

Countering a Drone in a 3D Space: Analyzing Deep Reinforcement Learning Methods



Abstract
1. Introduction
2. Contributions and Related Work
2.1. Counter-Drone Systems
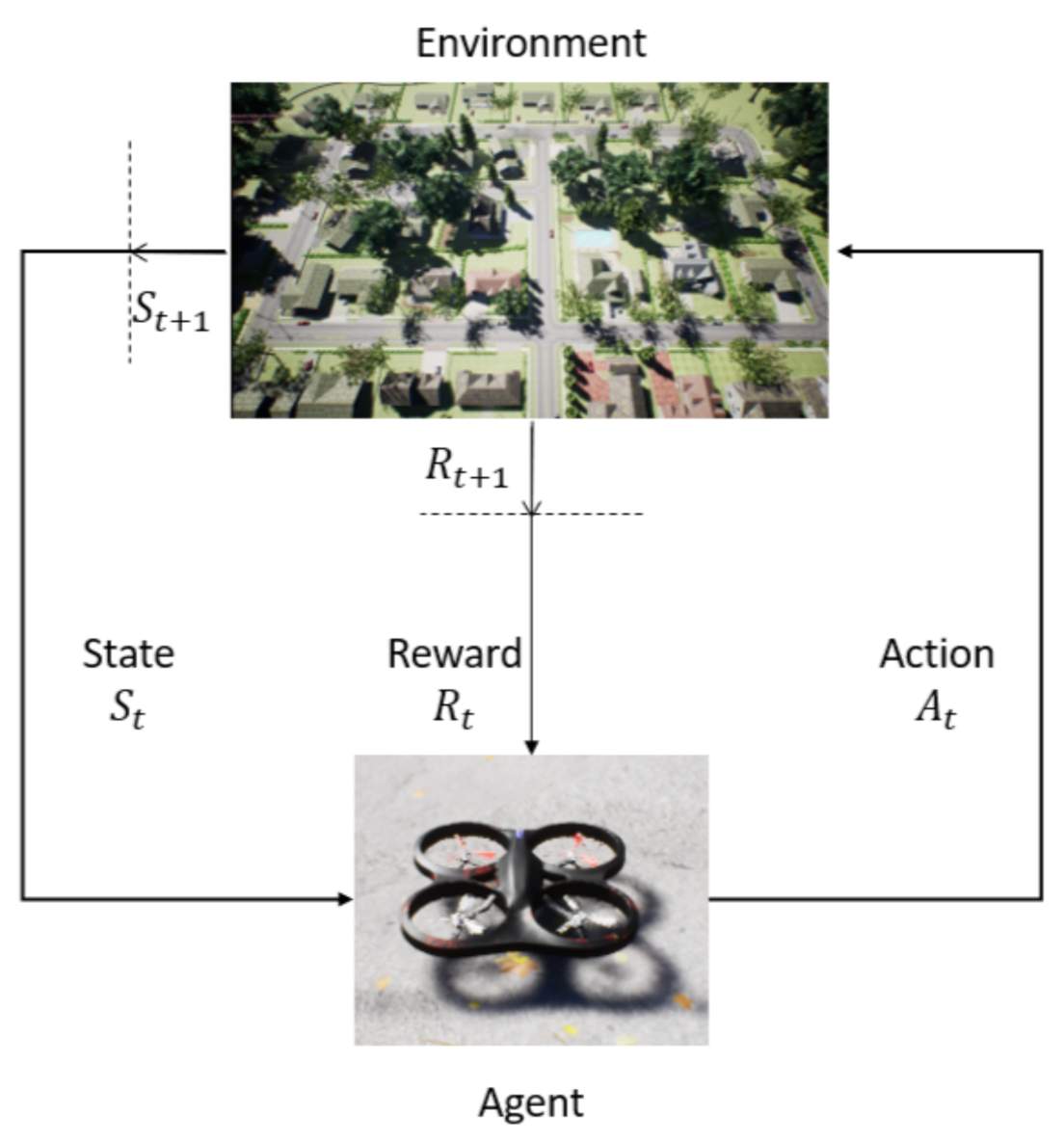
2.2. Reinforcement Learning
3. Materials and Methods
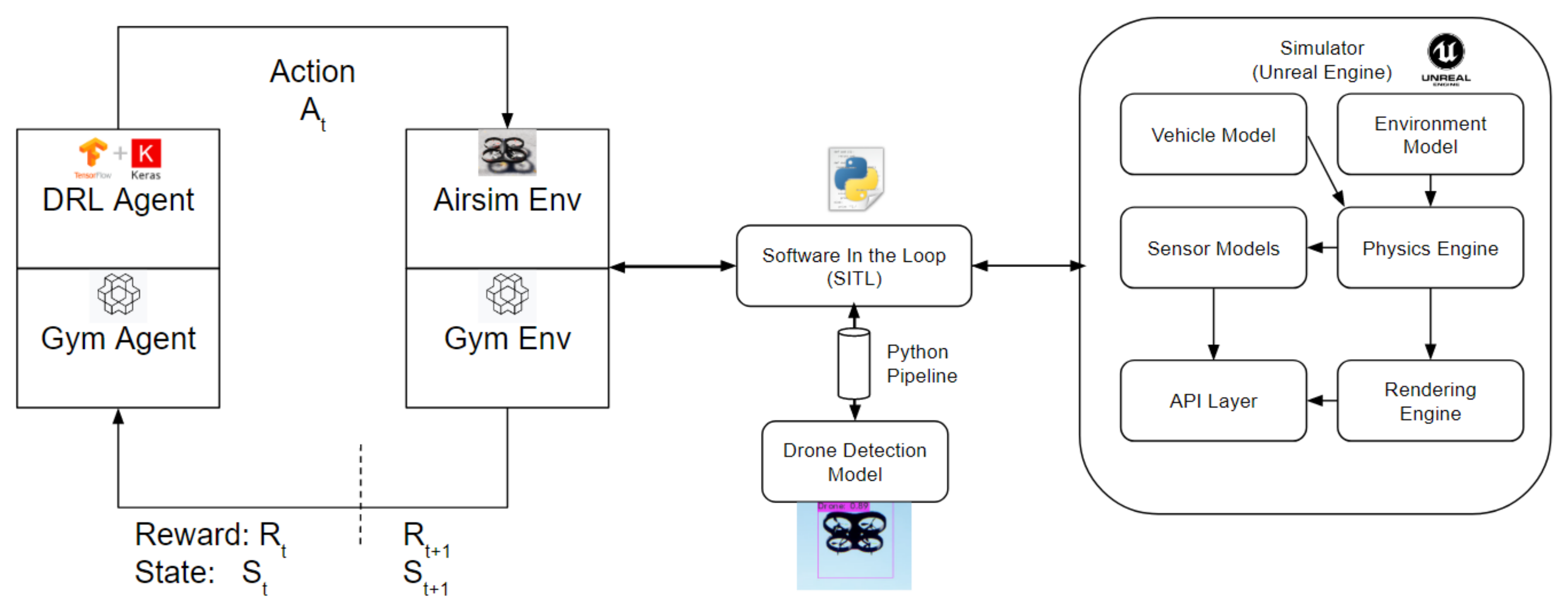
3.1. Tools
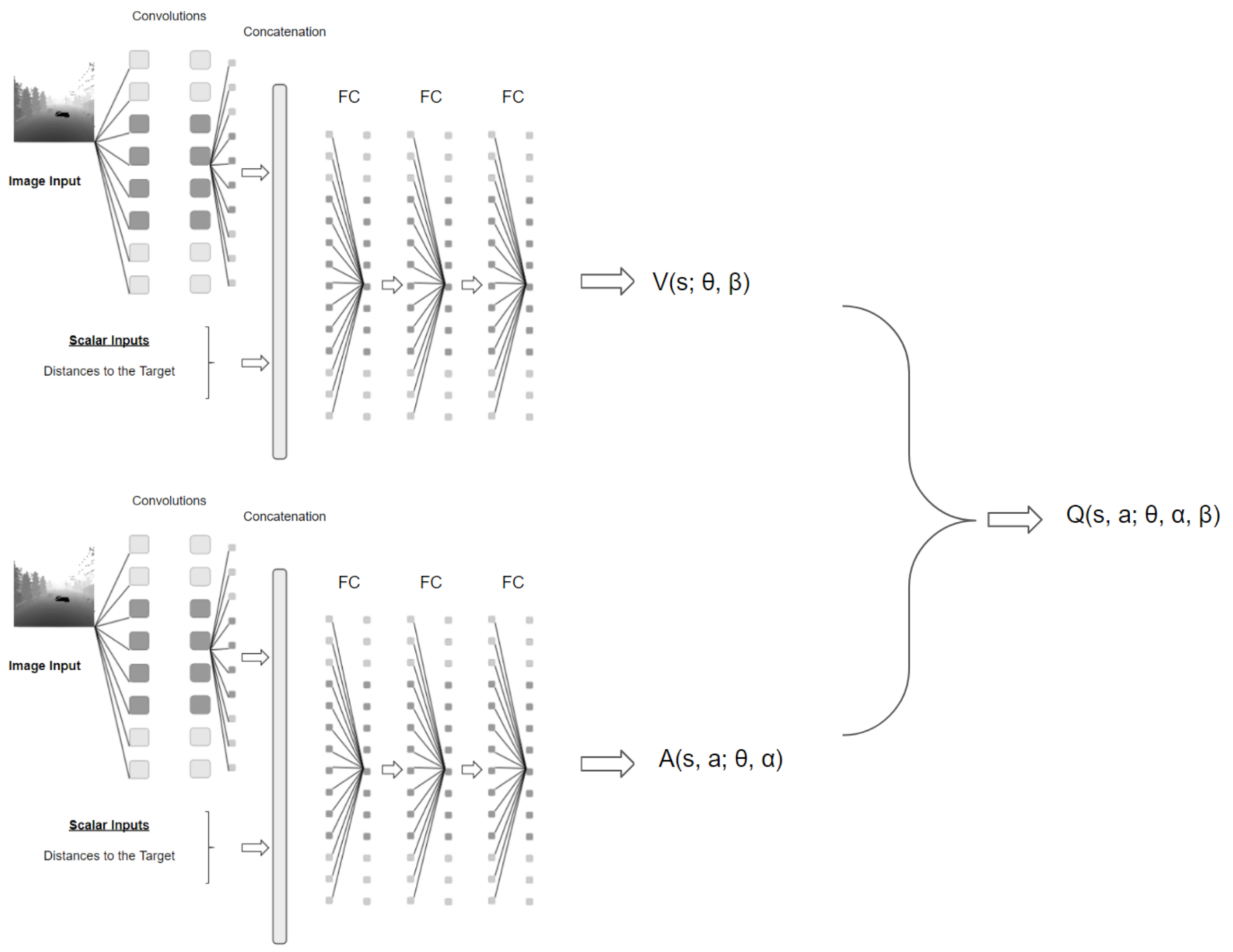
3.2. DQN, Double-DQN and Dueling Network Architecture

3.3. Prioritized Experience Replay
3.4. Drone Detection by State-of-the-Art Object Detection Model—EfficientNet
3.5. DRL Model
3.5.1. Environment
3.5.2. States
- Image State with Drone Detection
- Depth image, 84 × 84 pixels, and scene image, 256 × 144 pixels, are captured by using a drone onboard camera. The predicted image seen in Figure 3b is processed by a drone detection model to create bounding boxes when the target drone is detected on the image.The depth image seen in Figure 3a is used in the DRL model for detecting obstacles. After processing the images, the bounding box region in the depth image is filled with the color white and circles like a target in a game of darts are created inside the white bounding box region. The final image can be seen in Figure 3d.
