
Research on Pedestrian Detection Model and Compression Technology for UAV Images

Abstract
1. Introduction
2. Related Theories
2.1. Single-Stage Object Detection Algorithm
2.2. Model Compression Methods
3. Research Methodology
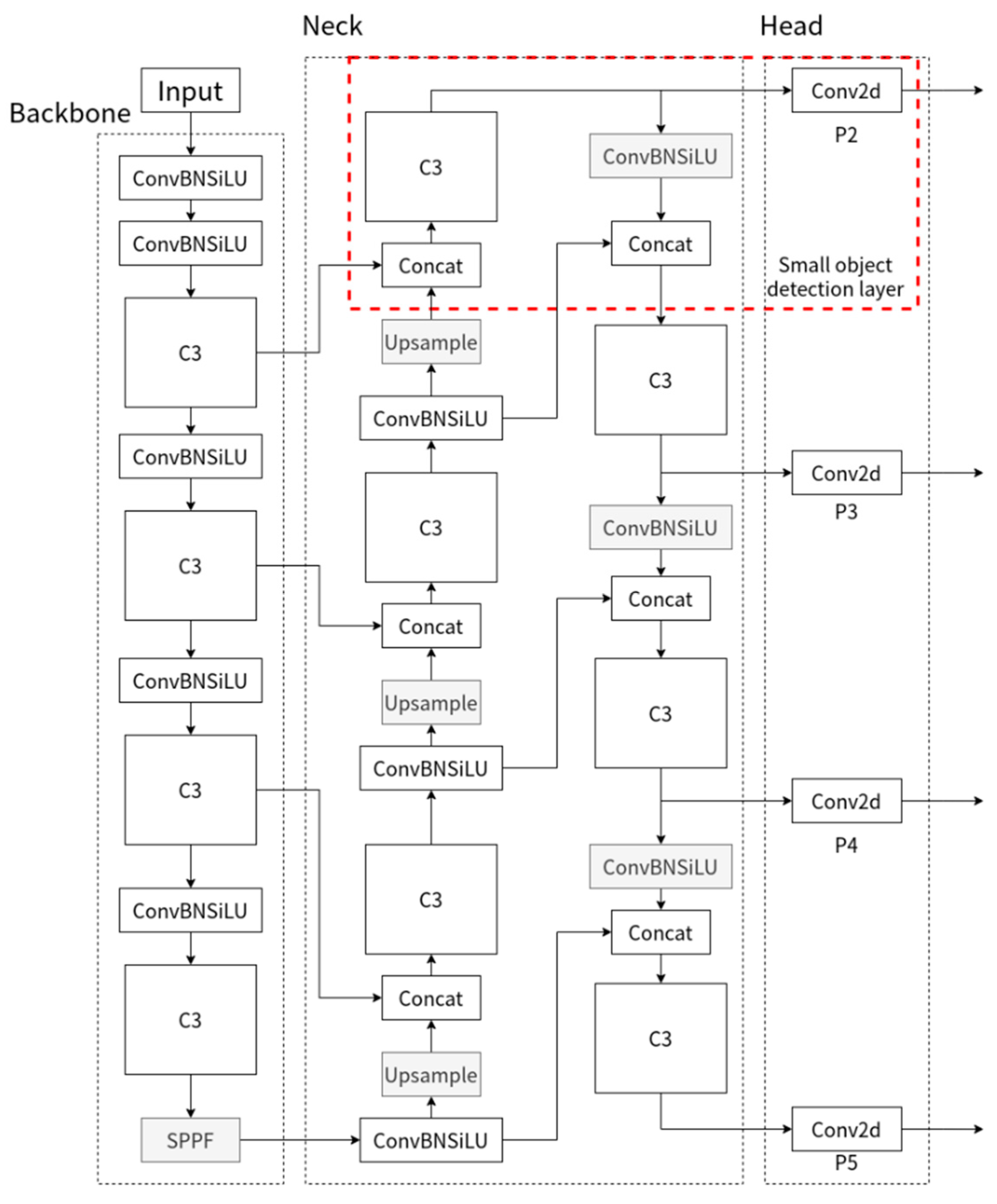
3.1. Improved YOLOv5-Based Pedestrian Detection Algorithm for UAV Images
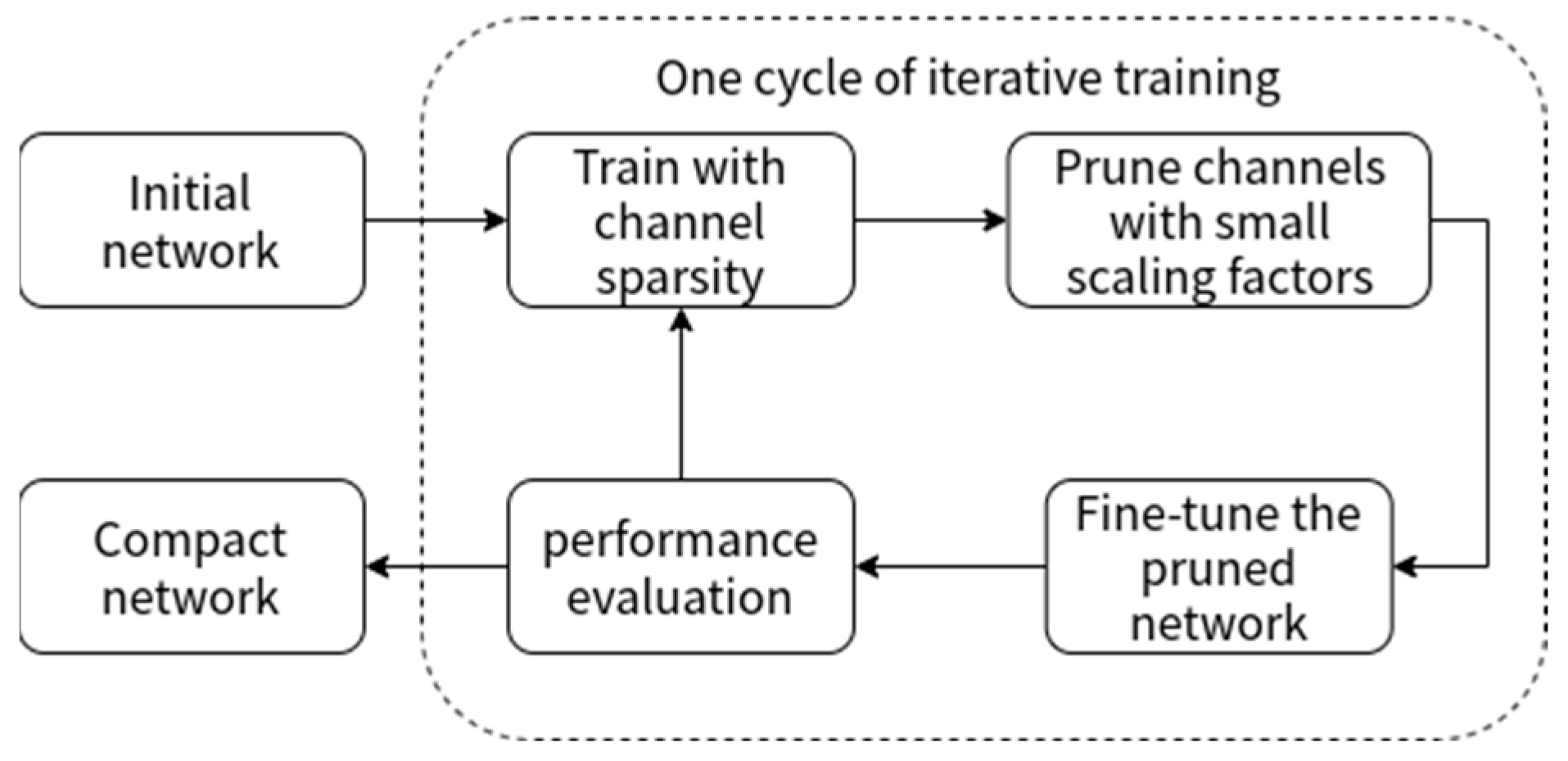
3.2. Model Compression
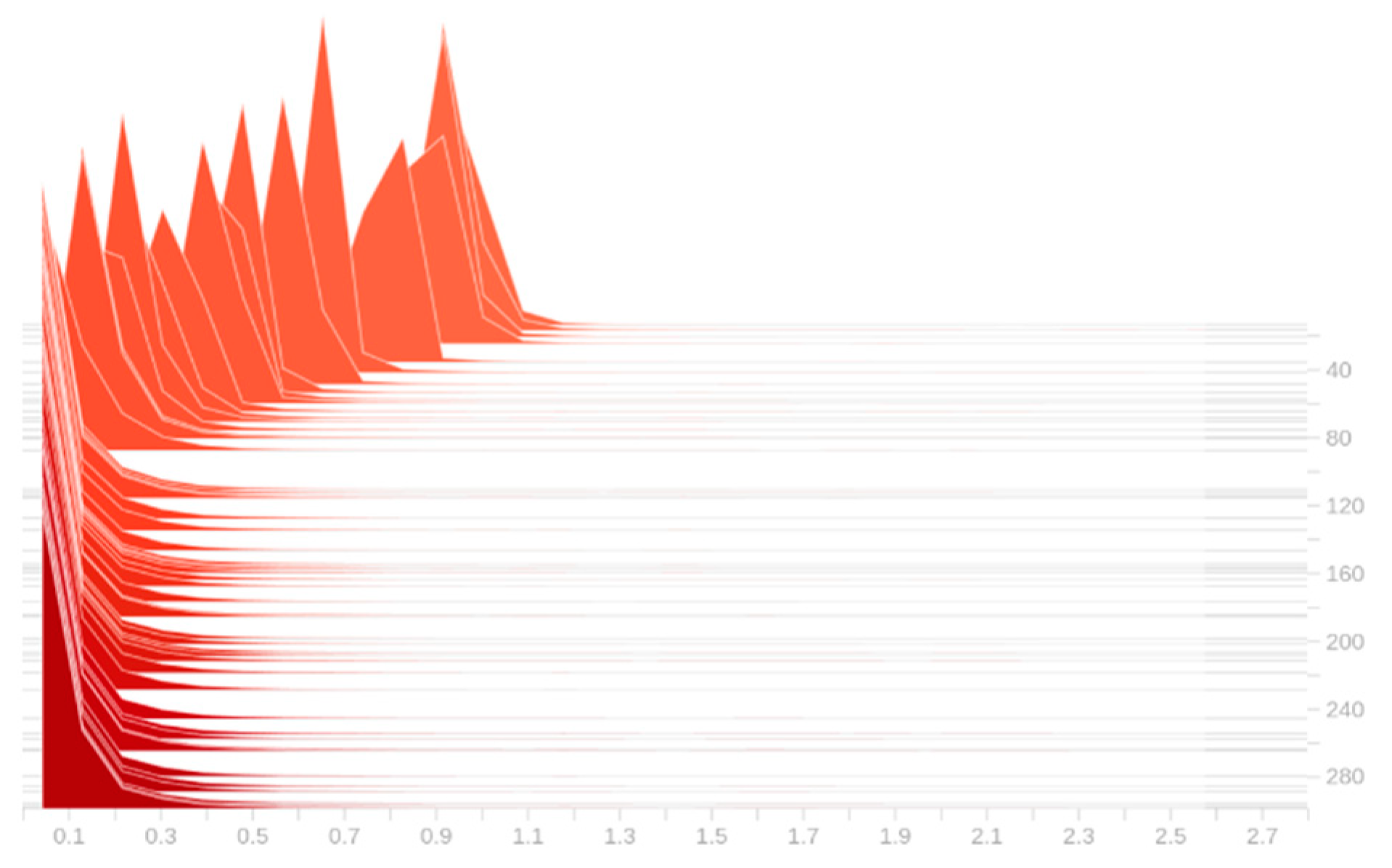
3.2.1. Sparse Training
3.2.2. Channel Pruning
