

SOCRATES: Introducing Depth in Visual Wildlife Monitoring Using Stereo Vision



Abstract
1. Introduction
- The detection and localization accuracy of animals is fostered by the additional depth information provided by SOCRATES (see Section 3.3 and Section 4.2).
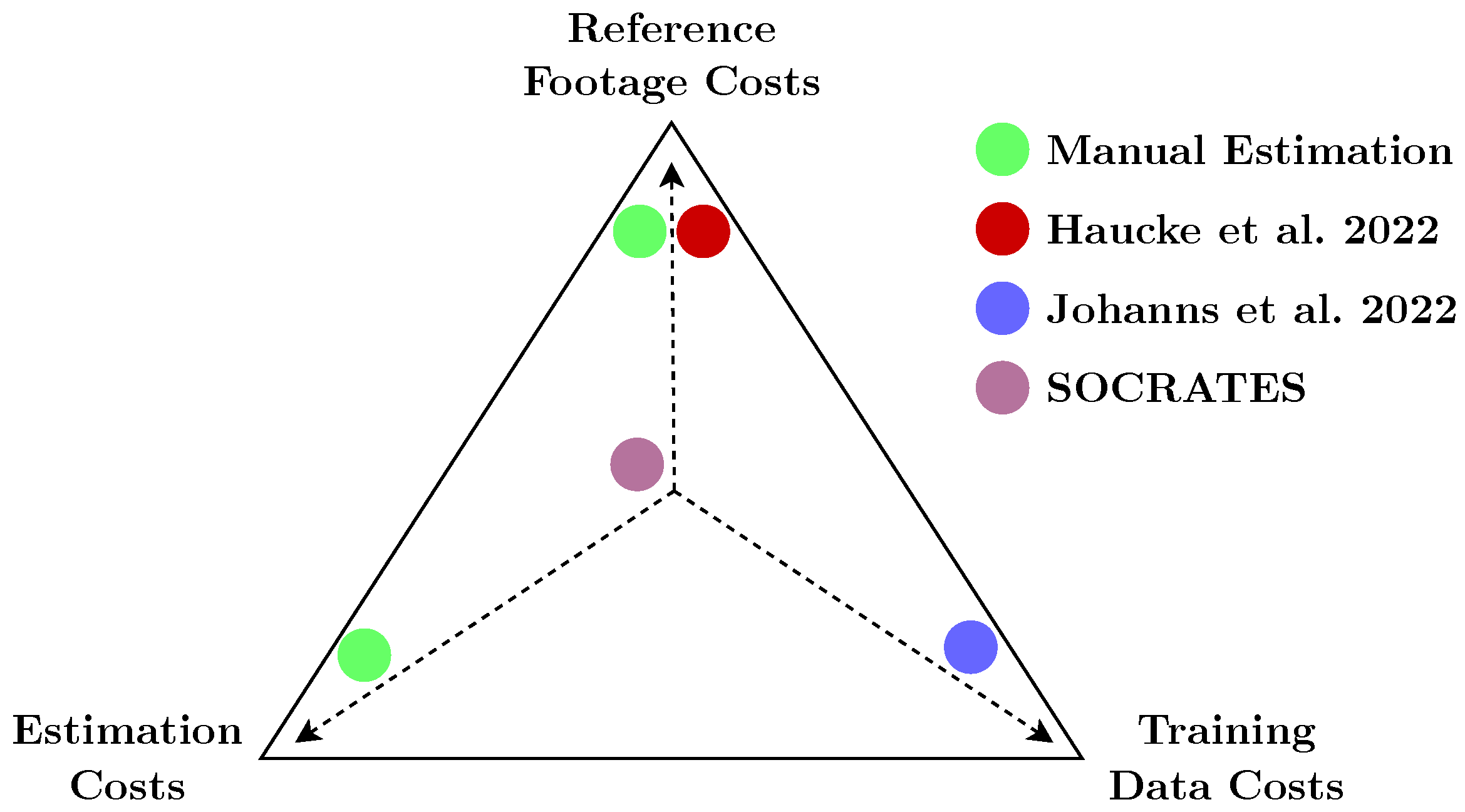
- Abundance estimation traditionally uses methods such as camera trap distance sampling (CTDS) with commercial camera traps, which requires laborious manual workflows. SOCRATES instead provides depth information in a fully automated way using stereo vision (see Section 2.1 and Section 4).