- Image State without Drone Detection
- The depth image seen in Figure 4, with 256 × 144 pixels captured continuously. This image is the default size that Airsim can output.In addition, the grid is drawn on the image if the drone comes closer to the geo-fence limits in all directions. The grids start to be drawn on the image when the distance between the drone and the geo-fence limits lower than or equal to 1 m. The thickness of the grid increases as the drone moves towards the geo-fence limits. An example of the grid image is shown in Figure 5. In Figure 5a, the grid is drawn if the agent is closer to the geo-fences on TOP. On the other hand, in Figure 5b, the grid is drawn on the bottom of the image if the agent is closer to the ground.
- Scalar Inputs
- Scalar inputs contain the agent’s distances to the goal in x, y and z directions and the Euclidean distance .
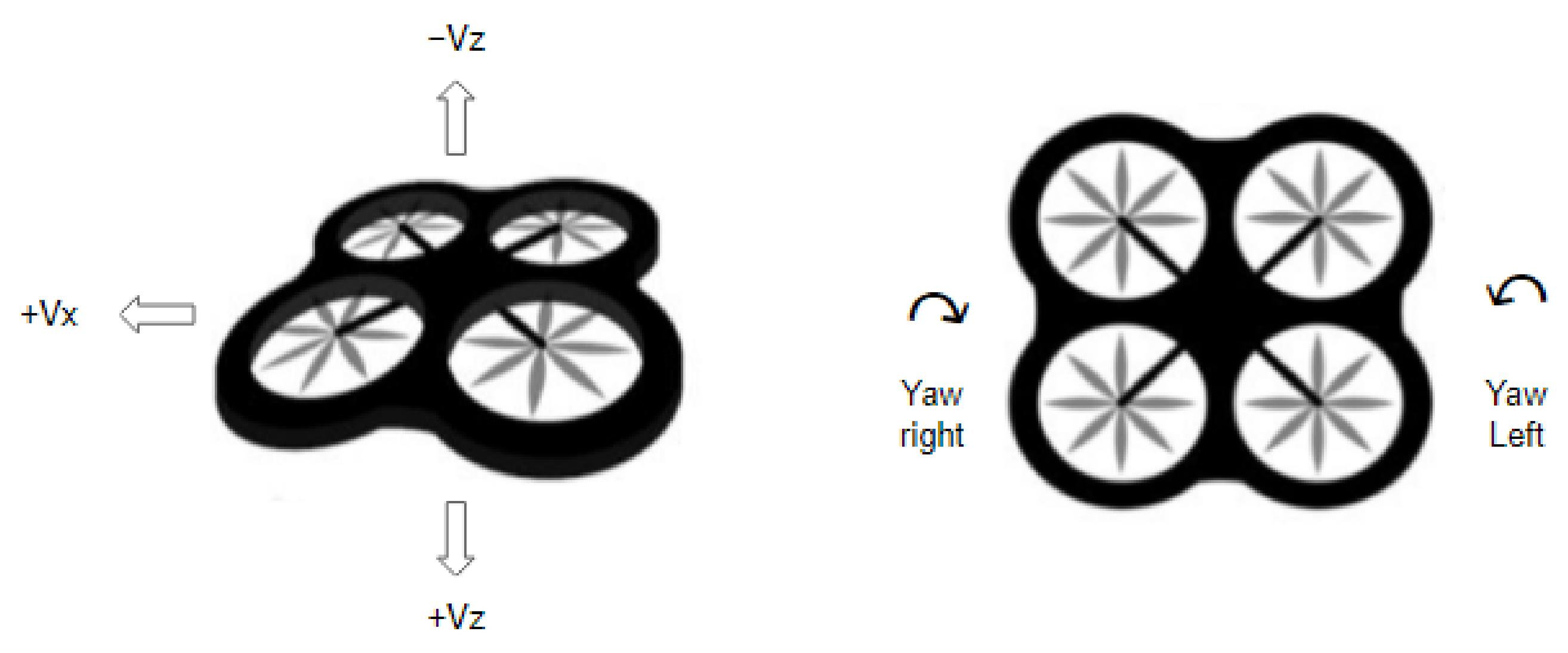
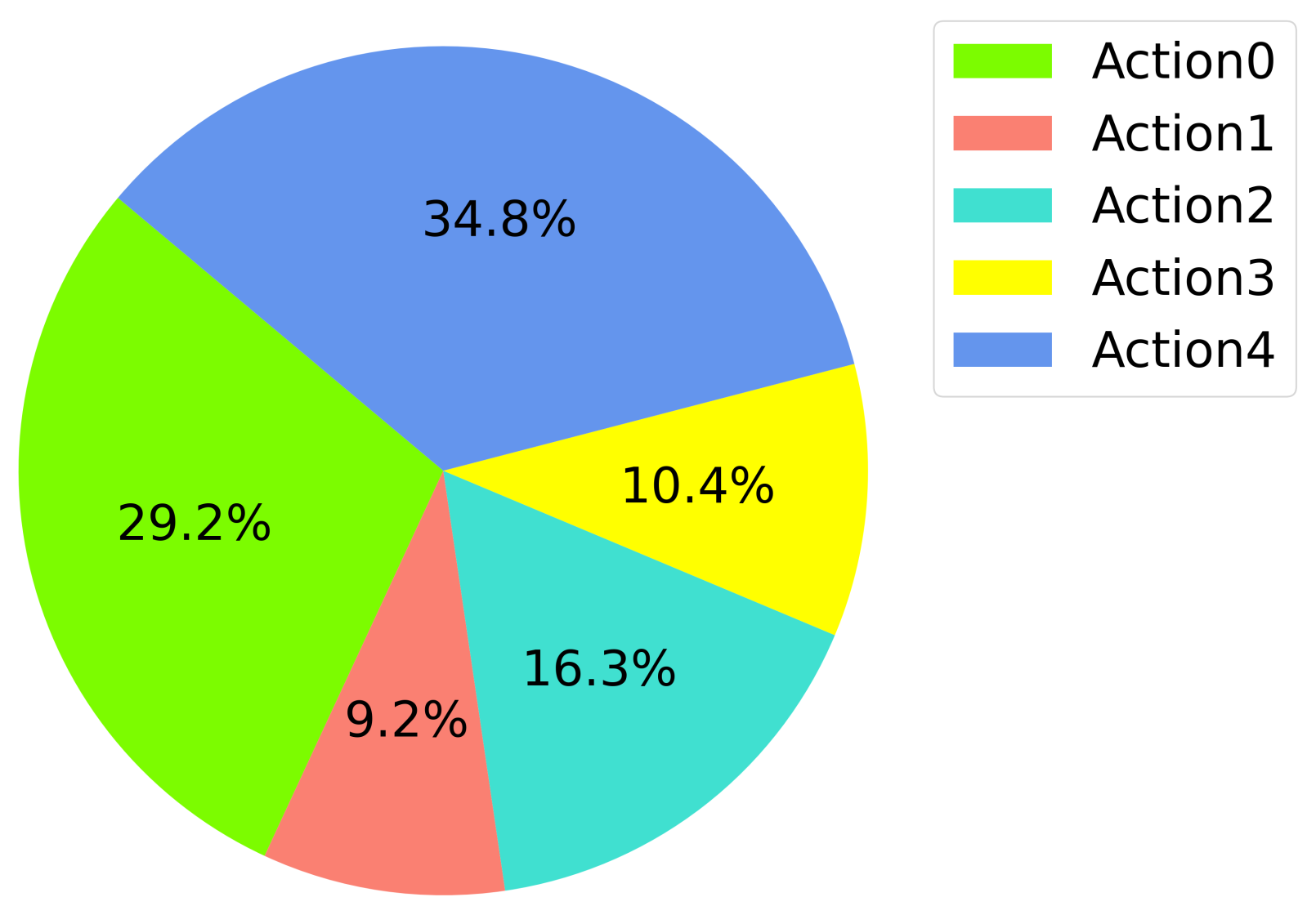
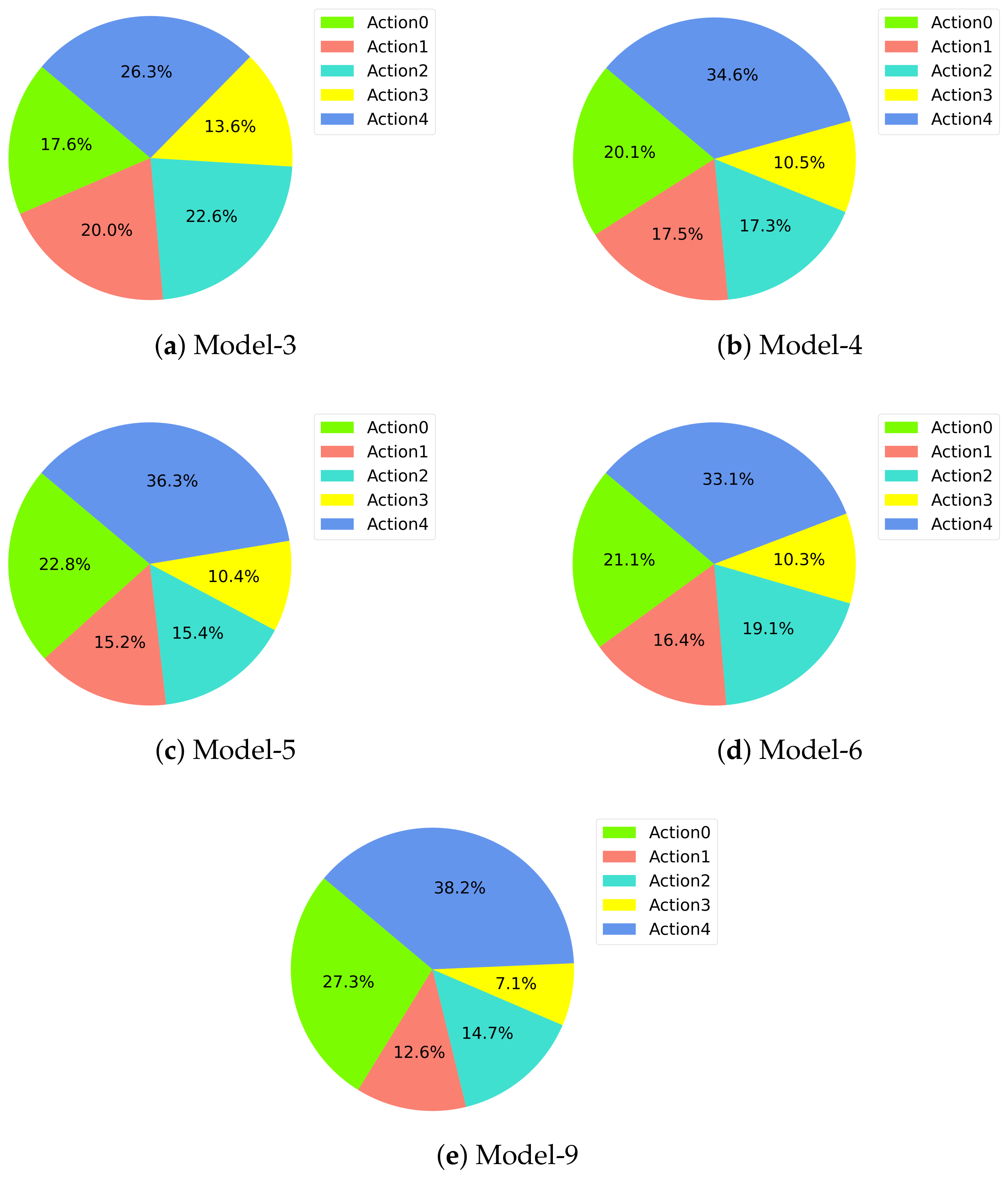
3.5.3. Actions
3.5.4. Rewards
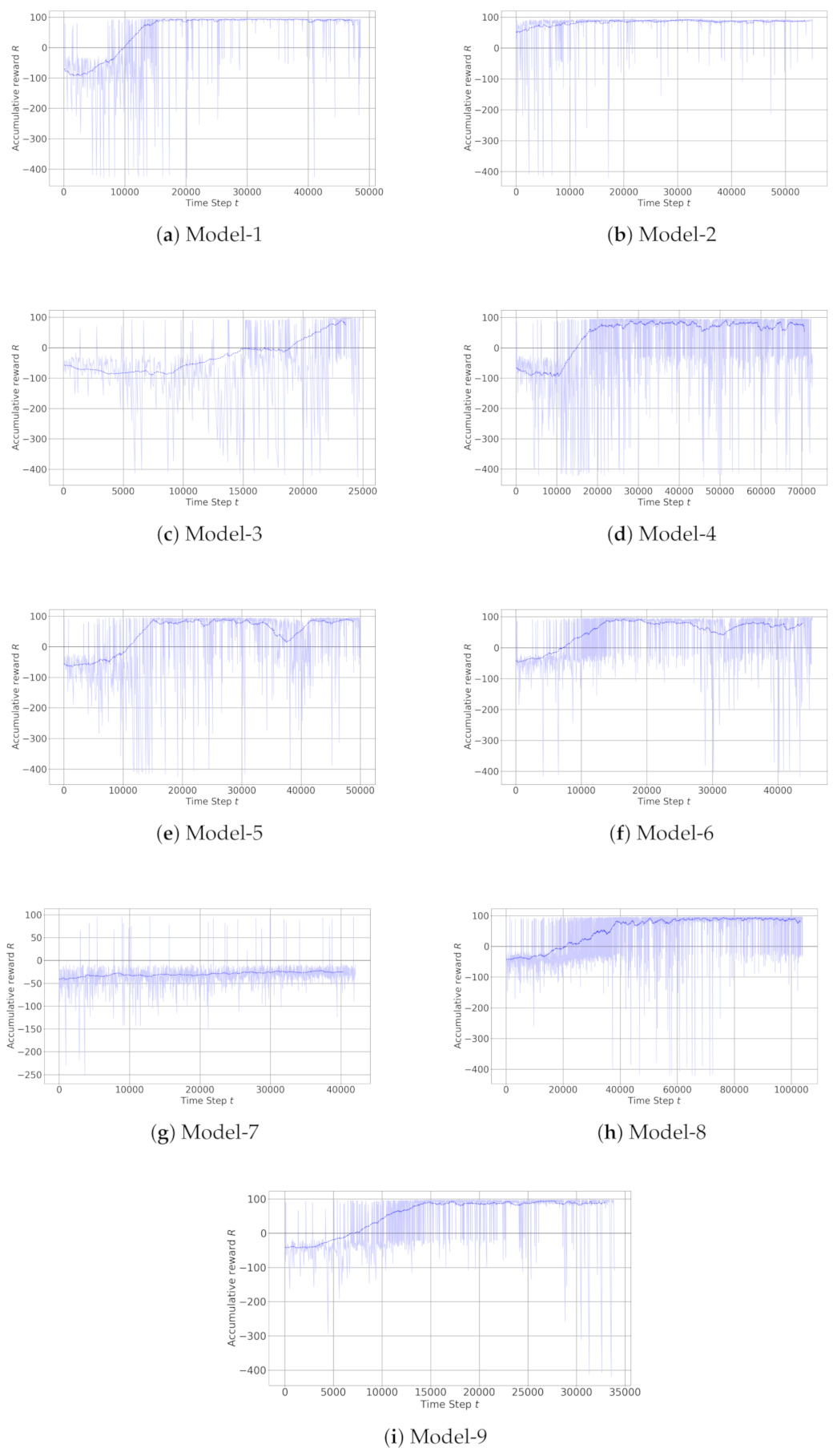
4. Training and Test Results
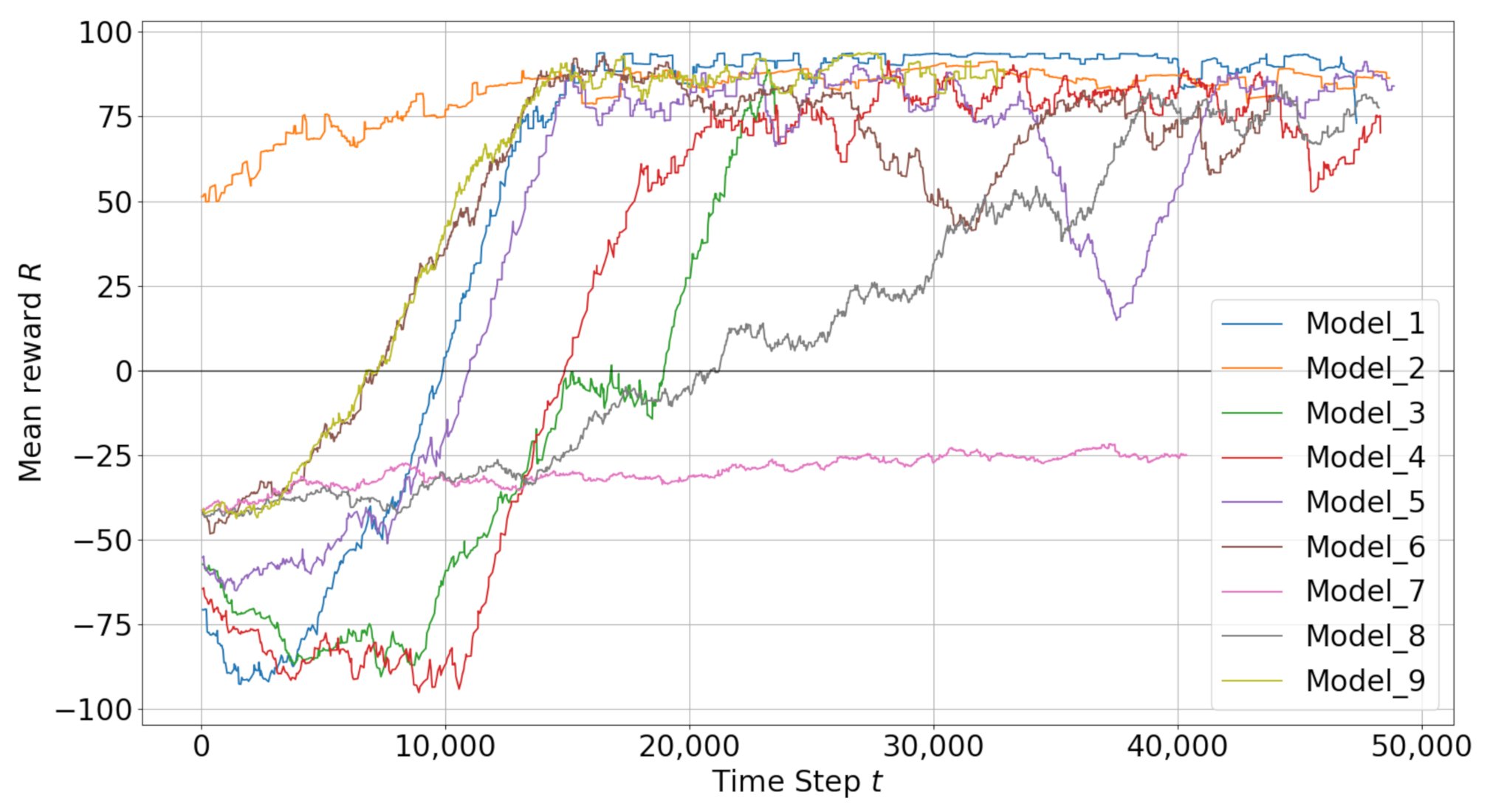
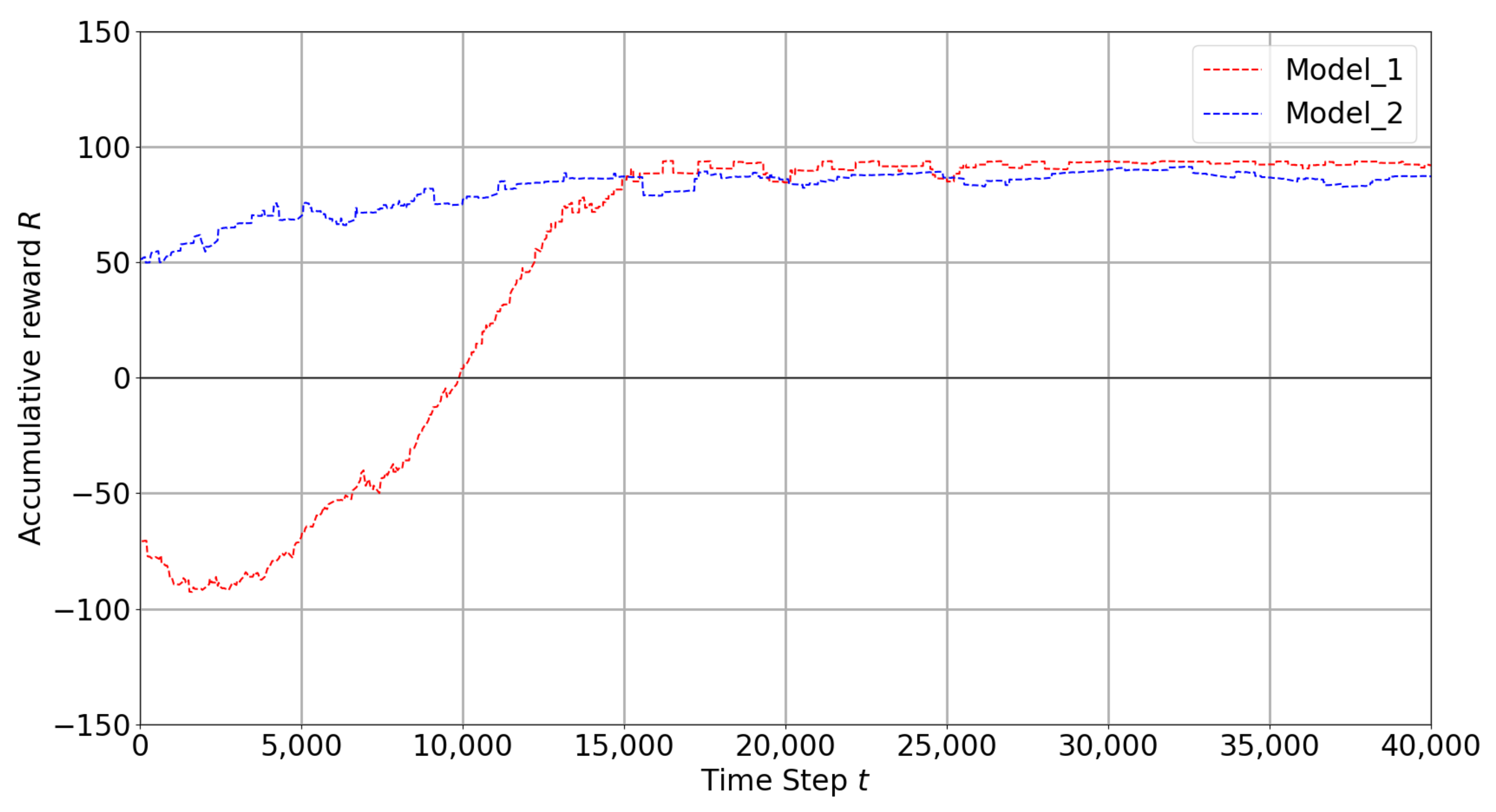
4.1. Best Models
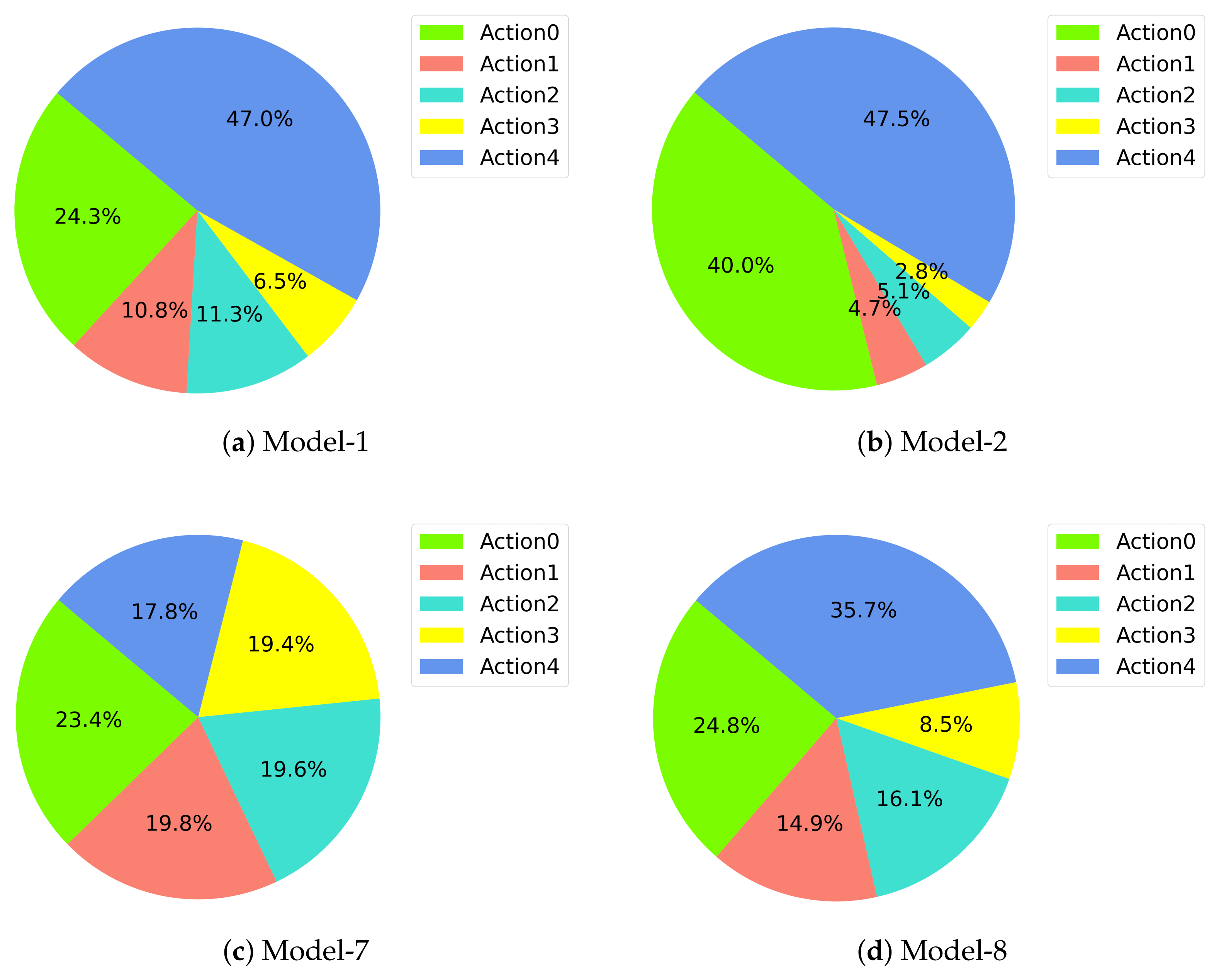
4.2. Analysis of Models
