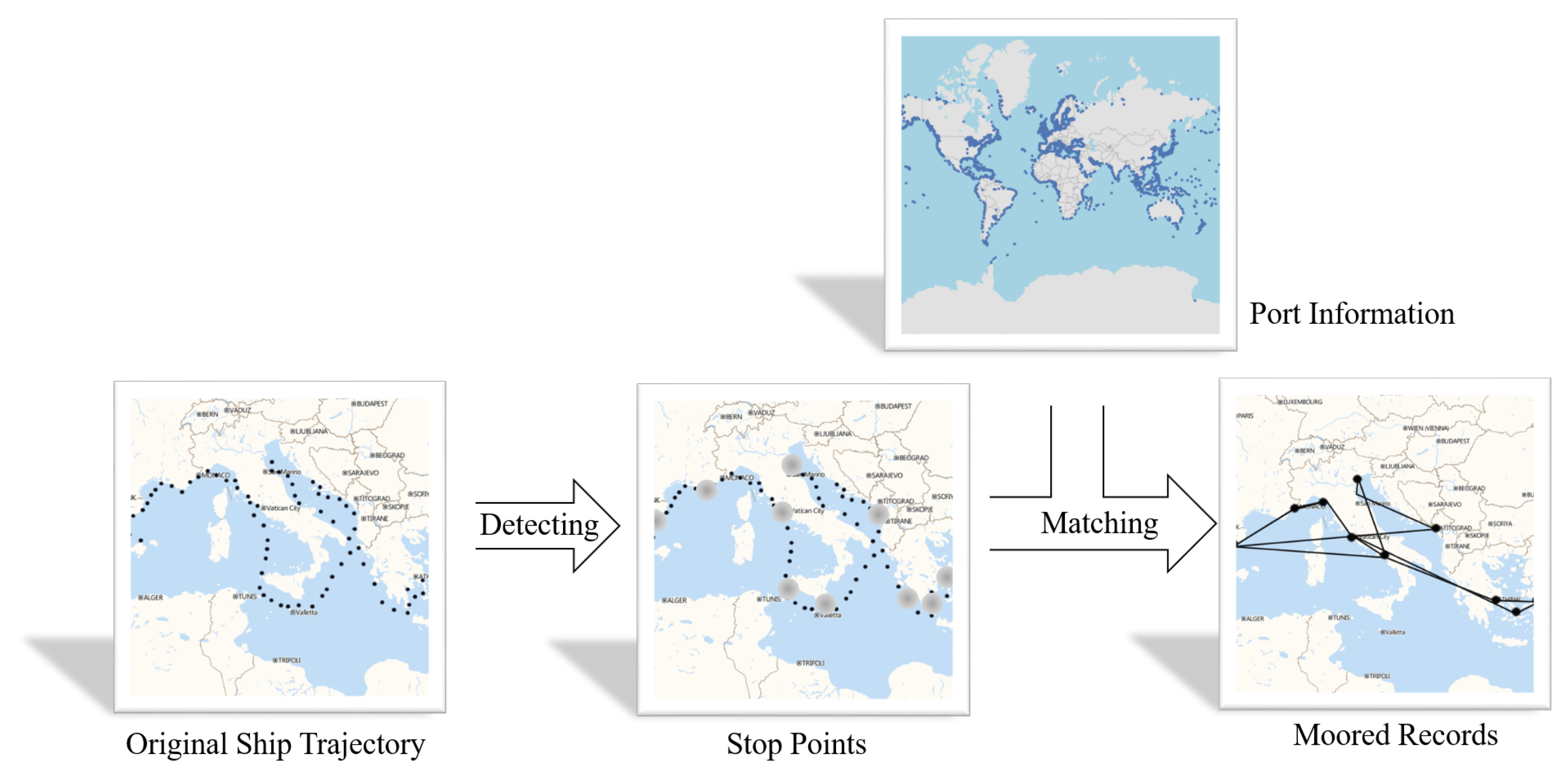
- We establish a framework for ship classification based on ship moored records. In this way, we introduce the port information, which increases the features of the trajectory and reduces the problem of uneven data distribution.
- We propose a spatial-temporal sequence classification method called Hi-STEM. Hi-STEM processes the temporal and spatial information simultaneously and uses the attention recurrent neural network to improve the classification accuracy of sequences.
