
A Local and Non-Local Features Based Feedback Network on Super-Resolution


Abstract
1. Introduction
- 1.
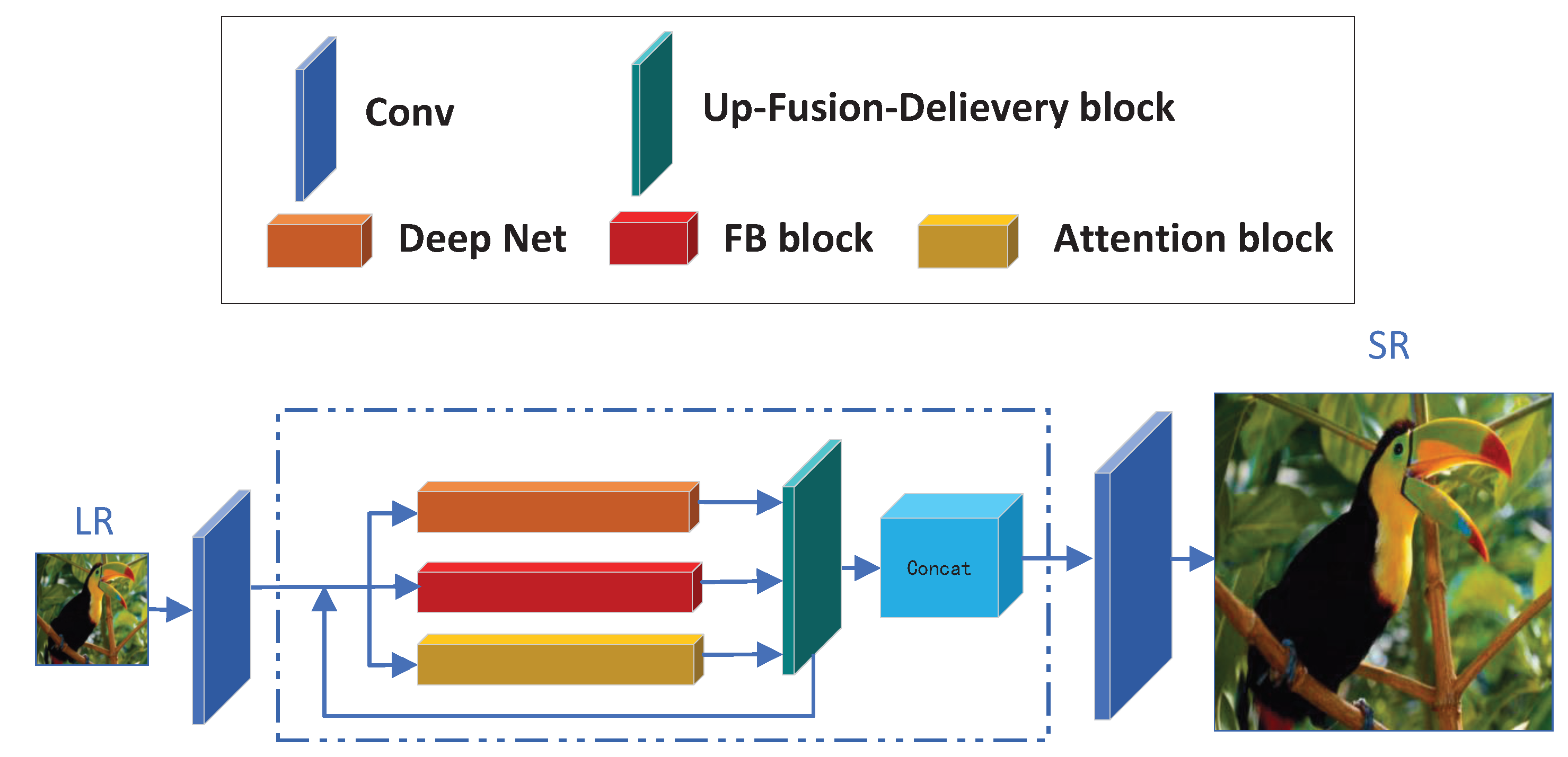
- We separate the SR images into five parts and choose three famous blocks (VDSR [3] block, SRFBN [4] block and CSNL [5] block) to generate the corresponding SR image parts. Because each block is designed to work on what they do best, this structure can take full use of each block’s advantage and compensate for its shortage with other blocks.
