
An End-to-End Automated License Plate Recognition System Using YOLO Based Vehicle and License Plate Detection with Vehicle Classification



 ,
,  and
and 
Abstract
1. Introduction
- A streamlined, generalizable ALPR pipeline
- A fully automated ALPR system that does not require any pre-defined rules or post-processing steps.
- A customized data augmentation technique and data generation to synthesize new license plates to increase data
- An elementary vehicle classifier that can be expanded on
- A methodological analysis of the proposed method with preceding works in literature.
- In addition, we have evaluated our ALPR system with five datasets from five different regions of the world, so we can show the generalizability of the proposed work and also in real-world applications such as different lighting conditions, backgrounds, and orientations.
2. Related Work
3. Proposed Method
3.1. Datasets
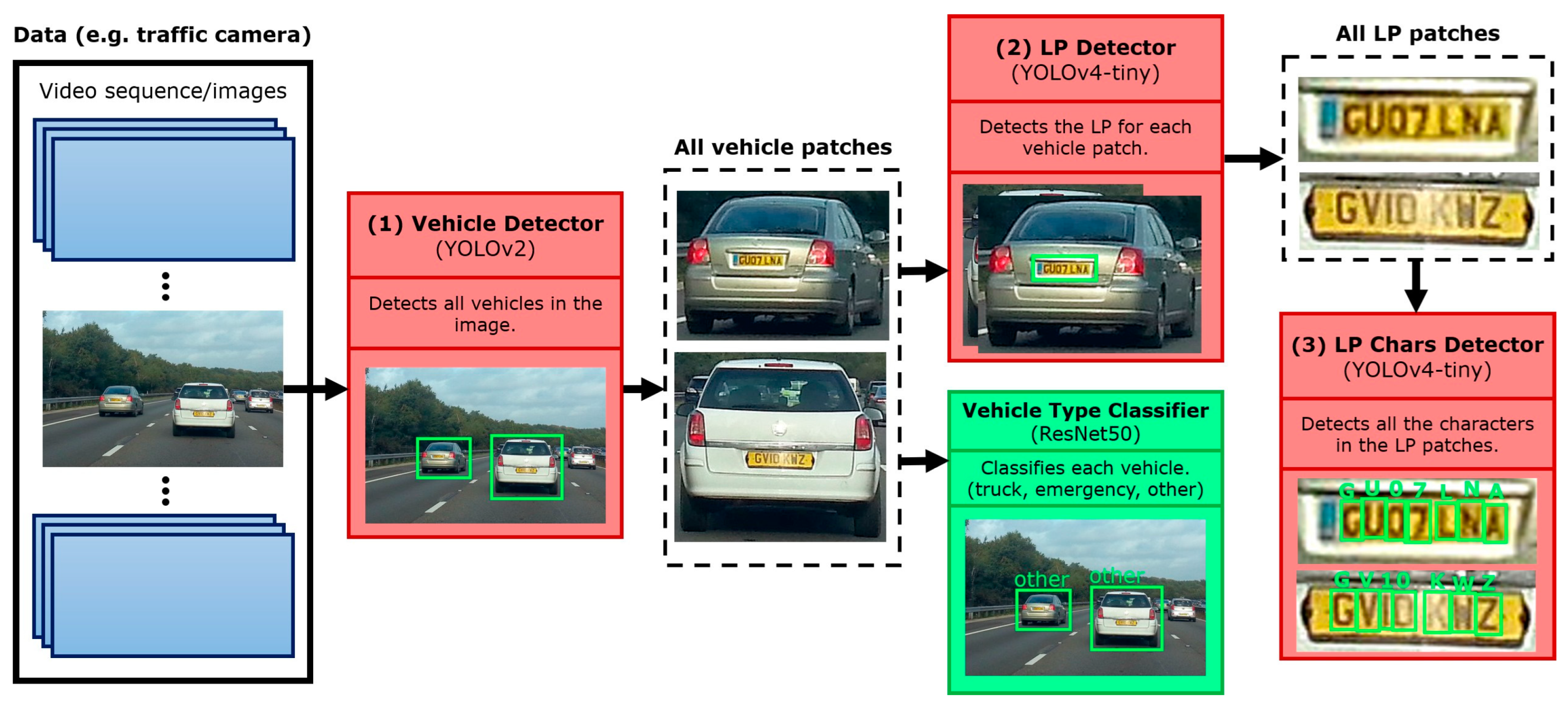
3.2. Proposed Framework
| Algorithm 1: ALP pipeline |
 |
3.3. Vehicle Detection (VD)
3.4. Vehicle Type Classification (VTC)
3.5. License Plate Detection (LPD)
3.6. License Plate Recognition (LPR)
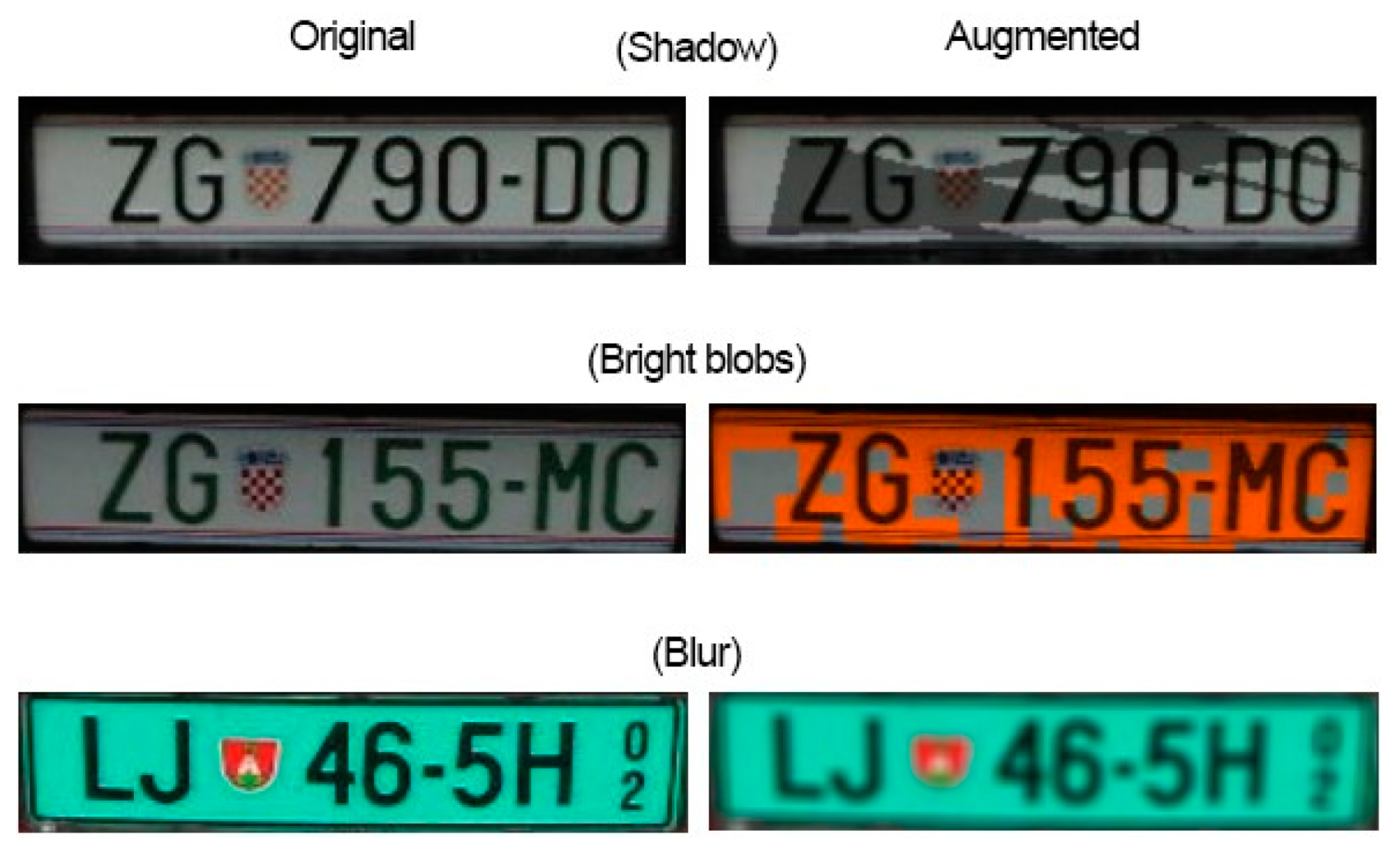
3.6.1. Data Permutations
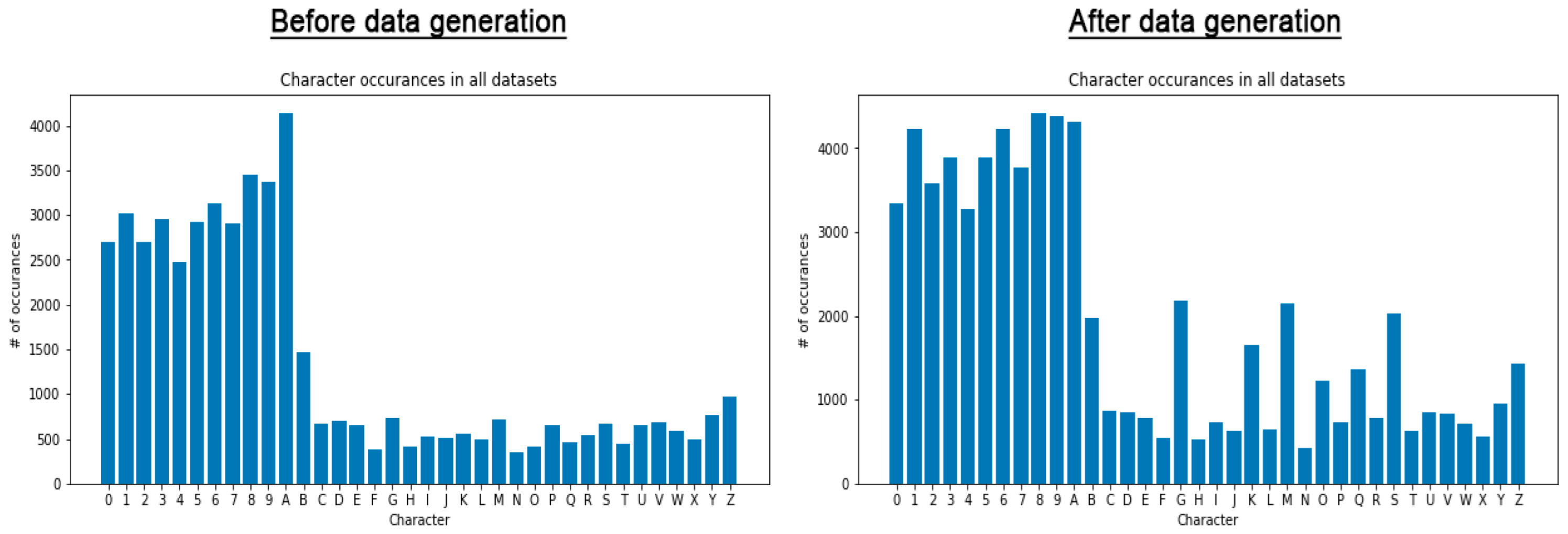
3.6.2. Data Generation
4. Results
4.1. Vehicle Detection Results
4.2. Vehicle Type Classification Results
4.3. LP Detection Results
4.4. LP Recognition Results
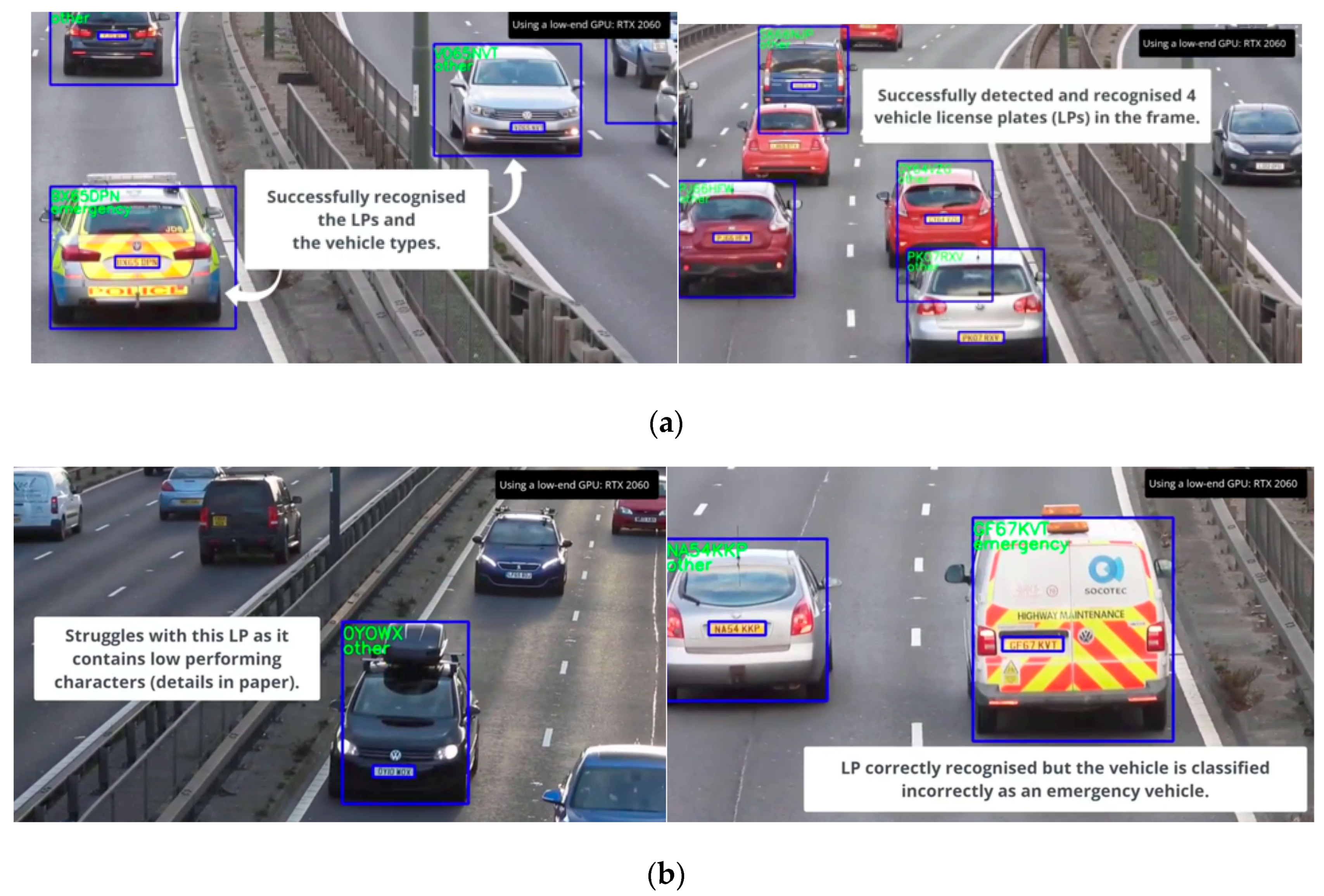
4.5. Full ALPR Pipeline Results
4.6. Comparison