- We verify the effectiveness and the robustness of our method on real-world datasets. The results show that our method can arrive over 80% accuracy on ship classification of four categories, beyond the naive deep neural network approach.
- We arrange the datasets for ship classification, which contains information such as ship type, the ship moored records, and port basic properties. Details of datasets and source code can be obtained at the website https://github.com/taos123/Ship_Classification_Moored (accessed on 25 November 2021).
2. Materials and Methods
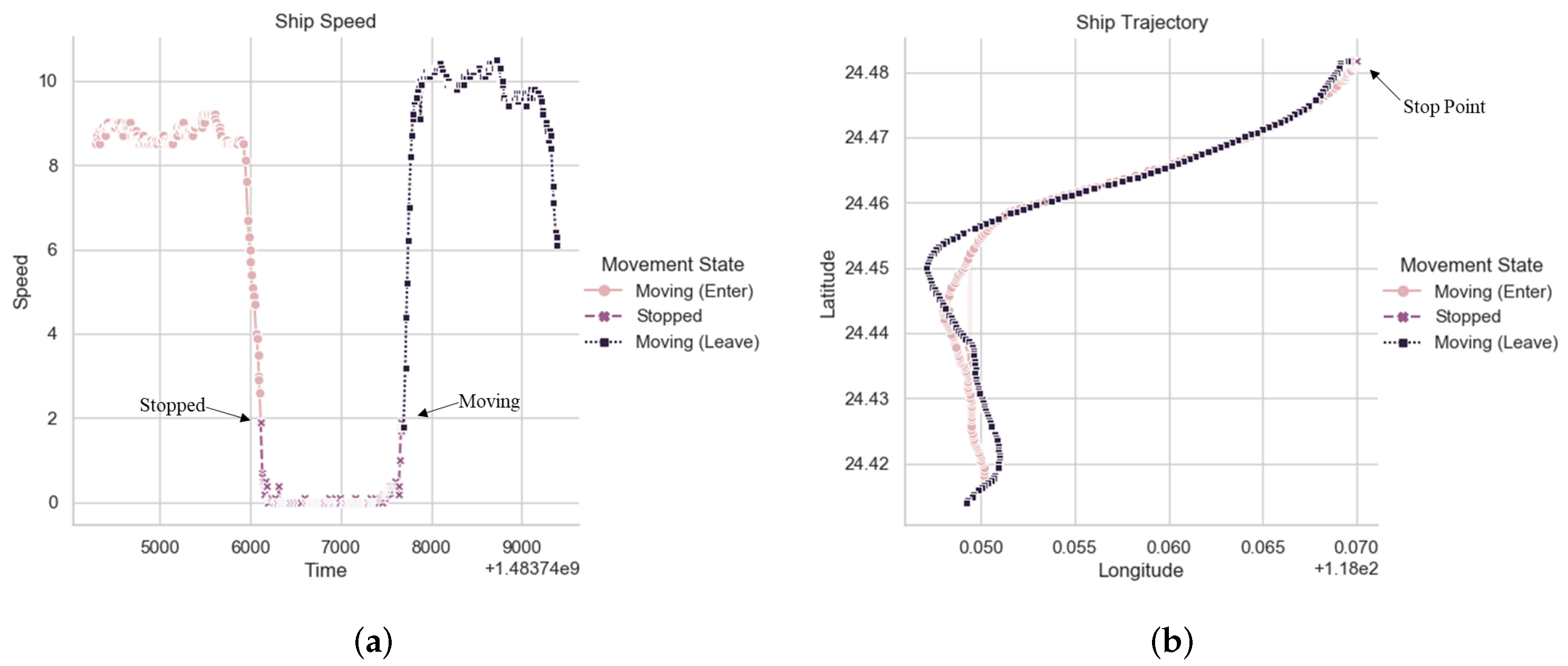
2.1. Data Preprocessing
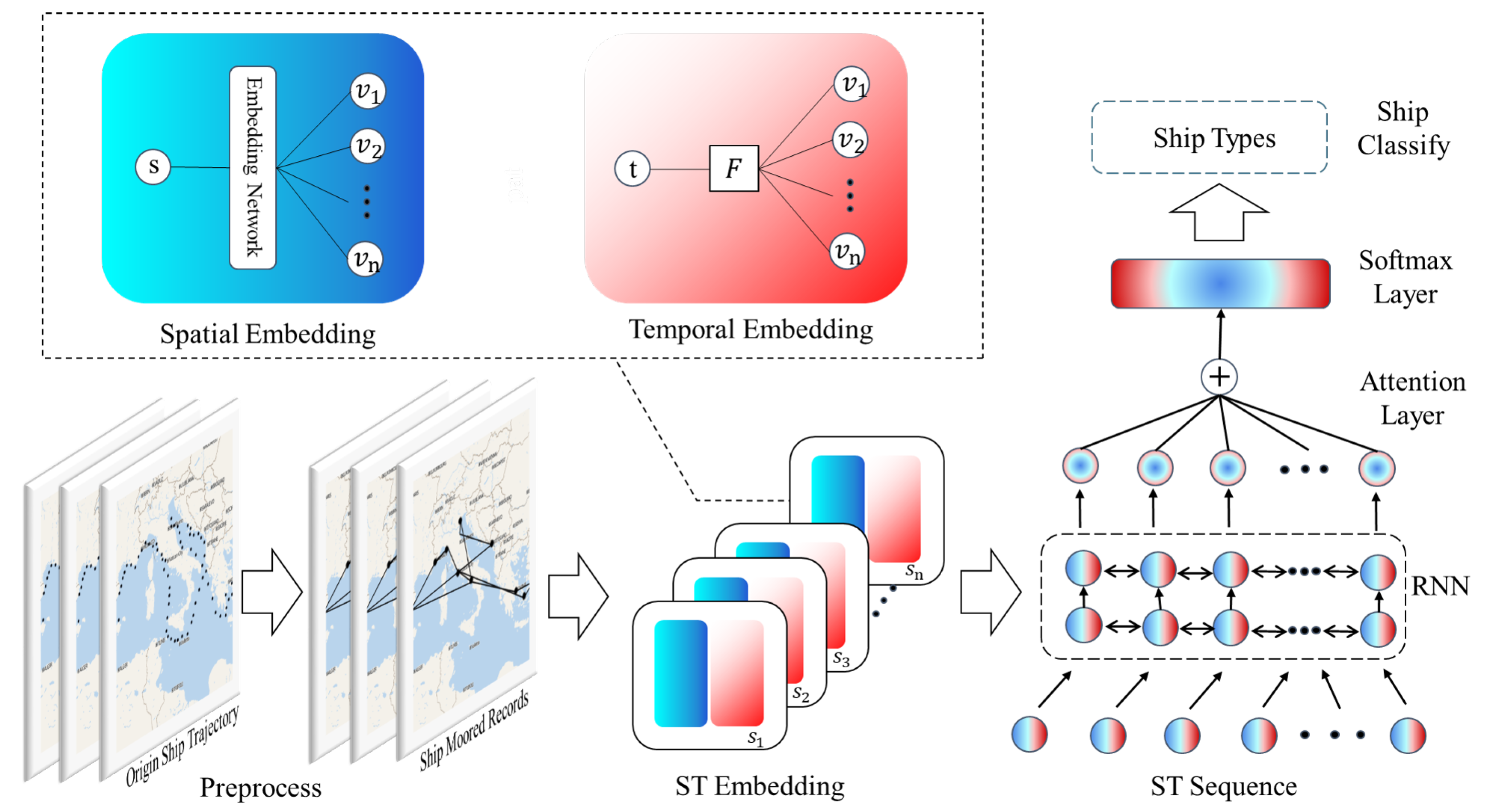
2.2. Hierarchical Spatial-Temporal Embedding Method for Ship Classification
2.2.1. Spatial-Temporal Embedding
2.2.2. Spatial-Temporal Sequence Classification
2.3. Parameter Setup
3. Results
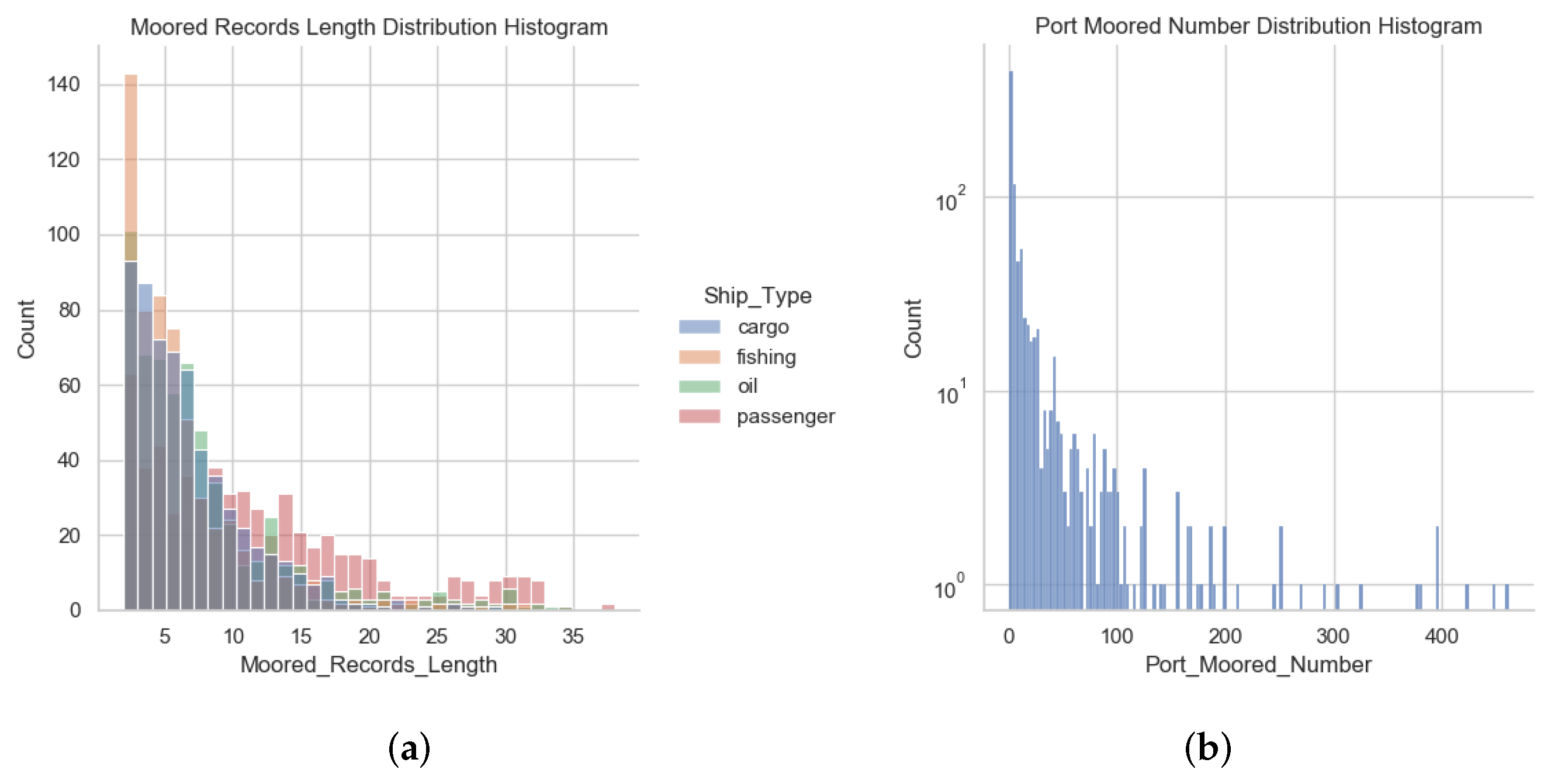
3.1. Datasets
3.2. Evaluation Metrics
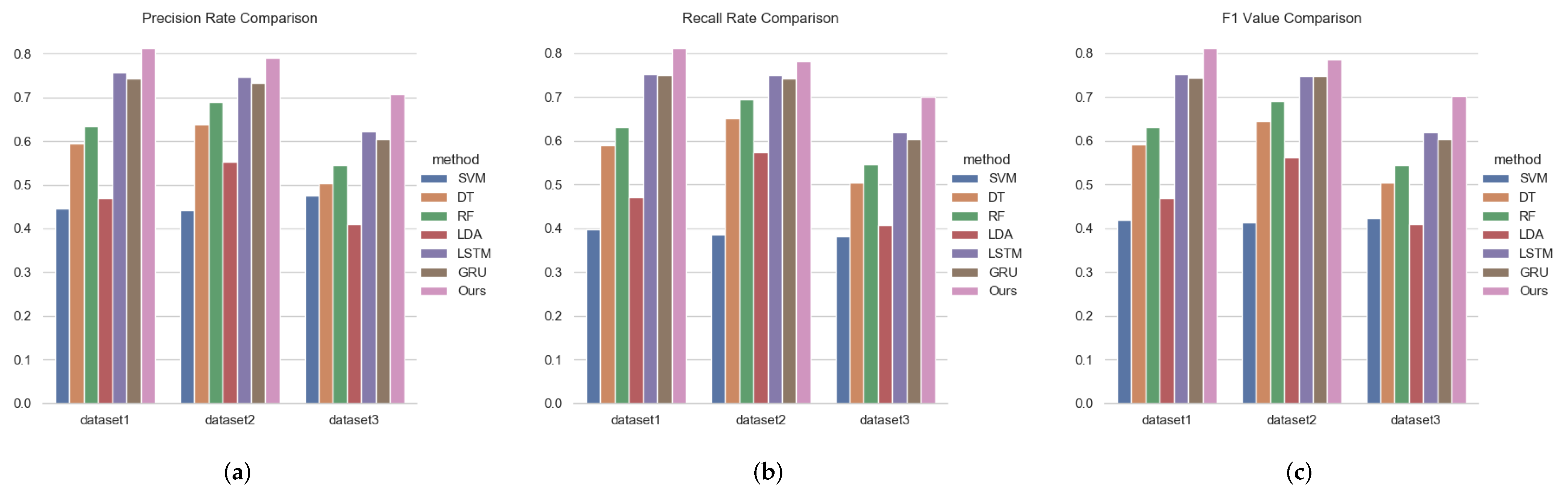
3.3. Effectiveness Analysis
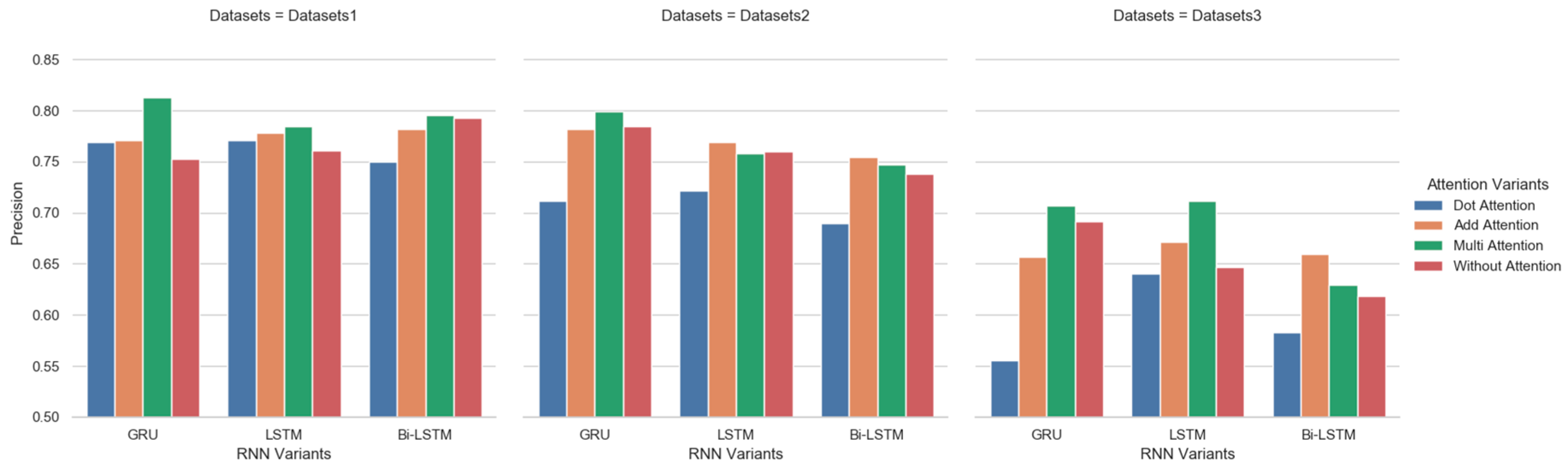
3.4. Robustness Analysis
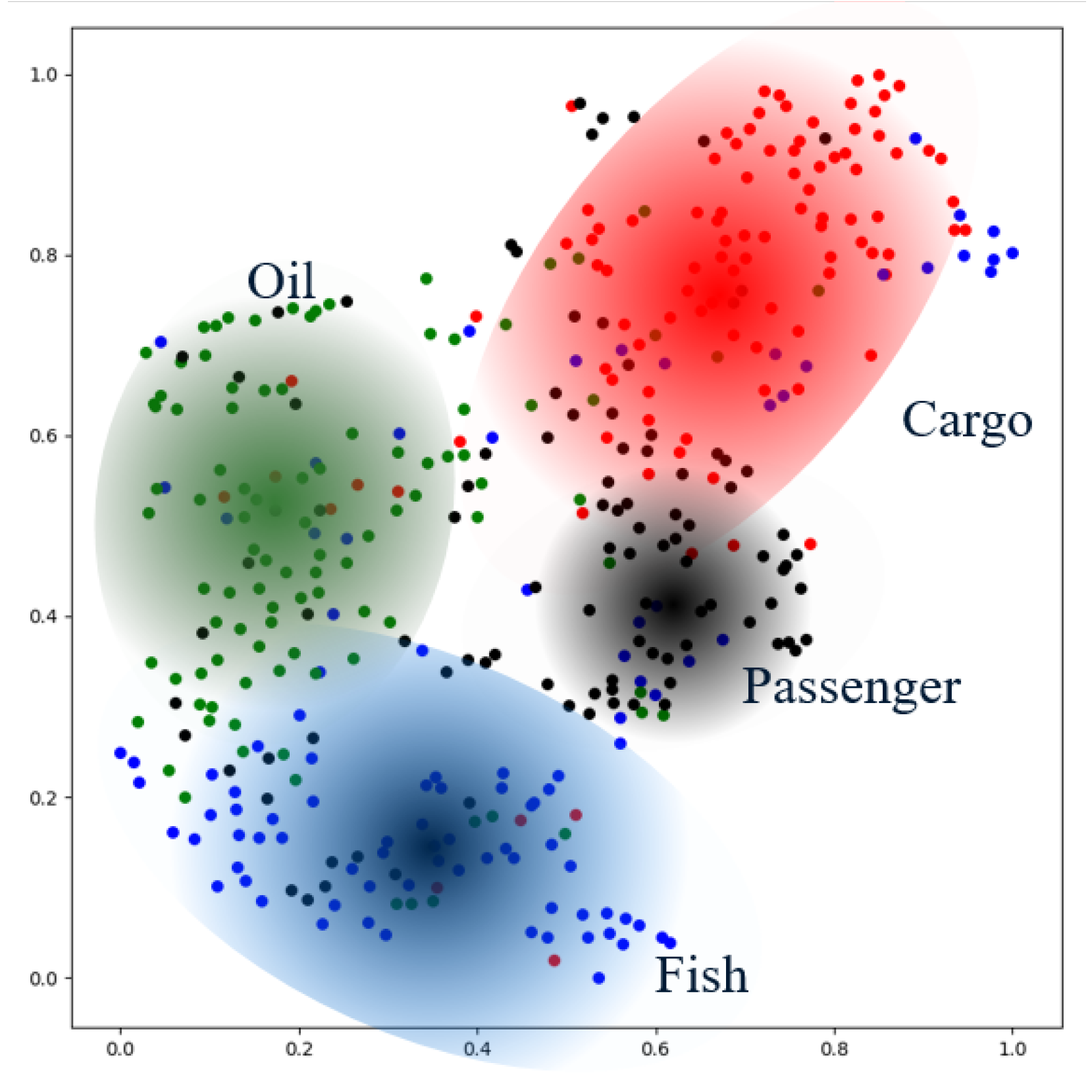