- 2.
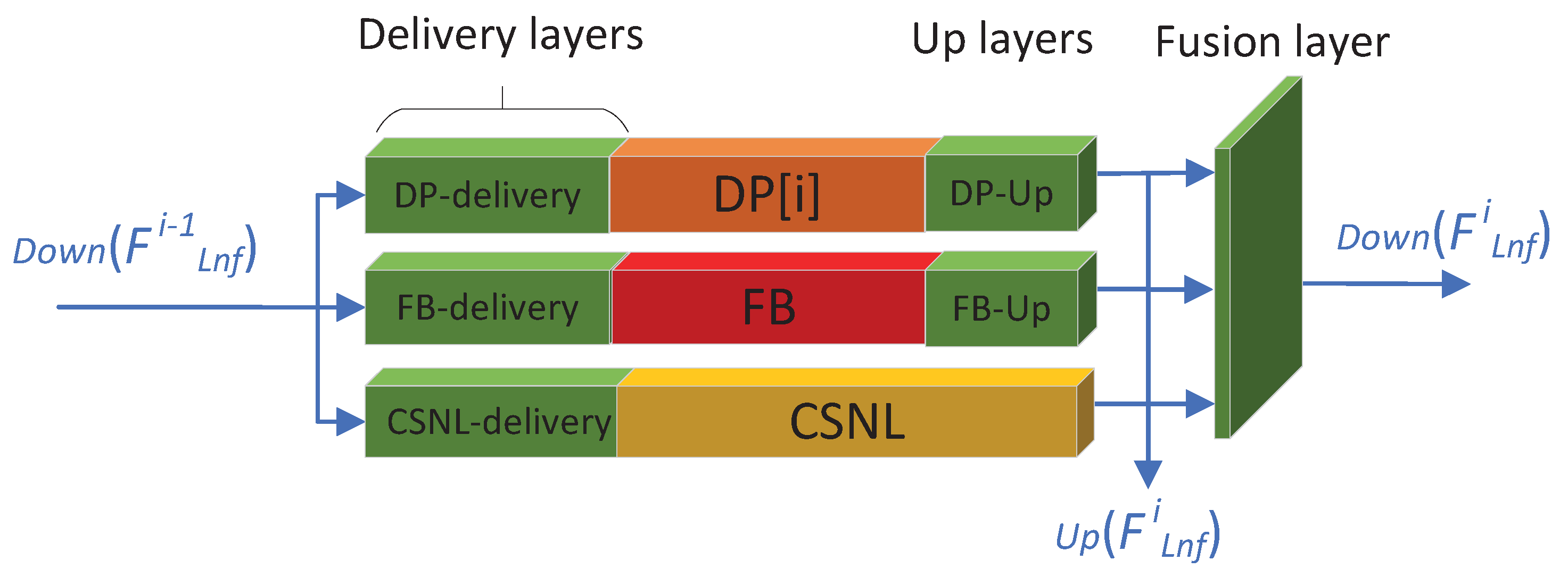
- We proposed the up-fusion-delivery block at the end of each iteration, which will help the feature be delivered to the right block on the next iteration. Features can be extracted and delivered to the right block quickly, so our LNFSR algorithm only needs fewer iterations to achieve comparable performance (6 for our LNFSR, while 12 for CSNLN).
