
Optical Fiber Vibration Signal Identification Method Based on Improved YOLOv4


Abstract
1. Introduction
- The YOLOv4 target detection algorithm is used to complete the location and classification of vibration signals simultaneously, which means that it is no longer necessary to complete the feature extraction and recognition classification of signals by the pattern-recognition method after the traditional endpoint-detection algorithm. This can avoid not only the loss of signal information caused by the conventional endpoint-detection algorithm due to signal noise and other factors, but also improve the efficiency of signal recognition;
- The deep separable convolution (DSC) network is used to replace the backbone feature extraction network in the YOLOv4 model, which makes the calculation amount of the improved model far less than that of YOLOv4. Additionally, it improves the recognition accuracy and detection rate of the signal;
- The focal loss function is used to replace the confidence loss function in YOLOv4, and the problem of unbalanced sample distribution in the dataset is solved by changing the loss weight, which makes the recognition accuracy of signal types with more samples higher, and the recognition accuracy of signal types with fewer samples is also improved.
2. Distributed Optical Fiber Vibration Sensing System
3. Dataset
3.1. Data Collection
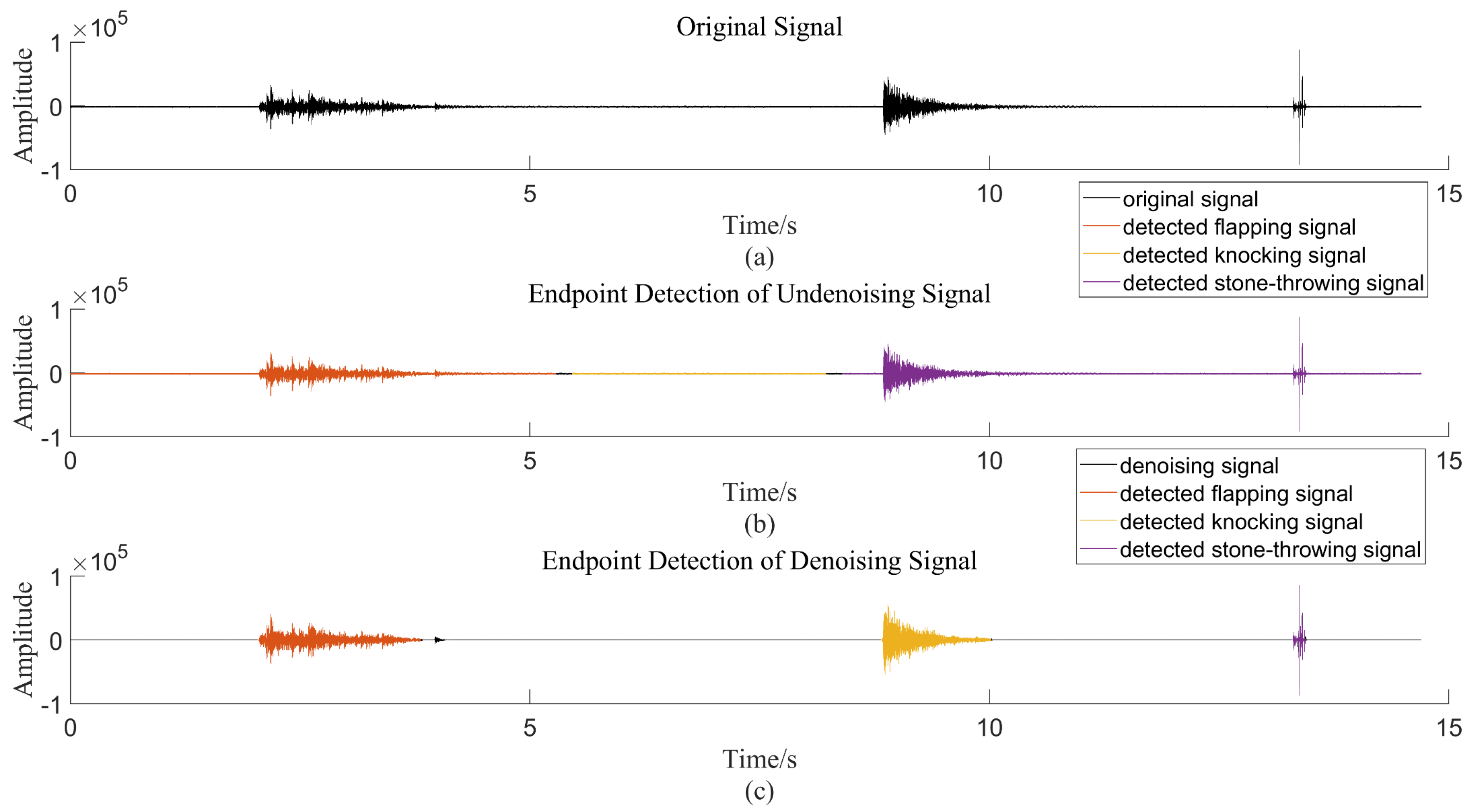
3.2. Oscillograph and Time-Frequency Diagram
3.3. Signal Labeling
4. Materials and Methods
4.1. YOLOv4
4.1.1. Innovation of YOLOv4
4.1.2. The Network Structure and Prediction Principles of Yolov4
4.1.3. Loss Function
4.1.4. Prediction of Bounding Boxes and Confidence Values
4.1.5. Evaluation Indicators
4.2. Improved YOLOv4
4.2.1. Improvement in Backbone Feature Extraction Network
4.2.2. Improvement in Loss Function
5. Results and Discussion
5.1. Environment Configuration and Training Parameter Settings
5.2. Training Results and Analysis
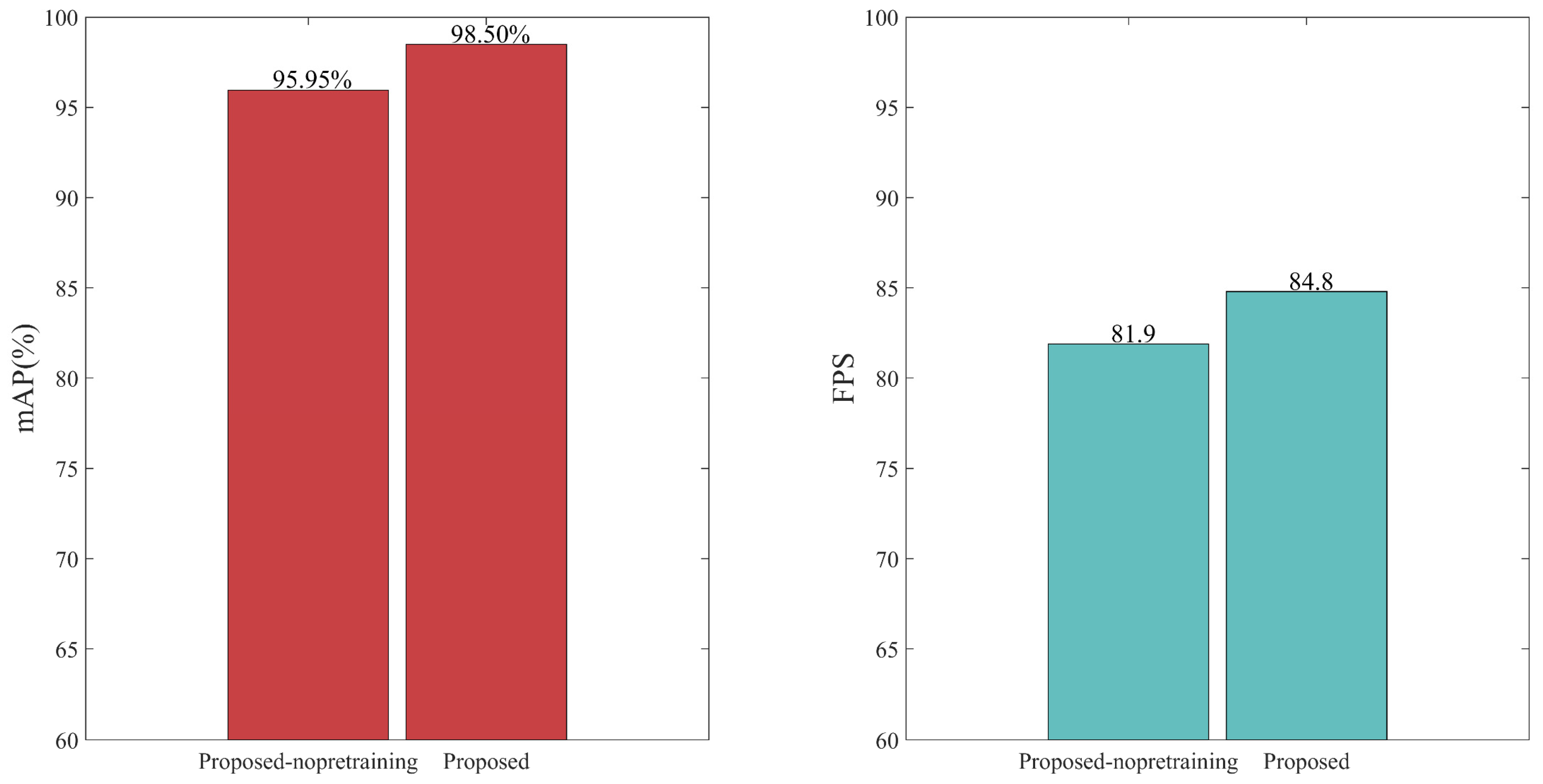
5.3. Pretraining
5.4. Comparison of Backbone Feature Extraction Networks
5.5. Comparison of Loss Functions