| Algorithm 1 Process of model compression |
| Input: M layers of model, pruning rate |
| Output: compact model |
| while (experimental results meet the requirements) do |
| Sparsity training and get sparse scaling factor of j-th channel of i-th layer |
| Sort from small to large and get new list L |
| Threshold |
| for to M do |
| for to N(channel numbers of i-th layer) do |
| if delete j-th channel of i-th layer |
| end for |
| end for |
4. Experiments and Results
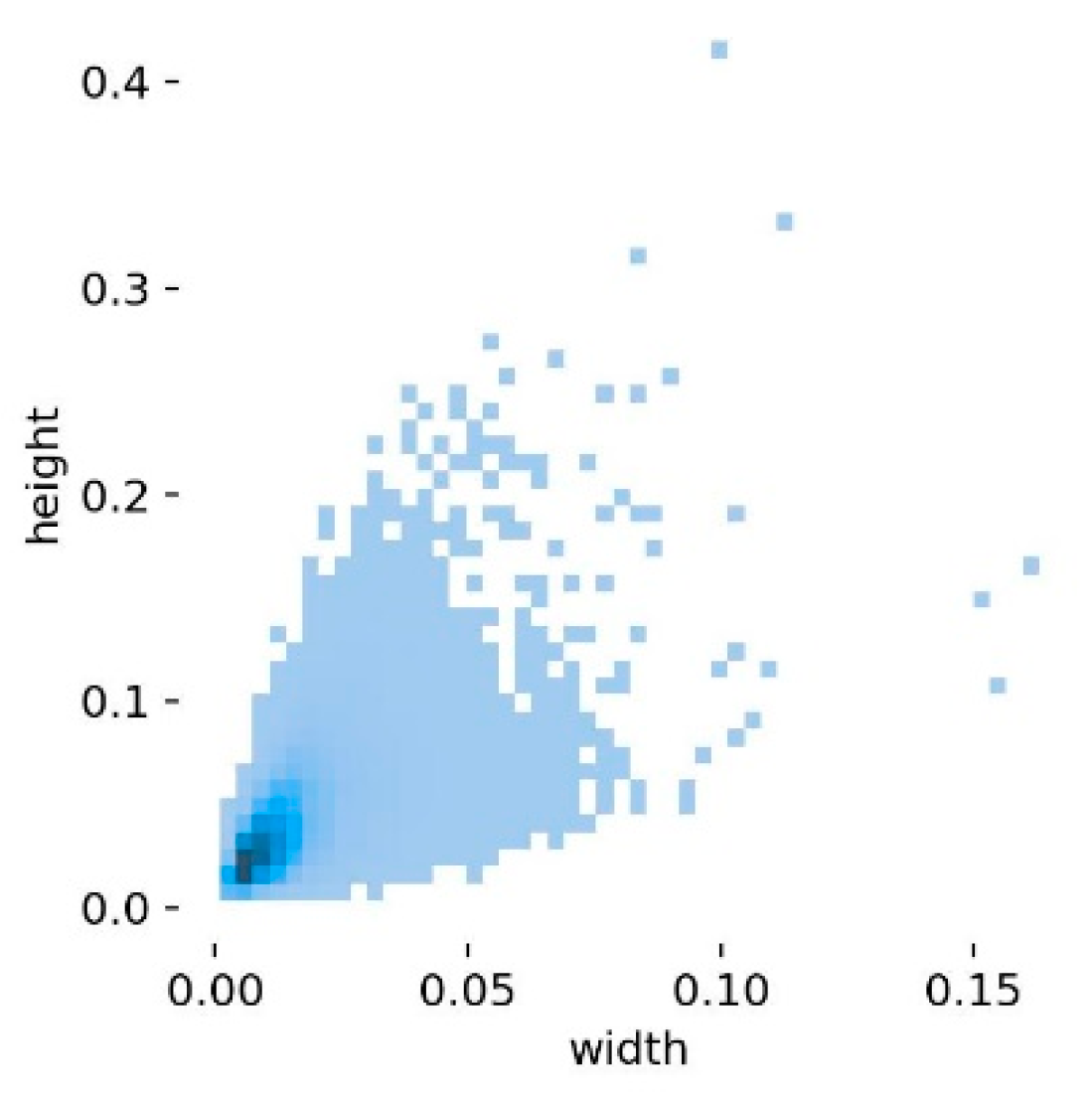
4.1. Experimental Data
4.2. Accuracy Metrics
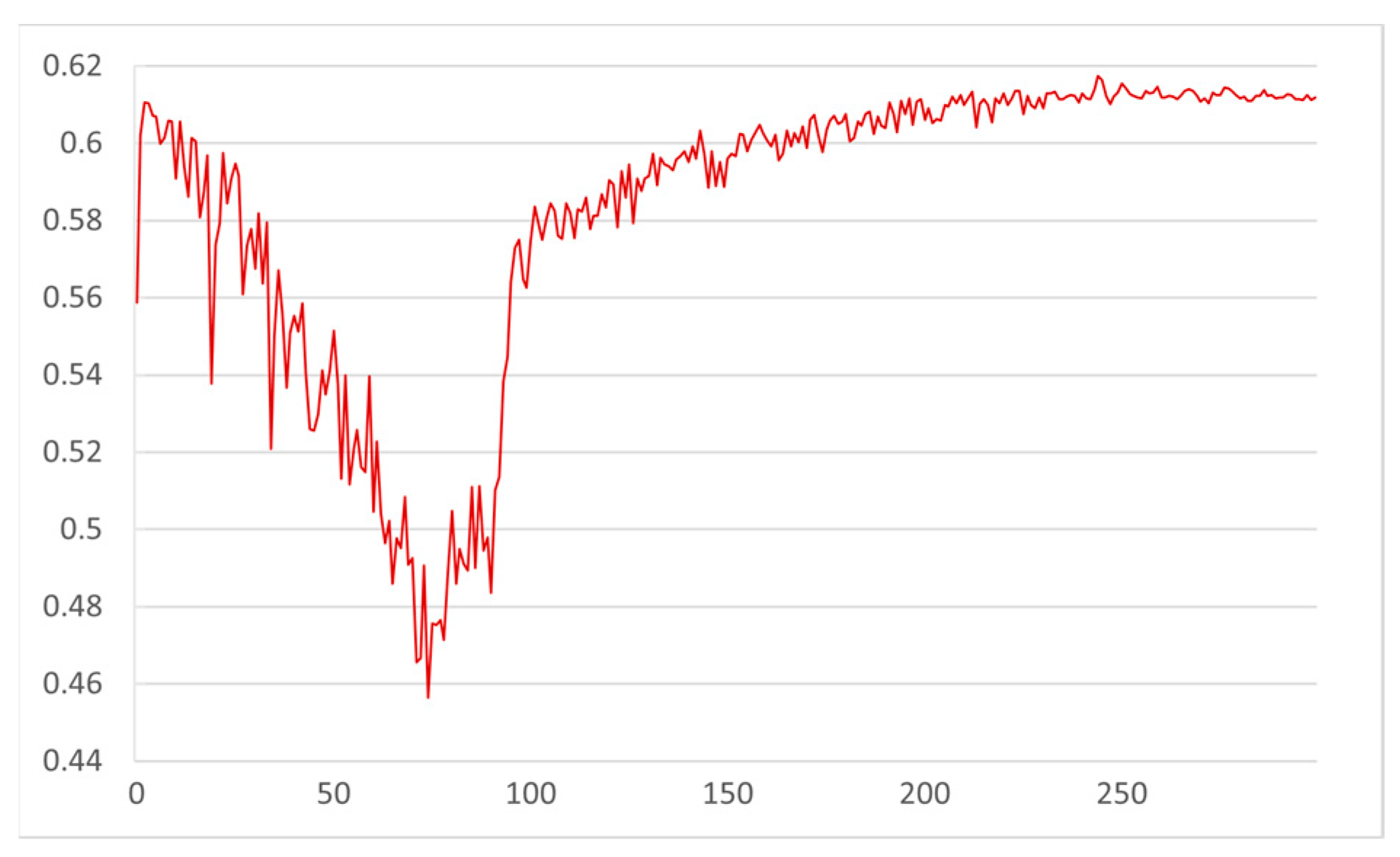
4.3. Model Training
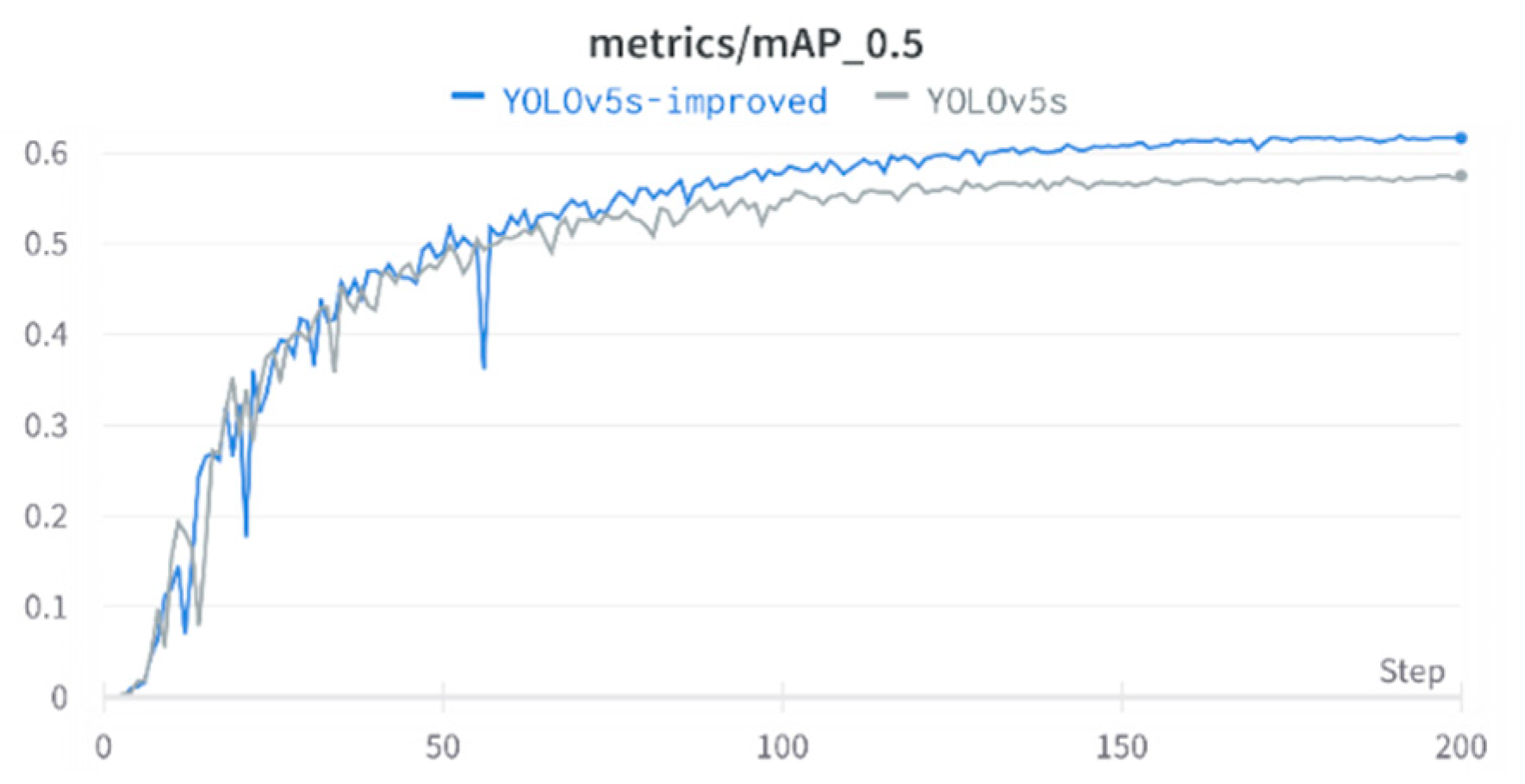
4.4. Experimental Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| UAV | Unmanned Aerial Vehicle |
| YOLO | You Only Look Once |
| RCNN | Region Convolutional Neural Network |
| RPN | Region Proposal Network |
| SPP | Spatial Pyramid Pooling |
| FPN | Feature Pyramid Network |
| PAN | Path Aggregation Network |