2. Related Works
3. Local and Non-Local Feature Based Feedback Network for SR (LNFSR)
3.1. The Network Architecture of our LNFSR
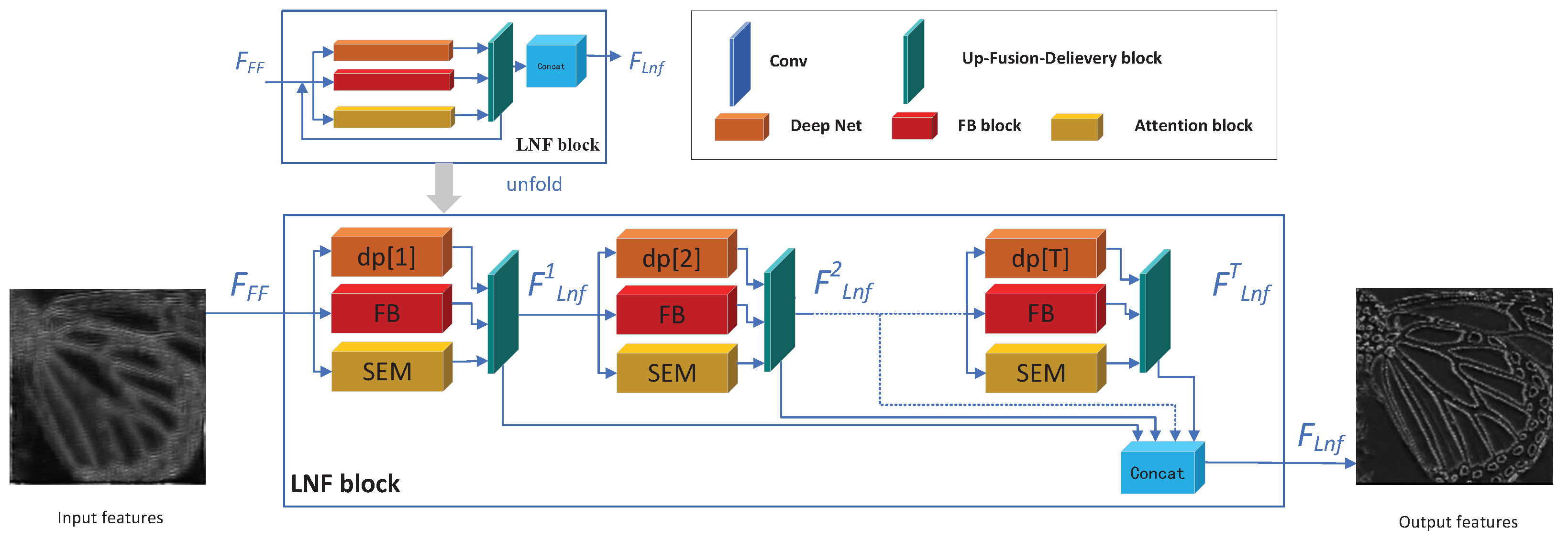
3.2. The Local and Non-Local Feature Extraction Block
- (4)
- Drop the based LR features: We drop the skip connection from input to the end for the based LR features, due to there being skip connection insider the CSNL block [5], which plays the same row as the skip connection directly. Experiments show that adding an additional skip connection will drop the performance, the reason we guess is the LR features play a critical role for the CSNL block to extract non-local features and the CSNL block has its own skip connection which serves the same work, so we drop the outer skip connection.
- (5)
- Drop the Non-local non-feedbackable features: We did not take another distinct block to extract the non-local non-feedbackable features, due to the reuse strategy. Because the non-local non-feedbackable features are similar to the local non-feedbackable features but far away, the non-local non-feedbackable features can be extracted by the CSNL block and then delivered into the DP block to refine them. With the help of our proposed up-fusion-delivery layers during each iteration, features can be delivered to the right block on the next iteration.
