
Developing an Improved Ensemble Learning Approach for Predictive Maintenance in the Textile Manufacturing Process


Abstract
1. Introduction
- To intelligenize the quality management by forecasting the defective class of product using ELAs.
- To enable the automatic notification by developing the proposed resource dispatching approach in data communication.
- To enhance the efficiency of PdM by integrating the above mentioned data analytics and systems in the textile product manufacturing process.
2. Related Work
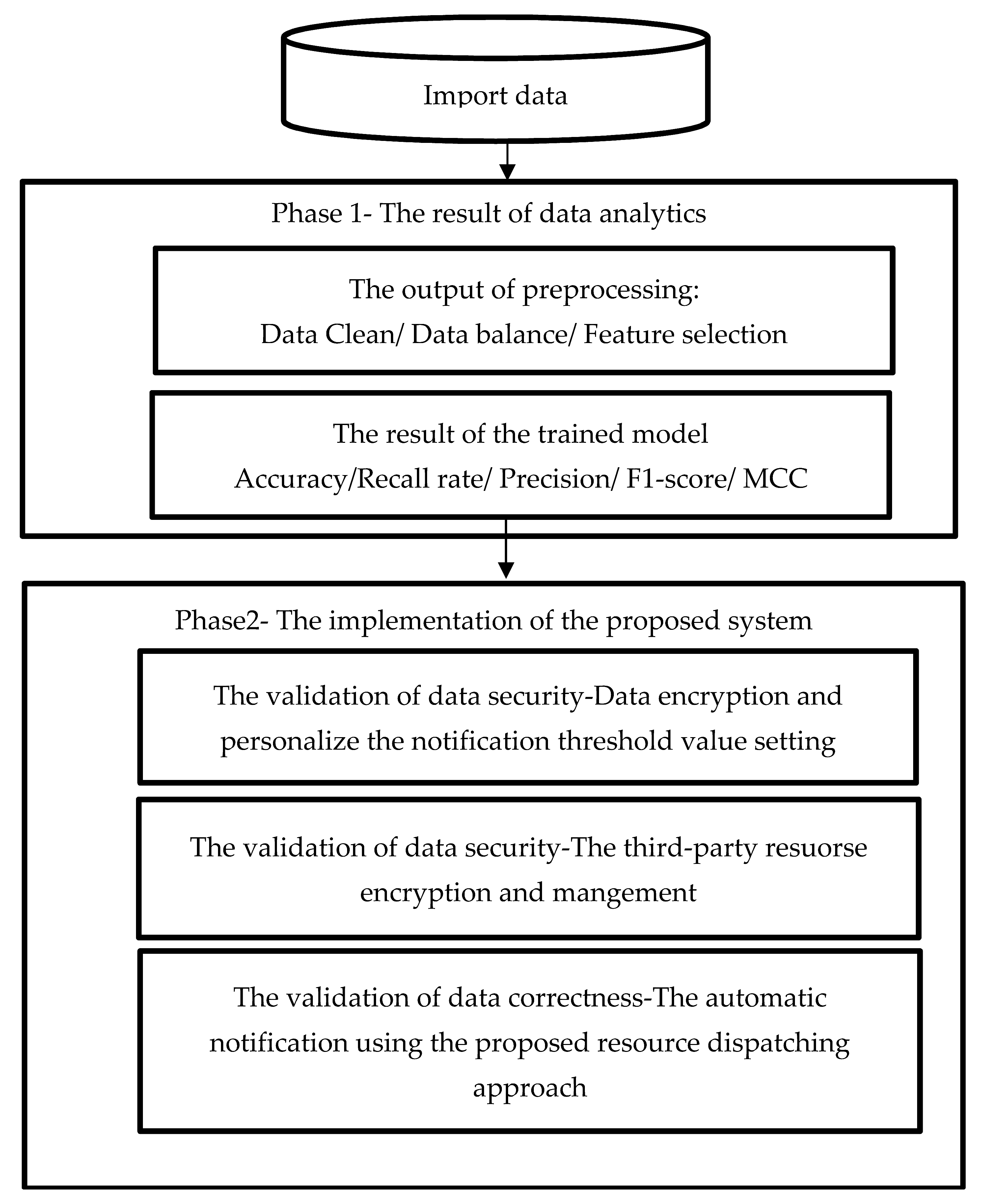
3. Methodology
3.1. Data Preprocessing
- ■
- Step 1: Explore the minority class input data point.
- ■
- Step 2: Find the k-nearest neighbors of explored input data point.
- ■
- Step 3: Select one of these neighbors’ point, and placing a new point on the path connecting the point under consideration and its chosen neighbor.
- ■
- Step 4: Repeat Steps 1 and 2 until the terminal condition (data had been balanced).
