1. Introduction
Industry 4.0 is a new phase of the industrial revolution that heavily relies on internet-connected hardware, automation, ML, and real-time data to enable the production process with negligible human intervention. The objective of Smart Manufacturing (SM) is to distinguish openings for mechanizing activities and use data analytics to further advance manufacturing performance. SM is a precise utilization of the Industrial Internet of Things (IIoT) [
1]. IIoT comprises inserting sensors in the manufacturing system to collect statistics on their functional status and performance. The amalgamation of IIoT technology in manufacturing brings adaptability and greater efficacy of production in the industrial environment [
2]. However, the introduction of IIoT in the industrial manufacturing process brings new challenges such as: security, physical damage, seamless integration, and skill gap [
3,
4,
5]. SM industries are exposed to a variety of cyber attacks such as DoS, eavesdropping, ransomware, side channel, port scan, passive replay, malicious code injection, buffer overflow and many more [
6].
When comparing the effects of these attacks on traditional IT systems and manufacturing systems, the results are catastrophic for manufacturing, because in manufacturing systems damages may include physical damage to the production system, physical environment and people. In Industry 4.0, as it is hard to identify the reason for the problem, possible sets of attacks and their effects are larger in smart manufacturing systems than in traditional IT systems [
7].
Thus, this drives the need for new anomaly detection approaches using AI. As AI for cybersecurity tools has improved the robustness, resilience and response to cybersecurity attacks [
8,
9], by watching a network, i.e., monitoring traffic and events and identifying cybersecurity threats such as malware [
7], software vulnerabilities [
10], fraudulent payments and network intrusion detection [
11]. It does this by modeling normal (and in some cases anomalous) behaviors and classifying events using either supervised or unsupervised learning techniques and issuing alerts when anomalous behavior is observed.
Vulnerabilities in Smart Manufacturing
To comprehend the potential attack vectors, one must first comprehend the system’s probable weaknesses. However, a lot of studies have been conducted to discover such vulnerabilities in smart manufacturing, but there will always be a new set of vulnerabilities that demand the development of advanced detection systems. Manufacturing systems are designed without considering security. It may be pre-assumed that these systems are isolated, so will not be subjected to security attacks. Hardware and software security is not considered while building these systems. As with the lack of literature and understanding related to vulnerabilities in SM, it can only be understood based on the behavior of other systems when they are attacked.
This shows that there is a high need, and also increased interest, observed in the literature to address such issues in smart manufacturing. The state of art approaches show their diversion towards using AI-based threat detection approaches in the past few years. Intrusion detection is the most commonly used method in IIoT to detect the presence of an attack so as to minimize its effects [
12]. However, huge data produced by IIoT devices have become a tough task to be handled with such anomaly detection techniques. Some other examples are [
13] used Q-learning to handle threats in software-defined IIoT. In [
8], the author proposed a deep learning-based solution to detect attacks in smart grid CPS. Further related work on cyber threat detection in smart manufacturing is discussed under
Section 2.
It is found that AI-based threat detection techniques used in SM, unfortunately, rely on the fact that there is always a large number of examples of various cyber threats available to build a high-quality intrusion detection model. However, in reality, one SM industry will have only a limited number of cyber threat examples to build the model which is quite challenging. Moreover, the owners of SM industries are not willing to share their information and data with each other to build a high-quality comprehensive model due to privacy concerns. So, in such a scenario, it is quite difficult and an intractable task to build a high-quality model to detect cyber threats in SM industries.
To address such issues, a novel distributed learning-based FL is utilized. FL enables collaborative decentralized training of an intrusion detection model [
14,
15,
16]. In FL, the model gradients are optimized collectively by a substantial number of edge devices without disclosing their personal data. Therefore, in this work, we propose an FL-enabled deep intrusion detection framework to detect cyber threats in SM industries. In the proposed FL-enabled framework, the Deep Intrusion Detection model is used to detect cyber threats using a hybrid CNN+LSTM+MLP model. Moreover, to ensure the privacy of model gradients and to handle FL-based attacks Paillier encryption is used. The main contributions of this paper are:
Developed a federated learning-enabled framework to construct a comprehensive intrusion detection model which can collaboratively train the model on multiple data from different industries without disclosing it to each other. As data does not leave the premises, thus data privacy is also achieved.
A proposed Deep Intrusion Detection model for cyber threat detection in SM using CNN, LSTM, and MLP. The proposed model is proven to be efficient in detecting cyber threats and incorporated with the federated learning framework.
Proposed a Paillier-based encryption to provide secure communication throughout the training process, in order to safeguard the privacy of model gradients and to handle the threats against the federated learning framework.
Tests carried out on an IIoT-based dataset using the proposed FLDID framework to prove its effectiveness in the industrial environment as well.
The rest of the paper is organized as: the present approaches used for cyber threat detection are discussed in
Section 2. The system model, assumptions made and threat model considered in this paper are presented in
Section 3.
Section 4 describes the material and methods used and
Section 5 shows the evaluation of the proposed framework and discusses the observations and results. Finally,
Section 6 presents the conclusion and discusses the future work.
