
Application for Recognizing Sign Language Gestures Based on an Artificial Neural Network


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
3. Implementation of the Application
3.1. Development of an Artificial Neural Network Model
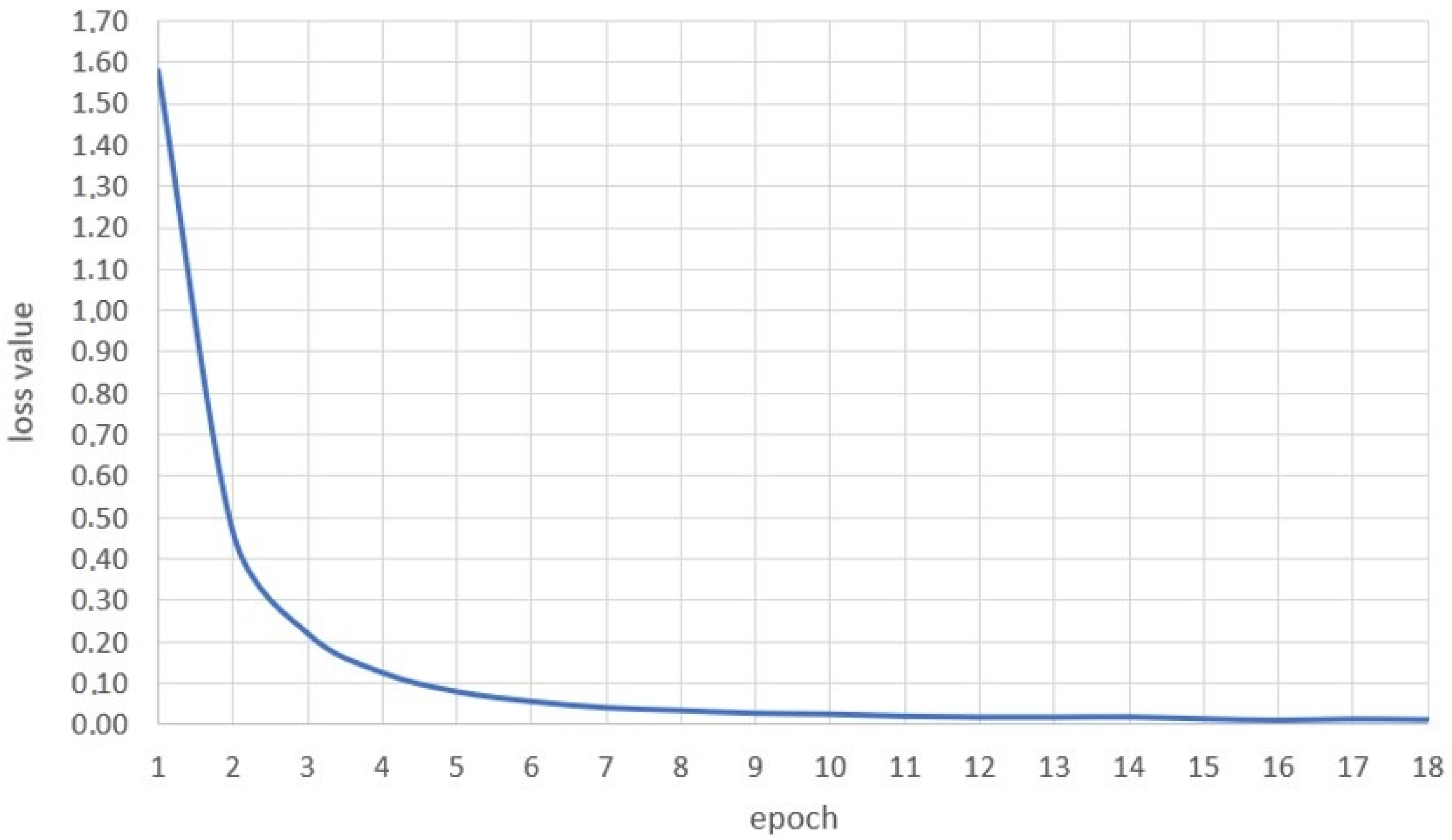
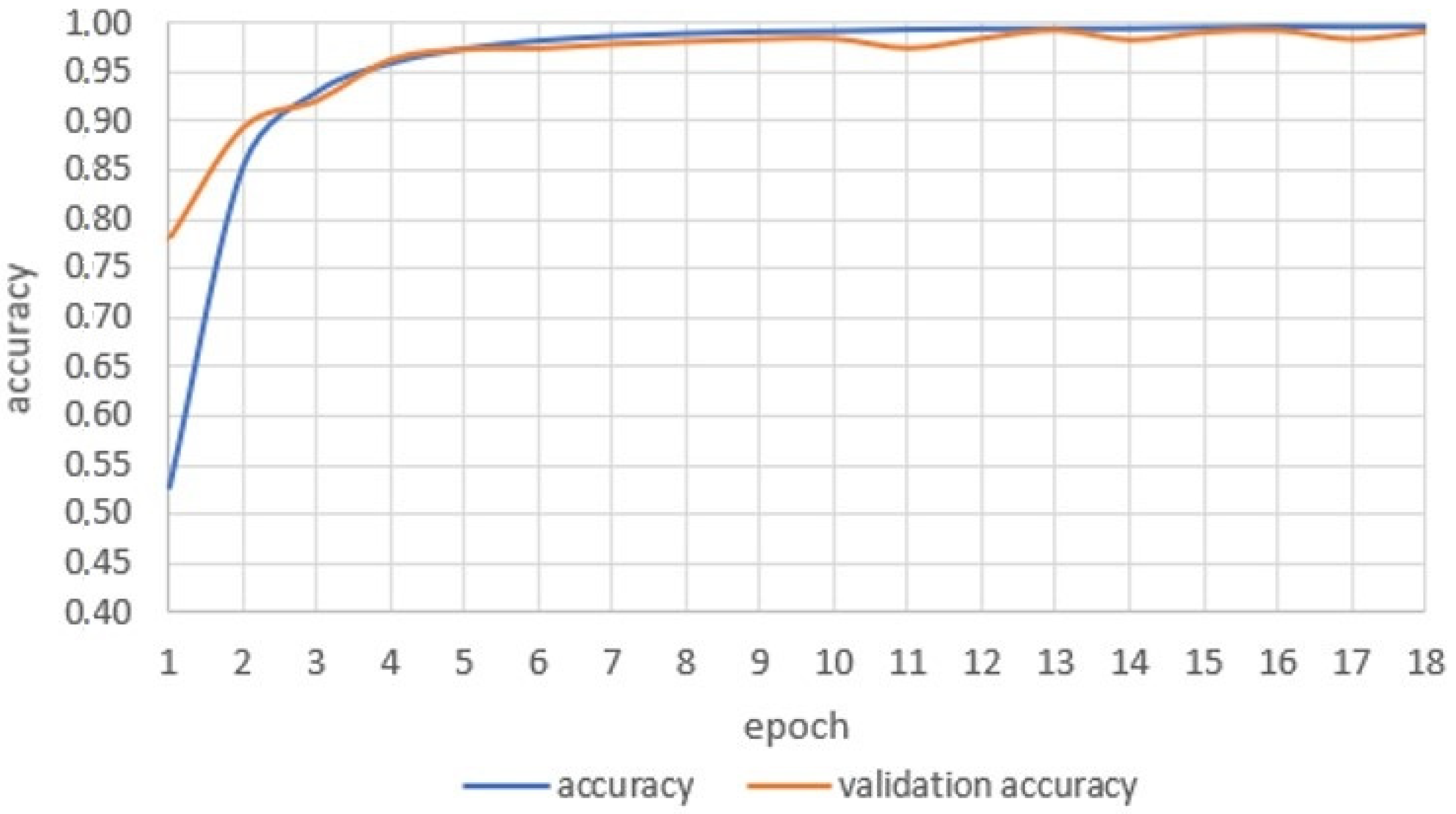
3.2. Compilation, Training and Tests of the Neural Model
3.3. Demonstration Module for Recognizing Any Photo
4. Results
4.1. Visualization and Verification of University Neural Network Results
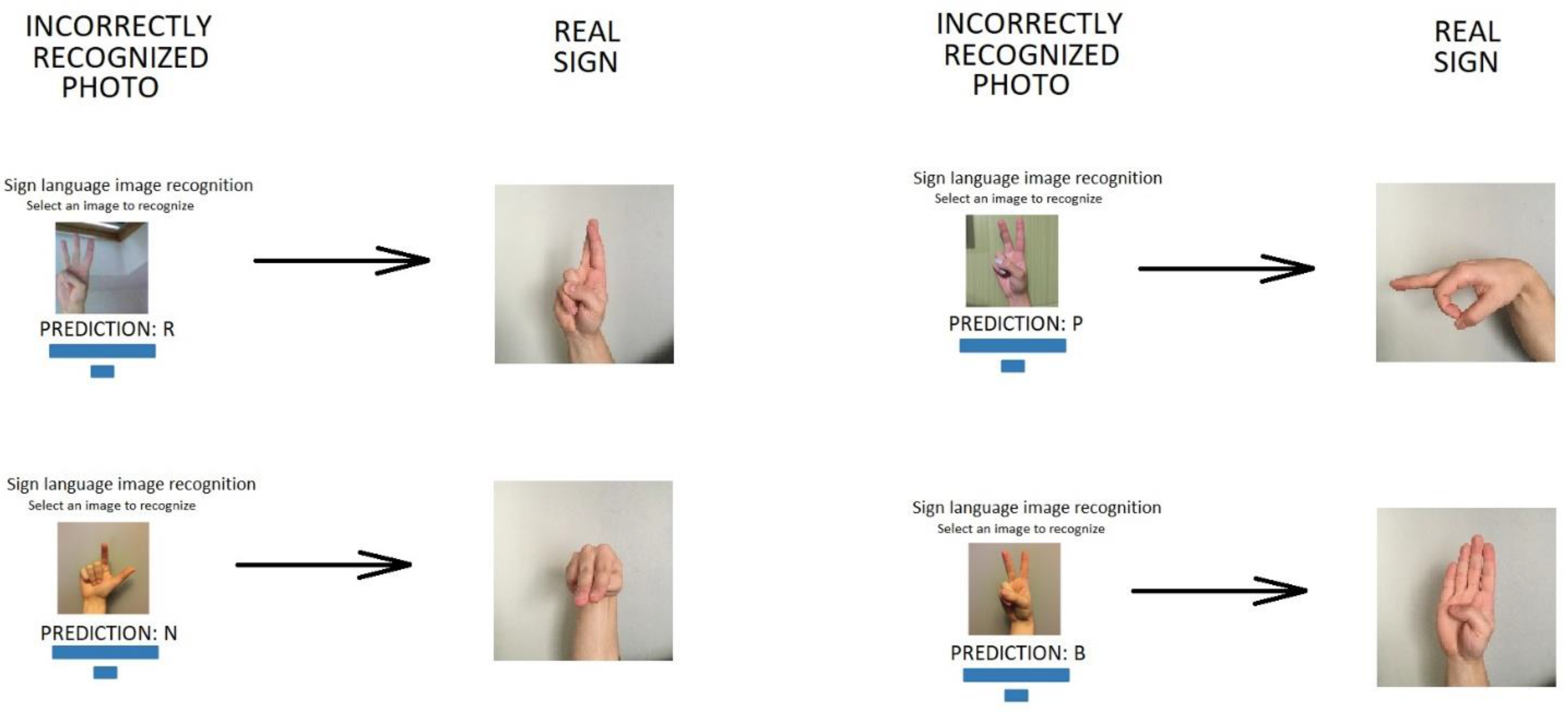
4.2. Identifying Unknown Images
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kolanska, K.; Chabbert-Buffet, N.; Daraï, E.; Antoine, J.M. Artificial intelligence in medicine: A matter of joy or concern? J. Gynecol. Obstet. Hum. Reprod. 2021, 50, 101962. [Google Scholar] [CrossRef] [PubMed]
- Mendels, D.A.; Dortet, L.; Emeraud, C.; Oueslati, S.; Girlich, D.; Ronat, J.B.; Bernabeu, S.; Bahi, S.; Atkinson, G.J.H.; Naas, T. Using artificial intelligence to improve COVID-19 rapid diagnostic test result interpretation. Proc. Natl. Acad. Sci. USA 2021, 118, e2019893118. [Google Scholar] [CrossRef] [PubMed]
- Thurzo, A.; Kosnáčová, H.S.; Kurilová, V.; Kosmeľ, S.; Beňuš, R.; Moravanský, N.; Kováč, P.; Kuracinová, K.M.; Palkovič, M.; Varga, I. Use of advanced artificial intelligence in forensic medicine, forensic anthropology, and clinical anatomy. Healthcare 2021, 9, 1545. [Google Scholar] [CrossRef] [PubMed]
- Cai, L.; Liu, W. Monitoring harmful bee colony with deep learning based on improved grey prediction algorithm. In Proceedings of the 2nd International Conference on Artificial Intelligence and Information Systems, Chongqing, China, 28–30 May 2021; pp. 1–6. [Google Scholar]
- Al-bayati, J.S.H.; Üstündağ, B.B. Artificial intelligence in smart agriculture: Modified evolutionary optimization approach for plant disease identification. In Proceedings of the 4th International Symposium on Multidisciplinary Studies and Innovative Technologies, Istanbul, Turkey, 22–24 October 2020; pp. 1–6. [Google Scholar]