3.2. Preliminaries Ensemble Learning Model
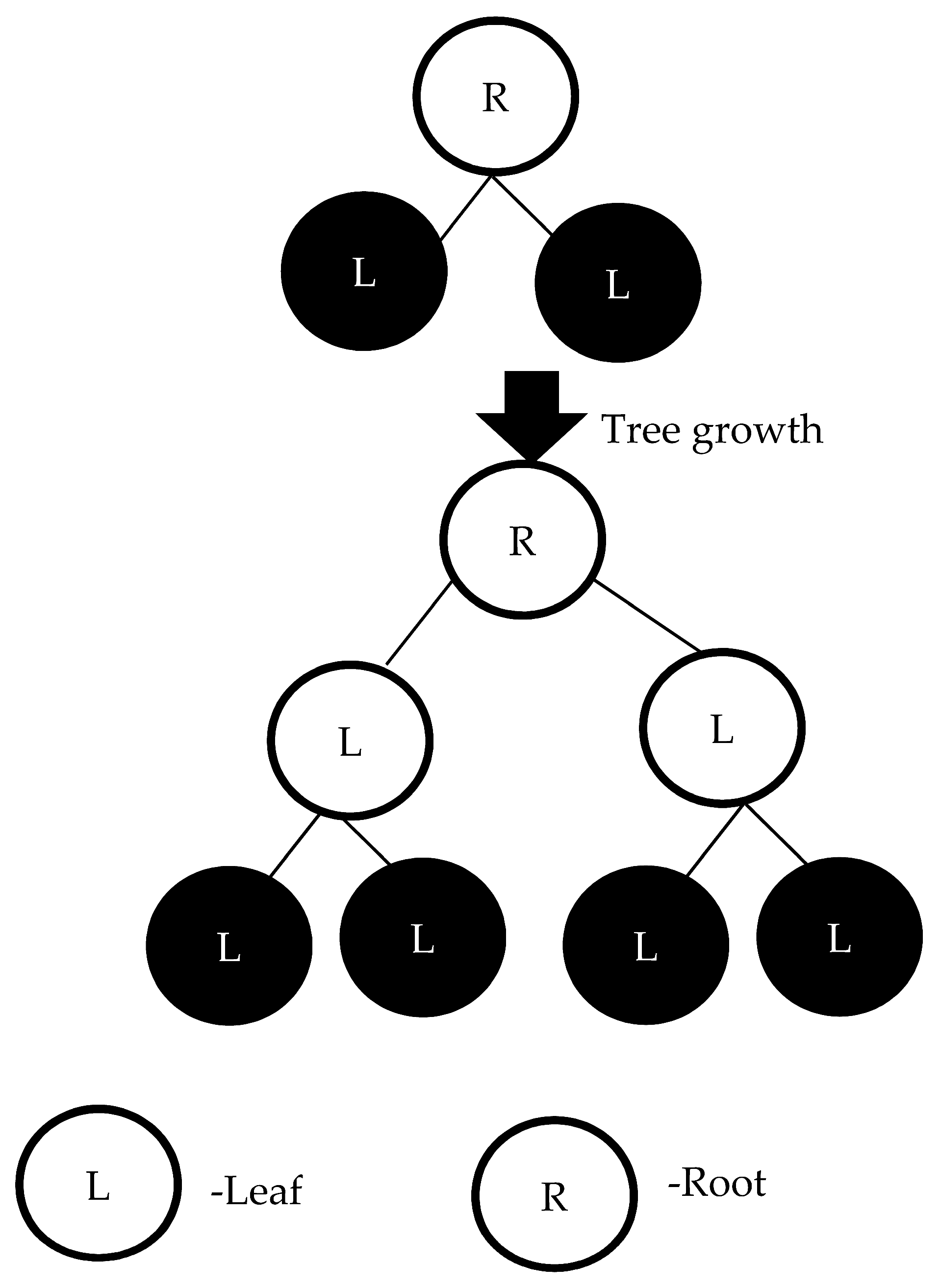
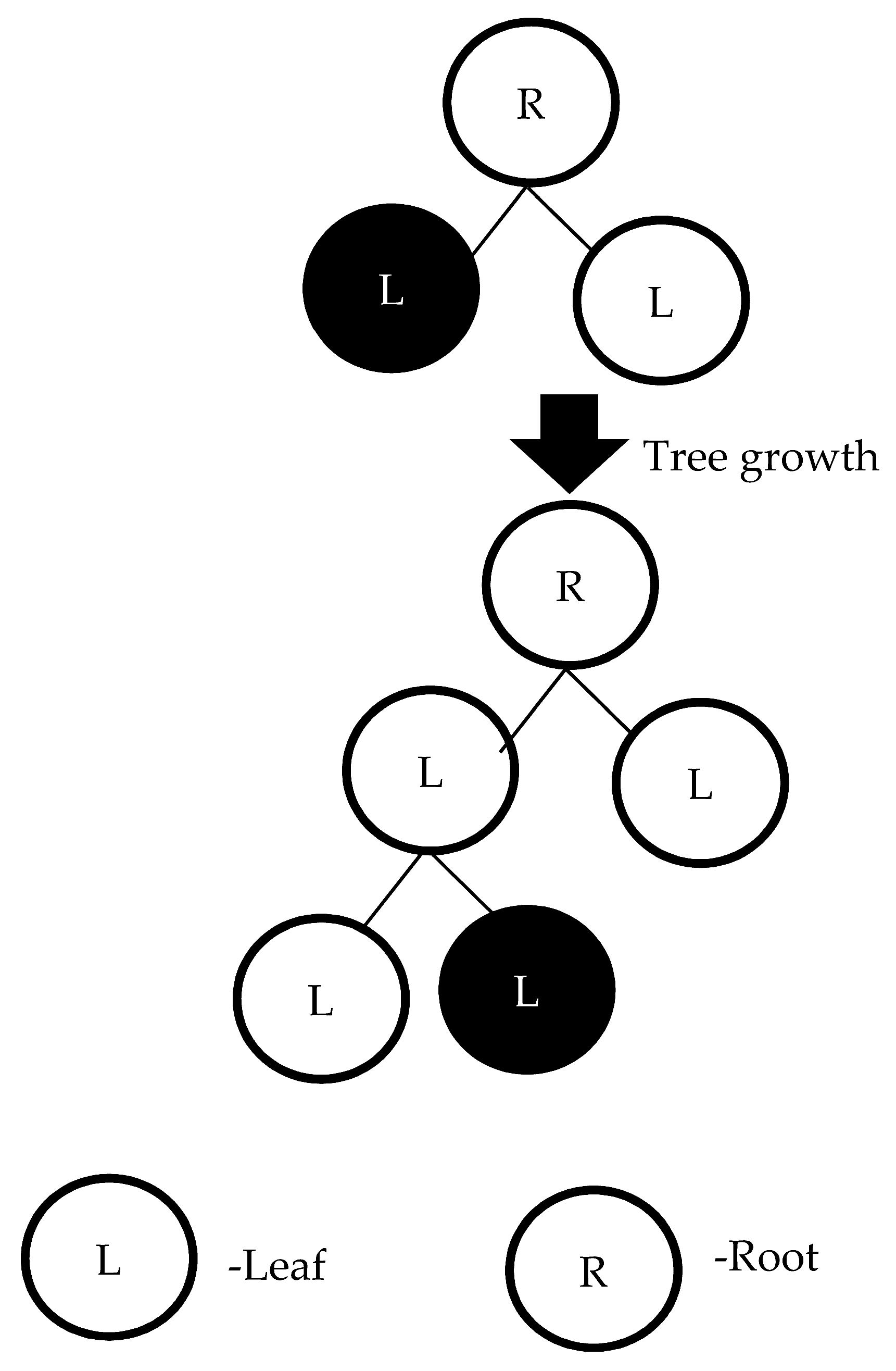
3.2.1. Random Forest
3.2.2. Decision Jungle
3.2.3. eXtreme Gradient Boosting (XGBoost)
3.2.4. LightGBM
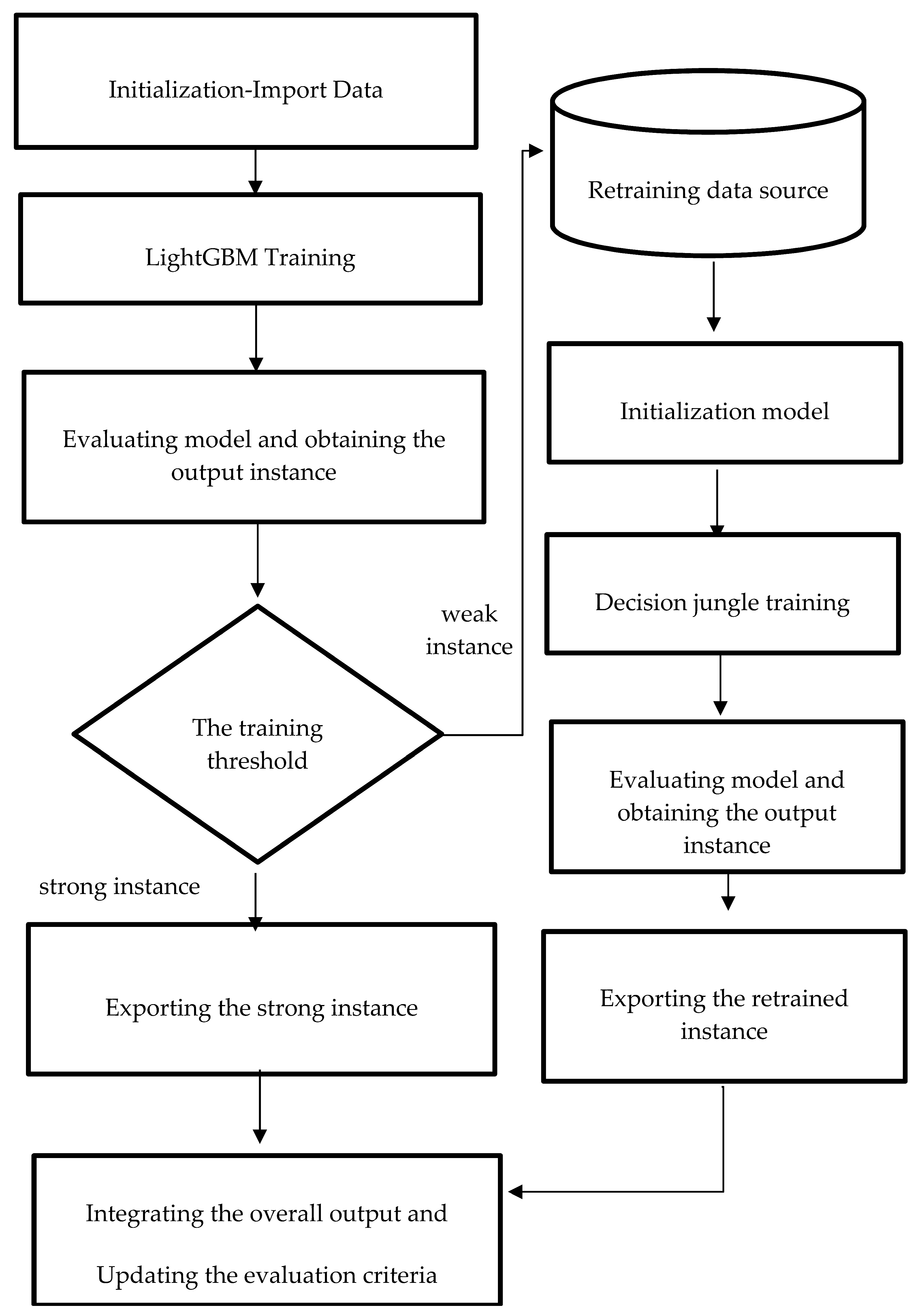
3.2.5. Proposed Method: Reinforcement Training for LightGBM
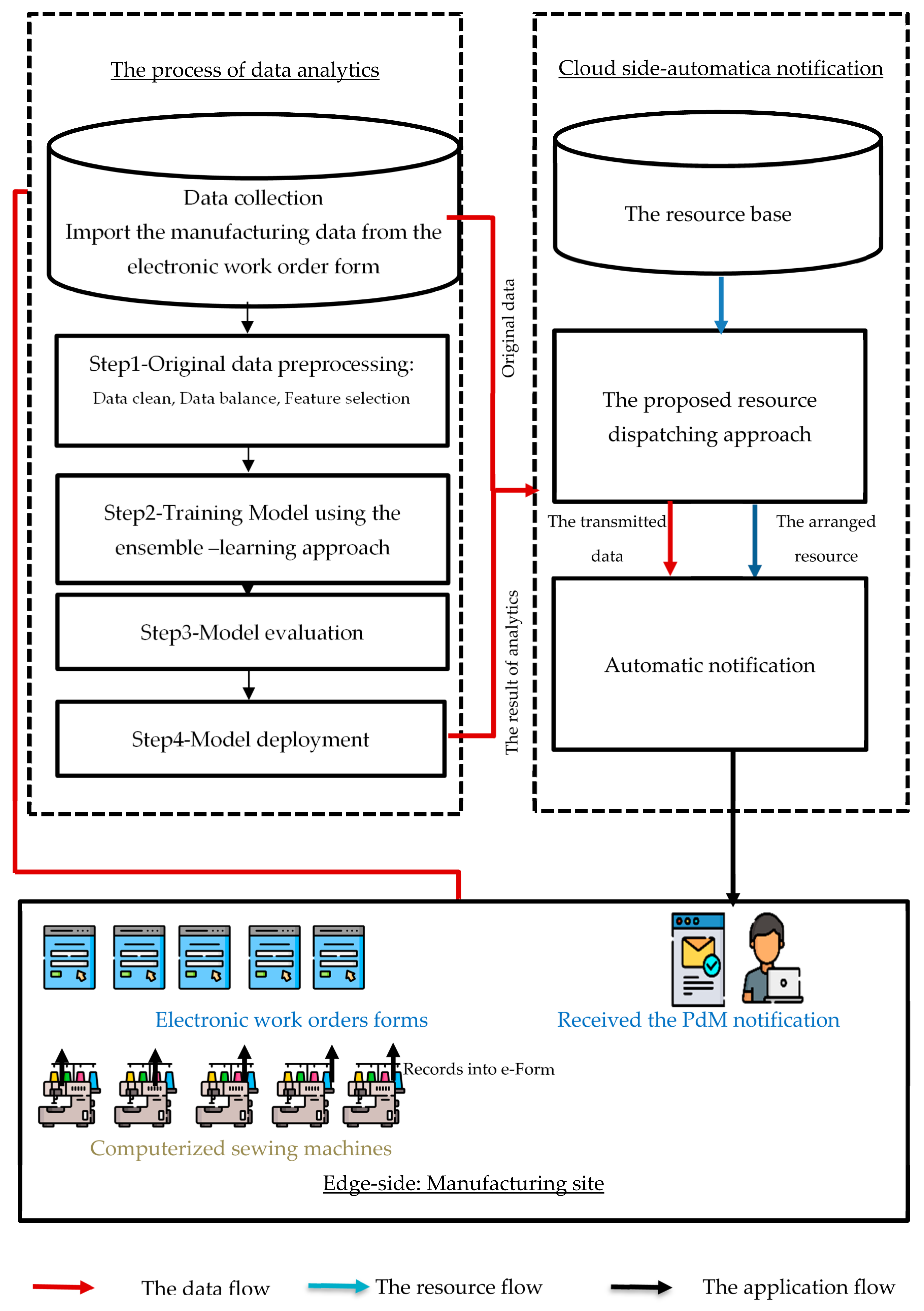
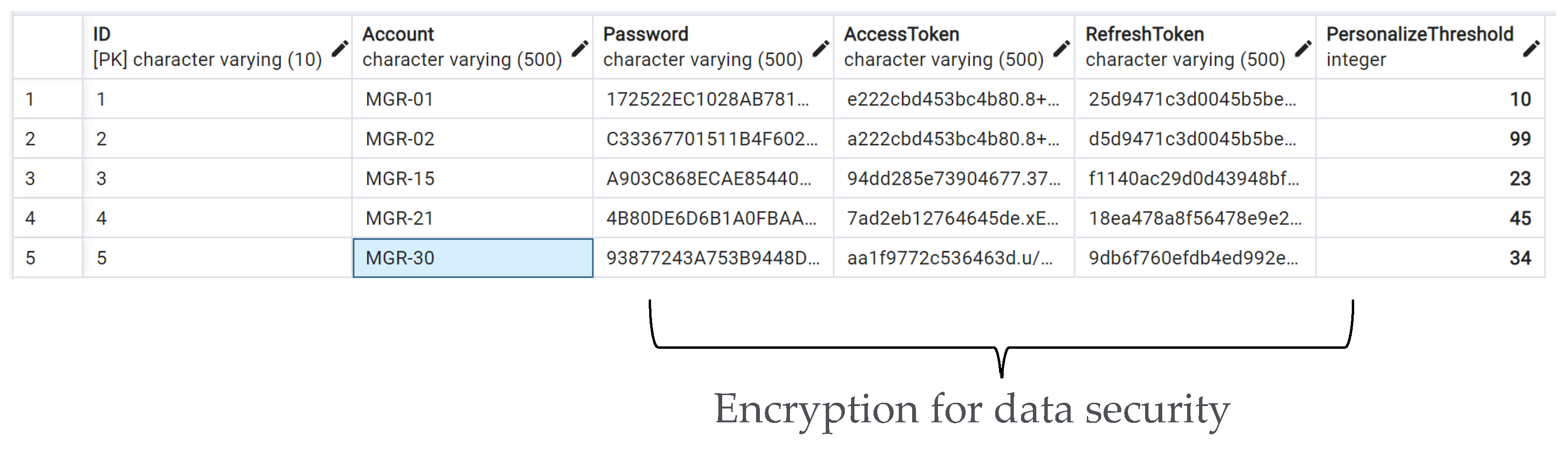
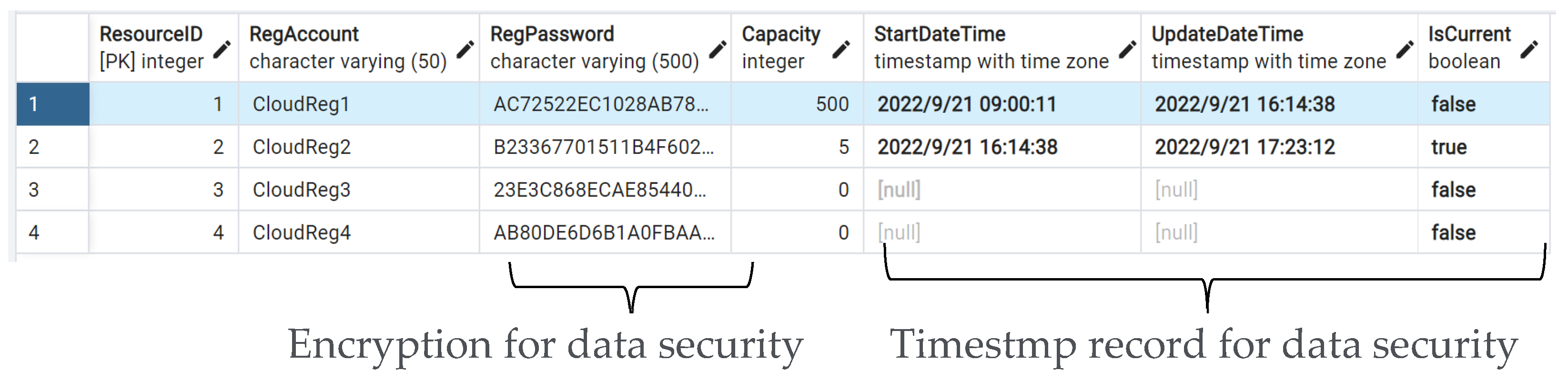
3.3. Data Communication Using the Proposed Resource Dispatching Approach
4. Experiment
4.1. Dataset and Computation Enviornment Description
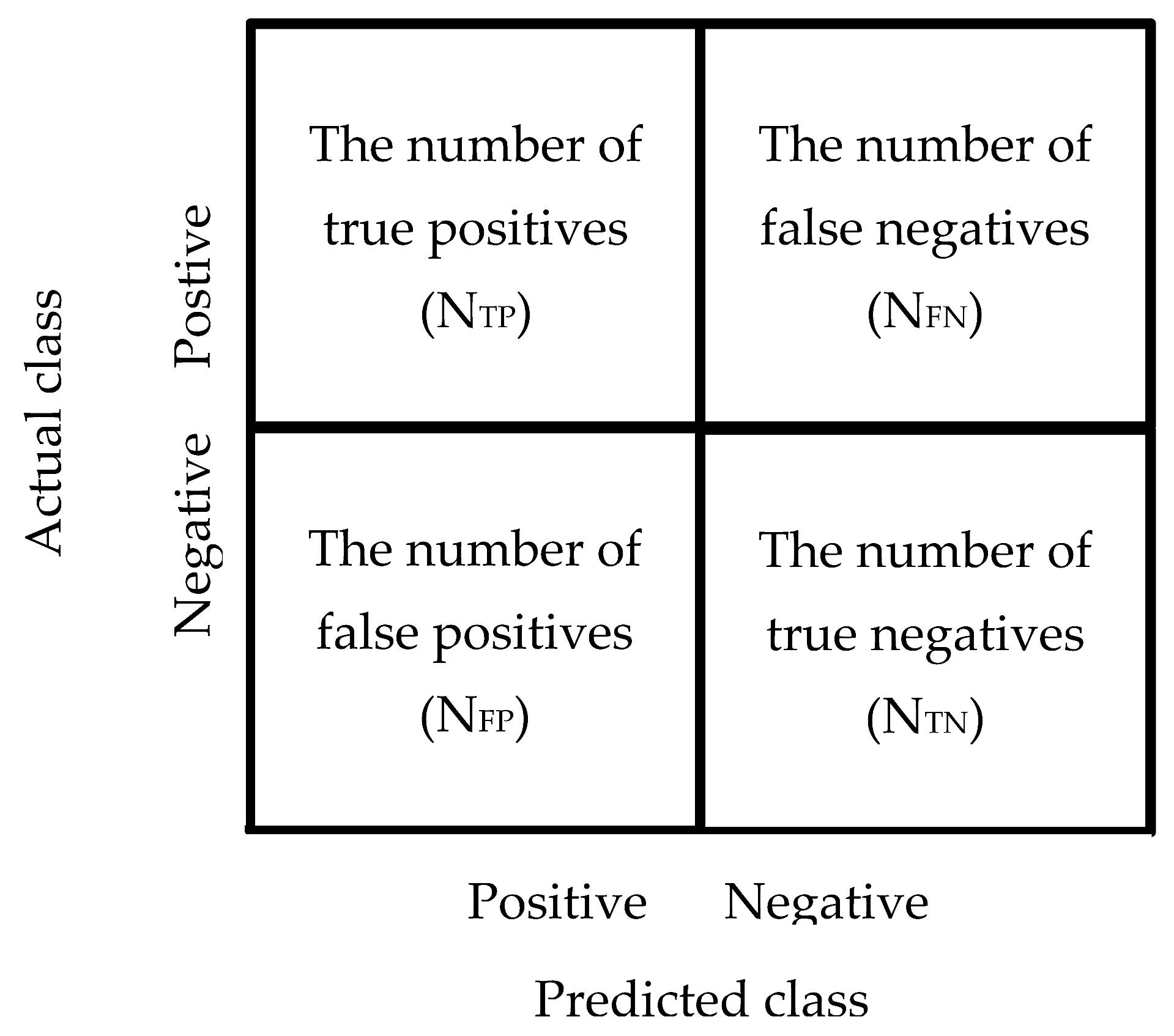
4.2. Evaluation Criteria
4.2.1. Accuracy
4.2.2. Precision Rate (Positive Predictive Value, PPV)
4.2.3. Recall Rate (True Positive Rate, TPP)
4.2.4. F1-Score
4.2.5. Matthews Correlation Coefficient
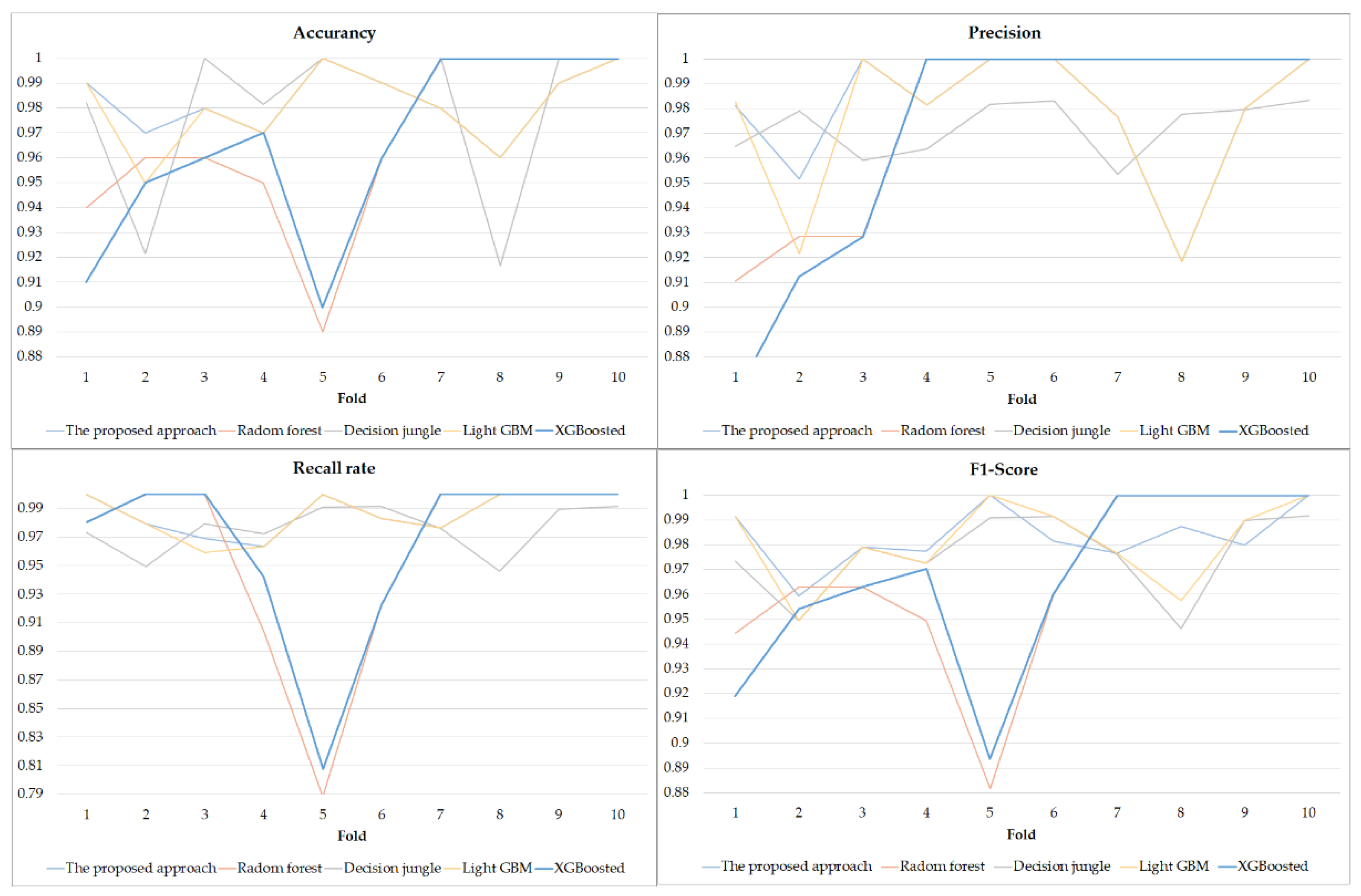
5. Results
5.1. The Aspect of Data Analytics-the Result of the ELAs in PdM
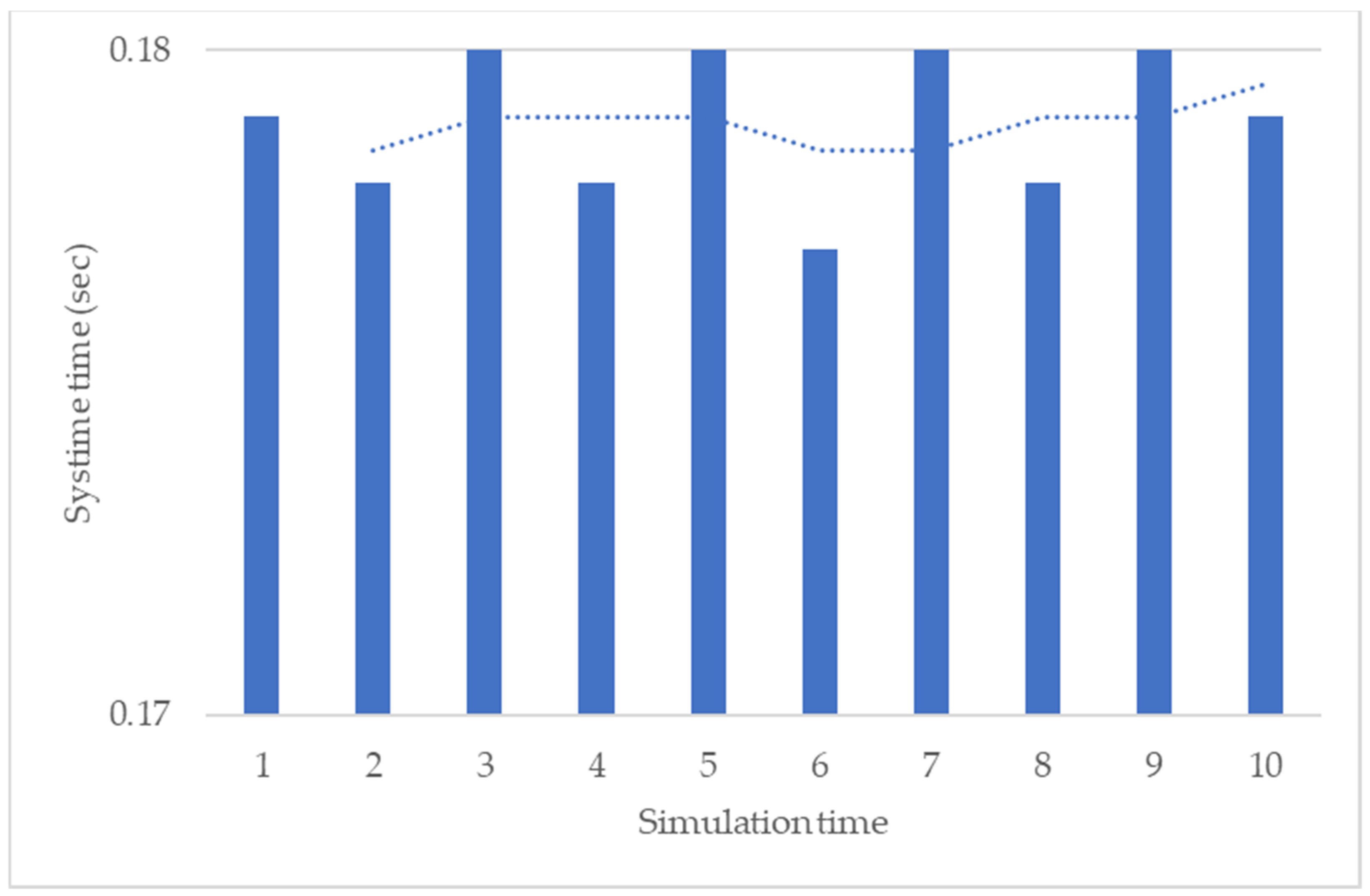
5.2. Aspects of System Implementation—Notification for PdM
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Åkerman, M.; Lundgren, C.; Bärring, M.; Folkesson, M.; Berggren, V.; Stahre, J.; Engström, U.; Friis, M. Challenges Building a Data Value Chain to Enable Data-Driven Decisions: A Predictive Maintenance Case in 5G-Enabled Manufacturing. Procedia Manuf. 2018, 17, 411–418. [Google Scholar] [CrossRef]
- Aivaliotis, P.; Georgoulias, K.; Chryssolouris, G. The use of Digital Twin for predictive maintenance in manufacturing. Int. J. Comput. Integr. Manuf. 2019, 32, 1067–1080. [Google Scholar] [CrossRef]