2. Related Work
Recent research has shown a tremendous increase in interest in addressing the issues of cybersecurity in smart manufacturing industries. Therefore, many researchers are focusing on developing AI-based Network Intrusion Detection Systems for smart manufacturing industries. These Intrusion Detection Systems monitor and detect intrusions across the industrial network. The IDS are broadly classified into signature-based IDS and anomaly-based IDS. Anomaly-based IDS have gained major attention for intrusion detection, due to their capability for identifying novel attacks from complex and heterogeneous data generated from the IIoT devices in SM industries [
17].
In the literature, there exist a wide range of anomaly detection methods proposed for cybersecurity in traditional networks [
18,
19,
20,
21]. However, these existing anomaly detection methods are not compatible with the new Industry 4.0 environment and do not achieve good accuracy. Therefore, to improve the accuracy of such systems while handling complex and heterogeneous data in SM industries, ML techniques have been employed [
22]. For example, [
23] investigates the problem of intrusion detection and offers a solution based on decision trees. In the paper [
24], the author proposed a Gaussian Naive Bayes with LSTM model to identify two different types of abnormalities. One is hardware anomalies, particularly those produced by various types of sensors, which may have issues including interference from the environment, device malfunction, and misreadings. Another is software anomalies, which can result in aberrant or altered data gathering due to programme exceptions, transmission faults, and malicious attacks. For the purpose of detecting DDoS in IoT networks, the author [
25] used a number of ML techniques and attains high detection accuracy by utilizing network behaviors for the feature selection process. Another study developed a framework for anomaly detection [
26] that utilized both a temporal-spatial model and a logging-tracing model to identify anomalies in network traffic.
Deep learning methods have recently produced impressive results and emerged as one of the successful ways for intrusion detection systems. A variety of deep learning approaches to security monitoring were reviewed by the author [
27]. They contrasted common deep learning models with a few traditional ML techniques. The findings in the review showed how useful deep learning techniques are for protecting against cybercrime. To specifically detect intrusions, the author [
28] incorporated deep neural networks and used the KDD99 dataset to prove the efficacy of the proposed approach. A dense random neural network was constructed in another study [
29] to identify cyberattacks. In contrast, in [
30], the author discovered that a deep neural network with three hidden layers produced classification results that were superior to those achieved with more classes when fewer invasive classes were used.
All of these centralized learning techniques necessitate central storage (server) of all data acquired on local devices. This necessity not only increases concerns about threats pertaining to privacy and data leaks, although it also heavily requires the server’s storing and computational capacities when the data is large. However, the distributed approach allows multiple systems to train model replicas with different data groups in parallel to solve the above problem. However, it still requires access to the entire training data set in order to partition it into uniformly distributed shards, thereby causing security and privacy issues.
To overcome such a problem FL has appeared as an intriguing method. FL intends to develop a global model that can be trained on data spread across several devices while maintaining data privacy. Some of the research using FL are: In [
31], the authors proposed a DNN-based client-server FL architecture. A large part of the suggested models achieved pretty good accuracy (99.00%) came from the dataset utilized, N-BaIoT, which is regarded as being highly simple and straightforward. However, adversarial attacks such as data and model poisoning dramatically reduced performance, demonstrating the requirement for more effective defenses. An FL-enabled GRU model is proposed in [
32] which employed a GRU to find the Mirai attack in an IoT network. However, the proposed model successfully detects the Mirai attack but lacks resilience and robustness while aggregating the gradients at the server. In the same year, an MT-DNN-FL has been proposed in [
33] to carry out the work for identifying anomalies in the network. An FDAGMM was given in [
34] to address the classic DAGMM’s performance issue for network anomaly detection due to a lack of data.
The author in [
35] used the X-IIOTID dataset to prove the effectiveness of their proposed approach for detecting targeted ransomware attacks for IIoT. They used asynchronous peer-to-peer FL and DL algorithms to detect ransomware attacks. The result shows that the proposed approach achieves a detection accuracy of 98.33%. Similarly in [
36] author developed safe data sharing architecture for IIoT devices using FL to handle the data breach and achieved an accuracy of 99.79% accuracy over the X-IIoTID dataset.
Despite the efficient anomaly identification achieved by earlier investigations, the following issues still exist. The first open issue is how to provide privacy-preserving intrusion detection. Second, given that clients and servers may be partially honest and how anomaly detection accuracy is improved. Third, the existing techniques are tested on an intrusion dataset created on a traditional network. However, it completely differs from the SM environment as it lacks interoperability and heterogeneity. Thus, in this paper, the FL-enabled deep intrusion detection framework is proposed and tested on the IIoT-based “X-IIoTID” intrusion dataset [
37] to solve the above problems in smart manufacturing systems.