5.6. Performance Comparison of the Overall Algorithm
5.7. Visual Comparison of Prediction Results
5.8. Comparison with Other Identification Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pan, C.; Liu, X.; Zhu, H.; Shan, X.; Sun, X. Distributed optical fiber vibration sensor based on Sagnac interference in conjunction with OTDR. Opt. Express 2017, 25, 20056–20070. [Google Scholar] [CrossRef] [PubMed]
- Fang, X. Fiber-optic distributed sensing by a two-loop Sagnac interferometer. Opt. Lett. 1996, 21, 444–446. [Google Scholar] [CrossRef] [PubMed]
- Spammer, S.J.; Swart, P.L.; Chtcherbakov, A.A. Merged Sagnac-Michelson interferometer for distributed disturbance detection. J. Light. Technol. 1997, 15, 972–976. [Google Scholar] [CrossRef]
- Xie, S.; Zou, Q.; Wang, L.; Zhang, M.; Li, Y.; Liao, Y. Positioning error prediction theory for dual Mach–Zehnder interferometric vibration sensor. J. Light. Technol. 2010, 29, 362–368. [Google Scholar] [CrossRef]
- Culshaw, B. The optical fibre Sagnac interferometer: An overview of its principles and applications. Meas. Sci. Technol. 2005, 17, R1. [Google Scholar] [CrossRef]
- Jalil, M.; Butt, F.A.; Malik, A. Short-time energy, magnitude, zero crossing rate and autocorrelation measurement for discriminating voiced and unvoiced segments of speech signals. In Proceedings of the 2013 International Conference on Technological Advances in Electrical, Electronics and Computer Engineering (TAEECE), Konya, Turkey, 9–11 May 2013; pp. 208–212. [Google Scholar]
- Hanifa, R.M.; Isa, K.; Mohamad, S.; Shah, S.M.; Nathan, S.S.; Ramle, R.; Berahim, M. Voiced and unvoiced separation in Malay speech using zero crossing rate and energy. Indones. J. Electr. Eng. Comput. Sci. 2019, 16, 775–780. [Google Scholar]
- Ghaffar, M.S.B.A.; Khan, U.S.; Iqbal, J.; Rashid, N.; Hamza, A.; Qureshi, W.S.; Tiwana, M.I.; Izhar, U. Improving classification performance of four class FNIRS-BCI using Mel Frequency Cepstral Coefficients (MFCC). Infrared Phys. Technol. 2021, 112, 103589. [Google Scholar] [CrossRef]