4.7. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sharma, P.; Gupta, S.; Singh, P.; Shejul, K.; Reddy, D. Automatic Number Plate Recognition and Parking Management. In Proceedings of the 2022 International Conference on Advances in Computing, Communication and Applied Informatics (ACCAI), Chennai, India, 28–29 January 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Soomro, S.R.; Javed, M.A.; Memon, F.A. Vehicle Number Recognition System for automatic toll tax collection. In Proceedings of the 2012 International Conference on Robotics and Artificial Intelligence, ICRAI, Rawalpindi, Pakistan, 22–23 October 2012; pp. 125–129. [Google Scholar] [CrossRef]
- Aalsalem, M.Y.; Khan, W.Z.; Dhabbah, K.M. An automated vehicle parking monitoring and management system using ANPR cameras. In Proceedings of the 2015 17th International Conference on Advanced Communication Technology (ICACT), PyeongChang, Korea, 1–3 July 2015; pp. 706–710. [Google Scholar]
- Kim, K.; Bae, S.; Huh, K. Intelligent surveillance and security robot systems. In Proceedings of the 2010 IEEE Workshop on Advanced Robotics and its Social Impacts, Seoul, Korea, 26–28 October 2010; pp. 70–73. [Google Scholar]
- Konovalenko, I.; Maruschak, P.; Brezinová, J.; Vináš, J.; Brezina, J. Steel Surface Defect Classification Using Deep Residual Neural Network. Metals 2020, 10, 846. [Google Scholar] [CrossRef]
- Zhuang, J.; Hou, S.; Wang, Z.; Zha, Z.-J. Towards human-level license plate recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 306–321. [Google Scholar]