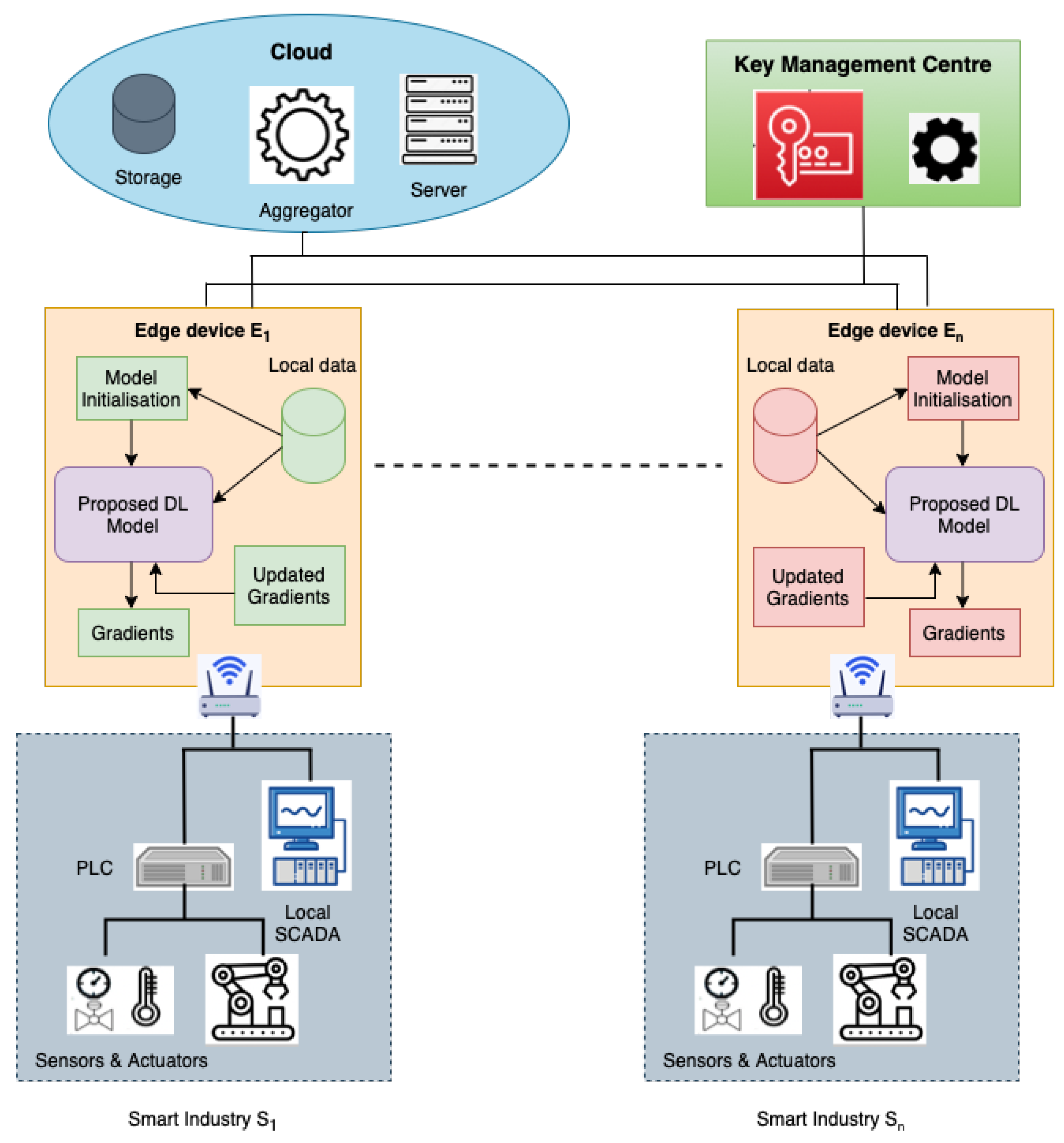
4. Materials and Methods
This section presents the elaboration of the proposed FLDID framework by first outlining the overall workflow of the framework, followed by introducing the Deep Intrusion Detection model designed for intrusion detection, and then discussing the Paillier encryption scheme used for securing the communication between edge devices and the server.
Algorithm 1 presents the complete procedure of the proposed FLDID framework. The performance of deep learning models can be enhanced by collaboratively training the model on multiple data resources which consist of a variety of attack examples. Thus, the proposed FLDID framework is designed to allow collaborative learning between different SM industries and to build a robust and comprehensive intrusion detection model using federated learning with secure communication. The major phases of the proposed FLDID framework are described below:
| Algorithm 1 Secured FL procedure |
| Input: Set of Edge devices and their associated local data , No. of communication rounds R |
| Output: Global DID model |
| 1: Cloud server initialize model parameter and |
| 2: Each informs the data size to server; |
| 3: Server computes contribution ratio ; |
| 4: For each KMC generates key pair using and establishes secure channel between each edge device and server; |
| 5: For r = 1 to R; |
| (i) computes round model gradients using Algorithm 2; |
| (ii) Encrypt model gradients as ; |
| (iii) Upload to cloud server; |
| End |
| 6: Cloud server aggregates as ; |
| 7: Server distributes C to all edge devices |
| 8: To obtain new global model performs decryption as |
| 9: updates model gradients using ; |
| 10: ; |
Step 1 (Model initialization): In this step, the server selects and sends the initial parameters for the DID model and other necessary parameters required for model training such as: Batch size B, Learning rate , loss function , momentum , and decay to the edge devices. Moreover, each edge device associated with SM industries informs the server about the size of the data it has from the industry, where , this helps the cloud server to calculate the contribution ratio for each edge device. A positive integer R defines the number of communication rounds between the edge devices and the cloud server.