- He, Y.; Gu, C.; Chen, Z.; Han, X. Integrated predictive maintenance strategy for manufacturing systems by combining quality control and mission reliability analysis. Int. J. Prod. Res. 2017, 55, 5841–5862. [Google Scholar] [CrossRef]
- Han, X.; Wang, Z.; Xie, M.; He, Y.; Li, Y.; Wang, W. Remaining useful life prediction and predictive maintenance strategies for multi-state manufacturing systems considering functional dependence. Reliab. Eng. Syst. Saf. 2021, 210, 107560. [Google Scholar] [CrossRef]
- He, Y.; Han, X.; Gu, C.; Chen, Z. Cost-oriented predictive maintenance based on mission reliability state for cyber manufacturing systems. Adv. Mech. Eng. 2018, 10, 1687814017751467. [Google Scholar] [CrossRef]
- Gutschi, C.; Furian, N.; Suschnigg, J.; Neubacher, D.; Voessner, S. Log-based predictive maintenance in discrete parts manufacturing. Procedia CIRP 2019, 79, 528–533. [Google Scholar] [CrossRef]
- Schirru, A.; Pampuri, S.; De Nicolao, G. Particle filtering of hidden Gamma processes for robust Predictive Maintenance in semiconductor manufacturing. In Proceedings of the 2010 IEEE International Conference on Automation Science and Engineering, Toronto, ON, Canada, 21–24 August 2010; pp. 51–56. [Google Scholar] [CrossRef]
- Annamalai, S.; Udendhran, R.; Vimal, S. Cloud-based predictive maintenance and machine monitoring for intelligent manufacturing for automobile industry. In Novel Practices and Trends in Grid and Cloud Computing; IGI Global: Hershey, PA, USA, 2019; pp. 74–89. [Google Scholar]
