
Power Transformer Voltages Classification with Acoustic Signal in Various Noisy Environments


Abstract
:1. Introduction
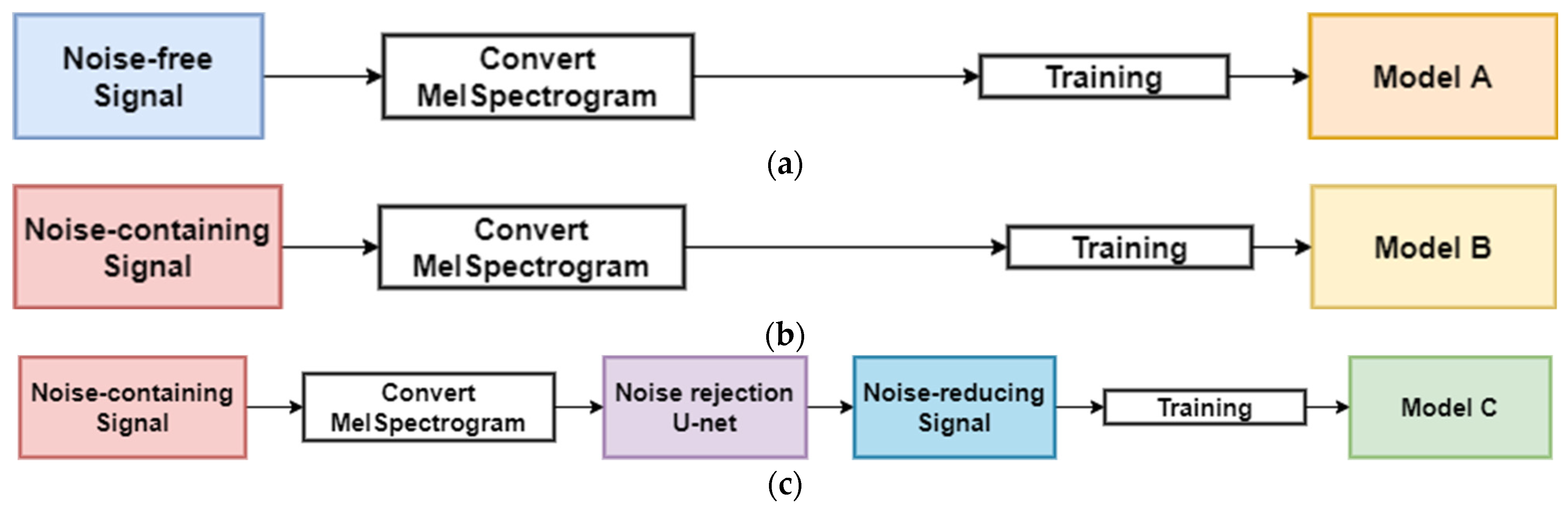
- Using a non-invasive method with the audio sensor and the acoustic signal in the audible frequency band to simulate the environment of human hearing, the over-, normal-, and under-voltage levels are classified according to the voltage supplied to the operating transformer. The classification model is designed based on the U-Net encoder layers to extract and express the important features from the acoustic signal.
- In the known noisy environment, the noise rejection method is designed by using U-Net-based deep learning to reduce noise. A predefined noise dataset, constructed by using nature (e.g., rain and wind), worksite (e.g., motor and welding), and city (e.g., vehicles and crowds) noises, is used.
- The ensemble model is designed to improve the classification accuracy in the unknown noisy environment. we exploit a concept of an ensemble technique that can be robust against unknown noises by improving the generalization performance of deep learning models through model diversity.
2. Background
2.1. Vibration–Acoustic Signal-Based Transformer Mechanical Fault Detection
2.2. Noise Rejection Method with U-Net
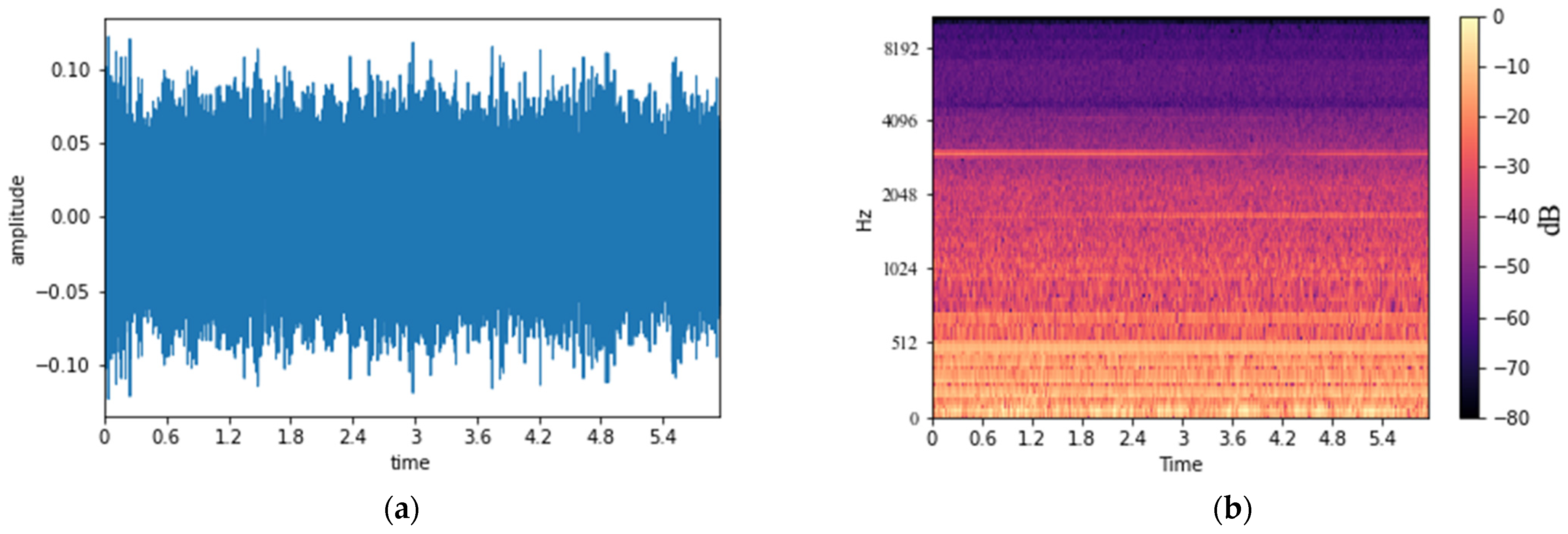
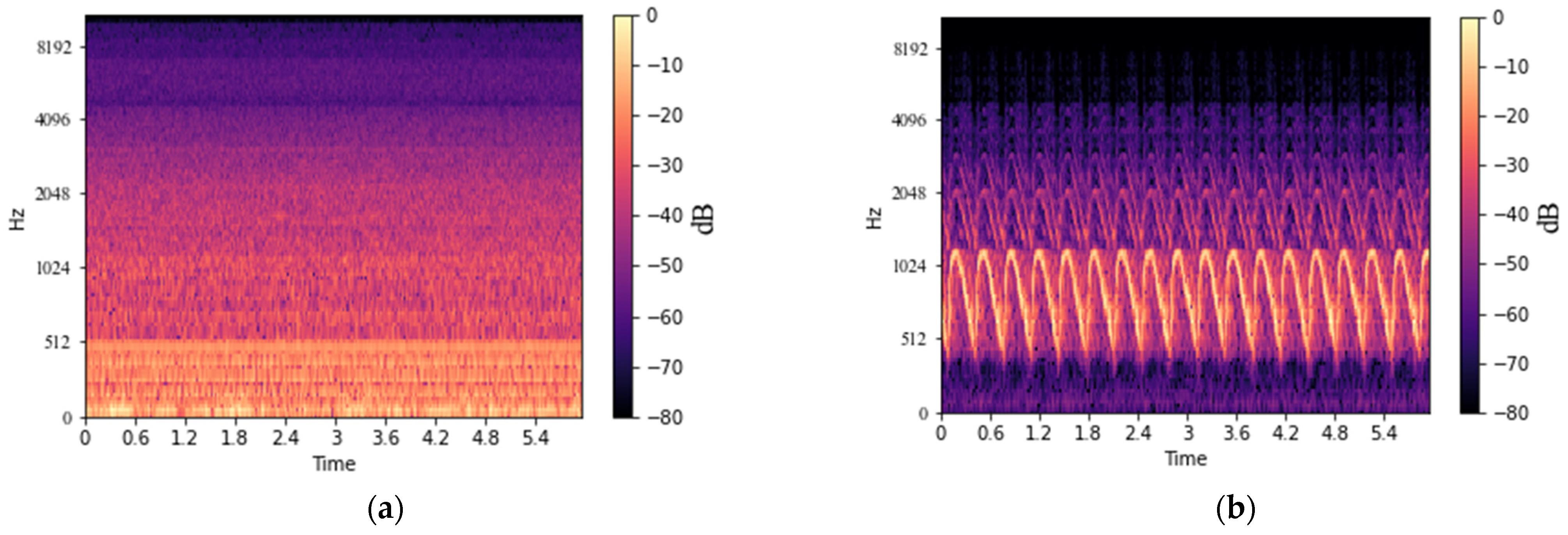
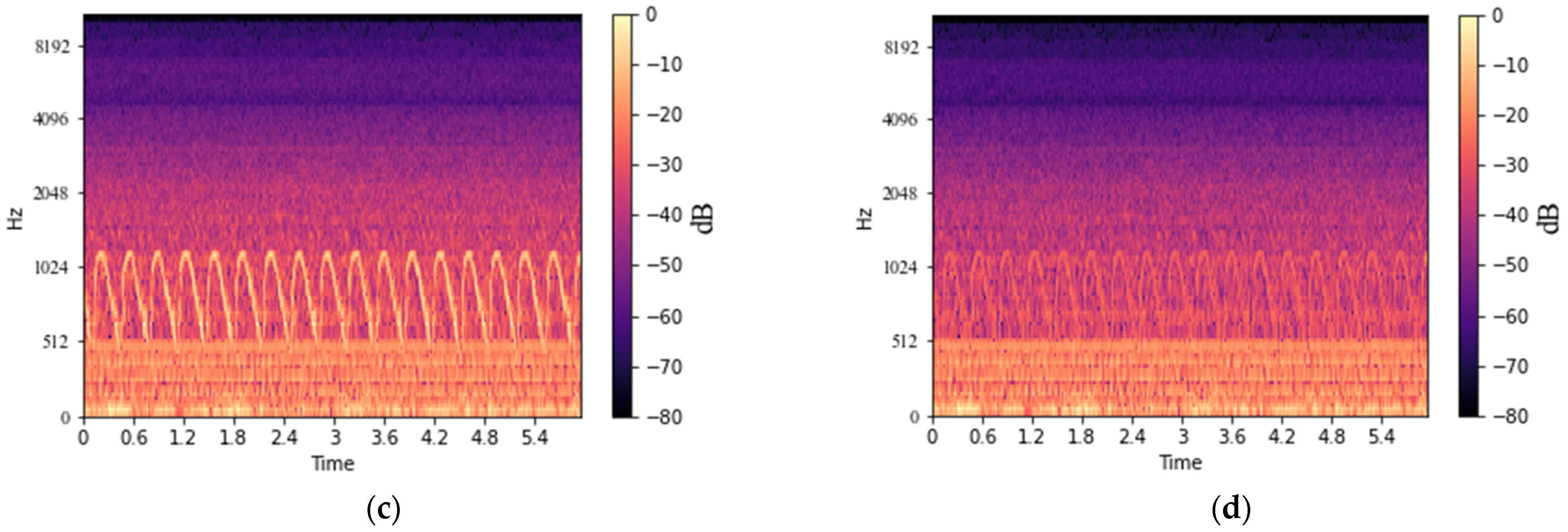
2.3. Acoustic Signal Analysis in Time–Frequency Domain
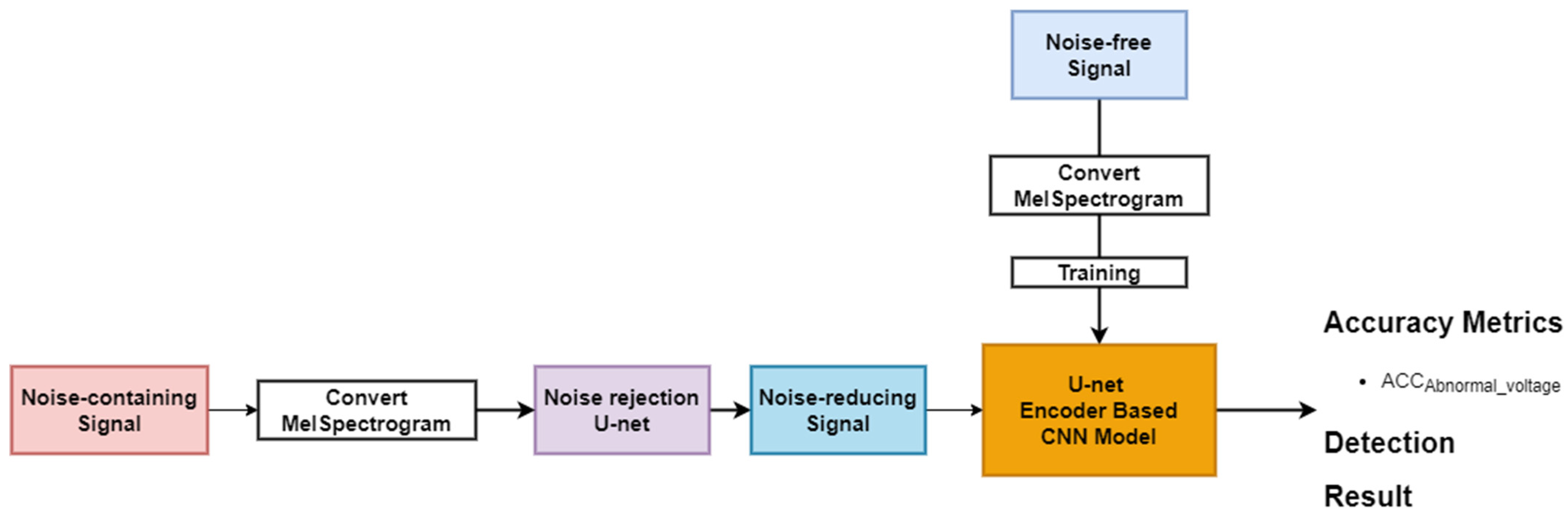
3. Proposed Method
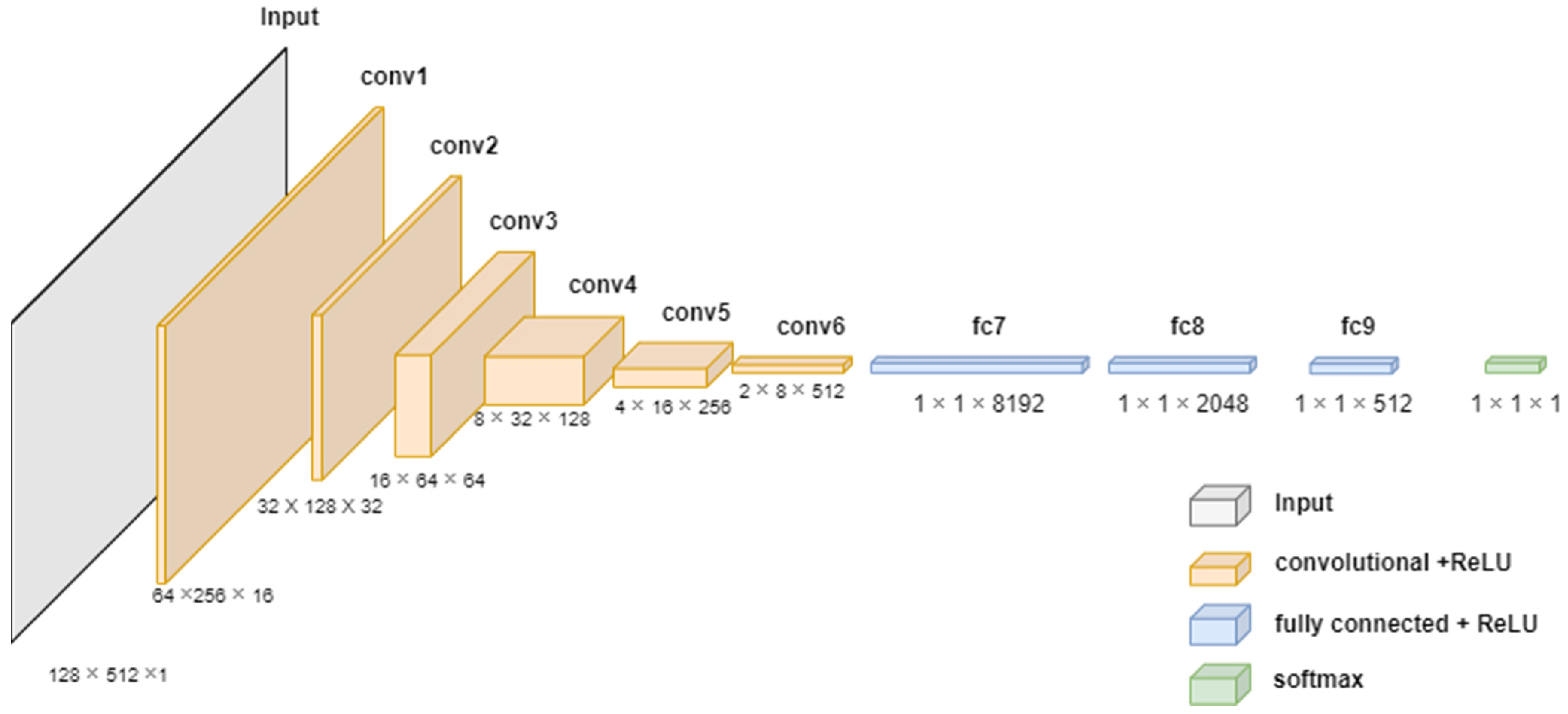
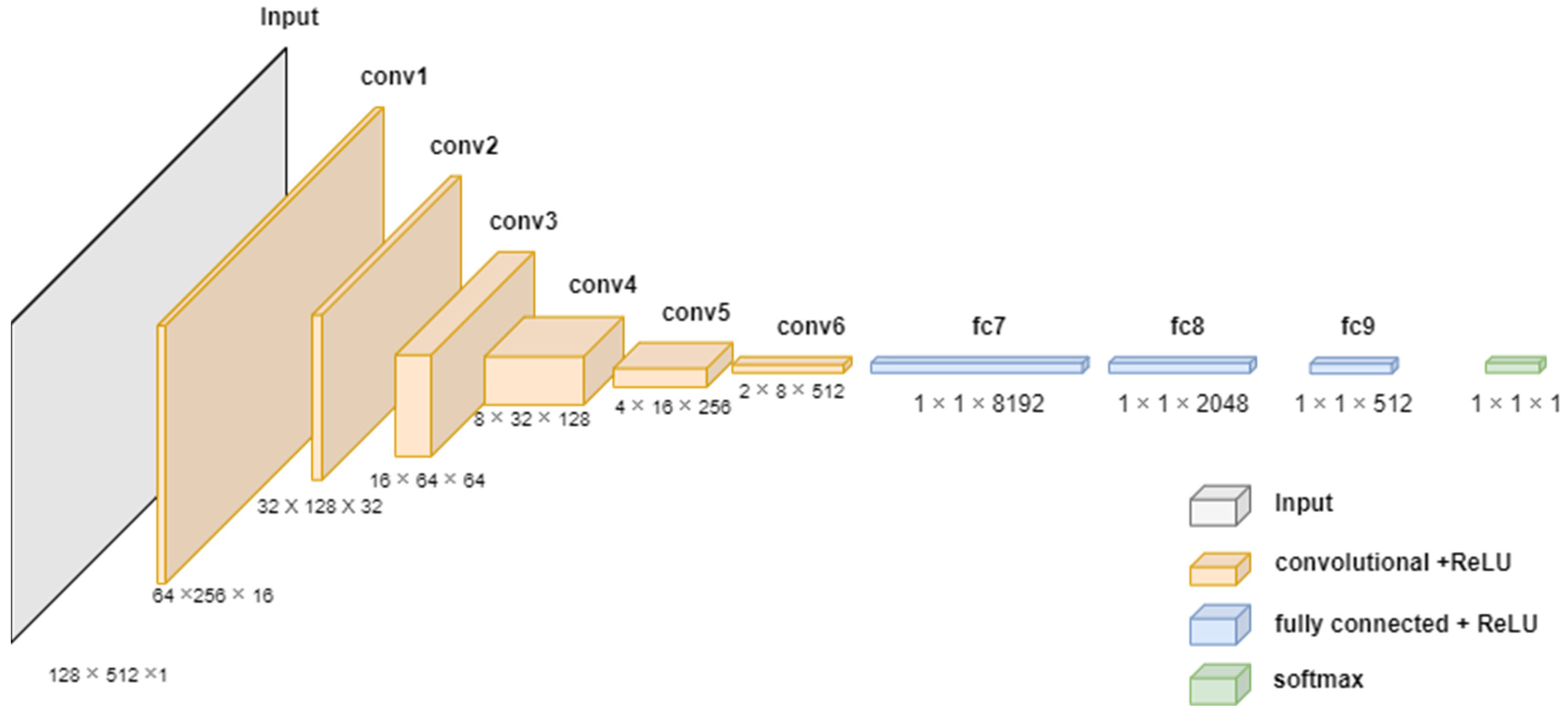
3.1. Deep Learning Model for Voltage Level Classification
| Algorithm 1. Voltage level classification | |
| Input: acoustic signal Output: Voltage levels | |