Step 2 (Key generation): In addition to the above parameters, next the public key and the private key are generated using by the KMC which is used in Paillier encryption to establish a secure path between the server and edge device.
Step 3 (Local model training): Based on the initial model parameters
,
received from the cloud server, each edge device performs the model training on their local data
. The model used for training at the edge devices is described in
Section 4.1. In the proposed DID model, a hybrid CNN+LSTM+MLP model is used to train the model for detecting intrusions in smart manufacturing. The elaborated training process is presented in Algorithm 2.
Step 4 (Gradient encryption): After training the model on the local data each edge device encrypts the model gradients using , where are the model gradients after training at edge device in the round. Then, the encrypted gradients of the local models by each edge device are sent to the cloud for aggregation to generate the comprehensive global model.
Step 5 (Global model construction): Cloud server aggregates the encrypted model gradients received from each edge device participating in the process of collaborative learning. The gradients are aggregated using , where is contribution ratio of each edge device. Then the aggregated encrypted gradients are sent back to edge devices as a cipher text C.
Step 6 (Local model updation): At each edge device after receiving the global model (aggregated gradients) as a cipher text, each edge device performs decryption using the private key. After receiving the decrypted gradients , local DID models are then updated and retrained with their local data.
| Algorithm 2 DL model training |
| Input:
|
| Output:
|
| 1: Divide , into equal size B batches with feature vector x; |
| 2: Set with initial values; |
| 3: For each Batch; |
| Forward x to ; |
| Forward to ; |
| Flatten ; |
| Forward to ; |
| Forward to ; |
| Forward to ; |
| Dropout ; |
| Forward to Output(Sigmoid); |
| 4: Compute loss function using: |
| ; |
| 5: Update ; |
| 6: Repeat until converges; |
4.1. Proposed Deep Intrusion Detection Model
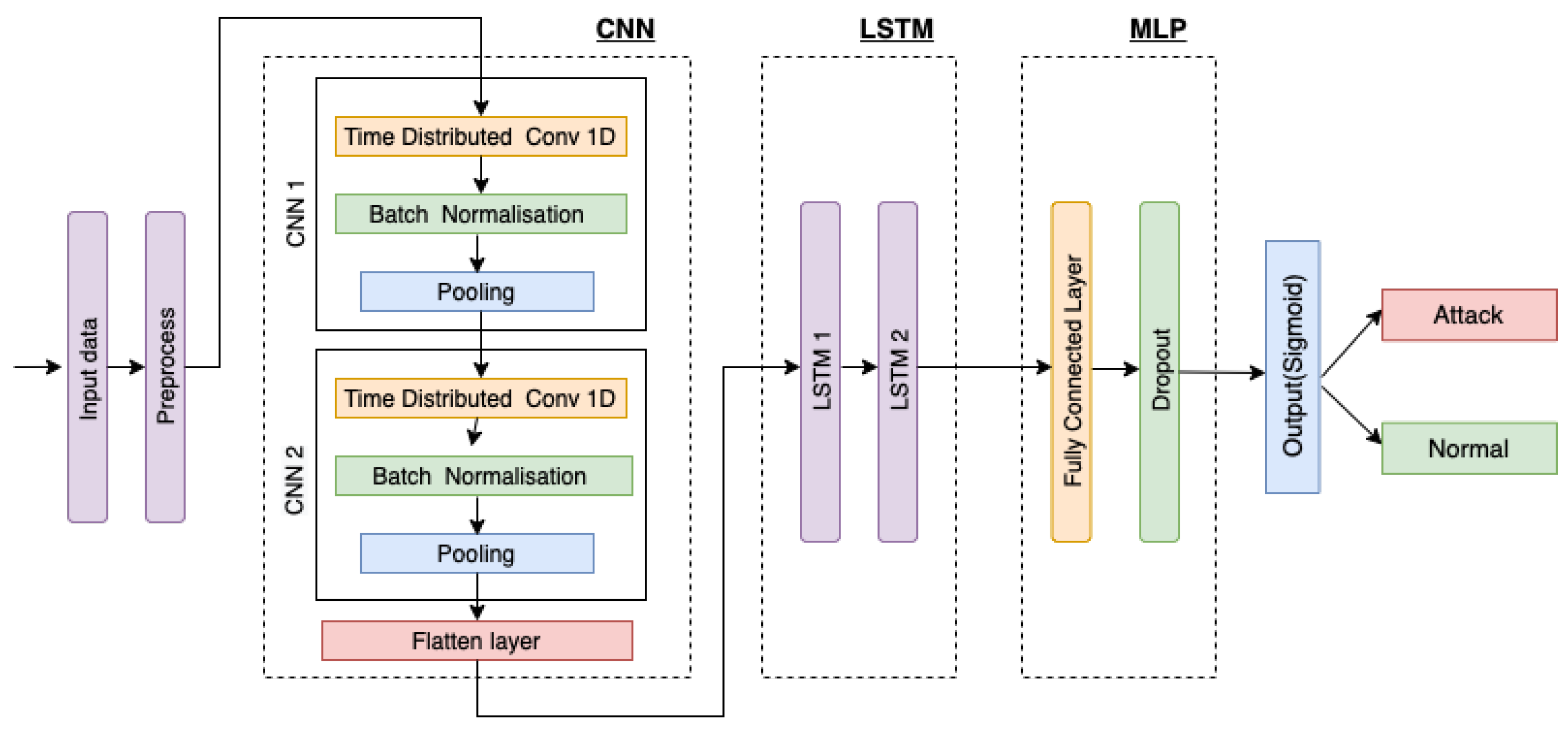
This section presents the hybrid deep learning-based intrusion detection model. The designed DID model consists of the pre-processing unit, and a CNN and LSTM unit followed by an MLP unit as shown in
Figure 2.
