1. Introduction
Haze is a phenomenon in which the visible distance is reduced due to dust, smoke particles, and polluting particles in the atmosphere. Particles in the atmosphere scatter light; thus, images obtained in these environments decrease contrast and, eventually, deteriorate visibility. Recently developed automatic navigation systems rely heavily on vision sensors [
1]. If the input image is in poor condition, the overall system will suffer. Therefore, dehazing technology, which can obtain clear images, can benefit systems such as image classification [
2,
3,
4,
5], image recognition [
6,
7,
8,
9,
10], visual odometry [
11,
12], and remote sensing [
13,
14,
15].
Currently, the most commonly used sensors for robots and vehicles include light detection and ranging (LiDAR) and camera. The sensors allow the performance of visual odometry, LiDAR odometry, SLAM, autonomous navigation, etc. For these purposes, they can be used as visual-only [
11,
12,
16,
17], LiDAR-only [
18,
19], or fused [
20]. When the LiDAR and visual are fused, the two sensors are used complementarily to increase robustness of the system [
20]. Even with the increase in robustness, damage to the resulting values can occur if the input data obtained from the sensors are inherently in poor condition. Therefore, it is necessary to make quality input data to prevent this degradation.
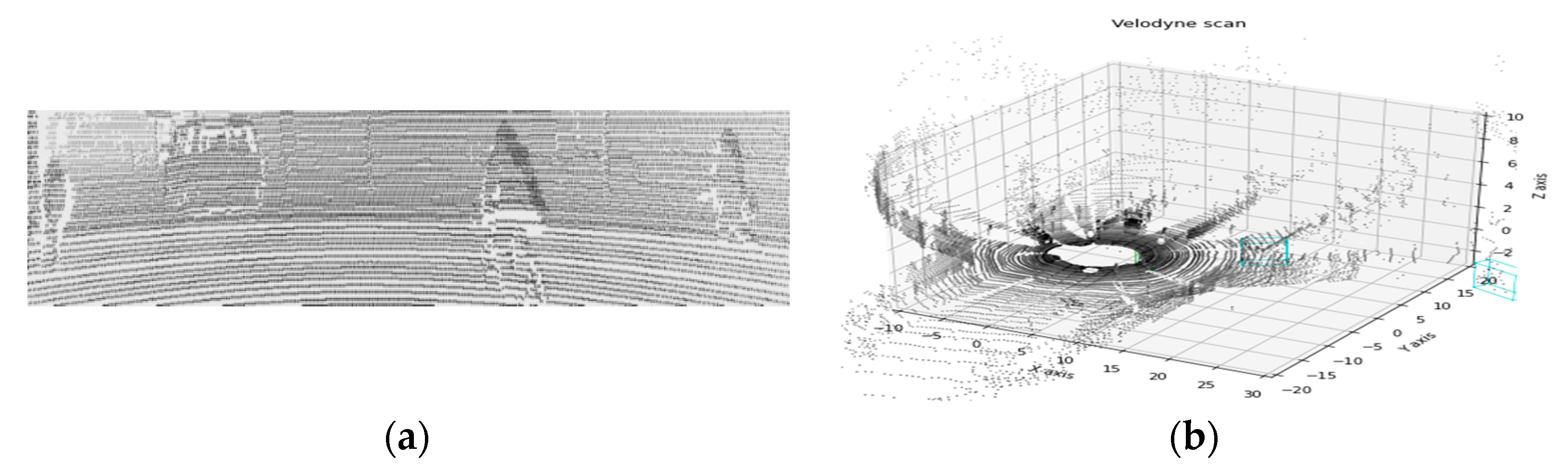
We can attach cameras to numerous platforms such as vehicles, drones, and robots to get image data. If the weather allows, we can get clear images such as
Figure 1a. In this case, dehazing is unnecessary for effective vision-based processes. However, in the event of haze due to smoke or fine dust in the atmosphere, such as in
Figure 1b, utilizing such processes becomes challenging [
21]. Therefore, the contrasts from images obtained in a hazed environment should be enhanced.
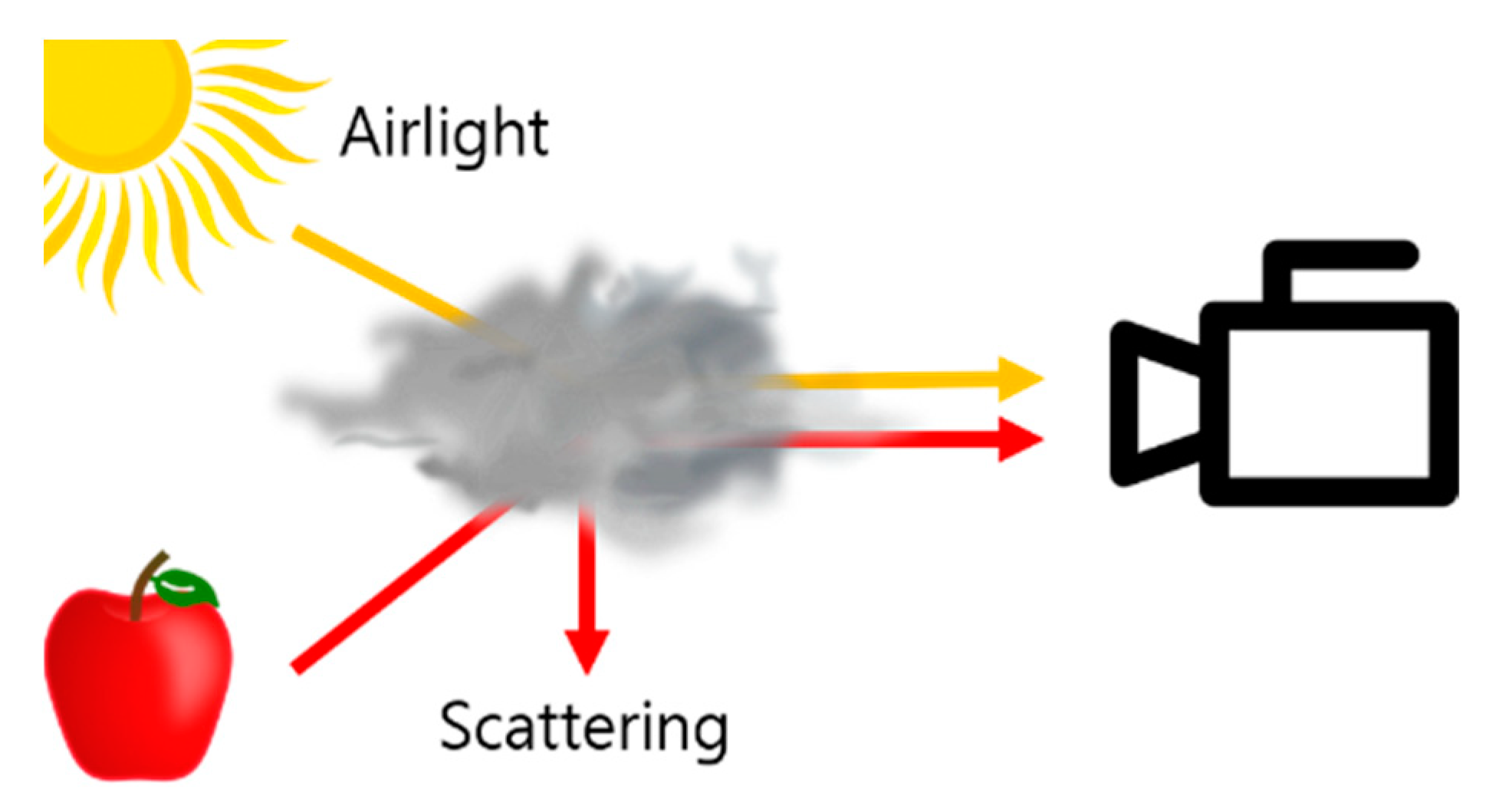
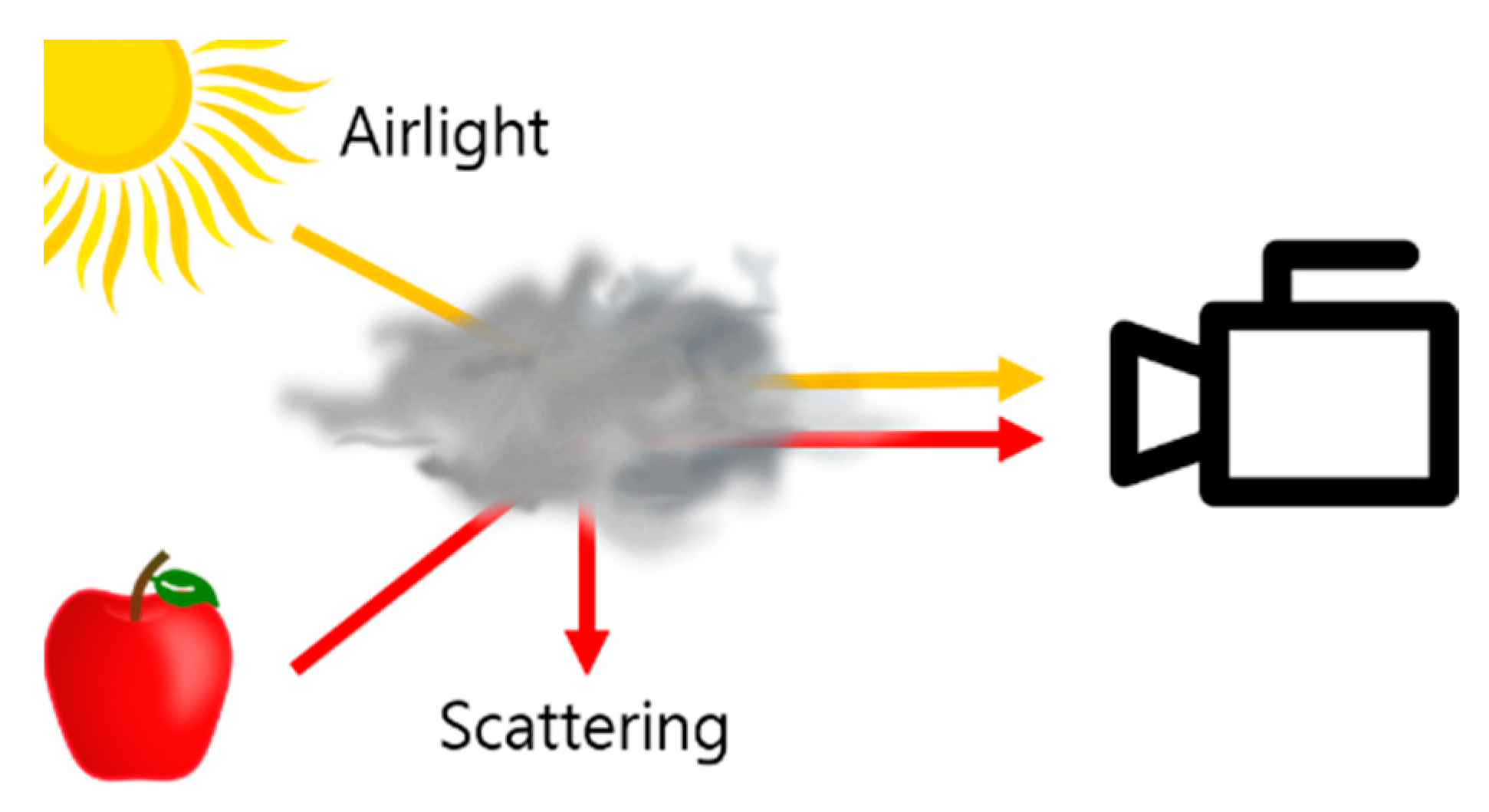
Each image pixel value in hazy images can be expressed with atmospheric scattering model, a linear combination of the pixel values from actual image, transmission image, and airlight [
22,
23,
24]. Airlight and transmission images are required to perform scene radiance recovery through the scattering coefficient model.