| BN | Batch Normalization |
| AP | Average Precision |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
| IoU | Intersection over Union |
References
- Zitong, H.; Kuerban, A. Real-time Pedestrian and Vehicle Detection Based on UAV. Comput. Eng. Appl. 2021, 57, 6. [Google Scholar]
- Qikai, Z.; Wei, Z.; Dongjin, L.; Fu, N. The Ship Classification and Detection Method of Optical Remote Sensing Image Based on improved YOLOv5s. Laser Optoelectron. Prog. 2022, 59, 1628008. [Google Scholar]
- Zhang, H.; Du, Y.; Ning, S.; Zhang, Y.; Yang, S.; Du, C. Pedestrian detection method based on Faster RCNN. Transducer Microsyst. Technol. 2019, 38, 147–149. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Xu, Q.; Li, Y.; Wang, G. Pedestrian-vehicle detection based on deep learning. J. Jilin Univ. 2019, 49, 1661–1667. [Google Scholar]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. Uav-yolo: Small object detection on unmanned aerial vehicle perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [PubMed]
- Mao, G.T.; Deng, T.M.; Yu, N.J. Object detection in UAV images based on multi-scale split attention. Acta Aeronaut. Astronaut. Sin. 2022, 43. [Google Scholar] [CrossRef]
- Jing, W.; Luxin, H.; Ying, S.; Shu, W.; Feng, H. Object Detection for UAV Based on Improved YOLOv4-tiny. Electron. Opt. Control 2021, 1–8. Available online: https://kns.cnki.net/kcms/detail/41.1227.tn.20211223.2010.002.html (accessed on 24 December 2021).