The approach followed provides a diverse combination of convolutional and recurrent neural networks. As network traffic events follow time series patterns, it is possible to categorize the present network connection record using the traffic connection records from the past. We feed freshly produced features from CNN’s unit to LSTM and sequentially to MLP in order to capture the time series patterns over time-steps and obtain the desired result.
The proposed DID model was selected following rigorous experimentation of several DL techniques, including CNN, MLP, and LSTM with different numbers of layers, as well as their topologies, network parameters, network architecture and hybrid combinations. CNN and its variations in our experimental setup and dataset outperforms traditional ML classifiers on comparing with them. The capacity of CNN to extract high-level feature representations, which represent the abstract form of low-level feature sets of network traffic links, is the fundamental driver for this success. The combination of two-layer CNN, two LSTM layers, and a densely integrated MLP layer produced the best results on the dataset considered in this work. Therefore, we decided to incorporate this model as an intrusion detection model into our proposed federated learning architecture to detect cyber threats in smart manufacturing. Each unit of the proposed DID model is described below:
4.1.1. Pre-Processing Unit
First, the data is pre-processed and given to the input layer. Data pre-processing is an important step as all the ML algorithms deal with numerical data. So the features that are of string types need to be label encoded. The numerical data that is obtained after the label encoding does not correspond to the same range. So, to normalize all the feature values, the min-max normalization technique is used [
38]. This makes all the feature values come under a similar range. The minimum value of the feature transforms into 0, the maximum value transforms into 1, and every other value gets transformed between 0 and 1. So, the final range of the values of the feature is in between [0, 1].
4.1.2. CNN Unit
CNN is employed in the proposed DID model to extract fine-grained characteristics. Two (1-D) CNN layers constitute this unit. Each layer constitutes convolution, batch normalization, and pooling layers. CNN’s local perception and weight sharing can enhance model learning by significantly reducing the number of parameters. These modules build layered structures that increasingly draw out more precise information by stacking convolutional layers and achieve sampling aggregation by employing pooling layers. Each convolution layer comprises convolution kernels. The layer of batch normalization enables the network’s layers to learn more independently. The output of the earlier layers is normalized using it. Batch normalization helps in high-yield learning and also prevents the over-fitting of the model. It serves as a bridge between the pooling layer and the convolution layer. As a result of this unit, a sequence of m features with size is achieved, where n specifies the length.
Following the convolution operation of the convolution layer and batch normalization layer, the features received possess high dimensionality. Thus, to reduce the feature dimension and training cost pooling layer is also employed. Given one-dimensional data from the time series events collected from SM industries as input vector
, where (
is the features available and
is the class label) being the input of the designed model, first given to the CNN unit. In this unit, a feature map
is constructed by the 1D convolution layer using convolution operation with filter
. From the available features
z, a new feature map
is obtained as:
where
denotes the bias, filter
is applied to each feature set
z to obtain the feature map as
further, this output is sent to the batch normalization and pooling layer. The complete process of the CNN unit is represented as
where
and
represent the convolutional blocks with batch normalization and pooling operation in the CNN and
are the hidden vectors. Further, the output of the second convolution block is flattened using the flatten layer and
is the final output of the CNN units.
is the
m feature sequence of length
n and can be represented as
.
4.1.3. LSTM Unit
The output of CNN is used as input to LSTM in the envisaged DID module. LSTM is the superior version of Recurrent Neural Network (RNN). Instead of using standard simple RNN units, LSTM uses memory blocks to handle the issue of disappearing and shattering gradients. LSTM manages long-term dependencies far more easily than conventional RNNs. This shows that LSTMs are capable of remembering and connecting knowledge that is far older than the present [
39]. A memory block in an LSTM is a relatively sophisticated processing unit made up of one or more memory cells. LSTM uses gates such as forge gates
, input gates
, and output gates
. Two multiplicative gates make up the input and output gates. The LSTM gate structures are defined as:
where
and
are the weight metrics and bias vectors for input
at time step
T. ∗ represents the element-wise multiplication,
represents the cell state.
and
are the hidden layer states at step
and at
T, respectively.
is the activation function used.