- Xie, L.; Ahmad, T.; Jin, L.; Liu, Y.; Zhang, S. A new cnn-based method for multi-directional car license plate detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 507–517. [Google Scholar] [CrossRef]
- Li, H.; Wang, P.; You, M.; Shen, C. Reading car license plates using deep neural networks. Image Vis. Comput. 2018, 72, 14–23. [Google Scholar] [CrossRef]
- Kessentini, Y.; Besbes, M.D.; Ammar, S.; Chabbouh, A. A two-stage deep neural network for multi-norm license plate detection and recognition. Expert Syst. Appl. 2019, 136, 159–170. [Google Scholar] [CrossRef]
- Kurpiel, F.D.; Minetto, R.; Nassu, B.T. Convolutional neural networks for license plate detection in images. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3395–3399. [Google Scholar]
- Montazzolli, S.; Jung, C. Real-time brazilian license plate detection and recognition using deep convolutional neural networks. In Proceedings of the 2017 30th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Niteroi, Brazil, 17–20 October 2017; pp. 55–62. [Google Scholar]
- Laroca, R.; Zanlorensi, L.A.; Gonc¸alves, G.R.; Todt, E.; Schwartz, W.R.; Menotti, D. An efficient and layout-independent automatic license plate recognition system based on the yolo detector. arXiv 2019, arXiv:1909.01754. [Google Scholar]
- Ning, G.; Zhang, Z.; Huang, C.; Ren, X.; Wang, H.; Cai, C.; He, Z. Spatially supervised recurrent convolutional neural networks for visual object tracking. IEEE Int. Symp. Circuits Syst. 2017, 1–4. [Google Scholar] [CrossRef]