| Step 1 Step 2 Step 3 Step 4 | input_shape = [128, 512, 1] X = model_input n_layers = 6 FILTERS_LAYER = 16 for i in range(n_layers): n_layers = FILTERS_LAYER × (2i) X = Conv2D(n_layers, kernel_size = (5,5), strides = (2,2), padding = 2)(X) X = BatchNormalization(momentum = 0.9, scale = True)(X) X = get_activation(activation)(“RelU”) X = Flatten()(X) X = Dense(8192)(X) X = Dropout(0.3)(X) X = Dense(1024)(X) X = Dropout(0.3)(X) X = Dense(512)(X) X = Dense(5)(X) X = get_activation(“softmax”)(X) model = Model(model_input, X) model.compile(optimizer = adam(lr = 0.0001), loss= ‘categorical_crossentropy’,metrics = [‘accuracy’]) |
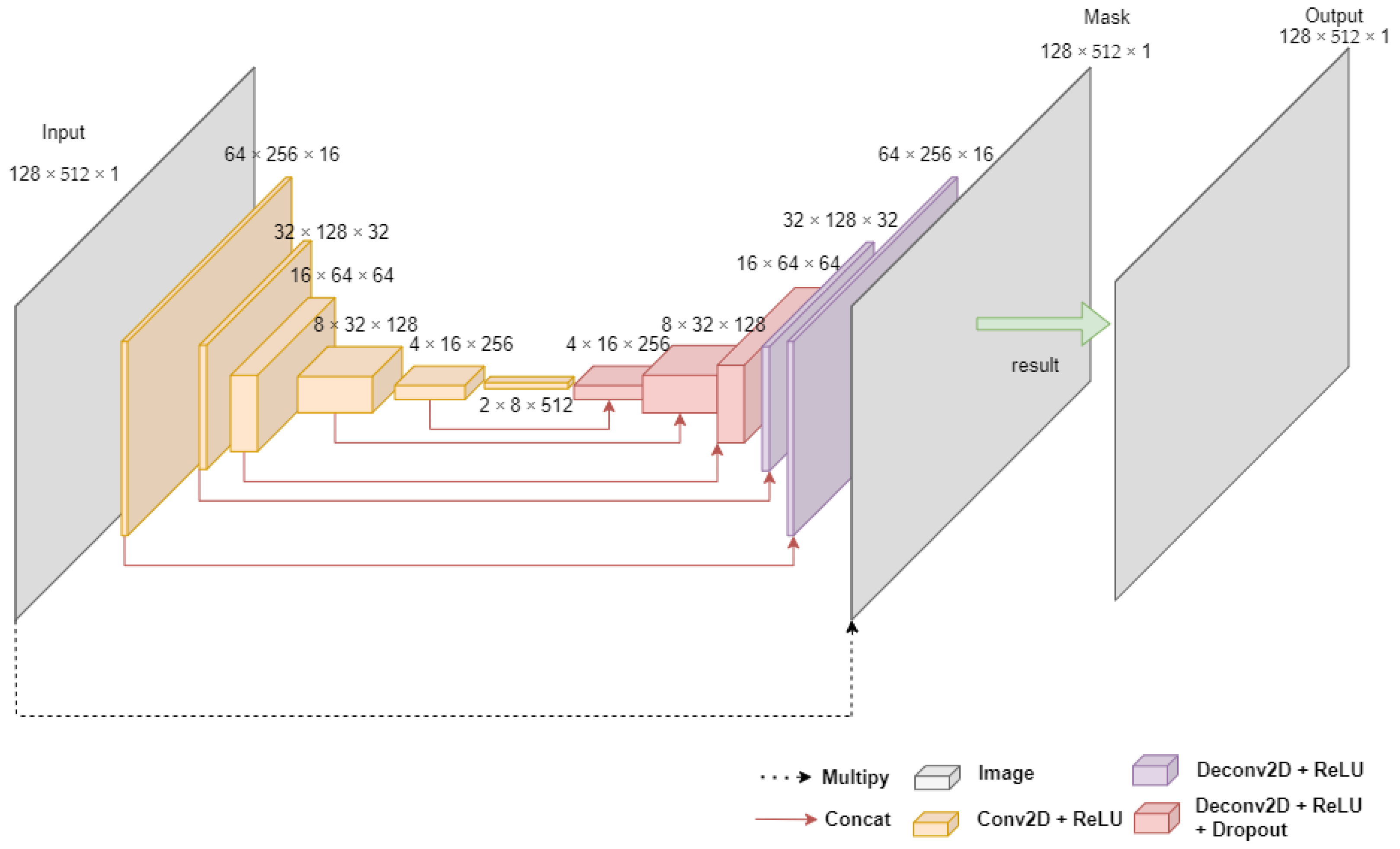
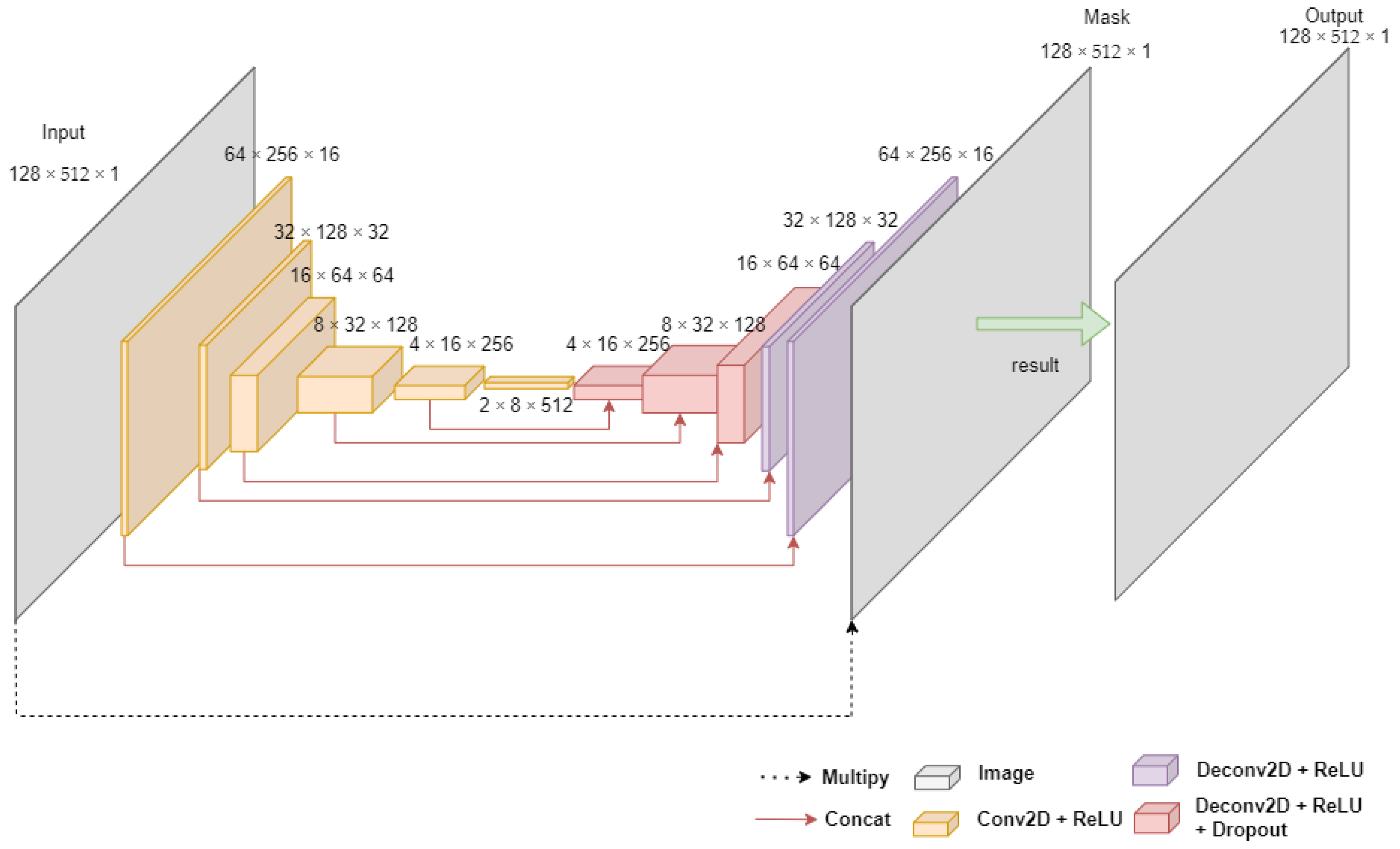
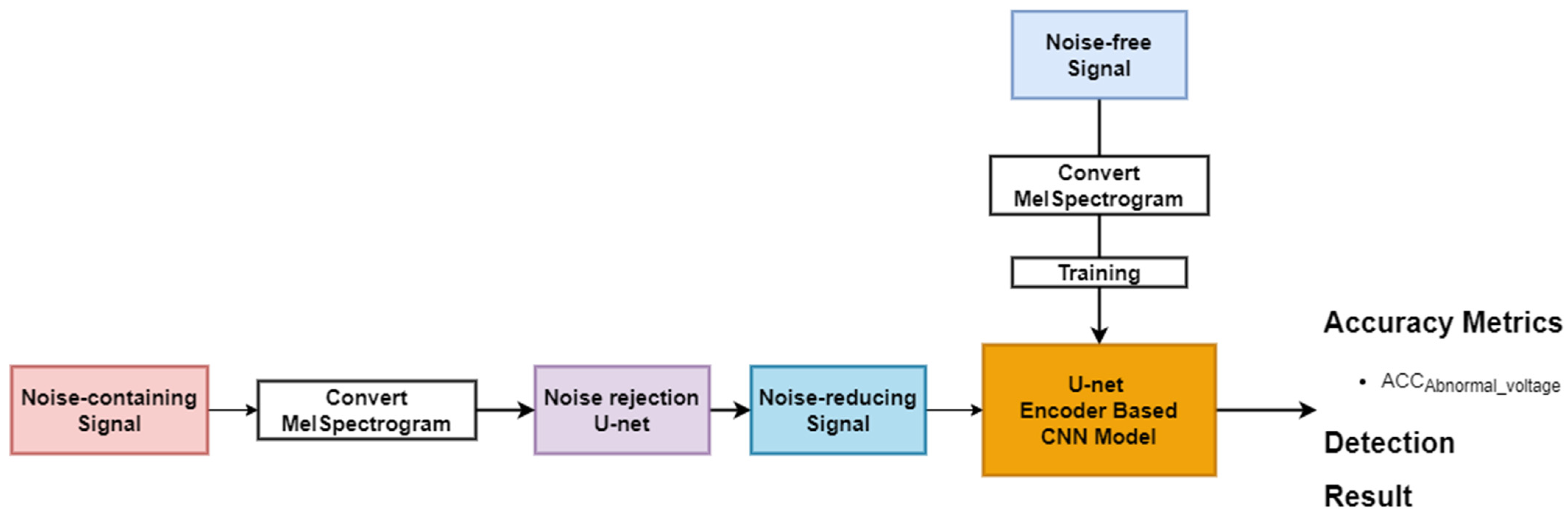
3.2. Noise Rejection Method for Voltage Level Classification
| Algorithm 2. Noise rejection method | |
| Input: Noise-containing signal Output: Noise-reducing signal | |
| Step 1 Step 2 Step 3 Step 4 Step 5 | input_shape = [128, 512, 1] X = model_input n_layers = 6 FILTERS_LAYER = 16 for i in range(n_layers): n_layers = FILTERS_LAYER × (2i) X = Conv2D(n_layers, kernel_size = (5,5), strides = (2,2), padding = 2)(X) X = BatchNormalization(momentum = 0.9, scale = True)(X) X = get_activation(activation)(“RelU”) for i in range(n_layers − 1): dropout = not (i == 1 or i == 2 or i == 3) if i > 0: X = Concatenate(axis = 3)([X, x_encoder_layers[n_layers −i−1]]) n_filters = encoder_layer.get_shape().as_list()[−1]//2 X = Conv2DTranspose(n_filters, kernel_size = (5,5), padding = ”same”, strides = (2,2))(X) X = BatchNormalization(momentum = 0.9, scale = True)(X) if dropout: X = Dropout(0.5)(X) X = get_activation(“ReLU”)(X) X = Concatenate(axis = 3)([X, x_encoder_layers[0]]) X = Conv2DTranspose(n_filters, kernel_size = (5,5), padding = 2, strides = (2,2))(X) X = get_activation(“Sigmoid”)(X) outputs = multiply([model_input, X]) model = Model(model_input, outputs) model.compile(optimizer = ”adam”, loss= ‘mean_absolute_error’) |