- Reproducibility and accessibility for practitioners: The SOCRATES approach takes the practitioner’s perspective and provides our raw and labeled data (see Section 3.1), code, detailed instructions, best practices, and 3D CAD models.
2. Related Work
2.1. Depth Using Stereo Vision
Stereo Camera Traps
2.2. Instance Segmentation
2.3. Abundance Estimation
3. Materials and Methods
3.1. Data Material
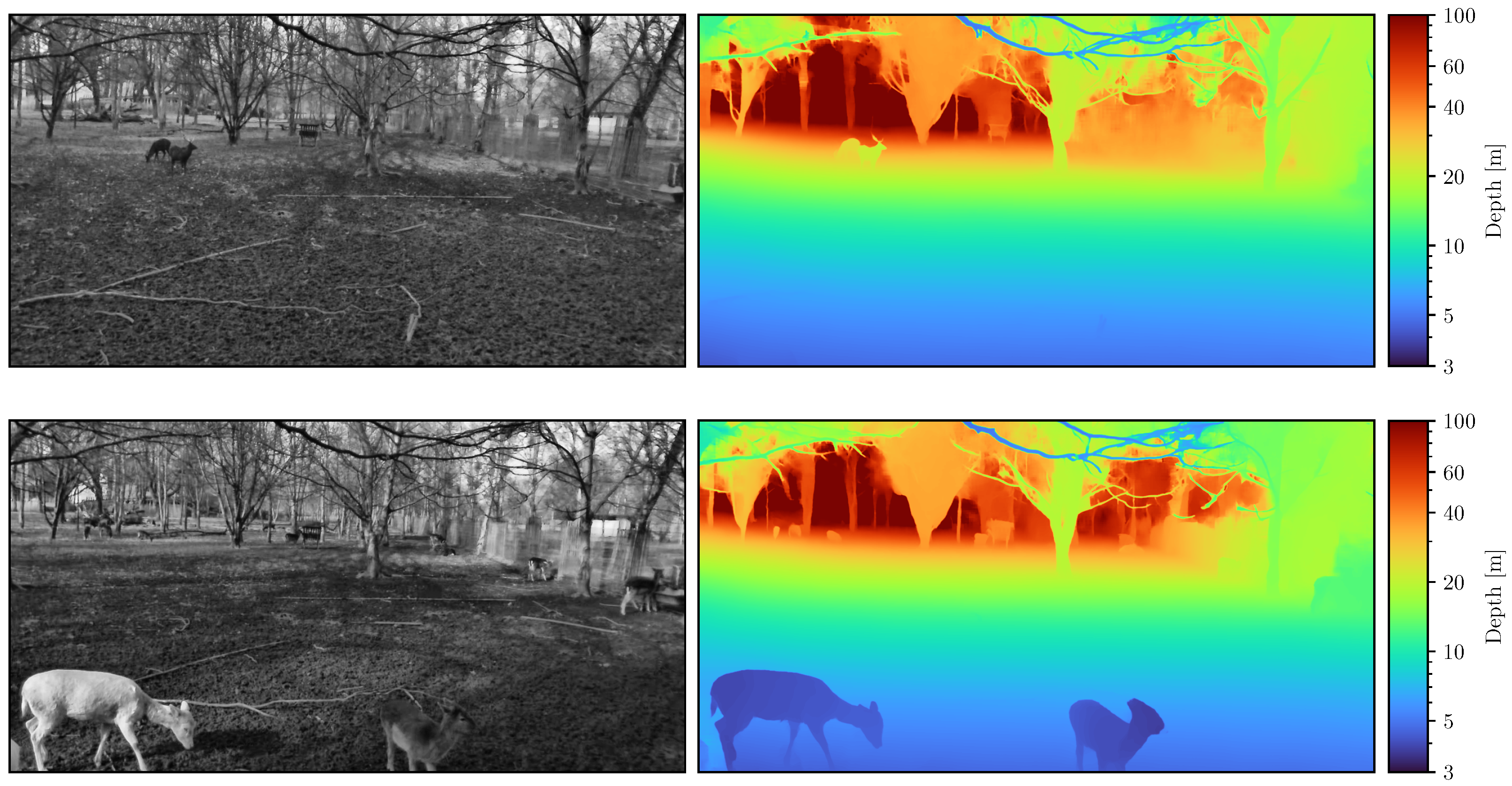
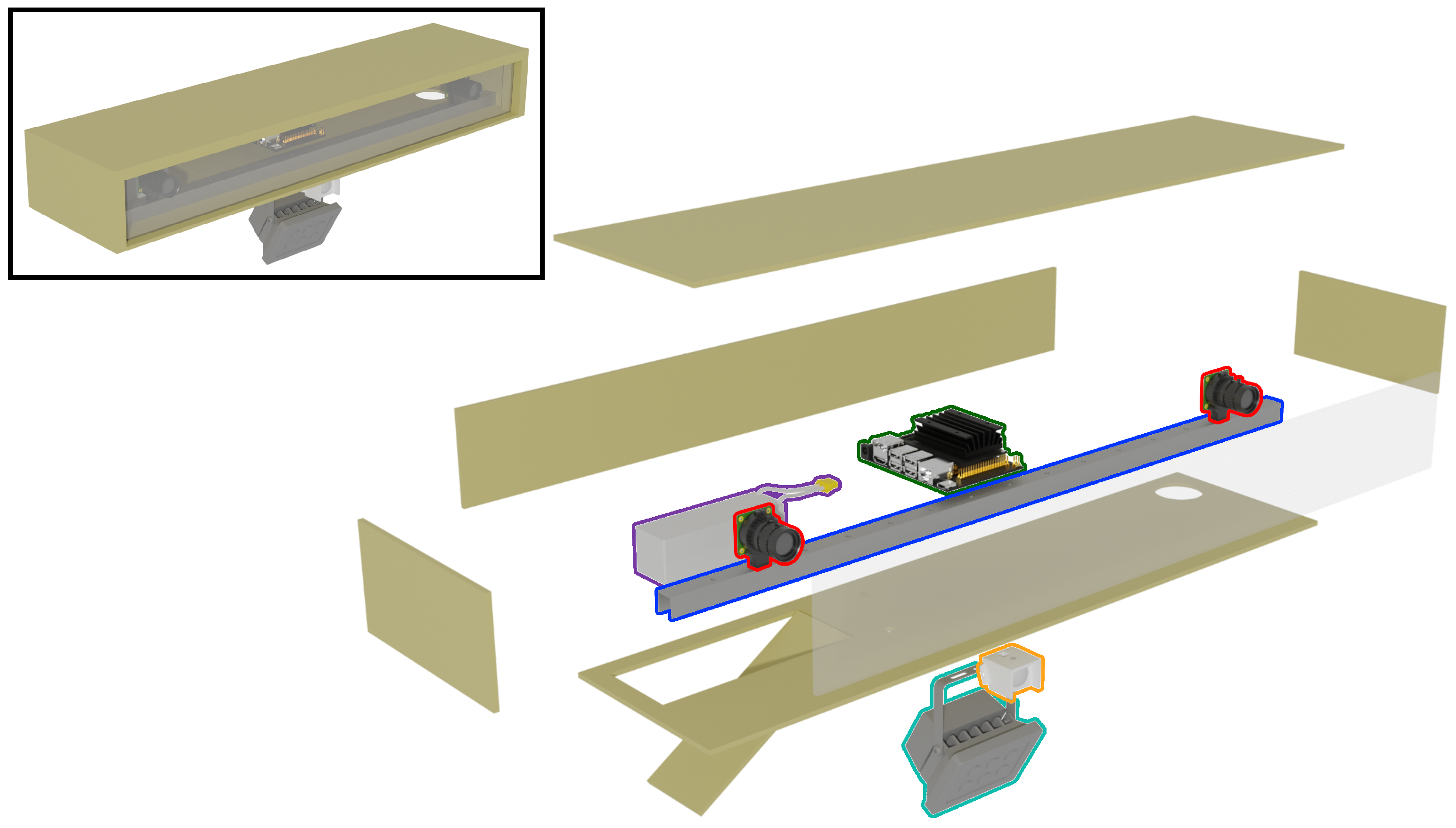
3.2. The SOCRATES Stereovision Sensor Platform
- Operability;
- (a)
- At day and night time as well as;
- (b)
- For a wide range of animal-camera distances;
- Effective and efficient power supply;
- Hardware and construction costs;
- Weather resistance.