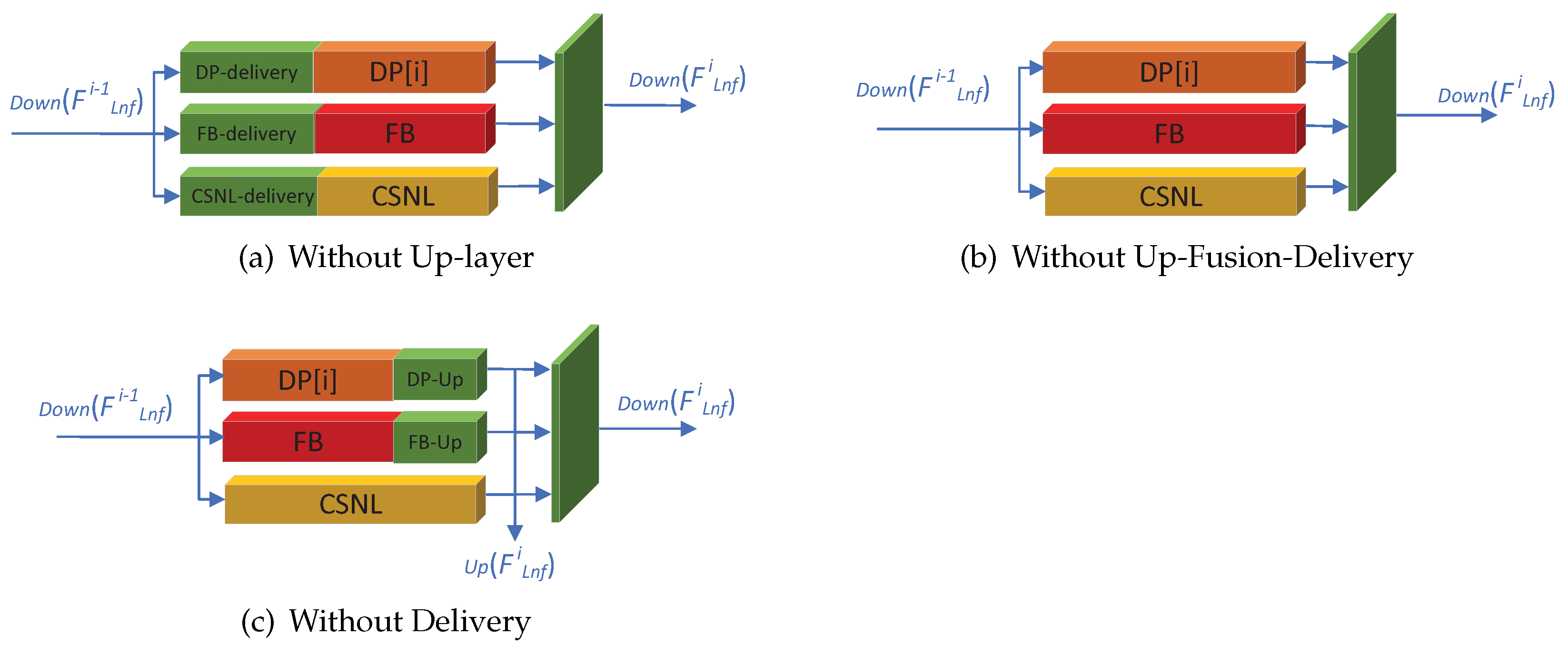
3.3. The Up-Fusion-Delivery Layers of Our LNFSR
3.4. Other Implementation Details
- (1)
- We follow the implementation details of the FB block and CSNL block. We use the ReLU as the activation function for DP blocks and PReLU as the activation function for other blocks.
- (2)
- We set all the feature channels as 64 for all three blocks (DP block, FB block and CSNL block). Due to half channels for CSNL inner block, the CSNL input feature channel is 128 then half to 64 for the inner block of CSNL. We set the number of feedback iterations for the LNF block as 6 to balance the performance and cost. Our LNFSR has more parameters than CSNLN, due to adding the DP and FB block, there are M () and M () parameters for CSNLN, while M () and M () parameters for our LNFSR. However, by half the iterations (12 for CSNLN), the computational cost of our LNFSR is close to that of CSNLN. For one training iteration, it cost about 16 min () and 140 min () for CSNLN, while 18 min () and 93 min () for our LNFSR on single NVIDIA 3090 GPU.
- (3)
- We choose loss to optimize our LNFSR, the Adam optimizer to optimize the parameters of the network with , and the initial learning rate , we reduce the learning rate by multiplying for every 200 epochs for a total of 1000 epochs. The network is implemented with the PyTorch framework and trained on a single NVIDIA 3090 GPU.