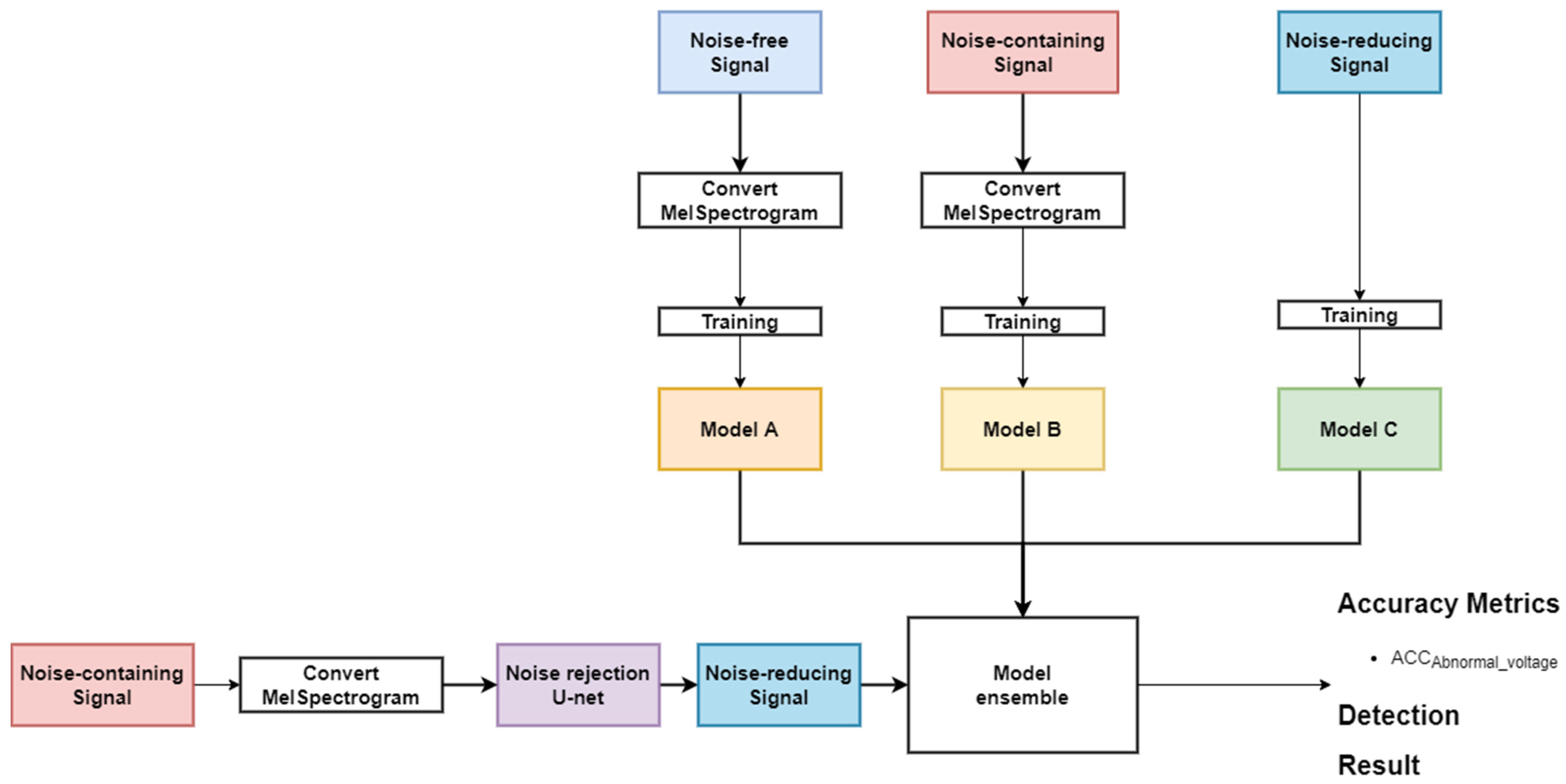
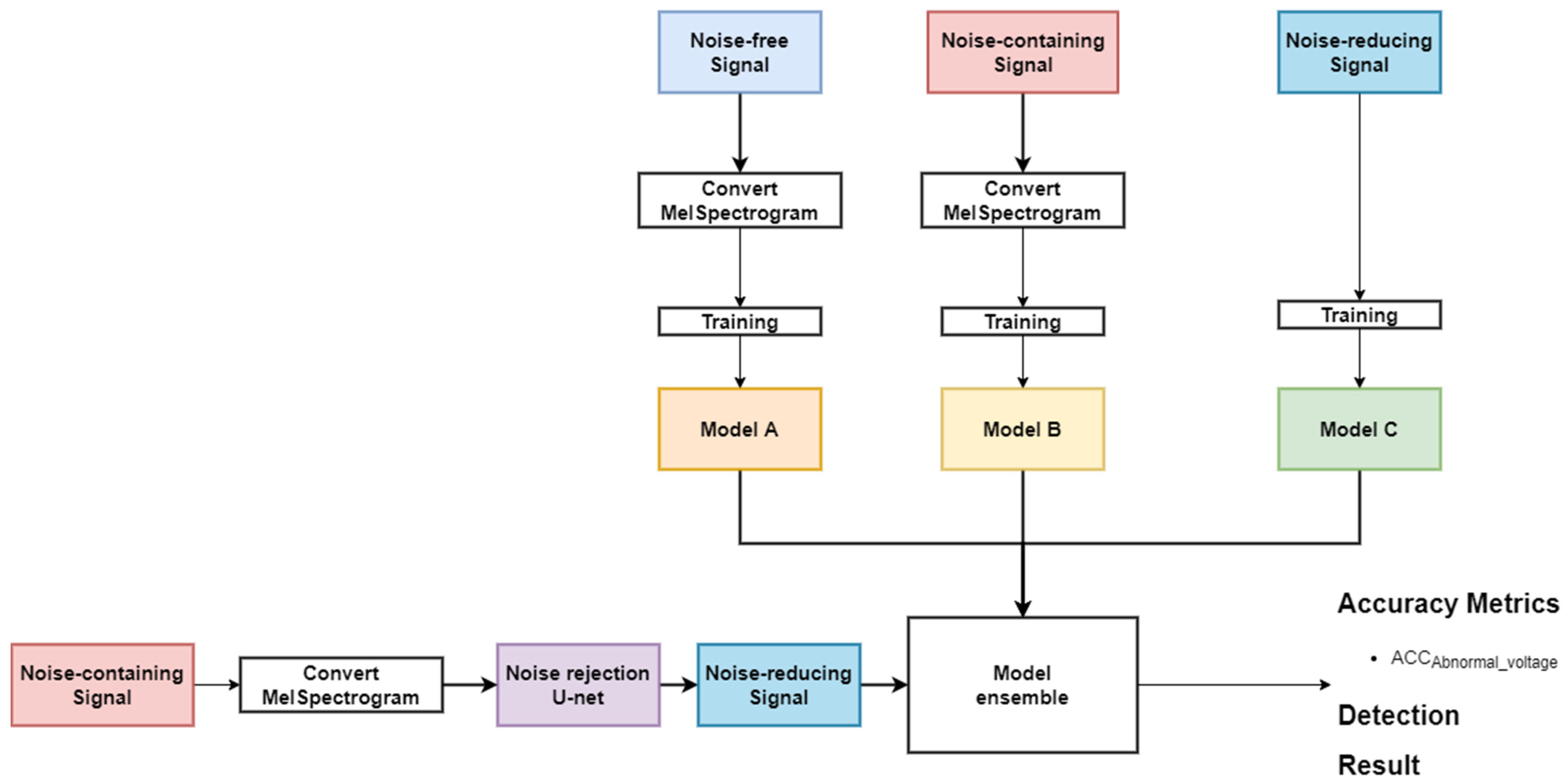
3.3. Ensemble Model in an Unknown Noise
| Algorithm 3. EnsembleABC model | |
| Input: Model A, B, C Output: Voltage levels | |
| Step 1 Step 2 Step 3 Step 4 Step 5 | ModelA: Noise-free signal ModelB: Noise-containing signal ModelC: Noise-reducing signal PredictA = ModelA.ouput PredictB = ModelB.ouput PredictC = ModelC.ouput MergeABC = Concat(PredictA, PredictB, PredictC) EnsembleABC = Dense(Voltages levels = 5)(MergeABC) EnsembleABC.compile(optimizer = adam, loss = ’categorical_crossentropy’ , metrics = [‘accuracy’] |
4. Experimental Results
4.1. Experimental Environments
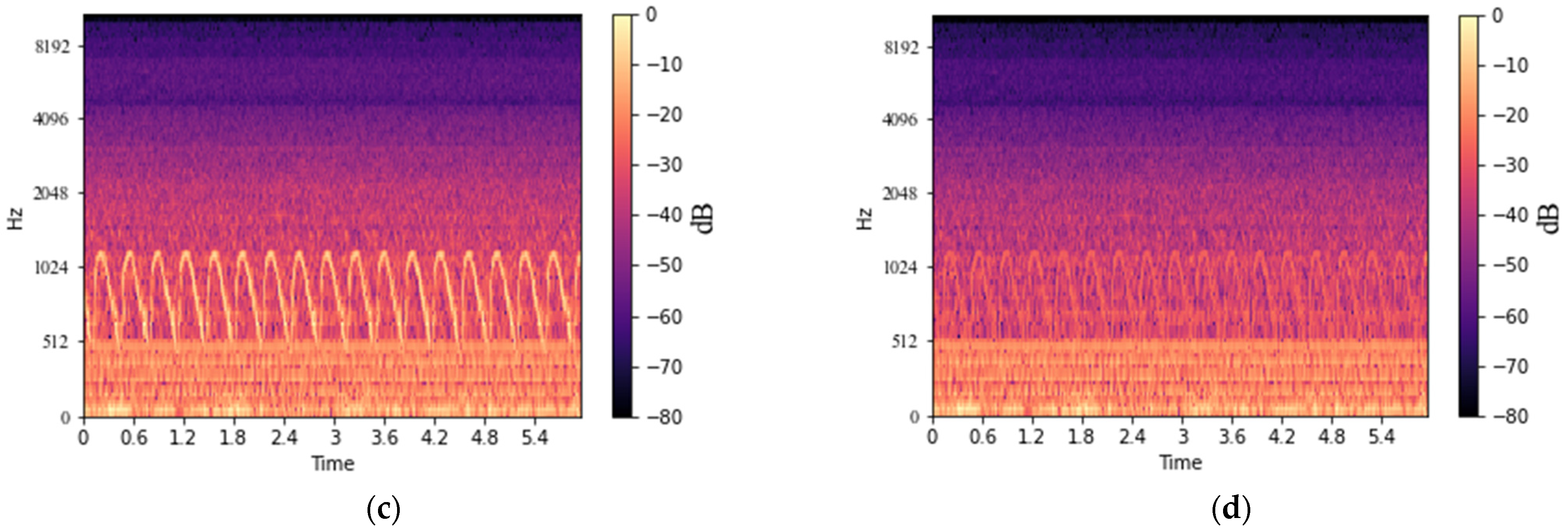
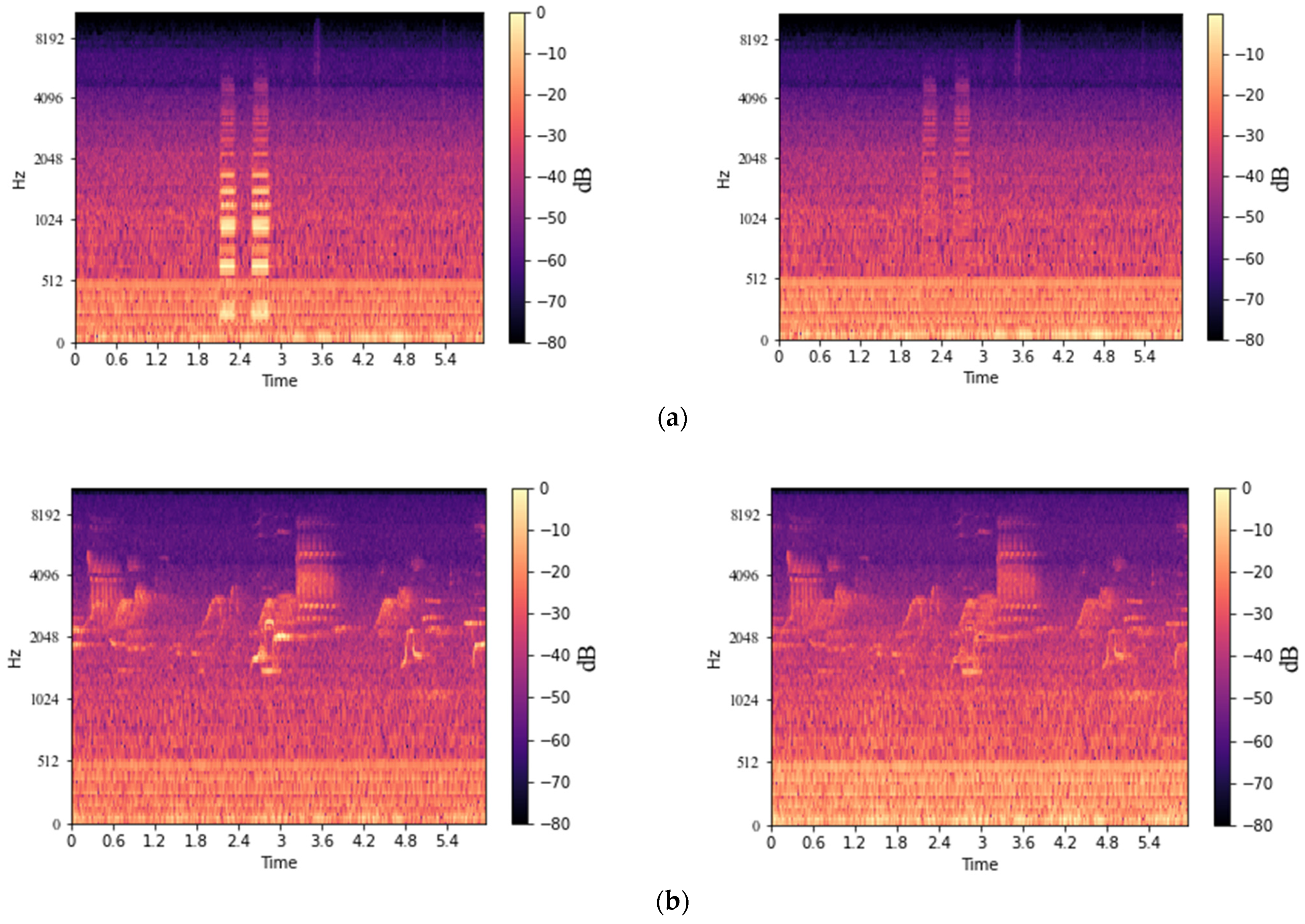
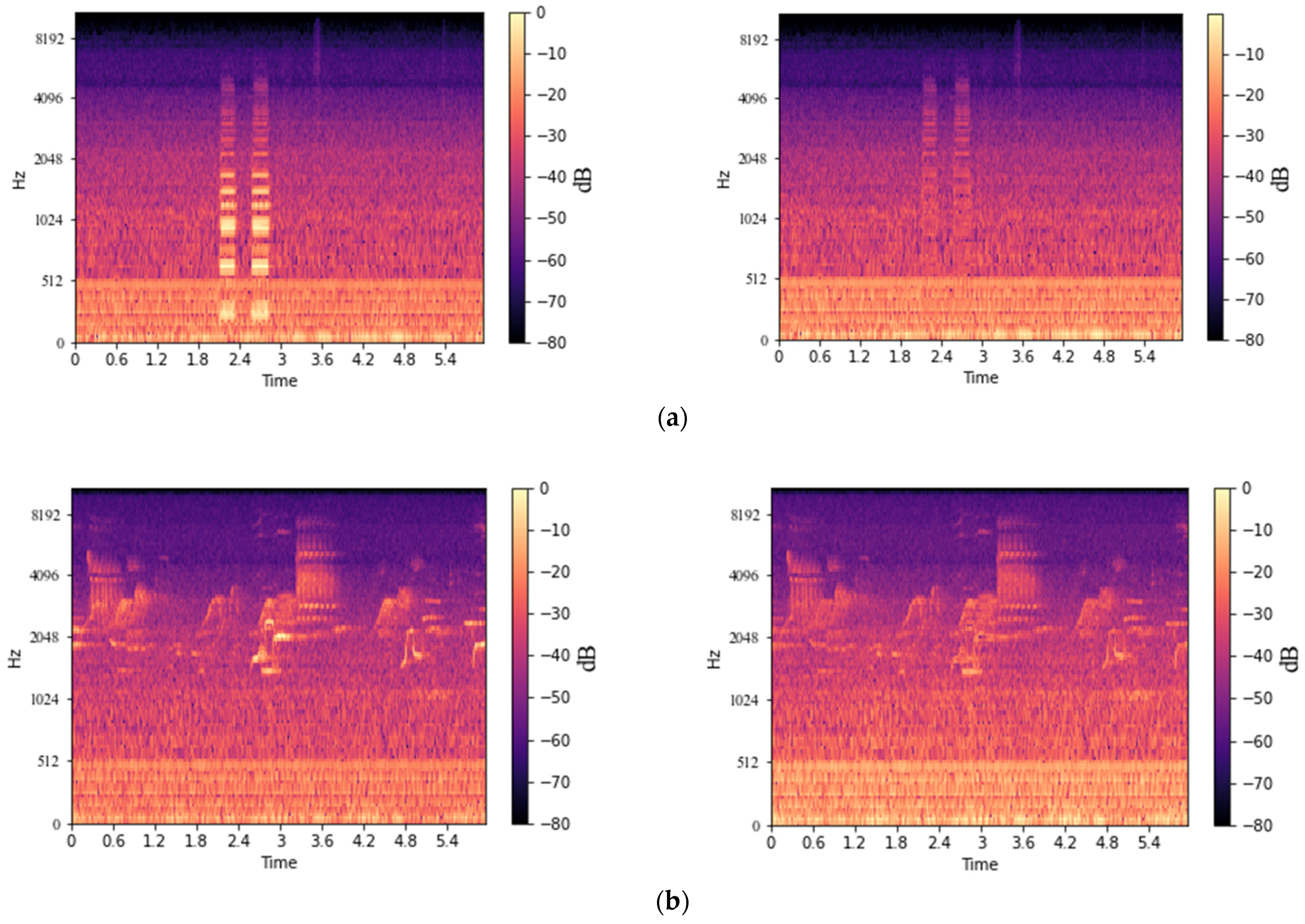
4.2. Performance of Noise Rejection with U-Net
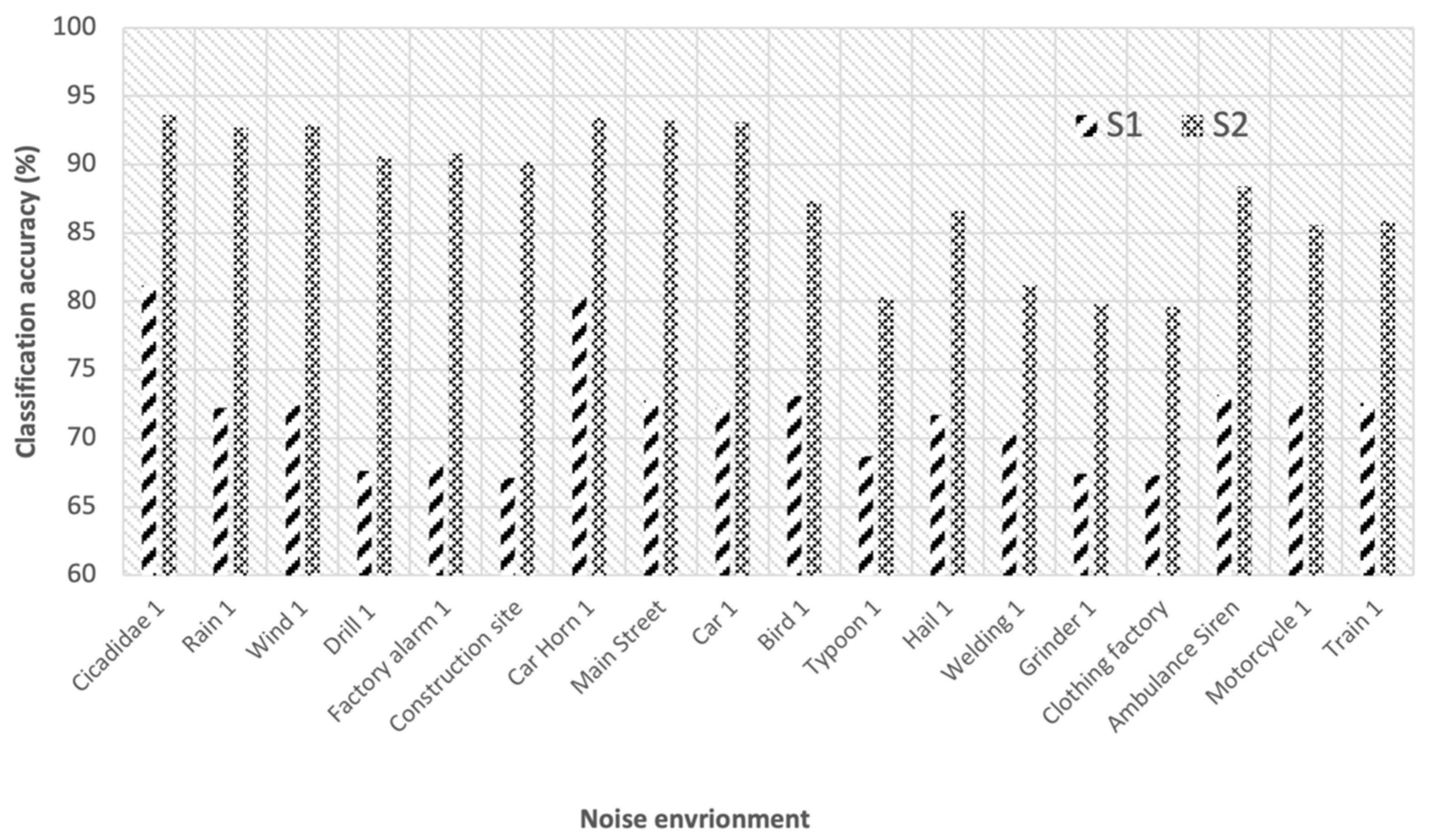
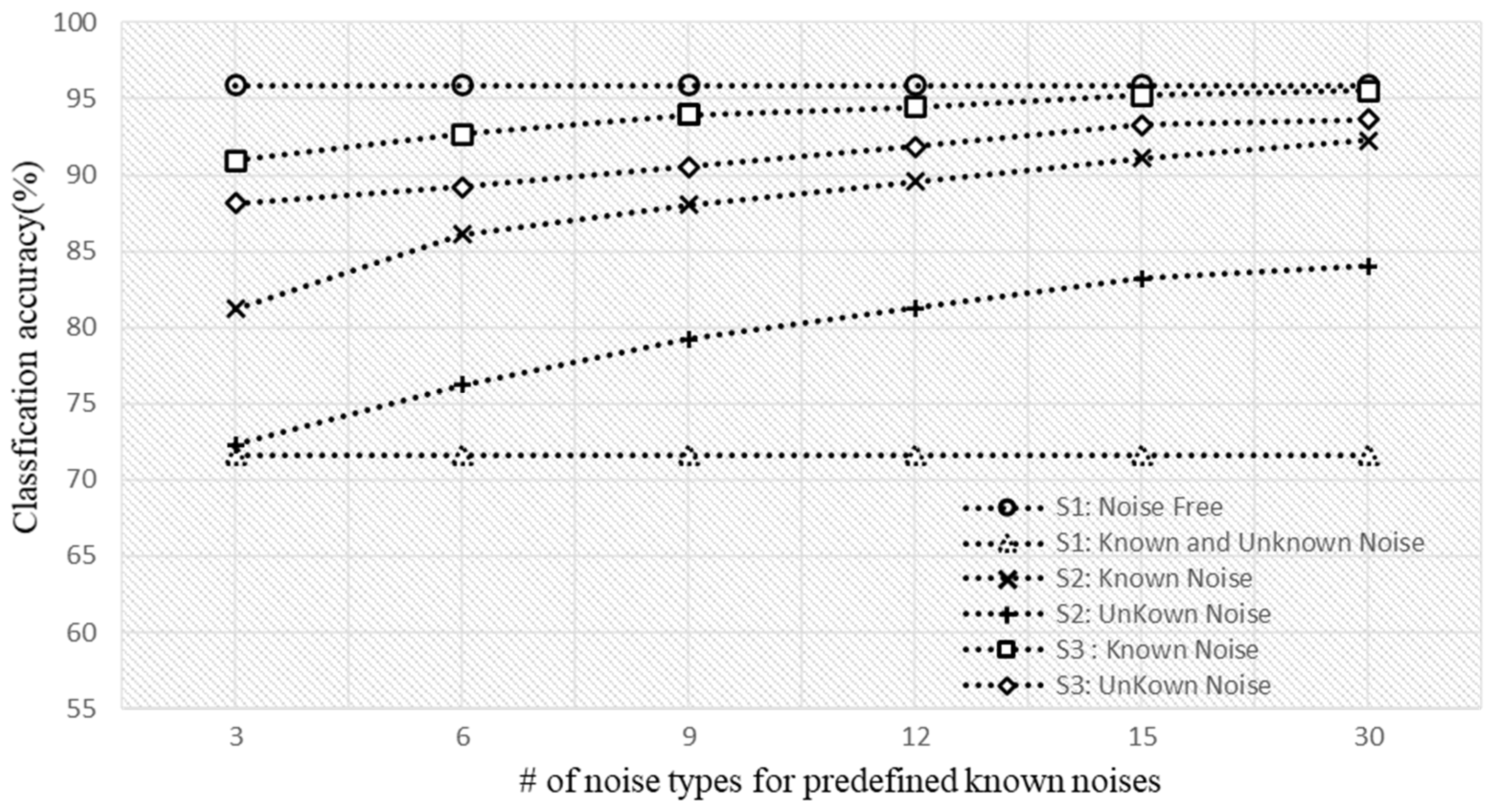
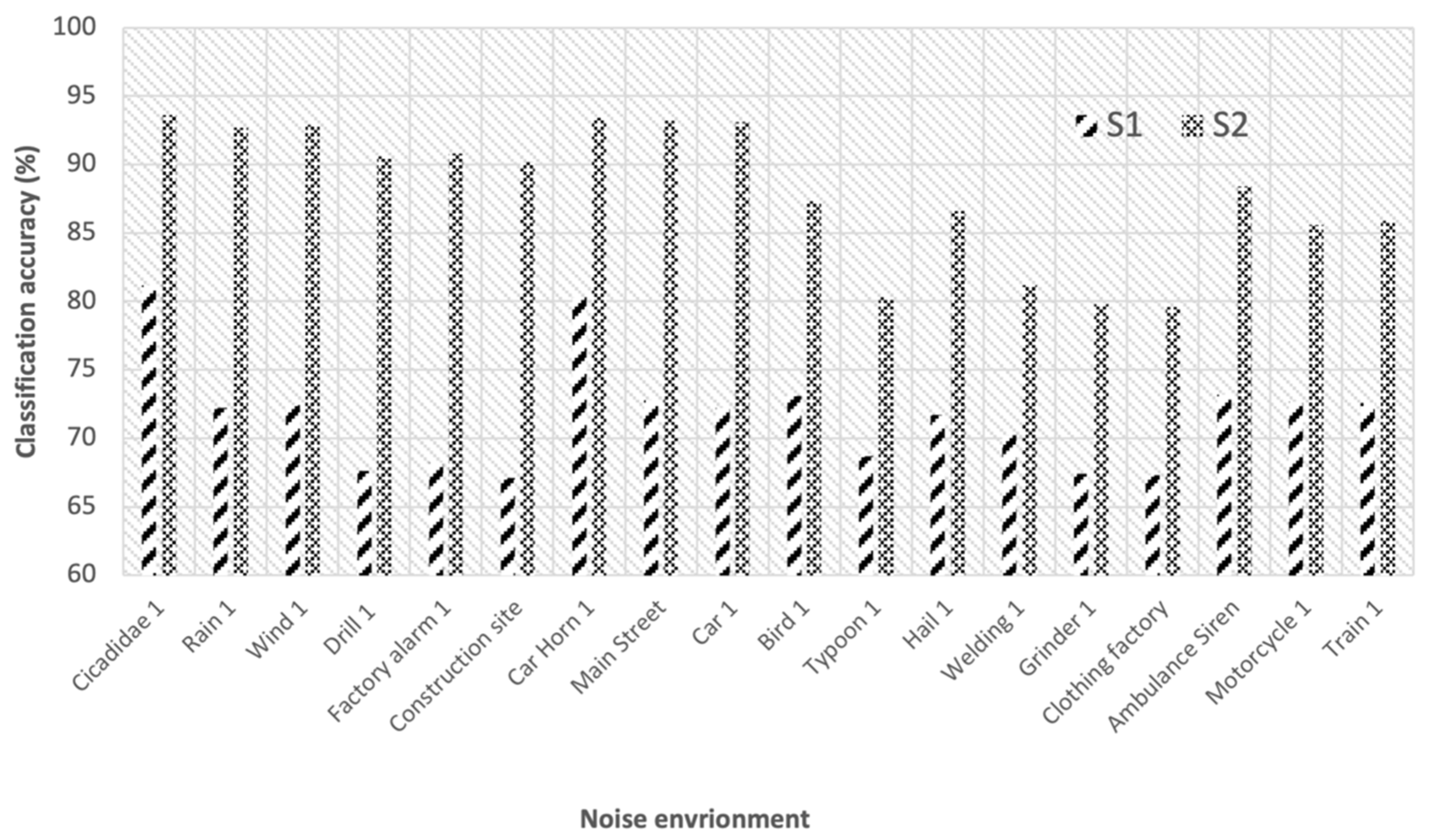
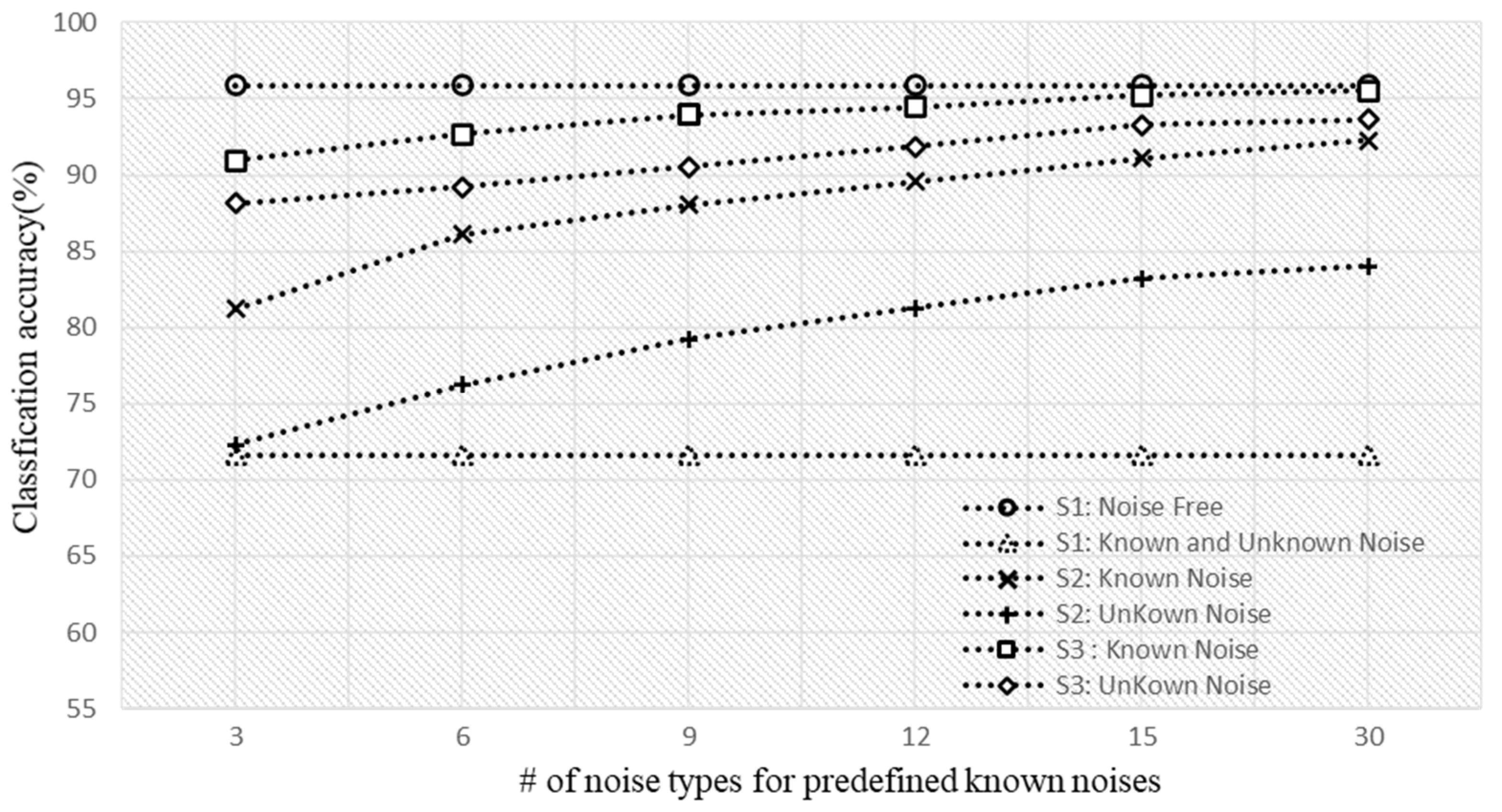
4.3. Performance in a Noise with Ensemble-Based Approach
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Secic, A.; Krpan, M.; Kuzle, I. Vibro-Acoustic Methods in the Condition Assessment of Power Transformers: A Survey. IEEE Access 2019, 7, 83915–83931. [Google Scholar] [CrossRef]
- Garcia, B.; Burgos, J.; Alonso, A. Transformer tank vibration modeling as a method of detecting winding deformations-part I: Theoretical foundation. IEEE Trans. Power Deliv. 2006, 21, 157–163. [Google Scholar] [CrossRef]
- Aidi, L.; Zebo, W.; Hai, H.; Jianping, Z.; Jinhui, W. Study of vibration sensitive areas on 500 kV power transformer tank. In Proceedings of the IEEE 10th International Conference on Industrial Informatics, Beijing, China, 25–27 July 2012; pp. 891–896. [Google Scholar]