- Espejo-Garcia, B.; Mylonas, N.; Athanasakos, L.; Vali, E.; Fountas, S. Combining generative adversarial networks and agricultural transfer learning for weeds identification. Biosyst. Eng. 2021, 204, 79–89. [Google Scholar] [CrossRef]
- Kharchenko, S.; Borshch, Y.; Kovalyshyn, S.; Piven, M.; Abduev, M.; Miernik, A.; Popardowski, E.; Kielbasa, P. Modeling of aerodynamic separation of preliminarily stratified grain mixture in vertical pneumatic separation duct. Appl. Sci. 2021, 11, 4383. [Google Scholar] [CrossRef]
- Loey, M. Big data and deep learning in plant leaf diseases classification for agriculture. In Enabling AI Applications in Data Science. Studies in Computational Intelligence, 1st ed.; Hassanien, A.E., Taha, M.H.N., Khalifa, N.E.M., Eds.; Springer: New York, NY, USA, 2021; pp. 185–200. [Google Scholar]
- Trzyniec, K.; Kowalewski, A. Use of an artificial neural network to assess the degree of training of an operator of selected devices used in precision agriculture. Energies 2020, 13, 6329. [Google Scholar] [CrossRef]
- Zagórda, M.; Popardowski, E.; Trzyniec, K.; Miernik, A. Mechatronic and IT systems used in modern agriculture. In 2019 Applications of Electromagnetics in Modern Engineering and Medicine; IEEE: New York, NY, USA, 2019; pp. 267–270. [Google Scholar]
- Jakubowski, T. The effect of stimulation of seed potatoes (Solanum tuberosum L.) in the magnetic field on selected vegetation parameters of potato plants. Przegląd Elektrotechniczny 2020, 1, 166–169. [Google Scholar]
- Sobol, Z.; Jakubowski, T. The effect of storage duration and UV-C stimulation of potato tubers and soaking of potato strips in water on the density of intermediates of French fries production. Przegląd Elektrotechniczny 2020, 1, 242–245. [Google Scholar] [CrossRef]
