1. Introduction
Optical coherence tomography angiography (OCTA), a non-invasive imaging technique, has been increasingly utilized for imaging the retinal and choroidal vascular system at capillary-level resolution. Compared with previous angiographic methods, OCTA has the merits of easier handling, faster imaging, and greater imaging depth, thus facilitating quantitative assessment of the morphological structure of the retinal and choroidal vascular system. Abnormalities on OCTA images usually indicate the presence of a number of diseases, such as early glaucomatous optic neuropathy [
1], diabetic retinopathy [
2], and age-related macular degeneration [
3]. Some other recent studies have shown that deep microvascular morphological changes revealed by OCTA images are associated with Alzheimer’s disease [
4] and mild cognitive impairment [
5]. This opens up new ideas to investigate the relationship between abnormalities in retinal vessels and various neurodegenerative diseases. This shows that the precise segmentation of retinal vessels, especially deep capillaries, is of great importance to clinicians.
Before the popularity of deep learning, most of the automatic vessel segmentation methods were based on filters, and such methods are generally referred to as traditional methods. Azzopardi et al. [
6] designed a rod structure selection filter based on the COSFIRE filter, which can effectively extract information about branching structure compared to other filters. A detailed review of the methods for conventional vessel detection and segmentation can be found in the literature [
7]. A common limitation of all these traditional vessel segmentation methods is that they usually require manual tuning of parameters for a specific dataset, which makes the algorithms less scalable.
Compared to traditional methods, deep learning performs better generalization. However, deep learning methods applied to medical images still face challenges, which Zhou et al. [
8] attribute to the characteristics of medical images itself: the lack of standardized big data; the multimodality of medical data; and the long-tailed distribution of morbidity. Such problems also exist in the field of ophthalmic images, and more detail can be found in earlier work [
9,
10,
11,
12,
13]. In previous retinal vascular datasets, the number of samples is generally low, such as in DRIVE [
14], CHASE-DB1 [
15], etc. To alleviate the shortage of such datasets, Li et al. [
16] released the largest multimodal OCTA image dataset, OCTA-500, and also proposed the IPN image projection network. Taking advantage of the vertical consistency of 3D OCTA images, the IPN method compresses information in a 3D image to a 2D image and finally outputs segmentation maps. Ma et al. [
17] constructed a dataset called ROSE with retinal superficial and deep vascular annotations, respectively, to make up for the lack of datasets in this domain. The segmentation network OCTA-Net was also proposed to first generate an initial confidence map of blood vessels and then optimize the vessel details using a finetune module.
Among many deep learning-based medical image segmentation networks, the core ideology of U-Net [
18] is the most prevalent, and our COSNet also takes advantage of it. The U-shaped structure facilitates the extraction of semantic information, while the skip connection contributes to restore positional information. In addition, the U-Net structure can be applied to all types of medical images virtually. In recent years, many variants based on the U-Net architecture have also emerged. Huang et al. [
19] proposed a UNet3+ segmentation network based on full-scale jump connections and deep supervision. Full-scale skip connections combine low-level details with high-level semantics of feature maps at different scales, whereas deep supervision learns hierarchical representations from full-size aggregated feature maps. Isensee et al. [
20] addressed the selection of pre-processing, architecture, training methods, and post-processing methods to propose a nn-UNet segmentation network that can automatically configure parameters, outperforming most methods on 23 international biomedical competition datasets. Tomar et al. [
21] proposed the feedback attention network FANet for the network’s inability to efficiently learn information from different iteration batches, which combines feature maps from the current and previous batches together so that the masks of the previous batches constitute hard attention to learn the feature maps of different convolutional layers. Although the above methods achieve good results in image segmentation tasks, they focus only on intra- and inter-pixel semantic information of a single image, which prevents them from forming a structured feature space (large inter-class distance and small intra-class distance), thus limiting the segmentation performance.
