

mmSafe: A Voice Security Verification System Based on Millimeter-Wave Radar


Abstract
1. Introduction
- This paper proposes a vibration signal processing method that solves the problem of clutter as well as the effects of motion and achieves an enhancement of the vocal cord vibration signal and vocal print information;
- This paper proposes the WMHS (Weighted MFCCs and Hog-based SVM) method, which converts the speaker verification problem into a binary classification problem by combining weighted MFCCs with a HOG feature-based SVM to improve the verification accuracy;
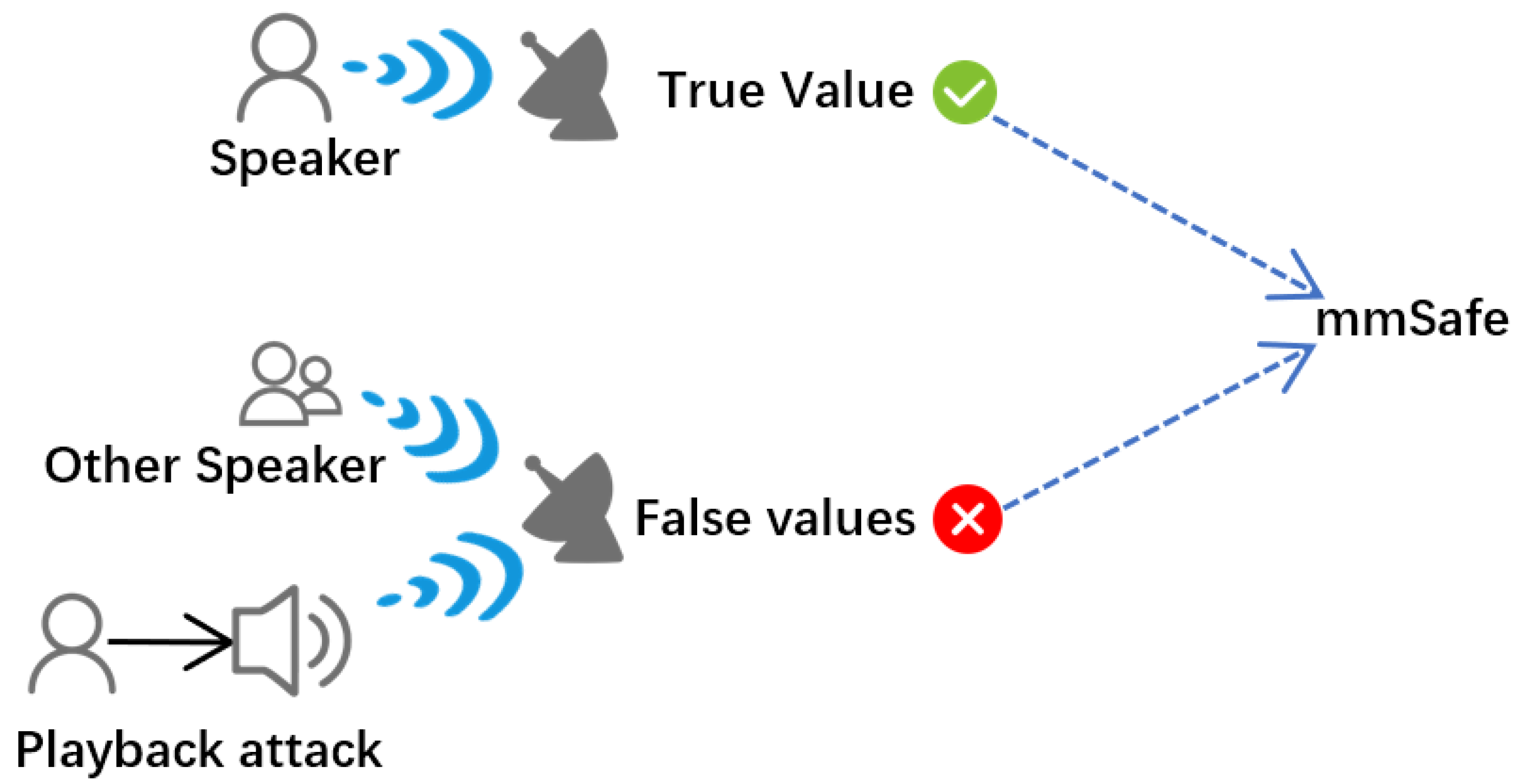
- This paper develops the mmSafe system, which senses speakers in a non-contact and more fine-grained way, and which has been proven to be effective in verifying speakers and resisting playback attacks through extensive experiments, achieving a 93.4% speaker verification accuracy and a 5.8% miss detection rate for playback attacks.