4. Experimental Results
4.1. Datasets and Evaluation Metrics
4.2. Ablation Study
4.3. Quantitative Comparisons with State-of-the-Arts
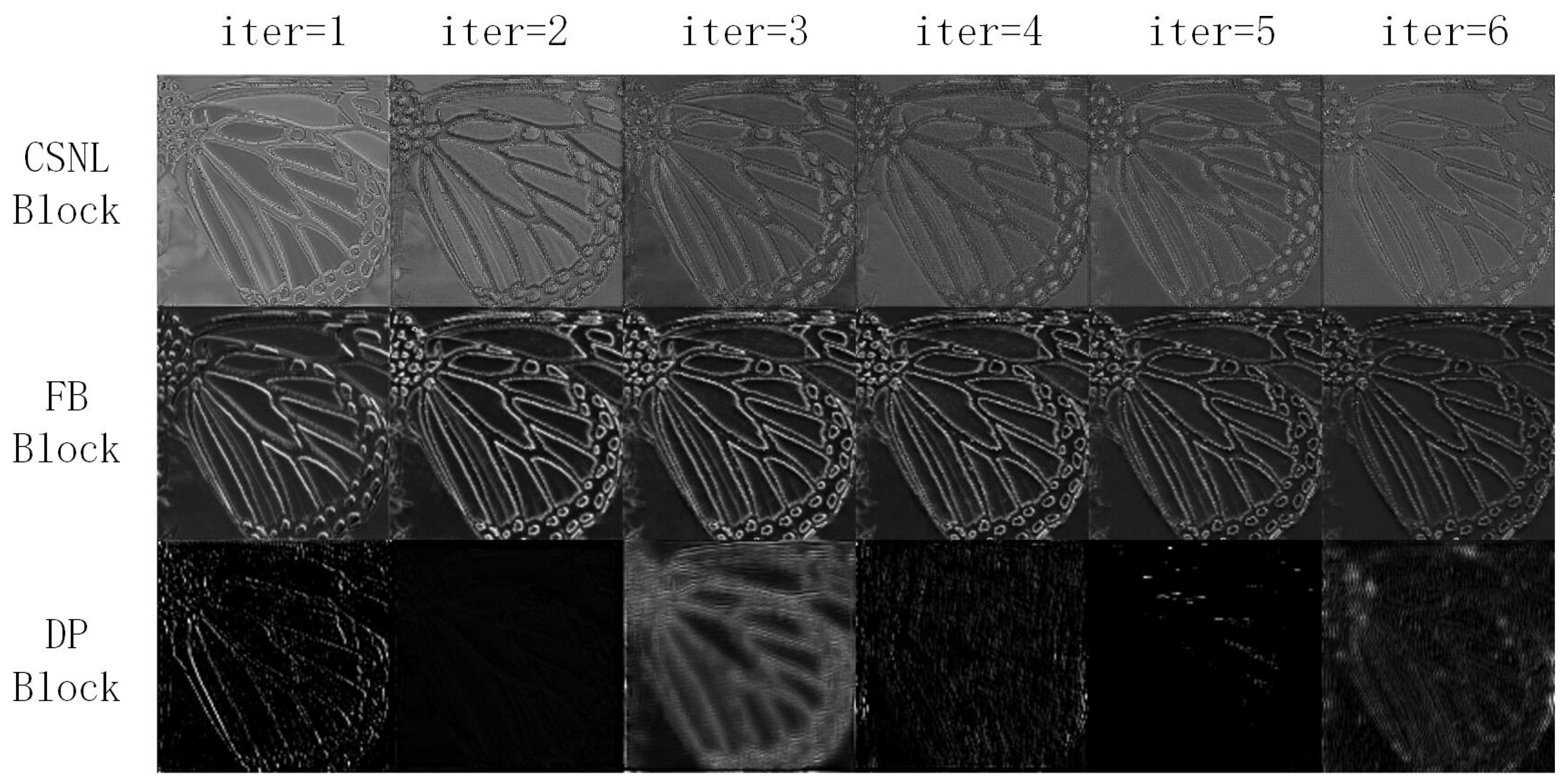
4.4. Visualized Comparisons with State-of-the-Arts
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronyms and Notations | Description |
|---|---|
| SISR | Single Image Super-Resolution |
| SR | Super-Resolution |
| HR | High-Resolution |
| LR | Low-Resolution |
| Super-Resolution image | |
| Low-Resolution image | |
| High-Resolution image | |
| the loss function | |
| the FF block | |
| the output features of the FF block | |
| the LNF block | |
| the i-th iteration output of the LNF block | |
| the output features of the LNF block | |
| the Rb block | |
| our proposed LNFSR algorithm | |
| DP[i] block | the i-th block of Deep Net (VDSR [3] in our paper) |
| FB block | the FeedBack block (SRFBN [4] in our paper) |
| CSNL block | the Cross-Scale Non-Local attention block |
| concat all the inputs | |
| on the feature dimension (second dimension) | |
| Up layer block in the Up-Fusion-Delivery layer | |
| down-scale the input to the LR scale | |
| the delivery layer of DP, FB and CSNL block | |
| the Up layer of DP and FB block | |
| the fusion layer |
References
- Wang, Z.; Chen, J.; Hoi, S.C. Deep Learning for Image Super-resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3365–3387. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the Computer Vision—ECCV, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar] [CrossRef]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback Network for Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3867–3876. [Google Scholar] [CrossRef]
- Mei, Y.; Fan, Y.; Zhou, Y.; Huang, L.; Huang, T.S.; Shi, H. Image Super-Resolution with Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 5690–5699. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2017; pp. 4681–4690. [Google Scholar] [CrossRef]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. ESRGAN: Enhanced Super-ResolutionGenerative Adversarial Networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2017; pp. 136–144. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual Feature Aggregation Network for Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2359–2368. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Li, B.; Guo, C. MASPC_Transform: A Plant Point Cloud Segmentation Network Based on Multi-Head Attention Separation and Position Code. Sensors 2022, 22, 9225. [Google Scholar] [CrossRef]