- Severo, E.; Laroca, R.; Bezerra, C.S.; Zanlorensi, L.A.; Weingaertner, D.; Moreira, G.; Menotti, D. A benchmark for iris location and a deep learning detector evaluation. Int. Jt. Conf. Neural Netw. 2018, 1–7. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Hsu, G.; Ambikapathi, A.; Chung, S.; Su, C. Robust license plate detection in the wild. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Loce, R.P.; Bala, R.; Trivedi, M. Automated License Plate Recognition. In Computer Vision and Imaging in Intelligent Transportation Systems; IEEE: New York, NY, USA, 2017; pp. 15–45. [Google Scholar] [CrossRef]
- Du, S.; Ibrahim, M.; Shehata, M.; Badawy, W. Automatic License Plate Recognition (ALPR): A State-of-the-Art Review. IEEE Trans. Circuits Syst. Video Technol. 2012, 23, 311–325. [Google Scholar] [CrossRef]
- Munusamy, D.; Alkawaz, M.H.; Jamal, A.; Hajamydeen, A.I. Notice of Violation of IEEE Publication Principles: An Automated Car Plate Identification Systems based on YOLO: Techniques and Methods. In Proceedings of the 2021 IEEE 12th Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, 7 August 2021; pp. 69–74. [Google Scholar] [CrossRef]
- Ahmad, I.S.; Boufama, B.; Habashi, P.; Anderson, W.; Elamsy, T. Automatic license plate recognition: A comparative study. In Proceedings of the 2015 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Abu Dhabi, United Arab Emirates, 7–10 December 2015. [Google Scholar]
- Redmon, J. Darknet: Open Source Neural Networks in C. Available online: http://pjreddie.com/darknet/ (accessed on 27 October 2022).