- March, S.T.; Scudder, G.D. Predictive maintenance: Strategic use of IT in manufacturing organizations. Inf. Syst. Front. 2019, 21, 327–341. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, L.; Duan, L.; Gao, R.X. A new paradigm of cloud-based predictive maintenance for intelligent manufacturing. J. Intell. Manuf. 2017, 28, 1125–1137. [Google Scholar] [CrossRef]
- Yu, W.; Dillon, T.S.; Mostafa, F.; Rahayu, W.; Liu, Y. A Global Manufacturing Big Data Ecosystem for Fault Detection in Predictive Maintenance. IEEE Trans. Ind. Inform. 2019, 16, 183–192. [Google Scholar] [CrossRef]
- Cinar, Z.M.; Abdussalam Nuhu, A.; Zeeshan, Q.; Korhan, O.; Asmael, M.; Safaei, B. Machine Learning in Predictive Maintenance towards Sustainable Smart Manufacturing in Industry 4.0. Sustainability 2020, 12, 8211. [Google Scholar] [CrossRef]
- Falamarzi, A.; Moridpour, S.; Nazem, M.; Cheraghi, S. Prediction of tram track gauge deviation using artificial neural network and support vector regression. Aust. J. Civ. Eng. 2019, 17, 63–71. [Google Scholar] [CrossRef]
- Xiang, S.; Huang, D.; Li, X. A generalized predictive framework for data driven prognostics and diagnostics using machine logs. In Proceedings of the TENCON 2018—2018 IEEE Region 10 Conference, Jeju, Republic of Korea, 28–31 October 2018; pp. 0695–0700. [Google Scholar] [CrossRef]
- Uhlmann, E.; Pontes, R.P.; Geisert, C.; Hohwieler, E. Cluster identification of sensor data for predictive maintenance in a Selective Laser Melting machine tool. Procedia Manuf. 2018, 24, 60–65. [Google Scholar] [CrossRef]
- Bekar, E.T.; Nyqvist, P.; Skoogh, A. An intelligent approach for data pre-processing and analysis in predictive maintenance with an industrial case study. Adv. Mech. Eng. 2020, 12, 1687814020919207. [Google Scholar] [CrossRef]