2. Related Work
2.1. Speaker Verification with Microphone
2.2. Speaker Verification with Millimeter-Wave Radar
2.3. Speaker Verification with Other Sensors
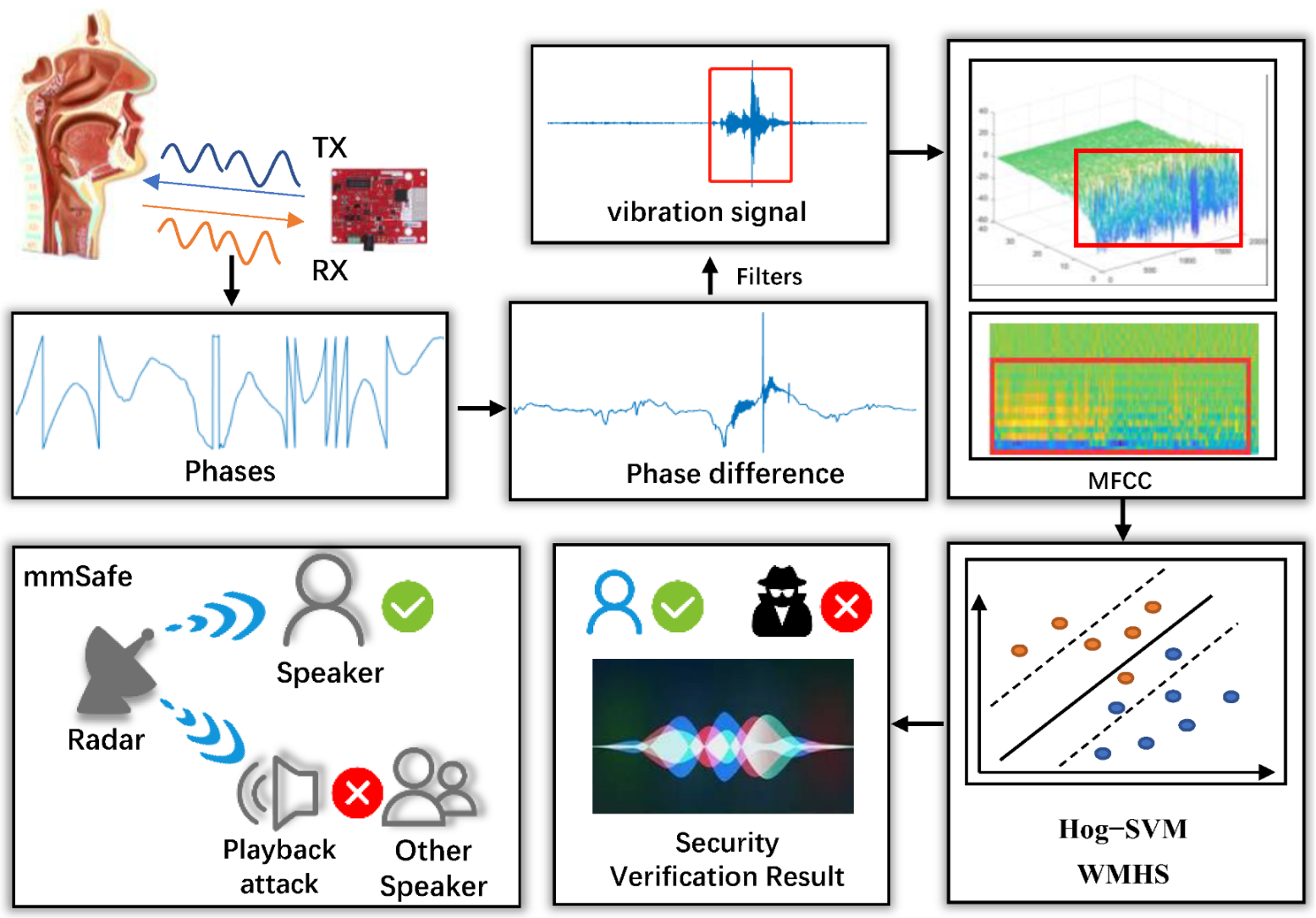
3. System Design
3.1. System Overview
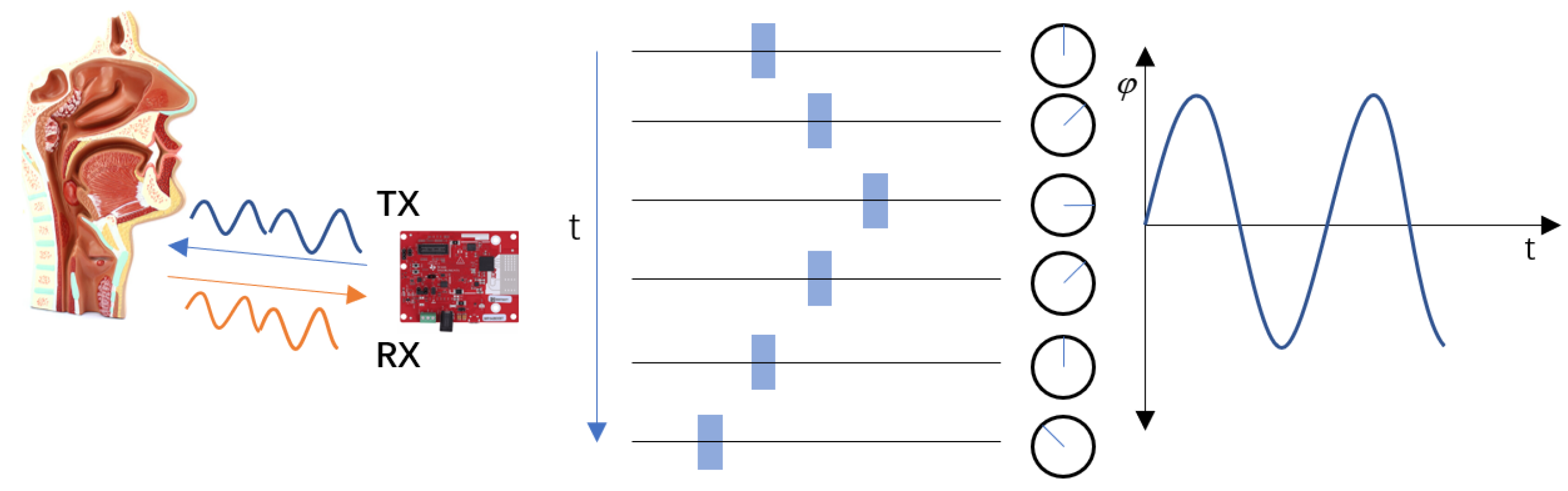
3.2. Radar Signal Processing Module
3.3. Vibration Feature Extraction Module
3.4. Speaker Verification Module
| Algorithm 1: WMHS. |
| Input: mfcc-final←[feat,defeat,dttfeat] |
| Output: verification results |
| 1: img.power←mfcc−final.img(255*255); |
| 2: G←gradient_magnitude←; // Calculate the total gradient value |
| 3: Angle←; |
| 4: function UPDATEBINS(self,G, Angle) |
| 5: while dividing the image into cells do |
| 6: bins←zeros((cell_G.shape[0], cell_G.shape[1],self.bin_count)); |
| 7: for i = range(bins.shape[0]) |
| 8: for j = range(bins.shape[1]) |
| 9: bins←tmp_unit←self.bin_count; // Vote for each gradient direction |
| 10: end for |
| 11: end for |
| 12: end while |
| 13: return bins; |
| 14: end function |
| 15: block←bins.feature |
| 16: ← block |
| 17: clf = svm. SVC(); // training model |
| 18: clf.fit(train_ reduction, train_ target); |
| 19: classification function ← |
| 20: pred = clf.predict(test_reduction) // predict |
| 21: return precision |
4. Experimentation and Evaluation
4.1. Experimental Setup
4.2. System Performance
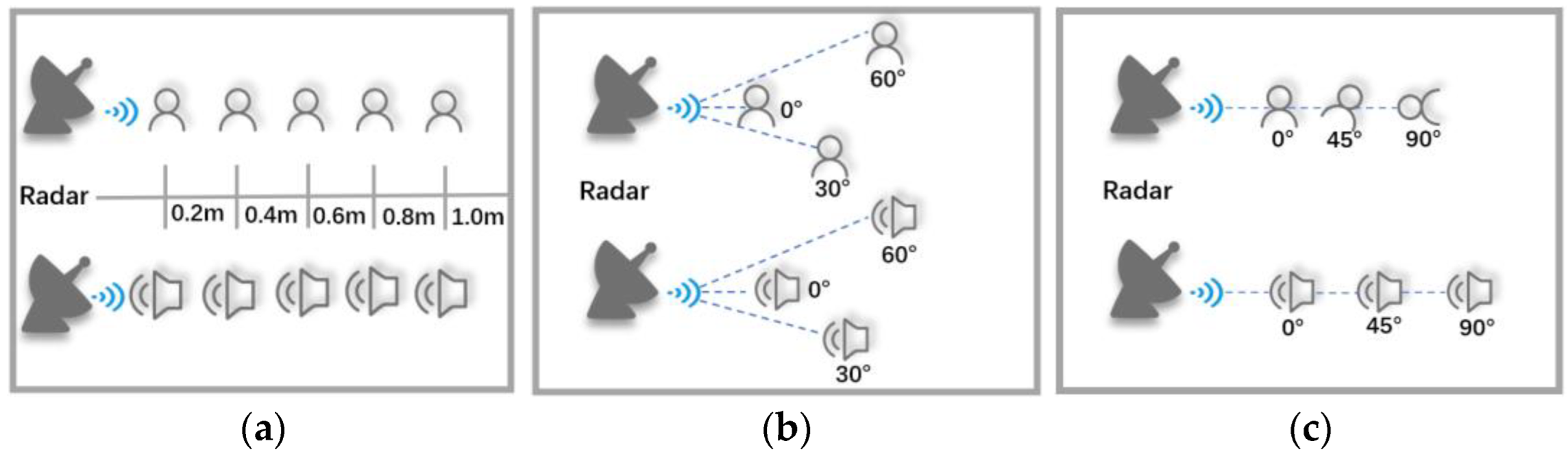
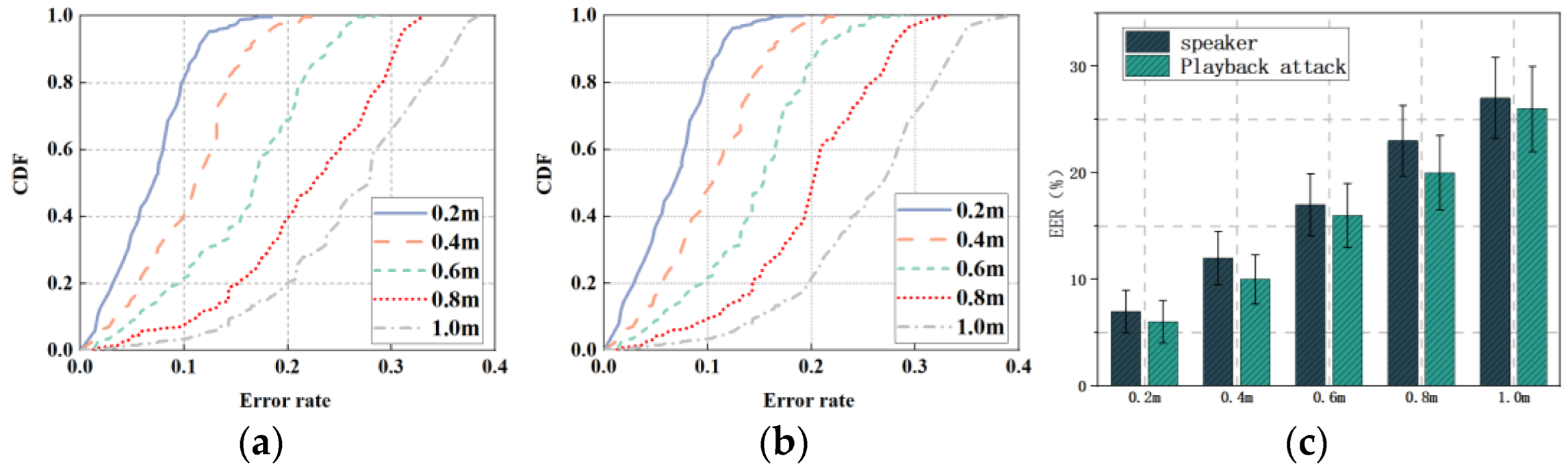
4.2.1. Spatial Dimension
- a
- Different distances
- b
- Different arrival angles
- c
- Different self-rotation angles
4.2.2. Algorithm Dimension
- d
