
ADFIST: Adaptive Dynamic Fuzzy Inference System Tree Driven by Optimized Knowledge Base for Indoor Air Quality Assessment


Abstract
:1. Introduction
2. Materials and Methods
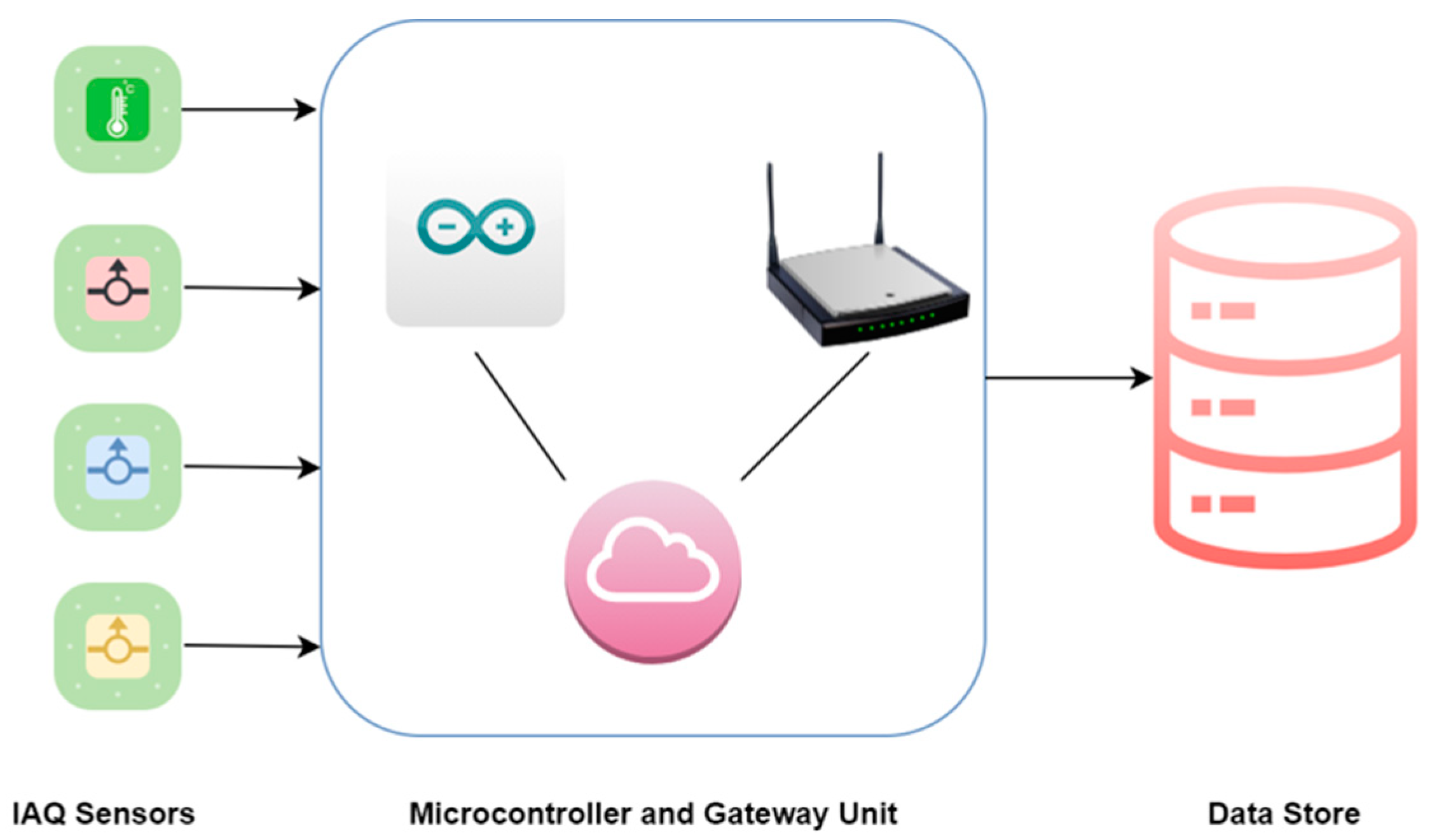
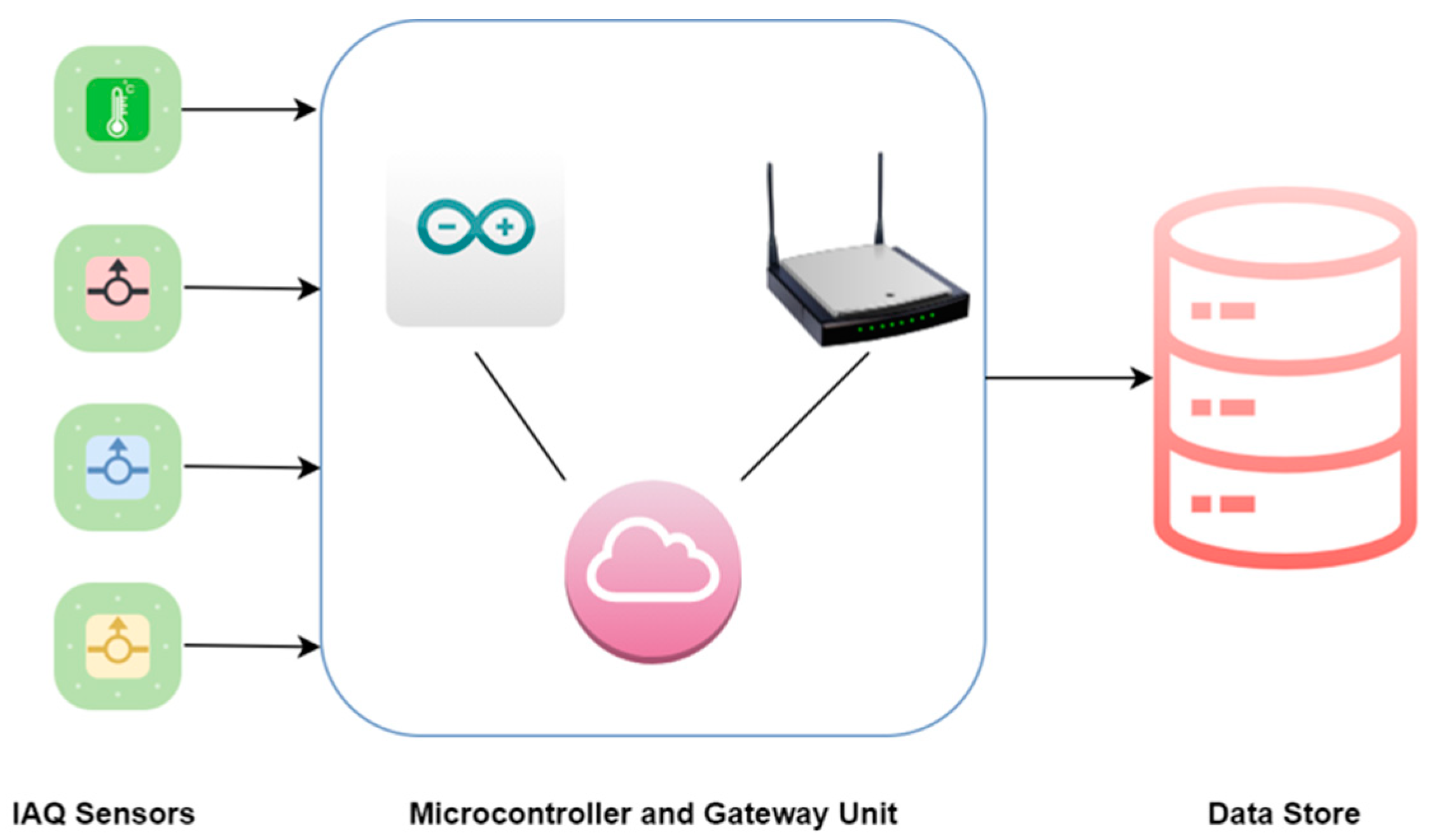
2.1. Monitoring System Design
2.2. Data Pre-Processing
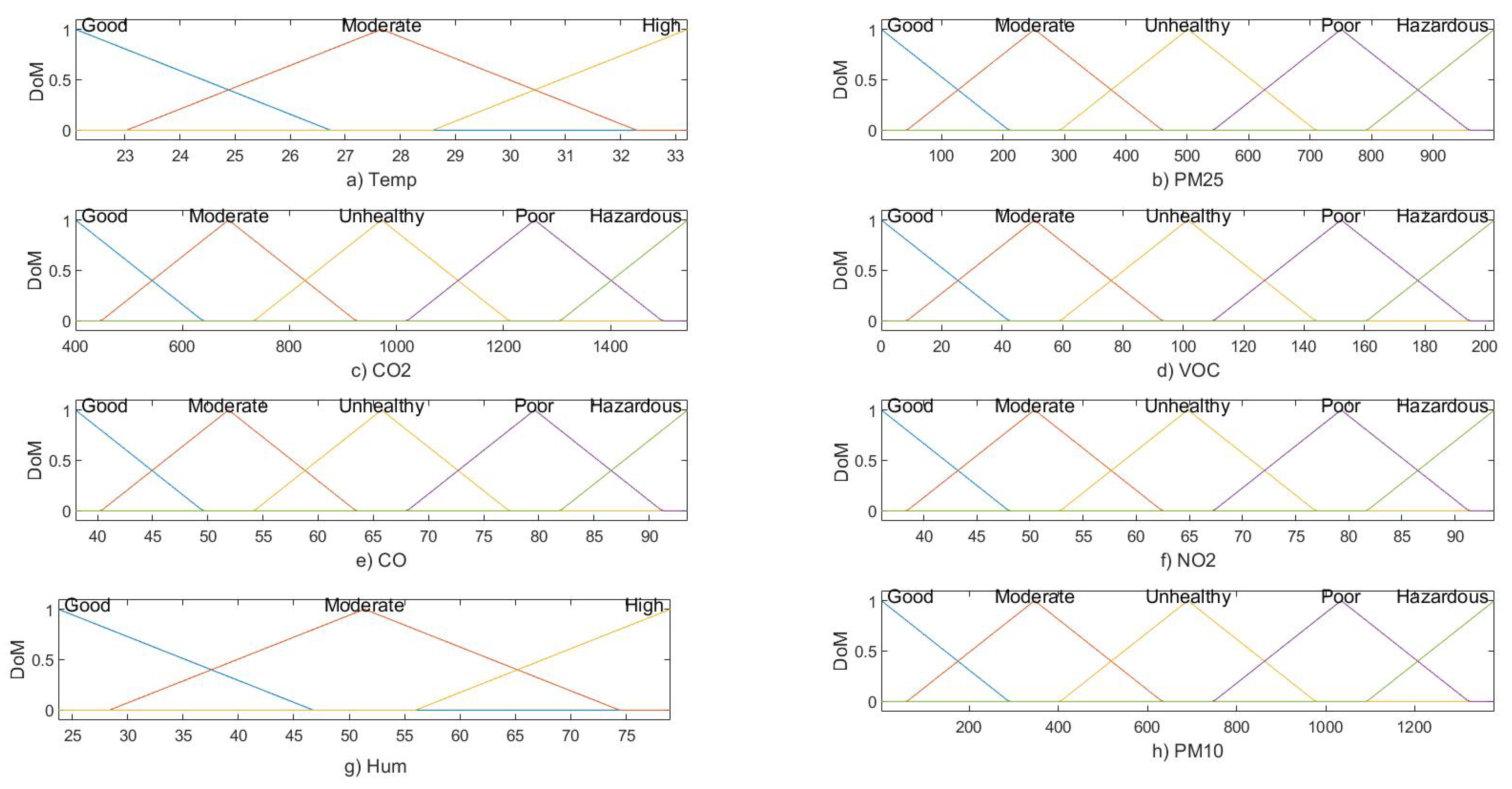
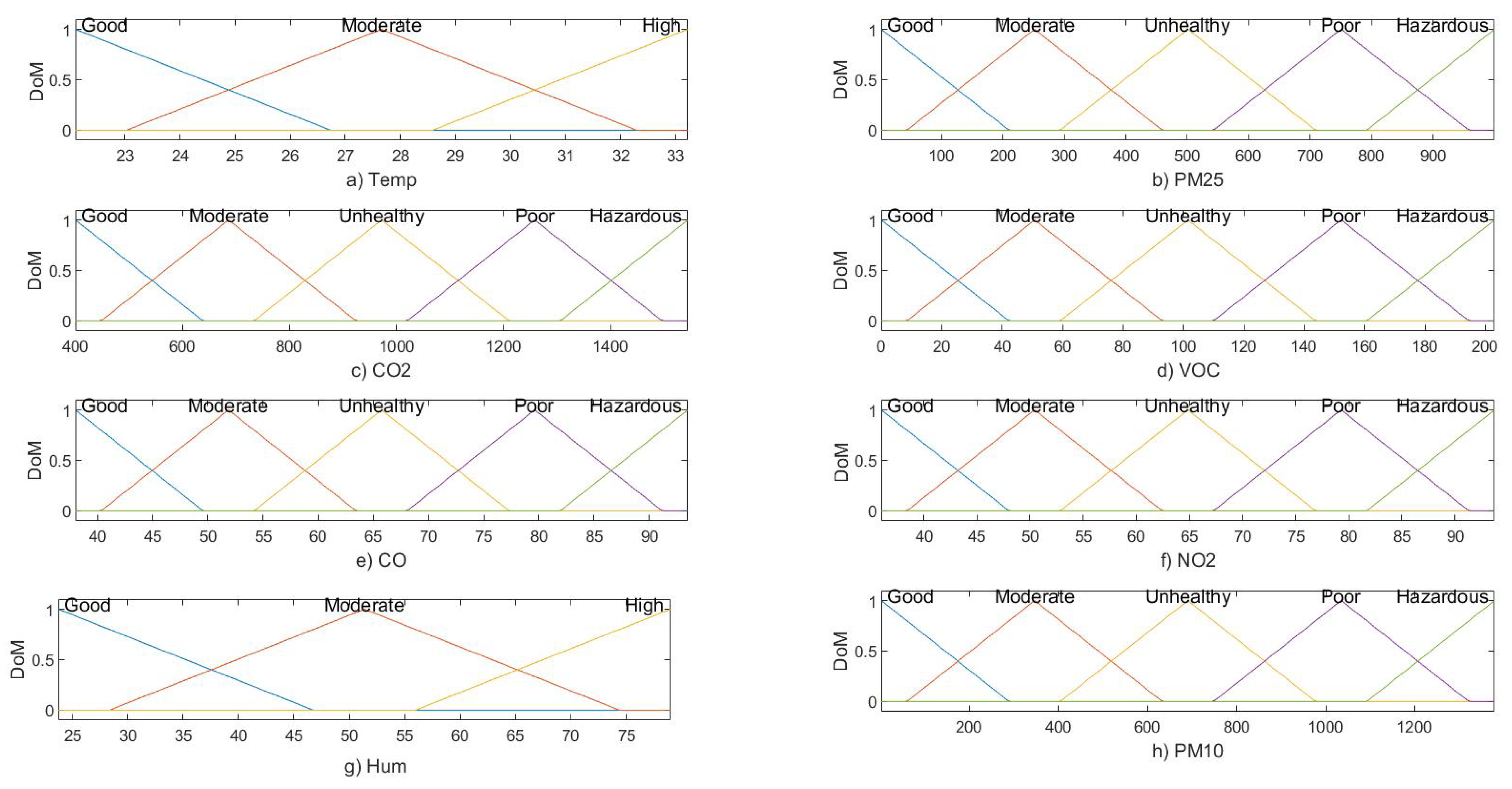
2.3. Parameter Classifications
- Good: This is considered appropriate to perform normal day-to-day activities.
- Moderate: Indoor activities can be performed; however, children and elderly people may be affected.
- Unhealthy: Indoor activities must be avoided; especially for children and adults with respiratory health issues.