- Gohel, H.A.; Upadhyay, H.; Lagos, L.; Cooper, K.; Sanzetenea, A. Predictive maintenance architecture development for nuclear infrastructure using machine learning. Nucl. Eng. Technol. 2020, 52, 1436–1442. [Google Scholar] [CrossRef]
- Calabrese, M.; Cimmino, M.; Fiume, F.; Manfrin, M.; Romeo, L.; Ceccacci, S.; Paolanti, M.; Toscano, G.; Ciandrini, G.; Carrotta, A.; et al. SOPHIA: An Event-Based IoT and Machine Learning Architecture for Predictive Maintenance in Industry 4.0. Information 2020, 11, 202. [Google Scholar] [CrossRef]
- Ayvaz, S.; Alpay, K. Predictive maintenance system for production lines in manufacturing: A machine learning approach using IoT data in real-time. Expert Syst. Appl. 2021, 173, 114598. [Google Scholar] [CrossRef]
- Winkler, D.; Haltmeier, M.; Kleidorfer, M.; Rauch, W.; Tscheikner-Gratl, F. Pipe failure modelling for water distribution networks using boosted decision trees. Struct. Infrastruct. Eng. 2018, 14, 1402–1411. [Google Scholar] [CrossRef]
- Shehadeh, A.; Alshboul, O.; Al Mamlook, R.E.; Hamedat, O. Machine learning models for predicting the residual value of heavy construction equipment: An evaluation of modified decision tree, LightGBM, and XGBoost regression. Autom. Constr. 2021, 129, 103827. [Google Scholar] [CrossRef]
- Li, Y.; Meng, X.; Zhang, Z.; Song, G. A Remaining Useful Life Prediction Method Considering the Dimension Optimization and the Iterative Speed. IEEE Access 2019, 7, 180383–180394. [Google Scholar] [CrossRef]