- Different feature dimensions
- e
- Different classifiers
4.2.3. Speaker State Dimensions
5. Conclusions
- 1
- In this work, the experimental parameters are set in such a way that the time for parsing the data is not sufficient, and the time set for each frame is too short, resulting in too many frames of speech and thus problems with the processing time;
- 2
- There is no continuous voice data in this work due to a lack of data richness.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FMCW | Frequency-modulated continuous wave |
| FFT | Fast Fourier transform |
| MFCCs | Mel Frequency Cepstrum Coefficients |
| SVM | Support vector machine |
| HOG | Histogram of oriented gradient |
| VC | Voice conversion |
| TTS | Text-to-speech synthesis |
| CMN | Cepstral Mean Normalization |
| CDFs | Cumulative distribution functions |
References
- Li, Q. Language ability evaluation of “Mi AI” intelligent speech system. Chin. Character Cult. 2021, 6, 141–142. [Google Scholar] [CrossRef]
- Lin, S. The Traffic Forecast Application of Urban Road Reconstruction and Expansion Problem; Southwest Jiaotong University: Chengdu, China, 2019. [Google Scholar] [CrossRef]
- Todisco, M.; Wang, X.; Vestman, V.; Sahidullah, M.; Delgado, H.; Nautsch, A.; Yamagishi, J.; Evans, N.W.D.; Kinnunen, T.; Lee, K.A. ASVspoof 2019: Future Horizons in Spoofed and Fake Audio Detection. In Proceedings of the INTERSPEECH 2019; Graz, Austria, 15–19 September 2019, 2019. [Google Scholar]
- Zhang, G.; Yan, C.; Ji, X.; Zhang, T.; Zhang, T.; Xu, W. DolphinAttack: Inaudible Voice Commands. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 103–117. [Google Scholar]