- Zhang, X.; Li, N.; Zhang, R. An improved lightweight network MobileNetv3 Based YOLOv3 for pedestrian detection. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 15–17 January 2021; pp. 114–118. [Google Scholar]
- Li, M.; Zhao, X.; Li, J.; Nan, L. COMNet: Combinational neural network for object detection in UAV-borne thermal images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6662–6673. [Google Scholar] [CrossRef]
- Jin, C.-J.; Shi, X.; Hui, T.; Li, D.; Ma, K. The automatic detection of pedestrians under the high-density conditions by deep learning techniques. J. Adv. Transp. 2021, 2021, 1396326. [Google Scholar] [CrossRef]
- Wang, C.; Luo, D.; Liu, Y.; Xu, B.; Zhou, Y. Near-surface pedestrian detection method based on deep learning for UAVs in low illumination environments. Opt. Eng. 2022, 61, 023103. [Google Scholar] [CrossRef]
- Kong, H.; Chen, Z.; Yue, W.; Ni, K. Improved YOLOv4 for pedestrian detection and counting in UAV images. Comput. Intell. Neurosci. 2022, 2022, 6106853. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Zhang, Y.; Zhang, W.; Zhou, H.; Yu, H. SDWBF algorithm: A novel pedestrian detection algorithm in the aerial scene. Drones 2022, 6, 76. [Google Scholar] [CrossRef]
- Shao, Y.; Zhang, X.; Chu, H.; Zhang, X.; Zhang, D.; Rao, Y. AIR-YOLOv3: Aerial Infrared Pedestrian Detection via an Improved YOLOv3 with Network Pruning. Appl. Sci. 2022, 12, 3627. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Khasawneh, N.; Fraiwan, M.; Fraiwan, L. Detection of K-complexes in EEG signals using deep transfer learning and YOLOv3. Clust. Comput. 2022, 1–11. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, P.; Liu, R.; Li, D. Immature apple detection method based on improved Yolov3. ASP Trans. Internet Things 2021, 1, 9–13. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An improvement of the fire detection and classification method using YOLOv3 for surveillance systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zhang, W.; Zhuang, X.; Wang, X.; Chen, Y.; Li, Y. DS-YOLO: A real-time small object detection algorithm on UAVs. J. Nanjing Univ. Posts Telecommun. 