- Xia, B.; Hang, Y.; Tian, Y.; Yang, W.; Liao, Q.; Zhou, J. Efficient Non-Local Contrastive Attention for Image Super-Resolution. In Proceedings of the The 36th AAAI Conference on Artificial Intelligence (AAAI-22), Virtual, 22 February–1 March 2022; pp. 2759–2767. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-Complexity Single-Image Super-Resolution based on Nonnegative Neighbor Embedding. In Proceedings of the 23rd British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012. [Google Scholar] [CrossRef]
- Zeyde, R.; Elad, M.; Protter, M. On Single Image Scale-Up using Sparse-Representation. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; pp. 711–730. [Google Scholar] [CrossRef]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A Database of Human Segmented Natural Images and its Application to Evaluating Segmentation Algorithms and Measuring Ecological Statistics. In Proceedings of the 8th IEEE International Conference on Computer Vision. ICCV, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar] [CrossRef]
- Huang, J.B.; Singh, A.; Ahuja, N. Single Image Super-resolution from Transformed Self-Exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar] [CrossRef]
- Gu, J.; Dong, C. Interpreting Super-Resolution Networks with Local Attribution Maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9199–9208. [Google Scholar] [CrossRef]
- Li, B.; Xiong, S.; Xu, H. Channel Pruning Base on Joint Reconstruction Error for Neural Network. Symmetry 2022, 14, 1372. [Google Scholar] [CrossRef]







| Algorithm | Only-DP | Only-FB | Only-CSNL | LNFSR-L |
|---|---|---|---|---|
| PSNR/SSIM | 37.37/0.9581 | 37.57/0.9590 | 37.84/0.9600 | 37.90/0.9603 |
| Algorithm | Without Up-Layer | Without Delivery | Without Up-Fusion-Delivery | LNFSR-L |
|---|---|---|---|---|
| PSNR/SSIM | 37.80/0.9600 | 37.68/0.9594 | 37.66/0.9593 | 37.90/0.9603 |
| Algorithm | Scale | Set5 | Set14 | B100 | Urban100 | ||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| BiCubic | 33.68 | 0.9303 | 32.23 | 0.8700 | 29.56 | 0.8435 | 26.87 | 0.8405 | |
| SRCNN [2] | 36.32 | 0.9519 | 32.24 | 0.9031 | 30.98 | 0.8824 | 28.96 | 0.8857 | |
| VDSR [3] | 37.46 | 0.9583 | 33.14 | 0.9131 | 31.91 | 0.8960 | 33.09 | 0.9170 | |
| RCAN [21] | 38.20 | 0.9612 | 33.93 | 0.9198 | 32.33 | 0.9015 | 32.83 | 0.9344 | |
| EDSR [9] | 38.11 | 0.9608 | 33.70 | 0.9182 | 32.23 | 0.9002 | 32.42 | 0.9308 | |