- Li, H.; Xu, C.; Rathore, A.S.; Li, Z.; Zhang, H.; Song, C.; Wang, K.; Su, L.; Lin, F.; Ren, K.; et al. VocalPrint: A MmWave-Based Unmediated Vocal Sensing System for Secure Authentication. IEEE Trans. Mob. Comput. 2021, 14, 1. [Google Scholar] [CrossRef]
- Kersta, L.G. Voiceprint Identification. Nature 1962, 34, 725. [Google Scholar]
- Chen, Y.; Shu, G.; Kuang, Z.; Yu, W.; Shen, Z. Research and implementation of speaker recognition system. Electr. Autom. 2021, 43, 83–85+89. [Google Scholar]
- Dong, Y.; Dong, Y.Y. Secure MmWave-Radar-Based Speaker Verification for IoT Smart Home. IEEE Internet Things J. 2021, 8, 3500–3511. [Google Scholar] [CrossRef]
- Ingo, R.T.; Eric, J.H. Normal Vibration Frequencies of the Vocal Ligament. J. Acoust. Soc. Am. 2004, 115, 2264–2269. [Google Scholar]
- Font, R.; Espín, J.M.; Cano, M.J. Experimental Analysis of Features for Replay Attack Detection—Results on the ASVspoof 2017 Challenge. In Proceedings of the Proc. Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 7–11. [Google Scholar]
- Wang, Z.-F.; Wei, G.; He, Q.-H. Channel Pattern Noise Based Playback Attack Detection Algorithm for Speaker Recognition. In Proceedings of the 2011 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2011; Volume 4, pp. 1708–1713. [Google Scholar]
- Chen, Z.; Luo, Y.; Mesgarani, N. Deep Attractor Network for Single-Microphone Speaker Separation. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); IEEE: Piscatvie, NJ, USA, 2017. [Google Scholar]