Traditional algorithms use color attenuation prior [
25] and dark channel prior [
26] to create a transmission image, whereas recent research uses deep learning to perform dehazing. The proposed method succeeds traditional methods, with its contribution in utilizing depth image and scattering coefficient to perform dehazing.
Existing methods for obtaining depth images include using stereo camera or depth camera. More recent research adopts deep learning in obtaining depth images from monocular images through training of existing depth images [
27]. In this paper, the depth image is obtained by 2D projection of LiDAR point cloud. In this way, by obtaining a depth image through LiDAR and performing dehazing on vision data, we would like to propose a more complementary and robust LiDAR–vision fusion system.
Our contribution is as follows: (1) Proposal of a depth image-based dehazing technique available in LiDAR–vision fusion systems; (2) Proposal of a scattering coefficient estimation technique through the DCM-scattering coefficient model.
An outline of the paper is as follows.
Section 2 outlines the theoretical background of dehazing and the related works applied to the proposed method.
Section 3 outlines the overall description of the proposed method, and
Section 4 summarizes the analysis of the simulation results obtained through the proposed method. Finally,
Section 5 briefly describes the conclusions, the limitations of the proposed method, and the future works for improving the limit.
3. Image Dehazing Based on LiDAR Generated Grayscale Depth Prior
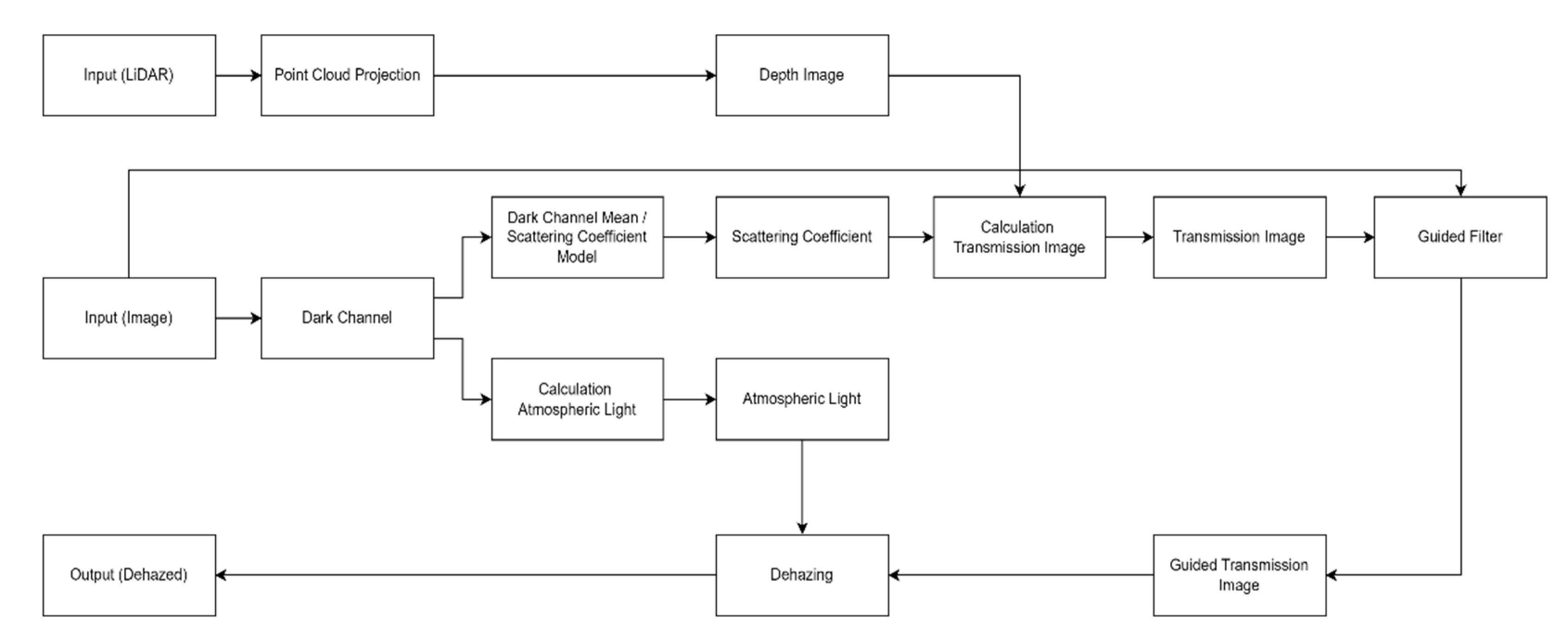
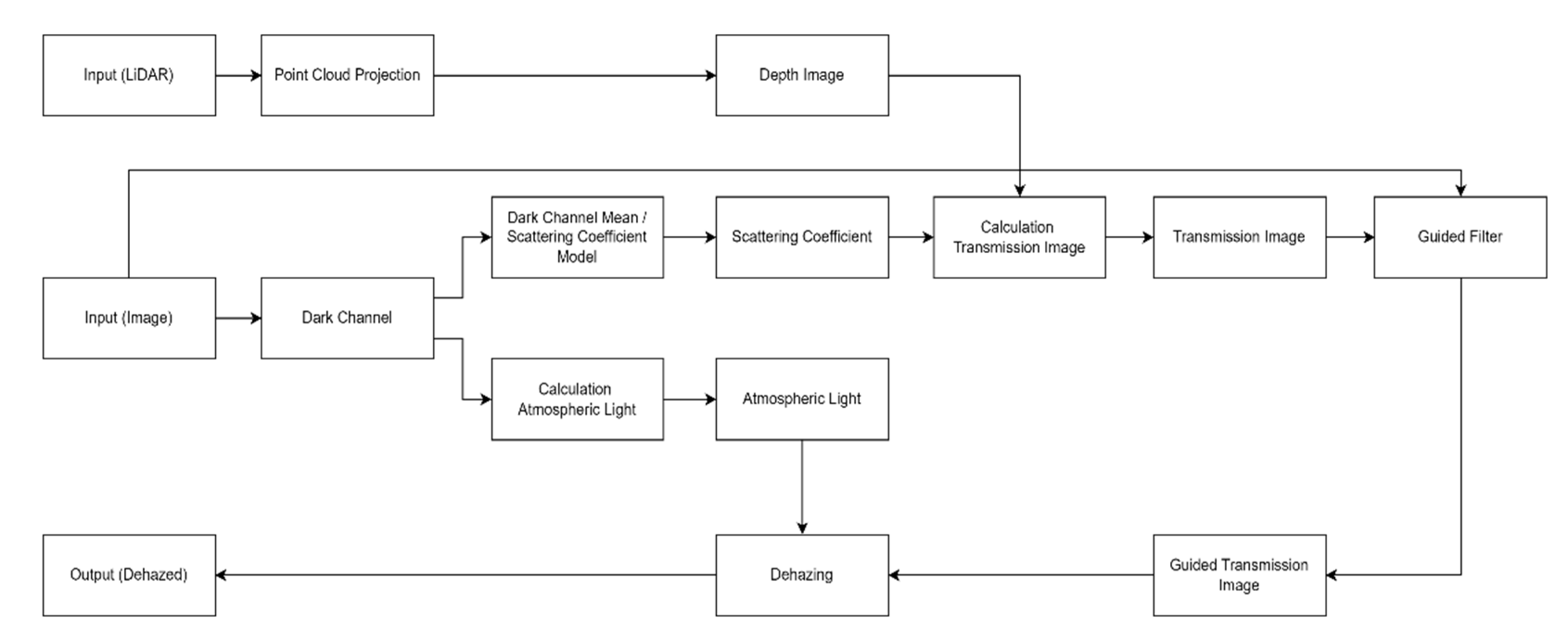
The structure of the proposed dehazing method is shown in
Figure 3. First, hazy image and point cloud are used as input data. Through a relationship in
Section 3.1, the point cloud is projected and converted into a depth image. When projecting the point cloud, the point cloud of the LiDAR must be projected within the camera frame through the calibration of the camera and LiDAR. Thereafter, the scattering coefficient is estimated through a relationship in
Section 3.2 by using the image with haze as an input image. The dark channel image used in
Section 3.2, obtained from the hazy image, is also used to estimate the atmospheric light. Finally, the transmission image is estimated through the depth image and the scattering coefficient, and after refining the transmission image by applying the guided filter in
Section 3.3, the dehazing is performed according to Equation (13).
3.1. Point Cloud Projection