Most current medical image segmentation methods rely entirely on accurate annotation, and medical image data are not as easily accessible as natural images. To address the data integration cost problem, researchers have introduced non-fully supervised methods to image segmentation tasks to reduce the reliance on annotation. In this paper, we focus on contrast learning, and the application of contrast learning to image segmentation is described below. Commonly used semantic segmentation methods for contrast learning are usually pre-trained on large unlabeled datasets first and then used for segmentation tasks, such as in the literature [
22]. To solve the problem of training overfitting on a small amount of labeled data, Zhao et al. [
23] proposed a new contrastive learning pre-training strategy, which is first pre-trained with label-based contrast loss and then fine-tuned with cross-entropy loss to improve intra-class compactness and inter-class separation. Zhong et al. [
24] proposed a semi-supervised semantic segmentation method that both maintains the continuity of the prediction space for the input transform and also ensures the contrastive nature of the feature space. In contrast to the previous stepwise contrast learning segmentation, the contrast loss and semi-supervised segmentation training in this work are performed jointly. Alonso et al. [
25] proposed a contrast learning module to perform pixel-level feature representation of similar samples from labeled and unlabeled data, and this work obtained good results in scenarios where the proportion of labeled data is small. Although all these methods noted above have achieved good results in the corresponding fields, they have not completely solved the problems of category imbalance and small target segmentation in medical image segmentation. COSNet in this paper also refers to similar loss function forms and utilizes the memory bank approach.