- Muñiz, R.; Cuevas-Valdés, M.; Roza-Delgado, B. Milk quality control requirement evaluation using a handheld near infrared reflectance spectrophotometer and a bespoke mobile application. J. Food Compos. Anal. 2020, 86, 103388. [Google Scholar] [CrossRef]
- Oberacher, H.; Sasse, M.; Antignac, J.P.; Guitton, Y.; Debrauwer, L.; Jamin, E.L.; Schulze, T.; Krauss, M.; Covaci, A.; Caballero-Casero, N.; et al. A European proposal for quality control and quality assurance of tandem mass spectral libraries. Environ. Sci. Eur. 2020, 32, 43. [Google Scholar] [CrossRef]
- Nguyen, M.T.; Truong, L.H.; Le, T.T.H. Video Surveillance processing algorithms utilizing artificial intelligent (AI) for unmanned autonomous vehicles (UAVs). MethodsX 2021, 8, 101472. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, M.T.; Truong, L.H.; Tran, T.T.; Chien, C.F. Artificial intelligence-based data processing algorithm for video surveillance to empower industry 3.5. Comput. Ind. Eng. 2020, 148, 106671. [Google Scholar] [CrossRef]
- Chen, Y.; Kong, R.; Kong, L. 14-Applications of artificial intelligence in astronomical big data. In Big Data in Astronomy, 1st ed.; Kong, L., Huang, T., Zhu, Y., Yu, S., Eds.; Elsevier: Amsterdam, The Netherlands, 2020; pp. 347–375. [Google Scholar]
- Fluke, C.J.; Jacobs, C. Surveying the reach and maturity of machine learning and artificial intelligence in astronomy. WIREs Data Min. Knowl. Discov. 2020, 10, e1349. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 6, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Lindsay, G.W. Convolutional neural networks as a model of the visual system: Past, present, and future. J. Cogn. Neurosci. 2021, 33, 2017–2031. [Google Scholar] [CrossRef] [PubMed]
- Bieder, F.; Sandkühler, R.; Cattin, P.C. Comparison of methods generalizing max- and average-pooling. arXiv 2021, arXiv:abs/2103.01746. [Google Scholar]
- Shah, K.; Shah, S.M. CNN-based iris recognition system under different pooling. In Emerging Technologies in Data Mining and Information Security. Advances in Intelligent Systems and Computin, 1st ed.; Hassanien, A.E., Bhattacharyya, S., Chakrabati, S., Bhattacharya, A., Dutta, S., Eds.; Springer: New York, NY, USA, 2021; pp. 167–170. [Google Scholar]