- Vision, C. CaltechCars. Available online: http://www.vision.caltech.edu/archive.html (accessed on 27 October 2022).
- Project “License Plates”. Available online: http://www.zemris.fer.hr/projects/LicensePlates/english/results.shtml (accessed on 27 October 2022).
- Hill, M. Open ALPR. Available online: https://github.com/openalpr/benchmarks/tree/master/%20endtoend/eu (accessed on 27 October 2022).
- Hsu, G.-S.; Chen, J.-C.; Chung, Y.-Z. Application-Oriented License Plate Recognition. IEEE Trans. Veh. Technol. 2012, 62, 552–561. [Google Scholar] [CrossRef]
- Laroca, R.; Severo, E.; Zanlorensi, L.A.; Oliveira, L.S.; Gonc¸alves, G.R.; Schwartz, W.R.; Menotti, D. A robust real-time automatic license plate recognition based on the yolo detector. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–10. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: New York, NY, USA, 2016; pp. 779–788. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. IJCV 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: New York, NY, USA, 2016; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Panahi, R.; Gholampour, I. Accurate Detection and Recognition of Dirty Vehicle Plate Numbers for High-Speed Applications. IEEE Trans. Intell. Transp. Syst. 2016, 18, 767–779. [Google Scholar] [CrossRef]
- Silva, S.M.; Jung, C.R. License plate detection and recognition in unconstrained scenarios. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2018; pp. 580–596. [Google Scholar]
- Silva, S.M.; Jung, C.R. Real-time license plate detection and recognition using deep convolutional neural networks. J. Vis. Commun. Image Represent. 2020, 71, 102773. [Google Scholar] [CrossRef]
- Masood, S.Z.; Shu, G.; Dehghan, A.; Ortiz, E.G. License plate detection and recognition using deeply learned convolutional neural networks. arXiv 2017, arXiv:1703.07330. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Resolution | Country | Year | # Samples |
|---|---|---|---|---|
| Caltech Cars | 896 × 592 | America | 1999 | 124 |
| English LP | 640 × 480 | EU | 2003 | 509 |
| OpenALPR EU | diverse | EU | 2016 | 108 |
| AOLP | diverse | Taiwan | 2013 | 2049 |
| UFPR ALPR | 1920 × 1080 | Brazil | 2018 | 4500 |
| Total Samples | 7290 | |||
| Layer | Filters | Size/Strd | Input | Output |
|---|---|---|---|---|
| 0 conv | 32 | 3 × 3/1 | 608 × 416 × 3 | 608 × 416 × 32 |
| 1 max | 2 × 2/2 | 608 × 416 × 32 | 304 × 208 × 32 | |
| 2 conv | 64 | 3 × 3/1 | 304 × 208 × 32 | 304 × 208 × 64 |
| 3 max | 2 × 2/2 | 304 × 208 × 64 | 152 × 104 × 64 | |
| 4 conv | 128 | 3 × 3/1 | 152 × 104 × 64 | 152 × 104 × 128 |
| 5 conv | 64 | 1 × 1/1 | 152 × 104 × 128 | 152 × 104 × 64 |
| 6 conv | 128 | 3 × 3/1 | 152 × 104 × 64 | 152 × 104 × 128 |
| 7 max | 2 × 2/2 | 152 × 104 × 128 | 76 × 52 × 128 | |
| 8 conv | 256 | 3 × 3/1 | 76 × 52 × 128 | 76 × 52 × 256 |
| 9 conv | 128 | 1 × 1/1 | 76 × 52 × 256 | 76 × 52 × 128 |
| 10 conv | 256 | 3 × 3/1 | 76 × 52 × 128 | 76 × 52 × 256 |
| 11 max | 2 × 2/2 | 76 × 52 × 256 | 38 × 26 × 256 | |
| 12 conv | 512 | 3 × 3/1 | 38 × 26 × 256 | 38 × 26 × 512 |