- Poor: Sensitive groups may experience serious discomfort. In this situation, it is necessary to implement pollution emission controlling measures on a priority basis.
- Hazardous: Recommendations for following serious measures to protect the health of the building occupants by using adequate ventilation and air quality purification measures.
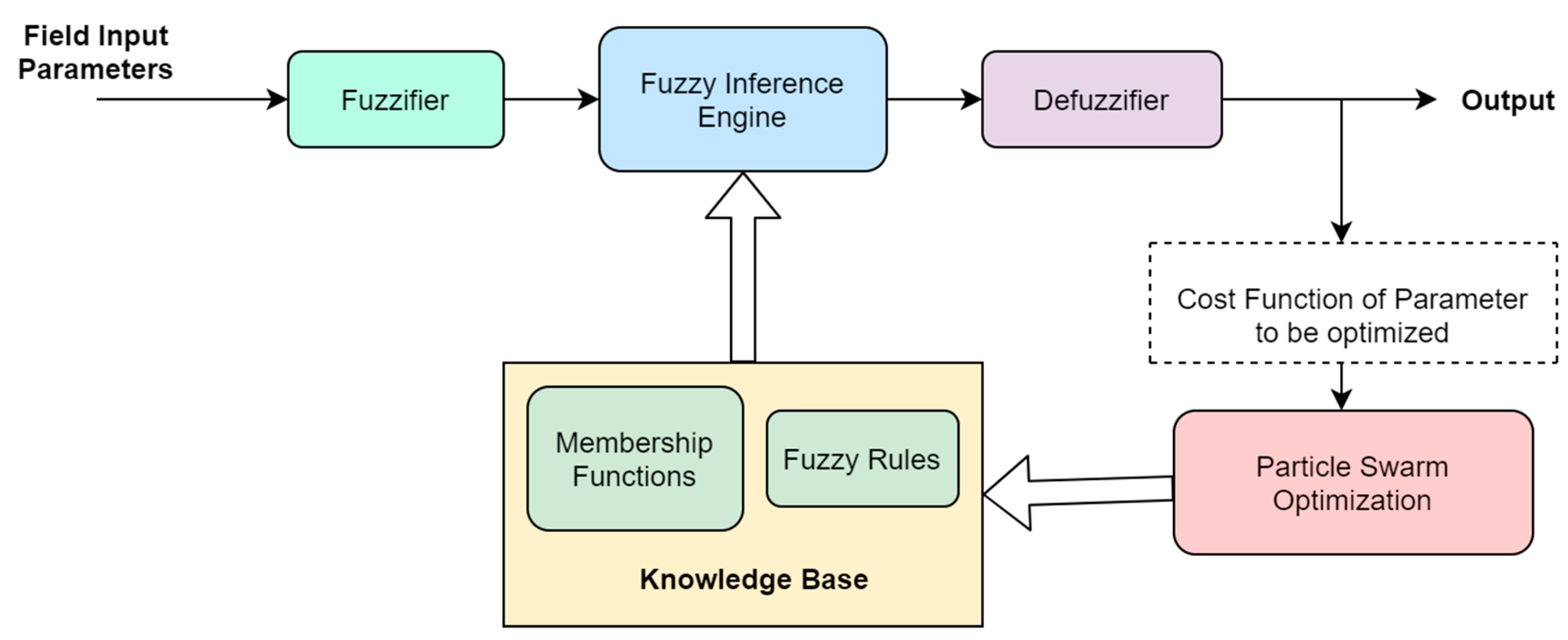
3. Methods
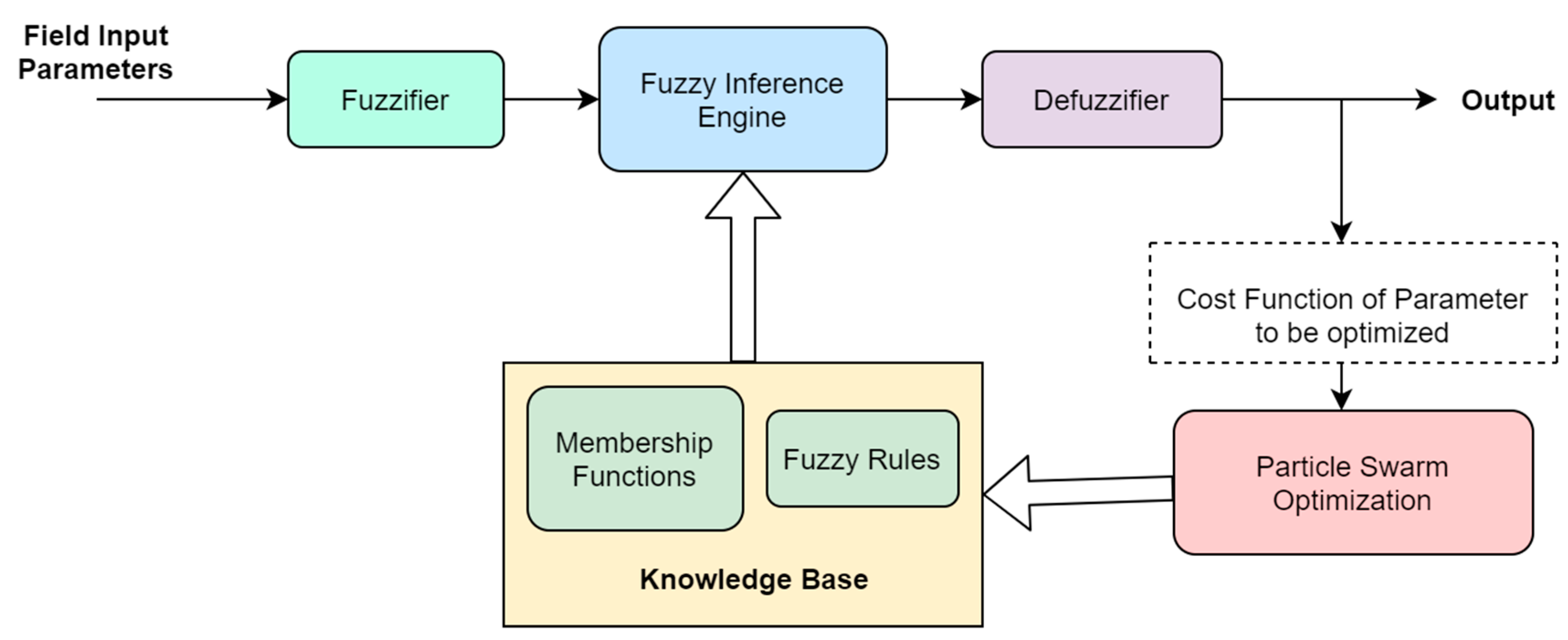
- The Fuzzification step converts crisp inputs into fuzzy systems. These crisp inputs are generally the data measured by sensors that are required to be passed to a fuzzy control system for further processing.