- De Pretis, F.; Landes, J. EA3: A softmax algorithm for evidence appraisal aggregation. PLoS ONE 2021, 16, e0253057. [Google Scholar] [CrossRef]
- Hussain, M.A.; Tsai, T.H. An efficient and fast Softmax hardware architecture (EFSHA) for deep neural networks. In Proceedings of the 2021 IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems, Washington, DC, USA, 6–9 June 2021; pp. 1–5. [Google Scholar]
- Jap, D.; Won, Y.S.; Bhasin, S. Fault injection attacks on SoftMax function in deep neural networks. In Proceedings of the 18th ACM International Conference on Computing Frontiers, New York, NY, USA, 11–13 May 2021; pp. 238–240. [Google Scholar]
- Posada-Gomez, R.; Sanchez-Medel, L.H.; Hernandez, G.A.; Martinez-Sibaja, A.; Aguilar-Laserre, A.; Leija-Salas, L. A Hands Gesture System of Control for an Intelligent Wheelchair. In Proceedings of the 4th International Conference on Electrical and Electronics Engineering, Mexico City, Mexico, 5–7 September 2007; 2007; pp. 68–71. [Google Scholar]
- Hu, B.; Wang, J. Deep Learning Based Hand Gesture Recognition and UAV Flight Controls. In Proceedings of the 24th International Conference on Automation and Computing (ICAC), Newcastle upon Tyne, UK, 6–7 September 2018; pp. 1–6. [Google Scholar]
- Kaczmarek, W.; Panasiuk, J.; Borys, S.; Banach, P. Industrial Robot Control by Means of Gestures and Voice Commands in Off-Line and On-Line Mode. Sensors 2020, 20, 6358. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.J.; Lai, S.C.; Jhuang, J.Y.; Ho, M.C.; Shiau, Y.C. Development of Smart Home Gesture-based Control System. Sens. Mater. 2021, 33, 3459–3471. [Google Scholar] [CrossRef]
- Shanta, S.S.; Anwar, S.T.; Kabir, M.R. Bangla Sign Language Detection using SIFT and CNN. In Proceedings of the 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, 10–12 July 2018; pp. 1–6. [Google Scholar]