In this study, synthetic haze image generation and verification of dehazing algorithm are performed using a KITTI dataset [
39]. In order to generate depth images required for the dehazing algorithm, the point cloud of the KITTI dataset was projected into an image [
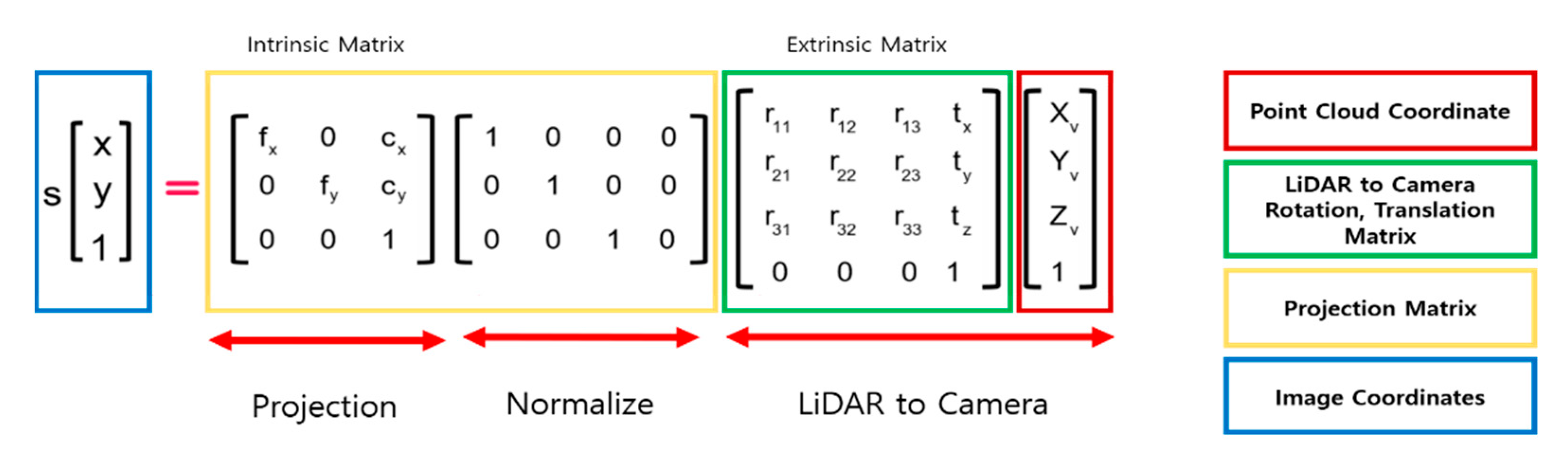
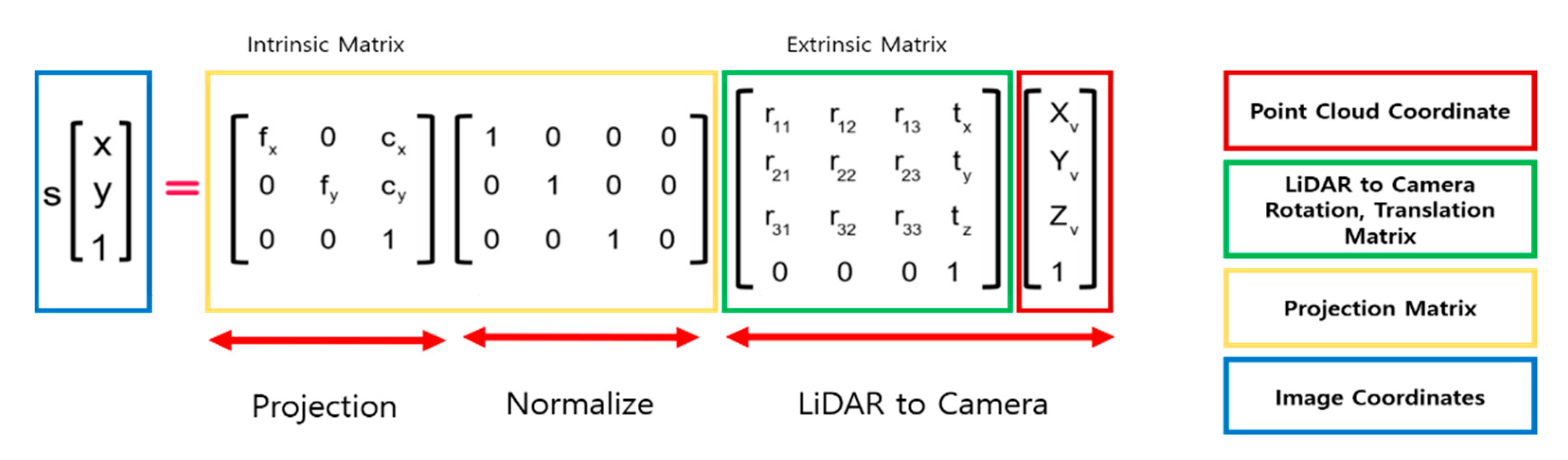
37]. Using the calibration data from the dataset, the projection, rotation, and translation matrices can be obtained, and the point cloud in 3D format projects into 2D through the relationship shown in
Figure 4.
First, when a point in the 3D space is represented as , its position on the 2D image is expressed in where , , and refer to the coordinates of a point cloud in the world frame, and and are image pixel coordinates in the camera frame. To perform a projection, points in the 3D space belonging to the world frame should be represented within the camera frame. This can be expressed by multiplying the world frame’s rotation with the matrix extrinsic matrix for translation.
Then,
can be projected onto a two-dimensional plane by normalizing the obtained values and multiplying them by the intrinsic matrix containing focal length
and principle points
.
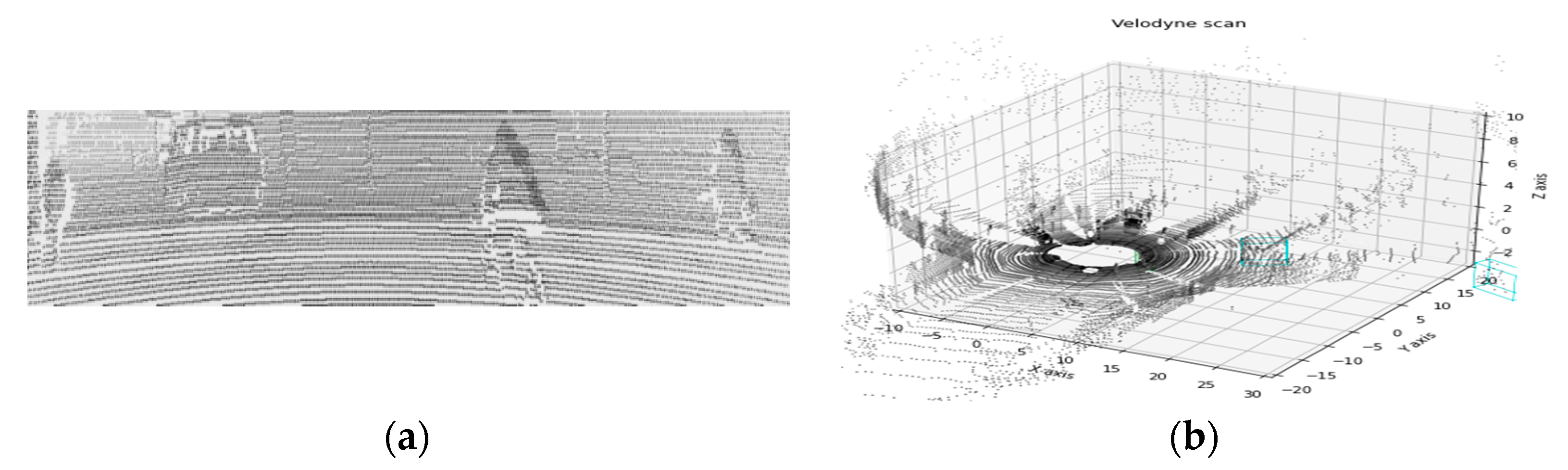
Figure 5 is a 2D depth image obtained through point cloud projection.