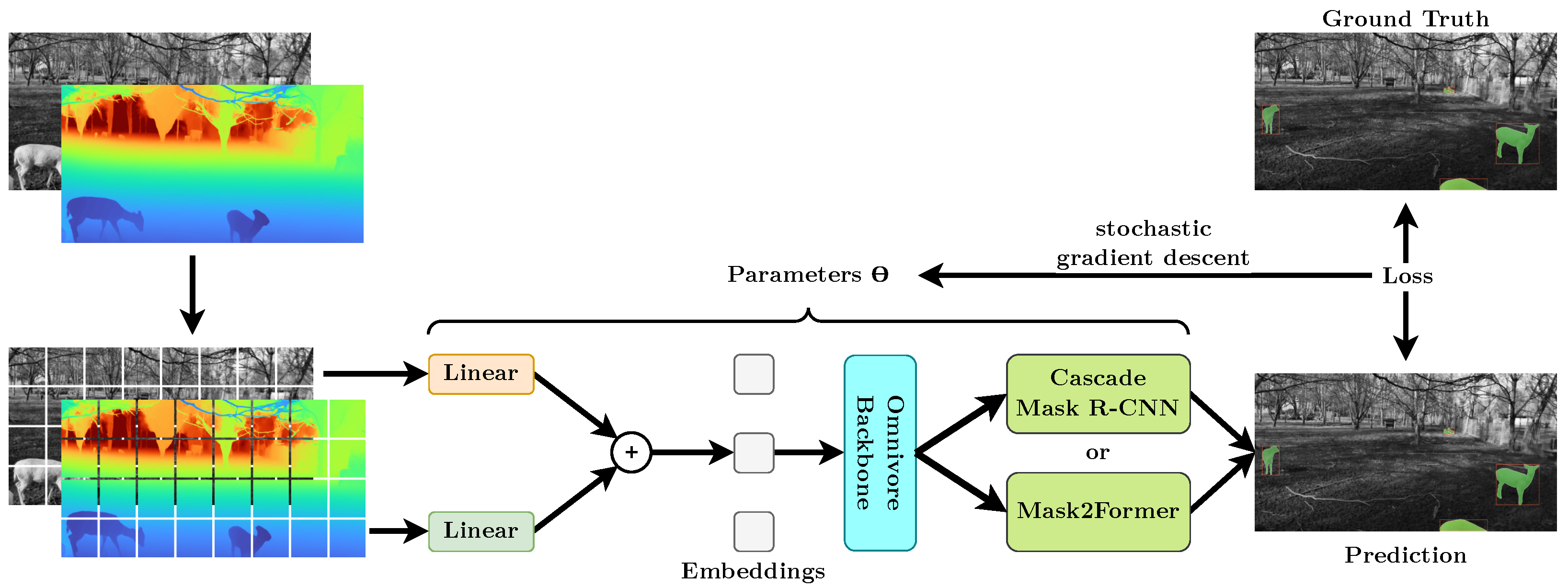
3.3. Depth-Aware Instance Segmentation
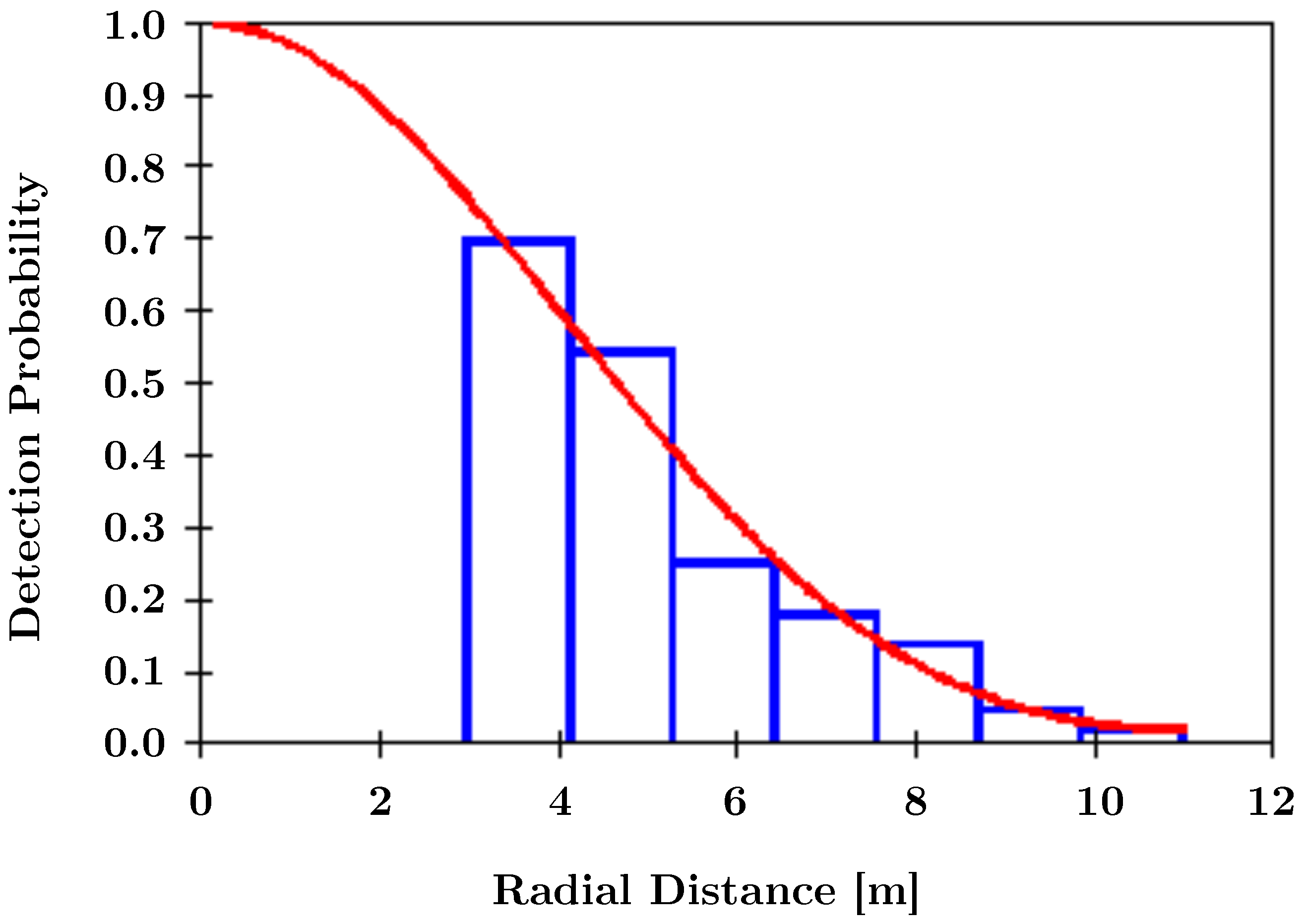
3.4. Camera Trap Distance Sampling Study
4. Evaluation
- It demonstrates that stereo camera traps are viable and worthwhile. We hope to convince commercial camera trap manufacturers to support stereo camera setups using off-the-shelf hardware.
- It facilitates the verification of monocular approaches. For example, abundance estimation using camera trap distance sampling might be performed twice, once using monocular approaches [25,26] and once using SOCRATES. Both raw animal distances and the resulting animal densities might then be compared.
- It allows generating training data for monocular depth estimation methods such as [55,56,57]. These approaches have been largely focused on human-centric scenes such as indoor and street scenes with a relatively simple geometry, which are highly unlike natural scenes such as forests. Gathering training data from natural scenes might help these methods generalize better to such scenes and, thus, allow monocular camera traps to more accurately estimate depth information in the future.