- Shi, W.; Bao, S.; Tan, D. FFESSD: An accurate and efficient single-shot detector for target detection. Appl. Sci. 2019, 9, 4276. [Google Scholar] [CrossRef]
- Li, J.; Wang, Y.; Wang, P.; Bai, Q.; Gao, Y.; Zhang, H.; Jin, B. Pattern recognition for distributed optical fiber vibration sensing: A review. IEEE Sens. J. 2021, 21, 11983–11998. [Google Scholar] [CrossRef]
- Eren, L.; Ince, T.; Kiranyaz, S. A generic intelligent bearing fault diagnosis system using compact adaptive 1D CNN classifier. J. Signal Process. Syst. 2019, 91, 179–189. [Google Scholar] [CrossRef]
- Yildirim, O.; Talo, M.; Ay, B.; Baloglu, U.B.; Aydin, G.; Acharya, U.R. Automated detection of diabetic subject using pre-trained 2D-CNN models with frequency spectrum images extracted from heart rate signals. Comput. Biol. Med. 2019, 113, 103387. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVRP), Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVRP), Las Vegas, NV, USA, 23–30 June 2016; pp. 779–788. [Google Scholar]
- Yang, N.; Zhao, Y.; Chen, J. Real-Time Φ-OTDR Vibration Event Recognition Based on Image Target Detection. Sensors 2022, 22, 1127. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Xiao, M.; Bartos, P.; Filip, M.; Geng, G. Remaining useful life prediction and fault diagnosis of rolling bearings based on short-time fourier transform and convolutional neural network. Shock. Vib. 2020, 2020, 8857307. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVRPW), Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Sifre, L.; Mallat, S. Rigid-motion scattering for texture classification. arXiv 2014, arXiv:1403.1687. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Oh, D.; Ji, D.; Jang, C.; Hyun, Y.; Bae, H.S.; Hwang, S. Segmenting 2k-videos at 36.5 fps with 24.3 gflops: Accurate and lightweight realtime semantic segmentation network. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 3153–3160. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Signal Type | Knocking | Flapping | Running | Walking | Stone-Throwing |
|---|---|---|---|---|---|
| Number of signals of each type | 7560 | 5516 | 3340 | 4604 | 2052 |
| Datasets | Methods | mAP50 | Precision | Recall | F1-Score | FPS | GFLOPs |