3.5. Embedding Visualization Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, G.; Zhang, G.; Xue, B. A Maximum-Information-Minimum-Redundancy-Based Feature Fusion Framework for Ship Classification in Moderate-Resolution SAR Image. Sensors 2021, 21, 519. [Google Scholar] [CrossRef]
- Del Mondo, G.; Peng, P.; Gensel, J.; Claramunt, C.; Lu, F. Leveraging Spatio-Temporal Graphs and Knowledge Graphs: Perspectives in the Field of Maritime Transportation. ISPRS Int. J. Geo-Inf. 2021, 10, 541. [Google Scholar] [CrossRef]
- Peng, P.; Cheng, S.; Chen, J.; Liao, M.; Wu, L.; Liu, X.; Lu, F. A fine-grained perspective on the robustness of global cargo ship transportation networks. J. Geogr. Sci. 2018, 28, 881–889. [Google Scholar] [CrossRef] [Green Version]
- Peng, P.; Yang, Y.; Cheng, S.; Lu, F.; Yuan, Z. Hub-and-spoke structure: Characterizing the global crude oil transport network with mass vessel trajectories. Energy 2019, 168, 966–974. [Google Scholar] [CrossRef]
- Li, C.; Liu, Z.; Ren, J.; Wang, W.; Xu, J. A Feature Optimization Approach Based on Inter-Class and Intra-Class Distance for Ship Type Classification. Sensors 2020, 20, 5429. [Google Scholar] [CrossRef] [PubMed]
- Pedroche, D.S.; Herrero, D.A.; García, J.; Molina, J.M. Architecture for Trajectory-Based Fishing Ship Classification with AIS Data. Sensors 2020, 20, 3782. [Google Scholar] [CrossRef]