- Liang, C.; Chen, J.; Guan, S.; Zhang, X.-L. Attention-Based Multi-Channel Speaker Verification with Ad-Hoc Microphone Arrays. In Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 14–17 December 2021; pp. 1111–1115. [Google Scholar]
- Schwering, F.K.; Violette, E.J. Millimeter-Wave Propagation in Vegetation: Experiments and Theory. IEEE Trans. Geosci. Remote Sens. 1988, 26, 355–367. [Google Scholar] [CrossRef]
- Lin, C.-S. Chang Microwave Human Vocal Vibration Signal Detection Based on Doppler Radar Technology. IEEE Trans. Microw. Theory Tech. 2010, 58, 2299–2306. [Google Scholar] [CrossRef]
- Guo, J.; He, Y.; Jiang, C.; Jin, M.; Li, S.; Zhang, J.; Xi, R.; Liu, Y. Measuring Micrometer-Level Vibrations with MmWave Radar. IEEE Trans. Mob. Comput. 2021, 1. [Google Scholar] [CrossRef]
- Liu, T.; Gao, M.; Lin, F.; Wang, C.; Ba, Z.; Han, J.; Xu, W.; Ren, K. Wavoice: A Noise-Resistant Multi-Modal Speech Recognition System Fusing MmWave and Audio Signals. In Proceedings of the 19th ACM Conference on Embedded Networked Sensor Systems, Coimbra, Portugal, 15–17 November 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 97–110. [Google Scholar]
- Liu, X.; Cheung, Y.-M. Learning Multi-Boosted HMMs for Lip-Password Based Speaker Verification. IEEE Trans Inf. Forensics Secur. 2014, 9, 233–246. [Google Scholar] [CrossRef]
- Cheung, Y.; Liu, X. Lip-Password Based Speaker Verification System. U.S. Patent 9,159,321, 13 October 2015. [Google Scholar]