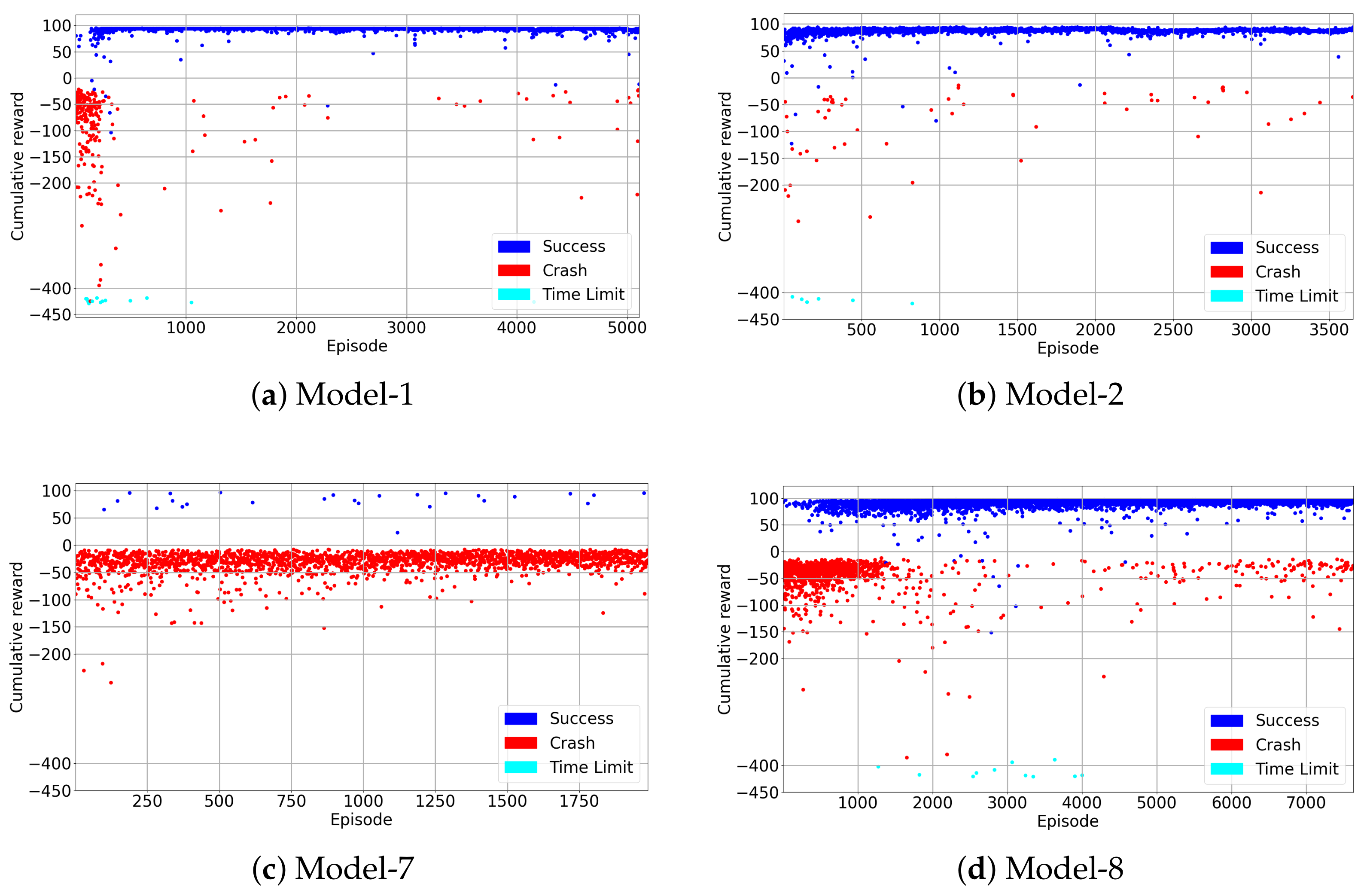
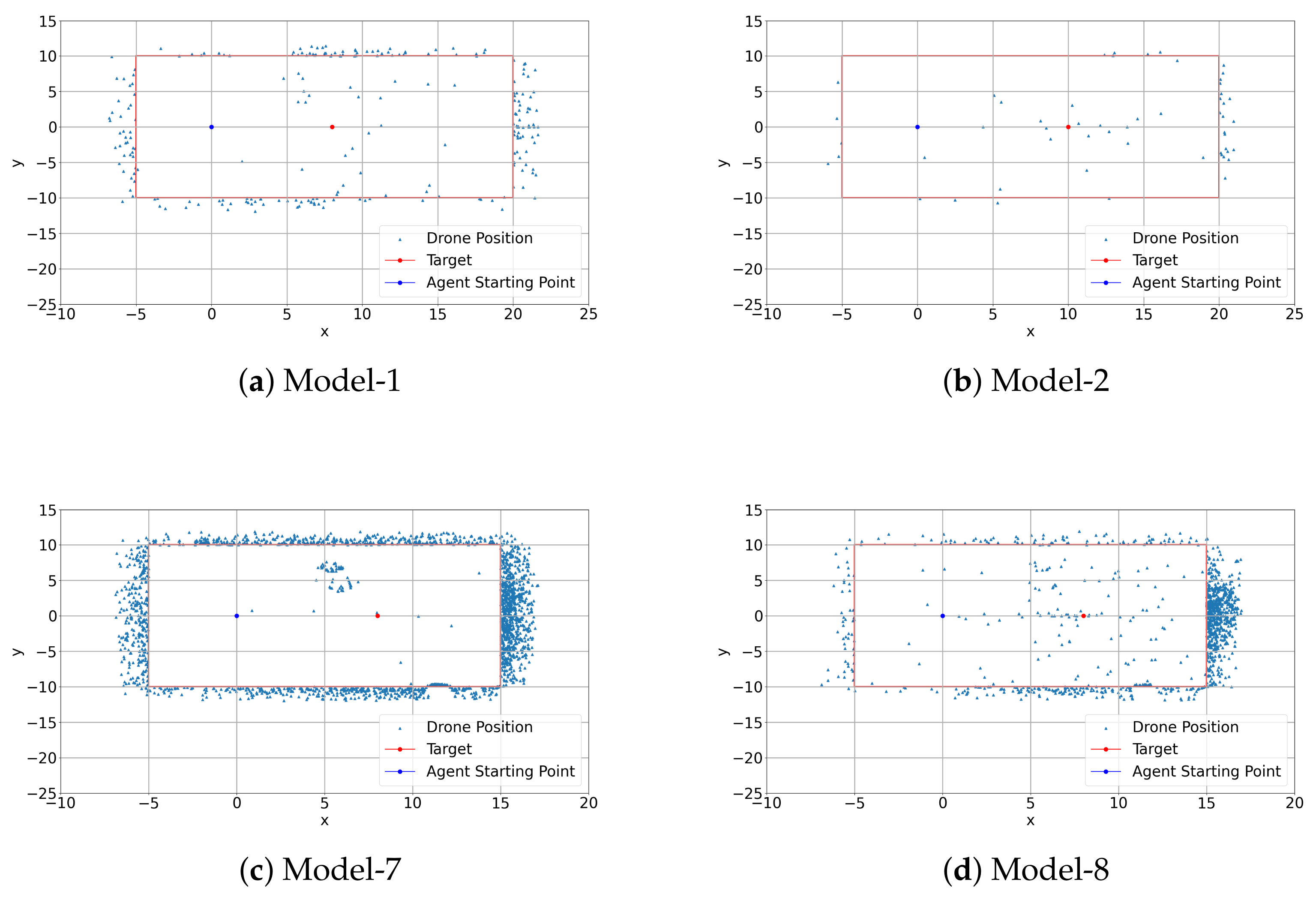
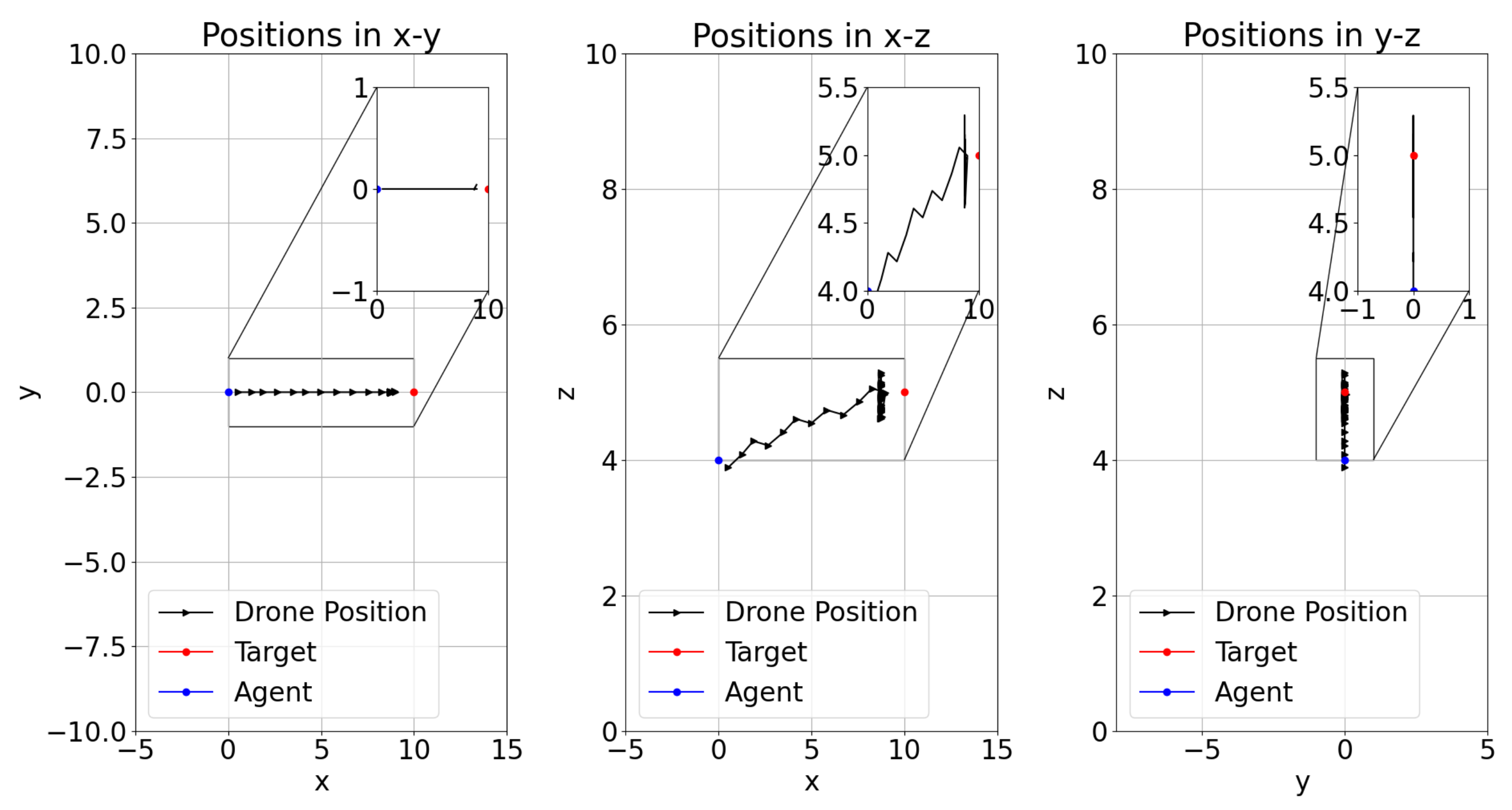
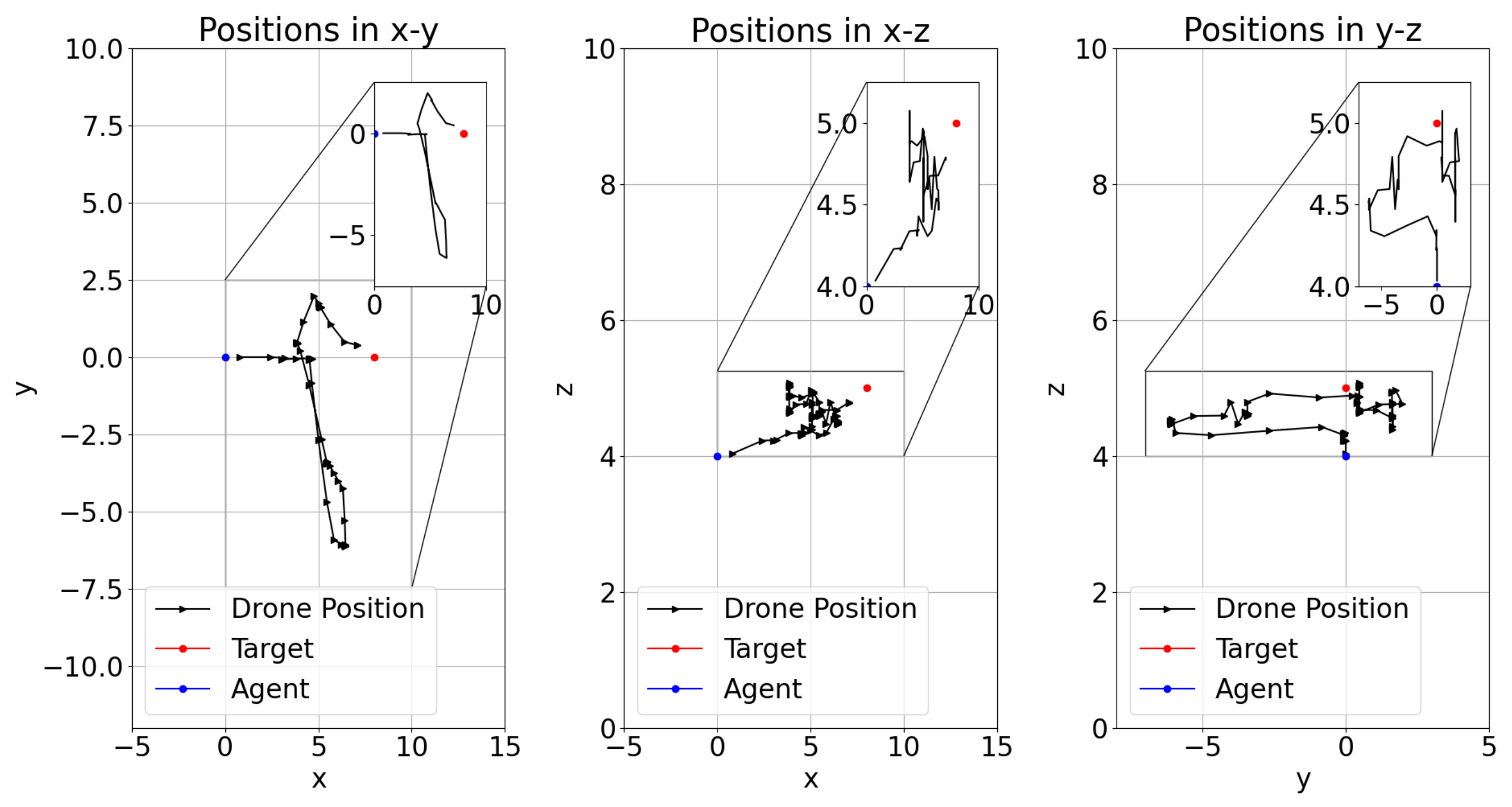
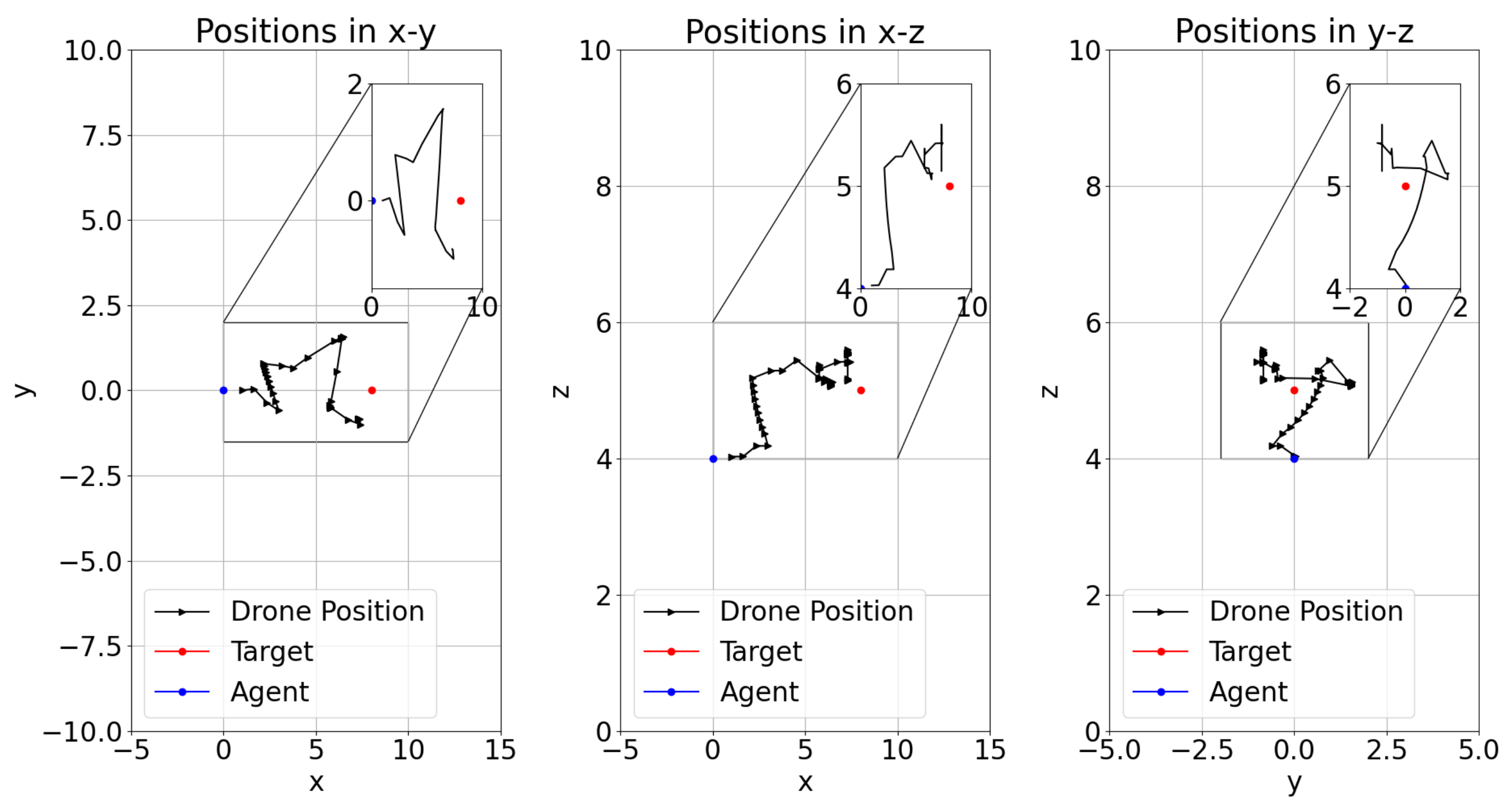
4.3. Test Results
5. Discussion
Deep Q-Learning from Demonstrations (DQfD)
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| UAV | Unmanned Aerial Vehicle |
| AI | Artificial Intelligence |
| DRL | Deep Reinforcement Learning |
| RL | Reinforcement Learning |
| TL | Transfer Learning |
| NED | North East Down |
| BVLOS | Beyond Visual Line of Sight |
| DDQN | Double Deep Q-network |
| PER | Prioritized Experience Replay |