- Herrero, D.A.; Pedroche, D.S.; García, J.; Molina, J.M. Segmentation Optimization in Trajectory-Based Ship Classification; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Guo, W.; Zhao, Z.; Zheng, Z.; Xu, Y. A Cloud-Based Approach for Ship Stay Behavior Classification Using Massive Trajectory Data; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Llerena, J.P.; García, J.; Molina, J.M. LSTM vs. CNN in Real Ship Trajectory Classification; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar] [CrossRef]
- Zheng, Y. Trajectory data mining: An overview. ACM Trans. Intell. Syst. Technol. (TIST) 2015, 6, 1–41. [Google Scholar] [CrossRef]
- Wang, S.; Cao, J.; Yu, P. Deep learning for spatio-temporal data mining: A survey. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Nanni, M.; Pedreschi, D. Time-focused clustering of trajectories of moving objects. J. Intell. Inf. Syst. 2006, 27, 267–289. [Google Scholar] [CrossRef]
- Chen, J.; Wang, R.; Liu, L.; Song, J. Clustering of trajectories based on Hausdorff distance. In Proceedings of the 2011 International Conference on Electronics, Communications and Control (ICECC), Ningbo, China, 9–11 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1940–1944. [Google Scholar]
- Gaffney, S.; Smyth, P. Trajectory clustering with mixtures of regression models. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 63–72. [Google Scholar]
- Cadez, I.V.; Gaffney, S.; Smyth, P. A general probabilistic framework for clustering individuals and objects. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 140–149. [Google Scholar]
- Lee, J.G.; Han, J.; Whang, K.Y. Trajectory clustering: A partition-and-group framework. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Beijing, China, 12–14 June 2007; pp. 593–604. [Google Scholar]
- Lee, J.G.; Han, J.; Li, X.; Gonzalez, H. TraClass: Trajectory classification using hierarchical region-based and trajectory-based clustering. Proc. VLDB Endow. 2008, 1, 1081–1094. [Google Scholar] [CrossRef]
- Pavlovic, V.; Frey, B.J.; Huang, T.S. Time-series classification using mixed-state dynamic Bayesian networks. In Proceedings of the Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 2, pp. 609–615. [Google Scholar]