- Beltle, M.; Tenbohlen, S. Usability of vibration measurement for power transformer diagnosis and monitoring. In Proceedings of the 2012 IEEE International Conference on Condition Monitoring and Diagnosis, Bali, Indonesia, 23–27 September 2012; pp. 281–284. [Google Scholar]
- Borucki, S. Diagnosis of technical condition of power transformers based on the analysis of vibroacoustic signals measured in transient operating conditions. IEEE Transection IEEE Trans. Power Deliv. 2012, 27, 670–676. [Google Scholar] [CrossRef]
- Munir, B.; Smit, J.; Rinaldi, I.G. Diagnosing winding and core condition of power transformer by vibration signal analysis. In Proceedings of the 2012 IEEE International Conference on Condition Monitoring and Diagnosis, Bali, Indonesia, 23–27 September 2012; pp. 429–432. [Google Scholar]
- Bagheri, M.; Naderi, M.; Blackburn, T. Advanced transformer winding deformation diagnosis: Moving from off-line to on-line. IEEE Trans. Dielectr. Electr. Insul. 2012, 19, 1860–1870. [Google Scholar] [CrossRef]
- Beltle, M.; Tenbohlen, S. Vibration analysis of power transformers. In Proceedings of the 18th international Symposium on High Voltage Engineering, Seoul, Korea, 25–30 August 2013; pp. 1816–1821. [Google Scholar]
- Li, K.; Xu, H.; Li, Y.; Zhou, Y.; Ma, H.; Liu, J.; Gong, J. Simulation test method for vibration monitoring research on winding looseness of power transformer. In Proceedings of the 2014 International Conference on Power System Technology, Chengdu, China, 20–22 October 2014; pp. 1602–1608. [Google Scholar]
- Guo, S.; Long, K.; Hao, Z.; Ma, J.; Yang, H.; Gan, J. The STUDY on vibration detection and diagnosis FOR distribution transformer in operation. In Proceedings of the 2014 China International Conference on Electricity Distribution (CICED), Shenzhen, China, 23–26 September 2014; pp. 983–987. [Google Scholar]