|---|---|---|---|---|---|---|---|
| Time-frequency diagram | YOLOv4 | 92.43% | 90.14% | 89.82% | 90.00% | 30.3 | 59.982 |
| Proposed | 93.48% | 94.52% | 85.62% | 89.85% | 69.9 | 10.652 | |
| Oscillograph | YOLOv4 | 96.20% | 96.26% | 95.20% | 95.73% | 42.9 | 59.982 |
| Proposed | 98.50% | 99.73% | 89.70% | 95.45% | 84.8 | 10.652 |
| Faster R-CNN | YOLOv4 | YOLOv5 | YOLOv7 | DSC | Focal Loss | No Pre- Training | mAP50 | Precision | Recall | F1-Score | FPS | GFLOPs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| √ | 97.83% | 86.74% | 98.59% | 92.29% | 7.8 | 370.210 | ||||||
| √ | 96.20% | 96.26% | 95.20% | 95.73% | 42.9 | 59.982 | ||||||
| √ | 97.92% | 97.90% | 97.10% | 97.50% | 64.5 | 17.156 | ||||||
| √ | 98.36% | 98.63% | 92.31% | 95.37% | 27.4 | 106.472 | ||||||
| √ | √ | 97.47% | 98.19% | 94.92% | 96.53% | 64.6 | 10.652 | |||||
| √ | √ | 97.07% | 96.82% | 94.18% | 95.48% | 44.4 | 59.982 | |||||
| √ | √ | √ | √ | 95.95% | 96.49% | 81.92% | 88.61% | 81.9 | 10.652 | |||
| √ | √ | √ | 98.50% | 99.73% | 89.70% | 95.45% | 84.8 | 10.652 |
| Methods | mAP | FPS |
|---|---|---|
| 1D-CNN | 83.74% | 2.4 |
| 2D-CNN | 76.93% | 3.4 |
| WPT-1D-CNN | 91.92% | 3.4 |
| WPT-2D-CNN | 96.66% | 3.6 |
| Proposed | 98.50% | 84.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Mo, J.; Ma, X.; Huang, J.; Song, F. Optical Fiber Vibration Signal Identification Method Based on Improved YOLOv4. Sensors 2022, 22, 9259. https://doi.org/10.3390/s22239259
Zhang J, Mo J, Ma X, Huang J, Song F. Optical Fiber Vibration Signal Identification Method Based on Improved YOLOv4. Sensors. 2022; 22(23):9259. https://doi.org/10.3390/s22239259
Chicago/Turabian StyleZhang, Jiangwei, Jiaqing Mo, Xinrong Ma, Jincheng Huang, and Fubao Song. 2022. "Optical Fiber Vibration Signal Identification Method Based on Improved YOLOv4" Sensors 22, no. 23: 9259. https://doi.org/10.3390/s22239259
APA StyleZhang, J., Mo, J., Ma, X., Huang, J., & Song, F. (2022). Optical Fiber Vibration Signal Identification Method Based on Improved YOLOv4. Sensors, 22(23), 9259. https://doi.org/10.3390/s22239259