- Nascimento, J.C.; Figueiredo, M.A.; Marques, J.S. Trajectory classification using switched dynamical hidden Markov models. IEEE Trans. Image Process. 2009, 19, 1338–1348. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, Y.; Liu, X.; Cao, X.; Huang, C.; Liu, E.; Qian, S.; Liu, X.; Wu, Y.; Dong, F.; Qiu, C.W.; et al. Artificial intelligence: A powerful paradigm for scientific research. Innovation 2021, 2, 100179. [Google Scholar] [CrossRef]
- Yu, Y.; Tang, H.; Wang, F.; Wu, L.; Qian, T.; Sun, T.; Xu, Y. TULSN: Siamese Network for Trajectory-user Linking. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–8. [Google Scholar]
- Sun, T.; Xu, Y.; Wang, F.; Wu, L.; Qian, T.; Shao, Z. Trajectory-User Link with Attention Recurrent Networks. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4589–4596. [Google Scholar]
- Jiang, X.; de Souza, E.N.; Pesaranghader, A.; Hu, B.; Silver, D.L.; Matwin, S. Trajectorynet: An embedded gps trajectory representation for point-based classification using recurrent neural networks. arXiv 2017, arXiv:1705.02636. [Google Scholar]
- Ferrero, C.A.; Alvares, L.O.; Zalewski, W.; Bogorny, V. Movelets: Exploring relevant subtrajectories for robust trajectory classification. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, Pau, France, 9–13 April 2018; pp. 849–856. [Google Scholar]