- Rule base plays an important role in fuzzy decision-making. Rule base or knowledge base is basically a set of in-then conditions developed from expert knowledge or field conditions.
- The inference engine defines the degree of match between fuzzy input and knowledge base. It decides which rules must be implemented to achieve the desired output as per the given input.
- Defuzzification is the process of converting fuzzy sets back into crisp values that can be further used in real-life environments.
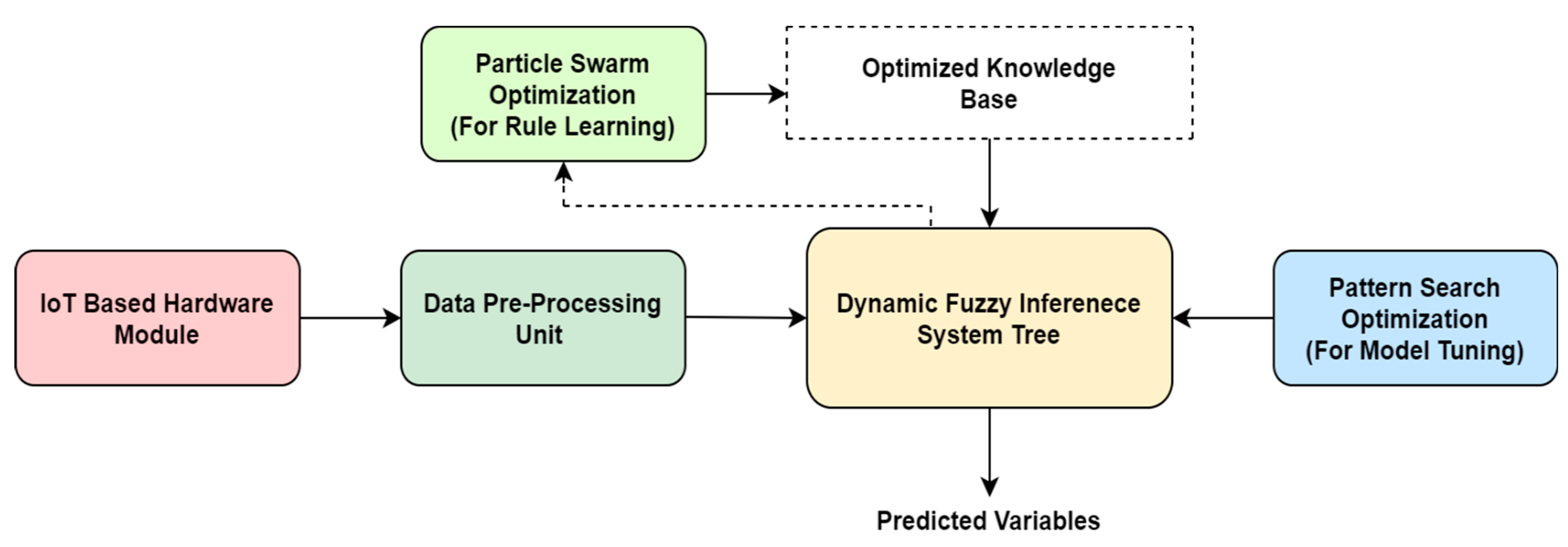
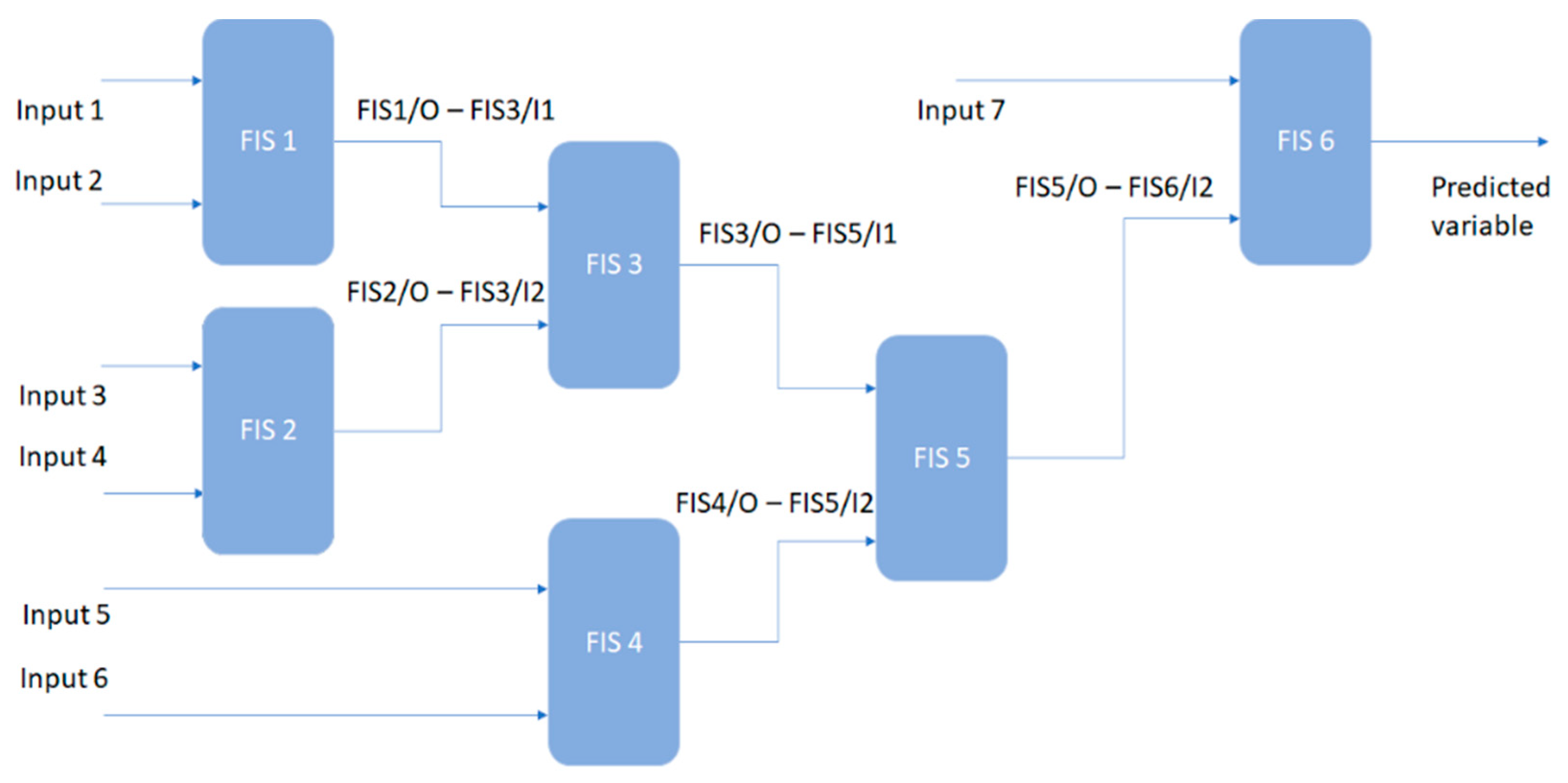
3.1. Fuzzy Inference System Tree
3.2. Particle Swarm Optimization
3.3. Pattern Search Algorithm
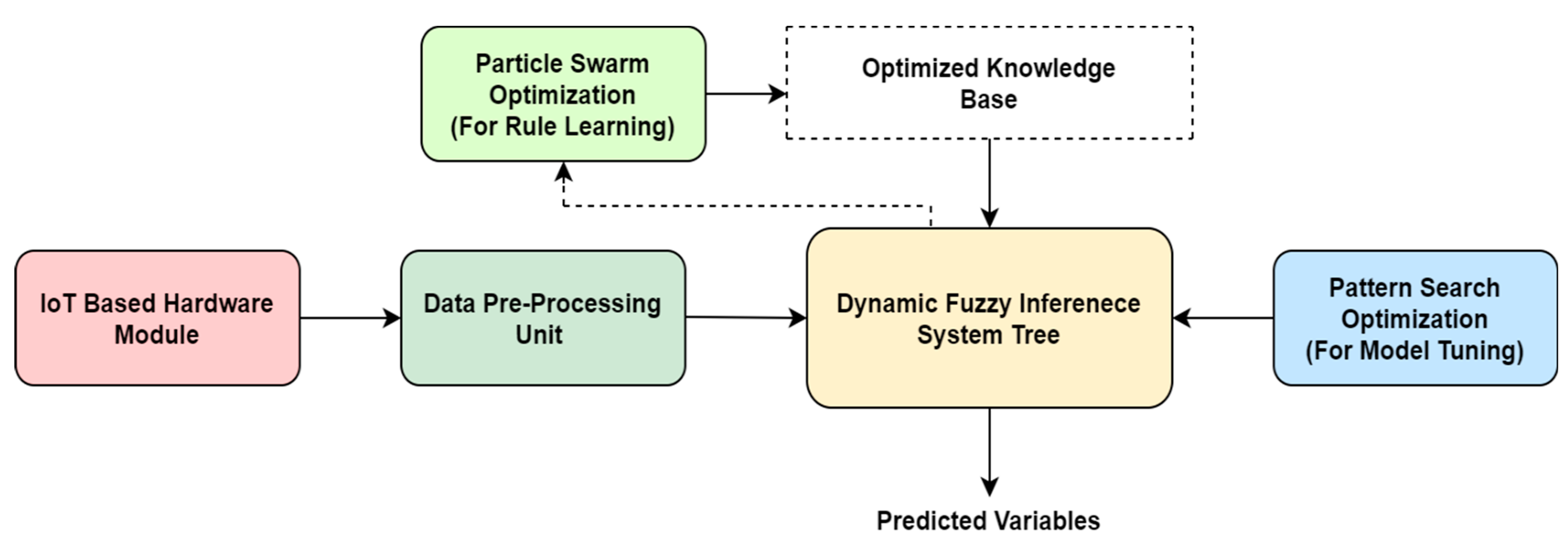
3.4. ADFIST Implementation
4. Results and Discussions
Model Validation with Online GAMS Dataset
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- U.S. Environmental Protection Agency. Indoor Air Quality. Available online: https://www.epa.gov/report-environment/indoor-air-quality (accessed on 17 May 2020).
- Drougka, F.; Liakakou, E.; Sakka, A.; Mitsos, D.; Zacharias, N.; Mihalopoulos, N.; Gerasopoulos, E. Indoor Air Quality Assessment at the Library of the National Observatory of Athens, Greece. Aerosol. Air Qual. Res. 2020, 20, 889–903. [Google Scholar] [CrossRef]
- Amoatey, P.; Omidvarborna, H.; Baawain, M.S.; Al-Mamun, A.; Bari, A.; Kindzierski, W.B. Association between Human Health and Indoor Air Pollution in the Gulf Cooperation Council (GCC) Countries: A Review. Rev. Environ. Health 2020, 35, 157–171. [Google Scholar] [CrossRef] [PubMed]
- Tielsch, J.M.; Katz, J.; Thulasiraj, R.D.; Coles, C.L.; Sheeladevi, S.; Yanik, E.L.; Rahmathullah, L. Exposure to Indoor Biomass Fuel and Tobacco Smoke and Risk of Adverse Reproductive Outcomes, Mortality, Respiratory Morbidity and Growth among Newborn Infants in South India. Int. J. Epidemiol. 2009, 38, 1351–1363. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Agarwal, A.; Kirwa, K.; Eliot, M.N.; Alenezi, F.; Menya, D.; Mitter, S.S.; Velazquez, E.J.; Vedanthan, R.; Wellenius, G.A.; Bloomfield, G.S. Household Air Pollution Is Associated with Altered Cardiac Function among Women in Kenya. Am. J. Respir. Crit. Care Med. 2017, 197, 958–961. [Google Scholar] [CrossRef]
- Tong, X.; Ho, J.M.W.; Li, Z.; Lui, K.-H.; Kwok, T.C.Y.; Tsoi, K.K.F.; Ho, K.F. Prediction Model for Air Particulate Matter Levels in the Households of Elderly Individuals in Hong Kong. Sci. Total Environ. 2019, 717, 135323. [Google Scholar] [CrossRef]
- Ryhl-Svendsen, M. Indoor Air Pollution in Museums: Prediction Models and Control Strategies. Stud. Conserv. 2006, 51, 27–41. [Google Scholar] [CrossRef]
- Mitter, S.S.; Vedanthan, R.; Islami, F.; Pourshams, A.; Khademi, H.; Kamangar, F.; Abnet, C.C.; Dawsey, S.M.; Pharoah, P.D.; Brennan, P.; et al. Household Fuel Use and Cardiovascular Disease Mortality: Golestan Cohort Study. Circulation 2016, 133, 2360–2369. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Liu, Q.; Guo, X. Short-Term Effects of Particulate Air Pollution on Human Health. In Encyclopedia of Environmental Health, 2nd ed.; Nriagu, J., Ed.; Elsevier: Oxford, UK, 2019; pp. 655–662. ISBN 978-0-444-63952-3. [Google Scholar]
- Horne, B.D.; Joy, E.A.; Hofmann, M.G.; Gesteland, P.H.; Cannon, J.B.; Lefler, J.S.; Blagev, D.P.; Korgenski, E.K.; Torosyan, N.; Hansen, G.I.; et al. Short-Term Elevation of Fine Particulate Matter Air Pollution and Acute Lower Respiratory Infection. Am. J. Respir. Crit. Care Med. 2018, 198, 759–766. [Google Scholar] [CrossRef]
- Valavanidis, A.; Vlachogianni, T.; Fiotakis, K.; Loridas, S. Pulmonary Oxidative Stress, Inflammation and Cancer: Respirable Particulate Matter, Fibrous Dusts and Ozone as Major Causes of Lung Carcinogenesis through Reactive Oxygen Species Mechanisms. Int. J. Environ. Res. Public Health 2013, 10, 3886–3907. [Google Scholar] [CrossRef]
- Boy Erick; Bruce Nigel; Delgado Hernán Birth Weight and Exposure to Kitchen Wood Smoke during Pregnancy in Rural Guatemala. Environ. Health Perspect. 2002, 110, 109–114. [CrossRef] [Green Version]