The LiDARs used in the KITTI dataset are mechanical spinning LiDARs with 360-degree coverage. These LiDARs have a high point cloud density, but when the point cloud is matched for that image, they are sparse, as shown in
Figure 5, and depth image using these sparse data is challenging to use. Therefore, by increasing the size of the projected point cloud, this sparsity should be lowered.
Figure 6 is the depth image depending on the different sizes of point cloud.
3.2. Scattering Coefficient Estimation
To obtain a transmission image for dehazing from depth image, a scattering coefficient is required. However, it is not easy to obtain an accurate scattering coefficient with only the image obtained from camera. Therefore, using synthetic haze image and ground truth image, a model that can estimate the scattering coefficient should be obtained.
The synthetic haze images required for this were synthesized based on the atmospheric scattering model using the KITTI dataset [
39] and depth images. The depth image used for the synthesis was generated by monodepth2 [
40].
Figure 7 shows that haze is generated throughout the images. Thus, estimating the dark channel of hazy image and calculating average brightness is higher than when calculated in a no-haze situation. This can be confirmed in
Figure 8. Such a relationship allows us to model equations that obtain the scattering coefficient from the dark channel’s average brightness. In this study, this average brightness is called the dark channel means (DCMs). To model the equation, an optimal scattering coefficient value for the haze image should be obtained. This can be obtained by performing dehazing of each value of the scattering coefficient, gradually increasing the scattering coefficient, and comparing the obtained results with the ground truth. Comparison of images is performed by calculating the mean square error (MSE) for pixels of each image, and when the mean square error becomes the smallest, the value at that time is set as the optimal scattering coefficient.