2021, 41, 86–98. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Liu, H.; Fan, K.; Ouyang, Q.; Li, N. Real-time small drones detection based on pruned yolov4. Sensors 2021, 21, 3374. [Google Scholar] [CrossRef] [PubMed]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and Tracking Meet Drones Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7380–7399. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Detection Heads | Anchors |
|---|---|---|
| YOLOv5s | P3 | [3, 6], [4, 10], [7, 9] |
| P4 | [6, 13], [9, 13], [7, 18] | |
| P5 | [10, 22], [16, 21], [18, 36] | |
| YOLOv5s_P2 | P2 | [3, 5], [4, 8], [6, 8] |
| P3 | [4, 12], [6, 13], [9, 12] | |
| P4 | [7, 17], [12, 15], [10, 23] | |
| P5 | [14, 26], [27, 27], [23, 50] |
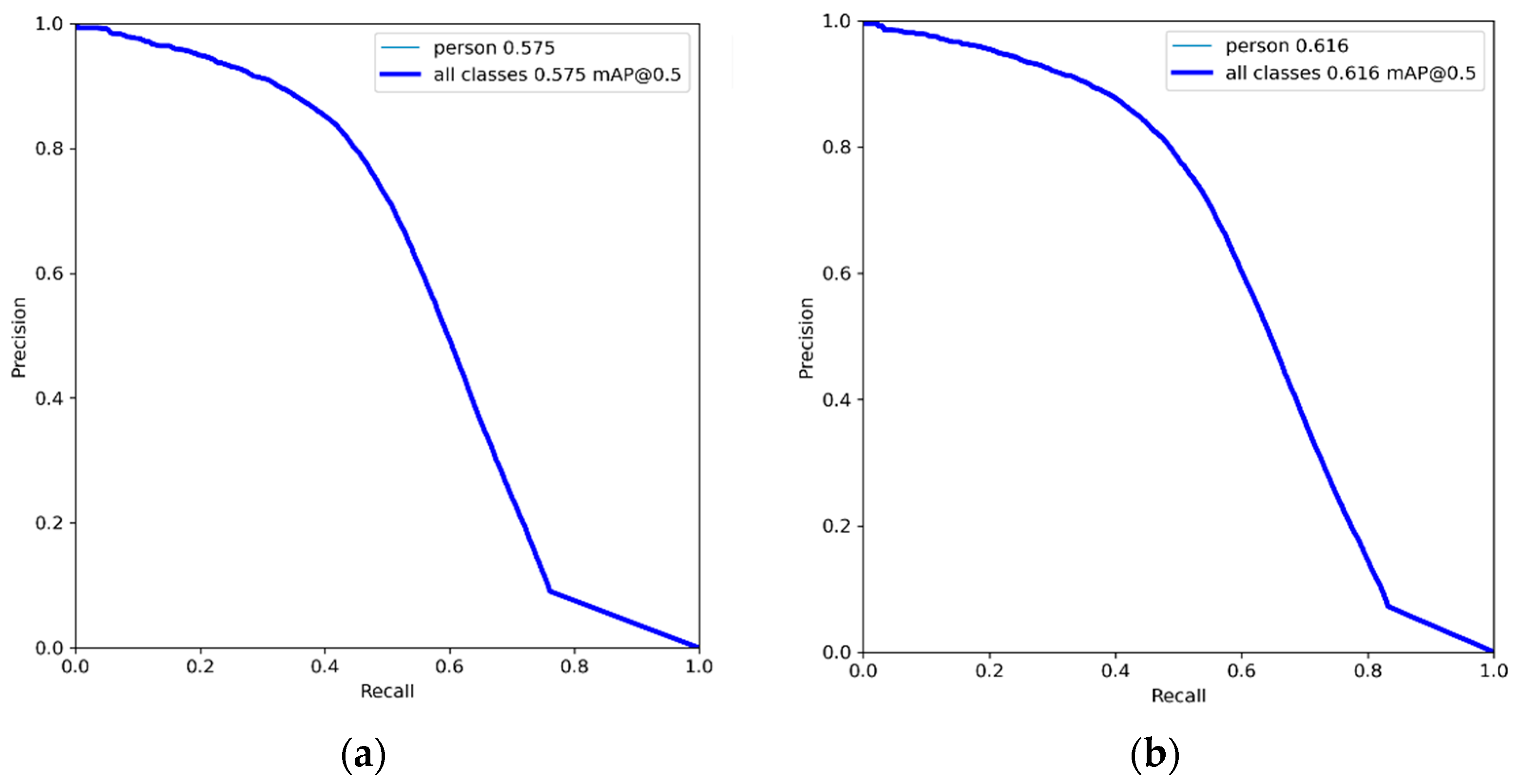
| Model | Precision Rate | Recall Rate | AP | Model Size (MB) | Single Picture Detection Time (ms) | GFLOPs |
|---|---|---|---|---|---|---|
| YOLOv5s | 0.701 | 0.507 | 0.572 | 14.4 | 4.6 | 15.8 |
| YOLOv5s_P2 | 0.714 | 0.541 | 0.616 | 15.2 | 7.5 | 18.5 |
| YOLOv5s_P2+ Compression | 0.733 | 0.542 | 0.612 | 11.2 | 6.8 | 16.3 |
| Model | Precision Rate | Recall Rate | AP | Model Size (MB) |
|---|---|---|---|---|
| YOLOv5s_P2+ Compression | 0.733 | 0.542 | 0.612 | 11.2 |
| YOLOv7 | 0.902 | 0.282 | 0.525 | 149.2 |
| FCOS | 0.856 | 0.274 | 0.463 | 128.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Wang, C.; Liu, L. Research on Pedestrian Detection Model and Compression Technology for UAV Images. Sensors 2022, 22, 9171. https://doi.org/10.3390/s22239171
Liu X, Wang C, Liu L. Research on Pedestrian Detection Model and Compression Technology for UAV Images. Sensors. 2022; 22(23):9171. https://doi.org/10.3390/s22239171
Chicago/Turabian StyleLiu, Xihao, Chengbo Wang, and Li Liu. 2022. "Research on Pedestrian Detection Model and Compression Technology for UAV Images" Sensors 22, no. 23: 9171. https://doi.org/10.3390/s22239171
APA StyleLiu, X., Wang, C., & Liu, L. (2022). Research on Pedestrian Detection Model and Compression Technology for UAV Images. Sensors, 22(23), 9171. https://doi.org/10.3390/s22239171