- Wu, D.; Jennings, C.; Terpenny, J.; Kumara, S. Cloud-based machine learning for predictive analytics: Tool wear prediction in milling. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 2062–2069. [Google Scholar]
- Magal, R.K.; Jacob, S.G. Improved Random Forest Algorithm for Software Defect Prediction through Data Mining Techniques. Int. J. Comput. Appl. 2015, 117, 18–22. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Wen, L.; Hughes, M. Coastal Wetland Mapping Using Ensemble Learning Algorithms: A Comparative Study of Bagging, Boosting and Stacking Techniques. Remote Sens. 2020, 12, 1683. [Google Scholar] [CrossRef]
- Schapire, R.E. The Boosting Approach to Machine Learning: An Overview. In Nonlinear Estimation and Classification; Springer: New York, NY, USA, 2003; Volume 171, pp. 149–171. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Qi, Y. Random forest for bioinformatics. In Ensemble Machine Learning; Springer: Boston, MA, USA, 2012; pp. 307–323. [Google Scholar] [CrossRef]
- Shotton, J.; Sharp, T.; Kohli, P.; Nowozin, S.; Winn, J.; Criminisi, A. Decision jungles: Compact and rich models for classification. In Advances in Neural Information Processing Systems 26; Curran Associates, Inc.: Red Hook, NY, USA, 2013. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K. Xgboost: Extreme gradient boosting. R Package Version 0.4-2 2015, 1, 1–4. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems 30; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Al Daoud, E. Comparison between XGBoost, LightGBM and CatBoost using a home credit dataset. Int. J. Comput. Inf. Eng. 2019, 13, 6–10. [Google Scholar]