- Sahidullah, M.; Thomsen, D.A.; Hautamäki, R.G.; Kinnunen, T.; Tan, Z.H.; Parts, R.; Pitkänen, M. Robust Voice Liveness Detection and Speaker Verification Using Throat Microphones. IEEEACM Trans. Audio Speech Lang. Process. TASLP 2018, 26, 44–56. [Google Scholar] [CrossRef]
- Zhang, L.; Tan, S.; Yang, J. Hearing Your Voice Is Not Enough: An Articulatory Gesture Based Liveness Detection for Voice Authentication. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 57–71. [Google Scholar]
- Wang, Q.; Lin, X.; Zhou, M.; Chen, Y.; Wang, C.; Li, Q.; Luo, X. VoicePop: A Pop Noise Based Anti-Spoofing System for Voice Authentication on Smartphones. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 2062–2070. [Google Scholar]
- Lohscheller, J.; Svec, J.G.; Döllinger, M. Vocal Fold Vibration Amplitude, Open Quotient, Speed Quotient and Their Variability along Glottal Length: Kymographic Data from Normal Subjects. Logoped. Phoniatr. Vocol. 2013, 38, 182–192. [Google Scholar] [CrossRef] [PubMed]
- Sharma, D.; Ali, I. A Modified MFCC Feature Extraction Technique For Robust Speaker Recognition. In Proceedings of the 2015 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Kochi, India, 10–13 August 2015; pp. 1052–1057. [Google Scholar]
- Wang, X.Y. The Improved MFCC Speech Feature Extraction Method and Its Application. Adv. Mater. Res. 2013, 756, 4059–4062. [Google Scholar] [CrossRef]
- Sun, M. Research on speaker recognition based on DenseNet. Master Electron. J. 2021. [Google Scholar] [CrossRef]
- Hu, Y.; Lu, Y.; Jiang, Y.; Lu, W. Vibration Recognition Method Based on MFCC and SVM. Inf. Technol. Informatiz. 2021, 11, 92–94. [Google Scholar]