| DQfD | Deep Q-learning from Demonstrations |
| CNN | Convolutional Neural Network |
| TD | Temporal Difference |
| API | Application Programming Interface |
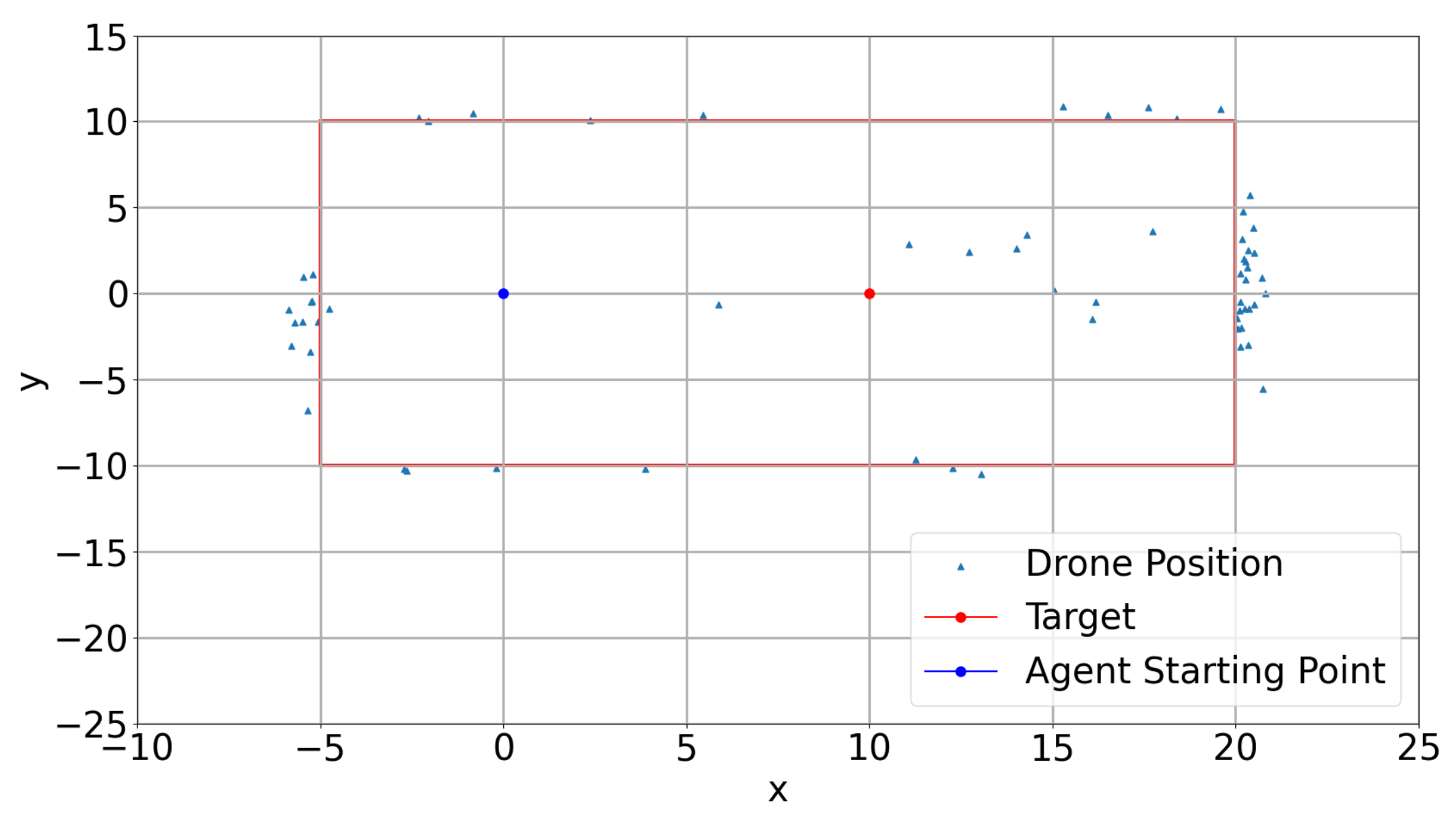
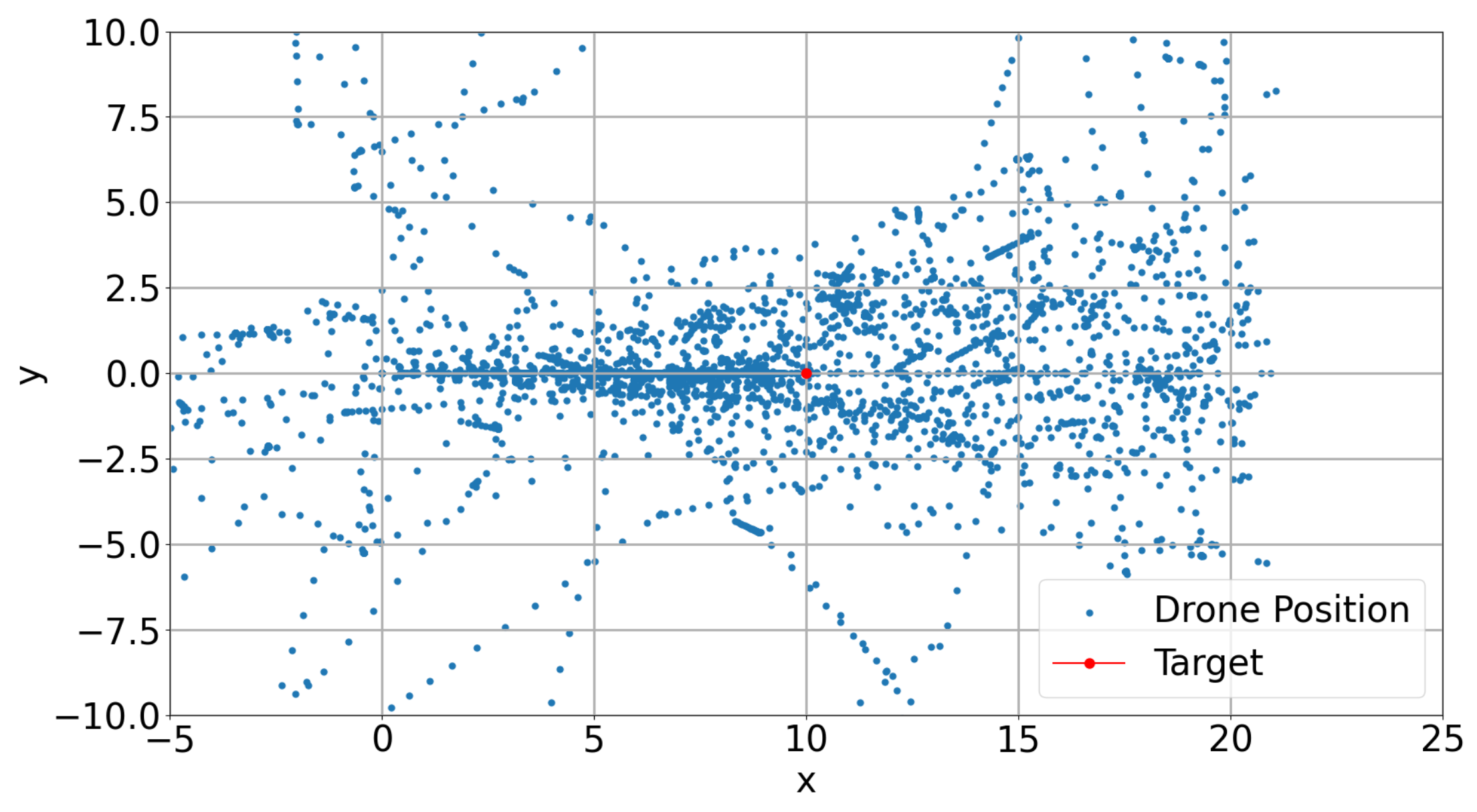
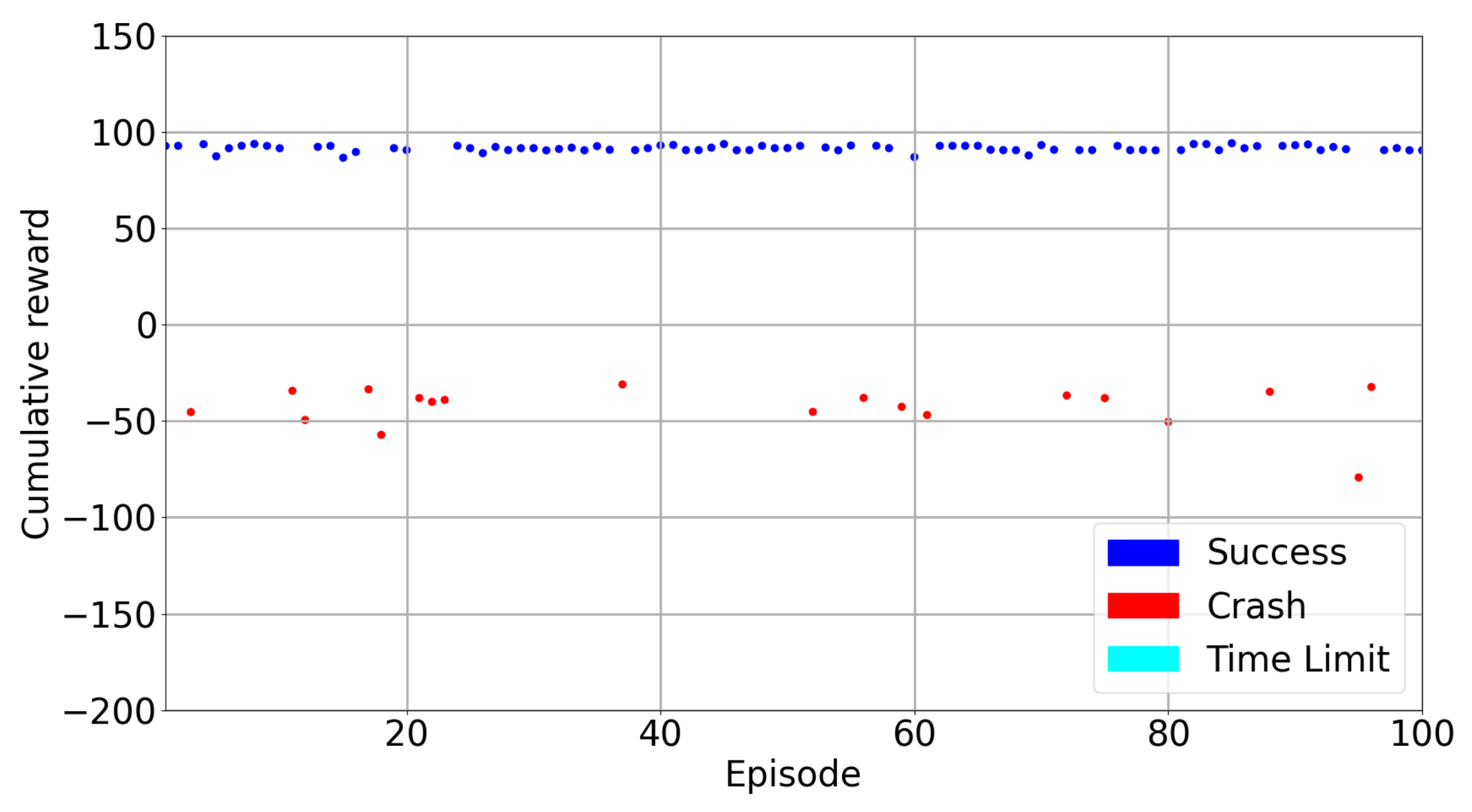
Appendix A. Results
Appendix A.1. Training Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value | Observations |
|---|---|---|
| Training steps | 75,000 | Changes in different scenarios (50,000–75,000) |
| Annealing length | 15,000 | Changes in different scenarios (15,000–45,000) |
| Annealing interval | [1–0.1] | Linear Annealed Policy (can be [0.1–0.01]) |