4.1. Stereo Correspondence
4.2. Visual Animal Detection
4.3. Depth-Aware Instance Segmentation on Cityscapes
4.4. Abundance Estimation Using SOCRATES
4.5. AMMOD Portal Case Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SOCRATES | StereO CameRA Trap for monitoring of biodivErSity |
| CTDS | camera trap distance sampling |
| RGB | red, green, blue (color channels) |
| IR | infrared |
| PIR sensor | pyroelectric infrared sensor |
| HEVC | High-Efficiency Video Coding |
Appendix A. Comparison with ResNet Backbones

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | ||||
|---|---|---|---|---|
| Depth-aware Omnivore-L | 0.5399 | 0.6048 | 0.4547 | 0.8147 |
| ResNet-18 | 0.3361 | 0.2754 | 0.2788 | 0.6669 |
| +depth-awareness | 0.3318 | 0.3194 | 0.3082 | 0.6408 |
| ResNet-50 | 0.3744 | 0.3624 | 0.3038 | 0.6936 |
| +depth-awareness | 0.4122 | 0.3804 | 0.3486 | 0.7164 |
| Backbone | ||||
| Depth-aware Omnivore-L | 0.4699 | 0.5427 | 0.4013 | 0.1138 |
| ResNet-18 | 0.1585 | 0.3129 | 0.2807 | 0.0987 |
| +depth-awareness | 0.2433 | 0.3487 | 0.2615 | 0.0563 |
| ResNet-50 | 0.2227 | 0.3572 | 0.3108 | 0.0703 |
| +depth-awareness | 0.2475 | 0.4128 | 0.3009 | 0.0724 |
References
- Wägele, J.; Bodesheim, P.; Bourlat, S.J.; Denzler, J.; Diepenbroek, M.; Fonseca, V.; Frommolt, K.H.; Geiger, M.F.; Gemeinholzer, B.; Glöckner, F.O.; et al. Towards a multisensor station for automated biodiversity monitoring. Basic Appl. Ecol. 2022, 59, 105–138. [Google Scholar] [CrossRef]
- Sixdenier, P.L.; Wildermann, S.; Ziegler, D.; Teich, J. SIDAM: A Design Space Exploration Framework for Multi-sensor Embedded Systems Powered by Energy Harvesting. In Proceedings of the Embedded Computer Systems: Architectures, Modeling, and Simulation, Samos, Greece, 3–7 July 2022; Orailoglu, A., Reichenbach, M., Jung, M., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 329–345. [Google Scholar]
- Longuet-Higgins, H.C. A computer algorithm for reconstructing a scene from two projections. Nature 1981, 293, 133–135. [Google Scholar] [CrossRef]
- Zbontar, J.; LeCun, Y. Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches. J. Mach. Learn. Res. 2016, 17, 65:1–65:32. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Pyramid Stereo Matching Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 15–23 June 2018; pp. 5410–5418. [Google Scholar]
- Zhang, F.; Prisacariu, V.; Yang, R.; Torr, P.H. GA-Net: Guided Aggregation Net for End-to-end Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 185–194. [Google Scholar]
- Xu, H.; Zhang, J. AANet: Adaptive Aggregation Network for Efficient Stereo Matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1959–1968. [Google Scholar]
- Li, J.; Wang, P.; Xiong, P.; Cai, T.; Yan, Z.; Yang, L.; Liu, J.; Fan, H.; Liu, S. Practical stereo matching via cascaded recurrent network with adaptive correlation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 16263–16272. [Google Scholar]
- Xu, Z.; Sun, L.; Wang, X.; Dong, H.; Lei, P.; Zhou, Y. Binocular camera trap for wildlife detection. In Proceedings of the Optoelectronic Imaging and Multimedia Technology VI, Hangzhou, China, 21–23 October 2019; Dai, Q., Shimura, T., Zheng, Z., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2019; Volume 11187, p. 111871C. [Google Scholar] [CrossRef]
- Xu, Z.; Sun, L.; Wang, X.; Lei, P.; He, J.; Zhou, Y. Stereo camera trap for wildlife in situ observations and measurements. Appl. Opt. 2020, 59, 3262–3269. [Google Scholar] [CrossRef]
- Haucke, T.; Steinhage, V. Exploiting Depth Information for Wildlife Monitoring. arXiv 2021, arXiv:cs.CV/2102.05607. [Google Scholar]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. arXiv 2017, arXiv:1703.06870. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention Mask Transformer for Universal Image Segmentation. arXiv 2022, arXiv:2112.01527. [Google Scholar]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In Proceedings of the International Conference on Artificial Neural Networks, Shenzhen, China, 8–10 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 270–279. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Girdhar, R.; Singh, M.; Ravi, N.; van der Maaten, L.; Joulin, A.; Misra, I. Omnivore: A Single Model for Many Visual Modalities. arXiv 2022, arXiv:2201.08377. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Rowcliffe, J.M.; Field, J.; Turvey, S.T.; Carbone, C. Estimating animal density using camera traps without the need for individual recognition. J. Appl. Ecol. 2008, 45, 1228–1236. [Google Scholar] [CrossRef]
