
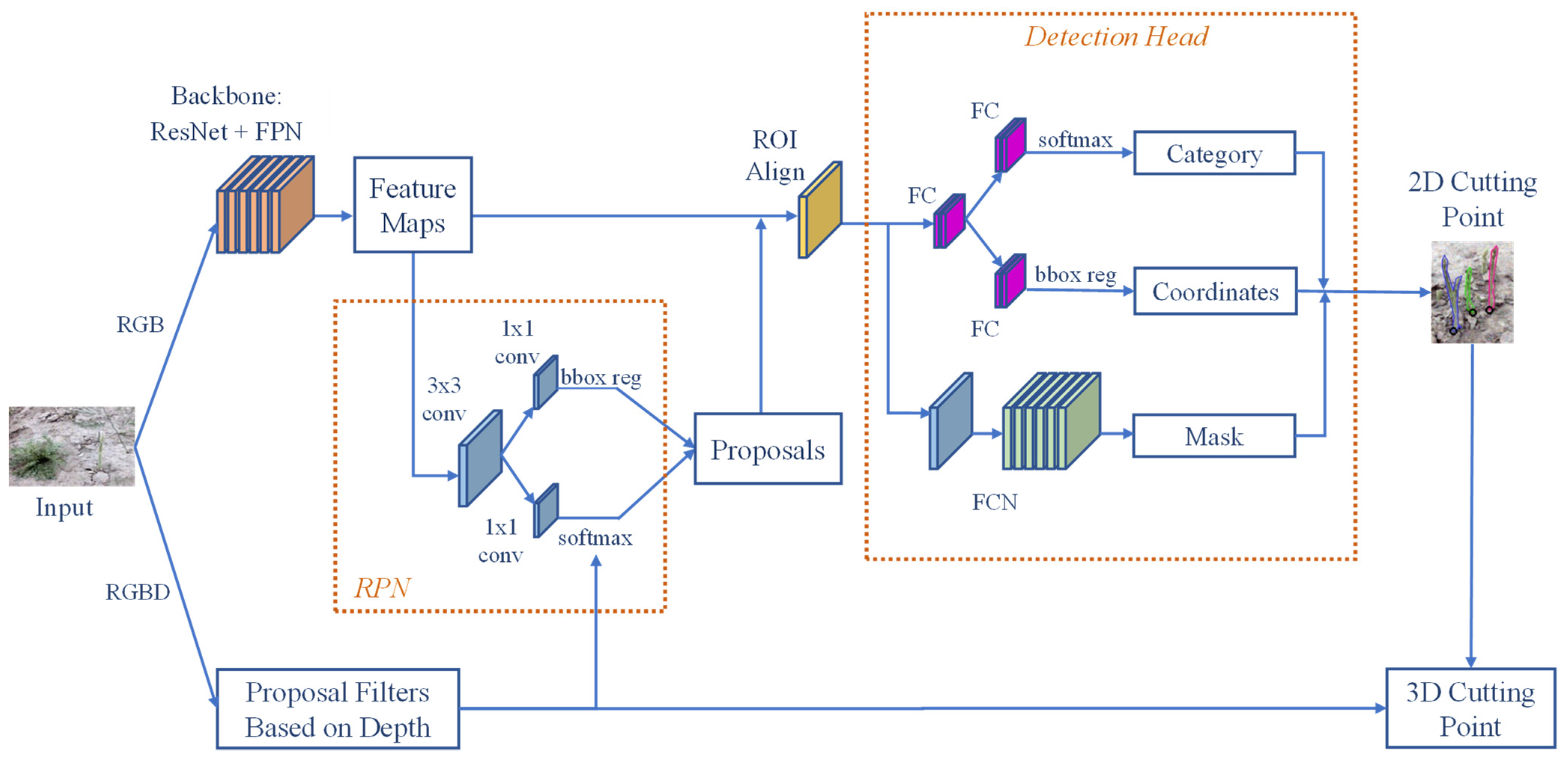
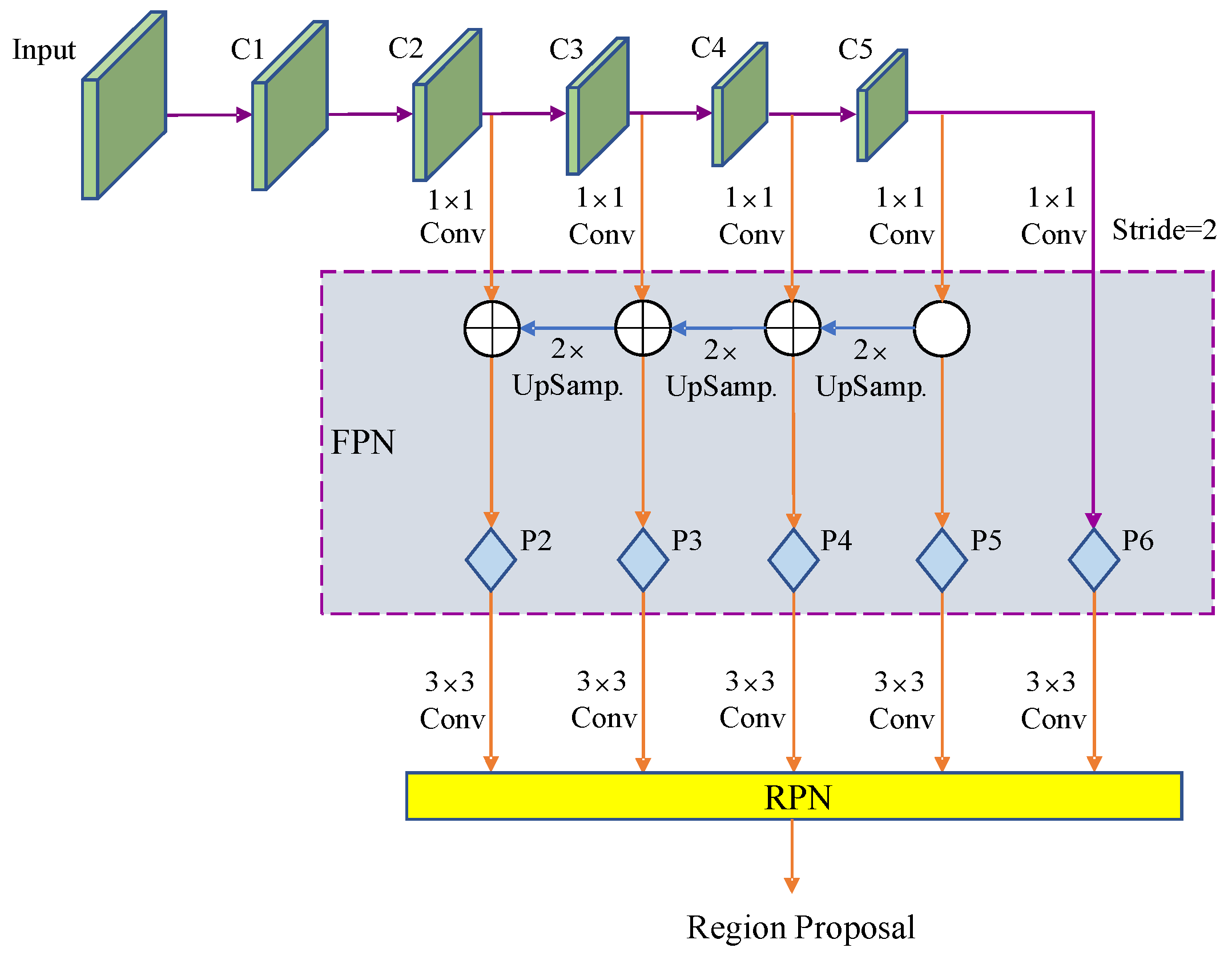
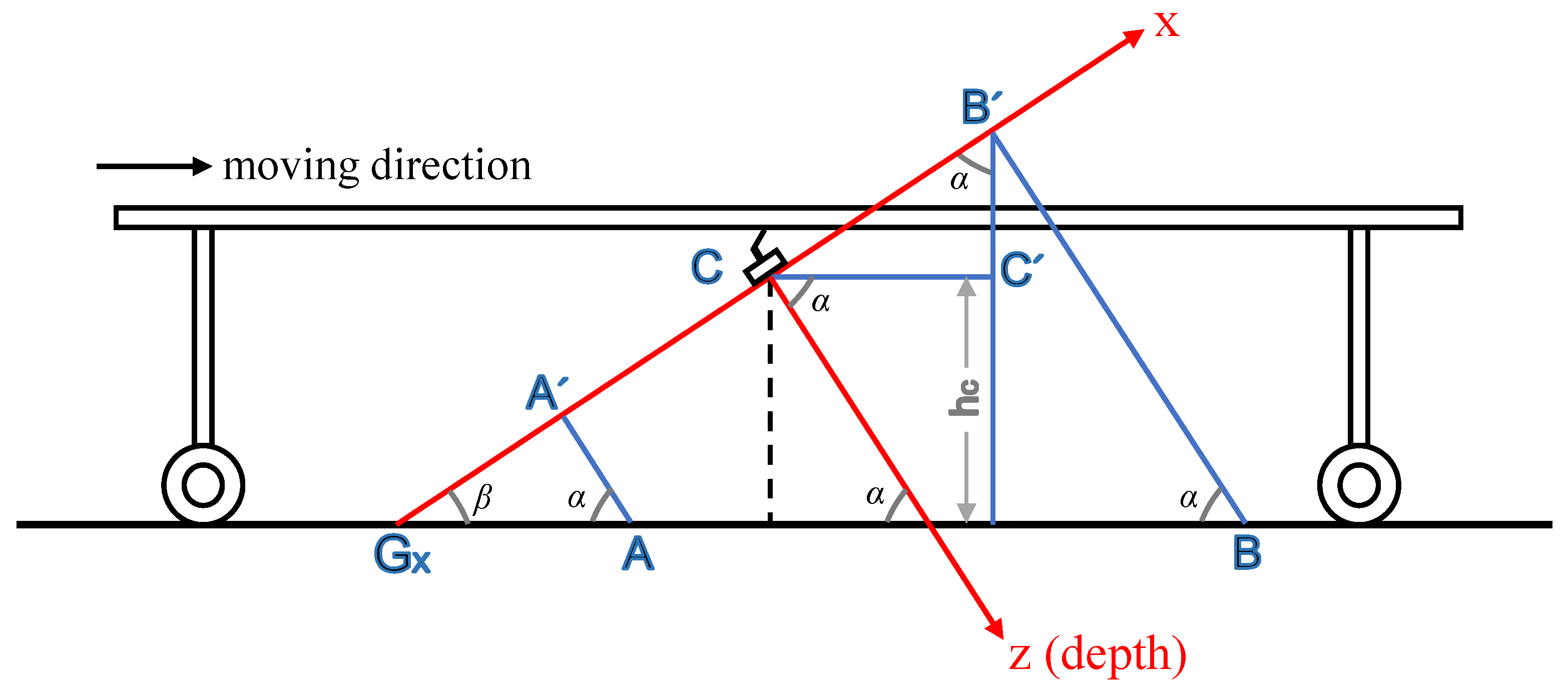
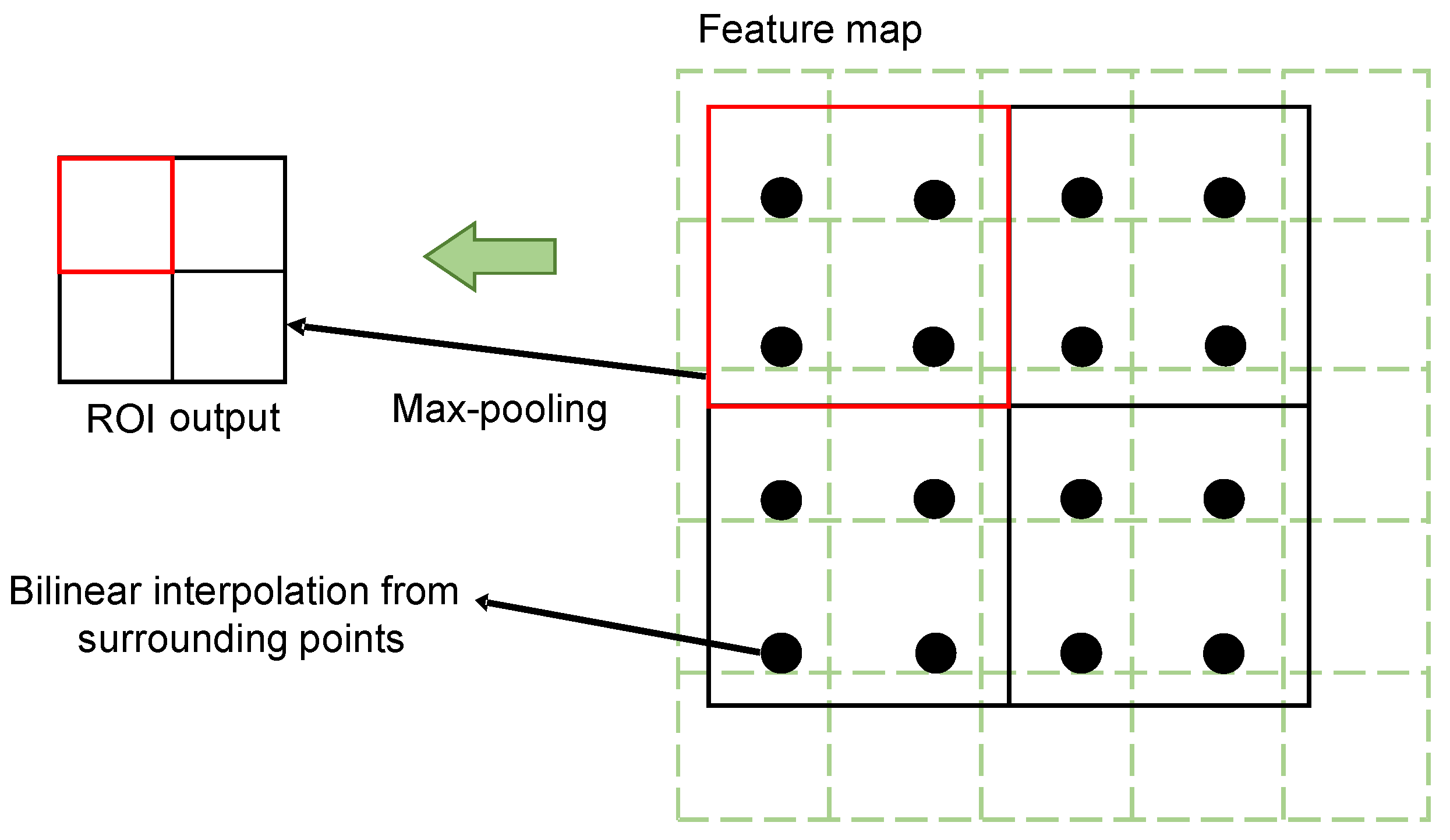
Detection of Green Asparagus Using Improved Mask R-CNN for Automatic Harvesting



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
Share and Cite
Liu, X.; Wang, D.; Li, Y.; Guan, X.; Qin, C. Detection of Green Asparagus Using Improved Mask R-CNN for Automatic Harvesting. Sensors 2022, 22, 9270. https://doi.org/10.3390/s22239270
Liu X, Wang D, Li Y, Guan X, Qin C. Detection of Green Asparagus Using Improved Mask R-CNN for Automatic Harvesting. Sensors. 2022; 22(23):9270. https://doi.org/10.3390/s22239270
Chicago/Turabian StyleLiu, Xiangpeng, Danning Wang, Yani Li, Xiqiang Guan, and Chengjin Qin. 2022. "Detection of Green Asparagus Using Improved Mask R-CNN for Automatic Harvesting" Sensors 22, no. 23: 9270. https://doi.org/10.3390/s22239270
APA StyleLiu, X., Wang, D., Li, Y., Guan, X., & Qin, C. (2022). Detection of Green Asparagus Using Improved Mask R-CNN for Automatic Harvesting. Sensors, 22(23), 9270. https://doi.org/10.3390/s22239270