- Baldacci, S.; Maio, S.; Cerrai, S.; Sarno, G.; Baïz, N.; Simoni, M.; Annesi-Maesano, I.; Viegi, G. Allergy and Asthma: Effects of the Exposure to Particulate Matter and Biological Allergens. Respir. Med. 2015, 109, 1089–1104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kurmi, O.P.; Semple, S.; Simkhada, P.; Smith, W.C.S.; Ayres, J.G. COPD and Chronic Bronchitis Risk of Indoor Air Pollution from Solid Fuel: A Systematic Review and Meta-Analysis. Thorax 2010, 65, 221–228. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Josyula, S.; Lin, J.; Xue, X.; Rothman, N.; Lan, Q.; Rohan, T.E.; Hosgood, H.D. Household Air Pollution and Cancers Other than Lung: A Meta-Analysis. Environ. Health 2015, 14, 24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McCracken, J.P.; Wellenius, G.A.; Bloomfield, G.S.; Brook, R.D.; Tolunay, H.E.; Dockery, D.W.; Rabadan-Diehl, C.; Checkley, W.; Rajagopalan, S. Household Air Pollution from Solid Fuel Use: Evidence for Links to CVD. Glob. Heart 2012, 7, 223–234. [Google Scholar] [CrossRef] [Green Version]
- Chamseddine, A.; El-Fadel, M. Exposure to Air Pollutants in Hospitals: Indoor–Outdoor Correlations. In WIT Transactions on The Built Environment; Brebbia, C.A., Ed.; WIT Press: Billerica, MA, USA, 2015; Volume 1, pp. 707–716. ISBN 978-1-78466-157-1. [Google Scholar]
- Persily, A. Challenges in Developing Ventilation and Indoor Air Quality Standards: The Story of ASHRAE Standard 62. Build. Environ. 2015, 91, 61–69. [Google Scholar] [CrossRef]
- Xie, H.; Ma, F.; Bai, Q. Prediction of Indoor Air Quality Using Artificial Neural Networks. In Proceedings of the 2009 Fifth International Conference on Natural Computation, Washington, DC, USA, 14–16 August 2009; pp. 414–418. [Google Scholar]
- Tagliabue, L.C.; Re Cecconi, F.; Rinaldi, S.; Ciribini, A.L.C. Data Driven Indoor Air Quality Prediction in Educational Facilities Based on IoT Network. Energy Build. 2021, 236, 110782. [Google Scholar] [CrossRef]
- Ahn, J.; Shin, D.; Kim, K.; Yang, J. Indoor Air Quality Analysis Using Deep Learning with Sensor Data. Sensors 2017, 17, 2476. [Google Scholar] [CrossRef] [Green Version]
- Saini, J.; Dutta, M.; Marques, G. A Comprehensive Review on Indoor Air Quality Monitoring Systems for Enhanced Public Health. Sustain. Environ. Res. 2020, 30, 6. [Google Scholar] [CrossRef] [Green Version]
- Saini, J.; Dutta, M.; Marques, G. Indoor Air Quality Monitoring Systems Based on Internet of Things: A Systematic Review. Int. J. Environ. Res. Public Health 2020, 17, 4942. [Google Scholar] [CrossRef]
- Saini, J.; Dutta, M.; Marques, G. Sensors for Indoor Air Quality Monitoring and Assessment through Internet of Things: A Systematic Review. Environ. Monit. Assess. 2021, 193, 66. [Google Scholar] [CrossRef]
- Saini, J.; Dutta, M.; Marques, G. Indoor Air Quality Prediction Systems for Smart Environments: A Systematic Review. AIS 2020, 12, 433–453. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. 2—Getting to Know Your Data. In Data Mining, 3rd ed.; Han, J., Kamber, M., Pei, J., Eds.; The Morgan Kaufmann Series in Data Management Systems; Morgan Kaufmann: Boston, MA, USA, 2012; pp. 39–82. ISBN 978-0-12-381479-1. [Google Scholar]
- Vinutha, H.P.; Poornima, B.; Sagar, B.M. Detection of Outliers Using Interquartile Range Technique from Intrusion Dataset. In Proceedings of the 6th International Conference on FICTA, Bhubaneswar, India, 14–16 October 2017; pp. 511–518. [Google Scholar]
- Wilcox, R. Chapter 3—Estimating Measures of Location and Scale. In Introduction to Robust Estimation and Hypothesis Testing, 4th ed.; Wilcox, R., Ed.; Statistical Modeling and Decision Science; Academic Press: Cambridge, MA, USA, 2017; pp. 45–106. ISBN 978-0-12-804733-0. [Google Scholar]
- Sim, J.; Lee, J.S.; Kwon, O. Missing Values and Optimal Selection of an Imputation Method and Classification Algorithm to Improve the Accuracy of Ubiquitous Computing Applications. Available online: https://www.hindawi.com/journals/mpe/2015/538613/ (accessed on 7 December 2020).