| SRFBN [4] | 38.03 | 0.9606 | 33.64 | 0.9177 | 33.22 | 0.9000 | 32.32 | 0.9304 | |
| CSNLN [5] | 38.17 | 0.9613 | 34.05 | 0.9213 | 32.32 | 0.9015 | 33.11 | 0.9371 | |
| LNFSR (our) | 38.22 | 0.9613 | 34.10 | 0.9229 | 32.35 | 0.9018 | 33.21 | 0.9377 | |
| BiCubic | 30.42 | 0.8688 | 27.58 | 0.7763 | 27.22 | 0.7395 | 24.46 | 0.7356 | |
| SRCNN[2] | 32.48 | 0.9046 | 29.07 | 0.8149 | 28.07 | 0.7768 | 25.79 | 0.7841 | |
| VDSR [3] | 33.73 | 0.9223 | 29.94 | 0.8343 | 28.84 | 0.7982 | 27.34 | 0.8326 | |
| RCAN [21] | 34.77 | 0.9298 | 30.58 | 0.8470 | 29.28 | 0.8095 | 28.95 | 0.8677 | |
| EDSR [9] | 34.69 | 0.9292 | 30.47 | 0.8455 | 29.22 | 0.8088 | 28.69 | 0.8644 | |
| SRFBN [4] | 34.57 | 0.9283 | 30.44 | 0.8442 | 29.17 | 0.8068 | 28.50 | 0.8594 | |
| CSNLN [5] | 34.63 | 0.9292 | 30.57 | 0.8470 | 29.26 | 0.8098 | 28.91 | 0.8682 | |
| LNFSR (our) | 34.72 | 0.9298 | 30.61 | 0.8468 | 29.26 | 0.8098 | 28.97 | 0.8677 | |
| BiCubic | 28.45 | 0.8110 | 26.04 | 0.7055 | 25.99 | 0.6692 | 23.15 | 0.6588 | |
| SRCNN [2] | 30.15 | 0.8531 | 27.20 | 0.7415 | 26.55 | 0.6985 | 24.05 | 0.7005 | |
| SRGAN [6] | 29.40 | 0.8472 | 26.02 | 0.7397 | 25.16 | 0.6688 | - | - | |
| VDSR [3] | 31.35 | 0.8825 | 28.16 | 0.7703 | 27.26 | 0.7244 | 25.28 | 0.7554 | |
| RCAN [21] | 32.51 | 0.8987 | 28.84 | 0.7876 | 27.73 | 0.7417 | 26.71 | 0.8058 | |
| EDSR [9] | 32.49 | 0.8985 | 28.81 | 0.7872 | 27.71 | 0.7409 | 26.58 | 0.8015 | |
| SRFBN [4] | 32.27 | 0.8963 | 28.69 | 0.7841 | 27.64 | 0.7379 | 26.35 | 0.7945 | |
| CSNLN [5] | 32.72 | 0.9008 | 28.97 | 0.7896 | 27.82 | 0.7451 | 27.34 | 0.8205 | |
| LNFSR (our) | 32.75 | 0.9013 | 28.97 | 0.7897 | 27.83 | 0.7451 | 27.33 | 0.8199 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Chu, Z.; Li, B. A Local and Non-Local Features Based Feedback Network on Super-Resolution. Sensors 2022, 22, 9604. https://doi.org/10.3390/s22249604
Liu Y, Chu Z, Li B. A Local and Non-Local Features Based Feedback Network on Super-Resolution. Sensors. 2022; 22(24):9604. https://doi.org/10.3390/s22249604
Chicago/Turabian StyleLiu, Yuhao, Zhenzhong Chu, and Bin Li. 2022. "A Local and Non-Local Features Based Feedback Network on Super-Resolution" Sensors 22, no. 24: 9604. https://doi.org/10.3390/s22249604
APA StyleLiu, Y., Chu, Z., & Li, B. (2022). A Local and Non-Local Features Based Feedback Network on Super-Resolution. Sensors, 22(24), 9604. https://doi.org/10.3390/s22249604