To address the problems of poor detail and class imbalance in small target segmentation tasks, we propose a global contrastive learning method for retinal OCTA image segmentation. Compared with previous methods, the method in this paper focuses on both single image information and global information (the whole dataset), which can achieve better results in a small sample medical dataset containing two kinds of annotations. The main contributions of this paper are as follows:
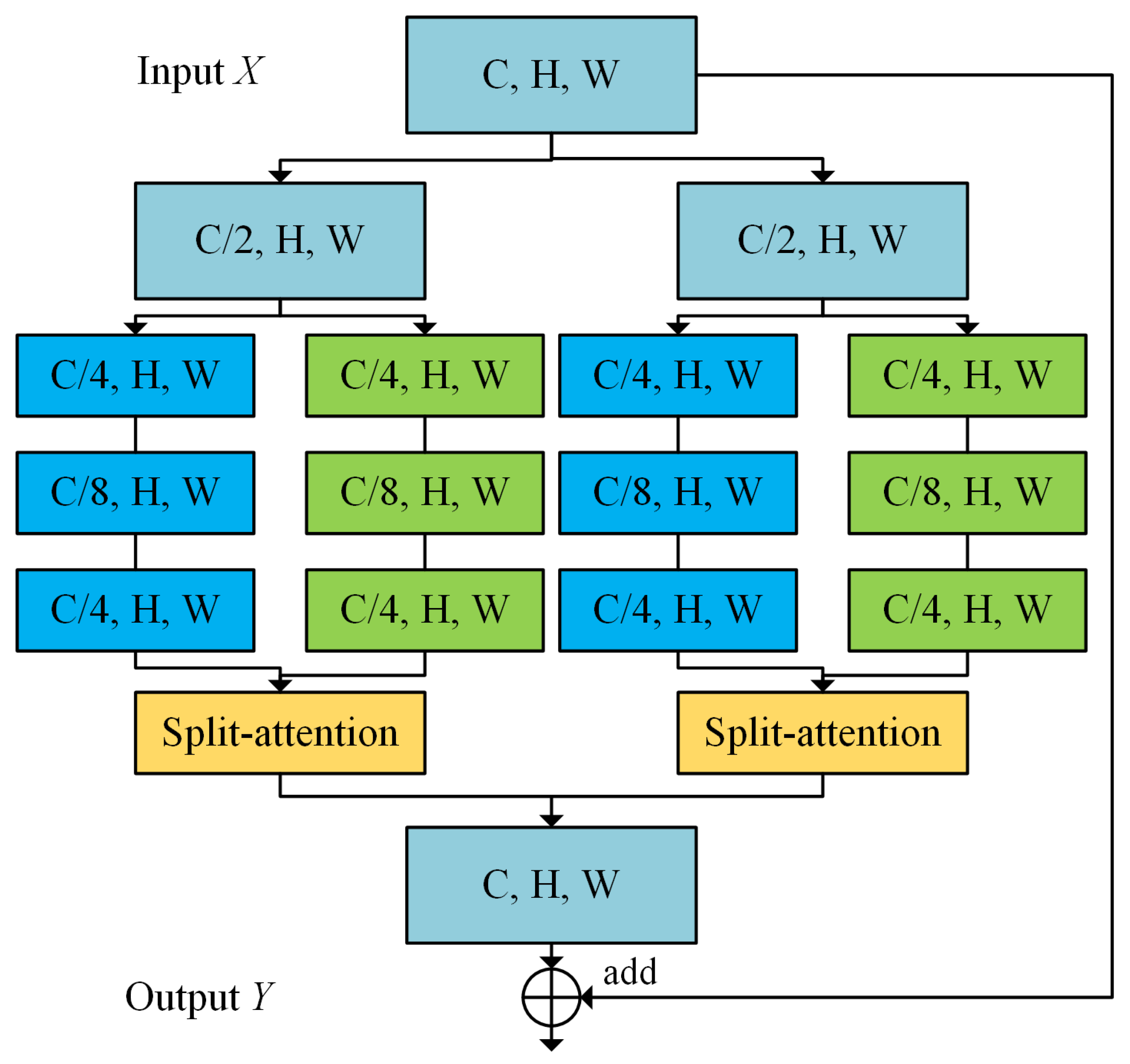
A two-branch contrastive learning network for retinal OCTA image segmentation is proposed. The model is able to effectively extract features of vascular images by learning superficial and deep vascular annotations while avoiding the feature vanishing of deep vessels. A segmentation head and a projection head are added at the end of the decoder to obtain both segmentation mapping and pixel embedding;
In this paper, a new pixel contrastive loss function is proposed. By saving same-class pixel queues and pixel embeddings in memory bank, features within a single image can be learned as well as same-class features in the whole dataset. The network model is guaranteed to learn more hard-to-segment samples, thus alleviating the class imbalance problem and improving the segmentation performance;
A contrast-limited adaptive histogram equalization (CLANE) method with fixed area is used for retinal OCTA images to mitigate noise caused by imaging artifacts.
The subsequent sections of the text contain Methods and Theory, Experiments and Results, Discussion, and Conclusions.
4. Discussion