- Kontopoulos, I.; Makris, A.; Tserpes, K. A Deep Learning Streaming Methodology for Trajectory Classification. ISPRS Int. J. Geo-Inf. 2021, 10, 250. [Google Scholar] [CrossRef]
- Wu, L.; Xu, Y.; Wang, Q.; Wang, F.; Xu, Z. Mapping global shipping density from AIS data. J. Navig. 2017, 70, 67–81. [Google Scholar] [CrossRef]
- Soldi, G.; Gaglione, D.; Forti, N.; Simone, A.D.; Daffina, F.C.; Bottini, G.; Quattrociocchi, D.; Millefiori, L.M.; Braca, P.; Carniel, S.; et al. Space-Based Global Maritime Surveillance. Part I: Satellite Technologies. IEEE Aerosp. Electron. Syst. Mag. 2021, 36, 8–28. [Google Scholar] [CrossRef]
- Wu, X.; Wu, L.; Xu, Y.; An, Z.; Diao, B. Vessel trajectory partitioning based on hierarchical fusion of position data. In Proceedings of the 2015 18th International Conference on Information Fusion (Fusion), Washington, DC, USA, 6–9 July 2015; pp. 1230–1237. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. Available online: https://eva-test.fing.edu.uy/pluginfile.php/211989/mod_resource/content/1/mikolov2013.pdf (accessed on 25 November 2021).
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Maaten, L.V.D. Accelerating t-SNE using tree-based algorithms. J. Mach. Learn. Res. 2014, 15, 3221–3245. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | ||||