- Hong, K.; Huang, H.; Zhou, J. Winding condition assessment of power transformers based on vibration correlation. IEEE Transection Power Deliv. 2015, 30, 1735–1742. [Google Scholar] [CrossRef]
- Brikci, F.; Giguere, P.; Soares, M.; Tardif, C. The vibro-acoustic method as fast diagnostic tool on load tap changers through the simultaneous analysis of vibration, dynamic resistance and high speed camera recordings. In Proceedings of the International Conference on Condition Monitor and Diagnosis Maintenance, CIGRÉ Condition Monitor, Diagnosis Maintenance, Bucharest, Romania, 11–15 October 2015; pp. 1–9. [Google Scholar]
- Hong, K.; Huang, H.; Fu, Y.; Zhou, J. A vibration measurement system for health monitoring of power transformers. J. Meas. 2016, 93, 135–147. [Google Scholar] [CrossRef]
- Mussin, N.; Suleimen, A.; Akhmenov, T.; Amanzholov, N.; Nurmanova, V.; Bagheri, M.; Naderi, M.; Abedinia, O. Transformer active part fault assessment using internet of things. Int. Conf. Comput. Netw. Commun. 2018, 9, 169–174. [Google Scholar]
- Zheng, J.; Pan, J.; Huang, H. An experimental study of winding vibration of a single-phase power transformer using a laser Doppler vibrometer. J. Appl. Acoust. 2015, 87, 30–37. [Google Scholar] [CrossRef]
- Zou, L.; Guo, Y.; Liu, H.; Zhang, L.; Zhao, T. A Method of Abnormal States Detection Based on Adaptive Extraction of Transformer Vibro-Acoustic Signals. J. Energ. 2017, 10, 2076. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y.; Ji, S.; Zhan, C.; Ren, F.; Zhu, L.; Pan, Z. Diagnosis on Winding Failure Through Impulsive Sound of Power Transformer. In Proceedings of the 2018 IEEE International Power Modulator and High Voltage Conference (IPMHVC), Jackson, WY, USA, 3–7 June 2018; pp. 105–110. [Google Scholar]
- Geng, S.; Wang, F.; Zhou, D. Mechanical Fault Diagnosis of Power Transformer by GFCC Time–frequency Map of Acoustic Signal and Convolutional Neural Network. In Proceedings of the 2019 IEEE Sustainable Power and Energy Conference (iSPEC), Beijing, China, 21–23 November 2019; pp. 2106–2110. [Google Scholar]