- Wijesekara, W.M.L.K.N.; Liyanage, L. Comparison of Imputation Methods for Missing Values in Air Pollution Data: Case Study on Sydney Air Quality Index. In Proceedings of the Advances in Information and Communication, Future of Information and Communication Conference (FICC), San Francisco, CA, USA, 5–6 March 2020; pp. 257–269. [Google Scholar]
- Pandey, J.; Agrawal, M. Diurnal and Seasonal Variations in Air Pollutant Concentrations in a Seasonally Dry Tropical Urban Environment. Curr. Sci. 1994, 66, 299–303. [Google Scholar]
- Chen, W.; Yan, L.; Zhao, H. Seasonal Variations of Atmospheric Pollution and Air Quality in Beijing. Atmosphere 2015, 6, 1753–1770. [Google Scholar] [CrossRef] [Green Version]
- Lapere, R.; Menut, L.; Mailler, S.; Huneeus, N. Seasonal Variation in Atmospheric Pollutants Transport in Central Chile: Dynamics and Consequences. Atmos. Chem. Phys. 2021, 21, 6431–6454. [Google Scholar] [CrossRef]
- Gressent, A.; Malherbe, L.; Colette, A.; Rollin, H.; Scimia, R. Data Fusion for Air Quality Mapping Using Low-Cost Sensor Observations: Feasibility and Added-Value. Environ. Int. 2020, 143, 105965. [Google Scholar] [CrossRef]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 532–538. ISBN 978-0-387-39940-9. [Google Scholar]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity Analysis of K-Fold Cross Validation in Prediction Error Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 569–575. [Google Scholar] [CrossRef]
- Pelillo, M.; Hancock, E.R. Similarity-Based Pattern Recognition. In Proceedings of the First International Workshop, SIMBAD 2011, Venice, Italy, 28–30 September 2011. [Google Scholar]
- Joseph, V.R.; Vakayil, A. SPlit: An Optimal Method for Data Splitting. Technometrics 2021, 1–11. [Google Scholar] [CrossRef]
- Nguyen, Q.H.; Ly, H.-B.; Ho, L.S.; Al-Ansari, N.; Le, H.V.; Tran, V.Q.; Prakash, I.; Pham, B.T. Influence of Data Splitting on Performance of Machine Learning Models in Prediction of Shear Strength of Soil. Math. Probl. Eng. 2021, 2021, e4832864. [Google Scholar] [CrossRef]
- Javid, A.; Hamedian, A.A.; Gharibi, H.; Sowlat, M.H. Towards the Application of Fuzzy Logic for Developing a Novel Indoor Air Quality Index (FIAQI). Iran J. Public Health 2016, 45, 203–213. [Google Scholar]
- Fuzzy Logic Toolbox User’s Guide. Available online: www.mathworks.com/help/pdf_doc/gads/gads_tb.pdf (accessed on 12 April 2021).
- Information Resources Management Association. Information Fuzzy Systems: Concepts, Methodologies, Tools, and Applications: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2017; ISBN 978-1-5225-1909-6. [Google Scholar]
- Hájek, P.; Olej, V. Air Quality Indices and Their Modelling by Hierarchical Fuzzy Inference Systems. WSEAS Trans. Environ. Dev. 2009, 10, 661–672. [Google Scholar]
- LaCasse, P.M.; Otieno, W.; Maturana, F.P. A Hierarchical, Fuzzy Inference Approach to Data Filtration and Feature Prioritization in the Connected Manufacturing Enterprise. J. Big Data 2018, 5, 45. [Google Scholar] [CrossRef]
- Majumdar, A. 7—Adaptive Neuro-Fuzzy Systems in Yarn Modelling. In Soft Computing in Textile Engineering; Majumdar, A., Ed.; Woodhead Publishing Series in Textiles; Woodhead Publishing: Sawston, UK, 2011; pp. 159–177. ISBN 978-1-84569-663-4. [Google Scholar]
- Ain, Q.; Iqbal, S.; Khan, S.A.; Malik, A.W.; Ahmad, I.; Javaid, N. IoT Operating System Based Fuzzy Inference System for Home Energy Management System in Smart Buildings. Sensors 2018, 18, 2802. [Google Scholar] [CrossRef] [PubMed]
- Eldakhly, N.M.; Aboul-Ela, M.; Abdalla, A. A Novel Approach of Weighted Support Vector Machine with Applied Chance Theory for Forecasting Air Pollution Phenomenon in Egypt. Int. J. Comput. Intell. Appl. 2018, 17, 1850001. [Google Scholar] [CrossRef]
- Espitia, H.; Soriano, J.; Machón, I.; López, H. Design Methodology for the Implementation of Fuzzy Inference Systems Based on Boolean Relations. Electronics 2019, 8, 1243. [Google Scholar] [CrossRef] [Green Version]
- Carbajal-Hernández, J.J.; Sánchez-Fernández, L.P.; Carrasco-Ochoa, J.A.; Martínez-Trinidad, J. Fco. Assessment and Prediction of Air Quality Using Fuzzy Logic and Autoregressive Models. Atmos. Environ. 2012, 60, 37–50. [Google Scholar] [CrossRef]
- Riyaz, R.; Pushpa, P.V. Air Quality Prediction in Smart Cities: A Fuzzy-Logic Based Approach. In Proceedings of the 2018 International Conference on Computational Techniques, Electronics and Mechanical Systems (CTEMS), Belagavi, India, 21–22 December 2018; pp. 172–178. [Google Scholar]
- Bougoudis, I.; Demertzis, K.; Iliadis, L.; Anezakis, V.-D.; Papaleonidas, A. FuSSFFra, a Fuzzy Semi-Supervised Forecasting Framework: The Case of the Air Pollution in Athens. Neural Comput. Appl. 2018, 29, 375–388. [Google Scholar] [CrossRef]
- Nihalani, S.A.; Moondra, N.; Khambete, A.K.; Christian, R.A.; Jariwala, N.D. Air Quality Assessment Using Fuzzy Inference Systems. In Proceedings of the International Conference on Advanced Engineering Optimization through Intelligent Techniques (AEOTIT) 2018, Surat, India, 3–5 August 2018; pp. 313–322. [Google Scholar]
- Naaz, S.; Alam, A.; Biswas, R. Effect of Different Defuzzification Methods in a Fuzzy Based Load Balancing Application. Int. J. Comput. Appl. 2011, 8, 261–267. [Google Scholar]
- Husain, D.S.; Ahmad, M.Y.; Sharma, M.; Ali, S. Comparative Analysis of Defuzzification Approaches from an Aspect of Real Life Problem. IOSR J. Comput. Eng. 2017, 19, 19–25. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Shi, Y. Particle Swarm Optimization: Developments, Applications and Resources. In Proceedings of the 2001 Congress on Evolutionary Computation (IEEE Cat. No.01TH8546), Seoul, Korea, 27–30 May 2001; Volume 1, pp. 81–86. [Google Scholar]