In this study, LSTM is designed to aid precise prediction in the time series data to find anomalies. LSTM processes
(output of CNN unit) in the following way:
4.1.4. MLP Unit
The MLP module is composed of a dense layer and an output layer separated by a dropout layer. In order to avoid model over-fitting, the output of the LSTM
in this module is provided as input to an MLP unit with dropout as follows:
where
and
are the two fully connected layers,
represents the dropout layer.
M and
are the output of dense layer 1 and the dropout layer, respectively. Additionally, because the output predicted class contains two values, either attack or normal, the output of the MLP dropout layer is passed to the output layer with the sigmoid function.
We utilized binary cross entropy as the loss function since the proposed DID model uses binary classification to identify attack and non-attack traces in the smart manufacturing industries, which is defined as follows:
where
B is the batch size,
is the corresponding target value and
is the corresponding predicted value.
Algorithm 2 shows the steps involved in training the local models at each edge device. Each edge device trains the local model on their local data . On each communication round, upon receiving cipher text C, each edge device decrypts it and obtains new gradients and updates accordingly. After updation, the DID model is retrained at each edge device on their local data until model convergence.
4.2. Encryption Method for Secure Communication
In order to ensure the privacy of data and model gradients, many encryption methods have been developed. Although, none of the methods are capable of performing computations on the encrypted data. Thus, to handle such issues and in order to mitigate malicious eavesdroppers and other attacks against the FL framework as mentioned in
Section 3.3, the Paillier-based encryption method is used. It is a type of partial homomorphic encryption scheme which is capable of performing computations of encrypted data.
In this encryption scheme, the key management center is only responsible for the generation of public and private keys for the clients but has no access to the data. KMC does not even have any idea about what data is being encrypted by the clients.