- Li, Z.; Wu, D.; Hu, C.; Terpenny, J. An ensemble learning-based prognostic approach with degradation-dependent weights for remaining useful life prediction. Reliab. Eng. Syst. Saf. 2019, 184, 110–122. [Google Scholar] [CrossRef]
- Chan, J.C.-W.; Huang, C.; DeFries, R. Enhanced algorithm performance for land cover classification from remotely sensed data using bagging and boosting. IEEE Trans. Geosci. Remote Sens. 2001, 39, 693–695. [Google Scholar] [CrossRef]
- Rehman, M.H.U.; Ahmed, E.; Yaqoob, I.; Hashem, I.A.T.; Imran, M.; Ahmad, S. Big Data Analytics in Industrial IoT Using a Concentric Computing Model. IEEE Commun. Mag. 2018, 56, 37–43. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Main Part | Specification |
|---|---|
| Central Processing Unit | Intel(R) Core(TM) i7-7660U CPU 2.50 GHz |
| Random Access Memory | 8.00 GB |
| Hard disk | 237 G |
| Power supply unit | 127-watt power supply |
| The Attribute | Description | Type | Total Instances |
|---|---|---|---|
| FormId | The id of the work order form | String | 500 non-defective: 96% defective: 4% |
| P_Width | The width of the finished product | Numeric | |
| P_Length | The length of the finished product | Numeric | |
| P_Height | The height of the finished product | Numeric | |
| P_EmpNo | employee number of operators | String | |
| P_Quality | The quality of the finished product | Binary (1 = non-defective, 0 = defective) |
| Evaluation Criteria (Variance/Standard Deviation) | The Proposed Approach | Random Forest | Decision Jungle | Light GBM | XGBoost |
|---|---|---|---|---|---|