| 13 conv | 256 | 1 × 1/1 | 38 × 26 × 512 | 38 × 26 × 256 |
| 14 conv | 512 | 3 × 3/1 | 38 × 26 × 256 | 38 × 26 × 512 |
| 15 conv | 256 | 1 × 1/1 | 38 × 26 × 512 | 38 × 26 × 256 |
| 16 conv | 512 | 3 × 3/1 | 38 × 26 × 256 | 38 × 26 × 512 |
| 17 max | 2 × 2/2 | 38 × 26 × 512 | 19 × 13 × 512 | |
| 18 conv | 1024 | 3 × 3/1 | 19 × 13 × 512 | 19 × 13 × 1024 |
| 19 conv | 512 | 1 × 1/1 | 19 × 13 × 1024 | 19 × 13 × 512 |
| 20 conv | 1024 | 3 × 3/1 | 19 × 13 × 512 | 19 × 13 × 1024 |
| 21 conv | 512 | 1 × 1/1 | 19 × 13 × 1024 | 19 × 13 × 512 |
| 22 conv | 1024 | 3 × 3/1 | 19 × 13 × 512 | 19 × 13 × 1024 |
| 23 conv | 1024 | 3 × 3/1 | 19 × 13 × 1024 | 19 × 13 × 1024 |
| 24 conv | 1024 | 3 × 3/1 | 19 × 13 × 1024 | 19 × 13 × 1024 |
| 25 route | 16 | 38 × 26 × 512 | ||
| 26 reorg | /2 | 38 × 26 × 512 | 19 × 13 × 2048 | |
| 27 route | 26–24 | 19 × 13 × 3072 | ||
| 28 conv | 1024 | 3 × 3/1 | 19 × 13 × 3072 | 19 × 13 × 1024 |
| 29 conv | 35 | 1 × 1/1 | 19 × 13 × 1024 | 19 × 13 × 35 |
| Layer | Filters | Size/Strd | Input | Output |
|---|---|---|---|---|
| 0 conv | 32 | 3 × 3/2 | 416 × 416 × 3 | 208 × 208 × 32 |
| 1 conv | 64 | 3 × 3/2 | 208 × 208 × 32 | 104 × 104 × 64 |
| 2 conv | 64 | 3 × 3/1 | 104 × 104 × 64 | 104 × 104 × 64 |
| 3 route | 2 | 1/2 | 104 × 104 × 32 | |
| 4 conv | 32 | 3 × 3/1 | 104 × 104 × 32 | 104 × 104 × 32 |
| 5 conv | 32 | 3 × 3/1 | 104 × 104 × 32 | 104 × 104 × 32 |
| 6 route | 54 | 104 × 104 × 64 | ||
| 7 conv | 64 | 1 × 1/1 | 104 × 104 × 64 | 104 × 104 × 64 |
| 8 route | 27 | 104 × 104 × 128 | ||
| 9 max | 2 × 2/2 | 104 × 104 × 128 | 52 × 52 × 128 | |
| 10 conv | 128 | 3 × 3/1 | 52 × 52 × 128 | 52 × 52 × 128 |
| 11 route | 10 | 1/2 | 52 × 52 × 64 | |
| 12 conv | 64 | 3 × 3/1 | 52 × 52 × 64 | 52 × 52 × 64 |
| 13 conv | 64 | 3 × 3/1 | 52 × 52 × 64 | 52 × 52 × 64 |
| 14 route | 13–12 | 52 × 52 × 128 | ||
| 15 conv | 128 | 1 × 1/1 | 52 × 52 × 128 | 52 × 52 × 128 |
| 16 route | 10–15 | 52 × 52 × 256 | ||
| 17 max | 2 × 2/2 | 52 × 52 × 256 | 26 × 26 × 256 | |
| 18 conv | 256 | 3 × 3/1 | 26 × 26 × 256 | 26 × 26 × 256 |
| 19 route | 18 | 1/2 | 26 × 26 × 128 | |
| 20 conv | 128 | 3 × 3/1 | 26 × 26 × 128 | 26 × 26 × 128 |
| 21 conv | 128 | 3 × 3/1 | 26 × 26 × 128 | 26 × 26 × 128 |
| 22 route | 21–20 | 26 × 26 × 256 | ||
| 23 conv | 256 | 1 × 1/1 | 26 × 26 × 256 | 26 × 26 × 256 |
| 24 route | 18–23 | 26 × 26 × 512 | ||
| 25 max | 2 × 2/2 | 26 × 26 × 512 | 13 × 13 × 512 | |
| 26 conv | 512 | 3 × 3/1 | 13 × 13 × 512 | 13 × 13 × 512 |
| 27 conv | 256 | 1 × 1/1 | 13 × 13 × 512 | 13 × 13 × 256 |
| 28 conv | 512 | 3 × 3/1 | 13 × 13 × 256 | 13 × 13 × 512 |
| 29 conv | 18 | 1 × 1/1 | 13 × 13 × 512 | 13 × 13 × 18 |
| 30 yolo | ||||
| 31 route | 27 | 13 × 13 × 256 | ||
| 32 conv | 128 | 1 × 1/1 | 13 × 13 × 256 | 13 × 13 × 128 |
| 33 up | 2x | 13 × 13 × 128 | 26 × 26 × 128 | |
| 34 route | 33–23 | 26 × 26 × 384 | ||
| 35 conv | 256 | 3 × 3/1 | 26 × 26 × 384 | 26 × 26 × 256 |
| 36 conv | 18 | 1 × 1/1 | 26 × 26 × 256 | 26 × 26 × 18 |
| 37 yolo |
| Layer | Filters | Size/Strd | Input | Output |
|---|---|---|---|---|