- Zhang, C.; He, Y.; Du, B.; Yuan, L.; Li, B.; Jiang, S. Transformer fault diagnosis method using IoT based monitoring system and ensemble machine learning. J. Future Gener. Comput. Syst. 2020, 108, 533–545. [Google Scholar] [CrossRef]
- Hong, L.; Shan, H.; Huan, X.; Shou, Q.; Wen, Z.; Wang, M. Mechanical Fault Diagnosis Based on Acoustic Features in Transformers. In Proceedings of the 2020 IEEE Conference on Electrical Insulation and Dielectric Phenomena (CEIDP), East Rutherford, NJ, USA, 18–30 October 2020; pp. 563–566. [Google Scholar]
- Gupta, H.; Gupta, D. LPC and LPCC method of feature extraction in Speech Recognition System. In Proceedings of the 2016 6th International Conference-Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 498–502. [Google Scholar]
- Dua, M.; Aggarwal, R.; Biswas, M. GFCC based discriminatively trained noise robust continuous ASR system for Hindi language. J. Ambient Intell. Humaniz. Comput. 2019, 10, 2301–2314. [Google Scholar] [CrossRef]
- Tran, T.; Lundgren, J. Drill Fault Diagnosis Based on the Scalogram and Mel Spectrogram of Sound Signals Using Artificial Intelligence. J. IEEE Access 2020, 8, 203655–203666. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image SegmentationU-Net. In International Conference on Computer Vision and Pattern Recognition; Springer: Cham, Switzerland, 2015; pp. 1–8. [Google Scholar]
- Jansson, A.; Humphrey, E.; Montecchio, N.; Bittner, R.; Kumar, A.; Weyde, T. Singing voice separation with deep U-Net convolutional networks. In Proceedings of the International Society for Music Information Retrieval Conference, Suzhou, China, 23–27 October 2017; pp. 745–751. [Google Scholar]