| Accuracy | 0.000/0.013 | 0.001/0.036 | 0.001/0.033 | 0.000/0.017 | 0.001/0.037 |
| Precision | 0.001/0.026 | 0.001/0.038 | 0.000/0.011 | 0.001/0.031 | 0.002/0.050 |
| Recall rate | 0.000/0.014 | 0.005/0.070 | 0.000/0.017 | 0.000/0.016 | 0.004/0.062 |
| F1-Score | 0.000/0.012 | 0.001/0.037 | 0.000/0.017 | 0.000/0.017 | 0.001/0.037 |
| Evaluation Criteria (Means of 10-Folds) | The Proposed Approach | Random Forest | Decision Jungle | Light GBM | XGBoost |
|---|---|---|---|---|---|
| Accuracy | 0.983 | 0.966 | 0.980 | 0.981 | 0.965 |
| Precision | 0.979 | 0.977 | 0.980 | 0.976 | 0.970 |
| Recall rate | 0.987 | 0.960 | 0.973 | 0.986 | 0.965 |
| F1-Score | 0.983 | 0.966 | 0.976 | 0.981 | 0.965 |
| MCC | 0.966 | 0.940 | 0.953 | 0.960 | 0.936 |
| Computing time | 6.2 s | 6.9 s | 5.9 s | 4.2 s | 6.67 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hung, Y.-H. Developing an Improved Ensemble Learning Approach for Predictive Maintenance in the Textile Manufacturing Process. Sensors 2022, 22, 9065. https://doi.org/10.3390/s22239065
Hung Y-H. Developing an Improved Ensemble Learning Approach for Predictive Maintenance in the Textile Manufacturing Process. Sensors. 2022; 22(23):9065. https://doi.org/10.3390/s22239065
Chicago/Turabian StyleHung, Yu-Hsin. 2022. "Developing an Improved Ensemble Learning Approach for Predictive Maintenance in the Textile Manufacturing Process" Sensors 22, no. 23: 9065. https://doi.org/10.3390/s22239065
APA StyleHung, Y.-H. (2022). Developing an Improved Ensemble Learning Approach for Predictive Maintenance in the Textile Manufacturing Process. Sensors, 22(23), 9065. https://doi.org/10.3390/s22239065