| 0 conv | 32 | 3 × 3/2 | 352 × 128 × 3 | 176 × 64 × 32 |
| 1 conv | 64 | 3 × 3/2 | 176 × 64 × 32 | 88 × 32 × 64 |
| 2 conv | 64 | 3 × 3/1 | 88 × 32 × 64 | 88 × 32 × 64 |
| 3 route | 2 | 1/2 | 88 × 32 × 32 | |
| 4 conv | 32 | 3 × 3/1 | 88 × 32 × 32 | 88 × 32 × 32 |
| 5 conv | 32 | 3 × 3/1 | 88 × 32 × 32 | 88 × 32 × 32 |
| 6 route | 54 | 88 × 32 × 64 | ||
| 7 conv | 64 | 1 × 1/1 | 88 × 32 × 64 | 88 × 32 × 64 |
| 8 route | 27 | 88 × 32 × 128 | ||
| 9 max | 0 | 2 × 2/2 | 88 × 32 × 128 | 44 × 16 × 128 |
| 10 conv | 128 | 3 × 3/1 | 44 × 16 × 128 | 44 × 16 × 128 |
| 11 route | 10 | 1/2 | 44 × 16 × 64 | |
| 12 conv | 64 | 3 × 3/1 | 44 × 16 × 64 | 44 × 16 × 64 |
| 13 conv | 64 | 3 × 3/1 | 44 × 16 × 64 | 44 × 16 × 64 |
| 14 route | 13–12 | 44 × 16 × 128 | ||
| 15 conv | 128 | 1 × 1/1 | 44 × 16 × 128 | 44 × 16 × 128 |
| 16 route | 10–15 | 44 × 16 × 256 | ||
| 17 max | 2 × 2/2 | 44 × 16 × 256 | 22 × 8 × 256 | |
| 18 conv | 256 | 3 × 3/1 | 22 × 8 × 256 | 22 × 8 × 256 |
| 19 route | 18 | 1/2 | 22 × 8 × 128 | |
| 20 conv | 128 | 3 × 3/1 | 22 × 8 × 128 | 22 × 8 × 128 |
| 21 conv | 128 | 3 × 3/1 | 22 × 8 × 128 | 22 × 8 × 128 |
| 22 route | 21–20 | 22 × 8 × 256 | ||
| 23 conv | 256 | 1 × 1/1 | 22 × 8 × 256 | 22 × 8 × 256 |
| 24 route | 18–23 | 22 × 8 × 512 | ||
| 25 max | 2 × 2/2 | 22 × 8 × 512 | 11 × 4 × 512 | |
| 26 conv | 512 | 3 × 3/1 | 11 × 4 × 512 | 11 × 4 × 512 |
| 27 conv | 256 | 1 × 1/1 | 11 × 4 × 512 | 11 × 4 × 256 |
| 28 conv | 512 | 3 × 3/1 | 11 × 4 × 256 | 11 × 4 × 512 |
| 29 conv | 123 | 1 × 1/1 | 11 × 4 × 512 | 11 × 4 × 123 |
| 30 yolo | ||||
| 31 route | 27 | 11 × 4 × 256 | ||
| 32 conv | 128 | 1 × 1/1 | 11 × 4 × 256 | 11 × 4 × 128 |
| 33 up | 2× | 11 × 4 × 128 | 22 × 8 × 128 | |
| 34 route | 33–23 | 22 × 8 × 384 | ||
| 35 conv | 256 | 3 × 3/1 | 22 × 8 × 384 | 22 × 8 × 256 |
| 36 conv | 123 | 1 × 1/1 | 22 × 8 × 256 | 22 × 8 × 123 |
| 37 yolo |
| Dataset | Precision | Recall | Avg IoU |
|---|---|---|---|
| Caltech cars | 100.00 | 100.00 | 96.84 |
| English LP | 99.88 | 100.00 | 94.98 |
| AOLP | 98.96 | 99.52 | 94.27 |
| Open ALPR EU | 100.00 | 100.00 | 95.30 |
| UFPR ALPR | 99.50 | 100.00 | 90.35 |
| Average | 99.71 | 99.90 | 94.35 |
| Accuracy (%) | Loss |
|---|---|
| 98.22 | 0.1130 |
| Dataset | Precision | Recall | Avg IoU |
|---|---|---|---|
| Caltech cars | 100.00 | 99.19 | 86.72 |
| English LP | 99.61 | 99.21 | 83.70 |
| AOLP | 99.43 | 99.67 | 86.26 |
| Open ALPR EU | 100.00 | 99.07 | 85.54 |
| UFPR ALPR | 96.78 | 98.67 | 83.52 |
| Average | 99.16 | 99.36 | 85.15 |
| Dataset | Precision | Recall | Avg IoU |
|---|---|---|---|
| Caltech cars | 100.00 | 98.98 | 90.42 |
| English LP | 99.91 | 99.87 | 93.16 |
| AOLP | 99.94 | 99.87 | 89.38 |
| Open ALPR EU | 100.00 | 98.66 | 91.30 |
| UFPR ALPR | 98.57 | 91.08 | 85.57 |
| Average | 99.68 | 97.69 | 89.97 |
| Dataset | Stage | TP | FN | Recall |
|---|---|---|---|---|
| VD | 14 | 0 | 100 | |
| Caltech cars | LPD LPR | 13 13 | 1 1 | 92.86 92.86 |
| VD | 52 | 0 | 100 | |
| English LP | LPD LPR | 50 50 | 2 2 | 96.15 96.15 |
| VD | 218 | 1 | 99.54 | |
| AOLP | LPD LPR | 216 214 | 3 5 | 98.63 97.72 |