- Assareh, E.; Behrang, M.A.; Assari, M.R.; Ghanbarzadeh, A. Application of PSO (Particle Swarm Optimization) and GA (Genetic Algorithm) Techniques on Demand Estimation of Oil in Iran. Energy 2010, 35, 5223–5229. [Google Scholar] [CrossRef]
- Basak, R.; Sanyal, A.; Nath, S.K.; Goswami, R. Comparative View of Genetic Algoithm and Pattern Search for Global Optimization. Int. J. Eng. Sci. 2013, 3, 9–12. [Google Scholar]
- Wetter, M.; Wright, J. Comparison of a generalized pattern search and a genetic algorithm optimization method. In Proceedings of the Eighth International IBPSA Conference, Eindhoven, The Netherlands, 11–14 August 2003; pp. 1401–1408. [Google Scholar]
- Kalibatienė, D.; Miliauskaitė, J. A Hybrid Systematic Review Approach on Complexity Issues in Data-Driven Fuzzy Inference Systems Development. Informatica 2021, 32, 85–118. [Google Scholar] [CrossRef]
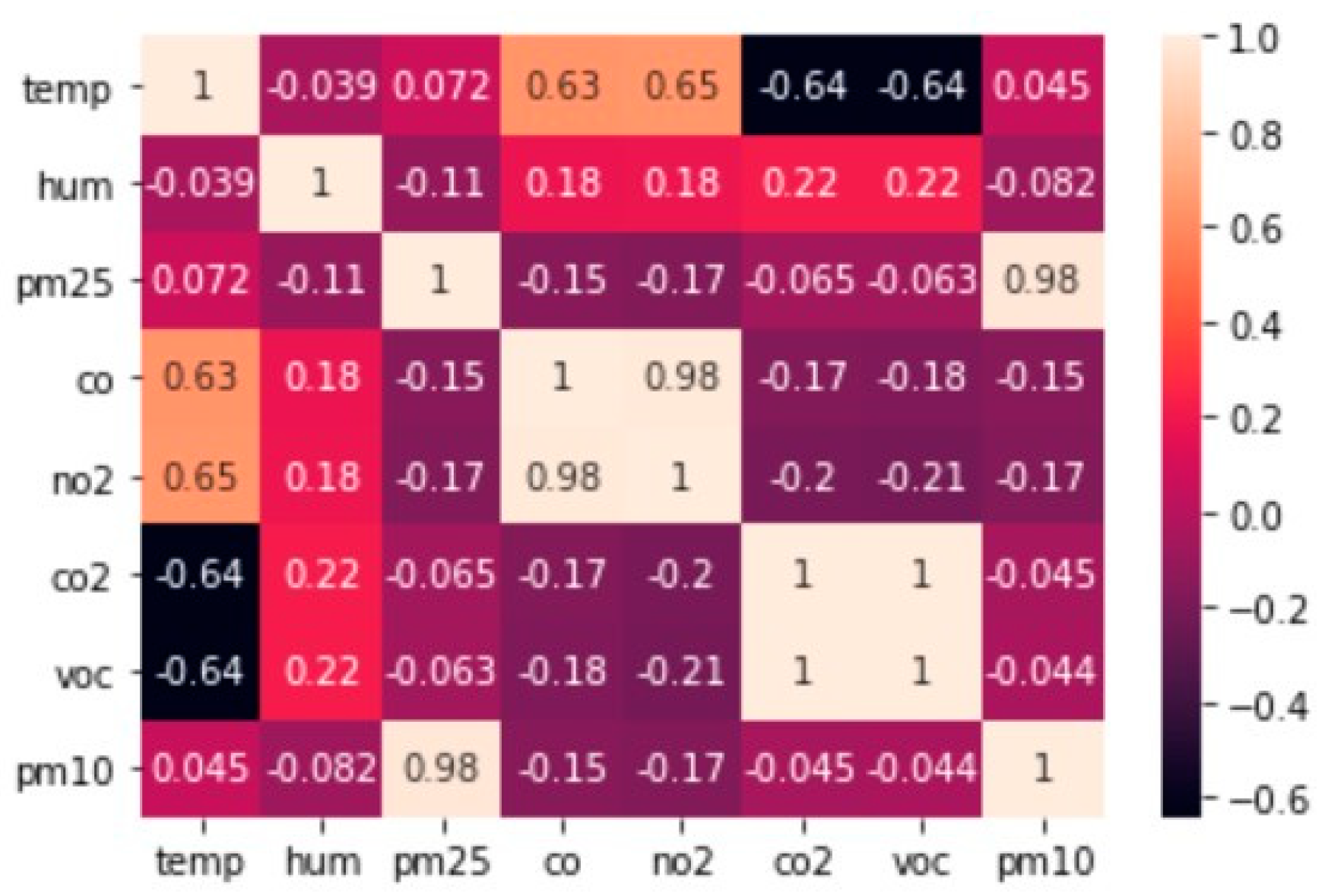
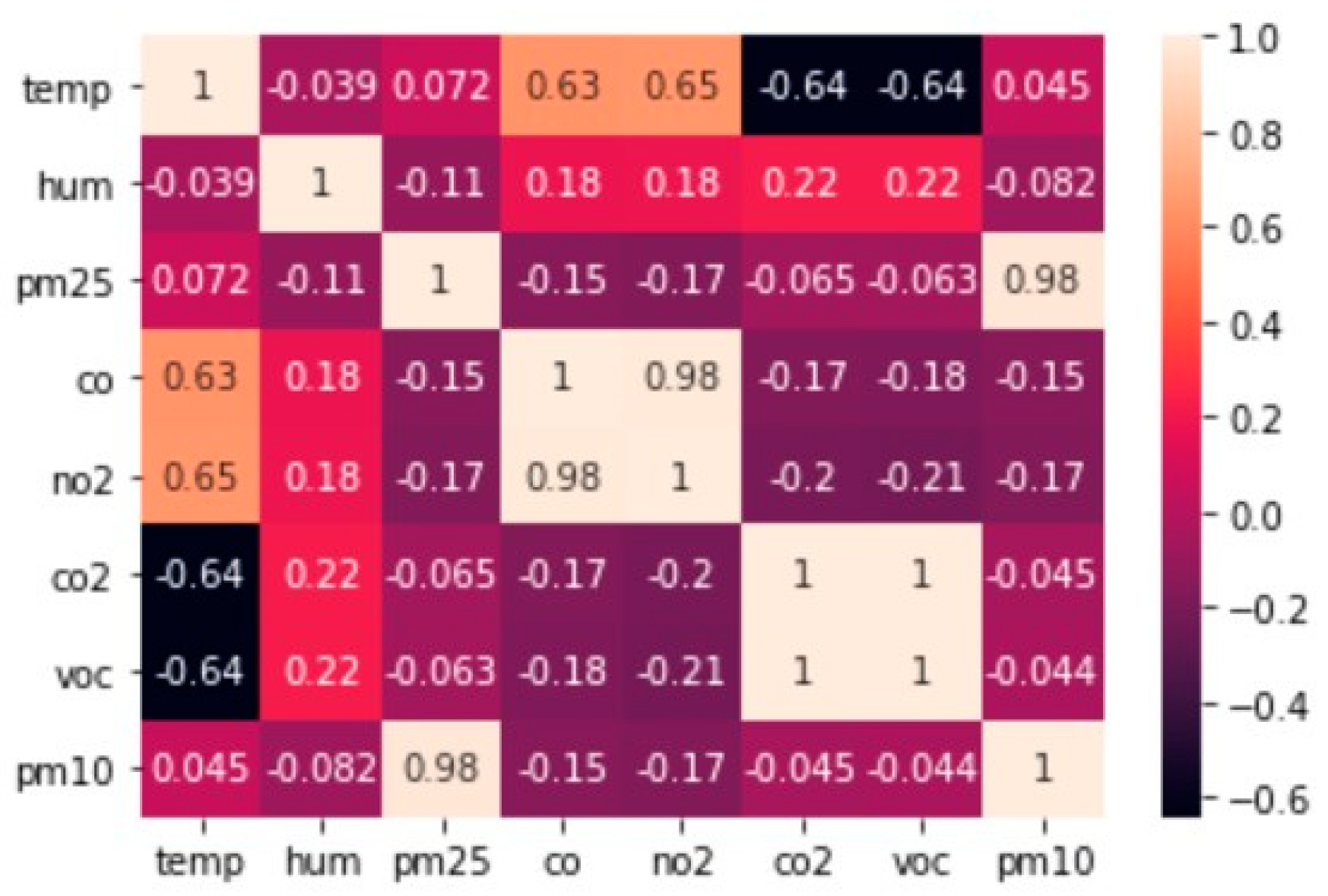
- Duangsoithong, R.; Windeatt, T. Correlation-Based and Causal Feature Selection Analysis for Ensemble Classifiers. In Artificial Neural Networks in Pattern Recognition; Schwenker, F., El Gayar, N., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 5998, pp. 25–36. ISBN 978-3-642-12158-6. [Google Scholar]
- Wosiak, A.; Zakrzewska, D. Integrating Correlation-Based Feature Selection and Clustering for Improved Cardiovascular Disease Diagnosis. Complexity 2018, 2018, e2520706. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, J.; Jahed Armaghani, D.; Tahir, M.M.; Pham, B.T.; Huynh, V.V. A Combination of Feature Selection and Random Forest Techniques to Solve a Problem Related to Blast-Induced Ground Vibration. Appl. Sci. 2020, 10, 869. [Google Scholar] [CrossRef] [Green Version]
- Botchkarev, A. Performance Metrics (Error Measures) in Machine Learning Regression, Forecasting and Prognostics: Properties and Typology. IJIKM 2019, 14, 45–76. [Google Scholar] [CrossRef] [Green Version]
- Botchkarev, A. Evaluating Performance of Regression Machine Learning Models Using Multiple Error Metrics in Azure Machine Learning Studio; Social Science Research Network: Rochester, NY, USA, 2018. [Google Scholar]
- Guillaume, S. Designing Fuzzy Inference Systems from Data: An Interpretability-Oriented Review. IEEE Trans. Fuzzy Syst. 2001, 9, 426–443. [Google Scholar] [CrossRef] [Green Version]
- Ojha, V.; Abraham, A.; Snasel, V. Heuristic Design of Fuzzy Inference Systems: A Review of Three Decades of Research. Eng. Appl. Artif. Intell. 2019, 85, 845–864. [Google Scholar] [CrossRef] [Green Version]
- Mikulić, I.; Lisjak, D.; Štefanić, N. A Rule-Based System for Human Performance Evaluation: A Case Study. Appl. Sci. 2021, 11, 2904. [Google Scholar] [CrossRef]
- Collotta, M.; Pau, G.; Maniscalco, V. A Fuzzy Logic Approach by Using Particle Swarm Optimization for Effective Energy Management in IWSNs. IEEE Trans. Ind. Electron. 2017, 64, 9496–9506. [Google Scholar] [CrossRef]
- Rastogi, K.; Lohani, D.; Acharya, D. An IoT-Based System to Evaluate Indoor Air Pollutants Using Grey Relational Analysis. In Proceedings of the 2020 International Conference on COMmunication Systems NETworkS (COMSNETS), Bangalore, India, 7–11 January 2020; pp. 762–767. [Google Scholar]
- Moursi, A.S.; El-Fishawy, N.; Djahel, S.; Shouman, M.A. An IoT Enabled System for Enhanced Air Quality Monitoring and Prediction on the Edge. Complex Intell. Syst. 2021, 7, 2923–2947. [Google Scholar] [CrossRef]
- Jin, N.; Zeng, Y.; Yan, K.; Ji, Z. Multivariate Air Quality Forecasting with Nested Long Short Term Memory Neural Network. IEEE Trans. Ind. Inform. 2021, 17, 8514–8522. [Google Scholar] [CrossRef]
- Chang, J.C.; Hanna, S.R. Air Quality Model Performance Evaluation. Meteorol. Atmos Phys. 2004, 87, 167–196. [Google Scholar] [CrossRef]
- Oztaner, Y.B.; Sakarya, S. Evaluation of Three Interpolation Methods for Particulate Matter Pollution Distribution under the Influence of Inversion as a Case Study for Istanbul and Izmit. In Proceedings of the 4th International Symposium and IUAPPA Regional Conference, Istanbul, Turkey, 10–13 September 2012. [Google Scholar]
- Alam, M.S.; Corcoran, L.; King, E.A.; McNabola, A.; Pilla, F. Modelling of Intra-Urban Variability of Prevailing Ambient Noise at Different Temporal Resolution. Noise Mapp. 2017, 4, 20–44. [Google Scholar] [CrossRef] [Green Version]
- Khazaei, B.; Shiehbeigi, A.; Haji Molla Ali Kani, A.R. Modeling Indoor Air Carbon Dioxide Concentration Using Artificial Neural Network. Int. J. Environ. Sci. Technol. 2019, 16, 729–736. [Google Scholar] [CrossRef]
- Kallio, J.; Tervonen, J.; Räsänen, P.; Mäkynen, R.; Koivusaari, J.; Peltola, J. Forecasting Office Indoor CO2 Concentration Using Machine Learning with a One-Year Dataset. Build. Environ. 2021, 187, 107409. [Google Scholar] [CrossRef]
- Russo, A.; Lind, P.G.; Raischel, F.; Trigo, R.; Mendes, M. Neural Network Forecast of Daily Pollution Concentration Using Optimal Meteorological Data at Synoptic and Local Scales. Atmos. Pollut. Res. 2015, 6, 540–549. [Google Scholar] [CrossRef] [Green Version]
- Lee, M.; Lin, L.; Chen, C.-Y.; Tsao, Y.; Yao, T.-H.; Fei, M.-H.; Fang, S.-H. Forecasting Air Quality in Taiwan by Using Machine Learning. Sci. Rep. 2020, 10, 4153. [Google Scholar] [CrossRef]
- Liu, Z.; Cheng, K.; Li, H.; Cao, G.; Wu, D.; Shi, Y. Exploring the Potential Relationship between Indoor Air Quality and the Concentration of Airborne Culturable Fungi: A Combined Experimental and Neural Network Modeling Study. Environ. Sci. Pollut. Res. 2018, 25, 3510–3517. [Google Scholar] [CrossRef]
- Hagler, G.S.W.; Williams, R.; Papapostolou, V.; Polidori, A. Air Quality Sensors and Data Adjustment Algorithms: When Is It No Longer a Measurement? Environ. Sci. Technol. 2018, 52, 5530–5531. [Google Scholar] [CrossRef] [Green Version]