In the case of the server, the data received here is in the form of cipher text which is encrypted by the clients. Moreover, the operations performed at the server are all homomorphic operations which are performed without the decryption process. So even if the server is compromised no plain text data is obtained, because at the server all the data is in encrypted form.
From clients, they obtain the key pair from KMC, then encrypt the gradients and send it to the server for aggregation. The server sends back the global model but in encrypted form. During the entire process, clients cannot access each other’s data or the gradients which can ensure data security.
This process is majorly performed in three steps:
: The key management center generates the Public key
and Private key
using Paillier cryptosystem as mentioned in [
40].
: Here, the model gradients
are encrypted using
and results in
. For example, if
m is the plain text and
C is the cipher text the encryption is represented as:
where
r is random number such that
.
: Each edge device performs decryption upon receiving the cipher text C from the cloud server and retrieves the updated gradients
. The decryption is performed on
C using the private key
to obtain the plaintext
m.
Analysis of Encryption Scheme
As far as the overhead and complexity of the encryption scheme are considered, each edge device
is required to perform the encryption and decryption task and it can be denoted by:
where
R is the number of communication rounds and
N is the number of edge devices participating in the process of federated learning.
, and
is the time complexity of the Paillier method, which requires total G exponentiation operation and relatively negligible multiplication operation in each round. Therefore, we can say that the computational cost at each edge device is linearly proportional to the number of gradients in the DL model. However, for the cloud server it only needs to perform
X time of additive operation while aggregating the encrypted gradients.
To obtain the overhead of Paillier encryption, the proposed scheme is evaluated for the percentage of CPU consumption, memory occupied, and time taken to build the model. From
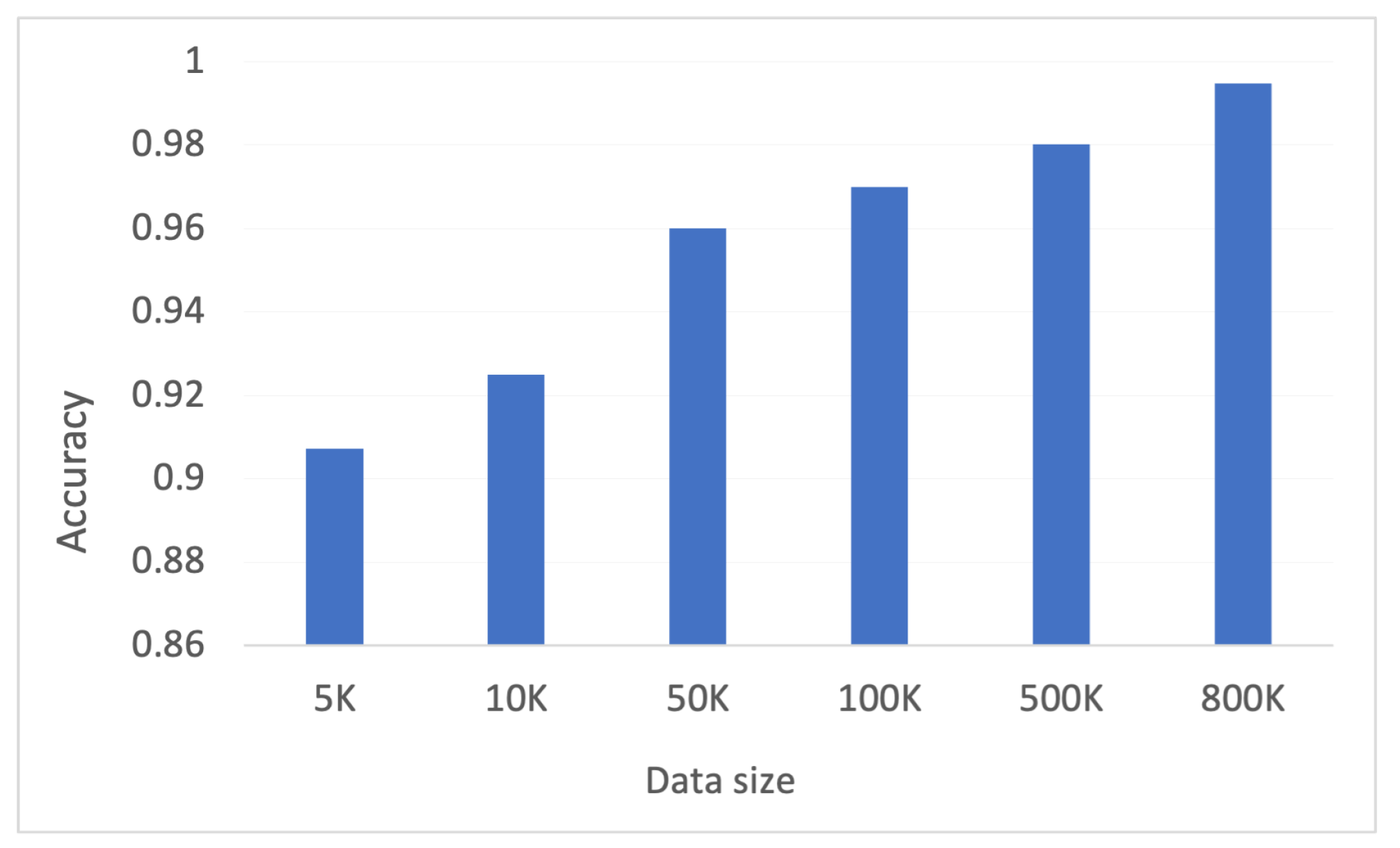
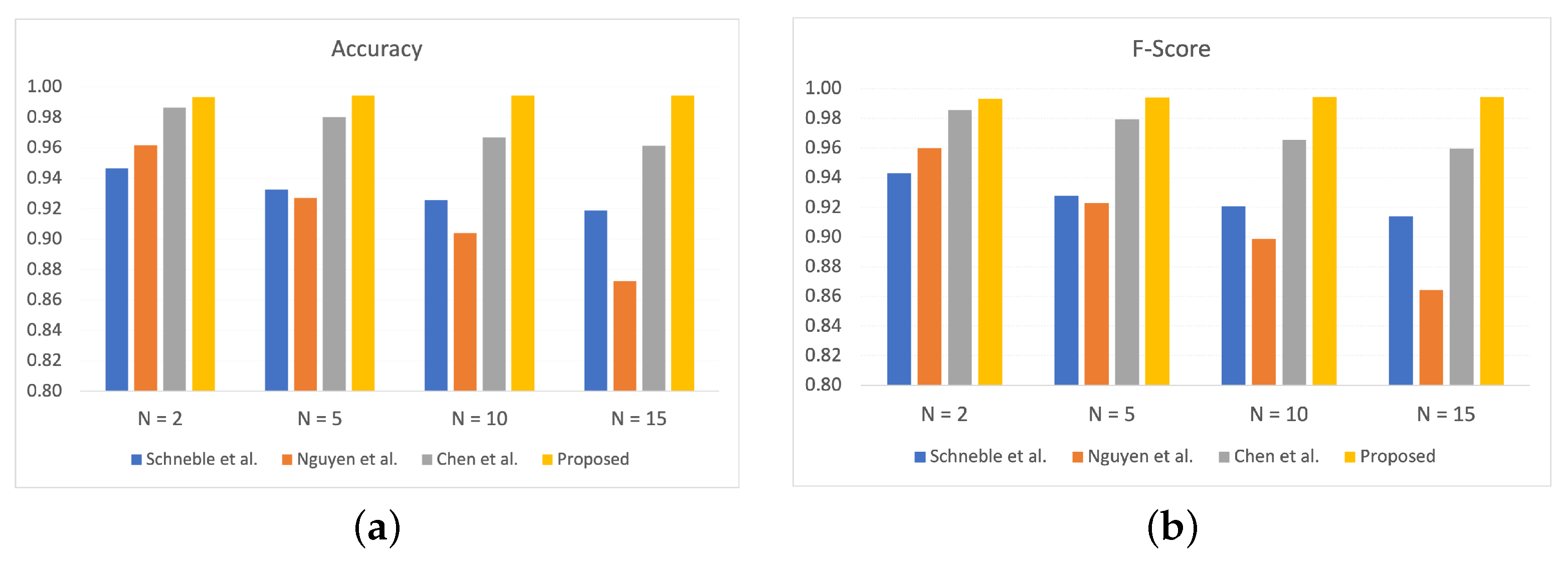
Table 1, it is evident that the proposed framework with Paillier encryption results in increased CPU and memory consumption with high training time in comparison to the proposed framework without Paillier encryption. This shows that using the Paillier encryption adds an extra overhead to the proposed framework.