- Mosavi, A.; Hosseini, F.; Choubin, B.; Goodarzi, M.; Dineva, A. Ensemble Boosting and Bagging Based Machine Learning Models for Groundwater Potential Prediction. Water Resour. Manag. 2020, 17, 23–37. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hintion, G. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Morgan Kaufmann: Las Vegas, NV, USA, 2012; pp. 1–9. [Google Scholar]
- Hertel, L.; Phan, H.; Mertins, A. Comparing time and frequency domain for audio event recognition using deep learning. In Proceedings of the 2016 International Joint Conference on Neural Networks (Ijcnn), Vancouver, BC, Canada, 24–29 July 2016; pp. 3407–3411. [Google Scholar]
- Kek, X.Y.; Cheng Siong, C.; Li, Y. Acoustic Scene Classification Using Bilinear Pooling on Time-liked and Frequency-liked Convolution Neural Network. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 3189–3194. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Non-Invasive Method | Considering Noise | Classification Method |
|---|---|---|---|
| [2,3,4,5,6,7,8,9,10,11,12,13,14] 2006–2018 | X | X | Signal Processing or Visual inspection |
| [15,16,17] 2015–2018 | O | X | Signal Processing |
| [18,19,20] 2019–2020 | O | Known Noise | Machine Learning |
| Ours2021 | O | Known Noise and Unknown Noise | Machine Learning |
| Noise Environment | Noise Detail | |
|---|---|---|
| Known | Nature | Rain 1, Rain 2, Rain 3, Cicadidae 1, Cicadidae 2, Thunder 1, Thunder 2,Wind 1, Wind 2, Wind 3 |
| Worksite | Excavator, Loader, Drill 1, Drill 2, Fork lift 1, Fork lift 2, Factory alarm 1, Factory alarm 2, Steel mill, Construction site | |
| City | Car Horn 1, Car Horn 2, Car Horn 3, Park 1, Park 2, Concert 1, Concert 2, Car 1, Car 2, Main Street | |
| Unknown | Nature | Bird 1, Bird 2, Bird 3, Typoon 1, Typoon 2, Typoon 3, Hail 1, Hail 2, Frog, Cricket Chirping |
| Worksite | Welding 1, Welding 2, Grinder 1, Grinder 2, Clothing factory, Building demolition, Air compressors, Breaker, Roller, Borewell drilling | |