- Giordano, M.R.; Malings, C.; Pandis, S.N.; Presto, A.A.; McNeill, V.F.; Westervelt, D.M.; Beekmann, M.; Subramanian, R. From Low-Cost Sensors to High-Quality Data: A Summary of Challenges and Best Practices for Effectively Calibrating Low-Cost Particulate Matter Mass Sensors. J. Aerosol. Sci. 2021, 158, 105833. [Google Scholar] [CrossRef]
- Kyriakidis, I.; Karatzas, K.D.; Papadourakis, G. Using Preprocessing Techniques in Air Quality forecasting with Artificial Neural Networks. In Information Technologies in Environmental Engineering. Environmental Science and Engineering; Athanasiadis, I.N., Rizzoli, A.E., Mitkas, P.A., Gómez, J.M., Eds.; Springer: Berlin, Heidelberg, 2009; pp. 357–372. [Google Scholar] [CrossRef]
- Al-jabery, K.K.; Obafemi-Ajayi, T.; Olbricht, G.R.; Wunsch II, D.C. 2—Data Preprocessing. In Computational Learning Approaches to Data Analytics in Biomedical Applications; Al-jabery, K.K., Obafemi-Ajayi, T., Olbricht, G.R., Wunsch, D.C., Eds.; Academic Press: Cambridge, MA, USA, 2020; pp. 7–27. ISBN 978-0-12-814482-4. [Google Scholar]
- Feng, Q.; Wu, S.; Du, Y.; Xue, H.; Xiao, F.; Ban, X.; Li, X. Improving Neural Network Prediction Accuracy for PM 10 Individual Air Quality Index Pollution Levels. Environ. Eng. Sci. 2013, 30, 725–732. [Google Scholar] [CrossRef] [Green Version]
- Abdullah, S.; Ismail, M.; Ahmed, A.N.; Abdullah, A.M. Forecasting Particulate Matter Concentration Using Linear and Non-Linear Approaches for Air Quality Decision Support. Atmosphere 2019, 10, 667. [Google Scholar] [CrossRef] [Green Version]
- Braik, M.; Sheta, A.; Al-Hiary, H. Hybrid Neural Network Models for Forecasting Ozone and Particulate Matter Concentrations in the Republic of China. Air Qual. Atmos. Health 2020, 13, 839–851. [Google Scholar] [CrossRef]
- Panigrahi, S.; Karali, Y.; Behera, H.S. Normalize Time Series and Forecast Using Evolutionary Neural Network. Int. J. Eng. Res. 2013, 2, 5. [Google Scholar]
- Kim, M.; Kim, Y.; Sung, S.; Yoo, C. Data-Driven Prediction Model of Indoor Air Quality by the Preprocessed Recurrent Neural Networks. In Proceedings of the 2009 ICCAS-SICE, Fukuoka, Japan, 18–21 August 2009; pp. 1688–1692. [Google Scholar]
- Xie, Q.; Ni, J.; Su, Z. A Prediction Model of Ammonia Emission from a Fattening Pig Room Based on the Indoor Concentration Using Adaptive Neuro Fuzzy Inference System. J. Hazard. Mater. 2017, 325, 301–309. [Google Scholar] [CrossRef]
- Elhariri, E.; Taie, S.A. H-Ahead Multivariate Microclimate Forecasting System Based on Deep Learning. In Proceedings of the 2019 International Conference on Innovative Trends in Computer Engineering (ITCE), Aswan, Egypt, 2–4 February 2019; pp. 168–173. [Google Scholar]
- Sun, G.; Hoff, S.J.; Zelle, B.C.; Nelson, M.A. Forecasting Daily Source Air Quality Using Multivariate Statistical Analysis and Radial Basis Function Networks. J. Air Waste Manag. Assoc. 2008, 58, 1571–1578. [Google Scholar] [CrossRef]
- Tian, F.C.; Kadri, C.; Zhang, L.; Feng, J.W.; Juan, L.H.; Na, P.L. A Novel Cost-Effective Portable Electronic Nose for Indoor-/In-Car Air Quality Monitoring. In Proceedings of the 2012 International Conference on Computer Distributed Control and Intelligent Environmental Monitoring, Zhangjiajie, China, 5–6 March 2012; pp. 4–8. [Google Scholar]
- Loy-Benitez, J.; Vilela, P.; Li, Q.; Yoo, C. Sequential Prediction of Quantitative Health Risk Assessment for the Fine Particulate Matter in an Underground Facility Using Deep Recurrent Neural Networks. Ecotoxicol. Environ. Saf. 2019, 169, 316–324. [Google Scholar] [CrossRef]
- Ha, Q.P.; Metia, S.; Phung, M.D. Sensing Data Fusion for Enhanced Indoor Air Quality Monitoring. IEEE Sens. J. 2020, 20, 4430–4441. [Google Scholar] [CrossRef] [Green Version]
- Prasad, K.; Gorai, A.K.; Goyal, P. Development of ANFIS Models for Air Quality Forecasting and Input Optimization for Reducing the Computational Cost and Time. Atmos. Environ. 2016, 128, 246–262. [Google Scholar] [CrossRef]
- Li, Y.; Jiang, P.; She, Q.; Lin, G. Research on Air Pollutant Concentration Prediction Method Based on Self-Adaptive Neuro-Fuzzy Weighted Extreme Learning Machine. Environ. Pollut. 2018, 241, 1115–1127. [Google Scholar] [CrossRef]
- Chen, S.; Mihara, K.; Wen, J. Time Series Prediction of CO2, TVOC and HCHO Based on Machine Learning at Different Sampling Points. Build. Environ. 2018, 146, 238–246. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Dehmer, M. Evaluation of Regression Models: Model Assessment, Model Selection and Generalization Error. Mach. Learn. Knowl. Extr. 2019, 1, 521–551. [Google Scholar] [CrossRef] [Green Version]
- GAMS Indoor Air Quality Dataset. Available online: https://github.com/twairball/gams-dataset (accessed on 6 August 2019).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor Name | Manufacturer | Type of Sensor | Measurement Parameter | Typical Range | Cost of Sensor/Unit (US Dollars) |
|---|---|---|---|---|---|
| CCS811 | SparkFun | Digital Sensor | CO2, tVOC | 0–1187 ppb (tVOC); 400–8192 ppm (CO2) | $24.28 |
| SDS011 | Nova Fitness | Laser Sensor | PM10, PM2.5 | 0.0–999.9 μg/m3 | $31.70 |
| Grove—Air quality sensor v1.3—MP503 | Seed Studio | Digital Sensor | CO, NO2 | NA | $12.82 |
| DHT11 | Aosong MPN | Negative Temperature Coefficient (NTC) | Temperature, Humidity | 0 °C to 50 °C; 20% to 90% | $1.35 |
| Temp | Hum | PM25 | PM10 | CO | NO2 | CO2 | tVOC | |
|---|---|---|---|---|---|---|---|---|
| Count | 3695.00 | 3695.00 | 3695.00 | 3695.00 | 3695.00 | 3695.00 | 3695.00 | 3695.00 |
| Mean | 29.900 | 53.921 | 124.117 | 144.724 | 67.477 | 67.088 | 745.133 | 52.780 |
| Std | 1.915 | 9.841 | 200.603 | 229.093 | 8.103 | 8.156 | 249.922 | 39.707 |