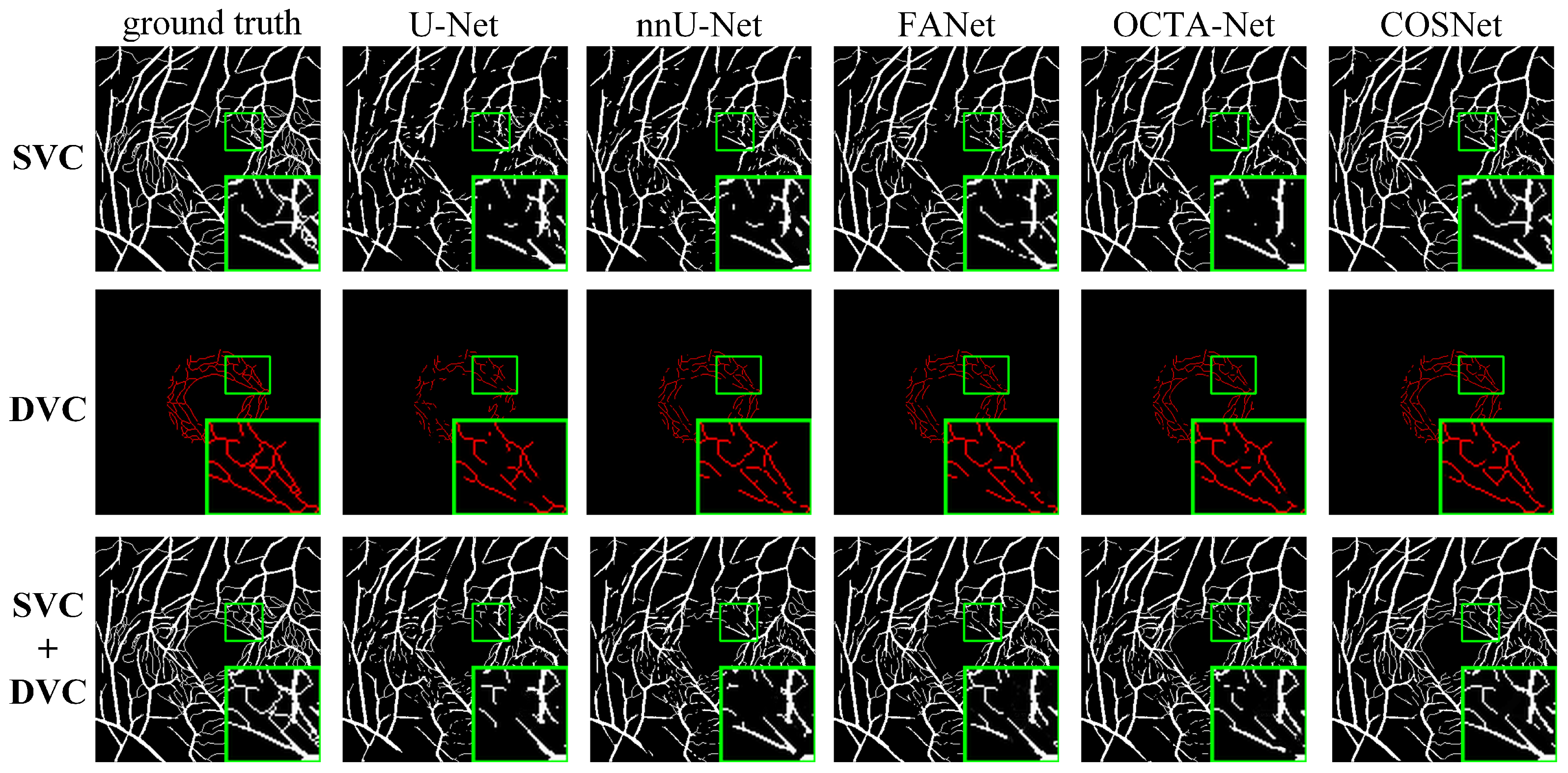
Experimental results show that our COSNet is generally superior to existing methods. In the case of small segmentation targets and class imbalance, methods that employ only strongly supervised loss functions (e.g., U-Net) usually perform poorly. The reason is that the strongly supervised loss pays attention only to information in single images, but the classes in a single image are inherently in an unbalanced state, which leads to the model inadequately learning information of minority class (vessels).
We believe that the essence of image segmentation lies in constructing a structured feature space (smaller intra-class distance and larger inter-class distance). Therefore, in the network architecture, our method extracts both local information (single images) and global information (same-class samples), which effectively alleviates class imbalance. Due to the characteristics of contrast learning, categorization by cosine similarity, distinctive target (vessels) and background are easily segmented. The segmentation results could be utilized for clinical diagnosis by the ratio of superficial and deep vessels width (e.g., Alzheimer’s disease). The previous method was only designed for processing images containing superficial vascular annotations, so the clinical application is less extensive.
The experiments also find that using different sampling strategies has a great impact on the results, which also validates previous studies on contrast learning. The selection of sampling strategies needs to be further investigated with regard to the features of data. In the fine-tune stage, the breakpoint problem has not been completely solved, so there is still potential for improvement.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}