Algorithm 1 is pseudocode for estimating optimal scattering coefficients. The input data of the algorithm is ground truth image (GT), hazy image (hazy), and depth image (depth) (line 3). The algorithm initializes the scattering coefficient to 0 and 0.01 (line 1 and 2), incrementally increases them (line 16 and 17), and dehazing is performed using Equation (2) (line 10 and 11) and Equation (3) (line 7 and 8).
After dehazing, MSE is obtained through the dehazed image and GT (line 13 and 14). When MSE becomes the smallest (line 5), the scattering coefficient is determined as the optimal scattering coefficient (line 20).
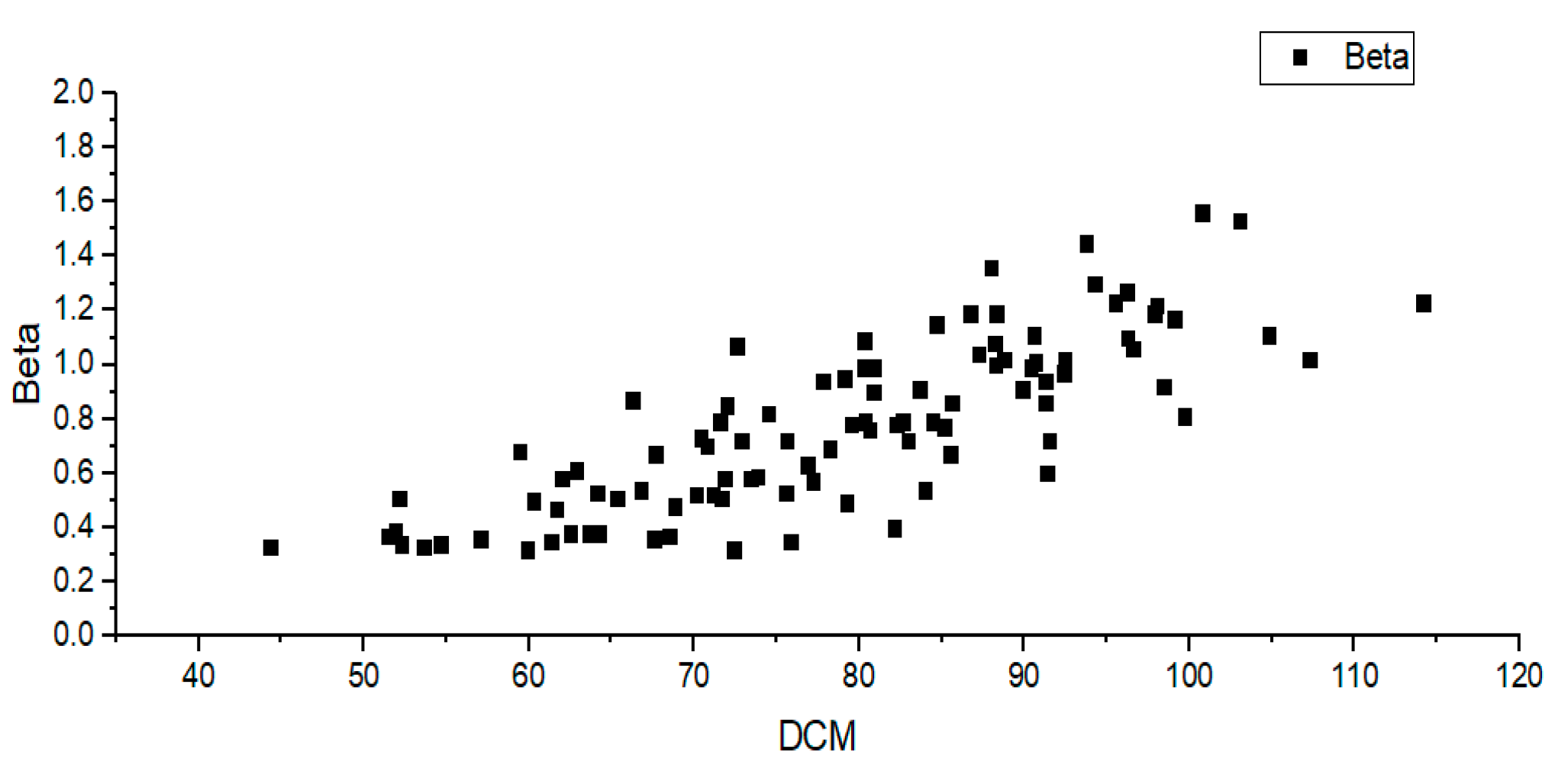
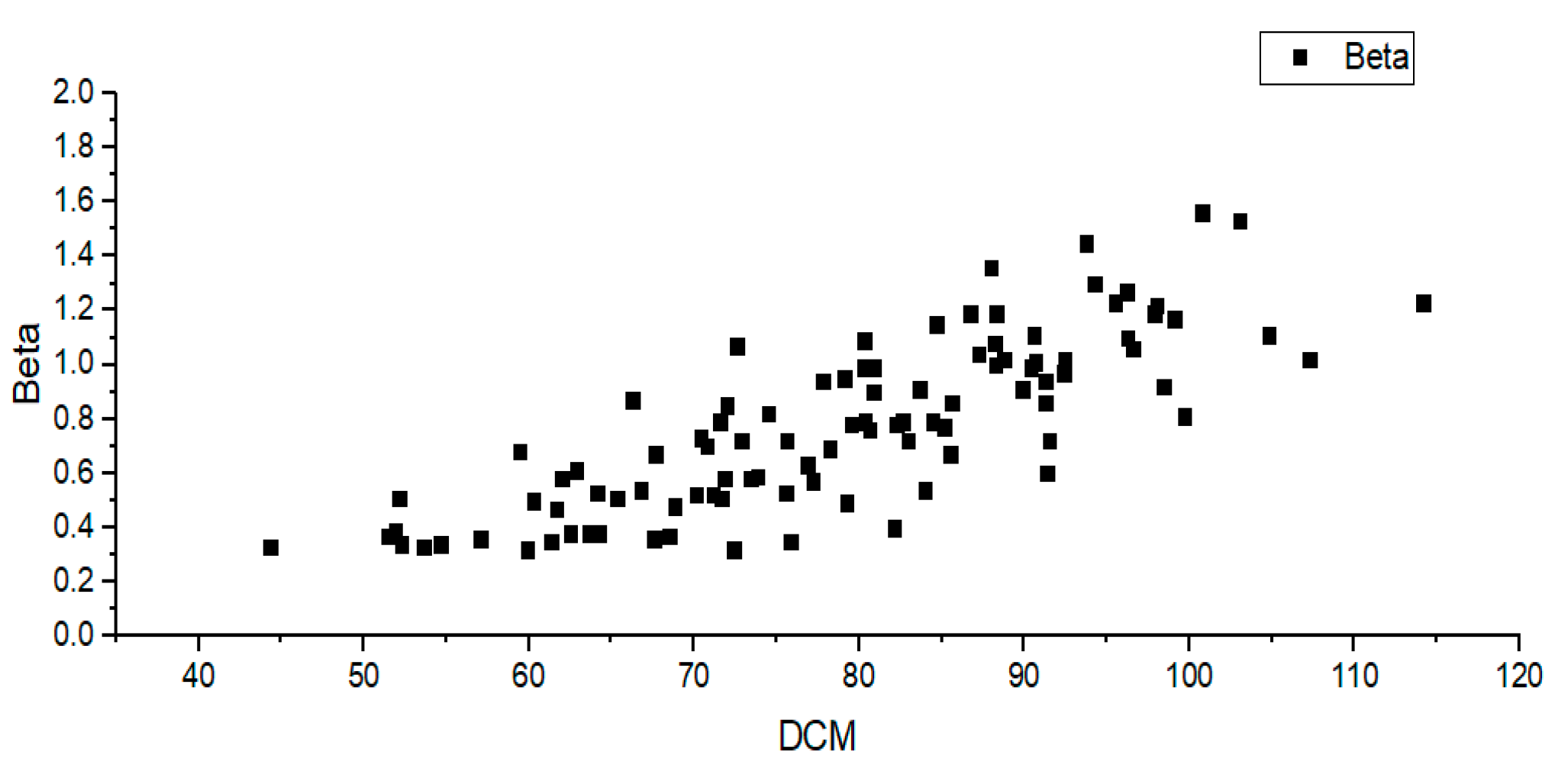
Using the method in Algorithm 1, the optimal scattering coefficient for each hazy image is estimated. Next, we obtain the DCM of each hazy image and create a distribution chart using the DCM and the optimal scattering coefficient. The following
Figure 9 refers to a scattering coefficient—DCM distribution chart obtained by the synthetic KITTI haze dataset. In
Figure 9, the x-axis represents the DCM, and the y-axis represents the scattering coefficient.
A total of 100 synthetic haze images were used to obtain the scattering coefficient model. This is the result of synthesizing 20 types of images in 5 stages depending on th level of haze generation.
Figure 10 shows synthetic haze images with varying scattering coefficients of step 5.
Using the distribution of the DCM-optimal scattering coefficient for 100 hazy synthetic images, the relationship between the two variables can be derived.
Equation (11) is a model obtained by linear regression of the DCM-optimal scattering coefficient distribution for 100 synthetic images.
| Algorithm 1 Estimate |
| 1:
|
| 2:
|
| 3:
Input: GT, hazy, depth
|
| 4: For do |
| 5: |
| 6: |
| 7:
|
| 8: |
| 9: |
| 10: |
| 11: |
| 12: |
| 13: end for |
| 14: return |
3.3. Transmission Image Refine
The transmission image of the atmospheric scattering model can be obtained by Equation (3). The raw transmission image is estimated using the depth image and the scattering coefficient, obtained by point cloud 2D projection and Equation (11), respectively.