- Nakashima, Y.; Fukasawa, K.; Samejima, H. Estimating animal density without individual recognition using information derivable exclusively from camera traps. J. Appl. Ecol. 2018, 55, 735–744. [Google Scholar] [CrossRef]
- Moeller, A.K.; Lukacs, P.M.; Horne, J.S. Three novel methods to estimate abundance of unmarked animals using remote cameras. Ecosphere 2018, 9, e02331. [Google Scholar] [CrossRef]
- Howe, E.J.; Buckland, S.T.; Després-Einspenner, M.L.; Kühl, H.S. Distance sampling with camera traps. Methods Ecol. Evol. 2017, 8, 1558–1565. [Google Scholar] [CrossRef]
- Haucke, T.; Kühl, H.S.; Hoyer, J.; Steinhage, V. Overcoming the distance estimation bottleneck in estimating animal abundance with camera traps. Ecol. Inform. 2022, 68, 101536. [Google Scholar] [CrossRef]
- Johanns, P.; Haucke, T.; Steinhage, V. Automated distance estimation for wildlife camera trapping. Ecol. Inform. 2022, 70, 101734. [Google Scholar] [CrossRef]
- Auda, E. (Wildlife Conservation Society, Phnom Penh, Cambodia). Overestimation of Animal Distances in Close-Up Scenarios. Personal communication, 2022. [Google Scholar]
- KaewTraKulPong, P.; Bowden, R. An improved adaptive background mixture model for real-time tracking with shadow detection. In Video-Based Surveillance Systems; Springer: Berlin/Heidelberg, Germany, 2002; pp. 135–144. [Google Scholar]
- Sofiiuk, K.; Petrov, I.A.; Konushin, A. Reviving iterative training with mask guidance for interactive segmentation. arXiv 2021, arXiv:2102.06583. [Google Scholar]
- Haucke, T.; Steinhage, V. SOCRATES Plittersdorf Raw Dataset. 2022. Available online: https://zenodo.org/record/6992653#.Y325eX1BxPY (accessed on 20 September 2022).
- Haucke, T.; Steinhage, V. SOCRATES Plittersdorf Instance Segmentation Dataset. 2022. Available online: https://zenodo.org/record/7035934#.Y325c31BxPY (accessed on 20 September 2022).
- Rasool, I. Raspberry Pi HQ Camera with arduCAM CS Mount Lens. Available online: https://grabcad.com/library/raspberry-pi-hq-camera-with-arducam-cs-mount-lens-1 (accessed on 16 July 2022).
- Minichiello, S. nVidia Jetson Nano Development Board. Available online: https://grabcad.com/library/nvidia-jetson-nano-development-board-1 (accessed on 16 July 2022).
- Medina, J.A.V. Infrared Illuminator. Available online: https://grabcad.com/library/infrared-illuminator-1 (accessed on 16 July 2022).
- Machado, M. PIR Sensor Wall Mount Enclosure. Licensed under the Creative Commons Attribution 4.0 International License. Available online: https://www.thingiverse.com/thing:1718985 (accessed on 16 July 2022).
- Stoudek, P. Tattu 4S 6750mAh LiPo Battery. Available online: https://grabcad.com/library/tattu-4s-6750mah-lipo-battery-1 (accessed on 16 July 2022).
- Sony Semiconductor Solutions Corporation. IMX477-AACK Product Information. Available online: https://www.sony-semicon.co.jp/products/common/pdf/IMX477-AACK_Flyer.pdf (accessed on 16 July 2022).
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Maye, J.; Furgale, P.; Siegwart, R. Self-supervised calibration for robotic systems. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast City, Australia, 23 June 2013; pp. 473–480. [Google Scholar]
- Olson, E. AprilTag: A robust and flexible visual fiducial system. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3400–3407. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Hassani, A.; Walton, S.; Shah, N.; Abuduweili, A.; Li, J.; Shi, H. Escaping the Big Data Paradigm with Compact Transformers. arXiv 2021, arXiv:2104.05704. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Beery, S.; Morris, D.; Yang, S. Efficient Pipeline for Camera Trap Image Review. arXiv 2019, arXiv:1907.06772. [Google Scholar]
- Thomas, L.; Buckland, S.T.; Rexstad, E.A.; Laake, J.L.; Strindberg, S.; Hedley, S.L.; Bishop, J.R.; Marques, T.A.; Burnham, K.P. Distance software: Design and analysis of distance sampling surveys for estimating population size. J. Appl. Ecol. 2010, 47, 5–14. [Google Scholar] [CrossRef]
- Newey, S.; Davidson, P.; Nazir, S.; Fairhurst, G.; Verdicchio, F.; Irvine, R.J.; van der Wal, R. Limitations of recreational camera traps for wildlife management and conservation research: A practitioner’s perspective. Ambio 2015, 44, 624–635. [Google Scholar] [CrossRef]
- Reconyx. HP2XC HyperFire 2 Cellular Professional Covert IR Camera. Available online: https://www.reconyx.com/product/hyperfire-2-cellular-professional-covert-ir-camera (accessed on 22 June 2022).