6. Conclusions
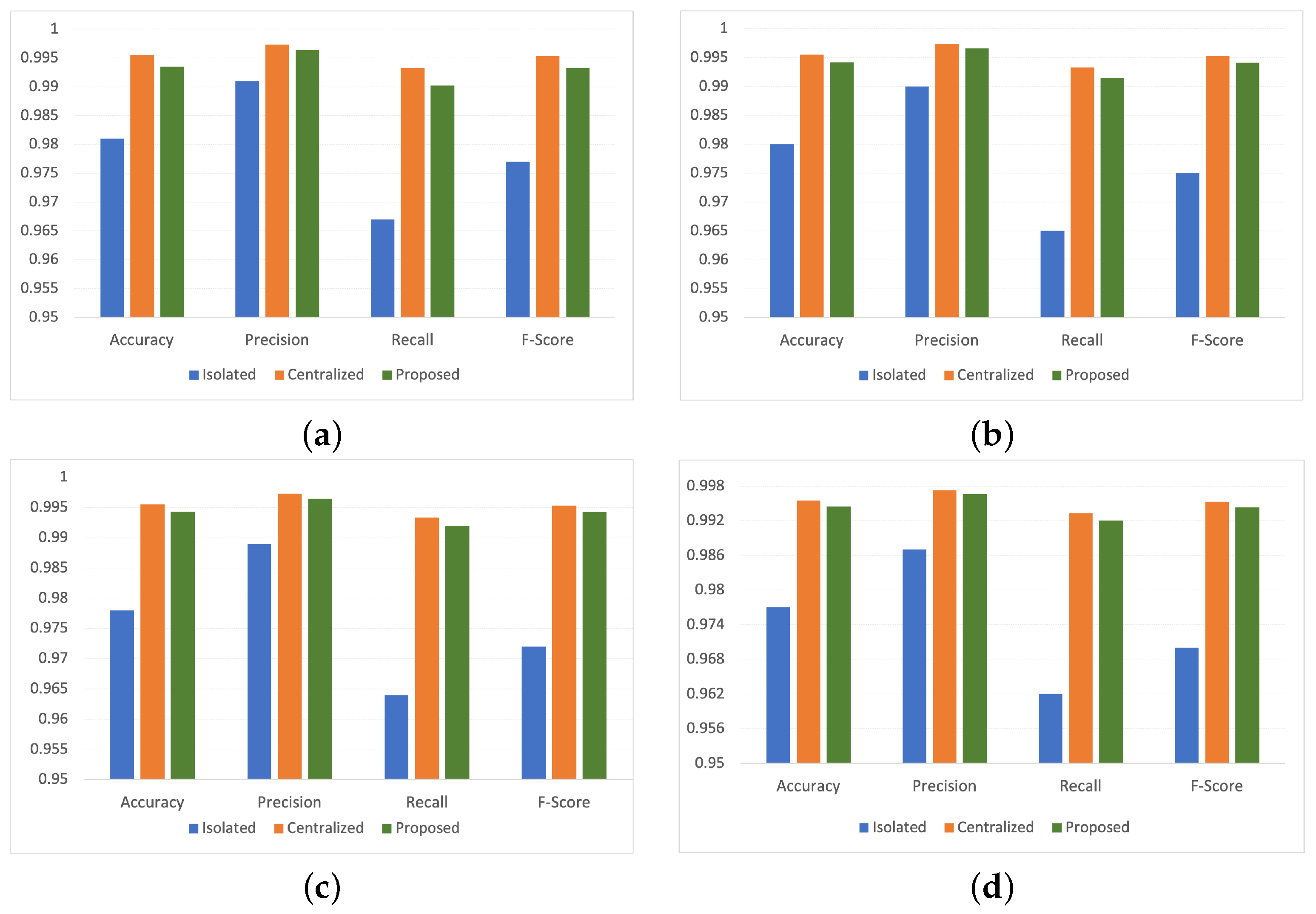
This work proposes a federated learning-enabled deep intrusion detection framework to detect cyber threats in smart manufacturing industries. The proposed framework enables multiple smart manufacturing industries to collaboratively build a comprehensive intrusion detection model through their representative edge devices. Moreover, in this work, the deep learning-based DID model using hybrid CNN+LSTM+MLP is used for intrusion detection. The experimental results show that the proposed FLDID framework outperforms the other state-of-the-art approaches and achieves good results for detecting cyber threats in smart manufacturing industries. While building the model collaboratively, the proposed framework also ensures it is built in a privacy-preserving way. The privacy of model parameters is achieved by building a secure channel between the edge devices and the cloud server using partial homomorphic encryption, i.e., the Paillier encryption method. However, homomorphic encryption will unavoidably result in increased overhead for the encryption and decryption process, which will substantially limit the effectiveness of training.
Therefore, in future work, the performance of the learning process will be accelerated by using efficient homomorphic encryption methods which results in low overhead. Moreover, a more robust and personalized federated learning should be considered, which helps to divide similar clients into clusters and handles the data poisoning attack. Additionally, to identify different types of attacks, we concentrate on providing the multiclass classification framework.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}