The raw transmission image is estimated as shown in
Figure 11c. Since the transmission image is generated from the depth image via point cloud 2D projection, the raw transmission image shows the block effect in He et al. [
26]. Therefore, the raw transmission image obtained through Equation (3) should be refined. To refine the transmission image, the hazy image and raw transmission image are used, and the guided filtering is performed.
3.4. Background Parameter
Background parameters are used to prevent dehazing performance degradation due to differences in detection range between camera and LiDAR. If an object can be seen from the camera, but is outside the detection range of LiDAR, the pixel value of the transmission image is 1 for the absence of point cloud, so dehazing is not effective. Therefore, for places where point cloud does not exist, it should be set to a value between the maximum pixel value that point cloud can have and the original maximum pixel value of 255. The compensation process for an empty space in which the point cloud does not exist is performed through a background parameter.
Figure 12 is the result of the transmission image after applying the background parameter.
The background parameter was set to 195 because it was the most effective after several times of dehazing through real-world haze photographs. It is impossible to set the parameter through quantitative analysis because there is no ground truth image for the actual haze occurrence image. Therefore, the background parameter was set by a heuristic approach.
Figure 13 is the result of dehazing through several background parameters.
3.5. Scene Radiance Recovery
3.5.1. Estimation of Atmospheric Light
Generally, the appropriate value for atmospheric light in the hazy image would be the strongest pixel value within the image. In this case, however, it has the disadvantage of not being able to distinguish white objects. To compensate for these shortcomings, the dark channel prior is used. After obtaining the dark channel prior from the hazy image, the top 0.1% of the brightest pixels are drawn from the dark channel. We can consider these pixels as the most hazy pixels. So, among these pixels, the brightest pixel in the input image , is selected as the atmospheric light .
3.5.2. Dehazing Process
The 2D depth image is obtained through projection of the point cloud, and the scattering coefficient is obtained through the DCM—scattering coefficient equation. Transmission images can then be obtained through the acquired depth image and the scattering coefficient. Thus, scene radiance recovery can be performed through the atmospheric scattering model.
To avoid noise generation due to the transmission image, it is necessary to set the lower bound of the transmission image. The equation in which the lower bound is added can be expressed as follows.
4. Simulation
The dehazing algorithm was written in Python, and simulations performed on the Intel i5-3470@3.20GHz, 8GB RAM. In simulation, the improvement of the image was determined by comparing the mean square error (MSE), peak signal-to-noise ratio (PSNR), image enhancement factor (IEF), and structural similarity index measure (SSIM) [
41] of the hazy image and dehazed image. In addition, our proposed algorithm was quantitatively and qualitatively compared to existing algorithms, such as He et al. [
26], Tan et al. [
28], and Fattal et al. [
29].
4.1. Quantitative Analysis of Dehazing Improvement Quality
Dehazing improvement performance of the proposed algorithm is quantitatively analyzed using performance improvement parameters. When the synthetic haze image is composed,
is set to 0.003 and atmospheric light is set to 210.
Figure 14b is the synthetic haze image and
Figure 14c is the result of dehazing.
Performance analysis of three pairs of hazy images and dehazed images was performed via PSNR, SSIM, and MSE. First, performance analysis for hazy image and ground truth image is shown in GT-Hazed in
Table 1,
Table 2 and
Table 3 and performance analysis for ground truth and the dehazed image is shown in GT-Dehazed in
Table 1,
Table 2 and
Table 3. The PSNR and SSIM of GT-Dehazed were higher than those of GT-Hazed, and the MSE of GT-Dehazed were lower than that of GT-Hazed. Therefore, the analysis results from the image analysis parameters show that all three images have been improved.
4.2. Quantitative Comparison of Different Dehazing Algorithm
We performed a quantitative performance analysis between the existing dehazing algorithm and the proposed algorithm. Existing algorithms used for comparison of performance are Tan et al. [
28], Fattal et al. [
29], and He et al. [
26]. Analysis of the resulting images was conducted via MSE, PSNR, IEF, and SSIM as shown in
Table 4,
Table 5 and
Table 6.
Figure 15 shows an input image, synthetic haze image, and a dehazing image generated from the proposed and existing algorithms, respectively.
The proposed algorithm is designed to make the MSE smallest. Thus, if the DCM of the hazy image input does not deviate significantly from the model of DCM and scattering coefficient, the proposed method achieves the smallest MSE of the four methods. In addition, as MSE became smaller, other performance parameters were improved.
6. Conclusions
We present a method for performing dehazing via LiDAR depth image and DCM-scattering coefficient model. The proposed algorithm obtains the scattering coefficient model through the DCM and scattering coefficient relationship. Dehazing is then performed through the scattering coefficient and point cloud projection depth image obtained from LiDAR. Through simulations, we confirmed that the dehazed image is obtained effectively. In the simulation, MSE showed improvement over conventional algorithms, and PSNR and IEF, which are dependent on MSE, have also shown improvements. Furthermore, SSIM, an important parameter used in image recognition, showed an average improvement of about 24% over conventional algorithms.
However, the proposed algorithm has a problem to solve. First, when estimated using DCM, the scattering coefficient was able to perform dehazing effectively on most haze images, but using only pixel value mean may be unreliable. If there are many colorful objects in the near distance, the DCM can still be low, even with much haze. Consequently, it will deviate from the scattering coefficient estimation model, which results in dehazing being ineffective. Such problems of DCM could be addressed by CNN and by supervised learning for image and effective scatter coefficient.
In addition, because the depth image is obtained through LiDAR, dehazing may not work effectively if LiDAR malfunctions. We will improve these existing problems through further research. Moreover, there is a real-time problem. As of now, there are difficulties in operating in real time. This occurs because the imaging operation is performed simply with CPU only. Therefore, it is planned to secure real time by making it possible to operate in parallel through GPU operations through future research.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}