- Shrader, A.M.; Ferreira, S.M.; Van Aarde, R.J. Digital photogrammetry and laser rangefinder techniques to measure African elephants. S. Afr. J. Wildl. Res. 2006, 36, 1–7. [Google Scholar]
- Klasen, M.; Steinhage, V. Improving wildlife tracking using 3D information. Ecol. Inform. 2022, 68, 101535. [Google Scholar] [CrossRef]
- Klasen, M.; Steinhage, V. Wildlife 3D multi-object tracking. Ecol. Inform. 2022, 71, 101790. [Google Scholar] [CrossRef]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into Self-Supervised Monocular Depth Prediction. arXiv 2019, arXiv:1806.01260. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1623–1637. [Google Scholar] [CrossRef]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision Transformers for Dense Prediction. arXiv 2021, arXiv:2103.13413. [Google Scholar]
- Vandewalle, P.; Varekamp, C. Disparity map quality for image-based rendering based on multiple metrics. In Proceedings of the 2014 International Conference on 3D Imaging (IC3D), Liège, Belgium, 9–10 December 2014; pp. 1–5. [Google Scholar]
- Farnebäck, G. Two-frame motion estimation based on polynomial expansion. In Proceedings of the Scandinavian Conference on Image Analysis, Halmstad, Sweden, 29 June–2 July 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 363–370. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Bormann, C.; Castellani, A.P.; Shelby, Z. CoAP: An Application Protocol for Billions of Tiny Internet Nodes. IEEE Internet Comput. 2012, 16, 62–67. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]









| HP2XC [51] | SOCRATES | |
|---|---|---|
| Provided Depth | ✗ | ✓ |
| Image Resolution | /3 MP | |
| Video Resolution | ||
| Video Length | max. at 2 FPS | Up to at 30 FPS |
| Daytime Imaging | RGB | Near-infrared |
| Nighttime Imaging | Near-infrared | Near-infrared |
| Illumination Wavelength | ||
| Dimensions | ||
| Connectivity | Cellular | Cellular/W-LAN/LAN |
| Battery Life | Up to a year | ∼9 days |
| Material Cost | USD 659.99 | ∼USD 900 |
| Backbone | ||||
|---|---|---|---|---|
| Swin-L | 0.5164 | 0.5272 | 0.4359 | 0.8328 |
| Omnivore-L | 0.5243 | 0.5702 | 0.4382 | 0.8353 |
| +depth-awareness | 0.5399 | 0.6048 | 0.4547 | 0.8147 |
| Backbone | ||||
| Swin-L | 0.4285 | 0.5192 | 0.3856 | 0.1285 |
| Omnivore-L | 0.4376 | 0.515 | 0.3895 | 0.1431 |
| +depth-awareness | 0.4699 | 0.5427 | 0.4013 | 0.1138 |
| Backbone | ||||||
|---|---|---|---|---|---|---|
| Swin-L | 0.437 | 0.714 | ||||
| Omnivore-L | 0.415 | 0.439 | 0.700 | 0.716 | 0.394 | 0.214 |
| Depth-aware Omnivore-L | 0.431 | 0.456 | 0.734 | 0.732 | 0.411 | 0.264 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haucke, T.; Kühl, H.S.; Steinhage, V. SOCRATES: Introducing Depth in Visual Wildlife Monitoring Using Stereo Vision. Sensors 2022, 22, 9082. https://doi.org/10.3390/s22239082
Haucke T, Kühl HS, Steinhage V. SOCRATES: Introducing Depth in Visual Wildlife Monitoring Using Stereo Vision. Sensors. 2022; 22(23):9082. https://doi.org/10.3390/s22239082
Chicago/Turabian StyleHaucke, Timm, Hjalmar S. Kühl, and Volker Steinhage. 2022. "SOCRATES: Introducing Depth in Visual Wildlife Monitoring Using Stereo Vision" Sensors 22, no. 23: 9082. https://doi.org/10.3390/s22239082
APA StyleHaucke, T., Kühl, H. S., & Steinhage, V. (2022). SOCRATES: Introducing Depth in Visual Wildlife Monitoring Using Stereo Vision. Sensors, 22(23), 9082. https://doi.org/10.3390/s22239082