- Wang, K.; Deng, G.; Zhou, H. On Design of Automobile Anti-Collision Radar Based on AWR1642. J. Southwest China Norm. Univ. (Nat. Sci. Ed.) 2020, 45, 93–98. [Google Scholar] [CrossRef]
- Xu, W.; Song, W.; Liu, J.; Liu, Y.; Cui, X.; Zheng, Y.; Han, J.; Wang, X.; Ren, K. Mask does not matter: Anti-spoofing face authentication using mmWave without on-site registration. In Proceedings of the 28th Annual International Conference on Mobile Computing and Networking, Sydney, Australia, 17–21 October 2022; pp. 310–323. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Methods | Accuracy |
|---|---|
| Knn | 67.4% |
| Lostic | 76.2% |
| SVM | 80.7% |
| WMHS | 93.4% |
| Classification Methods | Accuracy |
|---|---|
| Knn | 72.6% |
| Lostic | 78.4% |
| SVM | 84.2% |
| WMHS | 94.2% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, Z.; Peng, J.; Dang, X.; Yan, H.; Wang, R. mmSafe: A Voice Security Verification System Based on Millimeter-Wave Radar. Sensors 2022, 22, 9309. https://doi.org/10.3390/s22239309
Hao Z, Peng J, Dang X, Yan H, Wang R. mmSafe: A Voice Security Verification System Based on Millimeter-Wave Radar. Sensors. 2022; 22(23):9309. https://doi.org/10.3390/s22239309
Chicago/Turabian StyleHao, Zhanjun, Jianxiang Peng, Xiaochao Dang, Hao Yan, and Ruidong Wang. 2022. "mmSafe: A Voice Security Verification System Based on Millimeter-Wave Radar" Sensors 22, no. 23: 9309. https://doi.org/10.3390/s22239309
APA StyleHao, Z., Peng, J., Dang, X., Yan, H., & Wang, R. (2022). mmSafe: A Voice Security Verification System Based on Millimeter-Wave Radar. Sensors, 22(23), 9309. https://doi.org/10.3390/s22239309