| Steps to warm-up | 180 | Number of random steps to take before learning begins |
| Prioritized experience replay, memory limit | 100,000 | |
| Prioritized experience replay, alpha | 0.6 | Decides how much prioritization is used |
| Prioritized experience replay, beta | Decides how much we should compensate for the non-uniform probabilities | |
| Prioritized experience replay, start-beta | 0.4 | |
| Prioritized experience replay, end-beta | 0.4 | |
| Pretraining steps | 1000 | Length of ’pretraining’ |
| Large margin | 0.8 | Constant value |
| 1 | Imitation loss coefficient | |
| Dueling type | ’avg’ | A type of dueling architecture |
| Target model update | 0.001 | Frequency of the target network update |
| Discount factor | 0.99 | The discount factor of future rewards in the Q function |
| Learning rate | 0.00025 | Adam optimizer [35] |





References
- Anti-Drone Market “To Be Worth USD1.5 Billion” by 2023—New Report. Available online: https://www.unmannedairspace.info/utm-and-c-uas-market-analysis/anti-drone-market-to-be-worth-usd1-5-billion-by-2023-new-report/ (accessed on 21 August 2019).
- Drones by the Numbers. Available online: https://www.faa.gov/uas/resources/by_the_numbers/ (accessed on 4 August 2022).