- Al Rashid Agha, R.A.; Sefer, M.N.; Fattah, P. A comprehensive Study on Sign Languages Recognition Systems using (SVM, KNN, CNN and ANN). In Proceedings of the 1st International Conference on Data Science, E-Learning and Information Systems (DATA), Madrid, Spain, 1–2 October 2018; pp. 1–6. [Google Scholar]
- Mustafa, M. A study on Arabic sign language recognition for differently abled using advanced machine learning classifiers. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 4101–4115. [Google Scholar] [CrossRef]
- Das, A.; Patra, G.R.; Mohanty, M.N. LSTM based Odia Handwritten Numeral Recognition. In Proceedings of the 2020 International Conference on Communication and Signal Processing, Shanghai, China, 12–15 September 2020; pp. 538–541. [Google Scholar]
- He, J.; Pedroza, I.; Liu, Q. MetaNet: A boosting-inspired deep learning image classification ensemble technique. In Proceedings of the International Conference on Image Processing, Computer Vision, and Pattern Recognition, Las Vegas, NV, USA, 29 July–1 August 2019; pp. 51–54. [Google Scholar]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kozyra, K.; Trzyniec, K.; Popardowski, E.; Stachurska, M. Application for Recognizing Sign Language Gestures Based on an Artificial Neural Network. Sensors 2022, 22, 9864. https://doi.org/10.3390/s22249864
Kozyra K, Trzyniec K, Popardowski E, Stachurska M. Application for Recognizing Sign Language Gestures Based on an Artificial Neural Network. Sensors. 2022; 22(24):9864. https://doi.org/10.3390/s22249864
Chicago/Turabian StyleKozyra, Kamil, Karolina Trzyniec, Ernest Popardowski, and Maria Stachurska. 2022. "Application for Recognizing Sign Language Gestures Based on an Artificial Neural Network" Sensors 22, no. 24: 9864. https://doi.org/10.3390/s22249864
APA StyleKozyra, K., Trzyniec, K., Popardowski, E., & Stachurska, M. (2022). Application for Recognizing Sign Language Gestures Based on an Artificial Neural Network. Sensors, 22(24), 9864. https://doi.org/10.3390/s22249864