|---|---|---|---|---|
| Datasets | ||||
| Training Dataset 1 | 400 | 1200 | 16.9 | |
| Training Dataset 2 | 400 | 800 | 13.6 | |
| Training Dataset 3 | 400 | 400 | 14.5 | |
| Test Data | 400 | 400 | 15.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, T.; Xu, Y.; Zhang, Z.; Wu, L.; Wang, F. A Hierarchical Spatial-Temporal Embedding Method Based on Enhanced Trajectory Features for Ship Type Classification. Sensors 2022, 22, 711. https://doi.org/10.3390/s22030711
Sun T, Xu Y, Zhang Z, Wu L, Wang F. A Hierarchical Spatial-Temporal Embedding Method Based on Enhanced Trajectory Features for Ship Type Classification. Sensors. 2022; 22(3):711. https://doi.org/10.3390/s22030711
Chicago/Turabian StyleSun, Tao, Yongjun Xu, Zhao Zhang, Lin Wu, and Fei Wang. 2022. "A Hierarchical Spatial-Temporal Embedding Method Based on Enhanced Trajectory Features for Ship Type Classification" Sensors 22, no. 3: 711. https://doi.org/10.3390/s22030711
APA StyleSun, T., Xu, Y., Zhang, Z., Wu, L., & Wang, F. (2022). A Hierarchical Spatial-Temporal Embedding Method Based on Enhanced Trajectory Features for Ship Type Classification. Sensors, 22(3), 711. https://doi.org/10.3390/s22030711