| VD | 12 | 0 | 100 | |
| Open ALPR | LPD LPR | 12 12 | 0 0 | 100 100 |
| VD | 1800 | 0 | 100 | |
| UFPR ALPR | LPD LPR | 1769 1117 | 31 683 | 98.28 62.06 |
| UFPR ALPR as vid | LPR | 44 | 16 | 73.33 |
| Average LPR | 89.56 |
| Method | [33] | [5] | [34] | [35] | [36] | OpenALPR | [12] | Proposed |
|---|---|---|---|---|---|---|---|---|
| Dataset | ||||||||
| Caltech cars | - | - | - | - | 95.7 ± 2.7 | 99.1 ± 1.2 | 98.7 ± 1.2 | 97.1 |
| English LP | 97.0 | - | - | - | 92.5 ± 3.7 | 78.6 ± 3.6 | 95.7 ± 2.3 | 95.5 |
| AOLP | - | 99.8 * | - | - | 87.1 ± 0.8 | - | 99.2 ± 0.4 | 98.0 |
| Open ALPR EU | - | - | 93.5 | 85.2 | 93.5 | 91.7 | 97.8 ± 0.5 | 98.7 |
| UFPR ALPR | - | - | - | - | 62.3 | 82.2 | 90.0 ± 0.7 | 62.1 (73.3 **) |
| Average | - | - | - | - | 87.8 ± 2.4 | 90.7 ± 2.3 | 96.9 ± 1.0 | 90.3 |
| C | AP (%) TP | FP | C | AP (%) TP | FP |
|---|---|---|---|---|---|
| 0 | 98.26 724 | 22 | I | 98.90 94 | 0 |
| 1 | 99.65 844 | 4 | J | 100.00 145 | 0 |
| 2 | 100.00 497 | 0 | K | 83.86 115 | 0 |
| 3 | 99.51 645 | 0 | L | 100.00 146 | 0 |
| 4 | 99.93 811 | 16 | M | 86.50 165 | 23 |
| 5 | 100.00 758 | 0 | N | 100.00 48 | 0 |
| 6 | 99.94 922 | 6 | O | 38.96 35 | 28 |
| 7 | 99.17 669 | 15 | P | 99.99 282 | 0 |
| 8 | 98.72 1037 | 15 | Q | 70.84 43 | 1 |
| 9 | 99.66 1103 | 8 | R | 99.98 148 | 2 |
| A | 98.82 1494 | 2 | S | 96.47 228 | 0 |
| B | 97.98 363 | 0 | T | 100.00 112 | 0 |
| C | 97.64 133 | 3 | U | 100.00 128 | 0 |
| D | 99.53 99 | 13 | V | 100.00 171 | 0 |
| E | 97.59 136 | 6 | W | 95.70 229 | 1 |
| F | 99.06 40 | 1 | X | 98.69 107 | 0 |
| G | 95.68 147 | 0 | Y | 99.95 274 | 0 |
| H | 99.96 109 | 0 | Z | 100.00 280 | 0 |
| Vehicles Stage | 1 | 2 | 3 |
|---|---|---|---|
| Vehicle detection | 0.0349 | 0.0389 | 0.0449 |
| LP detection | 0.0080 | 0.0150 | 0.0239 |
| LP recognition | 0.0120 | 0.0239 | 0.0239 |
| Total FPS | 18 | 13 | 11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-batat, R.; Angelopoulou, A.; Premkumar, S.; Hemanth, J.; Kapetanios, E. An End-to-End Automated License Plate Recognition System Using YOLO Based Vehicle and License Plate Detection with Vehicle Classification. Sensors 2022, 22, 9477. https://doi.org/10.3390/s22239477
Al-batat R, Angelopoulou A, Premkumar S, Hemanth J, Kapetanios E. An End-to-End Automated License Plate Recognition System Using YOLO Based Vehicle and License Plate Detection with Vehicle Classification. Sensors. 2022; 22(23):9477. https://doi.org/10.3390/s22239477
Chicago/Turabian StyleAl-batat, Reda, Anastassia Angelopoulou, Smera Premkumar, Jude Hemanth, and Epameinondas Kapetanios. 2022. "An End-to-End Automated License Plate Recognition System Using YOLO Based Vehicle and License Plate Detection with Vehicle Classification" Sensors 22, no. 23: 9477. https://doi.org/10.3390/s22239477
APA StyleAl-batat, R., Angelopoulou, A., Premkumar, S., Hemanth, J., & Kapetanios, E. (2022). An End-to-End Automated License Plate Recognition System Using YOLO Based Vehicle and License Plate Detection with Vehicle Classification. Sensors, 22(23), 9477. https://doi.org/10.3390/s22239477