| Min | 22.100 | 23.750 | 1.736 | 2.337 | 38.000 | 36.000 | 400.000 | 0.000 |
| 25% | 29.690 | 48.916 | 8.608 | 13.051 | 62.833 | 62.333 | 566.090 | 24.784 |
| 50% | 29.900 | 53.921 | 20.381 | 30.541 | 67.477 | 67.088 | 735.166 | 50.416 |
| 75% | 31.250 | 60.818 | 124.117 | 144.724 | 72.916 | 72.727 | 770.606 | 55.958 |
| Max | 33.218 | 79.000 | 999.90 | 1378.90 | 93.500 | 93.714 | 1544.00 | 203.00 |
| Variance | 3.668 | 96.825 | 40,230.93 | 52,469.67 | 65.644 | 66.503 | 62,444.47 | 1576.28 |
| FIS1 | FIS2 | FIS4 | FIS6 | Response Variable | |||
|---|---|---|---|---|---|---|---|
| Input 1 | Input 2 | Input 1 | Input 2 | Input 1 | Input 2 | Input 1 | - |
| Temp | PM2.5 | CO2 | tVOC | CO | NO2 | Hum | PM10 |
| Hum | PM10 | CO2 | tVOC | CO | NO2 | Temp | PM2.5 |
| Hum | PM10 | PM2.5 | tVOC | CO | NO2 | Temp | CO2 |
| Temp | NO2 | CO2 | tVOC | PM2.5 | PM10 | Hum | CO |
| Temp | CO2 | PM10 | PM2.5 | CO | NO2 | Hum | tVOC |
| Temp | CO | CO2 | tVOC | PM2.5 | PM10 | Hum | NO2 |
| Number of Iterations (PSO Rule Learning + Pattern Search Tuning) | Number of Rules at Different Stages of ADFIST | Total Number of Rules | Response Variable | |||||
|---|---|---|---|---|---|---|---|---|
| - | FIS1 | FIS2 | FIS3 | FIS4 | FIS5 | FIS6 | - | - |
| 116 + 100 | 16 | 21 | 22 | 23 | 17 | 12 | 111 | PM10 |
| 145 + 100 | 12 | 19 | 17 | 21 | 20 | 10 | 99 | PM2.5 |
| 150 + 100 | 15 | 22 | 23 | 20 | 22 | 16 | 118 | CO2 |
| 133 + 100 | 14 | 22 | 22 | 20 | 22 | 13 | 113 | tVOC |
| 136 + 100 | 13 | 20 | 22 | 22 | 22 | 14 | 113 | CO |
| 140 + 100 | 13 | 20 | 24 | 23 | 20 | 15 | 115 | NO2 |
| Response Variable | NRMSE (Training Data) | NRMSE (Validation Data) |
|---|---|---|
| PM10 | 0.7000 | 0.6679 |
| PM2.5 | 0.6371 | 0.6218 |
| CO2 | 0.1018 | 0.1077 |
| tVOC | 0.2627 | 0.2585 |
| CO | 0.0677 | 0.0667 |
| NO2 | 0.0643 | 0.0635 |
| Performance Indicator | Response Variable | ADFIST | |
|---|---|---|---|
| DFIST + PSO | DFIST + PSO + Pattern Search | ||
| NRMSE | PM10 | 0.8046 | 0.6679 |
| PM2.5 | 0.7334 | 0.6218 | |
| CO2 | 0.1811 | 0.1077 | |
| tVOC | 0.3741 | 0.2585 | |
| CO | 0.0800 | 0.0667 | |
| NO2 | 0.0863 | 0.0635 | |
| NMSE | PM10 | 0.2645 | 0.1822 |
| PM2.5 | 0.2071 | 0.1489 | |
| CO2 | 0.2783 | 0.0983 | |
| tVOC | 0.2489 | 0.1189 | |
| CO | 0.4574 | 0.3176 | |
| NO2 | 0.5162 | 0.2799 | |
| R2 | PM10 | 0.7355 | 0.8178 |
| PM2.5 | 0.7929 | 0.8511 | |
| CO2 | 0.7217 | 0.9017 | |
| tVOC | 0.7511 | 0.8811 | |
| CO | 0.5426 | 0.6824 | |
| NO2 | 0.4838 | 0.7201 | |
| MAPE (%) | PM10 | 4.409 | 3.609 |
| PM2.5 | 4.657 | 4.428 | |
| CO2 | 0.0904 | 0.0666 | |
| tVOC | Inf | Inf | |
| CO | 0.0609 | 0.0500 | |
| NO2 | 0.0669 | 0.0457 | |
| Method | Dataset | Normalization | Response Variable | Performance | Ref |
|---|---|---|---|---|---|
| ANFIS | State Pollution Control Board, West Bengal, India (Ambient Air Pollution) | Yes | PM10 | R2 = 0.71 NMSE = 0.23 | [96] |
| CO | R2 = 0.77 NMSE = 0.33 | ||||
| NO2 | R2 = 0.85 NMSE = 0.00 | ||||
| ANFIS-WELM | Environmental Protection Administration, Northern Taiwan (Railway Station) | Yes | CO | MAPE = 22.13% | [97] |
| PM10 | MAPE = 7.1250% | ||||
| PM2.5 | MAPE = 30.948% | ||||
| SVM | INNOVA—Multipoint sampler and multi-gas monitor (School Campus) | NA | CO2 | R2 = 0.9883 MAPE = 1.59% | [98] |
| tVOC | R2 = 0.9636 MAPE = 2.01% | ||||
| Proposed Method (ADFIST) | IoT based Low-Cost Sensor Hardware (Rural Home) | No | PM10 | R2 = 0.8178 NMSE = 0.1822 MAPE = 3.609% | - |
| PM2.5 | MAPE = 4.428% | ||||
| CO2 | R2 = 0.9017 MAPE = 0.0666% | ||||
| CO | R2 = 0.6824 NMSE = 0.0667 MAPE = 0.0500% | ||||
| tVOC | R2 = 0.8811 MAPE = Inf | ||||
| NO2 | R2 = 0.7201 NMSE = 0.2799 |
| CO2 | Hum | PM10 | PM2.5 | Temp | VOC | |
|---|---|---|---|---|---|---|
| Count | 3058.00 | 3058.00 | 3058.00 | 3058.00 | 3058.00 | 3058.00 |
| Mean | 716.030509 | 38.422101 | 17.378770 | 15.826833 | 23.016499 | 0.117204 |
| Std | 402.048356 | 5.445556 | 12.662556 | 11.894725 | 2.058361 | 0.082843 |
| Min | 372.633333 | 22.140000 | 0.833333 | 0.733333 | 18.116818 | 0.062000 |
| 25% | 433.284545 | 34.766833 | 8.155833 | 7.266118 | 21.482593 | 0.064250 |
| 50% | 501.388889 | 38.422101 | 13.807500 | 12.301667 | 22.982167 | 0.079508 |
| 75% | 894.812500 | 41.974500 | 22.826147 | 20.848873 | 24.726168 | 0.138531 |
| Max | 2570.409091 | 68.351538 | 84.356250 | 72.896774 | 27.914815 | 0.695500 |
| Variance | 161,590.0219 | 29.644378 | 160.287883 | 141.438205 | 4.235465 | 0.006861 |
| Response Variable | Number of Rules | Number of Iterations | NRMSE | NMSE | R2 | MAPE (%) |
|---|---|---|---|---|---|---|
| PM10 | 70 | 100 + 80 | 0.3781 | 0.2655 | 0.7345 | 0.5503 |
| PM2.5 | 74 | 100 + 56 | 0.4799 | 0.3807 | 0.6193 | 0.9204 |
| CO2 | 69 | 93 + 80 | 0.3316 | 0.3258 | 0.6742 | 0.2422 |
| VOC | 65 | 96 + 80 | 0.6392 | 0.3473 | 0.6527 | 0.5374 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saini, J.; Dutta, M.; Marques, G. ADFIST: Adaptive Dynamic Fuzzy Inference System Tree Driven by Optimized Knowledge Base for Indoor Air Quality Assessment. Sensors 2022, 22, 1008. https://doi.org/10.3390/s22031008
Saini J, Dutta M, Marques G. ADFIST: Adaptive Dynamic Fuzzy Inference System Tree Driven by Optimized Knowledge Base for Indoor Air Quality Assessment. Sensors. 2022; 22(3):1008. https://doi.org/10.3390/s22031008
Chicago/Turabian StyleSaini, Jagriti, Maitreyee Dutta, and Gonçalo Marques. 2022. "ADFIST: Adaptive Dynamic Fuzzy Inference System Tree Driven by Optimized Knowledge Base for Indoor Air Quality Assessment" Sensors 22, no. 3: 1008. https://doi.org/10.3390/s22031008
APA StyleSaini, J., Dutta, M., & Marques, G. (2022). ADFIST: Adaptive Dynamic Fuzzy Inference System Tree Driven by Optimized Knowledge Base for Indoor Air Quality Assessment. Sensors, 22(3), 1008. https://doi.org/10.3390/s22031008