| City | Motorcycle 1, Motorcycle 2, Ambulance Siren, Police Siren, Fire Truck Siren, Train 1, Train 2, Fire Work 1, Fire Work 2 |
| Classification Methods | Learning Data | Noisy Environments | |
|---|---|---|---|
| S1 | Baseline | Noise-free | Noise-free |
| Known and Unknown noise | |||
| S2 | Noise rejection | Noise-free, Noise-containg | Known noise |
| Unknown noise | |||
| S3 | Ensemble | Noise-free, Noise-containg, Noise-reducing | Known noise |
| Unknown noise |
| Noise Environment | Noise Rejection Performance with# of Predefined Known Noises | |||
|---|---|---|---|---|
| 6 | 15 | 30 | ||
| Known noise | Nature | 0.30 | 0.61 | 0.72 |
| Worksite | 0.39 | 0.62 | 0.72 | |
| City | 0.42 | 0.69 | 0.79 | |
| Unknown noise | Nature | 0.22 | 0.32 | 0.46 |
| Worksite | 0.22 | 0.39 | 0.41 | |
| City | 0.35 | 0.40 | 0.47 | |
| Noisy Environment | S1 | S2 | S3 |
|---|---|---|---|
| Known noise | 72.56% | 92.27% | 95.33% |
| Unknown noise | 70.74% | 84.01% | 93.65% |
| Total average | 71.65% | 88.14% | 94.59% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Lee, S. Power Transformer Voltages Classification with Acoustic Signal in Various Noisy Environments. Sensors 2022, 22, 1248. https://doi.org/10.3390/s22031248
Kim M, Lee S. Power Transformer Voltages Classification with Acoustic Signal in Various Noisy Environments. Sensors. 2022; 22(3):1248. https://doi.org/10.3390/s22031248
Chicago/Turabian StyleKim, Mintai, and Sungju Lee. 2022. "Power Transformer Voltages Classification with Acoustic Signal in Various Noisy Environments" Sensors 22, no. 3: 1248. https://doi.org/10.3390/s22031248
APA StyleKim, M., & Lee, S. (2022). Power Transformer Voltages Classification with Acoustic Signal in Various Noisy Environments. Sensors, 22(3), 1248. https://doi.org/10.3390/s22031248