- Chiper, F.L.; Martian, A.; Vladeanu, C.; Marghescu, I.; Craciunescu, R.; Fratu, O. Drone Detection and Defense Systems: Survey and a Software-Defined Radio-Based Solution. Sensors 2022, 22, 1453. [Google Scholar] [CrossRef] [PubMed]
- Drozdowicz, J.; Wielgo, M.; Samczynski, P.; Kulpa, K.; Krzonkalla, J.; Mordzonek, M.; Bryl, M.; Jakielaszek, Z. 35 GHz FMCW drone detection system. In Proceedings of the 2016 17th International Radar Symposium (IRS), Krakow, Poland, 10–12 May 2016; pp. 1–4. [Google Scholar]
- Semkin, V.; Yin, M.; Hu, Y.; Mezzavilla, M.; Rangan, S. Drone detection and classification based on radar cross section signatures. In Proceedings of the 2020 International Symposium on Antennas and Propagation (ISAP), Osaka, Japan, 25–28 January 2021; pp. 223–224. [Google Scholar]
- Bernardini, A.; Mangiatordi, F.; Pallotti, E.; Capodiferro, L. Drone detection by acoustic signature identification. Electron. Imaging 2017, 2017, 60–64. [Google Scholar] [CrossRef]
- Mezei, J.; Fiaska, V.; Molnár, A. Drone sound detection. In Proceedings of the 2015 16th IEEE International Symposium on Computational Intelligence and Informatics (CINTI), Budapest, Hungary, 19–21 November 2015; pp. 333–338. [Google Scholar]
- Nguyen, P.; Ravindranatha, M.; Nguyen, A.; Han, R.; Vu, T. Investigating cost-effective RF-based detection of drones. In Proceedings of the 2nd Workshop on Micro Aerial Vehicle Networks, Systems, and Applications for Civilian Use, Singapore, 26 June 2016; pp. 17–22. [Google Scholar]
- Opromolla, R.; Fasano, G.; Accardo, D. A vision-based approach to UAV detection and tracking in cooperative applications. Sensors 2018, 18, 3391. [Google Scholar] [CrossRef] [PubMed]
- De Haag, M.U.; Bartone, C.G.; Braasch, M.S. Flight-test evaluation of small form-factor LiDAR and radar sensors for sUAS detect-and-avoid applications. In Proceedings of the 2016 IEEE/AIAA 35th Digital Avionics Systems Conference (DASC), Sacramento, CA, USA, 25–29 September 2016; pp. 1–11. [Google Scholar]
- Çetin, E.; Barrado, C.; Pastor, E. Improving real-time drone detection for counter-drone systems. Aeronaut. J. 2021, 125, 1871–1896. [Google Scholar] [CrossRef]
- Aker, C.; Kalkan, S. Using deep networks for drone detection. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Lykou, G.; Moustakas, D.; Gritzalis, D. Defending airports from UAS: A survey on cyber-attacks and counter-drone sensing technologies. Sensors 2020, 20, 3537. [Google Scholar] [CrossRef] [PubMed]
- Watkins, L.; Sartalamacchia, S.; Bradt, R.; Dhareshwar, K.; Bagga, H.; Robinson, W.H.; Rubin, A. Defending against consumer drone privacy attacks: A blueprint for a counter autonomous drone tool. In Proceedings of the Decentralized IoT Systems and Security (DISS) Workshop 2020, San Diego, CA, USA, 23–26 February 2020. [Google Scholar]
- Barišic, A.; Petric, F.; Bogdan, S. Brain over Brawn: Using a Stereo Camera to Detect, Track, and Intercept a Faster UAV by Reconstructing the Intruder’s Trajectory. arXiv 2022, arXiv:2107.00962. [Google Scholar] [CrossRef]
- Bertoin, D.; Gauffriau, A.; Grasset, D.; Gupta, J.S. Autonomous drone interception with Deep Reinforcement Learning. In Proceedings of the ATT’22: Workshop Agents in Traffic and Transportation, Vienna, Austria, 25 July 2022. [Google Scholar]
- Shim, D.H. Development of an Anti-Drone System Using a Deep Reinforcement Learning Algorithm. Ph.D. Thesis, Korea Advanced Institute of Science and Technology, Daejeon, Korea, 2021. [Google Scholar]
- Akhloufi, M.A.; Arola, S.; Bonnet, A. Drones Chasing Drones: Reinforcement Learning and Deep Search Area Proposal. Drones 2019, 3, 58. [Google Scholar] [CrossRef]
- He, L.; Aouf, N.; Whidborne, J.F.; Song, B. Deep reinforcement learning based local planner for UAV obstacle avoidance using demonstration data. arXiv 2020, arXiv:2008.02521. [Google Scholar]
- Çetin, E.; Barrado, C.; Pastor, E. Counter a Drone in a Complex Neighborhood Area by Deep Reinforcement Learning. Sensors 2020, 20, 2320. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2015, arXiv:1603.04467. [Google Scholar]
- Plappert, M. keras-rl. 2016. Available online: https://github.com/keras-rl/keras-rl (accessed on 10 October 2022).
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. arXiv 2017, arXiv:1705.05065. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef] [PubMed]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. arXiv 2016, arXiv:1509.06461. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M.A. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1995–2003. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Unreal Engine 4. Available online: https://www.unrealengine.com/en-US/what-is-unreal-engine-4 (accessed on 29 January 2019).
- Hester, T.; Vecerik, M.; Pietquin, O.; Lanctot, M.; Schaul, T.; Piot, B.; Horgan, D.; Quan, J.; Sendonaris, A.; Osband, I.; et al. Deep q-learning from demonstrations. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32, pp. 3223–3230. [Google Scholar]
- Piot, B.; Geist, M.; Pietquin, O. Boosted and reward-regularized classification for apprenticeship learning. In Proceedings of the 2014 International Conference on Autonomous Agents and Multi-Agent Systems, Paris, France, 5–9 May 2014; pp. 1249–1256. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: Amethod for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]




















| Action | Movement |
|---|---|
| 0 | 2 m/s in +x direction |
| 1 | 30 deg yaw left |
| 2 | 25 deg yaw right |
| 3 | m/s in +z direction |
| 4 | m/s in −z direction |
| Reward | The Reason |
|---|---|
| +100 | Target Caught |
| −1 + | Episode steps between 0–50 |
| −2 + | Episode steps between 50–100 |
| −3 + | Episode steps between 100–150 |
| −4 + | Episode steps between 150–200 |
| Models | Target Location in X Direction | Target Location in Z Direction | Teleportation and Random Heading | Transfer Learning | Dueling Network Architecture | Image State | Scalar States | Annealed Steps | Training Steps | Drone Detection |
|---|---|---|---|---|---|---|---|---|---|---|
| Model-1 | 8 | −5 | NO | NO | YES | (256,144) | 15,000 | <50,000 | NO | |
| Model-2 | 10 | −5 | NO | YES | YES | (84,84) | 20,000 | >50,000 | YES | |
| Model-3 | 8 | −5 | NO | NO | YES | (84,84) | 15,000 | <50,000 | YES | |
| Model-4 | 8 | −5 | NO | NO | YES | (84,84) | 20,000 | >50,000 | YES | |
| Model-5 | 10 | −5 | NO | NO | YES | (84,84) | 15,000 | <50,000 | YES | |
| Model-6 | 8 | −5 | NO | NO | NO | (84,84) | 15,000 | <50,000 | YES | |
| Model-7 | 8 | −5 | YES | NO | NO | (84,84) | 100,000 | <50,000 | YES | |
| Model-8 | 8 | −5 | YES (Random Heading) | NO | NO | (84,84) | 50,000 | >50,000 | YES | |
| Model-9 | 8 | −5 | NO | NO | NO | (84,84) | 15,000 | <50,000 | YES |
| Models | Average Cumulative Reward | Max. Cumulative Reward | Min. Cumulative Reward | Success Rates |
|---|---|---|---|---|
| Model-1 | 83.11 | 94.48 | −429.27 | 95% |
| Model-2 | 83.82 | 94.12 | −420.99 | 98% |
| Model-3 | −3.73 | 97.33 | −426.16 | 47% |
| Model-4 | 65.91 | 98.09 | −427.04 | 88% |
| Model-5 | 65.24 | 96.16 | −424.30 | 88% |
| Model-6 | 64.49 | 98.21 | −416.40 | 83% |
| Model-7 | −29.40 | 96.25 | −252.38 | 5% |
| Model-8 | 71.80 | 97.16 | −421.06 | 86% |
| Model-9 | 72.08 | 97.14 | −418.69 | 85% |
| Models | Average Cumulative Reward | Max. Cumulative Reward | Min. Cumulative Reward | Success Rates | Average Steps |
|---|---|---|---|---|---|
| Model-1 | 90.86 | 91.12 | 90.69 | 100% | 8.98 |
| Model-2 | 89.38 | 92.93 | 82.93 | 100% | 11.92 |
| Model-7 | −87.55 | 73.78 | −408.58 | 3% | 56.97 |
| Model-8 | 65.73 | 95.06 | −220.29 | 92% | 32.01 |
| DQfD Models | Average Cumulative Reward | Max. Cumulative Reward | Min. Cumulative Reward | Success Rates | Average Steps |
|---|---|---|---|---|---|
| DQfD Model Train | 7.95 | 93.67 | −403.94 | 55% | 35.21 |
| DQfD Model Test | 65.96 | 94.07 | −79.29 | 81% | 16.82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Çetin, E.; Barrado, C.; Pastor, E. Countering a Drone in a 3D Space: Analyzing Deep Reinforcement Learning Methods. Sensors 2022, 22, 8863. https://doi.org/10.3390/s22228863
Çetin E, Barrado C, Pastor E. Countering a Drone in a 3D Space: Analyzing Deep Reinforcement Learning Methods. Sensors. 2022; 22(22):8863. https://doi.org/10.3390/s22228863
Chicago/Turabian StyleÇetin, Ender, Cristina Barrado, and Enric Pastor. 2022. "Countering a Drone in a 3D Space: Analyzing Deep Reinforcement Learning Methods" Sensors 22, no. 22: 8863. https://doi.org/10.3390/s22228863
APA StyleÇetin, E., Barrado, C., & Pastor, E. (2022). Countering a Drone in a 3D Space: Analyzing Deep Reinforcement Learning Methods. Sensors, 22(22), 8863. https://doi.org/10.3390/s22228863